diff --git a/src/.gcloudignore b/src/.gcloudignore
index 432e34996ed..85e62c0bcfd 100644
--- a/src/.gcloudignore
+++ b/src/.gcloudignore
@@ -6,7 +6,11 @@
# For more information, run:
# $ gcloud topic gcloudignore
#
+# Note we are also using this for zip ignore in deploy.sh, so have to be a little
+# bit more verbose than gcloud demands, to exclude items
+
.gcloudignore
+
# If you would like to upload your .git directory, .gitignore file or files
# from your .gitignore file, remove the corresponding line
# below:
@@ -16,8 +20,24 @@
# Python pycache:
__pycache__/
.pytest_cache/
+__pycache__/*
+.pytest_cache/*
+**/__pycache__/*
+**/.pytest_cache/*
+*.pyc
+**/*.pyc
+
# Ignored by the build system
/setup.cfg
env/
+env/*
node_modules/
+node_modules/*
+static/html
+static/html/*
+.DS_Store
+**/.DS_Store
+Dockerfile
+.dockerignore
+deployed.zip
diff --git a/src/.gitignore b/src/.gitignore
index 19ecec6e6af..7913584e3ea 100644
--- a/src/.gitignore
+++ b/src/.gitignore
@@ -1,4 +1,8 @@
.idea/
.vscode/
node_modules/
+templates/*/*/chapters/
+templates/*/*/ebook.html
+templates/sitemap.xml
static/html/
+deployed.zip
diff --git a/src/README.md b/src/README.md
index f753c72648f..09324ec46a5 100644
--- a/src/README.md
+++ b/src/README.md
@@ -50,7 +50,7 @@ ptw
The chapter generation is dependent on nodejs, so you will need to have [nodejs](https://nodejs.org/en/) installed as well. All of the following commands must be run from within the `src` directory by executing `cd src` first.
-Note this is run automatically by a GitHub Action on merges to main, so does not need to be run manually.
+Note this is run automatically by a GitHub Action on merges to main, so does not need to be run manually unless you want to run the site locally.
Install the dependencies:
@@ -152,28 +152,27 @@ _Make sure you have generated the ebooks PDFs first in the main branch, by runni
gcloud init
```
-3. Stage the changes locally:
-
-```
-git checkout production
-git status
-git pull
-git pull origin main
-git push
-```
-
- - Check out the `production` branch
- - Run `git status` to ensure you don't have any uncommitted changes locally
- - Merge any remote changes (both origin/production and origin/main branches)
- - Push the merge-commit back up to origin/production
-
-4. Browse the website locally as one final QA test, then deploy the changes live:
+3. Deploy the site:
```
npm run deploy
```
-5. Browse the website in production to verify that the new changes have taken effect
+The deploy script will do the following:
+- Ask you to confirm you've updated the eBooks via GitHub Actions
+- Switch to the production branch
+- Merge changes from main
+- Do a clean install
+- Run the tests
+- Ask you to complete any local tests and confirm good to deploy
+- Ask for a version number (suggesing the last verision tagged and incrementing the patch)
+- Tag the release (after asking you for the version number to use)
+- Generate a `deploy.zip` file of what has been deployed
+- Deploy to GCP
+- Push changes to `production` branch on GitHub
+- Ask you to update the release section of GitHub
+
+4. Browse the website in production to verify that the new changes have taken effect. Not we have 3 hour caching so add random query params to pages to ensure you get latest version.
## Developing in Docker
diff --git a/src/package.json b/src/package.json
index 0ccfa389c45..cae3983b7b7 100644
--- a/src/package.json
+++ b/src/package.json
@@ -17,7 +17,7 @@
"test": "node ./tools/test",
"generate": "node ./tools/generate",
"ebooks": "node ./tools/generate/generate_ebook_pdfs",
- "deploy": "echo \"Y\" | gcloud app deploy --project webalmanac --stop-previous-version"
+ "deploy": "./tools/scripts/deploy.sh"
},
"devDependencies": {
"ejs": "^3.1.5",
diff --git a/src/templates/en/2019/chapters/accessibility.html b/src/templates/en/2019/chapters/accessibility.html
deleted file mode 100644
index bf3cf305de2..00000000000
--- a/src/templates/en/2019/chapters/accessibility.html
+++ /dev/null
@@ -1,381 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":9,"title":"Accessibility","description":"Accessibility chapter of the 2019 Web Almanac covering ease of reading, media, ease of navigation, and compatibility with assistive technologies.","authors":["nektarios-paisios","obto","kleinab"],"reviewers":["ljme"],"translators":null,"discuss":"1764","results":"https://docs.google.com/spreadsheets/d/16JGy-ehf4taU0w4ABiKjsHGEXNDXxOlb__idY8ifUtQ/","queries":"09_Accessibility","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-02T00:00:00.000Z","chapter":"accessibility"} %} {% block index %}
-
Accessibility on the web is essential for an inclusive and equitable society. As more of our social and work lives move to the online world, it becomes even more important for people with disabilities to be able to participate in all online interactions without barriers. Just as building architects can create or omit accessibility features such as wheelchair ramps, web developers can help or hinder the assistive technology users rely on.
-
When thinking about users with disabilities, we should remember that their user journeys are often the same—they just use different tools. These popular tools include but are not limited to: screen readers, screen magnifiers, browser or text size zooming, and voice controls.
-
Often, improving the accessibility of your site has benefits for everyone. While we typically think of people with disabilities as people with a permanent disability, anybody can have a temporary or situational disability. For example, someone might be permanently blind, have a temporary eye infection, or, situationally, be outside under a glaring sun. All of these might explain why someone is unable to see their screen. Everyone has situational disabilities, and so improving the accessibility of your web page will improve the experience of all users in any situation.
-
The Web Content Accessibility Guidelines (WCAG) advise on how to make a website accessible. These guidelines were used as the basis for our analysis. However, in many cases it is difficult to programmatically analyze the accessibility of a website. For instance, the web platform provides several ways of achieving similar functional results, but the underlying code powering them may be completely different. Therefore, our analysis is just an approximation of overall web accessibility.
-
We've split up our most interesting insights into four categories: ease of reading, media on the web, ease of page navigation, and compatibility with assistive technologies.
-
No significant difference in accessibility was found between desktop and mobile during testing. As a result, all of our presented metrics are the result of our desktop analysis unless otherwise stated.
The primary goal of a web page is to deliver content users want to engage with. This content might be a video or an assortment of images, but many times, it's simply the text on the page. It's extremely important that our textual content is legible to our readers. If visitors can't read a web page, they can't engage with it, which ends up with them leaving. In this section we'll look at three areas in which sites struggled.
There are many cases where visitors to your site may not be able see it perfectly. Visitors may be colorblind and unable to distinguish between the font and background color (1 in every 12 men and 1 in 200 women of European descent). Perhaps they're simply reading while the sun is out and creating tons of glare on their screen—significantly impairing their vision. Or maybe they've just grown older and their eyes can't distinguish colors as well as they used to.
-
In order to make sure your website is readable under these conditions, making sure your text has sufficient color contrast with its background is critical. It is also important to consider what contrasts will be shown when the colors are converted to grayscale.
Four colored boxes of brown and gray shades with white text overlaid inside creating two columns. The left column says Too lightly colored and has the brown background color written as #FCA469. The right column says Recommended and the brown background color is written as #BD5B0E. The top box in each column has an brown background with white text #FFFFFF and the bottom box has a gray background with white text #FFFFFF. The grayscale equivalents are #B8B8B8 and #707070 respectively. Courtesy of LookZook
- Figure 1. Example of what text with insufficient color contrast looks like. Courtesy of LookZook
-
-
Only 22.04% of sites gave all of their text sufficient color contrast. Or in other words: 4 out of every 5 sites have text which easily blends into the background, making it unreadable.
-
Note that we weren't able to analyze any text inside of images, so our reported metric is an upper-bound of the total number of websites passing the color contrast test.
Using a legible font size and target size helps users read and interact with your website. But even websites perfectly following all of these guidelines can't meet the specific needs of each visitor. This is why device features like pinch-to-zoom and scaling are so important: they allow users to tweak your pages so their needs are met. Or in the case of particularly inaccessible sites using tiny fonts and buttons, it gives users the chance to even use the site.
-
There are rare cases when disabling scaling is acceptable, like when the page in question is a web-based game using touch controls. If left enabled in this case, players' phones will zoom in and out every time the player taps twice on the game, ironically making it inaccessible.
-
Because of this, developers are given the ability to disable this feature by setting one of the following two properties in the meta viewport tag:
-
-
-
user-scalable set to 0 or no
-
-
-
maximum-scale set to 1, 1.0, etc
-
-
-
Sadly, developers have misused this so much that almost one out of every three sites on mobile (32.21%) disable this feature, and Apple (as of iOS 10) no longer allows web-developers to disable zooming. Mobile Safari simply ignores the tag. All sites, no matter what, can be zoomed and scaled on newer iOS devices.
Vertical measuring percentage data, ranging from 0 to 80 in increments of 20, vs. the device type, grouped into desktop and mobile. Desktop enabled: 75.46%; Desktop disabled 24.54%; Mobile enabled: 67.79%; Mobile disabled: 32.21%.
- Figure 2. Percentage of sites that disable zooming and scaling vs device type.
-
-
The web is full of wondrous amounts of content. However, there's a catch: over 1,000 different languages exist in the world, and the content you're looking for may not be written in one you are fluent in. In recent years, we've made great strides in translation technologies and you probably have used one of them on the web (e.g., Google translate).
-
- In order to facilitate this feature, the translation engines need to know what language your pages are written in. This is done by using the lang attribute. Without this, computers must guess what language your page is written in. As you might imagine, this leads to many errors, especially when pages use multiple languages (e.g., your page navigation is in English, but the post content is in Japanese).
-
-
This problem is even more pronounced on text-to-speech assistive technologies like screen readers, where if no language has been specified, they tend to read the text in the default user language.
-
Of the pages analyzed, 26.13% do not specify a language with the lang attribute. This leaves over a quarter of pages susceptible to all of the problems described above. The good news? Of sites using the lang attribute, they specify a valid language code correctly 99.68% of the time.
Some users, such as those with cognitive disabilities, have difficulties concentrating on the same task for long periods of time. These users don't want to deal with pages that include lots of motion and animations, especially when these effects are purely cosmetic and not related to the task at hand. At a minimum, these users need a way to turn all distracting animations off.
-
- Unfortunately, our findings indicate that infinitely looping animations are quite common on the web, with 21.04% of pages using them through infinite CSS animations or <marquee> and <blink> elements.
-
-
It is interesting to note however, that the bulk of this problem appears to be a few popular third-party stylesheets which include infinitely looping CSS animations by default. We were unable to determine how many pages actually used these animation styles.
Images are an essential part of the web experience. They can tell powerful stories, grab attention, and elicit emotion. But not everyone can see these images that we rely on to tell parts of our stories. Thankfully, in 1995, HTML 2.0 provided a solution to this problem: the alt attribute. The alt attribute provides web developers with the capability of adding a textual description to the images we use, so that when someone is unable to see our images (or the images are unable to load), they can read the alt text for a description. The alt text fills them in on the part of the story they would have otherwise missed.
-
Even though alt attributes have been around for 25 years, 49.91% of pages still fail to provide alt attributes for some of their images, and 8.68% of pages never use them at all.
Just as images are powerful storytellers, so too are audio and video in grabbing attention and expressing ideas. When audio and video content is not captioned, users who cannot hear this content miss out on large portions of the web. One of the most common things we hear from users who are Deaf or hard of hearing is the need to include captions for all audio and video content.
-
- Of sites using <audio> or <video> elements, only 0.54% provide captions (as measured by those that include the <track> element). Note that some websites have custom solutions for providing video and audio captions to users. We were unable to detect these and thus the true percentage of sites utilizing captions is slightly higher.
-
When you open the menu in a restaurant, the first thing you probably do is read all of the section headers: appetizers, salads, main course, and dessert. This allows you to scan a menu for all of the options and jump quickly to the dishes most interesting to you. Similarly, when a visitor opens a web page, their goal is to find the information they are most interested in—the reason they came to the page in the first place. In order to help users find their desired content as fast as possible (and prevent them from hitting the back button), we try to separate the contents of our pages into several visually distinct sections, for example: a site header for navigation, various headings in our articles so users can quickly scan them, a footer for other extraneous resources, and more.
-
While this is exceptionally important, we need to take care to mark up our pages so our visitors' computers can perceive these distinct sections as well. Why? While most readers use a mouse to navigate pages, many others rely on keyboards and screen readers. These technologies rely heavily on how well their computers understand your page.
Headings are not only helpful visually, but to screen readers as well. They allow screen readers to quickly jump from section to section and help indicate where one section ends and another begins.
-
In order to avoid confusing screen reader users, make sure you never skip a heading level. For example, don't go straight from an H1 to an H3, skipping the H2. Why is this a big deal? Because this is an unexpected change that will cause a screen reader user to think they've missed a piece of content. This might cause them to start looking all over for what they may have missed, even if there isn't anything missing. Plus, you'll help all of your readers by keeping a more consistent design.
-
With that being said, here are our results:
-
-
89.36% of pages use headings in some fashion. Awesome.
Vertical bar chart measuring percentage data, ranging from 0 to 80 in increments of 20, vs. bars representing each heading level h1 through h6. H1: 63.25%; H2: 67.86%; H3: 58.63%; H4: 36.38%; H5: 14.64%; H6: 6.91%.
A main landmark indicates to screen readers where the main content of a web page starts so users can jump right to it. Without this, screen reader users have to manually skip over your navigation every single time they go to a new page within your site. Obviously, this is rather frustrating.
-
We found only one in every four pages (26.03%) include a main landmark. And surprisingly, 8.06% of pages erroneously contained more than one main landmark, leaving these users guessing which landmark contains the actual main content.
Vertical bar chart displaying percentage data, ranging from 0 to 80 in increments of 20, vs. bars representing the number of “main” landmarks per page from 0 to 4. Source: HTTP Archive (July 2019). Zero: 73.97%; One: 17.97%; Two: 7.41%; Three: 0.15%; 4: 0.06%.
- Figure 4. Percent of pages by their number of "main" landmarks.
-
-
Since HTML5 was released in 2008, and made the official standard in 2014, there are many HTML elements to aid computers and screen readers in understanding our page layout and structure.
-
- Elements like <header>, <footer>, <navigation>, and <main> indicate where specific types of content live and allow users to quickly jump around your page. These are being used widely across the web, with most of them being used on over 50% of pages (<main> being the outlier).
-
-
- Others like <article>, <hr>, and <aside> aid readers in understanding a page's main content. For example, <article> says where one article ends and another begins. These elements are not used nearly as much, with each sitting at around 20% usage. Not all of these belong on every web page, so this isn't necessarily an alarming statistic.
-
-
All of these elements are primarily designed for accessibility support and have no visual effect, which means you can safely replace existing elements with them and suffer no unintended consequences.
Vertical bar chart with bars for each element type vs percent of pages ranging from 0 to 60 in increments of 20. nav: 53.94%; header: 54.82%; footer: 55.92%; main: 18.47%; aside: 16.99%; article: 22.59%; hr: 19.1%; section: 36.55%.
- Figure 5. Usage of various HTML semantic elements.
-
-
Many popular screen readers also allow users to navigate by quickly jumping through links, lists, list items, iframes, and form fields like edit fields, buttons, and list boxes. Figure 6 details how often we saw pages using these elements.
Vertical bar chart with bars for each element type vs percent of pages ranging from 0 to 100 in increments of 25. a: 98.22%; ul: 88.62%; input: 76.63%; iframe: 60.39%; button: 56.74%; select: 19.68%; textarea: 12.03%.
- Figure 6. Other HTML elements used for navigation.
-
-
A skip link is a link placed at the top of a page which allows screen readers or keyboard-only users to jump straight to the main content. It effectively "skips" over all navigational links and menus at the top of the page. Skip links are especially useful to keyboard users who don't use a screen reader, as these users don't usually have access to other modes of quick navigation (like landmarks and headings). 14.19% of the pages in our sample were found to have skip links.
-
If you'd like to see a skip link in action for yourself, you can! Just do a quick Google search and hit "tab" as soon as you land on the search result pages. You'll be greeted with a previously hidden link just like the one in Figure 7.
Screenshot of Google search results page for search 'http archive'. The visible 'Skip to main content' link is surrounded by a blue focus highlight and a yellow overlaid box with a red arrow pointing to the skip link reads 'A skip link on google.com'.
- Figure 7. What a skip link looks like on google.com.
-
-
In fact you don't need to even leave this site as we use them here too!
-
It's hard to accurately determine what a skip link is when analyzing sites. For this analysis, if we found an anchor link (href=#heading1) within the first 3 links on the page, we defined this as a page with a skip link. So 14.19% is a strict upper bound.
Activating an element on the page, like a link or button.
-
Giving a certain element on the page focus. For example, shifting focus to a certain input on the page, allowing a user to then start typing into it.
-
-
- Adoption of aria-keyshortcuts was almost absent from our sample, with it only being used on 159 sites out of over 4 million analyzed. The accesskey attribute was used more frequently, being found on 2.47% of web pages (1.74% on mobile). We believe the higher usage of shortcuts on desktop is due to developers expecting mobile sites to only be accessed via a touch screen and not a keyboard.
-
-
What is especially surprising here is 15.56% of mobile and 13.03% of desktop sites which use shortcut keys assign the same shortcut to multiple different elements. This means browsers have to guess which element should own this shortcut key.
Tables are one of the primary ways we organize and express large amounts of data. Many assistive technologies like screen readers and switches (which may be used by users with motor disabilities) might have special features allowing them to navigate this tabular data more efficiently.
Depending on the way a particular table is structured, the use of table headers makes it easier to read across columns or rows without losing context on what data that particular column or row refers to. Having to navigate a table lacking in header rows or columns is a subpar experience for a screen reader user. This is because it's hard for a screen reader user to keep track of their place in a table absent of headers, especially when the table is quite large.
-
- To mark up table headers, simply use the <th> tag (instead of <td>), or either of the ARIA columnheader or rowheader roles. Only 24.5% of pages with tables were found to markup their tables with either of these methods. So the three quarters of pages choosing to include tables without headers are creating serious challenges for screen reader users.
-
-
Using <th> and <td> was by far the most commonly used method for marking up table headers. The use of columnheader and rowheader roles was almost non-existent with only 677 total sites using them (0.058%).
- Table captions via the <caption> element are helpful in providing more context for readers of all kinds. A caption can prepare a reader to take in the information your table is sharing, and it can be especially useful for people who may get distracted or interrupted easily. They are also useful for people who may lose their place within a large table, such as a screen reader user or someone with a learning or intellectual disability. The easier you can make it for readers to understand what they're analyzing, the better.
-
-
Despite this, only 4.32% of pages with tables provide captions.
One of the most popular and widely used specifications for accessibility on the web is the Accessible Rich Internet Applications (ARIA) standard. This standard offers a large array of additional HTML attributes to help convey the purpose behind visual elements (i.e., their semantic meaning), and what kinds of actions they're capable of.
-
Using ARIA correctly and appropriately can be challenging. For example, of pages making use of ARIA attributes, we found 12.31% have invalid values assigned to their attributes. This is problematic because any mistake in the use of an ARIA attribute has no visual effect on the page. Some of these errors can be detected by using an automated validation tool, but generally they require hands-on use of real assistive software (like a screen reader). This section will examine how ARIA is used on the web, and specifically which parts of the standard are most prevalent.
The "role" attribute is the most important attribute in the entire ARIA specification. It's used to inform the browser what the purpose of a given HTML element is (i.e., the semantic meaning). For example, a <div> element, visually styled as a button using CSS, should be given the ARIA role of button.
-
Currently, 46.91% of pages use at least one ARIA role attribute. In Figure 9 below, we've compiled a list of the top ten most widely used ARIA role values.
Vertical bar chart with bars for each role type vs percent of sites using ranging from 0 to 25 in increments of 5. Navigation: 20.4%; search: 15.49%; main: 14.39%; banner: 13.62%; contentinfo: 11.23%; button: 10.59%; dialog: 7.87%; complementary: 6.06%; menu: 4.71%; form: 3.75%
Looking at the results in Figure 9, we found two interesting insights: updating UI frameworks may have a profound impact on accessibility across the web, and the impressive number of sites attempting to make dialogs accessible.
The top 5 roles, all appearing on 11% of pages or more, are landmark roles. These are used to aid navigation, not to describe the functionality of a widget, such as a combo box. This is a surprising result because the main motivator behind the development of ARIA was to give web developers the capability to describe the functionality of widgets made of generic HTML elements (like a <div>).
-
We suspect that some of the most popular web UI frameworks include navigation roles in their templates. This would explain the prevalence of landmark attributes. If this theory is correct, updating popular UI frameworks to include more accessibility support may have a huge impact on the accessibility of the web.
-
Another result pointing towards this conclusion is the fact that more "advanced" but equally important ARIA attributes don't appear to be used at all. Such attributes cannot easily be deployed through a UI framework because they might need to be customized based on the structure and the visual appearance of every site individually. For example, we found that the posinset and setsize attributes were only used on 0.01% of pages. These attributes convey to a screen reader user how many items are in a list or menu and which item is currently selected. So, if a visually impaired user is trying to navigate through a menu, they might hear index announcements like: "Home, 1 of 5", "Products, 2 of 5", "Downloads, 3 of 5", etc.
The relative popularity of the dialog role stands out because making dialogs accessible for screen reader users is very challenging. It is therefore exciting to see around 8% of the analyzed pages stepping up to the challenge. Again, we suspect this might be due to the use of some UI frameworks.
The most common way that a user interacts with a website is through its controls, such as links or buttons to navigate the website. However, many times screen reader users are unable to tell what action a control will perform once activated. Often the reason this confusion occurs is due to the lack of a textual label. For example, a button displaying a left-pointing arrow icon to signify it's the "Back" button, but containing no actual text.
-
Only about a quarter (24.39%) of pages that use buttons or links include textual labels with these controls. If a control is not labeled, a screen reader user might read something generic, such as the word "button" instead of a meaningful word like "Search".
-
Buttons and links are almost always included in the tab order and thus have extremely high visibility. Navigating through a website using the tab key is one of the primary ways through which users who use only the keyboard explore your website. So a user is sure to encounter your unlabeled buttons and links if they are moving through your website using the tab key.
- Filling out forms is a task many of us do every single day. Whether we're shopping, booking travel, or applying for a job, forms are the main way users share information with web pages. Because of this, ensuring your forms are accessible is incredibly important. The simplest means of accomplishing this is by providing labels (via the <label> element, aria-label or aria-labelledby) for each of your inputs. Sadly, only 22.33% of pages provide labels for all their form inputs, meaning 4 out of every 5 pages have forms that may be very difficult to fill out.
-
When we come across a field with a big red asterisk next to it, we know it's a required field. Or when we hit submit and are informed there were invalid inputs, anything highlighted in a different color needs to be corrected and then resubmitted. However, people with low or no vision cannot rely on these visual cues, which is why the HTML input attributes required, aria-required, and aria-invalid are so important. They provide screen readers with the equivalent of red asterisks and red highlighted fields. As a nice bonus, when you inform browsers what fields are required, they'll validate parts of your forms for you. No JavaScript required.
-
Of pages using forms, 21.73% use required or aria-required when marking up required fields. Only one in every five sites make use of this. This is a simple step to make your site accessible, and unlocks helpful browser features for all users.
-
We also found 3.52% of sites with forms make use of aria-invalid. However, since many forms only make use of this field once incorrect information is submitted, we could not ascertain the true percentage of sites using this markup.
- IDs can be used in HTML to link two elements together. For example, the <label> element works this way. You specify the ID of the input field this label is describing and the browser links them together. The result? Users can now click on this label to focus on the input field, and screen readers will use this label as the description.
-
-
Unfortunately, 34.62% of sites have duplicate IDs, which means on many sites the ID specified by the user could refer to multiple different inputs. So when a user clicks on the label to select a field, they may end up selecting something different than they intended. As you might imagine, this could have negative consequences in something like a shopping cart.
-
- This issue is even more pronounced for screen readers because their users may not be able to visually double check what is selected. Plus, many ARIA attributes, such as aria-describedby and aria-labelledby, work similarly to the label element detailed above. So to make your site accessible, removing all duplicate IDs is a good first step.
-
People with disabilities are not the only ones with accessibility needs. For example, anyone who has suffered a temporary wrist injury has experienced the difficulty of tapping small tap targets. Eyesight often diminishes with age, making text written in small fonts challenging to read. Finger dexterity is not the same across age demographics, making tapping interactive controls or swiping through content on mobile websites more difficult for a sizable percentage of users.
-
Similarly, assistive software is not only geared towards people with disabilities but for improving the day to day experience of everyone:
-
-
The recent popularity of voice assistance, both on mobile devices and in the home, has demonstrated that controlling a computing device using voice commands is both desirable and essential for many users. Voice commands like these used to only be an accessibility feature but are now turning into a mainstream product.
-
Drivers would benefit from a screen reading feature that, while they keep their eyes on the road, reads long pieces of text like news stories aloud.
-
Captions are enjoyed not only by people who cannot hear a video but also by people who want to watch a video in a loud restaurant or in a library.
-
-
Once a website is built, it's often hard to retrofit accessibility on top of existing site structures and widgets. Accessibility isn't something that can be easily sprinkled on afterwards, rather it needs to be part of the design and implementation process. Unfortunately, either through a lack of awareness or easy-to-use testing tools, many developers are not familiar with the needs of all their users and the requirements of the assistive software they use.
-
While not conclusive, our results indicate that the use of accessibility standards like ARIA and accessibility best practices (e.g., using alt text) are found on a sizable, but not substantial portion of the web. On the surface this is encouraging, but we suspect many of these positive trends are due to the popularity of certain UI frameworks. On one hand, this is disappointing because web developers cannot simply rely on UI frameworks to inject their sites with accessibility support. On the other hand though, it's encouraging to see how large of an effect UI frameworks could have on the accessibility of the web.
-
The next frontier, in our opinion, is making widgets which are available through UI frameworks more accessible. Since many complex widgets used in the wild (e.g., calendar pickers) are sourced from a UI library, it would be great for these widgets to be accessible out of the box. We hope that when we collect our results next time, the usage of more properly implemented complex ARIA roles is on the rise—signifying more complex widgets have also been made accessible. In addition, we hope to see more accessible media, like images and video, so all users can enjoy the richness of the web.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/caching.html b/src/templates/en/2019/chapters/caching.html
deleted file mode 100644
index dcbeae0a26f..00000000000
--- a/src/templates/en/2019/chapters/caching.html
+++ /dev/null
@@ -1,684 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":16,"title":"Caching","description":"Caching chapter of the 2019 Web Almanac covering cache-control, expires, TTLs, validitaty, vary, set-cookies, AppCache, Service Workers and opportunities.","authors":["paulcalvano"],"reviewers":["obto","bkardell"],"translators":null,"discuss":"1771","results":"https://docs.google.com/spreadsheets/d/1mnq03DqrRBwxfDV05uEFETK0_hPbYOynWxZkV3tFgNk/","queries":"16_Caching","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-06T00:00:00.000Z","chapter":"caching"} %} {% block index %}
-
Caching is a technique that enables the reuse of previously downloaded content. It provides a significant performance benefit by avoiding costly network requests and it also helps scale an application by reducing the traffic to a website's origin infrastructure. There's an old saying, "the fastest request is the one that you don't have to make," and caching is one of the key ways to avoid having to make requests.
-
There are three guiding principles to caching web content: cache as much as you can, for as long as you can, as close as you can to end users.
-
Cache as much as you can. When considering how much can be cached, it is important to understand whether a response is static or dynamic. Requests that are served as a static response are typically cacheable, as they have a one-to-many relationship between the resource and the users requesting it. Dynamically generated content can be more nuanced and require careful consideration.
-
Cache for as long as you can. The length of time you would cache a resource is highly dependent on the sensitivity of the content being cached. A versioned JavaScript resource could be cached for a very long time, while a non-versioned resource may need a shorter cache duration to ensure users get a fresh version.
-
Cache as close to end users as you can. Caching content close to the end user reduces download times by removing latency. For example, if a resource is cached on an end user's browser, then the request never goes out to the network and the download time is as fast as the machine's I/O. For first time visitors, or visitors that don't have entries in their cache, a CDN would typically be the next place a cached resource is returned from. In most cases, it will be faster to fetch a resource from a local cache or a CDN compared to an origin server.
-
Web architectures typically involve multiple tiers of caching. For example, an HTTP request may have the opportunity to be cached in:
-
-
An end user's browser
-
A service worker cache in the user's browser
-
A shared gateway
-
CDNs, which offer the ability to cache at the edge, close to end users
-
A caching proxy in front of the application, to reduce the backend workload
-
The application and database layers
-
-
This chapter will explore how resources are cached within web browsers.
For an HTTP client to cache a resource, it needs to understand two pieces of information:
-
-
"How long am I allowed to cache this for?"
-
"How do I validate that the content is still fresh?"
-
-
When a web browser sends a response to a client, it typically includes headers that indicate whether the resource is cacheable, how long to cache it for, and how old the resource is. RFC 7234 covers this in more detail in section 4.2 (Freshness) and 4.3 (Validation).
-
The HTTP response headers typically used for conveying freshness lifetime are:
-
-
Cache-Control allows you to configure a cache lifetime duration (i.e. how long this is valid for).
-
Expires provides an expiration date or time (i.e. when exactly this expires).
The HTTP response headers for validating the responses stored within the cache, i.e. giving conditional requests something to compare to on the server side, are:
-
-
Last-Modified indicates when the object was last changed.
-
Entity Tag (ETag) provides a unique identifier for the content.
The example below contains an excerpt of a request/response header from HTTP Archive's main.js file. These headers indicate that the resource can be cached for 43,200 seconds (12 hours), and it was last modified more than two months ago (difference between the Last-Modified and Date headers).
The tool RedBot.org allows you to input a URL and see a detailed explanation of how the response would be cached based on these headers. For example, a test for the URL above would output the following:
Redbot example response showing detailed information about when the resource was changed, whether caches can store it, how long it can be considered fresh for and warnings.
- Figure 1.Cache-Control information from RedBot.
-
-
If no caching headers are present in a response, then the client is permitted to heuristically cache the response. Most clients implement a variation of the RFC's suggested heuristic, which is 10% of the time since Last-Modified. However, some may cache the response indefinitely. So, it is important to set specific caching rules to ensure that you are in control of the cacheability.
-
72% of responses are served with a Cache-Control header, and 56% of responses are served with an Expires header. However, 27% of responses did not use either header, and therefore are subject to heuristic caching. This is consistent across both desktop and mobile sites.
A cacheable resource is stored by the client for a period of time and available for reuse on a subsequent request. Across all HTTP requests, 80% of responses are considered cacheable, meaning that a cache is permitted to store them. Out of these,
-
-
6% of requests have a time to live (TTL) of 0 seconds, which immediately invalidates a cached entry.
-
27% are cached heuristically because of a missing Cache-Control header.
-
47% are cached for more than 0 seconds.
-
-
The remaining responses are not permitted to be stored in browser caches.
A stacked bar chart showing 20% of desktop responses are not cacheable, 47% have a cache greater than zero, 27% are heuristically cached and 6% have a TTL of 0. The stats for mobile are very similar (19%, 47%, 27% and 7%)
- Figure 3. Distribution of cacheable responses.
-
-
The table below details the cache TTL values for desktop requests by type. Most content types are being cached however CSS resources appear to be consistently cached at high TTLs.
While most of the median TTLs are high, the lower percentiles highlight some of the missed caching opportunities. For example, the median TTL for images is 28 hours, however the 25th percentile is just one-two hours and the 10th percentile indicates that 10% of cacheable image content is cached for less than one hour.
-
By exploring the cacheability by content type in more detail in figure 5 below, we can see that approximately half of all HTML responses are considered non-cacheable. Additionally, 16% of images and scripts are non-cacheable.
A stacked bar chart showing the split of not cacheable, cached more than 0 seconds and cached for only 0 seconds by type for desktop. A small, but significant proportion are not cacheable and this goes up to 50% for HTML, most have caching greater than 0 and a smaller amount has a 0 TTL
- Figure 5. Distribution of cacheability by content type for desktop.
-
-
The same data for mobile is shown below. As can be seen, the cacheability of content types is consistent between desktop and mobile.
A stacked bar chart showing the split of not cacheable, cached more than 0 seconds and cached for only 0 seconds by type for mobile. A small, but significant proportion are not cacheable and this goes up to 50% for HTML, most have caching greater than 0 and a smaller amount has a 0 TTL
- Figure 6. Distribution of cacheability by content type for mobile.
-
-
In HTTP/1.0, the Expires header was used to indicate the date/time after which the response is considered stale. Its value is a date timestamp, such as:
-
Expires: Thu, 01 Dec 1994 16:00:00 GMT
-
HTTP/1.1 introduced the Cache-Control header, and most modern clients support both headers. This header provides much more extensibility via caching directives. For example:
-
-
no-store can be used to indicate that a resource should not be cached.
-
max-age can be used to indicate a freshness lifetime.
-
must-revalidate tells the client a cached entry must be validated with a conditional request prior to its use.
-
private indicates a response should only be cached by a browser, and not by an intermediary that would serve multiple clients.
-
-
53% of HTTP responses include a Cache-Control header with the max-age directive, and 54% include the Expires header. However, only 41% of these responses use both headers, which means that 13% of responses are caching solely based on the older Expires header.
A bar chart showing 53% of responses have a `Cache-Control: max-age`, 54%-55% use `Expires`, 41%-42% use both, and 34% use neither. The figures are given for both desktop and mobile but the figures are near identical with mobile having a percentage point higher in use of expires.
- Figure 7. Usage of Cache-Control versus Expires headers.
-
-
The HTTP/1.1 specification includes multiple directives that can be used in the Cache-Control response header and are detailed below. Note that multiple can be used in a single response.
-
-
-
-
-
-
-
Directive
-
Description
-
-
-
max-age
-
Indicates the number of seconds that a resource can be cached for.
-
-
-
public
-
Any cache may store the response.
-
-
-
no-cache
-
A cached entry must be revalidated prior to its use.
-
-
-
must-revalidate
-
A stale cached entry must be revalidated prior to its use.
-
-
-
no-store
-
Indicates that a response is not cacheable.
-
-
-
private
-
The response is intended for a specific user and should not be stored by shared caches.
-
-
-
no-transform
-
No transformations or conversions should be made to this resource.
-
-
-
proxy-revalidate
-
Same as must-revalidate but applies to shared caches.
-
-
-
s-maxage
-
Same as max age but applies to shared caches only.
-
-
-
immutable
-
Indicates that the cached entry will never change, and that revalidation is not necessary.
-
-
-
stale-while-revalidate
-
Indicates that the client is willing to accept a stale response while asynchronously checking in the background for a fresh one.
-
-
-
stale-if-error
-
Indicates that the client is willing to accept a stale response if the check for a fresh one fails.
For example, cache-control: public, max-age=43200 indicates that a cached entry should be stored for 43,200 seconds and it can be stored by all caches.
A bar chart of 15 cache control directives and their usage ranging from 74.8% for max-age, 37.8% for public, 27.8% for no-cache, 18% for no-store, 14.3% for private, 3.4% for immutable, 3.3% for no-transform, 2.4% for stale-while-revalidate, 2.2% for pre-check, 2.2% for post-check, 1.9% for s-maxage, 1.6% for proxy-revalidate, 0.3% for set-cookie and 0.2% for stale-if-error. The stats are near identical for desktop and mobile.
- Figure 9. Usage of Cache-Control directives on mobile.
-
-
Figure 9 above illustrates the top 15 Cache-Control directives in use on mobile websites. The results for desktop and mobile are very similar. There are a few interesting observations about the popularity of these cache directives:
-
-
max-age is used by almost 75% of Cache-Control headers, and no-store is used by 18%.
-
public is rarely necessary since cached entries are assumed public unless private is specified. Approximately 38% of responses include public.
Another interesting set of directives to show up in this list are pre-check and post-check, which are used in 2.2% of Cache-Control response headers (approximately 7.8 million responses). This pair of headers was introduced in Internet Explorer 5 to provide a background validation and was rarely implemented correctly by websites. 99.2% of responses using these headers had used the combination of pre-check=0 and post-check=0. When both of these directives are set to 0, then both directives are ignored. So, it seems these directives were never used correctly!
-
In the long tail, there are more than 1,500 erroneous directives in use across 0.28% of responses. These are ignored by clients, and include misspellings such as "nocache", "s-max-age", "smax-age", and "maxage". There are also numerous non-existent directives such as "max-stale", "proxy-public", "surrogate-control", etc.
When a response is not cacheable, the Cache-Controlno-store directive should be used. If this directive is not used, then the response is cacheable.
-
There are a few common errors that are made when attempting to configure a response to be non-cacheable:
-
-
Setting Cache-Control: no-cache may sound like the resource will not be cacheable. However, the no-cache directive requires the cached entry to be revalidated prior to use and is not the same as being non-cacheable.
-
Setting Cache-Control: max-age=0 sets the TTL to 0 seconds, but that is not the same as being non-cacheable. When max-age is set to 0, the resource is stored in the browser cache and immediately invalidated. This results in the browser having to perform a conditional request to validate the resource's freshness.
-
-
Functionally, no-cache and max-age=0 are similar, since they both require revalidation of a cached resource. The no-cache directive can also be used alongside a max-age directive that is greater than 0.
-
Over 3 million responses include the combination of no-store, no-cache, and max-age=0. Of these directives no-store takes precedence and the other directives are merely redundant
-
18% of responses include no-store and 16.6% of responses include both no-store and no-cache. Since no-store takes precedence, the resource is ultimately non-cacheable.
-
The max-age=0 directive is present on 1.1% of responses (more than four million responses) where no-store is not present. These resources will be cached in the browser but will require revalidation as they are immediately expired.
So far we've talked about how web servers tell a client what is cacheable, and how long it has been cached for. When designing cache rules, it is also important to understand how old the content you are serving is.
-
When you are selecting a cache TTL, ask yourself: "how often are you updating these assets?" and "what is their content sensitivity?". For example, if a hero image is going to be modified infrequently, then cache it with a very long TTL. If you expect a JavaScript resource to change frequently, then version it and cache it with a long TTL or cache it with a shorter TTL.
-
The graph below illustrates the relative age of resources by content type, and you can read a more detailed analysis here. HTML tends to be the content type with the shortest age, and a very large % of traditionally cacheable resources (scripts, CSS, and fonts) are older than one year!
A stack bar chart showing the age of content, split into weeks 0-52, > one year and > two years with null and negative figures shown too. The stats are split into first-party and third-party. The value 0 is used most particularly for first-party HTML, text and xml, and for up to 50% of third-party requests across all assets types. There is a mix using intermediary years and then considerable usage for one year and two year.
- Figure 10. Resource age distribution by content type.
-
-
By comparing a resources cacheability to its age, we can determine if the TTL is appropriate or too low. For example, the resource served by the response below was last modified on 25 Aug 2019, which means that it was 49 days old at the time of delivery. The Cache-Control header says that we can cache it for 43,200 seconds, which is 12 hours. It is definitely old enough to merit investigating whether a longer TTL would be appropriate.
Overall, 59% of resources served on the web have a cache TTL that is too short compared to its content age. Furthermore, the median delta between the TTL and age is 25 days.
-
When we break this out by first vs third-party, we can also see that 70% of first-party resources can benefit from a longer TTL. This clearly highlights a need to spend extra attention focusing on what is cacheable, and then ensuring caching is configured correctly.
-
-
-
-
-
-
-
Client
-
1st Party
-
3rd Party
-
Overall
-
-
-
Desktop
-
70.7%
-
47.9%
-
59.2%
-
-
-
Mobile
-
71.4%
-
46.8%
-
59.6%
-
-
-
-
-
- Figure 11. Percent of requests with short TTLs.
-
The HTTP response headers used for validating the responses stored within a cache are Last-Modified and ETag. The Last-Modified header does exactly what its name implies and provides the time that the object was last modified. The ETag header provides a unique identifier for the content.
-
For example, the response below was last modified on 25 Aug 2019 and it has an ETag value of "1566748830.0-3052-3932359948"
A client could send a conditional request to validate a cached entry by using the Last-Modified value in a request header named If-Modified-Since. Similarly, it could also validate the resource with an If-None-Match request header, which validates against the ETag value the client has for the resource in its cache.
-
In the example below, the cache entry is still valid, and an HTTP 304 was returned with no content. This saves the download of the resource itself. If the cache entry was no longer fresh, then the server would have responded with a 200 and the updated resource which would have to be downloaded again.
Overall, 65% of responses are served with a Last-Modified header, 42% are served with an ETag, and 38% use both. However, 30% of responses include neither a Last-Modified or ETag header.
A bar chart showing 64.4% of desktop requests have a last modified, 42.8% have an ETag, 37.9% have both and 30.7% have neither. The stats for mobile are almost identical at 65.3% for Last Modified, 42.8% for ETag, 38.0% for both and 29.9% for neither.
- Figure 12. Adoption of validating freshness via Last-Modified and ETag headers for desktop websites.
-
-
There are a few HTTP headers used to convey timestamps, and the format for these are very important. The Date response header indicates when the resource was served to a client. The Last-Modified response header indicates when a resource was last changed on the server. And the Expires header is used to indicate how long a resource is cacheable until (unless a Cache-Control header is present).
-
All three of these HTTP headers use a date formatted string to represent timestamps.
Most clients will ignore invalid date strings, which render them ineffective for the response they are served on. This can have consequences on cacheability, since an erroneous Last-Modified header will be cached without a Last-Modified timestamp resulting in the inability to perform a conditional request.
-
The Date HTTP response header is usually generated by the web server or CDN serving the response to a client. Because the header is typically generated automatically by the server, it tends to be less prone to error, which is reflected by the very low percentage of invalid Date headers. Last-Modified headers were very similar, with only 0.67% of them being invalid. What was very surprising to see though, was that 3.64% Expires headers used an invalid date format!
A bar chart showing 0.10% of desktop responses have an invalid date, 0.67% have an invalid Last-Modified and 3.64% have an invalid Expires. The stats for mobile are very similar with 0.06% of responses have an invalid date, 0.68% have an invalid Last-Modified and 3.50% have an invalid Expires.
- Figure 13. Invalid date formats in response headers.
-
-
Examples of some of the invalid uses of the Expires header are:
-
-
Valid date formats, but using a time zone other than GMT
-
Numerical values such as 0 or -1
-
Values that would be valid in a Cache-Control header
-
-
The largest source of invalid Expires headers is from assets served from a popular third-party, in which a date/time uses the EST time zone, for example Expires: Tue, 27 Apr 1971 19:44:06 EST.
One of the most important steps in caching is determining if the resource being requested is cached or not. While this may seem simple, many times the URL alone is not enough to determine this. For example, requests with the same URL could vary in what compression they used (gzip, brotli, etc.) or be modified and tailored for mobile visitors.
-
To solve this problem, clients give each cached resource a unique identifier (a cache key). By default, this cache key is simply the URL of the resource, but developers can add other elements (like compression method) by using the Vary header.
-
A Vary header instructs a client to add the value of one or more request header values to the cache key. The most common example of this is Vary: Accept-Encoding, which will result in different cached entries for Accept-Encoding request header values (i.e. gzip, br, deflate).
-
Another common value is Vary: Accept-Encoding, User-Agent, which instructs the client to vary the cached entry by both the Accept-Encoding values and the User-Agent string. When dealing with shared proxies and CDNs, using values other than Accept-Encoding can be problematic as it dilutes the cache keys and can reduce the amount of traffic served from cache.
-
In general, you should only vary the cache if you are serving alternate content to clients based on that header.
-
The Vary header is used on 39% of HTTP responses, and 45% of responses that include a Cache-Control header.
-
The graph below details the popularity for the top 10 Vary header values. Accept-Encoding accounts for 90% of Vary's use, with User-Agent (11%), Origin (9%), and Accept (3%) making up much of the rest.
A bar chart showing 90% use of accept-encoding, much smaller values for the rest with 10%-11% for user-agent, approximately 7%-8% for origin and less so for accept, almost not usage for cookie, x-forward-proto, accept-language, host, x-origin, access-control-request-method, and access-control-request-headers
When a response is cached, its entire headers are swapped into the cache as well. This is why you can see the response headers when inspecting a cached response via DevTools.
A screenshot of Chrome Developer Tools showing HTTP response headers for a cached response.
- Figure 15. Chrome Dev Tools for a cached resource.
-
-
But what happens if you have a Set-Cookie on a response? According to RFC 7234 Section 8, the presence of a Set-Cookie response header does not inhibit caching. This means that a cached entry might contain a Set-Cookie if it was cached with one. The RFC goes on to recommend that you should configure appropriate Cache-Control headers to control how responses are cached.
-
One of the risks of caching responses with Set-Cookie is that the cookie values can be stored and served to subsequent requests. Depending on the cookie's purpose, this could have worrying results. For example, if a login cookie or a session cookie is present in a shared cache, then that cookie might be reused by another client. One way to avoid this is to use the Cache-Controlprivate directive, which only permits the response to be cached by the client browser.
-
3% of cacheable responses contain a Set-Cookie header. Of those responses, only 18% use the private directive. The remaining 82% include 5.3 million HTTP responses that include a Set-Cookie which can be cached by public and private cache servers.
A bar chart showing 97% of responses do not use Set-Cookie, and 3% do. This 3% is zoomed into for another bar chart showing the split of 15.3% private, 84.7% public for desktop and similar for mobile at 18.4% public and 81.6% private.
- Figure 16. Cacheable responses of Set-Cookie responses.
-
-
A time series chart showing service worker controlled site usage from October 2016 until July 2019. Usage has been steadily growing throughout the years for both mobile and desktop but is still less than 0.6% for both.
Adoption is still below 1% of websites, but it has been steadily increasing since January 2017. The Progressive Web App chapter discusses this more, including the fact that it is used a lot more than this graph suggests due to its usage on popular sites, which are only counted once in above graph.
-
In the table below, you can see a summary of AppCache vs service worker usage. 32,292 websites have implemented a service worker, while 1,867 sites are still utilizing the deprecated AppCache feature.
-
-
-
-
-
-
-
-
Does Not Use Server Worker
-
Uses Service Worker
-
Total
-
-
-
-
-
Does Not Use AppCache
-
5,045,337
-
32,241
-
5,077,578
-
-
-
Uses AppCache
-
1,816
-
51
-
1,867
-
-
-
Total
-
5,047,153
-
32,292
-
5,079,445
-
-
-
-
-
- Figure 18. Number of websites using AppCache versus service worker.
-
-
If we break this out by HTTP vs HTTPS, then this gets even more interesting. 581 of the AppCache enabled sites are served over HTTP, which means that Chrome is likely disabling the feature. HTTPS is a requirement for using service workers, but 907 of the sites using them are served over HTTP.
-
-
-
-
-
-
-
-
-
Does Not Use Service Worker
-
Uses Service Worker
-
-
-
-
-
HTTP
-
Does Not Use AppCache
-
1,968,736
-
907
-
-
-
Uses AppCache
-
580
-
1
-
-
-
HTTPS
-
Does Not Use AppCache
-
3,076,601
-
31,334
-
-
-
Uses AppCache
-
1,236
-
50
-
-
-
-
-
- Figure 19. Number of websites using AppCache versus service worker usage by HTTP/HTTPS.
-
Google's Lighthouse tool enables users to run a series of audits against web pages, and the cache policy audit evaluates whether a site can benefit from additional caching. It does this by comparing the content age (via the Last-Modified header) to the cache TTL and estimating the probability that the resource would be served from cache. Depending on the score, you may see a caching recommendation in the results, with a list of specific resources that could be cached.
A screenshot of part of a report from the Google Lighthouse tool, with the 'Serve static assets with an efficient cache policy' section open where it lists a number of resources, who's names have been redacted, and the Cache TTL versus the size.
Lighthouse computes a score for each audit, ranging from 0% to 100%, and those scores are then factored into the overall scores. The caching score is based on potential byte savings. When we examine the Lighthouse results, we can get a perspective of how many sites are doing well with their cache policies.
A stacked bar chart 38.2% of websites get a score of < 10%, 29.0% of websites get a score between 10% and 39%, 18.7% of websites get a score of 40%-79%, 10.7% of websites get a score of 80% - 99%, and 3.4% of websites get a score of 100%.
- Figure 21. Distribution of Lighthouse scores for the "Uses Long Cache TTL" audit for mobile web pages.
-
-
Only 3.4% of sites scored a 100%, meaning that most sites can benefit from some cache optimizations. A vast majority of sites sore below 40%, with 38% scoring less than 10%. Based on this, there is a significant amount of caching opportunities on the web.
-
Lighthouse also indicates how many bytes could be saved on repeat views by enabling a longer cache policy. Of the sites that could benefit from additional caching, 82% of them can reduce their page weight by up to a whole Mb!
A stacked bar chart showing 56.8% of websites have potential byte savings of less than one MB, 22.1% could have savings of one to two MB, 8.3% could save two to three MB. 4.3% could save three to four MB and 6.0% could save more than four MB.
- Figure 22. Distribution of potential byte savings from the Lighthouse caching audit.
-
-
Caching is an incredibly powerful feature that allows browsers, proxies and other intermediaries (such as CDNs) to store web content and serve it to end users. The performance benefits of this are significant, since it reduces round trip times and minimizes costly network requests.
-
Caching is also a very complex topic. There are numerous HTTP response headers that can convey freshness as well as validate cached entries, and Cache-Control directives provide a tremendous amount of flexibility and control. However, developers should be cautious about the additional opportunities for mistakes that it comes with. Regularly auditing your site to ensure that cacheable resources are cached appropriately is recommended, and tools like Lighthouse and REDbot do an excellent job of helping to simplify the analysis.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/cdn.html b/src/templates/en/2019/chapters/cdn.html
deleted file mode 100644
index afe7b4f5392..00000000000
--- a/src/templates/en/2019/chapters/cdn.html
+++ /dev/null
@@ -1,1587 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":17,"title":"CDN","description":"CDN chapter of the 2019 Web Almanac covering CDN adoption and usage, RTT & TLS management, HTTP/2 adoption, caching and common library and content CDNs.","authors":["andydavies","colinbendell"],"reviewers":["yoavweiss","paulcalvano","pmeenan","enygren"],"translators":null,"discuss":"1772","results":"https://docs.google.com/spreadsheets/d/1Y7kAxjxUl8puuTToe6rL3kqJLX1ftOb0nCcD8m3lZBw/","queries":"17_CDN","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-04T00:00:00.000Z","chapter":"cdn"} %} {% block index %}
-
"Use a Content Delivery Network" was one of Steve Souders original recommendations for making web sites load faster. It's advice that remains valid today, and in this chapter of the Web Almanac we're going to explore how widely Steve's recommendation has been adopted, how sites are using Content Delivery Networks (CDNs), and some of the features they're using.
-
Fundamentally, CDNs reduce latency—the time it takes for packets to travel between two points on a network, say from a visitor's device to a server—and latency is a key factor in how quickly pages load.
-
A CDN reduces latency in two ways: by serving content from locations that are closer to the user and second, by terminating the TCP connection closer to the end user.
-
Historically, CDNs were used to cache, or copy, bytes so that the logical path from the user to the bytes becomes shorter. A file that is requested by many people can be retrieved once from the origin (your server) and then stored on a server closer to the user, thus saving transfer time.
-
CDNs also help with TCP latency. The latency of TCP determines how long it takes to establish a connection between a browser and a server, how long it takes to secure that connection, and ultimately how quickly content downloads. At best, network packets travel at roughly two-thirds of the speed of light, so how long that round trip takes depends on how far apart the two ends of the conversation are, and what's in between. Congested networks, overburdened equipment, and the type of network will all add further delays. Using a CDN to move the server end of the connection closer to the visitor reduces this latency penalty, shortening connection times, TLS negotiation times, and improving content download speeds.
-
Although CDNs are often thought of as just caches that store and serve static content close to the visitor, they are capable of so much more! CDNs aren't limited to just helping overcome the latency penalty, and increasingly they offer other features that help improve performance and security.
-
-
Using a CDN to proxy dynamic content (base HTML page, API responses, etc.) can take advantage of both the reduced latency between the browser and the CDN's own network back to the origin.
-
Some CDNs offer transformations that optimize pages so they download and render more quickly, or optimize images so they're the appropriate size (both dimensions and file size) for the device on which they're going to be viewed.
-
From a security perspective, malicious traffic and bots can be filtered out by a CDN before the requests even reach the origin, and their wide customer base means CDNs can often see and react to new threats sooner.
-
The rise of edge computing allows sites to run their own code close to their visitors, both improving performance and reducing the load on the origin.
-
-
Finally, CDNs also help sites to adopt new technologies without requiring changes at the origin, for example HTTP/2, TLS 1.3, and/or IPv6 can be enabled from the edge to the browser, even if the origin servers don't support it yet.
As with any observational study, there are limits to the scope and impact that can be measured. The statistics gathered on CDN usage for the the Web Almanac does not imply performance nor effectiveness of a specific CDN vendor.
-
There are many limits to the testing methodology used for the Web Almanac. These include:
-
-
Simulated network latency: The Web Almanac uses a dedicated network connection that synthetically shapes traffic.
-
Single geographic location: Tests are run from a single datacenter and cannot test the geographic distribution of many CDN vendors.
-
Cache effectiveness: Each CDN uses proprietary technology and many, for security reasons, do not expose cache performance.
-
Localization and internationalization: Just like geographic distribution, the effects of language and geo-specific domains are also opaque to the testing.
-
CDN detection is primarily done through DNS resolution and HTTP headers. Most CDNs use a DNS CNAME to map a user to an optimal datacenter. However, some CDNs use AnyCast IPs or direct A+AAAA responses from a delegated domain which hide the DNS chain. In other cases, websites use multiple CDNs to balance between vendors which is hidden from the single-request pass of WebPageTest. All of this limits the effectiveness in the measurements.
-
-
Most importantly, these results reflect a potential utilization but do not reflect actual impact. YouTube is more popular than "ShoesByColin" yet both will appear as equal value when comparing utilization.
-
With this in mind, there are a few intentional statistics that were not measured with the context of a CDN:
-
-
- TTFB: Measuring the Time to first byte by CDN would be intellectually dishonest without proper knowledge about cacheability and cache effectiveness. If one site uses a CDN for round trip time (RTT) management but not for caching, this would create a disadvantage when comparing another site that uses a different CDN vendor but does also caches the content. (Note: this does not apply to the TTFB analysis in the Performance chapter because it does not draw conclusions about the performance of individual CDNs.)
-
-
Cache Hit vs. Cache Miss performance: As mentioned previously, this is opaque to the testing apparatus and therefore repeat tests to test page performance with a cold cache vs. a hot cache are unreliable.
In future versions of the Web Almanac, we would expect to look more closely at the TLS and RTT management between CDN vendors. Of interest would the impact of OCSP stapling, differences in TLS Cipher performance. CWND (TCP congestion window) growth rate, and specifically the adoption of BBR v1, v2, and traditional TCP Cubic.
For websites, a CDN can improve performance for the primary domain (www.shoesbycolin.com), sub-domains or sibling domains (images.shoesbycolin.com or checkout.shoesbycolin.com), and finally third parties (Google Analytics, etc.). Using a CDN for each of these use cases improves performance in different ways.
-
Historically, CDNs were used exclusively for static resources like CSS, JavaScript, and images. These resources would likely be versioned (include a unique number in the path) and cached long-term. In this way we should expect to see higher adoption of CDNs on sub-domains or sibling domains compared to the base HTML domains. The traditional design pattern would expect that www.shoesbycolin.com would serve HTML directly from a datacenter (or origin) while static.shoesbycolin.com would use a CDN.
Stacked bar chart showing HTML is 80% served from origin, 20% from CDN, Sub-domains are 61%/39%, third-party is 34%/66%.
- Figure 1. CDN usage vs. origin-hosted resources.
-
-
Indeed, this traditional pattern is what we observe on the majority of websites crawled. The majority of web pages (80%) serve the base HTML from origin. This breakdown is nearly identical between mobile and desktop with only 0.4% lower usage of CDNs on desktop. This slight variance is likely due to the small continued use of mobile specific web pages ("mDot"), which more frequently use a CDN.
-
Likewise, resources served from sub-domains are more likely to utilize a CDN at 40% of sub-domain resources. Sub-domains are used either to partition resources like images and CSS or they are used to reflect organizational teams such as checkout or APIs.
-
Despite first-party resources still largely being served directly from origin, third-party resources have a substantially higher adoption of CDNs. Nearly 66% of all third-party resources are served from a CDN. Since third-party domains are more likely a SaaS integration, the use of CDNs are more likely core to these business offerings. Most third-party content breaks down to shared resources (JavaScript or font CDNs), augmented content (advertisements), or statistics. In all these cases, using a CDN will improve the performance and offload for these SaaS solutions.
There are two categories of CDN providers: the generic and the purpose-fit CDN. The generic CDN providers offer customization and flexibility to serve all kinds of content for many industries. In contrast, the purpose-fit CDN provider offers similar content distribution capabilities but are narrowly focused on a specific solution.
-
This is clearly represented when looking at the top CDNs found serving the base HTML content. The most frequent CDNs serving HTML are generic CDNs (Cloudflare, Akamai, Fastly) and cloud solution providers who offer a bundled CDN (Google, Amazon) as part of the platform service offerings. In contrast, there are only a few purpose-fit CDN providers, such as Wordpress and Netlify, that deliver base HTML markup.
-
Note: This does not reflect traffic or usage, only the number of sites using them.
Sub-domain requests have a very similar composition. Since many websites use sub-domains for static content, we see a shift to a higher CDN usage. Like the base page requests, the resources served from these sub-domains utilize generic CDN offerings.
- Figure 5. Top 25 resource CDNs for sub-domain requests.
-
-
The composition of top CDN providers dramatically shifts for third-party resources. Not only are CDNs more frequently observed hosting third-party resources, there is also an increase in purpose-fit CDN providers such as Facebook, Twitter, and Google.
CDNs can offer more than simple caching for website performance. Many CDNs also support a pass-through mode for dynamic or personalized content when an organization has a legal or other business requirement prohibiting the content from being cached. Utilizing a CDN's physical distribution enables increased performance for TCP RTT for end users. As others have noted, reducing RTT is the most effective means to improve web page performance compared to increasing bandwidth.
-
Using a CDN in this way can improve page performance in two ways:
-
-
-
Reduce RTT for TCP and TLS negotiation. The speed of light is only so fast and CDNs offer a highly distributed set of data centers that are closer to the end users. In this way the logical (and physical) distance that packets must traverse to negotiate a TCP connection and perform the TLS handshake can be greatly reduced.
-
Reducing RTT has three immediate benefits. First, it improves the time for the user to receive data, because TCP+TLS connection time are RTT-bound. Secondly, this will improve the time it takes to grow the congestion window and utilize the full amount of bandwidth the user has available. Finally, it reduces the probability of packet loss. When the RTT is high, network interfaces will time-out requests and resend packets. This can result in double packets being delivered.
-
-
CDNs can utilize pre-warmed TCP connections to the back-end origin. Just as terminating the connection closer to the user will improve the time it takes to grow the congestion window, the CDN can relay the request to the origin on pre-established TCP connections that have already maximized congestion windows. In this way the origin can return the dynamic content in fewer TCP round trips and the content can be more effectively ready to be delivered to the waiting user.
Since TLS negotiations require multiple TCP round trips before data can be sent from a server, simply improving the RTT can significantly improve the page performance. For example, looking at the base HTML page, the median TLS negotiation time for origin requests is 207 ms (for desktop WebPageTest). This alone accounts for 10% of a 2 second performance budget, and this is under ideal network conditions where there is no latency applied on the request.
-
In contrast, the median TLS negotiation for the majority of CDN providers is between 60 and 70 ms. Origin requests for HTML pages take almost 3x longer to complete TLS negotiation than those web pages that use a CDN. Even at the 90th percentile, this disparity perpetuates with origin TLS negotiation rates of 427 ms compared to most CDNs which complete under 140 ms!
-
A word of caution when interpreting these charts: it is important to focus on orders of magnitude when comparing vendors as there are many factors that impact the actual TLS negotiation performance. These tests were completed from a single datacenter under controlled conditions and do not reflect the variability of the internet and user experiences.
For resource requests (including same-domain and third-party), the TLS negotiation time takes longer and the variance increases. This is expected because of network saturation and network congestion. By the time that a third-party connection is established (by way of a resource hint or a resource request) the browser is busy rendering and making other parallel requests. This creates contention on the network. Despite this disadvantage, there is still a clear advantage for third-party resources that utilize a CDN over using an origin solution.
Graph showing most CDNs have a TLS negotiation time of around 80 ms, but some (Microsoft Azure, Yahoo, Edgecast, ORIGIN, and CDNetworks) start to creep out towards 200 ms - especially when going above the p50 percentile.
TLS handshake performance is impacted by a number of factors. These include RTT, TLS record size, and TLS certificate size. While RTT has the biggest impact on the TLS handshake, the second largest driver for TLS performance is the TLS certificate size.
-
During the first round trip of the TLS handshake, the server attaches its certificate. This certificate is then verified by the client before proceeding. In this certificate exchange, the server might include the certificate chain by which it can be verified. After this certificate exchange, additional keys are established to encrypt the communication. However, the length and size of the certificate can negatively impact the TLS negotiation performance, and in some cases, crash client libraries.
-
- The certificate exchange is at the foundation of the TLS handshake and is usually handled by isolated code paths so as to minimize the attack surface for exploits. Because of its low level nature, buffers are usually not dynamically allocated, but fixed. In this way, we cannot simply assume that the client can handle an unlimited-sized certificate. For example, OpenSSL CLI tools and Safari can successfully negotiate against https://10000-sans.badssl.com. Yet, Chrome and Firefox fail because of the size of the certificate.
-
-
While extreme sizes of certificates can cause failures, even sending moderately large certificates has a performance impact. A certificate can be valid for one or more hostnames which are are listed in the Subject-Alternative-Name (SAN). The more SANs, the larger the certificate. It is the processing of these SANs during verification that causes performance to degrade. To be clear, performance of certificate size is not about TCP overhead, rather it is about processing performance of the client.
-
Technically, TCP slow start can impact this negotiation but it is very improbable. TLS record length is limited to 16 KB, which fits into a typical initial congestion window of 10. While some ISPs might employ packet splicers, and other tools fragment congestion windows to artificially throttle bandwidth, this isn't something that a website owner can change or manipulate.
-
Many CDNs, however, depend on shared TLS certificates and will list many customers in the SAN of a certificate. This is often necessary because of the scarcity of IPv4 addresses. Prior to the adoption of Server-Name-Indicator (SNI) by end users, the client would connect to a server, and only after inspecting the certificate, would the client hint which hostname the user user was looking for (using the Host header in HTTP). This results in a 1:1 association of an IP address and a certificate. If you are a CDN with many physical locations, each location may require a dedicated IP, further aggravating the exhaustion of IPv4 addresses. Therefore, the simplest and most efficient way for CDNs to offer TLS certificates for websites that still have users that don't support SNI is to offer a shared certificate.
-
According to Akamai, the adoption of SNI is still not 100% globally. Fortunately there has been a rapid shift in recent years. The biggest culprits are no longer Windows XP and Vista, but now Android apps, bots, and corporate applications. Even at 99% adoption, the remaining 1% of 3.5 billion users on the internet can create a very compelling motivation for website owners to require a non-SNI certificate. Put another way, a pure play website can enjoy a virtually 100% SNI adoption among standard web browsers. Yet, if the website is also used to support APIs or WebViews in apps, particularly Android apps, this distribution can drop rapidly.
-
Most CDNs balance the need for shared certificates and performance. Most cap the number of SANs between 100 and 150. This limit often derives from the certificate providers. For example, LetsEncrypt, DigiCert, and GoDaddy all limit SAN certificates to 100 hostnames while Comodo's limit is 2,000. This, in turn, allows some CDNs to push this limit, cresting over 800 SANs on a single certificate. There is a strong negative correlation of TLS performance and the number of SANs on a certificate.
In addition to using a CDN for TLS and RTT performance, CDNs are often used to ensure patching and adoption of TLS ciphers and TLS versions. In general, the adoption of TLS on the main HTML page is much higher for websites that use a CDN. Over 76% of HTML pages are served with TLS compared to the 62% from origin-hosted pages.
Stacked bar chart showing TLS 1.0 is used 0.86% of the time for origin, TLS 1.2 55% of the time, TLS 1.3 6% of the time, and unencrypted 38% of the time. For CDN this changes to 35% for TLS 1.2, 41% for TLS 1.3, and 24% for unencrypted.
- Figure 15. HTML TLS version adoption (CDN vs. origin).
-
-
Each CDN offers different rates of adoption for both TLS and the relative ciphers and versions offered. Some CDNs are more aggressive and roll out these changes to all customers whereas other CDNs require website owners to opt-in to the latest changes and offer change-management to facilitate these ciphers and versions.
Division of secure vs non-secure connections established for initial HTML request broken down by CDN with some CDNs (e.g. Wordpress) at 100%, most between 80%-100%, and then ORIGIN at 62%, Google at 51%, ChinaNetCenter at 36%, and Yunjiasu at 29%.
Stacked bar chart showing the vast majority of CDNs use TLS for over 90% of third-party requests, with a few stragglers in the 75% - 90% range, and ORIGIN lower than them all at 68%.
Along with this general adoption of TLS, CDN use also sees higher adoption of emerging TLS versions like TLS 1.3.
-
In general, the use of a CDN is highly correlated with a more rapid adoption of stronger ciphers and stronger TLS versions compared to origin-hosted services where there is a higher usage of very old and compromised TLS versions like TLS 1.0.
-
It is important to emphasize that Chrome used in the Web Almanac will bias to the latest TLS versions and ciphers offered by the host. Also, these web pages were crawled in July 2019 and reflect the adoption of websites that have enabled the newer versions.
Bar chart showing that TLS 1.3 or TLS 1.2 is used by all CDNs when TLS is used. A few CDNs have adopted TLS 1.3 completely, some partially and a large proportion not at all and only using TLS 1.2.
Along with RTT management and improving TLS performance, CDNs also enable new standards like HTTP/2 and IPv6. While most CDNs offer support for HTTP/2 and many have signaled early support of the still-under-standards-development HTTP/3, adoption still depends on website owners to enable these new features. Despite the change-management overhead, the majority of the HTML served from CDNs has HTTP/2 enabled.
-
CDNs have over 70% adoption of HTTP/2, compared to the nearly 27% of origin pages. Similarly, sub-domain and third-party resources on CDNs see an even higher adoption of HTTP/2 at 90% or higher while third-party resources served from origin infrastructure only has 31% adoption. The performance gains and other features of HTTP/2 are further covered in the HTTP/2 chapter.
-
Note: All requests were made with the latest version of Chrome which supports HTTP/2. When only HTTP/1.1 is reported, this would indicate either unencrypted (non-TLS) servers or servers that don't support HTTP/2.
A website can control the caching behavior of browsers and CDNs with the use of different HTTP headers. The most common is the Cache-Control header which specifically determines how long something can be cached before returning to the origin to ensure it is up-to-date.
-
Another useful tool is the use of the Vary HTTP header. This header instructs both CDNs and browsers how to fragment a cache. The Vary header allows an origin to indicate that there are multiple representations of a resource, and the CDN should cache each variation separately. The most common example is compression. Declaring a resource as Vary: Accept-Encoding allows the CDN to cache the same content, but in different forms like uncompressed, with gzip, or Brotli. Some CDNs even do this compression on the fly so as to keep only one copy available. This Vary header likewise also instructs the browser how to cache the content and when to request new content.
Treemap graph showing accept-encoding dominates vary usage with 73% of the chart taken up with that. Cookie (13%) and user-agent (8%) having some usage, then a complete mixed of other headers.
- Figure 24. Usage of Vary for HTML served from CDNs.
-
-
While the main use of Vary is to coordinate Content-Encoding, there are other important variations that websites use to signal cache fragmentation. Using Vary also instructs SEO bots like DuckDuckGo, Google, and BingBot that alternate content would be returned under different conditions. This has been important to avoid SEO penalties for "cloaking" (sending SEO specific content in order to game the rankings).
-
For HTML pages, the most common use of Vary is to signal that the content will change based on the User-Agent. This is short-hand to indicate that the website will return different content for desktops, phones, tablets, and link-unfurling engines (like Slack, iMessage, and Whatsapp). The use of Vary: User-Agent is also a vestige of the early mobile era, where content was split between "mDot" servers and "regular" servers in the back-end. While the adoption for responsive web has gained wide popularity, this Vary form remains.
-
In a similar way, Vary: Cookie usually indicates that content that will change based on the logged-in state of the user or other personalization.
Set of four treemap graphs showing that for CDNs serving home pages the biggest use of Vary is for Cookie, followed by User-agent. For CDNs serving other resources it's origin, followed by accept, user-agent, x-origin and referrer. For Origins and home pages it's user-agent, followed by cookie. Finally for Origins and other resources it's primarily user-agent followed by origin, accept, then range and host.
- Figure 25. Comparison of Vary usage for HTML and resources served from origin and CDN.
-
-
Resources, in contrast, don't use Vary: Cookie as much as the HTML resources. Instead these resources are more likely to adapt based on the Accept, Origin, or Referer. Most media, for example, will use Vary: Accept to indicate that an image could be a JPEG, WebP, JPEG 2000, or JPEG XR depending on the browser's offered Accept header. In a similar way, third-party shared resources signal that an XHR API will differ depending on which website it is embedded. This way, a call to an ad server API will return different content depending on the parent website that called the API.
-
The Vary header also contains evidence of CDN chains. These can be seen in Vary headers such as Accept-Encoding, Accept-Encoding or even Accept-Encoding, Accept-Encoding, Accept-Encoding. Further analysis of these chains and Via header entries might reveal interesting data, for example how many sites are proxying third-party tags.
-
Many of the uses of the Vary are extraneous. With most browsers adopting double-key caching, the use of Vary: Origin is redundant. As is Vary: Range or Vary: Host or Vary: *. The wild and variable use of Vary is demonstrable proof that the internet is weird.
There are other HTTP headers that specifically target CDNs, or other proxy caches, such as the Surrogate-Control, s-maxage, pre-check, and post-check values in the Cache-Control header. In general usage of these headers is low.
-
Surrogate-Control allows origins to specify caching rules just for CDNs, and as CDNs are likely to strip the header before serving responses, its low visible usage isn't a surprise, in fact it's surprising that it's actually in any responses at all! (It was even seen from some CDNs that state they strip it).
-
Some CDNs support post-check as a method to allow a resource to be refreshed when it goes stale, and pre-check as a maxage equivalent. For most CDNs, usage of pre-check and post-check was below 1%. Yahoo was the exception to this and about 15% of requests had pre-check=0, post-check=0. Unfortunately this seems to be a remnant of an old Internet Explorer pattern rather than active usage. More discussion on this can be found in the Caching chapter.
-
The s-maxage directive informs proxies for how long they may cache a response. Across the Web Almanac dataset, jsDelivr is the only CDN where a high level of usage was seen across multiple resources—this isn't surprising given jsDelivr's role as a public CDN for libraries. Usage across other CDNs seems to be driven by individual customers, for example third-party scripts or SaaS providers using that particular CDN.
Bar chart showing 82% of jsDelivr serves responses with s-maxage, 14% of Level 3, 6.3% of Amazon CloudFront, 3.3% of Akamai, 3.1% of Fastly, 3% of Highwinds, 2% of Cloudflare, 0.91% of ORIGIN, 0.75% of Edgecast, 0.07% of Google.
- Figure 26. Adoption of s-maxage across CDN responses.
-
-
With 40% of sites using a CDN for resources, and presuming these resources are static and cacheable, the usage of s-maxage seems low.
-
Future research might explore cache lifetimes versus the age of the resources, and the usage of s-maxage versus other validation directives such as stale-while-revalidate.
So far, this chapter has explored the use of commercials CDNs which the site may be using to host its own content, or perhaps used by a third-party resource included on the site.
-
Common libraries like jQuery and Bootstrap are also available from public CDNs hosted by Google, Cloudflare, Microsoft, etc. Using content from one of the public CDNs instead of a self-hosting the content is a trade-off. Even though the content is hosted on a CDN, creating a new connection and growing the congestion window may negate the low latency of using a CDN.
-
Google Fonts is the most popular of the content CDNs and is used by 55% of websites. For non-font content, Google API, Cloudflare's JS CDN, and the Bootstrap's CDN are the next most popular.
Bar chart showing 55.33% of public content CDNs are made to fonts.googleapis.com, 19.86% to ajax.googleapis.com, 10.47% to cdnjs.cloudflare.com, 9.83% to maxcdn.bootstrapcdn.com, 5.95% to code.jquery.com, 4.29% to cdn.jsdelivr.net, 3.22% to use.fontawesome.com, 0.7% to stackpath.bootstrapcdn.com, 0.67% to unpkg.com, and 0.52% to ajax.aspnetcdn.com.
As more browsers implement partitioned caches, the effectiveness of public CDNs for hosting common libraries will decrease and it will be interesting to see whether they are less popular in future iterations of this research.
The reduction in latency that CDNs deliver along with their ability to store content close to visitors enable sites to deliver faster experiences while reducing the load on the origin.
-
Steve Souders' recommendation to use a CDN remains as valid today as it was 12 years ago, yet only 20% of sites serve their HTML content via a CDN, and only 40% are using a CDN for resources, so there's plenty of opportunity for their usage to grow further.
-
There are some aspects of CDN adoption that aren't included in this analysis, sometimes this was due to the limitations of the dataset and how it's collected, in other cases new research questions emerged during the analysis.
-
As the web continues to evolve, CDN vendors innovate, and sites use new practices CDN adoption remains an area rich for further research in future editions of the Web Almanac.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/cms.html b/src/templates/en/2019/chapters/cms.html
deleted file mode 100644
index 96c9dd1aa62..00000000000
--- a/src/templates/en/2019/chapters/cms.html
+++ /dev/null
@@ -1,691 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"III","chapter_number":14,"title":"CMS","description":"CMS chapter of the 2019 Web Almanac covering CMS adoption, how CMS suites are built, User experience of CMS powered websites, and CMS innovation.","authors":["ernee","amedina"],"reviewers":["sirjonathan"],"translators":null,"discuss":"1769","results":"https://docs.google.com/spreadsheets/d/1FDYe6QdoY3UtXodE2estTdwMsTG-hHNrOe9wEYLlwAw/","queries":"14_CMS","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"cms"} %} {% block index %}
-
The general term Content Management System (CMS) refers to systems enabling individuals and organizations to create, manage, and publish content. A CMS for web content, specifically, is a system aimed at creating, managing, and publishing content to be consumed and experienced via the open web.
-
Each CMS implements some subset of a wide range of content management capabilities and the corresponding mechanisms for users to build websites easily and effectively around their content. Such content is often stored in some type of database, providing users with the flexibility to reuse it wherever needed for their content strategy. CMSs also provide admin capabilities aimed at making it easy for users to upload and manage content as needed.
-
There is great variability on the type and scope of the support CMSs provide for building sites; some provide ready-to-use templates which are "hydrated" with user content, and others require much more user involvement for designing and constructing the site structure.
-
When we think about CMSs, we need to account for all the components that play a role in the viability of such a system for providing a platform for publishing content on the web. All of these components form an ecosystem surrounding the CMS platform, and they include hosting providers, extension developers, development agencies, site builders, etc. Thus, when we talk about a CMS, we usually refer to both the platform itself and its surrounding ecosystem.
At the beginning of (web evolution) time, the web ecosystem was powered by a simple growth loop, where users could become creators just by viewing the source of a web page, copy-pasting according to their needs, and tailoring the new version with individual elements like images.
-
As the web evolved, it became more powerful, but also more complicated. As a consequence, that simple growth loop was broken and it was not the case anymore that any user could become a creator. For those who could pursue the content creation path, the road became arduous and hard to achieve. The usage-capability gap, that is, the difference between what can be done in the web and what is actually done, grew steadily.
On the left, labeled circa 1999, we have a bar chart with two bars showing what can be done is close to what is actually done. On the right, labeled 2018, we have a similar bar chart but what can be done is much larger, and what is done is slightly larger. The gap between what can be done and what is actually done has greatly increased.
- Figure 1. Chart illustrating the increase in web capabilities from 1999 to 2018.
-
-
Here is where a CMS plays the very important role of making it easy for users with different degrees of technical expertise to enter the web ecosystem loop as content creators. By lowering the barrier of entry for content creation, CMSs activate the growth loop of the web by turning users into creators. Hence their popularity.
There are many interesting and important aspects to analyze and questions to answer in our quest to understand the CMS space and its role in the present and the future of the web. While we acknowledge the vastness and complexity of the CMS platforms space, and don't claim omniscient knowledge fully covering all aspects involved on all platforms out there, we do claim our fascination for this space and we bring deep expertise on some of the major players in the space.
-
In this chapter, we seek to scratch the surface area of the vast CMS space, trying to shed a beam of light on our collective understanding of the status quo of CMS ecosystems, and the role they play in shaping users' perception of how content can be consumed and experienced on the web. Our goal is not to provide an exhaustive view of the CMS landscape; instead, we will discuss a few aspects related to the CMS landscape in general, and the characteristics of web pages generated by these systems. This first edition of the Web Almanac establishes a baseline, and in the future we'll have the benefit of comparing data against this version for trend analysis.
- Figure 2. Percent of web pages powered by a CMS.
-
-
Today, we can observe that more than 40% of the web pages are powered by some CMS platform; 40.01% for mobile and 39.61% for desktop more precisely.
-
There are other datasets tracking market share of CMS platforms, such as W3Techs, and they reflect higher percentages of more than 50% of web pages powered by CMS platforms. Furthermore, they observe also that CMS platforms are growing, as fast as 12% year-over-year growth in some cases! The deviation between our analysis and W3Tech's analysis could be explained by a difference in research methodologies. You can read more about ours on the Methodology page.
-
In essence, this means that there are many CMS platforms available out there. The following picture shows a reduced view of the CMS landscape.
Logos of the top CMS providers, including WordPress, Drupal, Wix, etc.
- Figure 3. The top content management systems.
-
-
Some of them are open source (e.g. WordPress, Drupal, others) and some of them are proprietary (e.g. AEM, others). Some CMS platforms can be used on "free" hosted or self-hosted plans, and there are also advanced options for using these platforms on higher-tiered plans even at the enterprise level. The CMS space as a whole is a complex, federated universe of CMS ecosystems, all separated and at the same time intertwined in the vast fabric of the web.
-
It also means that there are hundreds of millions of websites powered by CMS platforms, and an order of magnitude more of users accessing the web and consuming content through these platforms. Thus, these platforms play a key role for us to succeed in our collective quest for an evergreen, healthy, and vibrant web.
A large swath of the web today is powered by one kind of CMS platform or another. There are statistics collected by different organizations that reflect this reality. Looking at the Chrome UX Report (CrUX) and HTTP Archive datasets, we get a picture that is consistent with stats published elsewhere, although quantitatively the proportions described may be different as a reflection of the specificity of the datasets.
-
Looking at web pages served on desktop and mobile devices, we observe an approximate 60-40 split in the percentage of such pages which were generated by some kind of CMS platform, and those that aren't.
Bar chart showing that 40% of desktop and 40% of mobile websites are built using a CMS.
- Figure 4. Percent of desktop and mobile websites that use a CMS.
-
-
CMS-powered web pages are generated by a large set of available CMS platforms. There are many such platforms to choose from, and many factors that can be considered when deciding to use one vs. another, including things like:
-
-
Core functionality
-
Creation/editing workflows and experience
-
Barrier of entry
-
Customizability
-
Community
-
And many others.
-
-
The CrUX and HTTP Archive datasets contain web pages powered by a mix of around 103 CMS platforms. Most of those platforms are very small in terms of relative market share. For the sake of our analysis, we will be focusing on the top CMS platforms in terms of their footprint on the web as reflected by the data. For a full analysis, see this chapter's results spreadsheet.
Bar chart showing WordPress making up 75% of all CMS websites. The next biggest CMS, Drupal, has about 6% of the CMS market share. The rest of the CMSs quickly shrink in adoption to less than 1%.
- Figure 5. Top CMS platforms as a percent of all CMS websites.
-
-
The most salient CMS platforms present in the datasets are shown above in Figure 5. WordPress comprises 74.19% of mobile and 73.47% of desktop CMS websites. Its dominance in the CMS landscape can be attributed to a number of factors that we'll discuss later, but it's a major player. Open source platforms like Drupal and Joomla, and closed SaaS offerings like Squarespace and Wix, round out the top 5 CMSs. The diversity of these platforms speak to the CMS ecosystem consisting of many platforms where user demographics and the website creation journey vary. What's also interesting is the long tail of small scale CMS platforms in the top 20. From enterprise offerings to proprietary applications developed in-house for industry specific use, content management systems provide the customizable infrastructure for groups to manage, publish, and do business on the web.
-
The WordPress project defines its mission as "democratizing publishing". Some of its main goals are ease of use and to make the software free and available for everyone to create content on the web. Another big component is the inclusive community the project fosters. In almost any major city in the world, one can find a group of people who gather regularly to connect, share, and code in an effort to understand and build on the WordPress platform. Attending local meetups and annual events as well as participating in web-based channels are some of the ways WordPress contributors, experts, businesses, and enthusiasts participate in its global community.
-
The low barrier of entry and resources to support users (online and in-person) with publishing on the platform and to develop extensions (plugins) and themes contribute to its popularity. There is also a thriving availability of and economy around WordPress plugins and themes that reduce the complexity of implementing sought after web design and functionality. Not only do these aspects drive its reach and adoption by newcomers, but also maintains its long-standing use over time.
-
The open source WordPress platform is powered and supported by volunteers, the WordPress Foundation, and major players in the web ecosystem. With these factors in mind, WordPress as the leading CMS makes sense.
Independent of the specific nuances and idiosyncrasies of different CMS platforms, the end goal for all of them is to output web pages to be served to users via the vast reach of the open web. The difference between CMS-powered and non-CMS-powered web pages is that in the former, the CMS platform makes most of the decisions of how the end result is built, while in the latter there are not such layers of abstraction and decisions are all made by developers either directly or via library configurations.
-
In this section we take a brief look at the status quo of the CMS space in terms of the characteristics of their output (e.g. total resources used, image statistics, etc.), and how they compare with the web ecosystem as a whole.
The building blocks of any website also make a CMS website: HTML, CSS, JavaScript, and media (images and video). CMS platforms give users powerfully streamlined administrative capabilities to integrate these resources to create web experiences. While this is one of the most inclusive aspects of these applications, it could have some adverse effects on the wider web.
Bar chart showing the distribution of CMS page weight. The median desktop CMS page weighs 2.3 MB. At the 10th percentile it is 0.7 MB, 25th percentile 1.2 MB, 75th percentile 4.2 MB, and 90th percentile 7.4 MB. Desktop values are very slightly higher than mobile.
Bar chart showing the distribution of CMS requests per page. The median desktop CMS page loads 86 resources. At the 10th percentile it loads 39 resources, 25th percentile 57 resources, 75th percentile 127 resources, and 90th percentile 183 resources. Desktop is consistently higher than mobile by a small margin of 3-6 resources.
- Figure 7. Distribution of CMS requests per page.
-
-
In Figures 6 and 7 above, we see the median desktop CMS page loads 86 resources and weighs 2.29 MB. Mobile page resource usage is not too far behind with 83 resources and 2.25 MB.
-
The median indicates the halfway point that all CMS pages either fall above or below. In short, half of all CMS pages load fewer requests and weigh less, while half load more requests and weigh more. At the 10th percentile, mobile and desktop pages have under 40 requests and 1 MB in weight, but at the 90th percentile we see pages with over 170 requests and at 7 MB, almost tripling in weight from the median.
-
How do CMS pages compare to pages on the web as a whole? In the Page Weight chapter, we find some telling data about resource usage. At the median, desktop pages load 74 requests and weigh 1.9 MB, and mobile pages on the web load 69 requests and weigh 1.7 MB. The median CMS page exceeds this. CMS pages also exceed resources on the web at the 90th percentile, but by a smaller margin. In short: CMS pages could be considered as some of the heaviest.
-
-
-
-
-
-
-
percentile
-
image
-
video
-
script
-
font
-
css
-
audio
-
html
-
-
-
-
-
50
-
1,233
-
1,342
-
456
-
140
-
93
-
14
-
33
-
-
-
75
-
2,766
-
2,735
-
784
-
223
-
174
-
97
-
66
-
-
-
90
-
5,699
-
5,098
-
1,199
-
342
-
310
-
287
-
120
-
-
-
-
-
- Figure 8. Distribution of desktop CMS page kilobytes per resource type.
-
-
-
-
-
-
-
-
percentile
-
image
-
video
-
script
-
css
-
font
-
audio
-
html
-
-
-
-
-
50
-
1,264
-
1,056
-
438
-
89
-
109
-
14
-
32
-
-
-
75
-
2,812
-
2,191
-
756
-
171
-
177
-
38
-
67
-
-
-
90
-
5,531
-
4,593
-
1,178
-
317
-
286
-
473
-
123
-
-
-
-
-
- Figure 9. Distribution of mobile CMS page kilobytes per resource type.
-
-
When we look closer at the types of resources that load on mobile or desktop CMS pages, images and video immediately stand out as primary contributors to their weight.
-
The impact doesn't necessarily correlate with the number of requests, but rather how much data is associated with those individual requests. For example, in the case of video resources with only two requests made at the median, they carry more than 1MB of associated load. Multimedia experiences also come with the use of scripts to integrate interactivity, deliver functionality and data to name a few use cases. In both mobile and desktop pages, those are the 3rd heaviest resource.
-
With our CMS experiences saturated with these resources, we must consider the impact this has on website visitors on the frontend- is their experience fast or slow? Additionally, when comparing mobile and desktop resource usage, the amount of requests and weight show little difference. This means that the same amount and weight of resources are powering both mobile and desktop CMS experiences. Variation in connection speed and mobile device quality adds another layer of complexity. Later in this chapter, we'll use data from CrUX to assess user experience in the CMS space.
Let's highlight a particular subset of resources to assess their impact in the CMS landscape. Third-party resources are those from origins not belonging to the destination site's domain name or servers. They can be images, videos, scripts, or other resource types. Sometimes these resources are packaged in combination such as with embedding an iframe for example. Our data reveals that the median amount of 3rd party resources for both desktop and mobile are close.
-
The median amount of 3rd party requests on mobile CMS pages is 15 and weigh 264.72 KB, while the median for these requests on desktop CMS pages is 16 and weigh 271.56 KB. (Note that this excludes 3P resources considered part of "hosting").
Bar chart of percentiles 10, 25, 50, 75, and 90 representing the distribution of third-party kilobytes on CMS pages for desktop and mobile. The median (50th percentile) desktop third-party weight is 272 KB. The 10th percentile is 27 KB, 25th 104 KB, 75th 577 KB, and 90th 940 KB. Mobile is slightly smaller in the smaller percentiles and slightly larger in the larger percentiles.
- Figure 10. Distribution of third-party weight (KB) on CMS pages.
-
-
-
-
-
-
-
Bar chart of percentiles 10, 25, 50, 75, and 90 representing the distribution of third-party requests on CMS pages for desktop and mobile. The median (50th percentile) desktop third-party request count is 16. The 10th percentile is 3, 25th 7, 75th 31, and 90th 52. Desktop and mobile have nearly equivalent distributions.
- Figure 11. Distribution of the number of third-party requests on CMS pages.
-
-
We know the median value indicates at least half of CMS web pages are shipping with more 3rd party resources than what we report here. At the 90th percentile, CMS pages can deliver up to 52 resources at approximately 940 KB, a considerable increase.
-
Given that third-party resources originate from remote domains and servers, the destination site has little control over the quality and impact these resources have on its performance. This unpredictability could lead to fluctuations in speed and affect the user experience, which we'll soon explore.
Bar chart of percentiles 10, 25, 50, 75, and 90 representing the distribution of image kilobytes on CMS pages for desktop and mobile. The median (50th percentile) desktop image weight is 1,232 KB. The 10th percentile is 198 KB, 25th 507 KB, 75th 2,763 KB, and 90th 5,694 KB. Desktop and mobile have nearly equivalent distributions.
- Figure 12. Distribution of image weight (KB) on CMS pages.
-
-
-
1,232 KB
- Figure 13. The median number of image kilobytes loaded per desktop CMS page.
-
-
Recall from Figures 8 and 9 earlier, images are a big contributor to the total weight of CMS pages. Figures 12 and 13 above show that the median desktop CMS page has 31 images and payload of 1,232 KB, while the median mobile CMS page has 29 images and payload of 1,263 KB. Again we have very close margins for the weight of these resources for both desktop and mobile experiences. The Page Weight chapter additionally shows that image resources well exceed the median weight of pages with the same amount of images on the web as a whole, which is 983 KB and 893 KB for desktop and mobile respectively. The verdict: CMS pages ship heavy images.
-
Which are the common formats found on mobile and desktop CMS pages? From our data JPG images on average are the most popular image format. PNG and GIF formats follow, while formats like SVG, ICO, and WebP trail significantly comprising approximately a little over 2% and 1%.
Bar chart of the adoption of image formats on CMS pages for desktop and mobile. JPEG makes up nearly half of all image formats, PNG comprises a third, GIF comprises a fifth, and the remaining 5% shared among SVG, ICO, and WebP. Desktop and mobile have nearly equivalent adoption.
- Figure 14. Adoption of image formats on CMS pages.
-
-
Perhaps this segmentation isn't surprising given the common use cases for these image types. SVGs for logos and icons are common as are JPEGs ubiquitous. WebP is still a relatively new optimized format with growing browser adoption. It will be interesting to see how this impacts its use in the CMS space in the years to come.
Success as a web content creator is all about user experience. Factors such as resource usage and other statistics regarding how web pages are composed are important indicators of the quality of a given site in terms of the best practices followed while building it. However, we are ultimately interested in shedding some light on how are users actually experiencing the web when consuming and engaging with content generated by these platforms.
- Figure 15. How humans perceive short durations of time.
-
-
If things happen within 0.1 seconds (100 milliseconds), for all of us they are happening virtually instantly. And when things take longer than a few seconds, the likelihood we go on with our lives without waiting any longer is very high. This is very important for content creators seeking sustainable success in the web, because it tells us how fast our sites must load if we want to acquire, engage, and retain our user base.
-
In this section we take a look at three important dimensions which can shed light on our understanding of how users are experiencing CMS-powered web pages in the wild:
First Contentful Paint measures the time it takes from navigation until content such as text or an image is first displayed. A successful FCP experience, or one that can be qualified as "fast," entails how quickly elements in the DOM are loaded to assure the user that the website is loading successfully. Although a good FCP score is not a guarantee that the corresponding site offers a good UX, a bad FCP almost certainly does guarantee the opposite.
Bar chart of the average distribution of FCP experiences per CMS. Refer to Figure 17 below for a data table of the top 5 CMSs.
- Figure 16. Average distribution of FCP experiences across CMSs.
-
-
-
-
-
-
-
-
CMS
-
Fast (< 1000ms)
-
Moderate
-
Slow (>= 3000ms)
-
-
-
-
-
WordPress
-
24.33%
-
40.24%
-
35.42%
-
-
-
Drupal
-
37.25%
-
39.39%
-
23.35%
-
-
-
Joomla
-
22.66%
-
46.48%
-
30.86%
-
-
-
Wix
-
14.25%
-
62.84%
-
22.91%
-
-
-
Squarespace
-
26.23%
-
43.79%
-
29.98%
-
-
-
-
-
- Figure 17. Average distribution of FCP experiences for the top 5 CMSs.
-
-
FCP in the CMS landscape trends mostly in the moderate range. The need for CMS platforms to query content from a database, send, and subsequently render it in the browser, could be a contributing factor to the delay that users experience. The resource loads we discussed in the previous sections could also play a role. In addition, some of these instances are on shared hosting or in environments that may not be optimized for performance, which could also impact the experience in the browser.
-
WordPress shows notably moderate and slow FCP experiences on mobile and desktop. Wix sits strongly in moderate FCP experiences on its closed platform. TYPO3, an enterprise open-source CMS platform, has consistently fast experiences on both mobile and desktop. TYPO3 advertises built-in performance and scalability features that may have a positive impact for website visitors on the frontend.
First Input Delay (FID) measures the time from when a user first interacts with your site (i.e. when they click a link, tap on a button, or use a custom, JavaScript-powered control) to the time when the browser is actually able to respond to that interaction. A "fast" FID from a user's perspective would be immediate feedback from their actions on a site rather than a stalled experience. This delay (a pain point) could correlate with interference from other aspects of the site loading when the user tries to interact with the site.
-
FID in the CMS space generally trends on fast experiences for both desktop and mobile on average. However, what's notable is the significant difference between mobile and desktop experiences.
Bar chart of the average distribution of FCP experiences per CMS. Refer to Figure 19 below for a data table of the top 5 CMSs.
- Figure 18. Average distribution of FID experiences across CMSs.
-
-
-
-
-
-
-
-
CMS
-
Fast (< 100ms)
-
Moderate
-
Slow (>= 300ms)
-
-
-
-
-
WordPress
-
80.25%
-
13.55%
-
6.20%
-
-
-
Drupal
-
74.88%
-
18.64%
-
6.48%
-
-
-
Joomla
-
68.82%
-
22.61%
-
8.57%
-
-
-
Squarespace
-
84.55%
-
9.13%
-
6.31%
-
-
-
Wix
-
63.06%
-
16.99%
-
19.95%
-
-
-
-
-
- Figure 19. Average distribution of FID experiences for the top 5 CMSs.
-
-
While this difference is present in FCP data, FID sees bigger gaps in performance. For example, the difference between mobile and desktop fast FCP experiences for Joomla is around 12.78%, for FID experiences the difference is significant: 27.76%. Mobile device and connection quality could play a role in the performance gaps that we see here. As we highlighted previously, there is a small margin of difference between the resources shipped to desktop and mobile versions of a website. Optimizing for the mobile (interactive) experience becomes more apparent with these results.
Lighthouse is an open-source, automated tool designed to help developers assess and improve the quality of their websites. One key aspect of the tool is that it provides a set of audits to assess the status of a website in terms of performance, accessibility, progressive web apps, and more. For the purposes of this chapter, we are interested in two specific audits categories: PWA and accessibility.
The term Progressive Web App (PWA) refers to web-based user experiences that are considered as being reliable, fast, and engaging. Lighthouse provides a set of audits which returns a PWA score between 0 (worst) and 1 (best). These audits are based on the Baseline PWA Checklist, which lists 14 requirements. Lighthouse has automated audits for 11 of the 14 requirements. The remaining 3 can only be tested manually. Each of the 11 automated PWA audits are weighted equally, so each one contributes approximately 9 points to your PWA score.
Bar chart showing the distribution of Lighthouse PWA category scores for all CMS pages. The most common score is 0.3 at 22% of CMS pages. There are two other peaks in the distribution: 11% of pages with scores of 0.15 and 8% of pages with scores of 0.56. Fewer than 1% of pages get a score above 0.6.
- Figure 20. Distribution of Lighthouse PWA category scores for CMS pages.
-
-
-
-
-
-
-
Bar chart showing the median Lighthouse PWA score per CMS. The median score for WordPress websites is 0.33. The next five CMSs (Joomla, Drupal, Wix, Squarespace, and 1C-Bitrix) all have a median score of 0.3. The CMSs with the top PWA scores are Jimdo with a score of 0.56 and TYPO3 at 0.41.
- Figure 21. Median Lighthouse PWA category scores per CMS.
-
-
An accessible website is a site designed and developed so that people with disabilities can use them. Lighthouse provides a set of accessibility audits and it returns a weighted average of all of them (see Scoring Details for a full list of how each audit is weighted).
-
Each accessibility audit is pass or fail, but unlike other Lighthouse audits, a page doesn't get points for partially passing an accessibility audit. For example, if some elements have screenreader-friendly names, but others don't, that page gets a 0 for the screenreader-friendly-names audit.
Bar chart showing the distribution of CMS pages' Lighthouse accessibility scores. The distribution is heavily skewed to the higher scores with a mode of about 0.85.
- Figure 22. Distribution of Lighthouse accessibility category scores for CMS pages.
-
-
-
-
-
-
-
Bar chart showing the median Lighthouse accessibility category score per CMS. Most CMSs get a score of about 0.75. Notable outliers include Wix with a median score of 0.93 and 1-C Bitrix with a score of 0.65.
- Figure 23. Median Lighthouse accessibility category scores per CMS.
-
-
As it stands now, only 1.27% of mobile CMS home pages get a perfect score of 100%. Of the top CMSs, Wix takes the lead by having the highest median accessibility score on its mobile pages. Overall, these figures are dismal when you consider how many websites (how much of the web that is powered by CMSs) are inaccessible to a significant segment of our population. As much as digital experiences impact so many aspects of our lives, this should be a mandate to encourage us to build accessible web experiences from the start, and to continue the work of making the web an inclusive space.
While we've taken a snapshot of the current landscape of the CMS ecosystem, the space is evolving. In efforts to address performance and user experience shortcomings, we're seeing experimental frameworks being integrated with the CMS infrastructure in both coupled and decoupled/ headless instances. Libraries and frameworks such as React.js, its derivatives like Gatsby.js and Next.js, and Vue.js derivative Nuxt.js are making slight marks of adoption.
-
-
-
-
-
-
-
CMS
-
React
-
Nuxt.js, React
-
Nuxt.js
-
Next.js, React
-
Gatsby, React
-
-
-
-
-
WordPress
-
131,507
-
-
21
-
18
-
-
-
-
Wix
-
50,247
-
-
-
-
-
-
-
Joomla
-
3,457
-
-
-
-
-
-
-
Drupal
-
2,940
-
-
8
-
15
-
1
-
-
-
DataLife Engine
-
1,137
-
-
-
-
-
-
-
Adobe Experience Manager
-
723
-
-
-
7
-
-
-
-
Contentful
-
492
-
7
-
114
-
909
-
394
-
-
-
Squarespace
-
385
-
-
-
-
-
-
-
1C-Bitrix
-
340
-
-
-
-
-
-
-
TYPO3 CMS
-
265
-
-
-
1
-
-
-
-
Weebly
-
263
-
-
1
-
-
-
-
-
Jimdo
-
248
-
-
-
-
2
-
-
-
PrestaShop
-
223
-
-
1
-
-
-
-
-
SDL Tridion
-
152
-
-
-
-
-
-
-
Craft CMS
-
123
-
-
-
-
-
-
-
-
-
- Figure 24. Adoption (number of mobile websites) of React and companion frameworks per CMS.
-
-
We also see hosting providers and agencies offering Digital Experience Platforms (DXP) as holistic solutions using CMSs and other integrated technologies as a toolbox for enterprise customer-focused strategies. These innovations show an effort to create turn-key, CMS-based solutions that make it possible, simple, and easy by default for the users (and their end users) to get the best UX when creating and consuming the content of these platforms. The aim: good performance by default, feature richness, and excellent hosting environments.
The CMS space is of paramount importance. The large portion of the web these applications power and the critical mass of users both creating and encountering its pages on a variety of devices and connections should not be trivialized. We hope this chapter and the others found here in the Web Almanac inspire more research and innovation to help make the space better. Deep investigations would provide us better context about the strengths, weaknesses, and opportunities these platforms provide the web as a whole. Content management systems can make an impact on preserving the integrity of the open web. Let's keep moving them forward!
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/compression.html b/src/templates/en/2019/chapters/compression.html
deleted file mode 100644
index 5a67c56019f..00000000000
--- a/src/templates/en/2019/chapters/compression.html
+++ /dev/null
@@ -1,330 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":15,"title":"Compression","description":"Compression chapter of the 2019 Web Almanac covering HTTP compression, algorithms, content types, 1st party and 3rd party compression and opportunities.","authors":["paulcalvano"],"reviewers":["obto","yoavweiss"],"translators":null,"discuss":"1770","results":"https://docs.google.com/spreadsheets/d/1IK9kaScQr_sJUwZnWMiJcmHEYJV292C9DwCfXH6a50o/","queries":"15_Compression","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-08T00:00:00.000Z","chapter":"compression"} %} {% block index %}
-
HTTP compression is a technique that allows you to encode information using fewer bits than the original representation. When used for delivering web content, it enables web servers to reduce the amount of data transmitted to clients. This increases the efficiency of the client's available bandwidth, reduces page weight, and improves web performance.
-
Compression algorithms are often categorized as lossy or lossless:
-
-
When a lossy compression algorithm is used, the process is irreversible, and the original file cannot be restored via decompression. This is commonly used to compress media resources, such as image and video content where losing some data will not materially affect the resource.
-
Lossless compression is a completely reversible process, and is commonly used to compress text based resources, such as HTML, JavaScript, CSS, etc.
-
-
In this chapter, we are going to explore how text-based content is compressed on the web. Analysis of non-text-based content forms part of the Media chapter.
- When a client makes an HTTP request, it often includes an Accept-Encoding header to advertise the compression algorithms it is capable of decoding. The server can then select from one of the advertised encodings it supports and serve a compressed response. The compressed response would include a Content-Encoding header so that the client is aware of which compression was used. Additionally, a Content-Type header is often used to indicate the MIME type of the resource being served.
-
-
In the example below, the client advertised support for gzip, brotli, and deflate compression. The server decided to return a gzip compressed response containing a text/html document.
The HTTP Archive contains measurements for 5.3 million web sites, and each site loaded at least 1 compressed text resource on their home page. Additionally, resources were compressed on the primary domain on 81% of web sites.
IANA maintains a list of valid HTTP content encodings that can be used with the Accept-Encoding and Content-Encoding headers. These include gzip, deflate, br (brotli), as well as a few others. Brief descriptions of these algorithms are given below:
-
-
Gzip uses the LZ77 and Huffman coding compression techniques, and is older than the web itself. It was originally developed for the UNIX gzip program in 1992. An implementation for web delivery has existed since HTTP/1.1, and most web browsers and clients support it.
-
Deflate uses the same algorithm as gzip, just with a different container. Its use was not widely adopted for the web because of compatibility issues with some servers and browsers.
-
Brotli is a newer compression algorithm that was invented by Google. It uses the combination of a modern variant of the LZ77 algorithm, Huffman coding, and second order context modeling. Compression via brotli is more computationally expensive compared to gzip, but the algorithm is able to reduce files by 15-25% more than gzip compression. Brotli was first used for compressing web content in 2015 and is supported by all modern web browsers.
-
-
Approximately 38% of HTTP responses are delivered with text-based compression. This may seem like a surprising statistic, but keep in mind that it is based on all HTTP requests in the dataset. Some content, such as images, will not benefit from these compression algorithms. The table below summarizes the percentage of requests served with each content encoding.
Of the resources that are served compressed, the majority are using either gzip (80%) or brotli (20%). The other compression algorithms are infrequently used.
- Figure 2. Adoption of compression algorithms on desktop pages.
-
-
Additionally, there are 67k requests that return an invalid Content-Encoding, such as "none", "UTF-8", "base64", "text", etc. These resources are likely served uncompressed.
-
We can't determine the compression levels from any of the diagnostics collected by the HTTP Archive, but the best practice for compressing content is:
If you can support brotli and precompress resources, then compress to brotli level 11. This is more computationally expensive than gzip - so precompression is an absolute must to avoid delays.
-
If you can support brotli and are unable to precompress, then compress to brotli level 5. This level will result in smaller payloads compared to gzip, with a similar computational overhead.
Most text based resources (such as HTML, CSS, and JavaScript) can benefit from gzip or brotli compression. However, it's often not necessary to use these compression techniques on binary resources, such as images, video, and some web fonts because their file formats are already compressed.
-
In the graph below, the top 25 content types are displayed with box sizes representing the relative number of requests. The color of each box represents how many of these resources were served compressed. Most of the media content is shaded orange, which is expected since gzip and brotli would have little to no benefit for them. Most of the text content is shaded blue to indicate that they are being compressed. However, the light blue shading for some content types indicate that they are not compressed as consistently as the others.
The application/json and image/svg+xml content types are compressed less than 65% of the time.
-
Most of the custom web fonts are served without compression, since they are already in a compressed format. However, font/ttf is compressible, but only 84% of TTF font requests are being served with compression so there is still room for improvement here.
-
The graphs below illustrate the breakdown of compression techniques used for each content type. Looking at the top three content types, we can see that across both desktop and mobile there are major gaps in compressing some of the most frequently requested content types. 56% of text/html as well as 18% of application/javascript and text/css resources are not being compressed. This presents a significant performance opportunity.
Stacked bar chart showing application/javascript is 36.18 Million/8.97 Million/10.47 Million by compression type (Gzip/Brotli/None), text/css is 24.29 M/8.31 M/7.20 M, text/html is 11.37 M/4.89 M/20.57 M, text/javascript is 23.21 M/1.72 M/3.03 M, application/x-javascript is 11.86 M/4.97 M/1.66 M, application/json is 4.06 M/0.50 M/3.23 M, image/svg+xml is 2.54 M/0.46 M/1.74 M, text/plain is 0.71 M/0.06 M/2.42 M, and image/x-icon is 0.58 M/0.10 M/1.11 M. Deflate is almost never used by any time and does not register on the chart..
- Figure 5. Compression by content type for desktop.
-
-
-
-
-
-
-
Stacked bar chart showing application/javascript is 43.07 Million/10.17 Million/12.19 Million by compression type (Gzip/Brotli/None), text/css is 28.3 M/9.91 M/8.56 M, text/html is 13.86 M/5.48 M/25.79 M, text/javascript is 27.41 M/1.94 M/3.33 M, application/x-javascript is 12.77 M/5.70 M/1.82 M, application/json is 4.67 M/0.50 M/3.53 M, image/svg+xml is 2.91 M/ 0.44 M/1.77 M, text/plain is 0.80 M/0.06 M/1.77 M, and image/x-icon is 0.62 M/0.11 M/1.22M. Deflate is almost never used by any time and does not register on the chart.
- Figure 6. Compression by content type for mobile.
-
-
The content types with the lowest compression rates include application/json, text/xml, and text/plain. These resources are commonly used for XHR requests to provide data that web applications can use to create rich experiences. Compressing them will likely improve user experience. Vector graphics such as image/svg+xml, and image/x-icon are not often thought of as text based, but they are and sites that use them would benefit from compression.
Stacked bar chart showing application/javascript is 65.1%/16.1%/18.8% by compression type (Gzip/Brotli/None), text/css is 61.0%/20.9%/18.1%, text/html is 30.9%/13.3%/55.8%, text/javascript is 83.0%/6.1%/10.8%, application/x-javascript is 64.1%/26.9%/9.0%, application/json is 52.1%/6.4%/41.4%, image/svg+xml is 53.5%/9.8%/36.7%, text/plain is 22.2%/2.0%/75.8%, and image/x-icon is 32.6%/5.3%/62.1%. Deflate is almost never used by any time and does not register on the chart.
- Figure 7. Compression by content type as a percent for desktop.
-
-
-
-
-
-
-
Stacked bar chart showing application/javascript is 65.8%/15.5%/18.6% by compression type (Gzip/Brotli/None), text/css is 60.5%/21.2%/18.3%, text/html is 30.7%/12.1%/57.1%, text/javascript is 83.9%/5.9%/10.2%, application/x-javascript is 62.9%/28.1%/9.0%, application/json is 53.6%/8.6%/34.6%, image/svg+xml is 23.4%/1.8%/74.8%, text/plain is 23.4%/1.8%/74.8%, and image/x-icon is 31.8%/5.5%/62.7%. Deflate is almost never used by any time and does not register on the chart.
- Figure 8. Compression by content type as a percent for mobile.
-
-
Across all content types, gzip is the most popular compression algorithm. The newer brotli compression is used less frequently, and the content types where it appears most are application/javascript, text/css and application/x-javascript. This is likely due to CDNs that automatically apply brotli compression for traffic that passes through them.
In the Third Parties chapter, we learned about third parties and their impact on performance. When we compare compression techniques between first and third parties, we can see that third-party content tends to be compressed more than first-party content.
-
Additionally, the percentage of brotli compression is higher for third-party content. This is likely due to the number of resources served from the larger third parties that typically support brotli, such as Google and Facebook.
-
-
-
-
-
-
-
-
Desktop
-
Mobile
-
-
-
Content Encoding
-
First-Party
-
Third-Party
-
First-Party
-
Third-Party
-
-
-
-
-
No Text Compression
-
66.23%
-
59.28%
-
64.54%
-
58.26%
-
-
-
gzip
-
29.33%
-
30.20%
-
30.87%
-
31.22%
-
-
-
br
-
4.41%
-
10.49%
-
4.56%
-
10.49%
-
-
-
deflate
-
0.02%
-
0.01%
-
0.02%
-
0.01%
-
-
-
Other / Invalid
-
0.01%
-
0.02%
-
0.01%
-
0.02%
-
-
-
-
-
- Figure 9. First-party versus third-party compression by device type.
-
Google's Lighthouse tool enables users to run a series of audits against web pages. The text compression audit evaluates whether a site can benefit from additional text-based compression. It does this by attempting to compress resources and evaluate whether an object's size can be reduced by at least 10% and 1,400 bytes. Depending on the score, you may see a compression recommendation in the results, with a list of specific resources that could be compressed.
A screenshot of a Lighthouse report showing a list of resources (with the names redacted) and showing the size and the potential saving. For the first item there is a potentially significant saving from 91 KB to 73 KB, while for other smaller files of 6 KB or less there are smaller savings of 4 KB to 1 KB.
Because the HTTP Archive runs Lighthouse audits for each mobile page, we can aggregate the scores across all sites to learn how much opportunity there is to compress more content. Overall, 62% of websites are passing this audit and almost 23% of websites have scored below a 40. This means that over 1.2 million websites could benefit from enabling additional text based compression.
Stacked bar chart showing 7.6% are costing less than 10%, 13.2% of sites are scoring between 10-39%, 13.7% of sites scoring between 40-79%, 2.9% of sites scoring between 80-99%, and 62.5% of sites have a pass with over 100% of text assets being compressed.
Lighthouse also indicates how many bytes could be saved by enabling text-based compression. Of the sites that could benefit from text compression, 82% of them can reduce their page weight by up to 1 MB!
HTTP compression is a widely used and highly valuable feature for reducing the size of web content. Both gzip and brotli compression are the dominant algorithms used, and the amount of compressed content varies by content type. Tools like Lighthouse can help uncover opportunities to compress content.
-
While many sites are making good use of HTTP compression, there is still room for improvement, particularly for the text/html format that the web is built upon! Similarly, lesser-understood text formats like font/ttf, application/json, text/xml, text/plain, image/svg+xml, and image/x-icon may take extra configuration that many websites miss.
-
At a minimum, websites should use gzip compression for all text-based resources, since it is widely supported, easily implemented, and has a low processing overhead. Additional savings can be found with brotli compression, although compression levels should be chosen carefully based on whether a resource can be precompressed.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/css.html b/src/templates/en/2019/chapters/css.html
deleted file mode 100644
index b09c01dce31..00000000000
--- a/src/templates/en/2019/chapters/css.html
+++ /dev/null
@@ -1,807 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":2,"title":"CSS","description":"CSS chapter of the 2019 Web Almanac covering color, units, selectors, layout, typography and fonts, spacing, decoration, animation, and media queries.","authors":["una","argyleink"],"reviewers":["meyerweb","huijing"],"translators":null,"discuss":"1757","results":"https://docs.google.com/spreadsheets/d/1uFlkuSRetjBNEhGKWpkrXo4eEIsgYelxY-qR9Pd7QpM/","queries":"02_CSS","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-06T00:00:00.000Z","chapter":"css"} %} {% block index %}
-
Cascading Style Sheets (CSS) are used to paint, format, and layout web pages. Their capabilities span concepts as simple as text color to 3D perspective. It also has hooks to empower developers to handle varying screen sizes, viewing contexts, and printing. CSS helps developers wrangle content and ensure it's adapting properly to the user.
-
When describing CSS to those not familiar with web technology, it can be helpful to think of it as the language to paint the walls of the house; describing the size and position of windows and doors, as well as flourishing decorations such as wallpaper or plant life. The fun twist to that story is that depending on the user walking through the house, a developer can adapt the house to that specific user's preferences or contexts!
-
In this chapter, we'll be inspecting, tallying, and extracting data about how CSS is used across the web. Our goal is to holistically understand what features are being used, how they're used, and how CSS is growing and being adopted.
-
Ready to dig into the fascinating data?! Many of the following numbers may be small, but don't mistake them as insignificant! It can take many years for new things to saturate the web.
Hex is the most popular way to describe color by far, with 93% usage, followed by RGB, and then HSL. Interestingly, developers are taking full advantage of the alpha-transparency argument when it comes to these color types: HSLA and RGBA are far more popular than HSL and RGB, with almost double the usage! Even though the alpha-transparency was added later to the web spec, HSLA and RGBA are supported as far back as IE9, so you can go ahead and use them, too!
Bar chart showing the adoption of HSL, HSLA, RGB, RGBA, and hex color formats. Hex is used on 93% of desktop pages, RGBA on 83%, RGB on 22%, HSLA 19%, and HSL 1%. Desktop and mobile adoption is similar for all color formats except HSL, for which mobile adoption is 9% (9 times higher).
There are 148 named CSS colors, not including the special values transparent and currentcolor. You can use these by their string name for more readable styling. The most popular named colors are black and white, unsurprisingly, followed by red and blue.
Language is interestingly inferred via color as well. There are more instances of the American-style "gray" than the British-style "grey". Almost every instance of gray colors (gray, lightgray, darkgray, slategray, etc.) had nearly double the usage when spelled with an "a" instead of an "e". If gr[a/e]ys were combined, they would rank higher than blue, solidifying themselves in the #4 spot. This could be why silver is ranked higher than grey with an "e" in the charts!
How many different font colors are used across the web? So this isn't the total number of unique colors; rather, it's how many different colors are used just for text. The numbers in this chart are quite high, and from experience, we know that without CSS variables, spacing, sizes and colors can quickly get away from you and fragment into lots of tiny values across your styles. These numbers reflect a difficulty of style management, and we hope this helps create some perspective for you to bring back to your teams or projects. How can you reduce this number into a manageable and reasonable amount?
Distribution showing the 10, 25, 50, 75, and 90th percentiles of colors per desktop and mobile page. On desktop the distribution is 8, 22, 48, 83, and 131. Mobile pages tend to have more colors by 1-10.
Well, we got curious here and wanted to inspect how many duplicate colors are present on a page. Without a tightly managed reusable class CSS system, duplicates are quite easy to create. It turns out that the median has enough duplicates that it could be worth doing a pass to unify them with custom properties.
Bar chart showing the distribution of colors per page. The median desktop page has 24 duplicate colors. The 10th percentile is 4 duplicate colors and the 90th percentile is 62. Desktop and mobile distributions are similar.
- Figure 4. Distribution of duplicate colors per page.
-
-
In CSS, there are many different ways to achieve the same visual result using different unit types: rem, px, em, ch, or even cm! So which unit types are most popular?
Bar chart of the popularity of various unit types. px and em are used on at over 90% of pages. rem is the next most popular unit type on 40% of pages and the popularity quickly falls for the remaining unit types.
Unsurprisingly, In Figure 5 above, px is the most used unit type, with about 95% of web pages using pixels in some form or another (this could be element sizing, font size, and so on). However, the em unit is almost as popular, with about 90% usage. This is over 2x more popular than the rem unit, which has only 40% frequency in web pages. If you're wondering what the difference is, em is based on the parent font size, while rem is based on the base font size set to the page. It doesn't change per-component like em could, and thus allows for adjustment of all spacing evenly.
-
When it comes to units based on physical space, the cm (or centimeter) unit is the most popular by far, followed by in (inches), and then Q. We know these types of units are specifically useful for print stylesheets, but we didn't even know the Q unit existed until this survey! Did you?
-
An earlier version of this chapter discussed the unexpected popularity of the Q unit. Thanks to the community discussion surrounding this chapter, we've identified that this was a bug in our analysis and have updated Figure 5 accordingly.
We saw larger differences in unit types when it comes to mobile and desktop usage for viewport-based units. 36.8% of mobile sites use vh (viewport height), while only 31% of desktop sites do. We also found that vh is more common than vw (viewport width) by about 11%. vmin (viewport minimum) is more popular than vmax (viewport maximum), with about 8% usage of vmin on mobile while vmax is only used by 1% of websites.
Custom properties are what many call CSS variables. They're more dynamic than a typical static variable though! They're very powerful and as a community we're still discovering their potential.
-
-
5%
- Figure 6. Percent of pages using custom properties.
-
-
We felt like this was exciting information, since it shows healthy growth of one of our favorite CSS additions. They were available in all major browsers since 2016 or 2017, so it's fair to say they're fairly new. Many folks are still transitioning from their CSS preprocessor variables to CSS custom properties. We estimate it'll be a few more years until custom properties are the norm.
CSS has a few ways to find elements on the page for styling, so let's put IDs and classes against each other to see which is more prevalent! The results shouldn't be too surprising: classes are more popular!
Bar chart showing the adoption of ID and class selector types. Classes are used on 95% of desktop and mobile pages. IDs are used on 89% of desktop and 87% of mobile pages.
- Figure 7. Popularity of selector types per page.
-
-
A nice follow up chart is this one, showing that classes take up 93% of the selectors found in a stylesheet.
Bar chart showing that 94% of selectors include the class selector for desktop and mobile, while 7% of desktop selectors include the ID selector (8% for mobile).
- Figure 8. Popularity of selector types per selector.
-
-
CSS has some very powerful comparison selectors. These are selectors like [target="_blank"], [attribute^="value"], [title~="rad"], [attribute$="-rad"] or [attribute*="value"]. Do you use them? Think they're used a lot? Let's compare how those are used with IDs and classes across the web.
Bar chart showing the popularity of operators used by ID attribute selectors. About 4% of desktop and mobile pages use star-equals and caret-equals. 1% of pages use equals and dollar-equals. 0% use tilde-equals.
- Figure 9. Popularity of operators per ID attribute selector.
-
-
-
-
-
-
-
Bar chart showing the popularity of operators used by class attribute selectors. 57% of pages use star-equals. 36% use caret-equals. 1% use equals and dollar-equals. 0% use tilde-equals.
- Figure 10. Popularity of operators per class attribute selector.
-
-
These operators are much more popular with class selectors than IDs, which feels natural since a stylesheet usually has fewer ID selectors than class selectors, but still neat to see the uses of all these combinations.
With the rise of OOCSS, atomic, and functional CSS strategies which can compose 10 or more classes on an element to achieve a design look, perhaps we'd see some interesting results. The query came back quite unexciting, with the median on mobile and desktop being 1 class per element.
-
-
1
- Figure 11. The median number of class names per class attribute (desktop and mobile).
-
-
Flexbox is a container style that directs and aligns its children; that is, it helps with layout in a constraint-based way. It had a quite rocky beginning on the web, as its specification went through two or three quite drastic changes between 2010 and 2013. Fortunately, it settled and was implemented across all browsers by 2014. Given that history, it had a slow adoption rate, but it's been a few years since then! It's quite popular now and has many articles about it and how to leverage it, but it's still new in comparison to other layout tactics.
Like flexbox, grid too went through a few spec alternations early on in its lifespan, but without changing implementations in publicly-deployed browsers. Microsoft had grid in the first versions of Windows 8, as the primary layout engine for its horizontally scrolling design style. It was vetted there first, transitioned to the web, and then hardened by the other browsers until its final release in 2017. It had a very successful launch in that nearly all browsers released their implementations at the same time, so web developers just woke up one day to superb grid support. Today, at the end of 2019, grid still feels like a new kid on the block, as folks are still awakening to its power and capabilities.
This shows just how little the web development community has exercised and explored their latest layout tool. We look forward to the eventual takeover of grid as the primary layout engine folks lean on when building a site. For us authors, we love writing grid: we typically reach for it first, then dial our complexity back as we realize and iterate on layout. It remains to be seen what the rest of the world will do with this powerful CSS feature over the next few years.
The web and CSS are international platform features, and writing modes offer a way for HTML and CSS to indicate a user's preferred reading and writing direction within our elements.
Bar chart showing the popularity of direction values ltr and rtl. ltr is used by 32% of desktop pages and 40% of mobile pages. rtl is used by 32% of desktop pages and 36% of mobile pages.
Distribution of the number of web fonts loaded per page. On desktop the 10, 25, 50, 75, and 90th percentiles are: 0, 1, 3, 6, and 9. This slightly higher than the mobile distribution which is one fewer font in the 75th and 90th percentiles.
- Figure 15. Distribution of the number of web fonts loaded per page.
-
-
A natural follow up to the inquiry of total number of fonts per page, is: what fonts are they?! Designers, tune in, because you'll now get to see if your choices are in line with what's popular or not.
Bar chart of the most popular fonts. Among desktop pages, they are Open Sans (24%), Roboto (15%), Montserrat (5%), Source Sans Pro (4%), Noto Sans JP (3%), and Lato (3%). On mobile the most notable differences are that Open Sans is used 22% of the time (down from 24%) and Roboto is used 19% of the time (up from 15%).
Open Sans is a huge winner here, with nearly 1 in 4 CSS @font-family declarations specifying it. We've definitely used Open Sans in projects at agencies.
-
It's also interesting to note the differences between desktop and mobile adoption. For example, mobile pages use Open Sans slightly less often than desktop. Meanwhile, they also use Roboto slightly more often.
This is a fun one, because if you asked a user how many font sizes they feel are on a page, they'd generally return a number of 5 or definitely less than 10. Is that reality though? Even in a design system, how many font sizes are there? We queried the web and found the median to be 40 on mobile and 38 on desktop. Might be time to really think hard about custom properties or creating some reusable classes to help you distribute your type ramp.
Bar chart showing the distribution of distinct font sizes per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 8, 20, 40, 66, and 92 font sizes. The desktop distribution diverges from mobile at the 75th percentile, where it is larger by 7 to 13 distinct sizes.
- Figure 17. Distribution of the number of distinct font sizes per page.
-
-
A margin is the space outside of elements, like the space you demand when you push your arms out from yourself. This often looks like the spacing between elements, but is not limited to that effect. In a website or app, spacing plays a huge role in UX and design. Let's see how much margin spacing code goes into a stylesheet, shall we?
Bar chart showing the distribution of distinct margin values per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 12, 47, 96, 167, and 248 distinct margin values. The desktop distribution diverges from mobile at the 75th percentile, where it is smaller by 12 to 31 distinct values.
- Figure 18. Distribution of the number of distinct margin values per page.
-
-
Quite a lot, it seems! The median desktop page has 96 distinct margin values and 104 on mobile. That makes for a lot of unique spacing moments in your design. Curious how many margins you have in your site? How can we make all this whitespace more manageable?
- Figure 19. Percent of desktop and mobile pages that include logical properties.
-
-
We estimate that the hegemony of margin-left and padding-top is of limited duration, soon to be supplemented by their writing direction agnostic, successive, logical property syntax. While we're optimistic, current usage is quite low at 0.67% usage on desktop pages. To us, this feels like a habit change we'll need to develop as an industry, while hopefully training new developers to use the new syntax.
Vertical layering, or stacking, can be managed with z-index in CSS. We were curious how many different values folks use in their sites. The range of what z-index accepts is theoretically infinite, bounded only by a browser's variable size limitations. Are all those stack positions used? Let's see!
Bar chart showing the distribution of distinct z-index values per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 1, 7, 16, 26, and 36 distinct z-index values. The desktop distribution is much higher than mobile, by as many as 16 distinct values at the 90th percentile.
- Figure 20. Distribution of the number of distinct z-index values per page.
-
-
From our work experience, any number of 9's seemed to be the most popular choice. Even though we taught ourselves to use the lowest number possible, that's not the communal norm. So what is then?! If folks need things on top, what are the most popular z-index numbers to pass in? Put your drink down; this one is funny enough you might lose it.
Scatterplot of all known z-index values and the number of times they're used, for both desktop and mobile. 1 and 2 are the most frequently used, but the rest of the popular values explode in orders of magnitude: 10, 100, 1,000, and so on all the way to numbers with hundreds of digits.
- Figure 21. Most frequently used z-index values.
-
-
-
Filters are a fun and great way to modify the pixels the browser intends to draw to the screen. It's a post-processing effect that is done against a flat version of the element, node, or layer that it's being applied to. Photoshop made them easy to use, then Instagram made them accessible to the masses through bespoke, stylized combinations. They've been around since about 2012, there are 10 of them, and they can be combined to create unique effects.
-
-
78%
- Figure 23. Percent of pages that include a stylesheet with the filter property.
-
-
We were excited to see that 78% of stylesheets contain the filter property! That number was also so high it seemed a little fishy, so we dug in and sought to explain the high number. Because let's be honest, filters are neat, but they don't make it into all of our applications and projects. Unless!
-
Upon further investigation, we discovered FontAwesome's stylesheet comes with some filter usage, as well as a YouTube embed. Therefore, we believe filter snuck in the back door by piggybacking onto a couple very popular stylesheets. We also believe that -ms-filter presence could have been included as well, contributing to the high percent of use.
Blend modes are similar to filters in that they are a post-processing effect that are run against a flat version of their target elements, but are unique in that they are concerned with pixel convergence. Said another way, blend modes are how 2 pixels should impact each other when they overlap. Whichever element is on the top or the bottom will affect the way that the blend mode manipulates the pixels. There are 16 blend modes -- let's see which ones are the most popular.
-
-
8%
- Figure 24. Percent of pages that include a stylesheet with the *-blend-mode property.
-
-
Overall, usage of blend modes is much lower than of filters, but is still enough to be considered moderately used.
-
In a future edition of the Web Almanac, it would be great to drill down into blend mode usage to get an idea of the exact modes developers are using, like multiply, screen, color-burn, lighten, etc.
CSS has this awesome interpolation power that can be simply used by just writing a single rule on how to transition those values. If you're using CSS to manage states in your app, how often are you employing transitions to do the task? Let's query the web!
Bar chart showing the distribution of transitions per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 0, 2, 16, 49, and 118 transitions. The desktop distribution is much lower than mobile, by as many as 77 transitions at the 90th percentile.
- Figure 25. Distribution of the number of transitions per page.
-
-
That's pretty good! We did see animate.css as a popular library to include, which brings in a ton of transition animations, but it's still nice to see folks are considering transitioning their UIs.
CSS keyframe animations are a great solution for your more complex animations or transitions. They allow you to be more explicit which provides higher control over the effects. They can be small, like one keyframe effect, or be large with many many keyframe effects composed into a robust animation. The median number of keyframe animations per page is much lower than CSS transitions.
Bar chart showing the distribution of keyframes per page. For mobile pages the 10, 25, 50, 75, and 90th percentiles are: 0, 0, 3, 18, and 76 keyframes. The mobile distribution is slightly higher than desktop by 6 keyframes at the 75th and 90th percentiles.
- Figure 26. Distribution of the number of keyframes per page.
-
-
Media queries let CSS hook into various system-level variables in order to adapt appropriately for the visiting user. Some of these queries could handle print styles, projector screen styles, and viewport/screen size. For a long time, media queries were primarily leveraged for their viewport knowledge. Designers and developers could adapt their layouts for small screens, large screens, and so forth. Later, the web started bringing more and more capabilities and queries, meaning media queries can now manage accessibility features on top of viewport features.
-
A good place to start with Media Queries, is just about how many are used per page? How many different moments or contexts does the typical page feel they want to respond to?
Bar chart showing the distribution of media queries per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 0, 3, 14, 27, and 43 keyframes. The desktop distribution is similar to the mobile distribution.
- Figure 27. Distribution of the number of media queries per page.
-
-
For viewport media queries, any type of CSS unit can be passed into the query expression for evaluation. In earlier days, folks would pass em and px into the query, but more units were added over time, making us very curious about what types of sizes were commonly found across the web. We assume most media queries will follow popular device sizes, but instead of assuming, let's look at the data!
Bar chart of the most popular media query snap points. 768px and 767px are the most popular at 23% and 16%, respectively. The list drops off quickly after that, with 992px used 6% of the time and 1200px used 4% of the time. Desktop and mobile have similar usage.
- Figure 28. Most frequently used snap points used in media queries.
-
-
Figure 28 above shows that part of our assumptions were correct: there's certainly a high amount of phone specific sizes in there, but there's also some that aren't. It's interesting also how it's very pixel dominant, with a few trickling entries using em beyond the scope of this chart.
The most popular query value from the popular breakpoint sizes looks to be 768px, which made us curious. Was this value primarily used to switch to a portrait layout, since it could be based on an assumption that 768px represents the typical mobile portrait viewport? So we ran a follow up query to see the popularity of using the portrait and landscape modes:
Bar chart showing the adoption of portrait and landscape orientation modes of media queries. 31% of pages specify landscape, 8% specify portrait, and 7% specify both. Adoption is the same for desktop and mobile pages.
- Figure 29. Adoption of media query orientation modes.
-
-
Interestingly, portrait isn't used very much, whereas landscape is used much more. We can only assume that 768px has been reliable enough as the portrait layout case that it's reached for much less. We also assume that folks on a desktop computer, testing their work, can't trigger portrait to see their mobile layout as easily as they can just squish the browser. Hard to tell, but the data is fascinating.
In the width and height media queries we've seen so far, pixels look like the dominant unit of choice for developers looking to adapt their UI to viewports. We wanted to exclusively query this though, and really take a look at the types of units folks use. Here's what we found.
When folks write a media query, are they typically checking for a viewport that's over or under a specific range, or both, checking if it's between a range of sizes? Let's ask the web!
Websites feel like digital paper, right? As users, it's generally known that you can just hit print from your browser and turn that digital content into physical content. A website isn't required to change itself for that use case, but it can if it wants to! Lesser known is the ability to adjust your website in the use case of it being read by a tool or robot. So just how often are these features taken advantage of?
Bar chart showing 35% of desktop pages using the "all" media query type, 46% using print, 72% using screen, and 0% using speech. Adoption is lower by about 5 percentage points for desktop compared to mobile.
- Figure 32. Adoption of the all, print, screen, and speech types of media queries.
-
-
How many stylesheets do you reference from your home page? How many from your apps? Do you serve more or less to mobile vs desktop? Here's a chart of everyone else!
Distribution of the number of stylesheets loaded per page. Desktop and mobile have identical distributions with 10, 25, 50, 75, and 90th percentiles: 1, 3, 6, 12, and 20 stylesheets per page.
- Figure 33. Distribution of the number of stylesheets loaded per page.
-
-
What do you name your stylesheets? Have you been consistent throughout your career? Have you slowly converged or consistently diverged? This chart shows a small glimpse into library popularity, but also a large glimpse into popular names of CSS files.
-
-
-
-
-
-
-
Stylesheet name
-
Desktop
-
Mobile
-
-
-
-
-
style.css
-
2.43%
-
2.55%
-
-
-
font-awesome.min.css
-
1.86%
-
1.92%
-
-
-
bootstrap.min.css
-
1.09%
-
1.11%
-
-
-
BfWyFJ2Rl5s.css
-
0.67%
-
0.66%
-
-
-
style.min.css?ver=5.2.2
-
0.64%
-
0.67%
-
-
-
styles.css
-
0.54%
-
0.55%
-
-
-
style.css?ver=5.2.2
-
0.41%
-
0.43%
-
-
-
main.css
-
0.43%
-
0.39%
-
-
-
bootstrap.css
-
0.40%
-
0.42%
-
-
-
font-awesome.css
-
0.37%
-
0.38%
-
-
-
style.min.css
-
0.37%
-
0.37%
-
-
-
styles__ltr.css
-
0.38%
-
0.35%
-
-
-
default.css
-
0.36%
-
0.36%
-
-
-
reset.css
-
0.33%
-
0.37%
-
-
-
styles.css?ver=5.1.3
-
0.32%
-
0.35%
-
-
-
custom.css
-
0.32%
-
0.33%
-
-
-
print.css
-
0.32%
-
0.28%
-
-
-
responsive.css
-
0.28%
-
0.31%
-
-
-
-
-
- Figure 34. Most frequently used stylesheet names.
-
-
Look at all those creative file names! style, styles, main, default, all. One stood out though, do you see it? BfWyFJ2Rl5s.css takes the number four spot for most popular. We went researching it a bit and our best guess is that it's related to Facebook "like" buttons. Do you know what that file is? Leave a comment, because we'd love to hear the story.
Distribution of the number of stylesheet bytes loaded per page. The desktop page's 10, 25, 50, 75, and 90th percentiles are: 8, 26, 62, 129, and 240 KB. The desktop distribution is slightly higher than the mobile distribution by 5 to 10 KB.
- Figure 35. Distribution of the number of stylesheet bytes (KB) loaded per page.
-
-
See the Page Weight chapter for a more in-depth look at the number of bytes websites are loading for each content type.
It's common, popular, convenient, and powerful to reach for a CSS library to kick start a new project. While you may not be one to reach for a library, we've queried the web in 2019 to see which are leading the pack. If the results astound you, like they did us, I think it's an interesting clue to just how small of a developer bubble we can live in. Things can feel massively popular, but when the web is inquired, reality is a bit different.
-
-
-
-
-
-
-
Library
-
Desktop
-
Mobile
-
-
-
-
-
Bootstrap
-
27.8%
-
26.9%
-
-
-
animate.css
-
6.1%
-
6.4%
-
-
-
ZURB Foundation
-
2.5%
-
2.6%
-
-
-
UIKit
-
0.5%
-
0.6%
-
-
-
Material Design Lite
-
0.3%
-
0.3%
-
-
-
Materialize CSS
-
0.2%
-
0.2%
-
-
-
Pure CSS
-
0.1%
-
0.1%
-
-
-
Angular Material
-
0.1%
-
0.1%
-
-
-
Semantic-ui
-
0.1%
-
0.1%
-
-
-
Bulma
-
0.0%
-
0.0%
-
-
-
Ant Design
-
0.0%
-
0.0%
-
-
-
tailwindcss
-
0.0%
-
0.0%
-
-
-
Milligram
-
0.0%
-
0.0%
-
-
-
Clarity
-
0.0%
-
0.0%
-
-
-
-
-
- Figure 36. Percent of pages that include a given CSS library.
-
-
This chart suggests that Bootstrap is a valuable library to know to assist with getting a job. Look at all the opportunity there is to help! It's also worth noting that this is a positive signal chart only: the math doesn't add up to 100% because not all sites are using a CSS framework. A little bit over half of all sites are not using a known CSS framework. Very interesting, no?!
CSS reset utilities intend to normalize or create a baseline for native web elements. In case you didn't know, each browser serves its own stylesheet for all HTML elements, and each browser gets to make their own unique decisions about how those elements look or behave. Reset utilities have looked at these files, found their common ground (or not), and ironed out any differences so you as a developer can style in one browser and have reasonable confidence it will look the same in another.
-
So let's take a peek at how many sites are using one! Their existence seems quite reasonable, so how many folks agree with their tactics and use them in their sites?
Bar chart showing the adoption of three CSS reset utilities: Normalize.css (33%), Reset CSS (3%), and Pure CSS (0%). There is no difference in adoption across desktop and mobile pages.
- Turns out that about one-third of the web is using normalize.css, which could be considered a more gentle approach to the task then a reset is. We looked a little deeper, and it turns out that Bootstrap includes normalize.css, which likely accounts for a massive amount of its usage. It's worth noting as well that normalize.css has more adoption than Bootstrap, so there are plenty of folks using it on its own.
-
CSS @supports is a way for the browser to check whether a particular property-value combination is parsed as valid, and then apply styles if the check returns as true.
Bar chart showing the popularity of @import and @supports "at" rules. On desktop, @import is used on 28% of pages and @supports is used on 31%. For mobile @import is used on 26% of pages and @supports is used on 29%.
Considering @supports was implemented across most browsers in 2013, it's not too surprising to see a high amount of usage and adoption. We're impressed at the mindfulness of developers here. This is considerate coding! 30% of all websites are checking for some display related support before using it.
-
An interesting follow up to this is that there's more usage of @supports than @imports! We did not expect that! @import has been in browsers since 1994.
There is so much more here to datamine! Many of the results surprised us, and we can only hope that they've surprised you as well. This surprising data set made the summarizing very fun, and left us with lots of clues and trails to investigate if we want to hunt down the reasons why some of the results are the way they are.
-
Which results did you find the most alarming? Which results make you head to your codebase for a quick query?
-
We felt the biggest takeaway from these results is that custom properties offer the most bang for your buck in terms of performance, DRYness, and scalability of your stylesheets. We look forward to scrubbing the internet's stylesheets again, hunting for new datums and provocative chart treats. Reach out to @una or @argyleink in the comments with your queries, questions, and assertions. We'd love to hear them!
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/ecommerce.html b/src/templates/en/2019/chapters/ecommerce.html
deleted file mode 100644
index 65691d9d419..00000000000
--- a/src/templates/en/2019/chapters/ecommerce.html
+++ /dev/null
@@ -1,635 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"III","chapter_number":13,"title":"Ecommerce","description":"Ecommerce chapter of the 2019 Web Almanac covering ecommerce platforms, payloads, images, third-parties, performance, seo, and PWAs.","authors":["samdutton","alankent"],"reviewers":["voltek62"],"translators":null,"discuss":"1768","results":"https://docs.google.com/spreadsheets/d/1FUMHeOPYBgtVeMU5_pl2r33krZFzutt9vkOpphOSOss/","queries":"13_Ecommerce","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"ecommerce"} %} {% block index %}
-
Nearly 10% of the home pages in this study were found to be on an ecommerce platform. An "ecommerce platform" is a set of software or services that enables you to create and operate an online store. There are several types of ecommerce platforms, for example:
-
-
Paid-for services such as Shopify that host your store and help you get started. They provide website hosting, site and page templates, product-data management, shopping carts and payments.
-
Software platforms such as Magento Open Source which you set up, host and manage yourself. These platforms can be powerful and flexible, but may be more complex to set up and run than services such as Shopify.
-
Hosted platforms such as Magento Commerce that offer the same features as their self-hosted counterparts, except that hosting is managed as a service by a third-party.
-
-
-
10%
- Figure 1. Percent of pages on an ecommerce platform.
-
-
This analysis could only detect sites built on an ecommerce platform. This means that most large online stores and marketplaces—such as Amazon, JD, and eBay—are not included here. Also note that the data here is for home pages only: not category, product or other pages. Learn more about our methodology.
How do we check if a page is on an ecommerce platform?
-
Detection is done through Wappalyzer. Wappalyzer is a cross-platform utility that uncovers the technologies used on websites. It detects content management systems, ecommerce platforms, web servers, JavaScript frameworks, analytics tools, and many more.
-
Page detection is not always reliable, and some sites explicitly block detection to protect against automated attacks. We might not be able to catch all websites that use a particular ecommerce platform, but we're confident that the ones we do detect are actually on that platform.
-
-
-
-
-
-
-
-
Mobile
-
Desktop
-
-
-
-
-
Ecommerce pages
-
500,595
-
424,441
-
-
-
Total pages
-
5,297,442
-
4,371,973
-
-
-
Adoption rate
-
9.45%
-
9.70%
-
-
-
-
-
- Figure 2. Percent of ecommerce platforms detected.
-
- Figure 3. Adoption of the top six ecommerce platforms.
-
-
Out of the 116 ecommerce platforms that were detected, only six are found on more than 0.1% of desktop or mobile websites. Note that these results do not show variation by country, by size of site, or other similar metrics.
-
Figure 3 above shows that WooCommerce has the largest adoption at around 4% of desktop and mobile websites. Shopify is second with about 1.6% adoption. Magento, PrestaShop, Bigcommerce, and Shopware follow with smaller and smaller adoption, approaching 0.1%.
Bar chart of the adoption of top 20 ecommerce platforms. Refer to Figure 3 above for a data table of adoption of the top six platforms.
- Figure 4. Adoption of top ecommerce platforms.
-
-
There are 110 ecommerce platforms that each have fewer than 0.1% of desktop or mobile websites. Around 60 of these have fewer than 0.01% of mobile or desktop websites.
The top six ecommerce platforms make up 8% of all websites. The rest of the 110 platforms only make up 1.5% of websites. The results for desktop and mobile are similar.
- Figure 5. Combined adoption of the top six ecommerce platforms versus the other 110 platforms.
-
-
7.87% of all requests on mobile and 8.06% on desktop are for home pages on one of the top six ecommerce platforms. A further 1.52% of requests on mobile and 1.59% on desktop are for home pages on the 110 other ecommerce platforms.
9.7% of desktop pages use an ecommerce platform and 9.5% of mobile pages use an ecommerce platform.
- Figure 6. Percent of pages using any ecommerce platform.
-
-
Although the desktop proportion of websites was slightly higher overall, some popular platforms (including WooCommerce, PrestaShop and Shopware) actually have more mobile than desktop websites.
Distribution of the 10, 25, 50, 75, and 90th percentiles of ecommerce page weight. The median desktop ecommerce page loads 2.7 MB. The 10th percentile is 1.0 MB, 25th 1.6 MB, 75th 4.5 MB, and 90th 7.6 MB. Desktop websites are slightly higher than mobile by tenths of a megabyte.
- Figure 7. Distribution of ecommerce page weight.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of requests per ecommerce page. The median desktop ecommerce page makes 108 requests. The 10th percentile is 53 requests, 25th 76, 75th 153, and 90th 210. Desktop websites are slightly higher than mobile by about 10 requests.
- Figure 8. Distribution of requests per ecommerce page.
-
-
The median desktop ecommerce platform page loads 108 requests and 2.7 MB. The median weight for all desktop pages is 74 requests and 1.9 MB. In other words, ecommerce pages make nearly 50% more requests than other web pages, with payloads around 35% larger. By comparison, the amazon.com home page makes around 300 requests on first load, for a page weight of around 5 MB, and ebay.com makes around 150 requests for a page weight of approximately 3 MB. The page weight and number of requests for home pages on ecommerce platforms is slightly smaller on mobile at every percentile, but around 10% of all ecommerce home pages load more than 7 MB and make over 200 requests.
-
This data accounts for home page payload and requests without scrolling. Clearly there are a significant proportion of sites that appear to be retrieving more files (the median is over 100), with a larger total payload, than should be necessary for first load. See also: Third-party requests and bytes below.
-
We need to do further research to better understand why so many home pages on ecommerce platforms make so many requests and have such large payloads. The authors regularly see home pages on ecommerce platforms that make hundreds of requests on first load, with multi-megabyte payloads. If the number of requests and payload are a problem for performance, then how can they be reduced?
- Figure 9. Percentiles of the distribution of page weight (in KB) by resource type.
-
-
-
-
-
-
-
-
Type
-
10
-
25
-
50
-
75
-
90
-
-
-
-
-
image
-
16
-
25
-
39
-
62
-
97
-
-
-
script
-
11
-
21
-
35
-
53
-
75
-
-
-
css
-
3
-
6
-
11
-
22
-
32
-
-
-
font
-
2
-
3
-
5
-
8
-
11
-
-
-
html
-
1
-
2
-
4
-
7
-
12
-
-
-
video
-
1
-
1
-
2
-
5
-
9
-
-
-
other
-
1
-
1
-
2
-
4
-
9
-
-
-
text
-
1
-
1
-
1
-
2
-
3
-
-
-
xml
-
1
-
1
-
1
-
2
-
2
-
-
-
audio
-
1
-
1
-
1
-
1
-
3
-
-
-
-
-
- Figure 10. Percentiles of the distribution of requests per page by resource type.
-
-
Images constitute the largest number of requests and the highest proportion of bytes for ecommerce pages. The median desktop ecommerce page includes 39 images weighing 1,514 KB (1.5 MB).
-
The number of JavaScript requests indicates that better bundling (and/or HTTP/2 multiplexing) could improve performance. JavaScript files are not significantly large in terms of total bytes, but many separate requests are made. According to the HTTP/2 chapter, more than 40% of requests are not via HTTP/2. Similarly, CSS files have the third highest number of requests but are generally small. Merging CSS files (and/or HTTP/2) could improve performance of such sites. In the authors' experience, many ecommerce pages have a high proportion of unused CSS and JavaScript. Videos may require a small number of requests, but (not surprisingly) consume a high proportion of the page weight, particularly on sites with heavy payloads.
Distribution of the 10, 25, 50, 75, and 90th percentiles of HTML bytes per ecommerce page. The median desktop ecommerce page has 36 KB of HTML. The 10th percentile is 12 KB, 25th 20, 75th 66, and 90th 118. Desktop websites have slightly more HTML bytes than mobile by 1 or 2 KB.
- Figure 11. Distribution of HTML bytes (in KB) per ecommerce page.
-
-
Note that HTML payloads may include other code such as inline JSON, JavaScript, or CSS directly in the markup itself, rather than referenced as external links. The median HTML payload size for ecommerce pages is 34 KB on mobile and 36 KB on desktop. However, 10% of ecommerce pages have an HTML payload of more than 115 KB.
-
Mobile HTML payload sizes are not very different from desktop. In other words, it appears that sites are not delivering significantly different HTML files for different devices or viewport sizes. On many ecommerce sites, home page HTML payloads are large. We don't know whether this is because of bloated HTML, or from other code (such as JSON) within HTML files.
Distribution of the 10, 25, 50, 75, and 90th percentiles of image bytes per ecommerce page. The median mobile ecommerce page has 1,517 KB of images. The 10th percentile is 318 KB, 25th 703, 75th 3,132, and 90th 5,881. Desktop and mobile websites have similar distributions.
- Figure 12. Distribution of image bytes (in KB) per ecommerce page.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of image requests per ecommerce page. The median desktop ecommerce page makes 40 image requests. The 10th percentile is 16 requests, 25th 25, 75th 62, and 90th 97. The desktop distribution is slightly higher than mobile by 2-10 requests at each percentile.
- Figure 13. Distribution of image requests per ecommerce page.
-
-
Note that because our data collection methodology does not simulate user interactions on pages like clicking or scrolling, images that are lazy loaded would not be represented in these results.
-
Figures 12 and 13 above show that the median ecommerce page has 37 images and an image payload of 1,517 KB on mobile, 40 images and 1,524 KB on desktop. 10% of home pages have 90 or more images and an image payload of nearly 6 MB!
-
-
1,517 KB
- Figure 14. The median number of image bytes per mobile ecommerce page.
-
-
A significant proportion of ecommerce pages have sizable image payloads and make a large number of image requests on first load. See HTTP Archive's State of Images report and the media and page weight chapters for more context.
-
Website owners want their sites to look good on modern devices. As a result, many sites deliver the same high resolution product images to every user without regard for screen resolution or size. Developers may not be aware of (or not want to use) responsive techniques that enable efficient delivery of the best possible image to different users. It's worth remembering that high-resolution images may not necessarily increase conversion rates. Conversely, overuse of heavy images is likely to impact page speed and can thereby reduce conversion rates. In the authors' experience from site reviews and events, some developers and other stakeholders have SEO or other concerns about using lazy loading for images.
-
We need to do more analysis to better understand why some sites are not using responsive image techniques or lazy loading. We also need to provide guidance that helps ecommerce platforms to reliably deliver beautiful images to those with high end devices and good connectivity, while simultaneously providing a best-possible experience to lower-end devices and those with poor connectivity.
Bar chart showing the popularity of various image formats. JPEG is the most popular format at 54% of images on desktop ecommerce pages. Next are PNG at 27%, GIF at 14%, SVG at 2%, and WebP and ICO at 1% each.
Note that some image services or CDNs will automatically deliver WebP (rather than JPEG or PNG) to platforms that support WebP, even for a URL with a `.jpg` or `.png` suffix. For example, IMG_20190113_113201.jpg returns a WebP image in Chrome. However, the way HTTP Archive detects image formats is to check for keywords in the MIME type first, then fall back to the file extension. This means that the format for images with URLs such as the above will be given as WebP, since WebP is supported by HTTP Archive as a user agent.
One in four images on ecommerce pages are PNG. The high number of PNG requests from pages on ecommerce platforms is probably for product images. Many commerce sites use PNG with photographic images to enable transparency.
-
Using WebP with a PNG fallback can be a far more efficient alternative, either via a picture element or by using user agent capability detection via an image service such as Cloudinary.
