对于内容型的公司,数据的安全性不言而喻。一个在线教育的平台,题目的数据很重要吧,但是被别人通过爬虫技术全部爬走了,那结果就是“凉凉”。再比说有个独立开发者想抄袭你的产品,通过抓包和爬虫手段将你核心的数据拿走,然后短期内做个网站和 App,短期内成为你的劲敌。成果:segmentfault 上发表过文章,获赞 152。
大前端的数据安全主要分为:客户端、网页端。客户端简单介绍下。
目前 App 的网络通信基本都是用 HTTPS 的服务,但是随便一个抓包工具都是可以看到 HTTPS 接口的详细数据,为了做到防止抓包和无法模拟接口的情况。我们可以采取 HTTPS 证书的双向认证,这样子实现的效果就是中间人在开启抓包软件分析 App 的网络请求的时候,网络会自动断掉,无法查看分析请求的情况
对于防止用户模仿我们的请求再次发起请求,我们可以采用 「防重放策略」,用户再也无法模仿我们的请求,再次去获取数据了。
虽然话题都是大前端时代的安全性,但是防重放策略篇幅较长,开了新的章节。感兴趣的同学请移步查看。
对于 App 内的 H5 资源,反爬虫方案可以采用上面的解决方案,H5 内部的网络请求可以通过 Hybrid 层让 Native 的能力去完成网络请求,完成之后将数据回调给 JS。这么做的目的是往往我们的 Native 层有完善的账号体系和网络层以及良好的安全策略、鉴权体系等等。
JS端发起网络请求代码:点击展开
var requestObject = {
url: arg.Api + "SearchInfo/getLawsInfo",
params: requestparams,
Hybrid_Request_Method: 0
};
requestHybrid({
tagname: 'NativeRequest',
param: requestObject,
encryption: 1,
callback: function (data) {
renderUI(data);
}
})Objective-C代码:点击展开
[self.bridge registerHandler:@"NativeRequest" handler:^(id data, WVJBResponseCallback responseCallback) {
NSAssert([data isKindOfClass:[NSDictionary class]], @"H5 端不按套路");
if ([data isKindOfClass:[NSDictionary class]]) {
NSDictionary *dict = (NSDictionary *)data;
RequestModel *requestModel = [RequestModel yy_modelWithJSON:dict];
NSAssert( (requestModel.Hybrid_Request_Method == Hybrid_Request_Method_Post) || (requestModel.Hybrid_Request_Method == Hybrid_Request_Method_Get ), @"H5 端不按套路");
[HybridRequest requestWithNative:requestModel hybridRequestSuccess:^(id responseObject) {
NSDictionary *json = [NSJSONSerialization JSONObjectWithData:responseObject options:NSJSONReadingMutableLeaves error:nil];
responseCallback([self convertToJsonData:@{@"success":@"1",@"data":json}]);
} hybridRequestfail:^{
LBPLog(@"H5 call Native`s request failed");
responseCallback([self convertToJsonData:@{@"success":@"0",@"data":@""}]);
}];
}
}];针对抓包工具可以截获 HTTPS 数据的情况,我们可以对请求参数和返回内容再做一次 RSA 加密处理。
- 客户端和服务器各自生成公钥、私钥
- 互相交换公钥
- 通信流程:客户端利用服务端的公钥加密请求参数 -> 服务端收到请求后利用服务端的私钥解密,验证合法性 -> 做可能的逻辑处理(DB、缓存、ES),组装数据 -> 处理数据到合适的格式 -> 利用客户端公钥加密数据 -> 客户端收到数据后利用客户端私钥解密。(服务器主动发起的请求也是一样的逻辑)
有些人觉得利用 RSA 加密虽然可以保证数据的安全,但是因为每次都是大量字符串的运算,觉得数据量大的情况下用 RSA 加解密会非常耗时。
对,肯定耗时,所以较好的做法就是将通信双方使用的密钥(对称加密)利用 RSA 的方式交换,然后两方在通信的时候,数据内容采用对称加密的方式进行。
但是私钥在本地如何存放呢?想到的办法就是将关键密钥的字符串提高到较高的安全级别,比如这个文件用加密保存。接下来推荐一个工具,可以将代码文件进行加密保存和解密访问。
数据加密、压缩 + 自定义报文
HTTP 1.1 版本存在大量的 Header 冗余信息,网络传输利用率低。接口可以抓包并模拟请求,安全性较低。基于此可以设计一套数据的加密.