Only 1% of images on ecommerce platforms are WebP, which tallies with the authors' experience of site reviews and partner work. WebP is supported by all modern browsers other than Safari and has good fallback mechanisms available. WebP supports transparency and is a far more efficient format than PNG for photographic images (see PNG section above).
-
We as a web community can provide better guidance/advocacy for enabling transparency using WebP with a PNG fallback and/or using WebP/JPEG with a solid color background. WebP appears to be rarely used on ecommerce platforms, despite the availability of guides and tools (e.g. Squoosh and cwebp). We need to do further research into why there hasn't been more take-up of WebP, which is now nearly 10 years old.
- Figure 16. Distribution of intrinsic image dimensions (in pixels) per ecommerce page.
-
-
The median ('mid-range') dimensions for images requested by ecommerce pages is 247x196 px on mobile and 240x192 px on desktop. 10% of images requested by ecommerce pages are at least 693x512 px on mobile and 800x546 px on desktop. Note that these dimensions are the intrinsic sizes of images, not their display size.
-
Given that image dimensions at each percentile up to the median are similar on mobile and desktop, or even slightly larger on mobile in some cases, it would seem that many sites are not delivering different image dimensions for different viewports, or in other words, not using responsive image techniques. The delivery of larger images to mobile in some cases may (or may not!) be explained by sites using device or screen detection.
-
We need to do more research into why many sites are (apparently) not delivering different image sizes to different viewports.
Many websites—especially online stores—load a significant amount of code and content from third-parties: for analytics, A/B testing, customer behavior tracking, advertising, and social media support. Third-party content can have a significant impact on performance. Patrick Hulce's third-party-web tool is used to determine third-party requests for this report, and this is discussed more in the Third Parties chapter.
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party requests per ecommerce page. The median number of third-party requests on desktop is 19. The 10, 25, 75, and 90th percentiles are: 4, 9, 34, and 54. The desktop distribution is higher at each percentile than mobile by only 1-2 requests.
- Figure 17. Distribution of third-party requests per ecommerce page.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party bytes per ecommerce page. The median number of third-party bytes on desktop is 320 KB. The 10, 25, 75, and 90th percentiles are: 42, 129, 651, and 1,071. The desktop distribution is higher at each percentile than mobile by 10-30 KB.
- Figure 18. Distribution of third-party bytes per ecommerce page.
-
-
The median ('mid-range') home page on an ecommerce platform makes 17 requests for third-party content on mobile and 19 on desktop. 10% of all home pages on ecommerce platforms make over 50 requests for third-party content, with a total payload of over 1 MB.
-
Other studies have indicated that third-party content can be a major performance bottleneck. This study shows that 17 or more requests (50 or more for the top 10%) is the norm for ecommerce pages.
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party requests per ecommerce page for each platform. Shopify and Bigcommerce load the most third-party requests across the distributions by about 40 requests at the median.
- Figure 19. Distribution of third-party requests per mobile page for each ecommerce platform.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party bytes (KB) per ecommerce page for each platform. Shopify and Bigcommerce load the most third-party bytes across the distributions by more than 1,000 KB at the median.
- Figure 20. Distribution of third-party bytes (KB) per mobile page for each ecommerce platform.
-
-
Platforms such as Shopify may extend their services using client-side JavaScript, whereas other platforms such as Magento use more server side extensions. This difference in architecture affects the figures seen here.
-
Clearly, pages on some ecommerce platforms make more requests for third-party content and incur a larger payload of third-party content. Further analysis could be done on why pages from some platforms make more requests and have larger third-party payloads than others.
Bar chart of the average distribution of FCP experiences for the top six ecommerce platforms. WooCommerce has the highest density of slow FCP experiences at 43%. Shopify has the highest density of fast FCP experiences at 47%.
- Figure 21. Average distribution of FCP experiences per ecommerce platform.
-
-
First Contentful Paint measures the time it takes from navigation until content such as text or an image is first displayed. In this context, fast means FCP in under one second, slow means FCP in 3 seconds or more, and moderate is everything in between. Note that third-party content and code may have a significant impact on FCP.
-
All top-six ecommerce platforms have worse FCP on mobile than desktop: less fast and more slow. Note that FCP is affected by device capability (processing power, memory, etc.) as well as connectivity.
-
We need to establish why FCP is worse on mobile than desktop. What are the causes: connectivity and/or device capability, or something else?
Distribution of Lighthouse's PWA category scores for ecommerce pages. On a scale of 0 (failing) to 1 (perfect), 40% of pages get a score of 0.33. 1% of pages get a score above 0.6.
- Figure 22. Distribution of Lighthouse PWA category scores for mobile ecommerce pages.
-
-
More than 60% of home pages on ecommerce platforms get a Lighthouse PWA score between 0.25 and 0.35. Less than 20% of home pages on ecommerce platforms get a score of more than 0.5 and less than 1% of home pages score more than 0.6.
-
Lighthouse returns a Progressive Web App (PWA) score between 0 and 1. 0 is the worst possible score, and 1 is the best. The PWA audits are based on the Baseline PWA Checklist, which lists 14 requirements. Lighthouse has automated audits for 11 of the 14 requirements. The remaining 3 can only be tested manually. Each of the 11 automated PWA audits are weighted equally, so each one contributes approximately 9 points to your PWA score.
-
If at least one of the PWA audits got a null score, Lighthouse nulls out the score for the entire PWA category. This was the case for 2.32% of mobile pages.
-
Clearly, the majority of ecommerce pages are failing most PWA checklist audits. We need to do further analysis to better understand which audits are failing and why.
This comprehensive study of ecommerce usage shows some interesting data and also the wide variations in ecommerce sites, even among those built on the same ecommerce platform. Even though we have gone into a lot of detail here, there is much more analysis we could do in this space. For example, we didn't get accessibility scores this year (checkout the accessibility chapter for more on that). Likewise, it would be interesting to segment these metrics by geography. This study detected 246 ad providers on home pages on ecommerce platforms. Further studies (perhaps in next year's Web Almanac?) could calculate what proportion of sites on ecommerce platforms shows ads. WooCommerce got very high numbers in this study so another interesting statistic we could look at next year is if some hosting providers are installing WooCommerce but not enabling it, thereby causing inflated figures.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/fonts.html b/src/templates/en/2019/chapters/fonts.html
deleted file mode 100644
index 07e634d8933..00000000000
--- a/src/templates/en/2019/chapters/fonts.html
+++ /dev/null
@@ -1,677 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":6,"title":"Fonts","description":"Fonts chapter of the 2019 Web Almanac covering where fonts are loaded from, font formats, font loading performance, variable fonts and color fonts.","authors":["zachleat"],"reviewers":["hyperpress","AymenLoukil"],"translators":null,"discuss":"1761","results":"https://docs.google.com/spreadsheets/d/108g6LXdC3YVsxmX1CCwrmpZ3-DmbB8G_wwgQHX5pn6Q/","queries":"06_Fonts","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-02T00:00:00.000Z","chapter":"fonts"} %} {% block index %}
-
Web fonts enable beautiful and functional typography on the web. Using web fonts not only empowers design, but it democratizes a subset of design, as it allows easier access to those who might not have particularly strong design skills. However, for all the good they can do, web fonts can also do great harm to your site's performance if they are not loaded properly.
-
Are they a net positive for the web? Do they provide more benefit than harm? Are the web standards cowpaths sufficiently paved to encourage web font loading best practices by default? And if not, what needs to change? Let's take a data-driven peek at whether or not we can answer those questions by inspecting how web fonts are used on the web today.
The first and most prominent question: performance. There is a whole chapter dedicated to performance but we will delve a little into font-specific performance issues here.
-
Using hosted web fonts enables ease of implementation and maintenance, but self-hosting offers the best performance. Given that web fonts by default make text invisible while the web font is loading (also known as the Flash of Invisible Text, or FOIT), the performance of web fonts can be more critical than non-blocking assets like images.
Differentiating self-hosting against third-party hosting is increasingly relevant in an HTTP/2 world, where the performance gap between a same-host and different-host connection can be wider. Same-host requests have the huge benefit of a better potential for prioritization against other same-host requests in the waterfall.
-
Recommendations to mitigate the performance costs of loading web fonts from another host include using the preconnect, dns-prefetch, and preloadresource hints, but high priority web fonts should be same-host requests to minimize the performance impact of web fonts. This is especially important for fonts used by very visually prominent content or body copy occupying the majority of a page.
Bar chart showing the popularity of third-party and self-hosting strategies for web fonts. 75% of mobile web pages use third-party hosts and 25% self-host. Desktop websites have similar usage.
- Figure 1. Popular web font hosting strategies.
-
-
The fact that three quarters are hosted is perhaps unsurprising given Google Fonts dominance that we will discuss below.
-
Google serves fonts using third-party CSS files hosted on https://fonts.googleapis.com. Developers add requests to these stylesheets using <link> tags in their markup. While these stylesheets are render blocking, they are very small. However, the font files are hosted on yet another domain, https://fonts.gstatic.com. The model of requiring two separate hops to two different domains makes preconnect a great option here for the second request that will not be discovered until the CSS is downloaded.
-
Note that while preload would be a nice addition to load the font files higher in the request waterfall (remember that preconnect sets up the connection, it doesn’t request the file content), preload is not yet available with Google Fonts. Google Fonts generates unique URLs for their font files which are subject to change.
- Figure 2. Top 20 font hosts by percent of requests.
-
-
The dominance of Google Fonts here was simultaneously surprising and unsurprising at the same time. It was unsurprising in that I expected the service to be the most popular and surprising in the sheer dominance of its popularity. 75% of font requests is astounding. TypeKit was a distant single-digit second place, with the Bootstrap library accounting for an even more distant third place.
-
-
29%
- Figure 3. Percent of pages that include a Google Fonts stylesheet link in the document <head>.
-
-
While the high usage of Google Fonts here is very impressive, it is also noteworthy that only 29% of pages included a Google Fonts <link> element. This could mean a few things:
-
-
When pages uses Google Fonts, they use a lot of Google Fonts. They are provided without monetary cost, after all. Perhaps they're being used in a popular WYSIWYG editor? This seems like a very likely explanation.
-
Or a more unlikely story is that it could mean that a lot of people are using Google Fonts with @import instead of <link>.
-
- Or if we want to go off the deep end into super unlikely scenarios, it could mean that many people are using Google Fonts with an HTTP Link: header instead.
-
-
-
-
0.4%
- Figure 4. Percent of pages that include a Google Fonts stylesheet link as the first child in the document <head>.
-
-
Google Fonts documentation encourages the <link> for the Google Fonts CSS to be placed as the first child in the <head> of a page. This is a big ask! In practice, this is not common as only half a percent of all pages (about 20,000 pages) took this advice.
-
More so, if a page is using preconnect or dns-prefetch as <link> elements, these would come before the Google Fonts CSS anyway. Read on for more about these resource hints.
As mentioned above, a super easy way to speed up web font requests to a third-party host is to use the preconnectresource hint.
-
-
1.7%
- Figure 5. Percent of mobile pages preconnecting to a web font host.
-
-
- Wow! Less than 2% of pages are using preconnect! Given that Google Fonts is at 75%, this should be higher! Developers: if you use Google Fonts, use preconnect! Google Fonts: proselytize preconnect more!
-
-
In fact, if you're using Google Fonts go ahead and add this to your <head> if it's not there already:
WOFF2 is pretty well supported in web browsers today. Google Fonts serves WOFF2, a format that offers improved compression over its predecessor WOFF, which was itself already an improvement over other existing font formats.
Bar chart showing the popularity of web font MIME types. WOFF2 is used on 74% of fonts, followed by 13% WOFF, 6% octet-stream, 3% TTF, 2% plain, 1% HTML, 1% SFNT, and fewer than 1% for all other types. Desktop and mobile have similar distributions.
- Figure 7. Popularity of web font MIME types.
-
-
From my perspective, an argument could be made to go WOFF2-only for web fonts after seeing the results here. I wonder where the double-digit WOFF usage is coming from? Perhaps developers still serving web fonts to Internet Explorer?
-
Third place octet-stream (and plain a little further down) would seem to suggest that a lot of web servers are configured improperly, sending an incorrect MIME type with web font file requests.
-
Let's dig a bit deeper and look at the format() values used in the src: property of @font-face declarations:
Bar chart showing the popularity of formats used in font-face declarations. 69% of desktop pages' @font-face declarations specify the WOFF2 format, 11% WOFF, 10% TrueType, 8% SVG, 2% EOT, and fewer than 1% OpenType, TTF, and OTF. The distribution for mobile pages is similar.
- Figure 8. Popularity of font formats in @font-face declarations.
-
-
I was hoping to see SVG fonts on the decline. They're buggy and implementations have been removed from every browser except Safari. Time to drop these, y'all.
-
The SVG data point here also makes me wonder what MIME type y'all are serving these SVG fonts with. I don't see image/svg+xml anywhere in Figure 7. Anyway, don't worry about fixing that, just get rid of them!
This dataset seems to suggest that the majority of people are already using WOFF2-only in their @font-face blocks. But this is misleading of course, per our earlier discussion on the dominance of Google Fonts in the data set. Google Fonts does some sniffing methods to serve a streamlined CSS file and only includes the most modern format(). Unsurprisingly, WOFF2 dominates the results here for that reason, as browser support for WOFF2 has been pretty broad for some time now.
-
Importantly, this particular data doesn't really support or detract from the case to go WOFF2-only yet, but it remains a tempting idea.
The number one tool we have to fight the default web font loading behavior of "invisible while loading" (also known as FOIT), is font-display. Adding font-display: swap to your @font-face block is an easy way to tell the browser to show fallback text while the web font is loading.
-
Browser support is great too. Internet Explorer and pre-Chromium Edge don't have support but they also render fallback text by default when a web font loads (no FOITs allowed here). For our Chrome tests, how commonly is font-display used?
-
-
26%
- Figure 10. Percent of mobile pages that utilize the font-display style.
-
-
Bar chart showing the usage of the font-display style. 2.6% of mobile pages set this style to "swap", 1.5% to "auto", 0.7% to "block", 0.4% to "fallback", 0.2% to optional, and 0.1% to "swap" enclosed in quotes, which is invalid. The desktop distribution is similar except "swap" usage is lower by 0.4 percentage points and "auto" usage is higher by 0.1 percentage points.
As an easy way to show fallback text while a web font is loading, font-display: swap reigns supreme and is the most common value. swap is also the default value used by new Google Fonts code snippets too. I would have expected optional (only render if cached) to have a bit more usage here as a few prominent developer evangelists lobbied for it a bit, but no dice.
This is a question that requires some measure of nuance. How are the fonts being used? For how much content on the page? Where does this content live in the layout? How are the fonts being rendered? In lieu of nuance however let's dive right into some broad and heavy handed analysis specifically centered on request counts.
Bar chart showing the distribution of font requests per page. The 10, 25, 50, 75, and 90th percentiles for desktop are: 0, 1, 3, 6, and 9 font requests. The distribution for mobile is identical until the 75th and 90th percentiles, where mobile pages request 1 fewer font.
- Figure 12. Distribution of font requests per page.
-
-
The median web page makes three web font requests. At the 90th percentile, requested six and nine web fonts on mobile and desktop, respectively.
Histogram showing the distribution of the number of font requests per page. The most popular number of font requests is 0 at 22% of desktop pages. The distribution drops to 9% of pages having 1 font, then crests at 10% for 2-4 fonts before falling as the number of fonts increases. The desktop and mobile distributions are similar, although the mobile distribution skews slightly toward having fewer fonts per page.
- Figure 13. Histogram of web fonts requested per page.
-
-
That said there are marginally more requests for fonts made on mobile devices. My hunch here is that fewer typefaces are available on mobile devices, which in turn means fewer local() hits in Google Fonts CSS, falling back to network requests for these.
- Figure 14. The most web font requests on a single page.
-
-
The award for the page that requests the most web fonts goes to a site that made 718 web font requests!
-
After diving into the code, all of those 718 requests are going to Google Fonts! It looks like a malfunctioning "Above the Page fold" optimization plugin for WordPress has gone rogue on this site and is requesting (DDoS-ing?) all the Google Fonts—oops!
-
Ironic that a performance optimization plugin can make your performance much worse!
- Figure 15. Percent of mobile pages that declare a web font with the unicode-range property.
-
-
- unicode-range is a great CSS property to let the browser know specifically which code points the page would like to use in the font file. If the @font-face declaration has a unicode-range, content on the page must match one of the code points in the range before the font is requested. It is a very good thing.
-
-
This is another metric that I expect was skewed by Google Fonts usage, as Google Fonts uses unicode-range in most (if not all) of its CSS. I'd expect this to be less common in user land, but perhaps filtering out Google Fonts requests in the next edition of the Almanac may be possible.
- Figure 16. Percent of mobile pages that declare a web font with the local() property.
-
-
local() is a nice way to reference a system font in your @font-facesrc. If the local() font exists, it doesn't need to make a request for a web font at all. This is used both extensively and controversially by Google Fonts, so it is likely another example of skewed data if we're trying to glean patterns from user land.
- Figure 17. Percent of desktop and mobile pages that include a style with the font-stretch property.
-
-
- Historically, font-stretch has suffered from poor browser support and was not a well-known @font-face property. Read more about font-stretch on MDN. But browser support has broadened.
-
-
It has been suggested that using condensed fonts on smaller viewports allows more text to be viewable, but this approach isn't commonly used. That being said, that this property is used half a percentage point more on desktop than mobile is unexpected, and 7% seems much higher than I would have predicted.
Bar chart showing the usage of the font-variation-settings property. 42% of properties on desktop pages are set to the "opsz" value, 32% to "wght", 16% to "wdth", 2% or fewer to "roun", "crsb", "slnt", "inln", and more. The most notable differences between desktop and mobile pages are 26% usage of "opsz", 38% of "wght", and 23% of "wdth".
- Figure 19. Usage of font-variation-settings axes.
-
-
Through the lens of this large data set, these are very low sample sizes-take these results with a grain of salt. However, opsz as the most common axis on desktop pages is notable, with wght and wdth trailing. In my experience, the introductory demos for variable fonts are usually weight-based.
- Figure 20. The number of desktop web pages that include a color font.
-
-
Usage here of these is basically nonexistent but you can check out the excellent resource Color Fonts! WTF? for more information. Similar (but not at all) to the SVG format for fonts (which is bad and going away), this allows you to embed SVG inside of OpenType files, which is awesome and cool.
The biggest takeaway here is that Google Fonts dominates the web font discussion. Approaches they've taken weigh heavily on the data we've recorded here. The positives here are easy access to web fonts, good font formats (WOFF2), and for-free unicode-range configurations. The downsides here are performance drawbacks associated with third-party hosting, different-host requests, and no access to preload.
-
I fully expect that in the future we'll see the "Rise of the Variable Font". This should be paired with a decline in web font requests, as Variable Fonts combine multiple individual font files into a single composite font file. But history has shown us that what usually happens here is that we optimize a thing and then add more things to fill the vacancy.
-
It will be very interesting to see if color fonts increase in popularity. I expect these to be far more niche than variable fonts but may see a lifeline in the icon font space.
-
Keep those fonts frosty, y'all.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/http2.html b/src/templates/en/2019/chapters/http2.html
deleted file mode 100644
index 2d5418f4566..00000000000
--- a/src/templates/en/2019/chapters/http2.html
+++ /dev/null
@@ -1,692 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":20,"title":"HTTP/2","description":"HTTP/2 chapter of the 2019 Web Almanac covering adoption and impact of HTTP/2, HTTP/2 Push, HTTP/2 Issues, and HTTP/3.","authors":["bazzadp"],"reviewers":["bagder","rmarx","dotjs"],"translators":null,"discuss":"1775","results":"https://docs.google.com/spreadsheets/d/1z1gdS3YVpe8J9K3g2UdrtdSPhRywVQRBz5kgBeqCnbw/","queries":"20_HTTP_2","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-05T00:00:00.000Z","chapter":"http2"} %} {% block index %}
-
HTTP/2 was the first major update to the main transport protocol of the web in nearly 20 years. It arrived with a wealth of expectations: it promised a free performance boost with no downsides. More than that, we could stop doing all the hacks and work arounds that HTTP/1.1 forced us into, due to its inefficiencies. Bundling, spriting, inlining, and even sharding domains would all become anti-patterns in an HTTP/2 world, as improved performance would be provided by default.
-
This meant that even those without the skills and resources to concentrate on web performance would suddenly have performant websites. However, the reality has been, as ever, a little more nuanced than that. It has been over four years since the formal approval of HTTP/2 as a standard in May 2015 as RFC 7540, so now is a good time to look over how this relatively new technology has fared in the real world.
For those not familiar with the technology, a bit of background is helpful to make the most of the metrics and findings in this chapter. Up until recently, HTTP has always been a text-based protocol. An HTTP client like a web browser opened a TCP connection to a server, and then sent an HTTP command like GET /index.html to ask for a resource.
-
This was enhanced in HTTP/1.0 to add HTTP headers, so various pieces of metadata could be included in addition to the request, such as what browser it is, the formats it understands, etc. These HTTP headers were also text-based and separated by newline characters. Servers parsed the incoming requests by reading the request and any HTTP headers line by line, and then the server responded with its own HTTP response headers in addition to the actual resource being requested.
-
The protocol seemed simple, but it also came with limitations. Because HTTP was essentially synchronous, once an HTTP request had been sent, the whole TCP connection was basically off limits to anything else until the response had been returned, read, and processed. This was incredibly inefficient and required multiple TCP connections (browsers typically use 6) to allow a limited form of parallelization.
-
That in itself brings its own issues as TCP connections take time and resources to set up and get to full efficiency, especially when using HTTPS, which requires additional steps to set up the encryption. HTTP/1.1 improved this somewhat, allowing reuse of TCP connections for subsequent requests, but still did not solve the parallelization issue.
-
Despite HTTP being text-based, the reality is that it was rarely used to transport text, at least in its raw format. While it was true that HTTP headers were still text, the payloads themselves often were not. Text files like HTML, JS, and CSS are usually compressed for transport into a binary format using gzip, brotli, or similar. Non-text files like images and videos are served in their own formats. The whole HTTP message is then often wrapped in HTTPS to encrypt the messages for security reasons.
-
So, the web had basically moved on from text-based transport a long time ago, but HTTP had not. One reason for this stagnation was because it was so difficult to introduce any breaking changes to such a ubiquitous protocol like HTTP (previous efforts had tried and failed). Many routers, firewalls, and other middleboxes understood HTTP and would react badly to major changes to it. Upgrading them all to support a new version was simply not possible.
-
In 2009, Google announced that they were working on an alternative to the text-based HTTP called SPDY, which has since been deprecated. This would take advantage of the fact that HTTP messages were often encrypted in HTTPS, which prevents them being read and interfered with en route.
-
Google controlled one of the most popular browsers (Chrome) and some of the most popular websites (Google, YouTube, Gmail…etc.) - so both ends of the connection when both were used together. Google's idea was to pack HTTP messages into a proprietary format, send them across the internet, and then unpack them on the other side. The proprietary format, SPDY, was binary-based rather than text-based. This solved some of the main performance problems with HTTP/1.1 by allowing more efficient use of a single TCP connection, negating the need to open the six connections that had become the norm under HTTP/1.1.
-
By using SPDY in the real world, they were able to prove that it was more performant for real users, and not just because of some lab-based experimental results. After rolling out SPDY to all Google websites, other servers and browser started implementing it, and then it was time to standardize this proprietary format into an internet standard, and thus HTTP/2 was born.
-
HTTP/2 has the following key concepts:
-
-
Binary format
-
Multiplexing
-
Flow control
-
Prioritization
-
Header compression
-
Push
-
-
Binary format means that HTTP/2 messages are wrapped into frames of a pre-defined format, making HTTP messages easier to parse and would no longer require scanning for newline characters. This is better for security as there were a number of exploits for previous versions of HTTP. It also means HTTP/2 connections can be multiplexed. Different frames for different streams can be sent on the same connection without interfering with each other as each frame includes a stream identifier and its length. Multiplexing allows much more efficient use of a single TCP connection without the overhead of opening additional connections. Ideally we would open a single connection per domain—or even for multiple domains!
-
Having separate streams does introduce some complexities along with some potential benefits. HTTP/2 needs the concept of flow control to allow the different streams to send data at different rates, whereas previously, with only one response in flight at any one time, this was controlled at a connection level by TCP flow control. Similarly, prioritization allows multiple requests to be sent together, but with the most important requests getting more of the bandwidth.
-
Finally, HTTP/2 introduced two new concepts: header compression and HTTP/2 push. Header compression allowed those text-based HTTP headers to be sent more efficiently, using an HTTP/2-specific HPACK format for security reasons. HTTP/2 push allowed more than one response to be sent in answer to a request, enabling the server to "push" resources before a client was even aware it needed them. Push was supposed to solve the performance workaround of having to inline resources like CSS and JavaScript directly into HTML to prevent holding up the page while those resources were requested. With HTTP/2 the CSS and JavaScript could remain as external files but be pushed along with the initial HTML, so they were available immediately. Subsequent page requests would not push these resources, since they would now be cached, and so would not waste bandwidth.
-
This whistle-stop tour of HTTP/2 gives the main history and concepts of the newish protocol. As should be apparent from this explanation, the main benefit of HTTP/2 is to address performance limitations of the HTTP/1.1 protocol. There were also security improvements as well - perhaps most importantly in being to address performance issues of using HTTPS since HTTP/2, even over HTTPS, is often much faster than plain HTTP. Other than the web browser packing the HTTP messages into the new binary format, and the web server unpacking it at the other side, the core basics of HTTP itself stayed roughly the same. This means web applications do not need to make any changes to support HTTP/2 as the browser and server take care of this. Turning it on should be a free performance boost, therefore adoption should be relatively easy. Of course, there are ways web developers can optimize for HTTP/2 to take full advantage of how it differs.
As mentioned above, internet protocols are often difficult to adopt since they are ingrained into so much of the infrastructure that makes up the internet. This makes introducing any changes slow and difficult. IPv6 for example has been around for 20 years but has struggled to be adopted.
-
-
95%
- Figure 1. The percent of global users who can use HTTP/2.
-
-
HTTP/2 however, was different as it was effectively hidden in HTTPS (at least for the browser uses cases), removing barriers to adoption as long as both the browser and server supported it. Browser support has been very strong for some time and the advent of auto updating evergreen browsers has meant that an estimated 95% of global users now support HTTP/2.
-
Our analysis is sourced from the HTTP Archive, which tests approximately 5 million of the top desktop and mobile websites in the Chrome browser. (Learn more about our methodology.)
Timeseries chart of HTTP/2 usage showing adoption at 55% for both desktop and mobile as of July 2019. The trend is growing steadily at about 15 points per year.
The results show that HTTP/2 usage is now the majority protocol-an impressive feat just 4 short years after formal standardization! Looking at the breakdown of all HTTP versions by request we see the following:
Figure 3 shows that HTTP/1.1 and HTTP/2 are the versions used by the vast majority of requests as expected. There is only a very small number of requests on the older HTTP/1.0 and HTTP/0.9 protocols. Annoyingly, there is a larger percentage where the protocol was not correctly tracked by the HTTP Archive crawl, particularly on desktop. Digging into this has shown various reasons, some of which can be explained and some of which can't. Based on spot checks, they mostly appear to be HTTP/1.1 requests and, assuming they are, desktop and mobile usage is similar.
-
Despite there being a little larger percentage of noise than we'd like, it doesn't alter the overall message being conveyed here. Other than that, the mobile/desktop similarity is not unexpected; HTTP Archive tests with Chrome, which supports HTTP/2 for both desktop and mobile. Real-world usage may have slightly different stats with some older usage of browsers on both, but even then support is widespread, so we would not expect a large variation between desktop and mobile.
-
At present, HTTP Archive does not track HTTP over QUIC (soon to be standardized as HTTP/3 separately, so these requests are currently listed under HTTP/2, but we'll look at other ways of measuring that later in this chapter.
-
Looking at the number of requests will skew the results somewhat due to popular requests. For example, many sites load Google Analytics, which does support HTTP/2, and so would show as an HTTP/2 request, even if the embedding site itself does not support HTTP/2. On the other hand, popular websites tend to support HTTP/2 are also underrepresented in the above stats as they are only measured once (e.g. "google.com" and "obscuresite.com" are given equal weighting). There are lies, damn lies, and statistics.
-
However, our findings are corroborated by other sources, like Mozilla's telemetry, which looks at real-world usage through the Firefox browser.
It is still interesting to look at home pages only to get a rough figure on the number of sites that support HTTP/2 (at least on their home page). Figure 4 shows less support than overall requests, as expected, at around 36%.
-
HTTP/2 is only supported by browsers over HTTPS, even though officially HTTP/2 can be used over HTTPS or over unencrypted non-HTTPS connections. As mentioned previously, hiding the new protocol in encrypted HTTPS connections prevents networking appliances which do not understand this new protocol from interfering with (or rejecting!) its usage. Additionally, the HTTPS handshake allows an easy method of the client and server agreeing to use HTTP/2.
-
-
-
-
-
-
-
Protocol
-
Desktop
-
Mobile
-
Both
-
-
-
-
-
-
0.09%
-
0.10%
-
0.09%
-
-
-
HTTP/1.0
-
0.06%
-
0.06%
-
0.06%
-
-
-
HTTP/1.1
-
45.81%
-
44.31%
-
45.01%
-
-
-
HTTP/2
-
54.04%
-
55.53%
-
54.83%
-
-
-
-
-
- Figure 5. HTTP version usage for HTTPS home pages.
-
-
The web is moving to HTTPS, and HTTP/2 turns the traditional argument of HTTPS being bad for performance almost completely on its head. Not every site has made the transition to HTTPS, so HTTP/2 will not even be available to those that have not. Looking at just those sites that use HTTPS, in Figure 5 we do see a higher adoption of HTTP/2 at around 55%, similar to the percent of all requests in Figure 2.
-
We have shown that browser support for HTTP/2 is strong and that there is a safe road to adoption, so why doesn't every site (or at least every HTTPS site) support HTTP/2? Well, here we come to the final item for support we have not measured yet: server support.
-
This is more problematic than browser support as, unlike modern browsers, servers often do not automatically upgrade to the latest version. Even when the server is regularly maintained and patched, that will often just apply security patches rather than new features like HTTP/2. Let's look first at the server HTTP headers for those sites that do support HTTP/2.
Nginx provides package repositories that allow ease of installing or upgrading to the latest version, so it is no surprise to see it leading the way here. Cloudflare is the most popular CDN and enables HTTP/2 by default, so again it is not surprising to see it hosts a large percentage of HTTP/2 sites. Incidently, Cloudflare uses a heavily customized version of nginx as their web server. After those, we see Apache at around 20% of usage, followed by some servers who choose to hide what they are, and then the smaller players such as LiteSpeed, IIS, Google Servlet Engine, and openresty, which is nginx based.
-
What is more interesting is those servers that that do not support HTTP/2:
Some of this will be non-HTTPS traffic that would use HTTP/1.1 even if the server supported HTTP/2, but a bigger issue is those that do not support HTTP/2 at all. In these stats, we see a much greater share for Apache and IIS, which are likely running older versions.
-
For Apache in particular, it is often not easy to add HTTP/2 support to an existing installation, as Apache does not provide an official repository to install this from. This often means resorting to compiling from source or trusting a third-party repository, neither of which is particularly appealing to many administrators.
-
Only the latest versions of Linux distributions (RHEL and CentOS 8, Ubuntu 18 and Debian 9) come with a version of Apache which supports HTTP/2, and many servers are not running those yet. On the Microsoft side, only Windows Server 2016 and above supports HTTP/2, so again those running older versions cannot support this in IIS.
-
Merging these two stats together, we can see the percentage of installs per server, that use HTTP/2:
-
-
-
-
-
-
-
Server
-
Desktop
-
Mobile
-
-
-
-
-
cloudflare
-
85.40%
-
83.46%
-
-
-
LiteSpeed
-
70.80%
-
63.08%
-
-
-
openresty
-
51.41%
-
45.24%
-
-
-
nginx
-
49.23%
-
46.19%
-
-
-
GSE
-
40.54%
-
35.25%
-
-
-
-
25.57%
-
27.49%
-
-
-
Apache
-
18.09%
-
18.56%
-
-
-
Microsoft-IIS
-
14.10%
-
13.47%
-
-
-
…
-
…
-
…
-
-
-
-
-
- Figure 8. Percentage installs of each server used to provide HTTP/2.
-
-
It's clear that Apache and IIS fall way behind with 18% and 14% of their installed based supporting HTTP/2, which has to be (at least in part) a consequence of it being more difficult to upgrade them. A full operating system upgrade is often required for many servers to get this support easily. Hopefully this will get easier as new versions of operating systems become the norm.
The impact of HTTP/2 is much more difficult to measure, especially using the HTTP Archive methodology. Ideally, sites should be crawled with both HTTP/1.1 and HTTP/2 and the difference measured, but that is not possible with the statistics we are investigating here. Additionally, measuring whether the average HTTP/2 site is faster than the average HTTP/1.1 site introduces too many other variables that require a more exhaustive study than we can cover here.
-
One impact that can be measured is in the changing use of HTTP now that we are in an HTTP/2 world. Multiple connections were a workaround with HTTP/1.1 to allow a limited form of parallelization, but this is in fact the opposite of what usually works best with HTTP/2. A single connection reduces the overhead of TCP setup, TCP slow start, and HTTPS negotiation, and it also allows the potential of cross-request prioritization.
Timeseries chart of the number of TCP connections per page, with the median desktop page having 14 connections and the median mobile page having 16 connections as of July 2019.
HTTP Archive measures the number of TCP connections per page, and that is dropping steadily as more sites support HTTP/2 and use its single connection instead of six separate connections.
Timeseries chart of the number of requests per page, with the median desktop page having 74 requests and the median mobile page having 69 requests as of July 2019. The trend is relatively flat.
Bundling assets to obtain fewer requests was another HTTP/1.1 workaround that went by many names: bundling, concatenation, packaging, spriting, etc. This is less necessary when using HTTP/2 as there is less overhead with requests, but it should be noted that requests are not free in HTTP/2, and those that experimented with removing bundling completely have noticed a loss in performance. Looking at the number of requests loaded per page over time, we do see a slight decrease in requests, rather than the expected increase.
-
This low rate of change can perhaps be attributed to the aforementioned observations that bundling cannot be removed (at least, not completely) without a negative performance impact and that many build tools currently bundle for historical reasons based on HTTP/1.1 recommendations. It is also likely that many sites may not be willing to penalize HTTP/1.1 users by undoing their HTTP/1.1 performance hacks just yet, or at least that they do not have the confidence (or time!) to feel that this is worthwhile.
-
The fact that the number of requests is staying roughly static is interesting, given the ever-increasing page weight, though perhaps this is not entirely related to HTTP/2.
HTTP/2 push has a mixed history despite being a much-hyped new feature of HTTP/2. The other features were basically performance improvements under the hood, but push was a brand new concept that completely broke the single request to single response nature of HTTP. It allowed extra responses to be returned; when you asked for the web page, the server could respond with the HTML page as usual, but then also send you the critical CSS and JavaScript, thus avoiding any additional round trips for certain resources. It would, in theory, allow us to stop inlining CSS and JavaScript into our HTML, and still get the same performance gains of doing so. After solving that, it could potentially lead to all sorts of new and interesting use cases.
-
The reality has been, well, a bit disappointing. HTTP/2 push has proved much harder to use effectively than originally envisaged. Some of this has been due to the complexity of how HTTP/2 push works, and the implementation issues due to that.
-
A bigger concern is that push can quite easily cause, rather than solve, performance issues. Over-pushing is a real risk. Often the browser is in the best place to decide what to request, and just as crucially when to request it but HTTP/2 push puts that responsibility on the server. Pushing resources that a browser already has in its cache, is a waste of bandwidth (though in my opinion so is inlining CSS but that gets must less of a hard time about that than HTTP/2 push!).
-
Proposals to inform the server about the status of the browser cache have stalled especially on privacy concerns. Even without that problem, there are other potential issues if push is not used correctly. For example, pushing large images and therefore holding up the sending of critical CSS and JavaScript will lead to slower websites than if you'd not pushed at all!
-
There has also been very little evidence to date that push, even when implemented correctly, results in the performance increase it promised. This is an area that, again, the HTTP Archive is not best placed to answer, due to the nature of how it runs (a crawl of popular sites using Chrome in one state), so we won't delve into it too much here. However, suffice to say that the performance gains are far from clear-cut and the potential problems are real.
-
Putting that aside let's look at the usage of HTTP/2 push.
- Figure 12. How much is pushed when it is used.
-
-
These stats show that the uptake of HTTP/2 push is very low, most likely because of the issues described previously. However, when sites do use push, they tend to use it a lot rather than for one or two assets as shown in Figure 12.
Pie chart breaking down the percent of asset types that are pushed. JavaScript makes up almost half of the assets, then CSS with about a quarter, images about an eighth, and various text-based types making up the rest.
- Figure 13. What asset types is push used for?
-
-
Figure 13 shows us which assets are most commonly pushed. JavaScript and CSS are the overwhelming majority of pushed items, both by volume and by bytes. After this, there is a ragtag assortment of images, fonts, and data. At the tail end we see around 100 sites pushing video, which may be intentional, or it may be a sign of over-pushing the wrong types of assets!
-
One concern raised by some is that HTTP/2 implementations have repurposed the preload HTTP link header as a signal to push. One of the most popular uses of the preload resource hint is to inform the browser of late-discovered resources, like fonts and images, that the browser will not see until the CSS has been requested, downloaded, and parsed. If these are now pushed based on that header, there was a concern that reusing this may result in a lot of unintended pushes.
-
However, the relatively low usage of fonts and images may mean that risk is not being seen as much as was feared. <link rel="preload" ... > tags are often used in the HTML rather than HTTP link headers and the meta tags are not a signal to push. Statistics in the Resource Hints chapter show that fewer than 1% of sites use the preload HTTP link header, and about the same amount use preconnect which has no meaning in HTTP/2, so this would suggest this is not so much of an issue. Though there are a number of fonts and other assets being pushed, which may be a signal of this.
-
As a counter argument to those complaints, if an asset is important enough to preload, then it could be argued these assets should be pushed if possible as browsers treat a preload hint as very high priority requests anyway. Any performance concern is therefore (again arguably) at the overuse of preload, rather than the resulting HTTP/2 push that happens because of this.
-
To get around this unintended push, you can provide the nopush attribute in your preload header:
5% of preload HTTP headers do make use of this attribute, which is higher than I would have expected as I would have considered this a niche optimization. Then again, so is the use of preload HTTP headers and/or HTTP/2 push itself!
HTTP/2 is mostly a seamless upgrade that, once your server supports it, you can switch on with no need to change your website or application. You can optimize for HTTP/2 or stop using HTTP/1.1 workarounds as much, but in general, a site will usually work without needing any changes—it will just be faster. There are a couple of gotchas to be aware of, however, that can impact any upgrade, and some sites have found these out the hard way.
-
One cause of issues in HTTP/2 is the poor support of HTTP/2 prioritization. This feature allows multiple requests in progress to make the appropriate use of the connection. This is especially important since HTTP/2 has massively increased the number of requests that can be running on the same connection. 100 or 128 parallel request limits are common in server implementations. Previously, the browser had a max of six connections per domain, and so used its skill and judgement to decide how best to use those connections. Now, it rarely needs to queue and can send all requests as soon as it knows about them. This can then lead to the bandwidth being "wasted" on lower priority requests while critical requests are delayed (and incidentally can also lead to swamping your backend server with more requests than it is used to!).
-
HTTP/2 has a complex prioritization model (too complex many say - hence why it is being reconsidered for HTTP/3!) but few servers honor that properly. This can be because their HTTP/2 implementations are not up to scratch, or because of so-called bufferbloat, where the responses are already en route before the server realizes there is a higher priority request. Due to the varying nature of servers, TCP stacks, and locations, it is difficult to measure this for most sites, but with CDNs this should be more consistent.
-
Patrick Meenan created an example test page, which deliberately tries to download a load of low priority, off-screen images, before requesting some high priority on-screen images. A good HTTP/2 server should be able to recognize this and send the high priority images shortly after requested, at the expense of the lower priority images. A poor HTTP/2 server will just respond in the request order and ignore any priority signals. Andy Davies has a page tracking the status of various CDNs for Patrick's test. The HTTP Archive identifies when a CDN is used as part of its crawl, and merging these two datasets can tell us the percent of pages using a passing or failing CDN.
-
-
-
-
-
-
-
CDN
-
Prioritizes Correctly?
-
Desktop
-
Mobile
-
Both
-
-
-
-
-
Not using CDN
-
Unknown
-
57.81%
-
60.41%
-
59.21%
-
-
-
Cloudflare
-
Pass
-
23.15%
-
21.77%
-
22.40%
-
-
-
Google
-
Fail
-
6.67%
-
7.11%
-
6.90%
-
-
-
Amazon CloudFront
-
Fail
-
2.83%
-
2.38%
-
2.59%
-
-
-
Fastly
-
Pass
-
2.40%
-
1.77%
-
2.06%
-
-
-
Akamai
-
Pass
-
1.79%
-
1.50%
-
1.64%
-
-
-
-
Unknown
-
1.32%
-
1.58%
-
1.46%
-
-
-
WordPress
-
Pass
-
1.12%
-
0.99%
-
1.05%
-
-
-
Sucuri Firewall
-
Fail
-
0.88%
-
0.75%
-
0.81%
-
-
-
Incapsula
-
Fail
-
0.39%
-
0.34%
-
0.36%
-
-
-
Netlify
-
Fail
-
0.23%
-
0.15%
-
0.19%
-
-
-
OVH CDN
-
Unknown
-
0.19%
-
0.18%
-
0.18%
-
-
-
-
-
- Figure 14. HTTP/2 prioritization support in common CDNs.
-
-
Figure 14 shows that a fairly significant portion of traffic is subject to the identified issue, totaling 26.82% on desktop and 27.83% on mobile. How much of a problem this is depends on exactly how the page loads and whether high priority resources are discovered late or not for the sites affected.
-
-
27.83%
- Figure 15. The percent of mobile requests with sub-optimal HTTP/2 prioritization.
-
-
Another issue is with the upgrade HTTP header being used incorrectly. Web servers can respond to requests with an upgrade HTTP header suggesting that it supports a better protocol that the client might wish to use (e.g. advertise HTTP/2 to a client only using HTTP/1.1). You might think this would be useful as a way of informing the browser a server supports HTTP/2, but since browsers only support HTTP/2 over HTTPS and since use of HTTP/2 can be negotiated through the HTTPS handshake, the use of this upgrade header for advertising HTTP/2 is pretty limited (for browsers at least).
-
Worse than that, is when a server sends an upgrade header in error. This could be because a backend server supporting HTTP/2 is sending the header and then an HTTP/1.1-only edge server is blindly forwarding it to the client. Apache emits the upgrade header when mod_http2 is enabled but HTTP/2 is not being used, and an nginx instance sitting in front of such an Apache instance happily forwards this header even when nginx does not support HTTP/2. This false advertising then leads to clients trying (and failing!) to use HTTP/2 as they are advised to.
-
108 sites use HTTP/2 while they also suggest upgrading to HTTP/2 in the upgrade header. A further 12,767 sites on desktop (15,235 on mobile) suggest upgrading an HTTP/1.1 connection delivered over HTTPS to HTTP/2 when it's clear this was not available, or it would have been used already. These are a small minority of the 4.3 million sites crawled on desktop and 5.3 million sites crawled on mobile, but it shows that this is still an issue affecting a number of sites out there. Browsers handle this inconsistently, with Safari in particular attempting to upgrade and then getting itself in a mess and refusing to display the site at all.
-
All of this is before we get into the few sites that recommend upgrading to http1.0, http://1.1, or even -all,+TLSv1.3,+TLSv1.2. There are clearly some typos in web server configurations going on here!
-
There are further implementation issues we could look at. For example, HTTP/2 is much stricter about HTTP header names, rejecting the whole request if you respond with spaces, colons, or other invalid HTTP header names. The header names are also converted to lowercase, which catches some by surprise if their application assumes a certain capitalization. This was never guaranteed previously, as HTTP/1.1 specifically states the header names are case insensitive, but still some have depended on this. The HTTP Archive could potentially be used to identify these issues as well, though some of them will not be apparent on the home page, but we did not delve into that this year.
The world does not stand still, and despite HTTP/2 not having even reached its fifth birthday, people are already seeing it as old news and getting more excited about its successor, HTTP/3. HTTP/3 builds on the concepts of HTTP/2, but moves from working over TCP connections that HTTP has always used, to a UDP-based protocol called QUIC. This allows us to fix one case where HTTP/2 is slower then HTTP/1.1, when there is high packet loss and the guaranteed nature of TCP holds up all streams and throttles back all streams. It also allows us to address some TCP and HTTPS inefficiencies, such as consolidating in one handshake for both, and supporting many ideas for TCP that have proven hard to implement in real life (TCP fast open, 0-RTT, etc.).
-
HTTP/3 also cleans up some overlap between TCP and HTTP/2 (e.g. flow control being implemented in both layers) but conceptually it is very similar to HTTP/2. Web developers who understand and have optimized for HTTP/2 should have to make no further changes for HTTP/3. Server operators will have more work to do, however, as the differences between TCP and QUIC are much more groundbreaking. They will make implementation harder so the rollout of HTTP/3 may take considerably longer than HTTP/2, and initially be limited to those with certain expertise in the field like CDNs.
-
QUIC has been implemented by Google for a number of years and it is now undergoing a similar standardization process that SPDY did on its way to HTTP/2. QUIC has ambitions beyond just HTTP, but for the moment it is the use case being worked on currently. Just as this chapter was being written, Cloudflare, Chrome, and Firefox all announced HTTP/3 support, despite the fact that HTTP/3 is still not formally complete or approved as a standard yet. This is welcome as QUIC support has been somewhat lacking outside of Google until recently, and definitely lags behind SPDY and HTTP/2 support from a similar stage of standardization.
-
Because HTTP/3 uses QUIC over UDP rather than TCP, it makes the discovery of HTTP/3 support a bigger challenge than HTTP/2 discovery. With HTTP/2 we can mostly use the HTTPS handshake, but as HTTP/3 is on a completely different connection, that is not an option here. HTTP/2 also used the upgrade HTTP header to inform the browser of HTTP/2 support, and although that was not that useful for HTTP/2, a similar mechanism has been put in place for QUIC that is more useful. The alternative services HTTP header (alt-svc) advertises alternative protocols that can be used on completely different connections, as opposed to alternative protocols that can be used on this connection, which is what the upgrade HTTP header is used for.
-
-
8.38%
- Figure 16. The percent of mobile sites which support QUIC.
-
-
Analysis of this header shows that 7.67% of desktop sites and 8.38% of mobile sites already support QUIC, which roughly represents Google's percentage of traffic, unsurprisingly enough, as it has been using this for a while. And 0.04% are already supporting HTTP/3. I would imagine by next year's Web Almanac, this number will have increased significantly.
This analysis of the available statistics in the HTTP Archive project has shown what many of us in the HTTP community were already aware of: HTTP/2 is here and proving to be very popular. It is already the dominant protocol in terms of number of requests, but has not quite overtaken HTTP/1.1 in terms of number of sites that support it. The long tail of the internet means that it often takes an exponentially longer time to make noticeable gains on the less well-maintained sites than on the high profile, high volume sites.
-
We've also talked about how it is (still!) not easy to get HTTP/2 support in some installations. Server developers, operating system distributors, and end customers all have a part to play in pushing to make that easier. Tying software to operating systems always lengthens deployment time. In fact, one of the very reasons for QUIC is to break a similar barrier with deploying TCP changes. In many instances, there is no real reason to tie web server versions to operating systems. Apache (to use one of the more popular examples) will run with HTTP/2 support in older operating systems, but getting an up-to-date version on to the server should not require the expertise or risk it currently does. Nginx does very well here, hosting repositories for the common Linux flavors to make installation easier, and if the Apache team (or the Linux distribution vendors) do not offer something similar, then I can only see Apache's usage continuing to shrink as it struggles to hold relevance and shake its reputation as old and slow (based on older installs) even though up-to-date versions have one of the best HTTP/2 implementations. I see that as less of an issue for IIS, since it is usually the preferred web server on the Windows side.
-
Other than that, HTTP/2 has been a relatively easy upgrade path, which is why it has had the strong uptake it has already seen. For the most part, it is a painless switch-on and, therefore, for most, it has turned out to be a hassle-free performance increase that requires little thought once your server supports it. The devil is in the details though (as always), and small differences between server implementations can result in better or worse HTTP/2 usage and, ultimately, end user experience. There has also been a number of bugs and even security issues, as is to be expected with any new protocol.
-
Ensuring you are using a strong, up-to-date, well-maintained implementation of any newish protocol like HTTP/2 will ensure you stay on top of these issues. However, that can take expertise and managing. The roll out of QUIC and HTTP/3 will likely be even more complicated and require more expertise. Perhaps this is best left to third-party service providers like CDNs who have this expertise and can give your site easy access to these features? However, even when left to the experts, this is not a sure thing (as the prioritization statistics show), but if you choose your server provider wisely and engage with them on what your priorities are, then it should be an easier implementation.
-
On that note it would be great if the CDNs prioritized these issues (pun definitely intended!), though I suspect with the advent of a new prioritization method in HTTP/3, many will hold tight. The next year will prove yet more interesting times in the HTTP world.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/javascript.html b/src/templates/en/2019/chapters/javascript.html
deleted file mode 100644
index a7784c01901..00000000000
--- a/src/templates/en/2019/chapters/javascript.html
+++ /dev/null
@@ -1,426 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":1,"title":"JavaScript","description":"JavaScript chapter of the 2019 Web Almanac covering how much JavaScript we use on the web, compression, libraries and frameworks, loading, and source maps.","authors":["housseindjirdeh"],"reviewers":["obto","paulcalvano","mathiasbynens"],"translators":null,"discuss":"1756","results":"https://docs.google.com/spreadsheets/d/1kBTglETN_V9UjKqK_EFmFjRexJnQOmLLr-I2Tkotvic/","queries":"01_JavaScript","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"javascript"} %} {% block index %}
-
JavaScript is a scripting language that makes it possible to build interactive and complex experiences on the web. This includes responding to user interactions, updating dynamic content on a page, and so forth. Anything involving how a web page should behave when an event occurs is what JavaScript is used for.
-
The language specification itself, along with many community-built libraries and frameworks used by developers around the world, has changed and evolved ever since the language was created in 1995. JavaScript implementations and interpreters have also continued to progress, making the language usable in many environments, not only web browsers.
-
The HTTP Archive crawls millions of pages every month and runs them through a private instance of WebPageTest to store key information of every page. (You can learn more about this in our methodology). In the context of JavaScript, HTTP Archive provides extensive information on the usage of the language for the entire web. This chapter consolidates and analyzes many of these trends.
JavaScript is the most costly resource we send to browsers; having to be downloaded, parsed, compiled, and finally executed. Although browsers have significantly decreased the time it takes to parse and compile scripts, download and execution have become the most expensive stages when JavaScript is processed by a web page.
-
Sending smaller JavaScript bundles to the browser is the best way to reduce download times, and in turn improve page performance. But how much JavaScript do we really use?
Bar chart showing 70 bytes of JavaScript are used in the p10 percentile, 174 bytes for p25, 373 bytes for p50, 693 bytes for p75, and 1,093 bytes for p90
- Figure 1. Distribution of JavaScript bytes per page.
-
-
Figure 1 above shows that we use 373 KB of JavaScript at the 50th percentile, or median. In other words, 50% of all sites ship more than this much JavaScript to their users.
-
Looking at these numbers, it's only natural to wonder if this is too much JavaScript. However in terms of page performance, the impact entirely depends on network connections and devices used. Which brings us to our next question: how much JavaScript do we ship when we compare mobile and desktop clients?
Bar chart showing 76 bytes/65 bytes of JavaScript are used in the p10 percentile on desktop and mobile respectively, 186/164 bytes for p25, 391/359 bytes for p50, 721/668 bytes for p75, and 1,131/1,060 bytes for p90.
- Figure 2. Distribution of JavaScript per page by device.
-
-
At every percentile, we're sending slightly more JavaScript to desktop devices than we are to mobile.
After being parsed and compiled, JavaScript fetched by the browser needs to processed (or executed) before it can be utilized. Devices vary, and their computing power can significantly affect how fast JavaScript can be processed on a page. What are the current processing times on the web?
-
We can get an idea by analyzing main thread processing times for V8 at different percentiles:
Bar chart showing 141 ms/377 ms of processing time is used in the p10 percentile on desktop and mobile respectively, 352/988 ms for p25, 849/2,437 ms for p50, 1,850/5,518 ms for p75, and 3,543/10,735 ms for p90.
- Figure 3. V8 Main thread processing times by device.
-
-
At every percentile, processing times are longer for mobile web pages than on desktop. The median total main thread time on desktop is 849 ms, while mobile is at a larger number: 2,437 ms.
-
Although this data shows how much longer it can take for a mobile device to process JavaScript compared to a more powerful desktop machine, mobile devices also vary in terms of computing power. The following chart shows how processing times on a single web page can vary significantly depending on the mobile device class.
Bar chart showing 3 different devices: at the top a Pixel 3 has small amount on both the main thread and the worker thread of less than 400ms. For a Moto G4 it is approximately 900 ms on main thread and a further 300 ms on worker thread. And the final bar is an Alcatel 1X 5059D with over 2,000 ms on the main thread and over 500 ms on worker thread.
One avenue worth exploring when trying to analyze the amount of JavaScript used by web pages is the number of requests shipped. With HTTP/2, sending multiple smaller chunks can improve page load over sending a larger, monolithic bundle. If we also break it down by device client, how many requests are being fetched?
Bar chart showing 4/4 requests for desktop and mobile respectively are used in the p10 percentile, 10/9 in p25, 19/18 in p50, 33/32 in p75 and 53/52 in p90.
- Figure 5. Distribution of total JavaScript requests.
-
-
At the median, 19 requests are sent for desktop and 18 for mobile.
Of the results analyzed so far, the entire size and number of requests were being considered. In a majority of websites however, a significant portion of the JavaScript code fetched and used comes from third-party sources.
-
Third-party JavaScript can come from any external, third-party source. Ads, analytics and social media embeds are all common use-cases for fetching third-party scripts. So naturally, this brings us to our next question: how many requests sent are third-party instead of first-party?
Bar chart showing 0/1 request on desktop are first-party and third-party respectively in p10 percentile, 2/4 in p25, 6/10 in p50, 13/21 in p75, and 24/38 in p90.
- Figure 6. Distribution of first and third-party scripts on desktop.
-
-
-
-
-
-
-
Bar chart showing 0/1 request on mobile are first-party and third-party respectively in p10 percentile, 2/3 in p25, 5/9 in p50, 13/20 in p75, and 23/36 in p90.
- Figure 7. Distribution of first and third party scripts on mobile.
-
-
For both mobile and desktop clients, more third-party requests are sent than first-party at every percentile. If this seems surprising, let's find out how much actual code shipped comes from third-party vendors.
Bar chart showing 0/17 bytes of JavaScript are downloaded on desktop for first-party and third-party requests respectively in the p10 percentile, 11/62 in p25, 89/232 in p50, 200/525 in p75, and 404/900 in p90.
- Figure 8. Distribution of total JavaScript downloaded on desktop.
-
-
-
-
-
-
-
Bar chart showing 0/17 bytes of JavaScript are downloaded on mobile for first-party and third-party requests respectively in the p10 percentile, 6/54 in p25, 83/217 in p50, 189/477 in p75, and 380/827 in p90.
- Figure 9. Distribution of total JavaScript downloaded on mobile.
-
-
At the median, 89% more third-party code is used than first-party code authored by the developer for both mobile and desktop. This clearly shows that third-party code can be one of the biggest contributors to bloat. For more information on the impact of third parties, refer to the "Third Parties" chapter.
In the context of browser-server interactions, resource compression refers to code that has been modified using a data compression algorithm. Resources can be compressed statically ahead of time or on-the-fly as they are requested by the browser, and for either approach the transferred resource size is significantly reduced which improves page performance.
-
There are multiple text-compression algorithms, but only two are mostly used for the compression (and decompression) of HTTP network requests:
-
-
Gzip (gzip): The most widely used compression format for server and client interactions
-
Brotli (br): A newer compression algorithm aiming to further improve compression ratios. 90% of browsers support Brotli encoding.
-
-
Compressed scripts will always need to be uncompressed by the browser once transferred. This means its content remains the same and execution times are not optimized whatsoever. Resource compression, however, will always improve download times which also is one of the most expensive stages of JavaScript processing. Ensuring JavaScript files are compressed correctly can be one of the most significant factors in improving site performance.
-
How many sites are compressing their JavaScript resources?
Bar chart showing 67%/65% of JavaScript resources are compressed with gzip on desktop and mobile respectively, and 15%/14% are compressed using Brotli.
- Figure 10. Percentage of sites compressing JavaScript resources with gzip or brotli.
-
-
The majority of sites are compressing their JavaScript resources. Gzip encoding is used on ~64-67% of sites and Brotli on ~14%. Compression ratios are similar for both desktop and mobile.
-
For a deeper analysis on compression, refer to the "Compression" chapter.
Open source code, or code with a permissive license that can be accessed, viewed and modified by anyone. From tiny libraries to entire browsers, such as Chromium and Firefox, open source code plays a crucial role in the world of web development. In the context of JavaScript, developers rely on open source tooling to include all types of functionality into their web page. Regardless of whether a developer decides to use a small utility library or a massive framework that dictates the architecture of their entire application, relying on open-source packages can make feature development easier and faster. So which JavaScript open-source libraries are used the most?
-
-
-
-
-
-
-
Library
-
Desktop
-
Mobile
-
-
-
-
-
jQuery
-
85.03%
-
83.46%
-
-
-
jQuery Migrate
-
31.26%
-
31.68%
-
-
-
jQuery UI
-
23.60%
-
21.75%
-
-
-
Modernizr
-
17.80%
-
16.76%
-
-
-
FancyBox
-
7.04%
-
6.61%
-
-
-
Lightbox
-
6.02%
-
5.93%
-
-
-
Slick
-
5.53%
-
5.24%
-
-
-
Moment.js
-
4.92%
-
4.29%
-
-
-
Underscore.js
-
4.20%
-
3.82%
-
-
-
prettyPhoto
-
2.89%
-
3.09%
-
-
-
Select2
-
2.78%
-
2.48%
-
-
-
Lodash
-
2.65%
-
2.68%
-
-
-
Hammer.js
-
2.28%
-
2.70%
-
-
-
YUI
-
1.84%
-
1.50%
-
-
-
Lazy.js
-
1.26%
-
1.56%
-
-
-
Fingerprintjs
-
1.21%
-
1.32%
-
-
-
script.aculo.us
-
0.98%
-
0.85%
-
-
-
Polyfill
-
0.97%
-
1.00%
-
-
-
Flickity
-
0.83%
-
0.92%
-
-
-
Zepto
-
0.78%
-
1.17%
-
-
-
Dojo
-
0.70%
-
0.62%
-
-
-
-
-
- Figure 11. Top JavaScript libraries on desktop and mobile.
-
-
jQuery, the most popular JavaScript library ever created, is used in 85.03% of desktop pages and 83.46% of mobile pages. The advent of many Browser APIs and methods, such as Fetch and querySelector, standardized much of the functionality provided by the library into a native form. Although the popularity of jQuery may seem to be declining, why is it still used in the vast majority of the web?
-
There are a number of possible reasons:
-
-
WordPress, which is used in more than 30% of sites, includes jQuery by default.
-
Switching from jQuery to a newer client-side library can take time depending on how large an application is, and many sites may consist of jQuery in addition to newer client-side libraries.
-
-
Other top used JavaScript libraries include jQuery variants (jQuery migrate, jQuery UI), Modernizr, Moment.js, Underscore.js and so on.
As mentioned in our methodology, the third-party detection library used in HTTP Archive (Wappalyzer) has a number of limitations with regards to how it detects certain tools. There is an open issue to improve detection of JavaScript libraries and frameworks, which will have impacted the results presented here.
-
In the past number of years, the JavaScript ecosystem has seen a rise in open-source libraries and frameworks to make building single-page applications (SPAs) easier. A single-page application is characterized as a web page that loads a single HTML page and uses JavaScript to modify the page on user interaction instead of fetching new pages from the server. Although this remains to be the main premise of single-page applications, different server-rendering approaches can still be used to improve the experience of such sites. How many sites use these types of frameworks?
Although there has been a shift towards a component-based model, many older frameworks that follow the MVC paradigm (AngularJS, Backbone.js, Ember) are still being used in thousands of pages. However, React, Vue and Angular are the most popular component-based frameworks (Zone.js is a package that is now part of Angular core).
JavaScript modules, or ES modules, are supported in all major browsers. Modules provide the capability to create scripts that can import and export from other modules. This allows anyone to build their applications architected in a module pattern, importing and exporting wherever necessary, without relying on third-party module loaders.
-
To declare a script as a module, the script tag must get the type="module" attribute:
-
<script type="module" src="main.mjs"></script>
-
How many sites use type="module" for scripts on their page?
Bar chart showing 0.6% of sites on desktop use 'type=module', and 0.8% of sites on mobile.
- Figure 13. Percentage of sites utilizing type=module.
-
-
Browser-level support for modules is still relatively new, and the numbers here show that very few sites currently use type="module" for their scripts. Many sites are still relying on module loaders (2.37% of all desktop sites use RequireJS for example) and bundlers (webpack for example) to define modules within their codebase.
-
If native modules are used, it's important to ensure that an appropriate fallback script is used for browsers that do not yet support modules. This can be done by including an additional script with a nomodule attribute.
-
<script nomodule src="fallback.js"></script>
-
When used together, browsers that support modules will completely ignore any scripts containing the nomodule attribute. On the other hand, browsers that do not yet support modules will not download any scripts with type="module". Since they do not recognize nomodule either, they will download scripts with the attribute normally. Using this approach can allow developers to send modern code to modern browsers for faster page loads. So, how many sites use nomodule for scripts on their page?
Preload and prefetch are resource hints which enable you to aid the browser in determining what resources need to be downloaded.
-
-
Preloading a resource with <link rel="preload"> tells the browser to download this resource as soon as possible. This is especially helpful for critical resources which are discovered late in the page loading process (e.g., JavaScript located at the bottom of your HTML) and are otherwise downloaded last.
-
Using <link rel="prefetch"> tells the browser to take advantage of any idle time it has to fetch these resources needed for future navigations
-
-
So, how many sites use preload and prefetch directives?
JavaScript continues to evolve as a language. A new version of the language standard itself, known as ECMAScript, is released every year with new APIs and features passing proposal stages to become a part of the language itself.
-
With HTTP Archive, we can take a look at any newer API that is supported (or is about to be) and see how widespread its usage is. These APIs may already be used in browsers that support them or with an accompanying polyfill to make sure they still work for every user.
Bar chart showing 25.5%/36.2% of sites on desktop and mobile respectivdely use WeakMap, 6.1%/17.2% use WeakSet, 3.9%/14.0% use Intl, 3.9%/4.4% use Proxy, 0.4%/0.4% use Atomics, and 0.2%/0.2% use SharedArrayBuffer.
In many build systems, JavaScript files undergo minification to minimize its size and transpilation for newer language features that are not yet supported in many browsers. Moreover, language supersets like TypeScript compile to an output that can look noticeably different from the original source code. For all these reasons, the final code served to the browser can be unreadable and hard to decipher.
-
A source map is an additional file accompanying a JavaScript file that allows a browser to map the final output to its original source. This can make debugging and analyzing production bundles much simpler.
-
Although useful, there are a number of reasons why many sites may not want to include source maps in their final production site, such as choosing not to expose complete source code to the public. So how many sites actually include sourcemaps?
Bar chart showing 18% of desktop sites and 17% of mobile sites use source maps.
- Figure 18. Percentage of sites using source maps.
-
-
For both desktop and mobile pages, the results are about the same. 17-18% include a source map for at least one script on the page (detected as a first-party script with sourceMappingURL).
The JavaScript ecosystem continues to change and evolve every year. Newer APIs, improved browser engines, and fresh libraries and frameworks are all things we can expect to happen indefinitely. HTTP Archive provides us with valuable insight on how sites in the wild use the language.
-
Without JavaScript, the web would not be where it is today, and all the data gathered for this article only proves this.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/markup.html b/src/templates/en/2019/chapters/markup.html
deleted file mode 100644
index f3cde7bb390..00000000000
--- a/src/templates/en/2019/chapters/markup.html
+++ /dev/null
@@ -1,354 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":3,"title":"Markup","description":"Markup chapter of the 2019 Web Almanac covering elements used, custom elements, value, products, and common use cases.","authors":["bkardell"],"reviewers":["zcorpan","tomhodgins","matthewp"],"translators":null,"discuss":"1758","results":"https://docs.google.com/spreadsheets/d/1WnDKLar_0Btlt9UgT53Giy2229bpV4IM2D_v6OM_WzA/","queries":"03_Markup","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"markup"} %} {% block index %}
-
In 2005, Ian "Hixie" Hickson posted some analysis of markup data building upon various previous work. Much of this work aimed to investigate class names to see if there were common informal semantics that were being adopted by developers which it might make sense to standardize upon. Some of this research helped inform new elements in HTML5.
-
14 years later, it's time to take a fresh look. Since then, we've also had the introduction of Custom Elements and the Extensible Web Manifesto encouraging that we find better ways to pave the cowpaths by allowing developers to explore the space of elements themselves and allow standards bodies to act more like dictionary editors. Unlike CSS class names, which might be used for anything, we can be far more certain that authors who used a non-standard element really intended this to be an element.
-
- As of July 2019, the HTTP Archive has begun collecting all used element names in the DOM for about 4.4 million desktop home pages, and about 5.3 million mobile home pages which we can now begin to research and dissect. (Learn more about our Methodology.)
-
-
This crawl encountered over 5,000 distinct non-standard element names in these pages, so we capped the total distinct number of elements that we count to the 'top' (explained below) 5,048.
Names of elements on each page were collected from the DOM itself, after the initial run of JavaScript.
-
Looking at a raw frequency count isn't especially helpful, even for standard elements: About 25% of all elements encountered are <div>. About 17% are <a>, about 11% are <span> -- and those are the only elements that account for more than 10% of occurrences. Languages are generally like this; a small number of terms are astoundingly used by comparison. Further, when we start looking at non-standard elements for uptake, this would be very misleading as one site could use a certain element a thousand times and thus make it look artificially very popular.
-
Instead, as in Hixie's original study, what we will look at is how many sites include each element at least once in their homepage.
-
Note: This is, itself, not without some potential biases. Popular products can be used by several sites, which introduce non-standard markup, even "invisibly" to individual authors. Thus, care must be taken to acknowledge that usage doesn't necessarily imply direct author knowledge and conscious adoption as much as it does the servicing of a common need, in a common way. During our research, we found several examples of this, some we will call out.
In 2005, Hixie's survey listed the top few most commonly used elements on pages. The top 3 were html, head and body which he noted as interesting because they are optional and created by the parser if omitted. Given that we use the post-parsed DOM, they'll show up universally in our data. Thus, we'll begin with the 4th most used element. Below is a comparison of the data from then to now (I've included the frequency comparison here as well just for fun).
-
-
-
-
-
-
-
2005 (per site)
-
2019 (per site)
-
2019 (frequency)
-
-
-
-
-
title
-
title
-
div
-
-
-
a
-
meta
-
a
-
-
-
img
-
a
-
span
-
-
-
meta
-
div
-
li
-
-
-
br
-
link
-
img
-
-
-
table
-
script
-
script
-
-
-
td
-
img
-
p
-
-
-
tr
-
span
-
option
-
-
-
-
-
- Figure 1. Comparison of the top elements from 2005 to 2019.
-
Graph showing a decreasing distribution of relative frequency as the number of elements increases
- Figure 2. Distribution of Hixie's 2005 analysis of element frequencies.
-
-
-
-
-
-
-
Graph showing about 2,500 pages start with approximately 30 elements, this increases peaking at 6,876 pages have 283 elements, before trailing fairly linearly to 327 pages having 2,000 elements.
Comparing the latest data in Figure 3 to that of Hixie's report from 2005 in Figure 2, we can see that the average size of DOM trees has gotten bigger.
-
-
-
-
Graph that relative frequency is a bell curve around the 19 elements point.
- Figure 4. Histogram of Hixie's 2005 analysis of element types per page.
-
-
-
-
-
-
-
Graph showing the average number of elements is a bell curve around the 30 elements marked, as used by 308,168 thousand sites.
- Figure 5. Histogram of element types per page as of 2019.
-
-
We can see that both the average number of types of elements per page has increased, as well as the maximum numbers of unique elements that we encounter.
Most of the elements we recorded are custom (as in simply 'not standard'), but discussing which elements are and are not custom can get a little challenging. Written down in some spec or proposal somewhere are, actually, quite a few elements. For purposes here, we considered 244 elements as standard (though, some of them are deprecated or unsupported):
-
-
145 Elements from HTML
-
68 Elements from SVG
-
31 Elements from MathML
-
-
In practice, we encountered only 214 of these:
-
-
137 from HTML
-
54 from SVG
-
23 from MathML
-
-
In the desktop dataset we collected data for the top 4,834 non-standard elements that we encountered. Of these:
-
-
155 (3%) are identifiable as very probable markup or escaping errors (they contain characters in the parsed tag name which imply that the markup is broken)
-
341 (7%) use XML-style colon namespacing (though, as HTML, they don't use actual XML namespaces)
-
3,207 (66%) are valid custom element names
-
1,211 (25%) are in the global namespace (non-standard, having neither dash, nor colon)
-
216 of these we have flagged as possible typos as they are longer than 2 characters and have a Levenshtein distance of 1 from some standard element name like <cript>,<spsn> or <artice>. Some of these (like <jdiv>), however, are certainly intentional.
-
-
Additionally, 15% of desktop pages and 16% of mobile pages contain deprecated elements.
-
Note: A lot of this is very likely due to the use of products rather than individual authors continuing to manually create this markup.
Bar chart showing 'center' in use by 8.31% of desktop sites (7.96% of mobile), 'font' in use by 8.01% of desktop sites (7.38% of mobile), 'marquee' in use by 1.07% of desktop sites (1.20% of mobile), 'nobr' in use by 0.71% of desktop sites (0.55% of mobile), 'big' in use by 0.53% of desktop sites (0.47% of mobile), 'frameset' in use by 0.39% of desktop sites (0.35% of mobile), 'frame' in use by 0.39% of desktop sites (0.35% of mobile), 'strike' in use by 0.33% of desktop sites (0.27% of mobile), and 'noframes' in use by 0.25% of desktop sites (0.27% of mobile).
- Figure 6. Most frequently used deprecated elements.
-
-
Figure 6 above shows the top 10 most frequently used deprecated elements. Most of these can seem like very small numbers, but perspective matters.
Bar chart showing a decreasing used of elements in descending order: html, head, body, title at above 99% usage, meta, a, div above 98% usage, link, script, img, span above 90% usage, ul, li , p, style, input, br, form above 70% usage, h2, h1, iframe, h3, button, footer, header, nav above 50% usage and other less well-known tags trailing down from below 50% to almost 0% usage.
In Figure 7 above, the top 150 element names, counting the number of pages where they appear, are shown. Note how quickly use drops off.
-
Only 11 elements are used on more than 90% of pages:
-
-
<html>
-
<head>
-
<body>
-
<title>
-
<meta>
-
<a>
-
<div>
-
<link>
-
<script>
-
<img>
-
<span>
-
-
There are only 15 other elements that occur on more than 50% of pages:
-
-
<ul>
-
<li>
-
<p>
-
<style>
-
<input>
-
<br>
-
<form>
-
<h2>
-
<h1>
-
<iframe>
-
<h3>
-
<button>
-
<footer>
-
<header>
-
<nav>
-
-
And there are only 40 other elements that occur on more than 5% of pages.
-
Even <video>, for example, doesn't make that cut. It appears on only 4% of desktop pages in the dataset (3% on mobile). While these numbers sound very low, 4% is actually quite popular by comparison. In fact, only 98 elements occur on more than 1% of pages.
-
It's interesting, then, to see what the distribution of these elements looks like and which ones have more than 1% use.
Scatter graph showing HTML, SVG, and Math ML use relatively few tags while non-standard elements (split into "in global ns", "dasherized" and "colon") are much more spread out.
- Figure 8. Element popularity categorized by standardization.
-
-
Figure 8 shows the rank of each element and which category they fall into. I've separated the data points into discrete sets simply so that they can be viewed (otherwise there just aren't enough pixels to capture all that data), but they represent a single 'line' of popularity; the bottom-most being the most common, the top-most being the least common. The arrow points to the end of elements that appear in more than 1% of the pages.
-
You can observe two things here. First, the set of elements that have more than 1% use are not exclusively HTML. In fact, 27 of the most popular 100 elements aren't even HTML - they are SVG! And there are non-standard tags at or very near that cutoff too! Second, note that a whole lot of HTML elements are used by less than 1% of pages.
-
So, are all of those elements used by less than 1% of pages "useless"? Definitely not. This is why establishing perspective matters. There are around two billion web sites on the web. If something appears on 0.1% of all websites in our dataset, we can extrapolate that this represents perhaps two million web sites in the whole web. Even 0.01% extrapolates to two hundred thousand sites. This is also why removing support for elements, even very old ones which we think aren't great ideas, is a very rare occurrence. Breaking hundreds of thousands or millions of sites just isn't a thing that browser vendors can do lightly.
-
Many elements, even the native ones, appear on fewer than 1% of pages and are still very important and successful. <code>, for example, is an element that I both use and encounter a lot. It's definitely useful and important, and yet it is used on only 0.57% of these pages. Part of this is skewed based on what we are measuring; home pages are generally less likely to include certain kinds of things (like <code> for example). Home pages serve a less general purpose than, for example, headings, paragraphs, links and lists. However, the data is generally useful.
-
We also collected information about which pages contained an author-defined (not native) .shadowRoot. About 0.22% of desktop pages and 0.15% of mobile pages had a shadow root. This might not sound like a lot, but it is roughly 6.5k sites in the mobile dataset and 10k sites on the desktop and is more than several HTML elements. <summary> for example, has about equivalent use on the desktop and it is the 146th most popular element. <datalist> appears on 0.04% of homepages and it's the 201st most popular element.
-
In fact, over 15% of elements we're counting as defined by HTML are outside the top 200 in the desktop dataset . <meter> is the least popular "HTML5 era" element, which we can define as 2004-2011, before HTML moved to a Living Standard model. It is around the 1,000th most popular element. <slot>, the most recently introduced element (April 2016), is only around the 1,400th most popular element.
With this perspective in mind about what use of native/standard features looks like in the dataset, let's talk about the non-standard stuff.
-
You might expect that many of the elements we measured are used only on a single web page, but in fact all of the 5,048 elements appear on more than one page. The fewest pages an element in our dataset appears on is 15. About a fifth of them occur on more than 100 pages. About 7% occur on more than 1,000 pages.
-
To help analyze the data, I hacked together a little tool with Glitch. You can use this tool yourself, and please share a permalink back with the @HTTPArchive along with your observations. (Tommy Hodgins has also built a similar CLI tool which you can use to explore.)
For several non-standard elements, their prevalence may have more to do with their inclusion in popular third-party tools than first-party adoption. For example, the <fb:like> element is found on 0.3% of pages not because site owners are explicitly writing it out but because they include the Facebook widget. Many of the elements Hixie mentioned 14 years ago seem to have dwindled, but others are still pretty huge:
-
-
- Popular elements created by Claris Home Page (whose last stable release was 21 years ago) still appear on over 100 pages. <x-claris-window>, for example, appears on 130 pages.
-
-
- Some of the <actinic:*> elements from British ecommerce provider Oxatis appear on even more pages. For example, <actinic:basehref> still shows up on 154 pages in the desktop data.
-
-
- Macromedia's elements seem to have largely disappeared. Only one element, <mm:endlock>, appears on our list and on only 22 pages.
-
-
- Adobe Go-Live's <csscriptdict> still appears on 640 pages in the desktop dataset.
-
-
Microsoft Office's <o:p> element still appears on 0.5% of desktop pages, over 20k pages.
-
-
But there are plenty of newcomers that weren't in Hixie's original report too, and with even bigger numbers.
-
-
- <ym-measure> is a tag injected by Yandex's Metrica analytics package. It's used on more than 1% of desktop and mobile pages, solidifying its place in the top 100 most used elements. That's huge!
-
-
- <g:plusone> from the now-defunct Google Plus occurs on over 21k pages.
-
-
- Facebook's <fb:like> occurs on 14k mobile pages.
-
-
- Similarly, <fb:like-box> occurs on 7.8k mobile pages.
-
-
- <app-root>, which is generally included in frameworks like Angular, appears on 8.2k mobile pages.
-
-
-
Let's compare these to a few of the native HTML elements that are below the 5% bar, for perspective.
Bar chart showing video is used by 184,149 sites, canvas by 108,355, ym-measure (a product-specific tag) by 52,146, code by 25,075, g:plusone (a product-specific tag) by 21,098, fb:like (a product-specific tag) by 12,773, fb:like-box (a product-specific tag) by 6,792, app-root (a product-specific tag) by 8,468, summary by 6,578, template by 5,913, and meter by 0.
- Figure 9. Popularity of product-specific and native elements under 5% adoption.
-
-
You could discover interesting insights like these all day long.
-
Here's one that's a little different: popular elements could be caused by outright errors in products. For example, <pclass="ddc-font-size-large"> occurs on over 1,000 sites. This was thanks to a missing space in a popular "as-a-service" kind of product. Happily, we reported this error during our research and it was quickly fixed.
-
In his original paper, Hixie mentions that:
-
The good thing, if we can be forgiven for trying to remain optimistic in the face of all this non-standard markup, is that at least these elements are all clearly using vendor-specific names. This massively reduces the likelihood that standards bodies will invent elements and attributes that clash with any of them.
-
- However, as mentioned above, this is not universal. Over 25% of the non-standard elements that we captured don't use any kind of namespacing strategy to avoid polluting the global namespace. For example, here is a list of 1157 elements like that from the mobile dataset. Many of those, as you can see, are likely to be non-problematic as they have obscure names, misspellings and so on. But at least a few probably present some challenges. You'll note, for example, that <toast> (which Googlers recently tried to propose as <std-toast>) appears in this list.
-
-
There are some popular elements that are probably not so challenging:
-
-
- <ymaps> from Yahoo Maps appears on ~12.5k mobile pages.
-
-
- <cufon> and <cufontext> from a font replacement library from 2008, appear on ~10.5k mobile pages.
-
-
- The <jdiv> element, which appears to be injected by the Jivo chat product, appears on ~40.3k mobile pages,
-
-
-
Placing these into our same chart as above for perspective looks something like this (again, it varies slightly based on the dataset)
A bar chart showing video is used by 184,149 sites, canvas by 108,355, ym-measure by 52,416, code by 25,075, g:plusone by 21,098, db:like by 12,773, cufon by 10,523, ymaps by 8,303, fb:like-box by 6,972, app-root by 8,468, summary by 6,578, template by 5,913, and meter by 0
- Figure 10. Other popular elements in the context of product-specific and native elements with under 5% adoption.
-
-
The interesting thing about these results is that they also introduce a few other ways that our tool can come in very handy. If we're interested in exploring the space of the data, a very specific tag name is just one possible measure. It's definitely the strongest indicator if we can find good "slang" developing. However, what if that's not all we're interested in?
What if, for example, we were interested in people solving common use cases? This could be because we're looking for solutions to use cases that we currently have ourselves, or for researching more broadly what common use cases people are solving with an eye toward incubating some standardization effort. Let's take a common example: tabs. Over the years there have been a lot of requests for things like tabs. We can use a fuzzy search here and find that there are many variants of tabs. It's a little harder to count usage here since we can't as easily distinguish if two elements appear on the same page, so the count provided there conservatively simply takes the one with the largest count. In most cases the real number of pages is probably significantly larger.
If we notice popular things pop up (like <jdiv>, solving chat) we can take knowledge of things we know (like, that is what <jdiv> is about, or <olark>) and try to look at at least 43 things we've built for tackling that and follow connections to survey the space.
Pages have more elements than they did 14 years ago, both on average and max.
-
The lifetime of things on home pages is very long. Deprecating or discontinuing things doesn't make them go away, and it might never.
-
There is a lot of broken markup out there in the wild (misspelled tags, missing spaces, bad escaping, misunderstandings).
-
Measuring what "useful" means is tricky. Lots of native elements don't pass the 5% bar, or even the 1% bar, but lots of custom ones do, and for lots of reasons. Passing 1% should definitely grab our attention at least, but perhaps so should 0.5% because that is, according to the data, comparatively very successful.
-
There is already a ton of custom markup out there. It comes in a lot of forms, but elements containing a dash definitely seem to have taken off.
-
We need to increasingly study this data and come up with good observations to help find and pave the cowpaths.
-
-
That last one is where you come in. We'd love to tap into the creativity and curiosity of the larger community to help explore this data using some of the tools (like https://rainy-periwinkle.glitch.me/). Please share your interesting observations and help build our commons of knowledge and understanding.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/media.html b/src/templates/en/2019/chapters/media.html
deleted file mode 100644
index f08b1f8108e..00000000000
--- a/src/templates/en/2019/chapters/media.html
+++ /dev/null
@@ -1,515 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":4,"title":"Media","description":"Media chapter of the 2019 Web Almanac covering image file sizes and formats, responsive images, client hints, lazy loading, accessibility and video.","authors":["colinbendell","dougsillars"],"reviewers":["ahmadawais","eeeps"],"translators":null,"discuss":"1759","results":"https://docs.google.com/spreadsheets/d/1hj9bY6JJZfV9yrXHsoCRYuG8t8bR-CHuuD98zXV7BBQ/","queries":"04_Media","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-12T00:00:00.000Z","chapter":"media"} %} {% block index %}
-
Images, animations, and videos are an important part of the web experience. They are important for many reasons: they help tell stories, engage audiences, and provide artistic expression in ways that often cannot be easily produced with other web technologies. The importance of these media resources can be demonstrated in two ways: by the sheer volume of bytes required to download for a page, and also the volume of pixels painted with media.
-
From a pure bytes perspective, HTTP Archive has historically reported an average of two-thirds of resource bytes associated from media. From a distribution perspective, we can see that virtually every web page depends on images and videos. Even at the tenth percentile, we see that 44% of the bytes are from media and can rise to 91% of the total bytes at the 90th percentile of pages.
Bar chart showing in the p10 percentile 44.1% of page bytes are media, in the p25 percentile 52.7% is media, in the p50 percentile 67.0% is media, in the p75 percentile 81.7% is media, and in the p90 percentile 91.2% is media.
- Figure 1. Web page bytes: image and video versus other.
-
-
While media are critical for the visual experience, the impact of this high volume of bytes has two side effects.
-
First, the network overhead required to download these bytes can be large and in cellular or slow network environments (like coffee shops or tethering when in an Uber) can dramatically slow down the page performance. Images are a lower priority request by the browser but can easily block CSS and JavaScript in the download. This by itself can delay the page rendering. Yet at other times, the image content is the visual cue to the user that the page is ready. Slow transfers of visual content, therefore, can give the perception of a slow web page.
-
The second impact is on the financial cost to the user. This is often an ignored aspect since it is not a burden on the website owner but a burden to the end-user. Anecdotally, it has been shared that some markets, like Japan, see a drop in purchases by students near the end of the month when data caps are reached, and users cannot see the visual content.
-
Further, the financial cost of visiting these websites in different parts of the world is disproportionate. At the median and 90th percentile, the volume of image bytes is 1 MB and 1.9 MB respectively. Using WhatDoesMySiteCost.com we can see that the gross national income (GNI) per capita cost to a user in Madagascar a single web page load at the 90th percentile would cost 2.6% of the daily gross income. By contrast, in Germany this would be 0.3% of the daily gross income.
The median web page on mobile requires 1 MB of images and 4.9 MB at the 90th percentile.
- Figure 2. Total image bytes per web page (mobile).
-
-
Looking at bytes per page results in just looking at the costs—to page performance and the user—but it overlooks the benefits. These bytes are important to render pixels on the screen. As such, we can see the importance of the images and video resources by also looking at the number of media pixels used per page.
-
There are three metrics to consider when looking at pixel volume: CSS pixels, natural pixels, and screen pixels:
-
-
-
CSS pixel volume is from the CSS perspective of layout. This measure focuses on the bounding boxes for which an image or video could be stretched or squeezed into. It also does not take into the actual file pixels nor the screen display pixels
-
-
-
Natural pixels refer to the logical pixels represented in a file. If you were to load this image in GIMP or Photoshop, the pixel file dimensions would be the natural pixels.
-
-
-
Screen pixels refer to the physical electronics on the display. Prior to mobile phones and modern high-resolution displays, there was a 1:1 relationship between CSS pixels and LED points on a screen. However, because mobile devices are held closer to the eye, and laptop screens are closer than the old mainframe terminals, modern screens have a higher ratio of physical pixels to traditional CSS pixels. This ratio is referred to as Device-Pixel-Ratio or colloquially referred to as Retina™ displays.
A comparison of the CSS pixels allocated to image content compared to the actual image pixels for mobile, showing p10 (0.07 MP actual, 0.04 MP CSS), p25 (0.38 MP actual, 0.18 MP CSS), p50 (1.6 MP actual, 0.65 MP CSS), p75 (5.1 MP actual, 1.8 MP CSS), and p90 (12 MP actual, 4.6 MP CSS)
- Figure 3. Image pixels per page (mobile): CSS versus actual.
-
-
-
-
-
-
-
A comparison of the CSS pixels allocated to image content compared to the actual image pixels for desktop, showing p10 (0.09 MP actual, 0.05 MP CSS), p25 (0.52 MP actual, 0.29 MP CSS), p50 (2.1 MP actual, 1.1 MP CSS), p75 (6.0 MP actual, 2.8 MP CSS), and p90 (14 MP actual, 6.3 MP CSS)
- Figure 4. Image pixels per page (desktop): CSS versus actual.
-
-
Looking at the CSS pixel and the natural pixel volume we can see that the median website has a layout that displays one megapixel (MP) of media content. At the 90th percentile, the CSS layout pixel volume grows to 4.6 MP and 6.3 MP mobile and desktop respectively. This is interesting not only because the responsive layout is likely different, but also because the form factor is different. In short, the mobile layout has less space allocated for media compared to the desktop.
-
In contrast, the natural, or file, pixel volume is between 2 and 2.6 times the layout volume. The median desktop web page sends 2.1MP of pixel content that is displayed in 1.1 MP of layout space. At the 90th percentile for mobile we see 12 MP squeezed into 4.6 MP.
-
Of course, the form factor for a mobile device is different than a desktop. A mobile device is smaller and usually held in portrait mode while the desktop is larger and used predominantly in landscape mode. As mentioned earlier, a mobile device also typically has a higher device pixel ratio (DPR) because it is held much closer to the eye, requiring more pixels per inch compared to what you would need on a billboard in Times Square. These differences force layout changes and users on mobile more commonly scroll through a site to consume the entirety of content.
-
Megapixels are a challenging metric because it is a largely abstract metric. A useful way to express this volume of pixels being used on a web page is to represent it as a ratio relative to the display size.
-
For the mobile device used in the web page crawl, we have a display of 512 x 360 which is 0.18 MP of CSS content. (Not to be confused with the physical screen which is 3x or 3^2 more pixels, which is 1.7MP). Dividing this viewer pixel volume by the number of CSS pixels allocated to images we get a relative pixel volume.
-
If we had one image that filled the entire screen perfectly, this would be a 1x pixel fill rate. Of course, rarely does a website fill the entire canvas with a single image. Media content tends to be mixed in with the design and other content. A value greater than 1x implies that the layout requires the user to scroll to see the additional image content.
-
Note: this is only looking at the CSS layout for both the DPR and the volume of layout content. It is not evaluating the effectiveness of the responsive images or the effectiveness of providing high DPR content.
For the median web page on desktop, only 46% of the display would have layout containing images and video. In contrast, on mobile, the volume of media pixels fills 3.5 times the actual viewport size. The layout has more content than can be filled in a single screen, requiring the user to scroll. At a minimum, there is 3.5 scrolling pages of content per site (assuming 100% saturation). At the 90th percentile for mobile, this grows substantially to 25x the viewport size!
-
Media resources are critical for the user experience.
Much has already been written on the subject of managing and optimizing images to help reduce the bytes and optimize the user experience. It is an important and critical topic for many because it is the creative media that define a brand experience. Therefore, optimizing image and video content is a balancing act between applying best practices that can help reduce the bytes transferred over the network while preserving the fidelity of the intended experience.
-
While the strategies that are utilized for images, videos, and animations are—in broad strokes—similar, the specific approaches can be very different. In general, these strategies boil down to:
-
-
File formats - utilizing the optimal file format
-
Responsive - applying responsive images techniques to transfer only the pixels that will be shown on screen
-
Lazy loading - to transfer content only when a human will see it
-
Accessibility - ensuring a consistent experience for all humans
-
-
A word of caution when interpreting these results. The web pages crawled for the Web Almanac were crawled on a Chrome browser. This implies that any content negotiation that might better apply for Safari or Firefox might not be represented in this dataset. For example, the use of file formats like JPEG2000, JPEG-XR, HEVC and HEIC are absent because these are not supported natively by Chrome. This does not mean that the web does not contain these other formats or experiences. Likewise, Chrome has native support for lazy loading (since v76) which is not yet available in other browsers. Read more about these caveats in our Methodology.
-
It is rare to find a web page that does not utilize images. Over the years, many different file formats have emerged to help present content on the web, each addressing a different problem. Predominantly, there are 4 main universal image formats: JPEG, PNG, GIF, and SVG. In addition, Chrome has enhanced the media pipeline and added support for a fifth image format: WebP. Other browsers have likewise added support for JPEG2000 (Safari), JPEG-XL (IE and Edge) and HEIC (WebView only in Safari).
-
Each format has its own merits and has ideal uses for the web. A very simplified summary would break down as:
-
-
-
-
-
-
-
Format
-
Highlights
-
Drawbacks
-
-
-
-
-
JPEG
-
-
-
Ubiquitously supported
-
Ideal for photographic content
-
-
-
-
-
There is always quality loss
-
Most decoders cannot handle high bit depth photographs from modern cameras (> 8 bits per channel)
-
No support for transparency
-
-
-
-
-
PNG
-
-
-
Like JPEG and GIF, shares wide support
-
It is lossless
-
Supports transparency, animation, and high bit depth
-
-
-
-
-
Much bigger files compared to JPEG
-
Not ideal for photographic content
-
-
-
-
-
GIF
-
-
-
The predecessor to PNG, is most known for animations
-
Lossless
-
-
-
-
-
Because of the limitation of 256 colors, there is always visual loss from conversion
-
Very large files for animations
-
-
-
-
-
SVG
-
-
-
A vector based format that can be resized without increasing file size
-
It is based on math rather than pixels and creates smooth lines
-
-
-
-
-
Not useful for photographic or other raster content
-
-
-
-
-
WebP
-
-
-
A newer file format that can produce lossless images like PNG and lossy images like JPEG
In aggregate, across all page, we indeed see the prevalence of these formats. JPEG, one of the oldest formats on the web, is by far the most commonly used image formats at 60% of the image requests and 65% of all image bytes. Interestingly, PNG is the second most commonly used image format 28% of image requests and bytes. The ubiquity of support along with the precision of color and creative content are likely explanations for its wide use. In contrast SVG, GIF, and WebP share nearly the same usage at 4%.
Of course, web pages are not uniform in their use of image content. Some depend on images more than others. Look no further than the home page of google.com and you will see very little imagery compared to a typical news website. Indeed, the median website has 13 images, 61 images at the 90th percentile, and a whopping 229 images at the 99th percentile.
A bar chart showing in p10 percentile no image formats are used at all, in the p25 percentile three JPGs and four PNGs are used, in the p50 percentile nine JPGs, four PNGs, and one GIF are used, in the p75 percentile 39 JPEGs, 18 PNGs, two SVGs, and two GIFs are used and in the p99 percentile, 119 JPGs, 49 PNGs, 28 WebPs, 19 SVGs and 14 GIFs are used.
While the median page has nine JPEGs and four PNGs, and only in the top 25% pages GIFs were used, this doesn't report the adoption rate. The use and frequency of each format per page doesn't provide insight into the adoption of the more modern formats. Specifically, what percent of pages include at least one image in each format?
A bar chart showing JPEGs are used on 90% of pages, PNGs on 89%, WebP on 9%, GIF on 37%, and SVG on 22%.
- Figure 9. Percent of pages using at least one image.
-
-
This helps explain why—even at the 90th percentile of pages—the frequency of WebP is still zero; only 9% of web pages have even one resource. There are many reasons that WebP might not be the right choice for an image, but adoption of media best practices, like adoption of WebP itself, still remain nascent.
A chart showing in p10 percentile 4 KB of JPEGs, 2 KB of PNG and 2 KB of GIFs are used, in the p25 percentile 9 KB JPGs, 4 KB of PNGs, 7 KB of WebP, and 3 KB of GIFs are used, in the p50 percentile 24 KB of JPGs, 11 KB of PNGs, 17 KB of WebP, 6 KB of GIFs, and 1 KB of SVGs are used, in the p75 percentile 68 KB of JPEGs, 43 KB of PNGs, 41 KB of WebPs, 17 KB of GIFs and 2 KB of SVGs are used and in the p90 percentile, 116 KB of JPGs, 152 KB of PNGs, 90 KB of WebPs, 87 KB of GIFs, and 8 KB of SVGs are used.
From this we can start to get a sense of how large or small a typical resource is on the web. However, this doesn't give us a sense of the volume of pixels represented on screen for these file distributions. To do this we can divide each resource bytes by the natural pixel volume of the image. A lower bytes-per-pixel indicates a more efficient transmission of visual content.
A candlestick chart showing in p10 percentile we have 0.1175 bytes-per-pixel for JPEG, 0.1197 for PNG, 0.1702 for GIF, 0.0586 for WebP, and 0.0293 for SVG. In the p25 percentile we have 0.1848 bytes-per-pixel for JPEGs, 0.2874 for PNG, 0.3641 for GIF, 0.1025 for WebP, and 0.174 for SVG. In the p50 percentile we have 0.2997 bytes-per-pixel for JPEGs, 0.6918 for PNG, 0.7967 for GIF, 0.183 for WebP, and 0.6766 for SVG. In the p75 percentile we have 0.5456 bytes-per-pixel for JPEGs, 1.4548 for PNG, 2.515 for GIF, 0.3272 for WebP, and 1.9261 for SVG. In the p90 percentile we have 0.9822 bytes-per-pixel for JPEGs, 2.5026 for PNG, 8.5151 for GIF, 0.6474 for WebP, and 4.1075 for SVG
While previously it appeared that GIF files were smaller than JPEG, we can now clearly see that the cause of the larger JPEG resources is due to the pixel volume. It is probably not a surprise that GIF shows a very low pixel density compared to the other formats. Additionally, while PNG can handle high bit depth and doesn't suffer from chroma subsampling blurriness, it is about twice the size of JPG or WebP for the same pixel volume.
-
Of note, the pixel volume used for SVG is the size of the DOM element on screen (in CSS pixels). While considerably smaller for file sizes, this hints that SVGs are generally used in smaller portions of the layout. This is why the bytes-per-pixel appears worse than PNG.
-
Again, it is worth emphasizing, this comparison of pixel density is not comparing equivalent images. Rather it is reporting typical user experience. As we will discuss next, even in each of these formats there are techniques that can be used to further optimize and reduce the bytes-per-pixel.
Selecting the best format for an experience is an art of balancing capabilities of the format and reducing the total bytes. For web pages one goal is to help improve web performance through optimizing images. Yet within each format there are additional features that can help reduce bytes.
-
Some features can impact the total experience. For example, JPEG and WebP can utilize quantization (commonly referred to as quality levels) and chroma subsampling, which can reduce the bits stored in the image without impacting the visual experience. Like MP3s for music, this technique depends on a bug in the human eye and allows for the same experience despite the loss of color data. However, not all images are good candidates for these techniques since this can create blocky or blurry images and may distort colors or make text overlays become unreadable.
-
Other format features simply organize the content and sometimes require contextual knowledge. For example, applying progressive encoding of a JPEG reorganizes the pixels into scan layers that allows the browser to complete layout sooner and coincidently reduces pixel volume.
-
One Lighthouse test is an A/B comparing baseline with a progressively encoded JPEG. This provides a smell to indicate whether the images overall can be further optimized with lossless techniques and potentially with lossy techniques like using different quality levels.
Bar chart showing in the p10 percentile 100% of images are optimized, same in p25 percentile, in the p50 percentile 98% of images are optimized (2% not), in the p75 percentile 83% of images are optimized (17% not), and in the p90 percentile 59% of images are optimized and 41% are not.
The savings in this AB Lighthouse test is not just about potential byte savings, which can accrue to several MBs at the p95, it also demonstrates the page performance improvement.
Bar chart showing in the p10 percentile 0 ms could be sized, same in p25 percentile, in the p50 percentile 150 ms could be saved, in the p75 percentile 1,460 ms could be saved and in the p90 percentile 5,720 ms could be saved.
- Figure 13. Projected page performance improvements from image optimization from Lighthouse.
-
-
Another axis for improving page performance is to apply responsive images. This technique focuses on reducing image bytes by reducing the extra pixels that are not shown on the display because of image shrinking. At the beginning of this chapter, you saw that the median web page on desktop used one MP of image placeholders yet transferred 2.1 MP of actual pixel volume. Since this was a 1x DPR test, 1.1 MP of pixels were transferred over the network, but not displayed. To reduce this overhead, we can use one of two (possibly three) techniques:
-
-
HTML markup - using a combination of the <picture> and <source> elements along with the srcset and sizes attributes allows the browser to select the best image based on the dimensions of the viewport and the density of the display.
-
Client Hints - this moves the selection of possible resized images to HTTP content negotiation.
-
BONUS: JavaScript libraries to delay image loading until the JavaScript can execute and inspect the Browser DOM and inject the correct image based on the container.
The most common method to implement responsive images is to build a list of alternative images using either <img srcset> or <source srcset>. If the srcset is based on DPR, the browser can select the correct image from the list without additional information. However, most implementations also use <img sizes> to help instruct the browser how to perform the necessary layout calculation to select the correct image in the srcset based on pixel dimensions.
A bar chart showing 18% of images uses 'sizes', 21% use 'srcset', and 2% use 'picture'.
- Figure 14. Percent of pages using responsive images with HTML.
-
-
The notably lower use of <picture> is not surprising given that it is used most often for advanced responsive web design (RWD) layouts like art direction.
The utility of srcset is usually dependent on the precision of the sizes media query. Without sizes the browser will assume the <img> tag will fill the entire viewport instead of smaller component. Interestingly, there are five common patterns that web developers have adopted for <img sizes>:
-
-
- <img sizes="100vw"> - this indicates that the image will fill the width of the viewport (also the default).
-
-
- <img sizes="200px"> - this is helpful for browsers selecting based on DPR.
-
-
- <img sizes="(max-width: 300px) 100vw, 300px"> - this is the second most popular design pattern. It is the one auto generated by WordPress and likely a few other platforms. It appears auto generated based on the original image size (in this case 300px).
-
-
- <img sizes="(max-width: 767px) 89vw, (max-width: 1000px) 54vw, ..."> - this pattern is the custom built design pattern that is aligned with the CSS responsive layout. Each breakpoint has a different calculation for sizes to use.
-
-
-
-
-
-
-
-
-
<img sizes>
-
Frequency (millions)
-
%
-
-
-
-
-
(max-width: 300px) 100vw, 300px
-
1.47
-
5%
-
-
-
(max-width: 150px) 100vw, 150px
-
0.63
-
2%
-
-
-
(max-width: 100px) 100vw, 100px
-
0.37
-
1%
-
-
-
(max-width: 400px) 100vw, 400px
-
0.32
-
1%
-
-
-
(max-width: 80px) 100vw, 80px
-
0.28
-
1%
-
-
-
-
-
- Figure 15. Percent of pages using the most popular sizes patterns.
-
-
-
-
- <img sizes="auto"> - this is the most popular use, which is actually non-standard and is an artifact of the use of the lazy_sizes JavaScript library. This uses client-side code to inject a better sizes calculation for the browser. The downside of this is that it depends on the JavaScript loading and DOM to be fully ready, delaying image loading substantially.
-
Bar chart showing 11.3 million images use 'img sizes="(max-width: 300px) 100vw, 300px"', 1.60 million use 'auto', 1.00 million use 'img sizes="(max-width: 767px) 89vw...etc."', 0.23 million use '100vw' and 0.13 million use '300px'
Client Hints allow content creators to move the resizing of images to HTTP content negotiation. In this way, the HTML does not need additional <img srcset> to clutter the markup, and instead can depend on a server or image CDN to select an optimal image for the context. This allows simplifying of HTML and enables origin servers to adapt overtime and disconnect the content and presentation layers.
-
To enable Client Hints, the web page must signal to the browser using either an extra HTTP header Accept-CH: DPR, Width, Viewport-Widthor by adding the HTML <meta http-equiv="Accept-CH" content="DPR, Width, Viewport-Width">. The convenience of one or the other technique depends on the team implementing and both are offered for convenience.
Bar chart showing 71% use the 'meta http-equiv', 30% use the 'Accept-CH' HTTP header and 1% use both.
- Figure 17. Usage of the Accept-CH header versus the equivalent <meta> tag.
-
-
The use of the <meta> tag in HTML to invoke Client Hints is far more common compared with the HTTP header. This is likely a reflection of the convenience to modify markup templates compared to adding HTTP headers in middle boxes. However, looking at the usage of the HTTP header, over 50% of these cases are from a single SaaS platform (Mercado).
-
Of the Client Hints invoked, the majority of pages use it for the original three use-cases of DPR, ViewportWidth and Width. Of course, the Width Client Hint that requires the use <img sizes> for the browser to have enough context about the layout.
A doughnut-style pie-chart showing 26.1% of client hints use 'dpr', 24.3% use 'viewport-width', 19.7% use 'width', 6.7% use 'save-data', 6.1% uses 'device-memory', 6.0% uses 'downlink', 5.6% uses 'rtt' and 5.6% uses 'ect'
Improving web page performance can be partially characterized as a game of illusions; moving slow things out of band and out of site of the user. In this way, lazy loading images is one of these illusions where the image and media content is only loaded when the user scrolls on the page. This improves perceived performance, even on slow networks, and saves the user from downloading bytes that are not otherwise viewed.
-
Earlier, in Figure 5, we showed that the volume of image content at the 75th percentile is far more than could theoretically be shown in a single desktop or mobile viewport. The offscreen images Lighthouse audit confirms this suspicion. The median web page has 27% of image content significantly below the fold. This grows to 84% at the 90th percentile.
A bar chart showing in the p10 percentile 0% of images are offscreen, in the p25 percentile 2% are offscreen, in the p50 percentile, 27% are offscreen, in the p75 percentile 64% are offscreen, and in the p90 percentile 84% of images are offscreen.
The Lighthouse audit provides us a smell as there are a number of situations that can provide tricky to detect such as the use of quality placeholders.
-
Lazy loading can be implemented in many different ways including using a combination of Intersection Observers, Resize Observers, or using JavaScript libraries like lazySizes, lozad, and a host of others.
-
In August 2019, Chrome 76 launched with the support for markup-based lazy loading using <img loading="lazy">. While the snapshot of websites used for the 2019 Web Almanac used July 2019 data, over 2,509 websites already utilized this feature.
At the heart of image accessibility is the alt tag. When the alt tag is added to an image, this text can be used to describe the image to a user who is unable to view the images (either due to a disability, or a poor internet connection).
-
We can detect all of the image tags in the HTML files of the dataset. Of 13 million image tags on desktop and 15 million on mobile, 91.6% of images have an alt tag present. At initial glance, it appears that image accessibility is in very good shape on the web. However, upon deeper inspection, the outlook is not as good. If we examine the length of the alt tags present in the dataset, we find that the median length of the alt tag is six characters. This maps to an empty alt tag (appearing as alt=""). Only 39% of images use alt text that is longer than six characters. The median value of "real" alt text is 31 characters, of which 25 actually describe the image.
While images dominate the media being served on web pages, videos are beginning to have a major role in content delivery on the web. According to HTTP Archive, we find that 4.06% of desktop and 2.99% of mobile sites are self-hosting video files. In other words, the video files are not hosted by websites like YouTube or Facebook.
Video can be delivered with many different formats and players. The dominant formats for mobile and desktop are .ts (segments of HLS streaming) and .mp4 (the H264 MPEG):
A bar chart showing 'ts' usage at 1,283,439 for desktop (792,952 for mobile), 'mp4' at 729,757 thousand for desktop (662,015 for mobile), 'webm' at 38,591 for desktop (32,417 for mobile), 'mov' at 22,194 for desktop (14,986 for mobile), 'm4s' at 17,338 for desktop (16,046 for mobile), 'm4v' at 7,466 for desktop (6,169 for mobile).
- Figure 20. Count of video files by extension.
-
-
Other formats that are seen include webm, mov, m4s, and m4v (MPEG-DASH streaming segments). It is clear that the majority of streaming on the web is HLS, and that the major format for static videos is the mp4.
-
The median video size for each format is shown below:
A bar chart showing 'ts' average file size at 335 KB for desktop (156 KB for mobile), 'mp4' at 175 KB for desktop (128 KB for mobile), 'webm' at 359 KB for desktop (192 KB for mobile), 'mov' at 128 KB for desktop (96 KB for mobile), 'm4s' at 324 KB for desktop (246 KB for mobile), and 'm4v' at 383 KB for desktop (161 KB for mobile)
- Figure 21. Median file size by video extension.
-
-
The median values are smaller on mobile, which probably just means that some sites that have very large videos on the desktop disable them for mobile, and that video streams serve smaller versions of videos to smaller screens.
When delivering video on the web, most videos are delivered with the HTML5 video player. The HTML video player is extremely customizable to deliver video for many different purposes. For example, to autoplay a video, the parameters autoplay and muted would be added. The controls attribute allows the user to start/stop and scan through the video. By parsing the video tags in the HTTP Archive, we're able to see the usage of each of these attributes:
A bar chart showing for desktop: 'autoplay' at 11.84%, 'buffered' at 0%, 'controls' at 12.05%, 'crossorigin' at 0.45%, 'currenttime' at 0.01%, 'disablepictureinpicture' at 0.01%, 'disableremoteplayback' at 0.01%, 'duration' at 0.05%, 'height' at 7.33%, 'intrinsicsize' at 0%, 'loop' at 14.57%, 'muted' at 13.92%, 'playsinline' at 6.49%, 'poster' at 8.98%, 'preload' at 11.62%, 'src' at 3.67%, 'use-credentials' at 0%, and 'width' at 9%. And for mobile 'autoplay' at 12.38%, 'buffered' at 0%, 'controls' at 13.88%, 'crossorigin' at 0.16%, 'currenttime' at 0.01%, disablepictureinpicture' at 0.01%, 'disableremoteplayback' at 0.02%, 'duration' at 0.09%, 'height' at 6.54%, intrinsicsize' at 0%, 'loop' at 14.44%, 'muted' at 13.55%, 'playsinline' at 6.15%, 'poster' at 9.29%, 'preload' at 10.34%, 'src' at 4.13%, 'use-credentials' at 0%, and 'width' at 9.03%.
- Figure 22. Usage of HTML video tag attributes.
-
-
The most common attributes are autoplay, muted and loop, followed by the preload tag and width and height. The use of the loop attribute is used in background videos, and also when videos are used to replace animated GIFs, so it is not surprising to see that it is often used on website home pages.
-
While most of the attributes have similar usage on desktop and mobile, there are a few that have significant differences. The two attributes with the largest difference between mobile and desktop are width and height, with 4% fewer sites using these attributes on mobile. Interestingly, there is a small increase of the poster attribute (placing an image over the video window before playback) on mobile.
-
From an accessibility point of view, the <track> tag can be used to add captions or subtitles. There is data in the HTTP Archive on how often the <track> tag is used, but on investigation, most of the instances in the dataset were commented out or pointed to an asset returning a 404 error. It appears that many sites use boilerplate JavaScript or HTML and do not remove the track, even when it is not in use.
For more advanced playback (and to play video streams), the HTML5 native video player will not work. There are a few popular video libraries that are used to playback the video:
Bar chart showing 'flowplayer' used by 3,365 desktop sites (3,400 mobile), 'hls' by 52,375 desktop sites (40,925 mobile), 'jwplayer' by 110,280 desktop sites (96,945 mobile), 'shaka' on 325 desktop sites (275 mobile) and 'video' used on 377,990 desktop sites (391,330 mobile)
The most popular (by far) is video.js, followed by JWPLayer and HLS.js. The authors do admit that it is possible that there are other files with the name "video.js" that may not be the same video playback library.
Nearly all web pages use images and video to some degree to enhance the user experience and create meaning. These media files utilize a large amount of resources and are a large percentage of the tonnage of websites (and they are not going away!) Utilization of alternative formats, lazy loading, responsive images, and image optimization can go a long way to lower the size of media on the web.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/mobile-web.html b/src/templates/en/2019/chapters/mobile-web.html
deleted file mode 100644
index df7ac8428db..00000000000
--- a/src/templates/en/2019/chapters/mobile-web.html
+++ /dev/null
@@ -1,334 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":12,"title":"Mobile Web","description":"Mobile Web chapter of the 2019 Web Almanac covering page loading, textual content, zooming and scaling, buttons and links, and ease of filling out forms.","authors":["obto"],"reviewers":["AymenLoukil","hyperpress"],"translators":null,"discuss":"1767","results":"https://docs.google.com/spreadsheets/d/1dPBDeHigqx9FVaqzfq7CYTz4KjllkMTkfq4DG4utE_g/","queries":"12_Mobile_Web","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-27T00:00:00.000Z","chapter":"mobile-web"} %} {% block index %}
-
Let's step back for a moment, to the year 2007. The "mobile web" is currently just a blip on the radar, and for good reason too. Why? Mobile browsers have little to no CSS support, meaning sites look nothing like they do on desktop — some browsers can only display text. Screens are incredibly small and can only display a few lines of text at a time. And the replacements for a mouse are these tiny little arrow keys you use to "tab around". Needless to say, browsing the web on a phone is truly a labor of love. However, all of this is just about to change.
-
In the middle of his presentation, Steve Jobs takes the newly unveiled iPhone, sits down, and begins to surf the web in a way we had only previously dreamed of. A large screen and fully featured browser displaying websites in their full glory. And most importantly, surfing the web using the most intuitive pointer device known to man: our fingers. No more tabbing around with tiny little arrow keys.
-
Since 2007, the mobile web has grown at an explosive rate. And now, 13 years later, mobile accounts for 59% of all searches and 58.7% of all web traffic, according to Akamai mPulse data in July 2019. It's no longer an afterthought, but the primary way people experience the web. So given how significant mobile is, what kind of experience are we providing our visitors? Where are we falling short? Let's find out.
The first part of the mobile web experience we analyzed is the one we're all most intimately familiar with: the page loading experience. But before we start diving into our findings, let's make sure we're all on the same page regarding what the typical mobile user really looks like. Because this will not only help you reproduce these results, but understand these users better.
-
Let's start with what phone the typical mobile user has. The average Android phone is ~$250, and one of the most popular phones in that range is a Samsung Galaxy S6. So this is likely the kind of phone they use, which is actually 4x slower than an iPhone 8. This user doesn't have access to a fast 4G connection, but rather a 2G connection (29% of the time) or 3G connection (28% of the time). And this is what it all adds up to:
- Figure 1. Technical profile of a typical mobile user.
-
-
I imagine some of you are surprised by these results. They may be far worse conditions than you've ever tested your site with. But now that we're all on the same page with what a mobile user truly looks like, let's get started.
The state of JavaScript on the mobile web is terrifying. According to HTTP Archive's JavaScript report, the median mobile site requires phones to download 375 KB of JavaScript. Assuming a 70% compression ratio, this means that phones have to parse, compile, and execute 1.25 MB of JavaScript at the median.
-
Why is this a problem? Because sites loading this much JS take upwards of 10 seconds to become consistently interactive. Or in other words, your page may appear fully loaded, but when a user clicks any of your buttons or menus, the user may experience some slowdown because the JavaScript hasn't finished executing. In the worst case scenario, users may be forced to keep clicking the button for upwards of 10 seconds, just waiting for that magical moment where something actually happens. Think about how confusing and frustrating that can be.
Video showing two web pages loading and each page has a figure tapping repeatedly on a button throughout the video, to no effect. There is a clock ticking up from 0 seconds at the top, and an initial happy emoji face for each website, that starts to turn less happy as clock passes 6 seconds, wide-eyed at 8 seconds, angry at 10 seconds, really angry at 13 seconds and crying at 19 seconds shortly after which the video ends.
- Figure 2. Example of how painful of an experience waiting for JS to load can be.
-
-
Let's delve deeper and look at another metric that focuses more on how well each page utilizes JavaScript. For example, does it really need as much JavaScript as it's loading? We call this metric the JavaScript Bloat Score, based on the web bloat score. The idea behind it is this:
-
-
JavaScript is often used to both generate and change the page as it loads.
-
It's also delivered as text to the browser. So it compresses well, and should be delivered faster than just a screenshot of the page.
-
So if the total amount of JavaScript a page downloads alone (not including images, css, etc) is larger than a PNG screenshot of the viewport, we are using far too much JavaScript. At this point, it'd be faster just to send that screenshot to get the initial page state!
-
-
The *JavaScript Bloat Score* is defined as: (total JavaScript size) / (size of PNG screenshot of viewport). Any number greater than 1.0 means it's faster to send a screenshot.
-
The results of this? Of the 5+ million websites analyzed, 75.52% were bloated with JavaScript. We have a long way to go.
-
Note that we were not able to capture and measure the screenshots of all 5 million+ sites we analyzed. Instead, we took a random sampling of 1000 sites to find what the median viewport screenshot size is (140 KB), and then compared each site's JavaScript download size to this number.
Browsers typically load all pages the same. They prioritize the download of some resources above others, follow the same caching rules, etc. Thanks to Service Workers though, we now have a way to directly control how our resources are handled by the network layer, often times resulting in quite significant improvements to our page load times.
-
Despite being available since 2016 and implemented on every major browser, only 0.64% of sites utilize them!
One of the most beautiful parts of the web is how web pages load progressively by nature. Browsers download and display content as soon as they are able, so users can engage with your content as soon as possible. However, this can have a detrimental effect if you don't design your site with this in mind. Specifically, content can shift position as resources load and impede the user experience.
A video showing a website progressively load. The text is displayed quickly, but as images continue to load the text gets shifted further and further down the page each time—making it very frustrating to read. The calculated CLS of this example is 42.59%. Image courtesy of LookZook
- Figure 3. Example of shifting content distracting a reader. CLS total of 42.59%. Image courtesy of LookZook
-
-
Imagine you're reading an article when all of a sudden, an image loads and pushes the text you're reading way down the screen. You now have to hunt for where you were or just give up on reading the article. Or, perhaps even worse, you begin to click a link right before an ad loads in the same spot, resulting in an accidental click on the ad instead.
-
So, how do we measure how much our sites shift? In the past it was quite difficult (if not impossible), but thanks to the new Layout Instability API we can do this in two steps:
-
-
Via the Layout Instability API, track each shift's impact on the page. This is reported to you as a percentage of how much content in the viewport has shifted.
-
-
Take all the shifts you've tracked and add them together. The result is what we call the Cumulative Layout Shift (CLS) score.
-
-
-
Because every visitor can have a different CLS, in order to analyze this metric across the web with the Chrome UX Report (CrUX), we combine every experience into three different buckets:
-
-
Small CLS: Experiences having CLS under 5%. That is, the page is mostly stable and does not shift very much at all. For perspective, the page in the video above has a CLS of 42.59%.
-
Large CLS: Experiences having CLS 100% or greater. These may consist of many small individual shifts or a few large and noticeable shifts.
-
Medium CLS: Anything in between small and large.
-
-
So what do we see when we look at CLS across the web?
-
-
Nearly two out of every three sites (65.32%) have medium or large CLS for 50% or more of all user experiences.
-
20.52% of sites have large CLS for at least half of all user experiences. That's about one of every five websites. Remember, the video in Figure 3 only has a CLS of 42.59% — these experiences are even worse than that!
-
-
We suspect much of this may be caused by websites not providing an explicit width and height for resources like ads and images that load after text has been painted to the screen. Before browsers can display a resource on the screen, they need to know how much room the resource will take up. So unless an explicit size is provided via CSS or HTML attributes, browsers have no way to know how how large the resource actually is and display it with a width and height of 0px until loaded. When the resource loads and browsers finally know how big it is, it shifts the page's contents, creating an unstable layout.
Over the last few years, the line between websites and "app store" apps has continued to blur. Even now, you have the ability to request access to a user's microphone, video camera, geolocation, ability to display notifications, and more.
-
While this has opened up even more capabilities for developers, needlessly requesting these permissions may leave users feeling wary of your web page, and can build mistrust. This is why we recommend to always tie a permission request to a user gesture, like tapping a "Find theaters near me" button.
-
Right now 1.52% of sites request permissions without a user interaction. Seeing such a low number is encouraging. However, it's important to note that we were only able to analyze home pages. So for example, sites requesting permissions only on their content pages (e.g., their blog posts) were not accounted for. See our Methodology page for more info.
The primary goal of a web page is to deliver content users want to engage with. This content might be a YouTube video or an assortment of images, but often times, it's simply the text on the page. It goes without saying that ensuring our textual content is legible to our visitors is extremely important. Because if visitors can't read it, there's nothing left to engage with, and they'll leave. There are two key things to check when ensuring your text is legible to readers: color contrast and font sizes.
When designing our sites we tend to be in more optimal conditions, and have far better eyes than many of our visitors. Visitors may be colorblind and unable to distinguish between the text and background color. 1 in every 12 men and 1 in 200 women of European descent are colorblind. Or perhaps visitors are reading the page while the sun is creating glare on their screen, which may similarly impair legibility.
-
To help us mitigate this problem, there are accessibility guidelines we can follow when choosing our text and background colors. So how are we doing in meeting these baselines? Only 22.04% of sites give all their text sufficient color contrast. This value is actually a lower limit, as we could only analyze text with solid backgrounds. Image and gradient backgrounds were unable to be analyzed.
Four colored boxes of brown and gray shades with white text overlaid inside creating two columns, one where the background color is too lightly colored compared to the white text and one where the background color is recommended compared to the white text. The hex code of each color is displayed, white is #FFFFFF, the light shade of brown background is #FCA469, and the recommended shade of brown background is #BD5B0E. The grayscale equivalents are #B8B8B8 and #707070 respectively. Image courtesy of LookZook
- Figure 4. Example of what text with insufficient color contrast looks like. Courtesy of LookZook.
-
-
For colorblindness stats for other demographics, see this paper.
The second part of legibility is ensuring that text is large enough to read easily. This is important for all users, but especially so for older age demographics. Font sizes under 12px tend to be harder to read.
-
Across the web we found 80.66% of web pages meet this baseline.
Designing your site to work perfectly across the tens of thousands of screen sizes and devices is incredibly difficult. Some users need larger font sizes to read, zoom in on your product images, or need a button to be larger because it's too small and slipped past your quality assurance team. Reasons like these are why device features like pinch-to-zoom and scaling are so important; they allow users to tweak our pages so their needs are met.
-
There do exist very rare cases when disabling this is acceptable, like when the page in question is a web-based game using touch controls. If left enabled in this case, players' phones will zoom in and out every time the player taps twice on the game, resulting in an unusable experience.
-
Because of this, developers are given the ability to disable this feature by setting one of the following two properties in the meta viewport tag:
Vertical grouped bar chart titled "Are zooming and scaling enabled?" measuring percentage data, ranging from 0 to 80 in increments of 20, vs. the device type, grouped into desktop and mobile. Desktop enabled: 75.46%; Desktop disabled 24.54%; Mobile enabled: 67.79%; Mobile disabled: 32.21%.
- Figure 5. Percent of desktop and mobile websites that enable or disable zooming/scaling.
-
-
However, developers have misused this so much that almost one out of every three sites (32.21%) disable this feature, and Apple (as of iOS 10) no longer allows web developers to disable zooming. Mobile Safari simply ignores the tag. All sites, no matter what, can be zoomed and scaled on newer Apple devices, which account for over 11% of all web traffic worldwide!
Mobile devices allow users to rotate them so your website can be viewed in the format users prefer. Users do not always keep the same orientation throughout a session however. When filling out forms, users may rotate to landscape mode to use the larger keyboard. Or while browsing products, some may prefer the larger product images landscape mode gives them. Because of these types of use cases, it's very important not to rob the user of this built-in ability of mobile devices. And the good news is that we found virtually no sites that disable this. Only 87 total sites (or 0.0016%) disable this feature. This is fantastic.
We're used to having precise devices like mice while on desktop, but the story is quite different on mobile. On mobile we engage with sites through these large and imprecise tools we call fingers. Because of how imprecise they can be, we constantly "fat finger" links and buttons, tapping on things we never intended.
-
Designing tap targets appropriately to mitigate this issue can be difficult because of how widely fingers vary in size. However, lots of research has now been done and there are safe standards for how large buttons should be and how far apart they need to be separated.
A diagram displaying two examples of difficult to tap buttons. The first example shows two buttons with no spacing between them; An example below it shows the same buttons but with the recommended amount of spacing between them (8px or 1-2mm). The second example shows a button far too small to tap; An example below it shows the same button enlarged to the recommended size of 40-48px (around 8mm). Image courtesy of LookZook
- Figure 6. Standards for sizing and spacing tap targets. Image courtesy of LookZook
-
-
As of now, 34.43% of sites have sufficiently sized tap targets. So we have quite a ways to go until "fat fingering" is a thing of the past.
Some designers love to use icons in place of text — they can make our sites look cleaner and more elegant. But while you and everyone on your team may know what these icons mean, many of your users will not. This is even the case with the infamous hamburger icon! If you don't believe us, do some user testing and see how often users get confused. You'll be astounded.
-
This is why it's important to avoid any confusion and add supporting text and labels to your buttons. As of now, at least 28.59% of sites include a button with only a single icon with no supporting text.
-
Note: The reported number above is only a lower bound. During our analysis, we only included buttons using font icons with no supporting text. Many buttons now use SVGs instead of font-icons however, so in future runs we will be including them as well.
From signing up for a new service, buying something online, or even to receive notifications of new posts from a blog, form fields are an essential part of the web and something we use daily. Unfortunately, these fields are infamous for how much of a pain they are to fill out on mobile. Thankfully, in recent years browsers have given developers new tools to help ease the pain of completing these fields we know all too well. So let's take a look at how much they've been getting used.
In the past, text and password were some of the only input types available to developers as it met almost all of our needs on desktop. This is not the case for mobile devices. Mobile keyboards are incredibly small, and a simple task, like entering an email address, may require users to switch between multiple keyboards: the standard keyboard and the special character keyboard for the "@" symbol. Simply entering a phone number can be difficult using the default keyboard's tiny numbers.
-
Many new input types have since been introduced, allowing developers to inform browsers what kind of data is expected, and enable browsers to provide customized keyboards specifically for these input types. For example, a type of email provides users with an alphanumeric keyboard including the "@" symbol, and a type of tel will display a numeric keypad.
-
When analyzing sites containing an email input, 56.42% use type="email". Similarly, for phone inputs, type="tel" is used 36.7% of the time. Other new input types have an even lower adoption rate.
-
-
-
-
-
-
-
Type
-
Frequency (pages)
-
-
-
phone
-
1,917
-
-
-
name
-
1,348
-
-
-
textbox
-
833
-
-
-
-
-
- Figure 7. Most commonly used invalid input types
-
-
Make sure to educate yourself and others on the large amount of input types available and double-check that you don't have any typos like the most common ones in Figure 7 above.
- The autocomplete input attribute enables users to fill out form fields in a single click. Users fill out tons of forms, often with the exact same information each time. Realizing this, browsers have begun to securely store this information so it can be used on future pages. All developers need to do is use this autocomplete attribute to tell browsers what exact piece of information needs to be filled in, and the browser does the rest.
-
-
-
29.62%
- Figure 8. Percent of pages that use autocomplete.
-
-
Currently, only 29.62% of pages with input fields utilize this feature.
Enabling users to copy and paste their passwords into your page is one way that allows them to use password managers. Password managers help users generate (and remember) strong passwords and fill them out automatically on web pages. Only 0.02% of web pages tested disable this functionality.
-
Note: While this is very encouraging, this may be an underestimation due to the requirement of our Methodology to only test home pages. Interior pages, like login pages, are not tested.
For over 13 years we've been treating the mobile web as an afterthought, like a mere exception to desktop. But it's time for this to change. The mobile web is now the web, and desktop is becoming the legacy one. There are now 4 billion active smartphones in the world, covering 70% of all potential users. What about desktops? They currently sit at 1.6 billion, and account for less and less of web usage every month.
-
How well are we doing catering to mobile users? According to our research, even though 71% of sites make some kind of effort to adjust their site for mobile, they're falling well below the mark. Pages take forever to load and become unusable thanks to an abuse of JavaScript, text is often impossible to read, engaging with sites via clicking links or buttons is error-prone and infuriating, and tons of great technologies invented to mitigate these problems (Service Workers, autocomplete, zooming, new image formats, etc) are barely being used at all.
-
The mobile web has now been around long enough for there to be an entire generation of kids where this is the only internet they've ever known. And what kind of experience are we giving them? We're essentially taking them back to the dial-up era. (Good thing I hear AOL still sells those CDs providing 1000 hours of free internet access!)
We defined sites making a mobile effort as those who adjust their designs for smaller screens. Or rather, those which have at least one CSS breakpoint at 600px or less.
-
-
Potential users, or the total addressable market, are those who are 15+ years old: 5.7 billion people.
The total number of active smartphones was found by totaling the number of active Androids and iPhones (made public by Apple and Google), and a bit of math to account for Chinese internet-connected phones. More info here.
-
-
-
The 1.6 billion desktops is calculated by numbers made public by Microsoft and Apple. It does not include linux PC users.
-
-
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/page-weight.html b/src/templates/en/2019/chapters/page-weight.html
deleted file mode 100644
index 163bfb6251e..00000000000
--- a/src/templates/en/2019/chapters/page-weight.html
+++ /dev/null
@@ -1,905 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":18,"title":"Page Weight","description":"Page Weight chapter of the 2019 Web Almanac covering why page weight matters, bandwidth, complex pages, page weight over time, page requests, and file formats.","authors":["tammyeverts","khempenius"],"reviewers":["paulcalvano"],"translators":null,"discuss":"1773","results":"https://docs.google.com/spreadsheets/d/1nWOo8efqDgzmA0wt1ipplziKhlReAxnVCW1HkjuFAxU/","queries":"18_PageWeight","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"page-weight"} %} {% block index %}
-
The median web page is around 1900KB in size and contains 74 requests. That doesn't sound too bad, right?
-
Here's the issue with medians: they mask problems. By definition, they focus only on the middle of the distribution. We need to consider percentiles at both extremes to get an understanding of the bigger picture.
-
Looking at the 90th percentile exposes the unpleasant stuff. Roughly 10% of the pages we're pushing at the unsuspecting public are in excess of 6 MB and contain 179 requests. This is, frankly, terrible. If this doesn't seem terrible to you, then you definitely need to read this chapter.
The common argument as to why page size doesn't matter anymore is that, thanks to high-speed internet and our souped-up devices, we can serve massive, complex (and massively complex) pages to the general population. This assumption works fine, as long as you're okay with ignoring the vast swathe of internet users who don't have access to said high-speed internet and souped-up devices.
-
Yes, you can build large robust pages that feel fast… to some users. But you should care about page bloat in terms of how it affects all your users, especially mobile-only users who deal with bandwidth constraints or data limits.
-
-
Check out Tim Kadlec's fascinating online calculator, What Does My Site Cost?, which calculates the cost—in dollars and Gross National Income per capita—of your pages in countries around the world. It's an eye-opener. For instance, Amazon's home page, which at the time of writing weighs 2.79MB, costs 1.89% of the daily per capita GNI of Mauritania. How global is the world wide web when people in some parts of the world would have to give up a day's wages just to visit a few dozen pages?
Even if more people had access to better devices and cheaper connections, that wouldn't be a complete solution. Double the bandwidth doesn't mean twice as fast. In fact, it has been demonstrated that increasing bandwidth by up to 1,233% only made pages 55% faster.
-
The problem is latency. Most of our networking protocols require a lot of round-trips, and each of those round trips imposes a latency penalty. For as long as latency continues to be a performance problem (which is to say, for the foreseeable future), the major performance culprit will continue to be that a typical web page today contains a hundred or so assets hosted on dozens of different servers. Many of these assets are unoptimized, unmeasured, unmonitored—and therefore unpredictable.
Here's a quick glossary of the page composition metrics that the HTTP Archive tracks, and how much they matter in terms of performance and user experience:
-
-
-
The total size is the total weight in bytes of the page. It matters especially to mobile users who have limited and/or metered data.
-
-
-
HTML is typically the smallest resource on the page. Its performance risk is negligible.
-
-
-
Unoptimized images are often the greatest contributor to page bloat. Looking at the 90th percentile of the distribution of page weight, images account for a whopping 5.2 MB of a roughly 7 MB page. In other words, images comprise almost 75% of the total page weight. And if that already wasn't enough, the number of images on a page has been linked to lower conversion rates on retail sites. (More on that later.)
-
-
-
JavaScript matters. A page can have a relatively low JavaScript weight but still suffer from JavaScript-inflicted performance problems. Even a single 100 KB third-party script can wreak havoc with your page. The more scripts on your page, the greater the risk.
-
It's not enough to focus solely on blocking JavaScript. It's possible for your pages to contain zero blocking resources and still have less-than-optimal performance because of how your JavaScript is rendered. That's why it's so important to understand CPU usage on your pages, because JavaScript consumes more CPU than all other browser activities combined. While JavaScript blocks the CPU, the browser can't respond to user input. This creates what's commonly called "jank": that annoying feeling of jittery, unstable page rendering.
-
-
-
CSS is an incredible boon for modern web pages. It solves a myriad of design problems, from browser compatibility to design maintenance and updating. Without CSS, we wouldn't have great things like responsive design. But, like JavaScript, CSS doesn't have to be bulky to cause problems. Poorly executed stylesheets can create a host of performance problems, ranging from stylesheets taking too long to download and parse, to improperly placed stylesheets that block the rest of the page from rendering. And, similarly to JavaScript, more CSS files equals more potential trouble.
Let's assume you're not a heartless monster who doesn't care about your site's visitors. But if you are, you should know that serving bigger, more complex pages hurts you, too. That was one of the findings of a Google-led machine learning study that gathered over a million beacons' worth of real user data from retail sites.
-
There were three really important takeaways from this research:
-
-
-
The total number of elements on a page was the greatest predictor of conversions. Hopefully this doesn't come as a huge surprise to you, given what we've just covered about the performance risks imposed by the various assets that make up a modern web page.
-
-
-
The number of images on a page was the second greatest predictor of conversions. Sessions in which users converted had 38% fewer images than in sessions that didn't convert.
Sessions with more scripts were less likely to convert. What's really fascinating about this chart isn't just the sharp drop-off in conversion probability after about 240 scripts. It's the long tail that demonstrates how many retail sessions contained up to 1,440 scripts!
Chart showing conversion rate climbing up until 80 scripts, and then dropping off as scripts increase up to 1440 scripts.
- Figure 2. Conversion rate dropping off as scripts increase.
-
-
Now that we've covered why page size and complexity matter, let's get into some juicy HTTP Archive stats so we can better understand the current state of the web and the impact of page bloat.
The statistics in this section are all based on the transfer size of a page and its resources. Not all resources on the web are compressed before sending, but if they are, this analysis uses the compressed size.
Roughly speaking, mobile sites are about 10% smaller than their desktop counterparts. The majority of the difference is due to mobile sites loading fewer image bytes than their desktop counterparts.
Over the past year the median size of a desktop site increased by 434 KB, and the median size of a mobile site increased by 179 KB. Images are overwhelmingly driving this increase.
- Figure 6. Change in desktop page weight since 2018.
-
-
For a longer-term perspective on how page weight has changed over time, check out this timeseries graph from HTTP Archive. Median page size has grown at a fairly constant rate since the HTTP Archive started tracking this metric in November 2010 and the increase in page weight observed over the past year is consistent with this.
The median desktop page makes 74 requests, and the median mobile page makes 69. Images and JavaScript account for the majority of these requests. There was no significant change in the quantity or distribution of requests over the last year.
The preceding analysis has focused on analyzing page weight through the lens of resource types. However, in the case of images and media, it's possible to dive a level deeper and look at the differences in resource sizes between specific file formats.
- Figure 9. Images file sizes on mobile broken down by image format.
-
-
Some of these results, particularly those for GIFs, are really surprising. If GIFs are so small, then why are they being replaced by formats like JPG, PNG, and WEBP?
-
The data above obscures the fact that the vast majority of GIFs on the web are actually tiny 1x1 pixels. These pixels are typically used as "tracking pixels", but can also be used as a hack to generate various CSS effects. While these 1x1 pixels are images in the literal sense, the spirit of their usage is probably closer to what we'd associate with scripts or CSS.
-
Further investigation into the data set revealed that 62% of GIFs are 43 bytes or smaller (43 bytes is the size of a transparent, 1x1 pixel GIF) and 84% of GIFs are 1 KB or smaller.
Chart showing 25% of GIFs are 35 bytes or smaller (which is the optimal size of a 1x1 white GIF) and 62% of GIFs are 43 bytes or smaller (which is the optimal size of a 1x1 transparent GIF). This increases to just over 75% of GIFs being 100 bytes or less.
- Figure 10. Cumulative distribution function of GIF file sizes.
-
-
The tables below show two different approaches to removing these tiny images from the data set: the first one is based on images with a file size greater than 100 bytes, the second is based on images with a file size greater than 1024 bytes.
- Figure 12. File size by image format for images > 1024 bytes.
-
-
The low file size of PNG images compared to JPEG images may seem surprising. JPEG uses lossy compression. Lossy compression results in data loss, which makes it possible to achieve smaller file sizes. Meanwhile, PNG uses lossless compression. This does not result in data loss, which this produces higher-quality, but larger images. However, this difference in file sizes is probably a reflection of the popularity of PNGs for iconography due to their transparency support, rather than differences in their encoding and compression.
MP4 is overwhelmingly the most popular video format on the web today. In terms of popularity, it is followed by WebM and MPEG-TS respectively.
-
Unlike some of the other tables in this data set, this one has mostly happy takeaways. Videos are consistently smaller on mobile, which is great to see. In addition, the median size of an MP4 video is a very reasonable 18 KB on mobile and 39 KB on desktop. The median numbers for WebM are even better but they should be taken with a grain of salt: the duplicate measurement of 0.29 KB across multiple clients and percentiles is a little bit suspicious. One possible explanation is that identical copies of one very tiny WebM video is included on many pages. Of the three formats, MPEG-TS consistently has the highest file size across all percentiles. This may be related to the fact that it was released in 1995, making it the oldest of these three media formats.
Over the past year, pages increased in size by roughly 10%. Brotli, performance budgets, and basic image optimization best practices are probably the three techniques which show the most promise for maintaining or improving page weight while also being widely applicable and fairly easy to implement. That being said, in recent years, improvements in page weight have been more constrained by the low adoption of best practices than by the technology itself. In other words, although there are many existing techniques for improving page weight, they won't make a difference if they aren't put to use.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/performance.html b/src/templates/en/2019/chapters/performance.html
deleted file mode 100644
index b670ea75dd2..00000000000
--- a/src/templates/en/2019/chapters/performance.html
+++ /dev/null
@@ -1,294 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":7,"title":"Performance","description":"Performance chapter of the 2019 Web Almanac covering First Contentful Paint (FCP), Time to First Byte (TTFB), and First Input Delay (FID).","authors":["rviscomi"],"reviewers":["JMPerez","obto","sergeychernyshev","zeman"],"translators":null,"discuss":"1762","results":"https://docs.google.com/spreadsheets/d/1zWzFSQ_ygb-gGr1H1BsJCfB7Z89zSIf7GX0UayVEte4/","queries":"07_Performance","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"performance"} %} {% block index %}
-
Performance is a visceral part of the user experience. For many websites, an improvement to the user experience by speeding up the page load time aligns with an improvement to conversion rates. Conversely, when performance is poor, users don't convert as often and have even been observed to be rage clicking on the page in frustration.
-
There are many ways to quantify web performance. The most important thing is to measure what actually matters to users. However, events like onload or DOMContentLoaded may not necessarily reflect what users experience visually. For example, when loading an email client, it might show an interstitial progress bar while the inbox contents load asynchronously. The problem is that the onload event doesn't wait for the inbox to asynchronously load. In this example, the loading metric that matters most to users is the "time to inbox", and focusing on the onload event may be misleading. For that reason, this chapter will look at more modern and universally applicable paint, load, and interactivity metrics to try to capture how users are actually experiencing the page.
-
There are two kinds of performance data: lab and field. You may have heard these referred to as synthetic testing and real-user measurement (or RUM). Measuring performance in the lab ensures that each website is tested under common conditions and variables like browser, connection speed, physical location, cache state, etc. remain the same. This guarantee of consistency makes each website comparable with one another. On the other hand, measuring performance in the field represents how users actually experience the web in all of the infinite combinations of conditions that we could never capture in the lab. For the purposes of this chapter and understanding real-world user experiences, we'll look at field data.
Almost all of the other chapters in the Web Almanac are based on data from the HTTP Archive. However, in order to capture how real users experience the web, we need a different dataset. In this section, we're using the Chrome UX Report (CrUX), a public dataset from Google that consists of all the same websites as the HTTP Archive, and aggregates how Chrome users actually experience them. Experiences are categorized by:
-
-
- The form factor of the users' devices
-
-
Desktop
-
Phone
-
Tablet
-
-
-
- Users' effective connection type (ECT) in mobile terms
-
-
Offline
-
Slow 2G
-
2G
-
3G
-
4G
-
-
-
Users' geographic locations
-
-
Experiences are measured monthly, including paint, load, and interactivity metrics. The first metric we'll look at is First Contentful Paint (FCP). This is the time users spend waiting for the page to display something useful to the screen, like an image or text. Then, we'll look at look at a loading metric, Time to First Byte (TTFB). This is a measure of how long the web page took from the time of the user's navigation until they received the first byte of the response. And, finally, the last field metric we'll look at is First Input Delay (FID). This is a relatively new metric and one that represents parts of the UX other than loading performance. It measures the time from a user's first interaction with a page's UI until the time the browser's main thread is ready to process the event.
-
So let's dive in and see what insights we can find.
Distribution of 1,000 websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0%.
- Figure 1. Distribution of websites' fast, moderate, and slow FCP performance.
-
-
In Figure 1 above, you can see how FCP experiences are distributed across the web. Out of the millions of websites in the CrUX dataset, this chart compresses the distribution down to 1,000 websites, where each vertical slice represents a single website. The chart is sorted by the percent of fast FCP experiences, which are those occurring in less than 1 second. Slow experiences occur in 3 seconds or more, and moderate (formerly known as "average") experiences are everything in between. At the extremes of the chart, there are some websites with almost 100% fast experiences and some websites with almost 100% slow experiences. In between that, websites that have a combination of fast, moderate, and slow performance seem to lean more towards fast or moderate than slow, which is good.
-
Note: When a user experiences slow performance, it's hard to say what the reason might be. It could be that the website itself was built poorly and inefficiently. Or there could be other environmental factors like the user's slow connection, empty cache, etc. So, when looking at this field data we prefer to say that the user experiences themselves are slow, and not necessarily the websites.
-
In order to categorize whether a website is sufficiently fast we will use the new PageSpeed Insights (PSI) methodology, where at least 75% of the website's FCP experiences must be faster than 1 second. Similarly, a sufficiently slow website has 25% or more FCP experiences slower than 3 seconds. We say a website has moderate performance when it doesn't meet either of these conditions.
Bar chart showing that 13% of websites have fast FCP, 66% have moderate FCP, and 20% have slow FCP.
- Figure 2. Distribution of websites labeled as having fast, moderate, or slow FCP.
-
-
The results in Figure 2 show that only 13% of websites are considered fast. This is a sign that there is still a lot of room for improvement, but many websites are painting meaningful content quickly and consistently. Two thirds of websites have moderate FCP experiences.
-
To help us understand how users experience FCP across different devices, let's segment by form factor.
Distribution of 1,000 desktop websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0% with a slight bulge in the middle.
- Figure 3. Distribution of desktop websites' fast, moderate, and slow FCP performance.
-
-
-
-
-
-
-
Distribution of 1,000 mobile websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0% without the same middle bulge seen for desktop websites.
- Figure 4. Distribution of phone websites' fast, moderate, and slow FCP performance.
-
-
In Figures 3 and 4 above, the FCP distributions are broken down by desktop and phone. It's subtle, but the torso of the desktop fast FCP distribution appears to be more convex than the distribution for phone users. This visual approximation suggests that desktop users experience a higher overall proportion of fast FCP. To verify this, we can apply the PSI methodology to each distribution.
Bar chart of the desktop and mobile FCP distributions. Desktop fast, moderate, slow: 17%, 67%, and 16% respectively. Mobile: 11%, 66%, and 23%.
- Figure 5. Distribution of websites labeled as having fast, moderate, or slow FCP, broken down by device type.
-
-
According to PSI's classification, 17% of websites have fast FCP experiences overall for desktop users, compared to 11% for mobile users. The entire distribution is skewed to being slightly faster for desktop experiences, with fewer slow websites and more in the fast and moderate category.
-
Why might desktop users experience fast FCP on a higher proportion of websites than phone users? We can only speculate, after all, this dataset is meant to answer how the web is performing and not necessarily why it's performing that way. But one guess could be that desktop users are connected to the internet on faster, more reliable networks like WiFi rather than cell towers. To help answer this question, we can also explore how user experiences vary by ECT.
Bar chart of FCP distributions per effective connection type. 4G fast, moderate, slow: 14%, 67%, and 19% respectively. 3G: 1%, 38%, and 61%. 2G: 0%, 9%, 90%. Slow 2G: 0%, 1%, 99%.
- Figure 6. Distribution of websites labeled as having fast, moderate, or slow FCP, broken down by ECT.
-
-
In Figure 6 above, FCP experiences are grouped by the ECT of the user experience. Interestingly, there is a correlation between ECT speed and the percent of websites serving fast FCP. As the ECT speeds decrease, the proportion of fast experiences approaches zero. 14% of websites that serve users with 4G ECT have fast FCP experiences, while 19% of those websites have slow experiences. 61% of websites serve slow FCP to users with 3G ECT, 90% to 2G ECT, and 99% to slow-2G ECT. These results suggest that websites seldom serve fast FCP consistently to users on connections effectively slower than 4G.
Bar chart of FCP distributions for the top 23 most popular geographies. Korea has the most fast websites at 36%. From there, the percent of fast websites declines rapidly for other geographies: Japan 28%, Taiwan 26%, Netherlands 21%, etc.
- Figure 7. Distribution of websites labeled as having fast, moderate, or slow FCP, broken down by geo.
-
-
Finally, we can slice FCP by users' geography (geo). The chart above shows the top 23 geos having the highest number of distinct websites, an indicator of overall popularity of the open web. Web users in the United States visit the most distinct websites at 1,211,002. The geos are sorted by the percent of websites having sufficiently fast FCP experiences. At the top of the list are three Asia-Pacific (APAC) geos: Korea, Taiwan, and Japan. This could be explained by the availability of extremely fast network connection speeds in these regions. Korea has 36% of websites meeting the fast FCP bar, and only 7% rated as slow FCP. Recall that the global distribution of fast/moderate/slow websites is approximately 13/66/20, making Korea a significantly positive outlier.
-
Other APAC geos tell a different story. Thailand, Vietnam, Indonesia, and India all have fewer than 10% of fast websites. These geos also have more than triple the proportion of slow websites than Korea.
Time to First Byte (TTFB) is a measure of how long the web page took from the time of the user's navigation until they received the first byte of the response.
Diagram showing the sequence of network phases in a page load: startTime (promptForUnload), redirect, AppCache, DNS, TCP, request, response, processing, and load.
- Figure 8. Navigation Timing API diagram of the events in a page navigation.
-
-
To help explain TTFB and the many factors that affect it, let's borrow a diagram from the Navigation Timing API spec. In Figure 8 above, TTFB is the duration from startTime to responseStart, including everything in between: unload, redirects, AppCache, DNS, SSL, TCP, and the time the server spends handling the request. Given that context, let's see how users are experiencing this metric.
Distribution of 1,000 websites' fast, moderate, and slow TTFB. The distribution of fast TTFB drops quickly from about 90% to 50% at the 10th fastest percentile. Then the distribution gradually decreases from 50% to 0% all the way down the remaining 90 percentiles.
- Figure 9. Distribution of websites' fast, moderate, and slow TTFB performance.
-
-
Similar to the FCP chart in Figure 1, this is a view of 1,000 representative samples ordered by fast TTFB. A fast TTFB is one that happens in under 0.2 seconds (200 ms), a slow TTFB happens in 1 second or more, and everything in between is moderate.
-
Looking at the curve of the fast proportions, the shape is quite different from that of FCP. There are very few websites that have a fast TTFB greater than 75%, while more than half are below 25%.
-
Let's apply a TTFB speed label to each website, taking inspiration from the PSI methodology used above for FCP. If a website serves fast TTFB to 75% or more user experiences, it's labeled as fast. Otherwise, if it serves slow TTFB to 25% or more user experiences, it's slow. If neither of those conditions apply, it's moderate.
Bar chart showing that 2% of websites have fast TTFB, 56% have moderate TTFB, and 42% have slow TTFB.
- Figure 10. Distribution of websites labeled as having fast, moderate, or slow TTFB.
-
-
42% of websites have slow TTFB experiences. This is significant because TTFB is a blocker for all other performance metrics to follow. By definition, a user cannot possibly experience a fast FCP if the TTFB takes more than 1 second.
Bar chart of TTFB distributions for the top 23 most popular geographies. Korea has the most fast websites at 14%. From there, the percent of fast websites declines rapidly for other geographies: Taiwan 7%, Japan 5%, Netherlands 4%, etc.
- Figure 11. Distribution of websites labeled as having fast, moderate, or slow TTFB, broken down by geo.
-
-
Now let's look at the percent of websites serving fast TTFB to users in different geos. APAC geos like Korea, Taiwan, and Japan are still outperforming users from the rest of the world. But no geo has more than 15% of websites with fast TTFB. India, for example, has fewer than 1% of websites with fast TTFB and 79% with slow TTFB.
The last field metric we'll look at is First Input Delay (FID). This metric represents the time from a user's first interaction with a page's UI until the time the browser's main thread is ready to process the event. Note that this doesn't include the time applications spend actually handling the input. At worst, slow FID results in a page that appears unresponsive and a frustrating user experience.
-
Let's start by defining some thresholds. According to the new PSI methodology, a fast FID is one that happens in less than 100 ms. This gives the application enough time to handle the input event and provide feedback to the user in a time that feels instantaneous. A slow FID is one that happens in 300 ms or more. Everything in between is moderate.
Distribution of 1,000 websites' fast, moderate, and slow FID. The distribution of fast FID holds above 75% for the fastest three quarters of websites, then drops quickly to 0%.
- Figure 12. Distribution of websites' fast, moderate, and slow FID performance.
-
-
You know the drill by now. This chart shows the distribution of websites' fast, moderate, and slow FID experiences. This is a dramatically different chart from the previous charts for FCP and TTFB. (See Figure 1 and Figure 9, respectively). The curve of fast FID very slowly descends from 100% to 75%, then takes a nosedive. The overwhelming majority of FID experiences are fast for most websites.
Bar chart showing that 40% of websites have fast FID, 45% have moderate FID, and 15% have slow FID.
- Figure 13. Distribution of websites labeled as having fast, moderate, or slow TTFB.
-
-
The PSI methodology for labeling a website as having sufficiently fast or slow FID is slightly different than that of FCP. For a site to be fast, 95% of its FID experiences must be fast. A site is slow if 5% of its FID experiences are slow. All other experiences are moderate.
-
Compared to the previous metrics, the distribution of aggregate FID performance is much more skewed towards fast and moderate experiences than slow. 40% of websites have fast FID and only 15% have slow FID. The nature of FID being an interactivity metric -- as opposed to a loading metric bound by network speeds -- makes for an entirely different way to characterize performance.
Distribution of 1,000 desktop websites' fast, moderate, and slow FID. The distribution of fast FID decreases very slowly from 100% to 90% for the fastest three quarters of websites. After that, fast FID decreases slightly to 75%. Nearly all desktop websites have more than 75% fast FID experiences.
- Figure 14. Distribution of desktop websites' fast, moderate, and slow FID performance.
-
-
-
-
-
-
-
Distribution of 1,000 mobile websites' fast, moderate, and slow FID. The distribution of fast FID declines steadily but much more quickly than desktop. It reaches 75% fast for at three quarters of websites then quickly drops to 0%.
- Figure 15. Distribution of phone websites' fast, moderate, and slow FID performance.
-
-
By breaking FID down by device, it becomes clear that there are two very different stories. Desktop users enjoy fast FID almost all the time. Sure, there are some websites that throw out a slow experience now and then, but the results are predominantly fast. Mobile users, on the other hand, have what seem to be one of two experiences: pretty fast (but not quite as often as desktop) and almost never fast. The latter is experienced by users on only the tail 10% of websites, but this is still a substantial difference.
Bar chart of the desktop and mobile FID distributions. Desktop fast, moderate, slow: 82%, 12%, and 5% respectively. Mobile: 26%, 52%, and 22%.
- Figure 16. Distribution of websites labeled as having fast, moderate, or slow FID, broken down by device type.
-
-
When we apply the PSI labeling to desktop and phone experiences, the distinction becomes crystal clear. 82% of websites' FID experienced by desktop users are fast compared to 5% slow. For mobile experiences, 26% of websites are fast while 22% are slow. Form factor plays a major role in the performance of interactivity metrics like FID.
Bar chart of FID distributions per effective connection type. 4G fast, moderate, slow: 41%, 45%, and 15% respectively. 3G: 22%, 52%, and 26%. 2G: 19%, 58%, 23%. Slow 2G: 15%, 58%, 27%.
- Figure 17. Distribution of websites labeled as having fast, moderate, or slow FID, broken down by ECT.
-
-
On its face, FID seems like it would be driven primarily by CPU speed. It'd be reasonable to assume that the slower the device itself is, the higher the likelihood that it will be busy when the user attempts to interact with a web page, right?
-
The ECT results above seem to suggest that there is a correlation between connection speed and FID performance. As users' effective connection speed decreases, the percent of websites on which they experience fast FID also decreases: 41% of websites visited by users with a 4G ECT have fast FID, 22% with 3G, 19% with 2G, and 15% with slow 2G.
Bar chart of FID distributions for the top 23 most popular geographies. Korea has the most fast websites at 69%. From there, the percent of fast websites declines steadily for other geographies: Australia 55%, United States 52%, Canada 51%, etc.
- Figure 18. Distribution of websites labeled as having fast, moderate, or slow FID, broken down by geo.
-
-
In this breakdown of FID by geographic location, Korea is out in front of everyone else again. But the top geos have some new faces: Australia, the United States, and Canada are next with more than 50% of websites having fast FID.
-
As with the other geo-specific results, there are so many possible factors that could be contributing to the user experience. For example, perhaps wealthier geos that are more privileged can afford faster network infrastructure also have residents with more money to spend on desktops and/or high-end mobile phones.
Quantifying how fast a web page loads is an imperfect science that can't be represented by a single metric. Conventional metrics like onload can miss the mark entirely by measuring irrelevant or imperceptible parts of the user experience. User-perceived metrics like FCP and FID more faithfully convey what users see and feel. Even still, neither metric can be looked at in isolation to draw conclusions about whether the overall page load experience was fast or slow. Only by looking at many metrics holistically, can we start to understand the performance for an individual website and the state of the web.
-
The data presented in this chapter showed that there is still a lot of work to do to meet the goals set for fast websites. Certain form factors, effective connection types, and geos do correlate with better user experiences, but we can't forget about the combinations of demographics with poor performance. In many cases, the web platform is used for business; making more money from improving conversion rates can be a huge motivator for speeding up a website. Ultimately, for all websites, performance is about delivering positive experiences to users in a way that doesn't impede, frustrate, or enrage them.
-
As the web gets another year older and our ability to measure how users experience it improves incrementally, I'm looking forward to developers having access to metrics that capture more of the holistic user experience. FCP is very early on the timeline of showing useful content to users, and newer metrics like Largest Contentful Paint (LCP) are emerging to improve our visibility into how page loads are perceived. The Layout Instability API has also given us a novel glimpse into the frustration users experience beyond page load.
-
Equipped with these new metrics, the web in 2020 will become even more transparent, better understood, and give developers an advantage to make more meaningful progress to improve performance and contribute to positive user experiences.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/pwa.html b/src/templates/en/2019/chapters/pwa.html
deleted file mode 100644
index 603f1310c9a..00000000000
--- a/src/templates/en/2019/chapters/pwa.html
+++ /dev/null
@@ -1,232 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":11,"title":"PWA","description":"PWA chapter of the 2019 Web Almanac covering service workers (registations, installability, events and filesizes), Web App Manifests properties, and Workbox.","authors":["tomayac","jeffposnick"],"reviewers":["hyperpress","ahmadawais"],"translators":null,"discuss":"1766","results":"https://docs.google.com/spreadsheets/d/19BI3RQc_vR9bUPPZfVsF_4gpFWLNT6P0pLcAdL-A56c/","queries":"11_PWA","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"pwa"} %} {% block index %}
-
Progressive Web Apps (PWAs) are a new class of web applications, building on top of platform primitives like the Service Worker APIs. Service workers allow apps to support network-independent loading by acting as a network proxy, intercepting your web app's outgoing requests, and replying with programmatic or cached responses. Service workers can receive push notifications and synchronize data in the background even when the corresponding app is not running. Additionally, service workers, together with Web App Manifests, allow users to install PWAs to their devices' home screens.
- Figure 1. Percent of desktop pages that register a service worker.
-
-
The first metric we explore are service worker installations. Looking at the data exposed through feature counters in the HTTP Archive, we find that 0.44% of all desktop and 0.37% of all mobile pages register a service worker, and both curves over time are steeply growing.
Timeseries chart of service worker installation. Since Janurary 2017, desktop and mobile have increased steadily from approximately 0.0% to about 0.4%.
- Figure 2. Service Worker installation over time for desktop and mobile.
-
-
Now this might not look overly impressive, but taking traffic data from Chrome Platform Status into account, we can see that a service worker controls about 15% of all page loads, which can be interpreted as popular, high-traffic sites increasingly having started to embrace service workers.
Bar chart showing the popularity of various service worker events. Fetch is used on 73% of mobile service workers, install 71%, activate 56%, notification click 10%, push 8%, message 5%, notification close 2%, and sync 1%. The usage on desktop service workers is similar, but slightly lower for fetch, install, and activate.
- Figure 4. Popularity of service worker events.
-
-
We have examined which of these events are being listened to by service workers we could find in the HTTP Archive. The results for mobile and desktop are very similar with fetch, install, and activate being the three most popular events, followed by notificationclick and push. If we interpret these results, offline use cases that service workers enable are the most attractive feature for app developers, far ahead of push notifications. Due to its limited availability, and less common use case, background sync doesn't play a significant role at the moment.
File size or lines of code are generally a bad proxy for the complexity of the task at hand. In this case, however, it is definitely interesting to compare (compressed) file sizes of service workers for mobile and desktop.
Bar chart showing the distribution of transfer sizes of service workers. The 10, 25, 50, 75, and 90th percentiles for desktop service worker transfer sizes are: 176, 350, 895, 2,010, and 4,138 bytes. Desktop service workers are larger across each percentile from as many as 1,000 bytes at the 90th percentile.
- Figure 5. Distribution of service worker transfer size.
-
-
- The median service worker file on desktop is 895 bytes, whereas on mobile it's 694 bytes. Throughout all percentiles desktop service workers are larger than mobile service workers. We note that these stats don't account for dynamically imported scripts through the importScripts() method, which likely skews the results higher.
-
The web app manifest is a simple JSON file that tells the browser about a web application and how it should behave when installed on the user's mobile device or desktop. A typical manifest file includes information about the app name, icons it should use, the start URL it should open at when launched, and more. Only 1.54% of all encountered manifests were invalid JSON, and the rest parsed correctly.
-
We looked at the different properties defined by the Web App Manifest specification, and also considered non-standard proprietary properties. According to the spec, the following properties are allowed:
-
-
dir
-
lang
-
name
-
short_name
-
description
-
icons
-
screenshots
-
categories
-
iarc_rating_id
-
start_url
-
display
-
orientation
-
theme_color
-
background_color
-
scope
-
serviceworker
-
related_applications
-
prefer_related_applications
-
-
The only property that we didn't observe in the wild was iarc_rating_id, which is a string that represents the International Age Rating Coalition (IARC) certification code of the web application. It is intended to be used to determine which ages the web application is appropriate for.
Bar chart showing the popularity of web app manifest properties for desktop and mobile. 88% of desktop web app manifests include the name property, 82% icons, 61% display, 55% theme color, 49% background color, 45% short name, 36% start URL, 19% GCM sender ID, 9% GCM user visible only, 9% orientation, 7% description, 5% scope, and 4% lang. The popularity of properties on mobile web app manifests is similar, plus or minus 2 percentage points.
- Figure 6. Popularity of web app manifest properties.
-
-
The proprietary properties we encountered frequently were gcm_sender_id and gcm_user_visible_only from the legacy Google Cloud Messaging (GCM) service. Interestingly there are almost no differences between mobile and desktop. On both platforms, however, there's a long tail of properties that are not interpreted by browsers yet contain potentially useful metadata like author or version. We also found a non-trivial amount of mistyped properties; our favorite being shot_name, as opposed to short_name. An interesting outlier is the serviceworker property, which is standard but not implemented by any browser vendor. Nevertheless, it was found on 0.09% of all web app manifests used by mobile and desktop pages.
Looking at the values developers set for the display property, it becomes immediately clear that they want PWAs to be perceived as "proper" apps that don't reveal their web technology origins.
Bar chart showing how the display property of web app manifests is used by desktop and mobile websites. In both cases, the "standalone" value is used 57% of the time. The property is not set at all in 38% of manifests. The "minimal UI", "browser", and "fullscreen" values each make up only 1 or 2% of usage.
- Figure 7. Usage of web app manifest display properties.
-
-
By choosing standalone, they make sure no browser UI is shown to the end-user. This is reflected by the majority of apps that make use of the prefers_related_applications property: more that 97% of both mobile and desktop applications do not prefer native applications.
The categories property describes the expected application categories to which the web application belongs. It is only meant as a hint to catalogs or app stores listing web applications, and it is expected that websites will make a best effort to list themselves in one or more appropriate categories.
Bar chart showing the top web app manifest categories. 60 mobile manifests are in the "shopping" category, 15 "business", 9 "web", 9 "technology", 8 "games", 8 "entertainment", 7 "social", etc. Desktop manifests follow a similar distribution except for "shopping", for which there is only 1 desktop manifest.
There were not too many manifests that made use of the property, but it is interesting to see the shift from "shopping" being the most popular category on mobile to "business", "technology", and "web" (whatever may be meant with that) on desktop that share the first place evenly.
Bar chart showing the usage of top web app manifest icon size property values. All values are given in height and width pixels, for example the top value in 23% of manifests is 192 by 192 pixels. The next most popular sizes are 144 at 11%, 96 at 11%, 72 at 10%, 48 at 10%, 512 at 9%, 36% at 9%, 256 at 5%, 384 at 2%, 128 at 1%, and 152 at 1%. Desktop and mobile have identical usage patterns.
Lighthouse's rule is probably the culprit for 192 pixels being the most popular choice of icon size on both desktop and mobile, despite Google's documentation explicitly recommending 512x512, which doesn't show as a particularly prominent option.
Bar chart showing the top web app manifest orientation values. "Portrait" is set in 6% of desktop manifests, followed by "any" in 2%, and the everything else in fewer than 1% of manifests. This is similar to usage in mobile manifests, except "portrait" is set in 8% of manifests and "portrait-primary" in 1%.
- Figure 10. Top web app manifest orientation values.
-
-
"portrait" orientation is the clear winner on both platforms, followed by "any" orientation.
Workbox is a set of libraries that help with common service worker use cases. For instance, Workbox has tools that can plug in to your build process and generate a manifest of files, which are then precached by your service worker. Workbox includes libraries to handle runtime caching, request routing, cache expiration, background sync, and more.
-
- Given the low-level nature of the service worker APIs, many developers have turned to Workbox as a way of structuring their service worker logic into higher-level, reusable chunks of code. Workbox adoption is also driven by its inclusion as a feature in a number of popular JavaScript framework starter kits, like create-react-app and Vue's PWA plugin.
-
-
The HTTP Archive shows that 12.71% of websites that register a service worker are using at least one of the Workbox libraries. This percentage is roughly consistent across desktop and mobile, with a slightly lower percentage (11.46%) on mobile compared to desktop (14.36%).
The stats in this chapter show that PWAs are still only used by a small percentage of sites. However, this relatively small usage is driven by the more popular sites which have a much larger share of traffic, and pages beyond the home page may use this more: we showed that 15% of page loads use a service workers. The advantages they give for performance and greater control over caching particularly for mobile should mean that usage will continue to grow.
PWAs provide a path forward for developers who would prefer to build and release on the web instead of on native platforms and app stores. Not every operating system and browser offers full parity with native software, but improvements continue, and perhaps 2020 is the year where we see an explosion in deployments?
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/resource-hints.html b/src/templates/en/2019/chapters/resource-hints.html
deleted file mode 100644
index c9813deebdb..00000000000
--- a/src/templates/en/2019/chapters/resource-hints.html
+++ /dev/null
@@ -1,272 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":19,"title":"Resource Hints","description":"Resource Hints chapter of the 2019 Web Almanac covering usage of dns-prefetch, preconnect, preload, prefetch, priority hints, and native lazy loading.","authors":["khempenius"],"reviewers":["andydavies","bazzadp","yoavweiss"],"translators":null,"discuss":"1774","results":"https://docs.google.com/spreadsheets/d/14QBP8XGkMRfWRBbWsoHm6oDVPkYhAIIpfxRn4iOkbUU/","queries":"19_Resource_Hints","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"resource-hints"} %} {% block index %}
-
Resource hints provide "hints" to the browser about what resources will be needed soon. The action that the browser takes as a result of receiving this hint will vary depending on the type of resource hint; different resource hints kick off different actions. When used correctly, they can improve page performance by giving a head start to important anticipated actions.
-
Examples of performance improvements as a result of resource hints include:
-
-
Jabong decreased Time to Interactive by 1.5 seconds by preloading critical scripts.
-
Barefoot Wine decreased Time to Interactive of future pages by 2.7 seconds by prefetching visible links.
-
Chrome.com decreased latency by 0.7 seconds by preconnecting to critical origins.
-
-
There are four separate resource hints supported by most browsers today: dns-prefetch, preconnect, preload, and prefetch.
- The role of dns-prefetch is to initiate an early DNS lookup. It's useful for completing the DNS lookup for third-parties. For example, the DNS lookup of a CDN, font provider, or third-party API.
-
- preconnect initiates an early connection, including DNS lookup, TCP handshake, and TLS negotiation. This hint is useful for setting up a connection with a third party. The uses of preconnect are very similar to those of dns-prefetch, but preconnect has less browser support. However, if you don't need IE 11 support, preconnect is probably a better choice.
-
- The preload hint initiates an early request. This is useful for loading important resources that would otherwise be discovered late by the parser. For example, if an important image is only discoverable once the browser has received and parsed the stylesheet, it may make sense to preload the image.
-
- prefetch initiates a low-priority request. It's useful for loading resources that will be used on the subsequent (rather than current) page load. A common use of prefetch is loading resources that the application "predicts" will be used on the next page load. These predictions could be based on signals like user mouse movement or common user flows/journeys.
-
Because the usage of resource hints in HTTP headers is so low, the remainder of this chapter will focus solely on analyzing the usage of resource hints in conjunction with the <link> tag. However, it's worth noting that in future years, usage of resource hints in HTTP headers may increase as HTTP/2 Push is adopted. This is due to the fact that HTTP/2 Push has repurposed the HTTP preload Link header as a signal to push resources.
Note: There was no noticeable difference between the usage patterns for resource hints on mobile versus desktop. Thus, for the sake of conciseness, this chapter only includes the statistics for mobile.
The relative popularity of dns-prefetch is unsurprising; it's a well-established API (it first appeared in 2009), it is supported by all major browsers, and it is the most "inexpensive" of all resource hints. Because dns-prefetch only performs DNS lookups, it consumes very little data, and therefore there is very little downside to using it. dns-prefetch is most useful in high-latency situations.
-
That being said, if a site does not need to support IE11 and below, switching from dns-prefetch to preconnect is probably a good idea. In an era where HTTPS is ubiquitous, preconnect yields greater performance improvements while still being inexpensive. Note that unlike dns-prefetch, preconnect not only initiates the DNS lookup, but also the TCP handshake and TLS negotiation. The certificate chain is downloaded during TLS negotiation and this typically costs a couple of kilobytes.
-
prefetch is used by 3% of sites, making it the least widely used resource hint. This low usage may be explained by the fact that prefetch is useful for improving subsequent—rather than current—page loads. Thus, it will be overlooked if a site is only focused on improving their landing page, or the performance of the first page viewed.
-
-
-
-
-
-
-
Resource Hint
-
Resource Hints Per Page: Median
-
Resource Hints Per Page: 90th Percentile
-
-
-
dns-prefetch
-
2
-
8
-
-
-
preload
-
2
-
4
-
-
-
preconnect
-
2
-
8
-
-
-
prefetch
-
1
-
3
-
-
-
prerender (deprecated)
-
1
-
1
-
-
-
-
-
- Figure 2. Median and 90th percentiles of the number of resource hints used per page, of all pages using that resource hint.
-
-
Resource hints are most effective when they're used selectively ("when everything is important, nothing is"). Figure 2 above shows the number of resource hints per page for pages using at least one resource hint. Although there is no clear cut rule for defining what an appropriate number of resource hints is, it appears that most sites are using resource hints appropriately.
Most "traditional" resources fetched on the web (images, stylesheets, and scripts) are fetched without opting in to Cross-Origin Resource Sharing (CORS). That means that if those resources are fetched from a cross-origin server, by default their contents cannot be read back by the page, due to the same-origin policy.
-
In some cases, the page can opt-in to fetch the resource using CORS if it needs to read its content. CORS enables the browser to "ask permission" and get access to those cross-origin resources.
-
For newer resource types (e.g. fonts, fetch() requests, ES modules), the browser defaults to requesting those resources using CORS, failing the requests entirely if the server does not grant it permission to access them.
-
-
-
-
-
-
-
crossorigin value
-
Usage
-
Explanation
-
-
-
Not set
-
92%
-
If the crossorigin attribute is absent, the request will follow the single-origin policy.
-
-
-
anonymous (or equivalent)
-
7%
-
Executes a cross-origin request that does not include credentials.
-
-
-
use-credentials
-
0.47%
-
Executes a cross-origin request that includes credentials.
-
-
-
-
-
- Figure 3. Adoption of the crossorigin attribute as a percent of resource hint instances.
-
-
In the context of resource hints, usage of the crossorigin attribute enables them to match the CORS mode of the resources they are supposed to match and indicates the credentials to include in the request. For example, anonymous enables CORS and indicates that no credentials should be included for those cross-origin requests:
as is an attribute that should be used with the preload resource hint to inform the browser of the type (e.g. image, script, style, etc.) of the requested resource. This helps the browser correctly prioritize the request and apply the correct Content Security Policy (CSP). CSP is a security mechanism, expressed via HTTP header, that helps mitigate the impact of XSS and other malicious attacks by declaring a safelist of trusted sources; only content from these sources can be rendered or executed.
-
-
88%
- Figure 4. The percent of resource hint instances using the as attribute.
-
-
88% of resource hint instances use the as attribute. When as is specified, it is overwhelmingly used for scripts: 92% of usage is script, 3% font, and 3% styles. This is unsurprising given the prominent role that scripts play in most sites' architecture as well the high frequency with which scripts are used as attack vectors (thereby making it therefore particularly important that scripts get the correct CSP applied to them).
At the moment, there are no proposals to expand the current set of resource hints. However, priority hints and native lazy loading are two proposed technologies that are similar in spirit to resource hints in that they provide APIs for optimizing the loading process.
Priority hints are an API for expressing the fetch priority of a resource: high, low, or auto. They can be used with a wide range of HTML tags: specifically <image>, <link>, <script>, and <iframe>.
- Figure 5. Example HTML of using priority hints on a carousel of images.
-
-
For example, if you had an image carousel, priority hints could be used to prioritize the image that users see immediately and deprioritize later images.
-
-
0.04%
- Figure 6. The rate of priority hint adoption.
-
-
Priority hints are implemented and can be tested via a feature flag in Chromium browsers versions 70 and up. Given that it is still an experimental technology, it is unsurprising that it is only used by 0.04% of sites.
-
85% of priority hint usage is with <img> tags. Priority hints are mostly used to deprioritize resources: 72% of usage is importance="low"; 28% of usage is importance="high".
Native lazy loading is a native API for deferring the load of off-screen images and iframes. This frees up resources during the initial page load and avoids loading assets that are never used. Previously, this technique could only be achieved through third-party JavaScript libraries.
-
The API for native lazy loading looks like this: <img src="cat.jpg" loading="lazy">.
-
Native lazy loading is available in browsers based on Chromium 76 and up. The API was announced too late for it to be included in the dataset for this year's Web Almanac, but it is something to keep an eye out for in the coming year.
Overall, this data seems to suggest that there is still room for further adoption of resource hints. Most sites would benefit from adopting and/or switching to preconnect from dns-prefetch. A much smaller subset of sites would benefit from adopting prefetch and/or preload. There is greater nuance in successfully using prefetch and preload, which constrains its adoption to a certain extent, but the potential payoff is also greater. HTTP/2 Push and the maturation of machine learning technologies is also likely to increase the adoption of preload and prefetch.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/security.html b/src/templates/en/2019/chapters/security.html
deleted file mode 100644
index b3a30c62414..00000000000
--- a/src/templates/en/2019/chapters/security.html
+++ /dev/null
@@ -1,931 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":8,"title":"Security","description":"Security chapter of the 2019 Web Almanac covering Transport Layer Security (TLS(), mixed content, security headers, cookies, and Subresource Integrity.","authors":["ScottHelme","arturjanc"],"reviewers":["bazzadp","ghedo","paulcalvano"],"translators":null,"discuss":"1763","results":"https://docs.google.com/spreadsheets/d/1Zq2tQhPE06YZUcbzryRrBE6rdZgHHlqEp2XcgS37cm8/","queries":"08_Security","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"security"} %} {% block index %}
-
This chapter of the Web Almanac looks at the current status of security on the web. With security and privacy becoming increasingly more important online there has been an increase in the availability of features to protect site operators and users. We're going to look at the adoption of these new features across the web.
Perhaps the largest push to increasing security and privacy online we're seeing at present is the widespread adoption of Transport Layer Security (TLS). TLS (or the older version, SSL) is the protocol that gives us the 'S' in HTTPS and allows secure and private browsing of websites. Not only are we seeing a great increase in the use of HTTPS across the web, but also an increase in more modern versions of TLS like TLSv1.2 and TLSv1.3, which is also important.
Horizontal bar chart showing desktop and mobile on similar TLS usage: 58% on TLSv1.2, 41% on TLSv1.3 and very little usage of TLSv1.0 (0.75%) and a tiny usage of TLSv1.1.
Figure 2 shows the support for various protocol versions. Use of legacy TLS versions like TLSv1.0 and TLSv1.1 is minimal and almost all support is for the newer TLSv1.2 and TLSv1.3 versions of the protocol. Even though TLSv1.3 is still very young as a standard (TLSv1.3 was only formally approved in August 2018), over 40% of requests using TLS are using the latest version!
-
This is likely due to many sites using requests from the larger players for third-party content. For example, any sites load Google Analytics, Google AdWords, or Google Fonts and these large players like Google are typically early adopters for new protocols.
-
If we look at just home pages, and not all the other requests made on sites, then the usage of TLS is considerably as expected, though still quite high which is likely due to CMS sites like Wordpress and CDNs:
Horizontal bar chart showing desktop and mobile on similar TLS usage: 47% on desktop (43% on mobile) on TLSv1.2, 20.2% on desktop (19.7% on mobile) on TLSv1.3 and very little usage of TLSv1.0 (1.1% - 1.2%) and a tiny usage of TLSv1.1.
- Figure 3. Usage of TLS protocol versions for home page requests only.
-
-
On the other hand, the methodology used by the Web Almanac will also under-report usage from large sites, as their sites themselves will likely form a larger volume of internet traffic in the real world, yet are crawled only once for these statistics.
Of course, if we want to use HTTPS on our website then we need a certificate from a Certificate Authority (CA). With the increase in the use of HTTPS comes the increase in use of CAs and their products/services. Here are the top ten certificate issuers based on the volume of TLS requests that use their certificate.
As previously discussed, the volume for Google likely reflects repeated use of Google Analytics, Google Adwords, or Google Fonts on other sites.
-
The rise of Let's Encrypt has been meteoric after their launch in early 2016, since then they've become one of the top certificate issuers in the world. The availability of free certificates and the automated tooling has been critically important to the adoption of HTTPS on the web. Let's Encrypt certainly had a significant part to play in both of those.
-
The reduced cost has removed the barrier to entry for HTTPS, but the automation Let's Encrypt uses is perhaps more important in the long run as it allows shorter certificate lifetimes which has many security benefits.
Alongside the important requirement to use HTTPS is the requirement to also use a good configuration. With so many configuration options and choices to make, this is a careful balance.
-
First of all, we'll look at the keys used for authentication purposes. Traditionally certificates have been issued based on keys using the RSA algorithm, however a newer and better algorithm uses ECDSA (Elliptic Curve Digital Signature Algorithm) which allows the use of smaller keys that demonstrate better performance than their RSA counterparts. Looking at the results of our crawl we still see a large % of the web using RSA.
Whilst ECDSA keys are stronger, which allows the use of smaller keys and demonstrate better performance than their RSA counterparts, concerns around backwards compatibility, and complications in supporting both in the meantime, do prevent some website operators from migrating.
Forward secrecy is a property of some key exchange mechanisms that secures the connection in such a way that it prevents each connection to a server from being exposed even in case of a future compromise of the server's private key. This is well understood within the security community as desirable on all TLS connections to safeguard the security of those connections. It was introduced as an optional configuration in 2008 with TLSv1.2 and has become mandatory in 2018 with TLSv1.3 requiring the use of Forward Secrecy.
-
Looking at the % of TLS requests that provide Forward Secrecy, we can see that support is tremendous. 96.92% of Desktop and 96.49% of mobile requests use Forward secrecy. We'd expect that the continuing increase in the adoption of TLSv1.3 will further increase these numbers.
TLS allows the use of various cipher suites - some newer and more secure, and some older and insecure. Traditionally newer TLS versions have added cipher suites but have been reluctant to remove older cipher suites. TLSv1.3 aims to simplify this by offering a reduced set of ciphers suites and will not permit the older, insecure, cipher suites to be used. Tools like SSL Labs allow the TLS setup of a website (including the cipher suites supported and their preferred order) to be easily seen, which helps drive better configurations. We can see that the majority of cipher suites negotiated for TLS requests were indeed excellent:
It is positive to see such wide stream use of GCM ciphers since the older CBC ciphers are less secure. CHACHA20_POLY1305 is still an niche cipher suite, and we even still have a very small use of the insecure 3DES ciphers.
-
It should be noticed that these were the cipher suites used for the crawl using Chrome, but sites will likely also support other cipher suites as well for older browsers. Other sources, for example SSL Pulse, can provide more detail on the range of all cipher suites and protocols supported.
Most sites on the web originally existed as HTTP websites and have had to migrate their site to HTTPS. This 'lift and shift' operation can be difficult and sometimes things get missed or left behind. This results in sites having mixed content, where their pages load over HTTPS but something on the page, perhaps an image or a style, is loaded over HTTP. Mixed content is bad for security and privacy and can be difficult to find and fix.
We can see that around 20% of sites across mobile (645,485 sites) and desktop (594,072 sites) present some form of mixed content. Whilst passive mixed content, something like an image, is less dangerous, we can still see that almost a quarter of sites with mixed content have active mixed content. Active mixed content, like JavaScript, is more dangerous as an attacker can insert their own hostile code into a page easily.
-
In the past web browsers have allowed passive mixed content and flagged it with a warning but blocked active mixed content. More recently however, Chrome announced it intends to improve here and as HTTPS becomes the norm it will block all mixed content instead.
Many new and recent features for site operators to better protect their users have come in the form of new HTTP response headers that can configure and control security protections built into the browser. Some of these features are easy to enable and provide a huge level of protection whilst others require a little more work from site operators. If you wish to check if a site is using these headers and has them correctly configured, you can use the Security Headers tool to scan it.
A vertical bar graph showing increasing usage of security headers list for both desktop and mobile listing from left to right: cross-origin-resource-policy (0 sites on both), feature policy (approx 8k desktop and mobile) report-to (74k desktop and 83k mobile), nel (74k desktop and 83k mobile), referrer-policy (142k desktop, 156k mobile), content-security-policy (240k desktop, 252k mobile), strict-transport-security (648k desktop, 679k mobile), x-xss-protection (642k desktop, 805k mobile), x-frame-options (743k desktop, 782k mobile) and finally x-content-type-options (770k desktop, 932k mobile).
The HSTS header allows a website to instruct a browser that it should only ever communicate with the site over a secure HTTPS connection. This means that any attempts to use a http:// URL will automatically be converted to https:// before a request is made. Given that over 40% of requests were capable of using TLS, we see a much lower % of requests instructing the browser to require it.
Less than 15% of mobile and desktop pages are issuing a HSTS with a max-age directive. This is a minimum requirement for a valid policy. Fewer still are including subdomains in their policy with the includeSubDomains directive and even fewer still are HSTS preloading. Looking at the median value for a HSTS max-age, for those that do use this, we can see that on both desktop and mobile it is 15768000, a strong configuration representing half a year (60 x 60 x 24 x 365/2).
-
-
-
-
-
-
-
-
Client
-
-
-
Percentile
-
Desktop
-
Mobile
-
-
-
-
-
10
-
300
-
300
-
-
-
25
-
7889238
-
7889238
-
-
-
50
-
15768000
-
15768000
-
-
-
75
-
31536000
-
31536000
-
-
-
90
-
63072000
-
63072000
-
-
-
-
-
-
- Figure 10. Medium values of HSTS `max-age` policy by percentile.
-
With the HSTS policy delivered via an HTTP response Header, when visiting a site for the first time a browser will not know whether a policy is configured. To avoid this Trust On First Use problem, a site operator can have the policy preloaded into the browser (or other user agents) meaning you are protected even before you visit the site for the first time.
-
There are a number of requirements for preloading, which are outlined on the HSTS preload site. We can see that only a small number of sites, 0.31% on desktop and 0.26% on mobile, are eligible according to current criteria. Sites should ensure they have fully transitions all sites under their domain to HTTPS before submitting to preload the domain or they risk blocking access to HTTP-only sites.
Web applications face frequent attacks where hostile content finds its way into a page. The most worrisome form of content is JavaScript and when an attacker finds a way to insert JavaScript into a page, they can launch damaging attacks. These attacks are known as Cross-Site Scripting (XSS) and Content Security Policy (CSP) provides an effective defense against these attacks.
-
CSP is an HTTP header (Content-Security-Policy) published by a website which tells the browser rules around content allowed on a site. If additional content is injected into the site due to a security flaw, and it is not allowed by the policy, the browser will block it from being used. Alongside XSS protection, CSP also offers several other key benefits such as making migration to HTTPS easier.
-
Despite the many benefits of CSP, it can be complicated to implement on websites since its very purpose is to limit what is acceptable on a page. The policy must allow all content and resources you need and can easily get large and complex. Tools like Report URI can help you analyze and build the appropriate policy.
-
We find that only 5.51% of desktop pages include a CSP and only 4.73% of mobile pages include a CSP, likely due to the complexity of deployment.
A common approach to CSP is to create an allowlist of 3rd party domains that are permitted to load content, such as JavaScript, into your pages. Creating and managing these lists can be difficult so hashes and nonces were introduced as an alternative approach. A hash is calculated based on contents of the script so if this is published by the website operator and the script is changed, or another script is added, then it will not match the hash and will be blocked. A nonce is a one-time code (which should be changed each time the page is loaded to prevent it being guessed) which is allowed by the CSP and which the script is tagged with. You can see an example of a nonce on this page by viewing the source to see how Google Tag Manager is loaded.
-
Of the sites surveyed only 0.09% of desktop pages use a nonce source and only 0.02% of desktop pages use a hash source. The number of mobile pages use a nonce source is slightly higher at 0.13% but the use of hash sources is lower on mobile pages at 0.01%.
- The proposal of strict-dynamic in the next iteration of CSP further reduces the burden on site operators for using CSP by allowing an approved script to load further script dependencies. Despite the introduction of this feature, which already has support in some modern browsers, only 0.03% of desktop pages and 0.1% of mobile pages include it in their policy.
-
XSS attacks come in various forms and Trusted-Types was created to help specifically with DOM-XSS. Despite being an effective mechanism, our data shows that only 2 mobile and desktop pages use the Trusted-Types directive.
When a CSP is deployed on a page, certain unsafe features like inline scripts or the use of eval() are disabled. A page can depend on these features and enable them in a safe fashion, perhaps with a nonce or hash source. Site operators can also re-enable these unsafe features with unsafe-inline or unsafe-eval in their CSP though, as their names suggest, doing so does lose much of the protections that CSP gives you. Of the 5.51% of desktop pages that include a CSP, 33.94% of them include unsafe-inline and 31.03% of them include unsafe-eval. On mobile pages we find that of the 4.73% that contain a CSP, 34.04% use unsafe-inline and 31.71% use unsafe-eval.
We mentioned earlier that a common problem that site operators face in their migration from HTTP to HTTPS is that some content can still be accidentally loaded over HTTP on their HTTPS page. This problem is known as mixed content and CSP provides an effective way to solve this problem. The upgrade-insecure-requests directive instructs a browser to load all subresources on a page over a secure connection, automatically upgrading HTTP requests to HTTPS requests as an example. Think of it like HSTS for subresources on a page.
-
We showed earlier in figure 7 that, of the HTTPS pages surveyed on the desktop, 16.27% of them loaded mixed-content with 3.99% of pages loading active mixed-content like JS/CSS/fonts. On mobile pages we see 15.37% of HTTPS pages loading mixed-content with 4.13% loading active mixed-content. By loading active content such as JavaScript over HTTP an attacker can easily inject hostile code into the page to launch an attack. This is what the upgrade-insecure-requests directive in CSP protects against.
-
The upgrade-insecure-requests directive is found in the CSP of 3.24% of desktop pages and 2.84% of mobile pages, indicating that an increase in adoption would provide substantial benefits. It could be introduced with relative ease, without requiring a fully locked-down CSP and the complexity that would entail, by allowing broad categories with a policy like below, or even including unsafe-inline and unsafe-eval:
Another common attack known as clickjacking is conducted by an attacker who will place a target website inside an iframe on a hostile website, and then overlay hidden controls and buttons that they are in control of. Whilst the X-Frame-Options header (discussed below) originally set out to control framing, it wasn't flexible and frame-ancestors in CSP stepped in to provide a more flexible solution. Site operators can now specify a list of hosts that are permitted to frame them and any other hosts attempting to frame them will be prevented.
-
Of the pages surveyed, 2.85% of desktop pages include the frame-ancestors directive in CSP with 0.74% of desktop pages setting Frame-Ancestors to 'none', preventing any framing, and 0.47% of pages setting frame-ancestors to 'self', allowing only their own site to frame itself. On mobile we see 2.52% of pages using frame-ancestors with 0.71% setting the value of 'none' and 0.41% setting the value to 'self'.
- The Referrer-Policy header allows a site to control what information will be sent in the Referer header when a user navigates away from the current page. This can be the source of information leakage if there is sensitive data in the URL, such as search queries or other user-dependent information included in URL parameters. By controlling what information is sent in the Referer header, ideally limiting it, a site can protect the privacy of their visitors by reducing the information sent to 3rd parties.
-
This table shows the valid values set by pages and that, of the pages which use this header, 99.75% of them on desktop and 96.55% of them on mobile are setting a valid policy. The most popular choice of configuration is no-referrer-when-downgrade which will prevent the Referer header being sent when a user navigates from a HTTPS page to a HTTP page. The second most popular choice is strict-origin-when-cross-origin which prevents any information being sent on a scheme downgrade (HTTPS to HTTP navigation) and when information is sent in the Referer it will only contain the origin of the source and not the full URL (for example https://www.example.com rather than https://www.example.com/page/). Details on the other valid configurations can be found in the Referrer Policy specification, though such a high usage of unsafe-url warrants further investigation but is likely to be a third-party component like analytics or advertisement libraries.
- As the web platform becomes more powerful and feature rich, attackers can abuse these new APIs in interesting ways. In order to limit misuse of powerful APIs, a site operator can issue a Feature-Policy header to disable features that are not required, preventing them from being abused.
-
-
Here are the 5 most popular features that are controlled with a Feature Policy.
We can see that the most popular feature to take control of is the microphone, with almost 11% of desktop and mobile pages issuing a policy that includes it. Delving deeper into the data we can look at what those pages are allowing or blocking.
-
-
-
-
-
-
-
Feature
-
Configuration
-
Usage
-
-
-
-
-
microphone
-
none
-
9.09%
-
-
-
microphone
-
none
-
8.97%
-
-
-
microphone
-
self
-
0.86%
-
-
-
microphone
-
self
-
0.85%
-
-
-
microphone
-
*
-
0.64%
-
-
-
microphone
-
*
-
0.53%
-
-
-
-
-
- Figure 13. Settings used for microphone feature.
-
-
By far the most common approach here is to block use of the microphone altogether, with about 9% of pages taking that approach. A small number of pages do allow the use of the microphone by their own origin and interestingly, a small selection of pages intentionally allow use of the microphone by any origin loading content in their page.
- The X-Frame-Options header allows a page to control whether or not it can be placed in an iframe by another page. Whilst lacking the flexibility of frame-ancestors in CSP, mentioned above, it was effective if you didn't require fine grained control of framing.
-
-
We see that the usage of the X-Frame-Options header is quite high on both desktop (16.99%) and mobile (14.77%) and can also look more closely at the specific configurations used.
It seems that the vast majority of pages restrict framing to only their own origin and the next significant approach is to prevent framing altogether. This is similar to frame-ancestors in CSP where these 2 approaches are also the most common. It should also be noted that the allow-from option, which in theory allow site owners to list the third-party domains allowed to frame was never well supported and has been deprecated.
- The X-Content-Type-Options header is the most widely deployed Security Header and is also the most simple, with only one possible configuration value nosniff. When this header is issued a browser must treat a piece of content as the MIME Type declared in the Content-Type header and not try to change the advertised value when it infers a file is of a different type. Various security flaws can be introduced if a browser is persuaded to incorrectly sniff the type..
-
-
We find that an identical 17.61% of pages on both mobile and desktop issue the X-Content-Type-Options header.
- The X-XSS-Protection header allows a site to control the XSS Auditor or XSS Filter built into a browser, which should in theory provide some XSS protection.
-
-
14.69% of Desktop requests, and 15.2% of mobile requests used the X-XSS-Protection header. Digging into the data we can see what the intention for most site operators was in figure 13.
The value 1 enables the filter/auditor and mode=block sets the protection to the strongest setting (in theory) where any suspected XSS attack would cause the page to not be rendered. The second most common configuration was to simply ensure the auditor/filter was turned on, by presenting a value of 1 and then the 3rd most popular configuration is quite interesting.
-
Setting a value of 0 in the header instructs the browser to disable any XSS auditor/filter that it may have. Some historic attacks demonstrated how the auditor or filter could be tricked into assisting an attacker rather than protecting the user so some site operators could disable it if they were confident they have adequate protection against XSS in place.
-
Due to these attacks, Edge retired their XSS Filter, Chrome deprecated their XSS Auditor and Firefox never implemented support for the feature. We still see widespread use of the header at approximately 15% of all sites, despite it being largely useless now.
The Reporting API was introduced to allow site operators to gather various pieces of telemetry from the browser. Many errors or problems on a site can result in a poor experience for the user yet a site operator can only find out if the user contacts them. The Reporting API provides a mechanism for a browser to automatically report these problems without any user interaction or interruption. The Reporting API is configured by delivering the Report-To header.
-
By specifying the header, which contains a location where the telemetry should be sent, a browser will automatically begin sending the data and you can use a 3rd party service like Report URI to collect the reports or collect them yourself. Given the ease of deployment and configuration, we can see that only a small fraction of desktop (1.70%) and mobile (1.57%) sites currently enable this feature. To see the kind of telemetry you can collect, refer to the Reporting API specification.
Network Error Logging (NEL) provides detailed information about various failures in the browser that can result in a site being inoperative. Whereas the Report-To is used to report problems with a page that is loaded, the NEL header allows sites to inform the browser to cache this policy and then to report future connection problems when they happen via the endpoint configured in the Reporting-To header above. NEL can therefore be seen as an extension of the Reporting API.
-
Of course, with NEL depending on the Reporting API, we shouldn't see the usage of NEL exceed that of the Reporting API, so we see similarly low numbers here too at 1.70% for desktop requests and 1.57% for mobile. The fact these numbers are identical suggest they are being deployed together.
-
NEL provides incredibly valuable information and you can read more about the type of information in the Network Error Logging specification.
With the increasing ability to store data locally on a user's device, via cookies, caches and local storage to name but a few, site operators needed a reliable way to manage this data. The Clear Site Data header provides a means to ensure that all data of a particular type is removed from the device, though it is not yet supported in all browsers.
-
Given the nature of the header, it is unsurprising to see almost no usage reported - just 9 desktop requests and 7 mobile requests. With our data only looking at the homepage of a site, we're unlikely to see the most common use of the header which would be on a logout endpoint. Upon logging out of a site, the site operator would return the Clear Site Data header and the browser would remove all data of the indicated types. This is unlikely to take place on the homepage of a site.
Cookies have many security protections available and whilst some of those are long standing, and have been available for years, some of them are really quite new have been introduced only in the last couple of years.
The Secure flag on a cookie instructs a browser to only send the cookie over a secure (HTTPS) connection and we find only a small % of sites (4.22% on desktop and 3.68% on mobile) issuing a cookie with the Secure flag set on their homepage. This is depressing considering the relative ease with which this feature can be used. Again, the high usage of analytics and advertisement third-party requests, which wish to collect data over both HTTP and HTTPS is likely skewing these numbers and it would be interesting research to see the usage on other cookies, like authentication cookies.
The HttpOnly flag on a cookie instructs the browser to prevent JavaScript on the page from accessing the cookie. Many cookies are only used by the server so are not needed by the JavaScript on the page, so restricting access to a cookie is a great protection against XSS attacks from stealing the cookie. We find that a much larger % of sites issuing a cookie with this flag on their homepage at 24.24% on desktop and 22.23% on mobile.
As a much more recent addition to cookie protections, the SameSite flag is a powerful protection against Cross-Site Request Forgery (CSRF) attacks (often also known as XSRF).
-
These attacks work by using the fact that browsers will typically include relevant cookies in all requests. Therefore, if you are logged in, and so have cookies set, and then visit a malicious site, it can make a call for an API and the browser will "helpfully" send the cookies. Adding the SameSite attribute to a Cookie, allows a website to inform the browser not to send the cookies when calls are issued from third-party sites and hence the attack fails.
-
Being a recently introduced mechanism, the usage of Same-Site cookies is much lower as we would expect at 0.1% of requests on both desktop and mobile. There are use cases when a cookie should be sent cross-site. For example, single sign-on sites implicitly work by setting the cookie along with an authentication token.
We can see that of those pages already using Same-Site cookies, more than half of them are using it in strict mode. This is closely followed by sites using Same-Site in lax mode and then a small selection of sites using the value none. This last value is used to opt-out of the upcoming change where browser vendors may implement lax mode by default.
-
Because it provides much needed protection against a dangerous attack, there are currently indications that leading browsers could implement this feature by default and enable it on cookies even though the value is not set. If this were to happen the SameSite protection would be enabled, though in its weaker setting of lax mode and not strict mode, as that would likely cause more breakage.
Another recent addition to cookies are Cookie Prefixes. These use the name of your cookie to add one of two further protections to those already covered. While the above flags can be accidentally unset on cookies, the name will not change so using the name to define security attributes can more reliably enforce them.
-
Currently the name of your cookie can be prefixed with either __Secure- or __Host-, with both offering additional security to the cookie.
As the figures show, the use of either prefix is incredibly low but as the more relaxed of the two, the __Secure- prefix does see more utilization already.
Another problem that has been on the rise recently is the security of 3rd party dependencies. When loading a script file from a 3rd party, we hope that the script file is always the library that we wanted, perhaps a particular version of jQuery. If a CDN or 3rd party hosting service is compromised, the script files they are hosting could be altered. In this scenario your application would now be loading malicious JavaScript that could harm your visitors. This is what subresource integrity protects against.
-
By adding an integrity attribute to a script or link tag, a browser can integrity check the 3rd party resource and reject it if it has been altered, in a similar manner that CSP hashes described above are used.
With only 0.06% (247,604) of desktop pages and 0.05% (272,167) of mobile pages containing link or script tags with the integrity attribute set, there's room for a lot of improvement in the use of SRI. With many CDNs now providing code samples that include the SRI integrity attribute we should see a steady increase in the use of SRI.
As the web grows in capabilities and allows access to more and more sensitive data, it becomes increasingly important for developers to adopt web security features to protect their applications. The security features reviewed in this chapter are defenses built into the web platform itself, available to every web author. However, as a review of the study results in this chapter shows, the coverage of several important security mechanisms extends only to a subset of the web, leaving a significant part of the ecosystem exposed to security or privacy bugs.
In the recent years, the web has made the most progress on the encryption of data in transit. As described in the TLS section section, thanks to a range of efforts from browser vendors, developers and Certificate Authorities such as Let's Encrypt, the fraction of the web using HTTPS has steadily grown. At the time of writing, the majority of sites are available over HTTPS, ensuring confidentiality and integrity of traffic. Importantly, over 99% of websites which enable HTTPS use newer, more secure versions of the TLS protocol (TLSv1.2 and TLSv1.3). The use of strong cipher suites such as AES in GCM mode is also high, accounting for over 95% of requests on all platforms.
-
At the same time, gaps in TLS configurations are still fairly common. Over 15% of pages suffer from mixed content issues, resulting in browser warnings, and 4% of sites contain active mixed content, blocked by modern browsers for security reasons. Similarly, the benefits of HTTP Strict Transport Security only extend to a small subset of major sites, and the majority of websites don't enable the most secure HSTS configurations and are not eligible for HSTS preloading. Despite progress in HTTPS adoption, a large number of cookies is still set without the Secure flag; only 4% of homepages that set cookies prevent them from being sent over unencrypted HTTP.
- Web developers working on sites with sensitive data often enable opt-in web security features to protect their applications from XSS, CSRF, clickjacking, and other common web bugs. These issues can be mitigated by setting a number of standard, broadly supported HTTP response headers, including X-Frame-Options, X-Content-Type-Options, and Content-Security-Policy.
-
-
- In large part due to the complexity of both the security features and web applications, only a minority of websites currently use these defenses, and often enable only those mechanisms which do not require significant refactoring efforts. The most common opt-in application security features are X-Content-Type-Options (enabled by 17% of pages), X-Frame-Options (16%), and the deprecated X-XSS-Protection header (15%). The most powerful web security mechanism—Content Security Policy—is only enabled by 5% of websites, and only a small subset of them (about 0.1% of all sites) use the safer configurations based on CSP nonces and hashes. The related Referrer-Policy, aiming to reduce the amount of information sent to third parties in the Referer headers is similarly only used by 3% of websites.
-
In the recent years, web browsers have implemented powerful new mechanisms which offer protections from major classes of vulnerabilities and new web threats; this includes Subresource Integrity, SameSite cookies, and cookie prefixes.
-
These features have seen adoption only by a relatively small number of websites; their total coverage is generally well below 1%. The even more recent security mechanisms such as Trusted Types, Cross-Origin Resource Policy or Cross-Origin-Opener Policy have not seen any widespread adoption as of yet.
-
- Similarly, convenience features such as the Reporting API, Network Error Logging and the Clear-Site-Data header are also still in their infancy and are currently being used by a small number of sites.
-
At web scale, the total coverage of opt-in platform security features is currently relatively low. Even the most broadly adopted protections are enabled by less than a quarter of websites, leaving the majority of the web without platform safeguards against common security issues; more recent security mechanisms, such as Content Security Policy or Referrer Policy, are enabled by less than 5% of websites.
-
It is important to note, however, that the adoption of these mechanisms is skewed towards larger web applications which frequently handle more sensitive user data. The developers of these sites more frequently invest in improving their web defenses, including enabling a range of protections against common vulnerabilities; tools such as Mozilla Observatory and Security Headers can provide a useful checklist of web available security features.
-
If your web application handles sensitive user data, consider enabling the security mechanisms outlined in this section to protect your users and make the web safer.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/seo.html b/src/templates/en/2019/chapters/seo.html
deleted file mode 100644
index e8c68d4ccdb..00000000000
--- a/src/templates/en/2019/chapters/seo.html
+++ /dev/null
@@ -1,456 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":10,"title":"SEO","description":"SEO chapter of the 2019 Web Almanac covering content, meta tags, indexability, linking, speed, structured data, internationalization, SPAs, AMP and security.","authors":["ymschaap","rachellcostello","AVGP"],"reviewers":["clarkeclark","andylimn","AymenLoukil","catalinred","mattludwig"],"translators":null,"discuss":"1765","results":"https://docs.google.com/spreadsheets/d/1uARtBWwz9nJOKqKPFinAMbtoDgu5aBtOhsBNmsCoTaA/","queries":"10_SEO","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"seo"} %} {% block index %}
-
Search Engine Optimization (SEO) isn't just a hobby or a side project for digital marketers, it is crucial for the success of a website. The primary goal of SEO is to make sure that a website is optimized for the search engine bots that need to crawl and index its pages, as well as for the users that will be navigating the website and consuming its content. SEO impacts everyone working on a website, from the developer who is building it, through to the digital marketer who will need to promote it to new potential customers.
-
Let's put the importance of SEO into perspective. Earlier this year, the SEO industry looked on in horror (and fascination) as ASOS reported an 87% decrease in profits after a "difficult year". The brand attributed their issues to a drop in search engine rankings which occurred after they launched over 200 microsites and significant changes to their website's navigation, among other technical changes. Yikes.
-
The purpose of the SEO chapter of the Web Almanac is to analyze on-site elements of the web that impact the crawling and indexing of content for search engines, and ultimately, website performance. In this chapter, we'll take a look at how well-equipped the top websites are to provide a great experience for users and search engines, and which ones still have work to do.
-
Our analysis includes data from Lighthouse, the Chrome UX Report, and HTML element analysis. We focused on SEO fundamentals like <title> elements, the different types of on-page links, content, and loading speed, but also the more technical aspects of SEO, including indexability, structured data, internationalization, and AMP across over 5 million websites.
-
Our custom metrics provide insights that, up until now, have not been exposed before. We are now able to make claims about the adoption and implementation of elements such as the hreflang tag, rich results eligibility, heading tag usage, and even anchor-based navigation for single page apps.
-
Note: Our data is limited to analyzing home pages only and has not been gathered from site-wide crawls. This will impact many metrics we'll discuss, so we've added any relevant limitations in this case whenever we mention a specific metric. Learn more about these limitations in our Methodology.
-
Read on to find out more about the current state of the web and its search engine friendliness.
Search engines have a three-step process: crawling, indexing, and ranking. To be search engine-friendly, a page needs to be discoverable, understandable, and contain quality content that would provide value to a user who is browsing the search engine results pages (SERPs).
-
We wanted to analyze how much of the web is meeting the basic standards of SEO best practices, so we assessed on-page elements such as body content, meta tags, and internal linking. Let's take a look at the results.
To be able to understand what a page is about and decide for which search queries it provides the most relevant answers, a search engine must be able to discover and access its content. What content are search engines currently finding, however? To help answer this, we created two custom metrics: word count and headings.
We assessed the content on the pages by looking for groups of at least 3 words and counting how many were found in total. We found 2.73% of desktop pages that didn't have any word groups, meaning that they have no body content to help search engines understand what the website is about.
Distribution of words per page. The median number of words per desktop page is 346 and 306 for mobile pages. Desktop pages have more word throughout the percentiles, by as many as 120 words at the 90th percentile.
- Figure 1. Distribution of the number of words per page.
-
-
The median desktop home page has 346 words, and the median mobile home page has a slightly lower word count at 306 words. This shows that mobile sites do serve a bit less content to their users, but at over 300 words, this is still a reasonable amount to read. This is especially true for home pages which will naturally contain less content than article pages, for example. Overall the distribution of words is broad, with between 22 words at the 10th percentile and up to 1,361 at the 90th percentile.
We also looked at whether pages are structured in a way that provides the right context for the content they contain. Headings (H1, H2, H3, etc.) are used to format and structure a page and make content easier to read and parse. Despite the importance of headings, 10.67% of pages have no heading tags at all.
Distribution of headings per page. The median number of headings per desktop and mobile page is 10. At the 10, 25, 75, and 90th percentiles, the number of headings per desktop page are: 0, 3, 21, and 39. This is slightly higher than the distribution of mobile headings per page.
- Figure 2. Distribution of the number of headings per page.
-
-
The median number of heading elements per page is 10. Headings contain 30 words on mobile pages and 32 words on desktop pages. This implies that the websites that utilize headings put significant effort in making sure that their pages are readable, descriptive, and clearly outline the page structure and context to search engine bots.
Distribution of the number of characters in the first H1 per page. The desktop and mobile distributions are nearly identical, with the 10, 25, 50, 75, and 90th percentiles as: 6, 11, 19, 31, and 47 characters.
- Figure 3. Distribution of H1 length per page.
-
-
In terms of specific heading length, the median length of the first H1 element found on desktop is 19 characters.
-
For advice on how to handle H1s and headings for SEO and accessibility, take a look at this video response by John Mueller in the Ask Google Webmasters series.
Meta tags allow us to give specific instructions and information to search engine bots about the different elements and content on a page. Certain meta tags can convey things like the topical focus of a page, as well as how the page should be crawled and indexed. We wanted to assess whether or not websites were making the most of these opportunities that meta tags provide.
- Figure 4. Percent of mobile pages that include a <title> tag.
-
-
Page titles are an important way of communicating the purpose of a page to a user or search engine. <title> tags are also used as headings in the SERPS and as the title for the browser tab when visiting a page, so it's no surprise to see that 97.1% of mobile pages have a document title.
Distribution of the number of characters per title element per page. The 10, 25, 50, 75, and 90th percentiles of title lengths for desktop are: 4, 9, 20, 40, and 66 characters. The mobile distribution is very similar.
- Figure 5. Distribution of title length per page.
-
-
Even though Google usually displays the first 50-60 characters of a page title within a SERP, the median length of the <title> tag was only 21 characters for mobile pages and 20 characters for desktop pages. Even the 75th percentile is still below the cutoff length. This suggests that some SEOs and content writers aren't making the most of the space allocated to them by search engines for describing their home pages in the SERPs.
Compared to the <title> tag, fewer pages were detected to have a meta description, as only 64.02% of mobile home pages have a meta description. Considering that Google often rewrites meta descriptions in the SERPs in response to the searcher's query, perhaps website owners place less importance on including a meta description at all.
Distribution of the number of characters per meta description per page. The 10, 25, 50, 75, and 90th percentiles of title lengths for desktop are: 9, 48, 123, 162, and 230 characters. The mobile distribution is slightly higher by fewer than 10 characters at any given percentile.
- Figure 6. Distribution of meta description length per page.
-
-
The median meta description length was also lower than the recommended length of 155-160 characters, with desktop pages having descriptions of 123 characters. Interestingly, meta descriptions were consistently longer on mobile than on desktop, despite mobile SERPs traditionally having a shorter pixel limit. This limit has only been extended recently, so perhaps more website owners have been testing the impact of having longer, more descriptive meta descriptions for mobile results.
Considering the importance of alt text for SEO and accessibility, it is far from ideal to see that only 46.71% of mobile pages use alt attributes on all of their images. This means that there are still improvements to be made with regard to making images across the web more accessible to users and understandable for search engines. Learn more about issues like these in the Accessibility chapter.
To show a page's content to users in the SERPs, search engine crawlers must first be permitted to access and index that page. Some of the factors that impact a search engine's ability to crawl and index pages include:
It is recommended to maintain a 200 OK status code for any important pages that you want search engines to index. The majority of pages tested were available for search engines to access, with 87.03% of initial HTML requests on desktop returning a 200 status code. The results were slightly lower for mobile pages, with only 82.95% of pages returning a 200 status code.
-
The next most commonly found status code on mobile was 302, a temporary redirect, which was found on 10.45% of mobile pages. This was higher than on desktop, with only 6.71% desktop home pages returning a 302 status code. This could be due to the fact that the mobile home pages were alternates to an equivalent desktop page, such as on non-responsive sites that have separate versions of the website for each device.
-
Note: Our results didn't include 4xx or 5xx status codes.
A noindex directive can be served in the HTML <head> or in the HTTP headers as an X-Robots directive. A noindex directive basically tells a search engine not to include that page in its SERPs, but the page will still be accessible for users when they are navigating through the website. noindex directives are usually added to duplicate versions of pages that serve the same content, or low quality pages that provide no value to users coming to a website from organic search, such as filtered, faceted, or internal search pages.
-
96.93% of mobile pages passed the Lighthouse indexing audit, meaning that these pages didn't contain a noindex directive. However, this means that 3.07% of mobile home pages did have a noindex directive, which is cause for concern, meaning that Google was prevented from indexing these pages.
-
The websites included in our research are sourced from the Chrome UX Report dataset, which excludes websites that are not publicly discoverable. This is a significant source of bias because we're unable to analyze sites that Chrome determines to be non-public. Learn more about our methodology.
Canonical tags are used to specify duplicate pages and their preferred alternates, so that search engines can consolidate authority which might be spread across multiple pages within the group onto one main page for improved rankings.
-
48.34% of mobile home pages were detected to have a canonical tag. Self-referencing canonical tags aren't essential, and canonical tags are usually required for duplicate pages. Home pages are rarely duplicated anywhere else across the site so seeing that less than half of pages have a canonical tag isn't surprising.
- One of the most effective methods for controlling search engine crawling is the robots.txt file. This is a file that sits on the root domain of a website and specifies which URLs and URL paths should be disallowed from being crawled by search engines.
-
-
It was interesting to observe that only 72.16% of mobile sites have a valid robots.txt, according to Lighthouse. The key issues we found are split between 22% of sites having no robots.txt file at all, and ~6% serving an invalid robots.txt file, and thus failing the audit. While there are many valid reasons to not have a robots.txt file, such as having a small website that doesn't struggle with crawl budget issues, having an invalid robots.txt is cause for concern.
One of the most important attributes of a web page is links. Links help search engines discover new, relevant pages to add to their index and navigate through websites. 96% of the web pages in our dataset contain at least one internal link, and 93% contain at least one external link to another domain. The small minority of pages that don't have any internal or external links will be missing out on the immense value that links pass through to target pages.
-
The number of internal and external links included on desktop pages were consistently higher than the number found on mobile pages. Often a limited space on a smaller viewport causes fewer links to be included in the design of a mobile page compared to desktop.
-
It's important to bear in mind that fewer internal links on the mobile version of a page might cause an issue for your website. With mobile-first indexing, which for new websites is the default for Google, if a page is only linked from the desktop version and not present on the mobile version, search engines will have a much harder time discovering and ranking it.
Distribution of the number of internal links per page. The 10, 25, 50, 75, and 90th percentiles of internal links for desktop are: 7, 29, 70, 142, and 261. The mobile distribution is much lower, by 30 links at the 90th percentile and 10 at the median.
- Figure 7. Distribution of internal links per page.
-
-
-
-
-
-
-
Distribution of the number of external links per page. The 10, 25, 50, 75, and 90th percentiles of external links for desktop are: 1, 4, 10, 22, and 51. The mobile distribution is much lower, by 11 links at the 90th percentile and 2 at the median.
- Figure 8. Distribution of external links per page.
-
-
The median desktop page includes 70 internal (same-site) links, whereas the median mobile page has 60 internal links. The median number of external links per page follows a similar trend, with desktop pages including 10 external links, and mobile pages including 8.
Distribution of the number of anchor links per page. The 10, 25, 50, 75, and 90th percentiles of internal anchor for desktop are: 0, 0, 0, 1, and 3. The mobile distribution is identical.
- Figure 9. Distribution of anchor links per page.
-
-
Anchor links, which link to a certain scroll position on the same page, are not very popular. Over 65% of home pages have no anchor links. This is probably due to the fact that home pages don't usually contain any long-form content.
-
There is good news from our analysis of the descriptive link text metric. 89.94% of mobile pages pass Lighthouse's descriptive link text audit. This means that these pages don't have generic "click here", "go", "here" or "learn more" links, but use more meaningful link text which helps users and search engines better understand the context of pages and how they connect with one another.
Having descriptive, useful content on a page that isn't being blocked from search engines with a noindex or Disallow directive isn't enough for a website to succeed in organic search. Those are just the basics. There is a lot more than can be done to enhance the performance of a website and its appearance in SERPs.
-
Some of the more technically complex aspects that have been gaining importance in successfully indexing and ranking websites include speed, structured data, internationalization, security, and mobile friendliness.
A fast-loading website is also crucial for a good user experience. Users that have to wait even a few seconds for a site to load have the tendency to bounce and try another result from one of your SERP competitors that loads quickly and meets their expectations of website performance.
-
The metrics we used for our analysis of load speed across the web is based on the Chrome UX Report (CrUX), which collects data from real-world Chrome users. This data shows that an astonishing 48% of websites are labeled as slow. A website is labeled slow if it more than 25% of FCP experiences slower than 3 seconds or 5% of FID experiences slower than 300 ms.
Distribution of the performance of desktop, phone, and tablet user experiences. Desktop: 2% fast, 52% moderate, 46% slow. Phone: 1% fast, 41% moderate, 58% slow. Tablet: 0% fast, 35% moderate, 65% slow.
- Figure 10. Distribution of the performance of user experiences by device type.
-
-
Split by device, this picture is even bleaker for tablet (65%) and phone (58%).
-
Although the numbers are bleak for the speed of the web, the good news is that SEO experts and tools have been focusing more and more on the technical challenges of speeding up websites. You can learn more about the state of web performance in the Performance chapter.
Structured data allows website owners to add additional semantic data to their web pages, by adding JSON-LD snippets or Microdata, for example. Search engines parse this data to better understand these pages and sometimes use the markup to display additional relevant information in the search results. Some of the useful types of structured data are:
The extra visibility that structured data can provide for websites is interesting for site owners, given that it can help to create more opportunities for traffic. For example, the relatively new FAQ schema will double the size of your snippet and the real estate of your site in the SERP.
-
During our research, we found that only 14.67% of sites are eligible for rich results on mobile. Interestingly, desktop site eligibility is slightly lower at 12.46%. This suggests that there is a lot more that site owners can be doing to optimize the way their home pages are appearing in search.
-
Among the sites with structured data markup, the five most prevalent types are:
-
-
WebSite (16.02%)
-
SearchAction (14.35%)
-
Organization (12.89%)
-
WebPage (11.58%)
-
ImageObject (5.35%)
-
-
Interestingly, one of the most popular data types that triggers a search engine feature is SearchAction, which powers the sitelinks searchbox.
-
The top five markup types all lead to more visibility in Google's search results, which might be the fuel for more widespread adoption of these types of structured data.
-
Seeing as we only looked at home pages within this analysis, the results might look very different if we were to consider interior pages, too.
-
Review stars are only found on 1.09% of the web's home pages (via AggregateRating). Also, the newly introduced QAPage appeared only in 48 instances, and the FAQPage at a slightly higher frequency of 218 times. These last two counts are expected to increase in the future as we run more crawls and dive deeper into Web Almanac analysis.
Internationalization is one of the most complex aspects of SEO, even according to some Google search employees. Internationalization in SEO focuses on serving the right content from a website with multiple language or country versions and making sure that content is being targeted towards the specific language and location of the user.
-
While 38.40% of desktop sites (33.79% on mobile) have the HTML lang attribute set to English, only 7.43% (6.79% on mobile) of the sites also contain an hreflang link to another language version. This suggests that the vast majority of websites that we analyzed don't offer separate versions of their home page that would require language targeting -- unless these separate versions do exist but haven't been configured correctly.
-
-
-
-
-
-
-
hreflang
-
Desktop
-
Mobile
-
-
-
-
-
en
-
12.19%
-
2.80%
-
-
-
x-default
-
5.58%
-
1.44%
-
-
-
fr
-
5.23%
-
1.28%
-
-
-
es
-
5.08%
-
1.25%
-
-
-
de
-
4.91%
-
1.24%
-
-
-
en-us
-
4.22%
-
2.95%
-
-
-
it
-
3.58%
-
0.92%
-
-
-
ru
-
3.13%
-
0.80%
-
-
-
en-gb
-
3.04%
-
2.79%
-
-
-
de-de
-
2.34%
-
2.58%
-
-
-
nl
-
2.28%
-
0.55%
-
-
-
fr-fr
-
2.28%
-
2.56%
-
-
-
es-es
-
2.08%
-
2.51%
-
-
-
pt
-
2.07%
-
0.48%
-
-
-
pl
-
2.01%
-
0.50%
-
-
-
ja
-
2.00%
-
0.43%
-
-
-
tr
-
1.78%
-
0.49%
-
-
-
it-it
-
1.62%
-
2.40%
-
-
-
ar
-
1.59%
-
0.43%
-
-
-
pt-br
-
1.52%
-
2.38%
-
-
-
th
-
1.40%
-
0.42%
-
-
-
ko
-
1.33%
-
0.28%
-
-
-
zh
-
1.30%
-
0.27%
-
-
-
sv
-
1.22%
-
0.30%
-
-
-
en-au
-
1.20%
-
2.31%
-
-
-
-
-
- Figure 11. Top 25 most popular hreflang values.
-
-
Next to English, the most common languages are French, Spanish, and German. These are followed by languages targeted towards specific geographies like English for Americans (en-us) or more obscure combinations like Spanish for the Irish (es-ie).
-
The analysis did not check for correct implementation, such as whether or not the different language versions properly link to each other. However, from looking at the low adoption of having an x-default version (only 3.77% on desktop and 1.30% on mobile), as is recommended, this is an indicator that this element is complex and not always easy to get right.
Single-page applications (SPAs) built with frameworks like React and Vue.js come with their own SEO complexity. Websites using a hash-based navigation, make it especially hard for search engines to properly crawl and index them. For example, Google had an "AJAX crawling scheme" workaround that turned out to be complex for search engines as well as developers, so it was deprecated in 2015.
-
The number of SPAs that were tested had a relatively low number of links served via hash URLs, with 13.08% of React mobile pages using hash URLs for navigation, 8.15% of mobile Vue.js pages using them, and 2.37% of mobile Angular pages using them. These results were very similar for desktop pages too. This is positive to see from an SEO perspective, considering the impact that hash URLs can have on content discovery.
-
The higher number of hash URLs in React pages is surprising, especially in contrast to the lower number of hash URLs found on Angular pages. Both frameworks promote the adoption of routing packages where the History API is the default for links, instead of relying on hash URLs. Vue.js is considering moving to using the History API as the default as well in version 3 of their vue-router package.
AMP (formerly known as "Accelerated Mobile Pages") was first introduced in 2015 by Google as an open source HTML framework. It provides components and infrastructure for websites to provide a faster experience for users, by using optimizations such as caching, lazy loading, and optimized images. Notably, Google adopted this for their search engine, where AMP pages are also served from their own CDN. This feature later became a standards proposal under the name Signed HTTP Exchanges.
-
Despite this, only 0.62% of mobile home pages contain a link to an AMP version. Given the visibility this project has had, this suggests that it has had a relatively low adoption. However, AMP can be more useful for serving article pages, so our home page-focused analysis won't reflect adoption across other page types.
A strong online shift in recent years has been for the web to move to HTTPS by default. HTTPS prevents website traffic from being intercepted on public Wi-Fi networks, for example, where user input data is then transmitted unsecurely. Google have been pushing for sites to adopt HTTPS, and even made HTTPS as a ranking signal. Chrome also supported the move to secure pages by labeling non-HTTPS pages as not secure in the browser.
-
For more information and guidance from Google on the importance of HTTPS and how to adopt it, please see Why HTTPS Matters.
-
We found that 67.06% of websites on desktop are now served over HTTPS. Just under half of websites still haven't migrated to HTTPS and are serving non-secure pages to their users. This is a significant number. Migrations can be hard work, so this could be a reason why the adoption rate isn't higher, but an HTTPS migration usually require an SSL certificate and a simple change to the .htaccess file. There's no real reason not to switch to HTTPS.
-
Google's HTTPS Transparency Report reports a 90% adoption of HTTPS for the top 100 non-Google domains (representing 25% of all website traffic worldwide). The difference between this number and ours could be explained by the fact that relatively smaller sites are adopting HTTPS at a slower rate.
-
Learn more about the state of security in the Security chapter.
Through our analysis, we observed that the majority of websites are getting the fundamentals right, in that their home pages are crawlable, indexable, and include the key content required to rank well in search engines' results pages. Not every person who owns a website will be aware of SEO at all, let alone its best practice guidelines, so it is promising to see that so many sites have got the basics covered.
-
However, more sites are missing the mark than expected when it comes to some of the more advanced aspects of SEO and accessibility. Site speed is one of these factors that many websites are struggling with, especially on mobile. This is a significant problem, as speed is one of the biggest contributors to UX, which is something that can impact rankings. The number of websites that aren't yet served over HTTPS is also problematic to see, considering the importance of security and keeping user data safe.
-
There is a lot more that we can all be doing to learn about SEO best practices and industry developments. This is essential due to the evolving nature of the search industry and the rate at which changes happen. Search engines make thousands of improvements to their algorithms each year, and we need to keep up if we want our websites to reach more visitors in organic search.
-{% endblock %}
diff --git a/src/templates/en/2019/chapters/third-parties.html b/src/templates/en/2019/chapters/third-parties.html
deleted file mode 100644
index be7254ffca6..00000000000
--- a/src/templates/en/2019/chapters/third-parties.html
+++ /dev/null
@@ -1,366 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":5,"title":"Third Parties","description":"Third Parties chapter of the 2019 Web Almanac covering data of what third parties are used, what they are used for, performance impacts and privacy impacts.","authors":["patrickhulce"],"reviewers":["zcorpan","obto","jasti"],"translators":null,"discuss":"1760","results":"https://docs.google.com/spreadsheets/d/1iC4WkdadDdkqkrTY32g7hHKhXs9iHrr3Bva8CuPjVrQ/","queries":"05_Third_Parties","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-02T00:00:00.000Z","chapter":"third-parties"} %} {% block index %}
-
The open web is vast, linkable, and interoperable by design. The ability to grab someone else's complex library and use it on your site with a single <link> or <script> element has supercharged developers' productivity and enabled awesome new web experiences. On the flip side, the immense popularity of a select few third-party providers raises important performance, privacy, and security concerns. This chapter examines the prevalence and impact of third-party code on the web in 2019, the usage patterns that lead to the popularity of third-party solutions, and potential repercussions for the future of web experiences.
A third party is an entity outside the primary site-user relationship, i.e. the aspects of the site not directly within the control of the site owner but present with their approval. For example, the Google Analytics script is an example of a common third-party resource.
-
Third-party resources are:
-
-
Hosted on a shared and public origin
-
Widely used by a variety of sites
-
Uninfluenced by an individual site owner
-
-
To match these goals as closely as possible, the formal definition used throughout this chapter of a third-party resource is a resource that originates from a domain whose resources can be found on at least 50 unique pages in the HTTP Archive dataset.
-
Note that using these definitions, third-party content served from a first-party domain is counted as first-party content. For example, self-hosting Google Fonts or bootstrap.css is counted as first-party content. Similarly, first-party content served from a third-party domain is counted as third-party content. For example, first-party images served over a CDN on a third-party domain are considered third-party content.
This chapter divides third-party providers into one of these broad categories. A brief description is included below and the mapping of domain to category can be found in the third-party-web repository.
-
-
Ad - display and measurement of advertisements
-
Analytics - tracking site visitor behavior
-
CDN - providers that host public shared utilities or private content of their users
-
Content - providers that facilitate publishers and host syndicated content
-
Customer Success - support and customer relationship management functionality
-
Hosting - providers that host the arbitrary content of their users
-
Marketing - sales, lead generation, and email marketing functionality
-
Social - social networks and their affiliated integrations
-
Tag Manager - provider whose sole role is to manage the inclusion of other third parties
-
Utility - code that aids the development objectives of the site owner
-
Video - providers that host the arbitrary video content of their users
-
Other - uncategorized or non-conforming activity
-
-
Note on CDNs: The CDN category here includes providers that provide resources on public CDN domains (e.g. bootstrapcdn.com, cdnjs.cloudflare.com, etc.) and does not include resources that are simply served over a CDN. i.e. putting Cloudflare in front of a page would not influence its first-party designation according to our criteria.
- Figure 1. Percentage of desktop pages that include at least one third-party resource.
-
-
Third-party code is everywhere. 93% of pages include at least one third-party resource, 76% of pages issue a request to an analytics domain, the median page requests content from at least 9 unique third-party domains that represent 35% of their total network activity, and the most active 10% of pages issue a whopping 175 third-party requests or more. It's not a stretch to say that third parties are an integral part of the web.
-
-
55.63%
- Figure 2. Percentage of desktop pages that include at least one ad resource.
-
-
If the ubiquity of third-party content is unsurprising, perhaps more interesting is the breakdown of third-party content by provider type.
-
While advertising might be the most user-visible example of third-party presence on the web, analytics providers are the most common third-party category with 76% of sites including at least one analytics request. CDNs at 63%, ads at 57%, and developer utilities like Sentry, Stripe, and Google Maps SDK at 56% follow up as a close second, third, and fourth for appearing on the most web properties. The popularity of these categories forms the foundation of our web usage patterns identified later in the chapter.
A relatively small set of providers dominate the third-party landscape: the top 100 domains account for 30% of network requests across the web. Powerhouses like Google, Facebook, and YouTube make the headlines here with full percentage points of share each, but smaller entities like Wix and Shopify command a substantial portion of third-party popularity as well.
-
While much could be said about every individual provider's popularity and performance impact, this more opinionated analysis is left as an exercise for the reader and other purpose-built tools such as third-party-web.
-
-
-
-
-
-
-
Rank
-
Third party domain
-
Percent of requests
-
-
-
-
-
1
-
fonts.gstatic.com
-
2.53%
-
-
-
2
-
www.facebook.com
-
2.38%
-
-
-
3
-
www.google-analytics.com
-
1.71%
-
-
-
4
-
www.google.com
-
1.17%
-
-
-
5
-
fonts.googleapis.com
-
1.05%
-
-
-
6
-
www.youtube.com
-
0.99%
-
-
-
7
-
connect.facebook.net
-
0.97%
-
-
-
8
-
googleads.g.doubleclick.net
-
0.93%
-
-
-
9
-
cdn.shopify.com
-
0.76%
-
-
-
10
-
maps.googleapis.com
-
0.75%
-
-
-
-
-
- Figure 3. Top 10 most popular third-party domains.
-
The resource type breakdown of third-party content also lends insight into how third-party code is used across the web. While first-party requests are 56% images, 23% script, 14% CSS, and only 4% HTML, third-party requests skew more heavily toward script and HTML at 32% script, 34% images, 12% HTML, and only 6% CSS. While this suggests that third-party code is less frequently used to aid the design and instead used more frequently to facilitate or observe interactions than first-party code, a breakdown of resource types by party status tells a more nuanced story. While CSS and images are dominantly first-party at 70% and 64% respectively, fonts are largely served by third-party providers with only 28% being served from first-party sources. This concept of usage patterns is explored in more depth later in this chapter.
Chart showing the breakdown of content types for each third party category. Images and scripts make up the majority of requests for each category. CDN requests have an especially large proportion of fonts.
- Figure 5. Percent of third-party requests by category and content type.
-
-
Several other amusing factoids jump out from this data. Tracking pixels (image requests to analytics domains) make up 1.6% of all network requests, six times as many video requests are to social networks like Facebook and Twitter than dedicated video providers like YouTube and Vimeo (presumably because the default YouTube embed consists of HTML and a preview thumbnail but not an autoplaying video), and there are still more requests for first-party images than all scripts combined.
49% of all requests are third-party. At 51%, first-party can still narrowly hold on to the crown in 2019 of comprising the majority of the web resources. Given that just under half of all the requests are third-party yet a small set of pages do not include any at all, the most active third-party users must be doing quite a bit more than their fair share. Indeed, at the 75th, 90th, and 99th percentiles we see nearly all of the page being comprised of third-party content. In fact, for some sites heavily relying on distributed WYSIWYG platforms like Wix and SquareSpace, the root document might be the sole first-party request!
-
-
The number of requests issued by each third-party provider also varies considerably by category. While analytics are the most widespread third-party category across websites, they account for only 7% of all third-party network requests. Ads, on the other hand, are found on nearly 20% fewer sites yet make up 25% of all third-party network requests. Their outsized resource impact compared to their popularity will be a theme we continue to uncover in the remaining data.
While 49% of requests are third-party, their share of the web in terms of bytes is quite a bit lower at only 28%. The same goes for the breakdown by multiple resource types. Third-party fonts make up 72% of all fonts, but they're only 53% of font bytes; 74% of HTML requests, but only 39% of HTML bytes; 68% of video requests, but only 31% of video bytes. All this seems to suggest third-party providers are responsible stewards who keep their response sizes low, and, for the most part, that is in fact the case until you look at scripts.
-
Despite serving 57% of scripts, third parties comprise 64% of script bytes. meaning their scripts are larger on average than first-party scripts. This is an early warning sign for their performance impact to come in the next few sections.
Chart showing the breakdown of bytes for each content type per third party category. Images and scripts are relatively evenly distributed across categories. 80% of fonts come from CDNs. Video comes from "content" third-parties.
- Figure 7. Distributions of resource bytes per third-party category.
-
-
-
As for specific third-party providers, the same juggernauts topping the request count leaderboards make their appearance in byte weight as well. The only few notable movements are the large, media-heavy providers such as YouTube, Shopify, and Twitter which climb to the top of the byte impact charts.
57% of script execution time is from third-party scripts, and the top 100 domains already account for 48% of all script execution time on the web. This underscores just how large an impact a select few entities really have on web performance. This topic is explored more in depth in the Repercussions > Performance section.
-
-
-
The category breakdowns among script execution largely follow that of resource counts. Here too advertising looms largest. Ad scripts comprise 25% of third-party script execution time with hosting and social providers in a distant tie for second at 12%.
-
-
-
While much could be said about every individual provider's popularity and performance impact, this more opinionated analysis is left as an exercise for the reader and other purpose-built tools such as the previously mentioned third-party-web.
Why do site owners use third-party code? How did third-party content grow to be nearly half of all network requests? What are all these requests doing? Answers to these questions lie in the three primary usage patterns of third-party resources. Broadly, site owners reach for third parties to generate and consume data from their users, monetize their site experiences, and simplify web development.
Analytics is the most popular third-party category found across the web and yet is minimally user-visible. Consider the volume of information at play in the lifetime of a web visit; there's user context, device, browser, connection quality, location, page interactions, session length, return visitor status, and more being generated continuously. It's difficult, cumbersome, and expensive to maintain tools that warehouse, normalize, and analyze time series data of this magnitude. While nothing categorically necessitates that analytics fall into the domain of third-party providers, the widespread attractiveness of understanding your users, deep complexity of the problem space, and increasing emphasis on managing data respectfully and responsibly naturally surfaces analytics as a popular third-party usage pattern.
-
There's also a flip side to user data though: consumption. While analytics is about generating data from your site's visitors, other third-party resources focus on consuming data about your visitors that is known only by others. Social providers fall squarely into this usage pattern. A site owner must use Facebook resources if they wish to integrate information from a visitor's Facebook profile into their site. As long as site owners are interested in personalizing their experience with widgets from social networks and leveraging the social networks of their visitors to increase their reach, social integrations are likely to remain the domain of third-party entities for the foreseeable future.
The open model of the web does not always serve the financial interests of content creators to their liking and many site owners resort to monetizing their sites with advertising. Because building direct relationships with advertisers and negotiating pricing contracts is a relatively difficult and time-consuming process, this concern is largely handled by third-party providers performing targeted advertising and real-time bidding. Widespread negative public opinion, the popularity of ad blocking technology, and regulatory action in major global markets such as Europe pose the largest threat to the continued use of third-party providers for monetization. While it's unlikely that site owners suddenly strike their own advertising deals or build bespoke ad networks, alternative monetization models like paywalls and experiments like Brave's Basic Attention Token have a real chance of shaking up the third-party ad landscape of the future.
Above all, third-party resources are used to simplify the web development experience. Even previous usage patterns could arguably fall into this pattern as well. Whether analyzing user behavior, communicating with advertisers, or personalizing the user experience, third-party resources are used to make first-party development easier.
-
Hosting providers are the most extreme example of this pattern. Some of these providers even enable anyone on Earth to become a site owner with no technical expertise necessary. They provide hosting of assets, tools to build sites without coding experience, and domain registration services.
-
The remainder of third-party providers also tend to fall into this usage pattern. Whether it's hosting of a utility library such as jQuery for usage by front-end developers cached on Cloudflare's edge servers or a vast library of common fonts served from a popular Google CDN, third-party content is another way to give the site owner one fewer thing to worry about and, maybe, just maybe, make the job of delivering a great experience a little bit easier.
The performance impact of third-party content is neither categorically good nor bad. There are good and bad actors across the spectrum and different category types have varying levels of influence.
-
The good: shared third-party font and stylesheet utilities are, on average, delivered more efficiently than their first-party counterparts.
-
Utilities, CDNs, and Content categories are the brightest spots on the third-party performance landscape. They offer optimized versions of the same sort of content that would otherwise be served from first-party sources. Google Fonts and Typekit serve optimized fonts that are smaller on average than first-party fonts, Cloudflare CDN serves a minified version of open source libraries that might be accidentally served in development mode by some site owners, Google Maps SDK efficiently delivers complex maps that might otherwise be naively shipped as large images.
-
The bad: a very small set of entities represent a very large chunk of JavaScript execution time carrying out narrow set of functionality on pages.
-
Ads, social, hosting, and certain analytics providers represent the largest negative impact on web performance. While hosting providers deliver a majority of a site's content and will understandably have a larger performance impact than other third-party categories, they also serve almost entirely static sites that demand very little JavaScript in most cases that should not justify the volume of script execution time. The other categories hurting performance though have even less of an excuse. They fill very narrow roles on each page they appear on and yet quickly take over a majority of resources. For example, the Facebook "Like" button and associated social widgets take up extraordinarily little screen real estate and are a fraction of most web experiences, and yet the median impact on pages with social third parties is nearly 20% of their total JavaScript execution time. The situation is similar for analytics - tracking libraries do not directly contribute to the perceived user experience, and yet the 90th percentile impact on pages with analytics third parties is 44% of their total JavaScript execution time.
-
The silver lining of such a small number of entities enjoying such large market share is that a very limited and concentrated effort can have an enormous impact on the web as a whole. Performance improvements at just the top few hosting providers can improve 2-3% of all web requests.
The abundance of analytics providers and top-heavy concentration of script execution raises two primary privacy concerns for site visitors: the largest use case of third-parties is for site owners to track their users and a handful of companies receive information on a large swath of web traffic.
-
The interest of site owners in understanding and analyzing user behavior is not malicious on its own, but the widespread and relatively behind-the-scenes nature of web analytics raises valid concerns, and users, companies, and lawmakers have taken notice in recent years with privacy regulation such as GDPR in Europe and the CCPA in California. Ensuring that developers handle user data responsibly, treat the user respectfully, and are transparent with what data is collected is key to keeping analytics the most popular third-party category and maintaining the symbiotic nature of analyzing user behavior to deliver future user value.
-
The top-heavy concentration of script execution is great for the potential impact of performance improvements, but less exciting for the privacy ramifications. 29% of all script execution time across the web is just from scripts on domains owned by Google or Facebook. That's a very large percentage of CPU time that is controlled by just two entities. It's critical to ensure that the same privacy protections held to analytics providers be applied in these other ad, social, and developer utility categories as well.
While the topic of security is covered more in-depth in the Security chapter, the security implications of introducing external dependencies to your site go hand-in-hand with privacy concerns. Allowing third parties to execute arbitrary JavaScript effectively provides them with complete control over your page. When a script can control the DOM and window, it can do everything. Even if code has no security concerns, it can introduce a single point of failure, which has been recognized as a potential problem for some time now.
-
Self-hosting third-party content addresses some of the concerns mentioned here - and others. Additionally with browsers increasingly partitioning HTTP caches the benefits of loading directly from the third-party are increasingly questionable. Perhaps this is a better way to consume third-party content for many use cases, even if it makes measuring its impact more difficult.
Third-party content is everywhere. This is hardly surprising; the entire basis of the web is to allow interconnectedness and linking. In this chapter we have examined third-party content in terms of assets hosted away from the main domain. If we had included self-hosted third-party content (e.g. common open source libraries hosted on the main domain), third-party usage would have been even larger!
-
While reuse in computer technologies is generally a best practice, third parties on the web introduce dependencies that have a considerable impact on the performance, privacy, and security of a page. Self-hosting and careful provider selection can go a long way to mitigate these effects
-
Regardless of the important question of how third-party content is added to a page, the conclusion is the same: third parties are an integral part of the web!
-{% endblock %}
diff --git a/src/templates/en/2019/ebook.html b/src/templates/en/2019/ebook.html
deleted file mode 100644
index 4a8e1dbe919..00000000000
--- a/src/templates/en/2019/ebook.html
+++ /dev/null
@@ -1,11356 +0,0 @@
-{% extends "%s/2019/base_ebook.html" % lang %} {% set metadata = {} %} {% block chapters %} {% set metadata = {"part_number":"I","chapter_number":1,"title":"JavaScript","description":"JavaScript chapter of the 2019 Web Almanac covering how much JavaScript we use on the web, compression, libraries and frameworks, loading, and source maps.","authors":["housseindjirdeh"],"reviewers":["obto","paulcalvano","mathiasbynens"],"translators":null,"discuss":"1756","results":"https://docs.google.com/spreadsheets/d/1kBTglETN_V9UjKqK_EFmFjRexJnQOmLLr-I2Tkotvic/","queries":"01_JavaScript","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"javascript"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
JavaScript is a scripting language that makes it possible to build interactive and complex experiences on the web. This includes responding to user interactions, updating dynamic content on a page, and so forth. Anything involving how a web page should behave when an event occurs is what JavaScript is used for.
-
The language specification itself, along with many community-built libraries and frameworks used by developers around the world, has changed and evolved ever since the language was created in 1995. JavaScript implementations and interpreters have also continued to progress, making the language usable in many environments, not only web browsers.
-
The HTTP Archive crawls millions of pages every month and runs them through a private instance of WebPageTest to store key information of every page. (You can learn more about this in our methodology). In the context of JavaScript, HTTP Archive provides extensive information on the usage of the language for the entire web. This chapter consolidates and analyzes many of these trends.
JavaScript is the most costly resource we send to browsers; having to be downloaded, parsed, compiled, and finally executed. Although browsers have significantly decreased the time it takes to parse and compile scripts, download and execution have become the most expensive stages when JavaScript is processed by a web page.
-
Sending smaller JavaScript bundles to the browser is the best way to reduce download times, and in turn improve page performance. But how much JavaScript do we really use?
Bar chart showing 70 bytes of JavaScript are used in the p10 percentile, 174 bytes for p25, 373 bytes for p50, 693 bytes for p75, and 1,093 bytes for p90
- Figure 1. Distribution of JavaScript bytes per page.
-
-
Figure 1 above shows that we use 373 KB of JavaScript at the 50th percentile, or median. In other words, 50% of all sites ship more than this much JavaScript to their users.
-
Looking at these numbers, it's only natural to wonder if this is too much JavaScript. However in terms of page performance, the impact entirely depends on network connections and devices used. Which brings us to our next question: how much JavaScript do we ship when we compare mobile and desktop clients?
Bar chart showing 76 bytes/65 bytes of JavaScript are used in the p10 percentile on desktop and mobile respectively, 186/164 bytes for p25, 391/359 bytes for p50, 721/668 bytes for p75, and 1,131/1,060 bytes for p90.
- Figure 2. Distribution of JavaScript per page by device.
-
-
At every percentile, we're sending slightly more JavaScript to desktop devices than we are to mobile.
After being parsed and compiled, JavaScript fetched by the browser needs to processed (or executed) before it can be utilized. Devices vary, and their computing power can significantly affect how fast JavaScript can be processed on a page. What are the current processing times on the web?
-
We can get an idea by analyzing main thread processing times for V8 at different percentiles:
Bar chart showing 141 ms/377 ms of processing time is used in the p10 percentile on desktop and mobile respectively, 352/988 ms for p25, 849/2,437 ms for p50, 1,850/5,518 ms for p75, and 3,543/10,735 ms for p90.
- Figure 3. V8 Main thread processing times by device.
-
-
At every percentile, processing times are longer for mobile web pages than on desktop. The median total main thread time on desktop is 849 ms, while mobile is at a larger number: 2,437 ms.
-
Although this data shows how much longer it can take for a mobile device to process JavaScript compared to a more powerful desktop machine, mobile devices also vary in terms of computing power. The following chart shows how processing times on a single web page can vary significantly depending on the mobile device class.
Bar chart showing 3 different devices: at the top a Pixel 3 has small amount on both the main thread and the worker thread of less than 400ms. For a Moto G4 it is approximately 900 ms on main thread and a further 300 ms on worker thread. And the final bar is an Alcatel 1X 5059D with over 2,000 ms on the main thread and over 500 ms on worker thread.
One avenue worth exploring when trying to analyze the amount of JavaScript used by web pages is the number of requests shipped. With HTTP/2, sending multiple smaller chunks can improve page load over sending a larger, monolithic bundle. If we also break it down by device client, how many requests are being fetched?
Bar chart showing 4/4 requests for desktop and mobile respectively are used in the p10 percentile, 10/9 in p25, 19/18 in p50, 33/32 in p75 and 53/52 in p90.
- Figure 5. Distribution of total JavaScript requests.
-
-
At the median, 19 requests are sent for desktop and 18 for mobile.
Of the results analyzed so far, the entire size and number of requests were being considered. In a majority of websites however, a significant portion of the JavaScript code fetched and used comes from third-party sources.
-
Third-party JavaScript can come from any external, third-party source. Ads, analytics and social media embeds are all common use-cases for fetching third-party scripts. So naturally, this brings us to our next question: how many requests sent are third-party instead of first-party?
Bar chart showing 0/1 request on desktop are first-party and third-party respectively in p10 percentile, 2/4 in p25, 6/10 in p50, 13/21 in p75, and 24/38 in p90.
- Figure 6. Distribution of first and third-party scripts on desktop.
-
-
-
-
-
-
-
Bar chart showing 0/1 request on mobile are first-party and third-party respectively in p10 percentile, 2/3 in p25, 5/9 in p50, 13/20 in p75, and 23/36 in p90.
- Figure 7. Distribution of first and third party scripts on mobile.
-
-
For both mobile and desktop clients, more third-party requests are sent than first-party at every percentile. If this seems surprising, let's find out how much actual code shipped comes from third-party vendors.
Bar chart showing 0/17 bytes of JavaScript are downloaded on desktop for first-party and third-party requests respectively in the p10 percentile, 11/62 in p25, 89/232 in p50, 200/525 in p75, and 404/900 in p90.
- Figure 8. Distribution of total JavaScript downloaded on desktop.
-
-
-
-
-
-
-
Bar chart showing 0/17 bytes of JavaScript are downloaded on mobile for first-party and third-party requests respectively in the p10 percentile, 6/54 in p25, 83/217 in p50, 189/477 in p75, and 380/827 in p90.
- Figure 9. Distribution of total JavaScript downloaded on mobile.
-
-
At the median, 89% more third-party code is used than first-party code authored by the developer for both mobile and desktop. This clearly shows that third-party code can be one of the biggest contributors to bloat. For more information on the impact of third parties, refer to the "Third Parties" chapter.
In the context of browser-server interactions, resource compression refers to code that has been modified using a data compression algorithm. Resources can be compressed statically ahead of time or on-the-fly as they are requested by the browser, and for either approach the transferred resource size is significantly reduced which improves page performance.
-
There are multiple text-compression algorithms, but only two are mostly used for the compression (and decompression) of HTTP network requests:
-
-
Gzip (gzip): The most widely used compression format for server and client interactions
-
Brotli (br): A newer compression algorithm aiming to further improve compression ratios. 90% of browsers support Brotli encoding.
-
-
Compressed scripts will always need to be uncompressed by the browser once transferred. This means its content remains the same and execution times are not optimized whatsoever. Resource compression, however, will always improve download times which also is one of the most expensive stages of JavaScript processing. Ensuring JavaScript files are compressed correctly can be one of the most significant factors in improving site performance.
-
How many sites are compressing their JavaScript resources?
Bar chart showing 67%/65% of JavaScript resources are compressed with gzip on desktop and mobile respectively, and 15%/14% are compressed using Brotli.
- Figure 10. Percentage of sites compressing JavaScript resources with gzip or brotli.
-
-
The majority of sites are compressing their JavaScript resources. Gzip encoding is used on ~64-67% of sites and Brotli on ~14%. Compression ratios are similar for both desktop and mobile.
-
For a deeper analysis on compression, refer to the "Compression" chapter.
Open source code, or code with a permissive license that can be accessed, viewed and modified by anyone. From tiny libraries to entire browsers, such as Chromium and Firefox, open source code plays a crucial role in the world of web development. In the context of JavaScript, developers rely on open source tooling to include all types of functionality into their web page. Regardless of whether a developer decides to use a small utility library or a massive framework that dictates the architecture of their entire application, relying on open-source packages can make feature development easier and faster. So which JavaScript open-source libraries are used the most?
-
-
-
-
-
-
-
Library
-
Desktop
-
Mobile
-
-
-
-
-
jQuery
-
85.03%
-
83.46%
-
-
-
jQuery Migrate
-
31.26%
-
31.68%
-
-
-
jQuery UI
-
23.60%
-
21.75%
-
-
-
Modernizr
-
17.80%
-
16.76%
-
-
-
FancyBox
-
7.04%
-
6.61%
-
-
-
Lightbox
-
6.02%
-
5.93%
-
-
-
Slick
-
5.53%
-
5.24%
-
-
-
Moment.js
-
4.92%
-
4.29%
-
-
-
Underscore.js
-
4.20%
-
3.82%
-
-
-
prettyPhoto
-
2.89%
-
3.09%
-
-
-
Select2
-
2.78%
-
2.48%
-
-
-
Lodash
-
2.65%
-
2.68%
-
-
-
Hammer.js
-
2.28%
-
2.70%
-
-
-
YUI
-
1.84%
-
1.50%
-
-
-
Lazy.js
-
1.26%
-
1.56%
-
-
-
Fingerprintjs
-
1.21%
-
1.32%
-
-
-
script.aculo.us
-
0.98%
-
0.85%
-
-
-
Polyfill
-
0.97%
-
1.00%
-
-
-
Flickity
-
0.83%
-
0.92%
-
-
-
Zepto
-
0.78%
-
1.17%
-
-
-
Dojo
-
0.70%
-
0.62%
-
-
-
-
-
- Figure 11. Top JavaScript libraries on desktop and mobile.
-
-
jQuery, the most popular JavaScript library ever created, is used in 85.03% of desktop pages and 83.46% of mobile pages. The advent of many Browser APIs and methods, such as Fetch and querySelector, standardized much of the functionality provided by the library into a native form. Although the popularity of jQuery may seem to be declining, why is it still used in the vast majority of the web?
-
There are a number of possible reasons:
-
-
WordPress, which is used in more than 30% of sites, includes jQuery by default.
-
Switching from jQuery to a newer client-side library can take time depending on how large an application is, and many sites may consist of jQuery in addition to newer client-side libraries.
-
-
Other top used JavaScript libraries include jQuery variants (jQuery migrate, jQuery UI), Modernizr, Moment.js, Underscore.js and so on.
As mentioned in our methodology, the third-party detection library used in HTTP Archive (Wappalyzer) has a number of limitations with regards to how it detects certain tools. There is an open issue to improve detection of JavaScript libraries and frameworks, which will have impacted the results presented here.
-
In the past number of years, the JavaScript ecosystem has seen a rise in open-source libraries and frameworks to make building single-page applications (SPAs) easier. A single-page application is characterized as a web page that loads a single HTML page and uses JavaScript to modify the page on user interaction instead of fetching new pages from the server. Although this remains to be the main premise of single-page applications, different server-rendering approaches can still be used to improve the experience of such sites. How many sites use these types of frameworks?
Although there has been a shift towards a component-based model, many older frameworks that follow the MVC paradigm (AngularJS, Backbone.js, Ember) are still being used in thousands of pages. However, React, Vue and Angular are the most popular component-based frameworks (Zone.js is a package that is now part of Angular core).
JavaScript modules, or ES modules, are supported in all major browsers. Modules provide the capability to create scripts that can import and export from other modules. This allows anyone to build their applications architected in a module pattern, importing and exporting wherever necessary, without relying on third-party module loaders.
-
To declare a script as a module, the script tag must get the type="module" attribute:
-
<script type="module" src="main.mjs"></script>
-
How many sites use type="module" for scripts on their page?
Bar chart showing 0.6% of sites on desktop use 'type=module', and 0.8% of sites on mobile.
- Figure 13. Percentage of sites utilizing type=module.
-
-
Browser-level support for modules is still relatively new, and the numbers here show that very few sites currently use type="module" for their scripts. Many sites are still relying on module loaders (2.37% of all desktop sites use RequireJS for example) and bundlers (webpack for example) to define modules within their codebase.
-
If native modules are used, it's important to ensure that an appropriate fallback script is used for browsers that do not yet support modules. This can be done by including an additional script with a nomodule attribute.
-
<script nomodule src="fallback.js"></script>
-
When used together, browsers that support modules will completely ignore any scripts containing the nomodule attribute. On the other hand, browsers that do not yet support modules will not download any scripts with type="module". Since they do not recognize nomodule either, they will download scripts with the attribute normally. Using this approach can allow developers to send modern code to modern browsers for faster page loads. So, how many sites use nomodule for scripts on their page?
Preload and prefetch are resource hints which enable you to aid the browser in determining what resources need to be downloaded.
-
-
Preloading a resource with <link rel="preload"> tells the browser to download this resource as soon as possible. This is especially helpful for critical resources which are discovered late in the page loading process (e.g., JavaScript located at the bottom of your HTML) and are otherwise downloaded last.
-
Using <link rel="prefetch"> tells the browser to take advantage of any idle time it has to fetch these resources needed for future navigations
-
-
So, how many sites use preload and prefetch directives?
JavaScript continues to evolve as a language. A new version of the language standard itself, known as ECMAScript, is released every year with new APIs and features passing proposal stages to become a part of the language itself.
-
With HTTP Archive, we can take a look at any newer API that is supported (or is about to be) and see how widespread its usage is. These APIs may already be used in browsers that support them or with an accompanying polyfill to make sure they still work for every user.
Bar chart showing 25.5%/36.2% of sites on desktop and mobile respectivdely use WeakMap, 6.1%/17.2% use WeakSet, 3.9%/14.0% use Intl, 3.9%/4.4% use Proxy, 0.4%/0.4% use Atomics, and 0.2%/0.2% use SharedArrayBuffer.
In many build systems, JavaScript files undergo minification to minimize its size and transpilation for newer language features that are not yet supported in many browsers. Moreover, language supersets like TypeScript compile to an output that can look noticeably different from the original source code. For all these reasons, the final code served to the browser can be unreadable and hard to decipher.
-
A source map is an additional file accompanying a JavaScript file that allows a browser to map the final output to its original source. This can make debugging and analyzing production bundles much simpler.
-
Although useful, there are a number of reasons why many sites may not want to include source maps in their final production site, such as choosing not to expose complete source code to the public. So how many sites actually include sourcemaps?
Bar chart showing 18% of desktop sites and 17% of mobile sites use source maps.
- Figure 18. Percentage of sites using source maps.
-
-
For both desktop and mobile pages, the results are about the same. 17-18% include a source map for at least one script on the page (detected as a first-party script with sourceMappingURL).
The JavaScript ecosystem continues to change and evolve every year. Newer APIs, improved browser engines, and fresh libraries and frameworks are all things we can expect to happen indefinitely. HTTP Archive provides us with valuable insight on how sites in the wild use the language.
-
Without JavaScript, the web would not be where it is today, and all the data gathered for this article only proves this.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":2,"title":"CSS","description":"CSS chapter of the 2019 Web Almanac covering color, units, selectors, layout, typography and fonts, spacing, decoration, animation, and media queries.","authors":["una","argyleink"],"reviewers":["meyerweb","huijing"],"translators":null,"discuss":"1757","results":"https://docs.google.com/spreadsheets/d/1uFlkuSRetjBNEhGKWpkrXo4eEIsgYelxY-qR9Pd7QpM/","queries":"02_CSS","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-06T00:00:00.000Z","chapter":"css"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Cascading Style Sheets (CSS) are used to paint, format, and layout web pages. Their capabilities span concepts as simple as text color to 3D perspective. It also has hooks to empower developers to handle varying screen sizes, viewing contexts, and printing. CSS helps developers wrangle content and ensure it's adapting properly to the user.
-
When describing CSS to those not familiar with web technology, it can be helpful to think of it as the language to paint the walls of the house; describing the size and position of windows and doors, as well as flourishing decorations such as wallpaper or plant life. The fun twist to that story is that depending on the user walking through the house, a developer can adapt the house to that specific user's preferences or contexts!
-
In this chapter, we'll be inspecting, tallying, and extracting data about how CSS is used across the web. Our goal is to holistically understand what features are being used, how they're used, and how CSS is growing and being adopted.
-
Ready to dig into the fascinating data?! Many of the following numbers may be small, but don't mistake them as insignificant! It can take many years for new things to saturate the web.
Hex is the most popular way to describe color by far, with 93% usage, followed by RGB, and then HSL. Interestingly, developers are taking full advantage of the alpha-transparency argument when it comes to these color types: HSLA and RGBA are far more popular than HSL and RGB, with almost double the usage! Even though the alpha-transparency was added later to the web spec, HSLA and RGBA are supported as far back as IE9, so you can go ahead and use them, too!
Bar chart showing the adoption of HSL, HSLA, RGB, RGBA, and hex color formats. Hex is used on 93% of desktop pages, RGBA on 83%, RGB on 22%, HSLA 19%, and HSL 1%. Desktop and mobile adoption is similar for all color formats except HSL, for which mobile adoption is 9% (9 times higher).
There are 148 named CSS colors, not including the special values transparent and currentcolor. You can use these by their string name for more readable styling. The most popular named colors are black and white, unsurprisingly, followed by red and blue.
Language is interestingly inferred via color as well. There are more instances of the American-style "gray" than the British-style "grey". Almost every instance of gray colors (gray, lightgray, darkgray, slategray, etc.) had nearly double the usage when spelled with an "a" instead of an "e". If gr[a/e]ys were combined, they would rank higher than blue, solidifying themselves in the #4 spot. This could be why silver is ranked higher than grey with an "e" in the charts!
How many different font colors are used across the web? So this isn't the total number of unique colors; rather, it's how many different colors are used just for text. The numbers in this chart are quite high, and from experience, we know that without CSS variables, spacing, sizes and colors can quickly get away from you and fragment into lots of tiny values across your styles. These numbers reflect a difficulty of style management, and we hope this helps create some perspective for you to bring back to your teams or projects. How can you reduce this number into a manageable and reasonable amount?
Distribution showing the 10, 25, 50, 75, and 90th percentiles of colors per desktop and mobile page. On desktop the distribution is 8, 22, 48, 83, and 131. Mobile pages tend to have more colors by 1-10.
Well, we got curious here and wanted to inspect how many duplicate colors are present on a page. Without a tightly managed reusable class CSS system, duplicates are quite easy to create. It turns out that the median has enough duplicates that it could be worth doing a pass to unify them with custom properties.
Bar chart showing the distribution of colors per page. The median desktop page has 24 duplicate colors. The 10th percentile is 4 duplicate colors and the 90th percentile is 62. Desktop and mobile distributions are similar.
- Figure 4. Distribution of duplicate colors per page.
-
-
In CSS, there are many different ways to achieve the same visual result using different unit types: rem, px, em, ch, or even cm! So which unit types are most popular?
Bar chart of the popularity of various unit types. px and em are used on at over 90% of pages. rem is the next most popular unit type on 40% of pages and the popularity quickly falls for the remaining unit types.
Unsurprisingly, In Figure 5 above, px is the most used unit type, with about 95% of web pages using pixels in some form or another (this could be element sizing, font size, and so on). However, the em unit is almost as popular, with about 90% usage. This is over 2x more popular than the rem unit, which has only 40% frequency in web pages. If you're wondering what the difference is, em is based on the parent font size, while rem is based on the base font size set to the page. It doesn't change per-component like em could, and thus allows for adjustment of all spacing evenly.
-
When it comes to units based on physical space, the cm (or centimeter) unit is the most popular by far, followed by in (inches), and then Q. We know these types of units are specifically useful for print stylesheets, but we didn't even know the Q unit existed until this survey! Did you?
-
An earlier version of this chapter discussed the unexpected popularity of the Q unit. Thanks to the community discussion surrounding this chapter, we've identified that this was a bug in our analysis and have updated Figure 5 accordingly.
We saw larger differences in unit types when it comes to mobile and desktop usage for viewport-based units. 36.8% of mobile sites use vh (viewport height), while only 31% of desktop sites do. We also found that vh is more common than vw (viewport width) by about 11%. vmin (viewport minimum) is more popular than vmax (viewport maximum), with about 8% usage of vmin on mobile while vmax is only used by 1% of websites.
Custom properties are what many call CSS variables. They're more dynamic than a typical static variable though! They're very powerful and as a community we're still discovering their potential.
-
-
5%
- Figure 6. Percent of pages using custom properties.
-
-
We felt like this was exciting information, since it shows healthy growth of one of our favorite CSS additions. They were available in all major browsers since 2016 or 2017, so it's fair to say they're fairly new. Many folks are still transitioning from their CSS preprocessor variables to CSS custom properties. We estimate it'll be a few more years until custom properties are the norm.
CSS has a few ways to find elements on the page for styling, so let's put IDs and classes against each other to see which is more prevalent! The results shouldn't be too surprising: classes are more popular!
Bar chart showing the adoption of ID and class selector types. Classes are used on 95% of desktop and mobile pages. IDs are used on 89% of desktop and 87% of mobile pages.
- Figure 7. Popularity of selector types per page.
-
-
A nice follow up chart is this one, showing that classes take up 93% of the selectors found in a stylesheet.
Bar chart showing that 94% of selectors include the class selector for desktop and mobile, while 7% of desktop selectors include the ID selector (8% for mobile).
- Figure 8. Popularity of selector types per selector.
-
-
CSS has some very powerful comparison selectors. These are selectors like [target="_blank"], [attribute^="value"], [title~="rad"], [attribute$="-rad"] or [attribute*="value"]. Do you use them? Think they're used a lot? Let's compare how those are used with IDs and classes across the web.
Bar chart showing the popularity of operators used by ID attribute selectors. About 4% of desktop and mobile pages use star-equals and caret-equals. 1% of pages use equals and dollar-equals. 0% use tilde-equals.
- Figure 9. Popularity of operators per ID attribute selector.
-
-
-
-
-
-
-
Bar chart showing the popularity of operators used by class attribute selectors. 57% of pages use star-equals. 36% use caret-equals. 1% use equals and dollar-equals. 0% use tilde-equals.
- Figure 10. Popularity of operators per class attribute selector.
-
-
These operators are much more popular with class selectors than IDs, which feels natural since a stylesheet usually has fewer ID selectors than class selectors, but still neat to see the uses of all these combinations.
With the rise of OOCSS, atomic, and functional CSS strategies which can compose 10 or more classes on an element to achieve a design look, perhaps we'd see some interesting results. The query came back quite unexciting, with the median on mobile and desktop being 1 class per element.
-
-
1
- Figure 11. The median number of class names per class attribute (desktop and mobile).
-
-
Flexbox is a container style that directs and aligns its children; that is, it helps with layout in a constraint-based way. It had a quite rocky beginning on the web, as its specification went through two or three quite drastic changes between 2010 and 2013. Fortunately, it settled and was implemented across all browsers by 2014. Given that history, it had a slow adoption rate, but it's been a few years since then! It's quite popular now and has many articles about it and how to leverage it, but it's still new in comparison to other layout tactics.
Like flexbox, grid too went through a few spec alternations early on in its lifespan, but without changing implementations in publicly-deployed browsers. Microsoft had grid in the first versions of Windows 8, as the primary layout engine for its horizontally scrolling design style. It was vetted there first, transitioned to the web, and then hardened by the other browsers until its final release in 2017. It had a very successful launch in that nearly all browsers released their implementations at the same time, so web developers just woke up one day to superb grid support. Today, at the end of 2019, grid still feels like a new kid on the block, as folks are still awakening to its power and capabilities.
This shows just how little the web development community has exercised and explored their latest layout tool. We look forward to the eventual takeover of grid as the primary layout engine folks lean on when building a site. For us authors, we love writing grid: we typically reach for it first, then dial our complexity back as we realize and iterate on layout. It remains to be seen what the rest of the world will do with this powerful CSS feature over the next few years.
The web and CSS are international platform features, and writing modes offer a way for HTML and CSS to indicate a user's preferred reading and writing direction within our elements.
Bar chart showing the popularity of direction values ltr and rtl. ltr is used by 32% of desktop pages and 40% of mobile pages. rtl is used by 32% of desktop pages and 36% of mobile pages.
Distribution of the number of web fonts loaded per page. On desktop the 10, 25, 50, 75, and 90th percentiles are: 0, 1, 3, 6, and 9. This slightly higher than the mobile distribution which is one fewer font in the 75th and 90th percentiles.
- Figure 15. Distribution of the number of web fonts loaded per page.
-
-
A natural follow up to the inquiry of total number of fonts per page, is: what fonts are they?! Designers, tune in, because you'll now get to see if your choices are in line with what's popular or not.
Bar chart of the most popular fonts. Among desktop pages, they are Open Sans (24%), Roboto (15%), Montserrat (5%), Source Sans Pro (4%), Noto Sans JP (3%), and Lato (3%). On mobile the most notable differences are that Open Sans is used 22% of the time (down from 24%) and Roboto is used 19% of the time (up from 15%).
Open Sans is a huge winner here, with nearly 1 in 4 CSS @font-family declarations specifying it. We've definitely used Open Sans in projects at agencies.
-
It's also interesting to note the differences between desktop and mobile adoption. For example, mobile pages use Open Sans slightly less often than desktop. Meanwhile, they also use Roboto slightly more often.
This is a fun one, because if you asked a user how many font sizes they feel are on a page, they'd generally return a number of 5 or definitely less than 10. Is that reality though? Even in a design system, how many font sizes are there? We queried the web and found the median to be 40 on mobile and 38 on desktop. Might be time to really think hard about custom properties or creating some reusable classes to help you distribute your type ramp.
Bar chart showing the distribution of distinct font sizes per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 8, 20, 40, 66, and 92 font sizes. The desktop distribution diverges from mobile at the 75th percentile, where it is larger by 7 to 13 distinct sizes.
- Figure 17. Distribution of the number of distinct font sizes per page.
-
-
A margin is the space outside of elements, like the space you demand when you push your arms out from yourself. This often looks like the spacing between elements, but is not limited to that effect. In a website or app, spacing plays a huge role in UX and design. Let's see how much margin spacing code goes into a stylesheet, shall we?
Bar chart showing the distribution of distinct margin values per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 12, 47, 96, 167, and 248 distinct margin values. The desktop distribution diverges from mobile at the 75th percentile, where it is smaller by 12 to 31 distinct values.
- Figure 18. Distribution of the number of distinct margin values per page.
-
-
Quite a lot, it seems! The median desktop page has 96 distinct margin values and 104 on mobile. That makes for a lot of unique spacing moments in your design. Curious how many margins you have in your site? How can we make all this whitespace more manageable?
- Figure 19. Percent of desktop and mobile pages that include logical properties.
-
-
We estimate that the hegemony of margin-left and padding-top is of limited duration, soon to be supplemented by their writing direction agnostic, successive, logical property syntax. While we're optimistic, current usage is quite low at 0.67% usage on desktop pages. To us, this feels like a habit change we'll need to develop as an industry, while hopefully training new developers to use the new syntax.
Vertical layering, or stacking, can be managed with z-index in CSS. We were curious how many different values folks use in their sites. The range of what z-index accepts is theoretically infinite, bounded only by a browser's variable size limitations. Are all those stack positions used? Let's see!
Bar chart showing the distribution of distinct z-index values per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 1, 7, 16, 26, and 36 distinct z-index values. The desktop distribution is much higher than mobile, by as many as 16 distinct values at the 90th percentile.
- Figure 20. Distribution of the number of distinct z-index values per page.
-
-
From our work experience, any number of 9's seemed to be the most popular choice. Even though we taught ourselves to use the lowest number possible, that's not the communal norm. So what is then?! If folks need things on top, what are the most popular z-index numbers to pass in? Put your drink down; this one is funny enough you might lose it.
Scatterplot of all known z-index values and the number of times they're used, for both desktop and mobile. 1 and 2 are the most frequently used, but the rest of the popular values explode in orders of magnitude: 10, 100, 1,000, and so on all the way to numbers with hundreds of digits.
- Figure 21. Most frequently used z-index values.
-
-
-
Filters are a fun and great way to modify the pixels the browser intends to draw to the screen. It's a post-processing effect that is done against a flat version of the element, node, or layer that it's being applied to. Photoshop made them easy to use, then Instagram made them accessible to the masses through bespoke, stylized combinations. They've been around since about 2012, there are 10 of them, and they can be combined to create unique effects.
-
-
78%
- Figure 23. Percent of pages that include a stylesheet with the filter property.
-
-
We were excited to see that 78% of stylesheets contain the filter property! That number was also so high it seemed a little fishy, so we dug in and sought to explain the high number. Because let's be honest, filters are neat, but they don't make it into all of our applications and projects. Unless!
-
Upon further investigation, we discovered FontAwesome's stylesheet comes with some filter usage, as well as a YouTube embed. Therefore, we believe filter snuck in the back door by piggybacking onto a couple very popular stylesheets. We also believe that -ms-filter presence could have been included as well, contributing to the high percent of use.
Blend modes are similar to filters in that they are a post-processing effect that are run against a flat version of their target elements, but are unique in that they are concerned with pixel convergence. Said another way, blend modes are how 2 pixels should impact each other when they overlap. Whichever element is on the top or the bottom will affect the way that the blend mode manipulates the pixels. There are 16 blend modes -- let's see which ones are the most popular.
-
-
8%
- Figure 24. Percent of pages that include a stylesheet with the *-blend-mode property.
-
-
Overall, usage of blend modes is much lower than of filters, but is still enough to be considered moderately used.
-
In a future edition of the Web Almanac, it would be great to drill down into blend mode usage to get an idea of the exact modes developers are using, like multiply, screen, color-burn, lighten, etc.
CSS has this awesome interpolation power that can be simply used by just writing a single rule on how to transition those values. If you're using CSS to manage states in your app, how often are you employing transitions to do the task? Let's query the web!
Bar chart showing the distribution of transitions per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 0, 2, 16, 49, and 118 transitions. The desktop distribution is much lower than mobile, by as many as 77 transitions at the 90th percentile.
- Figure 25. Distribution of the number of transitions per page.
-
-
That's pretty good! We did see animate.css as a popular library to include, which brings in a ton of transition animations, but it's still nice to see folks are considering transitioning their UIs.
CSS keyframe animations are a great solution for your more complex animations or transitions. They allow you to be more explicit which provides higher control over the effects. They can be small, like one keyframe effect, or be large with many many keyframe effects composed into a robust animation. The median number of keyframe animations per page is much lower than CSS transitions.
Bar chart showing the distribution of keyframes per page. For mobile pages the 10, 25, 50, 75, and 90th percentiles are: 0, 0, 3, 18, and 76 keyframes. The mobile distribution is slightly higher than desktop by 6 keyframes at the 75th and 90th percentiles.
- Figure 26. Distribution of the number of keyframes per page.
-
-
Media queries let CSS hook into various system-level variables in order to adapt appropriately for the visiting user. Some of these queries could handle print styles, projector screen styles, and viewport/screen size. For a long time, media queries were primarily leveraged for their viewport knowledge. Designers and developers could adapt their layouts for small screens, large screens, and so forth. Later, the web started bringing more and more capabilities and queries, meaning media queries can now manage accessibility features on top of viewport features.
-
A good place to start with Media Queries, is just about how many are used per page? How many different moments or contexts does the typical page feel they want to respond to?
Bar chart showing the distribution of media queries per page. For desktop pages the 10, 25, 50, 75, and 90th percentiles are: 0, 3, 14, 27, and 43 keyframes. The desktop distribution is similar to the mobile distribution.
- Figure 27. Distribution of the number of media queries per page.
-
-
For viewport media queries, any type of CSS unit can be passed into the query expression for evaluation. In earlier days, folks would pass em and px into the query, but more units were added over time, making us very curious about what types of sizes were commonly found across the web. We assume most media queries will follow popular device sizes, but instead of assuming, let's look at the data!
Bar chart of the most popular media query snap points. 768px and 767px are the most popular at 23% and 16%, respectively. The list drops off quickly after that, with 992px used 6% of the time and 1200px used 4% of the time. Desktop and mobile have similar usage.
- Figure 28. Most frequently used snap points used in media queries.
-
-
Figure 28 above shows that part of our assumptions were correct: there's certainly a high amount of phone specific sizes in there, but there's also some that aren't. It's interesting also how it's very pixel dominant, with a few trickling entries using em beyond the scope of this chart.
The most popular query value from the popular breakpoint sizes looks to be 768px, which made us curious. Was this value primarily used to switch to a portrait layout, since it could be based on an assumption that 768px represents the typical mobile portrait viewport? So we ran a follow up query to see the popularity of using the portrait and landscape modes:
Bar chart showing the adoption of portrait and landscape orientation modes of media queries. 31% of pages specify landscape, 8% specify portrait, and 7% specify both. Adoption is the same for desktop and mobile pages.
- Figure 29. Adoption of media query orientation modes.
-
-
Interestingly, portrait isn't used very much, whereas landscape is used much more. We can only assume that 768px has been reliable enough as the portrait layout case that it's reached for much less. We also assume that folks on a desktop computer, testing their work, can't trigger portrait to see their mobile layout as easily as they can just squish the browser. Hard to tell, but the data is fascinating.
In the width and height media queries we've seen so far, pixels look like the dominant unit of choice for developers looking to adapt their UI to viewports. We wanted to exclusively query this though, and really take a look at the types of units folks use. Here's what we found.
When folks write a media query, are they typically checking for a viewport that's over or under a specific range, or both, checking if it's between a range of sizes? Let's ask the web!
Websites feel like digital paper, right? As users, it's generally known that you can just hit print from your browser and turn that digital content into physical content. A website isn't required to change itself for that use case, but it can if it wants to! Lesser known is the ability to adjust your website in the use case of it being read by a tool or robot. So just how often are these features taken advantage of?
Bar chart showing 35% of desktop pages using the "all" media query type, 46% using print, 72% using screen, and 0% using speech. Adoption is lower by about 5 percentage points for desktop compared to mobile.
- Figure 32. Adoption of the all, print, screen, and speech types of media queries.
-
-
How many stylesheets do you reference from your home page? How many from your apps? Do you serve more or less to mobile vs desktop? Here's a chart of everyone else!
Distribution of the number of stylesheets loaded per page. Desktop and mobile have identical distributions with 10, 25, 50, 75, and 90th percentiles: 1, 3, 6, 12, and 20 stylesheets per page.
- Figure 33. Distribution of the number of stylesheets loaded per page.
-
-
What do you name your stylesheets? Have you been consistent throughout your career? Have you slowly converged or consistently diverged? This chart shows a small glimpse into library popularity, but also a large glimpse into popular names of CSS files.
-
-
-
-
-
-
-
Stylesheet name
-
Desktop
-
Mobile
-
-
-
-
-
style.css
-
2.43%
-
2.55%
-
-
-
font-awesome.min.css
-
1.86%
-
1.92%
-
-
-
bootstrap.min.css
-
1.09%
-
1.11%
-
-
-
BfWyFJ2Rl5s.css
-
0.67%
-
0.66%
-
-
-
style.min.css?ver=5.2.2
-
0.64%
-
0.67%
-
-
-
styles.css
-
0.54%
-
0.55%
-
-
-
style.css?ver=5.2.2
-
0.41%
-
0.43%
-
-
-
main.css
-
0.43%
-
0.39%
-
-
-
bootstrap.css
-
0.40%
-
0.42%
-
-
-
font-awesome.css
-
0.37%
-
0.38%
-
-
-
style.min.css
-
0.37%
-
0.37%
-
-
-
styles__ltr.css
-
0.38%
-
0.35%
-
-
-
default.css
-
0.36%
-
0.36%
-
-
-
reset.css
-
0.33%
-
0.37%
-
-
-
styles.css?ver=5.1.3
-
0.32%
-
0.35%
-
-
-
custom.css
-
0.32%
-
0.33%
-
-
-
print.css
-
0.32%
-
0.28%
-
-
-
responsive.css
-
0.28%
-
0.31%
-
-
-
-
-
- Figure 34. Most frequently used stylesheet names.
-
-
Look at all those creative file names! style, styles, main, default, all. One stood out though, do you see it? BfWyFJ2Rl5s.css takes the number four spot for most popular. We went researching it a bit and our best guess is that it's related to Facebook "like" buttons. Do you know what that file is? Leave a comment, because we'd love to hear the story.
Distribution of the number of stylesheet bytes loaded per page. The desktop page's 10, 25, 50, 75, and 90th percentiles are: 8, 26, 62, 129, and 240 KB. The desktop distribution is slightly higher than the mobile distribution by 5 to 10 KB.
- Figure 35. Distribution of the number of stylesheet bytes (KB) loaded per page.
-
-
See the Page Weight chapter for a more in-depth look at the number of bytes websites are loading for each content type.
It's common, popular, convenient, and powerful to reach for a CSS library to kick start a new project. While you may not be one to reach for a library, we've queried the web in 2019 to see which are leading the pack. If the results astound you, like they did us, I think it's an interesting clue to just how small of a developer bubble we can live in. Things can feel massively popular, but when the web is inquired, reality is a bit different.
-
-
-
-
-
-
-
Library
-
Desktop
-
Mobile
-
-
-
-
-
Bootstrap
-
27.8%
-
26.9%
-
-
-
animate.css
-
6.1%
-
6.4%
-
-
-
ZURB Foundation
-
2.5%
-
2.6%
-
-
-
UIKit
-
0.5%
-
0.6%
-
-
-
Material Design Lite
-
0.3%
-
0.3%
-
-
-
Materialize CSS
-
0.2%
-
0.2%
-
-
-
Pure CSS
-
0.1%
-
0.1%
-
-
-
Angular Material
-
0.1%
-
0.1%
-
-
-
Semantic-ui
-
0.1%
-
0.1%
-
-
-
Bulma
-
0.0%
-
0.0%
-
-
-
Ant Design
-
0.0%
-
0.0%
-
-
-
tailwindcss
-
0.0%
-
0.0%
-
-
-
Milligram
-
0.0%
-
0.0%
-
-
-
Clarity
-
0.0%
-
0.0%
-
-
-
-
-
- Figure 36. Percent of pages that include a given CSS library.
-
-
This chart suggests that Bootstrap is a valuable library to know to assist with getting a job. Look at all the opportunity there is to help! It's also worth noting that this is a positive signal chart only: the math doesn't add up to 100% because not all sites are using a CSS framework. A little bit over half of all sites are not using a known CSS framework. Very interesting, no?!
CSS reset utilities intend to normalize or create a baseline for native web elements. In case you didn't know, each browser serves its own stylesheet for all HTML elements, and each browser gets to make their own unique decisions about how those elements look or behave. Reset utilities have looked at these files, found their common ground (or not), and ironed out any differences so you as a developer can style in one browser and have reasonable confidence it will look the same in another.
-
So let's take a peek at how many sites are using one! Their existence seems quite reasonable, so how many folks agree with their tactics and use them in their sites?
Bar chart showing the adoption of three CSS reset utilities: Normalize.css (33%), Reset CSS (3%), and Pure CSS (0%). There is no difference in adoption across desktop and mobile pages.
- Turns out that about one-third of the web is using normalize.css, which could be considered a more gentle approach to the task then a reset is. We looked a little deeper, and it turns out that Bootstrap includes normalize.css, which likely accounts for a massive amount of its usage. It's worth noting as well that normalize.css has more adoption than Bootstrap, so there are plenty of folks using it on its own.
-
CSS @supports is a way for the browser to check whether a particular property-value combination is parsed as valid, and then apply styles if the check returns as true.
Bar chart showing the popularity of @import and @supports "at" rules. On desktop, @import is used on 28% of pages and @supports is used on 31%. For mobile @import is used on 26% of pages and @supports is used on 29%.
Considering @supports was implemented across most browsers in 2013, it's not too surprising to see a high amount of usage and adoption. We're impressed at the mindfulness of developers here. This is considerate coding! 30% of all websites are checking for some display related support before using it.
-
An interesting follow up to this is that there's more usage of @supports than @imports! We did not expect that! @import has been in browsers since 1994.
There is so much more here to datamine! Many of the results surprised us, and we can only hope that they've surprised you as well. This surprising data set made the summarizing very fun, and left us with lots of clues and trails to investigate if we want to hunt down the reasons why some of the results are the way they are.
-
Which results did you find the most alarming? Which results make you head to your codebase for a quick query?
-
We felt the biggest takeaway from these results is that custom properties offer the most bang for your buck in terms of performance, DRYness, and scalability of your stylesheets. We look forward to scrubbing the internet's stylesheets again, hunting for new datums and provocative chart treats. Reach out to @una or @argyleink in the comments with your queries, questions, and assertions. We'd love to hear them!
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":3,"title":"Markup","description":"Markup chapter of the 2019 Web Almanac covering elements used, custom elements, value, products, and common use cases.","authors":["bkardell"],"reviewers":["zcorpan","tomhodgins","matthewp"],"translators":null,"discuss":"1758","results":"https://docs.google.com/spreadsheets/d/1WnDKLar_0Btlt9UgT53Giy2229bpV4IM2D_v6OM_WzA/","queries":"03_Markup","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"markup"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
In 2005, Ian "Hixie" Hickson posted some analysis of markup data building upon various previous work. Much of this work aimed to investigate class names to see if there were common informal semantics that were being adopted by developers which it might make sense to standardize upon. Some of this research helped inform new elements in HTML5.
-
14 years later, it's time to take a fresh look. Since then, we've also had the introduction of Custom Elements and the Extensible Web Manifesto encouraging that we find better ways to pave the cowpaths by allowing developers to explore the space of elements themselves and allow standards bodies to act more like dictionary editors. Unlike CSS class names, which might be used for anything, we can be far more certain that authors who used a non-standard element really intended this to be an element.
-
- As of July 2019, the HTTP Archive has begun collecting all used element names in the DOM for about 4.4 million desktop home pages, and about 5.3 million mobile home pages which we can now begin to research and dissect. (Learn more about our Methodology.)
-
-
This crawl encountered over 5,000 distinct non-standard element names in these pages, so we capped the total distinct number of elements that we count to the 'top' (explained below) 5,048.
Names of elements on each page were collected from the DOM itself, after the initial run of JavaScript.
-
Looking at a raw frequency count isn't especially helpful, even for standard elements: About 25% of all elements encountered are <div>. About 17% are <a>, about 11% are <span> -- and those are the only elements that account for more than 10% of occurrences. Languages are generally like this; a small number of terms are astoundingly used by comparison. Further, when we start looking at non-standard elements for uptake, this would be very misleading as one site could use a certain element a thousand times and thus make it look artificially very popular.
-
Instead, as in Hixie's original study, what we will look at is how many sites include each element at least once in their homepage.
-
Note: This is, itself, not without some potential biases. Popular products can be used by several sites, which introduce non-standard markup, even "invisibly" to individual authors. Thus, care must be taken to acknowledge that usage doesn't necessarily imply direct author knowledge and conscious adoption as much as it does the servicing of a common need, in a common way. During our research, we found several examples of this, some we will call out.
In 2005, Hixie's survey listed the top few most commonly used elements on pages. The top 3 were html, head and body which he noted as interesting because they are optional and created by the parser if omitted. Given that we use the post-parsed DOM, they'll show up universally in our data. Thus, we'll begin with the 4th most used element. Below is a comparison of the data from then to now (I've included the frequency comparison here as well just for fun).
-
-
-
-
-
-
-
2005 (per site)
-
2019 (per site)
-
2019 (frequency)
-
-
-
-
-
title
-
title
-
div
-
-
-
a
-
meta
-
a
-
-
-
img
-
a
-
span
-
-
-
meta
-
div
-
li
-
-
-
br
-
link
-
img
-
-
-
table
-
script
-
script
-
-
-
td
-
img
-
p
-
-
-
tr
-
span
-
option
-
-
-
-
-
- Figure 1. Comparison of the top elements from 2005 to 2019.
-
Graph showing a decreasing distribution of relative frequency as the number of elements increases
- Figure 2. Distribution of Hixie's 2005 analysis of element frequencies.
-
-
-
-
-
-
-
Graph showing about 2,500 pages start with approximately 30 elements, this increases peaking at 6,876 pages have 283 elements, before trailing fairly linearly to 327 pages having 2,000 elements.
Comparing the latest data in Figure 3 to that of Hixie's report from 2005 in Figure 2, we can see that the average size of DOM trees has gotten bigger.
-
-
-
-
Graph that relative frequency is a bell curve around the 19 elements point.
- Figure 4. Histogram of Hixie's 2005 analysis of element types per page.
-
-
-
-
-
-
-
Graph showing the average number of elements is a bell curve around the 30 elements marked, as used by 308,168 thousand sites.
- Figure 5. Histogram of element types per page as of 2019.
-
-
We can see that both the average number of types of elements per page has increased, as well as the maximum numbers of unique elements that we encounter.
Most of the elements we recorded are custom (as in simply 'not standard'), but discussing which elements are and are not custom can get a little challenging. Written down in some spec or proposal somewhere are, actually, quite a few elements. For purposes here, we considered 244 elements as standard (though, some of them are deprecated or unsupported):
-
-
145 Elements from HTML
-
68 Elements from SVG
-
31 Elements from MathML
-
-
In practice, we encountered only 214 of these:
-
-
137 from HTML
-
54 from SVG
-
23 from MathML
-
-
In the desktop dataset we collected data for the top 4,834 non-standard elements that we encountered. Of these:
-
-
155 (3%) are identifiable as very probable markup or escaping errors (they contain characters in the parsed tag name which imply that the markup is broken)
-
341 (7%) use XML-style colon namespacing (though, as HTML, they don't use actual XML namespaces)
-
3,207 (66%) are valid custom element names
-
1,211 (25%) are in the global namespace (non-standard, having neither dash, nor colon)
-
216 of these we have flagged as possible typos as they are longer than 2 characters and have a Levenshtein distance of 1 from some standard element name like <cript>,<spsn> or <artice>. Some of these (like <jdiv>), however, are certainly intentional.
-
-
Additionally, 15% of desktop pages and 16% of mobile pages contain deprecated elements.
-
Note: A lot of this is very likely due to the use of products rather than individual authors continuing to manually create this markup.
Bar chart showing 'center' in use by 8.31% of desktop sites (7.96% of mobile), 'font' in use by 8.01% of desktop sites (7.38% of mobile), 'marquee' in use by 1.07% of desktop sites (1.20% of mobile), 'nobr' in use by 0.71% of desktop sites (0.55% of mobile), 'big' in use by 0.53% of desktop sites (0.47% of mobile), 'frameset' in use by 0.39% of desktop sites (0.35% of mobile), 'frame' in use by 0.39% of desktop sites (0.35% of mobile), 'strike' in use by 0.33% of desktop sites (0.27% of mobile), and 'noframes' in use by 0.25% of desktop sites (0.27% of mobile).
- Figure 6. Most frequently used deprecated elements.
-
-
Figure 6 above shows the top 10 most frequently used deprecated elements. Most of these can seem like very small numbers, but perspective matters.
Bar chart showing a decreasing used of elements in descending order: html, head, body, title at above 99% usage, meta, a, div above 98% usage, link, script, img, span above 90% usage, ul, li , p, style, input, br, form above 70% usage, h2, h1, iframe, h3, button, footer, header, nav above 50% usage and other less well-known tags trailing down from below 50% to almost 0% usage.
In Figure 7 above, the top 150 element names, counting the number of pages where they appear, are shown. Note how quickly use drops off.
-
Only 11 elements are used on more than 90% of pages:
-
-
<html>
-
<head>
-
<body>
-
<title>
-
<meta>
-
<a>
-
<div>
-
<link>
-
<script>
-
<img>
-
<span>
-
-
There are only 15 other elements that occur on more than 50% of pages:
-
-
<ul>
-
<li>
-
<p>
-
<style>
-
<input>
-
<br>
-
<form>
-
<h2>
-
<h1>
-
<iframe>
-
<h3>
-
<button>
-
<footer>
-
<header>
-
<nav>
-
-
And there are only 40 other elements that occur on more than 5% of pages.
-
Even <video>, for example, doesn't make that cut. It appears on only 4% of desktop pages in the dataset (3% on mobile). While these numbers sound very low, 4% is actually quite popular by comparison. In fact, only 98 elements occur on more than 1% of pages.
-
It's interesting, then, to see what the distribution of these elements looks like and which ones have more than 1% use.
Scatter graph showing HTML, SVG, and Math ML use relatively few tags while non-standard elements (split into "in global ns", "dasherized" and "colon") are much more spread out.
- Figure 8. Element popularity categorized by standardization.
-
-
Figure 8 shows the rank of each element and which category they fall into. I've separated the data points into discrete sets simply so that they can be viewed (otherwise there just aren't enough pixels to capture all that data), but they represent a single 'line' of popularity; the bottom-most being the most common, the top-most being the least common. The arrow points to the end of elements that appear in more than 1% of the pages.
-
You can observe two things here. First, the set of elements that have more than 1% use are not exclusively HTML. In fact, 27 of the most popular 100 elements aren't even HTML - they are SVG! And there are non-standard tags at or very near that cutoff too! Second, note that a whole lot of HTML elements are used by less than 1% of pages.
-
So, are all of those elements used by less than 1% of pages "useless"? Definitely not. This is why establishing perspective matters. There are around two billion web sites on the web. If something appears on 0.1% of all websites in our dataset, we can extrapolate that this represents perhaps two million web sites in the whole web. Even 0.01% extrapolates to two hundred thousand sites. This is also why removing support for elements, even very old ones which we think aren't great ideas, is a very rare occurrence. Breaking hundreds of thousands or millions of sites just isn't a thing that browser vendors can do lightly.
-
Many elements, even the native ones, appear on fewer than 1% of pages and are still very important and successful. <code>, for example, is an element that I both use and encounter a lot. It's definitely useful and important, and yet it is used on only 0.57% of these pages. Part of this is skewed based on what we are measuring; home pages are generally less likely to include certain kinds of things (like <code> for example). Home pages serve a less general purpose than, for example, headings, paragraphs, links and lists. However, the data is generally useful.
-
We also collected information about which pages contained an author-defined (not native) .shadowRoot. About 0.22% of desktop pages and 0.15% of mobile pages had a shadow root. This might not sound like a lot, but it is roughly 6.5k sites in the mobile dataset and 10k sites on the desktop and is more than several HTML elements. <summary> for example, has about equivalent use on the desktop and it is the 146th most popular element. <datalist> appears on 0.04% of homepages and it's the 201st most popular element.
-
In fact, over 15% of elements we're counting as defined by HTML are outside the top 200 in the desktop dataset . <meter> is the least popular "HTML5 era" element, which we can define as 2004-2011, before HTML moved to a Living Standard model. It is around the 1,000th most popular element. <slot>, the most recently introduced element (April 2016), is only around the 1,400th most popular element.
With this perspective in mind about what use of native/standard features looks like in the dataset, let's talk about the non-standard stuff.
-
You might expect that many of the elements we measured are used only on a single web page, but in fact all of the 5,048 elements appear on more than one page. The fewest pages an element in our dataset appears on is 15. About a fifth of them occur on more than 100 pages. About 7% occur on more than 1,000 pages.
-
To help analyze the data, I hacked together a little tool with Glitch. You can use this tool yourself, and please share a permalink back with the @HTTPArchive along with your observations. (Tommy Hodgins has also built a similar CLI tool which you can use to explore.)
For several non-standard elements, their prevalence may have more to do with their inclusion in popular third-party tools than first-party adoption. For example, the <fb:like> element is found on 0.3% of pages not because site owners are explicitly writing it out but because they include the Facebook widget. Many of the elements Hixie mentioned 14 years ago seem to have dwindled, but others are still pretty huge:
-
-
- Popular elements created by Claris Home Page (whose last stable release was 21 years ago) still appear on over 100 pages. <x-claris-window>, for example, appears on 130 pages.
-
-
- Some of the <actinic:*> elements from British ecommerce provider Oxatis appear on even more pages. For example, <actinic:basehref> still shows up on 154 pages in the desktop data.
-
-
- Macromedia's elements seem to have largely disappeared. Only one element, <mm:endlock>, appears on our list and on only 22 pages.
-
-
- Adobe Go-Live's <csscriptdict> still appears on 640 pages in the desktop dataset.
-
-
Microsoft Office's <o:p> element still appears on 0.5% of desktop pages, over 20k pages.
-
-
But there are plenty of newcomers that weren't in Hixie's original report too, and with even bigger numbers.
-
-
- <ym-measure> is a tag injected by Yandex's Metrica analytics package. It's used on more than 1% of desktop and mobile pages, solidifying its place in the top 100 most used elements. That's huge!
-
-
- <g:plusone> from the now-defunct Google Plus occurs on over 21k pages.
-
-
- Facebook's <fb:like> occurs on 14k mobile pages.
-
-
- Similarly, <fb:like-box> occurs on 7.8k mobile pages.
-
-
- <app-root>, which is generally included in frameworks like Angular, appears on 8.2k mobile pages.
-
-
-
Let's compare these to a few of the native HTML elements that are below the 5% bar, for perspective.
Bar chart showing video is used by 184,149 sites, canvas by 108,355, ym-measure (a product-specific tag) by 52,146, code by 25,075, g:plusone (a product-specific tag) by 21,098, fb:like (a product-specific tag) by 12,773, fb:like-box (a product-specific tag) by 6,792, app-root (a product-specific tag) by 8,468, summary by 6,578, template by 5,913, and meter by 0.
- Figure 9. Popularity of product-specific and native elements under 5% adoption.
-
-
You could discover interesting insights like these all day long.
-
Here's one that's a little different: popular elements could be caused by outright errors in products. For example, <pclass="ddc-font-size-large"> occurs on over 1,000 sites. This was thanks to a missing space in a popular "as-a-service" kind of product. Happily, we reported this error during our research and it was quickly fixed.
-
In his original paper, Hixie mentions that:
-
The good thing, if we can be forgiven for trying to remain optimistic in the face of all this non-standard markup, is that at least these elements are all clearly using vendor-specific names. This massively reduces the likelihood that standards bodies will invent elements and attributes that clash with any of them.
-
- However, as mentioned above, this is not universal. Over 25% of the non-standard elements that we captured don't use any kind of namespacing strategy to avoid polluting the global namespace. For example, here is a list of 1157 elements like that from the mobile dataset. Many of those, as you can see, are likely to be non-problematic as they have obscure names, misspellings and so on. But at least a few probably present some challenges. You'll note, for example, that <toast> (which Googlers recently tried to propose as <std-toast>) appears in this list.
-
-
There are some popular elements that are probably not so challenging:
-
-
- <ymaps> from Yahoo Maps appears on ~12.5k mobile pages.
-
-
- <cufon> and <cufontext> from a font replacement library from 2008, appear on ~10.5k mobile pages.
-
-
- The <jdiv> element, which appears to be injected by the Jivo chat product, appears on ~40.3k mobile pages,
-
-
-
Placing these into our same chart as above for perspective looks something like this (again, it varies slightly based on the dataset)
A bar chart showing video is used by 184,149 sites, canvas by 108,355, ym-measure by 52,416, code by 25,075, g:plusone by 21,098, db:like by 12,773, cufon by 10,523, ymaps by 8,303, fb:like-box by 6,972, app-root by 8,468, summary by 6,578, template by 5,913, and meter by 0
- Figure 10. Other popular elements in the context of product-specific and native elements with under 5% adoption.
-
-
The interesting thing about these results is that they also introduce a few other ways that our tool can come in very handy. If we're interested in exploring the space of the data, a very specific tag name is just one possible measure. It's definitely the strongest indicator if we can find good "slang" developing. However, what if that's not all we're interested in?
What if, for example, we were interested in people solving common use cases? This could be because we're looking for solutions to use cases that we currently have ourselves, or for researching more broadly what common use cases people are solving with an eye toward incubating some standardization effort. Let's take a common example: tabs. Over the years there have been a lot of requests for things like tabs. We can use a fuzzy search here and find that there are many variants of tabs. It's a little harder to count usage here since we can't as easily distinguish if two elements appear on the same page, so the count provided there conservatively simply takes the one with the largest count. In most cases the real number of pages is probably significantly larger.
If we notice popular things pop up (like <jdiv>, solving chat) we can take knowledge of things we know (like, that is what <jdiv> is about, or <olark>) and try to look at at least 43 things we've built for tackling that and follow connections to survey the space.
Pages have more elements than they did 14 years ago, both on average and max.
-
The lifetime of things on home pages is very long. Deprecating or discontinuing things doesn't make them go away, and it might never.
-
There is a lot of broken markup out there in the wild (misspelled tags, missing spaces, bad escaping, misunderstandings).
-
Measuring what "useful" means is tricky. Lots of native elements don't pass the 5% bar, or even the 1% bar, but lots of custom ones do, and for lots of reasons. Passing 1% should definitely grab our attention at least, but perhaps so should 0.5% because that is, according to the data, comparatively very successful.
-
There is already a ton of custom markup out there. It comes in a lot of forms, but elements containing a dash definitely seem to have taken off.
-
We need to increasingly study this data and come up with good observations to help find and pave the cowpaths.
-
-
That last one is where you come in. We'd love to tap into the creativity and curiosity of the larger community to help explore this data using some of the tools (like https://rainy-periwinkle.glitch.me/). Please share your interesting observations and help build our commons of knowledge and understanding.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
Images, animations, and videos are an important part of the web experience. They are important for many reasons: they help tell stories, engage audiences, and provide artistic expression in ways that often cannot be easily produced with other web technologies. The importance of these media resources can be demonstrated in two ways: by the sheer volume of bytes required to download for a page, and also the volume of pixels painted with media.
-
From a pure bytes perspective, HTTP Archive has historically reported an average of two-thirds of resource bytes associated from media. From a distribution perspective, we can see that virtually every web page depends on images and videos. Even at the tenth percentile, we see that 44% of the bytes are from media and can rise to 91% of the total bytes at the 90th percentile of pages.
Bar chart showing in the p10 percentile 44.1% of page bytes are media, in the p25 percentile 52.7% is media, in the p50 percentile 67.0% is media, in the p75 percentile 81.7% is media, and in the p90 percentile 91.2% is media.
- Figure 1. Web page bytes: image and video versus other.
-
-
While media are critical for the visual experience, the impact of this high volume of bytes has two side effects.
-
First, the network overhead required to download these bytes can be large and in cellular or slow network environments (like coffee shops or tethering when in an Uber) can dramatically slow down the page performance. Images are a lower priority request by the browser but can easily block CSS and JavaScript in the download. This by itself can delay the page rendering. Yet at other times, the image content is the visual cue to the user that the page is ready. Slow transfers of visual content, therefore, can give the perception of a slow web page.
-
The second impact is on the financial cost to the user. This is often an ignored aspect since it is not a burden on the website owner but a burden to the end-user. Anecdotally, it has been shared that some markets, like Japan, see a drop in purchases by students near the end of the month when data caps are reached, and users cannot see the visual content.
-
Further, the financial cost of visiting these websites in different parts of the world is disproportionate. At the median and 90th percentile, the volume of image bytes is 1 MB and 1.9 MB respectively. Using WhatDoesMySiteCost.com we can see that the gross national income (GNI) per capita cost to a user in Madagascar a single web page load at the 90th percentile would cost 2.6% of the daily gross income. By contrast, in Germany this would be 0.3% of the daily gross income.
The median web page on mobile requires 1 MB of images and 4.9 MB at the 90th percentile.
- Figure 2. Total image bytes per web page (mobile).
-
-
Looking at bytes per page results in just looking at the costs—to page performance and the user—but it overlooks the benefits. These bytes are important to render pixels on the screen. As such, we can see the importance of the images and video resources by also looking at the number of media pixels used per page.
-
There are three metrics to consider when looking at pixel volume: CSS pixels, natural pixels, and screen pixels:
-
-
-
CSS pixel volume is from the CSS perspective of layout. This measure focuses on the bounding boxes for which an image or video could be stretched or squeezed into. It also does not take into the actual file pixels nor the screen display pixels
-
-
-
Natural pixels refer to the logical pixels represented in a file. If you were to load this image in GIMP or Photoshop, the pixel file dimensions would be the natural pixels.
-
-
-
Screen pixels refer to the physical electronics on the display. Prior to mobile phones and modern high-resolution displays, there was a 1:1 relationship between CSS pixels and LED points on a screen. However, because mobile devices are held closer to the eye, and laptop screens are closer than the old mainframe terminals, modern screens have a higher ratio of physical pixels to traditional CSS pixels. This ratio is referred to as Device-Pixel-Ratio or colloquially referred to as Retina™ displays.
A comparison of the CSS pixels allocated to image content compared to the actual image pixels for mobile, showing p10 (0.07 MP actual, 0.04 MP CSS), p25 (0.38 MP actual, 0.18 MP CSS), p50 (1.6 MP actual, 0.65 MP CSS), p75 (5.1 MP actual, 1.8 MP CSS), and p90 (12 MP actual, 4.6 MP CSS)
- Figure 3. Image pixels per page (mobile): CSS versus actual.
-
-
-
-
-
-
-
A comparison of the CSS pixels allocated to image content compared to the actual image pixels for desktop, showing p10 (0.09 MP actual, 0.05 MP CSS), p25 (0.52 MP actual, 0.29 MP CSS), p50 (2.1 MP actual, 1.1 MP CSS), p75 (6.0 MP actual, 2.8 MP CSS), and p90 (14 MP actual, 6.3 MP CSS)
- Figure 4. Image pixels per page (desktop): CSS versus actual.
-
-
Looking at the CSS pixel and the natural pixel volume we can see that the median website has a layout that displays one megapixel (MP) of media content. At the 90th percentile, the CSS layout pixel volume grows to 4.6 MP and 6.3 MP mobile and desktop respectively. This is interesting not only because the responsive layout is likely different, but also because the form factor is different. In short, the mobile layout has less space allocated for media compared to the desktop.