比如 AES CBC 加密 + ZIP 压缩 + 自定义报文 这套方案数据既安全又传输高效。
要做某个事情肯定需要先现状分析、可行性分析。问了几个爬虫工程师和个人经验,爬取数据主要分为:
- 从渲染好的 html 页面直接找到感兴趣的节点,然后获取对应的文本
- 去分析对应的接口数据,更加方便、精确地获取数据
从这2个角度(网页所见非所得、查接口请求没用)出发,制定了下面的反爬方案。
- 使用 HTTPS 协议
- 登陆态下,单位时间内限制掉请求次数过多(等级1),则降低频率给账号返回数据
- 登陆态下,单位时间内限制掉请求次数过多(等级2),则返回错误的数据给该账号
- 登陆态下,单位时间内限制掉请求次数过多(等级3),则封锁该账号
- 前端技术限制 (接下来是核心技术)
该方案也可以覆盖 OCR 爬取场景。OCR 的前提是页面渲染完毕,页面所需业务数据需要通过接口获取。所以基于用户行为采集分析,基于日志分析用户在时间范围内的请求频次、用户行为是否正常,如果不正常,说明可能是爬虫程序,依据用户单位时间内情况恶略程度,可以采用降频、返回错误数据、封锁账号的策略。
比如需要正确显示的数据为“19950220”
- 先按照自己需求利用相应的规则(数字乱序映射,比如正常的0对应还是0,但是乱序就是 0 <-> 1,1 <-> 9,3 <-> 8,...)制作自定义字体(ttf)
- 根据上面的乱序映射规律,求得到需要返回的数据 19950220 -> 17730220
- 对于第一步得到的字符串,依次遍历每个字符,将每个字符根据按照线性变换(y=kx+b),其中,k 为当前的月份,b 为当月的号数。线性方程的系数和常数项是根据当前的日期计算得到的。比如当前的日期为“2018-07-24”,那么线性变换的 k 为 7,b 为 24。
- 然后将变换后的每个字符串用“3.1415926”拼接返回给接口调用者。(为什么是3.1415926,因为对数字伪造反爬,所以拼接的文本肯定是数字的话不太会引起研究者的注意,但是数字长度太短会误伤正常的数据,所以用所熟悉的 Π)
比如要对1995这个字符串进行加密(当前日期为07-24)
1 -> 1*7 + 24
9 -> 9*7 + 24
5 -> 5*7 + 24
最后结果为: 1*7 + 24 + '3.1415926' + 9*7 + 24 + '3.1415926'+ 9*7 + 24 + '3.1415926'+ 5*7 + 24
后端需要根据上一步设计的协议将数据进行加密处理**。**下面以 Node.js 为例讲解后端需要做的事情
- 首先后端设置接口路由
- 获取路由后面的参数
- 根据业务需要根据 SQL 语句生成对应的数据。如果是数字部分,则需要按照上面约定的方法加以转换。
- 将生成数据转换成 JSON 返回给调用者
// 服务端:数据的加工处理
var JoinOparatorSymbol = "3.1415926";
function encode(rawData, ruleType) {
if (!isNotEmptyStr(rawData)) {
return "";
}
var date = new Date();
var year = date.getFullYear();
var month = date.getMonth() + 1;
var day = date.getDate();
var encodeData = "";
for (var index = 0; index < rawData.length; index++) {
var datacomponent = rawData[index];
if (!isNaN(datacomponent)) {
if (ruleType < 3) {
var currentNumber = rawDataMap(String(datacomponent), ruleType);
encodeData += (currentNumber * month + day) + JoinOparatorSymbol;
}
else if (ruleType == 4) {