-
In contrast, the natural, or file, pixel volume is between 2 and 2.6 times the layout volume. The median desktop web page sends 2.1MP of pixel content that is displayed in 1.1 MP of layout space. At the 90th percentile for mobile we see 12 MP squeezed into 4.6 MP.
-
Of course, the form factor for a mobile device is different than a desktop. A mobile device is smaller and usually held in portrait mode while the desktop is larger and used predominantly in landscape mode. As mentioned earlier, a mobile device also typically has a higher device pixel ratio (DPR) because it is held much closer to the eye, requiring more pixels per inch compared to what you would need on a billboard in Times Square. These differences force layout changes and users on mobile more commonly scroll through a site to consume the entirety of content.
-
Megapixels are a challenging metric because it is a largely abstract metric. A useful way to express this volume of pixels being used on a web page is to represent it as a ratio relative to the display size.
-
For the mobile device used in the web page crawl, we have a display of 512 x 360 which is 0.18 MP of CSS content. (Not to be confused with the physical screen which is 3x or 3^2 more pixels, which is 1.7MP). Dividing this viewer pixel volume by the number of CSS pixels allocated to images we get a relative pixel volume.
-
If we had one image that filled the entire screen perfectly, this would be a 1x pixel fill rate. Of course, rarely does a website fill the entire canvas with a single image. Media content tends to be mixed in with the design and other content. A value greater than 1x implies that the layout requires the user to scroll to see the additional image content.
-
Note: this is only looking at the CSS layout for both the DPR and the volume of layout content. It is not evaluating the effectiveness of the responsive images or the effectiveness of providing high DPR content.
For the median web page on desktop, only 46% of the display would have layout containing images and video. In contrast, on mobile, the volume of media pixels fills 3.5 times the actual viewport size. The layout has more content than can be filled in a single screen, requiring the user to scroll. At a minimum, there is 3.5 scrolling pages of content per site (assuming 100% saturation). At the 90th percentile for mobile, this grows substantially to 25x the viewport size!
-
Media resources are critical for the user experience.
Much has already been written on the subject of managing and optimizing images to help reduce the bytes and optimize the user experience. It is an important and critical topic for many because it is the creative media that define a brand experience. Therefore, optimizing image and video content is a balancing act between applying best practices that can help reduce the bytes transferred over the network while preserving the fidelity of the intended experience.
-
While the strategies that are utilized for images, videos, and animations are—in broad strokes—similar, the specific approaches can be very different. In general, these strategies boil down to:
-
-
File formats - utilizing the optimal file format
-
Responsive - applying responsive images techniques to transfer only the pixels that will be shown on screen
-
Lazy loading - to transfer content only when a human will see it
-
Accessibility - ensuring a consistent experience for all humans
-
-
A word of caution when interpreting these results. The web pages crawled for the Web Almanac were crawled on a Chrome browser. This implies that any content negotiation that might better apply for Safari or Firefox might not be represented in this dataset. For example, the use of file formats like JPEG2000, JPEG-XR, HEVC and HEIC are absent because these are not supported natively by Chrome. This does not mean that the web does not contain these other formats or experiences. Likewise, Chrome has native support for lazy loading (since v76) which is not yet available in other browsers. Read more about these caveats in our Methodology.
-
It is rare to find a web page that does not utilize images. Over the years, many different file formats have emerged to help present content on the web, each addressing a different problem. Predominantly, there are 4 main universal image formats: JPEG, PNG, GIF, and SVG. In addition, Chrome has enhanced the media pipeline and added support for a fifth image format: WebP. Other browsers have likewise added support for JPEG2000 (Safari), JPEG-XL (IE and Edge) and HEIC (WebView only in Safari).
-
Each format has its own merits and has ideal uses for the web. A very simplified summary would break down as:
-
-
-
-
-
-
-
Format
-
Highlights
-
Drawbacks
-
-
-
-
-
JPEG
-
-
-
Ubiquitously supported
-
Ideal for photographic content
-
-
-
-
-
There is always quality loss
-
Most decoders cannot handle high bit depth photographs from modern cameras (> 8 bits per channel)
-
No support for transparency
-
-
-
-
-
PNG
-
-
-
Like JPEG and GIF, shares wide support
-
It is lossless
-
Supports transparency, animation, and high bit depth
-
-
-
-
-
Much bigger files compared to JPEG
-
Not ideal for photographic content
-
-
-
-
-
GIF
-
-
-
The predecessor to PNG, is most known for animations
-
Lossless
-
-
-
-
-
Because of the limitation of 256 colors, there is always visual loss from conversion
-
Very large files for animations
-
-
-
-
-
SVG
-
-
-
A vector based format that can be resized without increasing file size
-
It is based on math rather than pixels and creates smooth lines
-
-
-
-
-
Not useful for photographic or other raster content
-
-
-
-
-
WebP
-
-
-
A newer file format that can produce lossless images like PNG and lossy images like JPEG
In aggregate, across all page, we indeed see the prevalence of these formats. JPEG, one of the oldest formats on the web, is by far the most commonly used image formats at 60% of the image requests and 65% of all image bytes. Interestingly, PNG is the second most commonly used image format 28% of image requests and bytes. The ubiquity of support along with the precision of color and creative content are likely explanations for its wide use. In contrast SVG, GIF, and WebP share nearly the same usage at 4%.
Of course, web pages are not uniform in their use of image content. Some depend on images more than others. Look no further than the home page of google.com and you will see very little imagery compared to a typical news website. Indeed, the median website has 13 images, 61 images at the 90th percentile, and a whopping 229 images at the 99th percentile.
A bar chart showing in p10 percentile no image formats are used at all, in the p25 percentile three JPGs and four PNGs are used, in the p50 percentile nine JPGs, four PNGs, and one GIF are used, in the p75 percentile 39 JPEGs, 18 PNGs, two SVGs, and two GIFs are used and in the p99 percentile, 119 JPGs, 49 PNGs, 28 WebPs, 19 SVGs and 14 GIFs are used.
While the median page has nine JPEGs and four PNGs, and only in the top 25% pages GIFs were used, this doesn't report the adoption rate. The use and frequency of each format per page doesn't provide insight into the adoption of the more modern formats. Specifically, what percent of pages include at least one image in each format?
A bar chart showing JPEGs are used on 90% of pages, PNGs on 89%, WebP on 9%, GIF on 37%, and SVG on 22%.
- Figure 9. Percent of pages using at least one image.
-
-
This helps explain why—even at the 90th percentile of pages—the frequency of WebP is still zero; only 9% of web pages have even one resource. There are many reasons that WebP might not be the right choice for an image, but adoption of media best practices, like adoption of WebP itself, still remain nascent.
A chart showing in p10 percentile 4 KB of JPEGs, 2 KB of PNG and 2 KB of GIFs are used, in the p25 percentile 9 KB JPGs, 4 KB of PNGs, 7 KB of WebP, and 3 KB of GIFs are used, in the p50 percentile 24 KB of JPGs, 11 KB of PNGs, 17 KB of WebP, 6 KB of GIFs, and 1 KB of SVGs are used, in the p75 percentile 68 KB of JPEGs, 43 KB of PNGs, 41 KB of WebPs, 17 KB of GIFs and 2 KB of SVGs are used and in the p90 percentile, 116 KB of JPGs, 152 KB of PNGs, 90 KB of WebPs, 87 KB of GIFs, and 8 KB of SVGs are used.
From this we can start to get a sense of how large or small a typical resource is on the web. However, this doesn't give us a sense of the volume of pixels represented on screen for these file distributions. To do this we can divide each resource bytes by the natural pixel volume of the image. A lower bytes-per-pixel indicates a more efficient transmission of visual content.
A candlestick chart showing in p10 percentile we have 0.1175 bytes-per-pixel for JPEG, 0.1197 for PNG, 0.1702 for GIF, 0.0586 for WebP, and 0.0293 for SVG. In the p25 percentile we have 0.1848 bytes-per-pixel for JPEGs, 0.2874 for PNG, 0.3641 for GIF, 0.1025 for WebP, and 0.174 for SVG. In the p50 percentile we have 0.2997 bytes-per-pixel for JPEGs, 0.6918 for PNG, 0.7967 for GIF, 0.183 for WebP, and 0.6766 for SVG. In the p75 percentile we have 0.5456 bytes-per-pixel for JPEGs, 1.4548 for PNG, 2.515 for GIF, 0.3272 for WebP, and 1.9261 for SVG. In the p90 percentile we have 0.9822 bytes-per-pixel for JPEGs, 2.5026 for PNG, 8.5151 for GIF, 0.6474 for WebP, and 4.1075 for SVG
While previously it appeared that GIF files were smaller than JPEG, we can now clearly see that the cause of the larger JPEG resources is due to the pixel volume. It is probably not a surprise that GIF shows a very low pixel density compared to the other formats. Additionally, while PNG can handle high bit depth and doesn't suffer from chroma subsampling blurriness, it is about twice the size of JPG or WebP for the same pixel volume.
-
Of note, the pixel volume used for SVG is the size of the DOM element on screen (in CSS pixels). While considerably smaller for file sizes, this hints that SVGs are generally used in smaller portions of the layout. This is why the bytes-per-pixel appears worse than PNG.
-
Again, it is worth emphasizing, this comparison of pixel density is not comparing equivalent images. Rather it is reporting typical user experience. As we will discuss next, even in each of these formats there are techniques that can be used to further optimize and reduce the bytes-per-pixel.
Selecting the best format for an experience is an art of balancing capabilities of the format and reducing the total bytes. For web pages one goal is to help improve web performance through optimizing images. Yet within each format there are additional features that can help reduce bytes.
-
Some features can impact the total experience. For example, JPEG and WebP can utilize quantization (commonly referred to as quality levels) and chroma subsampling, which can reduce the bits stored in the image without impacting the visual experience. Like MP3s for music, this technique depends on a bug in the human eye and allows for the same experience despite the loss of color data. However, not all images are good candidates for these techniques since this can create blocky or blurry images and may distort colors or make text overlays become unreadable.
-
Other format features simply organize the content and sometimes require contextual knowledge. For example, applying progressive encoding of a JPEG reorganizes the pixels into scan layers that allows the browser to complete layout sooner and coincidently reduces pixel volume.
-
One Lighthouse test is an A/B comparing baseline with a progressively encoded JPEG. This provides a smell to indicate whether the images overall can be further optimized with lossless techniques and potentially with lossy techniques like using different quality levels.
Bar chart showing in the p10 percentile 100% of images are optimized, same in p25 percentile, in the p50 percentile 98% of images are optimized (2% not), in the p75 percentile 83% of images are optimized (17% not), and in the p90 percentile 59% of images are optimized and 41% are not.
The savings in this AB Lighthouse test is not just about potential byte savings, which can accrue to several MBs at the p95, it also demonstrates the page performance improvement.
Bar chart showing in the p10 percentile 0 ms could be sized, same in p25 percentile, in the p50 percentile 150 ms could be saved, in the p75 percentile 1,460 ms could be saved and in the p90 percentile 5,720 ms could be saved.
- Figure 13. Projected page performance improvements from image optimization from Lighthouse.
-
-
Another axis for improving page performance is to apply responsive images. This technique focuses on reducing image bytes by reducing the extra pixels that are not shown on the display because of image shrinking. At the beginning of this chapter, you saw that the median web page on desktop used one MP of image placeholders yet transferred 2.1 MP of actual pixel volume. Since this was a 1x DPR test, 1.1 MP of pixels were transferred over the network, but not displayed. To reduce this overhead, we can use one of two (possibly three) techniques:
-
-
HTML markup - using a combination of the <picture> and <source> elements along with the srcset and sizes attributes allows the browser to select the best image based on the dimensions of the viewport and the density of the display.
-
Client Hints - this moves the selection of possible resized images to HTTP content negotiation.
-
BONUS: JavaScript libraries to delay image loading until the JavaScript can execute and inspect the Browser DOM and inject the correct image based on the container.
The most common method to implement responsive images is to build a list of alternative images using either <img srcset> or <source srcset>. If the srcset is based on DPR, the browser can select the correct image from the list without additional information. However, most implementations also use <img sizes> to help instruct the browser how to perform the necessary layout calculation to select the correct image in the srcset based on pixel dimensions.
A bar chart showing 18% of images uses 'sizes', 21% use 'srcset', and 2% use 'picture'.
- Figure 14. Percent of pages using responsive images with HTML.
-
-
The notably lower use of <picture> is not surprising given that it is used most often for advanced responsive web design (RWD) layouts like art direction.
The utility of srcset is usually dependent on the precision of the sizes media query. Without sizes the browser will assume the <img> tag will fill the entire viewport instead of smaller component. Interestingly, there are five common patterns that web developers have adopted for <img sizes>:
-
-
- <img sizes="100vw"> - this indicates that the image will fill the width of the viewport (also the default).
-
-
- <img sizes="200px"> - this is helpful for browsers selecting based on DPR.
-
-
- <img sizes="(max-width: 300px) 100vw, 300px"> - this is the second most popular design pattern. It is the one auto generated by WordPress and likely a few other platforms. It appears auto generated based on the original image size (in this case 300px).
-
-
- <img sizes="(max-width: 767px) 89vw, (max-width: 1000px) 54vw, ..."> - this pattern is the custom built design pattern that is aligned with the CSS responsive layout. Each breakpoint has a different calculation for sizes to use.
-
-
-
-
-
-
-
-
-
<img sizes>
-
Frequency (millions)
-
%
-
-
-
-
-
(max-width: 300px) 100vw, 300px
-
1.47
-
5%
-
-
-
(max-width: 150px) 100vw, 150px
-
0.63
-
2%
-
-
-
(max-width: 100px) 100vw, 100px
-
0.37
-
1%
-
-
-
(max-width: 400px) 100vw, 400px
-
0.32
-
1%
-
-
-
(max-width: 80px) 100vw, 80px
-
0.28
-
1%
-
-
-
-
-
- Figure 15. Percent of pages using the most popular sizes patterns.
-
-
-
-
- <img sizes="auto"> - this is the most popular use, which is actually non-standard and is an artifact of the use of the lazy_sizes JavaScript library. This uses client-side code to inject a better sizes calculation for the browser. The downside of this is that it depends on the JavaScript loading and DOM to be fully ready, delaying image loading substantially.
-
Bar chart showing 11.3 million images use 'img sizes="(max-width: 300px) 100vw, 300px"', 1.60 million use 'auto', 1.00 million use 'img sizes="(max-width: 767px) 89vw...etc."', 0.23 million use '100vw' and 0.13 million use '300px'
Client Hints allow content creators to move the resizing of images to HTTP content negotiation. In this way, the HTML does not need additional <img srcset> to clutter the markup, and instead can depend on a server or image CDN to select an optimal image for the context. This allows simplifying of HTML and enables origin servers to adapt overtime and disconnect the content and presentation layers.
-
To enable Client Hints, the web page must signal to the browser using either an extra HTTP header Accept-CH: DPR, Width, Viewport-Widthor by adding the HTML <meta http-equiv="Accept-CH" content="DPR, Width, Viewport-Width">. The convenience of one or the other technique depends on the team implementing and both are offered for convenience.
Bar chart showing 71% use the 'meta http-equiv', 30% use the 'Accept-CH' HTTP header and 1% use both.
- Figure 17. Usage of the Accept-CH header versus the equivalent <meta> tag.
-
-
The use of the <meta> tag in HTML to invoke Client Hints is far more common compared with the HTTP header. This is likely a reflection of the convenience to modify markup templates compared to adding HTTP headers in middle boxes. However, looking at the usage of the HTTP header, over 50% of these cases are from a single SaaS platform (Mercado).
-
Of the Client Hints invoked, the majority of pages use it for the original three use-cases of DPR, ViewportWidth and Width. Of course, the Width Client Hint that requires the use <img sizes> for the browser to have enough context about the layout.
A doughnut-style pie-chart showing 26.1% of client hints use 'dpr', 24.3% use 'viewport-width', 19.7% use 'width', 6.7% use 'save-data', 6.1% uses 'device-memory', 6.0% uses 'downlink', 5.6% uses 'rtt' and 5.6% uses 'ect'
Improving web page performance can be partially characterized as a game of illusions; moving slow things out of band and out of site of the user. In this way, lazy loading images is one of these illusions where the image and media content is only loaded when the user scrolls on the page. This improves perceived performance, even on slow networks, and saves the user from downloading bytes that are not otherwise viewed.
-
Earlier, in Figure 5, we showed that the volume of image content at the 75th percentile is far more than could theoretically be shown in a single desktop or mobile viewport. The offscreen images Lighthouse audit confirms this suspicion. The median web page has 27% of image content significantly below the fold. This grows to 84% at the 90th percentile.
A bar chart showing in the p10 percentile 0% of images are offscreen, in the p25 percentile 2% are offscreen, in the p50 percentile, 27% are offscreen, in the p75 percentile 64% are offscreen, and in the p90 percentile 84% of images are offscreen.
The Lighthouse audit provides us a smell as there are a number of situations that can provide tricky to detect such as the use of quality placeholders.
-
Lazy loading can be implemented in many different ways including using a combination of Intersection Observers, Resize Observers, or using JavaScript libraries like lazySizes, lozad, and a host of others.
-
In August 2019, Chrome 76 launched with the support for markup-based lazy loading using <img>. While the snapshot of websites used for the 2019 Web Almanac used July 2019 data, over 2,509 websites already utilized this feature.
At the heart of image accessibility is the alt tag. When the alt tag is added to an image, this text can be used to describe the image to a user who is unable to view the images (either due to a disability, or a poor internet connection).
-
We can detect all of the image tags in the HTML files of the dataset. Of 13 million image tags on desktop and 15 million on mobile, 91.6% of images have an alt tag present. At initial glance, it appears that image accessibility is in very good shape on the web. However, upon deeper inspection, the outlook is not as good. If we examine the length of the alt tags present in the dataset, we find that the median length of the alt tag is six characters. This maps to an empty alt tag (appearing as alt=""). Only 39% of images use alt text that is longer than six characters. The median value of "real" alt text is 31 characters, of which 25 actually describe the image.
While images dominate the media being served on web pages, videos are beginning to have a major role in content delivery on the web. According to HTTP Archive, we find that 4.06% of desktop and 2.99% of mobile sites are self-hosting video files. In other words, the video files are not hosted by websites like YouTube or Facebook.
Video can be delivered with many different formats and players. The dominant formats for mobile and desktop are .ts (segments of HLS streaming) and .mp4 (the H264 MPEG):
A bar chart showing 'ts' usage at 1,283,439 for desktop (792,952 for mobile), 'mp4' at 729,757 thousand for desktop (662,015 for mobile), 'webm' at 38,591 for desktop (32,417 for mobile), 'mov' at 22,194 for desktop (14,986 for mobile), 'm4s' at 17,338 for desktop (16,046 for mobile), 'm4v' at 7,466 for desktop (6,169 for mobile).
- Figure 20. Count of video files by extension.
-
-
Other formats that are seen include webm, mov, m4s, and m4v (MPEG-DASH streaming segments). It is clear that the majority of streaming on the web is HLS, and that the major format for static videos is the mp4.
-
The median video size for each format is shown below:
A bar chart showing 'ts' average file size at 335 KB for desktop (156 KB for mobile), 'mp4' at 175 KB for desktop (128 KB for mobile), 'webm' at 359 KB for desktop (192 KB for mobile), 'mov' at 128 KB for desktop (96 KB for mobile), 'm4s' at 324 KB for desktop (246 KB for mobile), and 'm4v' at 383 KB for desktop (161 KB for mobile)
- Figure 21. Median file size by video extension.
-
-
The median values are smaller on mobile, which probably just means that some sites that have very large videos on the desktop disable them for mobile, and that video streams serve smaller versions of videos to smaller screens.
When delivering video on the web, most videos are delivered with the HTML5 video player. The HTML video player is extremely customizable to deliver video for many different purposes. For example, to autoplay a video, the parameters autoplay and muted would be added. The controls attribute allows the user to start/stop and scan through the video. By parsing the video tags in the HTTP Archive, we're able to see the usage of each of these attributes:
A bar chart showing for desktop: 'autoplay' at 11.84%, 'buffered' at 0%, 'controls' at 12.05%, 'crossorigin' at 0.45%, 'currenttime' at 0.01%, 'disablepictureinpicture' at 0.01%, 'disableremoteplayback' at 0.01%, 'duration' at 0.05%, 'height' at 7.33%, 'intrinsicsize' at 0%, 'loop' at 14.57%, 'muted' at 13.92%, 'playsinline' at 6.49%, 'poster' at 8.98%, 'preload' at 11.62%, 'src' at 3.67%, 'use-credentials' at 0%, and 'width' at 9%. And for mobile 'autoplay' at 12.38%, 'buffered' at 0%, 'controls' at 13.88%, 'crossorigin' at 0.16%, 'currenttime' at 0.01%, disablepictureinpicture' at 0.01%, 'disableremoteplayback' at 0.02%, 'duration' at 0.09%, 'height' at 6.54%, intrinsicsize' at 0%, 'loop' at 14.44%, 'muted' at 13.55%, 'playsinline' at 6.15%, 'poster' at 9.29%, 'preload' at 10.34%, 'src' at 4.13%, 'use-credentials' at 0%, and 'width' at 9.03%.
- Figure 22. Usage of HTML video tag attributes.
-
-
The most common attributes are autoplay, muted and loop, followed by the preload tag and width and height. The use of the loop attribute is used in background videos, and also when videos are used to replace animated GIFs, so it is not surprising to see that it is often used on website home pages.
-
While most of the attributes have similar usage on desktop and mobile, there are a few that have significant differences. The two attributes with the largest difference between mobile and desktop are width and height, with 4% fewer sites using these attributes on mobile. Interestingly, there is a small increase of the poster attribute (placing an image over the video window before playback) on mobile.
-
From an accessibility point of view, the <track> tag can be used to add captions or subtitles. There is data in the HTTP Archive on how often the <track> tag is used, but on investigation, most of the instances in the dataset were commented out or pointed to an asset returning a 404 error. It appears that many sites use boilerplate JavaScript or HTML and do not remove the track, even when it is not in use.
For more advanced playback (and to play video streams), the HTML5 native video player will not work. There are a few popular video libraries that are used to playback the video:
Bar chart showing 'flowplayer' used by 3,365 desktop sites (3,400 mobile), 'hls' by 52,375 desktop sites (40,925 mobile), 'jwplayer' by 110,280 desktop sites (96,945 mobile), 'shaka' on 325 desktop sites (275 mobile) and 'video' used on 377,990 desktop sites (391,330 mobile)
The most popular (by far) is video.js, followed by JWPLayer and HLS.js. The authors do admit that it is possible that there are other files with the name "video.js" that may not be the same video playback library.
Nearly all web pages use images and video to some degree to enhance the user experience and create meaning. These media files utilize a large amount of resources and are a large percentage of the tonnage of websites (and they are not going away!) Utilization of alternative formats, lazy loading, responsive images, and image optimization can go a long way to lower the size of media on the web.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":5,"title":"Third Parties","description":"Third Parties chapter of the 2019 Web Almanac covering data of what third parties are used, what they are used for, performance impacts and privacy impacts.","authors":["patrickhulce"],"reviewers":["zcorpan","obto","jasti"],"translators":null,"discuss":"1760","results":"https://docs.google.com/spreadsheets/d/1iC4WkdadDdkqkrTY32g7hHKhXs9iHrr3Bva8CuPjVrQ/","queries":"05_Third_Parties","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-02T00:00:00.000Z","chapter":"third-parties"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
The open web is vast, linkable, and interoperable by design. The ability to grab someone else's complex library and use it on your site with a single <link> or <script> element has supercharged developers' productivity and enabled awesome new web experiences. On the flip side, the immense popularity of a select few third-party providers raises important performance, privacy, and security concerns. This chapter examines the prevalence and impact of third-party code on the web in 2019, the usage patterns that lead to the popularity of third-party solutions, and potential repercussions for the future of web experiences.
A third party is an entity outside the primary site-user relationship, i.e. the aspects of the site not directly within the control of the site owner but present with their approval. For example, the Google Analytics script is an example of a common third-party resource.
-
Third-party resources are:
-
-
Hosted on a shared and public origin
-
Widely used by a variety of sites
-
Uninfluenced by an individual site owner
-
-
To match these goals as closely as possible, the formal definition used throughout this chapter of a third-party resource is a resource that originates from a domain whose resources can be found on at least 50 unique pages in the HTTP Archive dataset.
-
Note that using these definitions, third-party content served from a first-party domain is counted as first-party content. For example, self-hosting Google Fonts or bootstrap.css is counted as first-party content. Similarly, first-party content served from a third-party domain is counted as third-party content. For example, first-party images served over a CDN on a third-party domain are considered third-party content.
This chapter divides third-party providers into one of these broad categories. A brief description is included below and the mapping of domain to category can be found in the third-party-web repository.
-
-
Ad - display and measurement of advertisements
-
Analytics - tracking site visitor behavior
-
CDN - providers that host public shared utilities or private content of their users
-
Content - providers that facilitate publishers and host syndicated content
-
Customer Success - support and customer relationship management functionality
-
Hosting - providers that host the arbitrary content of their users
-
Marketing - sales, lead generation, and email marketing functionality
-
Social - social networks and their affiliated integrations
-
Tag Manager - provider whose sole role is to manage the inclusion of other third parties
-
Utility - code that aids the development objectives of the site owner
-
Video - providers that host the arbitrary video content of their users
-
Other - uncategorized or non-conforming activity
-
-
Note on CDNs: The CDN category here includes providers that provide resources on public CDN domains (e.g. bootstrapcdn.com, cdnjs.cloudflare.com, etc.) and does not include resources that are simply served over a CDN. i.e. putting Cloudflare in front of a page would not influence its first-party designation according to our criteria.
- Figure 1. Percentage of desktop pages that include at least one third-party resource.
-
-
Third-party code is everywhere. 93% of pages include at least one third-party resource, 76% of pages issue a request to an analytics domain, the median page requests content from at least 9 unique third-party domains that represent 35% of their total network activity, and the most active 10% of pages issue a whopping 175 third-party requests or more. It's not a stretch to say that third parties are an integral part of the web.
-
-
55.63%
- Figure 2. Percentage of desktop pages that include at least one ad resource.
-
-
If the ubiquity of third-party content is unsurprising, perhaps more interesting is the breakdown of third-party content by provider type.
-
While advertising might be the most user-visible example of third-party presence on the web, analytics providers are the most common third-party category with 76% of sites including at least one analytics request. CDNs at 63%, ads at 57%, and developer utilities like Sentry, Stripe, and Google Maps SDK at 56% follow up as a close second, third, and fourth for appearing on the most web properties. The popularity of these categories forms the foundation of our web usage patterns identified later in the chapter.
A relatively small set of providers dominate the third-party landscape: the top 100 domains account for 30% of network requests across the web. Powerhouses like Google, Facebook, and YouTube make the headlines here with full percentage points of share each, but smaller entities like Wix and Shopify command a substantial portion of third-party popularity as well.
-
While much could be said about every individual provider's popularity and performance impact, this more opinionated analysis is left as an exercise for the reader and other purpose-built tools such as third-party-web.
-
-
-
-
-
-
-
Rank
-
Third party domain
-
Percent of requests
-
-
-
-
-
1
-
fonts.gstatic.com
-
2.53%
-
-
-
2
-
www.facebook.com
-
2.38%
-
-
-
3
-
www.google-analytics.com
-
1.71%
-
-
-
4
-
www.google.com
-
1.17%
-
-
-
5
-
fonts.googleapis.com
-
1.05%
-
-
-
6
-
www.youtube.com
-
0.99%
-
-
-
7
-
connect.facebook.net
-
0.97%
-
-
-
8
-
googleads.g.doubleclick.net
-
0.93%
-
-
-
9
-
cdn.shopify.com
-
0.76%
-
-
-
10
-
maps.googleapis.com
-
0.75%
-
-
-
-
-
- Figure 3. Top 10 most popular third-party domains.
-
The resource type breakdown of third-party content also lends insight into how third-party code is used across the web. While first-party requests are 56% images, 23% script, 14% CSS, and only 4% HTML, third-party requests skew more heavily toward script and HTML at 32% script, 34% images, 12% HTML, and only 6% CSS. While this suggests that third-party code is less frequently used to aid the design and instead used more frequently to facilitate or observe interactions than first-party code, a breakdown of resource types by party status tells a more nuanced story. While CSS and images are dominantly first-party at 70% and 64% respectively, fonts are largely served by third-party providers with only 28% being served from first-party sources. This concept of usage patterns is explored in more depth later in this chapter.
Chart showing the breakdown of content types for each third party category. Images and scripts make up the majority of requests for each category. CDN requests have an especially large proportion of fonts.
- Figure 5. Percent of third-party requests by category and content type.
-
-
Several other amusing factoids jump out from this data. Tracking pixels (image requests to analytics domains) make up 1.6% of all network requests, six times as many video requests are to social networks like Facebook and Twitter than dedicated video providers like YouTube and Vimeo (presumably because the default YouTube embed consists of HTML and a preview thumbnail but not an autoplaying video), and there are still more requests for first-party images than all scripts combined.
49% of all requests are third-party. At 51%, first-party can still narrowly hold on to the crown in 2019 of comprising the majority of the web resources. Given that just under half of all the requests are third-party yet a small set of pages do not include any at all, the most active third-party users must be doing quite a bit more than their fair share. Indeed, at the 75th, 90th, and 99th percentiles we see nearly all of the page being comprised of third-party content. In fact, for some sites heavily relying on distributed WYSIWYG platforms like Wix and SquareSpace, the root document might be the sole first-party request!
-
-
The number of requests issued by each third-party provider also varies considerably by category. While analytics are the most widespread third-party category across websites, they account for only 7% of all third-party network requests. Ads, on the other hand, are found on nearly 20% fewer sites yet make up 25% of all third-party network requests. Their outsized resource impact compared to their popularity will be a theme we continue to uncover in the remaining data.
While 49% of requests are third-party, their share of the web in terms of bytes is quite a bit lower at only 28%. The same goes for the breakdown by multiple resource types. Third-party fonts make up 72% of all fonts, but they're only 53% of font bytes; 74% of HTML requests, but only 39% of HTML bytes; 68% of video requests, but only 31% of video bytes. All this seems to suggest third-party providers are responsible stewards who keep their response sizes low, and, for the most part, that is in fact the case until you look at scripts.
-
Despite serving 57% of scripts, third parties comprise 64% of script bytes. meaning their scripts are larger on average than first-party scripts. This is an early warning sign for their performance impact to come in the next few sections.
Chart showing the breakdown of bytes for each content type per third party category. Images and scripts are relatively evenly distributed across categories. 80% of fonts come from CDNs. Video comes from "content" third-parties.
- Figure 7. Distributions of resource bytes per third-party category.
-
-
-
As for specific third-party providers, the same juggernauts topping the request count leaderboards make their appearance in byte weight as well. The only few notable movements are the large, media-heavy providers such as YouTube, Shopify, and Twitter which climb to the top of the byte impact charts.
57% of script execution time is from third-party scripts, and the top 100 domains already account for 48% of all script execution time on the web. This underscores just how large an impact a select few entities really have on web performance. This topic is explored more in depth in the Repercussions > Performance section.
-
-
-
The category breakdowns among script execution largely follow that of resource counts. Here too advertising looms largest. Ad scripts comprise 25% of third-party script execution time with hosting and social providers in a distant tie for second at 12%.
-
-
-
While much could be said about every individual provider's popularity and performance impact, this more opinionated analysis is left as an exercise for the reader and other purpose-built tools such as the previously mentioned third-party-web.
Why do site owners use third-party code? How did third-party content grow to be nearly half of all network requests? What are all these requests doing? Answers to these questions lie in the three primary usage patterns of third-party resources. Broadly, site owners reach for third parties to generate and consume data from their users, monetize their site experiences, and simplify web development.
Analytics is the most popular third-party category found across the web and yet is minimally user-visible. Consider the volume of information at play in the lifetime of a web visit; there's user context, device, browser, connection quality, location, page interactions, session length, return visitor status, and more being generated continuously. It's difficult, cumbersome, and expensive to maintain tools that warehouse, normalize, and analyze time series data of this magnitude. While nothing categorically necessitates that analytics fall into the domain of third-party providers, the widespread attractiveness of understanding your users, deep complexity of the problem space, and increasing emphasis on managing data respectfully and responsibly naturally surfaces analytics as a popular third-party usage pattern.
-
There's also a flip side to user data though: consumption. While analytics is about generating data from your site's visitors, other third-party resources focus on consuming data about your visitors that is known only by others. Social providers fall squarely into this usage pattern. A site owner must use Facebook resources if they wish to integrate information from a visitor's Facebook profile into their site. As long as site owners are interested in personalizing their experience with widgets from social networks and leveraging the social networks of their visitors to increase their reach, social integrations are likely to remain the domain of third-party entities for the foreseeable future.
The open model of the web does not always serve the financial interests of content creators to their liking and many site owners resort to monetizing their sites with advertising. Because building direct relationships with advertisers and negotiating pricing contracts is a relatively difficult and time-consuming process, this concern is largely handled by third-party providers performing targeted advertising and real-time bidding. Widespread negative public opinion, the popularity of ad blocking technology, and regulatory action in major global markets such as Europe pose the largest threat to the continued use of third-party providers for monetization. While it's unlikely that site owners suddenly strike their own advertising deals or build bespoke ad networks, alternative monetization models like paywalls and experiments like Brave's Basic Attention Token have a real chance of shaking up the third-party ad landscape of the future.
Above all, third-party resources are used to simplify the web development experience. Even previous usage patterns could arguably fall into this pattern as well. Whether analyzing user behavior, communicating with advertisers, or personalizing the user experience, third-party resources are used to make first-party development easier.
-
Hosting providers are the most extreme example of this pattern. Some of these providers even enable anyone on Earth to become a site owner with no technical expertise necessary. They provide hosting of assets, tools to build sites without coding experience, and domain registration services.
-
The remainder of third-party providers also tend to fall into this usage pattern. Whether it's hosting of a utility library such as jQuery for usage by front-end developers cached on Cloudflare's edge servers or a vast library of common fonts served from a popular Google CDN, third-party content is another way to give the site owner one fewer thing to worry about and, maybe, just maybe, make the job of delivering a great experience a little bit easier.
The performance impact of third-party content is neither categorically good nor bad. There are good and bad actors across the spectrum and different category types have varying levels of influence.
-
The good: shared third-party font and stylesheet utilities are, on average, delivered more efficiently than their first-party counterparts.
-
Utilities, CDNs, and Content categories are the brightest spots on the third-party performance landscape. They offer optimized versions of the same sort of content that would otherwise be served from first-party sources. Google Fonts and Typekit serve optimized fonts that are smaller on average than first-party fonts, Cloudflare CDN serves a minified version of open source libraries that might be accidentally served in development mode by some site owners, Google Maps SDK efficiently delivers complex maps that might otherwise be naively shipped as large images.
-
The bad: a very small set of entities represent a very large chunk of JavaScript execution time carrying out narrow set of functionality on pages.
-
Ads, social, hosting, and certain analytics providers represent the largest negative impact on web performance. While hosting providers deliver a majority of a site's content and will understandably have a larger performance impact than other third-party categories, they also serve almost entirely static sites that demand very little JavaScript in most cases that should not justify the volume of script execution time. The other categories hurting performance though have even less of an excuse. They fill very narrow roles on each page they appear on and yet quickly take over a majority of resources. For example, the Facebook "Like" button and associated social widgets take up extraordinarily little screen real estate and are a fraction of most web experiences, and yet the median impact on pages with social third parties is nearly 20% of their total JavaScript execution time. The situation is similar for analytics - tracking libraries do not directly contribute to the perceived user experience, and yet the 90th percentile impact on pages with analytics third parties is 44% of their total JavaScript execution time.
-
The silver lining of such a small number of entities enjoying such large market share is that a very limited and concentrated effort can have an enormous impact on the web as a whole. Performance improvements at just the top few hosting providers can improve 2-3% of all web requests.
The abundance of analytics providers and top-heavy concentration of script execution raises two primary privacy concerns for site visitors: the largest use case of third-parties is for site owners to track their users and a handful of companies receive information on a large swath of web traffic.
-
The interest of site owners in understanding and analyzing user behavior is not malicious on its own, but the widespread and relatively behind-the-scenes nature of web analytics raises valid concerns, and users, companies, and lawmakers have taken notice in recent years with privacy regulation such as GDPR in Europe and the CCPA in California. Ensuring that developers handle user data responsibly, treat the user respectfully, and are transparent with what data is collected is key to keeping analytics the most popular third-party category and maintaining the symbiotic nature of analyzing user behavior to deliver future user value.
-
The top-heavy concentration of script execution is great for the potential impact of performance improvements, but less exciting for the privacy ramifications. 29% of all script execution time across the web is just from scripts on domains owned by Google or Facebook. That's a very large percentage of CPU time that is controlled by just two entities. It's critical to ensure that the same privacy protections held to analytics providers be applied in these other ad, social, and developer utility categories as well.
While the topic of security is covered more in-depth in the Security chapter, the security implications of introducing external dependencies to your site go hand-in-hand with privacy concerns. Allowing third parties to execute arbitrary JavaScript effectively provides them with complete control over your page. When a script can control the DOM and window, it can do everything. Even if code has no security concerns, it can introduce a single point of failure, which has been recognized as a potential problem for some time now.
-
Self-hosting third-party content addresses some of the concerns mentioned here - and others. Additionally with browsers increasingly partitioning HTTP caches the benefits of loading directly from the third-party are increasingly questionable. Perhaps this is a better way to consume third-party content for many use cases, even if it makes measuring its impact more difficult.
Third-party content is everywhere. This is hardly surprising; the entire basis of the web is to allow interconnectedness and linking. In this chapter we have examined third-party content in terms of assets hosted away from the main domain. If we had included self-hosted third-party content (e.g. common open source libraries hosted on the main domain), third-party usage would have been even larger!
-
While reuse in computer technologies is generally a best practice, third parties on the web introduce dependencies that have a considerable impact on the performance, privacy, and security of a page. Self-hosting and careful provider selection can go a long way to mitigate these effects
-
Regardless of the important question of how third-party content is added to a page, the conclusion is the same: third parties are an integral part of the web!
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":6,"title":"Fonts","description":"Fonts chapter of the 2019 Web Almanac covering where fonts are loaded from, font formats, font loading performance, variable fonts and color fonts.","authors":["zachleat"],"reviewers":["hyperpress","AymenLoukil"],"translators":null,"discuss":"1761","results":"https://docs.google.com/spreadsheets/d/108g6LXdC3YVsxmX1CCwrmpZ3-DmbB8G_wwgQHX5pn6Q/","queries":"06_Fonts","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-02T00:00:00.000Z","chapter":"fonts"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Web fonts enable beautiful and functional typography on the web. Using web fonts not only empowers design, but it democratizes a subset of design, as it allows easier access to those who might not have particularly strong design skills. However, for all the good they can do, web fonts can also do great harm to your site's performance if they are not loaded properly.
-
Are they a net positive for the web? Do they provide more benefit than harm? Are the web standards cowpaths sufficiently paved to encourage web font loading best practices by default? And if not, what needs to change? Let's take a data-driven peek at whether or not we can answer those questions by inspecting how web fonts are used on the web today.
The first and most prominent question: performance. There is a whole chapter dedicated to performance but we will delve a little into font-specific performance issues here.
-
Using hosted web fonts enables ease of implementation and maintenance, but self-hosting offers the best performance. Given that web fonts by default make text invisible while the web font is loading (also known as the Flash of Invisible Text, or FOIT), the performance of web fonts can be more critical than non-blocking assets like images.
Differentiating self-hosting against third-party hosting is increasingly relevant in an HTTP/2 world, where the performance gap between a same-host and different-host connection can be wider. Same-host requests have the huge benefit of a better potential for prioritization against other same-host requests in the waterfall.
-
Recommendations to mitigate the performance costs of loading web fonts from another host include using the preconnect, dns-prefetch, and preloadresource hints, but high priority web fonts should be same-host requests to minimize the performance impact of web fonts. This is especially important for fonts used by very visually prominent content or body copy occupying the majority of a page.
Bar chart showing the popularity of third-party and self-hosting strategies for web fonts. 75% of mobile web pages use third-party hosts and 25% self-host. Desktop websites have similar usage.
- Figure 1. Popular web font hosting strategies.
-
-
The fact that three quarters are hosted is perhaps unsurprising given Google Fonts dominance that we will discuss below.
-
Google serves fonts using third-party CSS files hosted on https://fonts.googleapis.com. Developers add requests to these stylesheets using <link> tags in their markup. While these stylesheets are render blocking, they are very small. However, the font files are hosted on yet another domain, https://fonts.gstatic.com. The model of requiring two separate hops to two different domains makes preconnect a great option here for the second request that will not be discovered until the CSS is downloaded.
-
Note that while preload would be a nice addition to load the font files higher in the request waterfall (remember that preconnect sets up the connection, it doesn’t request the file content), preload is not yet available with Google Fonts. Google Fonts generates unique URLs for their font files which are subject to change.
- Figure 2. Top 20 font hosts by percent of requests.
-
-
The dominance of Google Fonts here was simultaneously surprising and unsurprising at the same time. It was unsurprising in that I expected the service to be the most popular and surprising in the sheer dominance of its popularity. 75% of font requests is astounding. TypeKit was a distant single-digit second place, with the Bootstrap library accounting for an even more distant third place.
-
-
29%
- Figure 3. Percent of pages that include a Google Fonts stylesheet link in the document <head>.
-
-
While the high usage of Google Fonts here is very impressive, it is also noteworthy that only 29% of pages included a Google Fonts <link> element. This could mean a few things:
-
-
When pages uses Google Fonts, they use a lot of Google Fonts. They are provided without monetary cost, after all. Perhaps they're being used in a popular WYSIWYG editor? This seems like a very likely explanation.
-
Or a more unlikely story is that it could mean that a lot of people are using Google Fonts with @import instead of <link>.
-
- Or if we want to go off the deep end into super unlikely scenarios, it could mean that many people are using Google Fonts with an HTTP Link: header instead.
-
-
-
-
0.4%
- Figure 4. Percent of pages that include a Google Fonts stylesheet link as the first child in the document <head>.
-
-
Google Fonts documentation encourages the <link> for the Google Fonts CSS to be placed as the first child in the <head> of a page. This is a big ask! In practice, this is not common as only half a percent of all pages (about 20,000 pages) took this advice.
-
More so, if a page is using preconnect or dns-prefetch as <link> elements, these would come before the Google Fonts CSS anyway. Read on for more about these resource hints.
As mentioned above, a super easy way to speed up web font requests to a third-party host is to use the preconnectresource hint.
-
-
1.7%
- Figure 5. Percent of mobile pages preconnecting to a web font host.
-
-
- Wow! Less than 2% of pages are using preconnect! Given that Google Fonts is at 75%, this should be higher! Developers: if you use Google Fonts, use preconnect! Google Fonts: proselytize preconnect more!
-
-
In fact, if you're using Google Fonts go ahead and add this to your <head> if it's not there already:
WOFF2 is pretty well supported in web browsers today. Google Fonts serves WOFF2, a format that offers improved compression over its predecessor WOFF, which was itself already an improvement over other existing font formats.
Bar chart showing the popularity of web font MIME types. WOFF2 is used on 74% of fonts, followed by 13% WOFF, 6% octet-stream, 3% TTF, 2% plain, 1% HTML, 1% SFNT, and fewer than 1% for all other types. Desktop and mobile have similar distributions.
- Figure 7. Popularity of web font MIME types.
-
-
From my perspective, an argument could be made to go WOFF2-only for web fonts after seeing the results here. I wonder where the double-digit WOFF usage is coming from? Perhaps developers still serving web fonts to Internet Explorer?
-
Third place octet-stream (and plain a little further down) would seem to suggest that a lot of web servers are configured improperly, sending an incorrect MIME type with web font file requests.
-
Let's dig a bit deeper and look at the format() values used in the src: property of @font-face declarations:
Bar chart showing the popularity of formats used in font-face declarations. 69% of desktop pages' @font-face declarations specify the WOFF2 format, 11% WOFF, 10% TrueType, 8% SVG, 2% EOT, and fewer than 1% OpenType, TTF, and OTF. The distribution for mobile pages is similar.
- Figure 8. Popularity of font formats in @font-face declarations.
-
-
I was hoping to see SVG fonts on the decline. They're buggy and implementations have been removed from every browser except Safari. Time to drop these, y'all.
-
The SVG data point here also makes me wonder what MIME type y'all are serving these SVG fonts with. I don't see image/svg+xml anywhere in Figure 7. Anyway, don't worry about fixing that, just get rid of them!
This dataset seems to suggest that the majority of people are already using WOFF2-only in their @font-face blocks. But this is misleading of course, per our earlier discussion on the dominance of Google Fonts in the data set. Google Fonts does some sniffing methods to serve a streamlined CSS file and only includes the most modern format(). Unsurprisingly, WOFF2 dominates the results here for that reason, as browser support for WOFF2 has been pretty broad for some time now.
-
Importantly, this particular data doesn't really support or detract from the case to go WOFF2-only yet, but it remains a tempting idea.
The number one tool we have to fight the default web font loading behavior of "invisible while loading" (also known as FOIT), is font-display. Adding font-display: swap to your @font-face block is an easy way to tell the browser to show fallback text while the web font is loading.
-
Browser support is great too. Internet Explorer and pre-Chromium Edge don't have support but they also render fallback text by default when a web font loads (no FOITs allowed here). For our Chrome tests, how commonly is font-display used?
-
-
26%
- Figure 10. Percent of mobile pages that utilize the font-display style.
-
-
Bar chart showing the usage of the font-display style. 2.6% of mobile pages set this style to "swap", 1.5% to "auto", 0.7% to "block", 0.4% to "fallback", 0.2% to optional, and 0.1% to "swap" enclosed in quotes, which is invalid. The desktop distribution is similar except "swap" usage is lower by 0.4 percentage points and "auto" usage is higher by 0.1 percentage points.
As an easy way to show fallback text while a web font is loading, font-display: swap reigns supreme and is the most common value. swap is also the default value used by new Google Fonts code snippets too. I would have expected optional (only render if cached) to have a bit more usage here as a few prominent developer evangelists lobbied for it a bit, but no dice.
This is a question that requires some measure of nuance. How are the fonts being used? For how much content on the page? Where does this content live in the layout? How are the fonts being rendered? In lieu of nuance however let's dive right into some broad and heavy handed analysis specifically centered on request counts.
Bar chart showing the distribution of font requests per page. The 10, 25, 50, 75, and 90th percentiles for desktop are: 0, 1, 3, 6, and 9 font requests. The distribution for mobile is identical until the 75th and 90th percentiles, where mobile pages request 1 fewer font.
- Figure 12. Distribution of font requests per page.
-
-
The median web page makes three web font requests. At the 90th percentile, requested six and nine web fonts on mobile and desktop, respectively.
Histogram showing the distribution of the number of font requests per page. The most popular number of font requests is 0 at 22% of desktop pages. The distribution drops to 9% of pages having 1 font, then crests at 10% for 2-4 fonts before falling as the number of fonts increases. The desktop and mobile distributions are similar, although the mobile distribution skews slightly toward having fewer fonts per page.
- Figure 13. Histogram of web fonts requested per page.
-
-
That said there are marginally more requests for fonts made on mobile devices. My hunch here is that fewer typefaces are available on mobile devices, which in turn means fewer local() hits in Google Fonts CSS, falling back to network requests for these.
- Figure 14. The most web font requests on a single page.
-
-
The award for the page that requests the most web fonts goes to a site that made 718 web font requests!
-
After diving into the code, all of those 718 requests are going to Google Fonts! It looks like a malfunctioning "Above the Page fold" optimization plugin for WordPress has gone rogue on this site and is requesting (DDoS-ing?) all the Google Fonts—oops!
-
Ironic that a performance optimization plugin can make your performance much worse!
- Figure 15. Percent of mobile pages that declare a web font with the unicode-range property.
-
-
- unicode-range is a great CSS property to let the browser know specifically which code points the page would like to use in the font file. If the @font-face declaration has a unicode-range, content on the page must match one of the code points in the range before the font is requested. It is a very good thing.
-
-
This is another metric that I expect was skewed by Google Fonts usage, as Google Fonts uses unicode-range in most (if not all) of its CSS. I'd expect this to be less common in user land, but perhaps filtering out Google Fonts requests in the next edition of the Almanac may be possible.
- Figure 16. Percent of mobile pages that declare a web font with the local() property.
-
-
local() is a nice way to reference a system font in your @font-facesrc. If the local() font exists, it doesn't need to make a request for a web font at all. This is used both extensively and controversially by Google Fonts, so it is likely another example of skewed data if we're trying to glean patterns from user land.
- Figure 17. Percent of desktop and mobile pages that include a style with the font-stretch property.
-
-
- Historically, font-stretch has suffered from poor browser support and was not a well-known @font-face property. Read more about font-stretch on MDN. But browser support has broadened.
-
-
It has been suggested that using condensed fonts on smaller viewports allows more text to be viewable, but this approach isn't commonly used. That being said, that this property is used half a percentage point more on desktop than mobile is unexpected, and 7% seems much higher than I would have predicted.
Bar chart showing the usage of the font-variation-settings property. 42% of properties on desktop pages are set to the "opsz" value, 32% to "wght", 16% to "wdth", 2% or fewer to "roun", "crsb", "slnt", "inln", and more. The most notable differences between desktop and mobile pages are 26% usage of "opsz", 38% of "wght", and 23% of "wdth".
- Figure 19. Usage of font-variation-settings axes.
-
-
Through the lens of this large data set, these are very low sample sizes-take these results with a grain of salt. However, opsz as the most common axis on desktop pages is notable, with wght and wdth trailing. In my experience, the introductory demos for variable fonts are usually weight-based.
- Figure 20. The number of desktop web pages that include a color font.
-
-
Usage here of these is basically nonexistent but you can check out the excellent resource Color Fonts! WTF? for more information. Similar (but not at all) to the SVG format for fonts (which is bad and going away), this allows you to embed SVG inside of OpenType files, which is awesome and cool.
The biggest takeaway here is that Google Fonts dominates the web font discussion. Approaches they've taken weigh heavily on the data we've recorded here. The positives here are easy access to web fonts, good font formats (WOFF2), and for-free unicode-range configurations. The downsides here are performance drawbacks associated with third-party hosting, different-host requests, and no access to preload.
-
I fully expect that in the future we'll see the "Rise of the Variable Font". This should be paired with a decline in web font requests, as Variable Fonts combine multiple individual font files into a single composite font file. But history has shown us that what usually happens here is that we optimize a thing and then add more things to fill the vacancy.
-
It will be very interesting to see if color fonts increase in popularity. I expect these to be far more niche than variable fonts but may see a lifeline in the icon font space.
-
Keep those fonts frosty, y'all.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":7,"title":"Performance","description":"Performance chapter of the 2019 Web Almanac covering First Contentful Paint (FCP), Time to First Byte (TTFB), and First Input Delay (FID).","authors":["rviscomi"],"reviewers":["JMPerez","obto","sergeychernyshev","zeman"],"translators":null,"discuss":"1762","results":"https://docs.google.com/spreadsheets/d/1zWzFSQ_ygb-gGr1H1BsJCfB7Z89zSIf7GX0UayVEte4/","queries":"07_Performance","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"performance"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Performance is a visceral part of the user experience. For many websites, an improvement to the user experience by speeding up the page load time aligns with an improvement to conversion rates. Conversely, when performance is poor, users don't convert as often and have even been observed to be rage clicking on the page in frustration.
-
There are many ways to quantify web performance. The most important thing is to measure what actually matters to users. However, events like onload or DOMContentLoaded may not necessarily reflect what users experience visually. For example, when loading an email client, it might show an interstitial progress bar while the inbox contents load asynchronously. The problem is that the onload event doesn't wait for the inbox to asynchronously load. In this example, the loading metric that matters most to users is the "time to inbox", and focusing on the onload event may be misleading. For that reason, this chapter will look at more modern and universally applicable paint, load, and interactivity metrics to try to capture how users are actually experiencing the page.
-
There are two kinds of performance data: lab and field. You may have heard these referred to as synthetic testing and real-user measurement (or RUM). Measuring performance in the lab ensures that each website is tested under common conditions and variables like browser, connection speed, physical location, cache state, etc. remain the same. This guarantee of consistency makes each website comparable with one another. On the other hand, measuring performance in the field represents how users actually experience the web in all of the infinite combinations of conditions that we could never capture in the lab. For the purposes of this chapter and understanding real-world user experiences, we'll look at field data.
Almost all of the other chapters in the Web Almanac are based on data from the HTTP Archive. However, in order to capture how real users experience the web, we need a different dataset. In this section, we're using the Chrome UX Report (CrUX), a public dataset from Google that consists of all the same websites as the HTTP Archive, and aggregates how Chrome users actually experience them. Experiences are categorized by:
-
-
- The form factor of the users' devices
-
-
Desktop
-
Phone
-
Tablet
-
-
-
- Users' effective connection type (ECT) in mobile terms
-
-
Offline
-
Slow 2G
-
2G
-
3G
-
4G
-
-
-
Users' geographic locations
-
-
Experiences are measured monthly, including paint, load, and interactivity metrics. The first metric we'll look at is First Contentful Paint (FCP). This is the time users spend waiting for the page to display something useful to the screen, like an image or text. Then, we'll look at look at a loading metric, Time to First Byte (TTFB). This is a measure of how long the web page took from the time of the user's navigation until they received the first byte of the response. And, finally, the last field metric we'll look at is First Input Delay (FID). This is a relatively new metric and one that represents parts of the UX other than loading performance. It measures the time from a user's first interaction with a page's UI until the time the browser's main thread is ready to process the event.
-
So let's dive in and see what insights we can find.
Distribution of 1,000 websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0%.
- Figure 1. Distribution of websites' fast, moderate, and slow FCP performance.
-
-
In Figure 1 above, you can see how FCP experiences are distributed across the web. Out of the millions of websites in the CrUX dataset, this chart compresses the distribution down to 1,000 websites, where each vertical slice represents a single website. The chart is sorted by the percent of fast FCP experiences, which are those occurring in less than 1 second. Slow experiences occur in 3 seconds or more, and moderate (formerly known as "average") experiences are everything in between. At the extremes of the chart, there are some websites with almost 100% fast experiences and some websites with almost 100% slow experiences. In between that, websites that have a combination of fast, moderate, and slow performance seem to lean more towards fast or moderate than slow, which is good.
-
Note: When a user experiences slow performance, it's hard to say what the reason might be. It could be that the website itself was built poorly and inefficiently. Or there could be other environmental factors like the user's slow connection, empty cache, etc. So, when looking at this field data we prefer to say that the user experiences themselves are slow, and not necessarily the websites.
-
In order to categorize whether a website is sufficiently fast we will use the new PageSpeed Insights (PSI) methodology, where at least 75% of the website's FCP experiences must be faster than 1 second. Similarly, a sufficiently slow website has 25% or more FCP experiences slower than 3 seconds. We say a website has moderate performance when it doesn't meet either of these conditions.
Bar chart showing that 13% of websites have fast FCP, 66% have moderate FCP, and 20% have slow FCP.
- Figure 2. Distribution of websites labeled as having fast, moderate, or slow FCP.
-
-
The results in Figure 2 show that only 13% of websites are considered fast. This is a sign that there is still a lot of room for improvement, but many websites are painting meaningful content quickly and consistently. Two thirds of websites have moderate FCP experiences.
-
To help us understand how users experience FCP across different devices, let's segment by form factor.
Distribution of 1,000 desktop websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0% with a slight bulge in the middle.
- Figure 3. Distribution of desktop websites' fast, moderate, and slow FCP performance.
-
-
-
-
-
-
-
Distribution of 1,000 mobile websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0% without the same middle bulge seen for desktop websites.
- Figure 4. Distribution of phone websites' fast, moderate, and slow FCP performance.
-
-
In Figures 3 and 4 above, the FCP distributions are broken down by desktop and phone. It's subtle, but the torso of the desktop fast FCP distribution appears to be more convex than the distribution for phone users. This visual approximation suggests that desktop users experience a higher overall proportion of fast FCP. To verify this, we can apply the PSI methodology to each distribution.
Bar chart of the desktop and mobile FCP distributions. Desktop fast, moderate, slow: 17%, 67%, and 16% respectively. Mobile: 11%, 66%, and 23%.
- Figure 5. Distribution of websites labeled as having fast, moderate, or slow FCP, broken down by device type.
-
-
According to PSI's classification, 17% of websites have fast FCP experiences overall for desktop users, compared to 11% for mobile users. The entire distribution is skewed to being slightly faster for desktop experiences, with fewer slow websites and more in the fast and moderate category.
-
Why might desktop users experience fast FCP on a higher proportion of websites than phone users? We can only speculate, after all, this dataset is meant to answer how the web is performing and not necessarily why it's performing that way. But one guess could be that desktop users are connected to the internet on faster, more reliable networks like WiFi rather than cell towers. To help answer this question, we can also explore how user experiences vary by ECT.
Bar chart of FCP distributions per effective connection type. 4G fast, moderate, slow: 14%, 67%, and 19% respectively. 3G: 1%, 38%, and 61%. 2G: 0%, 9%, 90%. Slow 2G: 0%, 1%, 99%.
- Figure 6. Distribution of websites labeled as having fast, moderate, or slow FCP, broken down by ECT.
-
-
In Figure 6 above, FCP experiences are grouped by the ECT of the user experience. Interestingly, there is a correlation between ECT speed and the percent of websites serving fast FCP. As the ECT speeds decrease, the proportion of fast experiences approaches zero. 14% of websites that serve users with 4G ECT have fast FCP experiences, while 19% of those websites have slow experiences. 61% of websites serve slow FCP to users with 3G ECT, 90% to 2G ECT, and 99% to slow-2G ECT. These results suggest that websites seldom serve fast FCP consistently to users on connections effectively slower than 4G.
Bar chart of FCP distributions for the top 23 most popular geographies. Korea has the most fast websites at 36%. From there, the percent of fast websites declines rapidly for other geographies: Japan 28%, Taiwan 26%, Netherlands 21%, etc.
- Figure 7. Distribution of websites labeled as having fast, moderate, or slow FCP, broken down by geo.
-
-
Finally, we can slice FCP by users' geography (geo). The chart above shows the top 23 geos having the highest number of distinct websites, an indicator of overall popularity of the open web. Web users in the United States visit the most distinct websites at 1,211,002. The geos are sorted by the percent of websites having sufficiently fast FCP experiences. At the top of the list are three Asia-Pacific (APAC) geos: Korea, Taiwan, and Japan. This could be explained by the availability of extremely fast network connection speeds in these regions. Korea has 36% of websites meeting the fast FCP bar, and only 7% rated as slow FCP. Recall that the global distribution of fast/moderate/slow websites is approximately 13/66/20, making Korea a significantly positive outlier.
-
Other APAC geos tell a different story. Thailand, Vietnam, Indonesia, and India all have fewer than 10% of fast websites. These geos also have more than triple the proportion of slow websites than Korea.
Time to First Byte (TTFB) is a measure of how long the web page took from the time of the user's navigation until they received the first byte of the response.
Diagram showing the sequence of network phases in a page load: startTime (promptForUnload), redirect, AppCache, DNS, TCP, request, response, processing, and load.
- Figure 8. Navigation Timing API diagram of the events in a page navigation.
-
-
To help explain TTFB and the many factors that affect it, let's borrow a diagram from the Navigation Timing API spec. In Figure 8 above, TTFB is the duration from startTime to responseStart, including everything in between: unload, redirects, AppCache, DNS, SSL, TCP, and the time the server spends handling the request. Given that context, let's see how users are experiencing this metric.
Distribution of 1,000 websites' fast, moderate, and slow TTFB. The distribution of fast TTFB drops quickly from about 90% to 50% at the 10th fastest percentile. Then the distribution gradually decreases from 50% to 0% all the way down the remaining 90 percentiles.
- Figure 9. Distribution of websites' fast, moderate, and slow TTFB performance.
-
-
Similar to the FCP chart in Figure 1, this is a view of 1,000 representative samples ordered by fast TTFB. A fast TTFB is one that happens in under 0.2 seconds (200 ms), a slow TTFB happens in 1 second or more, and everything in between is moderate.
-
Looking at the curve of the fast proportions, the shape is quite different from that of FCP. There are very few websites that have a fast TTFB greater than 75%, while more than half are below 25%.
-
Let's apply a TTFB speed label to each website, taking inspiration from the PSI methodology used above for FCP. If a website serves fast TTFB to 75% or more user experiences, it's labeled as fast. Otherwise, if it serves slow TTFB to 25% or more user experiences, it's slow. If neither of those conditions apply, it's moderate.
Bar chart showing that 2% of websites have fast TTFB, 56% have moderate TTFB, and 42% have slow TTFB.
- Figure 10. Distribution of websites labeled as having fast, moderate, or slow TTFB.
-
-
42% of websites have slow TTFB experiences. This is significant because TTFB is a blocker for all other performance metrics to follow. By definition, a user cannot possibly experience a fast FCP if the TTFB takes more than 1 second.
Bar chart of TTFB distributions for the top 23 most popular geographies. Korea has the most fast websites at 14%. From there, the percent of fast websites declines rapidly for other geographies: Taiwan 7%, Japan 5%, Netherlands 4%, etc.
- Figure 11. Distribution of websites labeled as having fast, moderate, or slow TTFB, broken down by geo.
-
-
Now let's look at the percent of websites serving fast TTFB to users in different geos. APAC geos like Korea, Taiwan, and Japan are still outperforming users from the rest of the world. But no geo has more than 15% of websites with fast TTFB. India, for example, has fewer than 1% of websites with fast TTFB and 79% with slow TTFB.
The last field metric we'll look at is First Input Delay (FID). This metric represents the time from a user's first interaction with a page's UI until the time the browser's main thread is ready to process the event. Note that this doesn't include the time applications spend actually handling the input. At worst, slow FID results in a page that appears unresponsive and a frustrating user experience.
-
Let's start by defining some thresholds. According to the new PSI methodology, a fast FID is one that happens in less than 100 ms. This gives the application enough time to handle the input event and provide feedback to the user in a time that feels instantaneous. A slow FID is one that happens in 300 ms or more. Everything in between is moderate.
Distribution of 1,000 websites' fast, moderate, and slow FID. The distribution of fast FID holds above 75% for the fastest three quarters of websites, then drops quickly to 0%.
- Figure 12. Distribution of websites' fast, moderate, and slow FID performance.
-
-
You know the drill by now. This chart shows the distribution of websites' fast, moderate, and slow FID experiences. This is a dramatically different chart from the previous charts for FCP and TTFB. (See Figure 1 and Figure 9, respectively). The curve of fast FID very slowly descends from 100% to 75%, then takes a nosedive. The overwhelming majority of FID experiences are fast for most websites.
Bar chart showing that 40% of websites have fast FID, 45% have moderate FID, and 15% have slow FID.
- Figure 13. Distribution of websites labeled as having fast, moderate, or slow TTFB.
-
-
The PSI methodology for labeling a website as having sufficiently fast or slow FID is slightly different than that of FCP. For a site to be fast, 95% of its FID experiences must be fast. A site is slow if 5% of its FID experiences are slow. All other experiences are moderate.
-
Compared to the previous metrics, the distribution of aggregate FID performance is much more skewed towards fast and moderate experiences than slow. 40% of websites have fast FID and only 15% have slow FID. The nature of FID being an interactivity metric -- as opposed to a loading metric bound by network speeds -- makes for an entirely different way to characterize performance.
Distribution of 1,000 desktop websites' fast, moderate, and slow FID. The distribution of fast FID decreases very slowly from 100% to 90% for the fastest three quarters of websites. After that, fast FID decreases slightly to 75%. Nearly all desktop websites have more than 75% fast FID experiences.
- Figure 14. Distribution of desktop websites' fast, moderate, and slow FID performance.
-
-
-
-
-
-
-
Distribution of 1,000 mobile websites' fast, moderate, and slow FID. The distribution of fast FID declines steadily but much more quickly than desktop. It reaches 75% fast for at three quarters of websites then quickly drops to 0%.
- Figure 15. Distribution of phone websites' fast, moderate, and slow FID performance.
-
-
By breaking FID down by device, it becomes clear that there are two very different stories. Desktop users enjoy fast FID almost all the time. Sure, there are some websites that throw out a slow experience now and then, but the results are predominantly fast. Mobile users, on the other hand, have what seem to be one of two experiences: pretty fast (but not quite as often as desktop) and almost never fast. The latter is experienced by users on only the tail 10% of websites, but this is still a substantial difference.
Bar chart of the desktop and mobile FID distributions. Desktop fast, moderate, slow: 82%, 12%, and 5% respectively. Mobile: 26%, 52%, and 22%.
- Figure 16. Distribution of websites labeled as having fast, moderate, or slow FID, broken down by device type.
-
-
When we apply the PSI labeling to desktop and phone experiences, the distinction becomes crystal clear. 82% of websites' FID experienced by desktop users are fast compared to 5% slow. For mobile experiences, 26% of websites are fast while 22% are slow. Form factor plays a major role in the performance of interactivity metrics like FID.
Bar chart of FID distributions per effective connection type. 4G fast, moderate, slow: 41%, 45%, and 15% respectively. 3G: 22%, 52%, and 26%. 2G: 19%, 58%, 23%. Slow 2G: 15%, 58%, 27%.
- Figure 17. Distribution of websites labeled as having fast, moderate, or slow FID, broken down by ECT.
-
-
On its face, FID seems like it would be driven primarily by CPU speed. It'd be reasonable to assume that the slower the device itself is, the higher the likelihood that it will be busy when the user attempts to interact with a web page, right?
-
The ECT results above seem to suggest that there is a correlation between connection speed and FID performance. As users' effective connection speed decreases, the percent of websites on which they experience fast FID also decreases: 41% of websites visited by users with a 4G ECT have fast FID, 22% with 3G, 19% with 2G, and 15% with slow 2G.
Bar chart of FID distributions for the top 23 most popular geographies. Korea has the most fast websites at 69%. From there, the percent of fast websites declines steadily for other geographies: Australia 55%, United States 52%, Canada 51%, etc.
- Figure 18. Distribution of websites labeled as having fast, moderate, or slow FID, broken down by geo.
-
-
In this breakdown of FID by geographic location, Korea is out in front of everyone else again. But the top geos have some new faces: Australia, the United States, and Canada are next with more than 50% of websites having fast FID.
-
As with the other geo-specific results, there are so many possible factors that could be contributing to the user experience. For example, perhaps wealthier geos that are more privileged can afford faster network infrastructure also have residents with more money to spend on desktops and/or high-end mobile phones.
Quantifying how fast a web page loads is an imperfect science that can't be represented by a single metric. Conventional metrics like onload can miss the mark entirely by measuring irrelevant or imperceptible parts of the user experience. User-perceived metrics like FCP and FID more faithfully convey what users see and feel. Even still, neither metric can be looked at in isolation to draw conclusions about whether the overall page load experience was fast or slow. Only by looking at many metrics holistically, can we start to understand the performance for an individual website and the state of the web.
-
The data presented in this chapter showed that there is still a lot of work to do to meet the goals set for fast websites. Certain form factors, effective connection types, and geos do correlate with better user experiences, but we can't forget about the combinations of demographics with poor performance. In many cases, the web platform is used for business; making more money from improving conversion rates can be a huge motivator for speeding up a website. Ultimately, for all websites, performance is about delivering positive experiences to users in a way that doesn't impede, frustrate, or enrage them.
-
As the web gets another year older and our ability to measure how users experience it improves incrementally, I'm looking forward to developers having access to metrics that capture more of the holistic user experience. FCP is very early on the timeline of showing useful content to users, and newer metrics like Largest Contentful Paint (LCP) are emerging to improve our visibility into how page loads are perceived. The Layout Instability API has also given us a novel glimpse into the frustration users experience beyond page load.
-
Equipped with these new metrics, the web in 2020 will become even more transparent, better understood, and give developers an advantage to make more meaningful progress to improve performance and contribute to positive user experiences.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
This chapter of the Web Almanac looks at the current status of security on the web. With security and privacy becoming increasingly more important online there has been an increase in the availability of features to protect site operators and users. We're going to look at the adoption of these new features across the web.
Perhaps the largest push to increasing security and privacy online we're seeing at present is the widespread adoption of Transport Layer Security (TLS). TLS (or the older version, SSL) is the protocol that gives us the 'S' in HTTPS and allows secure and private browsing of websites. Not only are we seeing a great increase in the use of HTTPS across the web, but also an increase in more modern versions of TLS like TLSv1.2 and TLSv1.3, which is also important.
Horizontal bar chart showing desktop and mobile on similar TLS usage: 58% on TLSv1.2, 41% on TLSv1.3 and very little usage of TLSv1.0 (0.75%) and a tiny usage of TLSv1.1.
Figure 2 shows the support for various protocol versions. Use of legacy TLS versions like TLSv1.0 and TLSv1.1 is minimal and almost all support is for the newer TLSv1.2 and TLSv1.3 versions of the protocol. Even though TLSv1.3 is still very young as a standard (TLSv1.3 was only formally approved in August 2018), over 40% of requests using TLS are using the latest version!
-
This is likely due to many sites using requests from the larger players for third-party content. For example, any sites load Google Analytics, Google AdWords, or Google Fonts and these large players like Google are typically early adopters for new protocols.
-
If we look at just home pages, and not all the other requests made on sites, then the usage of TLS is considerably as expected, though still quite high which is likely due to CMS sites like Wordpress and CDNs:
Horizontal bar chart showing desktop and mobile on similar TLS usage: 47% on desktop (43% on mobile) on TLSv1.2, 20.2% on desktop (19.7% on mobile) on TLSv1.3 and very little usage of TLSv1.0 (1.1% - 1.2%) and a tiny usage of TLSv1.1.
- Figure 3. Usage of TLS protocol versions for home page requests only.
-
-
On the other hand, the methodology used by the Web Almanac will also under-report usage from large sites, as their sites themselves will likely form a larger volume of internet traffic in the real world, yet are crawled only once for these statistics.
Of course, if we want to use HTTPS on our website then we need a certificate from a Certificate Authority (CA). With the increase in the use of HTTPS comes the increase in use of CAs and their products/services. Here are the top ten certificate issuers based on the volume of TLS requests that use their certificate.
As previously discussed, the volume for Google likely reflects repeated use of Google Analytics, Google Adwords, or Google Fonts on other sites.
-
The rise of Let's Encrypt has been meteoric after their launch in early 2016, since then they've become one of the top certificate issuers in the world. The availability of free certificates and the automated tooling has been critically important to the adoption of HTTPS on the web. Let's Encrypt certainly had a significant part to play in both of those.
-
The reduced cost has removed the barrier to entry for HTTPS, but the automation Let's Encrypt uses is perhaps more important in the long run as it allows shorter certificate lifetimes which has many security benefits.
Alongside the important requirement to use HTTPS is the requirement to also use a good configuration. With so many configuration options and choices to make, this is a careful balance.
-
First of all, we'll look at the keys used for authentication purposes. Traditionally certificates have been issued based on keys using the RSA algorithm, however a newer and better algorithm uses ECDSA (Elliptic Curve Digital Signature Algorithm) which allows the use of smaller keys that demonstrate better performance than their RSA counterparts. Looking at the results of our crawl we still see a large % of the web using RSA.
Whilst ECDSA keys are stronger, which allows the use of smaller keys and demonstrate better performance than their RSA counterparts, concerns around backwards compatibility, and complications in supporting both in the meantime, do prevent some website operators from migrating.
Forward secrecy is a property of some key exchange mechanisms that secures the connection in such a way that it prevents each connection to a server from being exposed even in case of a future compromise of the server's private key. This is well understood within the security community as desirable on all TLS connections to safeguard the security of those connections. It was introduced as an optional configuration in 2008 with TLSv1.2 and has become mandatory in 2018 with TLSv1.3 requiring the use of Forward Secrecy.
-
Looking at the % of TLS requests that provide Forward Secrecy, we can see that support is tremendous. 96.92% of Desktop and 96.49% of mobile requests use Forward secrecy. We'd expect that the continuing increase in the adoption of TLSv1.3 will further increase these numbers.
TLS allows the use of various cipher suites - some newer and more secure, and some older and insecure. Traditionally newer TLS versions have added cipher suites but have been reluctant to remove older cipher suites. TLSv1.3 aims to simplify this by offering a reduced set of ciphers suites and will not permit the older, insecure, cipher suites to be used. Tools like SSL Labs allow the TLS setup of a website (including the cipher suites supported and their preferred order) to be easily seen, which helps drive better configurations. We can see that the majority of cipher suites negotiated for TLS requests were indeed excellent:
It is positive to see such wide stream use of GCM ciphers since the older CBC ciphers are less secure. CHACHA20_POLY1305 is still an niche cipher suite, and we even still have a very small use of the insecure 3DES ciphers.
-
It should be noticed that these were the cipher suites used for the crawl using Chrome, but sites will likely also support other cipher suites as well for older browsers. Other sources, for example SSL Pulse, can provide more detail on the range of all cipher suites and protocols supported.
Most sites on the web originally existed as HTTP websites and have had to migrate their site to HTTPS. This 'lift and shift' operation can be difficult and sometimes things get missed or left behind. This results in sites having mixed content, where their pages load over HTTPS but something on the page, perhaps an image or a style, is loaded over HTTP. Mixed content is bad for security and privacy and can be difficult to find and fix.
We can see that around 20% of sites across mobile (645,485 sites) and desktop (594,072 sites) present some form of mixed content. Whilst passive mixed content, something like an image, is less dangerous, we can still see that almost a quarter of sites with mixed content have active mixed content. Active mixed content, like JavaScript, is more dangerous as an attacker can insert their own hostile code into a page easily.
-
In the past web browsers have allowed passive mixed content and flagged it with a warning but blocked active mixed content. More recently however, Chrome announced it intends to improve here and as HTTPS becomes the norm it will block all mixed content instead.
Many new and recent features for site operators to better protect their users have come in the form of new HTTP response headers that can configure and control security protections built into the browser. Some of these features are easy to enable and provide a huge level of protection whilst others require a little more work from site operators. If you wish to check if a site is using these headers and has them correctly configured, you can use the Security Headers tool to scan it.
A vertical bar graph showing increasing usage of security headers list for both desktop and mobile listing from left to right: cross-origin-resource-policy (0 sites on both), feature policy (approx 8k desktop and mobile) report-to (74k desktop and 83k mobile), nel (74k desktop and 83k mobile), referrer-policy (142k desktop, 156k mobile), content-security-policy (240k desktop, 252k mobile), strict-transport-security (648k desktop, 679k mobile), x-xss-protection (642k desktop, 805k mobile), x-frame-options (743k desktop, 782k mobile) and finally x-content-type-options (770k desktop, 932k mobile).
The HSTS header allows a website to instruct a browser that it should only ever communicate with the site over a secure HTTPS connection. This means that any attempts to use a http:// URL will automatically be converted to https:// before a request is made. Given that over 40% of requests were capable of using TLS, we see a much lower % of requests instructing the browser to require it.
Less than 15% of mobile and desktop pages are issuing a HSTS with a max-age directive. This is a minimum requirement for a valid policy. Fewer still are including subdomains in their policy with the includeSubDomains directive and even fewer still are HSTS preloading. Looking at the median value for a HSTS max-age, for those that do use this, we can see that on both desktop and mobile it is 15768000, a strong configuration representing half a year (60 x 60 x 24 x 365/2).
-
-
-
-
-
-
-
-
Client
-
-
-
Percentile
-
Desktop
-
Mobile
-
-
-
-
-
10
-
300
-
300
-
-
-
25
-
7889238
-
7889238
-
-
-
50
-
15768000
-
15768000
-
-
-
75
-
31536000
-
31536000
-
-
-
90
-
63072000
-
63072000
-
-
-
-
-
-
- Figure 10. Medium values of HSTS `max-age` policy by percentile.
-
With the HSTS policy delivered via an HTTP response Header, when visiting a site for the first time a browser will not know whether a policy is configured. To avoid this Trust On First Use problem, a site operator can have the policy preloaded into the browser (or other user agents) meaning you are protected even before you visit the site for the first time.
-
There are a number of requirements for preloading, which are outlined on the HSTS preload site. We can see that only a small number of sites, 0.31% on desktop and 0.26% on mobile, are eligible according to current criteria. Sites should ensure they have fully transitions all sites under their domain to HTTPS before submitting to preload the domain or they risk blocking access to HTTP-only sites.
Web applications face frequent attacks where hostile content finds its way into a page. The most worrisome form of content is JavaScript and when an attacker finds a way to insert JavaScript into a page, they can launch damaging attacks. These attacks are known as Cross-Site Scripting (XSS) and Content Security Policy (CSP) provides an effective defense against these attacks.
-
CSP is an HTTP header (Content-Security-Policy) published by a website which tells the browser rules around content allowed on a site. If additional content is injected into the site due to a security flaw, and it is not allowed by the policy, the browser will block it from being used. Alongside XSS protection, CSP also offers several other key benefits such as making migration to HTTPS easier.
-
Despite the many benefits of CSP, it can be complicated to implement on websites since its very purpose is to limit what is acceptable on a page. The policy must allow all content and resources you need and can easily get large and complex. Tools like Report URI can help you analyze and build the appropriate policy.
-
We find that only 5.51% of desktop pages include a CSP and only 4.73% of mobile pages include a CSP, likely due to the complexity of deployment.
A common approach to CSP is to create an allowlist of 3rd party domains that are permitted to load content, such as JavaScript, into your pages. Creating and managing these lists can be difficult so hashes and nonces were introduced as an alternative approach. A hash is calculated based on contents of the script so if this is published by the website operator and the script is changed, or another script is added, then it will not match the hash and will be blocked. A nonce is a one-time code (which should be changed each time the page is loaded to prevent it being guessed) which is allowed by the CSP and which the script is tagged with. You can see an example of a nonce on this page by viewing the source to see how Google Tag Manager is loaded.
-
Of the sites surveyed only 0.09% of desktop pages use a nonce source and only 0.02% of desktop pages use a hash source. The number of mobile pages use a nonce source is slightly higher at 0.13% but the use of hash sources is lower on mobile pages at 0.01%.
- The proposal of strict-dynamic in the next iteration of CSP further reduces the burden on site operators for using CSP by allowing an approved script to load further script dependencies. Despite the introduction of this feature, which already has support in some modern browsers, only 0.03% of desktop pages and 0.1% of mobile pages include it in their policy.
-
XSS attacks come in various forms and Trusted-Types was created to help specifically with DOM-XSS. Despite being an effective mechanism, our data shows that only 2 mobile and desktop pages use the Trusted-Types directive.
When a CSP is deployed on a page, certain unsafe features like inline scripts or the use of eval() are disabled. A page can depend on these features and enable them in a safe fashion, perhaps with a nonce or hash source. Site operators can also re-enable these unsafe features with unsafe-inline or unsafe-eval in their CSP though, as their names suggest, doing so does lose much of the protections that CSP gives you. Of the 5.51% of desktop pages that include a CSP, 33.94% of them include unsafe-inline and 31.03% of them include unsafe-eval. On mobile pages we find that of the 4.73% that contain a CSP, 34.04% use unsafe-inline and 31.71% use unsafe-eval.
We mentioned earlier that a common problem that site operators face in their migration from HTTP to HTTPS is that some content can still be accidentally loaded over HTTP on their HTTPS page. This problem is known as mixed content and CSP provides an effective way to solve this problem. The upgrade-insecure-requests directive instructs a browser to load all subresources on a page over a secure connection, automatically upgrading HTTP requests to HTTPS requests as an example. Think of it like HSTS for subresources on a page.
-
We showed earlier in figure 7 that, of the HTTPS pages surveyed on the desktop, 16.27% of them loaded mixed-content with 3.99% of pages loading active mixed-content like JS/CSS/fonts. On mobile pages we see 15.37% of HTTPS pages loading mixed-content with 4.13% loading active mixed-content. By loading active content such as JavaScript over HTTP an attacker can easily inject hostile code into the page to launch an attack. This is what the upgrade-insecure-requests directive in CSP protects against.
-
The upgrade-insecure-requests directive is found in the CSP of 3.24% of desktop pages and 2.84% of mobile pages, indicating that an increase in adoption would provide substantial benefits. It could be introduced with relative ease, without requiring a fully locked-down CSP and the complexity that would entail, by allowing broad categories with a policy like below, or even including unsafe-inline and unsafe-eval:
Another common attack known as clickjacking is conducted by an attacker who will place a target website inside an iframe on a hostile website, and then overlay hidden controls and buttons that they are in control of. Whilst the X-Frame-Options header (discussed below) originally set out to control framing, it wasn't flexible and frame-ancestors in CSP stepped in to provide a more flexible solution. Site operators can now specify a list of hosts that are permitted to frame them and any other hosts attempting to frame them will be prevented.
-
Of the pages surveyed, 2.85% of desktop pages include the frame-ancestors directive in CSP with 0.74% of desktop pages setting Frame-Ancestors to 'none', preventing any framing, and 0.47% of pages setting frame-ancestors to 'self', allowing only their own site to frame itself. On mobile we see 2.52% of pages using frame-ancestors with 0.71% setting the value of 'none' and 0.41% setting the value to 'self'.
- The Referrer-Policy header allows a site to control what information will be sent in the Referer header when a user navigates away from the current page. This can be the source of information leakage if there is sensitive data in the URL, such as search queries or other user-dependent information included in URL parameters. By controlling what information is sent in the Referer header, ideally limiting it, a site can protect the privacy of their visitors by reducing the information sent to 3rd parties.
-
This table shows the valid values set by pages and that, of the pages which use this header, 99.75% of them on desktop and 96.55% of them on mobile are setting a valid policy. The most popular choice of configuration is no-referrer-when-downgrade which will prevent the Referer header being sent when a user navigates from a HTTPS page to a HTTP page. The second most popular choice is strict-origin-when-cross-origin which prevents any information being sent on a scheme downgrade (HTTPS to HTTP navigation) and when information is sent in the Referer it will only contain the origin of the source and not the full URL (for example https://www.example.com rather than https://www.example.com/page/). Details on the other valid configurations can be found in the Referrer Policy specification, though such a high usage of unsafe-url warrants further investigation but is likely to be a third-party component like analytics or advertisement libraries.
- As the web platform becomes more powerful and feature rich, attackers can abuse these new APIs in interesting ways. In order to limit misuse of powerful APIs, a site operator can issue a Feature-Policy header to disable features that are not required, preventing them from being abused.
-
-
Here are the 5 most popular features that are controlled with a Feature Policy.
We can see that the most popular feature to take control of is the microphone, with almost 11% of desktop and mobile pages issuing a policy that includes it. Delving deeper into the data we can look at what those pages are allowing or blocking.
-
-
-
-
-
-
-
Feature
-
Configuration
-
Usage
-
-
-
-
-
microphone
-
none
-
9.09%
-
-
-
microphone
-
none
-
8.97%
-
-
-
microphone
-
self
-
0.86%
-
-
-
microphone
-
self
-
0.85%
-
-
-
microphone
-
*
-
0.64%
-
-
-
microphone
-
*
-
0.53%
-
-
-
-
-
- Figure 13. Settings used for microphone feature.
-
-
By far the most common approach here is to block use of the microphone altogether, with about 9% of pages taking that approach. A small number of pages do allow the use of the microphone by their own origin and interestingly, a small selection of pages intentionally allow use of the microphone by any origin loading content in their page.
- The X-Frame-Options header allows a page to control whether or not it can be placed in an iframe by another page. Whilst lacking the flexibility of frame-ancestors in CSP, mentioned above, it was effective if you didn't require fine grained control of framing.
-
-
We see that the usage of the X-Frame-Options header is quite high on both desktop (16.99%) and mobile (14.77%) and can also look more closely at the specific configurations used.
It seems that the vast majority of pages restrict framing to only their own origin and the next significant approach is to prevent framing altogether. This is similar to frame-ancestors in CSP where these 2 approaches are also the most common. It should also be noted that the allow-from option, which in theory allow site owners to list the third-party domains allowed to frame was never well supported and has been deprecated.
- The X-Content-Type-Options header is the most widely deployed Security Header and is also the most simple, with only one possible configuration value nosniff. When this header is issued a browser must treat a piece of content as the MIME Type declared in the Content-Type header and not try to change the advertised value when it infers a file is of a different type. Various security flaws can be introduced if a browser is persuaded to incorrectly sniff the type..
-
-
We find that an identical 17.61% of pages on both mobile and desktop issue the X-Content-Type-Options header.
- The X-XSS-Protection header allows a site to control the XSS Auditor or XSS Filter built into a browser, which should in theory provide some XSS protection.
-
-
14.69% of Desktop requests, and 15.2% of mobile requests used the X-XSS-Protection header. Digging into the data we can see what the intention for most site operators was in figure 13.
The value 1 enables the filter/auditor and mode=block sets the protection to the strongest setting (in theory) where any suspected XSS attack would cause the page to not be rendered. The second most common configuration was to simply ensure the auditor/filter was turned on, by presenting a value of 1 and then the 3rd most popular configuration is quite interesting.
-
Setting a value of 0 in the header instructs the browser to disable any XSS auditor/filter that it may have. Some historic attacks demonstrated how the auditor or filter could be tricked into assisting an attacker rather than protecting the user so some site operators could disable it if they were confident they have adequate protection against XSS in place.
-
Due to these attacks, Edge retired their XSS Filter, Chrome deprecated their XSS Auditor and Firefox never implemented support for the feature. We still see widespread use of the header at approximately 15% of all sites, despite it being largely useless now.
The Reporting API was introduced to allow site operators to gather various pieces of telemetry from the browser. Many errors or problems on a site can result in a poor experience for the user yet a site operator can only find out if the user contacts them. The Reporting API provides a mechanism for a browser to automatically report these problems without any user interaction or interruption. The Reporting API is configured by delivering the Report-To header.
-
By specifying the header, which contains a location where the telemetry should be sent, a browser will automatically begin sending the data and you can use a 3rd party service like Report URI to collect the reports or collect them yourself. Given the ease of deployment and configuration, we can see that only a small fraction of desktop (1.70%) and mobile (1.57%) sites currently enable this feature. To see the kind of telemetry you can collect, refer to the Reporting API specification.
Network Error Logging (NEL) provides detailed information about various failures in the browser that can result in a site being inoperative. Whereas the Report-To is used to report problems with a page that is loaded, the NEL header allows sites to inform the browser to cache this policy and then to report future connection problems when they happen via the endpoint configured in the Reporting-To header above. NEL can therefore be seen as an extension of the Reporting API.
-
Of course, with NEL depending on the Reporting API, we shouldn't see the usage of NEL exceed that of the Reporting API, so we see similarly low numbers here too at 1.70% for desktop requests and 1.57% for mobile. The fact these numbers are identical suggest they are being deployed together.
-
NEL provides incredibly valuable information and you can read more about the type of information in the Network Error Logging specification.
With the increasing ability to store data locally on a user's device, via cookies, caches and local storage to name but a few, site operators needed a reliable way to manage this data. The Clear Site Data header provides a means to ensure that all data of a particular type is removed from the device, though it is not yet supported in all browsers.
-
Given the nature of the header, it is unsurprising to see almost no usage reported - just 9 desktop requests and 7 mobile requests. With our data only looking at the homepage of a site, we're unlikely to see the most common use of the header which would be on a logout endpoint. Upon logging out of a site, the site operator would return the Clear Site Data header and the browser would remove all data of the indicated types. This is unlikely to take place on the homepage of a site.
Cookies have many security protections available and whilst some of those are long standing, and have been available for years, some of them are really quite new have been introduced only in the last couple of years.
The Secure flag on a cookie instructs a browser to only send the cookie over a secure (HTTPS) connection and we find only a small % of sites (4.22% on desktop and 3.68% on mobile) issuing a cookie with the Secure flag set on their homepage. This is depressing considering the relative ease with which this feature can be used. Again, the high usage of analytics and advertisement third-party requests, which wish to collect data over both HTTP and HTTPS is likely skewing these numbers and it would be interesting research to see the usage on other cookies, like authentication cookies.
The HttpOnly flag on a cookie instructs the browser to prevent JavaScript on the page from accessing the cookie. Many cookies are only used by the server so are not needed by the JavaScript on the page, so restricting access to a cookie is a great protection against XSS attacks from stealing the cookie. We find that a much larger % of sites issuing a cookie with this flag on their homepage at 24.24% on desktop and 22.23% on mobile.
As a much more recent addition to cookie protections, the SameSite flag is a powerful protection against Cross-Site Request Forgery (CSRF) attacks (often also known as XSRF).
-
These attacks work by using the fact that browsers will typically include relevant cookies in all requests. Therefore, if you are logged in, and so have cookies set, and then visit a malicious site, it can make a call for an API and the browser will "helpfully" send the cookies. Adding the SameSite attribute to a Cookie, allows a website to inform the browser not to send the cookies when calls are issued from third-party sites and hence the attack fails.
-
Being a recently introduced mechanism, the usage of Same-Site cookies is much lower as we would expect at 0.1% of requests on both desktop and mobile. There are use cases when a cookie should be sent cross-site. For example, single sign-on sites implicitly work by setting the cookie along with an authentication token.
We can see that of those pages already using Same-Site cookies, more than half of them are using it in strict mode. This is closely followed by sites using Same-Site in lax mode and then a small selection of sites using the value none. This last value is used to opt-out of the upcoming change where browser vendors may implement lax mode by default.
-
Because it provides much needed protection against a dangerous attack, there are currently indications that leading browsers could implement this feature by default and enable it on cookies even though the value is not set. If this were to happen the SameSite protection would be enabled, though in its weaker setting of lax mode and not strict mode, as that would likely cause more breakage.
Another recent addition to cookies are Cookie Prefixes. These use the name of your cookie to add one of two further protections to those already covered. While the above flags can be accidentally unset on cookies, the name will not change so using the name to define security attributes can more reliably enforce them.
-
Currently the name of your cookie can be prefixed with either __Secure- or __Host-, with both offering additional security to the cookie.
As the figures show, the use of either prefix is incredibly low but as the more relaxed of the two, the __Secure- prefix does see more utilization already.
Another problem that has been on the rise recently is the security of 3rd party dependencies. When loading a script file from a 3rd party, we hope that the script file is always the library that we wanted, perhaps a particular version of jQuery. If a CDN or 3rd party hosting service is compromised, the script files they are hosting could be altered. In this scenario your application would now be loading malicious JavaScript that could harm your visitors. This is what subresource integrity protects against.
-
By adding an integrity attribute to a script or link tag, a browser can integrity check the 3rd party resource and reject it if it has been altered, in a similar manner that CSP hashes described above are used.
With only 0.06% (247,604) of desktop pages and 0.05% (272,167) of mobile pages containing link or script tags with the integrity attribute set, there's room for a lot of improvement in the use of SRI. With many CDNs now providing code samples that include the SRI integrity attribute we should see a steady increase in the use of SRI.
As the web grows in capabilities and allows access to more and more sensitive data, it becomes increasingly important for developers to adopt web security features to protect their applications. The security features reviewed in this chapter are defenses built into the web platform itself, available to every web author. However, as a review of the study results in this chapter shows, the coverage of several important security mechanisms extends only to a subset of the web, leaving a significant part of the ecosystem exposed to security or privacy bugs.
In the recent years, the web has made the most progress on the encryption of data in transit. As described in the TLS section section, thanks to a range of efforts from browser vendors, developers and Certificate Authorities such as Let's Encrypt, the fraction of the web using HTTPS has steadily grown. At the time of writing, the majority of sites are available over HTTPS, ensuring confidentiality and integrity of traffic. Importantly, over 99% of websites which enable HTTPS use newer, more secure versions of the TLS protocol (TLSv1.2 and TLSv1.3). The use of strong cipher suites such as AES in GCM mode is also high, accounting for over 95% of requests on all platforms.
-
At the same time, gaps in TLS configurations are still fairly common. Over 15% of pages suffer from mixed content issues, resulting in browser warnings, and 4% of sites contain active mixed content, blocked by modern browsers for security reasons. Similarly, the benefits of HTTP Strict Transport Security only extend to a small subset of major sites, and the majority of websites don't enable the most secure HSTS configurations and are not eligible for HSTS preloading. Despite progress in HTTPS adoption, a large number of cookies is still set without the Secure flag; only 4% of homepages that set cookies prevent them from being sent over unencrypted HTTP.
- Web developers working on sites with sensitive data often enable opt-in web security features to protect their applications from XSS, CSRF, clickjacking, and other common web bugs. These issues can be mitigated by setting a number of standard, broadly supported HTTP response headers, including X-Frame-Options, X-Content-Type-Options, and Content-Security-Policy.
-
-
- In large part due to the complexity of both the security features and web applications, only a minority of websites currently use these defenses, and often enable only those mechanisms which do not require significant refactoring efforts. The most common opt-in application security features are X-Content-Type-Options (enabled by 17% of pages), X-Frame-Options (16%), and the deprecated X-XSS-Protection header (15%). The most powerful web security mechanism—Content Security Policy—is only enabled by 5% of websites, and only a small subset of them (about 0.1% of all sites) use the safer configurations based on CSP nonces and hashes. The related Referrer-Policy, aiming to reduce the amount of information sent to third parties in the Referer headers is similarly only used by 3% of websites.
-
In the recent years, web browsers have implemented powerful new mechanisms which offer protections from major classes of vulnerabilities and new web threats; this includes Subresource Integrity, SameSite cookies, and cookie prefixes.
-
These features have seen adoption only by a relatively small number of websites; their total coverage is generally well below 1%. The even more recent security mechanisms such as Trusted Types, Cross-Origin Resource Policy or Cross-Origin-Opener Policy have not seen any widespread adoption as of yet.
-
- Similarly, convenience features such as the Reporting API, Network Error Logging and the Clear-Site-Data header are also still in their infancy and are currently being used by a small number of sites.
-
At web scale, the total coverage of opt-in platform security features is currently relatively low. Even the most broadly adopted protections are enabled by less than a quarter of websites, leaving the majority of the web without platform safeguards against common security issues; more recent security mechanisms, such as Content Security Policy or Referrer Policy, are enabled by less than 5% of websites.
-
It is important to note, however, that the adoption of these mechanisms is skewed towards larger web applications which frequently handle more sensitive user data. The developers of these sites more frequently invest in improving their web defenses, including enabling a range of protections against common vulnerabilities; tools such as Mozilla Observatory and Security Headers can provide a useful checklist of web available security features.
-
If your web application handles sensitive user data, consider enabling the security mechanisms outlined in this section to protect your users and make the web safer.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":9,"title":"Accessibility","description":"Accessibility chapter of the 2019 Web Almanac covering ease of reading, media, ease of navigation, and compatibility with assistive technologies.","authors":["nektarios-paisios","obto","kleinab"],"reviewers":["ljme"],"translators":null,"discuss":"1764","results":"https://docs.google.com/spreadsheets/d/16JGy-ehf4taU0w4ABiKjsHGEXNDXxOlb__idY8ifUtQ/","queries":"09_Accessibility","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-02T00:00:00.000Z","chapter":"accessibility"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Accessibility on the web is essential for an inclusive and equitable society. As more of our social and work lives move to the online world, it becomes even more important for people with disabilities to be able to participate in all online interactions without barriers. Just as building architects can create or omit accessibility features such as wheelchair ramps, web developers can help or hinder the assistive technology users rely on.
-
When thinking about users with disabilities, we should remember that their user journeys are often the same—they just use different tools. These popular tools include but are not limited to: screen readers, screen magnifiers, browser or text size zooming, and voice controls.
-
Often, improving the accessibility of your site has benefits for everyone. While we typically think of people with disabilities as people with a permanent disability, anybody can have a temporary or situational disability. For example, someone might be permanently blind, have a temporary eye infection, or, situationally, be outside under a glaring sun. All of these might explain why someone is unable to see their screen. Everyone has situational disabilities, and so improving the accessibility of your web page will improve the experience of all users in any situation.
-
The Web Content Accessibility Guidelines (WCAG) advise on how to make a website accessible. These guidelines were used as the basis for our analysis. However, in many cases it is difficult to programmatically analyze the accessibility of a website. For instance, the web platform provides several ways of achieving similar functional results, but the underlying code powering them may be completely different. Therefore, our analysis is just an approximation of overall web accessibility.
-
We've split up our most interesting insights into four categories: ease of reading, media on the web, ease of page navigation, and compatibility with assistive technologies.
-
No significant difference in accessibility was found between desktop and mobile during testing. As a result, all of our presented metrics are the result of our desktop analysis unless otherwise stated.
The primary goal of a web page is to deliver content users want to engage with. This content might be a video or an assortment of images, but many times, it's simply the text on the page. It's extremely important that our textual content is legible to our readers. If visitors can't read a web page, they can't engage with it, which ends up with them leaving. In this section we'll look at three areas in which sites struggled.
There are many cases where visitors to your site may not be able see it perfectly. Visitors may be colorblind and unable to distinguish between the font and background color (1 in every 12 men and 1 in 200 women of European descent). Perhaps they're simply reading while the sun is out and creating tons of glare on their screen—significantly impairing their vision. Or maybe they've just grown older and their eyes can't distinguish colors as well as they used to.
-
In order to make sure your website is readable under these conditions, making sure your text has sufficient color contrast with its background is critical. It is also important to consider what contrasts will be shown when the colors are converted to grayscale.
Four colored boxes of brown and gray shades with white text overlaid inside creating two columns. The left column says Too lightly colored and has the brown background color written as #FCA469. The right column says Recommended and the brown background color is written as #BD5B0E. The top box in each column has an brown background with white text #FFFFFF and the bottom box has a gray background with white text #FFFFFF. The grayscale equivalents are #B8B8B8 and #707070 respectively. Courtesy of LookZook
- Figure 1. Example of what text with insufficient color contrast looks like. Courtesy of LookZook
-
-
Only 22.04% of sites gave all of their text sufficient color contrast. Or in other words: 4 out of every 5 sites have text which easily blends into the background, making it unreadable.
-
Note that we weren't able to analyze any text inside of images, so our reported metric is an upper-bound of the total number of websites passing the color contrast test.
Using a legible font size and target size helps users read and interact with your website. But even websites perfectly following all of these guidelines can't meet the specific needs of each visitor. This is why device features like pinch-to-zoom and scaling are so important: they allow users to tweak your pages so their needs are met. Or in the case of particularly inaccessible sites using tiny fonts and buttons, it gives users the chance to even use the site.
-
There are rare cases when disabling scaling is acceptable, like when the page in question is a web-based game using touch controls. If left enabled in this case, players' phones will zoom in and out every time the player taps twice on the game, ironically making it inaccessible.
-
Because of this, developers are given the ability to disable this feature by setting one of the following two properties in the meta viewport tag:
-
-
-
user-scalable set to 0 or no
-
-
-
maximum-scale set to 1, 1.0, etc
-
-
-
Sadly, developers have misused this so much that almost one out of every three sites on mobile (32.21%) disable this feature, and Apple (as of iOS 10) no longer allows web-developers to disable zooming. Mobile Safari simply ignores the tag. All sites, no matter what, can be zoomed and scaled on newer iOS devices.
Vertical measuring percentage data, ranging from 0 to 80 in increments of 20, vs. the device type, grouped into desktop and mobile. Desktop enabled: 75.46%; Desktop disabled 24.54%; Mobile enabled: 67.79%; Mobile disabled: 32.21%.
- Figure 2. Percentage of sites that disable zooming and scaling vs device type.
-
-
The web is full of wondrous amounts of content. However, there's a catch: over 1,000 different languages exist in the world, and the content you're looking for may not be written in one you are fluent in. In recent years, we've made great strides in translation technologies and you probably have used one of them on the web (e.g., Google translate).
-
- In order to facilitate this feature, the translation engines need to know what language your pages are written in. This is done by using the lang attribute. Without this, computers must guess what language your page is written in. As you might imagine, this leads to many errors, especially when pages use multiple languages (e.g., your page navigation is in English, but the post content is in Japanese).
-
-
This problem is even more pronounced on text-to-speech assistive technologies like screen readers, where if no language has been specified, they tend to read the text in the default user language.
-
Of the pages analyzed, 26.13% do not specify a language with the lang attribute. This leaves over a quarter of pages susceptible to all of the problems described above. The good news? Of sites using the lang attribute, they specify a valid language code correctly 99.68% of the time.
Some users, such as those with cognitive disabilities, have difficulties concentrating on the same task for long periods of time. These users don't want to deal with pages that include lots of motion and animations, especially when these effects are purely cosmetic and not related to the task at hand. At a minimum, these users need a way to turn all distracting animations off.
-
- Unfortunately, our findings indicate that infinitely looping animations are quite common on the web, with 21.04% of pages using them through infinite CSS animations or <marquee> and <blink> elements.
-
-
It is interesting to note however, that the bulk of this problem appears to be a few popular third-party stylesheets which include infinitely looping CSS animations by default. We were unable to determine how many pages actually used these animation styles.
Images are an essential part of the web experience. They can tell powerful stories, grab attention, and elicit emotion. But not everyone can see these images that we rely on to tell parts of our stories. Thankfully, in 1995, HTML 2.0 provided a solution to this problem: the alt attribute. The alt attribute provides web developers with the capability of adding a textual description to the images we use, so that when someone is unable to see our images (or the images are unable to load), they can read the alt text for a description. The alt text fills them in on the part of the story they would have otherwise missed.
-
Even though alt attributes have been around for 25 years, 49.91% of pages still fail to provide alt attributes for some of their images, and 8.68% of pages never use them at all.
Just as images are powerful storytellers, so too are audio and video in grabbing attention and expressing ideas. When audio and video content is not captioned, users who cannot hear this content miss out on large portions of the web. One of the most common things we hear from users who are Deaf or hard of hearing is the need to include captions for all audio and video content.
-
- Of sites using <audio> or <video> elements, only 0.54% provide captions (as measured by those that include the <track> element). Note that some websites have custom solutions for providing video and audio captions to users. We were unable to detect these and thus the true percentage of sites utilizing captions is slightly higher.
-
When you open the menu in a restaurant, the first thing you probably do is read all of the section headers: appetizers, salads, main course, and dessert. This allows you to scan a menu for all of the options and jump quickly to the dishes most interesting to you. Similarly, when a visitor opens a web page, their goal is to find the information they are most interested in—the reason they came to the page in the first place. In order to help users find their desired content as fast as possible (and prevent them from hitting the back button), we try to separate the contents of our pages into several visually distinct sections, for example: a site header for navigation, various headings in our articles so users can quickly scan them, a footer for other extraneous resources, and more.
-
While this is exceptionally important, we need to take care to mark up our pages so our visitors' computers can perceive these distinct sections as well. Why? While most readers use a mouse to navigate pages, many others rely on keyboards and screen readers. These technologies rely heavily on how well their computers understand your page.
Headings are not only helpful visually, but to screen readers as well. They allow screen readers to quickly jump from section to section and help indicate where one section ends and another begins.
-
In order to avoid confusing screen reader users, make sure you never skip a heading level. For example, don't go straight from an H1 to an H3, skipping the H2. Why is this a big deal? Because this is an unexpected change that will cause a screen reader user to think they've missed a piece of content. This might cause them to start looking all over for what they may have missed, even if there isn't anything missing. Plus, you'll help all of your readers by keeping a more consistent design.
-
With that being said, here are our results:
-
-
89.36% of pages use headings in some fashion. Awesome.
Vertical bar chart measuring percentage data, ranging from 0 to 80 in increments of 20, vs. bars representing each heading level h1 through h6. H1: 63.25%; H2: 67.86%; H3: 58.63%; H4: 36.38%; H5: 14.64%; H6: 6.91%.
A main landmark indicates to screen readers where the main content of a web page starts so users can jump right to it. Without this, screen reader users have to manually skip over your navigation every single time they go to a new page within your site. Obviously, this is rather frustrating.
-
We found only one in every four pages (26.03%) include a main landmark. And surprisingly, 8.06% of pages erroneously contained more than one main landmark, leaving these users guessing which landmark contains the actual main content.
Vertical bar chart displaying percentage data, ranging from 0 to 80 in increments of 20, vs. bars representing the number of “main” landmarks per page from 0 to 4. Source: HTTP Archive (July 2019). Zero: 73.97%; One: 17.97%; Two: 7.41%; Three: 0.15%; 4: 0.06%.
- Figure 4. Percent of pages by their number of "main" landmarks.
-
-
Since HTML5 was released in 2008, and made the official standard in 2014, there are many HTML elements to aid computers and screen readers in understanding our page layout and structure.
-
- Elements like <header>, <footer>, <navigation>, and <main> indicate where specific types of content live and allow users to quickly jump around your page. These are being used widely across the web, with most of them being used on over 50% of pages (<main> being the outlier).
-
-
- Others like <article>, <hr>, and <aside> aid readers in understanding a page's main content. For example, <article> says where one article ends and another begins. These elements are not used nearly as much, with each sitting at around 20% usage. Not all of these belong on every web page, so this isn't necessarily an alarming statistic.
-
-
All of these elements are primarily designed for accessibility support and have no visual effect, which means you can safely replace existing elements with them and suffer no unintended consequences.
Vertical bar chart with bars for each element type vs percent of pages ranging from 0 to 60 in increments of 20. nav: 53.94%; header: 54.82%; footer: 55.92%; main: 18.47%; aside: 16.99%; article: 22.59%; hr: 19.1%; section: 36.55%.
- Figure 5. Usage of various HTML semantic elements.
-
-
Many popular screen readers also allow users to navigate by quickly jumping through links, lists, list items, iframes, and form fields like edit fields, buttons, and list boxes. Figure 6 details how often we saw pages using these elements.
Vertical bar chart with bars for each element type vs percent of pages ranging from 0 to 100 in increments of 25. a: 98.22%; ul: 88.62%; input: 76.63%; iframe: 60.39%; button: 56.74%; select: 19.68%; textarea: 12.03%.
- Figure 6. Other HTML elements used for navigation.
-
-
A skip link is a link placed at the top of a page which allows screen readers or keyboard-only users to jump straight to the main content. It effectively "skips" over all navigational links and menus at the top of the page. Skip links are especially useful to keyboard users who don't use a screen reader, as these users don't usually have access to other modes of quick navigation (like landmarks and headings). 14.19% of the pages in our sample were found to have skip links.
-
If you'd like to see a skip link in action for yourself, you can! Just do a quick Google search and hit "tab" as soon as you land on the search result pages. You'll be greeted with a previously hidden link just like the one in Figure 7.
Screenshot of Google search results page for search 'http archive'. The visible 'Skip to main content' link is surrounded by a blue focus highlight and a yellow overlaid box with a red arrow pointing to the skip link reads 'A skip link on google.com'.
- Figure 7. What a skip link looks like on google.com.
-
-
In fact you don't need to even leave this site as we use them here too!
-
It's hard to accurately determine what a skip link is when analyzing sites. For this analysis, if we found an anchor link (href=#heading1) within the first 3 links on the page, we defined this as a page with a skip link. So 14.19% is a strict upper bound.
Activating an element on the page, like a link or button.
-
Giving a certain element on the page focus. For example, shifting focus to a certain input on the page, allowing a user to then start typing into it.
-
-
- Adoption of aria-keyshortcuts was almost absent from our sample, with it only being used on 159 sites out of over 4 million analyzed. The accesskey attribute was used more frequently, being found on 2.47% of web pages (1.74% on mobile). We believe the higher usage of shortcuts on desktop is due to developers expecting mobile sites to only be accessed via a touch screen and not a keyboard.
-
-
What is especially surprising here is 15.56% of mobile and 13.03% of desktop sites which use shortcut keys assign the same shortcut to multiple different elements. This means browsers have to guess which element should own this shortcut key.
Tables are one of the primary ways we organize and express large amounts of data. Many assistive technologies like screen readers and switches (which may be used by users with motor disabilities) might have special features allowing them to navigate this tabular data more efficiently.
Depending on the way a particular table is structured, the use of table headers makes it easier to read across columns or rows without losing context on what data that particular column or row refers to. Having to navigate a table lacking in header rows or columns is a subpar experience for a screen reader user. This is because it's hard for a screen reader user to keep track of their place in a table absent of headers, especially when the table is quite large.
-
- To mark up table headers, simply use the <th> tag (instead of <td>), or either of the ARIA columnheader or rowheader roles. Only 24.5% of pages with tables were found to markup their tables with either of these methods. So the three quarters of pages choosing to include tables without headers are creating serious challenges for screen reader users.
-
-
Using <th> and <td> was by far the most commonly used method for marking up table headers. The use of columnheader and rowheader roles was almost non-existent with only 677 total sites using them (0.058%).
- Table captions via the <caption> element are helpful in providing more context for readers of all kinds. A caption can prepare a reader to take in the information your table is sharing, and it can be especially useful for people who may get distracted or interrupted easily. They are also useful for people who may lose their place within a large table, such as a screen reader user or someone with a learning or intellectual disability. The easier you can make it for readers to understand what they're analyzing, the better.
-
-
Despite this, only 4.32% of pages with tables provide captions.
One of the most popular and widely used specifications for accessibility on the web is the Accessible Rich Internet Applications (ARIA) standard. This standard offers a large array of additional HTML attributes to help convey the purpose behind visual elements (i.e., their semantic meaning), and what kinds of actions they're capable of.
-
Using ARIA correctly and appropriately can be challenging. For example, of pages making use of ARIA attributes, we found 12.31% have invalid values assigned to their attributes. This is problematic because any mistake in the use of an ARIA attribute has no visual effect on the page. Some of these errors can be detected by using an automated validation tool, but generally they require hands-on use of real assistive software (like a screen reader). This section will examine how ARIA is used on the web, and specifically which parts of the standard are most prevalent.
The "role" attribute is the most important attribute in the entire ARIA specification. It's used to inform the browser what the purpose of a given HTML element is (i.e., the semantic meaning). For example, a <div> element, visually styled as a button using CSS, should be given the ARIA role of button.
-
Currently, 46.91% of pages use at least one ARIA role attribute. In Figure 9 below, we've compiled a list of the top ten most widely used ARIA role values.
Vertical bar chart with bars for each role type vs percent of sites using ranging from 0 to 25 in increments of 5. Navigation: 20.4%; search: 15.49%; main: 14.39%; banner: 13.62%; contentinfo: 11.23%; button: 10.59%; dialog: 7.87%; complementary: 6.06%; menu: 4.71%; form: 3.75%
Looking at the results in Figure 9, we found two interesting insights: updating UI frameworks may have a profound impact on accessibility across the web, and the impressive number of sites attempting to make dialogs accessible.
The top 5 roles, all appearing on 11% of pages or more, are landmark roles. These are used to aid navigation, not to describe the functionality of a widget, such as a combo box. This is a surprising result because the main motivator behind the development of ARIA was to give web developers the capability to describe the functionality of widgets made of generic HTML elements (like a <div>).
-
We suspect that some of the most popular web UI frameworks include navigation roles in their templates. This would explain the prevalence of landmark attributes. If this theory is correct, updating popular UI frameworks to include more accessibility support may have a huge impact on the accessibility of the web.
-
Another result pointing towards this conclusion is the fact that more "advanced" but equally important ARIA attributes don't appear to be used at all. Such attributes cannot easily be deployed through a UI framework because they might need to be customized based on the structure and the visual appearance of every site individually. For example, we found that the posinset and setsize attributes were only used on 0.01% of pages. These attributes convey to a screen reader user how many items are in a list or menu and which item is currently selected. So, if a visually impaired user is trying to navigate through a menu, they might hear index announcements like: "Home, 1 of 5", "Products, 2 of 5", "Downloads, 3 of 5", etc.
The relative popularity of the dialog role stands out because making dialogs accessible for screen reader users is very challenging. It is therefore exciting to see around 8% of the analyzed pages stepping up to the challenge. Again, we suspect this might be due to the use of some UI frameworks.
The most common way that a user interacts with a website is through its controls, such as links or buttons to navigate the website. However, many times screen reader users are unable to tell what action a control will perform once activated. Often the reason this confusion occurs is due to the lack of a textual label. For example, a button displaying a left-pointing arrow icon to signify it's the "Back" button, but containing no actual text.
-
Only about a quarter (24.39%) of pages that use buttons or links include textual labels with these controls. If a control is not labeled, a screen reader user might read something generic, such as the word "button" instead of a meaningful word like "Search".
-
Buttons and links are almost always included in the tab order and thus have extremely high visibility. Navigating through a website using the tab key is one of the primary ways through which users who use only the keyboard explore your website. So a user is sure to encounter your unlabeled buttons and links if they are moving through your website using the tab key.
- Filling out forms is a task many of us do every single day. Whether we're shopping, booking travel, or applying for a job, forms are the main way users share information with web pages. Because of this, ensuring your forms are accessible is incredibly important. The simplest means of accomplishing this is by providing labels (via the <label> element, aria-label or aria-labelledby) for each of your inputs. Sadly, only 22.33% of pages provide labels for all their form inputs, meaning 4 out of every 5 pages have forms that may be very difficult to fill out.
-
When we come across a field with a big red asterisk next to it, we know it's a required field. Or when we hit submit and are informed there were invalid inputs, anything highlighted in a different color needs to be corrected and then resubmitted. However, people with low or no vision cannot rely on these visual cues, which is why the HTML input attributes required, aria-required, and aria-invalid are so important. They provide screen readers with the equivalent of red asterisks and red highlighted fields. As a nice bonus, when you inform browsers what fields are required, they'll validate parts of your forms for you. No JavaScript required.
-
Of pages using forms, 21.73% use required or aria-required when marking up required fields. Only one in every five sites make use of this. This is a simple step to make your site accessible, and unlocks helpful browser features for all users.
-
We also found 3.52% of sites with forms make use of aria-invalid. However, since many forms only make use of this field once incorrect information is submitted, we could not ascertain the true percentage of sites using this markup.
- IDs can be used in HTML to link two elements together. For example, the <label> element works this way. You specify the ID of the input field this label is describing and the browser links them together. The result? Users can now click on this label to focus on the input field, and screen readers will use this label as the description.
-
-
Unfortunately, 34.62% of sites have duplicate IDs, which means on many sites the ID specified by the user could refer to multiple different inputs. So when a user clicks on the label to select a field, they may end up selecting something different than they intended. As you might imagine, this could have negative consequences in something like a shopping cart.
-
- This issue is even more pronounced for screen readers because their users may not be able to visually double check what is selected. Plus, many ARIA attributes, such as aria-describedby and aria-labelledby, work similarly to the label element detailed above. So to make your site accessible, removing all duplicate IDs is a good first step.
-
People with disabilities are not the only ones with accessibility needs. For example, anyone who has suffered a temporary wrist injury has experienced the difficulty of tapping small tap targets. Eyesight often diminishes with age, making text written in small fonts challenging to read. Finger dexterity is not the same across age demographics, making tapping interactive controls or swiping through content on mobile websites more difficult for a sizable percentage of users.
-
Similarly, assistive software is not only geared towards people with disabilities but for improving the day to day experience of everyone:
-
-
The recent popularity of voice assistance, both on mobile devices and in the home, has demonstrated that controlling a computing device using voice commands is both desirable and essential for many users. Voice commands like these used to only be an accessibility feature but are now turning into a mainstream product.
-
Drivers would benefit from a screen reading feature that, while they keep their eyes on the road, reads long pieces of text like news stories aloud.
-
Captions are enjoyed not only by people who cannot hear a video but also by people who want to watch a video in a loud restaurant or in a library.
-
-
Once a website is built, it's often hard to retrofit accessibility on top of existing site structures and widgets. Accessibility isn't something that can be easily sprinkled on afterwards, rather it needs to be part of the design and implementation process. Unfortunately, either through a lack of awareness or easy-to-use testing tools, many developers are not familiar with the needs of all their users and the requirements of the assistive software they use.
-
While not conclusive, our results indicate that the use of accessibility standards like ARIA and accessibility best practices (e.g., using alt text) are found on a sizable, but not substantial portion of the web. On the surface this is encouraging, but we suspect many of these positive trends are due to the popularity of certain UI frameworks. On one hand, this is disappointing because web developers cannot simply rely on UI frameworks to inject their sites with accessibility support. On the other hand though, it's encouraging to see how large of an effect UI frameworks could have on the accessibility of the web.
-
The next frontier, in our opinion, is making widgets which are available through UI frameworks more accessible. Since many complex widgets used in the wild (e.g., calendar pickers) are sourced from a UI library, it would be great for these widgets to be accessible out of the box. We hope that when we collect our results next time, the usage of more properly implemented complex ARIA roles is on the rise—signifying more complex widgets have also been made accessible. In addition, we hope to see more accessible media, like images and video, so all users can enjoy the richness of the web.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
Search Engine Optimization (SEO) isn't just a hobby or a side project for digital marketers, it is crucial for the success of a website. The primary goal of SEO is to make sure that a website is optimized for the search engine bots that need to crawl and index its pages, as well as for the users that will be navigating the website and consuming its content. SEO impacts everyone working on a website, from the developer who is building it, through to the digital marketer who will need to promote it to new potential customers.
-
Let's put the importance of SEO into perspective. Earlier this year, the SEO industry looked on in horror (and fascination) as ASOS reported an 87% decrease in profits after a "difficult year". The brand attributed their issues to a drop in search engine rankings which occurred after they launched over 200 microsites and significant changes to their website's navigation, among other technical changes. Yikes.
-
The purpose of the SEO chapter of the Web Almanac is to analyze on-site elements of the web that impact the crawling and indexing of content for search engines, and ultimately, website performance. In this chapter, we'll take a look at how well-equipped the top websites are to provide a great experience for users and search engines, and which ones still have work to do.
-
Our analysis includes data from Lighthouse, the Chrome UX Report, and HTML element analysis. We focused on SEO fundamentals like <title> elements, the different types of on-page links, content, and loading speed, but also the more technical aspects of SEO, including indexability, structured data, internationalization, and AMP across over 5 million websites.
-
Our custom metrics provide insights that, up until now, have not been exposed before. We are now able to make claims about the adoption and implementation of elements such as the hreflang tag, rich results eligibility, heading tag usage, and even anchor-based navigation for single page apps.
-
Note: Our data is limited to analyzing home pages only and has not been gathered from site-wide crawls. This will impact many metrics we'll discuss, so we've added any relevant limitations in this case whenever we mention a specific metric. Learn more about these limitations in our Methodology.
-
Read on to find out more about the current state of the web and its search engine friendliness.
Search engines have a three-step process: crawling, indexing, and ranking. To be search engine-friendly, a page needs to be discoverable, understandable, and contain quality content that would provide value to a user who is browsing the search engine results pages (SERPs).
-
We wanted to analyze how much of the web is meeting the basic standards of SEO best practices, so we assessed on-page elements such as body content, meta tags, and internal linking. Let's take a look at the results.
To be able to understand what a page is about and decide for which search queries it provides the most relevant answers, a search engine must be able to discover and access its content. What content are search engines currently finding, however? To help answer this, we created two custom metrics: word count and headings.
We assessed the content on the pages by looking for groups of at least 3 words and counting how many were found in total. We found 2.73% of desktop pages that didn't have any word groups, meaning that they have no body content to help search engines understand what the website is about.
Distribution of words per page. The median number of words per desktop page is 346 and 306 for mobile pages. Desktop pages have more word throughout the percentiles, by as many as 120 words at the 90th percentile.
- Figure 1. Distribution of the number of words per page.
-
-
The median desktop home page has 346 words, and the median mobile home page has a slightly lower word count at 306 words. This shows that mobile sites do serve a bit less content to their users, but at over 300 words, this is still a reasonable amount to read. This is especially true for home pages which will naturally contain less content than article pages, for example. Overall the distribution of words is broad, with between 22 words at the 10th percentile and up to 1,361 at the 90th percentile.
We also looked at whether pages are structured in a way that provides the right context for the content they contain. Headings (H1, H2, H3, etc.) are used to format and structure a page and make content easier to read and parse. Despite the importance of headings, 10.67% of pages have no heading tags at all.
Distribution of headings per page. The median number of headings per desktop and mobile page is 10. At the 10, 25, 75, and 90th percentiles, the number of headings per desktop page are: 0, 3, 21, and 39. This is slightly higher than the distribution of mobile headings per page.
- Figure 2. Distribution of the number of headings per page.
-
-
The median number of heading elements per page is 10. Headings contain 30 words on mobile pages and 32 words on desktop pages. This implies that the websites that utilize headings put significant effort in making sure that their pages are readable, descriptive, and clearly outline the page structure and context to search engine bots.
Distribution of the number of characters in the first H1 per page. The desktop and mobile distributions are nearly identical, with the 10, 25, 50, 75, and 90th percentiles as: 6, 11, 19, 31, and 47 characters.
- Figure 3. Distribution of H1 length per page.
-
-
In terms of specific heading length, the median length of the first H1 element found on desktop is 19 characters.
-
For advice on how to handle H1s and headings for SEO and accessibility, take a look at this video response by John Mueller in the Ask Google Webmasters series.
Meta tags allow us to give specific instructions and information to search engine bots about the different elements and content on a page. Certain meta tags can convey things like the topical focus of a page, as well as how the page should be crawled and indexed. We wanted to assess whether or not websites were making the most of these opportunities that meta tags provide.
- Figure 4. Percent of mobile pages that include a <title> tag.
-
-
Page titles are an important way of communicating the purpose of a page to a user or search engine. <title> tags are also used as headings in the SERPS and as the title for the browser tab when visiting a page, so it's no surprise to see that 97.1% of mobile pages have a document title.
Distribution of the number of characters per title element per page. The 10, 25, 50, 75, and 90th percentiles of title lengths for desktop are: 4, 9, 20, 40, and 66 characters. The mobile distribution is very similar.
- Figure 5. Distribution of title length per page.
-
-
Even though Google usually displays the first 50-60 characters of a page title within a SERP, the median length of the <title> tag was only 21 characters for mobile pages and 20 characters for desktop pages. Even the 75th percentile is still below the cutoff length. This suggests that some SEOs and content writers aren't making the most of the space allocated to them by search engines for describing their home pages in the SERPs.
Compared to the <title> tag, fewer pages were detected to have a meta description, as only 64.02% of mobile home pages have a meta description. Considering that Google often rewrites meta descriptions in the SERPs in response to the searcher's query, perhaps website owners place less importance on including a meta description at all.
Distribution of the number of characters per meta description per page. The 10, 25, 50, 75, and 90th percentiles of title lengths for desktop are: 9, 48, 123, 162, and 230 characters. The mobile distribution is slightly higher by fewer than 10 characters at any given percentile.
- Figure 6. Distribution of meta description length per page.
-
-
The median meta description length was also lower than the recommended length of 155-160 characters, with desktop pages having descriptions of 123 characters. Interestingly, meta descriptions were consistently longer on mobile than on desktop, despite mobile SERPs traditionally having a shorter pixel limit. This limit has only been extended recently, so perhaps more website owners have been testing the impact of having longer, more descriptive meta descriptions for mobile results.
Considering the importance of alt text for SEO and accessibility, it is far from ideal to see that only 46.71% of mobile pages use alt attributes on all of their images. This means that there are still improvements to be made with regard to making images across the web more accessible to users and understandable for search engines. Learn more about issues like these in the Accessibility chapter.
To show a page's content to users in the SERPs, search engine crawlers must first be permitted to access and index that page. Some of the factors that impact a search engine's ability to crawl and index pages include:
It is recommended to maintain a 200 OK status code for any important pages that you want search engines to index. The majority of pages tested were available for search engines to access, with 87.03% of initial HTML requests on desktop returning a 200 status code. The results were slightly lower for mobile pages, with only 82.95% of pages returning a 200 status code.
-
The next most commonly found status code on mobile was 302, a temporary redirect, which was found on 10.45% of mobile pages. This was higher than on desktop, with only 6.71% desktop home pages returning a 302 status code. This could be due to the fact that the mobile home pages were alternates to an equivalent desktop page, such as on non-responsive sites that have separate versions of the website for each device.
-
Note: Our results didn't include 4xx or 5xx status codes.
A noindex directive can be served in the HTML <head> or in the HTTP headers as an X-Robots directive. A noindex directive basically tells a search engine not to include that page in its SERPs, but the page will still be accessible for users when they are navigating through the website. noindex directives are usually added to duplicate versions of pages that serve the same content, or low quality pages that provide no value to users coming to a website from organic search, such as filtered, faceted, or internal search pages.
-
96.93% of mobile pages passed the Lighthouse indexing audit, meaning that these pages didn't contain a noindex directive. However, this means that 3.07% of mobile home pages did have a noindex directive, which is cause for concern, meaning that Google was prevented from indexing these pages.
-
The websites included in our research are sourced from the Chrome UX Report dataset, which excludes websites that are not publicly discoverable. This is a significant source of bias because we're unable to analyze sites that Chrome determines to be non-public. Learn more about our methodology.
Canonical tags are used to specify duplicate pages and their preferred alternates, so that search engines can consolidate authority which might be spread across multiple pages within the group onto one main page for improved rankings.
-
48.34% of mobile home pages were detected to have a canonical tag. Self-referencing canonical tags aren't essential, and canonical tags are usually required for duplicate pages. Home pages are rarely duplicated anywhere else across the site so seeing that less than half of pages have a canonical tag isn't surprising.
- One of the most effective methods for controlling search engine crawling is the robots.txt file. This is a file that sits on the root domain of a website and specifies which URLs and URL paths should be disallowed from being crawled by search engines.
-
-
It was interesting to observe that only 72.16% of mobile sites have a valid robots.txt, according to Lighthouse. The key issues we found are split between 22% of sites having no robots.txt file at all, and ~6% serving an invalid robots.txt file, and thus failing the audit. While there are many valid reasons to not have a robots.txt file, such as having a small website that doesn't struggle with crawl budget issues, having an invalid robots.txt is cause for concern.
One of the most important attributes of a web page is links. Links help search engines discover new, relevant pages to add to their index and navigate through websites. 96% of the web pages in our dataset contain at least one internal link, and 93% contain at least one external link to another domain. The small minority of pages that don't have any internal or external links will be missing out on the immense value that links pass through to target pages.
-
The number of internal and external links included on desktop pages were consistently higher than the number found on mobile pages. Often a limited space on a smaller viewport causes fewer links to be included in the design of a mobile page compared to desktop.
-
It's important to bear in mind that fewer internal links on the mobile version of a page might cause an issue for your website. With mobile-first indexing, which for new websites is the default for Google, if a page is only linked from the desktop version and not present on the mobile version, search engines will have a much harder time discovering and ranking it.
Distribution of the number of internal links per page. The 10, 25, 50, 75, and 90th percentiles of internal links for desktop are: 7, 29, 70, 142, and 261. The mobile distribution is much lower, by 30 links at the 90th percentile and 10 at the median.
- Figure 7. Distribution of internal links per page.
-
-
-
-
-
-
-
Distribution of the number of external links per page. The 10, 25, 50, 75, and 90th percentiles of external links for desktop are: 1, 4, 10, 22, and 51. The mobile distribution is much lower, by 11 links at the 90th percentile and 2 at the median.
- Figure 8. Distribution of external links per page.
-
-
The median desktop page includes 70 internal (same-site) links, whereas the median mobile page has 60 internal links. The median number of external links per page follows a similar trend, with desktop pages including 10 external links, and mobile pages including 8.
Distribution of the number of anchor links per page. The 10, 25, 50, 75, and 90th percentiles of internal anchor for desktop are: 0, 0, 0, 1, and 3. The mobile distribution is identical.
- Figure 9. Distribution of anchor links per page.
-
-
Anchor links, which link to a certain scroll position on the same page, are not very popular. Over 65% of home pages have no anchor links. This is probably due to the fact that home pages don't usually contain any long-form content.
-
There is good news from our analysis of the descriptive link text metric. 89.94% of mobile pages pass Lighthouse's descriptive link text audit. This means that these pages don't have generic "click here", "go", "here" or "learn more" links, but use more meaningful link text which helps users and search engines better understand the context of pages and how they connect with one another.
Having descriptive, useful content on a page that isn't being blocked from search engines with a noindex or Disallow directive isn't enough for a website to succeed in organic search. Those are just the basics. There is a lot more than can be done to enhance the performance of a website and its appearance in SERPs.
-
Some of the more technically complex aspects that have been gaining importance in successfully indexing and ranking websites include speed, structured data, internationalization, security, and mobile friendliness.
A fast-loading website is also crucial for a good user experience. Users that have to wait even a few seconds for a site to load have the tendency to bounce and try another result from one of your SERP competitors that loads quickly and meets their expectations of website performance.
-
The metrics we used for our analysis of load speed across the web is based on the Chrome UX Report (CrUX), which collects data from real-world Chrome users. This data shows that an astonishing 48% of websites are labeled as slow. A website is labeled slow if it more than 25% of FCP experiences slower than 3 seconds or 5% of FID experiences slower than 300 ms.
Distribution of the performance of desktop, phone, and tablet user experiences. Desktop: 2% fast, 52% moderate, 46% slow. Phone: 1% fast, 41% moderate, 58% slow. Tablet: 0% fast, 35% moderate, 65% slow.
- Figure 10. Distribution of the performance of user experiences by device type.
-
-
Split by device, this picture is even bleaker for tablet (65%) and phone (58%).
-
Although the numbers are bleak for the speed of the web, the good news is that SEO experts and tools have been focusing more and more on the technical challenges of speeding up websites. You can learn more about the state of web performance in the Performance chapter.
Structured data allows website owners to add additional semantic data to their web pages, by adding JSON-LD snippets or Microdata, for example. Search engines parse this data to better understand these pages and sometimes use the markup to display additional relevant information in the search results. Some of the useful types of structured data are:
The extra visibility that structured data can provide for websites is interesting for site owners, given that it can help to create more opportunities for traffic. For example, the relatively new FAQ schema will double the size of your snippet and the real estate of your site in the SERP.
-
During our research, we found that only 14.67% of sites are eligible for rich results on mobile. Interestingly, desktop site eligibility is slightly lower at 12.46%. This suggests that there is a lot more that site owners can be doing to optimize the way their home pages are appearing in search.
-
Among the sites with structured data markup, the five most prevalent types are:
-
-
WebSite (16.02%)
-
SearchAction (14.35%)
-
Organization (12.89%)
-
WebPage (11.58%)
-
ImageObject (5.35%)
-
-
Interestingly, one of the most popular data types that triggers a search engine feature is SearchAction, which powers the sitelinks searchbox.
-
The top five markup types all lead to more visibility in Google's search results, which might be the fuel for more widespread adoption of these types of structured data.
-
Seeing as we only looked at home pages within this analysis, the results might look very different if we were to consider interior pages, too.
-
Review stars are only found on 1.09% of the web's home pages (via AggregateRating). Also, the newly introduced QAPage appeared only in 48 instances, and the FAQPage at a slightly higher frequency of 218 times. These last two counts are expected to increase in the future as we run more crawls and dive deeper into Web Almanac analysis.
Internationalization is one of the most complex aspects of SEO, even according to some Google search employees. Internationalization in SEO focuses on serving the right content from a website with multiple language or country versions and making sure that content is being targeted towards the specific language and location of the user.
-
While 38.40% of desktop sites (33.79% on mobile) have the HTML lang attribute set to English, only 7.43% (6.79% on mobile) of the sites also contain an hreflang link to another language version. This suggests that the vast majority of websites that we analyzed don't offer separate versions of their home page that would require language targeting -- unless these separate versions do exist but haven't been configured correctly.
-
-
-
-
-
-
-
hreflang
-
Desktop
-
Mobile
-
-
-
-
-
en
-
12.19%
-
2.80%
-
-
-
x-default
-
5.58%
-
1.44%
-
-
-
fr
-
5.23%
-
1.28%
-
-
-
es
-
5.08%
-
1.25%
-
-
-
de
-
4.91%
-
1.24%
-
-
-
en-us
-
4.22%
-
2.95%
-
-
-
it
-
3.58%
-
0.92%
-
-
-
ru
-
3.13%
-
0.80%
-
-
-
en-gb
-
3.04%
-
2.79%
-
-
-
de-de
-
2.34%
-
2.58%
-
-
-
nl
-
2.28%
-
0.55%
-
-
-
fr-fr
-
2.28%
-
2.56%
-
-
-
es-es
-
2.08%
-
2.51%
-
-
-
pt
-
2.07%
-
0.48%
-
-
-
pl
-
2.01%
-
0.50%
-
-
-
ja
-
2.00%
-
0.43%
-
-
-
tr
-
1.78%
-
0.49%
-
-
-
it-it
-
1.62%
-
2.40%
-
-
-
ar
-
1.59%
-
0.43%
-
-
-
pt-br
-
1.52%
-
2.38%
-
-
-
th
-
1.40%
-
0.42%
-
-
-
ko
-
1.33%
-
0.28%
-
-
-
zh
-
1.30%
-
0.27%
-
-
-
sv
-
1.22%
-
0.30%
-
-
-
en-au
-
1.20%
-
2.31%
-
-
-
-
-
- Figure 11. Top 25 most popular hreflang values.
-
-
Next to English, the most common languages are French, Spanish, and German. These are followed by languages targeted towards specific geographies like English for Americans (en-us) or more obscure combinations like Spanish for the Irish (es-ie).
-
The analysis did not check for correct implementation, such as whether or not the different language versions properly link to each other. However, from looking at the low adoption of having an x-default version (only 3.77% on desktop and 1.30% on mobile), as is recommended, this is an indicator that this element is complex and not always easy to get right.
Single-page applications (SPAs) built with frameworks like React and Vue.js come with their own SEO complexity. Websites using a hash-based navigation, make it especially hard for search engines to properly crawl and index them. For example, Google had an "AJAX crawling scheme" workaround that turned out to be complex for search engines as well as developers, so it was deprecated in 2015.
-
The number of SPAs that were tested had a relatively low number of links served via hash URLs, with 13.08% of React mobile pages using hash URLs for navigation, 8.15% of mobile Vue.js pages using them, and 2.37% of mobile Angular pages using them. These results were very similar for desktop pages too. This is positive to see from an SEO perspective, considering the impact that hash URLs can have on content discovery.
-
The higher number of hash URLs in React pages is surprising, especially in contrast to the lower number of hash URLs found on Angular pages. Both frameworks promote the adoption of routing packages where the History API is the default for links, instead of relying on hash URLs. Vue.js is considering moving to using the History API as the default as well in version 3 of their vue-router package.
AMP (formerly known as "Accelerated Mobile Pages") was first introduced in 2015 by Google as an open source HTML framework. It provides components and infrastructure for websites to provide a faster experience for users, by using optimizations such as caching, lazy loading, and optimized images. Notably, Google adopted this for their search engine, where AMP pages are also served from their own CDN. This feature later became a standards proposal under the name Signed HTTP Exchanges.
-
Despite this, only 0.62% of mobile home pages contain a link to an AMP version. Given the visibility this project has had, this suggests that it has had a relatively low adoption. However, AMP can be more useful for serving article pages, so our home page-focused analysis won't reflect adoption across other page types.
A strong online shift in recent years has been for the web to move to HTTPS by default. HTTPS prevents website traffic from being intercepted on public Wi-Fi networks, for example, where user input data is then transmitted unsecurely. Google have been pushing for sites to adopt HTTPS, and even made HTTPS as a ranking signal. Chrome also supported the move to secure pages by labeling non-HTTPS pages as not secure in the browser.
-
For more information and guidance from Google on the importance of HTTPS and how to adopt it, please see Why HTTPS Matters.
-
We found that 67.06% of websites on desktop are now served over HTTPS. Just under half of websites still haven't migrated to HTTPS and are serving non-secure pages to their users. This is a significant number. Migrations can be hard work, so this could be a reason why the adoption rate isn't higher, but an HTTPS migration usually require an SSL certificate and a simple change to the .htaccess file. There's no real reason not to switch to HTTPS.
-
Google's HTTPS Transparency Report reports a 90% adoption of HTTPS for the top 100 non-Google domains (representing 25% of all website traffic worldwide). The difference between this number and ours could be explained by the fact that relatively smaller sites are adopting HTTPS at a slower rate.
-
Learn more about the state of security in the Security chapter.
Through our analysis, we observed that the majority of websites are getting the fundamentals right, in that their home pages are crawlable, indexable, and include the key content required to rank well in search engines' results pages. Not every person who owns a website will be aware of SEO at all, let alone its best practice guidelines, so it is promising to see that so many sites have got the basics covered.
-
However, more sites are missing the mark than expected when it comes to some of the more advanced aspects of SEO and accessibility. Site speed is one of these factors that many websites are struggling with, especially on mobile. This is a significant problem, as speed is one of the biggest contributors to UX, which is something that can impact rankings. The number of websites that aren't yet served over HTTPS is also problematic to see, considering the importance of security and keeping user data safe.
-
There is a lot more that we can all be doing to learn about SEO best practices and industry developments. This is essential due to the evolving nature of the search industry and the rate at which changes happen. Search engines make thousands of improvements to their algorithms each year, and we need to keep up if we want our websites to reach more visitors in organic search.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":11,"title":"PWA","description":"PWA chapter of the 2019 Web Almanac covering service workers (registations, installability, events and filesizes), Web App Manifests properties, and Workbox.","authors":["tomayac","jeffposnick"],"reviewers":["hyperpress","ahmadawais"],"translators":null,"discuss":"1766","results":"https://docs.google.com/spreadsheets/d/19BI3RQc_vR9bUPPZfVsF_4gpFWLNT6P0pLcAdL-A56c/","queries":"11_PWA","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"pwa"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Progressive Web Apps (PWAs) are a new class of web applications, building on top of platform primitives like the Service Worker APIs. Service workers allow apps to support network-independent loading by acting as a network proxy, intercepting your web app's outgoing requests, and replying with programmatic or cached responses. Service workers can receive push notifications and synchronize data in the background even when the corresponding app is not running. Additionally, service workers, together with Web App Manifests, allow users to install PWAs to their devices' home screens.
- Figure 1. Percent of desktop pages that register a service worker.
-
-
The first metric we explore are service worker installations. Looking at the data exposed through feature counters in the HTTP Archive, we find that 0.44% of all desktop and 0.37% of all mobile pages register a service worker, and both curves over time are steeply growing.
Timeseries chart of service worker installation. Since Janurary 2017, desktop and mobile have increased steadily from approximately 0.0% to about 0.4%.
- Figure 2. Service Worker installation over time for desktop and mobile.
-
-
Now this might not look overly impressive, but taking traffic data from Chrome Platform Status into account, we can see that a service worker controls about 15% of all page loads, which can be interpreted as popular, high-traffic sites increasingly having started to embrace service workers.
Bar chart showing the popularity of various service worker events. Fetch is used on 73% of mobile service workers, install 71%, activate 56%, notification click 10%, push 8%, message 5%, notification close 2%, and sync 1%. The usage on desktop service workers is similar, but slightly lower for fetch, install, and activate.
- Figure 4. Popularity of service worker events.
-
-
We have examined which of these events are being listened to by service workers we could find in the HTTP Archive. The results for mobile and desktop are very similar with fetch, install, and activate being the three most popular events, followed by notificationclick and push. If we interpret these results, offline use cases that service workers enable are the most attractive feature for app developers, far ahead of push notifications. Due to its limited availability, and less common use case, background sync doesn't play a significant role at the moment.
File size or lines of code are generally a bad proxy for the complexity of the task at hand. In this case, however, it is definitely interesting to compare (compressed) file sizes of service workers for mobile and desktop.
Bar chart showing the distribution of transfer sizes of service workers. The 10, 25, 50, 75, and 90th percentiles for desktop service worker transfer sizes are: 176, 350, 895, 2,010, and 4,138 bytes. Desktop service workers are larger across each percentile from as many as 1,000 bytes at the 90th percentile.
- Figure 5. Distribution of service worker transfer size.
-
-
- The median service worker file on desktop is 895 bytes, whereas on mobile it's 694 bytes. Throughout all percentiles desktop service workers are larger than mobile service workers. We note that these stats don't account for dynamically imported scripts through the importScripts() method, which likely skews the results higher.
-
The web app manifest is a simple JSON file that tells the browser about a web application and how it should behave when installed on the user's mobile device or desktop. A typical manifest file includes information about the app name, icons it should use, the start URL it should open at when launched, and more. Only 1.54% of all encountered manifests were invalid JSON, and the rest parsed correctly.
-
We looked at the different properties defined by the Web App Manifest specification, and also considered non-standard proprietary properties. According to the spec, the following properties are allowed:
-
-
dir
-
lang
-
name
-
short_name
-
description
-
icons
-
screenshots
-
categories
-
iarc_rating_id
-
start_url
-
display
-
orientation
-
theme_color
-
background_color
-
scope
-
serviceworker
-
related_applications
-
prefer_related_applications
-
-
The only property that we didn't observe in the wild was iarc_rating_id, which is a string that represents the International Age Rating Coalition (IARC) certification code of the web application. It is intended to be used to determine which ages the web application is appropriate for.
Bar chart showing the popularity of web app manifest properties for desktop and mobile. 88% of desktop web app manifests include the name property, 82% icons, 61% display, 55% theme color, 49% background color, 45% short name, 36% start URL, 19% GCM sender ID, 9% GCM user visible only, 9% orientation, 7% description, 5% scope, and 4% lang. The popularity of properties on mobile web app manifests is similar, plus or minus 2 percentage points.
- Figure 6. Popularity of web app manifest properties.
-
-
The proprietary properties we encountered frequently were gcm_sender_id and gcm_user_visible_only from the legacy Google Cloud Messaging (GCM) service. Interestingly there are almost no differences between mobile and desktop. On both platforms, however, there's a long tail of properties that are not interpreted by browsers yet contain potentially useful metadata like author or version. We also found a non-trivial amount of mistyped properties; our favorite being shot_name, as opposed to short_name. An interesting outlier is the serviceworker property, which is standard but not implemented by any browser vendor. Nevertheless, it was found on 0.09% of all web app manifests used by mobile and desktop pages.
Looking at the values developers set for the display property, it becomes immediately clear that they want PWAs to be perceived as "proper" apps that don't reveal their web technology origins.
Bar chart showing how the display property of web app manifests is used by desktop and mobile websites. In both cases, the "standalone" value is used 57% of the time. The property is not set at all in 38% of manifests. The "minimal UI", "browser", and "fullscreen" values each make up only 1 or 2% of usage.
- Figure 7. Usage of web app manifest display properties.
-
-
By choosing standalone, they make sure no browser UI is shown to the end-user. This is reflected by the majority of apps that make use of the prefers_related_applications property: more that 97% of both mobile and desktop applications do not prefer native applications.
The categories property describes the expected application categories to which the web application belongs. It is only meant as a hint to catalogs or app stores listing web applications, and it is expected that websites will make a best effort to list themselves in one or more appropriate categories.
Bar chart showing the top web app manifest categories. 60 mobile manifests are in the "shopping" category, 15 "business", 9 "web", 9 "technology", 8 "games", 8 "entertainment", 7 "social", etc. Desktop manifests follow a similar distribution except for "shopping", for which there is only 1 desktop manifest.
There were not too many manifests that made use of the property, but it is interesting to see the shift from "shopping" being the most popular category on mobile to "business", "technology", and "web" (whatever may be meant with that) on desktop that share the first place evenly.
Bar chart showing the usage of top web app manifest icon size property values. All values are given in height and width pixels, for example the top value in 23% of manifests is 192 by 192 pixels. The next most popular sizes are 144 at 11%, 96 at 11%, 72 at 10%, 48 at 10%, 512 at 9%, 36% at 9%, 256 at 5%, 384 at 2%, 128 at 1%, and 152 at 1%. Desktop and mobile have identical usage patterns.
Lighthouse's rule is probably the culprit for 192 pixels being the most popular choice of icon size on both desktop and mobile, despite Google's documentation explicitly recommending 512x512, which doesn't show as a particularly prominent option.
Bar chart showing the top web app manifest orientation values. "Portrait" is set in 6% of desktop manifests, followed by "any" in 2%, and the everything else in fewer than 1% of manifests. This is similar to usage in mobile manifests, except "portrait" is set in 8% of manifests and "portrait-primary" in 1%.
- Figure 10. Top web app manifest orientation values.
-
-
"portrait" orientation is the clear winner on both platforms, followed by "any" orientation.
Workbox is a set of libraries that help with common service worker use cases. For instance, Workbox has tools that can plug in to your build process and generate a manifest of files, which are then precached by your service worker. Workbox includes libraries to handle runtime caching, request routing, cache expiration, background sync, and more.
-
- Given the low-level nature of the service worker APIs, many developers have turned to Workbox as a way of structuring their service worker logic into higher-level, reusable chunks of code. Workbox adoption is also driven by its inclusion as a feature in a number of popular JavaScript framework starter kits, like create-react-app and Vue's PWA plugin.
-
-
The HTTP Archive shows that 12.71% of websites that register a service worker are using at least one of the Workbox libraries. This percentage is roughly consistent across desktop and mobile, with a slightly lower percentage (11.46%) on mobile compared to desktop (14.36%).
The stats in this chapter show that PWAs are still only used by a small percentage of sites. However, this relatively small usage is driven by the more popular sites which have a much larger share of traffic, and pages beyond the home page may use this more: we showed that 15% of page loads use a service workers. The advantages they give for performance and greater control over caching particularly for mobile should mean that usage will continue to grow.
PWAs provide a path forward for developers who would prefer to build and release on the web instead of on native platforms and app stores. Not every operating system and browser offers full parity with native software, but improvements continue, and perhaps 2020 is the year where we see an explosion in deployments?
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":12,"title":"Mobile Web","description":"Mobile Web chapter of the 2019 Web Almanac covering page loading, textual content, zooming and scaling, buttons and links, and ease of filling out forms.","authors":["obto"],"reviewers":["AymenLoukil","hyperpress"],"translators":null,"discuss":"1767","results":"https://docs.google.com/spreadsheets/d/1dPBDeHigqx9FVaqzfq7CYTz4KjllkMTkfq4DG4utE_g/","queries":"12_Mobile_Web","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-27T00:00:00.000Z","chapter":"mobile-web"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Let's step back for a moment, to the year 2007. The "mobile web" is currently just a blip on the radar, and for good reason too. Why? Mobile browsers have little to no CSS support, meaning sites look nothing like they do on desktop — some browsers can only display text. Screens are incredibly small and can only display a few lines of text at a time. And the replacements for a mouse are these tiny little arrow keys you use to "tab around". Needless to say, browsing the web on a phone is truly a labor of love. However, all of this is just about to change.
-
In the middle of his presentation, Steve Jobs takes the newly unveiled iPhone, sits down, and begins to surf the web in a way we had only previously dreamed of. A large screen and fully featured browser displaying websites in their full glory. And most importantly, surfing the web using the most intuitive pointer device known to man: our fingers. No more tabbing around with tiny little arrow keys.
-
Since 2007, the mobile web has grown at an explosive rate. And now, 13 years later, mobile accounts for 59% of all searches and 58.7% of all web traffic, according to Akamai mPulse data in July 2019. It's no longer an afterthought, but the primary way people experience the web. So given how significant mobile is, what kind of experience are we providing our visitors? Where are we falling short? Let's find out.
The first part of the mobile web experience we analyzed is the one we're all most intimately familiar with: the page loading experience. But before we start diving into our findings, let's make sure we're all on the same page regarding what the typical mobile user really looks like. Because this will not only help you reproduce these results, but understand these users better.
-
Let's start with what phone the typical mobile user has. The average Android phone is ~$250, and one of the most popular phones in that range is a Samsung Galaxy S6. So this is likely the kind of phone they use, which is actually 4x slower than an iPhone 8. This user doesn't have access to a fast 4G connection, but rather a 2G connection (29% of the time) or 3G connection (28% of the time). And this is what it all adds up to:
- Figure 1. Technical profile of a typical mobile user.
-
-
I imagine some of you are surprised by these results. They may be far worse conditions than you've ever tested your site with. But now that we're all on the same page with what a mobile user truly looks like, let's get started.
The state of JavaScript on the mobile web is terrifying. According to HTTP Archive's JavaScript report, the median mobile site requires phones to download 375 KB of JavaScript. Assuming a 70% compression ratio, this means that phones have to parse, compile, and execute 1.25 MB of JavaScript at the median.
-
Why is this a problem? Because sites loading this much JS take upwards of 10 seconds to become consistently interactive. Or in other words, your page may appear fully loaded, but when a user clicks any of your buttons or menus, the user may experience some slowdown because the JavaScript hasn't finished executing. In the worst case scenario, users may be forced to keep clicking the button for upwards of 10 seconds, just waiting for that magical moment where something actually happens. Think about how confusing and frustrating that can be.
Video showing two web pages loading and each page has a figure tapping repeatedly on a button throughout the video, to no effect. There is a clock ticking up from 0 seconds at the top, and an initial happy emoji face for each website, that starts to turn less happy as clock passes 6 seconds, wide-eyed at 8 seconds, angry at 10 seconds, really angry at 13 seconds and crying at 19 seconds shortly after which the video ends.
- Figure 2. Example of how painful of an experience waiting for JS to load can be.
-
-
Let's delve deeper and look at another metric that focuses more on how well each page utilizes JavaScript. For example, does it really need as much JavaScript as it's loading? We call this metric the JavaScript Bloat Score, based on the web bloat score. The idea behind it is this:
-
-
JavaScript is often used to both generate and change the page as it loads.
-
It's also delivered as text to the browser. So it compresses well, and should be delivered faster than just a screenshot of the page.
-
So if the total amount of JavaScript a page downloads alone (not including images, css, etc) is larger than a PNG screenshot of the viewport, we are using far too much JavaScript. At this point, it'd be faster just to send that screenshot to get the initial page state!
-
-
The *JavaScript Bloat Score* is defined as: (total JavaScript size) / (size of PNG screenshot of viewport). Any number greater than 1.0 means it's faster to send a screenshot.
-
The results of this? Of the 5+ million websites analyzed, 75.52% were bloated with JavaScript. We have a long way to go.
-
Note that we were not able to capture and measure the screenshots of all 5 million+ sites we analyzed. Instead, we took a random sampling of 1000 sites to find what the median viewport screenshot size is (140 KB), and then compared each site's JavaScript download size to this number.
Browsers typically load all pages the same. They prioritize the download of some resources above others, follow the same caching rules, etc. Thanks to Service Workers though, we now have a way to directly control how our resources are handled by the network layer, often times resulting in quite significant improvements to our page load times.
-
Despite being available since 2016 and implemented on every major browser, only 0.64% of sites utilize them!
One of the most beautiful parts of the web is how web pages load progressively by nature. Browsers download and display content as soon as they are able, so users can engage with your content as soon as possible. However, this can have a detrimental effect if you don't design your site with this in mind. Specifically, content can shift position as resources load and impede the user experience.
A video showing a website progressively load. The text is displayed quickly, but as images continue to load the text gets shifted further and further down the page each time—making it very frustrating to read. The calculated CLS of this example is 42.59%. Image courtesy of LookZook
- Figure 3. Example of shifting content distracting a reader. CLS total of 42.59%. Image courtesy of LookZook
-
-
Imagine you're reading an article when all of a sudden, an image loads and pushes the text you're reading way down the screen. You now have to hunt for where you were or just give up on reading the article. Or, perhaps even worse, you begin to click a link right before an ad loads in the same spot, resulting in an accidental click on the ad instead.
-
So, how do we measure how much our sites shift? In the past it was quite difficult (if not impossible), but thanks to the new Layout Instability API we can do this in two steps:
-
-
Via the Layout Instability API, track each shift's impact on the page. This is reported to you as a percentage of how much content in the viewport has shifted.
-
-
Take all the shifts you've tracked and add them together. The result is what we call the Cumulative Layout Shift (CLS) score.
-
-
-
Because every visitor can have a different CLS, in order to analyze this metric across the web with the Chrome UX Report (CrUX), we combine every experience into three different buckets:
-
-
Small CLS: Experiences having CLS under 5%. That is, the page is mostly stable and does not shift very much at all. For perspective, the page in the video above has a CLS of 42.59%.
-
Large CLS: Experiences having CLS 100% or greater. These may consist of many small individual shifts or a few large and noticeable shifts.
-
Medium CLS: Anything in between small and large.
-
-
So what do we see when we look at CLS across the web?
-
-
Nearly two out of every three sites (65.32%) have medium or large CLS for 50% or more of all user experiences.
-
20.52% of sites have large CLS for at least half of all user experiences. That's about one of every five websites. Remember, the video in Figure 3 only has a CLS of 42.59% — these experiences are even worse than that!
-
-
We suspect much of this may be caused by websites not providing an explicit width and height for resources like ads and images that load after text has been painted to the screen. Before browsers can display a resource on the screen, they need to know how much room the resource will take up. So unless an explicit size is provided via CSS or HTML attributes, browsers have no way to know how how large the resource actually is and display it with a width and height of 0px until loaded. When the resource loads and browsers finally know how big it is, it shifts the page's contents, creating an unstable layout.
Over the last few years, the line between websites and "app store" apps has continued to blur. Even now, you have the ability to request access to a user's microphone, video camera, geolocation, ability to display notifications, and more.
-
While this has opened up even more capabilities for developers, needlessly requesting these permissions may leave users feeling wary of your web page, and can build mistrust. This is why we recommend to always tie a permission request to a user gesture, like tapping a "Find theaters near me" button.
-
Right now 1.52% of sites request permissions without a user interaction. Seeing such a low number is encouraging. However, it's important to note that we were only able to analyze home pages. So for example, sites requesting permissions only on their content pages (e.g., their blog posts) were not accounted for. See our Methodology page for more info.
The primary goal of a web page is to deliver content users want to engage with. This content might be a YouTube video or an assortment of images, but often times, it's simply the text on the page. It goes without saying that ensuring our textual content is legible to our visitors is extremely important. Because if visitors can't read it, there's nothing left to engage with, and they'll leave. There are two key things to check when ensuring your text is legible to readers: color contrast and font sizes.
When designing our sites we tend to be in more optimal conditions, and have far better eyes than many of our visitors. Visitors may be colorblind and unable to distinguish between the text and background color. 1 in every 12 men and 1 in 200 women of European descent are colorblind. Or perhaps visitors are reading the page while the sun is creating glare on their screen, which may similarly impair legibility.
-
To help us mitigate this problem, there are accessibility guidelines we can follow when choosing our text and background colors. So how are we doing in meeting these baselines? Only 22.04% of sites give all their text sufficient color contrast. This value is actually a lower limit, as we could only analyze text with solid backgrounds. Image and gradient backgrounds were unable to be analyzed.
Four colored boxes of brown and gray shades with white text overlaid inside creating two columns, one where the background color is too lightly colored compared to the white text and one where the background color is recommended compared to the white text. The hex code of each color is displayed, white is #FFFFFF, the light shade of brown background is #FCA469, and the recommended shade of brown background is #BD5B0E. The grayscale equivalents are #B8B8B8 and #707070 respectively. Image courtesy of LookZook
- Figure 4. Example of what text with insufficient color contrast looks like. Courtesy of LookZook.
-
-
For colorblindness stats for other demographics, see this paper.
The second part of legibility is ensuring that text is large enough to read easily. This is important for all users, but especially so for older age demographics. Font sizes under 12px tend to be harder to read.
-
Across the web we found 80.66% of web pages meet this baseline.
Designing your site to work perfectly across the tens of thousands of screen sizes and devices is incredibly difficult. Some users need larger font sizes to read, zoom in on your product images, or need a button to be larger because it's too small and slipped past your quality assurance team. Reasons like these are why device features like pinch-to-zoom and scaling are so important; they allow users to tweak our pages so their needs are met.
-
There do exist very rare cases when disabling this is acceptable, like when the page in question is a web-based game using touch controls. If left enabled in this case, players' phones will zoom in and out every time the player taps twice on the game, resulting in an unusable experience.
-
Because of this, developers are given the ability to disable this feature by setting one of the following two properties in the meta viewport tag:
Vertical grouped bar chart titled "Are zooming and scaling enabled?" measuring percentage data, ranging from 0 to 80 in increments of 20, vs. the device type, grouped into desktop and mobile. Desktop enabled: 75.46%; Desktop disabled 24.54%; Mobile enabled: 67.79%; Mobile disabled: 32.21%.
- Figure 5. Percent of desktop and mobile websites that enable or disable zooming/scaling.
-
-
However, developers have misused this so much that almost one out of every three sites (32.21%) disable this feature, and Apple (as of iOS 10) no longer allows web developers to disable zooming. Mobile Safari simply ignores the tag. All sites, no matter what, can be zoomed and scaled on newer Apple devices, which account for over 11% of all web traffic worldwide!
Mobile devices allow users to rotate them so your website can be viewed in the format users prefer. Users do not always keep the same orientation throughout a session however. When filling out forms, users may rotate to landscape mode to use the larger keyboard. Or while browsing products, some may prefer the larger product images landscape mode gives them. Because of these types of use cases, it's very important not to rob the user of this built-in ability of mobile devices. And the good news is that we found virtually no sites that disable this. Only 87 total sites (or 0.0016%) disable this feature. This is fantastic.
We're used to having precise devices like mice while on desktop, but the story is quite different on mobile. On mobile we engage with sites through these large and imprecise tools we call fingers. Because of how imprecise they can be, we constantly "fat finger" links and buttons, tapping on things we never intended.
-
Designing tap targets appropriately to mitigate this issue can be difficult because of how widely fingers vary in size. However, lots of research has now been done and there are safe standards for how large buttons should be and how far apart they need to be separated.
A diagram displaying two examples of difficult to tap buttons. The first example shows two buttons with no spacing between them; An example below it shows the same buttons but with the recommended amount of spacing between them (8px or 1-2mm). The second example shows a button far too small to tap; An example below it shows the same button enlarged to the recommended size of 40-48px (around 8mm). Image courtesy of LookZook
- Figure 6. Standards for sizing and spacing tap targets. Image courtesy of LookZook
-
-
As of now, 34.43% of sites have sufficiently sized tap targets. So we have quite a ways to go until "fat fingering" is a thing of the past.
Some designers love to use icons in place of text — they can make our sites look cleaner and more elegant. But while you and everyone on your team may know what these icons mean, many of your users will not. This is even the case with the infamous hamburger icon! If you don't believe us, do some user testing and see how often users get confused. You'll be astounded.
-
This is why it's important to avoid any confusion and add supporting text and labels to your buttons. As of now, at least 28.59% of sites include a button with only a single icon with no supporting text.
-
Note: The reported number above is only a lower bound. During our analysis, we only included buttons using font icons with no supporting text. Many buttons now use SVGs instead of font-icons however, so in future runs we will be including them as well.
From signing up for a new service, buying something online, or even to receive notifications of new posts from a blog, form fields are an essential part of the web and something we use daily. Unfortunately, these fields are infamous for how much of a pain they are to fill out on mobile. Thankfully, in recent years browsers have given developers new tools to help ease the pain of completing these fields we know all too well. So let's take a look at how much they've been getting used.
In the past, text and password were some of the only input types available to developers as it met almost all of our needs on desktop. This is not the case for mobile devices. Mobile keyboards are incredibly small, and a simple task, like entering an email address, may require users to switch between multiple keyboards: the standard keyboard and the special character keyboard for the "@" symbol. Simply entering a phone number can be difficult using the default keyboard's tiny numbers.
-
Many new input types have since been introduced, allowing developers to inform browsers what kind of data is expected, and enable browsers to provide customized keyboards specifically for these input types. For example, a type of email provides users with an alphanumeric keyboard including the "@" symbol, and a type of tel will display a numeric keypad.
-
When analyzing sites containing an email input, 56.42% use type="email". Similarly, for phone inputs, type="tel" is used 36.7% of the time. Other new input types have an even lower adoption rate.
-
-
-
-
-
-
-
Type
-
Frequency (pages)
-
-
-
phone
-
1,917
-
-
-
name
-
1,348
-
-
-
textbox
-
833
-
-
-
-
-
- Figure 7. Most commonly used invalid input types
-
-
Make sure to educate yourself and others on the large amount of input types available and double-check that you don't have any typos like the most common ones in Figure 7 above.
- The autocomplete input attribute enables users to fill out form fields in a single click. Users fill out tons of forms, often with the exact same information each time. Realizing this, browsers have begun to securely store this information so it can be used on future pages. All developers need to do is use this autocomplete attribute to tell browsers what exact piece of information needs to be filled in, and the browser does the rest.
-
-
-
29.62%
- Figure 8. Percent of pages that use autocomplete.
-
-
Currently, only 29.62% of pages with input fields utilize this feature.
Enabling users to copy and paste their passwords into your page is one way that allows them to use password managers. Password managers help users generate (and remember) strong passwords and fill them out automatically on web pages. Only 0.02% of web pages tested disable this functionality.
-
Note: While this is very encouraging, this may be an underestimation due to the requirement of our Methodology to only test home pages. Interior pages, like login pages, are not tested.
For over 13 years we've been treating the mobile web as an afterthought, like a mere exception to desktop. But it's time for this to change. The mobile web is now the web, and desktop is becoming the legacy one. There are now 4 billion active smartphones in the world, covering 70% of all potential users. What about desktops? They currently sit at 1.6 billion, and account for less and less of web usage every month.
-
How well are we doing catering to mobile users? According to our research, even though 71% of sites make some kind of effort to adjust their site for mobile, they're falling well below the mark. Pages take forever to load and become unusable thanks to an abuse of JavaScript, text is often impossible to read, engaging with sites via clicking links or buttons is error-prone and infuriating, and tons of great technologies invented to mitigate these problems (Service Workers, autocomplete, zooming, new image formats, etc) are barely being used at all.
-
The mobile web has now been around long enough for there to be an entire generation of kids where this is the only internet they've ever known. And what kind of experience are we giving them? We're essentially taking them back to the dial-up era. (Good thing I hear AOL still sells those CDs providing 1000 hours of free internet access!)
We defined sites making a mobile effort as those who adjust their designs for smaller screens. Or rather, those which have at least one CSS breakpoint at 600px or less.
-
-
Potential users, or the total addressable market, are those who are 15+ years old: 5.7 billion people.
The total number of active smartphones was found by totaling the number of active Androids and iPhones (made public by Apple and Google), and a bit of math to account for Chinese internet-connected phones. More info here.
-
-
-
The 1.6 billion desktops is calculated by numbers made public by Microsoft and Apple. It does not include linux PC users.
-
-
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"III","chapter_number":13,"title":"Ecommerce","description":"Ecommerce chapter of the 2019 Web Almanac covering ecommerce platforms, payloads, images, third-parties, performance, seo, and PWAs.","authors":["samdutton","alankent"],"reviewers":["voltek62"],"translators":null,"discuss":"1768","results":"https://docs.google.com/spreadsheets/d/1FUMHeOPYBgtVeMU5_pl2r33krZFzutt9vkOpphOSOss/","queries":"13_Ecommerce","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"ecommerce"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
Nearly 10% of the home pages in this study were found to be on an ecommerce platform. An "ecommerce platform" is a set of software or services that enables you to create and operate an online store. There are several types of ecommerce platforms, for example:
-
-
Paid-for services such as Shopify that host your store and help you get started. They provide website hosting, site and page templates, product-data management, shopping carts and payments.
-
Software platforms such as Magento Open Source which you set up, host and manage yourself. These platforms can be powerful and flexible, but may be more complex to set up and run than services such as Shopify.
-
Hosted platforms such as Magento Commerce that offer the same features as their self-hosted counterparts, except that hosting is managed as a service by a third-party.
-
-
-
10%
- Figure 1. Percent of pages on an ecommerce platform.
-
-
This analysis could only detect sites built on an ecommerce platform. This means that most large online stores and marketplaces—such as Amazon, JD, and eBay—are not included here. Also note that the data here is for home pages only: not category, product or other pages. Learn more about our methodology.
How do we check if a page is on an ecommerce platform?
-
Detection is done through Wappalyzer. Wappalyzer is a cross-platform utility that uncovers the technologies used on websites. It detects content management systems, ecommerce platforms, web servers, JavaScript frameworks, analytics tools, and many more.
-
Page detection is not always reliable, and some sites explicitly block detection to protect against automated attacks. We might not be able to catch all websites that use a particular ecommerce platform, but we're confident that the ones we do detect are actually on that platform.
-
-
-
-
-
-
-
-
Mobile
-
Desktop
-
-
-
-
-
Ecommerce pages
-
500,595
-
424,441
-
-
-
Total pages
-
5,297,442
-
4,371,973
-
-
-
Adoption rate
-
9.45%
-
9.70%
-
-
-
-
-
- Figure 2. Percent of ecommerce platforms detected.
-
- Figure 3. Adoption of the top six ecommerce platforms.
-
-
Out of the 116 ecommerce platforms that were detected, only six are found on more than 0.1% of desktop or mobile websites. Note that these results do not show variation by country, by size of site, or other similar metrics.
-
Figure 3 above shows that WooCommerce has the largest adoption at around 4% of desktop and mobile websites. Shopify is second with about 1.6% adoption. Magento, PrestaShop, Bigcommerce, and Shopware follow with smaller and smaller adoption, approaching 0.1%.
Bar chart of the adoption of top 20 ecommerce platforms. Refer to Figure 3 above for a data table of adoption of the top six platforms.
- Figure 4. Adoption of top ecommerce platforms.
-
-
There are 110 ecommerce platforms that each have fewer than 0.1% of desktop or mobile websites. Around 60 of these have fewer than 0.01% of mobile or desktop websites.
The top six ecommerce platforms make up 8% of all websites. The rest of the 110 platforms only make up 1.5% of websites. The results for desktop and mobile are similar.
- Figure 5. Combined adoption of the top six ecommerce platforms versus the other 110 platforms.
-
-
7.87% of all requests on mobile and 8.06% on desktop are for home pages on one of the top six ecommerce platforms. A further 1.52% of requests on mobile and 1.59% on desktop are for home pages on the 110 other ecommerce platforms.
9.7% of desktop pages use an ecommerce platform and 9.5% of mobile pages use an ecommerce platform.
- Figure 6. Percent of pages using any ecommerce platform.
-
-
Although the desktop proportion of websites was slightly higher overall, some popular platforms (including WooCommerce, PrestaShop and Shopware) actually have more mobile than desktop websites.
Distribution of the 10, 25, 50, 75, and 90th percentiles of ecommerce page weight. The median desktop ecommerce page loads 2.7 MB. The 10th percentile is 1.0 MB, 25th 1.6 MB, 75th 4.5 MB, and 90th 7.6 MB. Desktop websites are slightly higher than mobile by tenths of a megabyte.
- Figure 7. Distribution of ecommerce page weight.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of requests per ecommerce page. The median desktop ecommerce page makes 108 requests. The 10th percentile is 53 requests, 25th 76, 75th 153, and 90th 210. Desktop websites are slightly higher than mobile by about 10 requests.
- Figure 8. Distribution of requests per ecommerce page.
-
-
The median desktop ecommerce platform page loads 108 requests and 2.7 MB. The median weight for all desktop pages is 74 requests and 1.9 MB. In other words, ecommerce pages make nearly 50% more requests than other web pages, with payloads around 35% larger. By comparison, the amazon.com home page makes around 300 requests on first load, for a page weight of around 5 MB, and ebay.com makes around 150 requests for a page weight of approximately 3 MB. The page weight and number of requests for home pages on ecommerce platforms is slightly smaller on mobile at every percentile, but around 10% of all ecommerce home pages load more than 7 MB and make over 200 requests.
-
This data accounts for home page payload and requests without scrolling. Clearly there are a significant proportion of sites that appear to be retrieving more files (the median is over 100), with a larger total payload, than should be necessary for first load. See also: Third-party requests and bytes below.
-
We need to do further research to better understand why so many home pages on ecommerce platforms make so many requests and have such large payloads. The authors regularly see home pages on ecommerce platforms that make hundreds of requests on first load, with multi-megabyte payloads. If the number of requests and payload are a problem for performance, then how can they be reduced?
- Figure 9. Percentiles of the distribution of page weight (in KB) by resource type.
-
-
-
-
-
-
-
-
Type
-
10
-
25
-
50
-
75
-
90
-
-
-
-
-
image
-
16
-
25
-
39
-
62
-
97
-
-
-
script
-
11
-
21
-
35
-
53
-
75
-
-
-
css
-
3
-
6
-
11
-
22
-
32
-
-
-
font
-
2
-
3
-
5
-
8
-
11
-
-
-
html
-
1
-
2
-
4
-
7
-
12
-
-
-
video
-
1
-
1
-
2
-
5
-
9
-
-
-
other
-
1
-
1
-
2
-
4
-
9
-
-
-
text
-
1
-
1
-
1
-
2
-
3
-
-
-
xml
-
1
-
1
-
1
-
2
-
2
-
-
-
audio
-
1
-
1
-
1
-
1
-
3
-
-
-
-
-
- Figure 10. Percentiles of the distribution of requests per page by resource type.
-
-
Images constitute the largest number of requests and the highest proportion of bytes for ecommerce pages. The median desktop ecommerce page includes 39 images weighing 1,514 KB (1.5 MB).
-
The number of JavaScript requests indicates that better bundling (and/or HTTP/2 multiplexing) could improve performance. JavaScript files are not significantly large in terms of total bytes, but many separate requests are made. According to the HTTP/2 chapter, more than 40% of requests are not via HTTP/2. Similarly, CSS files have the third highest number of requests but are generally small. Merging CSS files (and/or HTTP/2) could improve performance of such sites. In the authors' experience, many ecommerce pages have a high proportion of unused CSS and JavaScript. Videos may require a small number of requests, but (not surprisingly) consume a high proportion of the page weight, particularly on sites with heavy payloads.
Distribution of the 10, 25, 50, 75, and 90th percentiles of HTML bytes per ecommerce page. The median desktop ecommerce page has 36 KB of HTML. The 10th percentile is 12 KB, 25th 20, 75th 66, and 90th 118. Desktop websites have slightly more HTML bytes than mobile by 1 or 2 KB.
- Figure 11. Distribution of HTML bytes (in KB) per ecommerce page.
-
-
Note that HTML payloads may include other code such as inline JSON, JavaScript, or CSS directly in the markup itself, rather than referenced as external links. The median HTML payload size for ecommerce pages is 34 KB on mobile and 36 KB on desktop. However, 10% of ecommerce pages have an HTML payload of more than 115 KB.
-
Mobile HTML payload sizes are not very different from desktop. In other words, it appears that sites are not delivering significantly different HTML files for different devices or viewport sizes. On many ecommerce sites, home page HTML payloads are large. We don't know whether this is because of bloated HTML, or from other code (such as JSON) within HTML files.
Distribution of the 10, 25, 50, 75, and 90th percentiles of image bytes per ecommerce page. The median mobile ecommerce page has 1,517 KB of images. The 10th percentile is 318 KB, 25th 703, 75th 3,132, and 90th 5,881. Desktop and mobile websites have similar distributions.
- Figure 12. Distribution of image bytes (in KB) per ecommerce page.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of image requests per ecommerce page. The median desktop ecommerce page makes 40 image requests. The 10th percentile is 16 requests, 25th 25, 75th 62, and 90th 97. The desktop distribution is slightly higher than mobile by 2-10 requests at each percentile.
- Figure 13. Distribution of image requests per ecommerce page.
-
-
Note that because our data collection methodology does not simulate user interactions on pages like clicking or scrolling, images that are lazy loaded would not be represented in these results.
-
Figures 12 and 13 above show that the median ecommerce page has 37 images and an image payload of 1,517 KB on mobile, 40 images and 1,524 KB on desktop. 10% of home pages have 90 or more images and an image payload of nearly 6 MB!
-
-
1,517 KB
- Figure 14. The median number of image bytes per mobile ecommerce page.
-
-
A significant proportion of ecommerce pages have sizable image payloads and make a large number of image requests on first load. See HTTP Archive's State of Images report and the media and page weight chapters for more context.
-
Website owners want their sites to look good on modern devices. As a result, many sites deliver the same high resolution product images to every user without regard for screen resolution or size. Developers may not be aware of (or not want to use) responsive techniques that enable efficient delivery of the best possible image to different users. It's worth remembering that high-resolution images may not necessarily increase conversion rates. Conversely, overuse of heavy images is likely to impact page speed and can thereby reduce conversion rates. In the authors' experience from site reviews and events, some developers and other stakeholders have SEO or other concerns about using lazy loading for images.
-
We need to do more analysis to better understand why some sites are not using responsive image techniques or lazy loading. We also need to provide guidance that helps ecommerce platforms to reliably deliver beautiful images to those with high end devices and good connectivity, while simultaneously providing a best-possible experience to lower-end devices and those with poor connectivity.
Bar chart showing the popularity of various image formats. JPEG is the most popular format at 54% of images on desktop ecommerce pages. Next are PNG at 27%, GIF at 14%, SVG at 2%, and WebP and ICO at 1% each.
Note that some image services or CDNs will automatically deliver WebP (rather than JPEG or PNG) to platforms that support WebP, even for a URL with a `.jpg` or `.png` suffix. For example, IMG_20190113_113201.jpg returns a WebP image in Chrome. However, the way HTTP Archive detects image formats is to check for keywords in the MIME type first, then fall back to the file extension. This means that the format for images with URLs such as the above will be given as WebP, since WebP is supported by HTTP Archive as a user agent.
One in four images on ecommerce pages are PNG. The high number of PNG requests from pages on ecommerce platforms is probably for product images. Many commerce sites use PNG with photographic images to enable transparency.
-
Using WebP with a PNG fallback can be a far more efficient alternative, either via a picture element or by using user agent capability detection via an image service such as Cloudinary.
Only 1% of images on ecommerce platforms are WebP, which tallies with the authors' experience of site reviews and partner work. WebP is supported by all modern browsers other than Safari and has good fallback mechanisms available. WebP supports transparency and is a far more efficient format than PNG for photographic images (see PNG section above).
-
We as a web community can provide better guidance/advocacy for enabling transparency using WebP with a PNG fallback and/or using WebP/JPEG with a solid color background. WebP appears to be rarely used on ecommerce platforms, despite the availability of guides and tools (e.g. Squoosh and cwebp). We need to do further research into why there hasn't been more take-up of WebP, which is now nearly 10 years old.
- Figure 16. Distribution of intrinsic image dimensions (in pixels) per ecommerce page.
-
-
The median ('mid-range') dimensions for images requested by ecommerce pages is 247x196 px on mobile and 240x192 px on desktop. 10% of images requested by ecommerce pages are at least 693x512 px on mobile and 800x546 px on desktop. Note that these dimensions are the intrinsic sizes of images, not their display size.
-
Given that image dimensions at each percentile up to the median are similar on mobile and desktop, or even slightly larger on mobile in some cases, it would seem that many sites are not delivering different image dimensions for different viewports, or in other words, not using responsive image techniques. The delivery of larger images to mobile in some cases may (or may not!) be explained by sites using device or screen detection.
-
We need to do more research into why many sites are (apparently) not delivering different image sizes to different viewports.
Many websites—especially online stores—load a significant amount of code and content from third-parties: for analytics, A/B testing, customer behavior tracking, advertising, and social media support. Third-party content can have a significant impact on performance. Patrick Hulce's third-party-web tool is used to determine third-party requests for this report, and this is discussed more in the Third Parties chapter.
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party requests per ecommerce page. The median number of third-party requests on desktop is 19. The 10, 25, 75, and 90th percentiles are: 4, 9, 34, and 54. The desktop distribution is higher at each percentile than mobile by only 1-2 requests.
- Figure 17. Distribution of third-party requests per ecommerce page.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party bytes per ecommerce page. The median number of third-party bytes on desktop is 320 KB. The 10, 25, 75, and 90th percentiles are: 42, 129, 651, and 1,071. The desktop distribution is higher at each percentile than mobile by 10-30 KB.
- Figure 18. Distribution of third-party bytes per ecommerce page.
-
-
The median ('mid-range') home page on an ecommerce platform makes 17 requests for third-party content on mobile and 19 on desktop. 10% of all home pages on ecommerce platforms make over 50 requests for third-party content, with a total payload of over 1 MB.
-
Other studies have indicated that third-party content can be a major performance bottleneck. This study shows that 17 or more requests (50 or more for the top 10%) is the norm for ecommerce pages.
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party requests per ecommerce page for each platform. Shopify and Bigcommerce load the most third-party requests across the distributions by about 40 requests at the median.
- Figure 19. Distribution of third-party requests per mobile page for each ecommerce platform.
-
-
-
-
-
-
-
Distribution of the 10, 25, 50, 75, and 90th percentiles of third-party bytes (KB) per ecommerce page for each platform. Shopify and Bigcommerce load the most third-party bytes across the distributions by more than 1,000 KB at the median.
- Figure 20. Distribution of third-party bytes (KB) per mobile page for each ecommerce platform.
-
-
Platforms such as Shopify may extend their services using client-side JavaScript, whereas other platforms such as Magento use more server side extensions. This difference in architecture affects the figures seen here.
-
Clearly, pages on some ecommerce platforms make more requests for third-party content and incur a larger payload of third-party content. Further analysis could be done on why pages from some platforms make more requests and have larger third-party payloads than others.
Bar chart of the average distribution of FCP experiences for the top six ecommerce platforms. WooCommerce has the highest density of slow FCP experiences at 43%. Shopify has the highest density of fast FCP experiences at 47%.
- Figure 21. Average distribution of FCP experiences per ecommerce platform.
-
-
First Contentful Paint measures the time it takes from navigation until content such as text or an image is first displayed. In this context, fast means FCP in under one second, slow means FCP in 3 seconds or more, and moderate is everything in between. Note that third-party content and code may have a significant impact on FCP.
-
All top-six ecommerce platforms have worse FCP on mobile than desktop: less fast and more slow. Note that FCP is affected by device capability (processing power, memory, etc.) as well as connectivity.
-
We need to establish why FCP is worse on mobile than desktop. What are the causes: connectivity and/or device capability, or something else?
Distribution of Lighthouse's PWA category scores for ecommerce pages. On a scale of 0 (failing) to 1 (perfect), 40% of pages get a score of 0.33. 1% of pages get a score above 0.6.
- Figure 22. Distribution of Lighthouse PWA category scores for mobile ecommerce pages.
-
-
More than 60% of home pages on ecommerce platforms get a Lighthouse PWA score between 0.25 and 0.35. Less than 20% of home pages on ecommerce platforms get a score of more than 0.5 and less than 1% of home pages score more than 0.6.
-
Lighthouse returns a Progressive Web App (PWA) score between 0 and 1. 0 is the worst possible score, and 1 is the best. The PWA audits are based on the Baseline PWA Checklist, which lists 14 requirements. Lighthouse has automated audits for 11 of the 14 requirements. The remaining 3 can only be tested manually. Each of the 11 automated PWA audits are weighted equally, so each one contributes approximately 9 points to your PWA score.
-
If at least one of the PWA audits got a null score, Lighthouse nulls out the score for the entire PWA category. This was the case for 2.32% of mobile pages.
-
Clearly, the majority of ecommerce pages are failing most PWA checklist audits. We need to do further analysis to better understand which audits are failing and why.
This comprehensive study of ecommerce usage shows some interesting data and also the wide variations in ecommerce sites, even among those built on the same ecommerce platform. Even though we have gone into a lot of detail here, there is much more analysis we could do in this space. For example, we didn't get accessibility scores this year (checkout the accessibility chapter for more on that). Likewise, it would be interesting to segment these metrics by geography. This study detected 246 ad providers on home pages on ecommerce platforms. Further studies (perhaps in next year's Web Almanac?) could calculate what proportion of sites on ecommerce platforms shows ads. WooCommerce got very high numbers in this study so another interesting statistic we could look at next year is if some hosting providers are installing WooCommerce but not enabling it, thereby causing inflated figures.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"III","chapter_number":14,"title":"CMS","description":"CMS chapter of the 2019 Web Almanac covering CMS adoption, how CMS suites are built, User experience of CMS powered websites, and CMS innovation.","authors":["ernee","amedina"],"reviewers":["sirjonathan"],"translators":null,"discuss":"1769","results":"https://docs.google.com/spreadsheets/d/1FDYe6QdoY3UtXodE2estTdwMsTG-hHNrOe9wEYLlwAw/","queries":"14_CMS","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"cms"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
The general term Content Management System (CMS) refers to systems enabling individuals and organizations to create, manage, and publish content. A CMS for web content, specifically, is a system aimed at creating, managing, and publishing content to be consumed and experienced via the open web.
-
Each CMS implements some subset of a wide range of content management capabilities and the corresponding mechanisms for users to build websites easily and effectively around their content. Such content is often stored in some type of database, providing users with the flexibility to reuse it wherever needed for their content strategy. CMSs also provide admin capabilities aimed at making it easy for users to upload and manage content as needed.
-
There is great variability on the type and scope of the support CMSs provide for building sites; some provide ready-to-use templates which are "hydrated" with user content, and others require much more user involvement for designing and constructing the site structure.
-
When we think about CMSs, we need to account for all the components that play a role in the viability of such a system for providing a platform for publishing content on the web. All of these components form an ecosystem surrounding the CMS platform, and they include hosting providers, extension developers, development agencies, site builders, etc. Thus, when we talk about a CMS, we usually refer to both the platform itself and its surrounding ecosystem.
At the beginning of (web evolution) time, the web ecosystem was powered by a simple growth loop, where users could become creators just by viewing the source of a web page, copy-pasting according to their needs, and tailoring the new version with individual elements like images.
-
As the web evolved, it became more powerful, but also more complicated. As a consequence, that simple growth loop was broken and it was not the case anymore that any user could become a creator. For those who could pursue the content creation path, the road became arduous and hard to achieve. The usage-capability gap, that is, the difference between what can be done in the web and what is actually done, grew steadily.
On the left, labeled circa 1999, we have a bar chart with two bars showing what can be done is close to what is actually done. On the right, labeled 2018, we have a similar bar chart but what can be done is much larger, and what is done is slightly larger. The gap between what can be done and what is actually done has greatly increased.
- Figure 1. Chart illustrating the increase in web capabilities from 1999 to 2018.
-
-
Here is where a CMS plays the very important role of making it easy for users with different degrees of technical expertise to enter the web ecosystem loop as content creators. By lowering the barrier of entry for content creation, CMSs activate the growth loop of the web by turning users into creators. Hence their popularity.
There are many interesting and important aspects to analyze and questions to answer in our quest to understand the CMS space and its role in the present and the future of the web. While we acknowledge the vastness and complexity of the CMS platforms space, and don't claim omniscient knowledge fully covering all aspects involved on all platforms out there, we do claim our fascination for this space and we bring deep expertise on some of the major players in the space.
-
In this chapter, we seek to scratch the surface area of the vast CMS space, trying to shed a beam of light on our collective understanding of the status quo of CMS ecosystems, and the role they play in shaping users' perception of how content can be consumed and experienced on the web. Our goal is not to provide an exhaustive view of the CMS landscape; instead, we will discuss a few aspects related to the CMS landscape in general, and the characteristics of web pages generated by these systems. This first edition of the Web Almanac establishes a baseline, and in the future we'll have the benefit of comparing data against this version for trend analysis.
- Figure 2. Percent of web pages powered by a CMS.
-
-
Today, we can observe that more than 40% of the web pages are powered by some CMS platform; 40.01% for mobile and 39.61% for desktop more precisely.
-
There are other datasets tracking market share of CMS platforms, such as W3Techs, and they reflect higher percentages of more than 50% of web pages powered by CMS platforms. Furthermore, they observe also that CMS platforms are growing, as fast as 12% year-over-year growth in some cases! The deviation between our analysis and W3Tech's analysis could be explained by a difference in research methodologies. You can read more about ours on the Methodology page.
-
In essence, this means that there are many CMS platforms available out there. The following picture shows a reduced view of the CMS landscape.
Logos of the top CMS providers, including WordPress, Drupal, Wix, etc.
- Figure 3. The top content management systems.
-
-
Some of them are open source (e.g. WordPress, Drupal, others) and some of them are proprietary (e.g. AEM, others). Some CMS platforms can be used on "free" hosted or self-hosted plans, and there are also advanced options for using these platforms on higher-tiered plans even at the enterprise level. The CMS space as a whole is a complex, federated universe of CMS ecosystems, all separated and at the same time intertwined in the vast fabric of the web.
-
It also means that there are hundreds of millions of websites powered by CMS platforms, and an order of magnitude more of users accessing the web and consuming content through these platforms. Thus, these platforms play a key role for us to succeed in our collective quest for an evergreen, healthy, and vibrant web.
A large swath of the web today is powered by one kind of CMS platform or another. There are statistics collected by different organizations that reflect this reality. Looking at the Chrome UX Report (CrUX) and HTTP Archive datasets, we get a picture that is consistent with stats published elsewhere, although quantitatively the proportions described may be different as a reflection of the specificity of the datasets.
-
Looking at web pages served on desktop and mobile devices, we observe an approximate 60-40 split in the percentage of such pages which were generated by some kind of CMS platform, and those that aren't.
Bar chart showing that 40% of desktop and 40% of mobile websites are built using a CMS.
- Figure 4. Percent of desktop and mobile websites that use a CMS.
-
-
CMS-powered web pages are generated by a large set of available CMS platforms. There are many such platforms to choose from, and many factors that can be considered when deciding to use one vs. another, including things like:
-
-
Core functionality
-
Creation/editing workflows and experience
-
Barrier of entry
-
Customizability
-
Community
-
And many others.
-
-
The CrUX and HTTP Archive datasets contain web pages powered by a mix of around 103 CMS platforms. Most of those platforms are very small in terms of relative market share. For the sake of our analysis, we will be focusing on the top CMS platforms in terms of their footprint on the web as reflected by the data. For a full analysis, see this chapter's results spreadsheet.
Bar chart showing WordPress making up 75% of all CMS websites. The next biggest CMS, Drupal, has about 6% of the CMS market share. The rest of the CMSs quickly shrink in adoption to less than 1%.
- Figure 5. Top CMS platforms as a percent of all CMS websites.
-
-
The most salient CMS platforms present in the datasets are shown above in Figure 5. WordPress comprises 74.19% of mobile and 73.47% of desktop CMS websites. Its dominance in the CMS landscape can be attributed to a number of factors that we'll discuss later, but it's a major player. Open source platforms like Drupal and Joomla, and closed SaaS offerings like Squarespace and Wix, round out the top 5 CMSs. The diversity of these platforms speak to the CMS ecosystem consisting of many platforms where user demographics and the website creation journey vary. What's also interesting is the long tail of small scale CMS platforms in the top 20. From enterprise offerings to proprietary applications developed in-house for industry specific use, content management systems provide the customizable infrastructure for groups to manage, publish, and do business on the web.
-
The WordPress project defines its mission as "democratizing publishing". Some of its main goals are ease of use and to make the software free and available for everyone to create content on the web. Another big component is the inclusive community the project fosters. In almost any major city in the world, one can find a group of people who gather regularly to connect, share, and code in an effort to understand and build on the WordPress platform. Attending local meetups and annual events as well as participating in web-based channels are some of the ways WordPress contributors, experts, businesses, and enthusiasts participate in its global community.
-
The low barrier of entry and resources to support users (online and in-person) with publishing on the platform and to develop extensions (plugins) and themes contribute to its popularity. There is also a thriving availability of and economy around WordPress plugins and themes that reduce the complexity of implementing sought after web design and functionality. Not only do these aspects drive its reach and adoption by newcomers, but also maintains its long-standing use over time.
-
The open source WordPress platform is powered and supported by volunteers, the WordPress Foundation, and major players in the web ecosystem. With these factors in mind, WordPress as the leading CMS makes sense.
Independent of the specific nuances and idiosyncrasies of different CMS platforms, the end goal for all of them is to output web pages to be served to users via the vast reach of the open web. The difference between CMS-powered and non-CMS-powered web pages is that in the former, the CMS platform makes most of the decisions of how the end result is built, while in the latter there are not such layers of abstraction and decisions are all made by developers either directly or via library configurations.
-
In this section we take a brief look at the status quo of the CMS space in terms of the characteristics of their output (e.g. total resources used, image statistics, etc.), and how they compare with the web ecosystem as a whole.
The building blocks of any website also make a CMS website: HTML, CSS, JavaScript, and media (images and video). CMS platforms give users powerfully streamlined administrative capabilities to integrate these resources to create web experiences. While this is one of the most inclusive aspects of these applications, it could have some adverse effects on the wider web.
Bar chart showing the distribution of CMS page weight. The median desktop CMS page weighs 2.3 MB. At the 10th percentile it is 0.7 MB, 25th percentile 1.2 MB, 75th percentile 4.2 MB, and 90th percentile 7.4 MB. Desktop values are very slightly higher than mobile.
Bar chart showing the distribution of CMS requests per page. The median desktop CMS page loads 86 resources. At the 10th percentile it loads 39 resources, 25th percentile 57 resources, 75th percentile 127 resources, and 90th percentile 183 resources. Desktop is consistently higher than mobile by a small margin of 3-6 resources.
- Figure 7. Distribution of CMS requests per page.
-
-
In Figures 6 and 7 above, we see the median desktop CMS page loads 86 resources and weighs 2.29 MB. Mobile page resource usage is not too far behind with 83 resources and 2.25 MB.
-
The median indicates the halfway point that all CMS pages either fall above or below. In short, half of all CMS pages load fewer requests and weigh less, while half load more requests and weigh more. At the 10th percentile, mobile and desktop pages have under 40 requests and 1 MB in weight, but at the 90th percentile we see pages with over 170 requests and at 7 MB, almost tripling in weight from the median.
-
How do CMS pages compare to pages on the web as a whole? In the Page Weight chapter, we find some telling data about resource usage. At the median, desktop pages load 74 requests and weigh 1.9 MB, and mobile pages on the web load 69 requests and weigh 1.7 MB. The median CMS page exceeds this. CMS pages also exceed resources on the web at the 90th percentile, but by a smaller margin. In short: CMS pages could be considered as some of the heaviest.
-
-
-
-
-
-
-
percentile
-
image
-
video
-
script
-
font
-
css
-
audio
-
html
-
-
-
-
-
50
-
1,233
-
1,342
-
456
-
140
-
93
-
14
-
33
-
-
-
75
-
2,766
-
2,735
-
784
-
223
-
174
-
97
-
66
-
-
-
90
-
5,699
-
5,098
-
1,199
-
342
-
310
-
287
-
120
-
-
-
-
-
- Figure 8. Distribution of desktop CMS page kilobytes per resource type.
-
-
-
-
-
-
-
-
percentile
-
image
-
video
-
script
-
css
-
font
-
audio
-
html
-
-
-
-
-
50
-
1,264
-
1,056
-
438
-
89
-
109
-
14
-
32
-
-
-
75
-
2,812
-
2,191
-
756
-
171
-
177
-
38
-
67
-
-
-
90
-
5,531
-
4,593
-
1,178
-
317
-
286
-
473
-
123
-
-
-
-
-
- Figure 9. Distribution of mobile CMS page kilobytes per resource type.
-
-
When we look closer at the types of resources that load on mobile or desktop CMS pages, images and video immediately stand out as primary contributors to their weight.
-
The impact doesn't necessarily correlate with the number of requests, but rather how much data is associated with those individual requests. For example, in the case of video resources with only two requests made at the median, they carry more than 1MB of associated load. Multimedia experiences also come with the use of scripts to integrate interactivity, deliver functionality and data to name a few use cases. In both mobile and desktop pages, those are the 3rd heaviest resource.
-
With our CMS experiences saturated with these resources, we must consider the impact this has on website visitors on the frontend- is their experience fast or slow? Additionally, when comparing mobile and desktop resource usage, the amount of requests and weight show little difference. This means that the same amount and weight of resources are powering both mobile and desktop CMS experiences. Variation in connection speed and mobile device quality adds another layer of complexity. Later in this chapter, we'll use data from CrUX to assess user experience in the CMS space.
Let's highlight a particular subset of resources to assess their impact in the CMS landscape. Third-party resources are those from origins not belonging to the destination site's domain name or servers. They can be images, videos, scripts, or other resource types. Sometimes these resources are packaged in combination such as with embedding an iframe for example. Our data reveals that the median amount of 3rd party resources for both desktop and mobile are close.
-
The median amount of 3rd party requests on mobile CMS pages is 15 and weigh 264.72 KB, while the median for these requests on desktop CMS pages is 16 and weigh 271.56 KB. (Note that this excludes 3P resources considered part of "hosting").
Bar chart of percentiles 10, 25, 50, 75, and 90 representing the distribution of third-party kilobytes on CMS pages for desktop and mobile. The median (50th percentile) desktop third-party weight is 272 KB. The 10th percentile is 27 KB, 25th 104 KB, 75th 577 KB, and 90th 940 KB. Mobile is slightly smaller in the smaller percentiles and slightly larger in the larger percentiles.
- Figure 10. Distribution of third-party weight (KB) on CMS pages.
-
-
-
-
-
-
-
Bar chart of percentiles 10, 25, 50, 75, and 90 representing the distribution of third-party requests on CMS pages for desktop and mobile. The median (50th percentile) desktop third-party request count is 16. The 10th percentile is 3, 25th 7, 75th 31, and 90th 52. Desktop and mobile have nearly equivalent distributions.
- Figure 11. Distribution of the number of third-party requests on CMS pages.
-
-
We know the median value indicates at least half of CMS web pages are shipping with more 3rd party resources than what we report here. At the 90th percentile, CMS pages can deliver up to 52 resources at approximately 940 KB, a considerable increase.
-
Given that third-party resources originate from remote domains and servers, the destination site has little control over the quality and impact these resources have on its performance. This unpredictability could lead to fluctuations in speed and affect the user experience, which we'll soon explore.
Bar chart of percentiles 10, 25, 50, 75, and 90 representing the distribution of image kilobytes on CMS pages for desktop and mobile. The median (50th percentile) desktop image weight is 1,232 KB. The 10th percentile is 198 KB, 25th 507 KB, 75th 2,763 KB, and 90th 5,694 KB. Desktop and mobile have nearly equivalent distributions.
- Figure 12. Distribution of image weight (KB) on CMS pages.
-
-
-
1,232 KB
- Figure 13. The median number of image kilobytes loaded per desktop CMS page.
-
-
Recall from Figures 8 and 9 earlier, images are a big contributor to the total weight of CMS pages. Figures 12 and 13 above show that the median desktop CMS page has 31 images and payload of 1,232 KB, while the median mobile CMS page has 29 images and payload of 1,263 KB. Again we have very close margins for the weight of these resources for both desktop and mobile experiences. The Page Weight chapter additionally shows that image resources well exceed the median weight of pages with the same amount of images on the web as a whole, which is 983 KB and 893 KB for desktop and mobile respectively. The verdict: CMS pages ship heavy images.
-
Which are the common formats found on mobile and desktop CMS pages? From our data JPG images on average are the most popular image format. PNG and GIF formats follow, while formats like SVG, ICO, and WebP trail significantly comprising approximately a little over 2% and 1%.
Bar chart of the adoption of image formats on CMS pages for desktop and mobile. JPEG makes up nearly half of all image formats, PNG comprises a third, GIF comprises a fifth, and the remaining 5% shared among SVG, ICO, and WebP. Desktop and mobile have nearly equivalent adoption.
- Figure 14. Adoption of image formats on CMS pages.
-
-
Perhaps this segmentation isn't surprising given the common use cases for these image types. SVGs for logos and icons are common as are JPEGs ubiquitous. WebP is still a relatively new optimized format with growing browser adoption. It will be interesting to see how this impacts its use in the CMS space in the years to come.
Success as a web content creator is all about user experience. Factors such as resource usage and other statistics regarding how web pages are composed are important indicators of the quality of a given site in terms of the best practices followed while building it. However, we are ultimately interested in shedding some light on how are users actually experiencing the web when consuming and engaging with content generated by these platforms.
- Figure 15. How humans perceive short durations of time.
-
-
If things happen within 0.1 seconds (100 milliseconds), for all of us they are happening virtually instantly. And when things take longer than a few seconds, the likelihood we go on with our lives without waiting any longer is very high. This is very important for content creators seeking sustainable success in the web, because it tells us how fast our sites must load if we want to acquire, engage, and retain our user base.
-
In this section we take a look at three important dimensions which can shed light on our understanding of how users are experiencing CMS-powered web pages in the wild:
First Contentful Paint measures the time it takes from navigation until content such as text or an image is first displayed. A successful FCP experience, or one that can be qualified as "fast," entails how quickly elements in the DOM are loaded to assure the user that the website is loading successfully. Although a good FCP score is not a guarantee that the corresponding site offers a good UX, a bad FCP almost certainly does guarantee the opposite.
Bar chart of the average distribution of FCP experiences per CMS. Refer to Figure 17 below for a data table of the top 5 CMSs.
- Figure 16. Average distribution of FCP experiences across CMSs.
-
-
-
-
-
-
-
-
CMS
-
Fast (< 1000ms)
-
Moderate
-
Slow (>= 3000ms)
-
-
-
-
-
WordPress
-
24.33%
-
40.24%
-
35.42%
-
-
-
Drupal
-
37.25%
-
39.39%
-
23.35%
-
-
-
Joomla
-
22.66%
-
46.48%
-
30.86%
-
-
-
Wix
-
14.25%
-
62.84%
-
22.91%
-
-
-
Squarespace
-
26.23%
-
43.79%
-
29.98%
-
-
-
-
-
- Figure 17. Average distribution of FCP experiences for the top 5 CMSs.
-
-
FCP in the CMS landscape trends mostly in the moderate range. The need for CMS platforms to query content from a database, send, and subsequently render it in the browser, could be a contributing factor to the delay that users experience. The resource loads we discussed in the previous sections could also play a role. In addition, some of these instances are on shared hosting or in environments that may not be optimized for performance, which could also impact the experience in the browser.
-
WordPress shows notably moderate and slow FCP experiences on mobile and desktop. Wix sits strongly in moderate FCP experiences on its closed platform. TYPO3, an enterprise open-source CMS platform, has consistently fast experiences on both mobile and desktop. TYPO3 advertises built-in performance and scalability features that may have a positive impact for website visitors on the frontend.
First Input Delay (FID) measures the time from when a user first interacts with your site (i.e. when they click a link, tap on a button, or use a custom, JavaScript-powered control) to the time when the browser is actually able to respond to that interaction. A "fast" FID from a user's perspective would be immediate feedback from their actions on a site rather than a stalled experience. This delay (a pain point) could correlate with interference from other aspects of the site loading when the user tries to interact with the site.
-
FID in the CMS space generally trends on fast experiences for both desktop and mobile on average. However, what's notable is the significant difference between mobile and desktop experiences.
Bar chart of the average distribution of FCP experiences per CMS. Refer to Figure 19 below for a data table of the top 5 CMSs.
- Figure 18. Average distribution of FID experiences across CMSs.
-
-
-
-
-
-
-
-
CMS
-
Fast (< 100ms)
-
Moderate
-
Slow (>= 300ms)
-
-
-
-
-
WordPress
-
80.25%
-
13.55%
-
6.20%
-
-
-
Drupal
-
74.88%
-
18.64%
-
6.48%
-
-
-
Joomla
-
68.82%
-
22.61%
-
8.57%
-
-
-
Squarespace
-
84.55%
-
9.13%
-
6.31%
-
-
-
Wix
-
63.06%
-
16.99%
-
19.95%
-
-
-
-
-
- Figure 19. Average distribution of FID experiences for the top 5 CMSs.
-
-
While this difference is present in FCP data, FID sees bigger gaps in performance. For example, the difference between mobile and desktop fast FCP experiences for Joomla is around 12.78%, for FID experiences the difference is significant: 27.76%. Mobile device and connection quality could play a role in the performance gaps that we see here. As we highlighted previously, there is a small margin of difference between the resources shipped to desktop and mobile versions of a website. Optimizing for the mobile (interactive) experience becomes more apparent with these results.
Lighthouse is an open-source, automated tool designed to help developers assess and improve the quality of their websites. One key aspect of the tool is that it provides a set of audits to assess the status of a website in terms of performance, accessibility, progressive web apps, and more. For the purposes of this chapter, we are interested in two specific audits categories: PWA and accessibility.
The term Progressive Web App (PWA) refers to web-based user experiences that are considered as being reliable, fast, and engaging. Lighthouse provides a set of audits which returns a PWA score between 0 (worst) and 1 (best). These audits are based on the Baseline PWA Checklist, which lists 14 requirements. Lighthouse has automated audits for 11 of the 14 requirements. The remaining 3 can only be tested manually. Each of the 11 automated PWA audits are weighted equally, so each one contributes approximately 9 points to your PWA score.
Bar chart showing the distribution of Lighthouse PWA category scores for all CMS pages. The most common score is 0.3 at 22% of CMS pages. There are two other peaks in the distribution: 11% of pages with scores of 0.15 and 8% of pages with scores of 0.56. Fewer than 1% of pages get a score above 0.6.
- Figure 20. Distribution of Lighthouse PWA category scores for CMS pages.
-
-
-
-
-
-
-
Bar chart showing the median Lighthouse PWA score per CMS. The median score for WordPress websites is 0.33. The next five CMSs (Joomla, Drupal, Wix, Squarespace, and 1C-Bitrix) all have a median score of 0.3. The CMSs with the top PWA scores are Jimdo with a score of 0.56 and TYPO3 at 0.41.
- Figure 21. Median Lighthouse PWA category scores per CMS.
-
-
An accessible website is a site designed and developed so that people with disabilities can use them. Lighthouse provides a set of accessibility audits and it returns a weighted average of all of them (see Scoring Details for a full list of how each audit is weighted).
-
Each accessibility audit is pass or fail, but unlike other Lighthouse audits, a page doesn't get points for partially passing an accessibility audit. For example, if some elements have screenreader-friendly names, but others don't, that page gets a 0 for the screenreader-friendly-names audit.
Bar chart showing the distribution of CMS pages' Lighthouse accessibility scores. The distribution is heavily skewed to the higher scores with a mode of about 0.85.
- Figure 22. Distribution of Lighthouse accessibility category scores for CMS pages.
-
-
-
-
-
-
-
Bar chart showing the median Lighthouse accessibility category score per CMS. Most CMSs get a score of about 0.75. Notable outliers include Wix with a median score of 0.93 and 1-C Bitrix with a score of 0.65.
- Figure 23. Median Lighthouse accessibility category scores per CMS.
-
-
As it stands now, only 1.27% of mobile CMS home pages get a perfect score of 100%. Of the top CMSs, Wix takes the lead by having the highest median accessibility score on its mobile pages. Overall, these figures are dismal when you consider how many websites (how much of the web that is powered by CMSs) are inaccessible to a significant segment of our population. As much as digital experiences impact so many aspects of our lives, this should be a mandate to encourage us to build accessible web experiences from the start, and to continue the work of making the web an inclusive space.
While we've taken a snapshot of the current landscape of the CMS ecosystem, the space is evolving. In efforts to address performance and user experience shortcomings, we're seeing experimental frameworks being integrated with the CMS infrastructure in both coupled and decoupled/ headless instances. Libraries and frameworks such as React.js, its derivatives like Gatsby.js and Next.js, and Vue.js derivative Nuxt.js are making slight marks of adoption.
-
-
-
-
-
-
-
CMS
-
React
-
Nuxt.js, React
-
Nuxt.js
-
Next.js, React
-
Gatsby, React
-
-
-
-
-
WordPress
-
131,507
-
-
21
-
18
-
-
-
-
Wix
-
50,247
-
-
-
-
-
-
-
Joomla
-
3,457
-
-
-
-
-
-
-
Drupal
-
2,940
-
-
8
-
15
-
1
-
-
-
DataLife Engine
-
1,137
-
-
-
-
-
-
-
Adobe Experience Manager
-
723
-
-
-
7
-
-
-
-
Contentful
-
492
-
7
-
114
-
909
-
394
-
-
-
Squarespace
-
385
-
-
-
-
-
-
-
1C-Bitrix
-
340
-
-
-
-
-
-
-
TYPO3 CMS
-
265
-
-
-
1
-
-
-
-
Weebly
-
263
-
-
1
-
-
-
-
-
Jimdo
-
248
-
-
-
-
2
-
-
-
PrestaShop
-
223
-
-
1
-
-
-
-
-
SDL Tridion
-
152
-
-
-
-
-
-
-
Craft CMS
-
123
-
-
-
-
-
-
-
-
-
- Figure 24. Adoption (number of mobile websites) of React and companion frameworks per CMS.
-
-
We also see hosting providers and agencies offering Digital Experience Platforms (DXP) as holistic solutions using CMSs and other integrated technologies as a toolbox for enterprise customer-focused strategies. These innovations show an effort to create turn-key, CMS-based solutions that make it possible, simple, and easy by default for the users (and their end users) to get the best UX when creating and consuming the content of these platforms. The aim: good performance by default, feature richness, and excellent hosting environments.
The CMS space is of paramount importance. The large portion of the web these applications power and the critical mass of users both creating and encountering its pages on a variety of devices and connections should not be trivialized. We hope this chapter and the others found here in the Web Almanac inspire more research and innovation to help make the space better. Deep investigations would provide us better context about the strengths, weaknesses, and opportunities these platforms provide the web as a whole. Content management systems can make an impact on preserving the integrity of the open web. Let's keep moving them forward!
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":15,"title":"Compression","description":"Compression chapter of the 2019 Web Almanac covering HTTP compression, algorithms, content types, 1st party and 3rd party compression and opportunities.","authors":["paulcalvano"],"reviewers":["obto","yoavweiss"],"translators":null,"discuss":"1770","results":"https://docs.google.com/spreadsheets/d/1IK9kaScQr_sJUwZnWMiJcmHEYJV292C9DwCfXH6a50o/","queries":"15_Compression","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-08T00:00:00.000Z","chapter":"compression"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
HTTP compression is a technique that allows you to encode information using fewer bits than the original representation. When used for delivering web content, it enables web servers to reduce the amount of data transmitted to clients. This increases the efficiency of the client's available bandwidth, reduces page weight, and improves web performance.
-
Compression algorithms are often categorized as lossy or lossless:
-
-
When a lossy compression algorithm is used, the process is irreversible, and the original file cannot be restored via decompression. This is commonly used to compress media resources, such as image and video content where losing some data will not materially affect the resource.
-
Lossless compression is a completely reversible process, and is commonly used to compress text based resources, such as HTML, JavaScript, CSS, etc.
-
-
In this chapter, we are going to explore how text-based content is compressed on the web. Analysis of non-text-based content forms part of the Media chapter.
- When a client makes an HTTP request, it often includes an Accept-Encoding header to advertise the compression algorithms it is capable of decoding. The server can then select from one of the advertised encodings it supports and serve a compressed response. The compressed response would include a Content-Encoding header so that the client is aware of which compression was used. Additionally, a Content-Type header is often used to indicate the MIME type of the resource being served.
-
-
In the example below, the client advertised support for gzip, brotli, and deflate compression. The server decided to return a gzip compressed response containing a text/html document.
The HTTP Archive contains measurements for 5.3 million web sites, and each site loaded at least 1 compressed text resource on their home page. Additionally, resources were compressed on the primary domain on 81% of web sites.
IANA maintains a list of valid HTTP content encodings that can be used with the Accept-Encoding and Content-Encoding headers. These include gzip, deflate, br (brotli), as well as a few others. Brief descriptions of these algorithms are given below:
-
-
Gzip uses the LZ77 and Huffman coding compression techniques, and is older than the web itself. It was originally developed for the UNIX gzip program in 1992. An implementation for web delivery has existed since HTTP/1.1, and most web browsers and clients support it.
-
Deflate uses the same algorithm as gzip, just with a different container. Its use was not widely adopted for the web because of compatibility issues with some servers and browsers.
-
Brotli is a newer compression algorithm that was invented by Google. It uses the combination of a modern variant of the LZ77 algorithm, Huffman coding, and second order context modeling. Compression via brotli is more computationally expensive compared to gzip, but the algorithm is able to reduce files by 15-25% more than gzip compression. Brotli was first used for compressing web content in 2015 and is supported by all modern web browsers.
-
-
Approximately 38% of HTTP responses are delivered with text-based compression. This may seem like a surprising statistic, but keep in mind that it is based on all HTTP requests in the dataset. Some content, such as images, will not benefit from these compression algorithms. The table below summarizes the percentage of requests served with each content encoding.
Of the resources that are served compressed, the majority are using either gzip (80%) or brotli (20%). The other compression algorithms are infrequently used.
- Figure 2. Adoption of compression algorithms on desktop pages.
-
-
Additionally, there are 67k requests that return an invalid Content-Encoding, such as "none", "UTF-8", "base64", "text", etc. These resources are likely served uncompressed.
-
We can't determine the compression levels from any of the diagnostics collected by the HTTP Archive, but the best practice for compressing content is:
If you can support brotli and precompress resources, then compress to brotli level 11. This is more computationally expensive than gzip - so precompression is an absolute must to avoid delays.
-
If you can support brotli and are unable to precompress, then compress to brotli level 5. This level will result in smaller payloads compared to gzip, with a similar computational overhead.
Most text based resources (such as HTML, CSS, and JavaScript) can benefit from gzip or brotli compression. However, it's often not necessary to use these compression techniques on binary resources, such as images, video, and some web fonts because their file formats are already compressed.
-
In the graph below, the top 25 content types are displayed with box sizes representing the relative number of requests. The color of each box represents how many of these resources were served compressed. Most of the media content is shaded orange, which is expected since gzip and brotli would have little to no benefit for them. Most of the text content is shaded blue to indicate that they are being compressed. However, the light blue shading for some content types indicate that they are not compressed as consistently as the others.
The application/json and image/svg+xml content types are compressed less than 65% of the time.
-
Most of the custom web fonts are served without compression, since they are already in a compressed format. However, font/ttf is compressible, but only 84% of TTF font requests are being served with compression so there is still room for improvement here.
-
The graphs below illustrate the breakdown of compression techniques used for each content type. Looking at the top three content types, we can see that across both desktop and mobile there are major gaps in compressing some of the most frequently requested content types. 56% of text/html as well as 18% of application/javascript and text/css resources are not being compressed. This presents a significant performance opportunity.
Stacked bar chart showing application/javascript is 36.18 Million/8.97 Million/10.47 Million by compression type (Gzip/Brotli/None), text/css is 24.29 M/8.31 M/7.20 M, text/html is 11.37 M/4.89 M/20.57 M, text/javascript is 23.21 M/1.72 M/3.03 M, application/x-javascript is 11.86 M/4.97 M/1.66 M, application/json is 4.06 M/0.50 M/3.23 M, image/svg+xml is 2.54 M/0.46 M/1.74 M, text/plain is 0.71 M/0.06 M/2.42 M, and image/x-icon is 0.58 M/0.10 M/1.11 M. Deflate is almost never used by any time and does not register on the chart..
- Figure 5. Compression by content type for desktop.
-
-
-
-
-
-
-
Stacked bar chart showing application/javascript is 43.07 Million/10.17 Million/12.19 Million by compression type (Gzip/Brotli/None), text/css is 28.3 M/9.91 M/8.56 M, text/html is 13.86 M/5.48 M/25.79 M, text/javascript is 27.41 M/1.94 M/3.33 M, application/x-javascript is 12.77 M/5.70 M/1.82 M, application/json is 4.67 M/0.50 M/3.53 M, image/svg+xml is 2.91 M/ 0.44 M/1.77 M, text/plain is 0.80 M/0.06 M/1.77 M, and image/x-icon is 0.62 M/0.11 M/1.22M. Deflate is almost never used by any time and does not register on the chart.
- Figure 6. Compression by content type for mobile.
-
-
The content types with the lowest compression rates include application/json, text/xml, and text/plain. These resources are commonly used for XHR requests to provide data that web applications can use to create rich experiences. Compressing them will likely improve user experience. Vector graphics such as image/svg+xml, and image/x-icon are not often thought of as text based, but they are and sites that use them would benefit from compression.
Stacked bar chart showing application/javascript is 65.1%/16.1%/18.8% by compression type (Gzip/Brotli/None), text/css is 61.0%/20.9%/18.1%, text/html is 30.9%/13.3%/55.8%, text/javascript is 83.0%/6.1%/10.8%, application/x-javascript is 64.1%/26.9%/9.0%, application/json is 52.1%/6.4%/41.4%, image/svg+xml is 53.5%/9.8%/36.7%, text/plain is 22.2%/2.0%/75.8%, and image/x-icon is 32.6%/5.3%/62.1%. Deflate is almost never used by any time and does not register on the chart.
- Figure 7. Compression by content type as a percent for desktop.
-
-
-
-
-
-
-
Stacked bar chart showing application/javascript is 65.8%/15.5%/18.6% by compression type (Gzip/Brotli/None), text/css is 60.5%/21.2%/18.3%, text/html is 30.7%/12.1%/57.1%, text/javascript is 83.9%/5.9%/10.2%, application/x-javascript is 62.9%/28.1%/9.0%, application/json is 53.6%/8.6%/34.6%, image/svg+xml is 23.4%/1.8%/74.8%, text/plain is 23.4%/1.8%/74.8%, and image/x-icon is 31.8%/5.5%/62.7%. Deflate is almost never used by any time and does not register on the chart.
- Figure 8. Compression by content type as a percent for mobile.
-
-
Across all content types, gzip is the most popular compression algorithm. The newer brotli compression is used less frequently, and the content types where it appears most are application/javascript, text/css and application/x-javascript. This is likely due to CDNs that automatically apply brotli compression for traffic that passes through them.
In the Third Parties chapter, we learned about third parties and their impact on performance. When we compare compression techniques between first and third parties, we can see that third-party content tends to be compressed more than first-party content.
-
Additionally, the percentage of brotli compression is higher for third-party content. This is likely due to the number of resources served from the larger third parties that typically support brotli, such as Google and Facebook.
-
-
-
-
-
-
-
-
Desktop
-
Mobile
-
-
-
Content Encoding
-
First-Party
-
Third-Party
-
First-Party
-
Third-Party
-
-
-
-
-
No Text Compression
-
66.23%
-
59.28%
-
64.54%
-
58.26%
-
-
-
gzip
-
29.33%
-
30.20%
-
30.87%
-
31.22%
-
-
-
br
-
4.41%
-
10.49%
-
4.56%
-
10.49%
-
-
-
deflate
-
0.02%
-
0.01%
-
0.02%
-
0.01%
-
-
-
Other / Invalid
-
0.01%
-
0.02%
-
0.01%
-
0.02%
-
-
-
-
-
- Figure 9. First-party versus third-party compression by device type.
-
Google's Lighthouse tool enables users to run a series of audits against web pages. The text compression audit evaluates whether a site can benefit from additional text-based compression. It does this by attempting to compress resources and evaluate whether an object's size can be reduced by at least 10% and 1,400 bytes. Depending on the score, you may see a compression recommendation in the results, with a list of specific resources that could be compressed.
A screenshot of a Lighthouse report showing a list of resources (with the names redacted) and showing the size and the potential saving. For the first item there is a potentially significant saving from 91 KB to 73 KB, while for other smaller files of 6 KB or less there are smaller savings of 4 KB to 1 KB.
Because the HTTP Archive runs Lighthouse audits for each mobile page, we can aggregate the scores across all sites to learn how much opportunity there is to compress more content. Overall, 62% of websites are passing this audit and almost 23% of websites have scored below a 40. This means that over 1.2 million websites could benefit from enabling additional text based compression.
Stacked bar chart showing 7.6% are costing less than 10%, 13.2% of sites are scoring between 10-39%, 13.7% of sites scoring between 40-79%, 2.9% of sites scoring between 80-99%, and 62.5% of sites have a pass with over 100% of text assets being compressed.
Lighthouse also indicates how many bytes could be saved by enabling text-based compression. Of the sites that could benefit from text compression, 82% of them can reduce their page weight by up to 1 MB!
HTTP compression is a widely used and highly valuable feature for reducing the size of web content. Both gzip and brotli compression are the dominant algorithms used, and the amount of compressed content varies by content type. Tools like Lighthouse can help uncover opportunities to compress content.
-
While many sites are making good use of HTTP compression, there is still room for improvement, particularly for the text/html format that the web is built upon! Similarly, lesser-understood text formats like font/ttf, application/json, text/xml, text/plain, image/svg+xml, and image/x-icon may take extra configuration that many websites miss.
-
At a minimum, websites should use gzip compression for all text-based resources, since it is widely supported, easily implemented, and has a low processing overhead. Additional savings can be found with brotli compression, although compression levels should be chosen carefully based on whether a resource can be precompressed.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
Caching is a technique that enables the reuse of previously downloaded content. It provides a significant performance benefit by avoiding costly network requests and it also helps scale an application by reducing the traffic to a website's origin infrastructure. There's an old saying, "the fastest request is the one that you don't have to make," and caching is one of the key ways to avoid having to make requests.
-
There are three guiding principles to caching web content: cache as much as you can, for as long as you can, as close as you can to end users.
-
Cache as much as you can. When considering how much can be cached, it is important to understand whether a response is static or dynamic. Requests that are served as a static response are typically cacheable, as they have a one-to-many relationship between the resource and the users requesting it. Dynamically generated content can be more nuanced and require careful consideration.
-
Cache for as long as you can. The length of time you would cache a resource is highly dependent on the sensitivity of the content being cached. A versioned JavaScript resource could be cached for a very long time, while a non-versioned resource may need a shorter cache duration to ensure users get a fresh version.
-
Cache as close to end users as you can. Caching content close to the end user reduces download times by removing latency. For example, if a resource is cached on an end user's browser, then the request never goes out to the network and the download time is as fast as the machine's I/O. For first time visitors, or visitors that don't have entries in their cache, a CDN would typically be the next place a cached resource is returned from. In most cases, it will be faster to fetch a resource from a local cache or a CDN compared to an origin server.
-
Web architectures typically involve multiple tiers of caching. For example, an HTTP request may have the opportunity to be cached in:
-
-
An end user's browser
-
A service worker cache in the user's browser
-
A shared gateway
-
CDNs, which offer the ability to cache at the edge, close to end users
-
A caching proxy in front of the application, to reduce the backend workload
-
The application and database layers
-
-
This chapter will explore how resources are cached within web browsers.
For an HTTP client to cache a resource, it needs to understand two pieces of information:
-
-
"How long am I allowed to cache this for?"
-
"How do I validate that the content is still fresh?"
-
-
When a web browser sends a response to a client, it typically includes headers that indicate whether the resource is cacheable, how long to cache it for, and how old the resource is. RFC 7234 covers this in more detail in section 4.2 (Freshness) and 4.3 (Validation).
-
The HTTP response headers typically used for conveying freshness lifetime are:
-
-
Cache-Control allows you to configure a cache lifetime duration (i.e. how long this is valid for).
-
Expires provides an expiration date or time (i.e. when exactly this expires).
The HTTP response headers for validating the responses stored within the cache, i.e. giving conditional requests something to compare to on the server side, are:
-
-
Last-Modified indicates when the object was last changed.
-
Entity Tag (ETag) provides a unique identifier for the content.
The example below contains an excerpt of a request/response header from HTTP Archive's main.js file. These headers indicate that the resource can be cached for 43,200 seconds (12 hours), and it was last modified more than two months ago (difference between the Last-Modified and Date headers).
The tool RedBot.org allows you to input a URL and see a detailed explanation of how the response would be cached based on these headers. For example, a test for the URL above would output the following:
Redbot example response showing detailed information about when the resource was changed, whether caches can store it, how long it can be considered fresh for and warnings.
- Figure 1.Cache-Control information from RedBot.
-
-
If no caching headers are present in a response, then the client is permitted to heuristically cache the response. Most clients implement a variation of the RFC's suggested heuristic, which is 10% of the time since Last-Modified. However, some may cache the response indefinitely. So, it is important to set specific caching rules to ensure that you are in control of the cacheability.
-
72% of responses are served with a Cache-Control header, and 56% of responses are served with an Expires header. However, 27% of responses did not use either header, and therefore are subject to heuristic caching. This is consistent across both desktop and mobile sites.
A cacheable resource is stored by the client for a period of time and available for reuse on a subsequent request. Across all HTTP requests, 80% of responses are considered cacheable, meaning that a cache is permitted to store them. Out of these,
-
-
6% of requests have a time to live (TTL) of 0 seconds, which immediately invalidates a cached entry.
-
27% are cached heuristically because of a missing Cache-Control header.
-
47% are cached for more than 0 seconds.
-
-
The remaining responses are not permitted to be stored in browser caches.
A stacked bar chart showing 20% of desktop responses are not cacheable, 47% have a cache greater than zero, 27% are heuristically cached and 6% have a TTL of 0. The stats for mobile are very similar (19%, 47%, 27% and 7%)
- Figure 3. Distribution of cacheable responses.
-
-
The table below details the cache TTL values for desktop requests by type. Most content types are being cached however CSS resources appear to be consistently cached at high TTLs.
While most of the median TTLs are high, the lower percentiles highlight some of the missed caching opportunities. For example, the median TTL for images is 28 hours, however the 25th percentile is just one-two hours and the 10th percentile indicates that 10% of cacheable image content is cached for less than one hour.
-
By exploring the cacheability by content type in more detail in figure 5 below, we can see that approximately half of all HTML responses are considered non-cacheable. Additionally, 16% of images and scripts are non-cacheable.
A stacked bar chart showing the split of not cacheable, cached more than 0 seconds and cached for only 0 seconds by type for desktop. A small, but significant proportion are not cacheable and this goes up to 50% for HTML, most have caching greater than 0 and a smaller amount has a 0 TTL
- Figure 5. Distribution of cacheability by content type for desktop.
-
-
The same data for mobile is shown below. As can be seen, the cacheability of content types is consistent between desktop and mobile.
A stacked bar chart showing the split of not cacheable, cached more than 0 seconds and cached for only 0 seconds by type for mobile. A small, but significant proportion are not cacheable and this goes up to 50% for HTML, most have caching greater than 0 and a smaller amount has a 0 TTL
- Figure 6. Distribution of cacheability by content type for mobile.
-
-
In HTTP/1.0, the Expires header was used to indicate the date/time after which the response is considered stale. Its value is a date timestamp, such as:
-
Expires: Thu, 01 Dec 1994 16:00:00 GMT
-
HTTP/1.1 introduced the Cache-Control header, and most modern clients support both headers. This header provides much more extensibility via caching directives. For example:
-
-
no-store can be used to indicate that a resource should not be cached.
-
max-age can be used to indicate a freshness lifetime.
-
must-revalidate tells the client a cached entry must be validated with a conditional request prior to its use.
-
private indicates a response should only be cached by a browser, and not by an intermediary that would serve multiple clients.
-
-
53% of HTTP responses include a Cache-Control header with the max-age directive, and 54% include the Expires header. However, only 41% of these responses use both headers, which means that 13% of responses are caching solely based on the older Expires header.
A bar chart showing 53% of responses have a `Cache-Control: max-age`, 54%-55% use `Expires`, 41%-42% use both, and 34% use neither. The figures are given for both desktop and mobile but the figures are near identical with mobile having a percentage point higher in use of expires.
- Figure 7. Usage of Cache-Control versus Expires headers.
-
-
The HTTP/1.1 specification includes multiple directives that can be used in the Cache-Control response header and are detailed below. Note that multiple can be used in a single response.
-
-
-
-
-
-
-
Directive
-
Description
-
-
-
max-age
-
Indicates the number of seconds that a resource can be cached for.
-
-
-
public
-
Any cache may store the response.
-
-
-
no-cache
-
A cached entry must be revalidated prior to its use.
-
-
-
must-revalidate
-
A stale cached entry must be revalidated prior to its use.
-
-
-
no-store
-
Indicates that a response is not cacheable.
-
-
-
private
-
The response is intended for a specific user and should not be stored by shared caches.
-
-
-
no-transform
-
No transformations or conversions should be made to this resource.
-
-
-
proxy-revalidate
-
Same as must-revalidate but applies to shared caches.
-
-
-
s-maxage
-
Same as max age but applies to shared caches only.
-
-
-
immutable
-
Indicates that the cached entry will never change, and that revalidation is not necessary.
-
-
-
stale-while-revalidate
-
Indicates that the client is willing to accept a stale response while asynchronously checking in the background for a fresh one.
-
-
-
stale-if-error
-
Indicates that the client is willing to accept a stale response if the check for a fresh one fails.
For example, cache-control: public, max-age=43200 indicates that a cached entry should be stored for 43,200 seconds and it can be stored by all caches.
A bar chart of 15 cache control directives and their usage ranging from 74.8% for max-age, 37.8% for public, 27.8% for no-cache, 18% for no-store, 14.3% for private, 3.4% for immutable, 3.3% for no-transform, 2.4% for stale-while-revalidate, 2.2% for pre-check, 2.2% for post-check, 1.9% for s-maxage, 1.6% for proxy-revalidate, 0.3% for set-cookie and 0.2% for stale-if-error. The stats are near identical for desktop and mobile.
- Figure 9. Usage of Cache-Control directives on mobile.
-
-
Figure 9 above illustrates the top 15 Cache-Control directives in use on mobile websites. The results for desktop and mobile are very similar. There are a few interesting observations about the popularity of these cache directives:
-
-
max-age is used by almost 75% of Cache-Control headers, and no-store is used by 18%.
-
public is rarely necessary since cached entries are assumed public unless private is specified. Approximately 38% of responses include public.
Another interesting set of directives to show up in this list are pre-check and post-check, which are used in 2.2% of Cache-Control response headers (approximately 7.8 million responses). This pair of headers was introduced in Internet Explorer 5 to provide a background validation and was rarely implemented correctly by websites. 99.2% of responses using these headers had used the combination of pre-check=0 and post-check=0. When both of these directives are set to 0, then both directives are ignored. So, it seems these directives were never used correctly!
-
In the long tail, there are more than 1,500 erroneous directives in use across 0.28% of responses. These are ignored by clients, and include misspellings such as "nocache", "s-max-age", "smax-age", and "maxage". There are also numerous non-existent directives such as "max-stale", "proxy-public", "surrogate-control", etc.
When a response is not cacheable, the Cache-Controlno-store directive should be used. If this directive is not used, then the response is cacheable.
-
There are a few common errors that are made when attempting to configure a response to be non-cacheable:
-
-
Setting Cache-Control: no-cache may sound like the resource will not be cacheable. However, the no-cache directive requires the cached entry to be revalidated prior to use and is not the same as being non-cacheable.
-
Setting Cache-Control: max-age=0 sets the TTL to 0 seconds, but that is not the same as being non-cacheable. When max-age is set to 0, the resource is stored in the browser cache and immediately invalidated. This results in the browser having to perform a conditional request to validate the resource's freshness.
-
-
Functionally, no-cache and max-age=0 are similar, since they both require revalidation of a cached resource. The no-cache directive can also be used alongside a max-age directive that is greater than 0.
-
Over 3 million responses include the combination of no-store, no-cache, and max-age=0. Of these directives no-store takes precedence and the other directives are merely redundant
-
18% of responses include no-store and 16.6% of responses include both no-store and no-cache. Since no-store takes precedence, the resource is ultimately non-cacheable.
-
The max-age=0 directive is present on 1.1% of responses (more than four million responses) where no-store is not present. These resources will be cached in the browser but will require revalidation as they are immediately expired.
So far we've talked about how web servers tell a client what is cacheable, and how long it has been cached for. When designing cache rules, it is also important to understand how old the content you are serving is.
-
When you are selecting a cache TTL, ask yourself: "how often are you updating these assets?" and "what is their content sensitivity?". For example, if a hero image is going to be modified infrequently, then cache it with a very long TTL. If you expect a JavaScript resource to change frequently, then version it and cache it with a long TTL or cache it with a shorter TTL.
-
The graph below illustrates the relative age of resources by content type, and you can read a more detailed analysis here. HTML tends to be the content type with the shortest age, and a very large % of traditionally cacheable resources (scripts, CSS, and fonts) are older than one year!
A stack bar chart showing the age of content, split into weeks 0-52, > one year and > two years with null and negative figures shown too. The stats are split into first-party and third-party. The value 0 is used most particularly for first-party HTML, text and xml, and for up to 50% of third-party requests across all assets types. There is a mix using intermediary years and then considerable usage for one year and two year.
- Figure 10. Resource age distribution by content type.
-
-
By comparing a resources cacheability to its age, we can determine if the TTL is appropriate or too low. For example, the resource served by the response below was last modified on 25 Aug 2019, which means that it was 49 days old at the time of delivery. The Cache-Control header says that we can cache it for 43,200 seconds, which is 12 hours. It is definitely old enough to merit investigating whether a longer TTL would be appropriate.
Overall, 59% of resources served on the web have a cache TTL that is too short compared to its content age. Furthermore, the median delta between the TTL and age is 25 days.
-
When we break this out by first vs third-party, we can also see that 70% of first-party resources can benefit from a longer TTL. This clearly highlights a need to spend extra attention focusing on what is cacheable, and then ensuring caching is configured correctly.
-
-
-
-
-
-
-
Client
-
1st Party
-
3rd Party
-
Overall
-
-
-
Desktop
-
70.7%
-
47.9%
-
59.2%
-
-
-
Mobile
-
71.4%
-
46.8%
-
59.6%
-
-
-
-
-
- Figure 11. Percent of requests with short TTLs.
-
The HTTP response headers used for validating the responses stored within a cache are Last-Modified and ETag. The Last-Modified header does exactly what its name implies and provides the time that the object was last modified. The ETag header provides a unique identifier for the content.
-
For example, the response below was last modified on 25 Aug 2019 and it has an ETag value of "1566748830.0-3052-3932359948"
A client could send a conditional request to validate a cached entry by using the Last-Modified value in a request header named If-Modified-Since. Similarly, it could also validate the resource with an If-None-Match request header, which validates against the ETag value the client has for the resource in its cache.
-
In the example below, the cache entry is still valid, and an HTTP 304 was returned with no content. This saves the download of the resource itself. If the cache entry was no longer fresh, then the server would have responded with a 200 and the updated resource which would have to be downloaded again.
Overall, 65% of responses are served with a Last-Modified header, 42% are served with an ETag, and 38% use both. However, 30% of responses include neither a Last-Modified or ETag header.
A bar chart showing 64.4% of desktop requests have a last modified, 42.8% have an ETag, 37.9% have both and 30.7% have neither. The stats for mobile are almost identical at 65.3% for Last Modified, 42.8% for ETag, 38.0% for both and 29.9% for neither.
- Figure 12. Adoption of validating freshness via Last-Modified and ETag headers for desktop websites.
-
-
There are a few HTTP headers used to convey timestamps, and the format for these are very important. The Date response header indicates when the resource was served to a client. The Last-Modified response header indicates when a resource was last changed on the server. And the Expires header is used to indicate how long a resource is cacheable until (unless a Cache-Control header is present).
-
All three of these HTTP headers use a date formatted string to represent timestamps.
Most clients will ignore invalid date strings, which render them ineffective for the response they are served on. This can have consequences on cacheability, since an erroneous Last-Modified header will be cached without a Last-Modified timestamp resulting in the inability to perform a conditional request.
-
The Date HTTP response header is usually generated by the web server or CDN serving the response to a client. Because the header is typically generated automatically by the server, it tends to be less prone to error, which is reflected by the very low percentage of invalid Date headers. Last-Modified headers were very similar, with only 0.67% of them being invalid. What was very surprising to see though, was that 3.64% Expires headers used an invalid date format!
A bar chart showing 0.10% of desktop responses have an invalid date, 0.67% have an invalid Last-Modified and 3.64% have an invalid Expires. The stats for mobile are very similar with 0.06% of responses have an invalid date, 0.68% have an invalid Last-Modified and 3.50% have an invalid Expires.
- Figure 13. Invalid date formats in response headers.
-
-
Examples of some of the invalid uses of the Expires header are:
-
-
Valid date formats, but using a time zone other than GMT
-
Numerical values such as 0 or -1
-
Values that would be valid in a Cache-Control header
-
-
The largest source of invalid Expires headers is from assets served from a popular third-party, in which a date/time uses the EST time zone, for example Expires: Tue, 27 Apr 1971 19:44:06 EST.
One of the most important steps in caching is determining if the resource being requested is cached or not. While this may seem simple, many times the URL alone is not enough to determine this. For example, requests with the same URL could vary in what compression they used (gzip, brotli, etc.) or be modified and tailored for mobile visitors.
-
To solve this problem, clients give each cached resource a unique identifier (a cache key). By default, this cache key is simply the URL of the resource, but developers can add other elements (like compression method) by using the Vary header.
-
A Vary header instructs a client to add the value of one or more request header values to the cache key. The most common example of this is Vary: Accept-Encoding, which will result in different cached entries for Accept-Encoding request header values (i.e. gzip, br, deflate).
-
Another common value is Vary: Accept-Encoding, User-Agent, which instructs the client to vary the cached entry by both the Accept-Encoding values and the User-Agent string. When dealing with shared proxies and CDNs, using values other than Accept-Encoding can be problematic as it dilutes the cache keys and can reduce the amount of traffic served from cache.
-
In general, you should only vary the cache if you are serving alternate content to clients based on that header.
-
The Vary header is used on 39% of HTTP responses, and 45% of responses that include a Cache-Control header.
-
The graph below details the popularity for the top 10 Vary header values. Accept-Encoding accounts for 90% of Vary's use, with User-Agent (11%), Origin (9%), and Accept (3%) making up much of the rest.
A bar chart showing 90% use of accept-encoding, much smaller values for the rest with 10%-11% for user-agent, approximately 7%-8% for origin and less so for accept, almost not usage for cookie, x-forward-proto, accept-language, host, x-origin, access-control-request-method, and access-control-request-headers
When a response is cached, its entire headers are swapped into the cache as well. This is why you can see the response headers when inspecting a cached response via DevTools.
A screenshot of Chrome Developer Tools showing HTTP response headers for a cached response.
- Figure 15. Chrome Dev Tools for a cached resource.
-
-
But what happens if you have a Set-Cookie on a response? According to RFC 7234 Section 8, the presence of a Set-Cookie response header does not inhibit caching. This means that a cached entry might contain a Set-Cookie if it was cached with one. The RFC goes on to recommend that you should configure appropriate Cache-Control headers to control how responses are cached.
-
One of the risks of caching responses with Set-Cookie is that the cookie values can be stored and served to subsequent requests. Depending on the cookie's purpose, this could have worrying results. For example, if a login cookie or a session cookie is present in a shared cache, then that cookie might be reused by another client. One way to avoid this is to use the Cache-Controlprivate directive, which only permits the response to be cached by the client browser.
-
3% of cacheable responses contain a Set-Cookie header. Of those responses, only 18% use the private directive. The remaining 82% include 5.3 million HTTP responses that include a Set-Cookie which can be cached by public and private cache servers.
A bar chart showing 97% of responses do not use Set-Cookie, and 3% do. This 3% is zoomed into for another bar chart showing the split of 15.3% private, 84.7% public for desktop and similar for mobile at 18.4% public and 81.6% private.
- Figure 16. Cacheable responses of Set-Cookie responses.
-
-
A time series chart showing service worker controlled site usage from October 2016 until July 2019. Usage has been steadily growing throughout the years for both mobile and desktop but is still less than 0.6% for both.
Adoption is still below 1% of websites, but it has been steadily increasing since January 2017. The Progressive Web App chapter discusses this more, including the fact that it is used a lot more than this graph suggests due to its usage on popular sites, which are only counted once in above graph.
-
In the table below, you can see a summary of AppCache vs service worker usage. 32,292 websites have implemented a service worker, while 1,867 sites are still utilizing the deprecated AppCache feature.
-
-
-
-
-
-
-
-
Does Not Use Server Worker
-
Uses Service Worker
-
Total
-
-
-
-
-
Does Not Use AppCache
-
5,045,337
-
32,241
-
5,077,578
-
-
-
Uses AppCache
-
1,816
-
51
-
1,867
-
-
-
Total
-
5,047,153
-
32,292
-
5,079,445
-
-
-
-
-
- Figure 18. Number of websites using AppCache versus service worker.
-
-
If we break this out by HTTP vs HTTPS, then this gets even more interesting. 581 of the AppCache enabled sites are served over HTTP, which means that Chrome is likely disabling the feature. HTTPS is a requirement for using service workers, but 907 of the sites using them are served over HTTP.
-
-
-
-
-
-
-
-
-
Does Not Use Service Worker
-
Uses Service Worker
-
-
-
-
-
HTTP
-
Does Not Use AppCache
-
1,968,736
-
907
-
-
-
Uses AppCache
-
580
-
1
-
-
-
HTTPS
-
Does Not Use AppCache
-
3,076,601
-
31,334
-
-
-
Uses AppCache
-
1,236
-
50
-
-
-
-
-
- Figure 19. Number of websites using AppCache versus service worker usage by HTTP/HTTPS.
-
Google's Lighthouse tool enables users to run a series of audits against web pages, and the cache policy audit evaluates whether a site can benefit from additional caching. It does this by comparing the content age (via the Last-Modified header) to the cache TTL and estimating the probability that the resource would be served from cache. Depending on the score, you may see a caching recommendation in the results, with a list of specific resources that could be cached.
A screenshot of part of a report from the Google Lighthouse tool, with the 'Serve static assets with an efficient cache policy' section open where it lists a number of resources, who's names have been redacted, and the Cache TTL versus the size.
Lighthouse computes a score for each audit, ranging from 0% to 100%, and those scores are then factored into the overall scores. The caching score is based on potential byte savings. When we examine the Lighthouse results, we can get a perspective of how many sites are doing well with their cache policies.
A stacked bar chart 38.2% of websites get a score of < 10%, 29.0% of websites get a score between 10% and 39%, 18.7% of websites get a score of 40%-79%, 10.7% of websites get a score of 80% - 99%, and 3.4% of websites get a score of 100%.
- Figure 21. Distribution of Lighthouse scores for the "Uses Long Cache TTL" audit for mobile web pages.
-
-
Only 3.4% of sites scored a 100%, meaning that most sites can benefit from some cache optimizations. A vast majority of sites sore below 40%, with 38% scoring less than 10%. Based on this, there is a significant amount of caching opportunities on the web.
-
Lighthouse also indicates how many bytes could be saved on repeat views by enabling a longer cache policy. Of the sites that could benefit from additional caching, 82% of them can reduce their page weight by up to a whole Mb!
A stacked bar chart showing 56.8% of websites have potential byte savings of less than one MB, 22.1% could have savings of one to two MB, 8.3% could save two to three MB. 4.3% could save three to four MB and 6.0% could save more than four MB.
- Figure 22. Distribution of potential byte savings from the Lighthouse caching audit.
-
-
Caching is an incredibly powerful feature that allows browsers, proxies and other intermediaries (such as CDNs) to store web content and serve it to end users. The performance benefits of this are significant, since it reduces round trip times and minimizes costly network requests.
-
Caching is also a very complex topic. There are numerous HTTP response headers that can convey freshness as well as validate cached entries, and Cache-Control directives provide a tremendous amount of flexibility and control. However, developers should be cautious about the additional opportunities for mistakes that it comes with. Regularly auditing your site to ensure that cacheable resources are cached appropriately is recommended, and tools like Lighthouse and REDbot do an excellent job of helping to simplify the analysis.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":17,"title":"CDN","description":"CDN chapter of the 2019 Web Almanac covering CDN adoption and usage, RTT & TLS management, HTTP/2 adoption, caching and common library and content CDNs.","authors":["andydavies","colinbendell"],"reviewers":["yoavweiss","paulcalvano","pmeenan","enygren"],"translators":null,"discuss":"1772","results":"https://docs.google.com/spreadsheets/d/1Y7kAxjxUl8puuTToe6rL3kqJLX1ftOb0nCcD8m3lZBw/","queries":"17_CDN","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-04T00:00:00.000Z","chapter":"cdn"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
"Use a Content Delivery Network" was one of Steve Souders original recommendations for making web sites load faster. It's advice that remains valid today, and in this chapter of the Web Almanac we're going to explore how widely Steve's recommendation has been adopted, how sites are using Content Delivery Networks (CDNs), and some of the features they're using.
-
Fundamentally, CDNs reduce latency—the time it takes for packets to travel between two points on a network, say from a visitor's device to a server—and latency is a key factor in how quickly pages load.
-
A CDN reduces latency in two ways: by serving content from locations that are closer to the user and second, by terminating the TCP connection closer to the end user.
-
Historically, CDNs were used to cache, or copy, bytes so that the logical path from the user to the bytes becomes shorter. A file that is requested by many people can be retrieved once from the origin (your server) and then stored on a server closer to the user, thus saving transfer time.
-
CDNs also help with TCP latency. The latency of TCP determines how long it takes to establish a connection between a browser and a server, how long it takes to secure that connection, and ultimately how quickly content downloads. At best, network packets travel at roughly two-thirds of the speed of light, so how long that round trip takes depends on how far apart the two ends of the conversation are, and what's in between. Congested networks, overburdened equipment, and the type of network will all add further delays. Using a CDN to move the server end of the connection closer to the visitor reduces this latency penalty, shortening connection times, TLS negotiation times, and improving content download speeds.
-
Although CDNs are often thought of as just caches that store and serve static content close to the visitor, they are capable of so much more! CDNs aren't limited to just helping overcome the latency penalty, and increasingly they offer other features that help improve performance and security.
-
-
Using a CDN to proxy dynamic content (base HTML page, API responses, etc.) can take advantage of both the reduced latency between the browser and the CDN's own network back to the origin.
-
Some CDNs offer transformations that optimize pages so they download and render more quickly, or optimize images so they're the appropriate size (both dimensions and file size) for the device on which they're going to be viewed.
-
From a security perspective, malicious traffic and bots can be filtered out by a CDN before the requests even reach the origin, and their wide customer base means CDNs can often see and react to new threats sooner.
-
The rise of edge computing allows sites to run their own code close to their visitors, both improving performance and reducing the load on the origin.
-
-
Finally, CDNs also help sites to adopt new technologies without requiring changes at the origin, for example HTTP/2, TLS 1.3, and/or IPv6 can be enabled from the edge to the browser, even if the origin servers don't support it yet.
As with any observational study, there are limits to the scope and impact that can be measured. The statistics gathered on CDN usage for the the Web Almanac does not imply performance nor effectiveness of a specific CDN vendor.
-
There are many limits to the testing methodology used for the Web Almanac. These include:
-
-
Simulated network latency: The Web Almanac uses a dedicated network connection that synthetically shapes traffic.
-
Single geographic location: Tests are run from a single datacenter and cannot test the geographic distribution of many CDN vendors.
-
Cache effectiveness: Each CDN uses proprietary technology and many, for security reasons, do not expose cache performance.
-
Localization and internationalization: Just like geographic distribution, the effects of language and geo-specific domains are also opaque to the testing.
-
CDN detection is primarily done through DNS resolution and HTTP headers. Most CDNs use a DNS CNAME to map a user to an optimal datacenter. However, some CDNs use AnyCast IPs or direct A+AAAA responses from a delegated domain which hide the DNS chain. In other cases, websites use multiple CDNs to balance between vendors which is hidden from the single-request pass of WebPageTest. All of this limits the effectiveness in the measurements.
-
-
Most importantly, these results reflect a potential utilization but do not reflect actual impact. YouTube is more popular than "ShoesByColin" yet both will appear as equal value when comparing utilization.
-
With this in mind, there are a few intentional statistics that were not measured with the context of a CDN:
-
-
- TTFB: Measuring the Time to first byte by CDN would be intellectually dishonest without proper knowledge about cacheability and cache effectiveness. If one site uses a CDN for round trip time (RTT) management but not for caching, this would create a disadvantage when comparing another site that uses a different CDN vendor but does also caches the content. (Note: this does not apply to the TTFB analysis in the Performance chapter because it does not draw conclusions about the performance of individual CDNs.)
-
-
Cache Hit vs. Cache Miss performance: As mentioned previously, this is opaque to the testing apparatus and therefore repeat tests to test page performance with a cold cache vs. a hot cache are unreliable.
In future versions of the Web Almanac, we would expect to look more closely at the TLS and RTT management between CDN vendors. Of interest would the impact of OCSP stapling, differences in TLS Cipher performance. CWND (TCP congestion window) growth rate, and specifically the adoption of BBR v1, v2, and traditional TCP Cubic.
For websites, a CDN can improve performance for the primary domain (www.shoesbycolin.com), sub-domains or sibling domains (images.shoesbycolin.com or checkout.shoesbycolin.com), and finally third parties (Google Analytics, etc.). Using a CDN for each of these use cases improves performance in different ways.
-
Historically, CDNs were used exclusively for static resources like CSS, JavaScript, and images. These resources would likely be versioned (include a unique number in the path) and cached long-term. In this way we should expect to see higher adoption of CDNs on sub-domains or sibling domains compared to the base HTML domains. The traditional design pattern would expect that www.shoesbycolin.com would serve HTML directly from a datacenter (or origin) while static.shoesbycolin.com would use a CDN.
Stacked bar chart showing HTML is 80% served from origin, 20% from CDN, Sub-domains are 61%/39%, third-party is 34%/66%.
- Figure 1. CDN usage vs. origin-hosted resources.
-
-
Indeed, this traditional pattern is what we observe on the majority of websites crawled. The majority of web pages (80%) serve the base HTML from origin. This breakdown is nearly identical between mobile and desktop with only 0.4% lower usage of CDNs on desktop. This slight variance is likely due to the small continued use of mobile specific web pages ("mDot"), which more frequently use a CDN.
-
Likewise, resources served from sub-domains are more likely to utilize a CDN at 40% of sub-domain resources. Sub-domains are used either to partition resources like images and CSS or they are used to reflect organizational teams such as checkout or APIs.
-
Despite first-party resources still largely being served directly from origin, third-party resources have a substantially higher adoption of CDNs. Nearly 66% of all third-party resources are served from a CDN. Since third-party domains are more likely a SaaS integration, the use of CDNs are more likely core to these business offerings. Most third-party content breaks down to shared resources (JavaScript or font CDNs), augmented content (advertisements), or statistics. In all these cases, using a CDN will improve the performance and offload for these SaaS solutions.
There are two categories of CDN providers: the generic and the purpose-fit CDN. The generic CDN providers offer customization and flexibility to serve all kinds of content for many industries. In contrast, the purpose-fit CDN provider offers similar content distribution capabilities but are narrowly focused on a specific solution.
-
This is clearly represented when looking at the top CDNs found serving the base HTML content. The most frequent CDNs serving HTML are generic CDNs (Cloudflare, Akamai, Fastly) and cloud solution providers who offer a bundled CDN (Google, Amazon) as part of the platform service offerings. In contrast, there are only a few purpose-fit CDN providers, such as Wordpress and Netlify, that deliver base HTML markup.
-
Note: This does not reflect traffic or usage, only the number of sites using them.
Sub-domain requests have a very similar composition. Since many websites use sub-domains for static content, we see a shift to a higher CDN usage. Like the base page requests, the resources served from these sub-domains utilize generic CDN offerings.
- Figure 5. Top 25 resource CDNs for sub-domain requests.
-
-
The composition of top CDN providers dramatically shifts for third-party resources. Not only are CDNs more frequently observed hosting third-party resources, there is also an increase in purpose-fit CDN providers such as Facebook, Twitter, and Google.
CDNs can offer more than simple caching for website performance. Many CDNs also support a pass-through mode for dynamic or personalized content when an organization has a legal or other business requirement prohibiting the content from being cached. Utilizing a CDN's physical distribution enables increased performance for TCP RTT for end users. As others have noted, reducing RTT is the most effective means to improve web page performance compared to increasing bandwidth.
-
Using a CDN in this way can improve page performance in two ways:
-
-
-
Reduce RTT for TCP and TLS negotiation. The speed of light is only so fast and CDNs offer a highly distributed set of data centers that are closer to the end users. In this way the logical (and physical) distance that packets must traverse to negotiate a TCP connection and perform the TLS handshake can be greatly reduced.
-
Reducing RTT has three immediate benefits. First, it improves the time for the user to receive data, because TCP+TLS connection time are RTT-bound. Secondly, this will improve the time it takes to grow the congestion window and utilize the full amount of bandwidth the user has available. Finally, it reduces the probability of packet loss. When the RTT is high, network interfaces will time-out requests and resend packets. This can result in double packets being delivered.
-
-
CDNs can utilize pre-warmed TCP connections to the back-end origin. Just as terminating the connection closer to the user will improve the time it takes to grow the congestion window, the CDN can relay the request to the origin on pre-established TCP connections that have already maximized congestion windows. In this way the origin can return the dynamic content in fewer TCP round trips and the content can be more effectively ready to be delivered to the waiting user.
Since TLS negotiations require multiple TCP round trips before data can be sent from a server, simply improving the RTT can significantly improve the page performance. For example, looking at the base HTML page, the median TLS negotiation time for origin requests is 207 ms (for desktop WebPageTest). This alone accounts for 10% of a 2 second performance budget, and this is under ideal network conditions where there is no latency applied on the request.
-
In contrast, the median TLS negotiation for the majority of CDN providers is between 60 and 70 ms. Origin requests for HTML pages take almost 3x longer to complete TLS negotiation than those web pages that use a CDN. Even at the 90th percentile, this disparity perpetuates with origin TLS negotiation rates of 427 ms compared to most CDNs which complete under 140 ms!
-
A word of caution when interpreting these charts: it is important to focus on orders of magnitude when comparing vendors as there are many factors that impact the actual TLS negotiation performance. These tests were completed from a single datacenter under controlled conditions and do not reflect the variability of the internet and user experiences.
For resource requests (including same-domain and third-party), the TLS negotiation time takes longer and the variance increases. This is expected because of network saturation and network congestion. By the time that a third-party connection is established (by way of a resource hint or a resource request) the browser is busy rendering and making other parallel requests. This creates contention on the network. Despite this disadvantage, there is still a clear advantage for third-party resources that utilize a CDN over using an origin solution.
Graph showing most CDNs have a TLS negotiation time of around 80 ms, but some (Microsoft Azure, Yahoo, Edgecast, ORIGIN, and CDNetworks) start to creep out towards 200 ms - especially when going above the p50 percentile.
TLS handshake performance is impacted by a number of factors. These include RTT, TLS record size, and TLS certificate size. While RTT has the biggest impact on the TLS handshake, the second largest driver for TLS performance is the TLS certificate size.
-
During the first round trip of the TLS handshake, the server attaches its certificate. This certificate is then verified by the client before proceeding. In this certificate exchange, the server might include the certificate chain by which it can be verified. After this certificate exchange, additional keys are established to encrypt the communication. However, the length and size of the certificate can negatively impact the TLS negotiation performance, and in some cases, crash client libraries.
-
- The certificate exchange is at the foundation of the TLS handshake and is usually handled by isolated code paths so as to minimize the attack surface for exploits. Because of its low level nature, buffers are usually not dynamically allocated, but fixed. In this way, we cannot simply assume that the client can handle an unlimited-sized certificate. For example, OpenSSL CLI tools and Safari can successfully negotiate against https://10000-sans.badssl.com. Yet, Chrome and Firefox fail because of the size of the certificate.
-
-
While extreme sizes of certificates can cause failures, even sending moderately large certificates has a performance impact. A certificate can be valid for one or more hostnames which are are listed in the Subject-Alternative-Name (SAN). The more SANs, the larger the certificate. It is the processing of these SANs during verification that causes performance to degrade. To be clear, performance of certificate size is not about TCP overhead, rather it is about processing performance of the client.
-
Technically, TCP slow start can impact this negotiation but it is very improbable. TLS record length is limited to 16 KB, which fits into a typical initial congestion window of 10. While some ISPs might employ packet splicers, and other tools fragment congestion windows to artificially throttle bandwidth, this isn't something that a website owner can change or manipulate.
-
Many CDNs, however, depend on shared TLS certificates and will list many customers in the SAN of a certificate. This is often necessary because of the scarcity of IPv4 addresses. Prior to the adoption of Server-Name-Indicator (SNI) by end users, the client would connect to a server, and only after inspecting the certificate, would the client hint which hostname the user user was looking for (using the Host header in HTTP). This results in a 1:1 association of an IP address and a certificate. If you are a CDN with many physical locations, each location may require a dedicated IP, further aggravating the exhaustion of IPv4 addresses. Therefore, the simplest and most efficient way for CDNs to offer TLS certificates for websites that still have users that don't support SNI is to offer a shared certificate.
-
According to Akamai, the adoption of SNI is still not 100% globally. Fortunately there has been a rapid shift in recent years. The biggest culprits are no longer Windows XP and Vista, but now Android apps, bots, and corporate applications. Even at 99% adoption, the remaining 1% of 3.5 billion users on the internet can create a very compelling motivation for website owners to require a non-SNI certificate. Put another way, a pure play website can enjoy a virtually 100% SNI adoption among standard web browsers. Yet, if the website is also used to support APIs or WebViews in apps, particularly Android apps, this distribution can drop rapidly.
-
Most CDNs balance the need for shared certificates and performance. Most cap the number of SANs between 100 and 150. This limit often derives from the certificate providers. For example, LetsEncrypt, DigiCert, and GoDaddy all limit SAN certificates to 100 hostnames while Comodo's limit is 2,000. This, in turn, allows some CDNs to push this limit, cresting over 800 SANs on a single certificate. There is a strong negative correlation of TLS performance and the number of SANs on a certificate.
In addition to using a CDN for TLS and RTT performance, CDNs are often used to ensure patching and adoption of TLS ciphers and TLS versions. In general, the adoption of TLS on the main HTML page is much higher for websites that use a CDN. Over 76% of HTML pages are served with TLS compared to the 62% from origin-hosted pages.
Stacked bar chart showing TLS 1.0 is used 0.86% of the time for origin, TLS 1.2 55% of the time, TLS 1.3 6% of the time, and unencrypted 38% of the time. For CDN this changes to 35% for TLS 1.2, 41% for TLS 1.3, and 24% for unencrypted.
- Figure 15. HTML TLS version adoption (CDN vs. origin).
-
-
Each CDN offers different rates of adoption for both TLS and the relative ciphers and versions offered. Some CDNs are more aggressive and roll out these changes to all customers whereas other CDNs require website owners to opt-in to the latest changes and offer change-management to facilitate these ciphers and versions.
Division of secure vs non-secure connections established for initial HTML request broken down by CDN with some CDNs (e.g. Wordpress) at 100%, most between 80%-100%, and then ORIGIN at 62%, Google at 51%, ChinaNetCenter at 36%, and Yunjiasu at 29%.
Stacked bar chart showing the vast majority of CDNs use TLS for over 90% of third-party requests, with a few stragglers in the 75% - 90% range, and ORIGIN lower than them all at 68%.
Along with this general adoption of TLS, CDN use also sees higher adoption of emerging TLS versions like TLS 1.3.
-
In general, the use of a CDN is highly correlated with a more rapid adoption of stronger ciphers and stronger TLS versions compared to origin-hosted services where there is a higher usage of very old and compromised TLS versions like TLS 1.0.
-
It is important to emphasize that Chrome used in the Web Almanac will bias to the latest TLS versions and ciphers offered by the host. Also, these web pages were crawled in July 2019 and reflect the adoption of websites that have enabled the newer versions.
Bar chart showing that TLS 1.3 or TLS 1.2 is used by all CDNs when TLS is used. A few CDNs have adopted TLS 1.3 completely, some partially and a large proportion not at all and only using TLS 1.2.
Along with RTT management and improving TLS performance, CDNs also enable new standards like HTTP/2 and IPv6. While most CDNs offer support for HTTP/2 and many have signaled early support of the still-under-standards-development HTTP/3, adoption still depends on website owners to enable these new features. Despite the change-management overhead, the majority of the HTML served from CDNs has HTTP/2 enabled.
-
CDNs have over 70% adoption of HTTP/2, compared to the nearly 27% of origin pages. Similarly, sub-domain and third-party resources on CDNs see an even higher adoption of HTTP/2 at 90% or higher while third-party resources served from origin infrastructure only has 31% adoption. The performance gains and other features of HTTP/2 are further covered in the HTTP/2 chapter.
-
Note: All requests were made with the latest version of Chrome which supports HTTP/2. When only HTTP/1.1 is reported, this would indicate either unencrypted (non-TLS) servers or servers that don't support HTTP/2.
A website can control the caching behavior of browsers and CDNs with the use of different HTTP headers. The most common is the Cache-Control header which specifically determines how long something can be cached before returning to the origin to ensure it is up-to-date.
-
Another useful tool is the use of the Vary HTTP header. This header instructs both CDNs and browsers how to fragment a cache. The Vary header allows an origin to indicate that there are multiple representations of a resource, and the CDN should cache each variation separately. The most common example is compression. Declaring a resource as Vary: Accept-Encoding allows the CDN to cache the same content, but in different forms like uncompressed, with gzip, or Brotli. Some CDNs even do this compression on the fly so as to keep only one copy available. This Vary header likewise also instructs the browser how to cache the content and when to request new content.
Treemap graph showing accept-encoding dominates vary usage with 73% of the chart taken up with that. Cookie (13%) and user-agent (8%) having some usage, then a complete mixed of other headers.
- Figure 24. Usage of Vary for HTML served from CDNs.
-
-
While the main use of Vary is to coordinate Content-Encoding, there are other important variations that websites use to signal cache fragmentation. Using Vary also instructs SEO bots like DuckDuckGo, Google, and BingBot that alternate content would be returned under different conditions. This has been important to avoid SEO penalties for "cloaking" (sending SEO specific content in order to game the rankings).
-
For HTML pages, the most common use of Vary is to signal that the content will change based on the User-Agent. This is short-hand to indicate that the website will return different content for desktops, phones, tablets, and link-unfurling engines (like Slack, iMessage, and Whatsapp). The use of Vary: User-Agent is also a vestige of the early mobile era, where content was split between "mDot" servers and "regular" servers in the back-end. While the adoption for responsive web has gained wide popularity, this Vary form remains.
-
In a similar way, Vary: Cookie usually indicates that content that will change based on the logged-in state of the user or other personalization.
Set of four treemap graphs showing that for CDNs serving home pages the biggest use of Vary is for Cookie, followed by User-agent. For CDNs serving other resources it's origin, followed by accept, user-agent, x-origin and referrer. For Origins and home pages it's user-agent, followed by cookie. Finally for Origins and other resources it's primarily user-agent followed by origin, accept, then range and host.
- Figure 25. Comparison of Vary usage for HTML and resources served from origin and CDN.
-
-
Resources, in contrast, don't use Vary: Cookie as much as the HTML resources. Instead these resources are more likely to adapt based on the Accept, Origin, or Referer. Most media, for example, will use Vary: Accept to indicate that an image could be a JPEG, WebP, JPEG 2000, or JPEG XR depending on the browser's offered Accept header. In a similar way, third-party shared resources signal that an XHR API will differ depending on which website it is embedded. This way, a call to an ad server API will return different content depending on the parent website that called the API.
-
The Vary header also contains evidence of CDN chains. These can be seen in Vary headers such as Accept-Encoding, Accept-Encoding or even Accept-Encoding, Accept-Encoding, Accept-Encoding. Further analysis of these chains and Via header entries might reveal interesting data, for example how many sites are proxying third-party tags.
-
Many of the uses of the Vary are extraneous. With most browsers adopting double-key caching, the use of Vary: Origin is redundant. As is Vary: Range or Vary: Host or Vary: *. The wild and variable use of Vary is demonstrable proof that the internet is weird.
There are other HTTP headers that specifically target CDNs, or other proxy caches, such as the Surrogate-Control, s-maxage, pre-check, and post-check values in the Cache-Control header. In general usage of these headers is low.
-
Surrogate-Control allows origins to specify caching rules just for CDNs, and as CDNs are likely to strip the header before serving responses, its low visible usage isn't a surprise, in fact it's surprising that it's actually in any responses at all! (It was even seen from some CDNs that state they strip it).
-
Some CDNs support post-check as a method to allow a resource to be refreshed when it goes stale, and pre-check as a maxage equivalent. For most CDNs, usage of pre-check and post-check was below 1%. Yahoo was the exception to this and about 15% of requests had pre-check=0, post-check=0. Unfortunately this seems to be a remnant of an old Internet Explorer pattern rather than active usage. More discussion on this can be found in the Caching chapter.
-
The s-maxage directive informs proxies for how long they may cache a response. Across the Web Almanac dataset, jsDelivr is the only CDN where a high level of usage was seen across multiple resources—this isn't surprising given jsDelivr's role as a public CDN for libraries. Usage across other CDNs seems to be driven by individual customers, for example third-party scripts or SaaS providers using that particular CDN.
Bar chart showing 82% of jsDelivr serves responses with s-maxage, 14% of Level 3, 6.3% of Amazon CloudFront, 3.3% of Akamai, 3.1% of Fastly, 3% of Highwinds, 2% of Cloudflare, 0.91% of ORIGIN, 0.75% of Edgecast, 0.07% of Google.
- Figure 26. Adoption of s-maxage across CDN responses.
-
-
With 40% of sites using a CDN for resources, and presuming these resources are static and cacheable, the usage of s-maxage seems low.
-
Future research might explore cache lifetimes versus the age of the resources, and the usage of s-maxage versus other validation directives such as stale-while-revalidate.
So far, this chapter has explored the use of commercials CDNs which the site may be using to host its own content, or perhaps used by a third-party resource included on the site.
-
Common libraries like jQuery and Bootstrap are also available from public CDNs hosted by Google, Cloudflare, Microsoft, etc. Using content from one of the public CDNs instead of a self-hosting the content is a trade-off. Even though the content is hosted on a CDN, creating a new connection and growing the congestion window may negate the low latency of using a CDN.
-
Google Fonts is the most popular of the content CDNs and is used by 55% of websites. For non-font content, Google API, Cloudflare's JS CDN, and the Bootstrap's CDN are the next most popular.
Bar chart showing 55.33% of public content CDNs are made to fonts.googleapis.com, 19.86% to ajax.googleapis.com, 10.47% to cdnjs.cloudflare.com, 9.83% to maxcdn.bootstrapcdn.com, 5.95% to code.jquery.com, 4.29% to cdn.jsdelivr.net, 3.22% to use.fontawesome.com, 0.7% to stackpath.bootstrapcdn.com, 0.67% to unpkg.com, and 0.52% to ajax.aspnetcdn.com.
As more browsers implement partitioned caches, the effectiveness of public CDNs for hosting common libraries will decrease and it will be interesting to see whether they are less popular in future iterations of this research.
The reduction in latency that CDNs deliver along with their ability to store content close to visitors enable sites to deliver faster experiences while reducing the load on the origin.
-
Steve Souders' recommendation to use a CDN remains as valid today as it was 12 years ago, yet only 20% of sites serve their HTML content via a CDN, and only 40% are using a CDN for resources, so there's plenty of opportunity for their usage to grow further.
-
There are some aspects of CDN adoption that aren't included in this analysis, sometimes this was due to the limitations of the dataset and how it's collected, in other cases new research questions emerged during the analysis.
-
As the web continues to evolve, CDN vendors innovate, and sites use new practices CDN adoption remains an area rich for further research in future editions of the Web Almanac.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
The median web page is around 1900KB in size and contains 74 requests. That doesn't sound too bad, right?
-
Here's the issue with medians: they mask problems. By definition, they focus only on the middle of the distribution. We need to consider percentiles at both extremes to get an understanding of the bigger picture.
-
Looking at the 90th percentile exposes the unpleasant stuff. Roughly 10% of the pages we're pushing at the unsuspecting public are in excess of 6 MB and contain 179 requests. This is, frankly, terrible. If this doesn't seem terrible to you, then you definitely need to read this chapter.
The common argument as to why page size doesn't matter anymore is that, thanks to high-speed internet and our souped-up devices, we can serve massive, complex (and massively complex) pages to the general population. This assumption works fine, as long as you're okay with ignoring the vast swathe of internet users who don't have access to said high-speed internet and souped-up devices.
-
Yes, you can build large robust pages that feel fast… to some users. But you should care about page bloat in terms of how it affects all your users, especially mobile-only users who deal with bandwidth constraints or data limits.
-
-
Check out Tim Kadlec's fascinating online calculator, What Does My Site Cost?, which calculates the cost—in dollars and Gross National Income per capita—of your pages in countries around the world. It's an eye-opener. For instance, Amazon's home page, which at the time of writing weighs 2.79MB, costs 1.89% of the daily per capita GNI of Mauritania. How global is the world wide web when people in some parts of the world would have to give up a day's wages just to visit a few dozen pages?
Even if more people had access to better devices and cheaper connections, that wouldn't be a complete solution. Double the bandwidth doesn't mean twice as fast. In fact, it has been demonstrated that increasing bandwidth by up to 1,233% only made pages 55% faster.
-
The problem is latency. Most of our networking protocols require a lot of round-trips, and each of those round trips imposes a latency penalty. For as long as latency continues to be a performance problem (which is to say, for the foreseeable future), the major performance culprit will continue to be that a typical web page today contains a hundred or so assets hosted on dozens of different servers. Many of these assets are unoptimized, unmeasured, unmonitored—and therefore unpredictable.
Here's a quick glossary of the page composition metrics that the HTTP Archive tracks, and how much they matter in terms of performance and user experience:
-
-
-
The total size is the total weight in bytes of the page. It matters especially to mobile users who have limited and/or metered data.
-
-
-
HTML is typically the smallest resource on the page. Its performance risk is negligible.
-
-
-
Unoptimized images are often the greatest contributor to page bloat. Looking at the 90th percentile of the distribution of page weight, images account for a whopping 5.2 MB of a roughly 7 MB page. In other words, images comprise almost 75% of the total page weight. And if that already wasn't enough, the number of images on a page has been linked to lower conversion rates on retail sites. (More on that later.)
-
-
-
JavaScript matters. A page can have a relatively low JavaScript weight but still suffer from JavaScript-inflicted performance problems. Even a single 100 KB third-party script can wreak havoc with your page. The more scripts on your page, the greater the risk.
-
It's not enough to focus solely on blocking JavaScript. It's possible for your pages to contain zero blocking resources and still have less-than-optimal performance because of how your JavaScript is rendered. That's why it's so important to understand CPU usage on your pages, because JavaScript consumes more CPU than all other browser activities combined. While JavaScript blocks the CPU, the browser can't respond to user input. This creates what's commonly called "jank": that annoying feeling of jittery, unstable page rendering.
-
-
-
CSS is an incredible boon for modern web pages. It solves a myriad of design problems, from browser compatibility to design maintenance and updating. Without CSS, we wouldn't have great things like responsive design. But, like JavaScript, CSS doesn't have to be bulky to cause problems. Poorly executed stylesheets can create a host of performance problems, ranging from stylesheets taking too long to download and parse, to improperly placed stylesheets that block the rest of the page from rendering. And, similarly to JavaScript, more CSS files equals more potential trouble.
Let's assume you're not a heartless monster who doesn't care about your site's visitors. But if you are, you should know that serving bigger, more complex pages hurts you, too. That was one of the findings of a Google-led machine learning study that gathered over a million beacons' worth of real user data from retail sites.
-
There were three really important takeaways from this research:
-
-
-
The total number of elements on a page was the greatest predictor of conversions. Hopefully this doesn't come as a huge surprise to you, given what we've just covered about the performance risks imposed by the various assets that make up a modern web page.
-
-
-
The number of images on a page was the second greatest predictor of conversions. Sessions in which users converted had 38% fewer images than in sessions that didn't convert.
Sessions with more scripts were less likely to convert. What's really fascinating about this chart isn't just the sharp drop-off in conversion probability after about 240 scripts. It's the long tail that demonstrates how many retail sessions contained up to 1,440 scripts!
Chart showing conversion rate climbing up until 80 scripts, and then dropping off as scripts increase up to 1440 scripts.
- Figure 2. Conversion rate dropping off as scripts increase.
-
-
Now that we've covered why page size and complexity matter, let's get into some juicy HTTP Archive stats so we can better understand the current state of the web and the impact of page bloat.
The statistics in this section are all based on the transfer size of a page and its resources. Not all resources on the web are compressed before sending, but if they are, this analysis uses the compressed size.
Roughly speaking, mobile sites are about 10% smaller than their desktop counterparts. The majority of the difference is due to mobile sites loading fewer image bytes than their desktop counterparts.
Over the past year the median size of a desktop site increased by 434 KB, and the median size of a mobile site increased by 179 KB. Images are overwhelmingly driving this increase.
- Figure 6. Change in desktop page weight since 2018.
-
-
For a longer-term perspective on how page weight has changed over time, check out this timeseries graph from HTTP Archive. Median page size has grown at a fairly constant rate since the HTTP Archive started tracking this metric in November 2010 and the increase in page weight observed over the past year is consistent with this.
The median desktop page makes 74 requests, and the median mobile page makes 69. Images and JavaScript account for the majority of these requests. There was no significant change in the quantity or distribution of requests over the last year.
The preceding analysis has focused on analyzing page weight through the lens of resource types. However, in the case of images and media, it's possible to dive a level deeper and look at the differences in resource sizes between specific file formats.
- Figure 9. Images file sizes on mobile broken down by image format.
-
-
Some of these results, particularly those for GIFs, are really surprising. If GIFs are so small, then why are they being replaced by formats like JPG, PNG, and WEBP?
-
The data above obscures the fact that the vast majority of GIFs on the web are actually tiny 1x1 pixels. These pixels are typically used as "tracking pixels", but can also be used as a hack to generate various CSS effects. While these 1x1 pixels are images in the literal sense, the spirit of their usage is probably closer to what we'd associate with scripts or CSS.
-
Further investigation into the data set revealed that 62% of GIFs are 43 bytes or smaller (43 bytes is the size of a transparent, 1x1 pixel GIF) and 84% of GIFs are 1 KB or smaller.
Chart showing 25% of GIFs are 35 bytes or smaller (which is the optimal size of a 1x1 white GIF) and 62% of GIFs are 43 bytes or smaller (which is the optimal size of a 1x1 transparent GIF). This increases to just over 75% of GIFs being 100 bytes or less.
- Figure 10. Cumulative distribution function of GIF file sizes.
-
-
The tables below show two different approaches to removing these tiny images from the data set: the first one is based on images with a file size greater than 100 bytes, the second is based on images with a file size greater than 1024 bytes.
- Figure 12. File size by image format for images > 1024 bytes.
-
-
The low file size of PNG images compared to JPEG images may seem surprising. JPEG uses lossy compression. Lossy compression results in data loss, which makes it possible to achieve smaller file sizes. Meanwhile, PNG uses lossless compression. This does not result in data loss, which this produces higher-quality, but larger images. However, this difference in file sizes is probably a reflection of the popularity of PNGs for iconography due to their transparency support, rather than differences in their encoding and compression.
MP4 is overwhelmingly the most popular video format on the web today. In terms of popularity, it is followed by WebM and MPEG-TS respectively.
-
Unlike some of the other tables in this data set, this one has mostly happy takeaways. Videos are consistently smaller on mobile, which is great to see. In addition, the median size of an MP4 video is a very reasonable 18 KB on mobile and 39 KB on desktop. The median numbers for WebM are even better but they should be taken with a grain of salt: the duplicate measurement of 0.29 KB across multiple clients and percentiles is a little bit suspicious. One possible explanation is that identical copies of one very tiny WebM video is included on many pages. Of the three formats, MPEG-TS consistently has the highest file size across all percentiles. This may be related to the fact that it was released in 1995, making it the oldest of these three media formats.
Over the past year, pages increased in size by roughly 10%. Brotli, performance budgets, and basic image optimization best practices are probably the three techniques which show the most promise for maintaining or improving page weight while also being widely applicable and fairly easy to implement. That being said, in recent years, improvements in page weight have been more constrained by the low adoption of best practices than by the technology itself. In other words, although there are many existing techniques for improving page weight, they won't make a difference if they aren't put to use.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
Resource hints provide "hints" to the browser about what resources will be needed soon. The action that the browser takes as a result of receiving this hint will vary depending on the type of resource hint; different resource hints kick off different actions. When used correctly, they can improve page performance by giving a head start to important anticipated actions.
-
Examples of performance improvements as a result of resource hints include:
-
-
Jabong decreased Time to Interactive by 1.5 seconds by preloading critical scripts.
-
Barefoot Wine decreased Time to Interactive of future pages by 2.7 seconds by prefetching visible links.
-
Chrome.com decreased latency by 0.7 seconds by preconnecting to critical origins.
-
-
There are four separate resource hints supported by most browsers today: dns-prefetch, preconnect, preload, and prefetch.
- The role of dns-prefetch is to initiate an early DNS lookup. It's useful for completing the DNS lookup for third-parties. For example, the DNS lookup of a CDN, font provider, or third-party API.
-
- preconnect initiates an early connection, including DNS lookup, TCP handshake, and TLS negotiation. This hint is useful for setting up a connection with a third party. The uses of preconnect are very similar to those of dns-prefetch, but preconnect has less browser support. However, if you don't need IE 11 support, preconnect is probably a better choice.
-
- The preload hint initiates an early request. This is useful for loading important resources that would otherwise be discovered late by the parser. For example, if an important image is only discoverable once the browser has received and parsed the stylesheet, it may make sense to preload the image.
-
- prefetch initiates a low-priority request. It's useful for loading resources that will be used on the subsequent (rather than current) page load. A common use of prefetch is loading resources that the application "predicts" will be used on the next page load. These predictions could be based on signals like user mouse movement or common user flows/journeys.
-
Because the usage of resource hints in HTTP headers is so low, the remainder of this chapter will focus solely on analyzing the usage of resource hints in conjunction with the <link> tag. However, it's worth noting that in future years, usage of resource hints in HTTP headers may increase as HTTP/2 Push is adopted. This is due to the fact that HTTP/2 Push has repurposed the HTTP preload Link header as a signal to push resources.
Note: There was no noticeable difference between the usage patterns for resource hints on mobile versus desktop. Thus, for the sake of conciseness, this chapter only includes the statistics for mobile.
The relative popularity of dns-prefetch is unsurprising; it's a well-established API (it first appeared in 2009), it is supported by all major browsers, and it is the most "inexpensive" of all resource hints. Because dns-prefetch only performs DNS lookups, it consumes very little data, and therefore there is very little downside to using it. dns-prefetch is most useful in high-latency situations.
-
That being said, if a site does not need to support IE11 and below, switching from dns-prefetch to preconnect is probably a good idea. In an era where HTTPS is ubiquitous, preconnect yields greater performance improvements while still being inexpensive. Note that unlike dns-prefetch, preconnect not only initiates the DNS lookup, but also the TCP handshake and TLS negotiation. The certificate chain is downloaded during TLS negotiation and this typically costs a couple of kilobytes.
-
prefetch is used by 3% of sites, making it the least widely used resource hint. This low usage may be explained by the fact that prefetch is useful for improving subsequent—rather than current—page loads. Thus, it will be overlooked if a site is only focused on improving their landing page, or the performance of the first page viewed.
-
-
-
-
-
-
-
Resource Hint
-
Resource Hints Per Page: Median
-
Resource Hints Per Page: 90th Percentile
-
-
-
dns-prefetch
-
2
-
8
-
-
-
preload
-
2
-
4
-
-
-
preconnect
-
2
-
8
-
-
-
prefetch
-
1
-
3
-
-
-
prerender (deprecated)
-
1
-
1
-
-
-
-
-
- Figure 2. Median and 90th percentiles of the number of resource hints used per page, of all pages using that resource hint.
-
-
Resource hints are most effective when they're used selectively ("when everything is important, nothing is"). Figure 2 above shows the number of resource hints per page for pages using at least one resource hint. Although there is no clear cut rule for defining what an appropriate number of resource hints is, it appears that most sites are using resource hints appropriately.
Most "traditional" resources fetched on the web (images, stylesheets, and scripts) are fetched without opting in to Cross-Origin Resource Sharing (CORS). That means that if those resources are fetched from a cross-origin server, by default their contents cannot be read back by the page, due to the same-origin policy.
-
In some cases, the page can opt-in to fetch the resource using CORS if it needs to read its content. CORS enables the browser to "ask permission" and get access to those cross-origin resources.
-
For newer resource types (e.g. fonts, fetch() requests, ES modules), the browser defaults to requesting those resources using CORS, failing the requests entirely if the server does not grant it permission to access them.
-
-
-
-
-
-
-
crossorigin value
-
Usage
-
Explanation
-
-
-
Not set
-
92%
-
If the crossorigin attribute is absent, the request will follow the single-origin policy.
-
-
-
anonymous (or equivalent)
-
7%
-
Executes a cross-origin request that does not include credentials.
-
-
-
use-credentials
-
0.47%
-
Executes a cross-origin request that includes credentials.
-
-
-
-
-
- Figure 3. Adoption of the crossorigin attribute as a percent of resource hint instances.
-
-
In the context of resource hints, usage of the crossorigin attribute enables them to match the CORS mode of the resources they are supposed to match and indicates the credentials to include in the request. For example, anonymous enables CORS and indicates that no credentials should be included for those cross-origin requests:
as is an attribute that should be used with the preload resource hint to inform the browser of the type (e.g. image, script, style, etc.) of the requested resource. This helps the browser correctly prioritize the request and apply the correct Content Security Policy (CSP). CSP is a security mechanism, expressed via HTTP header, that helps mitigate the impact of XSS and other malicious attacks by declaring a safelist of trusted sources; only content from these sources can be rendered or executed.
-
-
88%
- Figure 4. The percent of resource hint instances using the as attribute.
-
-
88% of resource hint instances use the as attribute. When as is specified, it is overwhelmingly used for scripts: 92% of usage is script, 3% font, and 3% styles. This is unsurprising given the prominent role that scripts play in most sites' architecture as well the high frequency with which scripts are used as attack vectors (thereby making it therefore particularly important that scripts get the correct CSP applied to them).
At the moment, there are no proposals to expand the current set of resource hints. However, priority hints and native lazy loading are two proposed technologies that are similar in spirit to resource hints in that they provide APIs for optimizing the loading process.
Priority hints are an API for expressing the fetch priority of a resource: high, low, or auto. They can be used with a wide range of HTML tags: specifically <image>, <link>, <script>, and <iframe>.
- Figure 5. Example HTML of using priority hints on a carousel of images.
-
-
For example, if you had an image carousel, priority hints could be used to prioritize the image that users see immediately and deprioritize later images.
-
-
0.04%
- Figure 6. The rate of priority hint adoption.
-
-
Priority hints are implemented and can be tested via a feature flag in Chromium browsers versions 70 and up. Given that it is still an experimental technology, it is unsurprising that it is only used by 0.04% of sites.
-
85% of priority hint usage is with <img> tags. Priority hints are mostly used to deprioritize resources: 72% of usage is importance="low"; 28% of usage is importance="high".
Native lazy loading is a native API for deferring the load of off-screen images and iframes. This frees up resources during the initial page load and avoids loading assets that are never used. Previously, this technique could only be achieved through third-party JavaScript libraries.
-
The API for native lazy loading looks like this: <img src="cat.jpg">.
-
Native lazy loading is available in browsers based on Chromium 76 and up. The API was announced too late for it to be included in the dataset for this year's Web Almanac, but it is something to keep an eye out for in the coming year.
Overall, this data seems to suggest that there is still room for further adoption of resource hints. Most sites would benefit from adopting and/or switching to preconnect from dns-prefetch. A much smaller subset of sites would benefit from adopting prefetch and/or preload. There is greater nuance in successfully using prefetch and preload, which constrains its adoption to a certain extent, but the potential payoff is also greater. HTTP/2 Push and the maturation of machine learning technologies is also likely to increase the adoption of preload and prefetch.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":20,"title":"HTTP/2","description":"HTTP/2 chapter of the 2019 Web Almanac covering adoption and impact of HTTP/2, HTTP/2 Push, HTTP/2 Issues, and HTTP/3.","authors":["bazzadp"],"reviewers":["bagder","rmarx","dotjs"],"translators":null,"discuss":"1775","results":"https://docs.google.com/spreadsheets/d/1z1gdS3YVpe8J9K3g2UdrtdSPhRywVQRBz5kgBeqCnbw/","queries":"20_HTTP_2","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-05T00:00:00.000Z","chapter":"http2"} %} {% set chapter_image_dir = ("/static/images/2019/%s" % metadata.chapter) %}
-
-
HTTP/2 was the first major update to the main transport protocol of the web in nearly 20 years. It arrived with a wealth of expectations: it promised a free performance boost with no downsides. More than that, we could stop doing all the hacks and work arounds that HTTP/1.1 forced us into, due to its inefficiencies. Bundling, spriting, inlining, and even sharding domains would all become anti-patterns in an HTTP/2 world, as improved performance would be provided by default.
-
This meant that even those without the skills and resources to concentrate on web performance would suddenly have performant websites. However, the reality has been, as ever, a little more nuanced than that. It has been over four years since the formal approval of HTTP/2 as a standard in May 2015 as RFC 7540, so now is a good time to look over how this relatively new technology has fared in the real world.
For those not familiar with the technology, a bit of background is helpful to make the most of the metrics and findings in this chapter. Up until recently, HTTP has always been a text-based protocol. An HTTP client like a web browser opened a TCP connection to a server, and then sent an HTTP command like GET /index.html to ask for a resource.
-
This was enhanced in HTTP/1.0 to add HTTP headers, so various pieces of metadata could be included in addition to the request, such as what browser it is, the formats it understands, etc. These HTTP headers were also text-based and separated by newline characters. Servers parsed the incoming requests by reading the request and any HTTP headers line by line, and then the server responded with its own HTTP response headers in addition to the actual resource being requested.
-
The protocol seemed simple, but it also came with limitations. Because HTTP was essentially synchronous, once an HTTP request had been sent, the whole TCP connection was basically off limits to anything else until the response had been returned, read, and processed. This was incredibly inefficient and required multiple TCP connections (browsers typically use 6) to allow a limited form of parallelization.
-
That in itself brings its own issues as TCP connections take time and resources to set up and get to full efficiency, especially when using HTTPS, which requires additional steps to set up the encryption. HTTP/1.1 improved this somewhat, allowing reuse of TCP connections for subsequent requests, but still did not solve the parallelization issue.
-
Despite HTTP being text-based, the reality is that it was rarely used to transport text, at least in its raw format. While it was true that HTTP headers were still text, the payloads themselves often were not. Text files like HTML, JS, and CSS are usually compressed for transport into a binary format using gzip, brotli, or similar. Non-text files like images and videos are served in their own formats. The whole HTTP message is then often wrapped in HTTPS to encrypt the messages for security reasons.
-
So, the web had basically moved on from text-based transport a long time ago, but HTTP had not. One reason for this stagnation was because it was so difficult to introduce any breaking changes to such a ubiquitous protocol like HTTP (previous efforts had tried and failed). Many routers, firewalls, and other middleboxes understood HTTP and would react badly to major changes to it. Upgrading them all to support a new version was simply not possible.
-
In 2009, Google announced that they were working on an alternative to the text-based HTTP called SPDY, which has since been deprecated. This would take advantage of the fact that HTTP messages were often encrypted in HTTPS, which prevents them being read and interfered with en route.
-
Google controlled one of the most popular browsers (Chrome) and some of the most popular websites (Google, YouTube, Gmail…etc.) - so both ends of the connection when both were used together. Google's idea was to pack HTTP messages into a proprietary format, send them across the internet, and then unpack them on the other side. The proprietary format, SPDY, was binary-based rather than text-based. This solved some of the main performance problems with HTTP/1.1 by allowing more efficient use of a single TCP connection, negating the need to open the six connections that had become the norm under HTTP/1.1.
-
By using SPDY in the real world, they were able to prove that it was more performant for real users, and not just because of some lab-based experimental results. After rolling out SPDY to all Google websites, other servers and browser started implementing it, and then it was time to standardize this proprietary format into an internet standard, and thus HTTP/2 was born.
-
HTTP/2 has the following key concepts:
-
-
Binary format
-
Multiplexing
-
Flow control
-
Prioritization
-
Header compression
-
Push
-
-
Binary format means that HTTP/2 messages are wrapped into frames of a pre-defined format, making HTTP messages easier to parse and would no longer require scanning for newline characters. This is better for security as there were a number of exploits for previous versions of HTTP. It also means HTTP/2 connections can be multiplexed. Different frames for different streams can be sent on the same connection without interfering with each other as each frame includes a stream identifier and its length. Multiplexing allows much more efficient use of a single TCP connection without the overhead of opening additional connections. Ideally we would open a single connection per domain—or even for multiple domains!
-
Having separate streams does introduce some complexities along with some potential benefits. HTTP/2 needs the concept of flow control to allow the different streams to send data at different rates, whereas previously, with only one response in flight at any one time, this was controlled at a connection level by TCP flow control. Similarly, prioritization allows multiple requests to be sent together, but with the most important requests getting more of the bandwidth.
-
Finally, HTTP/2 introduced two new concepts: header compression and HTTP/2 push. Header compression allowed those text-based HTTP headers to be sent more efficiently, using an HTTP/2-specific HPACK format for security reasons. HTTP/2 push allowed more than one response to be sent in answer to a request, enabling the server to "push" resources before a client was even aware it needed them. Push was supposed to solve the performance workaround of having to inline resources like CSS and JavaScript directly into HTML to prevent holding up the page while those resources were requested. With HTTP/2 the CSS and JavaScript could remain as external files but be pushed along with the initial HTML, so they were available immediately. Subsequent page requests would not push these resources, since they would now be cached, and so would not waste bandwidth.
-
This whistle-stop tour of HTTP/2 gives the main history and concepts of the newish protocol. As should be apparent from this explanation, the main benefit of HTTP/2 is to address performance limitations of the HTTP/1.1 protocol. There were also security improvements as well - perhaps most importantly in being to address performance issues of using HTTPS since HTTP/2, even over HTTPS, is often much faster than plain HTTP. Other than the web browser packing the HTTP messages into the new binary format, and the web server unpacking it at the other side, the core basics of HTTP itself stayed roughly the same. This means web applications do not need to make any changes to support HTTP/2 as the browser and server take care of this. Turning it on should be a free performance boost, therefore adoption should be relatively easy. Of course, there are ways web developers can optimize for HTTP/2 to take full advantage of how it differs.
As mentioned above, internet protocols are often difficult to adopt since they are ingrained into so much of the infrastructure that makes up the internet. This makes introducing any changes slow and difficult. IPv6 for example has been around for 20 years but has struggled to be adopted.
-
-
95%
- Figure 1. The percent of global users who can use HTTP/2.
-
-
HTTP/2 however, was different as it was effectively hidden in HTTPS (at least for the browser uses cases), removing barriers to adoption as long as both the browser and server supported it. Browser support has been very strong for some time and the advent of auto updating evergreen browsers has meant that an estimated 95% of global users now support HTTP/2.
-
Our analysis is sourced from the HTTP Archive, which tests approximately 5 million of the top desktop and mobile websites in the Chrome browser. (Learn more about our methodology.)
Timeseries chart of HTTP/2 usage showing adoption at 55% for both desktop and mobile as of July 2019. The trend is growing steadily at about 15 points per year.
The results show that HTTP/2 usage is now the majority protocol-an impressive feat just 4 short years after formal standardization! Looking at the breakdown of all HTTP versions by request we see the following:
Figure 3 shows that HTTP/1.1 and HTTP/2 are the versions used by the vast majority of requests as expected. There is only a very small number of requests on the older HTTP/1.0 and HTTP/0.9 protocols. Annoyingly, there is a larger percentage where the protocol was not correctly tracked by the HTTP Archive crawl, particularly on desktop. Digging into this has shown various reasons, some of which can be explained and some of which can't. Based on spot checks, they mostly appear to be HTTP/1.1 requests and, assuming they are, desktop and mobile usage is similar.
-
Despite there being a little larger percentage of noise than we'd like, it doesn't alter the overall message being conveyed here. Other than that, the mobile/desktop similarity is not unexpected; HTTP Archive tests with Chrome, which supports HTTP/2 for both desktop and mobile. Real-world usage may have slightly different stats with some older usage of browsers on both, but even then support is widespread, so we would not expect a large variation between desktop and mobile.
-
At present, HTTP Archive does not track HTTP over QUIC (soon to be standardized as HTTP/3 separately, so these requests are currently listed under HTTP/2, but we'll look at other ways of measuring that later in this chapter.
-
Looking at the number of requests will skew the results somewhat due to popular requests. For example, many sites load Google Analytics, which does support HTTP/2, and so would show as an HTTP/2 request, even if the embedding site itself does not support HTTP/2. On the other hand, popular websites tend to support HTTP/2 are also underrepresented in the above stats as they are only measured once (e.g. "google.com" and "obscuresite.com" are given equal weighting). There are lies, damn lies, and statistics.
-
However, our findings are corroborated by other sources, like Mozilla's telemetry, which looks at real-world usage through the Firefox browser.
It is still interesting to look at home pages only to get a rough figure on the number of sites that support HTTP/2 (at least on their home page). Figure 4 shows less support than overall requests, as expected, at around 36%.
-
HTTP/2 is only supported by browsers over HTTPS, even though officially HTTP/2 can be used over HTTPS or over unencrypted non-HTTPS connections. As mentioned previously, hiding the new protocol in encrypted HTTPS connections prevents networking appliances which do not understand this new protocol from interfering with (or rejecting!) its usage. Additionally, the HTTPS handshake allows an easy method of the client and server agreeing to use HTTP/2.
-
-
-
-
-
-
-
Protocol
-
Desktop
-
Mobile
-
Both
-
-
-
-
-
-
0.09%
-
0.10%
-
0.09%
-
-
-
HTTP/1.0
-
0.06%
-
0.06%
-
0.06%
-
-
-
HTTP/1.1
-
45.81%
-
44.31%
-
45.01%
-
-
-
HTTP/2
-
54.04%
-
55.53%
-
54.83%
-
-
-
-
-
- Figure 5. HTTP version usage for HTTPS home pages.
-
-
The web is moving to HTTPS, and HTTP/2 turns the traditional argument of HTTPS being bad for performance almost completely on its head. Not every site has made the transition to HTTPS, so HTTP/2 will not even be available to those that have not. Looking at just those sites that use HTTPS, in Figure 5 we do see a higher adoption of HTTP/2 at around 55%, similar to the percent of all requests in Figure 2.
-
We have shown that browser support for HTTP/2 is strong and that there is a safe road to adoption, so why doesn't every site (or at least every HTTPS site) support HTTP/2? Well, here we come to the final item for support we have not measured yet: server support.
-
This is more problematic than browser support as, unlike modern browsers, servers often do not automatically upgrade to the latest version. Even when the server is regularly maintained and patched, that will often just apply security patches rather than new features like HTTP/2. Let's look first at the server HTTP headers for those sites that do support HTTP/2.
Nginx provides package repositories that allow ease of installing or upgrading to the latest version, so it is no surprise to see it leading the way here. Cloudflare is the most popular CDN and enables HTTP/2 by default, so again it is not surprising to see it hosts a large percentage of HTTP/2 sites. Incidently, Cloudflare uses a heavily customized version of nginx as their web server. After those, we see Apache at around 20% of usage, followed by some servers who choose to hide what they are, and then the smaller players such as LiteSpeed, IIS, Google Servlet Engine, and openresty, which is nginx based.
-
What is more interesting is those servers that that do not support HTTP/2:
Some of this will be non-HTTPS traffic that would use HTTP/1.1 even if the server supported HTTP/2, but a bigger issue is those that do not support HTTP/2 at all. In these stats, we see a much greater share for Apache and IIS, which are likely running older versions.
-
For Apache in particular, it is often not easy to add HTTP/2 support to an existing installation, as Apache does not provide an official repository to install this from. This often means resorting to compiling from source or trusting a third-party repository, neither of which is particularly appealing to many administrators.
-
Only the latest versions of Linux distributions (RHEL and CentOS 8, Ubuntu 18 and Debian 9) come with a version of Apache which supports HTTP/2, and many servers are not running those yet. On the Microsoft side, only Windows Server 2016 and above supports HTTP/2, so again those running older versions cannot support this in IIS.
-
Merging these two stats together, we can see the percentage of installs per server, that use HTTP/2:
-
-
-
-
-
-
-
Server
-
Desktop
-
Mobile
-
-
-
-
-
cloudflare
-
85.40%
-
83.46%
-
-
-
LiteSpeed
-
70.80%
-
63.08%
-
-
-
openresty
-
51.41%
-
45.24%
-
-
-
nginx
-
49.23%
-
46.19%
-
-
-
GSE
-
40.54%
-
35.25%
-
-
-
-
25.57%
-
27.49%
-
-
-
Apache
-
18.09%
-
18.56%
-
-
-
Microsoft-IIS
-
14.10%
-
13.47%
-
-
-
…
-
…
-
…
-
-
-
-
-
- Figure 8. Percentage installs of each server used to provide HTTP/2.
-
-
It's clear that Apache and IIS fall way behind with 18% and 14% of their installed based supporting HTTP/2, which has to be (at least in part) a consequence of it being more difficult to upgrade them. A full operating system upgrade is often required for many servers to get this support easily. Hopefully this will get easier as new versions of operating systems become the norm.
The impact of HTTP/2 is much more difficult to measure, especially using the HTTP Archive methodology. Ideally, sites should be crawled with both HTTP/1.1 and HTTP/2 and the difference measured, but that is not possible with the statistics we are investigating here. Additionally, measuring whether the average HTTP/2 site is faster than the average HTTP/1.1 site introduces too many other variables that require a more exhaustive study than we can cover here.
-
One impact that can be measured is in the changing use of HTTP now that we are in an HTTP/2 world. Multiple connections were a workaround with HTTP/1.1 to allow a limited form of parallelization, but this is in fact the opposite of what usually works best with HTTP/2. A single connection reduces the overhead of TCP setup, TCP slow start, and HTTPS negotiation, and it also allows the potential of cross-request prioritization.
Timeseries chart of the number of TCP connections per page, with the median desktop page having 14 connections and the median mobile page having 16 connections as of July 2019.
HTTP Archive measures the number of TCP connections per page, and that is dropping steadily as more sites support HTTP/2 and use its single connection instead of six separate connections.
Timeseries chart of the number of requests per page, with the median desktop page having 74 requests and the median mobile page having 69 requests as of July 2019. The trend is relatively flat.
Bundling assets to obtain fewer requests was another HTTP/1.1 workaround that went by many names: bundling, concatenation, packaging, spriting, etc. This is less necessary when using HTTP/2 as there is less overhead with requests, but it should be noted that requests are not free in HTTP/2, and those that experimented with removing bundling completely have noticed a loss in performance. Looking at the number of requests loaded per page over time, we do see a slight decrease in requests, rather than the expected increase.
-
This low rate of change can perhaps be attributed to the aforementioned observations that bundling cannot be removed (at least, not completely) without a negative performance impact and that many build tools currently bundle for historical reasons based on HTTP/1.1 recommendations. It is also likely that many sites may not be willing to penalize HTTP/1.1 users by undoing their HTTP/1.1 performance hacks just yet, or at least that they do not have the confidence (or time!) to feel that this is worthwhile.
-
The fact that the number of requests is staying roughly static is interesting, given the ever-increasing page weight, though perhaps this is not entirely related to HTTP/2.
HTTP/2 push has a mixed history despite being a much-hyped new feature of HTTP/2. The other features were basically performance improvements under the hood, but push was a brand new concept that completely broke the single request to single response nature of HTTP. It allowed extra responses to be returned; when you asked for the web page, the server could respond with the HTML page as usual, but then also send you the critical CSS and JavaScript, thus avoiding any additional round trips for certain resources. It would, in theory, allow us to stop inlining CSS and JavaScript into our HTML, and still get the same performance gains of doing so. After solving that, it could potentially lead to all sorts of new and interesting use cases.
-
The reality has been, well, a bit disappointing. HTTP/2 push has proved much harder to use effectively than originally envisaged. Some of this has been due to the complexity of how HTTP/2 push works, and the implementation issues due to that.
-
A bigger concern is that push can quite easily cause, rather than solve, performance issues. Over-pushing is a real risk. Often the browser is in the best place to decide what to request, and just as crucially when to request it but HTTP/2 push puts that responsibility on the server. Pushing resources that a browser already has in its cache, is a waste of bandwidth (though in my opinion so is inlining CSS but that gets must less of a hard time about that than HTTP/2 push!).
-
Proposals to inform the server about the status of the browser cache have stalled especially on privacy concerns. Even without that problem, there are other potential issues if push is not used correctly. For example, pushing large images and therefore holding up the sending of critical CSS and JavaScript will lead to slower websites than if you'd not pushed at all!
-
There has also been very little evidence to date that push, even when implemented correctly, results in the performance increase it promised. This is an area that, again, the HTTP Archive is not best placed to answer, due to the nature of how it runs (a crawl of popular sites using Chrome in one state), so we won't delve into it too much here. However, suffice to say that the performance gains are far from clear-cut and the potential problems are real.