encodeData += rawDataMap(String(datacomponent), ruleType);
}
else {
encodeData += rawDataMap(String(datacomponent), ruleType) + JoinOparatorSymbol;
}
}
else if (ruleType == 4) {
encodeData += rawDataMap(String(datacomponent), ruleType);
}
}
if (encodeData.length >= JoinOparatorSymbol.length) {
var lastTwoString = encodeData.substring(encodeData.length - JoinOparatorSymbol.length, encodeData.length);
if (lastTwoString == JoinOparatorSymbol) {
encodeData = encodeData.substring(0, encodeData.length - JoinOparatorSymbol.length);
}
}
}//字体映射处理
function rawDataMap(rawData, ruleType) {
if (!isNotEmptyStr(rawData) || !isNotEmptyStr(ruleType)) {
return;
}
var mapData;
var rawNumber = parseInt(rawData);
var ruleTypeNumber = parseInt(ruleType);
//字体文件1下的数据加密规则
if (ruleTypeNumber == 1) {
if (rawNumber == 1) {
mapData = 1;
}
else if (rawNumber == 2) {
mapData = 2;
}
else if (rawNumber == 3) {
mapData = 4;
}
else if (rawNumber == 4) {
mapData = 5;
}
else if (rawNumber == 5) {
mapData = 3;
}
else if (rawNumber == 6) {
mapData = 8;
}
else if (rawNumber == 7) {
mapData = 6;
}
else if (rawNumber == 8) {
mapData = 9;
}
else if (rawNumber == 9) {
mapData = 7;
}
else if (rawNumber == 0) {
mapData = 0;
}
}
//字体文件2下的数据加密规则
else if (ruleTypeNumber == 0) {
if (rawNumber == 1) {
mapData = 4;
}
else if (rawNumber == 2) {
mapData = 2;
}
else if (rawNumber == 3) {
mapData = 3;
}
else if (rawNumber == 4) {
mapData = 1;
}
else if (rawNumber == 5) {
mapData = 8;
}
else if (rawNumber == 6) {
mapData = 5;
}
else if (rawNumber == 7) {
mapData = 6;
}
else if (rawNumber == 8) {
mapData = 7;
}
else if (rawNumber == 9) {
mapData = 9;
}
else if (rawNumber == 0) {
mapData = 0;
}
}
//字体文件3下的数据加密规则
else if (ruleTypeNumber == 2) {
if (rawNumber == 1) {
mapData = 6;
}
else if (rawNumber == 2) {