-
Putting that aside let's look at the usage of HTTP/2 push.
- Figure 12. How much is pushed when it is used.
-
-
These stats show that the uptake of HTTP/2 push is very low, most likely because of the issues described previously. However, when sites do use push, they tend to use it a lot rather than for one or two assets as shown in Figure 12.
Pie chart breaking down the percent of asset types that are pushed. JavaScript makes up almost half of the assets, then CSS with about a quarter, images about an eighth, and various text-based types making up the rest.
- Figure 13. What asset types is push used for?
-
-
Figure 13 shows us which assets are most commonly pushed. JavaScript and CSS are the overwhelming majority of pushed items, both by volume and by bytes. After this, there is a ragtag assortment of images, fonts, and data. At the tail end we see around 100 sites pushing video, which may be intentional, or it may be a sign of over-pushing the wrong types of assets!
-
One concern raised by some is that HTTP/2 implementations have repurposed the preload HTTP link header as a signal to push. One of the most popular uses of the preload resource hint is to inform the browser of late-discovered resources, like fonts and images, that the browser will not see until the CSS has been requested, downloaded, and parsed. If these are now pushed based on that header, there was a concern that reusing this may result in a lot of unintended pushes.
-
However, the relatively low usage of fonts and images may mean that risk is not being seen as much as was feared. <link rel="preload" ... > tags are often used in the HTML rather than HTTP link headers and the meta tags are not a signal to push. Statistics in the Resource Hints chapter show that fewer than 1% of sites use the preload HTTP link header, and about the same amount use preconnect which has no meaning in HTTP/2, so this would suggest this is not so much of an issue. Though there are a number of fonts and other assets being pushed, which may be a signal of this.
-
As a counter argument to those complaints, if an asset is important enough to preload, then it could be argued these assets should be pushed if possible as browsers treat a preload hint as very high priority requests anyway. Any performance concern is therefore (again arguably) at the overuse of preload, rather than the resulting HTTP/2 push that happens because of this.
-
To get around this unintended push, you can provide the nopush attribute in your preload header:
5% of preload HTTP headers do make use of this attribute, which is higher than I would have expected as I would have considered this a niche optimization. Then again, so is the use of preload HTTP headers and/or HTTP/2 push itself!
HTTP/2 is mostly a seamless upgrade that, once your server supports it, you can switch on with no need to change your website or application. You can optimize for HTTP/2 or stop using HTTP/1.1 workarounds as much, but in general, a site will usually work without needing any changes—it will just be faster. There are a couple of gotchas to be aware of, however, that can impact any upgrade, and some sites have found these out the hard way.
-
One cause of issues in HTTP/2 is the poor support of HTTP/2 prioritization. This feature allows multiple requests in progress to make the appropriate use of the connection. This is especially important since HTTP/2 has massively increased the number of requests that can be running on the same connection. 100 or 128 parallel request limits are common in server implementations. Previously, the browser had a max of six connections per domain, and so used its skill and judgement to decide how best to use those connections. Now, it rarely needs to queue and can send all requests as soon as it knows about them. This can then lead to the bandwidth being "wasted" on lower priority requests while critical requests are delayed (and incidentally can also lead to swamping your backend server with more requests than it is used to!).
-
HTTP/2 has a complex prioritization model (too complex many say - hence why it is being reconsidered for HTTP/3!) but few servers honor that properly. This can be because their HTTP/2 implementations are not up to scratch, or because of so-called bufferbloat, where the responses are already en route before the server realizes there is a higher priority request. Due to the varying nature of servers, TCP stacks, and locations, it is difficult to measure this for most sites, but with CDNs this should be more consistent.
-
Patrick Meenan created an example test page, which deliberately tries to download a load of low priority, off-screen images, before requesting some high priority on-screen images. A good HTTP/2 server should be able to recognize this and send the high priority images shortly after requested, at the expense of the lower priority images. A poor HTTP/2 server will just respond in the request order and ignore any priority signals. Andy Davies has a page tracking the status of various CDNs for Patrick's test. The HTTP Archive identifies when a CDN is used as part of its crawl, and merging these two datasets can tell us the percent of pages using a passing or failing CDN.
-
-
-
-
-
-
-
CDN
-
Prioritizes Correctly?
-
Desktop
-
Mobile
-
Both
-
-
-
-
-
Not using CDN
-
Unknown
-
57.81%
-
60.41%
-
59.21%
-
-
-
Cloudflare
-
Pass
-
23.15%
-
21.77%
-
22.40%
-
-
-
Google
-
Fail
-
6.67%
-
7.11%
-
6.90%
-
-
-
Amazon CloudFront
-
Fail
-
2.83%
-
2.38%
-
2.59%
-
-
-
Fastly
-
Pass
-
2.40%
-
1.77%
-
2.06%
-
-
-
Akamai
-
Pass
-
1.79%
-
1.50%
-
1.64%
-
-
-
-
Unknown
-
1.32%
-
1.58%
-
1.46%
-
-
-
WordPress
-
Pass
-
1.12%
-
0.99%
-
1.05%
-
-
-
Sucuri Firewall
-
Fail
-
0.88%
-
0.75%
-
0.81%
-
-
-
Incapsula
-
Fail
-
0.39%
-
0.34%
-
0.36%
-
-
-
Netlify
-
Fail
-
0.23%
-
0.15%
-
0.19%
-
-
-
OVH CDN
-
Unknown
-
0.19%
-
0.18%
-
0.18%
-
-
-
-
-
- Figure 14. HTTP/2 prioritization support in common CDNs.
-
-
Figure 14 shows that a fairly significant portion of traffic is subject to the identified issue, totaling 26.82% on desktop and 27.83% on mobile. How much of a problem this is depends on exactly how the page loads and whether high priority resources are discovered late or not for the sites affected.
-
-
27.83%
- Figure 15. The percent of mobile requests with sub-optimal HTTP/2 prioritization.
-
-
Another issue is with the upgrade HTTP header being used incorrectly. Web servers can respond to requests with an upgrade HTTP header suggesting that it supports a better protocol that the client might wish to use (e.g. advertise HTTP/2 to a client only using HTTP/1.1). You might think this would be useful as a way of informing the browser a server supports HTTP/2, but since browsers only support HTTP/2 over HTTPS and since use of HTTP/2 can be negotiated through the HTTPS handshake, the use of this upgrade header for advertising HTTP/2 is pretty limited (for browsers at least).
-
Worse than that, is when a server sends an upgrade header in error. This could be because a backend server supporting HTTP/2 is sending the header and then an HTTP/1.1-only edge server is blindly forwarding it to the client. Apache emits the upgrade header when mod_http2 is enabled but HTTP/2 is not being used, and an nginx instance sitting in front of such an Apache instance happily forwards this header even when nginx does not support HTTP/2. This false advertising then leads to clients trying (and failing!) to use HTTP/2 as they are advised to.
-
108 sites use HTTP/2 while they also suggest upgrading to HTTP/2 in the upgrade header. A further 12,767 sites on desktop (15,235 on mobile) suggest upgrading an HTTP/1.1 connection delivered over HTTPS to HTTP/2 when it's clear this was not available, or it would have been used already. These are a small minority of the 4.3 million sites crawled on desktop and 5.3 million sites crawled on mobile, but it shows that this is still an issue affecting a number of sites out there. Browsers handle this inconsistently, with Safari in particular attempting to upgrade and then getting itself in a mess and refusing to display the site at all.
-
All of this is before we get into the few sites that recommend upgrading to http1.0, http://1.1, or even -all,+TLSv1.3,+TLSv1.2. There are clearly some typos in web server configurations going on here!
-
There are further implementation issues we could look at. For example, HTTP/2 is much stricter about HTTP header names, rejecting the whole request if you respond with spaces, colons, or other invalid HTTP header names. The header names are also converted to lowercase, which catches some by surprise if their application assumes a certain capitalization. This was never guaranteed previously, as HTTP/1.1 specifically states the header names are case insensitive, but still some have depended on this. The HTTP Archive could potentially be used to identify these issues as well, though some of them will not be apparent on the home page, but we did not delve into that this year.
The world does not stand still, and despite HTTP/2 not having even reached its fifth birthday, people are already seeing it as old news and getting more excited about its successor, HTTP/3. HTTP/3 builds on the concepts of HTTP/2, but moves from working over TCP connections that HTTP has always used, to a UDP-based protocol called QUIC. This allows us to fix one case where HTTP/2 is slower then HTTP/1.1, when there is high packet loss and the guaranteed nature of TCP holds up all streams and throttles back all streams. It also allows us to address some TCP and HTTPS inefficiencies, such as consolidating in one handshake for both, and supporting many ideas for TCP that have proven hard to implement in real life (TCP fast open, 0-RTT, etc.).
-
HTTP/3 also cleans up some overlap between TCP and HTTP/2 (e.g. flow control being implemented in both layers) but conceptually it is very similar to HTTP/2. Web developers who understand and have optimized for HTTP/2 should have to make no further changes for HTTP/3. Server operators will have more work to do, however, as the differences between TCP and QUIC are much more groundbreaking. They will make implementation harder so the rollout of HTTP/3 may take considerably longer than HTTP/2, and initially be limited to those with certain expertise in the field like CDNs.
-
QUIC has been implemented by Google for a number of years and it is now undergoing a similar standardization process that SPDY did on its way to HTTP/2. QUIC has ambitions beyond just HTTP, but for the moment it is the use case being worked on currently. Just as this chapter was being written, Cloudflare, Chrome, and Firefox all announced HTTP/3 support, despite the fact that HTTP/3 is still not formally complete or approved as a standard yet. This is welcome as QUIC support has been somewhat lacking outside of Google until recently, and definitely lags behind SPDY and HTTP/2 support from a similar stage of standardization.
-
Because HTTP/3 uses QUIC over UDP rather than TCP, it makes the discovery of HTTP/3 support a bigger challenge than HTTP/2 discovery. With HTTP/2 we can mostly use the HTTPS handshake, but as HTTP/3 is on a completely different connection, that is not an option here. HTTP/2 also used the upgrade HTTP header to inform the browser of HTTP/2 support, and although that was not that useful for HTTP/2, a similar mechanism has been put in place for QUIC that is more useful. The alternative services HTTP header (alt-svc) advertises alternative protocols that can be used on completely different connections, as opposed to alternative protocols that can be used on this connection, which is what the upgrade HTTP header is used for.
-
-
8.38%
- Figure 16. The percent of mobile sites which support QUIC.
-
-
Analysis of this header shows that 7.67% of desktop sites and 8.38% of mobile sites already support QUIC, which roughly represents Google's percentage of traffic, unsurprisingly enough, as it has been using this for a while. And 0.04% are already supporting HTTP/3. I would imagine by next year's Web Almanac, this number will have increased significantly.
This analysis of the available statistics in the HTTP Archive project has shown what many of us in the HTTP community were already aware of: HTTP/2 is here and proving to be very popular. It is already the dominant protocol in terms of number of requests, but has not quite overtaken HTTP/1.1 in terms of number of sites that support it. The long tail of the internet means that it often takes an exponentially longer time to make noticeable gains on the less well-maintained sites than on the high profile, high volume sites.
-
We've also talked about how it is (still!) not easy to get HTTP/2 support in some installations. Server developers, operating system distributors, and end customers all have a part to play in pushing to make that easier. Tying software to operating systems always lengthens deployment time. In fact, one of the very reasons for QUIC is to break a similar barrier with deploying TCP changes. In many instances, there is no real reason to tie web server versions to operating systems. Apache (to use one of the more popular examples) will run with HTTP/2 support in older operating systems, but getting an up-to-date version on to the server should not require the expertise or risk it currently does. Nginx does very well here, hosting repositories for the common Linux flavors to make installation easier, and if the Apache team (or the Linux distribution vendors) do not offer something similar, then I can only see Apache's usage continuing to shrink as it struggles to hold relevance and shake its reputation as old and slow (based on older installs) even though up-to-date versions have one of the best HTTP/2 implementations. I see that as less of an issue for IIS, since it is usually the preferred web server on the Windows side.
-
Other than that, HTTP/2 has been a relatively easy upgrade path, which is why it has had the strong uptake it has already seen. For the most part, it is a painless switch-on and, therefore, for most, it has turned out to be a hassle-free performance increase that requires little thought once your server supports it. The devil is in the details though (as always), and small differences between server implementations can result in better or worse HTTP/2 usage and, ultimately, end user experience. There has also been a number of bugs and even security issues, as is to be expected with any new protocol.
-
Ensuring you are using a strong, up-to-date, well-maintained implementation of any newish protocol like HTTP/2 will ensure you stay on top of these issues. However, that can take expertise and managing. The roll out of QUIC and HTTP/3 will likely be even more complicated and require more expertise. Perhaps this is best left to third-party service providers like CDNs who have this expertise and can give your site easy access to these features? However, even when left to the experts, this is not a sure thing (as the prioritization statistics show), but if you choose your server provider wisely and engage with them on what your priorities are, then it should be an easier implementation.
-
On that note it would be great if the CDNs prioritized these issues (pun definitely intended!), though I suspect with the advent of a new prioritization method in HTTP/3, many will hold tight. The next year will prove yet more interesting times in the HTTP world.
-
-
-
- {% for author in metadata.get('authors') %} {% if loop.index == 1 %}
-
{{ add_footnote_links(localizedContributors[author] if localizedContributors[author]|length) | safe }}
-
-
- {% endfor %}
-
-
-
-
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/css.html b/src/templates/es/2019/chapters/css.html
deleted file mode 100644
index fdbf922c592..00000000000
--- a/src/templates/es/2019/chapters/css.html
+++ /dev/null
@@ -1,807 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":2,"title":"CSS","description":"Capítulo CSS del 2019 Web Almanac que cubre el color, las unidades, los selectores, el diseño, la tipografía y las fuentes, el espaciado, la decoración, la animación y las consultas de medios.","authors":["una","argyleink"],"reviewers":["meyerweb","huijing"],"translators":["c-torres"],"discuss":"1757","results":"https://docs.google.com/spreadsheets/d/1uFlkuSRetjBNEhGKWpkrXo4eEIsgYelxY-qR9Pd7QpM/","queries":"02_CSS","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-06T00:00:00.000Z","chapter":"css"} %} {% block index %}
-
Las Hojas de Estilo en Cascada (CSS por sus siglas en inglés) se utilizan para pintar, formatear y diseñar páginas web. Sus capacidades abarcan conceptos tan simples como el color del texto hasta perspectiva 3D. También tiene ganchos para permitir a los desarrolladores manejar diferentes tamaños de pantalla, contextos de visualización e impresión. CSS ayuda a los desarrolladores a lidiar con el contenido y a asegurarse de que se adapte correctamente al usuario.
-
Al describir CSS a aquellos que no están familiarizados con la tecnología web, puede ser útil pensar que es el lenguaje para pintar las paredes de la casa; describiendo el tamaño y la posición de ventanas y puertas, así como decoraciones florecientes como papel tapiz o vida vegetal. El giro divertido de esa historia es que, dependiendo del usuario que camina por la casa, ¡un desarrollador puede adaptar la casa a las preferencias o contextos específicos de ese usuario!
-
En este capítulo, inspeccionaremos, contaremos y extraeremos datos sobre cómo se usa CSS en la web. Nuestro objetivo es comprender de manera integral qué características se están utilizando, cómo se usan y cómo CSS está creciendo y siendo adoptado.
-
¿Listo para profundizar en los datos fascinantes? ¡Muchos de los siguientes números pueden ser pequeños, pero no los confundas como insignificantes! Pueden pasar muchos años hasta que nuevas cosas saturen la web.
Hex es la forma más popular de describir el color por mucho, con un 93% de uso, seguido de RGB y luego HSL. Curiosamente, los desarrolladores están aprovechando al máximo el argumento de la transparencia alfa cuando se trata de estos tipos de colores: HSLA y RGBA son mucho más populares que HSL y RGB, ¡con casi el doble de uso! Aunque la transparencia alfa se agregó más tarde a la especificación web, HSLA y RGBA son compatibles desde IE9, por lo que puede seguir adelante, y ¡usarlos a ellos tambien!
Gráfico de barras que muestra la adopción de los formatos HSL, HSLA, RGB, RGBA y hexadecimal. Hex se usa en el 93% de las páginas de escritorio, RGBA en el 83%, RGB en el 22%, HSLA 19% y HSL 1%. La adopción móvil y de escritorio es similar para todos los formatos de color, excepto HSL, para el cual la adopción móvil es del 9% (9 veces mayor).
- Figura 1. Popularidad de los formatos de color.
-
-
Existen 148 colores de CSS nombrados, sin incluir los valores especiales transparent y currentcolor. Puede usarlos por su nombre en cadena de texto para un estilo más legible. Los colores con nombre más populares son black y white, sin sorprender, seguidos por red y blue.
Gráfico circular que muestra los colores con nombre más populares. El blanco es el más popular al 40%, luego el negro al 22%, el rojo al 11% y el azul al 5%.
El idioma también se infiere de manera interesante a través del color. Hay más instancias del "gray" de estilo americano que del "grey" de estilo británico. Casi cada instancia de colores grises (gray, lightgray, darkgray, slategray, etc.) tenía casi el doble de uso cuando se deletreaba con una "a" en lugar de una "e". Si la combinación gr[a/e]ys se tomara en cuenta, tendrían un rango más alto que el azul, solidificándose en el puesto #4. ¡Esta podría ser la razón por la cual plata ocupa un lugar más alto que grey con una "e" en las listas!
¿Cuántos colores de fuente diferentes se utilizan en la web? Entonces este no es el número total de colores únicos; más bien, es cuántos colores diferentes se usan solo para el texto. Los números en este gráfico son bastante altos y, por experiencia, sabemos que sin variables CSS, el espaciado, los tamaños y los colores pueden escaparse rápidamente de y fragmentarse en muchos valores pequeños en sus estilos. Estos números reflejan una dificultad en la gestión del estilo, y esperamos que esto ayude a crear alguna perspectiva para que pueda traer de vuelta a sus equipos o proyectos. ¿Cómo puede reducir este número a una cantidad manejable y razonable?
Distribución que muestra los percentiles 10, 25, 50, 75 y 90 de colores por computadoras de escritorio y página móvil. En computadoras de escritorio, la distribución es 8, 22, 48, 83 y 131. Las páginas móviles tienden a tener más colores entre 1 y 10.
- Figura 3. Distribución de colores por página.
-
-
Bueno, tenemos curiosidad aquí y queríamos inspeccionar cuántos colores duplicados hay en una página. Sin un sistema CSS de clase reutilizable bien administrado, los duplicados son bastante fáciles de crear. Resulta que la mediana tiene suficientes duplicados que valdría la pena hacer un pase para unificarlos con propiedades personalizadas.
Gráfico de barras que muestra la distribución de colores por página. La página de escritorio promedio tiene 24 colores duplicados. El percentil 10 es de 4 colores duplicados y el percentil 90 es de 62. Las distribuciones de escritorio y móviles son similares.
- Figura 4. Distribución de colores duplicados por página.
-
-
En CSS, hay muchas formas diferentes de lograr el mismo resultado visual utilizando diferentes tipos de unidades: rem, px, em, ch, o ¡incluso cm! Entonces, ¿qué tipos de unidades son más populares?
Gráfico de barras de la popularidad de varios tipos de unidades.Las unidades px y em se utilizan en más del 90% de las páginas. La unidad rem es el siguiente tipo de unidad más popular en el 40% de las páginas y la popularidad cae rápidamente para los tipos de unidades restantes.
- Figura 5. Popularidad de los tipos de unidades.
-
-
Como era de esperar, en la figura 5, px es el tipo de unidad más utilizado, es el tipo de unidad más utilizado con aproximadamente el 95% de las páginas web usando píxeles de una forma u otra (esto podría ser el tamaño del elemento, el tamaño de la fuente, etc.). Sin embargo, la unidad em es casi tan popular, con uso alrededor del 90%. Esto es más de 2 veces más popular que la unidad rem,que tiene solo un 40% de frecuencia en las páginas web. Si te preguntas cuál es la diferencia, em se basa en el tamaño de fuente principal, mientras que rem se basa en el tamaño de fuente base establecido en la página. No cambia por componente como podría hacerlo em,y así permite el ajuste de todos los espacios de manera uniforme.
-
Cuando se trata de unidades basadas en el espacio físico, la unidad cm (or centímetros) es la más popular por mucho, seguida por in (pulgadas), y luego por Q.Sabemos que este tipo de unidades son específicamente útiles para imprimir hojas de estilo, ¡pero ni siquiera sabíamos que la unidad Q existía hasta esta encuesta! ¿Sabías?
-
Una versión anterior de este capítulo discutia la inesperada popularidad de la unidadQ. Gracias a la discusión de la comunidad alrededor de este capítulo, hemos identificado que esto fue un error en nuestro análisis y hemos actualizado la Figura 5 en consecuencia.
Vimos mayores diferencias en los tipos de unidades cuando se trata del uso en dispositivos móviles y computadoras de escritorio para unidades basadas en el viewport. 36.8% de los sitios móviles usan vh (altura del viewport), mientras que solo el 31% de los sitios de escritorio lo hacen. También encontramos que vh es más común que vw (ancho del viewport) en aproximadamente un 11%. vmin (mínimo del viewport) es más popular que vmax(máximo del viewport), con alrededor del 8% de uso de vmin en dispositivos móviles, mientras que vmax solo lo usa el 1% de los sitios web.
Las propiedades personalizadas son lo que muchos llaman variables CSS. Sin embargo, son más dinámicas que una variable estática típica. Son muy poderosas y como comunidad todavía estamos descubriendo su potencial.
-
-
5%
- Figura 6. Porcentaje de páginas que usan propiedades personalizadas.
-
-
Sentimos que esta era una información emocionante, ya que muestra un crecimiento saludable de una de nuestras adiciones CSS favoritas. Estaban disponibles en todos los principales navegadores desde 2016 o 2017, por lo que es justo decir que son bastante nuevos. Muchas personas todavía están haciendo la transición de sus variables de preprocesador CSS a propiedades personalizadas CSS. Estimamos que pasarán algunos años más hasta que las propiedades personalizadas sean la norma.
CSS tiene algunas formas de encontrar elementos en la página para el estilo, así que pongamos los ID y las clases uno contra el otro para ver cuál es más frecuente. Los resultados no deberían ser demasiado sorprendentes: ¡las clases son más populares!
Gráfico de barras que muestra la adopción de ID y tipos de selector de clase. Las clases se usan en el 95% de las páginas de escritorio y móviles. Las ID se usan en el 89% de las páginas de escritorio y el 87% de las páginas móviles.
- Figura 7. Popularidad de los tipos de selector por página.
-
-
Un buen cuadro de seguimiento es este, que muestra que las clases ocupan el 93% de los selectores encontrados en una hoja de estilo.
Gráfico de barras que muestra que el 94% de los selectores incluyen el selector de clase para computadoras de escritorio y dispositivos móviles, mientras que el 7% de los selectores de escritorio incluyen el selector de ID (8% para dispositivos móviles).
- Figura 8. Popularidad de los tipos de selector por selector.
-
-
CSS tiene algunos selectores de comparación muy potentes. Estos son selectores como [target="_blank"], [attribute^="value"], [title~="rad"], [attribute$="-rad"] o [attribute*="value"]. ¿Los usas? ¿Crees que se usan mucho? Comparemos cómo se usan con IDs y clases en la web.
Gráfico de barras que muestra la popularidad de los operadores utilizados por los selectores de atributos de ID. Alrededor del 4% de las páginas de escritorio y móviles usan asterisco igual y signo de intercalación igual. El 1% de las páginas usan igual y dólar igual. 0% usa virgulilla igual.
- Figura 9. Popularidad de operadores por selector de atributo ID.
-
-
-
-
-
-
-
Gráfico de barras que muestra la popularidad de los operadores utilizados por los selectores de atributos de clase. El 57% de las páginas usan asterisco igual. El 36% usa signo de interalación igual. El 1% usa igual y dólar igual. 0% usa virgulilla igual.
- Figura 10. Popularidad de operadores por selector de atributo de clase.
-
-
Estos operadores son mucho más populares con los selectores de clase que con los ID, lo cual se siente natural ya que una hoja de estilo generalmente tiene menos selectores de ID que los selectores de clase, pero aún así es interesante ver los usos de todas estas combinaciones.
Con el surgimiento de las estrategias OOCSS, atómicas y funcionales de CSS que pueden combinar 10 o más clases en un elemento para lograr una apariencia de diseño, quizás veamos algunos resultados interesantes. La consulta resultó bastante aburrida, con una mediana en dispositivos móviles y computadoras de escritorio de 1 clase por elemento.
-
-
1
- Figura 11. La mediana del número de nombres de clase por atributo de clase (escritorio y dispositivo móvil).
-
-
Flexbox es un estilo contenedor que dirige y alinea a sus hijos; es decir, ayuda con el diseño de una manera basada en restricciones. Tuvo un comienzo bastante difícil en la web, ya que su especificación experimentó dos o tres cambios bastante drásticos entre 2010 y 2013. Afortunadamente, se resolvió y se implementó en todos los navegadores en 2014. Dado ese historial, tuvo una tasa de adopción lenta, ¡pero han pasado algunos años desde entonces! Es bastante popular ahora, tiene muchos artículos sobre su uso y cómo sacarle provecho, pero aún es nuevo en comparación con otras tácticas de diseño.
Similar a flexbox, grid también pasó por algunas alteraciones de especificaciones al principio de su vida útil, pero sin cambiar las implementaciones en los navegadores lanzados al público. Microsoft tenía grid en las primeras versiones de Windows 8, como el motor de diseño primario para su estilo de diseño de desplazamiento horizontal. Primero se investigó allí, se hizo la transición a la web y luego los otros navegadores lo maduraron hasta su lanzamiento final en 2017. Tuvo un lanzamiento muy exitoso en el sentido de que casi todos los navegadores lanzaron sus implementaciones al mismo tiempo, por lo que los desarrolladores web simplemente se despertaron un día con un excelente soporte de grid. Hoy, a fines de 2019, grid todavía se siente como un niño nuevo en el bloque, ya que la gente todavía está despertando a su poder y capacidades.
-
-
2%
- Figura 13. Porcentaje de sitios web que usan grid.
-
-
Esto muestra lo poco que la comunidad de desarrollo web ha utilizado y explorado su última herramienta de diseño. Esperamos que grid eventualmente tome control y se convierta en el motor de diseño primario para la construcción de sitios web. Para nosotros, los autores, nos encanta escribir grid: normalmente lo buscamos primero, luego reducimos nuestra complejidad a medida que nos damos cuenta e iteramos en el diseño. Queda por ver qué hará el resto del mundo con esta potente función CSS en los próximos años.
La web y CSS son características de la plataforma internacional, y los modos de escritura ofrecen una forma para que HTML y CSS indiquen la dirección de lectura y escritura preferida por el usuario dentro de nuestros elementos.
Gráfico de barras que muestra la popularidad de los valores de dirección ltr y rtl. ltr es utilizado por el 32% de las páginas de escritorio y el 40% de las páginas móviles. rtl es utilizado por el 32% de las páginas de escritorio y el 36% de las páginas móviles.
- Figura 14. Popularidad de los valores de dirección.
-
-
Distribución de la cantidad de fuentes web cargadas por página. En computadoras de escritorio, los percentiles 10, 25, 50, 75 y 90 son: 0, 1, 3, 6 y 9. Esto es ligeramente más alto que la distribución para dispositivos móviles, que es una fuente menos en los percentiles 75 y 90.
- Figura 15. Distribución de la cantidad de fuentes web cargadas por página.
-
-
Una pregunta de seguimineto a la consulta del número total de fuentes por página es: ¿qué fuentes son? Diseñadores, sintonicen, porque ahora podrán ver si sus elecciones están en línea con lo que es popular o no.
Gráfico de barras de las fuentes más populares. Entre las páginas de escritorio, están Open Sans (24%), Roboto (15%), Montserrat (5%), Source Sans Pro (4%), Noto Sans JP (3%) y Lato (3%). En los dispositivos móviles, las diferencias más notables son que Open Sans se usa el 22% del tiempo (en lugar del 24%) y Roboto se usa el 19% del tiempo (en lugar del 15%).
Open Sans es un gran ganador aquí, con casi 1 de cada 4 declaraciones CSS @ font-family que lo especifican. Definitivamente hemos usado Open Sans en proyectos en las agencias.
-
También es interesante notar las diferencias entre la adopción de escritorio y móvil. Por ejemplo, las páginas móviles usan Open Sans con menos frecuencia que las de escritorio. Mientras tanto, también usan Roboto un poco más a menudo.
Esta es divertida, porque si le pregunta a un usuario cuántos tamaños de fuente siente que hay en una página, generalmente devolvería un número de 5 o definitivamente menos de 10. ¿Es esa la realidad? Incluso en un sistema de diseño, ¿cuántos tamaños de fuente hay? Consultamos la web y descubrimos que la mediana era 40 en el móvil y 38 en el escritorio. Puede ser el momento de pensar realmente en las propiedades personalizadas o de crear algunas clases reutilizables para ayudarlo a distribuir su rampa de tipos.
Gráfico de barras que muestra la distribución de distintos tamaños de fuente por página. Para las páginas de escritorio, los percentiles 10, 25, 50, 75 y 90 son: 8, 20, 40, 66 y 92 tamaños de fuente. La distribución de escritorio difiere de la móvil en el percentil 75, donde es más grande en 7 tamaños distintos y para el percentil 90 en 13 tamaños.
- Figura 17. Distribución del número de tamaños de fuente distintos por página.
-
-
Un margen es el espacio fuera de los elementos, como el espacio que exige cuando empuja los brazos hacia afuera. Esto a menudo parece el espacio entre elementos, pero no se limita a ese efecto. En un sitio web o aplicación, el espaciado juega un papel muy importante en UX y diseño. Veamos cuánto código de espaciado de margen va en una hoja de estilo, ¿de acuerdo?
Gráfico de barras que muestra la distribución de valores de margen distintos por página. Para las páginas de escritorio, los percentiles 10, 25, 50, 75 y 90 son: 12, 47, 96, 167 y 248 valores de margen distintos. La distribución de escritorio difiere de la móvil en el percentil 75, donde es más pequeña en 12 a 31 valores distintos.
- Figura 18. Distribución del número de valores de margen distintos por página.
-
-
¡Bastante, al parecer! La página de escritorio promedio tiene 96 valores de margen distintos y 104 en dispositivos móviles. Eso crea muchos momentos de espaciado únicos en su diseño. ¿Curioso de cuántos márgenes tienes en tu sitio? ¿Cómo podemos hacer que todo este espacio en blanco sea más manejable?
- Figura 19. Porcentaje de páginas de escritorio y móviles que incluyen propiedades lógicas.
-
-
Estimamos que la hegemonía de margin-left y padding-top es de duración limitada, que pronto se complementará por su dirección de escritura agnóstica, sucesiva, sintaxis de propiedad lógica. Si bien somos optimistas, el uso actual es bastante bajo, con un 0,67% de uso en las páginas de escritorio. Para nosotros, esto se siente como un cambio de hábito que necesitaremos desarrollar como industria, mientras esperamos capacitar a nuevos desarrolladores para usar la nueva sintaxis.
Las capas verticales, o apilamiento, se pueden administrar con z-index en CSS. Teníamos curiosidad sobre cuántos valores diferentes usan las personas en sus sitios. El rango de lo que acepta el z-index es teóricamente infinito, limitado solo por las límites de tamaño variable de un navegador. ¿Se utilizan todas esas posiciones de pila? ¡Veamos!
Gráfico de barras que muestra la distribución de distintos valores de z-index por página. Para las páginas de escritorio, los percentiles 10, 25, 50, 75 y 90 son: 1, 7, 16, 26 y 36 valores distintos de z-index. La distribución de escritorio es mucho más alta que la móvil, en hasta 16 valores distintos en el percentil 90.
- Figura 20. Distribución del número de valores distintos de z-index por página.
-
-
Según nuestra experiencia laboral, cualquier número con 9s parecía ser la opción más popular. Aunque nos enseñamos a nosotros mismos a usar el menor número posible, esa no es la norma comunitaria. ¿Cuál es entonces? Si la gente necesita cosas al frente, ¿cuáles son los números más populares de z-index que se usan? Deja a un lado tu bebida; este es lo suficientemente divertido como para perdérselo.
Diagrama de dispersión de todos los valores de z-index conocidos y la cantidad de veces que se usan, tanto para escritorio como para dispositivos móviles. 1 y 2 son los más utilizados, pero el resto de los valores populares explotan en órdenes de magnitud: 10, 100, 1,000, y así sucesivamente hasta números con cientos de dígitos.
- Figura 21. Los valores de z-index más utilizados.
-
-
-
Los filtros son una forma divertida y excelente de modificar los píxeles que el navegador intenta dibujar en la pantalla. Es un efecto de procesamiento posterior que se realiza contra una versión plana del elemento, nodo o capa a la que se aplica. Photoshop los hizo fáciles de usar, luego Instagram los hizo accesibles a las masas a través de combinaciones personalizadas y estilizadas. Han existido desde aproximadamente 2012, hay 10 de ellos, y se pueden combinar para crear efectos únicos.
-
-
78%
- Figura 23. Porcentaje de páginas que incluyen una hoja de estilo con la propiedad filter.
-
-
¡Nos entusiasmó ver que el 78% de las hojas de estilo contienen la propiedad filter! Ese número también era tan alto que parecía un poco sospechoso, así que buscamos y explicamos el número alto. Porque seamos honestos, los filtros son limpios, pero no se incluyen en todas nuestras aplicaciones y proyectos. ¡A no ser que!
-
Tras una investigación más profunda, descubrimos que las hojas de estilo de FontAwesome viene con cierto uso de filter, de igual manera el contenido empotrado de YouTube. Por lo tanto, nosotros creemos filter se coló en la puerta de atrás al ser utilizada en un par de hojas de estilo muy populares. También creemos que la presencia de -ms-filter podría haberse incluido también, contribuyendo al alto porcentaje de uso.
Los modos de mezcla son similares a los filtros en que son un efecto de posprocesamiento que se ejecuta contra una versión plana de sus elementos de destino, pero son únicos en el sentido de que están relacionados con la convergencia de píxeles. Dicho de otra manera, los modos de mezcla son cómo los 2 píxeles deberían impactar entre sí cuando se superponen. Cualquier elemento que se encuentre en la parte superior o inferior afectará la forma en que el modo de mezcla manipula los píxeles. Hay 16 modos de mezcla, veamos cuáles son los más populares.
-
-
8%
- Figura 24. Porcentaje de páginas que incluyen una hoja de estilo con la propiedad *-blend-mode.
-
-
En general, el uso de los modos de mezcla es mucho menor que el de los filtros, pero aún es suficiente para ser considerado moderadamente utilizado.
-
En una futura edición de Web Almanac, sería genial profundizar en el uso del modo de mezcla para tener una idea de los modos exactos que usan los desarrolladores, como multiplicar, pantalla, quemar colores, aclarar, etc.
CSS tiene este increíble poder de interpolación que se puede usar simplemente escribiendo una sola regla sobre cómo hacer la transición de esos valores. Si está utilizando CSS para administrar estados en su aplicación, ¿con qué frecuencia emplea transiciones para realizar la tarea? ¡Vamos a consultar la web!
Gráfico de barras que muestra la distribución de las transiciones por página. Para las páginas de escritorio, los percentiles 10, 25, 50, 75 y 90 son: 0, 2, 16, 49 y 118 transiciones. La distribución del escritorio es mucho más baja que la del móvil, hasta 77 transiciones en el percentil 90.
- Figura 25. Distribución del número de transiciones por página.
-
-
¡Eso es bastante bueno! Nosotros vimos animate.css como una biblioteca popular para incluir, que trae un montón de animaciones de transición, pero aún así es agradable ver que la gente está considerando la transición de sus interfaces de usuario.
Las animaciones de keyframe CSS son una excelente solución para sus animaciones o transiciones más complejas. Le permiten ser más explícito, lo que proporciona un mayor control sobre los efectos. Pueden ser pequeños, como un efecto de keyframe, o grandes con muchos efectos de keyframe compuestos en una animación robusta. El número medio de animaciones de keyframes por página es mucho menor que las transiciones CSS.
Gráfico de barras que muestra la distribución de keyframes por página. Para las páginas móviles, los percentiles 10, 25, 50, 75 y 90 son: 0, 0, 3, 18 y 76 fotogramas clave. La distribución móvil es ligeramente superior a la de escritorio en 6 fotogramas clave en los percentiles 75 y 90.
- Figura 26. Distribución del número de keyframe por página.
-
-
Las media queries permiten que CSS se enganche en varias variables de nivel de sistema para adaptarse adecuadamente al usuario visitante. Algunas de estas consultas podrían manejar estilos de impresión, estilos de pantalla de proyector y tamaño de ventana / vista. Durante mucho tiempo, las consultas de los medios se aprovecharon principalmente para su conocimiento de la vista. Los diseñadores y desarrolladores podrían adaptar sus diseños para pantallas pequeñas, pantallas grandes, etc. Más tarde, la web comenzó a brindar más y más capacidades y consultas, lo que significa que las media queries ahora pueden administrar las funciones de accesibilidad además de las funciones de la ventana gráfica.
-
Un buen lugar para comenzar con las media queries, ¿es aproximadamente cuántas se usan por página? ¿A cuántos momentos o contextos diferentes siente la página típica que quiere responder?
Gráfico de barras que muestra la distribución de consultas de medios por página. Para las páginas de escritorio, los percentiles 10, 25, 50, 75 y 90 son: 0, 3, 14, 27 y 43 media queries. La distribución de escritorio es similar a la distribución móvil.
- Figura 27. Distribución del número de consultas de media queries por página.
-
-
Para media queries de ventana gráfica, cualquier tipo de unidad CSS se puede pasar a la expresión de consulta para su evaluación. En días anteriores, la gente pasaba em y px a la consulta, pero con el tiempo se agregaban más unidades, lo que nos da mucha curiosidad sobre qué tipos de tamaños se encuentran comúnmente en la web. Suponemos que la mayoría de las consultas de medios seguirán los tamaños de dispositivos populares, pero en lugar de suponer, ¡echemos un vistazo a los datos!
Gráfico de barras de los puntos de referencia de media queries más populares. 768px y 767px son los más populares con 23% y 16%, respectivamente. La lista cae rápidamente después de eso, con 992px usado el 6% del tiempo y 1200px usado el 4% del tiempo. Las computadoras de escritorio y los dispositivos móviles tienen un uso similar.
- Figura 28. Puntos de ajuste más utilizados en media queries.
-
-
La Figura 28 anterior muestra que parte de nuestras suposiciones eran correctas: ciertamente hay una gran cantidad de tamaños específicos de teléfonos allí, pero también hay algunos que no lo son. Es interesante también cómo es muy dominante en píxeles, con unas pocas entradas que utilizan em más allá del alcance de este gráfico.
El valor de media query más popular de los tamaños de punto de interrupción populares parece ser 768px, lo que nos hizo sentir curiosidad. ¿Se usó este valor principalmente para cambiar a un diseño vertical, ya que podría basarse en la suposición de que 768px representa la típica ventana vertical de un móvil? Así que realizamos una consulta de seguimiento para ver la popularidad del uso de los modos vertical y horizontal:
Gráfico de barras que muestra la adopción de modos de orientación vertical y horizontal en media queries. El 31% de las páginas especifican horizontal, el 8% especifica vertical y el 7% especifica ambas. La adopción es la misma para páginas de escritorio y móviles.
- Figura 29. Adopción de modos de orientación en media queries.
-
-
Curiosamente, vertical no se usa mucho, mientras que horizontal se usa mucho más. Solo podemos suponer que 768px ha sido lo suficientemente confiable como el caso de diseño vertical se ha alcanzado por mucho menos. También suponemos que las personas en una computadora de escritorio, que prueban su trabajo, no pueden activar el modo vertical para ver su diseño móvil tan fácilmente como pueden simplemente aplastar el navegador. Difícil de decir, pero los datos son fascinantes.
En las media queries de ancho y alto que hemos visto hasta ahora, los píxeles se ven como la unidad de elección dominante para los desarrolladores que buscan adaptar su interfaz de usuario a las ventanas gráficas. Sin embargo, queríamos consultar esto exclusivamente, y realmente echar un vistazo a los tipos de unidades que usan las personas. Esto es lo que encontramos.
Gráfico de barras que muestra el 75% de los puntos de referencia de las media queries especifican píxeles, el 8% que especifica ems y el 1% que especifica rems.
- Figura 30. Adopción de unidades en puntos de referencia de media queries.
-
-
Cuando las personas escriben una media query, ¿están generalmente buscando una ventana gráfica que esté por encima o por debajo de un rango específico, o ambos, verificando si está entre un rango de tamaños? ¡Preguntémosle a la web!
Gráfico de barras que muestra el 74% de las páginas de escritorio usan max-width, el 70% con min-width y el 68% con ambas propiedades. La adopción es similar para páginas móviles.
- Figura 31. Adopción de propiedades utilizadas en puntos de referencia de media queries.
-
-
No hay ganadores claros aquí; max-width y min-width se usan casi por igual.
Los sitios web se sienten como papel digital, ¿verdad? Como usuarios, generalmente se sabe que puede presionar imprimir desde su navegador y convertir ese contenido digital en contenido físico. No se requiere que un sitio web cambie para ese caso de uso, ¡pero puede hacerlo si lo desea! Menos conocida es la capacidad de ajustar su sitio web en el caso de que lo lea una herramienta o un robot. Entonces, ¿con qué frecuencia se aprovechan estas características?
Gráfico de barras que muestra el 35% de las páginas de escritorio con el tipo de media query "todos", el 46% con impresión, el 72% con pantalla y el 0% con voz. La adopción es inferior en aproximadamente 5 puntos porcentuales para el escritorio en comparación con el móvil.
- Figura 32. Adopción de las media queries para todos, impresión, pantalla y voz.
-
-
¿A cuántas hojas de estilo hace referencia desde su página de inicio? ¿Cuántos de tus aplicaciones? ¿Sirven más o menos para dispositivos móviles frente a computadoras de escritorio? ¡Aquí hay una tabla de todos los demás!
Distribución de la cantidad de hojas de estilo cargadas por página. Las computadoras de escritorio y los dispositivos móviles tienen distribuciones idénticas con percentiles 10, 25, 50, 75 y 90: 1, 3, 6, 12 y 20 hojas de estilo por página.
- Figura 33. Distribución del número de hojas de estilo cargadas por página.
-
-
¿Cómo nombras tus hojas de estilo? ¿Has sido constante a lo largo de tu carrera? ¿Has convergido lentamente o divergido constantemente? Este gráfico muestra una pequeña visión de la popularidad de la biblioteca, pero también una gran visión de los nombres populares de los archivos CSS.
-
-
-
-
-
-
-
Nombre de hoja de estilo
-
Escritorio
-
Móvil
-
-
-
-
-
style.css
-
2.43%
-
2.55%
-
-
-
font-awesome.min.css
-
1.86%
-
1.92%
-
-
-
bootstrap.min.css
-
1.09%
-
1.11%
-
-
-
BfWyFJ2Rl5s.css
-
0.67%
-
0.66%
-
-
-
style.min.css?ver=5.2.2
-
0.64%
-
0.67%
-
-
-
styles.css
-
0.54%
-
0.55%
-
-
-
style.css?ver=5.2.2
-
0.41%
-
0.43%
-
-
-
main.css
-
0.43%
-
0.39%
-
-
-
bootstrap.css
-
0.40%
-
0.42%
-
-
-
font-awesome.css
-
0.37%
-
0.38%
-
-
-
style.min.css
-
0.37%
-
0.37%
-
-
-
styles__ltr.css
-
0.38%
-
0.35%
-
-
-
default.css
-
0.36%
-
0.36%
-
-
-
reset.css
-
0.33%
-
0.37%
-
-
-
styles.css?ver=5.1.3
-
0.32%
-
0.35%
-
-
-
custom.css
-
0.32%
-
0.33%
-
-
-
print.css
-
0.32%
-
0.28%
-
-
-
responsive.css
-
0.28%
-
0.31%
-
-
-
-
-
- Figura 34. Nombres de hojas de estilo más utilizados.
-
-
¡Mira todos esos nombres de archivos creativos! style, styles, main, default, all. Sin embargo, uno se destacó, ¿lo ves? BfWyFJ2Rl5s.css toma el lugar número cuatro para el más popular. Lo investigamos un poco y nuestra mejor suposición es que está relacionado con los botones "me gusta" de Facebook. ¿Sabes cuál es ese archivo? Deja un comentario, porque nos encantaría escuchar la historia.
¿Qué tan grandes son estas hojas de estilo? ¿Es nuestro tamaño CSS algo de qué preocuparse? A juzgar por estos datos, nuestro CSS no es uno de los principales culpables de la hinchazón de las páginas.
Distribución del número de bytes de hoja de estilo cargados por página. Los percentiles 10, 25, 50, 75 y 90 de la página de escritorio son: 8, 26, 62, 129 y 240 KB. La distribución de escritorio es ligeramente superior a la distribución móvil en 5 a 10 KB.
- Figura 35. Distribución del número de bytes de hoja de estilo (KB) cargados por página.
-
-
Consulte el capítulo Page Weight) para obtener una visión más detallada de la cantidad de bytes que los sitios web están cargando para cada tipo de contenido.
Es común, popular, conveniente y poderoso llegar a una biblioteca CSS para iniciar un nuevo proyecto. Si bien es posible que usted no sea delos que consumen bibliotecas, hemos consultado la web en 2019 para ver cuáles lideran el paquete. Si los resultados lo sorprenden, como lo hicieron con nosotros, creo que es una pista interesante de cuán pequeña es la burbuja de desarrollador en la que podemos vivir. Las cosas pueden sentirse enormemente populares, pero cuando la web pregunta, la realidad es un poco diferente.
-
-
-
-
-
-
-
Biblioteca
-
Escritorio
-
Móvil
-
-
-
-
-
Bootstrap
-
27.8%
-
26.9%
-
-
-
animate.css
-
6.1%
-
6.4%
-
-
-
ZURB Foundation
-
2.5%
-
2.6%
-
-
-
UIKit
-
0.5%
-
0.6%
-
-
-
Material Design Lite
-
0.3%
-
0.3%
-
-
-
Materialize CSS
-
0.2%
-
0.2%
-
-
-
Pure CSS
-
0.1%
-
0.1%
-
-
-
Angular Material
-
0.1%
-
0.1%
-
-
-
Semantic-ui
-
0.1%
-
0.1%
-
-
-
Bulma
-
0.0%
-
0.0%
-
-
-
Ant Design
-
0.0%
-
0.0%
-
-
-
tailwindcss
-
0.0%
-
0.0%
-
-
-
Milligram
-
0.0%
-
0.0%
-
-
-
Clarity
-
0.0%
-
0.0%
-
-
-
-
-
- Figura 36. Porcentaje de páginas que incluyen una biblioteca CSS determinada.
-
-
Este cuadro sugiere que Bootstrap es una biblioteca valiosa que debe saber para ayudar a conseguir un trabajo. ¡Mira toda la oportunidad que hay para ayudar! También vale la pena señalar que este es solo un gráfico de señales positivas: las matemáticas no suman 100% porque no todos los sitios están usando un framework CSS. Un poco más de la mitad de todos los sitios no utilizan un framework CSS conocido. Muy interesante, ¿no?
Las utilidades de restablecimiento de CSS tienen la intención de normalizar o crear una línea base para elementos web nativos. En caso de que no lo supiera, cada navegador sirve su propia hoja de estilo para todos los elementos HTML, y cada navegador toma sus propias decisiones únicas sobre cómo se ven o se comportan esos elementos. Las utilidades de restablecimiento han analizado estos archivos, han encontrado sus puntos en común (o no) y han solucionado cualquier diferencia para que usted, como desarrollador, pueda diseñar en un navegador y tener una confianza razonable de que se verá igual en otro.
-
¡Así que echemos un vistazo a cuántos sitios están usando uno! Su existencia parece bastante razonable, entonces, ¿cuántas personas están de acuerdo con sus tácticas y las usan en sus sitios?
Gráfico de barras que muestra la adopción de tres utilidades de restablecimiento de CSS: Normalize.css (33%), Reset CSS (3%) y Pure CSS (0%). No hay diferencia en la adopción en páginas de escritorio y móviles.
- Figura 37. Adopción de utilidades de restablecimiento CSS.
-
-
- Resulta que aproximadamente un tercio de la web está usando normalize.css, que podría considerarse un enfoque más suave para la tarea que un reinicio. Miramos un poco más profundo, y resulta que Bootstrap incluye normalize.css, lo que probablemente representa una gran cantidad de su uso. Vale la pena señalar también que normalize.css tiene más adopción que Bootstrap, por lo que hay muchas personas que lo usan solo.
-
CSS @supports es una forma para que el navegador verifique si una combinación particular de propiedad-valor se analiza como válida y luego aplica estilos si la verificación regresa como verdadera.
Gráfico de barras que muestra la popularidad de las reglas @import y @supports "arroba". En el escritorio, @import se usa en el 28% de las páginas y @supports se usa en el 31%. Para dispositivos móviles, @import se usa en el 26% de las páginas y @supports se usa en el 29%.
- Figura 38. Popularidad de las reglas CSS 'arroba'.
-
-
Considerando que @supports se implementó en la mayoría de los navegadores en 2013, no es demasiado sorprendente ver una gran cantidad de uso y adopción. Estamos impresionados por la atención plena de los desarrolladores aquí. ¡Esto es una codificación considerada! El 30% de todos los sitios web están buscando algún soporte relacionado con la visualización antes de usarlo.
-
Un seguimiento interesante de esto es que hay más uso de @supports que de @imports ¡No esperábamos eso! @import ha estado en los navegadores desde 1994.
¡Hay mucho más aquí para investigar! Muchos de los resultados nos sorprendieron, y solo podemos esperar que ellos también lo hayan sorprendido a usted. Este sorprendente conjunto de datos hizo que el resumen fuera muy divertido, y nos dejó con muchos rastros y pistas para investigar si queremos descubrir las razones por qué algunos de los resultados son como son.
-
¿Qué resultados le parecieron más alarmantes? ¿Qué resultados te llevan a tu base de código para una consulta rápida?
-
Consideramos que la conclusión más importante de estos resultados es que las propiedades personalizadas ofrecen el máximo rendimiento en términos de rendimiento, DRYness y escalabilidad de sus hojas de estilo. Esperamos analizar las hojas de estilo de Internet nuevamente, en busca de nuevos datos y tentativas cartas. Comuníquese con @una o @argyleink en los comentarios con sus consultas, preguntas y afirmaciones. ¡Nos encantaría escucharlos!
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/ecommerce.html b/src/templates/es/2019/chapters/ecommerce.html
deleted file mode 100644
index 9d717a15aee..00000000000
--- a/src/templates/es/2019/chapters/ecommerce.html
+++ /dev/null
@@ -1,637 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"III","chapter_number":13,"title":"Ecommerce","description":"Capítulo sobre comercio electrónico del Almanaque Web de 2019 que cubre plataformas de comercio electrónico, payloads, imágenes, third-parties, rendimiento, seo y PWAs.","authors":["samdutton","alankent"],"reviewers":["voltek62"],"translators":["JMPerez"],"discuss":"1768","results":"https://docs.google.com/spreadsheets/d/1FUMHeOPYBgtVeMU5_pl2r33krZFzutt9vkOpphOSOss/","queries":"13_Ecommerce","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-12T00:00:00.000Z","chapter":"ecommerce"} %} {% block index %}
-
Casi el 10% de las páginas de inicio en este estudio resultaron ser parte de una plataforma de comercio electrónico. Una "plataforma de comercio electrónico" es un conjunto de software o servicios que permiten crear y operar una tienda en línea. Existen varios tipos de plataformas de comercio electrónico, por ejemplo:
-
-
Servicios de pago como Shopify que alojan su tienda y lo ayuda a comenzar. Proporcionan alojamiento de sitios web, plantillas de sitios y páginas, gestión de datos de productos, carritos de compras y pagos.
-
Plataformas de software como Magento Open Source que configura, aloja y administra usted mismo. Estas plataformas pueden ser potentes y flexibles, pero pueden ser más complejas de configurar y ejecutar que servicios como Shopify.
-
- Plataformas hosted o alojadas como Magento Commerce que ofrecen las mismas funciones que sus homólogos autohospedados, excepto que el alojamiento es administrado como un servicio por un tercero.
-
-
-
-
10%
- Figura 1. Porcentaje de páginas servidas por una plataforma de comercio electrónico.
-
-
Este análisis sólo pudo detectar sitios creados en una plataforma de comercio electrónico. Esto significa que las tiendas y mercados en línea más grandes, como Amazon, JD y eBay, no están incluidos aquí. También tenga en cuenta que los datos aquí proceden sólo de las páginas de inicio, por lo que no se incluyen páginas de categoría, producto u otras páginas. Lea más información sobre nuestra metodología.
¿Cómo comprobamos si una página está en una plataforma de comercio electrónico?
-
La detección se realiza a través de Wappalyzer. Wappalyzer es una utilidad multiplataforma que descubre las tecnologías utilizadas en los sitios web. Detecta sistemas de gestión de contenido, plataformas de comercio electrónico, servidores web, frameworks JavaScript, herramientas de analíticas y muchos más.
-
La detección de páginas no siempre es confiable, y algunos sitios bloquean explícitamente la detección para protegerse contra ataques automáticos. Es posible que no podamos capturar todos los sitios web que usan una plataforma de comercio electrónico en particular, pero estamos seguros de que los que detectamos están realmente en esa plataforma.
-
-
-
-
-
-
-
-
Móvil
-
Escritorio
-
-
-
-
-
Páginas de comercio electrónico
-
500.595
-
424.441
-
-
-
Total de páginas
-
5.297.442
-
4.371.973
-
-
-
Índice de adopción
-
9,45%
-
9,70%
-
-
-
-
-
- Figura 2. Porcentaje de plataformas de comercio electrónico detectado.
-
- Figura 3. Adopción de las 6 principales plataformas de comercio electrónico.
-
-
De las 116 plataformas de comercio electrónico que se detectaron, sólo seis se encuentran en más del 0,1% de los sitios web de escritorio o móviles. Tenga en cuenta que estos resultados no muestran variaciones por país, por tamaño de sitio u otras métricas similares.
-
La Figura 3 anterior muestra que WooCommerce tiene la mayor adopción con alrededor del 4% de los sitios web de escritorio y móviles. Shopify es el segundo con aproximadamente el 1,6% de adopción. Magento, PrestaShop, Bigcommerce y Shopware siguen con una adopción cada vez más pequeña, acercándose al 0,1%.
Gráfico de barras de la adopción de las 20 principales plataformas de comercio electrónico. Consulte la Figura 3 anterior para obtener una tabla de datos de adopción de las 6 plataformas principales.
- Figura 4. Adopción de las principales plataformas de comercio electrónico.
-
-
Hay 110 plataformas de comercio electrónico usadas por menos de un 0,1% de sitios web de escritorio o móvil. Alrededor de 60 de éstas tienen menos del 0,01% de sitios web móviles o de escritorio.
Las 6 principales plataformas de comercio electrónico representan el 8% de todos los sitios web. El resto de las 110 plataformas solo representan el 1,5% de los sitios web. Los resultados para escritorio y móvil son similares.
- Figura 5. Adopción combinada de las 6 principales plataformas de comercio electrónico versus las otras 110 plataformas.
-
-
El 7,87% de todas las peticiones en dispositivos móviles y el 8,06% en escritorio son para páginas de inicio servidas en una de las seis principales plataformas de comercio electrónico. Otro 1,52% de las peticiones en dispositivos móviles y 1,59% en escritorio son para páginas de inicio en las otras 110 plataformas de comercio electrónico.
El 9,7% de las páginas de escritorio usan una plataforma de comercio electrónico y el 9,5% de las páginas móviles usan una plataforma de comercio electrónico.
- Figura 6. Porcentaje de páginas que utilizan una plataforma de comercio electrónico.
-
-
Aunque la proporción de sitios web de escritorio fue ligeramente mayor en general, algunas plataformas populares (incluyendo WooCommerce, PrestaShop y Shopware) en realidad tienen más sitios web móviles que de escritorio.
Distribución de los percentiles 10, 25, 50, 75 y 90 del peso de la página de comercio electrónico. La página de comercio electrónico de escritorio situada en la mediana carga 2,7 MB. El percentil 10 es 1,0 MB, el 25 es 1,6 MB, el 75 es 4,5 MB y el 90 es 7,6 MB. Los sitios web de escritorio son ligeramente más altos que los móviles por décimas de megabytes.
- Figura 7. Distribución del peso de la página de comercio electrónico.
-
-
-
-
-
-
-
Distribución de los percentiles 10, 25, 50, 75 y 90 de peticiones por página de comercio electrónico. La página de comercio electrónico de escritorio situada en la mediana realiza 108 peticiones. El percentil 10 es 53 peticiones, el 25 es 76, el 75 es 153 y el 90 es 210. Los sitios web de escritorio son ligeramente más altos que los móviles en aproximadamente 10 peticiones.
- Figura 8. Distribución de peticiones por página de comercio electrónico.
-
-
La página de una plataforma de comercio electrónico de escritorio situada en la mediana carga 108 peticiones y 2,7 MB. El peso medio para todas páginas de escritorio es 74 peticiones y 1,9 MB. En otras palabras, las páginas de comercio electrónico realizan casi un 50% más de peticiones que otras páginas web, con payloads aproximadamente un 35% más grandes. En comparación, la página de inicio de amazon.com realiza alrededor de 300 peticiones en la primera carga, con un peso de página de alrededor de 5 MB, y ebay.com realiza alrededor de 150 peticiones con un peso de página de aproximadamente 3 MB. El peso de la página y el número de peticiones de páginas de inicio en plataformas de comercio electrónico es ligeramente menor en dispositivos móviles en cada percentil, pero alrededor del 10% de todas las páginas de inicio de comercio electrónico cargan más de 7 MB y realizan más de 200 peticiones.
-
Estos datos representan el payload y las peticiones sin hacer scroll. Claramente, hay una proporción significativa de sitios que parecen estar haciendo peticiones para más archivos (la mediana es superior a 100), con un payload total mayor que la que debería ser necesaria para la primera carga. Consulte también: Solicitudes y bytes de terceros más adelante.
-
Necesitamos investigar más para comprender mejor por qué tantas páginas de inicio en plataformas de comercio electrónico hacen tantas peticiones y tienen payloads tan grandes. Los autores ven regularmente páginas de inicio en plataformas de comercio electrónico que realizan cientos de peticiones en la primera carga, con payloads de varios megabytes. Si el número de peticiones y el payload son un problema para el rendimiento, ¿cómo se pueden reducir?
Los siguientes gráficos son para peticiones de escritorio:
-
-
-
-
-
-
-
Tipo
-
10
-
25
-
50
-
75
-
90
-
-
-
-
-
imagen
-
353
-
728
-
1.514
-
3.104
-
6.010
-
-
-
vídeo
-
156
-
453
-
1.325
-
2.935
-
5.965
-
-
-
script
-
199
-
330
-
572
-
915
-
1.331
-
-
-
fuente
-
47
-
85
-
144
-
226
-
339
-
-
-
css
-
36
-
59
-
102
-
180
-
306
-
-
-
html
-
12
-
20
-
36
-
66
-
119
-
-
-
audio
-
7
-
7
-
11
-
17
-
140
-
-
-
xml
-
0
-
0
-
0
-
1
-
3
-
-
-
otro
-
0
-
0
-
0
-
0
-
3
-
-
-
texto
-
0
-
0
-
0
-
0
-
0
-
-
-
-
-
- Figura 9. Percentiles de la distribución del peso de la página (en KB) por tipo de recurso.
-
-
-
-
-
-
-
-
Tipo
-
10
-
25
-
50
-
75
-
90
-
-
-
-
-
imagen
-
16
-
25
-
39
-
62
-
97
-
-
-
script
-
11
-
21
-
35
-
53
-
75
-
-
-
css
-
3
-
6
-
11
-
22
-
32
-
-
-
fuente
-
2
-
3
-
5
-
8
-
11
-
-
-
html
-
1
-
2
-
4
-
7
-
12
-
-
-
vídeo
-
1
-
1
-
2
-
5
-
9
-
-
-
otro
-
1
-
1
-
2
-
4
-
9
-
-
-
texto
-
1
-
1
-
1
-
2
-
3
-
-
-
xml
-
1
-
1
-
1
-
2
-
2
-
-
-
audio
-
1
-
1
-
1
-
1
-
3
-
-
-
-
-
- Figura 10. Percentiles de la distribución de peticiones por página por tipo de recurso.
-
-
Las imágenes constituyen el mayor número de peticiones y la mayor proporción de bytes para las páginas de comercio electrónico. La página de comercio electrónico de escritorio promedio incluye 39 imágenes con un peso de 1.514 KB (1,5 MB).
-
El número de peticiones JavaScript indica que un mejor bundling (y/o multiplexación HTTP/2) podría mejorar el rendimiento. Los archivos JavaScript no son significativamente grandes en términos de bytes totales, pero se realizan muchas peticiones por separado. Según el capítulo HTTP/2, más del 40% de las peticiones no se realizan usando HTTP/2. Del mismo modo, los archivos CSS tienen el tercer mayor número de peticiones, pero generalmente son pequeños. La combinación de archivos CSS (y/o HTTP/2) podría mejorar el rendimiento de dichos sitios. Según la experiencia de los autores, muchas páginas de comercio electrónico tienen una alta proporción de CSS y JavaScript no utilizados. Los vídeos pueden requerir una pequeña cantidad de peticiones pero, como es lógico, representan una alta proporción del peso de la página, particularmente en sitios con payloads pesadas.
Distribución de los percentiles 10, 25, 50, 75 y 90 de bytes de HTML por página de comercio electrónico. La página de comercio electrónico de escritorio promedio tiene 36 KB de HTML. El percentil 10 es 12 KB, el 25 es 20, el 75 es 66 y el 90 es 118. Los sitios web de escritorio tienen 1 ó 2 KB más de HTML que los sitios móviles.
- Figura 11. Distribución de bytes de HTML (en KB) por página de comercio electrónico.
-
-
Tenga en cuenta que el payload de HTML puede incluir otro código, como JSON, JavaScript o CSS incrustado en el marcado, en lugar de referenciarse como enlaces externos. El tamaño medio del HTML para las páginas de comercio electrónico es de 34 KB en dispositivos móviles y 36 KB en escritorio. Sin embargo, el 10% de las páginas de comercio electrónico tienen un tamaño de HTML de más de 115 KB.
-
Los tamaños de HTML en móvil no son muy diferentes de los de escritorio. En otras palabras, parece que los sitios no están entregando archivos HTML significativamente diferentes para diferentes dispositivos o tamaños de pantalla. En muchos sitios de comercio electrónico, el HTML de la página de inicio es grande. No sabemos si esto se debe a HTML hinchado o a otro código (como JSON) dentro de los archivos HTML.
Distribución de los percentiles 10, 25, 50, 75 y 90 de bytes de imagen por página de comercio electrónico. La página de comercio electrónico móvil promedio tiene 1.517 KB de imágenes. El percentil 10 es 318 KB, el 25 es 703, el 75 es 3.132 y el 90 es 5.881. Los sitios web para escritorio y dispositivos móviles tienen distribuciones similares.
- Figura 12. Distribución de bytes de imagen (en KB) por página de comercio electrónico.
-
-
-
-
-
-
-
Distribución de los percentiles 10, 25, 50, 75 y 90 de peticiones de imágenes por página de comercio electrónico. La página mediana de comercio electrónico de escritorio realiza 40 peticiones de imágenes. El percentil 10 es 16 peticiones, el 25 es 25, el 75 es 62 y el 90 es 97. La distribución de escritorio es ligeramente superior a la móvil en 2-10 peticiones en cada percentil.
- Figura 13. Distribución de peticiones de imágenes por página de comercio electrónico.
-
-
Tenga en cuenta que debido a que nuestra metodología de recopilación de datos no simula las interacciones del usuario en páginas como hacer clic o scroll, las imágenes cargadas de forma diferida (_lazy loading_) no se representarían en estos resultados.
-
Las Figuras 12 y 13 muestran que la página de comercio electrónico promedio tiene 37 imágenes y representan un tráfico de 1.517 KB en dispositivos móviles, 40 imágenes y 1.524 KB en computadoras de escritorio. ¡El 10% de las páginas de inicio tienen 90 o más imágenes y representan en total casi 6 MB!
-
-
1.517 KB
- Figura 14. El número medio de bytes de imagen por página de comercio electrónico en móvil.
-
-
Una proporción significativa de las páginas de comercio electrónico tienen un payload de imágenes considerable y realizan una gran cantidad de peticiones de imágenes en la primera carga. Consulte el informe Estado de las imágenes de HTTP Archive y los capítulos media y peso de página para más contexto.
-
Los propietarios de sitios web quieren que sus sitios se vean bien en dispositivos modernos. Como resultado, muchos sitios ofrecen las mismas imágenes de productos de alta resolución a todos los usuarios, sin importar la resolución o el tamaño de la pantalla. Es posible que los desarrolladores no estén al tanto (o no quieran usar) técnicas responsive que permitan servir de forma eficiente la mejor imagen posible a diferentes usuarios. Vale la pena recordar que las imágenes de alta resolución no necesariamente aumentan las tasas de conversión. Por el contrario, el uso excesivo de imágenes pesadas puede afectar la velocidad de la página y, por lo tanto, puede reducir las tasas de conversión. En la experiencia de los autores revisando sitios, algunos desarrolladores y otras partes interesadas no adoptan lazy loading de imágenes por preocupaciones sobre SEO entre otros.
-
Necesitamos hacer más análisis para comprender mejor por qué algunos sitios no están utilizando técnicas de imágenes responsive o lazy loading. También necesitamos proporcionar una guía que ayude a las plataformas de comercio electrónico a entregar imágenes nítidas de manera confiable a aquellos con dispositivos de alta gama y buena conectividad, al tiempo que brindamos la mejor experiencia posible a los dispositivos de gama baja y aquellos con una conectividad pobre.
Gráfico de barras que muestra la popularidad de varios formatos de imagen. JPEG es el formato más popular con el 54% de las imágenes en las páginas de comercio electrónico de escritorio. Los siguientes son PNG con un 27%, GIF con un 14%, SVG con un 2% y WebP e ICO con un 1% cada uno.
Tenga en cuenta que algunos servicios de imágenes o CDN entregarán automáticamente WebP (en lugar de JPEG o PNG) a plataformas que admitan WebP, incluso para una URL con el sufijo `.jpg` o` .png`. Por ejemplo, IMG_20190113_113201.jpg devuelve una imagen WebP en Chrome. Sin embargo, la forma en que HTTP Archive detecta los formatos de imagen es verificar primero las palabras clave en el tipo MIME y usar como alternativa la extensión de archivo. Esto significa que el formato para imágenes con una URL como la anterior se clasifica como WebP, ya que WebP es compatible con HTTP Archive como agente de usuario.
Una de cada cuatro imágenes en las páginas de comercio electrónico son PNG. La gran cantidad de peticiones de PNG desde las páginas de plataformas de comercio electrónico es probablemente para imágenes de productos. Muchos sitios de comercio usan PNG con imágenes fotográficas porque soportan transparencia.
-
El uso de WebP haciendo fallback a PNG puede ser una alternativa mucho más eficiente, ya sea a través de un elemento de imagen o mediante la detección del soporte del agente de usuario a través de un servicio de imágenes como Cloudinary.
Sólo el 1% de las imágenes en las plataformas de comercio electrónico son WebP, lo que coincide con la experiencia de los autores en las revisiones del sitio. WebP es compatible con todos los navegadores modernos excepto Safari y tiene buenos mecanismos de fallback disponibles. WebP admite transparencia y es un formato mucho más eficiente que PNG para imágenes fotográficas (consulte la sección PNG anterior).
-
Nosotros, como comunidad web, podemos abogar por proporcionar transparencia usando WebP con unn fallback a PNG y/o usando WebP/JPEG con un fondo de color sólido. Parece que WebP rara vez se usa en plataformas de comercio electrónico, a pesar de la disponibilidad de guías y herramientas (por ejemplo, Squoosh y cwebp). Necesitamos investigar más sobre por qué no ha habido más aceptación de WebP, que ahora tiene casi 10 años.
- Figura 16. Distribución de las dimensiones intrínsecas de imagen (en píxeles) por página de comercio electrónico.
-
-
Las dimensiones medias ('rango medio') para las imágenes solicitadas por las páginas de comercio electrónico son 247x196 px en dispositivos móviles y 240x192 px en escritorio. El 10% de las imágenes solicitadas por las páginas de comercio electrónico tienen al menos 693x512 px en dispositivos móviles y 800x546 px en escritorio. Tenga en cuenta que estas dimensiones son los tamaños intrínsecos de las imágenes, no su tamaño de visualización.
-
Las dimensiones de la imagen en cada percentil hasta la mediana son similares en dispositivos móviles y escritorio, o incluso en algunos casos un poco más grandes en dispositivos móviles. Parece que muchos sitios no ofrecen diferentes dimensiones de imágenes para diferentes ventanas o, en otras palabras, no utilizando técnicas de imagen responsive. Servir imágenes más grandes en móvil en algunos casos puede (o no) explicarse por sitios que utilizan detección de dispositivo o pantalla.
-
Necesitamos investigar más sobre por qué muchos sitios (aparentemente) no ofrecen diferentes tamaños de imagen a diferentes tamaños de pantalla.
Muchos sitios web, especialmente las tiendas en línea, cargan una cantidad significativa de código y contenido de terceros: para análisis, pruebas A/B, seguimiento del comportamiento del cliente, publicidad y soporte de redes sociales. El contenido de terceros puede tener un impacto significativo en el rendimiento. La herramienta third-party-web de Patrick Hulce se utiliza para determinar las solicitudes de terceros para este informe, y esto se discute más en el capítulo de Third Parties.
Distribución de los percentiles 10, 25, 50, 75 y 90 de las solicitudes de terceros por página de comercio electrónico. El número medio de solicitudes de terceros en escritorio es 19. Los percentiles 10, 25, 75 y 90 son: 4, 9, 34 y 54. En escritorio hay 1 ó 2 peticiones más que en móvil en cada percentil.
- Figura 17. Distribución de peticiones de terceros por página de comercio electrónico.
-
-
-
-
-
-
-
Distribución de los percentiles 10, 25, 50, 75 y 90 de bytes de terceros por página de comercio electrónico. El número medio de bytes de terceros en el escritorio es de 320 KB. Los percentiles 10, 25, 75 y 90 son: 42, 129, 651 y 1.071. En escriorio es 10-30 KB más alto que en móvil en cada percentil.
- Figura 18. Distribución de bytes de terceros por página de comercio electrónico.
-
-
La página de inicio mediana ('rango medio') en una plataforma de comercio electrónico realiza 17 peticiones de contenido de terceros en dispositivos móviles y 19 en escritorio. El 10% de todas las páginas de inicio en plataformas de comercio electrónico realizan más de 50 peticiones de contenido de terceros, lo que supone un total de más de 1 MB.
-
Otros estudios han indicado que el contenido de terceros puede ser un gran cuello de botella en el rendimiento. Este estudio muestra que 17 o más peticiones (50 o más para el 10% superior) es la norma para las páginas de comercio electrónico.
Distribución de los percentiles 10, 25, 50, 75 y 90 de peticiones de terceros por página de comercio electrónico para cada plataforma. Shopify y Bigcommerce cargan la mayoría de las peticiones de terceros en las distribuciones con unas 40 peticiones en la mediana.
- Figura 19. Distribución de solicitudes de terceros por página móvil para cada plataforma de comercio electrónico.
-
-
-
-
-
-
-
Distribución de los percentiles 10, 25, 50, 75 y 90 de bytes de terceros (KB) por página de comercio electrónico para cada plataforma. Shopify y Bigcommerce cargan la mayoría de los bytes de terceros en las distribuciones con más de 1.000 KB en la mediana.
- Figura 20. Distribución de bytes de terceros (KB) por página móvil para cada plataforma de comercio electrónico.
-
-
Las plataformas como Shopify pueden extender sus servicios usando JavaScript del lado del cliente, mientras que otras plataformas como Magento usan más extensiones del lado del servidor. Esta diferencia en la arquitectura afecta a los números mostrados aquí.
-
Claramente, las páginas en algunas plataformas de comercio electrónico hacen más peticiones de contenido de terceros e incurren en una mayor carga de contenido de terceros. Se podría realizar un análisis adicional de por qué las páginas de algunas plataformas realizan más peticiones y tienen payloads de terceros más grandes que otras.
Gráfico de barras de la distribución promedio de las experiencias de FCP para las seis principales plataformas de comercio electrónico. WooCommerce tiene la mayor densidad de experiencias FCP lentas con un 43%. Shopify tiene la mayor densidad de experiencias rápidas de FCP con 47%.
- Figura 21. Distribución promedio de experiencias FCP por plataforma de comercio electrónico.
-
-
First Contentful Paint mide el tiempo que transcurre desde la navegación hasta que se muestra por primera vez contenido como texto o una imagen. En este contexto, rápido significa FCP en menos de un segundo, lento significa FCP en 3 segundos o más, y moderado es el resto. Tenga en cuenta que el contenido y el código de terceros pueden tener un impacto significativo en FCP.
-
Las seis principales plataformas de comercio electrónico tienen peor FCP en dispositivos móviles que en escritorio: menos rápido y más lento. Tenga en cuenta que el FCP se ve afectado por la capacidad del dispositivo (potencia de procesamiento, memoria, etc.) así como por la conectividad.
-
Necesitamos establecer por qué FCP es peor en dispositivos móviles que en escritorio. ¿Cuáles son las causas: conectividad y/o capacidad del dispositivo, o algo más?
Distribución de las puntuaciones de la categoría PWA de Lighthouse para páginas de comercio electrónico. En una escala de 0 (fallando) a 1 (perfecto), el 40% de las páginas obtienen una puntuación de 0,33. El 1% de las páginas obtienen una puntuación superior a 0,6.
- Figura 22. Distribución de las puntuaciones en la categoría PWA en Lighthouse para páginas de comercio electrónico móvil.
-
-
Más del 60% de las páginas de inicio en plataformas de comercio electrónico obtienen una puntuación de PWA en Lighthouse de entre 0,25 y 0,35. Menos del 20% de las páginas de inicio en las plataformas de comercio electrónico obtienen una puntuación de más de 0,5 y menos del 1% de las páginas de inicio obtienen una puntuación de más de 0,6.
-
Lighthouse devuelve una puntuación de Progressive Web App (PWA) entre 0 y 1. 0 es la peor puntuación posible y 1 es la mejor. Las auditorías de PWA se basan en la lista de verificación de PWA de referencia, que enumera 14 requisitos. Lighthouse ha realizado auditorías automatizadas para 11 de los 14 requisitos. Los 3 restantes sólo pueden probarse manualmente. Cada una de las 11 auditorías PWA automatizadas se ponderan por igual, por lo que cada una aporta aproximadamente 9 puntos a su puntuación PWA.
-
Si al menos una de las auditorías de PWA obtuvo una puntuación nula, Lighthouse anula la puntuación para toda la categoría de PWA. Este fue el caso del 2,32% de las páginas móviles.
-
Claramente, la mayoría de las páginas de comercio electrónico fallan en la mayoría de las auditorías de la lista de verificación de PWA. Necesitamos hacer más análisis para comprender mejor qué auditorías están fallando y por qué.
Este estudio exhaustivo sobre el uso del comercio electrónico muestra algunos datos interesantes y también las amplias variaciones en los sitios de comercio electrónico, incluso entre aquellos creados en la misma plataforma de comercio electrónico. Aunque hemos entrado en muchos detalles aquí, hay muchos más análisis que podríamos hacer en este espacio. Por ejemplo, no obtuvimos puntuaciones de accesibilidad este año (consulte el capítulo de accesibilidad para obtener más información al respecto). Del mismo modo, sería interesante segmentar estas métricas por geografía. Este estudio detectó 246 proveedores de anuncios en páginas de inicio en plataformas de comercio electrónico. Otros estudios (¿tal vez en el Almanaque Web del próximo año?) podrían calcular qué proporción de sitios en plataformas de comercio electrónico muestran anuncios. WooCommerce obtuvo números muy altos en este estudio, por lo que otra estadística interesante que podríamos ver el próximo año es si algunos proveedores de alojamiento están instalando WooCommerce pero no lo habilitan, lo que causa cifras infladas.
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/fonts.html b/src/templates/es/2019/chapters/fonts.html
deleted file mode 100644
index 529b3d687ae..00000000000
--- a/src/templates/es/2019/chapters/fonts.html
+++ /dev/null
@@ -1,678 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":6,"title":"Fuentes","description":"Capítulo Fuentes del Almanaque Web de 2019 que cubre desde dónde se cargan las fuentes, formatos de fuente, rendimiento de carga de fuentes, fuentes variables y fuentes de color.","authors":["zachleat"],"reviewers":["hyperpress","AymenLoukil"],"translators":["c-torres"],"discuss":"1761","results":"https://docs.google.com/spreadsheets/d/108g6LXdC3YVsxmX1CCwrmpZ3-DmbB8G_wwgQHX5pn6Q/","queries":"06_Fonts","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-23T00:00:00.000Z","chapter":"fonts"} %} {% block index %}
-
Las fuentes web permiten una tipografía hermosa y funcional en la web. El uso de fuentes web no solo fortalece el diseño, sino que democratiza un subconjunto del diseño, ya que permite un acceso más fácil a aquellos que quizás no tengan habilidades de diseño particularmente sólidas. Sin embargo, a pesar de todo lo bueno que pueden hacer, las fuentes web también pueden causar un gran daño al rendimiento de su sitio si no se cargan correctamente.
-
¿Son positivas para la web? ¿Proporcionan más beneficios que daños? ¿Están los estándares web suficientemente pavimentados para fomentar las mejores prácticas de carga de fuentes web de forma predeterminada? Y si no es así, ¿qué necesita cambiar? Echemos un vistazo basado en datos para ver si podemos o no responder a esas preguntas inspeccionando cómo se utilizan las fuentes web en la web hoy en día.
La primera y más destacada pregunta: rendimiento. Hay un capítulo completo dedicado al rendimiento pero aquí profundizaremos un poco en los problemas de rendimiento específicos de la fuente.
-
El uso de fuentes web alojadas facilita la implementación y el mantenimiento, pero el alojamiento propio ofrece el mejor rendimiento. Dado que las fuentes web de forma predeterminada hacen que el texto sea invisible mientras se carga la fuente web (también conocido como Destello de Texto Invisible, o FOIT por sus siglas en inglés), el rendimiento de las fuentes web puede ser más crítico que los activos que no bloquean, como las imágenes.
Diferenciar el alojamiento propio del alojamiento de terceros es cada vez más relevante en un mundo [HTTP/2] (./ http2), donde la brecha de rendimiento entre una conexión del mismo dominio y de un dominio diferente puede ser más amplia. Las solicitudes del mismo dominio tienen el gran beneficio de un mejor potencial de priorización frente a otras solicitudes del mismo dominio en la cascada.
-
Las recomendaciones para mitigar los costos de rendimiento de cargar fuentes web desde otro dominio incluyen el uso de preconnect, dns-prefetch y preloadsugerencias de recursos, pero las fuentes web de alta prioridad deben ser solicitadas al alojamiento propio para minimizar el impacto en el rendimiento de las fuentes web. Esto es especialmente importante para las fuentes utilizadas por contenido visualmente prominente o cuerpo de texto que ocupan la mayor parte de una página.
Gráfico de barras que muestra la popularidad de las estrategias de alojamiento propio y de terceros para fuentes web. El 75% de las páginas web móviles utilizan dominios de terceros y el 25% alojamiento propio. Los sitios web de escritorio tienen un uso similar.
- Figura 1. Estrategias populares de alojamiento de fuentes web.
-
-
El hecho de que tres cuartas partes estén alojadas tal vez no sea sorprendente dado el dominio de Google Fonts que discutiremos más adelante.
-
Google ofrece fuentes que utilizan archivos CSS de terceros alojados en https://fonts.googleapis.com. Los desarrolladores agregan solicitudes a estas hojas de estilo usando etiquetas<link> en su código. Si bien estas hojas de estilo bloquean el procesamiento, son muy pequeñas. Sin embargo, los archivos de fuentes se alojan en otro dominio, https://fonts.gstatic.com. El modelo de requerir dos peticiones separadas a dos dominios diferentes hace que preconnect sea una gran opción aquí para la segunda solicitud que no se descubrirá hasta que se descargue el CSS.
-
Tenga en cuenta que, si bien preload sería una buena adición para cargar los archivos de fuentes más arriba en la cascada de solicitudes (recuerde que preconnect configura la conexión, no solicita el contenido del archivo), preload aún no está disponible con Google Fonts. Google Fonts genera URLs únicas para sus archivos de fuentes que están sujetos a cambios.
- Figura 2. Los 20 dominios principales de fuentes por porcentaje de solicitudes.
-
-
El dominio de Google Fonts aquí fue simultáneamente sorprendente y no sorprendente. No fue sorprendente porque esperaba que el servicio fuera el más popular y sorprendente por el dominio absoluto de su popularidad. El 75% de las solicitudes de fuentes es asombroso. TypeKit fue un distante segundo lugar de un solo dígito, con la biblioteca Bootstrap representando un tercer lugar aún más distante.
-
-
29%
- Figura 3. Porcentaje de páginas que incluyen un vínculo de hoja de estilo de Google Fonts en el documento <head>.
-
-
Si bien el alto uso de Google Fonts aquí es muy impresionante, también es digno de mención que solo el 29% de las páginas incluían un elemento <link> de Google Fonts. Esto podría significar algunas cosas:
-
-
Cuando las páginas usan fuentes de Google, usan muchas fuentes de Google. Se proporcionan sin costo monetario, después de todo. ¿Quizás están siendo utilizados en un editor WYSIWYG popular? Esta parece una explicación muy probable.
-
O una historia más improbable es que podría significar que mucha gente está usando Google Fonts con @import en lugar de <link>.
-
- O si queremos irnos al extremo profundo hacia escenarios súper improbables, podría significar que muchas personas están usando Google Fonts con un HTTP Link: header en su lugar.
-
-
-
-
0.4%
- Figura 4. Porcentaje de páginas que incluyen un vínculo de hoja de estilo de Google Fonts como primer elemento secundario del documento <head>.
-
-
La documentación de Google Fonts recomienda que el <link> del CSS de Google Fonts se coloque como el primer hijo en el <head> de una página. ¡Esta es una gran pregunta! En la práctica, esto no es común, ya que solo cerca del medio porciento de todas las páginas (unas 20.000 páginas) siguió este consejo.
-
Más aún, si una página usa preconnect o dns-prefetch como elementos <link>, estos vendrían antes del CSS de Google Fonts de todos modos. Siga leyendo para obtener más información sobre estas sugerencias de recursos.
Como se mencionó anteriormente, una manera súper fácil de acelerar las solicitudes de fuentes web a un dominio de terceros es usar la sugerencia de recursospreconnect.
-
-
1.7%
- Figura 5. Porcentaje de páginas móviles que se pre-conectan previamente a un dominio de fuentes web.
-
-
- ¡Guauu! ¡Menos del 2% de las páginas están usando preconnect! Dado que Google Fonts está al 75%, ¡debería ser más alto! Desarrolladores: si usa Google Fonts, use preconnect! Google Fonts: ¡proselitice más preconnect!
-
-
De hecho, si está usando Google Fonts, continúe y agregue esto a su <head> si aún no está allí:
WOFF2 está bastante bien soportado en los navegadores web hoy. Google Fonts sirve WOFF2, un formato que ofrece una compresión mejorada con respecto a su predecesor WOFF, que en sí mismo ya era una mejora con respecto a otros formatos de fuente existentes.
Gráfico de barras que muestra la popularidad de los tipos MIME de fuentes web. WOFF2 se utiliza en el 74% de las fuentes, seguido del 13% WOFF, el 6% de octet-stream, el 3% TTF, el 2% plano, el 1% HTML, el 1% SFNT y menos del 1% para todos los demás tipos. Las computadoras de escritorio y los dispositivos móviles tienen distribuciones similares.
- Figura 7. Popularidad de los tipos MIME de fuentes web.
-
-
Desde mi perspectiva, se podría argumentar que solo se opte por WOFF2 para fuentes web después de ver los resultados aquí. Me pregunto de dónde viene el doble dígito en uso de WOFF. ¿Quizás los desarrolladores todavía ofrecen fuentes web en Internet Explorer?
-
Tercer lugar octet-stream (y plano un poco mas abajo) parecería sugerir que muchos servidores web están configurados incorrectamente, enviando un tipo MIME incorrecto con solicitudes de archivos de fuentes web.
-
Profundicemos un poco más y veamos los valores format() usados en la propiedad src: de las declaraciones @font-face:
Gráfico de barras que muestra la popularidad de los formatos utilizados en las declaraciones de fuentes. El 69% de las declaraciones @font-face de las páginas de escritorio especifican el formato WOFF2, 11% WOFF, 10% TrueType, 8% SVG, 2% EOT y menos del 1% OpenType, TTF y OTF. La distribución de las páginas móviles es similar.
- Figura 8. Popularidad de los formatos de fuente en las declaraciones @font-face.
-
-
Estaba esperando ver fuentes SVG en declive. Tienen errores y las implementaciones se han eliminado de todos los navegadores excepto Safari. Es hora de dejarlas a todas.
-
El punto de datos SVG aquí también me hace preguntarme con qué tipo de MIME están sirviendo estas fuentes SVG. No veo image/svg+xml en ninguna parte de la Figura 7. De todos modos, no se preocupe por arreglar eso, ¡simplemente deshágase de ellas!
- Figura 9. Las 20 principales combinaciones de formatos de fuente.
-
-
Este conjunto de datos parece sugerir que la mayoría de las personas ya están usando WOFF2-only en sus bloques @font-face. Pero esto es engañoso, por supuesto, según nuestra discusión anterior sobre el dominio de Google Fonts en el conjunto de datos. Google Fonts utiliza algunos métodos de rastreo para ofrecer un archivo CSS simplificado y solo incluye el format() más moderno. Como era de esperar, WOFF2 domina los resultados aquí por esa razón, ya que el soporte del navegador para WOFF2 ha sido bastante amplio desde hace algún tiempo.
-
Es importante destacar que estos datos en particular no respaldan ni restan mérito al caso de pasar solo a WOFF2 todavía, pero sigue siendo una idea tentadora.
La herramienta número uno que tenemos para combatir el comportamiento de carga de fuentes web predeterminado de "invisible durante la carga" (también conocido como FOIT por sus siglas en inglés), es font-display. Agregar font-display: swap a su bloque @font-face es una manera fácil de decirle al navegador que muestre el texto de respaldo mientras se carga la fuente web.
-
Soporte de navegador es genial tambien. Internet Explorer y la versión anterior a Chromium Edge no son compatibles, pero también representan el texto de respaldo de forma predeterminada cuando se carga una fuente web (aquí no se permiten FOIT). Para nuestras pruebas de Chrome, ¿con qué frecuencia se usa font-display?
-
-
26%
- Figura 10. Porcentaje de páginas móviles que utilizan el estilo font-display.
-
-
Gráfico de barras que muestra el uso del estilo font-display. El 2,6% de las páginas móviles configuran este estilo en "swap", 1,5% en "auto", 0,7% en "block", 0,4% en "fallback", 0,2% en "optional" y 0,1% en "swap" entre comillas. que no es válido. La distribución de escritorio es similar, excepto que el uso de "swap" es menor en 0.4 puntos porcentuales y el uso "auto" es mayor en 0.1 puntos porcentuales.
Como una manera fácil de mostrar texto de respaldo mientras se carga una fuente web, font-display: swap reina suprema y es el valor más común. swap también es el valor predeterminado utilizado por los nuevos fragmentos de código de Google Fonts. Hubiera esperado que optional (solo renderizado si se almacena en caché) tuviera un poco más de uso aquí, ya que algunos promotores prominentes de los desarrolladores presionaron un poco por ello, pero sin lugar.
Ésta es una pregunta que requiere cierto matiz. ¿Cómo se utilizan las fuentes? ¿Por cuánto contenido hay en la página? ¿Dónde vive este contenido en el diseño? ¿Cómo se renderizan las fuentes? Sin embargo, en lugar de matices, profundicemos en un análisis amplio y de mano dura centrado específicamente en el recuento de solicitudes.
Gráfico de barras que muestra la distribución de solicitudes de fuentes por página. Los percentiles 10, 25, 50, 75 y 90 para escritorio son: 0, 1, 3, 6 y 9 solicitudes de fuentes. La distribución para móviles es idéntica hasta los percentiles 75 y 90, donde las páginas móviles solicitan 1 fuente menos.
- Figura 12. Distribución de solicitudes de fuentes por página.
-
-
La página web mediana realiza tres solicitudes de fuentes web. En el percentil 90, solicitó seis y nueve fuentes web en dispositivos móviles y computadoras de escritorio, respectivamente.
Histograma que muestra la distribución del número de solicitudes de fuentes por página. El número más popular de solicitudes de fuentes es 0 en el 22% de las páginas de escritorio. La distribución cae al 9% de las páginas que tienen 1 fuente, luego alcanza el 10% para 2-4 fuentes antes de caer a medida que aumenta el número de fuentes. Las distribuciones de escritorio y móvil son similares, aunque la distribución móvil se inclina ligeramente hacia tener menos fuentes por página.
- Figura 13. Histograma de fuentes web solicitadas por página.
-
-
Dicho esto, hay un poco más de solicitudes de fuentes realizadas en dispositivos móviles. Mi corazonada aquí es que hay menos tipos de letra disponibles en dispositivos móviles, lo que a su vez significa menos accesos local() en Google Fonts CSS, recurriendo a las solicitudes de red para estos.
- Figura 14. La mayor cantidad de solicitudes de fuentes web en una sola página.
-
-
El premio a la página que solicita más fuentes web es para un sitio que hizo 718 solicitudes de fuentes web!
-
Después de sumergirse en el código, ¡todas esas 718 solicitudes van a Google Fonts! Parece que un plugin de optimización del contenido "de la parte superior de la página" para WordPress que funciona mal se ha vuelto loco en este sitio y está solicitando (¿Ataque DDoS?) todas las fuentes de Google.
-
Es irónico que un complemento de optimización del rendimiento pueda empeorar su rendimiento.
- Figura 15. Porcentaje de páginas móviles que declaran una fuente web con la propiedad unicode-range.
-
-
- unicode-range es una excelente propiedad de CSS para que el navegador sepa específicamente qué puntos de código le gustaría usar la página en el archivo de fuente. Si la declaración @font-face tiene un unicode-range, el contenido de la página debe coincidir con uno de los puntos de código en el rango antes de que se solicite la fuente. Es algo muy bueno.
-
-
Esta es otra métrica que espero que esté sesgada por el uso de Google Fonts, ya que Google Fonts usa unicode-range en la mayoría (si no en todos) de su CSS. Espero que esto sea menos común en la tierra de los usuarios, pero tal vez sea posible filtrar las solicitudes de Google Fonts en la próxima edición del Almanaque.
- Figura 16. Porcentaje de páginas móviles que declaran una fuente web con la propiedad local ().
-
-
local() es una buena forma de hacer referencia a una fuente del sistema en su @font-facesrc. Si la fuente local() existe, no necesita solicitar una fuente web en absoluto. Google Fonts usa esto de manera extensa y controvertida, por lo que es probable que sea otro ejemplo de datos sesgados si estamos tratando de obtener patrones de la tierra del usuario.
- +
- Figura 17. Porcentaje de páginas de escritorio y móviles que incluyen un estilo con la propiedad font-stretch.
-
-
- Históricamente, font-stretch ha sufrido de un soporte deficiente del navegador y no era una prpopiedad @font-face conocida. Lee mas sobre font-stretch en MDN. Pero el soporte de los navegadores se ha ampliado.
-
-
Se ha sugerido que el uso de fuentes condensadas en ventanas gráficas más pequeñas permite ver más texto, pero este enfoque no se usa comúnmente. Dicho esto, que esta propiedad se use medio punto porcentual más en computadoras de escritorio que en dispositivos móviles es inesperado, y el 7% parece mucho más alto de lo que hubiera predicho.
Las fuentes variables permite incluir varios tamaños y estilos de fuente en un archivo de fuente.
-
-
1.8%
- Figura 18. Porcentaje de páginas que incluyen una fuente variable.
-
-
Incluso con un 1.8%, esto fue más alto de lo esperado, aunque estoy emocionado de ver esto despegar. Google Fonts v2 incluye cierto soporte para fuentes variables.
Gráfico de barras que muestra el uso de la propiedad font-variation-settings. El 42% de las propiedades en las páginas de escritorio se establecen en el valor "opsz", el 32% en "wght", el 16% en "wdth", el 2% o menos en "roun", "crsb", "slnt", "inln" , y más. Las diferencias más notables entre las páginas de escritorio y móviles son el 26% de uso de "opsz", el 38% de "wght" y el 23% de "wdth".
- Figura 19. Uso de los ejes font-variation-settings.
-
-
A través del lente de este gran conjunto de datos, estos son tamaños de muestra muy bajos; tome estos resultados con un grano de sal. Sin embargo, opsz como el eje más común en las páginas de escritorio es notable, con wght y wdth al final. En mi experiencia, las demostraciones introductorias de fuentes variables suelen estar basadas en el peso.
- Figura 20. El número de páginas web de escritorio que incluyen una fuente de color.
-
-
El uso aquí de estas es básicamente inexistente, pero puede consultar el excelente recurso Color Fonts! WTF? para obtener más información. Similar (pero no en absoluto) al formato SVG para fuentes (que es malo y va a desaparecer), esta le permite incrustar SVG dentro de archivos OpenType, lo cual es increíble y genial.
Lo más importante aquí es que Google Fonts domina la discusión de fuentes web. Los enfoques que han adoptado pesan mucho sobre los datos que hemos registrado aquí. Los aspectos positivos aquí son el fácil acceso a fuentes web, buenos formatos de fuente (WOFF2) y configuraciones gratuitas de unicode-range. Las desventajas aquí son los inconvenientes de rendimiento asociados con el alojamiento de terceros, las solicitudes de dominios diferentes y la falta de acceso al preload.
-
Espero que en el futuro veamos el "Aumento de la fuente variable". Esto debe combinarse con una disminución en las solicitudes de fuentes web, ya que las fuentes variables combinan varios archivos de fuentes individuales en un solo archivo de fuentes compuestas. Pero la historia nos ha demostrado que lo que suele pasar aquí es que optimizamos una cosa y luego añadimos más cosas para cubrir la vacante.
-
Será muy interesante ver si las fuentes de color aumentan en popularidad. Espero que estos sean mucho más especializados que las fuentes variables, pero es posible que vean una línea de vida en el espacio de fuente del icono.
-
Mantengan esas fuentes heladas.
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/javascript.html b/src/templates/es/2019/chapters/javascript.html
deleted file mode 100644
index 156197f0632..00000000000
--- a/src/templates/es/2019/chapters/javascript.html
+++ /dev/null
@@ -1,433 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":1,"title":"JavaScript","description":"JavaScript chapter of the 2019 Web Almanac covering how much JavaScript we use on the web, compression, libraries and frameworks, loading, and source maps.","authors":["housseindjirdeh"],"reviewers":["obto","paulcalvano","mathiasbynens"],"translators":["c-torres"],"discuss":"1756","results":"https://docs.google.com/spreadsheets/d/1kBTglETN_V9UjKqK_EFmFjRexJnQOmLLr-I2Tkotvic/","queries":"01_JavaScript","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"javascript"} %} {% block index %}
-
JavaScript es un lenguaje de script que permite construir experiencias interactivas y complejas en la web. Esto incluye responder a las interacciones del usuario, actualizar contenido dinámico en una página, etc. Cualquier cosa que involucre el comportamiento de una página web cuando ocurra un evento es para lo que se usa JavaScript.
-
La especificación del lenguaje en sí, junto con muchas bibliotecas y marcos creados por la comunidad utilizados por desarrolladores de todo el mundo, ha cambiado y evolucionado desde que se creó el lenguaje en 1995. Las implementaciones e intérpretes de JavaScript también han seguido progresando, haciendo que el lenguaje sea utilizable en muchos entornos, no solo navegadores web.
-
HTTP Archive explora millones de páginas todos los meses y los ejecuta a través de una instancia privada de WebPageTest para almacenar información clave de cada página. (Puedes aprender más sobre esto en nuestra metodología). En el context de JavaScript, HTTP Archive proporciona información extensa sobre el uso del lenguaje en toda la web. Este capítulo consolida y analiza muchas de estas tendencias.
JavaScript es el recurso más costoso que enviamos a los navegadores, ya que tiene que ser descargado, analizado, compilado y finalmente ejecutado. Aunque los navegadores han disminuido significativamente el tiempo que lleva analizar y compilar scripts, la descarga y la ejecución se han convertido en las etapas más costosas cuando JavaScript es procesado por una página web.
-
Enviar paquetes de JavaScript más pequeños al navegador es la mejor manera de reducir los tiempos de descarga y, a su vez, mejorar el rendimiento de la página.Pero, ¿cuánto JavaScript utilizamos realmente?
Gráfico de barras que muestra que 70 bytes de JavaScript se usa en el percentil p10, 174 bytes para p25, 373 bytes para p50, 693 bytes para p75 y 1.093 bytes para p90
- Figura 1. Distribución de bytes de JavaScript por página.
-
-
La Figura 1 anterior muestra que utilizamos 373 KB de JavaScript en el percentil 50, o mediana. En otras palabras, el 50% de todos los sitios envían más de este JavaScript a sus usuarios.
-
Mirando estos números, es natural preguntarse si esto es demasiado JavaScript. Sin embargo, en términos de rendimiento de la página, el impacto depende completamente de las conexiones de red y los dispositivos utilizados. Lo que nos lleva a nuestra siguiente pregunta: ¿cuánto JavaScript enviamos cuando comparamos clientes móviles y de escritorio?
Gráfico de barras que muestra 76 bytes / 65 bytes de JavaScript se usa en el percentil p10 en computadoras de escritorio y dispositivos móviles respectivamente, 186/164 bytes para p25, 391/359 bytes para p50, 721/668 bytes para p75 y 1.131 / 1.060 bytes para p90 .
- Figura 2. Distribución de JavaScript por página por dispositivo.
-
-
En cada percentil, estamos enviando un poco más de JavaScript a los dispositivos de escritorio que a los dispositivos móviles.
Después de ser analizado y compilado, el JavaScript cargado por el navegador debe procesarse (o ejecutarse) antes de poder ser utilizado. Los dispositivos varían y su potencia de cálculo puede afectar significativamente la rapidez con que se puede procesar JavaScript en una página. ¿Cuáles son los tiempos de procesamiento actuales en la web?
-
Podemos tener una idea analizando los tiempos de procesamiento de subprocesos principales para V8 en diferentes percentiles:
Gráfico de barras que muestra 141 ms / 377 ms de tiempo de procesamiento se utiliza en el percentil p10 en computadoras de escritorio y dispositivos móviles respectivamente, 352/988 ms para p25, 849 / 2.437 ms para p50, 1.850 / 5.518 ms para p75 y 3.543 / 10.735 ms para p90.
- Figura 3. Tiempos de procesamiento de subprocesos principales según V8 por dispositivo.
-
-
En cada percentil, los tiempos de procesamiento son más largos para las páginas web móviles que para las computadoras de escritorio. La mediana del tiempo total de subprocesos principales en el escritorio es de 849 ms, mientras que el móvil está en un número mayor: 2.437 ms.
-
Aunque estos datos muestran cuánto tiempo puede llevar un dispositivo móvil procesar JavaScript en comparación con una máquina de escritorio más potente, los dispositivos móviles también varían en términos de potencia informática. El siguiente cuadro muestra cómo los tiempos de procesamiento en una sola página web pueden variar significativamente según la clase de dispositivo móvil.
Gráfico de barras que muestra 3 dispositivos diferentes: en la parte superior, un Pixel 3, que tiene un tiempo de procesamiento pequeño tanto en el hilo principal como en el hilo worker de menos de 400 ms. Para un Moto G4 es de aproximadamente 900 ms en el subproceso principal y otros 300 ms en el subproceso del worker. Y la barra final es un Alcatel 1X 5059D con más de 2.000 ms en el subproceso principal y más de 500 ms en el subproceso del worker.
Una vía que vale la pena explorar al tratar de analizar la cantidad de JavaScript utilizado por las páginas web es la cantidad de solicitudes enviadas. Con HTTP/2 el envío de múltiples fragmentos más pequeños puede mejorar la carga de la página sobre el envío de un paquete monolítico más grande. Si también lo desglosamos por tipo de dispositivo, ¿cuántas solicitudes se están enviando?
Gráfico de barras que muestra 4/4 solicitudes se utilizan para computadoras de escritorio y dispositivos móviles respectivamente en el percentil p10, 10/9 en p25, 19/18 en p50, 33/32 en p75 y 53/52 en p90.
- Figura 5. Distribución del total de solicitudes de JavaScript.
-
-
En la mediana, se envían 19 solicitudes para computadoras de escritorio y 18 para dispositivos móviles.
De los resultados analizados hasta ahora, se estaban considerando el tamaño completo y el número de solicitudes. Sin embargo, en la mayoría de los sitios web, una parte importante del código JavaScript obtenido y utilizado proviene de contenido de terceros.
-
JavaScript de contenido de terceros puede provenir de cualquier fuente externa de terceros. Los anuncios, herramientas de análisis y contenido de redes sociales son casos de uso comunes para obtener scripts de terceros. Entonces, naturalmente, esto nos lleva a nuestra siguiente pregunta: ¿cuántas solicitudes enviadas son de contenido de terceros en lugar de de contenido de origen?
Gráfico de barras que muestra las solicitudes 0/1 en el escritorio es contenido de origen y contenido de terceros, respectivamente, en el percentil p10, 2/4 en la p25, 6/10 en la p50, 13/21 en la p75 y 24/38 en la p90.
- Figura 6. Distribución de scripts de origen y de terceros en dispositivos de escritorio.
-
-
-
-
-
-
-
Gráfico de barras que muestra las solicitudes 0/1 en dispositivos móviles es de contenido de origen y contenido de terceros, respectivamente, en el percentil p10, 2/3 en la p25, 5/9 en la p50, 13/20 en la p75 y 23/36 en la p90.
- Figura 7. Distribución de scripts de origen y de terceros en dispositivos móviles.
-
-
Para clientes móviles y de escritorio, se envían más solicitudes de contenido de terceros que de contenido de origen en cada percentil. Si esto parece sorprendente, descubramos cuánto código real enviado proviene de proveedores externos.
Gráfico de barras que muestra 0/17 bytes de JavaScript se descarga en dispositivos de escritorio para contenido de origen y contenido de terceros, respectivamente, en el percentil p10, 11/62 en p25, 89/232 en p50, 200/525 en p75 y 404/900 en p90.
- Figura 8. Distribución del JavaScript total descargado en dispositivos de escritorio.
-
-
-
-
-
-
-
Gráfico de barras que muestra 0/17 bytes de JavaScript se descarga en dispositivos móviles para contenido de origen y contenido de terceros, respectivamente, en el percentil p10, 6/54 en p25, 83/217 en p50, 189/477 en p75 y 380/827 en p90.
- Figura 9. Distribución del JavaScript total descargado en dispositivos móviles.
-
-
En la mediana, se utiliza un 89% más de código de contenido de terceros que el código de contenido de origen creado por el desarrollador para dispositivos móviles y de escritorio. Esto muestra claramente que el código de terceros puede ser uno de los mayores contribuyentes a la inflación.
En el contexto de las interacciones navegador-servidor, la compresión de recursos se refiere al código que se ha modificado utilizando un algoritmo de compresión de datos. Los recursos se pueden comprimir estáticamente antes de tiempo o sobre la marcha según lo solicite el navegador, y para cualquier enfoque, el tamaño del recurso transferido se reduce significativamente, lo que mejora el rendimiento de la página.
-
Existen varios algoritmos de compresión de texto, pero solo dos se utilizan principalmente para la compresión (y descompresión) de solicitudes de red HTTP:
-
-
Gzip (gzip): El formato de compresión más utilizado para las interacciones de servidor y cliente.
-
Brotli (br): Un algoritmo de compresión más nuevo que apunta a mejorar aún más las relaciones de compresión. 90% de los navegadores soportan la codificación Brotli.
-
-
Los scripts comprimidos siempre deberán ser descomprimidos por el navegador una vez transferidos. Esto significa que su contenido sigue siendo el mismo y los tiempos de ejecución no están optimizados en absoluto. Sin embargo, la compresión de recursos siempre mejorará los tiempos de descarga, que también es una de las etapas más caras del procesamiento de JavaScript. Asegurarse de que los archivos JavaScript se comprimen correctamente puede ser uno de los factores más importantes para mejorar el rendimiento del sitio.
-
¿Cuántos sitios están comprimiendo sus recursos de JavaScript?
Gráfico de barras que muestra el 67% / 65% de los recursos de JavaScript se comprime con gzip en computadoras de escritorio y dispositivos móviles respectivamente, y el 15% / 14% se comprime con Brotli.
- Figura 10. Porcentaje de sitios que comprimen recursos de JavaScript con gzip o brotli.
-
-
La mayoría de los sitios están comprimiendo sus recursos de JavaScript. La codificación Gzip se usa en ~ 64-67% de los sitios y Brotli en ~ 14%. Las relaciones de compresión son similares tanto para computadoras de escritorio como para dispositivos móviles.
-
Para un análisis más profundo sobre la compresión, consulte el capítulo de "Compresión".
Código fuente abierto, o código con una licencia permisiva a la que cualquier persona pueda acceder, ver y modificar. Desde pequeñas bibliotecas hasta navegadores completos, como Chromium y Firefox, el código fuente abierto juega un papel crucial en el mundo del desarrollo web. En el contexto de JavaScript, los desarrolladores confían en herramientas de código abierto para incluir todo tipo de funcionalidad en su página web. Independientemente de si un desarrollador decide usar una pequeña biblioteca de utilidades o un framework masivo que dicta la arquitectura de toda su aplicación, confiar en paquetes de código abierto puede hacer que el desarrollo de funciones sea más fácil y rápido.
-
¿Qué bibliotecas de código abierto de JavaScript se usan más?
-
-
-
-
-
-
-
Librería
-
Escritorio
-
Móvil
-
-
-
-
-
jQuery
-
85.03%
-
83.46%
-
-
-
jQuery Migrate
-
31.26%
-
31.68%
-
-
-
jQuery UI
-
23.60%
-
21.75%
-
-
-
Modernizr
-
17.80%
-
16.76%
-
-
-
FancyBox
-
7.04%
-
6.61%
-
-
-
Lightbox
-
6.02%
-
5.93%
-
-
-
Slick
-
5.53%
-
5.24%
-
-
-
Moment.js
-
4.92%
-
4.29%
-
-
-
Underscore.js
-
4.20%
-
3.82%
-
-
-
prettyPhoto
-
2.89%
-
3.09%
-
-
-
Select2
-
2.78%
-
2.48%
-
-
-
Lodash
-
2.65%
-
2.68%
-
-
-
Hammer.js
-
2.28%
-
2.70%
-
-
-
YUI
-
1.84%
-
1.50%
-
-
-
Lazy.js
-
1.26%
-
1.56%
-
-
-
Fingerprintjs
-
1.21%
-
1.32%
-
-
-
script.aculo.us
-
0.98%
-
0.85%
-
-
-
Polyfill
-
0.97%
-
1.00%
-
-
-
Flickity
-
0.83%
-
0.92%
-
-
-
Zepto
-
0.78%
-
1.17%
-
-
-
Dojo
-
0.70%
-
0.62%
-
-
-
-
-
- Figura 11. Principales bibliotecas de JavaScript en computadoras de escritorio y dispositivos móviles.
-
-
jQuery, la biblioteca JavaScript más popular jamás creada, se utiliza en el 85,03% de las páginas de escritorio y el 83,46% de las páginas móviles. El advenimiento de muchas API y métodos del navegador, tales como Fetch y querySelector, estandarizaron gran parte de la funcionalidad proporcionada por la biblioteca en una forma nativa. Aunque la popularidad de jQuery puede parecer estar disminuyendo, ¿por qué todavía se usa en la gran mayoría de la web?
-
Hay varias razones posibles:
-
-
WordPress, que se usa en más del 30% de los sitios, incluye jQuery por defecto.
-
Cambiar de jQuery a una biblioteca más nueva del lado del cliente puede llevar tiempo dependiendo de qué tan grande sea una aplicación, y muchos sitios pueden consistir en jQuery y además bibliotecas más nuevas del lado del cliente.
-
-
Otras bibliotecas JavaScript más utilizadas incluyen variantes de jQuery (jQuery migrate, jQuery UI), Modernizr, Moment.js, Underscore.js, etc.
En los últimos años, el ecosistema de JavaScript ha visto un aumento en las bibliotecas y frameworks de código abierto para facilitar la construcción de aplicaciones de página única (SPA por sus siglas en inglés). Una aplicación página única se caracteriza por ser una página web que carga una sola página HTML y usa JavaScript para modificar la página en la interacción del usuario en lugar de buscar nuevas páginas del servidor. Aunque esta sigue siendo la premisa principal de las aplicaciones de página única, todavía se pueden utilizar diferentes enfoques de representación del servidor para mejorar la experiencia de dichos sitios.
Gráfico de barras que muestra que el 4,6% de los sitios usan React, 2,0% AngiularJS, 1,8% Backbone.js, 0,8% Vue.js, 0,4% Knockout.js, 0,3% Zone.js, 0,3% Angular, 0,1% AMP, 0,1% Ember. js.
- Figura 12. Los frameworks más utilizados en el escritorio.
-
-
Aquí solo se analiza un subconjunto de marcos populares, pero es importante tener en cuenta que todos ellos siguen uno de estos dos enfoques:
Aunque ha habido un cambio hacia un modelo basado en componentes, muchos frameworks más antiguos que siguen el paradigma MVC (AngularJS, Backbone.js, Ember) todavía se usan en miles de páginas. Sin embargo, React, Vue y Angular son los frameworks basados en componentes más populares (Zone.js es un paquete que ahora forma parte del núcleo angular).
-
Aunque este análisis es interesante, es importante tener en cuenta que estos resultados se basan en una biblioteca de detección de terceros - Wappalyzer. Todos estos números de uso dependen de la precisión de cada uno de los mecanismos de detección.
Los módulos JavaScript, o ES modules, son soportados en todos los navegadores principales. Los módulos proporcionan la capacidad de crear scripts que pueden importar y exportar desde otros módulos. Esto permite a cualquier persona construir sus aplicaciones diseñadas en un patrón de módulo, importando y exportando donde sea necesario, sin depender de cargadores de módulos de terceros.
-
Para declarar un script como módulo, la etiqueta del script debe tener el código type="module":
-
<script type="module" src="main.mjs"></script>
-
- ¿Cuántos sitios usan type ="module" para los scripts en su página?
-
Gráfico de barras que muestra el 0,6% de los sitios en computadoras de escritorio usan 'type=module' y el 0,8% de los sitios en dispositivos móviles.
- Figura 13. Porcentaje de sitios que utilizan type=module.
-
-
El soporte a nivel de navegador para módulos todavía es relativamente nuevo, y los números aquí muestran que muy pocos sitios usan actualmente type="module" para sus scripts. Muchos sitios todavía dependen de cargadores de módulos (2,37% de todos los sitios de escritorio usan RequireJS por ejemplo) y bundlers (webpack por ejemplo) para definir módulos dentro de su código fuente.
-
Si se usan módulos nativos, es importante asegurarse de que se use un script de respaldo apropiado para los navegadores que aún no admiten módulos. Esto se puede hacer incluyendo un script adicional con un atributo nomodule.
-
<script nomodule src="fallback.js"></script>
-
Cuando se usan juntos, los navegadores que admiten módulos ignorarán por completo cualquier script que contenga el atributo nomodule. Por otro lado, los navegadores que aún no admiten módulos no descargarán ningún script con type ="module". Como tampoco reconocen nomodule, normalmente descargarán scripts con el atributo. El uso de este enfoque puede permitir a los desarrolladores enviar código moderno a navegadores modernos para cargas de página más rápidas.
-
- Así que, ¿Cuántos sitios usan nomodule para los scripts en su página?
-
Preload y prefetch son directivas que le permiten ayudar al navegador a determinar qué recursos deben descargarse.
-
-
Precargar un recurso con <link rel="preload"> le dice al navegador que descargue este recurso lo antes posible. Esto es especialmente útil para los recursos críticos que se descubren tarde en el proceso de carga de la página (por ejemplo, JavaScript ubicado en la parte inferior de su HTML) y que, de lo contrario, se descargan al final.
-
Usar <link rel="prefetch"> le dice al navegador que aproveche el tiempo de inactividad que tiene para obtener estos recursos necesarios para futuras navegaciones
-
-
Entonces, ¿cuántos sitios usan directivas de preload y prefetch?
Gráfico de barras que muestra que el 14% de los sitios en computadoras de escritorio usan 'rel=preload 'para scripts, y el 15% de los sitios en dispositivos móviles.
- Figura 15. Porcentaje de sitios que usan rel=preload para scripts.
-
-
Para todos los sitios medidos en HTTP Archive, el 14.33% de los sitios de computadoras de escritorio y el 14.84% de los sitios en dispositivos móviles usan <link rel="preload"> para los scripts en su página.
Gráfico de barras que muestra el 0,08% de los sitios en computadoras de escritorio usan 'rel=prefetch' y el 0,08% de los sitios en dispositivos móviles.
- Figura 16. Porcentaje de sitios que usan rel=prefetch para scripts.
-
-
Tanto para dispositivos móviles como para computadoras de escritorio, el 0,08% de las páginas aprovechan la captación previa para cualquiera de sus scripts.
JavaScript continúa evolucionando como lenguaje. Todos los años se lanza una nueva versión del estándar del lenguaje, conocido como ECMAScript, con nuevas API y características que pasan las etapas de la propuesta para formar parte del lenguaje en sí.
-
Con HTTP Archive, podemos echar un vistazo a cualquier API más nueva que sea compatible (o esté a punto de serlo) y ver qué tan extendido es su uso. Estas API ya se pueden usar en navegadores que las admiten o con un polyfill adjunto para asegurarse de que aún funcionan para todos los usuarios.
Gráfico de barras que muestra el 25,5% / 36,2% de los sitios en computadoras de escritorio y dispositivos móviles usa WeakMap, 6,1% / 17,2% usa WeakSet, 3,9% / 14,0% usa Intl, 3,9% / 4,4% usa Proxy, 0,4% / 0,4% usa Atomics, y 0,2% / 0,2% usan SharedArrayBuffer.
En muchos sistemas de compilación, los archivos JavaScript sufren una minificación para minimizar su tamaño y transpilación para las nuevas funciones de lenguaje que aún no son compatibles con muchos navegadores. Asimismo, superconjuntos de lenguage como TypeScript compilan a una salida que pueda verse notablemente diferente del código fuente original. Por todas estas razones, el código final servido al navegador puede ser ilegible y difícil de descifrar.
-
Un mapa fuente es un archivo adicional que acompaña a un archivo JavaScript que permite que un navegador asigne la salida final a su fuente original. Esto puede hacer que la depuración y el análisis de paquetes de producción sean mucho más simples.
-
Aunque es útil, hay una serie de razones por las cuales muchos sitios pueden no querer incluir mapas fuente en su sitio de producción final, como elegir no exponer el código fuente completo al público. Entonces, ¿cuántos sitios realmente incluyen mapas fuente?
Gráfico de barras que muestra el 18% de los sitios de escritorio y el 17% de los sitios móviles utilizan mapas fuente.
- Figura 18. Porcentaje de sitios que usan mapas fuente.
-
-
Para las páginas de escritorio y móviles, los resultados son casi los mismos. Un 17-18% incluye un mapa fuente para al menos un script en la página (detectado como un script de contenido de origen con sourceMappingURL).
El ecosistema de JavaScript continúa cambiando y evolucionando cada año. Las API más nuevas, los motores de navegador mejorados y las bibliotecas y frameworks nuevos son cosas que podemos esperar que sucedan indefinidamente. HTTP Archive nos proporciona información valiosa sobre cómo los sitios en la naturaleza usan el lenguaje.
-
Sin JavaScript, la web no estaría donde está hoy, y todos los datos recopilados para este artículo solo lo demuestran.
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/markup.html b/src/templates/es/2019/chapters/markup.html
deleted file mode 100644
index b94cdb406a0..00000000000
--- a/src/templates/es/2019/chapters/markup.html
+++ /dev/null
@@ -1,349 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":3,"title":"Markup","description":"Capítulo sobre marcado del Web Almanac de 2019 que cubre elementos utilizados, elementos personalizados, valor, productos y casos de uso comunes.","authors":["bkardell"],"reviewers":["zcorpan","tomhodgins","matthewp"],"translators":["c-torres"],"discuss":"1758","results":"https://docs.google.com/spreadsheets/d/1WnDKLar_0Btlt9UgT53Giy2229bpV4IM2D_v6OM_WzA/","queries":"03_Markup","published":"2019-11-04T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"markup"} %} {% block index %}
-
En 2005, Ian "Hixie" Hickson publicó algunos análisis de datos de marcado basándose en varios trabajos anteriores. Gran parte de este trabajo tenía como objetivo investigar los nombres de las clases para ver si había una semántica informal común que los desarrolladores estaban adoptando y que podría tener sentido estandarizar. Parte de esta investigación ayudó a darle forma a nuevos elementos en HTML5.
-
14 años después, es hora de dar un nuevo vistazo. Desde entonces, hemos tenido la introducción de Elementos Personalizados y del Manifesto Web Extensible alentando a que encontremos mejores formas de pavimentar los caminos de acceso al permitir a los desarrolladores explorar el espacio de los elementos y permitir a los organismos de estándares actuar más como editores de diccionario. A diferencia de los nombres de clase CSS, que podrían usarse para cualquier cosa, podemos estar mucho más seguros de que los autores que usaron un elemento no estándar realmente pretendían que fuera un elemento.
-
- A partir de julio de 2019, el HTTP Archive ha comenzado a recopilar todos los nombres de elementos usados en el DOM para aproximadamente 4,4 millones de páginas de inicio de computadoras de escritorio y alrededor de 5,3 millones de páginas de inicio de dispositivos móviles que ahora podemos comenzar a investigar y diseccionar. (Conozca más sobre nuestra Metodología.)
-
-
Esta exploración encontró más de 5.000 nombres distintos de elementos no estándar en estas páginas, por lo que limitamos el número total de elementos distintos que contamos a los 'principales' (explicado a continuación) 5.048.
Los nombres de los elementos en cada página se recopilaron del DOM mismo, después de la ejecución inicial de JavaScript.
-
Mirar un recuento de frecuencia sin procesar no es especialmente útil, incluso para elementos estándar: Alrededor del 25% de todos los elementos encontrados son <div>. Alrededor del 17% son <a>, alrededor del 11% son <span> -- y esos son los únicos elementos que representan más del 10% de las ocurrencias. Los lenguajes generalmente son así; un pequeño número de términos se usan asombrosamente en comparación. Además, cuando comenzamos a buscar elementos no estándar para la captación, esto podría ser muy engañoso, ya que un sitio podría usar un cierto elemento miles de veces y, por lo tanto, parecer artificialmente muy popular.
-
En lugar, como en el estudio original de Hixie, Lo que veremos es cuántos sitios incluyen cada elemento al menos una vez en su página de inicio.
-
Nota: Esto es, en sí mismo, no sin algunos sesgos potenciales. Varios sitios pueden utilizar productos populares, lo que introduce un marcado no estándar, incluso "invisible" para autores individuales. Por lo tanto, se debe tener cuidado al reconocer que el uso no implica necesariamente el conocimiento directo del autor y la adopción consciente tanto como el servicio de una necesidad común, de una manera común. Durante nuestra investigación, encontramos varios ejemplos de esto, algunos los indicaremos.
En 2005, la encuesta de Hixie enumeró los elementos más comunes utilizados en las páginas. Los 3 principales fueron html, head y body lo que señaló como interesante porque son opcionales y creados por el parser si se omiten. Dado que utilizamos el DOM después del parseo , aparecerán universalmente en nuestros datos. Por lo tanto, comenzaremos con el cuarto elemento más utilizado. A continuación se muestra una comparación de los datos de entonces a ahora. (También he incluido la comparación de frecuencias aquí solo por diversión).
-
-
-
-
-
-
-
2005 (por sitio)
-
2019 (por sitio)
-
2019 (frecuencia)
-
-
-
-
-
title
-
title
-
div
-
-
-
a
-
meta
-
a
-
-
-
img
-
a
-
span
-
-
-
meta
-
div
-
li
-
-
-
br
-
link
-
img
-
-
-
table
-
script
-
script
-
-
-
td
-
img
-
p
-
-
-
tr
-
span
-
option
-
-
-
-
-
- Figura 1.Comparación de los principales elementos de 2005 y 2019.
-
-
-
- Figura 2. Distribución del análisis de Hixie en 2005 de las frecuencias de los elementos.
-
-
-
- Figura 3. Frecuencias de elementos de acuerdo al 2019.
-
-
Comparando los últimos datos en la Figura 3 con los del informe de Hixie de 2005 en la Figura 2, podemos ver que el tamaño promedio de los árboles DOM ha aumentado.
-
-
-
-
Graph that relative frequency is a bell curve around the 19 elements point.
- Figura 4. Histograma del análisis de Hixie de 2005 de los tipos de elementos por página.
-
-
-
- Figura 5. Histograma de tipos de elementos por página a partir de 2019.
-
-
Podemos ver que tanto el número promedio de tipos de elementos por página ha aumentado, como el número máximo de elementos únicos que encontramos.
La mayoría de los elementos que grabamos son personalizados (como en simplemente "no estándar"), pero discutir qué elementos son y no son personalizados puede ser un poco difícil. Escrito en alguna especificación o propuesta en algún lugar hay, en realidad, bastantes elementos. Para fines aquí, consideramos 244 elementos como estándar (aunque algunos de ellos están en desuso o no son compatibles):
-
-
145 Elementos de HTML
-
68 Elementos de SVG
-
31 Elementos de MathML
-
-
En la práctica, encontramos solo 214 de estos:
-
-
137 de HTML
-
54 de SVG
-
23 de MathML
-
-
En el conjunto de datos de escritorio, recopilamos datos para los principales 4,834 elementos no estándar que encontramos. De estos:
-
-
155 (3%) son identificables como muy probable marcado o errores de escape (contienen caracteres en el nombre de la etiqueta analizada, lo que implica que el marcado está roto)
-
341 (7%) usan espacios de nombre de dos puntos al estilo XML (aunque, como HTML, no usan espacios de nombres XML reales)
-
3,207 (66%) son nombres de elementos personalizados válidos
-
1,211 (25%) se encuentran en el espacio de nombres global (no estándar, sin guión ni dos puntos)
-
216 de estos los hemos marcado como probables errores tipográficos, ya que tienen más de 2 caracteres y tienen una distancia de Levenshtein de 1 desde algún nombre de elemento estándar como <cript>,<spsn> or <artice>. Algunos de estos (como <jdiv>), sin embargo, son ciertamente intencionales.
-
-
Además, el 15% de las páginas de escritorio y el 16% de las páginas móviles contienen elementos obsoletos.
-
Nota: Mucho de esto es muy probable debido al uso de productos en lugar de que los autores individuales sigan creando manualmente el marcado.
Bar chart showing 'center' in use by 8.31% of desktop sites (7.96% of mobile), 'font' in use by 8.01% of desktop sites (7.38% of mobile), 'marquee' in use by 1.07% of desktop sites (1.20% of mobile), 'nobr' in use by 0.71% of desktop sites (0.55% of mobile), 'big' in use by 0.53% of desktop sites (0.47% of mobile), 'frameset' in use by 0.39% of desktop sites (0.35% of mobile), 'frame' in use by 0.39% of desktop sites (0.35% of mobile), 'strike' in use by 0.33% of desktop sites (0.27% of mobile), and 'noframes' in use by 0.25% of desktop sites (0.27% of mobile).
- Figura 6. Elementos en desuso más utilizados.
-
-
La Figura 6 anterior muestra los 10 elementos obsoletos más utilizados. La mayoría de estos pueden parecer números muy pequeños, pero la perspectiva es importante.
Bar chart showing a decreasing used of elements in descending order: html, head, body, title at above 99% usage, meta, a, div above 98% usage, link, script, img, span above 90% usage, ul, li , p, style, input, br, form above 70% usage, h2, h1, iframe, h3, button, footer, header, nav above 50% usage and other less well-known tags trailing down from below 50% to almost 0% usage.
En la Figura 7 anterior, se muestran los 150 nombres de elementos principales, contando el número de páginas donde aparecen. Observe lo rápido que se cae el uso.
-
Solo se utilizan 11 elementos en más del 90% de las páginas:
-
-
<html>
-
<head>
-
<body>
-
<title>
-
<meta>
-
<a>
-
<div>
-
<link>
-
<script>
-
<img>
-
<span>
-
-
Solo hay otros 15 elementos que ocurren en más del 50% de las páginas:
-
-
<ul>
-
<li>
-
<p>
-
<style>
-
<input>
-
<br>
-
<form>
-
<h2>
-
<h1>
-
<iframe>
-
<h3>
-
<button>
-
<footer>
-
<header>
-
<nav>
-
-
Y solo hay otros 40 elementos que ocurren en más del 5% de las páginas.
-
Incluso <video>, por ejemplo, no cumple con el corte. Aparece solo en el 4% de las páginas de escritorio en el conjunto de datos (3% en dispositivos móviles). Si bien estos números suenan muy bajos, el 4% es en realidad bastante popular en comparación. De hecho, solo 98 elementos ocurren en más del 1% de las páginas.
-
Es interesante, entonces, ver cómo se ve la distribución de estos elementos y cuáles tienen más del 1% de uso.
Scatter graph showing HTML, SVG, and Math ML use relatively few tags while non-standard elements (split into "in global ns", "dasherized" and "colon") are much more spread out.
- Figura 8. Elemento de popularidad categorizado por estandarización.
-
-
La Figura 8 muestra el rango de cada elemento y en qué categoría se encuentran. He separado los puntos de datos en conjuntos discretos simplemente para que puedan verse (de lo contrario, no hay suficientes píxeles para capturar todos esos datos), pero representan una única "línea" de popularidad; el más bajo es el más común, el más alto es el menos común. La flecha apunta al final de los elementos que aparecen en más del 1% de las páginas.
-
Se pueden observar dos cosas aquí. Primero, el conjunto de elementos que tienen más del 1% de uso no son exclusivamente HTML. De hecho, 27 de los 100 elementos más populares ni siquiera son HTML - son SVG! Y hay etiquetas no estándar en o muy cerca de ese límite también! Segundo, tenga en cuenta que menos del 1% de las páginas utilizan una gran cantidad de elementos HTML.
-
Entonces, ¿todos esos elementos que son utilizados por menos del 1% de las páginas "inútiles"? Definitivamente no. Por eso es importante establecer una perspectiva. Hay alrededor dos mil millones de sitios web en la web. Si algo aparece en el 0.1% de todos los sitios web de nuestro conjunto de datos, podemos extrapolar que esto representa quizás dos milliones de sitios web en toda la web. Incluso 0,01% se extrapola a doscientos mil sitios. Esta es también la razón por la cual eliminar el soporte para elementos, incluso aquellos muy antiguos que creemos que no son buenas ideas, es algo muy raro. Romper cientos de miles o millones de sitios simplemente no es algo que los proveedores de navegadores puedan hacer a la ligera.
-
Muchos elementos, incluso los nativos, aparecen en menos del 1% de las páginas y siguen siendo muy importantes y exitosos. <code>, por ejemplo, es un elemento que uso y encuentro mucho. Definitivamente es útil e importante, y sin embargo, se usa solo en el 0,57% de estas páginas. Parte de esto está sesgado según lo que estamos midiendo; las páginas de inicio son generalmente menos probable para incluir ciertos tipos de cosas (como <code> por ejemplo). Las páginas de inicio tienen un propósito menos general que, por ejemplo, encabezados, párrafos, enlaces y listas. Sin embargo, los datos son generalmente útiles.
-
También recopilamos información sobre qué páginas contenían un autor definido (no nativo) .shadowRoot. Alrededor del 0,22% de las páginas de escritorio y el 0,15% de las páginas móviles tenían un shadow root. Esto puede no parecer mucho, pero es más o menos 6.500 sitios en el conjunto de datos móviles y 10.000 sitios en el escritorio y es más que varios elementos HTML. <summary> por ejemplo, tiene un uso equivalente en el escritorio y es el elemento número 146 más popular. <datalist> aparece en el 0,04% de las páginas de inicio y es el elemento 201 más popular.
-
De hecho, más del 15% de los elementos que contamos según lo definido por HTML están fuera de los 200 primeros en el conjunto de datos de escritorio. <meter> es el elemento menos popular de la "era HTML5", que podemos definir como 2004-2011, antes de que HTML se moviera a un modelo de Living Standard. Es alrededor del elemento número 1.000 en popularidad. <slot>, el elemento introducido más recientemente (abril de 2016) está situado alrededor del puesto 1.400 en cuanto a popularidad.
Con esta perspectiva en mente acerca de cómo se ve el uso de características nativas / estándar en el conjunto de datos, hablemos de las cosas no estándar.
-
Puede esperar que muchos de los elementos que medimos se usen solo en una sola página web, pero de hecho, todos los 5.048 elementos aparecen en más de una página. La menor cantidad de páginas en las que aparece un elemento de nuestro conjunto de datos es 15. Aproximadamente una quinta parte de ellas ocurre en más de 100 páginas. Alrededor del 7% se produce en más de 1.000 páginas.
-
Para ayudar a analizar los datos, hackee en conjunto una pequeña herramienta con Glitch. Puede usar esta herramienta usted mismo y por favor comparta un enlace permanente con el @HTTPArchive junto con sus observaciones. (Tommy Hodgins también ha construido una herramienta similar CLI Tool que se puede usar para explorar.)
Para varios elementos no estándar, su prevalencia puede tener más que ver con su inclusión en herramientas populares de terceros que la adopción por parte de primeros. Por ejemplo, el elemento <fb:like> se encuentra en el 0,3% de las páginas no porque los propietarios del sitio lo escriban explícitamente sino porque incluyen el widget de Facebook. Muchos de los elementos que Hixie mencionó hace 14 años parece haber disminuido, pero otros siguen siendo bastante grandes:
-
-
- Elementos populares creados por Claris Home Page (cuya última versión estable fue hace 21 años) todavía aparece en más de 100 páginas. <x-claris-window>, por ejemplo, aparece en 130 páginas.
-
-
- Algunos de los <actinic:*> elementos del proveedor de comercio electrónico británico Oxatis aparecen en incluso más páginas. Por ejemplo, <actinic:basehref> todavía aparece en 154 páginas en los datos del escritorio.
-
-
- Los elementos de Macromedia parecen haber desaparecido en gran medida. Solo un elemento, <mm:endlock>, aparece en nuestra lista y en solo 22 páginas.
-
-
- El elemento de Adobe Go-Live <csscriptdict> todavía aparece en 640 páginas en el escritorio dataset.
-
-
- El elemento de Microsoft Office <o:p> El elemento todavía aparece en el 0,5% de las páginas de escritorio, más de 20.000 páginas.
-
-
-
Pero hay muchos recién llegados que tampoco estaban en el informe original de Hixie, y con números aún mayores.
-
-
- <ym-measure> es una etiqueta inyectada por Yandex del paquete de analisis Metrica. Se utiliza en más del 1% de las páginas de escritorio y móviles, consolidando su lugar en los 100 elementos más utilizados. ¡Eso es enorme!
-
-
- <g:plusone> del ahora desaparecido Google Plus se produce en más de 21.000 páginas.
-
-
- Facebook <fb:like> ocurre en 14.000 páginas móviles.
-
-
- De manera similar, <fb:like-box> ocurre en 7.800 páginas móviles.
-
-
- <app-root>, que generalmente se incluye en frameworks como Angular, aparece en algo más de 8.200 páginas móviles.
-
-
-
Comparemos esto con algunos de los elementos HTML nativos que están por debajo de la barra del 5%, por perspectiva.
Bar chart showing video is used by 184,149 sites, canvas by 108,355, ym-measure (a product-specific tag) by 52,146, code by 25,075, g:plusone (a product-specific tag) by 21,098, fb:like (a product-specific tag) by 12,773, fb:like-box (a product-specific tag) by 6,792, app-root (a product-specific tag) by 8,468, summary by 6,578, template by 5,913, and meter by 0.
- Figura 9. Popularidad de elementos nativos y específicos del producto por debajo del 5% de adopción.
-
-
Usted podría descubrir ideas interesantes como estas durante todo el día.
-
- Aquí hay una que es un poco diferente: los elementos populares pueden ser causados por errores directos en los productos. Por ejemplo, <pclass="ddc-font-size-large"> ocurre en más de 1,000 sitios. Esto fue gracias a la falta de espacio en un popular tipo de producto "como servicio". Afortunadamente, informamos este error durante nuestra investigación y se solucionó rápidamente.
-
-
En su artículo original, Hixie menciona que:
-
Lo bueno, si se nos puede perdonar por tratar de seguir siendo optimistas ante todo este marcado no estándar, es que al menos estos elementos están claramente usando nombres específicos del proveedor. Esto reduce enormemente la probabilidad de que los organismos de normalización inventen elementos y atributos que entren en conflicto con cualquiera de ellos.
-
- Sin embargo, como se mencionó anteriormente, esto no es universal. Más del 25% de los elementos no estándar que capturamos no utilizan ningún tipo de estrategia de espacio de nombres para evitar contaminar el espacio de nombres global. Por ejemplo, aquí está una lista de 1.157 elementos como ese del conjunto de datos móviles. Es probable que muchos de ellos no sean problemáticos, ya que tienen nombres oscuros, faltas de ortografía, etc. Pero al menos algunos probablemente presentan algunos desafíos. Se puede notar, por ejemplo, que <toast> (el cual Googlers recientemente intentaron proponer como <std-toast>) aparece en esta lista.
-
-
Hay algunos elementos populares que probablemente no sean tan desafiantes:
-
-
- <ymaps> de Yahoo Maps aparece en ~12.500 páginas móviles.
-
-
- <cufon> and <cufontext> de una biblioteca de reemplazo de fuentes de 2008, aparece en ~10.500 páginas móviles.
-
-
- El elemento <jdiv>, que parece estar inyectado por el producto JivoChat, aparece en ~40.300 páginas móviles.
-
-
-
Colocar estos elementos en nuestro mismo cuadro anterior para obtener una perspectiva se parece a esto (nuevamente, varía ligeramente según el conjunto de datos)
A bar chart showing video is used by 184,149 sites, canvas by 108,355, ym-measure by 52,416, code by 25,075, g:plusone by 21,098, db:like by 12,773, cufon by 10,523, ymaps by 8,303, fb:like-box by 6,972, app-root by 8,468, summary by 6,578, template by 5,913, and meter by 0
- Figura 10. Otros elementos populares en el contexto de elementos nativos y específicos del producto con menos del 5% de adopción.
-
-
Lo interesante de estos resultados es que también introducen algunas otras formas en que nuestra herramienta puede ser muy útil. Si estamos interesados en explorar el espacio de los datos, un nombre de etiqueta muy específico es solo una medida posible. Definitivamente es el indicador más fuerte si podemos encontrar un buen desarrollo de "jerga". Sin embargo, ¿qué pasa si eso no es todo lo que nos interesa?
¿Qué pasaría si, por ejemplo, estuviéramos interesados en las personas resolviendo casos de uso comunes? Esto podría deberse a que estamos buscando soluciones para casos de uso que tenemos actualmente, o para investigar de manera más amplia qué casos de uso común están resolviendo las personas con miras a incubar algún esfuerzo de estandarización. Tomemos un ejemplo común: pestañas. A lo largo de los años ha habido muchas solicitudes de cosas como pestañas. Podemos usar una búsqueda rápida aquí y encontrar que hay muchas variantes de pestañas. Es un poco más difícil contar el uso aquí ya que no podemos distinguir tan fácilmente si aparecen dos elementos en la misma página, por lo que el conteo provisto allí conservadoramente simplemente toma el que tiene el mayor conteo. En la mayoría de los casos, el número real de páginas es probablemente significativamente mayor.
Si notamos que surgen cosas populares (como <jdiv>, resolviendo chat) podemos tomar conocimiento de las cosas que sabemos (como, que es lo que <jdiv> resuelve, o <olark>) e intenta mirar al menos 43 cosas que hemos construido para abordar eso y seguir las conexiones para inspeccionar el espacio.
Entonces, hay muchos datos aquí, pero para resumir:
-
-
Las páginas tienen más elementos que hace 14 años, tanto en promedio como en máximo.
-
La vida útil de las cosas en las páginas de inicio es muy larga. Marcar como obsoleto o descontinuar las cosas no las hace desaparecer, y puede que nunca lo haga.
-
Hay una gran cantidad de marcado roto en la naturaleza (etiquetas mal escritas, espacios faltantes, mal escape, malentendidos).
-
Medir lo que significa "útil" es complicado. Muchos elementos nativos no pasan la barra del 5%, o incluso la barra del 1%, pero muchos de los personalizados sí, y por muchas razones. Pasar del 1% definitivamente debería captar nuestra atención al menos, pero tal vez incluso debería ser del 0.5% porque, según los datos, es comparativamente muy exitoso.
-
Ya hay un montón de marcas personalizadas por ahí. Viene en muchas formas, pero los elementos que contienen un guión definitivamente parecen haber despegado.
-
Necesitamos estudiar cada vez más estos datos y generar buenas observaciones para ayudar a encontrar y pavimentar los senderos.
-
-
En este último es donde usted entra. Nos encantaría aprovechar la creatividad y la curiosidad de la comunidad en general para ayudar a explorar estos datos utilizando algunas de las herramientas. (como https://rainy-periwinkle.glitch.me/). Comparta sus observaciones interesantes y ayude a construir nuestros conocimientos y entendimientos.
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/media.html b/src/templates/es/2019/chapters/media.html
deleted file mode 100644
index 3d1e960b18d..00000000000
--- a/src/templates/es/2019/chapters/media.html
+++ /dev/null
@@ -1,526 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":4,"title":"Media","description":"Capítulo Multimedia del 2019 Web Almanac que cubre los tamaños y formatos de archivo de imagen, las imágenes adaptables (responsive), los client hints, el lazy loading, la accesibilidad y los vídeos.","authors":["colinbendell","dougsillars"],"reviewers":["ahmadawais","eeeps"],"translators":["garcaplay"],"discuss":"1759","results":"https://docs.google.com/spreadsheets/d/1hj9bY6JJZfV9yrXHsoCRYuG8t8bR-CHuuD98zXV7BBQ/","queries":"04_Media","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-12T00:00:00.000Z","chapter":"media"} %} {% block index %}
-
Las imágenes, animaciones y vídeos son una parte importante de la experiencia web. Son importantes por muchas razones: ayudan a contar historias, atraen a la audiencia y proporcionan expresión artística de una forma que a menudo no puede ser conseguida fácilmente a través de otras tecnologías web. La importancia de estos recursos multimedia puede ser demostrada de dos formas: por la gran cantidad de bytes que se requieren para descargar cada página, y también por la cantidad de píxeles que componen esos recursos.
-
Desde una perspectiva puramente de bytes, el HTTP Archive ha registrado históricamente una media de dos tercios de bytes de recursos vinculados con recursos multimedia. Desde la perspectiva de la distribución, podemos ver que prácticamente toda página web depende de imágenes y vídeos. Incluso en el percentil 10, podemos ver que un 44% de los bytes son de recursos multimedia y puede llegar al 91% del total de bytes en las páginas del percentil 90.
Gráfico de barras mostrando que en el percentil p10 un 44,1% de los bytes de la página son recursos multimedia, en el percentil p25 un 52,7% son recursos multimedia, en el percentil p50 un 67,0% son recursos multimedia, en el percentil p75 un 81,7% son recursos multimedia, y en el percentil p90 un 91,2% son recursos multimedia.
- Figura 1. Bytes por página web: imagen y vídeo frente a otros.
-
-
Mientras que los recursos multimedia son esenciales para la experiencia visual, el impacto de este gran volumen de bytes tiene dos efectos colaterales.
-
Primero, la carga de red requerida para descargar estos bytes puede ser alta y en un móvil o una red lenta (como la de las cafeterías o el Uber) puede ralentizar drásticamente el rendimiento de la página. Las imágenes son la petición del navegador de menor prioridad pero pueden bloquear fácilmente la descarga del CSS y JavaScript. Esto, por sí mismo, puede ralentizar el renderizado de la página. Aun así, en otras ocasiones, el contenido de la imagen es, para el usuario, la indicación visual de que la página se ha cargado. Por lo tanto, las transferencias lentas del contenido visual pueden dar la impresión de una página web lenta.
-
La segunda consecuencia es el coste económico que supone para el usuario. Normalmente, este aspecto es poco tenido en cuenta ya que no afecta al dueño del sitio web, sino al usuario final. Como anécdota, se ha difundido que algunos mercados, como el de Japón, han visto una caída en las compras hechas por estudiantes a finales de mes, cuando alcanzan los límites de datos y no pueden ver el contenido visual.
-
- Es más, el coste económico de visitar estos sitios web en diferentes partes del mundo es desproporcionado. En la mediana y en el percentil 90, la cantidad de bytes por imagen es de 1 MB y de 1,9 MB respectivamente. A través de WhatDoesMySiteCost.com, podemos ver que el Producto Interior Bruto (PIB) per cápita en Madagascar supone al usuario un coste tal que la carga de una sola página web del percentil 90 equivaldría al 2,6% del ingreso bruto diario. Por el contrario, en Alemania esto supondría el 0,3% del ingreso bruto diario.
-
En la mediana, una página web en formato móvil requiere 1 MB para imágenes, y 4,9 MB en el percentil 90.
- Figura 2. Total de bytes de una imagen por sitio web (móvil).
-
-
Analizar los bytes por página significa analizar el gasto por rendimiento de la página y por usuario, pero se pasan por alto los beneficios. Estos bytes son importantes para renderizar los píxeles en la pantalla. De este modo, también podemos ver la importancia de las imágenes y los recursos visuales a través del análisis de la cantidad de píxeles usados de media por página.
-
Hay tres métricas a tener en cuenta cuando se analiza el tamaño de píxeles: píxeles CSS, píxeles lógicos y píxeles físicos:
-
-
-
El tamaño de pixel CSS es desde el punto de vista del diseño. Esta medida se centra en la caja delimitadora a la que la imagen o el vídeo pueden adaptarse, expandiéndose o comprimiéndose. No tiene en cuenta ni los verdaderos píxeles del archivo ni los de la pantalla.
-
-
-
Los píxeles lógicos se refieren a aquellos píxeles que conforman un archivo. Si tuvieras que cargar esa imagen en GIMP o en Photoshop, las dimensiones en píxeles de dicho archivo serían los píxeles lógicos (o píxeles naturales).
-
-
-
Los píxeles físicos se refieren a las partes electrónicas de la pantalla. Antes del móvil y de las modernas pantallas de alta resolución, había una relación 1:1 entre los píxeles CSS y los puntos LED de una pantalla. Sin embargo, debido a que los dispositivos móviles son sostenidos muy próximos al ojo y que las pantallas de los ordenadores están más cerca que los monitores de los terminales antiguos, las pantallas actuales tienen un ratio mayor de píxeles físicos que los tradicionales píxeles CSS. Este ratio es el Device-Pixel-Ratio, coloquialmente llamado Retina™.
Una comparación entre los píxeles CSS distribuidos en el contenido de la imagen y los píxeles reales en móvil, mostrando el p10 (0,07 MP reales, 0,04 MP CSS), el p25 (0,38MP reales, 0,18 MP CSS), el p50 (1,6 MP reales, 0,65 MP CSS), el p75 (5,1 MP reales, 1,8 MP CSS), y el p90 (12 MP reales, 4,6 MP CSS).
- Figura 3. Píxeles de una imagen por página (móvil): CSS versus real.
-
-
-
-
-
-
-
Una comparación entre los píxeles CSS distribuidos en el contenido de la imagen y los píxeles reales en escritorio, mostrando el p10 (0,09 MP reales, 0,05 MP CSS), el p25(0,52 MP reales, 0,29 MP CSS), el p50 (2,1 MP reales, 1,1 MP CSS), el p75 (6,0 MP reales, 2,8 MP CSS), y el p90 (14 MP reales, 6,3 MP CSS).
- Figura 4. Píxeles de una imagen por página (escritorio): CSS versus real.
-
-
Si miramos el volumen del pixel CSS y del pixel lógico, podemos observar que el sitio web medio tiene un diseño que muestra un megapixel (MP) de contenido multimedia. En el percentil 90, el volumen de la distribución del pixel CSS aumenta hasta 4,6 MP y 6,3 MP en móvil y escritorio respectivamente. Esto es interesante, no solo porque probablemente el diseño responsive sea diferente, sino también porque el factor de forma es diferente. En resumen, el diseño móvil tiene menos espacio para el contenido multimedia comparado con el de escritorio.
-
Por el contrario, el volumen del pixel lógico, o real, es entre 2 y 2,6 veces el volumen del diseño. La página web para escritorio media envía 2,1 MP de contenido pixel que es distribuido en 1,1 MP de espacio en el diseño. En el percentil 90 para móvil vemos que 12 MP son comprimidos a 4,6 MP.
-
Por supuesto, el factor forma para dispositivos móviles es diferente al de escritorio. Un dispositivo móvil es más pequeño y normalmente se sujeta en vertical, mientras que un ordenador es más grande y se usa principalmente en horizontal. Como se ha mencionado anteriormente, un dispositivo móvil también tiene habitualmente un ratio pixel-dispositivo (DPR por sus siglas en inglés: Device Pixel Ratio) mayor porque se sujeta mucho más cerca del ojo, necesitando más píxeles por pulgada, en comparación, que los que se necesitan para una pantalla publicitaria en Times Square. Estas diferencias fuerzan cambios en el diseño y los usuarios desde móviles tienen normalmente que hacer scroll por el sitio para poder consumir la totalidad de su contenido.
-
Los megapíxeles son una unidad de medida compleja porque es bastante abstracta. Una forma muy útil de expresar la cantidad de píxeles que están siendo usados en una página web es representándola como el ratio relativo al tamaño de la pantalla.
-
Para los dispositivos móviles usados en el rastreo (crawl) de páginas web, tenemos unas dimensiones de 512 x 360, que suponen un 0,18 MP de contenido CSS (no confundir con las pantallas físicas para las cuales es 3x o 3^2 píxeles más, 1,7 MP). Si se divide esta cantidad de píxeles del visor por el número de píxeles CSS correspondiente a las imágenes, obtenemos la cantidad de píxeles relativa.
-
Si tuviéramos una imagen que ocupase perfectamente la totalidad de la pantalla, el ratio de relleno de píxeles sería de 1x. Por supuesto, rara vez una página web ocupa la pantalla completa con una única imagen. El contenido multimedia suele mezclarse con el diseño y otro tipo de contenido. Un valor superior a 1x significa que el diseño requiere que el usuario haga scroll para ver el resto de la imagen.
-
Nota: esto es únicamente analizando el diseño CSS para tanto el DPR como para la cantidad de contenido del diseño. No está evaluándose la efectividad de las imágenes responsive o la efectividad de facilitar un contenido con alto DPR.
Una comparación entre la cantidad de píxeles necesaria por página en relación con el tamaño real de la pantalla en píxeles CSS, mostrando el p10 (20% en móvil, 20% en escritorio), el p25 (97% en móvil, 13% en escritorio), el p50 (354% en móvil, 46% en escritorio), el p75 (1003% en móvil, 123% en escritorio), y el p90 (2477% en móvil, 273% en escritorio).
- Figura 5. Cantidad de píxeles en una imagen versus el tamaño de la pantalla (píxeles CSS).
-
-
Para la página web media en formato escritorio, solamente el 46% de la pantalla tendría contenido con imágenes y vídeo. En contraposición, en móvil, la cantidad de píxeles multimedia sería 3,5 veces el tamaño real de la ventana. El diseño tiene más contenido que lo que puede ser mostrado en una sola pantalla, requiriendo el uso del scroll. Como mínimo, hay 3,5 páginas de contenido con scroll por sitio (dando por hecho un 100% de saturación). En el percentil 90 para móvil, ¡esto aumenta sustancialmente a 25x el tamaño de la ventana!
-
Los recursos multimedia son esenciales para la experiencia del usuario.
Ya se ha escrito mucho sobre la gestión y optimización de imágenes para ayudar a reducir los bytes y mejorar la experiencia de usuario. Este es un tema importante y esencial para muchos porque son los medios creativos los que definen la experiencia de marca. Por ello, optimizar el contenido de imagen y vídeo es un equilibrio entre aplicar las mejores prácticas que ayuden a reducir los bytes transferidos por la red y mantener la fidelidad de la experiencia prevista.
-
Mientras que el enfoque utilizado para imágenes, vídeos y animaciones son, a grandes rasgos, similares, sus abordajes específicos pueden ser muy diferentes. En general, estas estrategias se reducen a:
-
-
Formatos de archivo - utilizando el formato de archivo óptimo.
-
Adaptable - aplicando técnicas de imágenes responsive para transferir únicamente los píxeles que serán mostrados en pantalla.
-
- Lazy loading - para trasladar solamente contenido que pueda ser visto por un humano.
-
-
Accesibilidad - asegurando una experiencia consistente para todos los seres humanos.
-
-
Una advertencia a la hora de interpretar estos resultados. Las páginas webs rastreadas para el Web Almanac fueron rastreadas con un navegador Chrome. Esto significa que la negociación de contenido que pueda estar mejor integrada para Safari o Firefox podría no estar representada en este conjunto de datos. Por ejemplo, el uso de formatos de archivos como JPEG2000, JPEG-XR, HEVC, y HEIC no están representados porque estos no son compatibles de forma nativa con Chrome. Esto no significa que la web no contenga estos otros formatos o experiencias. Del mismo modo, Chrome tiene soporte nativo para lazy loading (desde la v76) el cual no está disponible en otros navegadores. Puedes leer más sobre estas excepciones en Metodología.
-
Es raro encontrar una página web que no utilice imágenes. A lo largo de los años, han aparecido muchos formatos de archivo diferentes para ayudar a mostrar el contenido en la web, cada uno abordando un problema diferente. Principalmente, hay 4 formatos de imagen universales: JPEG, PNG, GIF, y SVG. Además, Chrome ha mejorado el canal multimedia y añadido soporte a un quinto formato de imagen: WebP. Otros navegadores, del mismo modo, han añadido soporte para JPEG2000 (Safari), JPEG-XL (IE y Edge) y HEIC (WebView solamente en Safari).
-
Cada formato tiene sus propias ventajas y usos para la web. Una forma muy simple de resumirlo sería:
-
-
-
-
-
-
-
Formato
-
Ventajas
-
Desventajas
-
-
-
-
-
JPEG
-
-
-
Soporte generalizado
-
Perfecto para contenido fotográfico
-
-
-
-
-
Siempre hay pérdida de calidad
-
La mayoría de decodificadores no pueden manejar fotografías de alta profundidad de bits tomadas con cámaras modernas (> 8 bits por canal)
-
No hay soporte para transparencia
-
-
-
-
-
PNG
-
-
-
Como el JPEG y el GIF, comparte amplia compatibilidad
-
Sin pérdidas
-
Soporta transparencia, animación y alta profundidad de bits
-
-
-
-
-
Archivos más grandes en comparación con el JPEG
-
No es el ideal para contenido fotográfico
-
-
-
-
-
GIF
-
-
-
El predecesor del PNG, más conocido por las animaciones
-
Sin pérdidas
-
-
-
-
-
Debido a la limitación de 256 colores, durante la conversión siempre hay pérdida visual
-
Archivos muy grandes para las animaciones
-
-
-
-
-
SVG
-
-
-
Un formato vectorial que puede ser redimensionado sin aumentar el tamaño del archivo
-
Se basa en matemáticas más que en píxeles y genera unas líneas muy suaves
-
-
-
-
-
No es útil para fotografía u otros contenidos de gráfico por puntos
-
-
-
-
-
WebP
-
-
-
Un formato de archivo más nuevo que puede crear imágenes sin pérdida, como el PNG, y con pérdida, como el JPEG
Además, en toda la página, podemos ver la prevalencia de estos formatos. JPEG, uno de los formatos más antiguos de la web, es de lejos el que más comúnmente se utiliza como formato de imagen, con un 60% de peticiones de imagen y un 65% de todos los bytes de imagen. Curiosamente, el PNG es el segundo formato de imagen más común, con un 28% de peticiones de imágenes y bytes. La ubicuidad de la compatibilidad junto con la precisión del color y el contenido creativo son, probablemente, el porqué de su extendido uso. Por otro lado, SVG, GIF y WebP comparten un porcentaje de uso muy similar, el 4%.
Un gráfico de estructura de árbol mostrando que los JPEGs son usados un 60,27% de las veces, los PNGs el 28,2%, el WebP el 4,2%, el GIF el 3,67% y el SVG el 3,63%.
- Figura 7: Uso del formato de imagen.
-
-
Por supuesto, las páginas webs no son uniformes en el uso del contenido de imagen. Algunas dependen de las imágenes más que otras. Basta con que mires la página principal de google.com y veas las pocas imágenes que muestra en comparación con el resto de las típicas páginas webs modernas. De hecho, la página web media tiene 13 imágenes, 61 imágenes en el percentil 90, y se dispara en el percentil 99 a 229 imágenes.
Un gráfico de barras mostrando en el percentil p10 que no se usa ningún tipo de formato de imagen, en el percentil p25 se usan tres JPGS y cuatro PNGs, en el percentil p50 nueve JPGs, cuatro PNGs y un GIF, en el percentil p75 39 JPEGs, 18 PNGs, dos SVGs, y dos GIFs, y en el percentil p99 119 JPGs, 49 PNGs, 28 WebPs, 19 SVGs y 14 GIFs.
- Figura 8. Formato de imagen usado por página.
-
-
Mientras que la página media tiene nueve JPEGS y cuatro PNGs, y solamente en el primer 25% de las páginas se usan GIFs, esto no representa la tasa de adopción. El uso y recurrencia de cada formato por página no proporciona información sobre la adopción de formatos más modernos. Concretamente, qué porcentaje de páginas incluye al menos una imagen por cada formato.
Un gráfico de barras mostrando que los JPEGs son usados en el 90% de las páginas, los PNGs en un 89%, el WebP en un 9%, el GIF en un 37% y el SVG un 22%.
- Figura 9. Porcentaje de páginas que usan al menos una imagen.
-
-
Esto ayuda a explicar por qué, incluso en el percentil 90 de las páginas, la recurrencia del WebP es todavía nula; únicamente el 9% de las páginas web tienen al menos un recurso. Hay muchas razones por las que WebP podría no ser la mejor elección para una imagen, pero la adopción de las mejores prácticas multimedia, como la adopción del propio WebP, es todavía incipiente.
Un gráfico mostrando que en el percentil p10 se usan 4 KB de JPEGs, 2 KB de PNGs y 2 KB de GIFs, en el percentil p25 se usan 9KB de JPGs, 4 KB de PNGs, 7 KB de WebP, y 3 KB de GIFs, en el percentil p50 se usan 24 KB de JPGs, 11 KB de PNGs, 17 KB de WebP, 6 KB de GIFs y 1 KB de SVGs, en el percentil p75 se usan 68 KB de JPEGs, 43 KB de PNGs 41 KB de WebPs, 17 KB de GIFs y 2 KB de SVGs, y en el percentil p90 se usan 116 KB de JPGs, 152 KB de PNGs, 90 KB de WebPs, 87 KB de GIFs y 8 KB de SVGs.
- Figura 10. Tamaño de archivo (KB) por formato de imagen.
-
-
A partir de esto, podemos hacer una idea de cuán grande o pequeño es el recurso habitual de una web. Sin embargo, esto no nos muestra la cantidad de píxeles en pantalla para estas distribuciones de archivo. Para ello podemos dividir cada recurso de bytes por la cantidad de píxeles lógicos de la imagen. A menor cuantía de bytes por pixel, mayor eficiencia en la transmisión del contenido visual.
Un gráfico de velas que muestra en el percentil p10 que tenemos 0,1175 bytes por pixel para JPEG, 0,1197 para PNG, 0,1702 para GIF, 0,0586 para WebP y 0,0293 para SVG. En el percentil p25 tenemos 0,1848 bytes por pixel para JPEGs, 0,2874 para PNG, 0,3641 para GIF, 0,1025 para WebP, y 0,174 para SVG. En el percentil p50 tenemos 0,2997 bytes por pixel para JPEGs, 0,6918 para PNG, 0,7967 para GIF, 0,183 para WebP, y 0,6766 para SVG. En el percentil p75 tenemos 0,5456 bytes por pixel para JPEGs, 1,4548 para PNG, 2,515 para GIF, 0,3272 para WebP, y 1,9261 para SVG. En el percentil p90 tenemos 0,9822 bytes por pixel para JPEGs, 2,5026 para PNG, 8,5151 para GIF, 0,6474 para WebP, y 4,1075 para SVG
Aunque previamente se había visto que los archivos GIF son más pequeños que los JPEG, ahora podemos ver claramente que la razón de esos recursos JPEG de mayor envergadura es su cantidad de píxeles. Seguramente no sea una sorpresa ver que los GIF muestran una densidad de píxeles mucho menor que la de otros formatos, en comparación. Además, aunque el PNG puede gestionar una alta profundidad de bits y no verse afectado por el desenfoque del submuestreo de crominancia, se traduce en el doble de tamaño que en JPG o WebP para el mismo número de píxeles.
-
Cabe señalar que el volumen de pixel usado para SVG es el tamaño del elemento del DOM en pantalla (en píxeles CSS). Pese a ser considerablemente menor en tamaño de archivo, esto nos da pie a pensar que normalmente los SVGs son usados en las partes del diseño más pequeñas. Esta es la razón por la que los bytes por pixel empeoran en comparación con el PNG.
-
Nuevamente, cabe destacar que esta comparación de densidad de pixel no es equivalente a comparar las imágenes. Más bien muestra la experiencia de usuario típica. Como veremos más adelante, incluso en cada uno de estos formatos hay diferentes técnicas que pueden ser usadas para optimizar todavía más y reducir los bytes por pixel.
Ser capaz de seleccionar el mejor formato para cada experiencia es el arte de poder equilibrar las capacidades del formato reduciendo el total de bytes. Con las páginas web, un objetivo es la mejora del rendimiento de la web mediante la optimización de imágenes. Y aún así, dentro de cada formato hay funciones adicionales que permiten reducir los bytes.
-
Algunas funciones pueden afectar a la experiencia de usuario. Por ejemplo, tanto JPEG como WebP pueden utilizar la cuantificación (comúnmente conocida como niveles de calidad) y el submuestreo de crominancia, con lo que reducen los bits almacenados en la imagen sin afectar la experiencia visual. Como el MP3 para la música, esta técnica depende de un fallo en el ojo humano que nos permite disfrutar de la misma experiencia pese a haber perdido información del color. Pese a todo, no todas las imágenes son adecuadas para usar estas técnicas ya que podrían volverse borrosas o dentadas, así como que se distorsionen los colores o que los bloques de texto se vuelvan ilegibles.
-
Otras funciones del formato simplemente organizan el contenido y, a veces, necesitan tener un contexto. Por ejemplo, aplicar una encriptación progresiva en un JPEG reorganizará los píxeles en capas digitales que permitirán al navegador completar la estructura más rápidamente y, a su vez, reducirá el volumen de píxeles.
-
- El test Lighthouse es una comparación A/B con una encriptación progresiva del JPEG. Esto facilita una guía para saber qué imágenes pueden ser optimizadas un poco más con técnicas sin pérdida y potencialmente con técnicas con pérdida como usar diferentes niveles de calidad.
-
Gráfico de barras mostrando que en el percentil p10 el 100% de las imágenes están optimizadas, igual que en el percentil p25, en el percentil p50 el 98% de las imágenes están optimizadas (un 2% no lo están), en el percentil p75 un 83% de las imágenes están optimizadas (un 17% no lo están), y en el percentil p90 un 59% de las imágenes están optimizadas y un 41% no lo están.
- Figura 12. Porcentaje de imágenes 'optimizadas'
-
-
La ventaja de este test AB Lighthouse no es solo la potencial reducción de bytes, la cual puede suponer bastantes MBs en el p95, sino que también muestra la mejora del rendimiento de la página.
Gráfico de barras que muestra que en el percentil p10 0 ms pudieron ser medidos, lo mismo pasa en el percentil p25, en el percentil p50 se redujeron 150 ms, en el percentil p75 se redujeron 1.460 ms, y en el percentil p90 se redujeron 5.720 ms.
- Figura 13. Estimación de la mejora del rendimiento de la página tras la optimización de imagen de Lighthouse.
-
-
Otra forma de mejorar el rendimiento de la página es usar imágenes responsive. Esta técnica se basa en la reducción de bytes por imagen, mediante la reducción de aquellos pixeles de más que no estarán visibles debido al encogimiento de la imagen. Al comenzar este capítulo, viste cómo la página web media, en escritorio, usaba un MP de marcadores de imagen aunque transfiere 2,1 MP de volumen de pixel. Dado que esto era un test de 1x DPR, 1,1 MP de píxeles fueron transferidos por la red, pero no mostrados. Para reducir esta carga, podemos usar cualquiera de estas dos (posiblemente tres) técnicas:
-
-
Marcado HTML - a través de la combinación de los elementos <picture> y <source>, junto con los atributos srcset y sizes, se facilita que el navegador pueda seleccionar la mejor imagen, basándose en las dimensiones de la ventana y la densidad de pantalla.
-
- Client Hints - esto pasa la selección de posibles imágenes redimensionadas a negociación de contenido HTTP.
-
-
BONUS: Librerías de JavaScript para retrasar la carga de las imágenes hasta que el código JavaScript pueda ejecutar e inspeccionar el DOM del navegador e inyectar la mejor imagen para ese contenedor.
El método más usado para implementar las imágenes responsive es construir una lista de imágenes alternativas usando tanto <img srcset> como <source srcset>. Si el srcset está basado en DPR, el navegador podrá seleccionar la imagen correcta del listado sin información adicional. De todos modos, la mayoría de implementaciones también usan <img sizes> para ayudar a enseñar al navegador cómo realizar los cálculos de estructura necesarios para seleccionar la imagen correcta en el srcset en función de las dimensiones en píxeles.
Un gráfico de barras que muestra que el 18% de las imágenes usan 'sizes', un 21% usan 'srcset', y un 2% usan 'picture'.
- Figura 14. Porcentaje de páginas que usan imágenes adaptables con HTML.
-
-
No es sorprendente el notable menor uso del <picture> ya que se usan más a menudo para el diseño web responsive (RWD, siglas del inglés responsive web design) avanzado como el de dirección de arte.
La utilidad de srcset normalmente depende de la precisión de la media query sizes. Sin sizes el navegador asumirá que la etiqueta <img> ocupará la ventana entera en lugar de un componente de menor tamaño. Curiosamente, hay 5 patrones comunes que los desarrolladores web han adoptado para <img sizes>:
-
-
- <img sizes="100vw"> - este indica que la imagen ocupará toda la anchura de la ventana (el que se aplica por defecto).
-
-
- <img sizes="200px"> - este es útil para la selección del navegador basada en DPR.
-
-
- <img sizes="(max-width: 300px) 100vw, 300px"> - este es el segundo patrón de diseño más popular. Es el que se autogenera por WordPress y otro par de plataformas. Aparece autogenerado en base a su tamaño de imagen original (en este caso 300px).
-
-
- <img sizes="(max-width: 767px) 89vw, (max-width: 1000px) 54vw, ..."> - este patrón es el patrón de diseño personalizado que se alinea con el diseño responsive del CSS. Cada punto de ruptura (breakpoint) tiene un cálculo diferente para los tamaños a usar.
-
-
-
-
-
-
-
-
-
<img sizes>
-
Frecuencia (millones)
-
%
-
-
-
-
-
(max-width: 300px) 100vw, 300px
-
1.47
-
5%
-
-
-
(max-width: 150px) 100vw, 150px
-
0.63
-
2%
-
-
-
(max-width: 100px) 100vw, 100px
-
0.37
-
1%
-
-
-
(max-width: 400px) 100vw, 400px
-
0.32
-
1%
-
-
-
(max-width: 80px) 100vw, 80px
-
0.28
-
1%
-
-
-
-
-
- Figura 15. Porcentaje de páginas que usan los patrones sizes más populares.
-
-
-
-
- <img sizes="auto"> - éste es el que más se usa, aunque en realidad no es standard, sino producto del uso de la librería JavaScript lazy_sizes. Ésta usa un código del lado del cliente que inyecta mejores cálculos de sizes para el navegador. Su desventaja es que depende de la carga del JavaScript y de que el DOM esté completamente listo, retrasando sustancialmente la carga de las imágenes.
-
Gráfico de barras que muestra que 11,3 millones de imágenes usan 'img sizes="(max-width: 300px) 100vw, 300px"', 1,60 millones usan 'auto', 1 millón usan 'img sizes="(max-width: 767px) 89vw...etc."', 0,23 millones usan '100vw' y 0,13 millones usan '300px'
- Los Client Hints permiten a los creadores de contenido cambiar el redimensionamiento de imágenes por la negociación de contenido HTTP. De este modo, el HTML no necesita de <img srcset> adicionales para reordenar el marcado, y en su lugar depende de un servidor o imagen CDN para elegir la imagen óptima en cada contexto. Esto permite simplificar el HTML y habilita a los servidores de origen para adaptar y desconectar el contenido y las capas de presentación.
-
-
Para habilitar los Client Hints, la página web debe señalizárselo al navegador usando bien un encabezado HTTP adicional Accept-CH: DPR, Width, Viewport-Widtho bien añadiendo el HTML <meta http-equiv="Accept-CH" content="DPR, Width, Viewport-Width">. La conveniencia de usar una u otra técnica depende del equipo que las esté implementando, ambas se ofrecen por conveniencia.
Gráfico de barras mostrando que un 71% usa el 'meta http-equiv', un 30% usa el encabezado 'Accept-CH' HTTP y un 1% usa ambos.
- Figura 17. Uso del encabezado Accept-CH versus la etiqueta <meta> equivalente.
-
-
El uso de la etiqueta <meta> en HTML para invocar los Client Hints es bastante más común en comparación con el del encabezado HTTP. Esto es un claro reflejo de la comodidad de modificar el marcado de las plantillas en comparación con añadir los encabezados HTTP en cajas intermedias. De todos modos, analizando el uso del encabezado HTTP, más del 50% de estos casos provienen de una sola plataforma SaaS (Mercado).
-
De los Client Hints solicitados, la mayoría de las páginas los usan para los tres casos originales de DPR, ViewportWidth y Width. Por supuesto, el Client HintWidth necesita del uso de <img sizes> para que el navegador tenga el contexto necesario relativo al diseño.
Un gráfico circular de estilo donut que muestra que el 26,1% de los client hints usa 'dpr', 24,3% usa 'viewport-width', 19,7% usa 'width', 6,7% usa 'save-data', 6,1% usan 'device-memory', 6,0% usan 'downlink', 5,6% usan 'rtt' y 5,6% usan 'ect'
Mejorar el rendimiento de una página web puede ser parcialmente descrito como un juego de ilusiones; moviendo las cosas más lentas fuera de banda y lejos de la vista del usuario. De este modo, el lazy loading de imágenes es una de esas ilusiones donde la imagen y el contenido multimedia solamente se cargan cuando el usuario se desplaza por la página. Esto mejora el rendimiento que se percibe, incluso en conexiones lentas, y evita al usuario la descarga de bytes que no van a estar visibles.
-
Anteriormente, en la Figura 5, mostramos como el volumen del contenido de imagen en el percentil 75 es bastante más de lo que, en principio, puede verse en una sola ventana de escritorio o móvil. La auditoría Lighthouse de imágenes fuera de pantalla confirma nuestras sospechas. La página web media tiene un 27% de contenido de imagen significativamente por debajo del borde. Esto aumenta hasta el 84% en el percentil 90.
Un gráfico de barras que muestra que en el percentil p10 un 0% de las imágenes se encuentran fuera de pantalla, en el percentil p25 un 2% están fuera de pantalla, en el percentil p50 un 27% están fuera de pantalla, en el percentil p75 un 64% están fuera de pantalla, y en el percentil p90 un 84% de las imágenes están fuera de pantalla.
- Figura 19. Auditoría Lighthouse: Fuera de pantalla.
-
-
La auditoría Lighthouse nos da solo una idea ya que hay un buen número de situaciones que pueden ser difíciles de detectar, como el uso de marcadores de calidad.
-
El lazy loadingpuede ser implementado de muchas maneras, incluyendo el uso de una combinación de Observadores de intersección (Intersection Observers), Observadores de redimensión (Resize Observers), o el uso de librerías de JavaScript como lazySizes, lozad, y otras tantas.
-
En agosto de 2019, Chrome 76 fue lanzado con la compatibilidad para un lazy loading basado en marcado usando <img loading="lazy">. Aunque la instantánea de los sitios web usada para el 2019 Web Almanac utilizaba datos de julio de 2019, más de 2.509 sitios web ya utilizaban esta función.
En el centro de la accesibilidad de imagen se encuentra la etiqueta alt. Cuando la etiqueta alt es añadida a una imagen, su texto puede ser usado para describir la imagen a un usuario que no puede ver dichas imágenes (bien debido a una discapacidad, o bien debido a una mala conexión a internet).
-
Podemos encontrar todas las etiquetas de imagen en los archivos HTML del conjunto de datos. De las 13 millones de etiquetas de imagen que hay en versión escritorio y de las 15 millones que hay en versión móvil, un 91,6% tienen una etiqueta alt asociada. A primera vista, parece que la accesibilidad de imagen en la web está en muy buena forma. Pero, tras un análisis más profundo, el panorama no pinta tan bien. Si estudiamos la longitud de las etiquetas alt presentes en el conjunto de datos, podemos ver que su longitud media es de seis caracteres. Esto nos conduce a una etiqueta alt vacía (representada como alt=""). Solamente un 39% de las imágenes usa un texto alt con más de seis caracteres. El valor medio de texto alt "real" es de 31 caracteres, de los cuales 25 realmente se corresponden con la descripción de la imagen.
Aunque las imágenes dominan los medios multimedia de las páginas web, los vídeos están empezando a adquirir mayor relevancia como transmisores de contenido en la web. Según el HTTP Archive, vemos que el 4,06% de sitios para escritorio y el 2,99% de sitios para móvil tienen archivos de vídeo auto-hospedados (self-hosting). En otras palabras, archivos de vídeo que no están alojados en otro sitio web como Youtube o Facebook.
El vídeo puede ser mostrado en muchos formatos y reproductores diferentes. Los formatos que dominan en móvil y escritorio son el .ts (segmentos de transmisión HLS) y el .mp4 (el H264 MPEG):
Un gráfico de barras que muestra el uso de 'ts' es de 1.283.439 para escritorio (792.952 para móvil), de 'mp4' es de 729.757 para escritorio (662.015 para móvil), el de 'webm' es de 38.591 para escritorio (32.417 para móvil), el de 'mov' es de 22.194 para escritorio (14.986 para móvil), el de 'm4s' es de 17.338 para escritorio (16.046 para móvil), el de 'm4v' es de 7.466 para escritorio (6.169 para móvil).
- Figura 20. Recuento de archivos de vídeo por extensión.
-
-
Otros formatos vistos incluyen webm, mov, m4s y m4v (segmentos de transmisión MPEG-DASH). Queda claro que la mayoría de las transmisiones (streamings) en la web son HLS y que el formato por excelencia para vídeos estáticos es el mp4.
-
Bajo estas líneas puede verse el tamaño de vídeo medio para cada formato:
Un gráfico de barras mostrando que el tamaño medio de un archivo 'ts' es 335 KB para escritorio (156 KB para móvil), el de 'mp4' es de 175 KB para escritorio (128 KB para móvil), el de 'webm' es de 359 KB para escritorio (192 KB para móvil), el de 'mov' es de 128 KB para escritorio (96 KB para móvil), el de 'm4s' es de 324 KB para escritorio (246 KB para móvil), y el de 'm4v' es de 383 KB para escritorio (161 KB para móvil)
- Figura 21. Tamaño medio de archivo por extensión de vídeo.
-
-
Los valores medios son menores en versión móvil, lo que puede significar simplemente que algunos sitios que tienen vídeos de gran tamaño en versión de escritorio no los muestran en la versión móvil, y que las transmisiones de vídeo ofrecen versiones menores de dichos vídeos para las pantallas más pequeñas.
Cuando se muestran vídeos en la web, la mayoría de ellos son reproducidos con el reproductor de vídeo de HTML5. El reproductor de vídeo de HTML es altamente personalizable para poder mostrar vídeos con fines muy diferentes. Por ejemplo, para reproducir un vídeo automáticamente, los parámetros autoplay y muted han de ser añadidos. El atributo controls permite al usuario iniciar/parar y moverse a través del vídeo. Si analizamos las etiquetas de vídeo en el HTTP Archive, podemos ver el uso de cada uno de estos atributos:
Un gráfico de barras que muestra para escritorio: 'autoplay' en el 11.84%, 'buffered' en el 0%, 'controls' en el 12.05%, 'crossorigin' en el 0.45%, 'currenttime' en el 0.01%, 'disablepictureinpicture' en el 0.01%, 'disableremoteplayback' en el 0.01%, 'duration' en el 0.05%, 'height' en el 7.33%, 'intrinsicsize' en el 0%, 'loop' en el 14.57%, 'muted' en el 13.92%, 'playsinline' en el 6.49%, 'poster' en el 8.98%, 'preload' en el 11.62%, 'src' en el 3.67%, 'use-credentials' en el 0%, y 'width' en el 9%. Y para móvil: 'autoplay' en el 12.38%, 'buffered' en el 0%, 'controls' en el 13.88%, 'crossorigin' en el 0.16%, 'currenttime' en el 0.01%, disablepictureinpicture' en el 0.01%, 'disableremoteplayback' en el 0.02%, 'duration' en el 0.09%, 'height' en el 6.54%, intrinsicsize' en el 0%, 'loop' en el 14.44%, 'muted' en el 13.55%, 'playsinline' en el 6.15%, 'poster' en el 9.29%, 'preload' en el 10.34%, 'src' en el 4.13%, 'use-credentials' en el 0%, y 'width' en el 9.03%.
- Figura 22. Uso de los atributos de la etiqueta HTML de vídeo.
-
-
Los atributos más comunes son autoplay, muted y loop, seguidos por la etiqueta preload y por width y height. El uso del atributo loop es para vídeos de fondo y también para vídeos usados para reemplazar animaciones GIFs, así que no es sorprendente ver que se usa habitualmente en la página de inicio de los sitios web.
-
Aunque muchos de estos atributos tienen un uso muy parecido tanto en escritorio como en móvil, hay unos pocos que tienen diferencias significativas. Los dos atributos que mayor diferencia presentan entre móvil y escritorio son width y height, con un 4% menos de sitios que los usen en móvil. Curiosamente, hay un pequeño incremento del atributo poster (sitúa una imagen sobre la ventana de vídeo antes de la reproducción) en móvil.
-
Desde el punto de vista de la accesibilidad, la etiqueta <track> puede ser usada para añadir descripciones o subtítulos. Hay información en el HTTP Archive sobre con qué frecuencia se usa <track>, pero tras analizarlo, la mayoría de instancias del conjunto de datos estaban comentadas o apuntaban a una dirección que devolvía un error 404. Parece ser que muchos sitios usan plantillas de JavaScript o HTML y no eliminan el registro, incluso cuando éste ya no se usa más.
Para una reproducción más avanzada (y para iniciar la transmisión de vídeo), el reproductor de vídeo nativo de HTML5 no servirá. Hay otras pocas librerías de vídeo populares que son usadas para reproducir vídeo:
Gráfico de barras mostrando que 'flowplayer' se usa en 3.365 sitios web para escritorio (3.400 para móvil), 'hls' en 52.375 sitios web para escritorio (40.925 para móvil), 'jwplayer' en 110.280 sitios web para escritorio (96.945 para móvil), 'shaka' en 325 sitios web para escritorio (275 para móvil) y 'vídeo' se usa en 377.990 sitios web para escritorio (391.330 para móvil)
- Figura 23. Top de reproductores de vídeo de JavaScript.
-
-
El más popular (de lejos) es el vídeo.js, seguido por JWPLayer y HLS.js. Los autores advierten de que es posible que haya otros archivos con el nombre "vídeo.js" que puedan no ser la misma librería de reproducción de vídeo.
Casi todas las páginas web usan imágenes y vídeo en cierta medida para mejorar la experiencia de usuario y crear significado. Estos archivos multimedia utilizan una gran cantidad de recursos y son un gran porcentaje del tonelaje de las páginas web (¡y no se van a ir!) El uso de formatos alternativos, lazy loading, imágenes adaptables, y la optimización de imagen pueden ayudar mucho a minimizar el tamaño de los archivos multimedia en la web.
-{% endblock %}
diff --git a/src/templates/es/2019/chapters/performance.html b/src/templates/es/2019/chapters/performance.html
deleted file mode 100644
index b0c5fd71792..00000000000
--- a/src/templates/es/2019/chapters/performance.html
+++ /dev/null
@@ -1,294 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":7,"title":"Rendimiento","description":"Capítulo sobre rendimiento del Web Almanac de 2019 que explica First Contentful Paint (FCP), Time to First Byte (TTFB) y First Input Delay (FID) ","authors":["rviscomi"],"reviewers":["JMPerez","obto","sergeychernyshev","zeman"],"translators":["JMPerez"],"discuss":"1762","results":"https://docs.google.com/spreadsheets/d/1zWzFSQ_ygb-gGr1H1BsJCfB7Z89zSIf7GX0UayVEte4/","queries":"07_Performance","published":"2019-11-04T00:00:00.000Z","last_updated":"2020-08-23T00:00:00.000Z","chapter":"performance"} %} {% block index %}
-
El rendimiento es una parte esencial de la experiencia del usuario. En muchos sitios web, una mejora en la experiencia del usuario al acelerar el tiempo de carga de la página se corresponde con una mejora en las tasas de conversión. Por el contrario, cuando el rendimiento es deficiente, los usuarios no realizan conversiones con tanta frecuencia e incluso se ha observado que realizan ráfagas de clicks en la página como muestra de frustración.
-
Hay muchas formas de cuantificar el rendimiento web. Lo más importante es medir lo que realmente importa a los usuarios. Eventos como onload o DOMContentLoaded pueden no reflejar necesariamente lo que los usuarios experimentan visualmente. Por ejemplo, al cargar un cliente de correo electrónico, puede mostrar una barra de progreso mientras el contenido de la bandeja de entrada se carga de forma asincróna. El problema es que el evento onload no espera a que la bandeja de entrada se cargue asincrónamente. En este ejemplo, la métrica de carga que más le importa a los usuarios es el "tiempo para la bandeja de entrada", y centrarse en el evento onload puede ser engañoso. Por esa razón, este capítulo analizará métricas de pintado, carga e interactividad más modernas y de aplicación universal para tratar de capturar cómo los usuarios realmente están experimentando la página.
-
Hay dos tipos de datos de rendimiento: laboratorio y campo. También se les denomina pruebas sintéticas y medidas de usuario real (real-user measurement o RUM). La medición del rendimiento en el laboratorio garantiza que cada sitio web se pruebe bajo condiciones comunes y las variables como el navegador, la velocidad de conexión, la ubicación física, el estado de la memoria caché, etc., permanecen iguales. Esta garantía de consistencia hace que cada sitio web sea comparable entre sí. Por otro lado, medir el rendimiento en el campo representa cómo los usuarios realmente experimentan la web en todas las combinaciones infinitas de condiciones que nunca podríamos capturar en el laboratorio. Para los propósitos de este capítulo y para comprender las experiencias de los usuarios del mundo real, nos centraremos en los datos de campo.
Casi todos los otros capítulos en el Almanaque Web se basan en datos de HTTP Archive. Sin embargo, para capturar cómo los usuarios reales experimentan la web, necesitamos un conjunto de datos diferente. En esta sección estamos utilizando el Informe de Chrome UX (CrUX), un conjunto de datos público de Google que consta de los mismos sitios web que HTTP Archive, y agrega cómo los usuarios de Chrome realmente los experimentan. Las experiencias se clasifican por:
-
-
- El factor de forma de los dispositivos de los usuarios.
-
-
Escritorio
-
Teléfono
-
Tableta
-
-
-
- Tipo de conexión efectiva (ECT) de los usuarios en términos móviles
-
-
Sin conexión
-
2G lento
-
2G
-
3G
-
4G
-
-
-
Ubicaciones geográficas de los usuarios
-
-
Las experiencias se miden mensualmente, incluidas las métricas de pintado, carga e interactividad. La primera métrica que veremos es First Contentful Paint (FCP). Este es el tiempo que los usuarios pasan esperando que la página muestre algo útil en la pantalla, como una imagen o texto. Luego, veremos una métrica de carga, Time to First Byte (TTFB). Ésta es una medida del tiempo que tarda la página web desde el momento de la navegación del usuario hasta que recibe el primer byte de la respuesta. Y, finalmente, la última métrica de campo que veremos es First Input Delay (FID). Ésta es una métrica relativamente nueva y representa partes de la experiencia de usuario que no sean el rendimiento de carga. Mide el tiempo desde la primera interacción de un usuario con la interfaz de usuario de una página hasta el momento en que el hilo principal del navegador está listo para procesar el evento.
-
Así que vamos a profundizar y ver qué resultados podemos encontrar.
Distribution of 1,000 websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0%.
- Figura 1. Distribución del rendimiento rápido, moderado y lento de FCP.
-
-
En la Figura 1 anterior, se puede ver cómo se distribuyen las experiencias de FCP en la web. De los millones de sitios web en el conjunto de datos de CrUX, este gráfico comprime la distribución a 1.000 sitios web, donde cada segmento vertical representa un sólo sitio web. El cuadro está ordenado por el porcentaje de experiencias rápidas de FCP, que son las que ocurren en menos de 1 segundo. Las experiencias lentas ocurren en 3 segundos o más, y las experiencias moderadas (anteriormente conocidas como "promedias") son todo lo que hay en medio. En los extremos de la tabla hay algunos sitios web con experiencias casi 100% rápidas y algunos sitios web con experiencias casi 100% lentas. Entre medias, los sitios web que tienen una combinación de rendimiento rápido, moderado y lento parecen inclinarse más hacia rápido o moderado que lento, lo cual es bueno.
-
Nota: cuando un usuario experimenta un rendimiento lento es difícil decir cuál podría ser el motivo. Podría ser que el sitio web en sí mismo se construyó de manera deficiente e ineficiente. O podría haber otros factores ambientales como la conexión lenta del usuario, la caché vacía, etc. Por lo tanto, cuando miramos estos datos de campo, preferimos decir que las experiencias del usuario son lentas y no necesariamente los sitios web.
-
Para clasificar si un sitio web es lo suficientemente rápido utilizaremos la nueva metodología PageSpeed Insights (PSI), donde al menos el 75% de las experiencias de FCP del sitio web deben ser más rápidas que 1 segundo. Del mismo modo, un sitio web lo suficientemente lento tiene un 25% o más de experiencias FCP más lentas que 3 segundos. Decimos que un sitio web tiene un rendimiento moderado cuando no cumple con ninguna de estas condiciones.
Bar chart showing that 13% of websites have fast FCP, 66% have moderate FCP, and 20% have slow FCP.
- Figure 2. Distribución de sitios web etiquetados con FCP rápido, moderado o lento.
-
-
Los resultados en la Figura 2 muestran que sólo el 13% de los sitios web se consideran rápidos. Esta es una señal de que todavía hay mucho margen de mejora, pero muchos sitios web están pintando contenido significativo de manera rápida y consistente. Dos tercios de los sitios web tienen experiencias moderadas de FCP.
-
Para ayudarnos a comprender cómo los usuarios experimentan FCP en diferentes dispositivos, segmentemos por factor de forma.
Distribution of 1,000 desktop websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0% with a slight bulge in the middle.
- Figura 3. Distribución del rendimiento en sitios de escritorio según su FCP, entre rápidos, moderados y lentos.
-
-
-
-
-
-
-
Distribution of 1,000 mobile websites' fast, moderate, and slow FCP. The distribution of fast FCP appears to be linear from 100% to 0% without the same middle bulge seen for desktop websites.
- Figura 4. Distribución del rendimiento en sitios móviles según su FCP, entre rápidos, moderados y lentos.
-
-
En las Figuras 3 y 4 anteriores las distribuciones de FCP se desglosan por computadora y teléfono. Es sutil, pero el torso de la distribución rápida de FCP en escritorio parece ser más convexo que la distribución para usuarios de teléfonos. Esta aproximación visual sugiere que los usuarios de escritorio experimentan una mayor proporción general de FCP rápido. Para verificar esto, podemos aplicar la metodología PSI a cada distribución.
Bar chart of the desktop and mobile FCP distributions. Desktop fast, moderate, slow: 17%, 67%, and 16% respectively. Mobile: 11%, 66%, and 23%.
- Figura 5. Distribución de sitios web etiquetados como que tienen FCP rápido, moderado o lento, desglosados por tipo de dispositivo.
-
-
Según la clasificación de PSI, el 17% de los sitios web tienen experiencias rápidas de FCP en general para usuarios de escritorio, en comparación con el 11% para usuarios de dispositivos móviles. La distribución completa está sesgada hacia ser un poco más rápida para las experiencias de escritorio, con menos sitios web lentos y más en la categoría rápida y moderada.
-
¿Por qué los usuarios de escritorio pueden experimentar un FCP rápido en una mayor proporción de sitios web que los usuarios de teléfonos? Después de todo, sólo podemos especular que este conjunto de datos está destinado a responder cómo está funcionando la web y no necesariamente por qué está funcionando de esa manera. Pero una suposición podría ser que los usuarios de escritorio están conectados a Internet en redes más rápidas y fiables como WiFi en lugar de torres de telefonía celular. Para ayudar a responder esta pregunta, también podemos explorar cómo las experiencias de los usuarios varían según el ECT.
Bar chart of FCP distributions per effective connection type. 4G fast, moderate, slow: 14%, 67%, and 19% respectively. 3G: 1%, 38%, and 61%. 2G: 0%, 9%, 90%. Slow 2G: 0%, 1%, 99%.
- Figura 6. Distribución de sitios web etiquetados como que tienen FCP rápido, moderado o lento, desglosados por ECT.
-
-
En la Figura 6 anterior, las experiencias de FCP se agrupan por la ECT de la experiencia del usuario. Curiosamente, existe una correlación entre la velocidad de ECT y el porcentaje de sitios web que sirven FCP rápido. A medida que las velocidades de ECT disminuyen, la proporción de experiencias rápidas se acerca a cero. El 14% de los sitios web que sirven a los usuarios 4G ECT tienen experiencias rápidas de FCP, mientras que el 19% de esos sitios web tienen experiencias lentas. El 61% de los sitios web ofrecen FCP lento a usuarios con 3G ECT, 90% a 2G ECT y 99% a 2G lento ECT. Estos resultados sugieren que los sitios web rara vez sirven FCP rápido de manera consistente a los usuarios en conexiones efectivamente más lentas que 4G.
Bar chart of FCP distributions for the top 23 most popular geographies. Korea has the most fast websites at 36%. From there, the percent of fast websites declines rapidly for other geographies: Japan 28%, Taiwan 26%, Netherlands 21%, etc.
- Figura 7. Distribución de sitios web etiquetados como que tienen FCP rápido, moderado o lento, desglosados por geo.
-
-
Finalmente, podemos estudiar el FCP basándonos en la geografía de los usuarios (geo). El cuadro anterior muestra los 23 principales geos que tienen el mayor número de sitios web distintos, un indicador de la popularidad general de la web abierta. Los usuarios de la web en los Estados Unidos visitan la mayor cantidad de sitios distintos, con un total de 1.211.002. Los geos se ordenan por el porcentaje de sitios web que tienen experiencias FCP suficientemente rápidas. En la parte superior de la lista hay tres geos de Asia-Pacífico (APAC): Corea, Taiwán y Japón. Esto podría explicarse por la disponibilidad de velocidades de conexión de red extremadamente rápidas en estas regiones. Corea tiene el 36% de los sitios web que cumplen con la barra rápida de FCP, y solo el 7% clasificados como FCP lento. Recuerde que la distribución global de sitios web rápidos/moderados/lentos es aproximadamente 13/66/20, lo que hace que Corea sea un valor atípico significativamente positivo.
-
Otros geos de APAC cuentan una historia diferente. Tailandia, Vietnam, Indonesia e India tienen menos del 10% de sitios web rápidos. Estos geos también tienen más del triple de la proporción de sitios web lentos que Corea.
Time to First Byte (TTFB) es una medida de cuánto tiempo tarda la página web desde el momento de la navegación del usuario hasta que recibe el primer byte de la respuesta.
Diagram showing the sequence of network phases in a page load: startTime (promptForUnload), redirect, AppCache, DNS, TCP, request, response, processing, and load.
- Figura 8. Diagrama de la API de Navigation Timing de los eventos en la navegación de una página.
-
-
Para ayudar a explicar TTFB y los muchos factores que lo afectan, tomemos prestado un diagrama de la especificación de la API de Navigation Timing. En la Figura 8 anterior, TTFB es la duración desde startTime hasta responseStart, que incluye todo lo que se encuentra entre: unload, redirects, AppCache, DNS, SSL, TCP y el tiempo el servidor pasa gestionando la petición. Dado ese contexto, veamos cómo los usuarios están experimentando esta métrica.
Distribution of 1,000 websites' fast, moderate, and slow TTFB. The distribution of fast TTFB drops quickly from about 90% to 50% at the 10th fastest percentile. Then the distribution gradually decreases from 50% to 0% all the way down the remaining 90 percentiles.
- Figura 9. Distribución del rendimiento TTFB rápido, moderado y lento.
-
-
De forma similar a la tabla de FCP en la Figura 1, ésta es una vista de 1.000 muestras representativas ordenadas por TTFB rápido. Un TTFB rápido es el que ocurre en menos de 0,2 segundos (200 ms), un TTFB lento ocurre en 1 segundo o más, y todo en medio es moderado.
-
Mirando la curva de las proporciones rápidas, la forma es bastante diferente de la del FCP. Hay muy pocos sitios web que tienen un TTFB rápido superior al 75%, mientras que más de la mitad están por debajo del 25%.
-
Apliquemos una etiqueta de velocidad TTFB a cada sitio web, inspirándonos en la metodología PSI utilizada anteriormente para FCP. Si un sitio web ofrece TTFB rápido al 75% o más de experiencias de usuario, se etiqueta como rápido. De lo contrario, si sirve TTFB lento al 25% o más de experiencias de usuario, es lento. Si ninguna de esas condiciones se aplica, es moderada.
Bar chart showing that 2% of websites have fast TTFB, 56% have moderate TTFB, and 42% have slow TTFB.
- Figura 10. Distribución de sitios web etiquetados como que tienen TTFB rápido, moderado o lento.
-
-
El 42% de los sitios web tienen experiencias de TTFB lento. Esto es significativo porque el TTFB es un bloqueador para todas las demás métricas de rendimiento subsiguientes. Por definición, un usuario no puede experimentar un FCP rápido si el TTFB tarda más de 1 segundo.
Bar chart of TTFB distributions for the top 23 most popular geographies. Korea has the most fast websites at 14%. From there, the percent of fast websites declines rapidly for other geographies: Taiwan 7%, Japan 5%, Netherlands 4%, etc.
- Figura 11. Distribución de sitios web etiquetados como que tienen TTFB rápido, moderado o lento, desglosados por geo.
-
-
Ahora echemos un vistazo al porcentaje de sitios web que sirven TTFB rápido a usuarios en diferentes geos. Los geos de APAC como Corea, Taiwán y Japón siguen superando a los usuarios del resto del mundo. Pero ninguna geo tiene más del 15% de sitios web con TTFB rápido. India, por ejemplo, tiene menos del 1% de los sitios web con TTFB rápido y el 79% con TTFB lento.
La última métrica de campo que veremos es First Input Delay (FID). Esta métrica representa el tiempo desde la primera interacción de un usuario con la interfaz de usuario de una página hasta el momento en que el hilo principal del navegador está listo para procesar el evento. Tenga en cuenta que esto no incluye el tiempo que las aplicaciones pasan realmente manejando el evento de entrada. En el peor de los casos, un FID lento da como resultado una página que parece no responder y una experiencia de usuario frustrante.
-
Comencemos definiendo algunos umbrales. De acuerdo con la nueva metodología PSI, un FID rápido es uno que ocurre en menos de 100 ms. Esto le da a la aplicación suficiente tiempo para manejar el evento de entrada y proporcionar feedback al usuario en un momento que se siente instantáneo. Un FID lento es uno que ocurre en 300 ms o más. Todo entre medias es moderado.
Distribution of 1,000 websites' fast, moderate, and slow FID. The distribution of fast FID holds above 75% for the fastest three quarters of websites, then drops quickly to 0%.
- Figura 12. Distribución de sitios web según si su rendimiento FID es rápido, moderado o lento.
-
-
Seguimos el mismo procedimiento que hasta ahora. Este gráfico muestra la distribución de las experiencias FID rápidas, moderadas y lentas de los sitios web. Éste es un gráfico dramáticamente diferente de los gráficos anteriores para FCP y TTFB. (Ver Figura 1 y Figura 9 respectivamente). La curva de FID rápido desciende muy lentamente del 100% al 75% y luego cae en picada. La gran mayoría de las experiencias de FID son rápidas para la mayoría de los sitios web.
Bar chart showing that 40% of websites have fast FID, 45% have moderate FID, and 15% have slow FID.
- Figura 13. Distribución de sitios web etiquetados como que tienen un TTFB rápido, moderado o lento.
-
-
La metodología de PSI para etiquetar un sitio web con un FID suficientemente rápido o lento es ligeramente diferente de la de FCP. Para que un sitio sea rápido, el 95% de sus experiencias FID debe ser rápido. Un sitio es lento si el 5% de sus experiencias FID son lentas. Todas las demás experiencias son moderadas.
-
En comparación con las métricas anteriores, la distribución del rendimiento agregado de FID está mucho más sesgada hacia experiencias rápidas y moderadas que lentas. El 40% de los sitios web tienen FID rápido y sólo el 15% tiene FID lento. Dado que FID es una métrica de interactividad, a diferencia de una métrica de carga limitada por las velocidades de red, la convierte en una forma completamente diferente de representar el rendimiento.
Distribution of 1,000 desktop websites' fast, moderate, and slow FID. The distribution of fast FID decreases very slowly from 100% to 90% for the fastest three quarters of websites. After that, fast FID decreases slightly to 75%. Nearly all desktop websites have more than 75% fast FID experiences.
- Figura 14. Distribución de sitios web de escritorio según si su rendimiento de FID es rápido, moderado o lento.
-
-
-
-
-
-
-
Distribution of 1,000 mobile websites' fast, moderate, and slow FID. The distribution of fast FID declines steadily but much more quickly than desktop. It reaches 75% fast for at three quarters of websites then quickly drops to 0%.
- Figura 15. Distribución de sitios web móviles según si su rendimiento de FID es rápido, moderado o lento.
-
-
Al desglosar el FID por dispositivo queda claro que hay dos historias muy diferentes. Los usuarios de escritorio disfrutan de un FID rápido casi todo el tiempo. Por supuesto, hay algunos sitios web que sirven una experiencia lenta de vez en cuando, pero los resultados son predominantemente rápidos. Los usuarios móviles, por otro lado, tienen lo que parece ser una de dos posibles experiencias: bastante rápido (pero no tan a menudo como en escritorio) y casi nunca rápido. Los usuarios experimentan este último sólo en un ~10% de los sitios web situados en la cola, pero esto sigue siendo una diferencia sustancial.
Bar chart of the desktop and mobile FID distributions. Desktop fast, moderate, slow: 82%, 12%, and 5% respectively. Mobile: 26%, 52%, and 22%.
- Figura 16. Distribución de sitios web etiquetados como que tienen un FID rápido, moderado o lento, desglosado por tipo de dispositivo.
-
-
Cuando aplicamos el etiquetado PSI a las experiencias de escritorio y móvil, la distinción se vuelve clara como el cristal. El 82% del FID de los sitios web experimentado por los usuarios de escritorio es rápido en comparación con el 5% lento. Para las experiencias móviles, el 26% de los sitios web son rápidos, mientras que el 22% son lentos. El tipo de dispositivo juega un papel importante en el rendimiento de las métricas de interactividad como FID.
Bar chart of FID distributions per effective connection type. 4G fast, moderate, slow: 41%, 45%, and 15% respectively. 3G: 22%, 52%, and 26%. 2G: 19%, 58%, 23%. Slow 2G: 15%, 58%, 27%.
- Figura 17. Distribución de sitios web etiquetados como que tienen un FID rápido, moderado o lento, desglosados por ECT.
-
-
A primera vista parece que FID estaría relacionado principalmente con la velocidad de la CPU. Sería razonable suponer que cuanto más lento es el dispositivo, mayor es la probabilidad de que esté ocupado cuando el usuario intente interactuar con una página web, ¿verdad?
-
Los resultados de ECT anteriores parecen sugerir que existe una correlación entre la velocidad de conexión y el rendimiento del FID. A medida que disminuye la velocidad de conexión efectiva de los usuarios, el porcentaje de sitios web en los que experimentan FID rápido también disminuye: el 41% de los sitios web visitados por los usuarios con un ECT 4G tienen FID rápido, el 22% con 3G, el 19% con 2G y el 15% con 2G lento.
Bar chart of FID distributions for the top 23 most popular geographies. Korea has the most fast websites at 69%. From there, the percent of fast websites declines steadily for other geographies: Australia 55%, United States 52%, Canada 51%, etc.
- Figura 18. Distribución de sitios web etiquetados como que tienen un FID rápido, moderado o lento, desglosados por geo.
-
-
En este desglose del FID por ubicación geográfica, Corea está nuevamente al frente. Pero los principales geos tienen algunas caras nuevas: Australia, Estados Unidos y Canadá son los siguientes, con más del 50% de los sitios web que tienen una FID rápida.
-
Al igual que con los otros resultados geoespecíficos, hay muchos factores posibles que podrían estar contribuyendo a la experiencia del usuario. Por ejemplo, quizás los geos más ricos que son más privilegiados pueden permitirse una infraestructura de red más rápida y también tienen residentes con más dinero para gastar en computadoras de escritorio y/o teléfonos móviles de alta gama.
Cuantificar cómo de rápido carga una página web es una ciencia imperfecta que no puede ser representada por una única métrica. Las métricas convencionales como onload pueden fallar por completo al medir partes irrelevantes o imperceptibles de la experiencia del usuario. Las métricas percibidas por el usuario, como FCP y FID, transmiten más fielmente lo que los usuarios ven y sienten. Aún así, ninguna de las métricas se puede considerar de forma aislada para sacar conclusiones sobre si la experiencia general de carga de la página es rápida o lenta. Sólo observando muchas métricas de manera integral podemos comenzar a comprender el rendimiento de un sitio web individual y el estado de la web.
-
Los datos presentados en este capítulo mostraron que todavía hay mucho trabajo por hacer para cumplir los objetivos establecidos para los sitios web rápidos. Ciertos factores de forma, tipos de conexión efectivos y geos se correlacionan con mejores experiencias de usuario, pero no podemos olvidarnos de las combinaciones de datos demográficos con bajo rendimiento. En muchos casos la plataforma web se utiliza para negocios; ganar más dinero mejorando las tasas de conversión puede ser un gran motivador para acelerar un sitio web. En última instancia, para todos los sitios web, el rendimiento consiste en brindar experiencias positivas a los usuarios de una manera que no los impida, los frustre o los enfurezca.
-
A medida que la web envejece un año más y nuestra capacidad de medir cómo los usuarios la experimentan mejora gradualmente, espero que los desarrolladores tengan acceso a métricas que capturan más la experiencia holística del usuario. FCP ocurre muy pronto en la línea de tiempo de mostrar contenido útil a los usuarios, y están surgiendo métricas más nuevas como Largest Contentful Paint (LCP) para mejorar nuestra visibilidad sobre cómo la carga de la página es percibida. La API de Layout Instability también nos ha dado una nueva visión de la frustración que experimentan los usuarios más allá de la carga de la página.
-
Equipados con estas nuevas métricas, la web en 2020 se volverá aún más transparente, mejor entendida y brindará a los desarrolladores una ventaja para lograr un progreso más significativo para mejorar el rendimiento y contribuir a experiencias de usuario positivas.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/accessibility.html b/src/templates/fr/2019/chapters/accessibility.html
deleted file mode 100644
index 5e599dd1d63..00000000000
--- a/src/templates/fr/2019/chapters/accessibility.html
+++ /dev/null
@@ -1,400 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":9,"title":"Accessibilité","description":"Chapitre Accessibilité du web Almanac 2019, couvrant la facilité de lecture, les medias, l’aisance de navigation et la compatibilité avec les technologies d’assistance.","authors":["nektarios-paisios","obto","kleinab"],"reviewers":["ljme"],"translators":["nico3333fr"],"discuss":"1764","results":"https://docs.google.com/spreadsheets/d/16JGy-ehf4taU0w4ABiKjsHGEXNDXxOlb__idY8ifUtQ/","queries":"09_Accessibility","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-03T00:00:00.000Z","chapter":"accessibility"} %} {% block index %}
-
L’accessibilité sur le web est essentielle pour une société inclusive et équitable. Alors que nos vies sociales et professionnelles se déplacent de plus en plus vers le monde en ligne, il devient encore plus important pour les personnes handicapées de pouvoir participer à toutes les interactions en ligne sans barrières. Tout comme les architectes en bâtiment peuvent créer ou omettre des fonctionnalités d’accessibilité telles que des rampes pour fauteuils roulants, les développeurs et développeuses web peuvent aider ou entraver la technologie d’assistance sur laquelle les utilisateurs se basent.
-
Lorsque nous pensons aux utilisateurs handicapés, nous devons nous rappeler que leur parcours utilisateur est souvent le même — ils utilisent simplement des outils différents. Ces outils populaires incluent, sans s’y limiter : les lecteurs d’écran, les loupes d’écran, le zoom global ou de la taille du texte du navigateur et les commandes vocales.
-
Souvent, l’amélioration de l’accessibilité des sites présente des avantages pour tout le monde. Alors que nous considérons généralement les personnes handicapées comme des personnes ayant une incapacité permanente, tout le monde peut avoir une incapacité temporaire ou situationnelle. Par exemple, une personne peut être aveugle en permanence, avoir une infection oculaire temporaire ou, à l’occasion, être à l’extérieur sous un soleil éclatant. Tout cela pourrait expliquer pourquoi quelqu’un ne peut pas voir son écran. Tout le monde a des handicaps situationnels, et donc améliorer l’accessibilité de votre page web améliorera l’expérience de tous les utilisateurs dans toutes les situations.
-
Les directives pour l’accessibilité du contenu web (WCAG) donnent des conseils sur comment rendre un site web accessible. Ces lignes directrices ont servi de base à notre analyse. Cependant, dans de nombreux cas, il est difficile d’analyser programmatiquement l’accessibilité d’un site web. Par exemple, la plate-forme web offre plusieurs façons d’obtenir des résultats fonctionnels similaires, mais le code sous-jacent qui les alimente peut être complètement différent. Par conséquent, notre analyse n’est qu’une approximation de l’accessibilité globale du web.
-
Nous avons réparti nos informations les plus intéressantes en quatre catégories : facilité de lecture, médias sur le web, facilité de navigation dans les pages et compatibilité avec les technologies d’assistance.
-
Aucune différence significative d’accessibilité n’a été trouvée entre le bureau et le mobile pendant les tests. En conséquence, toutes nos mesures présentées sont le résultat de notre analyse de bureau, sauf indication contraire.
Le principal objectif d’une page web est de fournir du contenu avec lequel les utilisateurs souhaitent interagir. Ce contenu peut être une vidéo ou un assortiment d’images, mais souvent c’est simplement le texte sur la page. Il est extrêmement important que nos contenus textuels soient lisibles pour nos lecteurs. Si les visiteurs ne peuvent pas lire une page web, ils ne peuvent pas interagir avec, ce qui se termine par un abandon de leur part. Dans cette section, nous examinerons trois domaines dans lesquels les sites ont connu des difficultés.
Il existe de nombreux cas où les visiteurs de votre site peuvent ne pas le voir parfaitement. Les visiteurs peuvent être daltoniens et être dans l’impossibilité de faire la distinction entre la police et la couleur d’arrière-plan (1 homme sur 12 et 1 femme sur 200 en Europe). Peut-être qu’ils lisent simplement en extérieur avec un soleil créant des tonnes de reflets sur leur écran — ce qui nuit considérablement à leur vision. Ou peut-être qu’ils ont simplement vieilli et que leurs yeux ne peuvent pas distinguer les couleurs aussi bien qu’auparavant.
-
Afin de vous assurer que votre site web soit lisible dans ces conditions, un contraste de couleur suffisant entre le texte et son arrière-plan est capital. Il est également important de prendre en compte les contrastes qui seront affichés lorsque les couleurs seront converties en niveaux de gris.
Quatre boîtes colorées de nuances marron et grises avec, par-dessus, du texte blanc à l’intérieur créant deux colonnes. La colonne de gauche indique « Trop légèrement coloré » et a la couleur de fond marron écrite comme `#FCA469`. La colonne de droite indique « Recommandé » et la couleur d’arrière-plan marron est écrite comme `#BD5B0E`. La zone supérieure de chaque colonne a un fond marron avec du texte blanc `#FFFFFF` et la zone inférieure a un fond gris avec du texte blanc `#FFFFFF`. Les équivalents en niveaux de gris sont respectivement #B8B8B8 et #707070. Gracieusement mis à disposition par LookZook
- Figure 1. Exemple de texte présentant un contraste de couleurs insuffisant. Gracieusement mis à disposition par LookZook
-
-
Seuls 22,04 % des sites ont donné à l’ensemble de leurs textes un contraste de couleurs suffisant. En d’autres termes : 4 sites sur 5 ont un texte qui se confond facilement avec son arrière-plan, le rendant illisible.
-
Notez que nous n’avons pas été en mesure d’analyser du texte pris dans des images, de sorte que notre statistique est une limite supérieure du nombre total de sites web réussissant le test de contraste des couleurs.
Utiliser une taille de police lisible et une taille de cible raisonnablement grande aide les utilisateurs à lire et à interagir avec votre site web. Mais même les sites web qui suivent parfaitement toutes ces directives ne peuvent pas répondre aux besoins spécifiques de chaque visiteur. C’est pourquoi les fonctionnalités de l’appareil telles que le pincement au zoom et la mise à l’échelle sont si importantes : elles permettent aux utilisateurs de modifier vos pages pour répondre à leurs besoins. Ou dans le cas de sites particulièrement inaccessibles utilisant de minuscules polices et boutons, cela donne aux utilisateurs la possibilité même d’utiliser le site.
-
Il existe de rares cas où la désactivation de la mise à l’échelle est acceptable, comme lorsque la page en question est un jeu web utilisant des commandes tactiles. Si laissé activé dans ce cas, les téléphones des joueurs et joueuses feront un zoom avant et arrière à chaque fois qu’ils tapoteront deux fois sur le jeu, ce qui — ironiquement — le rendra inaccessible.
-
De fait, les développeurs et développeuses ont la possibilité de désactiver cette fonctionnalité en définissant l’une des deux propriétés suivantes dans la balise meta viewport :
-
-
-
user-scalable mis à 0 ou no ;
-
-
-
maximum-scale mis à 1, 1.0, etc.
-
-
-
Malheureusement, les développeurs et développeuses web en ont tellement abusé que près d’un site sur trois sur mobile (32,21 %) désactive cette fonctionnalité, et Apple (à partir d’iOS 10) ne leur permet plus de désactiver le zoom. Safari mobile ignore simplement la balise. Tous les sites, quels qu’ils soient, peuvent être zoomés et mis à l’échelle sur les nouveaux appareils iOS.
Graphes verticaux en pourcentages, allant de 0 à 80 de 20 en 20, par rapport au type d’appareil, regroupées en ordinateur de bureau et mobile. Bureau activé : 75,46 % ; Bureau désactivé : 24,54 % ; Mobile activé : 67,79 % ; Mobile désactivé : 32,21 %.
- Figure 2. Pourcentage de sites qui désactivent le zoom et la mise à l’échelle par rapport au type d’appareil.
-
-
Le web regorge de merveilleuses quantités de contenus. Cependant, il y a un hic : plus de 1000 langues différentes existent dans le monde, et le contenu que vous recherchez peut ne pas être écrit dans une langue que vous maîtrisez. Ces dernières années, nous avons fait de grands progrès dans les technologies de traduction et vous avez probablement utilisé l’un d’eux sur le web (par exemple, Google translate).
-
- Afin de faciliter cette fonctionnalité, les moteurs de traduction doivent savoir dans quelle langue vos pages sont écrites. Cela se fait en utilisant l’attribut lang. Sans cela, les ordinateurs doivent deviner dans quelle langue votre page est écrite. Comme vous pouvez l’imaginer, cela conduit à de nombreuses erreurs, en particulier lorsque les pages utilisent plusieurs langues (par exemple, la navigation de votre page est en anglais, mais le contenu de la publication est en japonais).
-
-
Ce problème est encore plus prononcé sur les technologies d’assistance de synthèse vocale telles que les lecteurs d’écran qui, si aucune langue n’a été spécifiée, ont tendance à lire le texte dans la langue utilisateur par défaut.
-
Sur les pages analysées, 26,13 % ne spécifient pas de langue avec l’attribut lang. Cela laisse plus d’un quart des pages affectées par tous les problèmes décrits ci-dessus. La bonne nouvelle ? Les sites utilisant l’attribut lang spécifient correctement un code de langue valide 99,68 % du temps.
Certains utilisateurs, comme ceux qui ont des troubles cognitifs, ont du mal à se concentrer sur la même tâche pendant de longues périodes. Ces utilisateurs ne veulent pas avoir affaire à des pages qui contiennent beaucoup de mouvements et d’animations, surtout lorsque ces effets sont purement cosmétiques et non liés à la tâche à accomplir. Au minimum, ces utilisateurs ont besoin d’un moyen de désactiver toutes les animations parasitant l’attention.
-
- Malheureusement, nos résultats indiquent que les animations en boucle infinie sont assez courantes sur le web, avec 21,04 % des pages les utilisant via des animations CSS infinies ou via <marquee> et <blink>.
-
-
Il est intéressant de noter cependant que le nœud du problème semble être quelques feuilles de style tierces populaires qui incluent par défaut des animations CSS en boucle infinie. Nous n’avons pas pu déterminer le nombre de pages utilisant réellement ces styles d’animation.
- Les images sont une part essentielle de l’expérience web. Elles peuvent raconter des histoires puissantes, attirer l’attention et susciter des émotions. Mais tout le monde ne peut pas voir ces images sur lesquelles nous nous appuyons pour raconter des parties de nos histoires. Heureusement, en 1995, HTML 2.0 a fourni une solution à ce problème : l’attribut alt. L’attribut alt offre aux développeurs et développeuses web la possibilité d’ajouter une description textuelle aux images utilisées, de sorte que lorsqu’une personne ne peut pas voir ces images (ou si les images ne peuvent pas se charger), elle peut lire le texte de remplacement pour en avoir une description. Le texte alternatif les renseigne sur la partie de l’histoire qu’elles auraient autrement manquée.
-
-
Même si les attributs alt existent depuis 25 ans, 49,91 % des pages ne fournissent toujours pas d’attributs alt pour certaines de leurs images, et 8,68 % des pages ne les utilisent pas du tout.
Tout comme les images sont de puissants vecteurs, il en va de même pour l’audio et la vidéo qui attirent l’attention et expriment des idées. Lorsque les contenus audio et vidéo ne sont pas sous-titrés, les utilisateurs qui ne peuvent pas entendre ces contenus passent à côté de grandes parties du web. L’une des choses les plus courantes que nous entendons des utilisateurs sourds ou malentendants est la nécessité d’inclure des sous-titres pour tous les contenus audio et vidéo.
-
- Sur les sites utilisant <audio> ou <video>, seuls 0,54 % fournissent des légendes (comptabilisées par le <track>). Notez que certains sites web ont des solutions personnalisées pour fournir des sous-titres vidéo et audio aux utilisateurs. Nous n’avons pas pu les détecter et le pourcentage réel de sites utilisant des sous-titres est donc légèrement plus élevé.
-
Lorsque vous ouvrez le menu dans un restaurant, la première chose à faire est probablement de lire tous les en-têtes de section : apéritifs, salades, plats principaux et desserts. Cela vous permet de vous orienter dans un menu et de passer rapidement aux plats les plus intéressants pour vous. De même, lorsqu’une personne ouvre une page web, son objectif est de trouver les informations qui l’intéresse le plus — la raison pour laquelle il est venu sur la page en premier lieu. Afin d’aider les utilisateurs à trouver le contenu souhaité aussi rapidement que possible (et leur éviter d’appuyer sur le bouton « précédent »), nous essayons de structurer le contenu de nos pages en plusieurs sections visuellement distinctes, par exemple : un en-tête de site pour la navigation, diverses rubriques dans nos articles pour que les utilisateurs puissent les analyser rapidement, un pied de page pour d’autres ressources, et plus encore.
-
C’est extrêmement important, nous devons prendre soin de baliser nos pages afin que les ordinateurs de nos visiteurs puissent également percevoir ces sections distinctes. Pourquoi ? Alors que la plupart des lecteurs utilisent une souris pour parcourir les pages, de nombreux autres s’appuient sur des claviers et des lecteurs d’écran. Ces technologies dépendent fortement de la façon dont leurs ordinateurs comprennent votre page.
Les en-têtes sont non seulement utiles visuellement, mais aussi pour les lecteurs d’écran. Ils permettent à ces derniers de passer rapidement d’une section à l’autre et aident à indiquer où se termine une section et où commence une autre.
-
Afin d’éviter de dérouter les utilisateurs de lecteurs d’écran, assurez-vous de ne jamais sauter un niveau de titre. Par exemple, ne passez pas directement d’un h1 à un h3 en sautant le h2. Pourquoi est-ce un gros problème ? Parce qu’il s’agit d’un changement inattendu, ce qui amènera un utilisateur ou une utilisatrice de lecteur d’écran à penser qu’il ou elle a manqué un morceau de contenu. Cela pourrait l’amener à chercher partout ce qu’il pourrait avoir manqué, même s’il ne manque rien. De plus, vous aiderez tous vos lecteurs en ayant une conception plus cohérente.
-
Cela étant dit, voici nos résultats :
-
-
89,36 % des pages utilisent des titres d’une manière ou d’une autre ; impressionnant ;
-
38,6 % des pages sautent des niveaux de titre ;
-
Curieusement, les h2 se trouvent sur plus de sites que les h1.
Graphique à barres verticales mesurant des données de pourcentage, allant de 0 à 80 de 20 en 20, par rapport aux barres représentant chaque niveau de `h1` à `h6`. `h1` : 63,25 % ; `h2` : 67,86 % ; `h3` : 58,63 % ; `h4` : 36,38 % ; `h5` : 14,64 %; `h6` : 6,91 %.
- Une
- zone de contenu principale main
- indique aux lecteurs d’écran où commence le contenu principal d’une page web afin que les utilisateurs puissent y aller directement. Sans cela, les utilisateurs de lecteurs d’écran doivent tabuler manuellement votre navigation chaque fois qu’ils accèdent à une nouvelle page de votre site. Évidemment, c’est plutôt frustrant.
-
-
Nous avons constaté qu’une seule page sur quatre (26,03 %) comprend une zone de contenu principale. Et étonnamment, 8,06 % des pages contenaient par erreur plus d’une zone de contenu principale, laissant ces utilisateurs deviner laquelle contient le contenu principal réel.
Graphique à barres verticales affichant des pourcentages de données allant de 0 à 80 de 20 en 20, par rapport à des barres représentant le nombre de repères « principaux » par page de 0 à 4. Source: HTTP Archive (juillet 2019). Zéro : 73,97 % ; Un : 17,97 % ; Deux : 7,41 % ; Trois : 0,15 % ; 4 : 0,06 %.
- Figure 4. Pourcentage des pages selon leur nombre d’éléments `main`.
-
-
Depuis que HTML5 a été publié en 2008 et est devenu la norme officielle en 2014, il existe de nombreux éléments HTML pour aider les ordinateurs et les lecteurs d’écran à comprendre nos mises en page et nos structures.
-
- Des éléments comme <header>, <footer>, <navigation> et <main> indiquent où se situent des types de contenu spécifiques et permettent aux utilisateurs de parcourir rapidement votre page. Celles-ci sont largement utilisées sur le web, la plupart d’entre elles étant utilisées sur plus de 50 % des pages (<main> étant la valeur la plus utilisée).
-
-
- D’autres comme <article>, <hr> et <aside> aident les lecteurs à comprendre le contenu principal d’une page. Par exemple, <article> indique où se termine un article et où commence un autre. Ces éléments ne sont pas autant utilisés, chacun étant à environ 20 % d’utilisation. Tous ces éléments ne sont pas pertinents pour chaque page web, ce n’est donc pas nécessairement une statistique alarmante.
-
-
Tous ces éléments sont principalement conçus pour la prise en charge de l’accessibilité et n’ont aucun effet visuel, ce qui signifie que vous pouvez remplacer en toute sécurité les éléments existants et ne subir aucune conséquence involontaire.
Graphique à barres verticales avec des barres pour chaque type d’élément par rapport au pourcentage de pages allant de 0 à 60 de 20 en 20. `nav` : 53,94 % ; `header` : 54,82 % ; `footer` : 55,92 % ; `main` : 18,47 % ; `aside` : 16,99 % ; `article` : 22,59 % ; `hr` : 19,1 % ; `section` : 36,55 %.
De nombreux lecteurs d’écran populaires permettent également aux utilisateurs de naviguer en parcourant rapidement les liens, les listes, les éléments de liste, les iframes et les champs de formulaire tels que les champs d’édition, les boutons et les zones de liste. La figure 6 détaille la fréquence à laquelle nous avons vu des pages utilisant ces éléments.
Graphique à barres verticales avec des barres pour chaque type d’élément par rapport au pourcentage de pages allant de 0 à 100 de 25 en 25. `a` : 98,22 % ; `ul` : 88,62 % ; `input`: 76,63 % ; `iframe`: 60,39 % ; `button` : 56,74 % ; `select` : 19,68 % ; `textarea` : 12,03 %.
- Figure 6. Autres éléments HTML utilisés pour la navigation
-
-
Un lien d’évitement est un lien placé en haut d’une page qui permet aux lecteurs d’écran ou aux utilisateurs de clavier d’accéder directement au contenu principal. Il « saute » efficacement tous les liens et menus de navigation en haut de la page. Les liens d’évitement sont particulièrement utiles aux utilisateurs de clavier qui n’utilisent pas de lecteur d’écran, car ces utilisateurs n’ont généralement pas accès à d’autres modes de navigation rapide (comme les zones de contenus principales et les en-têtes). 14,19 % des pages de notre échantillon avaient des liens d’évitement.
-
Si vous souhaitez voir un lien d’évitement en action par vous-même, vous pouvez ! Faites simplement une recherche rapide sur Google et tapez sur « Tab » dès que vous atterrissez sur les pages de résultats de recherche. Vous serez accueilli avec un lien précédemment masqué, comme celui sur la figure 7.
Capture d’écran de la page de résultats de recherche Google pour la recherche « http archive ». Le lien visible « Passer au contenu principal » est entouré d’un surlignage bleu et une boîte jaune superposée avec une flèche rouge pointant vers le lien de saut indique en anglais « Un lien d’évitement sur google.com ».
- Figure 7. Ce à quoi un lien d’évitement ressemble sur google.com.
-
-
Il est difficile de déterminer avec précision ce qu’est un lien d’évitement lors de l’analyse des sites. Pour cette analyse, si nous avons trouvé un lien-ancre (href=#heading1) dans les 3 premiers liens de la page, nous l’avons défini comme une page avec un lien d’évitement. Donc, 14,19 % est une limite supérieure stricte.
- Des raccourcis clavier définis via aria-keyshortcuts ou accesskey peuvent être utilisés de deux manières :
-
-
-
activer un élément sur la page, comme un lien ou un bouton ;
-
donner le focus à un certain élément de la page. Par exemple, déplacer le focus sur un champ de la page, permettant à l’utilisateur ou l’utilisatrice de commencer à taper dedans.
-
-
- L’adoption de aria-keyshortcuts était quasiment absente de notre échantillon, elle n’était utilisée que sur 159 sites sur plus de 4 millions analysés. L’attribut accesskey a été utilisé plus fréquemment, se trouvant sur 2,47 % des pages web (1,74 % sur les mobiles). Nous pensons que l’utilisation accrue des raccourcis sur le bureau est due au fait que les développeurs et développeuses s’attendent à ce que les sites mobiles ne soient accessibles que via un écran tactile et non un clavier.
-
-
Ce qui est particulièrement surprenant ici, c’est que 15,56 % des sites mobiles et 13,03 % des sites de bureau qui utilisent des touches de raccourci attribuent le même raccourci à plusieurs éléments différents. Cela signifie que les navigateurs doivent deviner à quel élément se rapporte cette touche de raccourci.
Les tableaux sont l’un des principaux moyens par lesquels nous organisons et exprimons de grandes quantités de données. De nombreuses technologies d’assistance comme les lecteurs d’écran et les commutateurs (qui peuvent être utilisés par les utilisateurs handicapés moteurs) peuvent avoir des fonctionnalités spéciales leur permettant de naviguer plus efficacement dans ces données tabulaires.
Selon la façon dont un tableau est structuré, l’utilisation des en-têtes de tableau facilite la lecture entre les colonnes ou les lignes sans perdre le contexte auxquelles cette colonne ou ligne particulière fait référence. Devoir naviguer dans un tableau sans lignes ou colonnes d’en-tête est une expérience médiocre pour un utilisateur ou une utilisatrice de lecteur d’écran. En effet, il est difficile pour ce dernier de garder ne pas perdre le fil dans un tableau sans en-têtes, en particulier lorsque ledit tableau est assez grand.
-
- Pour baliser les en-têtes de tableau, utilisez simplement la balise <th> (au lieu de <td>), ou l’un des rôles ARIA columnheader ou rowheader. Seulement 24,5 % des pages contenant des tableaux ont balisé ces derniers avec l’une ou l’autre de ces méthodes. Ainsi, les trois quarts des pages qui choisissent d’inclure des tableaux sans en-têtes créent de sérieuses complications pour les utilisateurs de lecteurs d’écran.
-
-
L’utilisation de <th> et <td> était de loin la méthode la plus couramment utilisée pour baliser les en-têtes de tableau. L’utilisation des rôles columnheader et rowheader était presque inexistante avec seulement 677 sites au total les utilisant (0,058 %).
- La légende (ou titre) de tableau via l’élément <caption> est utile pour fournir plus de contexte aux lecteurs de toutes sortes. Une légende peut préparer un lecteur à saisir les informations que votre tableau partage, et elle peut être particulièrement utile pour les personnes qui peuvent être distraites ou interrompues facilement. Elles sont également utiles pour les personnes qui peuvent se perdre dans un grand tableau, comme une personne utilisant un lecteur d’écran ou ayant une déficience cognitive ou intellectuelle. Plus il est facile pour les lecteurs de comprendre ce qu’ils analysent, mieux c’est.
-
-
Malgré cela, seulement 4,32 % des pages avec des tableaux fournissent des légendes à ces derniers.
L’une des spécifications les plus populaires et les plus utilisées pour l’accessibilité sur le web est la norme Accessible Rich Internet Applications (ARIA). Cette norme offre un large éventail d’attributs HTML supplémentaires pour aider à transmettre l’objectif derrière les éléments visuels (c’est-à-dire leur signification sémantique) et les types d’actions dont ils sont capables.
-
L’utilisation correcte et appropriée d’ARIA peut être difficile. Par exemple, sur les pages utilisant des attributs ARIA, 12,31 % ont des valeurs non valides en attribut. Cela est problématique car toute erreur dans l’utilisation d’un attribut ARIA n’a aucun effet visuel sur la page. Certaines de ces erreurs peuvent être détectées à l’aide d’un outil de validation automatisé, mais généralement elles nécessitent l’utilisation réelle d’un logiciel d’assistance (comme un lecteur d’écran). Cette section examinera comment ARIA est utilisé sur le web, et en particulier quelles parties de la norme sont les plus répandues.
L’attribut role est le plus important de toute la spécification ARIA. Il est utilisé pour informer le navigateur de la finalité d’un élément HTML donné (c’est-à-dire la signification sémantique). Par exemple, un élément <div> ayant via CSS le visuel d’un bouton devrait se voir attribuer le rôle ARIA de button.
-
Actuellement, 46,91 % des pages utilisent au moins un attribut de rôle ARIA. Dans la figure 9 ci-dessous, nous avons compilé une liste des dix valeurs de rôles ARIA les plus utilisées.
Graphique à barres verticales avec des barres pour chaque type de rôle par rapport au pourcentage de sites utilisant de 0 à 25 de 5 en 5. `navigation` : 20,4 % ; `search` : 15,49 % ; `main` : 14,39 % ; `banner` : 13,62 % ; `contentinfo` : 11,23 % ; `button` : 10,59 % ; `dialog` : 7,87 % ; `complementary` : 6,06 % ; `menu` : 4,71 % ; `form` : 3,75 %
En examinant les résultats de la figure 9, nous avons trouvé deux informations intéressantes : la mise à jour des frameworks d’interface pourrait avoir un impact profond sur l’accessibilité sur le web, et le nombre impressionnant de sites tentant de rendre les modales accessibles.
Les 5 premiers rôles, tous apparaissant sur 11 % des pages ou plus, sont des rôles de type landmark. Ils sont utilisés pour faciliter la navigation, pas pour décrire les fonctionnalités d’un widget, comme une zone de liste déroulante. C’est un résultat surprenant, car le principal facteur de motivation du développement d’ARIA était justement de donner aux développeurs et développeuses web la possibilité de décrire la fonctionnalité de widgets constitués d’éléments HTML génériques (comme un <div>).
-
Nous pensons que certains des frameworks d’interface les plus populaires incluent des rôles de navigation dans leurs modèles. Cela expliquerait la prévalence d’attributs de type landmark. Si cette théorie est correcte, la mise à jour des frameworks d’interface populaires pour inclure davantage de prise en charge de l’accessibilité peut avoir un impact énorme sur l’accessibilité du web.
-
Un autre résultat amenant à cette conclusion est le fait que les attributs ARIA plus « avancés » mais tout aussi importants ne semblent pas du tout être utilisés. Ces attributs ne peuvent pas être facilement déployés via des frameworks d’interface, car ils doivent être personnalisés en fonction de la structure et de l’apparence visuelle de chaque site, individuellement. Par exemple, nous avons constaté que les attributs posinset et setsize n’étaient utilisés que sur 0,01 % des pages. Ces attributs indiquent à un utilisateur ou une utilisatrice de lecteur d’écran combien d’éléments se trouvent dans une liste ou un menu et quel élément est actuellement sélectionné. Ainsi, si une personne malvoyante essaie de naviguer dans un menu, il peut entendre des annonces d’index telles que : « Accueil, 1 sur 5 », « Produits, 2 sur 5 », « Téléchargements, 3 sur 5 », etc.
- La popularité relative du rôle dialog se démarque, car rendre les modales accessibles aux utilisateurs de lecteurs d’écran est très difficile. Il est donc passionnant de voir environ 8 % des pages analysées relever le défi. Encore une fois, nous pensons que cela pourrait être dû à l’utilisation de certains frameworks d’interface.
-
La façon la plus courante qu’a un utilisateur pour interagir avec un site web consiste à utiliser ses contrôles, tels que des liens ou des boutons, pour naviguer sur le site web. Cependant, de nombreuses fois les utilisateurs de lecteurs d’écran ne sont pas en mesure de dire quelle action un contrôle effectuera une fois activé. Souvent, la raison de cette confusion est due à l’absence d’une étiquette textuelle. Par exemple, un bouton affichant une icône de flèche pointant vers la gauche pour indiquer qu’il s’agit du bouton « Retour », mais ne contenant aucun texte réel.
-
Seulement environ un quart (24,39 %) des pages qui utilisent des boutons ou des liens incluent des étiquettes textuelles avec ces commandes. Si un contrôle n’est pas étiqueté, une personne utilisant un lecteur d’écran peut lire quelque chose de générique, comme le mot « bouton » au lieu d’un mot significatif comme « Rechercher ».
-
Les boutons et les liens sont presque toujours inclus dans l’ordre de tabulation et ont donc une visibilité extrêmement élevée. La navigation sur un site web à l’aide de la touche de tabulation est l’un des principaux moyens par lesquels les personnes qui utilisent uniquement le clavier explorent votre site web. Ainsi, une personne est sûre de rencontrer vos boutons et liens sans étiquette si elle se déplace sur votre site web à l’aide de la touche de tabulation.
- Remplir des formulaires est une tâche que beaucoup d’entre nous accomplissent chaque jour. Que nous achetions, réservions un voyage ou postulions, les formulaires sont le principal moyen utilisé pour partager des informations avec des pages web. Pour cette raison, il est extrêmement important de s’assurer que vos formulaires sont accessibles. Le moyen le plus simple d’y parvenir est de fournir des étiquettes (via l’élément <label>, aria-label ou aria-labelledby) pour chacune de vos entrées. Malheureusement, seulement 22,33 % des pages fournissent des étiquettes pour toutes leurs entrées de formulaire, ce qui signifie que 4 pages sur 5 ont des formulaires qui peuvent être très difficiles à remplir.
-
Lorsque nous rencontrons un champ avec un gros astérisque rouge à côté, nous savons que c’est un champ obligatoire. Ou lorsque nous appuyons sur « Soumettre » et que nous sommes informés qu’il y avait des entrées non valides, tout ce qui est mis en surbrillance dans une couleur différente doit être corrigé puis soumis à nouveau. Cependant, les personnes malvoyantes ou sans vision ne peuvent pas se fier à ces repères visuels, c’est pourquoi les attributs d’entrée HTML required, aria-required et aria-invalid sont si importants. Ils fournissent aux lecteurs d’écran l’équivalent d’astérisques rouges et de champs surlignés en rouge. En prime, lorsque vous informez les navigateurs des champs obligatoires, ils valideront des parties de vos formulaires pour vous. Aucun JavaScript requis.
-
Sur les pages utilisant des formulaires, 21,73 % utilisent required ou aria-required lors du balisage des champs obligatoires. Seul un site sur cinq en fait usage. Il s’agit d’une étape simple pour rendre votre site accessible qui déverrouille des fonctionnalités de navigateur utiles pour tous les utilisateurs.
-
Nous avons également constaté que 3,52 % des sites avec des formulaires utilisent aria-invalid. Cependant, étant donné que de nombreux formulaires n’utilisent ce champ qu’une fois que des informations incorrectes ont été soumises, nous n’avons pas pu déterminer le pourcentage réel de sites utilisant ce balisage.
- Les id peuvent être utilisés en HTML pour lier deux éléments ensemble. Par exemple, l’élément <label> fonctionne de cette façon. Vous spécifiez l’id du champ de saisie que cette étiquette décrit et le navigateur les relie. Le résultat ? Les utilisateurs peuvent maintenant cliquer sur cette étiquette pour se concentrer sur le champ de saisie et les lecteurs d’écran utiliseront cette étiquette comme description.
-
-
Malheureusement, 34,62 % des sites ont des id en double, ce qui signifie que sur de nombreux sites, l’id spécifié par l'utilisateur peut faire référence à plusieurs entrées différentes. Ainsi, lorsqu’une personne clique sur l’étiquette pour sélectionner un champ, il peut finir par sélectionner quelque chose de différent que ce qui était souhaité. Comme vous pouvez l’imaginer, cela pourrait avoir des conséquences négatives dans un cas comme un panier d’achat.
-
- Ce problème est encore plus prononcé pour les lecteurs d’écran, car leurs utilisateurs peuvent ne pas être en mesure de vérifier visuellement ce qui est sélectionné. De plus, de nombreux attributs ARIA, tels que aria-describedby et aria-labelledby, fonctionnent de manière similaire à l’élément d’étiquette détaillé ci-dessus. Donc, pour rendre votre site accessible, la suppression de tous les id en double est une bonne première étape.
-
Les personnes handicapées ne sont pas les seules à avoir des besoins d’accessibilité. Par exemple, toute personne qui a subi une blessure temporaire au poignet a eu du mal à taper sur de petites cibles. La vue diminue souvent avec l’âge, ce qui rend le texte écrit en petites polices difficile à lire. La dextérité des doigts n’est pas la même pour toutes les tranches d’âge, ce qui rend plus difficile l’utilisation de commandes interactives ou le balayage de contenu sur des sites web mobiles pour un pourcentage important d’utilisateurs.
-
De même, les logiciels d’assistance ne s’adressent pas seulement aux personnes handicapées mais améliorent l’expérience quotidienne de chacun :
-
-
la popularité récente de l’assistance vocale, à la fois sur les appareils mobiles et à domicile, a démontré que le contrôle d’un appareil informatique à l’aide de commandes vocales est à la fois souhaitable et essentiel pour de nombreux utilisateurs. Les commandes vocales comme celles-ci n’étaient auparavant qu’une fonctionnalité d’accessibilité, mais se transforment désormais en un produit traditionnel ;
-
les conducteurs bénéficieraient d’une fonction de lecture d’écran qui, tout en gardant les yeux sur la route, lit à haute voix de longs textes comme des actualités ;
-
les sous-titres sont appréciés non seulement par les personnes qui ne peuvent pas entendre une vidéo, mais aussi par les personnes qui veulent regarder une vidéo dans un restaurant bruyant ou dans une bibliothèque.
-
-
Une fois un site web créé, il est souvent difficile de moderniser l’accessibilité par-dessus les structures et widgets du site existants. L’accessibilité n’est pas quelque chose qui peut être facilement saupoudré par la suite, mais doit plutôt faire partie du processus de conception et de mise en œuvre. Malheureusement, par manque de sensibilisation ou d'outils de test faciles à utiliser, de nombreux développeurs et développeuses ne connaissent pas les besoins de tous leurs utilisateurs et les exigences des logiciels d’assistance qu’ils utilisent.
-
Bien qu’ils ne soient pas concluants, nos résultats indiquent que l’utilisation de normes d’accessibilité comme ARIA et les meilleures pratiques d’accessibilité (par exemple, utiliser du texte alternatif) se trouvent sur une partie importante, mais non substantielle du web. À première vue, cela est encourageant, mais nous soupçonnons que bon nombre de ces tendances positives sont dues à la popularité de certains frameworks d’interface. D’une part, cela est décevant, car les développeurs et développeuses web ne peuvent pas simplement s’appuyer sur des frameworks d’interface pour injecter dans leurs sites un support d’accessibilité. D’un autre côté cependant, il est encourageant de voir à quel point les frameworks d’interface peuvent avoir un effet sur l’accessibilité du web.
-
À notre avis, la prochaine frontière est de rendre les widgets disponibles via les frameworks d’interface plus accessibles. Étant donné que de nombreux widgets complexes utilisés (par exemple, les sélecteurs de calendrier) proviennent d’une bibliothèque d’interface utilisateur, il serait formidable que ces widgets soient accessibles dès la sortie de la boîte. Nous espérons que lorsque nous collecterons nos résultats la prochaine fois, l’utilisation de rôles ARIA complexes plus correctement mis en œuvre augmentera - ce qui signifie que des widgets plus complexes auront également été rendus accessibles. De plus, nous espérons voir des médias plus accessibles, comme des images et des vidéos, afin que toutes les personnes utilisant le web puissent profiter de sa richesse.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/caching.html b/src/templates/fr/2019/chapters/caching.html
deleted file mode 100644
index cb77522b871..00000000000
--- a/src/templates/fr/2019/chapters/caching.html
+++ /dev/null
@@ -1,686 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":16,"title":"Mise en cache","description":"Le chapitre sur la mise en cache de Web Almanac couvre la gestion de la mise en cache, sa validité, les TTLs, les headers Vary, les cookies, l'AppCache, les service workers et d'autres possibilités.","authors":["paulcalvano"],"reviewers":["obto","bkardell"],"translators":["allemas"],"discuss":"1771","results":"https://docs.google.com/spreadsheets/d/1mnq03DqrRBwxfDV05uEFETK0_hPbYOynWxZkV3tFgNk/","queries":"16_Caching","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-12T00:00:00.000Z","chapter":"caching"} %} {% block index %}
-
La mise en cache est une technique permettant de réutiliser un contenu précédemment téléchargé. Elle offre un avantage significatif en termes de performance en évitant de rejouer de coûteuses requêtes. La mise en cache facilite la montée en charge d'une application, en réduisant le trafic sur le réseau à destination du serveur d'origine. Un vieux dicton dit que "la requête la plus rapide est celle que vous n'avez pas à faire " et la mise en cache est l'un des principaux moyens d'éviter d'avoir à refaire des requêtes.
-
La mise en cache sur le web s'appuie sur trois principes fondamentaux : mettre en cache autant que possible, aussi longtemps que possible et aussi près que possible des utilisateurs finaux.
-
Mettre en cache autant que vous le pouvez. Lorsque l'on s'intéresse aux données pouvant être mises en cache, il est important de débuter en identifiant les réponses statiques et dynamiques, qui évoluent ou non en fonction du contexte d'appel. Généralement, les réponses statiques, ne changeant pas, peuvent être mises en cache. Mettre en cache les réponses statiques permettra de les partager entre les utilisateurs. Les contenus dynamiques nécessitent, quant à eux, une analyse plus poussée.
-
Mettre en cache aussi longtemps que possible. La durée de mise en cache d'une ressource dépend fortement de sa sensibilité et de son contenu. Une ressource JavaScript versionnée peut être mise en cache pendant très longtemps, alors qu'une ressource non versionnée peut nécessiter une durée de cache plus courte afin de garantir aux utilisateurs de disposer des données a jour.
-
Cachez le plus près possible des utilisateurs finaux. Une mise en cache proche des utilisateurs réduit les temps de téléchargement en réduisant les latences réseau. Par exemple, pour une ressource mise en cache sur le navigateur de l'utilisateur, la requête ne sera jamais envoyée sur le réseau et le temps de téléchargement sera aussi rapide que les I/O de la machine. Pour les premiers visiteurs, ou les visiteurs qui n'ont pas encore leurs données cachées, un CDN est généralement la prochaine localisation d'une ressource cachée. Dans la plupart des cas, il sera plus rapide de récupérer une ressource à partir d'un cache local ou d'un CDN que sur le serveur d'origine.
-
Les architectures Web impliquent généralement une mise en cache en plusieurs niveaux. Par exemple une requête HTTP peut être mise en cache de différentes manière :
-
-
dans le cache du navigateur ;
-
dans le cache d'un service worker dans le navigateur ;
-
dans une passerelle partagée ;
-
au niveau des CDN, qui offrent la possibilité de mettre en cache à proximité des utilisateurs ;
-
dans un proxy de cache en amont des applications pour réduire la charge sur les serveurs back-end ;
-
au niveau de l'application et de la base de données.
-
-
Ce chapitre explique comment les ressources sont mises en cache dans les navigateurs Web.
Pour qu'un client HTTP mette en cache une ressource, il doit répondre a deux questions :
-
-
"Combien de temps dois-je mettre en cache ?"
-
"Comment puis-je valider que le contenu est encore frais ?"
-
-
Lorsqu'un navigateur Web envoie une réponse à un client, il inclut généralement dans sa réponse des en-têtes qui indiquent si la ressource peut être mise en cache, pour combien de temps et quel est son âge. La RFC 7234 traite plus en détail de ce point dans la section 4.2 (Freshness) et 4.3 (Validation).
-
Les en-têtes de réponse HTTP généralement utilisées pour transmettre la durée de vie sont :
-
-
- Cache-Control vous permet de configurer la durée de vie du cache (c'est-à-dire sa durée de validité).
-
-
Expires fournit une date ou une heure d'expiration (c.-à-d. quand exactement celle-ci expire).
Les en-têtes de réponse HTTP permettant de valider les données stockées en cache, c'est à dire donner les informations nécessaires pour comparer une ressource à sa contrepartie côté serveur :
-
-
Last-Modified indique quand la ressource a été modifiée pour la dernière fois.
-
ETag fournit l'identifiant unique d'une ressource.
L'exemple ci-dessous contient un extrait d'un en-tête requête/réponse du fichier main.js de HTTP Archive. Ces en-têtes indiquent que la ressource peut être mise en cache pendant 43 200 secondes (12 heures), et qu'elle a été modifiée pour la dernière fois il y a plus de deux mois (différence entre les en-têtes Last-Modified et Date).
L'outil RedBot.org vous permet d'entrer une URL et de voir un rapport détaillé de la façon dont la réponse sera mise en cache en fonction de ses en-têtes. Par exemple,un test pour l'URL ci-dessus produirait ce qui suit :
Exemple de réponse Redbot montrant des informations détaillées sur le moment où la ressource a été modifiée ; si les caches peuvent la stocker ; pour combien de temps elle peut être considérée valide ; si nécessaire les avertissements.
- Figure 1. Informations de RedBot relatives au Cache-Control.
-
-
Si aucun en-tête de mise en cache n'est renseigné dans la réponse, alors l'application peut mettre en cache en suivant une heuristique générique. La plupart des clients implémentent une variation de l'heuristique suggérée par le RFC, qui est 10 % du temps depuis le Last-Modified. Toutefois, certains peuvent mettre la réponse en cache indéfiniment. Il est donc important de définir des règles de mise en cache spécifiques pour s'assurer que vous maîtrisez la cachabilité.
-
72 % des réponses HTTP sont servies avec un en-tête Cache-Control, et 56 % des réponses sont servies avec un en-tête Expires. Cependant, 27 % des réponses n'utilisaient ni l'un ni l'autre, et peuvent alors être mises en cache en suivant cette heuristique. C'est un constat partagé par les sites pour ordinateurs de bureau et les sites mobiles.
Ces deux diagrammes à barres identiques pour le mobile et les ordinateurs de bureau montrent que 72 % des requêtes utilisent des en-têtes Cache-Control et que 56 % utilisent Expires et les 27 % n'utilisent aucun des deux.
- Figure 2. Présence des en-tête HTTP Cache-Control et Expires.
-
-
Une ressource mise en cache est stockée par le client pendant un certain temps et peut être réutilisée ultérieurement. Pour les requêtes HTTP, 80 % des réponses peuvent certainement être mises en cache, ce qui signifie qu'un système de cache peut les stocker. En dehors de ça,
-
-
6 % des requêtes ont un Time To Live (TTL) de 0 seconde, qui invalide immédiatement une entrée en cache.
-
27 % sont mis en cache par heuristique, à cause d'un Cache-Control manquant en en-tête.
-
47 % sont mis en cache pendant plus de 0 seconde.
-
-
Les autres réponses ne peuvent pas être stockées dans le cache du navigateur.
Un graphique à barres superposées montrant que 20 % des réponses pour ordinateurs de bureau ne peuvent être mises en cache, 47 % ont un cache supérieur à zéro, 27 % sont mises en cache de manière heuristique et 6 % ont un TTL de 0. Les statistiques pour les mobiles sont très similaires (19 %, 47 %, 27 % et 7 %)
- Figure 3. Distribution des réponses pouvant être mises en cache.
-
-
Le tableau ci-dessous détaille les TTL du cache pour les requêtes en provenance d'ordinateurs de bureau. La plupart des types de contenu sont mis en cache, mais les ressources CSS semblent toujours être mises en cache à des valeurs TTL élevées.
-
-
-
-
-
-
-
-
Percentiles TTL du cache des ordinateurs de bureau (Heures)
-
-
-
-
10
-
25
-
50
-
75
-
90
-
-
-
-
-
Audio
-
12
-
24
-
720
-
8,760
-
8,760
-
-
-
CSS
-
720
-
8,760
-
8,760
-
8,760
-
8,760
-
-
-
Police d'écriture
-
< 1
-
3
-
336
-
8,760
-
87,600
-
-
-
HTML
-
< 1
-
168
-
720
-
8,760
-
8,766
-
-
-
Image
-
< 1
-
1
-
28
-
48
-
8,760
-
-
-
Autre
-
< 1
-
2
-
336
-
8,760
-
8,760
-
-
-
Script
-
< 1
-
< 1
-
1
-
6
-
720
-
-
-
Texte
-
21
-
336
-
7,902
-
8,357
-
8,740
-
-
-
Vidéo
-
< 1
-
4
-
24
-
24
-
336
-
-
-
XML
-
< 1
-
< 1
-
< 1
-
< 1
-
< 1
-
-
-
-
-
- Figure 4. Percentiles du TTL par type de ressources, pour ordinateurs de bureau.
-
-
Bien que la plupart des TTL médians sont élevées, les percentiles inférieurs mettent en évidence certaines occasions manquées de mise en cache. Par exemple, le TTL médian pour les images est de 28 heures, mais le 25e percentile n'est que d'une à deux heures et le 10e percentile indique que 10 % du volume d'images en cache l'est pendant moins d'une heure.
-
En explorant plus en détail les possibilités de mise en cache par type de contenu dans la figure 5 ci-dessous, nous pouvons voir qu'environ la moitié de toutes les réponses HTML sont considérées comme non cachables. De plus, 16 % des images et des scripts ne peuvent pas être mis en cache.
Un diagramme à barres montrant la répartition des éléments non cachables, mis en cache pendant plus de 0 seconde et mis en cache pendant seulement 0 seconde par type pour les ordinateurs de bureau. Une petite, mais significative proportion n'est pas cachable et cela va jusqu'à 50 % pour le HTML, la plupart ont une mise en cache supérieure à 0 et une plus petite quantité a un TTL de 0
- Figure 5. Distribution de la cachabilité pour les types de contenu destinés aux ordinateurs de bureau.
-
-
Les mêmes données pour le mobile sont présentées ci-dessous. Comme on peut le voir, la mise en cache des types de contenu est similaire entre les ordinateurs de bureau et les mobiles.
Un diagramme à barres montrant la répartition des éléments non cachables, mis en cache pendant plus de 0 seconde et mis en cache pendant seulement 0 seconde par type pour les ordinateurs de bureau. Une petite, mais significative proportion n'est pas cachable et cela va jusqu'à 50 % pour le HTML, la plupart ont une mise en cache supérieure à 0 et une plus petite quantité a un TTL de 0
- Figure 6. Distribution de la cachabilité pour les types de contenu mobile.
-
-
Dans HTTP/1.0, l'en-tête Expires était utilisé pour indiquer la date/heure après laquelle la réponse était considérée comme périmée. Sa valeur est un horodatage, par exemple :
-
Expires: Thu, 01 Dec 1994 16:00:00 GMT
-
HTTP/1.1 a introduit l'en-tête Cache-Control, et la plupart des clients modernes supportent les deux en-têtes. Cet en-tête est beaucoup plus extensible, via des directives de mise en cache. Par exemple :
-
-
no-store peut être utilisé pour indiquer qu'une ressource ne doit pas être mise en cache.
-
max-age peut être utilisé pour indiquer une durée de vie.
-
must-revalidate indique au client que la ressource mise en cache doit être revalidée avec une requête conditionnelle avant son utilisation.
-
private indique qu'une réponse ne doit être mise en cache que par un navigateur, et non par un intermédiaire qui servirait plusieurs clients.
-
-
53 % des réponses HTTP incluent un en-tête Cache-Control avec la directive max-age, et 54 % incluent l'en-tête Expires. Cependant, seulement 41 % de ces réponses utilisent les deux en-têtes, ce qui signifie que 13 % des réponses sont basées uniquement sur l'ancien en-tête Expires.
Un diagramme à barres montrant que 53 % des réponses ont un `Cache-Control: max-age`, 54 %-55 % utilisent `Expire`, 41 %-42 % utilisent les deux, et 34 % n'utilisent aucun des deux. Les chiffres sont donnés à la fois pour les ordinateurs de bureau et les mobiles, mais les chiffres sont presque identiques, les mobiles ayant un point de pourcentage d'utilisation des expirations plus élevé.
- Figure 7. Utilisation comparée des en-têtes Cache-Control et Expires.
-
-
La specification HTTP/1.1 inclut de multiples directives qui peuvent être utilisées dans l'en-tête de réponse Cache-Control et sont détaillées ci-dessous. Notez que plusieurs directives peuvent être utilisées dans une seule réponse.
-
-
-
-
-
-
-
Directive
-
Description
-
-
-
max-age
-
Indique le nombre de secondes pendant lesquelles une ressource peut être mise en cache.
-
-
-
public
-
N'importe quel cache peut stocker la réponse.
-
-
-
no-cache
-
Une entrée en cache doit être revalidée avant son utilisation.
-
-
-
must-revalidate
-
Une entrée en cache périmée doit être revalidée avant son utilisation.
-
-
-
no-store
-
Indique qu'une réponse ne doit pas être mise en cache.
-
-
-
private
-
La réponse est destinée à un utilisateur spécifique et ne doit pas être stockée par des caches partagés.
-
-
-
no-transform
-
Aucune transformation ou conversion ne doit être effectuée sur cette ressource.
-
-
-
proxy-revalidate
-
Identique à must-revalidate mais pour les caches partagés.
-
-
-
s-maxage
-
Identique à l'âge maximum mais pour les caches partagés.
-
-
-
immutable
-
Indique que l'entrée en cache ne changera jamais, et qu'une revalidation n'est pas nécessaire.
-
-
-
stale-while-revalidate
-
Indique que le client est prêt à accepter une réponse périmée tout en vérifiant de manière asynchrone en arrière-plan l'existence d'une ressource plus fraiche.
-
-
-
stale-if-error
-
Indique que le client est prêt à accepter une réponse périmée même si la vérification qu'une ressource plus fraiche échoue.
Par exemple, cache-control:public, max-age=43200 indique qu'une entrée mise en cache doit être stockée pendant 43.200 secondes et qu'elle peut être stockée par tous les caches.
Un diagramme à barres de 15 directives `Cache-Control` et leur utilisation allant de 74,8 % pour max-age, 37,8 % pour public, 27,8 % pour no-cache, 18 % pour no-store, 14,3 % pour private, 3,4 % pour l'immutable, 3.3. 3 % pour no-transform, 2,4 % pour le stale-while-revalidate, 2,2 % pour pre-check, 2,2 % pour post-check, 1,9 % pour s-maxage, 1,6 % pour proxy-revalidate, 0,3 % pour le set-cookie et 0,2 % pour le stale-if-error. Les statistiques sont presque identiques pour les ordinateurs de bureaux et les téléphones portables.
- Figure 9. Utilisation de la directive Cache-Control sur mobile.
-
-
La figure 9 ci-dessus illustre les 15 directives Cache-Control les plus utilisées sur les sites Web mobiles. Les résultats pour les sites destinés aux ordinateurs de bureau et les sites mobiles sont très similaires. Il y a quelques observations intéressantes sur la popularité de ces directives de cache :
-
-
max-age est utilisé par presque 75 % des en-têtes Cache-Control, et no-store est utilisé par 18 %.
-
public (publique) est rarement nécessaire car les entrées en cache sont supposées public à moins que private (privé) ne soit spécifié. Environ 38 % des réponses incluent public.
Un autre ensemble intéressant de directives à faire apparaître dans cette liste sont pre-check et post-check, qui sont utilisées dans 2,2 % des en-têtes Cache-Control (environ 7,8 millions de réponses). Cette paire d'en-têtes a été introduite dans Internet Explorer 5 pour fournir une validation en arrière-plan et a rarement été implémentée correctement par les sites web. 99,2 % des réponses utilisant ces en-têtes avaient utilisé la combinaison pre-check=0 et post-check=0. Quand ces deux directives sont mises à 0, alors les deux directives sont ignorées. Il semble donc que ces directives n'aient jamais été utilisées correctement !
-
Il y a plus de 1 500 directives erronées utilisées dans 0,28 % des réponses. Ces directives sont ignorées par les clients, comprennent des erreurs d'orthographe telles que nocache, s-max-age, smax-age et maxage. Il y a aussi de nombreuses directives inexistantes comme max-stale, proxy-public, subsrogate-control, etc.
Lorsqu'une réponse ne doit pas être mise en cache, la directive Cache-Controlno-store doit être utilisée. Si cette directive n'est pas utilisée, alors la réponse peut être mise en cache.
-
Il y a quelques erreurs courantes, commises lorsqu'on essaie de configurer une réponse pour qu'elle ne puisse pas être mise en cache :
-
-
configurer Cache-Control: no-cache peut donner l'impression que la ressource ne doit pas être mise en cache. En réalité, no-cache précise que l'entrée mise en cache doit être revalidée avant d'être utilisée et n'indique pas que la ressource ne peut pas être mise en cache.
-
Cache-Control: max-age=0 fixe le TTL à 0 seconde, mais ce n'est pas la même chose que de ne pas pouvoir mettre en cache. Quand max-age est fixé à 0, la ressource est stockée dans le cache du navigateur et immédiatement invalidée. Le navigateur doit donc effectuer une requête conditionnelle pour valider la fraîcheur de la ressource.
-
-
Fonctionnellement, no-cache et max-age=0 sont similaires, puisqu'ils nécessitent tous deux la revalidation d'une ressource mise en cache. La directive no-cache peut aussi être utilisée avec une directive max-age supérieure à 0.
-
Plus de 3 millions de réponses comprennent la combinaison de no-store, no-cache, et max-age=0. Parmi ces directives, no-store est prioritaire et les autres directives sont simplement redondantes.
-
18 % des réponses comprennent no-store et 16,6 % des réponses comprennent à la fois no-store et no-cache. Puisque no-store a la priorité, la ressource n'est finalement pas cachable.
-
La directive max-age=0 est présente sur 1,1 % des réponses (plus de quatre millions de réponses) où no-store n'est pas présent. Ces ressources seront mises en cache dans le navigateur mais devront être revalidées car elles sont immédiatement expirées.
Jusqu'à présent, nous avons parlé de la façon dont les serveurs Web indiquent à un client ce qui peut être mis en cache, et pendant combien de temps. Lors de la conception des règles de mise en cache, il est également important de comprendre l'âge du contenu que vous servez.
-
Lorsque vous choisissez un cache TTL, demandez-vous : "à quelle fréquence allez-vous mettre à jour ces ressources ?" et "quelle est la sensibilité de leur contenu ?". Par exemple, si une Hero Image va être modifiée peu fréquemment, alors cachez-la avec un TTL très long. Si vous vous attendez à ce qu'une ressource JavaScript soit modifiée fréquemment, alors versionnez-la puis mettez-la en cache avec un long TTL ou cachez-la avec un TTL plus court.
-
Le graphique ci-dessous illustre l'âge relatif des ressources par type de contenu, et vous pouvez lire une analyse plus détaillée ici. Le HTML tend à être le type de contenu ayant l'âge le plus court, et un très grand pourcentage des ressources traditionnellement mises en cache (scripts, CSS, et polices d'écriture) ont plus d'un an !
Un diagramme à barres indiquant l'âge du contenu, divisé en semaines 0-52, > un an et > deux ans, avec des chiffres nuls et négatifs. Les statistiques sont divisées entre ressources principales et ressources de tierces parties. La valeur 0 est utilisée plus particulièrement pour le HTML, le texte et le XML issue du domaine principal. C'est également le cas pour plus de 50 % des requêtes de tiers dans tous les types de ressources. Il existe un mélange utilisant des portions d'années, puis une utilisation considérable pendant un an et deux ans.
- Figure 10. Répartition de l'âge des ressources par type de contenu.
-
-
En comparant la capacité de mise en cache d'une ressource à son âge, nous pouvons déterminer si le TTL est approprié ou trop faible. Par exemple, la ressource servie par la réponse ci-dessous a été modifiée pour la dernière fois le 25 août 2019, ce qui signifie qu'elle avait 49 jours au moment où elle a été servie. L'en-tête Cache-Control indique que nous pouvons la mettre en cache pendant 43 200 secondes, soit 12 heures. La ressource est largement assez vieille pour mériter qu'on se demande si un TTL plus long serait approprié.
Dans l'ensemble, 59 % des ressources servies sur le Web ont un TTL de cache trop court par rapport à l'âge de leur contenu. De plus, le delta médian entre le TTL et l'âge est de 25 jours.
-
Si l'on compare les ressources du domaine principal et celles des tierces parties, on constate que 70 % des ressources du domaine principal peuvent bénéficier d'une durée de vie plus longue. Cela met clairement en évidence la nécessité d'accorder une attention particulière à ce qui peut être mis en cache, puis de s'assurer que la mise en cache est configurée correctement.
-
-
-
-
-
-
-
Client
-
1ere partie
-
3e partie
-
Global
-
-
-
Bureau
-
70.7 %
-
47.9 %
-
59.2 %
-
-
-
Mobile
-
71.4 %
-
46.8 %
-
59.6 %
-
-
-
-
-
- Figure 11. Pourcentage des requêtes avec des TTL courts.
-
Les en-têtes HTTP utilisés pour valider les réponses stockées dans un cache sont Last-Modified et ETag. L'en-tête Last-Modified fait exactement ce que son nom implique et fournit l'heure à laquelle l'objet a été modifié pour la dernière fois. L'en-tête ETag fournit un identifiant unique pour le contenu.
-
Par exemple, la réponse ci-dessous a été modifiée pour la dernière fois le 25 août 2019 et elle a une valeur ETag de "1566748830.0-3052-3932359948".
Un client peut envoyer une requête conditionnelle pour valider une entrée en cache en utilisant la valeur Last-Modified dans un en-tête de requête nommé If-Modified-Since. De même, il pourrait aussi valider la ressource avec un en-tête de requête If-None-Match, qui valide par rapport à la valeur ETag que le client a pour la ressource dans son cache.
-
Dans l'exemple ci-dessous, le cache semble toujours valide, et un HTTP 304 a été renvoyé sans contenu. Cela permet d'économiser le téléchargement de la ressource elle-même. Si l'entrée de cache n'était plus fraîche, alors le serveur aurait répondu avec un 200 et la ressource mise à jour qui aurait dû être téléchargée à nouveau.
Dans l'ensemble, 65 % des réponses sont servies avec un en-tête Last-Modified, 42 % sont servies avec un ETag, et 38 % utilisent les deux. Cependant, 30 % des réponses n'incluent ni un en-tête Last-Modified ni un en-tête ETag.
Le diagramme à barres montre que 64,4 % des requêtes sur ordinateurs de bureau ont un Last Modified, 42,8 % ont un ETag, 37,9 % ont les deux et 30,7 % n'ont ni l'un ni l'autre. Les statistiques pour les mobiles sont presque identiques : 65,3 % pour la dernière modification, 42,8 % pour l'ETag, 38,0 % pour les deux et 29,9 % pour aucune des deux.
- Figure 12. Adoption de la validation de la fraîcheur via les en-têtes Last-Modified et ETag pour sites sur ordinateurs de bureau.
-
-
Le format des en-têtes HTTP utilisés pour transmettre les horodatages, et le format de ceux-ci, sont importants. L'en-tête Date indique quand la ressource a été servie à un client. L'en-tête Last-Modified indique quand une ressource a été modifiée pour la dernière fois sur le serveur. Et l'en-tête Expires est utilisé pour indiquer combien de temps une ressource doit être mise en cache (à moins qu'un en-tête Cache-Control soit présent).
-
Tous ces en-têtes HTTP utiliser des dates sous forme de chaine de carractères pour représenter des horodatages.
La plupart des clients ignorent les dates invalides, ce qui les rend incapables de comprendre la réponse qui leur est servie. Cela peut avoir des conséquences sur la possibilité de mise en cache, puisqu'un en-tête Last-Modified erroné sera mis en cache sans l'horodatage Last-Modified, ce qui rendra impossible l'exécution d'une requête conditionnelle.
-
L'en-tête de réponse HTTP Date est généralement généré par le serveur web ou le CDN qui sert la réponse à un client. Comme l'en-tête est généralement généré automatiquement par le serveur, il a tendance à être moins sujet aux erreurs, ce qui se reflète dans le très faible pourcentage d'en-têtes Date invalides. Les en-têtes Last-Modified sont très similaires, avec seulement 0,67 % d'en-têtes invalides. Ce qui est très surprenant, c'est que 3,64 % des en-têtes Expires utilisent un format de date invalide !
Le diagramme à barres montre que 0,10 % des réponses sur ordinateurs de bureau ont une date non valide, 0,67 % ont une date Last-Modified non valide et 3,64 % ont une date d'Expires non valide. Les statistiques pour les mobiles sont très similaires avec 0,06 % des réponses ayant une date non valide, 0,68 % ayant une date Last-Modified non valide et 3,50 % ayant une date d'Expires non valide.
- Figure 13. Formats de date invalides dans les en-têtes de réponse.
-
-
Voici des exemples d'utilisations incorrectes de l'en-tête Expires :
-
-
Formats de date valides, mais utilisant un fuseau horaire autre que GMT
-
Valeurs numériques telles que 0 ou -1
-
Valeurs qui seraient valides dans un en-tête Cache-Control
-
-
La plus grande source d'en-têtes Expires invalides provient de ressources servies par une tierce partie , dans lesquels un horodatage utilise le fuseau horaire EST, par exemple Expires: Tue, 27 Apr 1971 19:44:06 EST.
L'une des étapes les plus importantes de la mise en cache est de déterminer si la ressource demandée est mise en cache ou non. Bien que cela puisse paraître simple, il arrive souvent que l'URL seule ne suffise pas à le déterminer. Par exemple, les requêtes ayant la même URL peuvent varier en fonction de la compression utilisée (gzip, brotli, etc.) ou être modifiées et adaptées aux visiteurs mobiles.
-
Pour résoudre ce problème, les clients donnent à chaque ressource mise en cache un identifiant unique (une clé de cache). Par défaut, cette clé de cache est simplement l'URL de la ressource, mais les développeurs et développeuses peuvent ajouter d'autres éléments (comme la méthode de compression) en utilisant l'en-tête Vary.
-
Un en-têteVary demande au client d'ajouter la valeur d'une ou plusieurs valeurs d'en-tête de requête à la clé de cache. L'exemple le plus courant est Vary : Accept-Encoding, qui se traduira par différentes entrées en cache pour les valeurs d'en-tête de requête Accept-Encoding (c'est-à-dire gzip, br, deflate).
-
Une autre valeur commune est Vary: Accept-Encoding, User-Agent, qui demande au client de varier l'entrée en cache à la fois par les valeurs de Accept-Encoding et par la chaîne User-Agent. Lorsqu'il s'agit de proxies et de CDN partagés, l'utilisation de valeurs autres que Accept-Encoding peut être problématique car elle dilue les clés de cache et peut réduire le volume de trafic servi à partir du cache.
-
En général, vous ne devez modifier le cache que si vous servez un contenu alternatif aux clients en fonction de cet en-tête.
-
L'en-tête Vary est utilisé sur 39 % des réponses HTTP, et 45 % des réponses qui incluent un en-tête Cache-Control.
-
Le graphique ci-dessous détaille la popularité des 10 premières valeurs d'en-tête Vary. L'Accept-Encoding représente 90 % de l'utilisation de Vary, avec User-Agent (11 %), Origin (9 %), et Accept (3 %) constituant la majeure partie du reste.
Le diagramme à barres montre que 90 % des utilisations se basent sur accept-encoding, et pour le reste des valeurs beaucoup plus petites avec 10 à 11 % pour l'user-agent, environ 7 à 8 % pour origin et moins pour accept, presque pas d'utilisation pour les en-têtes cookie, x-forward-proto, accept-language, host, x-origin, access-control-request-method, et access-control-request-heads
Lorsqu'une réponse est mise en cache, tous ses en-têtes sont également stockés dans le cache. C'est pourquoi vous pouvez voir les en-têtes de réponse lorsque vous inspectez une réponse mise en cache via DevTools.
Une capture d'écran de Chrome Developer Tools montrant les en-têtes de réponse HTTP pour une réponse en cache.
- Figure 15. Outils de développement Chrome pour une ressource en cache.
-
-
Mais que se passe-t-il si vous avez un Set-Cookie dans une réponse ? Selon la RFC 7234 Section 8, la présence d'un en-tête de réponse Set-Cookie n'empêche pas la mise en cache. Cela signifie qu'une entrée mise en cache peut contenir un Set-Cookie si elle a été mise en cache avec. La RFC recommande ensuite que vous configuriez des en-têtes Cache-Control appropriés pour contrôler la mise en cache des réponses.
-
L'un des risques de la mise en cache avec Set-Cookie est que les valeurs des cookies puissent être stockées et servies à des requêtes ultérieures. Suivant l'objectif du cookie, cela pourrait avoir des résultats inquiétants. Par exemple, si un cookie de connexion ou un cookie de session est présent dans un cache partagé, alors ce cookie pourrait être réutilisé par un autre client. Une façon d'éviter cela est d'utiliser la directive Cache-Controlprivate, qui permet uniquement la mise en cache de la réponse par le navigateur du client.
-
3 % des réponses pouvant être mises en cache contiennent un en-tête Set-Cookie. Parmi ces réponses, seulement 18 % utilisent la directive private. Les 82 % restants comprennent 5,3 millions de réponses HTTP qui incluent un Set-Cookie qui peut être mis en cache par des serveurs de cache publics et privés.
Le graphique à barres montre que 97 % des réponses n'utilisent pas Set-Cookie alors que 3 % le font. Ces 3 % sont zoomés pour obtenir un autre diagramme à barres montrant la répartition entre 15,3 % de réponses private, 84,7 % de réponses public pour les ordinateurs de bureau et réciproquement pour les téléphones portables, 18,4 % de réponses public et 81,6 % de réponses private.
- Figure 16. Réponses pouvant être mises en cache avec Set-Cookie.
-
-
Un graphique de séries chronologiques montre l'utilisation des sites contrôlés par les service worker d'octobre 2016 à juillet 2019. L'utilisation a augmenté régulièrement au fil des ans, tant pour les téléphones portables que pour les ordinateurs de bureau, mais reste inférieure à 0,6 % pour les deux.
- Figure 17. Série chronologique de pages contrôlées par des service workers. (Source : HTTP Archive)
-
-
L'adoption est toujours inférieure à 1 % des sites web, mais elle est en constante augmentation depuis janvier 2017. Le chapitre Progressive Web App en parle davantage, notamment du fait qu'ils sont beaucoup plus utilisés que ne le suggère ce graphique en raison de leur utilisation sur des sites populaires, qui ne sont comptés qu'une fois dans le graphique ci-dessus.
-
Dans le tableau ci-dessous, vous pouvez voir un résumé de l'utilisation d'AppCache par rapport aux service workers. 32 292 sites web ont mis en place un service worker, tandis que 1 867 sites utilisent toujours la fonctionnalité AppCache, qui est obsolète.
-
-
-
-
-
-
-
-
N'utilisent pas de Server Worker
-
Utilisent un Service Worker
-
Total
-
-
-
-
-
N'utilise pas AppCache
-
5,045,337
-
32,241
-
5,077,578
-
-
-
Utilise AppCache
-
1,816
-
51
-
1,867
-
-
-
Total
-
5,047,153
-
32,292
-
5,079,445
-
-
-
-
-
- Figure 18. Nombre de sites web utilisant AppCache par rapport aux Service Workers.
-
-
Si on fait une comparaison entre HTTP et HTTPS, cela devient encore plus intéressant. 581 des sites compatibles avec l'AppCache sont servis en HTTP, ce qui signifie que Chrome a probablement désactivé cette fonctionnalité. Le HTTPS est obligatoire pour l'utilisation des services workers, mais 907 des sites qui les utilisent sont servis en HTTP.
-
-
-
-
-
-
-
-
-
N'utilise pas Service Worker
-
Utilise Service Worker
-
-
-
-
-
HTTP
-
N'utilise pas AppCache
-
1,968,736
-
907
-
-
-
Utilise AppCache
-
580
-
1
-
-
-
HTTPS
-
N'utilise pas AppCache
-
3,076,601
-
31,334
-
-
-
Utilise AppCache
-
1,236
-
50
-
-
-
-
-
- Figure 19. Nombre de sites web utilisant AppCache par rapport à l'utilisation des service worker par HTTP/HTTPS.
-
L'outil Lighthouse de Google permet aux utilisateurs d'effectuer une série d'audits sur les pages web, et l'audit de la politique de cache évalue si un site peut bénéficier d'une mise en cache supplémentaire. Pour ce faire, il compare l'âge du contenu (via l'en-tête Last-Modified) au TTL de la ressource en cache et estime la probabilité que la ressource soit servie à partir du cache. En fonction du score, vous pouvez voir dans les résultats une recommandation de mise en cache, avec une liste de ressources spécifiques qui pourraient être mises en cache.
Une capture d'écran d'une partie d'un rapport de l'outil Google Lighthouse, avec la section "Servir des ressources statiques avec une politique de cache efficace" ouverte où il énumère un certain nombre de ressources, dont les noms ont été masqués, et le TTL du cache par rapport à la taille.
- Figure 20. Rapport Lighthouse soulignant les améliorations possibles de la politique des caches.
-
-
Lighthouse calcule un score pour chaque audit, allant de 0 à 100 %, et ces scores sont ensuite pris en compte dans les scores globaux. Le score de mise en cache est basé sur les économies potentielles d'octets. En examinant les résultats de Lighthouse, on peut se faire une idée du nombre de sites qui réussissent bien avec leur politique de cache.
Un diagramme à barres superposées : 38,2 % des sites web obtiennent un score de < 10 %, 29,0 % des sites web obtiennent un score entre 10 et 39 %, 18,7 % des sites web obtiennent un score de 40 à 79 %, 10,7 % des sites web obtiennent un score de 80 à 99 %, et 3,4 % des sites web obtiennent un score de 100 %.
- Figure 21. Distribution des scores Lighthouse pour l'audit "Définit un long cache TTL" pour les pages web mobiles.
-
-
Seuls 3,4 % des sites ont obtenu un score de 100 %, ce qui signifie que la plupart des sites peuvent bénéficier de certaines optimisations du cache. La grande majorité des sites ont un score inférieur à 40 %, 38 % ayant un score inférieur à 10 %. En partant de là, on peut affirmer qu'il existe un nombre important d'opportunités de mise en cache sur le web.
-
Lighthouse indique également combien d'octets pourraient être économisés sur les vues répétées en permettant une politique de cache plus longue. Parmi les sites qui pourraient bénéficier d'une mise en cache supplémentaire, 82 % d'entre eux peuvent réduire le poids de leurs pages jusqu'à un Mo entier !
Un diagramme à barres superposées montrant que 56,8 % des sites web ont un potentiel d'économie d'octets de moins d'un Mo, 22,1 % pourraient avoir une économie d'un à deux Mo, 8,3 % pourraient économiser deux à trois Mo. 4,3 % pourraient permettre d'économiser trois à quatre Mo et 6,0 % pourraient permettre d'économiser plus de quatre Mo.
- Figure 22. Répartition des économies potentielles d'octets résultant de l'audit de la mise en cache de Lighthouse.
-
-
La mise en cache est une fonction incroyablement puissante qui permet aux navigateurs, aux serveurs de proxy et autres intermédiaires (tels que les CDN) de stocker le contenu du web et de le servir aux utilisateurs finaux. Les avantages en termes de performances sont considérables, puisqu'elle réduit les temps de trajet (aller-retour) et minimise les requêtes coûteuses sur le réseau.
-
La mise en cache est également un sujet très complexe. Il existe de nombreux en-têtes de réponse HTTP qui peuvent transmettre la fraîcheur ainsi que valider les entrées mises en cache, et les directives Cache-Control offrent une très grande souplesse et un très grand contrôle. Cependant, les développeurs et développeuses doivent être prudent·e·s quant aux possibilités supplémentaires d'erreurs que ces directives offrent. Il est recommandé de vérifier régulièrement votre site pour s'assurer que les ressources pouvant être mises en cache le sont correctement, et des outils comme Lighthouse et REDbot font un excellent travail pour aider à simplifier l'analyse.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/cms.html b/src/templates/fr/2019/chapters/cms.html
deleted file mode 100644
index f40081cb147..00000000000
--- a/src/templates/fr/2019/chapters/cms.html
+++ /dev/null
@@ -1,691 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"III","chapter_number":14,"title":"CMS","description":"Chapitre CMS de l'Almanach Web 2019 couvrant l'adoption des CMS, la façon dont les solutions CMS sont construites, l'expérience utilisateur des sites web propulsés par les CMS et l'innovation des CMS.","authors":["ernee","amedina"],"reviewers":["sirjonathan"],"translators":["JustinyAhin"],"discuss":"1769","results":"https://docs.google.com/spreadsheets/d/1FDYe6QdoY3UtXodE2estTdwMsTG-hHNrOe9wEYLlwAw/","queries":"14_CMS","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"cms"} %} {% block index %}
-
Le terme général Système de gestion de contenu (SGC, ou CMS pour Content Management System en anglais) désigne les systèmes permettant aux personnes et aux organisations de créer, de gérer et de publier du contenu. Un CMS pour le contenu web, plus précisément, est un système visant à créer, gérer et publier du contenu à consommer et à expérimenter via le web ouvert.
-
Chaque CMS met en œuvre un sous-ensemble d'un large éventail de capacités de gestion de contenu et les mécanismes correspondants pour permettre aux utilisateurs de construire facilement et efficacement des sites web autour de leur contenu. Ce contenu est souvent stocké dans un certain type de base de données, ce qui permet aux utilisateurs de le réutiliser partout où cela est nécessaire pour leur stratégie de contenu. Les CMS offrent également des capacités d'administration visant à faciliter le téléversement et la gestion du contenu par les utilisateurs, selon leurs besoins.
-
Le type et la portée du support fourni par les CMS pour la construction de sites varient considérablement ; certains fournissent des modèles prêts à l'emploi qui sont "hydratés" par le contenu de l'utilisateur, et d'autres exigent une participation beaucoup plus importante de l'utilisateur à la conception et à la construction de la structure du site.
-
Lorsque nous parlons des CMS, nous devons tenir compte de tous les éléments qui jouent un rôle dans la viabilité d'un tel système pour fournir une plate-forme de publication de contenu sur le web. Tous ces composants forment un écosystème autour de la plate-forme du CMS, et ils incluent les fournisseurs d'hébergement, les développeurs d'extension, les agences de développement, les constructeurs de sites, etc. Ainsi, lorsque nous parlons d'un CMS, nous faisons généralement référence à la fois à la plate-forme elle-même et à l'écosystème qui l'entoure.
Au début des temps ("de l'évolution du web"), l'écosystème du web était alimenté par une simple boucle de croissance, où les utilisateurs pouvaient devenir des créateurs simplement en visualisant la source d'une page web, en faisant du copier-coller selon leurs besoins, et en adaptant la nouvelle version avec des éléments individuels comme des images.
-
Au fur et à mesure de son évolution, le web est devenu plus puissant, mais aussi plus compliqué. En conséquence, cette simple boucle de croissance a été rompue et il n'était plus possible que n'importe quel utilisateur devienne un créateur. Pour ceux qui pouvaient poursuivre le chemin de la création de contenu, la route devenait ardue et difficile à parcourir. Le fossé des capacités d'utilisation, c'est-à-dire la différence entre ce qui peut être fait sur le web et ce qui est réellement fait, a augmenté régulièrement.
Sur la gauche, intitulée circa 1999, nous avons un diagramme à barres avec deux barres montrant que ce qui peut être fait est proche de ce qui est réellement fait. Sur la droite, intitulée 2018, nous avons un diagramme en bâtons similaire, mais ce qui peut être fait est beaucoup plus grand, et ce qui est fait est légèrement plus grand. L'écart entre ce qui peut être fait et ce qui est réellement fait a beaucoup augmenté.
- Figure 1. Graphique illustrant l'augmentation des fonctionnalités du web de 1999 à 2018.
-
-
C'est ici qu'un CMS joue un rôle très important en permettant à des utilisateurs ayant différents degrés d'expertise technique d'entrer facilement dans la boucle de l'écosystème web en tant que créateurs de contenu. En abaissant la barrière d'entrée pour la création de contenu, les CMS activent la boucle de croissance du web en transformant les utilisateurs en créateurs. D'où leur popularité.
Il y a beaucoup d'aspects intéressants et importants à analyser et de questions auxquelles répondre dans notre quête pour comprendre le monde des CMS et son rôle dans le présent et le futur du web. Bien que nous reconnaissions l'immensité et la complexité du monde des plateformes CMS, et que nous ne revendiquions pas une connaissance omnisciente couvrant tous les aspects impliqués sur toutes les plateformes CMS, nous revendiquons notre fascination pour cet univers et nous apportons une expertise approfondie sur certains de ses acteurs principaux.
-
Dans ce chapitre, nous cherchons à explorer la surface du vaste univers des CMS, en essayant d'éclairer notre compréhension collective du statu quo de ces écosystèmes et du rôle qu'ils jouent dans la perception des utilisateurs sur la façon dont le contenu peut être consommé et expérimenté sur le web. Notre but n'est pas de fournir une vue exhaustive du paysage des CMS ; nous allons plutôt discuter de quelques aspects liés au paysage des CMS en général, et des caractéristiques des pages web générées par ces systèmes. Cette première édition du Web Almanac établit une base de référence, et à l'avenir nous aurons l'avantage de pouvoir comparer les données avec cette version pour l'analyse des tendances.
- Figure 2. Pourcentage de pages web propulsées par un CMS.
-
-
Aujourd'hui, nous remarquons que plus de 40% des pages web sont propulsées par une plateforme CMS ; 40.01% pour les mobiles et 39.61% pour les ordinateur de bureau plus précisément.
-
Il existe d'autres ensembles de données qui suivent la part de marché des plateformes CMS, comme W3Techs, et ils reflètent des pourcentages plus élevés de plus de 50% de pages web propulsées par des plateformes CMS. De plus, ils indiquent également que les plateformes CMS sont en expansion, jusqu'à 12 % de croissance d'une année à l'autre dans certains cas ! L'écart entre notre analyse et celle de W3Tech pourrait s'expliquer par une différence dans les méthodologies de recherche. Vous pouvez en lire plus sur la nôtre sur la page Méthodologie.
-
En gros, cela signifie qu'il existe de nombreuses plateformes CMS disponibles sur le marché. L'image suivante montre une vue réduite du paysage CMS.
Logos des principaux fournisseurs de CMS, notamment WordPress, Drupal, Wix, etc.
- Figure 3. Les principaux systèmes de gestion de contenu.
-
-
Certains d'entre eux sont open source (par exemple WordPress, Drupal, et autres) et d'autres sont propriétaires ( comme AEM, et autres). Certaines plates-formes CMS peuvent être utilisées sur des formules "gratuites" hébergées ou auto-hébergées, et il existe également des options avancées pour utiliser ces plates-formes sur des formules de niveau supérieur, y compris au sein des entreprises. Dans son ensemble, le secteur des CMS est un univers complexe et fédéré d' écosystèmes CMS, tous séparés et en même temps entrelacés dans le vaste tissu du web.
-
Cela signifie également qu'il y a des centaines de millions de sites web propulsés par des plateformes CMS, et un ordre de grandeur plus élevé d'utilisateurs accédant au web et consommant du contenu à travers ces plateformes. Ainsi, ces plateformes jouent un rôle clé pour nous permettre de réussir dans notre quête collective d'un web toujours vert, sain et dynamique.
Une grande partie du web aujourd'hui est alimentée par un type de plateforme CMS ou un autre. Il existe des statistiques recueillies par différentes organisations qui reflètent cette réalité. En regardant les jeux de données Chrome UX Report (CrUX) et HTTP Archive, nous arrivons à une image qui est cohérente avec les statistiques publiées ailleurs, bien que quantitativement les proportions décrites puissent être différentes en tant que reflet de la spécificité des jeux de données.
-
En examinant les pages web servies sur les appareils de bureau et mobiles, nous observons une répartition approximative de 60-40 dans le pourcentage de ces pages qui ont été générées par une sorte de plateforme CMS, et celles qui ne le sont pas.
Diagramme en bâtons montrant que 40 % des sites web desktop et 40 % des sites web mobiles sont construits à l'aide d'un CMS.
- Figure 4. Pourcentage de sites web desktop et mobiles qui utilisent un CMS.
-
-
Les pages web propulsées par les CMS sont générées par un large ensemble des plateformes CMS existantes. Le choix de ces plateformes est très vaste, et de nombreux facteurs peuvent être pris en compte lorsqu'on décide d'utiliser l'une ou l'autre, notamment:
-
-
Fonctionnalité de base
-
Création/édition de workflows et expérience
-
Barrière d'entrée
-
Possibilité de personnalisation
-
Communauté
-
Et beaucoup d'autres.
-
-
Les jeux de données CrUX et HTTP Archive contiennent des pages web propulsées par un ensemble d'environ 103 plateformes CMS. La plupart de ces plates-formes sont très petites en termes de part de marché relative. Pour les besoins de notre analyse, nous nous concentrerons sur les principales plates-formes CMS en termes de leur impact sur le web, tel que reflété par les données. Pour une analyse complète, voir la feuille de calcul des résultats de ce chapitre.
Diagramme en bâtons montrant que WordPress représente 75% de tous les sites web créés avec un CMS. Le deuxième plus grand CMS, Drupal, a environ 6% de la part de marché des CMS. Le reste des CMS se réduit rapidement à moins de 1%.
- Figure 5. Principales plateformes CMS en pourcentage de tous les sites web CMS.
-
-
Les principales plates-formes CMS présentes dans les jeux de données sont indiquées ci-dessus à la figure 5. WordPress est utilisé par 74,19 % des sites web utilisant un CMS pour les téléphones mobiles et 73,47 % des sites web utilisant un CMS pour les ordinateurs de bureau. Sa domination dans le milieu des CMS peut être attribuée à un certain nombre de facteurs dont nous parlerons plus loin, mais c'est un acteur major. Les plateformes open source comme Drupal et Joomla, et les solutions SaaS propriétaires comme Squarespace et Wix, complètent le top 5 des CMS. La diversité de ces plateformes reflète l'écosystème des CMS, composé de nombreuses plateformes où la démographie des utilisateurs et le parcours de création de sites web varient. Ce qui est également intéressant, c'est la longue liste des plateformes CMS de petites tailles qui se trouvent dans le top 20. Des offres d'entreprise aux applications propriétaires développées en interne pour une utilisation spécifique à un secteur, les systèmes de gestion de contenu fournissent une infrastructure personnalisable permettant aux groupes de gérer, de publier et de faire des affaires sur le web.
-
Le projet WordPress définit sa mission en ces termes : "démocratiser la publication". Certains de ses principaux objectifs sont de faciliter l'utilisation et de rendre le logiciel libre et disponible à tous pour créer du contenu sur le web. Un autre élément important est la communauté inclusive que le projet promeut. Dans presque toutes les grandes villes du monde, on peut trouver un groupe de personnes qui se réunissent régulièrement pour se rencontrer, partager et coder dans un effort de compréhension et de construction sur la plate-forme WordPress. La participation aux rencontres locales et aux événements annuels, ainsi que la participation aux réseaux basés sur le web sont quelques unes des façons dont les contributeurs, les experts, les entreprises et les passionnés de WordPress participent à sa communauté globale.
-
La faible barrière d'entrée et les ressources pour aider les utilisateurs (en ligne et en personne) à publier sur la plateforme et à développer des extensions (plugins) et des thèmes contribuent à sa popularité. La disponibilité et l'économie autour des extensions et des thèmes WordPress contribuent également à réduire la complexité dans la mise en œuvre de la conception et des fonctionnalités web recherchées. Non seulement ces aspects favorisent sa portée et son adoption par les nouveaux venus, mais ils permettent également de maintenir au fil du temps son utilisation régulière.
-
La plateforme open source WordPress est propulsée et soutenue par des bénévoles, la WordPress Foundation, et des acteurs majeurs de l'écosystème web. En gardant ces facteurs à l'esprit, le fait que WordPress soit le principal système de gestion de contenu (CMS) est tout à fait logique.
Indépendamment des nuances spécifiques et des particularités des différentes plateformes CMS, leur objectif final est de produire des pages web qui seront mises à la disposition des utilisateurs par le biais de la vaste portée du web ouvert. La différence entre les pages web propulsées par un CMS et celles qui ne le sont pas est que dans le premier cas, la plate-forme CMS prend la plupart des décisions sur la façon dont le résultat final est construit, tandis que dans le second, il n'y a pas de telles couches d'abstraction et les décisions sont toutes prises par les développeurs, soit directement, soit via des configurations de bibliothèques.
-
Dans cette section, nous examinons brièvement le statu quo de l'espace CMS en termes de caractéristiques de leur résultat (par exemple, les ressources totales utilisées, les statistiques sur les images, entre autres), et nous les comparons avec celles de l'écosystème web en général.
Les éléments de base de tout site web constituent également un site web géré par un CMS : [HTML](. /markup), [CSS](. /css), [JavaScript](. /javascript), et [media](. /media) (images et vidéo). Les CMS offrent aux utilisateurs des fonctionnalités de gestion puissamment optimisées pour intégrer ces ressources afin de créer des expériences web. Bien que ce soit l'un des aspects les plus inclusifs de ces applications, il est possible qu'il ait des effets négatifs sur le web en général.
Diagramme en bâtons montrant la distribution du poids des pages CMS. La page CMS moyenne sur ordinateur de bureau pèse 2.3 MB. Au 10e percentile, elle pèse 0,7 Mo, au 25e percentile, 1,2 Mo, au 75e percentile, 4,2 Mo et au 90e percentile, 7,4 Mo. Les valeurs pour les ordinateurs de bureau sont très légèrement supérieures à celles des mobiles.
- Figure 6. Répartition du poids des pages sur les CMS.
-
-
-
-
-
-
-
Diagramme en bâtons montrant la répartition des requêtes des CMS par page. La page CMS moyenne sur ordinateur de bureau charge 86 ressources. Au 10e percentile, elle charge 39 ressources, au 25e percentile 57 ressources, au 75e percentile 127 ressources et au 90e percentile 183 ressources. Le desktop est constamment plus élevé que le mobile par une petite marge de 3-6 ressources.
- Figure 7. Répartition des requêtes des CMS par page.
-
-
Dans les figures 6 et 7 ci-dessus, nous voyons que la page médiane sur un CMS sur un ordinateur de bureau charge 86 ressources et pèse 2,29 Mo. L'utilisation des ressources des pages mobiles n'est pas très loin derrière avec 83 ressources et 2,25 Mo.
-
La médiane indique le point médian où toutes les pages du CMS se situent soit au-dessus, soit au-dessous. En bref, la moitié de toutes les pages web sur un CMS chargent moins de requêtes et sont moins lourdes, tandis que l'autre moitié charge plus de requêtes et est plus lourde. Au 10e percentile, les pages mobiles et sur bureau ont moins de 40 requêtes et pèsent moins de 1 Mo, mais au 90e percentile, nous avons des pages avec plus de 170 requêtes et pesant 7 Mo, soit presque trois fois plus que la médiane.
-
Comment sont les pages CMS par rapport aux pages du web dans son ensemble ? Dans le chapitre [Poids de la page](. /page-weight), nous trouvons quelques données révélatrices sur l'utilisation des ressources. À la médiane, les pages de bureau chargent 74 requêtes et pèsent 1,9 Mo, et les pages mobiles sur le Web chargent 69 requêtes et pèsent 1,7 Mo. La page CMS moyenne dépasse ce chiffre. Les pages sur les CMS surpassent également les ressources sur le web au 90e percentile, mais avec une marge plus faible. En bref : les pages sur les CMS pourraient être classées parmi les plus lourdes.
-
-
-
-
-
-
-
percentile
-
image
-
video
-
script
-
font
-
css
-
audio
-
html
-
-
-
-
-
50
-
1,233
-
1,342
-
456
-
140
-
93
-
14
-
33
-
-
-
75
-
2,766
-
2,735
-
784
-
223
-
174
-
97
-
66
-
-
-
90
-
5,699
-
5,098
-
1,199
-
342
-
310
-
287
-
120
-
-
-
-
-
- Figure 8. Répartition des kilo-octets des pages CMS de bureau par type de ressources.
-
-
-
-
-
-
-
-
percentile
-
image
-
video
-
script
-
css
-
font
-
audio
-
html
-
-
-
-
-
50
-
1,264
-
1,056
-
438
-
89
-
109
-
14
-
32
-
-
-
75
-
2,812
-
2,191
-
756
-
171
-
177
-
38
-
67
-
-
-
90
-
5,531
-
4,593
-
1,178
-
317
-
286
-
473
-
123
-
-
-
-
-
- Figure 9. Répartition des kilo-octets des pages CMS de bureau par type de ressources.
-
-
Lorsque nous regardons de plus près les types de ressources qui se chargent sur les pages sur les CMS sur mobile ou sur desktop, les images et la vidéo apparaissent immédiatement comme les principaux contributeurs à leur poids.
-
L'impact n'est pas nécessairement en corrélation avec le nombre de requêtes, mais plutôt avec la quantité de données associées à ces requêtes individuelles. Par exemple, dans le cas des ressources vidéo dont seulement deux demandes sont faites à la médiane, elles ont un poids de plus de 1Mo. Les expériences multimédias s'accompagnent également de l'utilisation de scripts pour intégrer l'interactivité, fournir des fonctionnalités et des données, pour ne citer que quelques cas d'utilisation. Sur les pages mobiles comme sur les pages sur ordinateur de bureau, ces ressources sont les troisièmes plus lourdes.
-
Avec nos expériences des CMS qui sont saturées de ces ressources, nous devons considérer l'impact que cela a sur les visiteurs du site web sur le front-end - leur expérience est-elle rapide ou lente ? De plus, lorsque l'on compare l'utilisation des ressources mobiles et ordinateur de bureau, la quantité de requêtes et le poids ne montrent que peu de différence. Cela signifie que la même quantité et le même poids de ressources alimentent à la fois les expériences CMS sur mobile et sur ordinateur de bureau. La variation de la vitesse de connexion et de la qualité des appareils mobiles ajoute une autre couche de complexité. Plus tard dans ce chapitre, nous utiliserons les données du CrUX pour évaluer l'expérience des utilisateurs dans l'écosystème des CMS.
Soulignons un sous-ensemble spécifique de ressources pour évaluer leur impact dans l'écosystème des CMS. Les ressources Tierce partie sont celles qui proviennent d'origines n'appartenant pas au nom de domaine ou aux serveurs du site de destination. Elles peuvent être des images, des vidéos, des scripts ou d'autres types de ressources. Parfois, ces ressources sont combinées entre elles, comme par exemple avec l'intégration d'une iframe. Nos données révèlent que la quantité médiane de ressources tierces sur ordinateur de bureau et sur mobile est très similaire.
-
La quantité médiane de requêtes tierces sur les pages CMS mobiles est de 15 et pèse 264,72 Ko, tandis que la médiane de ces requêtes sur les pages CMS sur ordinateur de bureau est de 16 et pèse 271,56 Ko. (Il est à noter que cela exclut les ressources 3P considérées comme faisant partie de l' "hébergement".
Diagramme en bâtons des percentiles 10, 25, 50, 75 et 90 représentant la distribution des kilo-octets de tierces parties sur les pages CMS pour les ordinateurs de bureau et les mobiles. Le poids médian (50e percentile) des pages de bureau de tierces parties est de 272 Ko. Le 10e percentile est de 27 Ko, le 25e de 104 Ko, le 75e de 577 Ko et le 90e de 940 Ko. Le mobile est légèrement plus petit dans les petits percentiles et légèrement plus grand dans les grands percentiles.
- Figure 10. Répartition du poids des tierces parties (en Ko) sur les pages CMS.
-
-
-
-
-
-
-
Diagramme en bâtons des percentiles 10, 25, 50, 75 et 90 représentant la distribution des requêtes de tierces-parties sur les pages CMS sur ordinateur de bureau et mobile. Le nombre médian (50e percentile) de requêtes de tierces-parties sur ordinateur de bureau est de 16. Le 10e percentile est 3, le 25e 7, le 75e 31 et le 90e 52. Les ordinateurs de bureau et les mobiles ont des distributions presque équivalentes.
- Figure 11. Répartition du nombre de requêtes de tiers sur les pages CMS.
-
-
Nous savons que la valeur médiane indique qu'au moins la moitié des pages Web des CMS sont envoyées avec plus de ressources tierces que ce que nous signalons ici. Au 90e percentile, les pages des CMS peuvent livrer jusqu'à 52 ressources à environ 940 Ko, ce qui représente une augmentation considérable.
-
Étant donné que les ressources tierces proviennent de domaines et de serveurs distants, le site de destination a peu de contrôle sur la qualité et l'impact de ces ressources sur sa performance. Cette imprévisibilité pourrait entraîner des fluctuations de vitesse et affecter l'expérience de l'utilisateur, ce que nous allons bientôt explorer.
Diagramme en bâtons des percentiles 10, 25, 50, 75 et 90 représentant la distribution des kilo-octets d'images sur les pages CMS bureau et mobile. Le poids médian (50e percentile) des images sur bureau est de 1 232 Ko. Le 10e percentile est de 198 Ko, le 25e de 507 Ko, le 75e de 2 763 Ko et le 90e de 5 694 Ko. Les ordinateurs de bureau et les mobiles ont des distributions presque équivalentes.
- Figure 12. Répartition du poids des images (KB) sur les pages CMS.
-
-
-
1,232 KB
- Figure 13. Nombre médian de kilo-octets d'images chargés par page CMS sur ordinateur de bureau.
-
-
Rappelez-vous des figures 8 et 9 précédentes, les images sont un grand contributeur au poids total des pages des CMS. Les figures 12 et 13 ci-dessus montrent que la page médiane des CMS sur ordinateur de bureau a 31 images et un poids total de 1 232 Ko, tandis que la page médiane des CMS sur mobile a 29 images et un poids total de 1 263 Ko. Encore une fois, les différences de poids de ces ressources sont très faibles, tant pour les expériences de bureau que pour les expériences mobiles. Le chapitre [Poids de la page](. /page-weight) montre en outre que les ressources en images dépassent largement le poids médian des pages ayant la même quantité d'images sur l'ensemble du Web, qui est de 983 Ko et de 893 Ko pour ordinateur de bureau et pour mobile respectivement. Le verdict : Les pages des CMS envoient des images lourdes.
-
Quels sont les formats courants que l'on trouve sur les pages CMS sur ordinateur de bureau et mobile ? D'après nos données, les images JPG sont en moyenne le format d'image le plus populaire. Les formats PNG et GIF suivent, tandis que les formats comme SVG, ICO et WebP suivent de manière significative, avec environ un peu plus de 2% et 1%.
Diagramme en bâtons illustrant l'adoption de formats d'images sur les pages CMS pour les ordinateurs de bureau et les mobiles. Le JPEG représente près de la moitié de tous les formats d'image, le PNG en représente un tiers, le GIF un cinquième, et les 5% restants sont partagés entre le SVG, l'ICO et le WebP. Les ordinateurs de bureau et les téléphones portables ont une adoption presque équivalente.
- Figure 14. Adoption de formats d'images sur les pages CMS.
-
-
Cette segmentation n'est peut-être pas surprenante étant donné les cas d'utilisation courants pour ces types d'images. Les SVG pour les logos et les icônes sont courants, tout comme les JPEG sont omniprésents. Le WebP est encore un format optimisé relativement nouveau avec adoption croissante des navigateurs. Il sera intéressant de voir comment cela aura un impact sur son utilisation dans les prochaines années dans le monde des CMS.