mapData = 2;
}
else if (rawNumber == 3) {
mapData = 1;
}
else if (rawNumber == 4) {
mapData = 3;
}
else if (rawNumber == 5) {
mapData = 4;
}
else if (rawNumber == 6) {
mapData = 8;
}
else if (rawNumber == 7) {
mapData = 3;
}
else if (rawNumber == 8) {
mapData = 7;
}
else if (rawNumber == 9) {
mapData = 9;
}
else if (rawNumber == 0) {
mapData = 0;
}
}
else if (ruleTypeNumber == 3) {
if (rawNumber == 1) {
mapData = "";
}
else if (rawNumber == 2) {
mapData = "";
}
else if (rawNumber == 3) {
mapData = "";
}
else if (rawNumber == 4) {
mapData = "";
}
else if (rawNumber == 5) {
mapData = "";
}
else if (rawNumber == 6) {
mapData = "";
}
else if (rawNumber == 7) {
mapData = "";
}
else if (rawNumber == 8) {
mapData = "";
}
else if (rawNumber == 9) {
mapData = "";
}
else if (rawNumber == 0) {
mapData = "";
}
} else if (ruleTypeNumber == 4) {
var sources = ["年", "万", "业", "人", "信", "元", "千", "司", "州", "资", "造", "钱", "杭", "城", "小", "刘", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9"];
//判断字符串为汉字
if (/^[\u4e00-\u9fa5]*$/.test(rawData)) {
if (sources.indexOf(rawData) > -1) {
var currentChineseHexcod = rawData.charCodeAt(0).toString(16);
var lastCompoent;
var mapComponetnt;
var numbers = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"];
var characters = ["a", "b", "c", "d", "e", "f"]
if (currentChineseHexcod.length == 4) {
lastCompoent = currentChineseHexcod.substr(3, 1);
var locationInComponents = 0;
if (/[0-9]/.test(lastCompoent)) {
locationInComponents = numbers.indexOf(lastCompoent);
mapComponetnt = numbers[(locationInComponents + 1) % 10];
}
else if (/[a-z]/.test(lastCompoent)) {
locationInComponents = characters.indexOf(lastCompoent);
mapComponetnt = characters[(locationInComponents + 1) % 6];
}
mapData = "&#x" + currentChineseHexcod.substr(0, 3) + mapComponetnt + ";";
}
} else {
mapData = `ff${rawData}`;
}
} else {
mapData = `ff${rawData}`;
}
}
return mapData;
}
function encode(rawData, ruleType) {
if (!isNotEmptyStr(rawData)) {
return "�";
}
var date = new Date();
var year = date.getFullYear();
var month = date.getMonth() + 1;
var day = date.getDate();
var encodeData = "";
for (var index = 0; index < rawData.length; index++) {
var datacomponent = rawData[index];
if (!isNaN(datacomponent)) {
if (ruleType < 3) {
var currentNumber = rawDataMap(String(datacomponent), ruleType);
encodeData += (currentNumber * month + day) + JoinOparatorSymbol;
}
else if (ruleType == 4) {
encodeData += rawDataMap(String(datacomponent), ruleType);
}
else {
encodeData += rawDataMap(String(datacomponent), ruleType) + JoinOparatorSymbol;
}
}
else if (ruleType == 4) {
encodeData += rawDataMap(String(datacomponent), ruleType);
}
}
if (encodeData.length >= JoinOparatorSymbol.length) {
var lastTwoString = encodeData.substring(encodeData.length - JoinOparatorSymbol.length, encodeData.length);
if (lastTwoString == JoinOparatorSymbol) {
encodeData = encodeData.substring(0, encodeData.length - JoinOparatorSymbol.length);
}
}
console.log(encodeData);
return encodeData;
}// 根据路由,返回数据
module.exports = {
"GET /api/products": async (ctx, next) => {
ctx.response.type = "application/json";
ctx.response.body = {
products: products
};
},
"GET /api/solution1": async (ctx, next) => {
try {
var data = fs.readFileSync(pathname, "utf-8");
ruleJson = JSON.parse(data);
rule = ruleJson.data.rule;
} catch (error) {
console.log("fail: " + error);
}
var data = {
code: 200,
message: "success",
data: {
name: "@杭城小刘",
year: LBPEncode("1995", rule),
month: LBPEncode("02", rule),
day: LBPEncode("20", rule),
analysis : rule
}
}
ctx.set("Access-Control-Allow-Origin", "*");
ctx.response.type = "application/json";
ctx.response.body = data;
},
"GET /api/solution2": async (ctx, next) => {
try {
var data = fs.readFileSync(pathname, "utf-8");
ruleJson = JSON.parse(data);
rule = ruleJson.data.rule;
} catch (error) {
console.log("fail: " + error);
}
var data = {
code: 200,
message: "success",
data: {
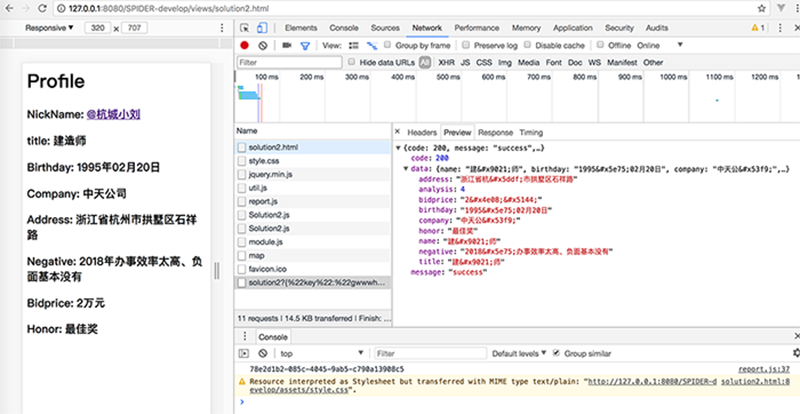
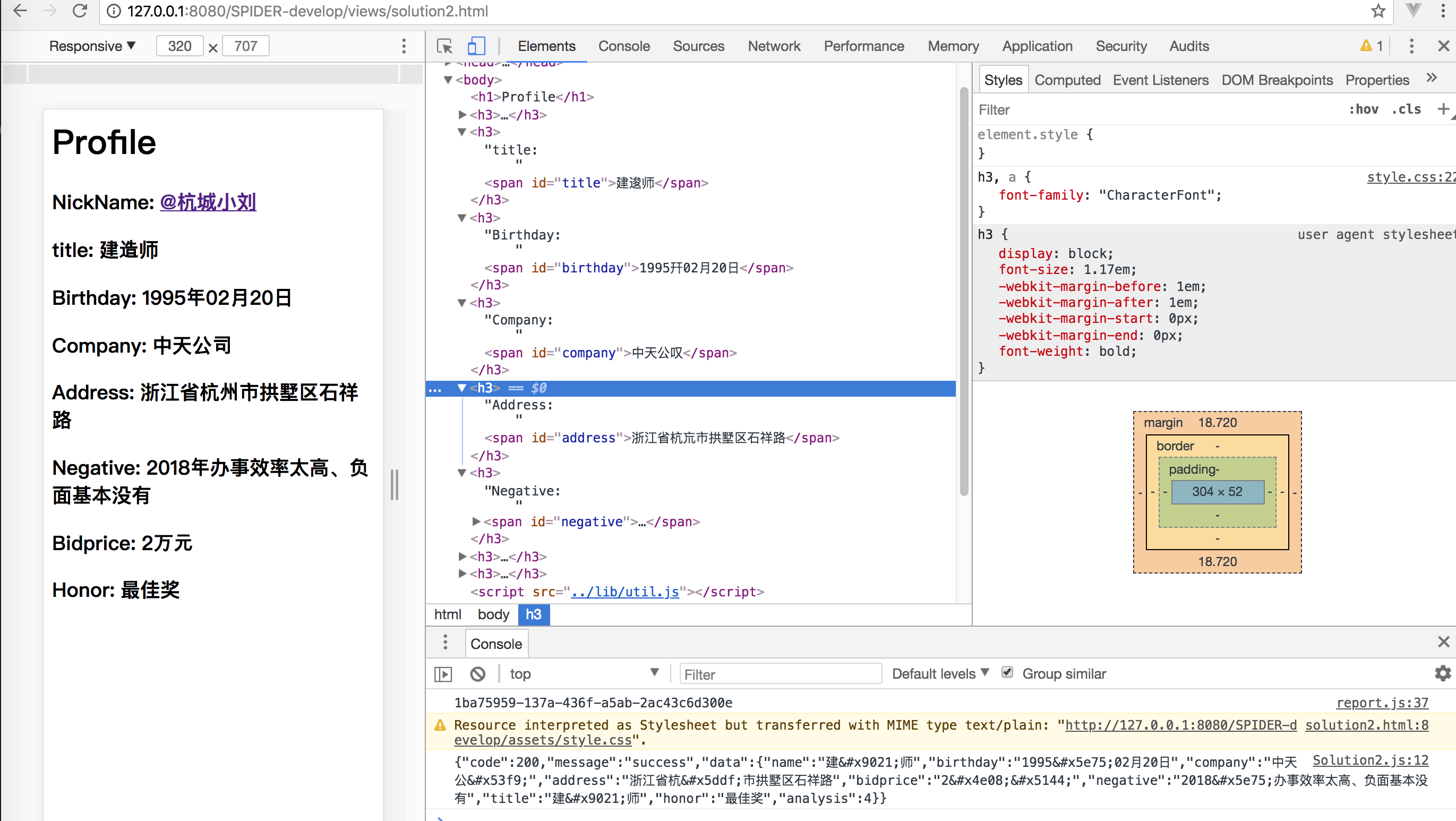
name: LBPEncode("建造师",rule),
birthday: LBPEncode("1995年02月20日",rule),
company: LBPEncode("中天公司",rule),
address: LBPEncode("浙江省杭州市拱墅区石祥路",rule),
bidprice: LBPEncode("2万元",rule),
negative: LBPEncode("2018年办事效率太高、负面基本没有",rule),
title: LBPEncode("建造师",rule),
honor: LBPEncode("最佳奖",rule),
analysis : rule
}
}
ctx.set("Access-Control-Allow-Origin", "*");
ctx.response.type = "application/json";
ctx.response.body = data;
},
"POST /api/products": async (ctx, next) => {
var p = {
name: ctx.request.body.name,
price: ctx.request.body.price
};
products.push(p);
ctx.response.type = "application/json";
ctx.response.body = p;
}
};前端拿到数据后再解密,解密后根据自定义的字体 Render 页面。
- 先将拿到的字符串按照“3.1415926”拆分为数组
- 对数组的每1个数据,按照“线性变换”(y=kx+b,k和b同样按照当前的日期求解得到),逆向求解到原本的值。
- 将步骤2的的到的数据依次拼接,再根据 ttf 文件 Render 页面上。
// 前端:CSS应用字体文字 style.css
@font-face {
font-family: "NumberFont";
src: url('http://127.0.0.1:8080/Util/analysis');
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
@font-face {
font-family: "CharacterFont";
src: url('http://127.0.0.1:8080/Util/map');
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
h2 {
font-family: "NumberFont";
}
h3,a{
font-family: "CharacterFont";
}// 前端根据服务端返回的数据逆向解密
$("#year").html(getRawData(data.year,log));
// util.js
var JoinOparatorSymbol = "3.1415926";
function isNotEmptyStr($str) {
if (String($str) == "" || $str == undefined || $str == null || $str == "null") {
return false;
}
return true;
}
function getRawData($json,analisys) {
$json = $json.toString();
if (!isNotEmptyStr($json)) {
return;
}
var date= new Date();
var year = date.getFullYear();
var month = date.getMonth() + 1;
var day = date.getDate();
var datacomponents = $json.split(JoinOparatorSymbol);
var orginalMessage = "";
for(var index = 0;index < datacomponents.length;index++){
var datacomponent = datacomponents[index];
if (!isNaN(datacomponent) && analisys < 3){
var currentNumber = parseInt(datacomponent);
orginalMessage += (currentNumber - day)/month;
} else if(analisys == 4){
orginalMessage += $json.split("ff").filter((idx, value) => idx !== '' ).join("");
} else {
//其他情况待续,本 Demo 根据本人在研究反爬方面的技术并实践后持续更新
}
}
return orginalMessage;
}比如后端返回的是323.14743.14743.1446,根据我们约定的算法,可以的到结果为1773
根据 ttf 文件 Render 页面
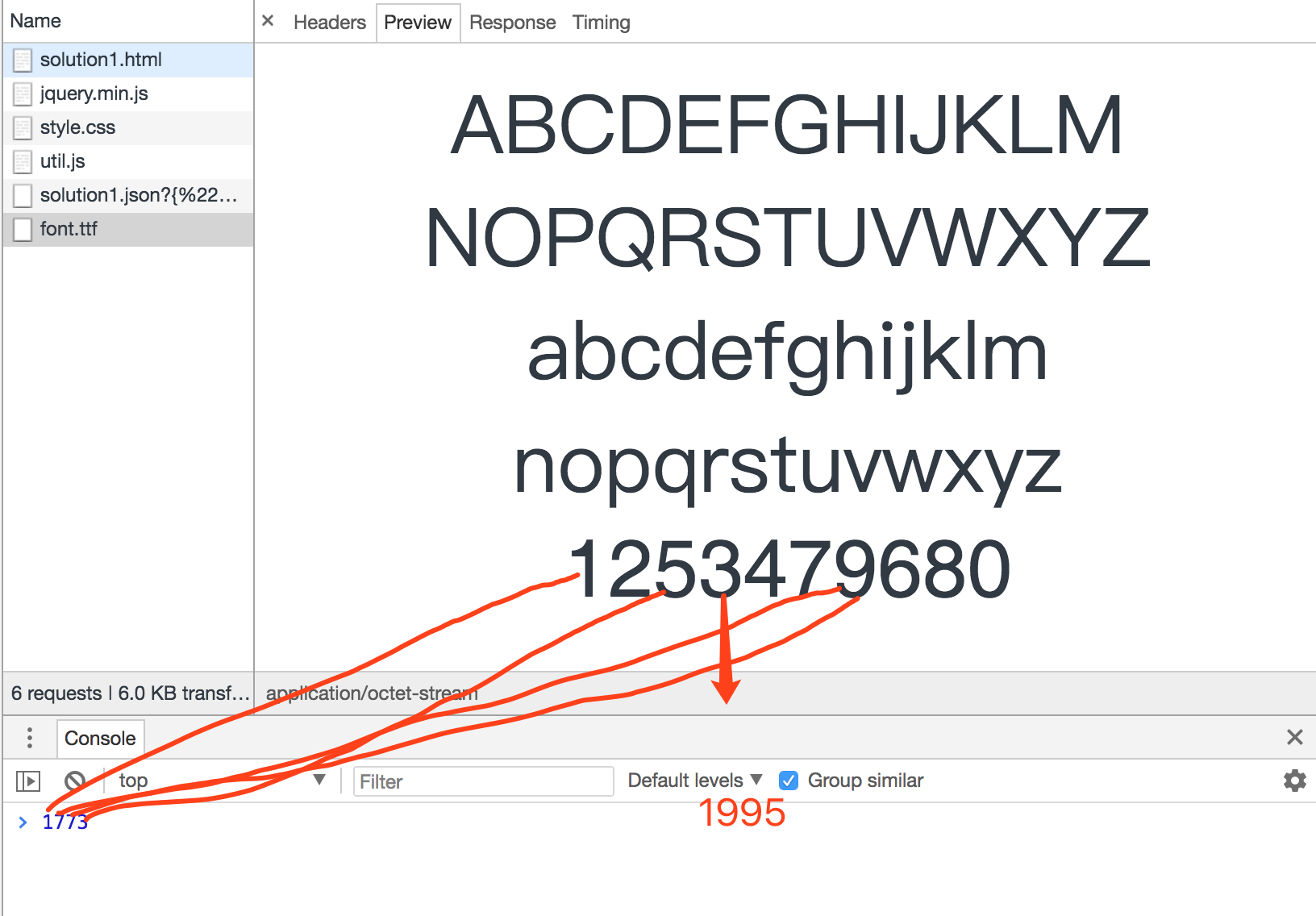 上面计算的到的1773,然后根据ttf文件,页面看到的就是1995
上面计算的到的1773,然后根据ttf文件,页面看到的就是1995
为了防止爬虫人员查看 JS 研究问题(假设一般的爬虫工程师不会是资深前端开发,对于混淆的 JS 会头大),所以对 JS 的文件进行了加密处理。如果你的技术栈是 Vue 、React 等,webpack 为你提供了 JS 加密的插件,也很方便处理
个人觉得这种方式还不是很安全。于是想到了各种方案的组合拳。比如
上述方案对于一个前端经验丰富的爬虫开发者来说,上面的方案可能还是会存在被破解的可能,所以在之前的基础上做了升级版本
虽然请求的链接是同一个,但是根据当前的时间戳的最后一个数字取模,比如 Demo 中对4取模,有4种值 0、1、2、3。这4种值对应不同的字体文件,所以当爬虫绞尽脑汁爬到1种情况下的字体时,没想到再次请求,字体文件的规则变掉了
前面的规则是字体问题乱序,但是只是数字映射规则打乱掉。比如 1 -> 4, 5 -> 8。其实可以针对数据做数字映射乱序和 unicode 乱序2种策略。接下来的套路就是每个数字对应一个 unicode 码 ,然后制作自己需要的字体,可以是 .ttf、.woff 等等。

对于你站点频率最高的词云,做一个汉字映射,也就是自定义字体文件,步骤跟数字一样。先将常用的汉字生成对应的 ttf 文件;根据下面提供的链接,将 ttf 文件转换为 svg 文件,然后在下面的“字体映射”链接点进去的网站上面选择前面生成的 svg 文件,将svg文件里面的每个汉字做个映射,也就是将汉字专为 unicode 码(注意这里的 unicode 码不要去在线直接生成,因为直接生成的东西也就是有规律的。我给的做法是先用网站生成,然后将得到的结果做个简单的变化,比如将“e342”转换为 “e231”);然后接口返回的数据按照我们的这个字体文件的规则反过去映射出来。
将网站的重要字体,将 html 部分生成图片,这样子爬虫要识别到需要的内容成本就很高了,需要用到 OCR。效率也很低。所以可以拦截钓一部分的爬虫
看到携程的技术分享“反爬的最高境界就是 Canvas 的指纹,原理是不同的机器不同的硬件对于 Canvas 画出的图总是存在像素级别的误差,因此我们判断当对于访问来说大量的 canvas 的指纹一致的话,则认为是爬虫,则可以封掉它。
我将关键步骤做成了一个 checklist,你可以按照下面的步骤来落地。
- 先根据你们的产品找到常用的关键词,生成词云
- 根据词云,将每个字生成对应的 unicode 码
- 将词云包括的汉字做成一个字体库
- 将字体库 .ttf 做成 svg 格式,然后上传到 icomoon 制作自定义的字体,但是有规则,比如 “年” 对应的 unicode 码是 “\u5e74” ,但是我们需要做一个 恺撒加密 ,比如我们设置 偏移量 为1,那么经过恺撒加密 “年”对应的 unicode 码是“\u5e75” 。利用这种规则制作我们需要的字体库
- 在每次调用接口的时候服务端做的事情是:服务端封装某个方法,将数据经过方法判断是不是在词云中,如果是词云中的字符,利用规则(找到汉字对应的 unicode 码,再根据凯撒加密,设置对应的偏移量,Demo 中为1,将每个汉字加密处理)加密处理后返回数据
- 客户端做的事情:
- 先引入我们前面制作好的汉字字体库
- 调用接口拿到数据,显示到对应的 Dom 节点上
- 如果是汉字文本,我们将对应节点的 css 类设置成汉字类,该类对应的 font-family 是我们上面引入的汉字字体库
传送门
- 页面上看到的数据跟审查元素看到的结果不一致
- 去查看接口数据跟审核元素和界面看到的三者不一致
- 页面每次刷新之前得出的结果更不一致
- 对于数字和汉字的处理手段都不一致
这几种组合拳打下来。对于一般的爬虫就放弃了
具体代码可以访问 Demo
// 客户端。先查看本机 ip
// 在 Demo/Spider-develop/Solution/Solution1.js 和 Demo/Spider-develop/Solution/Solution2.js 里面将接口地址修改为本机 ip
// 服务端 先安装依赖
$ cd REST/
$ npm install
$ node app.js
$ cd Demo
$ node file-Server.js
// Server is runnig at http://127.0.0.1:8080/



其实经常有很多来自不同端的开发者和我聊安全问题。交流下来发现有些人可以明白设计的有点,有些人还是没有明白。这里我总结下:
-
爬虫与反爬技术,没有终点。都是需要在衡量 ROI 的情况下, 找到符合业务、技术现状的“最佳”解决方案
-
每次刷新,页面显示的数据固定,但是网络接口数据、审查元素看到的数据,都是不断变化的。且汉字字符、数字字符都不一样
-
OCR 可以爬取数据,但是成本较高。同样可以利用其他策略,比如同一个浏览器 canvas 指纹的情况下,短时间多次请求某些数据,则认为是非法行为,可以延迟返回数据、返回错误数据、账号封锁等策略。
OCR 的对策也有,比如根据单位时间内限制掉请求次数划分等级。OCR 的前提是页面渲染完毕,页面所需业务数据需要通过接口获取。所以基于用户行为采集分析,基于日志分析用户在时间范围内的请求频次、用户行为是否正常,如果不正常,说明可能是爬虫程序,依据用户单位时间内情况恶略程度,可以采用降频、返回错误数据、封锁账号的策略。
爬虫工程师要么从接口爬取数据、要么观察分析页面结构找到目标数据的 xPath 获取 DOM 节点对应的数据。从这2个角度出发,当前的设计方案解决了该问题
可能有些人就会问:爬虫工程师一般会不需要关心技术如何实现,直接用无头浏览器“原封不动”的去请求,直接拿到数据不就好了
其实你仔细想想,无头浏览器是可以去请求,但是本质上就是对数据的只读而已。因为该方案的设计就是基于:字体文件映射 + 数据线性加密。无头浏览器拿到的数据其实和审查元素看到的 DOM 节点内的数据是一个效果的。所以是无效数据。
如果你也是大前端路上的一名修行者,可以加我 Wechat:704568245,拉你入群一起在「大前端自习室」学习交流。