Le succès en tant que créateur de contenu web est lié à l'expérience utilisateur. Des facteurs tels que l'utilisation des ressources et d'autres statistiques concernant la composition des pages web sont des indicateurs importants de la qualité d'un site en termes de bonnes pratiques suivies lors de sa conception. Cependant, nous souhaitons en fin de compte faire la lumière sur la façon dont les utilisateurs vivent réellement le web lorsqu'ils consomment et s'engagent avec le contenu généré par ces plateformes.
- Figure 15. Comment les humains perçoivent les courtes durées de temps.
-
-
Si les événements se produisent dans un délai de 0,1 seconde (100 millisecondes), pour nous tous, ils se produisent pratiquement instantanément. Et lorsque les événements durent plus de quelques secondes, la probabilité que nous poursuivions notre chemin sans attendre plus longtemps est très élevée. C'est très important pour les créateurs de contenu qui cherchent un succès continu sur le Web, car cela nous indique à quelle vitesse nos sites doivent se charger si nous voulons acquérir, engager et conserver notre base d'utilisateurs.
-
Dans cette section, nous examinons trois dimensions importantes qui peuvent éclairer notre compréhension de la façon dont les utilisateurs font l'expérience des pages web propulsées par les CMS dans la nature :
Le First Contentful Paint mesure le temps qui s'écoule entre le début de la navigation et le premier affichage d'un contenu tel que du texte ou une image. Une expérience FCP réussie, ou pouvant être qualifiée de "rapide", implique la rapidité avec laquelle les éléments du DOM sont chargés pour assurer à l'utilisateur que le site web se charge avec succès. Bien qu'un bon score FCP ne soit pas une garantie que le site correspondant offre un bon UX, un mauvais FCP garantit presque certainement le contraire.
Diagramme en bâtons de la distribution moyenne des expériences de FCP par CMS. Voir la figure 17 ci-dessous pour un tableau des données des cinq CMS les plus populaires.
- Figure 16. Répartition moyenne des expériences de FCP entre les CMS.
-
-
-
-
-
-
-
-
CMS
-
Rapide (< 1000ms)
-
Moderé
-
Lent (>= 3000ms)
-
-
-
-
-
WordPress
-
24.33%
-
40.24%
-
35.42%
-
-
-
Drupal
-
37.25%
-
39.39%
-
23.35%
-
-
-
Joomla
-
22.66%
-
46.48%
-
30.86%
-
-
-
Wix
-
14.25%
-
62.84%
-
22.91%
-
-
-
Squarespace
-
26.23%
-
43.79%
-
29.98%
-
-
-
-
-
- Figure 17. Répartition moyenne des expériences de FCP entre les CMS.
-
-
Le FCP dans l'écosystème des CMS tend surtout à se situer dans la plage des valeurs moyennes. La nécessité pour les plateformes CMS d'interroger le contenu d'une base de données, de l'envoyer, puis de le rendre dans le navigateur, pourrait être un facteur qui contribue au retard que connaissent les utilisateurs. Les charges de ressources dont nous avons discuté dans les sections précédentes pourraient également jouer un rôle. De plus, certaines de ces instances sont sur un hébergement partagé ou dans des environnements qui ne sont peut-être pas optimisés pour les performances, ce qui pourrait également avoir un impact sur l'expérience dans le navigateur.
-
WordPress montre notamment des expériences FCP modérées et lentes sur le mobile et le bureau. Wix se situe fortement dans les expériences FCP moyennes sur sa plateforme propriétaire. TYPO3, une plateforme CMS open-source d'entreprise, a des expériences rapides et constantes sur mobile et sur ordinateur de bureau. TYPO3 annonce des fonctionnalités intégrées de performance et d'évolutivité qui peuvent avoir un impact positif pour les visiteurs du site web en frontend.
Le First Input Delay (FID) mesure le temps écoulé entre le moment où un utilisateur interagit pour la première fois avec votre site (c'est-à-dire lorsqu'il clique sur un lien, tape sur un bouton ou utilise une option paramétrée en JavaScript) et le moment où le navigateur est réellement capable de répondre à cette interaction. Du point de vue de l'utilisateur, un FID "rapide" serait une réponse immédiate à ses actions sur un site plutôt qu'une expérience retardée. Ce délai (un point sensible) pourrait être en corrélation avec l'interférence d'autres aspects du chargement du site lorsque l'utilisateur essaie d'interagir avec le site.
-
Le FID dans l'écosystème CMS tend généralement vers des expériences rapides à la fois pour les ordinateurs de bureau et les mobiles en moyenne. Cependant, ce qui est remarquable, c'est la différence significative entre les expériences mobiles et sur ordinateur de bureau.
Diagramme en bâtons de la distribution moyenne des expériences de FCP par CMS. Voir la figure 19 ci-dessous pour un tableau des données des cinq CMS les plus populaires.
- Figure 18. Répartition moyenne des expériences de FID entre les CMS.
-
-
-
-
-
-
-
-
CMS
-
Rapide (< 100ms)
-
Moderé
-
Lent (>= 300ms)
-
-
-
-
-
WordPress
-
80.25%
-
13.55%
-
6.20%
-
-
-
Drupal
-
74.88%
-
18.64%
-
6.48%
-
-
-
Joomla
-
68.82%
-
22.61%
-
8.57%
-
-
-
Squarespace
-
84.55%
-
9.13%
-
6.31%
-
-
-
Wix
-
63.06%
-
16.99%
-
19.95%
-
-
-
-
-
- Figure 19. Répartition moyenne des expériences de FID pour les cinq CMS les plus populaires.
-
-
Bien que cette différence soit présente dans les données du FCP, le FID a des écarts de performances plus importants. Par exemple, la différence entre les expériences FCP rapides pour les téléphones portables et les ordinateurs de bureau pour Joomla est d'environ 12,78 %, pour les expériences FID, la différence est significative : 27,76 %. La qualité des appareils mobiles et des connexions pourrait jouer un rôle dans les écarts de performance que nous constatons ici. Comme nous l'avons souligné précédemment, il y a une petite marge de différence entre les ressources envoyées aux versions ordinateur de bureau et mobile d'un site web. L'optimisation pour l'expérience mobile (interactive) devient plus évidente avec ces résultats.
Lighthouse est un outil automatisé et open-source conçu pour aider les développeurs à évaluer et à améliorer la qualité de leurs sites web. Un aspect clé de l'outil est qu'il fournit un ensemble d'audits pour évaluer le statut d'un site web en termes de performance, accessibilité, applications web progressives, et plus encore. Pour les besoins de ce chapitre, nous nous intéressons à deux catégories de vérifications spécifiques : les PWA et l'accessibilité.
Le terme Progressive Web App (PWA) fait référence aux expériences d'utilisateurs sur le Web qui sont considérées comme étant fiables, rapides et engageantes. Lighthouse fournit un ensemble de vérifications qui donnent une note PWA entre 0 ( la plus mauvaise) et 1 ( la meilleure). Ces vérifications sont basées sur la Checklist de référence des PWA, qui contient 14 critères. Lighthouse a automatisé des vérifications pour 11 des 14 exigences. Les trois autres ne peuvent être vérifiées que manuellement. Chacune des 11 vérifications automatisées des PWA a une pondération égale, de sorte que chacune d'entre elles contribue à environ 9 points à votre note PWA.
Diagramme en bâtons montrant la distribution des notes Lighthouse de la catégorie PWA pour toutes les pages CMS. La note la plus fréquente est de 0,3 pour 22 % des pages CMS. Il y a deux autres pics dans la distribution : 11 % des pages avec un score de 0,15 et 8 % des pages avec un score de 0,56. Moins de 1% des pages obtiennent un score supérieur à 0,6.
- Figure 20. Distribution des notes Lighthouse de la catégorie PWA pour les pages CMS.
-
-
-
-
-
-
-
Diagramme en bâtons montrant la note médiane Lighthouse PWA par CMS. Le score médian pour les sites web WordPress est de 0,33. Les cinq prochains CMS (Joomla, Drupal, Wix, Squarespace et 1C-Bitrix) ont tous un score médian de 0,3. Les CMS avec les meilleurs scores PWA sont Jimdo avec un score de 0,56 et TYPO3 à 0,41.
- Figure 21. Notes Lighthouse médianes de la catégorie PWA par CMS.
-
-
Un site web accessible est un site conçu et développé pour que les personnes souffrant d'un handicap puissent les utiliser. Lighthouse fournit un ensemble de vérifications de l'accessibilité et retourne une moyenne pondérée de toutes ces vérifications (voir la section Détails des scores pour une liste complète de la pondération de chaque vérification).
-
Chaque audit d'accessibilité est réussi ou échoué, mais contrairement aux autres audits de Lighthouse, une page ne reçoit pas de points pour avoir partiellement réussi un audit d'accessibilité. Par exemple, si certains éléments ont des noms compréhensibles par les lecteurs d'écran, mais pas d'autres, cette page obtient un 0 pour l'audit des noms compréhensibles par les lecteurs d'écran.
Diagramme en bâtons montrant la distribution des scores d'accessibilité Lighthouse des pages CMS. La distribution est fortement asymétrique vers les scores les plus élevés avec un mode d'environ 0,85.
- Figure 22. Distribution des scores d'accessibilité de Lighthouse pour les pages CMS.
-
-
-
-
-
-
-
Diagramme en bâtons montrant la note Lighthouse médiane d'accessibilité par CMS. La plupart des CMS obtiennent un score d'environ 0,75. Parmi les valeurs les plus aberrantes, on retrouve Wix avec un score médian de 0,93 et 1-C Bitrix avec un score de 0,65.
Actuellement, seulement 1,27% des pages d'accueil des CMS sur mobiles obtiennent un score parfait de 100%. Parmi les meilleurs CMS, Wix prend la tête en ayant le plus haut score médian d'accessibilité sur ses pages mobiles. Dans l'ensemble, ces chiffres sont lamentables quand on considère le nombre de sites web (la part du web qui est propulsée par des CMS) qui sont inaccessibles à un segment significatif de notre population. Autant les expériences numériques ont un impact sur de nombreux aspects de notre vie, autant cela devrait être un impératif pour nous encourager à construire des expériences web accessibles dès le départ, et à poursuivre le travail pour faire du web un espace inclusif.
Bien que nous ayons pris un instantané du paysage actuel de l'écosystème des CMS, celui-ci est en pleine évolution. Dans le cadre des efforts visant à remédier aux lacunes en matière de performance et d'expérience utilisateur, nous constatons que des systèmes expérimentaux sont intégrés à l'infrastructure des CMS à la fois dans des cas couplés et découplés/headless. Des bibliothèques et des frameworks tels que React.js, ses dérivés comme Gatsby.js et Next.js, et le dérivé Nuxt.js de Vue.js font de légères avancées.
-
-
-
-
-
-
-
CMS
-
React
-
Nuxt.js, React
-
Nuxt.js
-
Next.js, React
-
Gatsby, React
-
-
-
-
-
WordPress
-
131,507
-
-
21
-
18
-
-
-
-
Wix
-
50,247
-
-
-
-
-
-
-
Joomla
-
3,457
-
-
-
-
-
-
-
Drupal
-
2,940
-
-
8
-
15
-
1
-
-
-
DataLife Engine
-
1,137
-
-
-
-
-
-
-
Adobe Experience Manager
-
723
-
-
-
7
-
-
-
-
Contentful
-
492
-
7
-
114
-
909
-
394
-
-
-
Squarespace
-
385
-
-
-
-
-
-
-
1C-Bitrix
-
340
-
-
-
-
-
-
-
TYPO3 CMS
-
265
-
-
-
1
-
-
-
-
Weebly
-
263
-
-
1
-
-
-
-
-
Jimdo
-
248
-
-
-
-
2
-
-
-
PrestaShop
-
223
-
-
1
-
-
-
-
-
SDL Tridion
-
152
-
-
-
-
-
-
-
Craft CMS
-
123
-
-
-
-
-
-
-
-
-
- Figure 24. Adoption (nombre de sites web mobiles) de React et des frameworks connexes par CMS.
-
-
Nous voyons également des fournisseurs et des agences d'hébergement offrant des plateformes d'expérience numérique (DXP) comme solutions holistiques utilisant des CMS et d'autres technologies intégrées comme boîte à outils pour les stratégies d'entreprise axées sur le client. Ces innovations témoignent d'un effort pour créer des solutions clés en main, basées sur des CMS, qui permettent aux utilisateurs (et leurs utilisateurs finaux) d'obtenir par défaut le meilleur UX lors de la création et de la consommation du contenu de ces plateformes. L'objectif: de bonnes performances par défaut, une richesse de fonctionnalités et d'excellents environnements d'hébergement.
L'espace des CMS est d'une importance primordiale. La grande partie du web dont ces applications propulsent et la masse critique d'utilisateurs qui créent et consultent ses pages sur une variété de terminaux et de connexions ne doivent pas être banalisées. Nous espérons que ce chapitre et les autres qui se trouvent ici dans le Web Almanac inspireront plus de recherche et d'innovation pour aider à rendre cet espace meilleur. Des enquêtes approfondies nous fourniraient un meilleur contexte sur les forces, les faiblesses et les opportunités que ces plateformes offrent au web dans son ensemble. Les systèmes de gestion de contenu peuvent avoir un impact sur la préservation de l'intégrité du web ouvert. Continuons à les faire avancer !
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/compression.html b/src/templates/fr/2019/chapters/compression.html
deleted file mode 100644
index 99301edbb76..00000000000
--- a/src/templates/fr/2019/chapters/compression.html
+++ /dev/null
@@ -1,329 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":15,"title":"Compression","description":"Chapitre sur la compression par Web Almanac 2019, les algorithmes, les types de contenu, la compression 1ere partie et tierce partie et les possibilités.","authors":["paulcalvano"],"reviewers":["obto","yoavweiss"],"translators":["allemas"],"discuss":"1770","results":"https://docs.google.com/spreadsheets/d/1IK9kaScQr_sJUwZnWMiJcmHEYJV292C9DwCfXH6a50o/","queries":"15_Compression","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-07-12T00:00:00.000Z","chapter":"compression"} %} {% block index %}
-
La compression HTTP est une technique qui permet de coder des informations en utilisant moins de bits que la représentation originale. Lorsqu’elle est utilisée pour la diffusion de contenu web, elle permet aux serveurs web de réduire la quantité de données transmises aux clients. La compression HTTP augmente l’efficacité de la bande passante disponible au client, réduit le poids des pages, et améliore les performances web.
-
Les algorithmes de compression sont souvent classés comme avec ou sans perte :
-
-
Lorsqu’un algorithme de compression avec perte est utilisé, le processus est irréversible et le fichier original ne peut pas être restauré par décompression. Cette méthode est couramment utilisée pour comprimer les ressources medias, comme les images et les contenus vidéo, lorsque la perte de certaines données n’affecte pas sensiblement la ressource.
-
La compression sans perte est un processus entièrement réversible, et est couramment utilisée pour compresser les ressources textuelles, comme HTML, JavaScript, CSS, etc.
-
-
Dans ce chapitre, nous allons analyser comment le contenu textuel est compressé sur le web. L’analyse des contenus non textuels est traité dans le chapitre Media.
- Lorsqu’un client effectue une requête HTTP, celle-ci comprend souvent un en-tête Accept-Encoding pour communiquer les algorithmes qu’il est capable de décoder. Le serveur peut alors choisir parmi eux un encodage qu’il prend en charge et servir la réponse compressée. La réponse compressée comprendra un en-tête Content-Encoding afin que le client sache quelle compression a été utilisée. En outre, l’en-tête Content-Type est souvent utilisé pour indiquer le type MIME de la ressource servie.
-
-
Dans l’exemple ci-dessous, le client indique supporter la compression gzip, brotli et deflate. Le serveur a décidé de renvoyer une réponse compressée avec gzip contenant un document text/html.
HTTP Archive contient des mesures pour 5,3 millions de sites web, et chaque site a chargé au moins une ressource texte compressée sur sa page d’accueil. En outre, les ressources ont été compressées dans le domaine principal sur 81 % des sites web.
L’IANA tient à jour une liste des encodages de contenu HTTP valide qui peuvent être utilisés avec les en-têtes « Accept-Encoding » et « Content-Encoding ». On y retrouve notamment gzip, deflate, br (brotli), ainsi que de quelques autres. De brèves descriptions de ces algorithmes sont données ci-dessous :
-
-
Gzip utilise les techniques de compression LZ77 et le codage de Huffman qui sont plus ancienes que le web lui-même. Elles ont été développés à l’origine pour le programme gzip d’UNIX en 1992. Une implémentation pour la diffusion sur le web existe depuis HTTP/1.1, et la plupart des navigateurs et clients web la prennent en charge.
-
Deflate utilise le même algorithme que gzip, mais avec un conteneur différent. Son utilisation n’a pas été largement adoptée sur le web pour des raisons de compatibilité avec d’autres serveurs et navigateurs.
-
Brotli est un algorithme de compression plus récent qui a été inventé par Google. Il utilise la combinaison d’une variante moderne de l’algorithme LZ77, le codage de Huffman et la modélisation du contexte du second ordre. La compression via brotli est plus coûteuse en termes de calcul par rapport à gzip, mais l’algorithme est capable de réduire les fichiers de 15-25 % de plus que la compression gzip. Brotli a été utilisé pour la première fois pour la compression de contenu web en 2015 et est supporté par tous les navigateurs web modernes.
-
-
Environ 38 % des réponses HTTP sont fournies avec de la compression de texte. Cette statistique peut sembler surprenante, mais n’oubliez pas qu’elle est basée sur toutes les requêtes HTTP de l’ensemble de données. Certains contenus, tels que les images, ne bénéficieront pas de ces algorithmes de compression. Le tableau ci-dessous résume le pourcentage de requêtes servies pour chaque type de compression.
-
-
-
-
-
-
-
-
Pourcentage de requêtes
-
Requêtes
-
-
-
Type de compression
-
Ordinateur de bureau
-
Mobile
-
Ordinateur de bureau
-
Ordinateur de bureau
-
-
-
-
-
Pas de compression de texte
-
62,87 %
-
61,47 %
-
260,245,106
-
285,158,644
-
-
-
gzip
-
29,66 %
-
30,95 %
-
122,789,094
-
143,549,122
-
-
-
br
-
7.43 %
-
7.55 %
-
30,750,681
-
35,012,368
-
-
-
deflate
-
0,02 %
-
0,02 %
-
68,802
-
70,679
-
-
-
Autre / Invalide
-
0,02 %
-
0,01 %
-
67,527
-
68,352
-
-
-
identité
-
0,000709 %
-
0,000563 %
-
2,935
-
2,611
-
-
-
x-gzip
-
0,000193 %
-
0,000179 %
-
800
-
829
-
-
-
compress
-
0,000008 %
-
0,000007 %
-
33
-
32
-
-
-
x-compress
-
0,000002 %
-
0,000006 %
-
8
-
29
-
-
-
-
-
- Illustration 1. Adoption des algorithmes de compression.
-
-
Parmi les ressources qui sont servies compressées, la majorité utilise soit gzip (80 %), soit brotli (20 %). Les autres algorithmes de compression sont peu utilisés.
Diagramme circulaire du tableau de données de la figure 1.
- Illustration 2. Adoption des algorithmes de compression sur les pages d’ordinateur de bureau.
-
-
De plus, il y a 67k requêtes qui renvoient un Content-Encoding invalide, tel que « none », « UTF-8 », « base64 », « text », etc. Ces ressources sont probablement servies sans compression.
-
Nous ne pouvons pas déterminer les niveaux de compression à partir des diagnostics recueillis par HTTP Archive, mais les bonnes pratiques pour compresser du contenu sont :
Si vous pouvez supporter brotli et la précompression des ressources, alors compressez au niveau 11. Cette méthode est plus coûteuse en termes de calcul que gzip - la précompression est donc absolument nécessaire pour éviter les délais.
-
Si vous pouvez supporter le brotli et que vous ne pouvez pas le précompresser, alors compressez au niveau 5. Ce niveau se traduira par un cout de compression plus petit que gzip, avec un coût de calcul similaire.
La plupart des ressources textuelles (telles que HTML, CSS et JavaScript) peuvent bénéficier de la compression gzip ou brotli. Cependant, il n’est souvent pas nécessaire d’utiliser ces techniques sur des ressources binaires, telles que les images, les vidéos et certaines polices Web, leurs formats de fichiers sont déjà compressés.
-
Dans le graphique ci-dessous, les 25 premiers types de contenus sont affichés sous forme de boîtes dont les dimensions représentent le nombre de requêtes correspondantes. La couleur de chaque boîte représente le nombre de ces ressources qui ont été servies compressées. La plupart des contenus médias sont nuancés en orange, ce qui est normal puisque gzip et brotli ne leur apporteraient que peu ou pas d’avantages. La plupart des contenus textuels sont nuancés en bleu pour indiquer qu’ils sont compressés. Cependant, la teinte bleu clair de certains types de contenu indique qu’ils ne sont pas compressés de manière aussi cohérente que les autres.
Diagramme arborescent montrant les polices/woff2 (22 622 918 demandes - 3,87 % de compression), application/json (16 501 326 demandes - 59,02 % de compression), image/webp (12 911 688 demandes - 1,66 % de compression), image/svg+xml (9 862 643 demandes - 64. 42 % de compression), text/plain (6 622 361 demandes - 24,72 % de compression), application/octet-stream (3 884 287 demandes - 6,01 % de compression), image/x-icon (3 737 030 demandes - 37,60 % de compression), application/font-woff2 (3 061 857 demandes - 5. 90 % de compression), application/font-woff (2 117 999 requêtes - 23,61 % de compression), image/vnd.microsoft.icon (1 774 995 requêtes - 15,55 % de compression), video/mp4 (1 472 880 requêtes - 0,03 % de compression), font/woff (1 255 093 requêtes - 24. 33 % de compression), font/ttf (1 062 747 demandes - 84,27 % de compression), application/x-font-woff (1 048 398 demandes - 30,77 % de compression), image/jpg (951 610 demandes - 6,66 % de compression), application/ocsp-response (883 603 demandes - 0,00 % de compression)
- Illustration 4. Types de contenus compressés, à l’exception des 8 premiers.
-
-
Les types de contenus application/json et image/svg+xml sont compressés moins de 65 % du temps.
-
La majeure partie des polices web customisées sont servies sans compression, car elles sont déjà dans un format compressé. Cependant, font/ttf est compressible, mais seulement 84 % des requêtes de polices TTF sont servies avec compression, il y a donc encore des possibilités d’amélioration dans ce domaine.
-
Les graphiques ci-dessous illustrent la répartition des techniques de compression utilisées pour chaque type de contenu. En examinant les trois premiers types de contenus, on constate que, tant sur les ordinateurs de bureau que sur les téléphones portables, il existe des écarts importants dans la compression de certains des types de contenus les plus fréquemment demandés. 56 % des ressources texte/html ainsi que 18 % des ressources application/javascript et text/css ne sont pas compressées. Cela représente une opportunité de performance significative.
Le graphique à barres empilées montrant l’application/javascript est de 36,18 M/8,97 M/10,47 M par type de compression (Gzip/Brotli/None), text/css est de 24,29 M/8,31 M/7,20 M, text/html est de 11,37 M/4,89 M/20,57 M, text/javascript est de 23,21 M/1,72 M/3,03 M, application/x-javascript est de 11. 86 M/4,97 M/1,66 M, application/json est 4,06 M/0,50 M/3,23 M, image/svg+xml est 2,54 M/0,46 M/1,74 M, text/plain est 0,71 M/0,06 M/2,42 M, et image/x-icon est 0,58 M/0,10 M/1,11 M. Deflate n’est presque jamais utilisé à aucun moment et ne s’inscrit pas sur la carte.
- Illustration 5. Compression par type de contenu pour les ordinateurs de bureau.
-
-
-
-
-
-
-
Le graphique à barres empilées montrant l’application/javascript est de 43,07 M/10,17 M/12,19 M par type de compression (Gzip/Brotli/None), text/css est de 28,3 M/9,91 M/8,56 M, text/html est de 13,86 M/5,48 M/25,79 M, text/javascript est de 27. 41 M/1,94 M/3,33 M, application/x-javascript est 12,77 M/5,70 M/1,82 M, application/json est 4,67 M/0,50 M/3,53 M, image/svg+xml est 2,91 M/ 0,44 M/1,77 M, text/plain est 0,80 M/0,06 M/1,77 M, et image/x-icon est 0,62 M/0,11 M/1,22M. La fonction Deflate n’est presque jamais utilisée et ne s’inscrit pas sur la carte.
- Illustration 6. Compression par type de contenu pour le mobile.
-
-
Les types de contenus ayant les taux de compression les plus faibles sont application/json, texte/xml et text/plain. Ces ressources sont couramment utilisées pour les requêtes XHR afin de fournir des données que les applications web peuvent utiliser pour créer des expériences riches. Leur compression améliorera certainement l’expérience de l’utilisateur. Les graphiques vectoriels tels que image/svg+xml et image/x-icon ne sont pas souvent considérés comme du texte, mais ils le sont et les sites qui les utilisent bénéficieraient de la compression.
Le graphique à barres empilées montrant l’application/javascript est de 65,1 %/16,1 %/18,8 % par type de compression (Gzip/Brotli/None), text/css est de 61,0 %/20,9 %/18,1 %, text/html est de 30,9 %/13,3 %/55,8 %, text/javascript est de 83,0 %/6. 1 %/10,8 %, application/x-javascript est de 64,1 %/26,9 %/9,0 %, application/json est de 52,1 %/6,4 %/41,4 %, image/svg+xml est de 53,5 %/9,8 %/36,7 %, text/plain est de 22,2 %/2,0 %/75,8 %, et image/x-icon est de 32,6 %/5,3 %/62,1 %. Deflate n’est presque jamais utilisé et ne s’inscrit pas sur le graphique.
- Illustration 7. Compression par type de contenu en pourcentage pour les ordinateurs de bureau.
-
-
-
-
-
-
-
Le graphique à barres empilées montrant l’application/javascript est de 65,8 %/15,5 %/18,6 % par type de compression (Gzip/Brotli/None), text/css est de 60,5 %/21,2 %/18,3 %, text/html est de 30,7 %/12,1 %/57,1 %, text/javascript est de 83,9 %/5. 9 %/10,2 %, application/x-javascript est 62,9 %/28,1 %/9,0 %, application/json est 53,6 %/8,6 %/34,6 %, image/svg+xml est 23,4 %/1,8 %/74,8 %, text/plain est 23,4 %/1,8 %/74,8 %, et image/x-icon est 31,8 %/5,5 %/62,7 %. Deflate n’est presque jamais utilisé et ne s’inscrit pas sur le graphique.
- Illustration 8. Compression par type de contenu en pourcentage pour les mobiles.
-
-
Dans tous les types de contenus, gzip est l’algorithme de compression le plus populaire. La compression brotli, plus récente, est utilisée moins fréquemment, et les types de contenus où elle apparaît le plus sont application/javascript, text/css et application/x-javascript. Cela est probablement dû aux CDN qui appliquent automatiquement la compression brotli pour le trafic qui y transite.
Dans le chapitre les tierces parties, nous avons appris le rôle des tiers et leur impact sur les performances. Lorsque nous comparons les techniques de compression entre les premières et les tierces parties, nous pouvons constater que le contenu des tierces parties a tendance à être plus compressé que le contenu des premières parties.
-
En outre, le pourcentage de compression brotli est plus élevé pour les contenus tiers. Cela est probablement dû au nombre de ressources servies par les grands tiers qui soutiennent généralement le brotli, comme Google et Facebook.
-
-
-
-
-
-
-
-
Ordinateur de bureau
-
Mobile
-
-
-
Type de compression
-
Première partie
-
Tierce partie
-
Première partie
-
Tierce partie
-
-
-
-
-
Pas de compression de texte
-
66.23 %
-
59.28 %
-
64.54 %
-
58.26 %
-
-
-
gzip
-
29.33 %
-
30.20 %
-
30.87 %
-
31.22 %
-
-
-
br
-
4.41 %
-
10.49 %
-
4.56 %
-
10.49 %
-
-
-
deflate
-
0.02 %
-
0.01 %
-
0.02 %
-
0.01 %
-
-
-
Autre / Invalide
-
0.01 %
-
0.02 %
-
0.01 %
-
0.02 %
-
-
-
-
-
- Illustration 9. Compression de première partie ou de tierce partie par type d’appareil.
-
L’outil Google Lighthouse permet aux utilisateurs d’effectuer une série d’audits sur les pages web. L’audit de la compression de texte évalue si un site peut bénéficier d’une compression de texte supplémentaire. Pour ce faire, il tente de comprimer les ressources et évalue si la taille d’un objet peut être réduite d’au moins 10 % et de 1 400 octets. En fonction du score, vous pouvez voir une recommandation de compression dans les résultats, avec une liste de ressources spécifiques qui pourraient être compressées.
Une capture d’écran d’un rapport Lighthouse montrant une liste de ressources (avec les noms flouté) et montrant la taille et l’économie potentielle. Pour le premier élément, il y a une économie potentiellement importante de 91 KB à 73 KB, tandis que pour d’autres fichiers plus petits de 6 KB ou moins, il y a une économie plus faible de 4 KB à 1 KB.
- Illustration 10. Suggestions de compressions par Lighthouse.
-
-
Comme HTTP Archive effectue des audits Lighthouse pour chaque page mobile, nous pouvons agréger les scores de tous les sites pour savoir dans quelle mesure il est possible de compresser davantage le contenu. Dans l’ensemble, 62 % des sites web ont réussi cet audit et près de 23 % des sites web ont obtenu une note inférieure à 40. Cela signifie que plus de 1,2 million de sites web pourraient bénéficier d’une compression du texte supplémentaire.
Diagramme à barres empilées montrant que 7,6 % des sites coûtent moins de 10 %, 13,2 % des sites ont un score compris entre 10 et 39 %, 13,7 % des sites ont un score compris entre 40 et 79 %, 2,9 % des sites ont un score compris entre 80 et 99 %, et 62,5 % des sites ont un laissez-passer avec plus de 100 % des textes compressés.
- Illustration 11. Les résultats de l’audit « Activer la compression de texte » de Lighthouse.
-
-
Lighthouse indique également combien d’octets pourraient être économisés en permettant la compression du texte. Parmi les sites qui pourraient bénéficier de la compression de texte, 82 % d’entre eux peuvent réduire le poids de leur page de 1 Mo !
-
-
-
-
Diagramme à barres empilées montrant que 82,11 % des sites pourraient économiser moins de 1 Mo, 15,88 % des sites pourraient économiser 1 - 2 Mo et 2 % des sites pourraient économiser > 3 Mo.<
- Illustration 12. Audit Lighthouse « activer la compression de texte »: économies d’octets potentielles.
-
-
La compression HTTP est une fonctionnalité très utilisée et très précieuse pour réduire la taille des contenus web. La compression gzip et brotli sont les deux algorithmes les plus utilisés, et la quantité de contenu compressé varie selon le type de contenu. Des outils comme Lighthouse peuvent aider à découvrir des solutions pour comprimer le contenu.
-
Bien que de nombreux sites fassent bon usage de la compression HTTP, il y a encore des possibilités d’amélioration, en particulier pour le format text/html sur lequel le web est construit ! De même, les formats de texte moins bien compris comme font/ttf, application/json, text/xml, text/plain, image/svg+xml, et image/x-icon peuvent nécessiter une configuration supplémentaire qui manque à de nombreux sites web.
-
Au minimum, les sites web devraient utiliser la compression gzip pour toutes les ressources textuelles, car elle est largement prise en charge, facile à mettre en œuvre et a un faible coût de traitement. Des économies supplémentaires peuvent être réalisées grâce à la compression brotli, bien que les niveaux de compression doivent être choisis avec soin en fonction de la possibilité de précompression d’une ressource.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/javascript.html b/src/templates/fr/2019/chapters/javascript.html
deleted file mode 100644
index 52ff9bc1d48..00000000000
--- a/src/templates/fr/2019/chapters/javascript.html
+++ /dev/null
@@ -1,430 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":1,"title":"JavaScript","description":"Chapitre JavaScript du Web Almanac 2019 couvrant la quantité de JavaScript que nous utilisons sur le web, la compression, les bibliothèques et les frameworks, le chargement et les cartographies de code source (source maps).","authors":["housseindjirdeh"],"reviewers":["obto","paulcalvano","mathiasbynens"],"translators":["borisschapira"],"discuss":"1756","results":"https://docs.google.com/spreadsheets/d/1kBTglETN_V9UjKqK_EFmFjRexJnQOmLLr-I2Tkotvic/","queries":"01_JavaScript","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-08-25T00:00:00.000Z","chapter":"javascript"} %} {% block index %}
-
JavaScript est un langage de script qui permet de construire des expériences interactives et complexes sur le web. Il permet notamment de répondre aux interactions des utilisateurs et utilisatrices, de mettre à jour le contenu dynamique d’une page, etc. Le JavaScript est utilisé partout où il est question de la façon dont une page web doit se comporter lorsqu’un événement se produit.
-
La spécification du langage elle-même, ainsi que les nombreuses bibliothèques et frameworks communautaires utilisés par les développeurs du monde entier, ont changé et évolué depuis la création du langage en 1995. Les implémentations et les interpréteurs JavaScript ont également continué à progresser, rendant le langage utilisable dans de nombreux environnements, et pas seulement dans les navigateurs web.
-
HTTP Archive parcourt des millions de pages chaque mois et les soumet à une instance privée de WebPageTest pour stocker les informations clés de chaque page (vous pouvez en savoir plus à ce sujet dans notre méthodologie). Dans le contexte de JavaScript, HTTP Archive fournit des informations détaillées sur l’utilisation du langage pour l’ensemble du web. Ce chapitre regroupe et analyse un grand nombre de ces tendances.
JavaScript est la ressource la plus consommatrice que nous envoyons aux navigateurs : il doit être téléchargé, analysé, compilé et enfin exécuté. Bien que les navigateurs aient considérablement réduit le temps nécessaire pour analyser et compiler les scripts, le téléchargement et l’exécution sont devenus les étapes les plus coûteuses lorsque JavaScript est traité par une page web.
-
Envoyer de plus petits paquets de JavaScript au navigateur est le meilleur moyen de réduire les temps de téléchargement et d’améliorer ainsi les performances des pages. Mais quelle quantité de JavaScript utilisons-nous réellement ?
Diagramme à barres montrant que 70 octets de JavaScript sont utilisés au 10e percentile, 174 octets au 25e, 373 octets au 50e, 693 octets au 75e et 1093 octets au 90e
- Figure 1. Répartition des octets de JavaScript par page.
-
-
La Figure 1 ci-dessus montre que nous utilisons 373 Ko de JavaScript au 50e percentile (aussi appelé médiane). En d’autres termes, 50 % des sites envoient plus que cette quantité de JavaScript à leurs utilisateurs.
-
En regardant ces chiffres, il est naturel de se demander si ce n’est pas trop de JavaScript. Cependant, en termes de performances des pages, l’impact dépend entièrement des connexions réseau et des appareils utilisés. Ce qui nous amène à notre prochaine question : quelle quantité de JavaScript envoyons-nous lorsque nous comparons les tests sur mobiles et sur ordinateurs de bureau ?
Un diagramme à barres montrant que 76 octets / 65 octets de JavaScript sont utilisés au 10e percentile sur ordinateur de bureau et mobile respectivement, 186 / 164 octets au 25e, 391 / 359 octets au 50e, 721 / 668 octets au 75e, et 1 131 / 1 060 octets au 90e.
- Figure 2. Distribution de JavaScript par page et par type d’appareil.
-
-
À chaque centile, nous envoyons un peu plus de JavaScript aux ordinateurs de bureau qu’aux mobiles.
Après avoir été analysé et compilé, le JavaScript récupéré par le navigateur doit être traité (ou exécuté) avant de pouvoir être utilisé. Les appareils varient, et leur puissance de calcul peut affecter de manière significative la vitesse à laquelle JavaScript peut être traité sur une page. Quels sont les temps de traitement actuels sur le web ?
-
Nous pouvons nous faire une idée en analysant les temps de traitement du fil d’exécution principal pour V8 à différents percentiles :
Un diagramme à barres indiquant que 141 ms / 377 ms de temps de traitement sont utilisés au 10e percentile sur le bureau et le mobile respectivement, 352 / 988 ms au 25e, 849 / 2 437 ms au 50e, 1 850 / 5 518 ms au 75e, et 3 543 / 10 735 ms au 90e.
- Figure 3. Temps de traitement du fil d’exécution principal V8 par appareil.
-
-
À chaque centile, les délais de traitement sont plus longs pour les pages web testées sur mobiles que pour les pages testées sur ordinateurs de bureau. Le temps total médian du fil d’exécution principal sur ordinateurs de bureau est de 849 ms, tandis que sur mobiles, il est plus important : 2 437 ms.
-
Bien que ces données montrent combien de temps il peut falloir à un appareil mobile pour traiter JavaScript par rapport à un ordinateur de bureau plus puissant, les appareils mobiles varient également en termes de puissance de calcul. Le tableau suivant montre comment les temps de traitement d’une seule page web peuvent varier considérablement selon la catégorie d’appareil mobile.
Diagramme à barres montrant 3 appareils différents : en haut, un Pixel 3 présentant une petite portion à la fois sur le fil principal et le fil secondaire de moins de 400 ms. Dans le cas du Moto G4, cela représente environ 900 ms sur le fil principal et 300 ms sur le fil secondaire. La dernière barre est celle d’un Alcatel 1X 5059D avec plus de 2 000 ms sur le fil principal et plus de 500 ms sur le fil secondaire.
Une piste à explorer pour analyser la quantité de JavaScript utilisée par les pages web est le nombre de requêtes envoyées. Avec HTTP/2, l’envoi de plusieurs petits paquets peut améliorer le chargement des pages par rapport à l’envoi d’un paquet monolithique plus important. Si nous ventilons également par type de matériel, combien de ressources sont récupérées ?
Le diagramme à barres montrant 4 / 4 requêtes sur ordinateurs de bureau et mobiles respectivement sont utilisés au 10e percentile, 10 / 9 au 25e, 19 / 18 au 50e, 33 / 32 au 75e et 53 / 52 au 90e.
- Figure 5. Répartition de l’ensemble des requêtes JavaScript.
-
-
À la médiane, 19 requêtes sont envoyées pour les ordinateurs de bureau et 18 pour les mobiles.
Parmi les résultats analysés jusqu’à présent, la totalité du poids des ressources JavaScript et des requêtes ont été considérés. Cependant, dans la majorité des sites web, une partie significative du code JavaScript récupéré et utilisé provient de parties tierces.
-
Le JavaScript tiers peut provenir de n’importe quelle source externe, en tierce partie. Les publicités, les outils de télémétrie et les services de médias sociaux sont tous des cas d’utilisation courants dans lesquels des scripts tiers sont utilisés. Cela nous amène naturellement à la question suivante : parmi les requêtes envoyées, combien proviennent de tierces parties et non du domaine principal ?
Diagramme à barres montrant 0 / 1 requêtes sur ordinateurs de bureau pour le domaine principal et les domaines tiers respectivement au 10e percentile, 2 / 4 25e, 6 / 10 au 50e, 13 / 21 au 75e, et 24 / 38 au 90e.
- Figure 6. Distribution des scripts entre domaine principal et tiers, sur ordinateurs de bureau.
-
-
-
-
-
-
-
Diagramme à barres montrant 0 / 1 requêtes sur mobile pour le domaine principal et les domaines tiers respectivement au 10e percentile, 2 / 3 au 25e, 5 / 9 au 50e, 13 / 20 au 75e, et 23 / 36 au 90e.
- Figure 7. Distribution des scripts entre domaine principal et tiers, sur mobile
-
-
Tant sur les mobiles que sur les ordinateurs de bureau, les requêtes vers des tierces parties sont plus nombreuses que les requêtes sur le domaine principal, à chaque centile. Si cela vous semble surprenant, découvrons quelle quantité de code téléchargé provient de fournisseurs tiers.
Diagramme à barres montrant 0 / 17 octets de JavaScript téléchargés sur ordinateurs de bureau issus de requêtes vers le domaine principal et, respectivement, vers des domaines tiers, au 10 percentile, 11 / 62 au 25e, 89 / 232 au 50e, 200 / 525 au 75e, et 404 / 900 au 90e.
- Figure 8. Répartition de l’ensemble du JavaScript téléchargé sur ordinateurs de bureau.
-
-
-
-
-
-
-
Diagramme à barres montrant 0 / 17 octets de JavaScript téléchargés sur mobiles issus de requêtes vers le domaine principal et, respectivement, vers des domaines tiers, au 10e percentile, 6 / 54 au 25e, 83 / 217 au 50e, 189 / 477 au 75e, et 380 / 827 au 90e.
- Figure 9. Répartition de l’ensemble du JavaScript téléchargé sur mobile.
-
-
À la médiane, on utilise 89 % plus de code tiers que de code du domaine principal rédigé par l’équipe de développement, tant sur mobiles que sur ordinateurs de bureau. Cela montre clairement que le code tiers peut être un des principaux facteurs de lourdeur d’une page web. Pour plus d’informations sur l’impact des tiers, consultez le chapitre « Tierces Parties ».
Dans le contexte des interactions entre navigateur et serveur, la compression des ressources fait référence au code qui a été transformé à l’aide d’un algorithme de compression des données. Les ressources peuvent être compressées statiquement à l’avance ou à la volée, au moment où le navigateur en fait la demande. Dans les deux cas, la taille de la ressource transférée est considérablement réduite, ce qui améliore les performances de la page.
-
Il existe de nombreux algorithmes de compression de texte, mais seuls deux sont principalement utilisés pour la compression (et la décompression) des requêtes sur le réseau HTTP :
-
-
Gzip (gzip) : le format de compression le plus utilisé pour les interactions entre serveurs et clients ;
-
Brotli (br) : un algorithme de compression plus récent visant à améliorer encore les taux de compression. 90 % des navigateurs supportent la compression Brotli.
-
-
Les scripts compressés devront toujours être décompressés par le navigateur une fois transférés. Cela signifie que son contenu reste le même et que les temps d’exécution ne sont pas du tout optimisés. Cependant, la compression des ressources améliorera toujours leur temps de téléchargement, qui est également l’une des étapes les plus coûteuses du traitement JavaScript. S’assurer que les fichiers JavaScript sont correctement compressés peut constituer un des principaux facteurs d’amélioration des performances pour un site web.
-
Combien de sites compressent leurs ressources JavaScript ?
Diagramme à barres montrant que 67 % / 65 % des ressources JavaScript sont compressées avec gzip sur les ordinateurs de bureau et les mobiles respectivement, et 15 % / 14 % sont compressées en utilisant Brotli.
- Figure 10. Pourcentage de sites compressant des ressources JavaScript avec gzip ou brotli.
-
-
La majorité des sites compressent leurs ressources JavaScript. L’encodage Gzip est utilisé sur ~64-67 % des sites et Brotli sur ~14 %. Les taux de compression sont similaires sur ordinateurs de bureau et mobiles.
-
Pour une analyse plus approfondie sur la compression, reportez-vous au chapitre « Compression ».
Parlons ici du code source ouvert (open source), ou du code sous licence permissive, qui peut être consulté, visualisé et modifié par n’importe qui. Des minuscules bibliothèques aux navigateurs complets, tels que Chromium et Firefox, le code source open source joue un rôle crucial dans le monde du développement web. Dans le contexte de JavaScript, les équipes de développement s’appuient sur des outils open source pour inclure tous types de fonctionnalités dans leur page web. Qu’un développeur ou une développeuse décide d’utiliser une petite bibliothèque d’utilitaires ou un énorme framework qui dicte l’architecture de toute son application, le fait de s’appuyer sur du code open source peut rendre le développement de fonctionnalités plus facile et plus rapide. Quelles sont donc les bibliothèques JavaScript open source les plus utilisées ?
-
-
-
-
-
-
-
Librairie
-
Ordinateur de bureau
-
Mobile
-
-
-
-
-
jQuery
-
85,03 %
-
83,46 %
-
-
-
jQuery Migrate
-
31,26 %
-
31,68 %
-
-
-
jQuery UI
-
23,60 %
-
21,75 %
-
-
-
Modernizr
-
17,80 %
-
16,76 %
-
-
-
FancyBox
-
7,04 %
-
6,61 %
-
-
-
Lightbox
-
6,02 %
-
5,93 %
-
-
-
Slick
-
5,53 %
-
5,24 %
-
-
-
Moment.js
-
4,92 %
-
4,29 %
-
-
-
Underscore.js
-
4,20 %
-
3,82 %
-
-
-
prettyPhoto
-
2,89 %
-
3,09 %
-
-
-
Select2
-
2,78 %
-
2,48 %
-
-
-
Lodash
-
2,65 %
-
2,68 %
-
-
-
Hammer.js
-
2,28 %
-
2,70 %
-
-
-
YUI
-
1,84 %
-
1,50 %
-
-
-
Lazy.js
-
1,26 %
-
1,56 %
-
-
-
Fingerprintjs
-
1,21 %
-
1,32 %
-
-
-
script.aculo.us
-
0,98 %
-
0,85 %
-
-
-
Polyfill
-
0,97 %
-
1,00 %
-
-
-
Flickity
-
0,83 %
-
0,92 %
-
-
-
Zepto
-
0,78 %
-
1,17 %
-
-
-
Dojo
-
0,70 %
-
0,62 %
-
-
-
-
-
- Figure 11. Principales bibliothèques JavaScript sur ordinateurs de bureau et mobiles.
-
-
jQuery, la bibliothèque JavaScript la plus populaire jamais créée, est utilisée dans 85,03 % des pages sur ordinateurs de bureau et 83,46 % des pages mobiles. L’avènement de nombreuses API et fonctionnalités de navigateurs, comme Fetch et querySelector, a standardisé une grande partie des fonctionnalités fournies par la bibliothèque dans une forme native. Bien que la popularité de jQuery semble en déclin, pourquoi est-il encore utilisé dans la grande majorité du web ?
-
Il y a plusieurs raisons possibles :
-
-
WordPress, qui est utilisé par plus de 30 % des sites, inclut jQuery par défaut.
-
Passer de jQuery à une bibliothèque plus récente côté client peut prendre du temps en fonction de la taille de l’application, et de nombreux sites peuvent utiliser jQuery en plus de bibliothèques plus récentes côté client.
-
-
Les autres bibliothèques JavaScript les plus utilisées comprennent les variantes de jQuery (jQuery migrate, jQuery UI), Modernizr, Moment.js, Underscore.js et ainsi de suite.
- Comme mentionné dans notre méthodologie, la bibliothèque de détection tierce utilisée dans HTTP Archive (Wappalyzer) a un certain nombre de limitations en ce qui concerne la manière dont elle détecte certains outils. Un ticket est ouvert concernant l’amélioration de la détection des bibliothèques et frameworks JavaScript, ce qui aura eu un impact sur les résultats présentés ici.
-
-
Au cours des dernières années, l’écosystème JavaScript a connu une augmentation du nombre de bibliothèques et frameworks open-source pour faciliter la création d’applications monopages (SPA). Une application monopage se caractérise par une page web qui charge une seule page HTML et utilise JavaScript pour modifier la page lors de l’interaction avec l’utilisateur au lieu de télécharger de nouvelles pages depuis le serveur. Bien que cela reste la principale prémisse des applications monopages, différentes approches de rendu du serveur peuvent encore être utilisées pour améliorer l’expérience de ces sites. Combien de sites utilisent ces types de frameworks ?
- Figure 12.Frameworks les plus fréquemment utilisés sur ordinateurs de bureau.
-
-
Seul un sous-ensemble de frameworks populaires est analysé ici, mais il est important de noter que tous suivent l’une ou l’autre de ces deux approches :
Bien qu’il y ait eu une évolution vers un modèle basé sur les composants, de nombreux frameworks plus anciens suivent le paradigme MVC. (AngularJS, Backbone.js, Ember) sont toujours utilisées dans des milliers de pages. Cependant, React, Vue et Angular sont les frameworks à base de composants les plus populaires. (Zone.js est un module qui fait maintenant partie du noyau Angular).
Les modules JavaScript, ou modules ES, sont supportés par tous les navigateurs principaux. Les modules offrent la possibilité de créer des scripts qui peuvent être importés et exportés à partir d’autres modules. Cela permet à quiconque de construire ses applications architecturées de manière modulaire, en les important et en les exportant partout où cela est nécessaire, sans avoir recours à des chargeurs de modules en tierce partie.
-
Pour déclarer un script comme module, la balise script doit avoir l’attribut type="module" :
-
<script type="module" src="main.mjs"></script>
-
Combien de site utilisent type="module" sur des scripts dans leurs pages ?
Diagramme à barres montrant que 0,6 % des sites sur ordinateurs de bureau utilisent type=module, et 0,8 % des sites sur mobiles.
- Figure 13. Pourcentage de sites utilisant type=module.
-
-
La prise en charge des modules au niveau du navigateur est encore relativement récente, et les chiffres montrent que très peu de sites utilisent actuellement le type="module" pour leurs scripts. De nombreux sites s’appuient encore sur des chargeurs de modules (2,37 % de tous les sites sur ordinateurs de bureau utilisent RequireJS par exemple) et des bundlers (webpack par exemple) pour définir des modules au sein de leur base de code.
-
Si des modules natifs sont utilisés, il est important de s’assurer qu’un script de recours approprié est utilisé pour les navigateurs qui ne supportent pas encore les modules. Cela peut être fait en incluant un script supplémentaire avec un attribut nomodule.
-
<script nomodule src="fallback.js"></script>
-
Lorsqu’ils sont utilisés ensemble, les navigateurs qui prennent en charge les modules ignorent complètement tout script contenant l’attribut nomodule. En revanche, les navigateurs qui ne supportent pas encore les modules ne téléchargeront aucun script avec l’attribut type="module". Comme ils ne reconnaissent pas non plus nomodule, ils téléchargeront normalement les scripts ayant cet attribut. L’utilisation de cette approche peut permettre aux développeurs d’envoyer du code moderne à des navigateurs modernes pour un chargement plus rapide des pages. Alors, combien de sites utilisent nomodule pour des scripts sur leur page ?
Preload et prefetch sont des Indices de Ressources qui permettent d’aider le navigateur à déterminer quelles ressources doivent être téléchargées.
-
-
Le préchargement d’une ressource avec <link rel="preload"> indique au navigateur de télécharger cette ressource dès que possible. C’est particulièrement utile pour les ressources critiques qui sont découvertes tard dans le processus de chargement de la page (par exemple, du JavaScript situé au bas de votre HTML) et qui seraient, sinon, téléchargées en dernier.
-
L’utilisation de <link rel="prefetch"> indique au navigateur de profiter de tout le temps d’inactivité dont il dispose pour aller chercher ces ressources nécessaires aux navigations futures.
-
-
Alors, combien de sites utilisent les directives preload et prefetch ?
Diagramme à barres montrant que 14 % des sites sur ordinateurs de bureau utilisent rel=preload pour les scripts, et 15 % des sites sur mobiles.
- Figure 15. Pourcentage de sites utilisant rel=preload pour les scripts.
-
-
Sur tous les sites mesurés par HTTP Archive, 14,33 % des sites sur ordinateurs de bureau et 14,84 % des sites sur mobiles utilisent <link rel="preload"> pour des scripts de leur page.
JavaScript continue d’évoluer en tant que langage. Une nouvelle version de la norme de langage elle-même, connue sous le nom d’ECMAScript, est publiée chaque année avec de nouvelles API et comprend des fonctionnalités qui franchissent les étapes de proposition pour devenir une partie du langage lui-même.
-
Grâce à HTTP Archive, nous pouvons examiner toute nouvelle API prise en charge (ou sur le point de l’être) et voir à quel point son utilisation est répandue. Ces API peuvent déjà être utilisées dans les navigateurs qui les prennent en charge ou avec un polyfill d’accompagnement pour s’assurer qu’elles fonctionnent quel que soit le navigateur.
Diagramme à barres montrant que 25,5 % / 36,2 % des sites sur ordinateurs de bureau et, respectivement, sur mobile, utilisent WeakMap, 6,1 % / 17,2 % utilisent WeakSet, 3,9 % / 14,0 % utilisent Intl, 3,9 % / 4,4 % utilisent Proxy, 0,4 % / 0,4 % utilisent Atomics, et 0,2 % / 0,2 % utilisent SharedArrayBuffer.
- Figure 17. Utilisation de nouvelles API JavaScript.
-
-
Atomics (0,38 %) et SharedArrayBuffer (0,20 %) sont à peine visibles sur ce graphique dans la mesure où ils sont utilisés sur un très petit nombre de pages.
-
Il est important de noter que les chiffres indiqués ici sont des approximations et qu’ils ne s’appuient pas sur UseCounter pour mesurer l’utilisation des fonctionnalités.
Dans de nombreux moteurs de compilation, les fichiers JavaScript subissent une minification afin de minimiser leur taille et une transpilation pour les nouvelles fonctionnalités du langage qui ne sont pas encore prises en charge par de nombreux navigateurs. Par ailleurs, les surensembles de langage comme TypeScript se compilent en un résultat qui peut être sensiblement différent du code source original. Pour toutes ces raisons, le code final servi au navigateur peut être illisible et difficile à déchiffrer.
-
Une cartographie de code source, ou sourcemap est un fichier supplémentaire accompagnant un fichier JavaScript qui permet à un navigateur de faire correspondre la version finale à sa source d’origine. Cela peut rendre le débogage et l’analyse des bundles de production beaucoup plus simples.
-
Bien qu’utile, il existe un certain nombre de raisons pour lesquelles de nombreux sites peuvent ne pas vouloir inclure de cartographie des sources dans leur site de production final, par exemple en choisissant de ne pas exposer le code source complet au public. Combien de sites incluent donc réellement des sourcemaps ?
Diagramme à barres montrant que 18 % des sites sur ordinateurs de bureau et 17 % des sites sur mobiles utilisent des source maps.
- Figure 18. Pourcentage de sites utilisant des source maps.
-
-
Les résultats sont à peu près les mêmes pour les pages sur ordinateurs de bureau et les pages sur mobiles. 17-18 % incluent un sourcemap pour au moins un script sur la page (détecté comme un script du domaine principal avec sourceMappingURL).
L’écosystème JavaScript continue de changer et d’évoluer chaque année. Nous verront toujours apparaitre des API plus récentes, des moteurs de navigation améliorés, de nouvelles bibliothèques ou frameworks. HTTP Archive nous fournit des informations précieuses sur la façon dont les sites utilisent le langage sur le terrain.
-
Sans JavaScript, le web ne serait pas là où il est aujourd’hui, et toutes les données recueillies pour cet article ne font que le prouver.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/markup.html b/src/templates/fr/2019/chapters/markup.html
deleted file mode 100644
index fbd21cb8ba5..00000000000
--- a/src/templates/fr/2019/chapters/markup.html
+++ /dev/null
@@ -1,359 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":3,"title":"Balisage Web","description":"Chapitre sur le balisage web du rapport Web Almanac 2019. Découvrez des statistiques sur l’usage des balises, leurs valeurs, les solutions et des cas d’utilisation courants.","authors":["bkardell"],"reviewers":["zcorpan","tomhodgins","matthewp"],"translators":["borisschapira","SilentJMA"],"discuss":"1758","results":"https://docs.google.com/spreadsheets/d/1WnDKLar_0Btlt9UgT53Giy2229bpV4IM2D_v6OM_WzA/","queries":"03_Markup","published":"2019-12-23T00:00:00.000Z","last_updated":"2020-03-01T00:00:00.000Z","chapter":"markup"} %} {% block index %}
-
En 2005, Ian "Hixie" Hickson a publié une analyse sur les données de balisage web à partir de différents travaux précédents. Une grande partie de ce travail visait à examiner les noms de classes pour voir s’il existait une sémantique informelle commune adoptée par les développeurs et développeuses, sur laquelle il serait peut-être logique de standardiser. Certaines de ses recherches ont permis de proposer de nouveaux éléments en HTML5.
-
14 ans plus tard, il est temps de jeter un nouveau coup d’œil aux usages. Depuis cette époque, nous avons vu apparaître les éléments personnalisés et l’Extensible Web manifesto, ce qui nous a encouragé à trouver de meilleures méthodes pour accompagner les développements. Cela implique de permettre aux équipes de développement d’explorer l’espace des éléments de balisage elles-mêmes et aux organismes de normalisation d’agir comme des éditeurs de dictionnaires. À l’inverse des noms de classes CSS, qui peuvent être utilisés pour n’importe quoi, nous pouvons être certains que les auteurs qui ont utilisé un élément non standard l’ont fait volontairement.
-
- À partir de juillet 2019, HTTP Archive a commencé à collecter tous les noms de éléments utilisés dans le DOM, environ 4,4 millions de pages d’accueil pour ordinateurs de bureau et environ 5,3 millions de pages d’accueil sur mobiles que nous pouvons maintenant commencer à analyser et à disséquer (en savoir plus sur notre méthodologie).
-
-
Lors de cette collecte, nous avons découvert plus de 5 000 noms d’éléments non standard distincts dans les pages. Nous avons donc limité le nombre total d’éléments distincts que nous comptons aux 5 048 "premiers" (explications ci-dessous).
Les noms des éléments sur chaque page ont été collectés à partir du DOM lui-même, après l’exécution initiale de JavaScript.
-
Examiner un nombre de fréquences brut n’est pas particulièrement utile, même pour les éléments standards : environ 25 % des éléments rencontrés sont des <div>. Environ 17 % sont des <a>, environ 11 % sont des <span> – et ce sont les seuls éléments qui comptent pour plus de 10 % des occurrences. C’est un peu comme ça dans toutes les langues ; un petit nombre de termes est surreprésenté en termes de fréquence. D’autant plus que, si nous commençons à examiner l’adoption des éléments non standards, cela peut être très trompeur. Il suffirait qu’un site utilise un certain élément mille fois pour lui conférer artificiellement une grande popularité.
-
Au lieu de faire ça, nous allons examiner combien de sites incluent chaque élément au moins une fois dans leur page d’accueil, comme dans l’étude originale de Hixie.
-
Remarque : cette démarche n’est pas dénuée, en soi, de biais potentiels. Des solutions populaires, pouvant être utilisées par plusieurs sites, peuvent introduire un balisage non standard "invisible" à chaque auteur. Ainsi, il faut veiller à reconnaître que l’utilisation n’implique pas nécessairement la connaissance directe de l’auteur et l’adoption consciente puisqu’elle répond à un besoin commun, d’une manière commune. Au cours de notre recherche, nous avons trouvé plusieurs exemples, dont certains seront explicités.
En 2005, l’enquête de Hixie a listé les principaux éléments les plus fréquemment utilisés sur les pages. Les 3 premiers étaient html, head et body, ce qu’il a noté comme intéressant, car ils sont facultatifs et créés par l’analyseur s’ils sont omis. Étant donné que nous utilisons le DOM après interprétation, ils apparaissent universellement dans nos données. C’est pourquoi nous commencerons par le 4e élément le plus utilisé. Vous trouverez ci-dessous une comparaison des données collectées à son époque et aujourd’hui (j’ai inclus ici la comparaison en fréquence, pour le plaisir).
-
-
-
-
-
-
-
2005 (par site)
-
2019 (par site)
-
2019 (fréquence)
-
-
-
-
-
title
-
title
-
div
-
-
-
a
-
meta
-
a
-
-
-
img
-
a
-
span
-
-
-
meta
-
div
-
li
-
-
-
br
-
link
-
img
-
-
-
table
-
script
-
script
-
-
-
td
-
img
-
p
-
-
-
tr
-
span
-
option
-
-
-
-
-
- Figure 1. Comparaison des principaux éléments entre 2005 et 2019.
-
Graphique montrant une distribution décroissante de la fréquence relative à mesure que le nombre d’éléments augmente
- Figure 2. Distribution des fréquences d’éléments , d’après l’étude de Hixie en 2005.
-
-
-
-
-
-
-
Graphique représentant environ 2 500 pages commençant par environ 30 éléments, il passe à 6 876 pages et compte 283 éléments, avant de se terminer d’une manière relativement linéaire jusqu’à 327 pages comportant 2 000 éléments.
En comparant les dernières données de la figure 3 à celles du rapport d’Hixie de 2005 à la figure 2, nous pouvons constater que la taille moyenne des arbres DOM a augmenté.
-
-
-
-
Graphique montrant que la fréquence relative est une courbe en cloche autour d’un point culminant correspondant à 19 éléments.
- Figure 4. Histogramme des types d’éléments par page, d’après l’étude de Hixie en 2005
-
-
-
-
-
-
-
Graphique montrant que la fréquence relative est une courbe en cloche autour d’un point culminant correspondant à 30 éléments, tel qu’utilisés par 308 168 sites.
- Figure 5. Histogramme des types d’éléments par page en 2019.
-
-
Nous pouvons voir sur les deux graphiques que le nombre moyen de types d’éléments par page a augmenté, ainsi que le nombre maximal d’éléments uniques rencontrés.
La plupart des éléments que nous avons enregistrés sont personnalisés (c’est-à-dire non standards), mais il peut être un peu difficile de déterminer quels éléments sont vraiment personnalisés ou non. Car il existe de nombreux élément en cours de spécification ou de proposition. Dans notre démarche, nous avons considéré 244 éléments comme standards (cependant, certains d’entre eux sont obsolètes ou non supporté) :
-
-
145 éléments HTML ;
-
68 éléments SVG ;
-
31 éléments MathML.
-
-
En pratique, nous n’avons rencontré que 214 d’entre eux:
-
-
137 Éléments de HTML ;
-
54 Éléments de SVG ;
-
23 Éléments de MathML.
-
-
Dans le jeu de données pour ordinateurs de bureau, nous avons collecté des données pour les premiers 4 834 éléments non standards rencontrés. Parmi ceux-ci:
-
-
155 (3 %) sont identifiables comme de très probables erreurs de balisage ou d’échappement (ils contiennent des caractères dans le nom de balise analysé qui laissent à penser que le balisage est cassé) ;
-
341 (7 %) utilisent un espace de nom de type XML à deux-points (bien que, comme HTML, ils n’utilisent pas de véritables espaces de noms XML) ;
-
3 207 (66 %) sont des noms d’élément personnalisé valides ;
-
- 1 211 (25 %) sont dans l’espace de noms global (ce qui n’est pas standard, puisqu’ils n’ont ni tiret ni deux-points) ;
-
-
216 parmi ceux-ci ont été marqués comme de possibles fautes de frappe, car ils sont plus longs que 2 caractères et ont une distance de Levenshtein de 1 par rapport à un nom d’élément standard comme <cript>,<spsn> ou <artice>. Certains d’entre eux (comme <jdiv>), cependant, sont certainement volontaires.
-
-
-
-
En outre, 15 % des pages pour ordinateurs de bureau et 16 % des pages mobiles contiennent des éléments obsolètes.
-
Remarque : Il est très probable que cela soit dû en grande partie à l’utilisation de solutions plutôt qu’à des auteurs isolés qui continueraient à créer manuellement ce balisage.
Diagramme à barres montrant que 'center' est utilisé par 8,31 % des sites pour ordinateurs de bureau (7,96 % des sites mobiles), 'font' par 8,01 % des sites pour ordinateurs de bureau (7,38 % des sites mobiles), 'marquee' utilisé par 1,07 % des sites pour ordinateurs de bureau (1,20 % des sites mobiles), 'nobr' utilisé par 0,71 % des sites pour ordinateurs de bureau (0,55 % des sites mobiles), 'big' utilisé par 0,53 % des sites pour ordinateurs de bureau (0,47 % des sites mobiles), 'frameset' utilisé par 0,39 % des sites version web (0,35 % des sites mobiles), 'frame' utilisé par 0,39 % des sites pour ordinateurs de bureau (0,35 % des sites mobiles), 'strike' utilisé par 0,33 % des sites pour ordinateurs de bureau (0,27 % des sites mobiles), et 'noframes' utilisé par 0,25 % des sites pour ordinateurs de bureau (0,27 % des sites mobiles).
- Figure 6. Éléments obsolètes les plus fréquemment utilisés.
-
-
La figure 6 ci-dessus montre les 10 éléments les plus fréquemment utilisés. Dans la plupart des cas, les nombres peuvent sembler petits mais dans l’ensemble, ce n’est pas négligeable.
Diagramme à barres illustrant une décroissance des éléments par ordre descendant : html, head, body, title au dessus de 99 % d’utilisation, meta, a, div plus de 98 % d’utilisation, link, script, img, span plus de 90 % d’utilisation, ul, li , p, style, input, br, form plus de 70 % d’utilisation, h2, h1, iframe, h3, button, footer, header, nav plus de 50 % d’utilisation et d’autres tags moins connus passant de moins de 50 % à presque 0 %.
Dans la figure 7 ci-dessus, sont affichés les 150 premiers noms d’éléments, en comptant le nombre de pages où ils apparaissent. Notez la rapidité avec laquelle l’utilisation diminue.
-
Seuls 11 éléments sont utilisés sur plus de 90 % des pages:
-
-
<html>
-
<head>
-
<body>
-
<title>
-
<meta>
-
<a>
-
<div>
-
<link>
-
<script>
-
<img>
-
<span>
-
-
Il n’y a que 15 autres éléments qui apparaissent sur plus de 50 % des pages:
-
-
<ul>
-
<li>
-
<p>
-
<style>
-
<input>
-
<br>
-
<form>
-
<h2>
-
<h1>
-
<iframe>
-
<h3>
-
<button>
-
<footer>
-
<header>
-
<nav>
-
-
Et il n’y a que 40 autres éléments qui apparaissent sur plus de 5 % des pages.
-
Même <video>, par exemple, n’atteint pas ce score. Il apparaît sur seulement 4 % des pages pour ordinateurs de bureau du jeu de données (3 % sur mobile). Bien que ces chiffres semblent très faibles, 4 % correspond à une utilisation assez populaires, comparativement. En effet, seuls 98 éléments apparaissent sur plus de 1 % des pages.
-
Il est donc intéressant de voir à quoi ressemble la distribution de ces éléments et quels sont ceux qui sont utilisés à plus de 1 %.
Le graphique en nuage de points montrant HTML, SVG et Math ML utilise relativement peu de balises alors que des éléments non standard "dans le namespace global", "avec des tirets" et "avec des deux-points") sont beaucoup plus dispersés.
- Figure 8. Popularité des éléments classée par norme.
-
-
La figure 8 montre le classement de chaque élément et la norme dans laquelle il se situe. J’ai séparé les points de données en ensembles discrets simplement pour pouvoir les visualiser (sinon, il n’ya tout simplement pas assez de pixels pour capturer toutes ces données), mais ils représentent une unique "ligne" de popularité ; le plus bas étant le plus commun, le plus haut étant le plus rare. La flèche pointe vers la fin des éléments qui apparaissent dans plus de 1 % des pages.
-
Vous pouvez observer deux choses ici. Premièrement, l’ensemble des éléments utilisés à plus de 1 % n’est pas exclusivement HTML. En fait, 27 des 100 éléments les plus populaires ne sont même pas issus de HTML – ils sont en SVG ! Et il y a aussi des balises non standards au niveau ou très près de cette démarcation! Deuxièmement, notez que de nombreux éléments HTML sont utilisés par moins de 1 % des pages.
-
Alors, tous ces éléments utilisés par moins de 1 % des pages sont-ils "inutiles"? Définitivement, non. C’est pourquoi il est important de prendre du recul. Il y a environ deux milliards de sites sur le Web. Si quelque chose apparaît sur 0,1 % de tous les sites web de notre ensemble de données, nous pouvons extrapoler que cela représente peut-être deux millions de sites web sur l’ensemble du web. Même 0,01 % extrapolent à deux cent mille sites. C’est aussi pourquoi il est très rare qu’on supprime le support d’éléments, même les très anciens, dont nous considérons l’usage comme une mauvaise pratique. Briser des centaines de milliers ou des millions de sites n’est pas une chose que les éditeurs de navigateurs peuvent faire à la légère.
-
De nombreux éléments, même natifs, apparaissent sur moins de 1 % des pages et restent très importants et prospères. <code>, par exemple, est un élément que j’utilise et rencontre souvent. Il est très certainement utile et important, et pourtant, il n’est utilisé que sur 0,57 % des pages. Tout ça est en partie faussé par ce que nous mesurons : les pages d’accueil sont généralement moins susceptibles d’inclure certains types d’éléments (comme <code>, par exemple). Les pages d’accueil n’ont pas vocation à accueillir autre chose que des en-têtes, des paragraphes, des liens et des listes. Cependant, les données sont généralement utiles.
-
Nous avons également collecté des informations sur les pages contenant un .shadowRoot défini par l’auteur (non natif). Environ 0,22 % des pages pour ordinateurs de bureau et 0,15 % des pages mobiles avaient un shadow dom. Cela peut sembler peu, mais il s’agit d’environ 6,5k sites dans le jeu de données mobile et de 10k sites pour ordinateurs de bureau et représente plus que plusieurs éléments HTML. <summary> par exemple, est à peu près autant utilisé sur les ordinateurs et est le 146e élément le plus populaire. <datalist> apparaît sur 0,04 % des pages d’accueil et constitue le 201e élément le plus populaire.
-
En fait, plus de 15 % des éléments que nous comptons, tels que définis par HTLM, sont en dehors des 200 premiers de l’ensemble de données de bureau. <meter> est l’élément le moins populaire de "l’ère HTML5", que nous pouvons définir comme 2004-2011, avant que HTML ne devienne un Living Standard. Il se situe autour du 1 000e élément le plus populaire. <slot>, l’élément le plus récemment introduit (avril 2016), est seulement autour du 1 400e élément le plus populaire.
En gardant à l’esprit cette perspective sur l’utilisation des fonctionnalités natives / standard dans le jeu de données, parlons des éléments non standards.
-
Vous pourriez vous attendre à ce que beaucoup des éléments que nous avons analysés ne soient utilisés que sur une seule page web. En fait, les 5 048 éléments apparaissent tous sur plus d’une page. Le nombre de pages sur lesquelles un élément de notre ensemble de données apparaît est de 15 au minimum. Environ un cinquième d’entre eux apparaissent sur plus de 100 pages. Environ 7 % d’entre eux apparaissent sur plus de 1 000 pages.
-
Pour aider à analyser les données, j’ai bidouillé un petit outil avec Glitch. Vous pouvez utiliser cet outil vous-même et envoyer un lien permanent à @HTTPArchive avec vos observations. (Tommy Hodgins a également construit un outil CLI similaire que vous pouvez utiliser pour explorer les données).
La prévalence de plusieurs éléments non standards est sûrement plus liée à leur inclusion dans des outils tiers populaires qu’à leur adoption par les équipes de développement. Par exemple, l’élément <fb:like> se trouve sur 0,3 % des pages ; non pas parce que les propriétaires du site l’écrivent explicitement, mais parce qu’ils incluent le widget Facebook. Beaucoup d’éléments mentionnés par Hixie il y a 14 ans apparaitre moins fréquemment, mais d’autres sont encore assez récurrents :
-
-
- Des éléments populaires créés par la Page d’accueil Claris (dont la dernière version stable date d’il y a 21 ans) sont encore affichés sur plus de 100 pages. <x-claris-window>, par exemple, apparaît sur 130 pages.
-
-
- Certains éléments <actinic:*> du fournisseur britannique de commerce électronique Oxatis apparaissent sur plus de pages encore. Par exemple, <actinic:basehref> s’affiche toujours sur 154 pages dans les données issues des pages pour ordinateur de bureau.
-
-
- Les éléments de Macromedia semblent avoir, en grande partie, disparus. Un seul élément, <mm:endlock>, apparaît sur notre liste et sur 22 pages seulement.
-
-
- L’élément <csscriptdict> d’Adobe Go-Live apparaît toujours sur 640 pages pour ordinateur de bureau.
-
-
L’élément <o:p> de Microsoft Office apparaît toujours sur 0,5 % des pages pour ordinateur de bureau, soit plus de 20 000 pages.
-
-
Mais beaucoup de nouveaux arrivants ne figuraient pas non plus dans le rapport initial d’Hixie, et avec des chiffres plus importants.
-
-
- <ym-measure> est une balise injectée par le paquet de télémétrie Metrica de Yandex. Il est utilisé sur plus de 1 % des pages d’ordinateur et mobiles, consolidant ainsi sa place dans le top 100 des éléments les plus utilisés. C’est énorme !
-
-
- <g:plusone>, qui provient du défunt Google Plus, apparaît sur plus de 21k pages.
-
-
- <fb:like> de Facebook apparaît sur 14k pages mobiles.
-
-
- De même, <fb:like-box> apparaît sur 7,8k pages mobiles.
-
-
- <app-root>, qui est généralement inclus dans des systèmes comme Angular, apparaît sur 8,2k pages mobiles.
-
-
-
Comparons-les à quelques-uns des éléments HTML natifs inférieurs à la barre des 5 %, en perspective.
Le graphique à barres montre que 'video' est utilisé par 184 149 sites, 'canvas' par 108 355, 'ym-measure' (une balise spécifique à une solution) par 52 146, 'code' par 25 075, 'g:plusone' (un tag spécifique à une solution) par 21 098, 'fb:like' (une balise spécifique à une solution) par 12 773, 'fb:like-box' (une balise spécifique à une solution) par 6 792, 'app-root' (une balise spécifique à une solution) par 8 468, 'summary' par 6 578, 'template' par 5 913, et 'meter' par 0.
- Figure 9. Popularité des éléments natifs et spécifiques à des solutions adoptés à moins de 5 %.
-
-
Vous pourriez découvrir des enseignements intéressants comme ceux-ci à longueur de journée.
-
Voici un qui est un peu différent : les élements les plus courants peuvent être causé par des erreurs flagrantes dans des solutions. Par exemple, <pclass ="ddc-font-size-large"> apparaissait sur plus de 1 000 sites. Cela était dû à un espace manquant dans une solution "as-a-Service" très connue. Heureusement, nous avons signalé cette erreur lors de notre recherche et elle a été rapidement corrigée.
-
Dans son article original, Hixie mentionne que:
-
Ce qui est bien, si l’on peut nous pardonner d’essayer de rester optimistes face à tout ce balisage non standard, c’est qu’au moins ces éléments utilisent bien des noms spécifiques aux fournisseurs. Cela réduit massivement la probabilité que les organismes de normalisation inventent des éléments et des attributs qui entrent en conflit avec l’un d’eux.
-
- Cependant, comme mentionné ci-dessus, ce n’est pas universel. Plus de 25 % des éléments non standard que nous avons capturés n’utilisent aucune stratégie d’espace de nom afin d’éviter de polluer l’espace de noms global. Par exemple, voici une liste de 1 157 éléments issus du jeu de données mobile. Comme vous pouvez le constater, ces éléments ne poseront probablement aucun problème, car ils portent des noms obscurs, des fautes d’orthographe, etc. Mais au moins quelques-uns présentent probablement des défis. Vous remarquerez, par exemple, que <toast> (que les Googlers ont récemment essayé de proposer comme <std-toast>) apparaît dans cette liste.
-
-
Il y a certains éléments très répandus qui ne posent probablement pas de difficultés :
-
-
- <ymaps> de Yahoo Maps apparaît sur ~12,5k pages mobiles.
-
-
- <cufon> et <cufontext> issus d’une bibliothèque de remplacement de polices datant de 2008, apparaissent environ sur ~10.5k pages sur mobiles.
-
-
- <jdiv> semble être injecté par la solution de discussion Jivo, et apparaît sur ~40,3k pages mobile.
-
-
-
Les placer dans le même graphique que ci-dessus donne la perspective suivante (encore une fois, elle varie légèrement en fonction de l’ensemble de données).
Un graphique à barres montrant que video est utilisé par 184 149 sites, canvas par 108 355, ym-measure par 52 416, code par 25 075, g:plusone par 21 098, db:like par 12 773, cufon par 10 523, ymaps par 8 303, fb:like-box par 6 972, app-root par 8 468, summary par 6 578, template par 5 913, et meter par 0
- Figure 10. Autres éléments populaires dans le contexte d’éléments natifs et spécifiques à des solutions adoptés à moins de 5 %.
-
-
Ce qui est intéressant dans ces résultats, c’est qu’ils introduisent également quelques autres façons dont notre outil peut être très utile. Si nous voulons explorer l’espace des données, un nom de balise très spécifique n’est qu’une mesure possible. C’est certainement l’indicateur le plus fort en termes de "jargon" du développement. Cependant, que faire si ce n’est pas tout ce qui nous intéresse ?
Et si, par exemple, nous nous intéressions aux personnes qui solutionnent les cas d’utilisation courants ? Nous pourrions le faire parce que nous cherchons des solutions pour résoudre des cas existants, ou pour faire des recherches plus générales sur les situations d’utilisation courantes que les gens résolvent en vue de lancer un processus de normalisation. Prenons un exemple courant : les onglets. Au fil des ans, il y a eu beaucoup de demandes pour des choses de ce genre. Nous pouvons utiliser une recherche approximative ici et trouver qu’il y a de nombreuses variantes d’onglets. Il est un peu plus difficile de compter l’utilisation ici, car nous ne pouvons pas distinguer aussi facilement si deux éléments apparaissent sur la même page, donc le compte fourni ici de manière traditionnelle prend simplement celui avec le plus grand nombre. Dans la plupart des cas, le nombre réel de pages est probablement beaucoup plus grand.
Si nous remarquons que des choses populaires apparaissent (comme <jdiv>, pour la discussion), nous pouvons prendre connaissance de choses que nous connaissons (comme, voici en quoi <jdiv> consiste, ou <olark>) et essayer de regarder les 43 éléments – au moins – que nous avons collecté et qui répondent à ce besoin et de suivre les liens entre ces éléments pour comprendre le marché.
Alors, il y a beaucoup de données ici, mais pour résumer :
-
-
Les pages ont plus d’éléments qu’il y a 14 ans, en moyenne et au maximum.
-
La durée de vie des éléments sur les pages d’accueil est très longue. Le fait de déprécier ou d’abandonner des éléments ne les fait pas disparaître, et cela pourrait ne jamais arriver.
-
Il y a beaucoup de balises erronées dans la nature (balises mal orthographiées, espaces manquants, mauvaise échappement, méprises).
-
Il est difficile de mesurer ce que signifie "utile". Beaucoup d’éléments natifs ne passent pas la barre des 5%, ou même celle des 1%, mais beaucoup d’éléments personnalisés le font, et pour beaucoup de raisons. Passer le 1% devrait certainement attirer notre attention, mais peut-être aussi le 0.5% parce que c’est, selon les données, comparativement très populaire.
-
Il y a déjà une tonne de balisage personnalisé sur le marché. Il y en a de toutes les formes, mais les éléments contenant un tiret semblent définitivement avoir décollé.
-
Nous devons de plus en plus étudier ces données et faire de bonnes observations pour identifier les pratiques et standardiser.
-
-
C’est dans ce dernier cas que vous intervenez. Nous aimerions profiter de la créativité et de la curiosité de la communauté pour aider à explorer ces données en utilisant certains des outils (comme https://rainy-periwinkle.glitch.me/). Veuillez nous faire part de vos précieuses observations et nous aider à bâtir notre patrimoine commun de connaissances et de compréhension.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/mobile-web.html b/src/templates/fr/2019/chapters/mobile-web.html
deleted file mode 100644
index 468800b6d42..00000000000
--- a/src/templates/fr/2019/chapters/mobile-web.html
+++ /dev/null
@@ -1,338 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":12,"title":"Web Mobile","description":"Chapitre sur les web mobile du Web Almanac 2019, couvrant le chargement des pages, du contenu textuel, du zoom et de la mise à l’échelle, des boutons et des liens, ainsi que de la facilité à remplir les formulaires.","authors":["obto"],"reviewers":["AymenLoukil","hyperpress"],"translators":["borisschapira"],"discuss":"1767","results":"https://docs.google.com/spreadsheets/d/1dPBDeHigqx9FVaqzfq7CYTz4KjllkMTkfq4DG4utE_g/","queries":"12_Mobile_Web","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-27T00:00:00.000Z","chapter":"mobile-web"} %} {% block index %}
-
Remontons un instant dans le temps, jusqu’à l’année 2007. Le « web mobile » n’est pour l’instant que balbutiant, et pour de bonnes raisons. Pourquoi ? Les navigateurs mobiles ne prennent pas ou peu en charge le CSS, ce qui signifie que les sites ne ressemblent pas du tout à leur version sur ordinateur de bureau – certains navigateurs ne peuvent afficher que du texte. Les écrans sont incroyablement petits et ne peuvent afficher que quelques lignes de texte à la fois. Et en guise de souris, de minuscules touches fléchées utilisées pour « tabuler ». Il va sans dire que naviguer sur le web avec un téléphone est un véritable sacerdoce. Mais tout est sur le point de changer.
-
Au milieu de sa présentation, Steve Jobs prend l’iPhone qu’il vient juste de dévoiler, s’assoit et commence à surfer sur le web d’une manière dont nous n’avions jamais rêvé auparavant. Un grand écran et un navigateur complet affichant les sites web dans toute leur splendeur. Et surtout, en surfant sur le web à l’aide du dispositif de pointage le plus intuitif connu de l’Homme : ses doigts. Plus besoin de tabulations avec de minuscules touches fléchées.
-
Depuis 2007, le web mobile s’est développé à un rythme explosif. Aujourd’hui, 13 ans plus tard, le mobile représente 59 % de toutes les recherches et 58,7 % de tout le trafic web, selon les données de Akamai mPulse de juillet 2019. Ce n’est plus un usage secondaire, mais la principale façon dont les gens vivent le web. Alors, étant donné l’importance du mobile, quel genre d’expérience offrons-nous à nos visiteurs et visiteuses ? Quels sont les points faibles ? C’est ce que nous allons découvrir.
La première partie de l’expérience du web mobile que nous avons analysée est celle que nous connaissons tous et toutes le mieux : l’expérience de chargement des pages. Mais avant de commencer à plonger dans nos découvertes, assurons-nous d’être en phase sur la définition du profil-type des personnes sur mobiles. Cela vous aidera non seulement à reproduire ces résultats, mais aussi à mieux comprendre ces personnes.
-
Commençons par le téléphone dont dispose ce profil-type. Le téléphone Android moyen coûte ~250 dollars (environ 230 € hors taxe), et l’un des téléphones les plus populaires de cette gamme est le Samsung Galaxy S6. C’est donc probablement le type de téléphone utilisé, qui est concrètement 4 fois plus lent qu’un iPhone 8. Ce profil-type n’a pas accès à une connexion 4G rapide, mais plutôt à une connexion 2G (29 % du temps) ou 3G (28 % du temps). En synthèse, voici ce que donne ce profil-type :
J’imagine que des personnes seront surprises par ces résultats. Il se peut que les conditions soient bien pires que celles avec lesquelles vous avez testé votre site. Mais maintenant que nous sommes sur la même longueur d’onde en ce qui concerne le profil d’une personne sur mobile, commençons.
La quantité de code JavaScript sur le web mobile est alarmante. Selon le rapport JavaScript de HTTP Archive, en médiane, un site mobile demande aux téléphones de télécharger 375 Ko de JavaScript. En supposant un taux de compression de 70 %, cela signifie qu’en médiane, les téléphones doivent analyser, compiler et exécuter 1,25 Mo de JavaScript.
-
Pourquoi est-ce un problème ? Parce que les sites qui chargent autant de JS peuvent prendre plus de 10 secondes pour devenir durablement interactifs. En d’autres termes, votre page peut sembler entièrement chargée, mais lorsqu’une personne clique sur l’un de vos boutons ou menus, il peut ne rien se passer parce que le JavaScript n’a pas fini de s’exécuter. Dans le pire des scénarios, les personnes concernées se sentiront obligées de cliquer sur le bouton pendant plus de 10 secondes, en attendant le moment magique où quelque chose se passe enfin. Pensez à combien cela peut être déroutant et frustrant.
Vidéo montrant deux pages web en train de se charger. Sur chaque page, un doigt tape à plusieurs reprises sur un bouton tout au long de la vidéo, sans effet. Il y a une horloge qui fait tic-tac à partir de 0 seconde en haut, et un premier visage d'emoji heureux pour chaque site web, qui commence à devenir moins heureux lorsque l'horloge passe 6 secondes, les yeux écarquillés à 8 secondes, en colère à 10 secondes, vraiment en colère à 13 secondes et pleurant à 19 secondes, peu de temps après que la vidéo se soit terminée.
- Figure 2. Exemple d’une expérience pénible où l’on attend que JS se charge.
-
-
Allons plus loin et examinons une autre mesure qui se concentre davantage sur comment chaque page utilise JavaScript. Par exemple, a-t-elle vraiment besoin d’autant de JavaScript pendant qu’elle se charge ? Nous appelons cette mesure le JavaScript Bloat Score (en français, score de surcharge de JavaScript), basé sur le web bloat score. L’idée derrière tout cela est la suivante :
-
-
JavaScript est souvent utilisé pour générer et modifier la page lors de son chargement ;
-
il est également livré sous forme de texte au navigateur. Il se compresse donc bien et devrait être livré plus rapidement qu’une simple capture d’écran de la page ;
-
ainsi, si la quantité totale de JavaScript qu’une page télécharge (sans compter les images, CSS, etc.) est supérieure à une capture d’écran PNG du viewport, nous utilisons beaucoup trop de JavaScript. À ce stade, il serait plus rapide d’envoyer cette capture d’écran pour obtenir l’état initial de la page !
-
-
Le JavaScript Bloat Score est défini comme suit : (taille totale du JavaScript) / (taille de la capture d’écran PNG du port d’affichage). Tout nombre supérieur à 1 signifie qu’il est plus rapide d’envoyer une capture d’écran.
-
Quels en sont les résultats ? Sur les plus de 5 millions de sites web analysés, 75,52 % étaient surchargés de JavaScript. Nous avons encore un long chemin à parcourir.
-
Notez que nous n’avons pas été en mesure de capturer et de mesurer les captures d’écran de plus de 5 millions de sites que nous avons analysés. Nous avons plutôt pris un échantillon aléatoire de 1000 sites pour trouver la taille médiane des captures d’écran (140 Ko), puis nous avons comparé la taille de téléchargement de JavaScript de chaque site à ce nombre.
Les navigateurs chargent généralement toutes les pages de la même manière. Ils donnent la priorité au téléchargement de certaines ressources par rapport à d’autres, suivent les mêmes règles de mise en cache, etc. Grâce aux Service Workers, nous avons maintenant un moyen de contrôler directement la façon dont nos ressources sont gérées par la couche réseau, ce qui permet souvent d’améliorer considérablement le temps de chargement des pages.
-
Mais bien qu’ils soient disponibles depuis 2016 et mis en œuvre sur tous les principaux navigateurs, seuls 0,64 % des sites les utilisent !
L’une des plus belles réussites du web est la façon dont les pages web se chargent progressivement. Les navigateurs téléchargent et affichent le contenu dès qu’ils le peuvent, afin que les utilisateurs puissent y accéder le plus rapidement possible. Cependant, cela peut avoir un effet négatif si vous ne concevez pas votre site dans cette optique. Plus précisément, le contenu peut changer de position au fur et à mesure que les ressources se chargent, ce qui nuit à l’expérience utilisateur.
Une vidéo montrant le chargement progressif d’un site web. Le texte s’affiche rapidement, mais à mesure que les images continuent à se charger, le texte se déplace de plus en plus vers le bas de la page, ce qui rend la lecture très frustrante. Le CLS calculé pour cet exemple est de 42,59 %. Image reproduite avec l’aimable autorisation de LookZook
- Figure 3. Exemple de décalage du contenu qui distrait le lecteur. CLS total de 42,59 %. Image reproduite avec l’aimable autorisation de LookZook
-
-
Imaginez que vous êtes en train de lire un article quand, tout à coup, une image se charge et repousse le texte que vous lisez tout en bas de l’écran. Vous devez maintenant chercher où vous étiez ou simplement abandonner la lecture de l’article. Ou, pire encore, vous commencez à cliquer sur un lien juste avant qu’une annonce se charge au même endroit, ce qui se traduit par un clic accidentel sur l’annonce au lieu du lien.
-
Alors, comment mesurer à quel point nos sites se transforment ? Dans le passé, c’était assez difficile (voire impossible), mais grâce à la nouvelle Layout Instability API (en français, « API relatives à l’instabilité de la mise en page »), nous pouvons le faire en deux étapes :
-
-
-
via l’API Layout Instability, vous pouvez mesurer l’impact de chaque mouvement dans la page. Cette mesure vous est communiqué sous la forme d’un pourcentage de la quantité de contenu du viewport (la fenêtre de visualisation) qui a changé.
-
-
-
additionnez tous les changements que vous avez relevés. Le résultat est ce que nous appelons le score de Cumulative Layout Shift (CLS).
-
-
-
Comme chaque visiteur peut avoir un CLS différent, afin d’analyser cette mesure sur le web avec le Chrome UX Report (CrUX), nous rangeons chaque expérience dans l’un de ces trois ensembles distincts :
-
-
Petit CLS : regroupe les expériences ayant des CLS en dessous de 5 %. C’est-à-dire que la page est globalement stable ; ne varie pas beaucoup voire pas du tout. Pour mettre les choses en perspective, la page de la vidéo ci-dessus a un CLS de 42,59 %.
-
Grand CLS : regroupe les expériences ayant un CLS de 100 % ou plus. Il peut s’agir de nombreuses petites variations individuelles ou d’un nombre plus réduit de changements importants et significatifs.
-
CLS moyen : tout ce qui se situe entre le petit et le grand.
-
-
Que constatons-nous lorsque nous regardons le CLS sur le web ?
-
-
Près de deux sites sur trois (65,32 %) ont des CLS moyens ou grands pour 50 % ou plus de toutes les expériences utilisateurs.
-
20,52 % des sites ont des CLS importants pour au moins la moitié de toutes les expériences des utilisateurs. Cela représente environ un site sur cinq. N’oubliez pas que la vidéo de la figure 3 n’a qu’un CLS de 42,59 %. Ces expériences sont donc encore pires !
-
-
Nous pensons que cette situation est due en grande partie au fait que les sites web ne fournissent pas une largeur et une hauteur explicites pour les ressources qui se chargent après que le texte a été affiché à l’écran, comme les publicités et les images. Avant que les navigateurs puissent afficher une ressource à l’écran, ils doivent savoir quelle surface la ressource occupera. À moins qu’une taille explicite ne soit fournie via des attributs CSS ou HTML, les navigateurs n’ont aucun moyen de connaître la taille réelle de la ressource. Ils affichent donc celle-ci avec une largeur et une hauteur de 0 px jusqu’à ce qu’elle soit chargée. Lorsque la ressource est chargée et que les navigateurs savent enfin quelle est sa taille, ils déplacent le reste du contenu de la page, créant ainsi une instabilité dans la mise en page.
Ces dernières années, la démarcation entre les sites web et les applications « App Store » n’a cessé de s’estomper. Au point qu'aujourd’hui, vous avez la possibilité de demander l’accès au microphone, à la caméra vidéo, à la géolocalisation, à la possibilité d’afficher des notifications, etc.
-
Bien que cela ait ouvert encore plus de possibilités aux équipes de développement, le fait de demander inutilement ces autorisations peut inciter les utilisateurs et utilisatrices à se méfier de votre page web. C’est pourquoi nous recommandons de toujours lier une demande de permission à une action de la personne utilisant le site, par exemple en appuyant sur le bouton « Trouver des cinémas près de chez moi ».
-
Actuellement, 1,52 % des sites demandent des autorisations sans aucune intervention. Il est encourageant de voir un nombre aussi faible. Cependant, il est important de noter que nous n’avons pu analyser que les pages d’accueil. Ainsi, par exemple, les sites ne demandant des autorisations que sur leurs pages de contenu (par exemple, leurs articles de blog) n’ont pas été pris en compte. Voir notre page Méthodologie pour plus d’informations.
L’objectif premier d’une page web est de fournir un contenu exploitable par les utilisateurs et utilisatrices. Ce contenu peut être une vidéo YouTube ou un éventail d’images mais, le plus souvent, il s’agit simplement du texte de la page. Il va sans dire qu’il est extrêmement important de s’assurer que notre contenu textuel est lisible pour nos visiteurs. Car si les visiteurs ne peuvent pas le lire, il n’y a plus rien à faire, et ils partiront. Il y a deux éléments clés à vérifier pour s’assurer que votre texte est lisible : le contraste des couleurs et la taille des polices.
Lorsque nous concevons nos sites, nous avons tendance à être dans des conditions plus favorables et à avoir de bien meilleurs yeux que bon nombre de nos visiteurs. Les visiteurs peuvent être daltoniens et incapables de distinguer la couleur du texte et du fond. 1 femme sur 200 et 1 homme sur 12 d’origine européenne sont daltoniens. Pensez aussi que des personnes peuvent consulter la page au moment où le soleil crée des reflets sur leur écran, ce qui peut également nuire à la lisibilité.
-
Pour nous aider à surmonter ces problèmes, il existe des directives d’accessibilité que nous pouvons suivre pour choisir nos couleurs de texte et de fond. Comment respectons-nous ces lignes directrices ? Seuls 22,04 % des sites donnent à l’ensemble de leur texte un contraste de couleur suffisant. Cette valeur est en fait une limite inférieure, car nous n’avons pu analyser que les textes avec un fond plein. Les images et les fonds dégradés n’ont pas pu être analysés.
Quatre cases colorées de tons marron et gris avec du texte blanc superposé à l’intérieur créant deux colonnes, une où la couleur de fond n’est pas assez colorée par rapport au texte blanc et une où la couleur de fond est recommandée par rapport au texte blanc. Le code hexadécimal de chaque couleur est affiché, le blanc est #FFFFFF, la nuance claire du fond marron est #FCA469, et la nuance recommandée du fond marron est #BD5B0E. Les équivalents en niveaux de gris sont respectivement #B8B8B8 et #707070. Image reproduite avec l’aimable autorisation de LookZook
- Figure 4. Exemple de ce à quoi ressemble un texte dont le contraste des couleurs est insuffisant. Avec l’aimable autorisation de LookZook
-
-
Pour des statistiques sur le daltonisme dans d’autres groupes démographiques, voir ce document.
La deuxième partie de la lisibilité consiste à s’assurer que le texte est suffisamment grand pour être lu facilement. C’est important pour tous les types d'utilisateurs, mais surtout pour les personnes âgées. Les tailles de police inférieures à 12 px ont tendance à être plus difficiles à lire.
-
Sur l’ensemble du web, nous avons constaté que 80,66 % des pages web répondent à ce critère de référence.
Il est incroyablement difficile de concevoir un site qui fonctionne parfaitement sur des dizaines de milliers de tailles d’écran et de dispositifs. Certaines personnes ont besoin d’une taille de police plus importante pour lire, zoomer sur les images de vos produits, ou ont besoin d’un bouton plus grand parce qu’il est trop petit et a échappé à votre équipe d’assurance qualité. C’est pour de telles raisons que les fonctions de zoom et de mise à l’échelle des appareils sont si importantes : elles permettent aux gens de modifier nos pages pour qu’elles répondent à leurs besoins.
-
Il existe de très rares cas où la désactivation est acceptable, par exemple lorsque la page en question est un jeu en ligne utilisant des commandes tactiles. Si cette option est laissée activée dans ce cas, les téléphones des joueurs feront un zoom avant et arrière chaque fois que le joueur tapera deux fois sur le jeu, ce qui rendra l’expérience inutilisable.
-
Pour cette raison, les équipes de développement ont la possibilité de désactiver cette fonctionnalité en définissant l’une des deux propriétés suivantes dans la balise meta viewport :
Diagramme à barres verticales groupées intitulé « Le zoom et la mise à l’échelle sont-ils activés ? » mesurant les données en pourcentage, allant de 0 à 80 par incréments de 20, par rapport au type d’appareil, regroupées en bureau et mobile. Activé sur le bureau : 75,46 % ; bureau désactivé 24,54 % ; mobile activé : 67,79 % ; Mobile désactivé : 32,21 %.
- Figure 5. Pourcentage de sites web de bureau et mobiles qui activent ou désactivent la possibilité de zoomer / la mise à l’échelle.
-
-
Cependant, les équipes de développement ont tellement abusé de cette fonctionnalité qu’aujourd’hui, près d’un site sur trois (32,21 %) la désactive, et Apple (à partir d’iOS 10) ne permet plus aux équipes de développement web de désactiver le zoom. Safari Mobile ignore simplement la balise. Tous les sites, quoi qu’il en soit, peuvent être zoomés et mis à l’échelle sur les nouveaux appareils Apple, qui représentent plus de 11 % de tout le trafic web dans le monde !
Certains appareils mobiles peuvent être tournés afin que votre site web soit affiché au format préféré des utilisateurs et utilisatrices. Cependant, les gens ne gardent pas toujours la même orientation tout au long d’une session. Lorsqu’ils remplissent des formulaires, ils peuvent passer en mode paysage pour utiliser le clavier plus grand. Ou bien, lorsqu’ils naviguent sur les produits, certains peuvent préférer les images de produits plus grandes que leur propose le mode paysage. En raison de ces types de cas d’utilisation, il est très important de ne pas les priver de cette capacité intégrée des appareils mobiles. Et la bonne nouvelle, c’est que nous n’avons trouvé pratiquement aucun site qui désactive cette fonction. Seuls 87 sites au total (soit 0,0016 %) désactivent cette fonction. C’est fantastique.
Nous sommes habitués à avoir des dispositifs de pointage précis, comme des souris, lorsque nous utilisons des ordinateurs de bureau, mais c’est une autre histoire sur mobile. Sur mobile, nous interagissons avec les sites grâce à ces outils volumineux et imprécis que nous appelons des doigts. En raison de leur imprécision, nous appuyons constamment sur des liens et des boutons sur lesquels nous ne voulions pas appuyer.
-
Il peut être difficile de concevoir des cibles d’appui appropriées pour atténuer ce problème en raison de la grande variété de taille des doigts. Cependant, de nombreuses recherches ont été menées et il existe des normes sûres concernant la taille des boutons et la distance qui doit les séparer.
Un diagramme montrant deux exemples de boutons difficiles à toucher. Le premier exemple montre deux boutons sans espacement entre eux. L’exemple ci-dessous montre les mêmes boutons mais avec l’espacement recommandé (8 px ou 1-2 mm). Le second exemple montre un bouton beaucoup trop petit pour être appuyé ; l’exemple ci-dessous montre le même bouton agrandi à la taille recommandée de 40-48 px (environ 8 mm). Image reproduite avec l’aimable autorisation de LookZook
- Figure 6. Normes de dimensionnement et d’espacement des cibles d’appui. Image reproduite avec l’aimable autorisation de LookZook.
-
-
À l’heure actuelle, 34,43 % des sites ont des cibles d’appui suffisamment grandes. Nous avons donc encore beaucoup de chemin à parcourir avant que les erreurs liées aux « gros doigts » soient derrière nous.
Certains designers aiment utiliser des icônes à la place du texte ; elles peuvent donner à nos sites un aspect plus net et plus élégant. Mais si vous et tous les membres de votre équipe savez ce que ces icônes signifient, beaucoup de vos visiteurs et visiteuses ne le sauront pas. C’est même le cas de la fameuse icône « hamburger » ! Si vous ne nous croyez pas, faites des tests utilisateurs et voyez à quel point ils peuvent être confus. Vous serez stupéfait·e.
-
C’est pourquoi il est important d’éviter toute confusion et d’ajouter du texte complémentaire et des étiquettes à vos boutons. À l’heure actuelle, au moins 28,59 % des sites incluent un bouton avec une seule icône sans texte complémentaire.
-
Note : le nombre indiqué ci-dessus n’est qu’une limite inférieure. Au cours de notre analyse, nous n’avons inclus que les boutons utilisant des icônes de police sans texte complémentaire. Cependant, de nombreux boutons utilisent désormais des SVG au lieu d’icônes de police, aussi les inclurons-nous également dans les prochaines exécutions.
Qu’il s’agisse de s’inscrire à un nouveau service, d’acheter quelque chose en ligne ou même de recevoir des notifications de nouveaux messages sur un blog, les champs de formulaire sont une partie essentielle du web et sont utilisés quotidiennement. Malheureusement, ces champs sont tristement célèbres parce qu’ils sont très pénibles à remplir sur un téléphone portable. Heureusement, ces dernières années, les navigateurs ont donné aux équipes de développement de nouveaux outils pour faciliter le remplissage de ces champs que nous ne connaissons que trop bien. Voyons donc à quel point ils ont été utilisés.
Dans le passé, text et password étaient parmi les seuls types de saisie (<input>) disponibles pour les équipes de développement, car ils répondaient à presque tous nos besoins sur ordinateurs de bureau. Ce n’est pas le cas pour les appareils mobiles. Les claviers mobiles sont incroyablement petits, et une tâche simple, comme la saisie d’une adresse électronique, peut obliger les utilisateurs à passer d’un clavier à l’autre : le clavier standard et le clavier à caractères spéciaux pour le symbole @. La simple saisie d’un numéro de téléphone peut être difficile en utilisant les minuscules chiffres du clavier par défaut.
-
De nombreux nouveaux types de saisies ont été introduits depuis, permettant aux équipes de développement d’informer les navigateurs du type de données attendu et permettant aux navigateurs de fournir des claviers personnalisés spécifiquement pour ces types de saisie. Par exemple, le type email permet au navigateur de fournir un clavier alphanumérique comprenant le symbole @, et le type tel, un clavier numérique.
-
Lors de l’analyse des sites contenant une saisie d’email, 56,42 % utilisent type="email". De même, pour les saisies de numéros de téléphone, type="tel" est utilisé 36,7 % du temps. Les autres nouveaux types de saisie ont un taux d’adoption encore plus faible.
-
-
-
-
-
-
-
Type
-
Fréquence (pages)
-
-
-
phone
-
1,917
-
-
-
name
-
1,348
-
-
-
textbox
-
833
-
-
-
-
-
- Figure 7. Types de saisie invalides les plus couramment utilisés
-
-
Assurez-vous de bien vous informer et de renseigner les autres sur la grande quantité de types de saisie disponibles et vérifiez que vous n’avez pas de fautes de frappe, à l’image des plus courantes, reprises dans la figure 7 ci-dessus.
- L’attribut autocomplete de l’élément <input> permet aux gens de remplir les champs du formulaire en un seul clic. Ils remplissent des tonnes de formulaires, souvent avec exactement les mêmes informations à chaque fois. Conscients de ce fait, les navigateurs ont commencé à stocker ces informations de manière sécurisée afin de pouvoir les réutiliser. Tout ce que les équipes de développement doivent faire, c’est utiliser cet attribut autocomplete pour indiquer aux navigateurs quelle est l’information exacte à remplir, et le navigateur fait le reste.
-
-
-
29,62 %
- Figure 8. Pourcentage des pages utilisant autocomplete.
-
-
Actuellement, seules 29,62 % des pages comportant des champs de saisie utilisent cette fonction.
Permettre aux utilisateurs de copier et de coller leurs mots de passe dans votre page leur permet d’utiliser un gestionnaire de mots de passe. Les gestionnaires de mots de passe aident les utilisateurs à générer (et à mémoriser) des mots de passe forts et à les remplir automatiquement sur les pages web. Seulement 0,02 % des pages web testées désactivent cette fonctionnalité.
-
Note : Bien que cela soit très encourageant, il s’agit peut-être d’une sous-estimation en raison de l’exigence de notre méthodologie de ne tester que les pages d’accueil. Les pages intérieures, comme les pages de connexion, ne sont pas testées.
Pendant plus de 13 ans, nous avons traité le web mobile de façon accessoire, comme une vulgaire alternative aux sites pour ordinateurs de bureau. Mais il est temps que cela change. Le web mobile est maintenant le web, et les sites pour ordinateurs de bureau tombent en désuétude. Il y a maintenant 4 milliards de smartphones actifs dans le monde, couvrant 70 % de tous les utilisateurs potentiels. Qu’en est-il des ordinateurs de bureau ? Ils sont actuellement 1,6 milliard et représentent de moins en moins d’utilisateurs du web chaque mois.
-
Comment nous débrouillons-nous pour répondre aux besoins des utilisateurs de téléphones portables ? Selon nos recherches, même si 71 % des sites font des efforts pour adapter leur site au mobile, ils sont loin d’atteindre leur objectif. Les pages mettent une éternité à se charger et deviennent inutilisables en raison d’un abus de JavaScript, le texte est souvent impossible à lire, l’interaction avec les sites en cliquant sur des liens ou des boutons est source d’erreurs et d’exaspération, et des tonnes de fonctionnalités formidables inventées pour atténuer ces problèmes (Service Workers, saisie automatique, zoom, nouveaux formats d’image, etc) sont à peine utilisées.
-
Le web mobile existe maintenant depuis assez longtemps pour qu’il y ait toute une génération d’enfants pour qui c’est le seul internet qu’ils aient jamais connu. Et quel genre d’expérience leur donnons-nous ? Nous les ramenons essentiellement à l’ère du modem (heureusement qu’AOL vend encore ces CD qui offrent 1000 heures d’accès gratuit à l’internet) !
Nous avons considéré que les sites faisant un effort en matière de mobile sont ceux qui adaptent leur design à des écrans plus petits. Ou plutôt, ceux qui ont au moins un point de rupture CSS à 600 px ou moins.
-
-
Les utilisateurs et utilisatrices potentielles, ou le marché total adressable, se composent des personnes âgées de 15 ans et plus : soit 5,7 milliards de personnes.
Le nombre total de smartphones actifs a été trouvé en additionnant le nombre de téléphones Android et iPhone actifs (rendus publics par Apple et Google), et un peu de maths pour prendre en compte les téléphones chinois connectés à Internet. Plus d’infos ici.
-
-
-
Le nombre de 1,6 milliards d’ordinateurs de bureau est calculé à partir de nombres rendus publics par Microsoft et Apple. Il n’inclut pas les ordinateurs Linux.
-
-
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/resource-hints.html b/src/templates/fr/2019/chapters/resource-hints.html
deleted file mode 100644
index 34d0def7d9d..00000000000
--- a/src/templates/fr/2019/chapters/resource-hints.html
+++ /dev/null
@@ -1,275 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"IV","chapter_number":19,"title":"Indices de Ressources","description":"Chapitre sur les indices de ressources du Web Almanac 2019, couvrant les usages de dns-prefetch, preconnect, preload, prefetch, les indices de priorités et le lazy loading natif.","authors":["khempenius"],"reviewers":["andydavies","bazzadp","yoavweiss"],"translators":["borisschapira"],"discuss":"1774","results":"https://docs.google.com/spreadsheets/d/14QBP8XGkMRfWRBbWsoHm6oDVPkYhAIIpfxRn4iOkbUU/","queries":"19_Resource_Hints","published":"2019-12-24T00:00:00.000Z","last_updated":"2020-06-30T00:00:00.000Z","chapter":"resource-hints"} %} {% block index %}
-
Les indices de ressources fournissent des "suggestions" au navigateur sur les ressources qui seront rapidement nécessaires. L'action que le navigateur entreprend à la suite de cet indice varie selon le type d'indice ; différents indices déclenchent différentes actions. Lorsqu'ils sont utilisés correctement, ils peuvent améliorer les performances de la page en donnant une longueur d'avance aux actions importantes, par anticipation.
-
Quelques exemples d'amélioration de performance suite à l'usage d'indices des ressources :
-
-
Jabong a réduit son Time To Interactive de 1,5 seconde en préchargeant les scripts critiques.
-
Barefoot Wine a réduit le Time To Interactive des futures pages de 2,7 secondes en préchargeant les liens visibles.
-
Chrome.com a réduit sa latence de 0,7 seconde en se préconnectant à des domaines critiques.
-
-
La plupart des navigateurs actuels prennent en charge quatre indices de ressources distincts : dns-prefetch, preconnect, preload et prefetch.
- Le rôle de dns-prefetch est de lancer une résolution DNS par anticipation. On peut ainsi anticiper la résolution DNS de tierces parties. Par exemple, la résolution DNS d'un CDN, d'un fournisseur de polices d'écriture ou d'une API en tierce partie.
-
- preconnect initie une connexion anticipée, y compris la résolution DNS, la poignée de main TCP et la négociation TLS. Cette fonctionnalité est utile pour établir une connexion avec une tierce partie. Les utilisations de preconnect sont très similaires à celles de dns-prefetch, mais preconnect est moins bien supporté par les navigateurs. Cependant, si vous n'avez pas besoin du support d'IE 11, preconnect est probablement un meilleur choix.
-
- preload initie une requête au plus tôt. Il permet de charger des ressources importantes plutôt que d'attendre que l'analyseur les découvre plus tardivement. Par exemple, si une image importante ne peut être découverte qu'une fois que le navigateur a reçu et analysé la feuille de style, il est peut-être judicieux de précharger l'image.
-
- prefetch lance une requête de faible priorité. C'est utile pour charger les ressources qui seront utilisées lors du chargement de la page suivante (plutôt que de la page actuelle). Une utilisation courante de prefetch est le chargement de ressources dont l'application "prédit" qu'elles seront utilisées lors du chargement de la page suivante. Ces prédictions peuvent être basées sur des signaux tels que le mouvement de la souris de l'utilisateur ou des scénarios / parcours utilisateurs courants.
-
Comme l'utilisation des indices de ressources dans les en-têtes HTTP est très faible, le reste de ce chapitre se concentrera uniquement sur l'analyse de l'utilisation des indices de ressources passant par la balise <link>. Cependant, il convient de noter que dans les années à venir, l'utilisation des indices de ressources dans les en-têtes HTTP pourrait augmenter avec l'adoption de HTTP/2 Push. En effet, HTTP/2 Push réutilise l'en-tête HTTP de préchargement Link comme un signal permettant de pousser des ressources.
Note: il n'y a pas de différence notable entre l'usage des indices de ressources sur les pages web destinées aux ordinateurs ou périphériques mobiles. C'est pourquoi, par souci de concision, ce chapitre n'inclut que les statistiques relatives aux mobiles.
La popularité relative de dns-prefetch n'est pas surprenante&nbps;: c'est une API bien connue (elle est apparue pour la première fois en 2009), elle est prise en charge par tous les principaux navigateurs et c'est le moins "coûteux" de tous les indices de ressources. Parce que dns-prefetch n'effectue que des recherches DNS, il consomme très peu de données et il y a donc très peu d'inconvénients à l'utiliser. dns-prefetch est particulièrement utile dans les situations de latence élevée.
-
Cela étant dit, si un site n'a pas besoin de supporter IE11 et les versions inférieures, passer de dns-prefetch à preconnect est probablement une bonne idée. À une époque où le HTTPS est omniprésent, preconnect permet d'améliorer les performances tout en restant peu risqué. Notez que contrairement à dns-prefetch, preconnect initie non seulement la recherche DNS, mais aussi la poignée de main TCP et la négociation TLS. La chaîne de certificats est téléchargée pendant la négociation TLS et cela coûte généralement quelques kilo-octets.
-
prefetch est utilisé par 3 % des sites, ce qui en fait l'indice de ressources le moins utilisé. Cette faible utilisation peut s'expliquer par le fait que prefetch est utile pour améliorer le chargement des pages suivantes, plutôt que celui de la page actuelle. Ainsi, il sera négligé si un site se concentre uniquement sur l'amélioration de sa page d'accueil, ou sur les performances de la première page consultée.
-
-
-
-
-
-
-
Indice de ressource
-
Indices de ressources par page : Médiane
-
Indices de ressources par page : 90e percentile
-
-
-
dns-prefetch
-
2
-
8
-
-
-
preload
-
2
-
4
-
-
-
preconnect
-
2
-
8
-
-
-
prefetch
-
1
-
3
-
-
-
prerender (déprécié)
-
1
-
1
-
-
-
-
-
- Figure 2. Médiane en 90e percentile du nombre d'indices de ressources utilisés sur les pages en utilisant au moins un.
-
-
Les indices de ressources sont plus efficaces lorsqu'ils sont utilisés de manière sélective ("quand tout est important, rien ne l'est"). La figure 2 ci-dessus montre le nombre d'indices de ressources sur les pages en utilisant au moins un. Bien qu'il n'existe pas de règle précise pour définir ce qu'est un nombre approprié d'indices de ressources, il semble que la plupart des sites les utilisent de manière appropriée.
La plupart des ressources "traditionnelles" récupérées sur le web (les images, les feuilles de style et les scripts) sont récupérées sans avoir à activer le partage de ressources entre origines multiples (en anglais, Cross-Origin Resource Sharing ou CORS). Cela signifie que si ces ressources sont extraites d'un serveur Cross-Origin, par défaut, leur contenu ne peut pas être relu par la page, en raison de la politique Same-Origin.
-
Dans certains cas, la page peut choisir d'aller chercher la ressource à l'aide de CORS si elle a besoin d'en lire le contenu. Le système CORS permet au navigateur de "demander la permission" et d'accéder à ces ressources d'origines mixtes.
-
Pour les types de ressources plus récentes (par exemple les polices, les requêtes fetch(), les modules ES), le navigateur demande par défaut ces ressources en utilisant CORS et provoque l'échec total des requêtes si le serveur ne lui accorde pas la permission d'accéder aux ressources.
-
-
-
-
-
-
-
Valeur crossorigin
-
Utilisation
-
Explication
-
-
-
Non définie
-
92 %
-
Si l'attribut crossorigin est absent, la requête suivra la politique d'origine unique.
-
-
-
anonyme (ou équivalent)
-
7 %
-
Exécute une requête crossorigin qui ne comprend pas d'identifiant.
-
-
-
use-credentials
-
0,47 %
-
Exécute une requête crossorigin qui inclut des identifiants.
-
-
-
-
-
- Figure 3. Adoption de l'attribut crossorigin en pourcentage du nombre d'indices de ressources.
-
-
Dans le contexte des indices de ressources, l'utilisation de l'attribut crossorigin leur permet de correspondre au mode CORS des ressources auxquelles ils sont censés correspondre et indique les références à inclure dans la requête. Par exemple, anonymous active le mode CORS et indique qu'aucun identifiant ne doit être inclus pour ces requêtes cross-origin :
Bien que d'autres éléments HTML prennent en charge l'attribut crossorigin, cette analyse ne porte que sur l'utilisation avec des indices de ressources.
as est un attribut qui doit être utilisé avec le indices de ressources preload pour informer le navigateur du type (par exemple, image, script, style, etc.) de la ressource demandée. Cela aide le navigateur à classer correctement la requête par ordre de priorité et à appliquer la politique de sécurité du contenu (ou Content Security Policy, CSP). La CSP est un mécanisme de sécurité, exprimé par un en-tête HTTP, qui contribue à atténuer l'impact des attaques XSS et d'autres attaques malveillantes en déclarant une liste de sources fiables ; seul le contenu de ces sources peut alors être rendu ou exécuté.
-
-
88 %
- Figure 4. Pourcentage des indices de ressources qui utilisent l'attribut as.
-
-
88 % des indices de ressources utilisent l'attribut as. Quand as est spécifié, il est utilisé de façon écrasante pour les scripts : 92 % de l'utilisation concerne les scripts, 3 % les polices et 3 % les styles. Ce n'est pas surprenant étant donné le rôle prépondérant que les scripts jouent dans l'architecture de la plupart des sites ainsi que la fréquence élevée à laquelle les scripts sont utilisés comme vecteurs d'attaque (d'où l'importance particulière de leur appliquer la bonne CSP).
Pour le moment, il n'y a pas de propositions visant à élargir le jeu actuel d'indices de ressources. Cependant, les indices de priorités et le lazy loading natif sont deux technologies proposées qui s'apparentent aux indices de ressources dans la mesure où elles fournissent, elles aussi, des API pour optimiser le processus de chargement.
Les indices de priorités sont une API permettant d'exprimer des priorités dans la récupération de certaines ressources : high (haute), low (basse), ou auto. Ils peuvent être utilisés avec un large éventail de balises HTML : spécifiquement <image>, <link>, <script> et <iframe>.
- Figure 5. Exemple HTML d'utilisation d'indices de priorités sur un carrousel d'images.
-
-
Par exemple, si vous disposez d'un carrousel d'images, des indices de priorités pourraient être utilisés pour prioriser l'image que les utilisateurs voient immédiatement et déprioriser les images ultérieures.
-
-
0,04 %
- Figure 6. Taux d'adoption des indices de priorités.
-
-
Les indices de priorités sont mis en œuvre et peuvent être testés au moyen d'un drapeau de fonctionnalité dans les versions 70 et supérieures du navigateur Chromium. Étant donné qu'il s'agit encore d'une technologie expérimentale, il n'est pas surprenant qu'elle soit utilisée par 0,04 % des sites.
-
85 % de l'utilisation des indices de priorités se fait avec les balises <img>. Les indices de priorités sont surtout utilisés pour déprioriser des ressources : 72 % de l'utilisation est importance="low" ; 28 % de l'utilisation est importance="high".
- Le lazy loading natif est une API native permettant de différer le chargement des images et des iframes situées hors écran. Cela permet de libérer des ressources lors du chargement initial de la page et d'éviter de charger des ressources qui ne sont jamais utilisées. Auparavant, cette technique ne pouvait être réalisée qu'à l'aide de bibliothèques JavaScript tierces.
-
-
L'API pour le lazy loading natif se présente comme telle : <img src="cat.jpg" loading="lazy">.
-
Le lazy loading natif est disponible dans les navigateurs basés sur le Chrome 76 et plus. L'API a été annoncée trop tard pour être incluse dans l'ensemble de données du Web Almanac de cette année, mais il faut la surveiller pour l'année prochaine.
Dans l'ensemble, ces données semblent suggérer qu'il est pertinent de poursuivre l'adoption des indices de ressources. La plupart des sites gagneraient à adopter et / ou à passer de dns-prefetch à preconnect. Un sous-ensemble de sites beaucoup plus restreint pourrait bénéficier de l'adoption de la fonction prefetch et / ou preload. Utiliser avec succès prefetch et preload peut être plus délicat, ce qui tend à limiter leur adoption, mais les bénéfices potentiels sont également plus importants. Le HTTP/2 Push et la maturation des technologies d'apprentissage machine sont également susceptibles d'accroître l'adoption de preload et prefetch.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/seo.html b/src/templates/fr/2019/chapters/seo.html
deleted file mode 100644
index 0a4f7d2e67e..00000000000
--- a/src/templates/fr/2019/chapters/seo.html
+++ /dev/null
@@ -1,456 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"I","chapter_number":10,"title":"SEO","description":"Chapitre SEO du web Almanac 2019. Découvrez des statistiques sur le contenu, les meta tags, l'indexation, les liens, la performance web...","authors":["ymschaap","rachellcostello","AVGP"],"reviewers":["clarkeclark","andylimn","AymenLoukil","catalinred","mattludwig"],"translators":["AymenLoukil"],"discuss":"1765","results":"https://docs.google.com/spreadsheets/d/1uARtBWwz9nJOKqKPFinAMbtoDgu5aBtOhsBNmsCoTaA/","queries":"10_SEO","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-09T00:00:00.000Z","chapter":"seo"} %} {% block index %}
-
L'optimisation pour les moteurs de recherche (SEO) n'est pas seulement un passe-temps ou un projet parallèle pour les spécialistes du marketing digital, ce métier est crucial pour le succès d'un site web. Le but principal du référencement naturel est de s'assurer qu'un site internet est optimisé pour les robots des moteurs de recherche qui ont besoin d'explorer et d'indexer ses pages, ainsi que pour les utilisateurs qui naviguent et consomment des contenus. Le référencement a un impact sur tous ceux qui travaillent sur un site web, du développeur qui le construit au marketeur digital qui en fait la promotion auprès de nouveaux clients potentiels.
-
Mettons en perspective l'importance du référencement naturel. En avril 2019, l'industrie du référencement a regardé avec horreur et fascination ASOS signaler une baisse de revenus de 87 % après une "année difficile". La marque a attribué ce résultat à une baisse de classement et de visibilité dans les moteurs de recherche survenue après le lancement de plus de 200 microsites et à des changements importants dans la navigation de leur site web, entre autres changements techniques. Ouch.
-
L'objectif du chapitre SEO du web Almanac est d'analyser les éléments des sites web qui ont un impact sur l'exploration et l'indexation des contenus pour les moteurs de recherche et, par conséquence, sur leurs performances. Dans ce chapitre, nous allons voir dans quelle mesure les sites web les plus fréquentés sont prêts à offrir une excellente expérience aux utilisateurs et aux moteurs de recherche, et quels sont ceux qui ont encore du travail à faire.
-
Notre étude se base sur des données de Lighthouse, de Chrome UX Report, et l'analyse des balises HTML. Nous nous sommes concentrés sur les fondements du SEO comme la balise <title>, les différents types de liens HTML, le contenu et la vitesse de chargement, mais aussi d'autres aspects techniques du référencement à savoir l'indexation, les données structurées, l'internationalisation, et les pages accélérées pour mobile (AMP) à travers 5 millions de sites web.
-
Nos métriques personnalisées fournissent des informations qui, jusqu'à présent, n'avaient pas été exposées auparavant. Nous sommes maintenant en mesure de faire des constats sur l'adoption et la mise en œuvre d'éléments tels que des balises link avec attribut hreflang, l'éligibilité des résultats enrichis, l'utilisation de la balise title et même la navigation basée sur les ancres pour les applications d'une seule page (SPA).
-
Remarque : nos données se limitent à l'analyse des pages d'accueil uniquement et n'ont pas été collectées à partir d'analyses de toutes les pages des sites web. Cela aura un impact sur de nombreuses mesures dont nous discuterons, nous avons donc ajouté toutes les limitations pertinentes à chaque fois que nous mentionnons une mesure personnalisée. En savoir plus sur ces limitations dans notre méthodologie.
-
Lisez la suite pour en savoir plus sur l'état actuel du web et sa compatibilité pour les moteurs de recherche.
Les moteurs de recherche ont un processus en trois étapes : l'exploration, l'indexation et le positionnement. Pour être optimisé pour les moteurs de recherche, une page doit être découvrable, compréhensible et contenir un contenu de qualité qui fournirait de la valeur à un utilisateur qui consulte les pages de résultats des moteurs de recherche (SERP).
-
Nous voulions analyser dans quelle mesure le web répond aux normes de base des meilleures pratiques SEO, donc nous avons évalué les éléments sur les pages, tels que le contenu principal, les balises meta et les liens internes. Jetons un coup d'œil sur les résultats.
Pour pouvoir comprendre ce qu'est une page web et décider pour quelles requêtes de recherche elle fournit les réponses les plus pertinentes, un moteur de recherche doit être capable de découvrir et d'accéder à son contenu. Mais quel contenu les moteurs de recherche trouvent-ils actuellement? Pour vous aider à répondre à cette question, nous avons créé deux mesures personnalisées: le nombre de mots et les en-têtes.
Nous avons évalué le contenu des pages en recherchant des groupes d'au moins 3 mots et en comptant le nombre total de mots trouvés. Nous avons trouvé 2,73 % des pages sur ordinateur qui ne comportaient aucun groupe de mots, ce qui signifie qu'elles n'ont pas de contenu principal pour aider les moteurs de recherche à comprendre le sujet du site web.
Distribution du nombre de mots par page. Le nombre médian de mots par page de bureau est de 346 et 306 pour les pages mobiles. Les pages de bureau contiennent plus de mots dans les centiles, jusqu'à 120 mots au 90e centile
- Figure 1. Distribution du nombre de mots par page.
-
-
La page d'accueil médiane du bureau contient 346 mots et la page d'accueil médiane du mobile a un nombre de mots légèrement inférieur à 306 mots. Cela montre que les sites mobiles offrent un peu moins de contenu à leurs utilisateurs, mais à plus de 300 mots, c'est toujours une quantité raisonnable à lire. Cela est particulièrement vrai pour les pages d'accueil qui contiennent naturellement moins de contenu que les pages d'article, par exemple. Dans l'ensemble, la distribution des mots est large, avec entre 22 mots au 10e centile et jusqu'à 1 361 au 90e centile.
Nous avons également examiné si les pages sont structurées de manière à fournir le bon contexte pour le contenu qu'elles contiennent. Les éléments d'en-tête (H1, H2, H3, etc.) sont utilisés pour formater et structurer une page et rendre le contenu plus facile à lire et à analyser. Malgré l’importance des titres, 10,67 % des pages ne en comportent pas.
Répartition du nombre de titres par page. Répartition des titres par page. Le nombre médian d'en-têtes par page de bureau et mobile est de 10. Aux 10, 25, 75 et 90e centiles, le nombre d'en-têtes par page de bureau est de 0, 3, 21 et 39. C'est légèrement plus élevé que la distribution d'en-têtes mobiles par page
- Répartition du nombre de titres par page.
-
-
Le nombre médian d'éléments de titre par page est de 10. Les titres contiennent 30 mots sur les pages mobiles et 32 mots sur les pages de bureau. Cela implique que les sites web qui utilisent des titres mettent beaucoup d'efforts pour s'assurer que leurs pages sont lisibles, descriptives et décrivent clairement la structure de la page et le contexte du moteur de recherche.
Répartition du nombre de caractères dans le premier H1 par page. Les distributions de bureau et mobile sont presque identiques, avec les 10, 25, 50, 75 et 90e centiles sous la forme: 6, 11, 19, 31 et 47 caractères.
- Figure 3. Répartition du nombre de caractères dans le premier H1 par page.
-
-
En termes de longueur de titre spécifique, la longueur médiane du premier élément H1 trouvé sur le bureau est de 19 caractères.
-
Pour obtenir des conseils sur la façon de gérer les H1 et les rubriques pour le référencement et l'accessibilité, jetez un œil à cette réponse vidéo de John Mueller dans le Ask Google Série de webmasters.
Les balises meta nous permettent de donner des instructions et des informations spécifiques aux robots des moteurs de recherche sur les différents éléments et contenus d'une page. Certaines balises meta peuvent transmettre des éléments tels que le sujet principal de la page, ainsi que la façon dont la page doit être explorée et indexée. Nous voulions évaluer si les sites web exploitaient ou non les opportunités offertes par les balises meta.
- Figure 4. Pourcentage des pages mobiles qui ont une balise title
-
-
Les titres de page sont un moyen important de communiquer l'objectif d'une page à un utilisateur ou à un moteur de recherche. Les balises sont également utilisées comme en-têtes dans le SERPS et comme titre pour l'onglet du navigateur lors de la visite d'une page, il n'est donc pas surprenant de voir que 97,1 % des pages mobiles ont un titre de document.
Répartition du nombre de caractères par élément de titre par page. Les 10, 25, 50, 75 et 90e centiles des longueurs de titre pour le bureau sont : 4, 9, 20, 40 et 66 caractères. La distribution mobile est très similaire
- Figure 5. Distribution de la longueur du titre par page.
-
-
Même si Google affiche généralement les 50 à 60 premiers caractères d'un titre de page dans une page de résultats de recherche. La longueur médiane title de la balise ne comportait que 21 caractères pour les pages mobiles et 20 caractères pour les pages de bureau. Même le 75e centile est toujours inférieur à la longueur préconisée. Cela suggère que certains SEO et rédacteurs de contenu ne profitent pas de l'espace qui leur est alloué par les moteurs de recherche pour décrire leurs pages d'accueil dans les SERP.
Par rapport à la balise title, moins de pages ont implémenté une méta description. Seulement 64,02 % des pages d'accueil mobiles ont une méta description. Étant donné que Google réécrit souvent les descriptions méta dans le SERP en réponse à la requête de l'internaute, les propriétaires de sites web accordent peut-être moins d'importance à l'inclusion des metas descriptions.
Répartition du nombre de caractères par méta description par page. Les 10, 25, 50, 75 et 90e centiles des longueurs de titre pour le bureau sont : 9, 48, 123, 162 et 230 caractères. La distribution mobile est légèrement supérieure de moins de 10 caractères à un centile donné.
- Figure 6. Distribution des pages par longueurs de meta description.
-
-
La longueur médiane de la description de la méta était également inférieure à la longueur recommandée de 155 à 160 caractères, les pages de bureau ayant des descriptions de 123 caractères. Fait intéressant, les méta descriptions étaient toujours plus longues sur mobile que sur ordinateur, malgré les SERP mobiles ayant traditionnellement une limite de pixels plus courte. Cette limite n'a été étendue que récemment, donc peut-être qu'un plus grand nombre de propriétaires de sites web ont testé l'impact d'avoir des méta descriptions plus longues et plus descriptives pour les résultats mobiles.
Compte tenu de l'importance de l'attribut Alt pour le référencement et l'accessibilité, il est loin d'être idéal de voir que seulement 46,71 % des pages mobiles utilisent des attributs alt sur toutes leurs images. Cela signifie qu'il y a encore des améliorations à faire pour rendre les images sur le web plus accessibles aux utilisateurs et compréhensibles pour les moteurs de recherche. En savoir plus sur ces problèmes dans le chapitre Accessibilité.
Pour afficher le contenu d'une page aux utilisateurs dans les SERP, les robots des moteurs de recherche doivent d'abord être autorisés à accéder à cette page et à l'indexer. Certains des facteurs qui influent sur la capacité d'un moteur de recherche à explorer et à indexer des pages sont les suivants:
Il est recommandé de conserver un code de réponse HTTP 200 OK pour toutes les pages importantes que vous souhaitez voir indexées par les moteurs de recherche. La majorité des pages testées étaient accessibles aux moteurs de recherche, 87,03 % des demandes HTML initiales sur le bureau renvoyant un code d'état 200. Les résultats étaient légèrement inférieurs pour les pages mobiles, avec seulement 82,95 % des pages renvoyant un code d'état 200.
-
Le code de réponse suivant le plus fréquemment trouvé sur mobile était le 302, une redirection temporaire, qui a été trouvée sur 10,45 % des pages mobiles. C'était plus élevé que sur le bureau, avec seulement 6,71 % des pages d'accueil du bureau renvoyant un code d'état 302. Cela pourrait être dû au fait que les pages d'accueil mobiles étaient des alternatives vers une page de bureau équivalente, comme sur des sites non responsive qui ont des versions distinctes du site web pour chaque appareil.
-
Remarque : nos résultats n'incluaient pas les codes d'état 4xx ou 5xx.
La directive noindex peut être indiquée dans le HTML ou bien dans les entêtes HTTP X-Robots. Une directive noindex indique essentiellement à un moteur de recherche de ne pas inclure cette page dans ses SERPs, mais la page sera toujours accessible aux utilisateurs lorsqu'ils naviguent sur le site web. Les directives noindex sont généralement ajoutées aux versions en double des pages qui servent le même contenu, ou aux pages de faible qualité qui n'apportent aucune valeur aux utilisateurs qui arrivent sur un site web à partir d'une recherche organique, telles que les pages de recherche filtrées, à facettes ou internes.
-
96,93 % des pages mobiles ont réussi l'audit d'indexation de Lighthouse, ce qui signifie que ces pages ne contenaient pas de directive noindex. Cependant, cela signifie que 3,07 % des pages d'accueil mobiles ont une directive noindex, ce qui est préoccupant et signifie que Google n'a pas pu indexer ces pages.
-
Les sites web inclus dans notre recherche proviennent de Chrome UX Report, qui exclut les site web non publiques. Il s'agit d'une source importante de biais, car nous ne sommes pas en mesure d'analyser les sites que Chrome juge non publics. Plus de détails sur notre méthodologie.
Les balises canoniques sont utilisées pour spécifier les pages en double et leurs alternatives préférées, afin que les moteurs de recherche puissent consolider l'autorité qui pourrait être répartie sur plusieurs pages du groupe sur une seule page principale pour un meilleur classement.
-
48,34 % des pages d'accueil mobiles ont été détectées avoir une balise canonique. Les balises canoniques auto-référencées ne sont pas essentielles et les balises canoniques sont généralement requises pour les pages en double. Les pages d'accueil sont rarement dupliquées ailleurs sur le site, il n'est donc pas surprenant de constater que moins de la moitié des pages ont une balise canonique.
L'une des méthodes les plus efficaces pour contrôler l'exploration des moteurs de recherche est le fichier [robots.txt]. Il s'agit d'un fichier qui se trouve sur le domaine racine d'un site web et spécifie quelles URL et chemins d'URL doivent être interdits à l'exploration par les moteurs de recherche.
-
Il était intéressant de constater que seulement 72,16 % des sites mobiles ont un robots.txt valide, selon Lighthouse. Les principaux problèmes que nous avons constatés sont répartis entre 22 % des sites n'ayant aucun fichier robots.txt et ~ 6 % servant un fichier robots.txt non valide, et échouent ainsi à l'audit. Bien qu'il existe de nombreuses raisons valables de ne pas avoir de fichier robots.txt, comme avoir un petit site web qui n'a pas de soucis de budget de crawl, avoir un robots.txt invalide peut être problématique surtout avec le Mobile First Index.
Les liens sont l'un des attributs les plus importants d'une page web. Les liens aident les moteurs de recherche à découvrir de nouvelles pages pertinentes à ajouter à leur index et à naviguer sur les sites web. 96 % des pages web de notre ensemble de données contiennent au moins un lien interne et 93 % contiennent au moins un lien externe vers un autre domaine. La petite minorité de pages qui n'ont pas de liens internes ou externes passeront à côté de l'immense valeur que les liens transmettent aux pages cibles.
-
Le nombre de liens internes et externes inclus sur les pages de bureau était constamment supérieur au nombre trouvé sur les pages mobiles. Souvent, un espace limité sur une fenêtre plus petite entraîne moins de liens à inclure dans la conception d'une page mobile par rapport au bureau.
-
Il est important de garder à l'esprit que moins de liens internes sur la version mobile d'une page pourraient causer un problème pour votre site web. Avec le Mobile-First index, si une page est uniquement liée à partir de la version bureau, Google ne prendra pas compte de ses liens si le site fait partie de l'index Mobile.
Répartition du nombre de liens internes par page. Les 10, 25, 50, 75 et 90e centiles de liens internes pour les ordinateurs de bureau sont : 7, 29, 70, 142 et 261. La distribution mobile est beaucoup plus faible, de 30 liens au 90e centile et 10 à la médiane.
- Figure 7. Répartition du nombre de liens internes par page.
-
-
-
-
-
-
-
Répartition du nombre de liens externes par page. Les 10, 25, 50, 75 et 90e centiles de liens externes pour ordinateur de bureau sont : 1, 4, 10, 22 et 51. La distribution mobile est beaucoup plus faible, de 11 liens au 90e centile et 2 au médian
- Figure 8. Répartition du nombre de liens externes par page.
-
-
La page de bureau médiane comprend 70 liens internes (même site), tandis que la page mobile médiane comporte 60 liens internes. Le nombre médian de liens externes par page suit une tendance similaire, avec des pages de bureau comprenant 10 liens externes et des pages mobiles 8.
Répartition du nombre de liens d'ancrage par page. Les 10, 25, 50, 75 et 90e centiles d'ancrage interne pour le bureau sont : 0, 0, 0, 1 et 3. La distribution sur mobile est identique.
- Figure 9. Répartition du nombre de liens d'ancrage par page.
-
-
Les liens d'ancrage, qui pointent vers une certaine position de défilement sur la même page, ne sont pas très populaires. Plus de 65 % des pages d'accueil n'ont pas de liens d'ancrage. Cela est probablement dû au fait que les pages d'accueil ne contiennent généralement pas de contenu long.
-
Il y a de bonnes nouvelles de notre analyse de la métrique de texte du lien descriptif. 89,94 % des pages mobiles réussissent [l'audit de texte du lien descriptif] de Lighthouse (https://developers.google.com/web/tools/lighthouse/audits/descriptive-link-text). Cela signifie que ces pages n'ont pas de liens génériques "cliquez ici", "aller", "ici" ou "en savoir plus", mais utilisent un texte de lien plus significatif qui aide les utilisateurs et les moteurs de recherche à mieux comprendre le contexte des pages et comment elles se connectent les unes aux autres.
Avoir un contenu descriptif et utile sur une page qui n'est pas bloquée des moteurs de recherche avec une directive noindex ou Disallow n'est pas suffisant pour qu'un site web réussisse dans la recherche organique. Ce ne sont que les bases. Il y a beaucoup plus que ce qui peut être fait pour améliorer les performances d'un site web et son apparence dans les SERPs.
-
Certains des aspects les plus complexes sur le plan technique qui ont gagné en importance dans l'indexation et le classement réussi des sites web comprennent la performance web (vitesse de chargement), les données structurées, l'internationalisation, la sécurité et la compatibilité mobile.
Un site web à chargement rapide est également essentiel pour une bonne expérience utilisateur. Les utilisateurs qui doivent attendre, même quelques secondes, pour qu'un site se charge ont tendance à rebondir et à essayer un autre résultat de l'un de vos concurrents qui se charge rapidement et répond à leurs attentes de performances.
-
- Les métriques que nous avons utilisées pour notre analyse de la vitesse de chargement sur le web sont basées sur le Chrome UX Report (CrUX), qui recueille des données auprès des utilisateurs réels de Chrome. Ces données montrent qu'un que 48 % des sites web sont étiquetés comme lents. Un site web est considéré lent s'il présente plus de 25 % d'expériences FCP (First Contentful Paint) plus lentes que 3 secondes ou 5 % d'expériences FID (First input Delay) plus lentes que 300 ms.
-
Distribution des performances des expériences utilisateur des ordinateurs de bureau, des téléphones et des tablettes. Ordinateur de bureau : 2 % rapide, 52 % modéré, 46 % lent. Téléphone : 1 % rapide, 41 % modéré, 58 % lent. Tablette : 0 % rapide, 35 % modérée, 65 % lente.
- Figure 10. Distribution des performances des expériences utilisateur par type d'appareil.
-
-
Segmentée par type d'appareil, cette image est encore plus sombre pour la tablette (65 %) et le mobile (58 %).
-
Bien que les chiffres soient inquiétants pour la vitesse du web, la bonne nouvelle est que les experts et les outils SEO se concentrent de plus en plus sur les défis techniques de l'accélération des sites. Vous pouvez en savoir plus sur l'état des performances web dans le chapitre Performances.
Les données structurées permettent aux propriétaires de sites web d'ajouter des données sémantiques supplémentaires à leurs pages web, en ajoutant des extraits de code JSON-LD ou des microdonnées, par exemple. Les moteurs de recherche analysent ces données pour mieux comprendre ces pages et utilisent parfois le balisage pour afficher des informations pertinentes supplémentaires dans les résultats de la recherche. Les types de données structurées les plus courants sont :
La visibilité supplémentaire que les données structurées peuvent fournir aux sites web est intéressante pour les propriétaires de sites, car elle peut aider à créer plus d'opportunités de trafic . Par exemple, le [schéma de FAQ] relativement nouveau (https://developers.google.com/search/docs/data-types/faqpage) doublera la taille de votre extrait sur les pages de résultats de recherche.
-
Au cours de nos recherches, nous avons constaté que seuls 14,67 % des sites sont éligibles pour des résultats riches sur mobile. Fait intéressant, l'admissibilité au site de bureau est légèrement inférieure à 12,46 %. Cela suggère que les propriétaires de sites peuvent faire beaucoup plus pour optimiser la façon dont leurs pages d'accueil apparaissent dans la recherche.
-
Parmi les sites avec un balisage de données structuré, les cinq types les plus implémentés sont:
-
-
WebSite (16,02 %)
-
SearchAction (14,35 %)
-
Organization (12,89 %)
-
WebPage (11,58 %)
-
ImageObject (5,35 %)
-
-
Fait intéressant, l'un des types de données les plus populaires qui déclenche une fonctionnalité de moteur de recherche est SearchAction, qui alimente la boîte de recherche des liens annexes.
-
Les cinq principaux types de balisage conduisent tous à une plus grande visibilité dans les résultats de recherche de Google, ce qui pourrait être le facteur d'une adoption plus répandue de ces types de données structurées.
-
Étant donné que nous n'avons examiné que les pages d'accueil, les résultats pourraient sembler très différents si nous considérions également les pages intérieures.
-
Les étoiles d'avis ne se trouvent que sur 1,09 % des pages d'accueil du web (via AggregateRating). En outre, le [QAPage] nouvellement introduit (https://schema.org/QAPage) n'est apparu que dans 48 cas, et le FAQPage à une fréquence légèrement plus élevée de 218 fois. Ces deux derniers décomptes devraient augmenter à l'avenir alors que nous effectuons davantage d'analyses et approfondissons l'analyse Web Almanac.
L'internationalisation est l'un des aspects les plus complexes du référencement naturel, même selon certains employés de la recherche Google. L'internationalisation du référencement se concentre sur la diffusion du bon contenu à partir d'un site web avec plusieurs versions linguistiques ou nationales et sur le ciblage du contenu vers la langue et l'emplacement spécifiques de l'utilisateur.
-
Alors que 38,40 % des sites de bureau (33,79 % sur mobile) ont l'attribut HTML lang réglé sur anglais, seulement 7,43 % (6,79 % sur mobile) des sites contiennent également un attribut hreflang de balise link pointant vers une autre version linguistique. Cela suggère que la grande majorité des sites web que nous avons analysés n'offrent pas de versions distinctes de leur page d'accueil qui nécessiteraient un ciblage linguistique - sauf si ces versions distinctes existent mais n'ont pas été configurées correctement.
-
-
-
-
-
-
-
hreflang
-
Desktop
-
Mobile
-
-
-
-
-
en
-
12.19 %
-
2.80 %
-
-
-
x-default
-
5.58 %
-
1.44 %
-
-
-
fr
-
5.23 %
-
1.28 %
-
-
-
es
-
5.08 %
-
1.25 %
-
-
-
de
-
4.91 %
-
1.24 %
-
-
-
en-us
-
4.22 %
-
2.95 %
-
-
-
it
-
3.58 %
-
0.92 %
-
-
-
ru
-
3.13 %
-
0.80 %
-
-
-
en-gb
-
3.04 %
-
2.79 %
-
-
-
de-de
-
2.34 %
-
2.58 %
-
-
-
nl
-
2.28 %
-
0.55 %
-
-
-
fr-fr
-
2.28 %
-
2.56 %
-
-
-
es-es
-
2.08 %
-
2.51 %
-
-
-
pt
-
2.07 %
-
0.48 %
-
-
-
pl
-
2.01 %
-
0.50 %
-
-
-
ja
-
2.00 %
-
0.43 %
-
-
-
tr
-
1.78 %
-
0.49 %
-
-
-
it-it
-
1.62 %
-
2.40 %
-
-
-
ar
-
1.59 %
-
0.43 %
-
-
-
pt-br
-
1.52 %
-
2.38 %
-
-
-
th
-
1.40 %
-
0.42 %
-
-
-
ko
-
1.33 %
-
0.28 %
-
-
-
zh
-
1.30 %
-
0.27 %
-
-
-
sv
-
1.22 %
-
0.30 %
-
-
-
en-au
-
1.20 %
-
2.31 %
-
-
-
-
-
- Figure 11. Les 25 valeurs hreflang les plus utilisées.
-
-
À côté de l'anglais, les langues les plus courantes sont le français, l'espagnol et l'allemand. Ils sont suivis de langues ciblées vers des zones géographiques spécifiques comme l'anglais pour les américains (en-us) ou des combinaisons plus obscures comme l'espagnol pour l'irlandais (es-ie).
-
L'analyse n'a pas vérifié la bonne mise en œuvre, par exemple si les différentes versions linguistiques se lient correctement les unes aux autres. Cependant, en examinant la faible adoption d'une version x-default (seulement 3,77 % sur ordinateur et 1,30 % sur mobile), comme cela est recommandé, c'est un indicateur que cet élément est complexe et pas toujours facile à bien faire.
Les applications monopages (SPA) construites avec des frameworks comme React et Vue.js ont leur propre complexité SEO. Les sites web utilisant une navigation basée sur le hachage, rendent particulièrement difficile pour les moteurs de recherche de les explorer et de les indexer correctement. Par exemple, Google avait une solution de contournement "AJAX crawling scheme" qui s'est avérée complexe pour les moteurs de recherche ainsi que pour les développeurs, elle a donc été déconseillée en 2015.
-
Le nombre de SPA testés avait un nombre relativement faible de liens servis via des URL de hachage, avec 13,08 % des pages mobiles React utilisant des URL de hachage pour la navigation, 8,15 % des pages mobiles Vue.js les utilisant et 2,37 % des pages angulaires mobiles les utiliser. Ces résultats étaient également très similaires pour les pages de bureau. Cela est positif à voir du point de vue du référencement, compte tenu de l'impact que les URL de hachage peuvent avoir sur la découverte de contenu.
-
Le nombre plus élevé d'URL de hachage dans les pages React est surprenant, en particulier contrairement au nombre plus faible d'URL de hachage trouvées sur les pages angulaires. Les deux frameworks favorisent l'adoption de packages de routage où API historique est la valeur par défaut pour les liens, au lieu de s'appuyer sur des URL de hachage. Vue.js envisage de passer à l'utilisation de l'API Historique par défaut ainsi que dans la version 3 de leur package vue-router.
AMP (Accelerated Mobile Pages, Pages Mobiles Accélérées en français) a été introduit pour la première fois en 2015 par Google en tant que framework HTML open source. Il fournit des composants et une infrastructure aux sites web pour offrir une expérience plus rapide aux utilisateurs, en utilisant des optimisations telles que la mise en cache, le chargement différé et des images optimisées. Notamment, Google a adopté cela pour son moteur de recherche, où les pages AMP sont également servies à partir de leur propre CDN. Cette fonctionnalité est devenue plus tard une proposition de normes sous le nom échanges HTTP signés.
-
Malgré cela, seulement 0,62 % des pages d'accueil mobiles contiennent un lien vers une version AMP. Compte tenu de la visibilité de ce projet, cela suggère qu'il a été relativement peu adopté. Cependant, AMP peut être plus utile pour diffuser des pages d'articles, de sorte que notre analyse axée sur la page d'accueil ne reflétera pas l'adoption sur d'autres types de page.
Le passage en HTTPS par défaut, était un fort changement sur le web ces dernières années. HTTPS empêche le trafic du site web d'être intercepté sur les réseaux Wi-Fi publics, par exemple, où les données d'entrée des utilisateurs sont ensuite transmises de manière non sécurisée. Google a fait pression pour que les sites adoptent le HTTPS, et a même fait du HTTPS un signal de classement SEO. Chrome a également pris en charge le passage aux pages sécurisées en étiquetant les pages non HTTPS comme non sécurisées dans le navigateur.
-
Pour plus d'informations et des conseils de Google sur l'importance du HTTPS et comment l'adopter, veuillez consulter Pourquoi le HTTPS est important.
-
Nous avons constaté que 67,06 % des sites web sur ordinateur sont désormais servis via HTTPS. Un peu moins de la moitié des sites web n'ont toujours pas migré vers HTTPS et fournissent des pages non sécurisées à leurs utilisateurs. C'est un nombre important. Les migrations peuvent être un travail difficile, donc cela pourrait être une raison pour laquelle le taux d'adoption n'est pas plus élevé, mais une migration HTTPS nécessite généralement un certificat SSL et une simple modification du fichier .htaccess. Il n'y a aucune vraie raison de ne pas passer en HTTPS.
-
Le [Rapport de transparence HTTPS] de Google (https://transparencyreport.google.com/https/overview) signale une adoption de 90 % de HTTPS pour les 100 principaux domaines non Google (ce qui représente 25 % de tout le trafic de sites web dans le monde). La différence entre ce nombre et le nôtre pourrait s'expliquer par le fait que des sites relativement plus petits adoptent le HTTPS à un rythme plus lent.
-
En savoir plus sur l'état de la sécurité dans le chapitre Sécurité.
Grâce à notre analyse, nous avons observé que la majorité des sites web suivent les bonnes pratiques, dans la mesure où leurs pages d'accueil sont explorables, indexables et incluent le contenu clé requis pour bien se classer dans les pages de résultats des moteurs de recherche. Toutes les personnes qui possèdent un site web ne sont pas du tout au courant du SEO, sans parler des directives de meilleures pratiques, il est donc prometteur de voir que tant de sites ont couvert les bases.
-
Cependant, il manque plus de sites que prévu en ce qui concerne certains des aspects les plus avancés du référencement et de l'accessibilité. La vitesse du site est l'un de ces facteurs avec lesquels de nombreux sites web ont du mal, en particulier sur mobile. C'est un problème important, car la performance est l'un des plus gros contributeurs à l'UX, ce qui peut avoir un impact sur les classements. Le nombre de sites web qui ne sont pas encore desservis via HTTPS est également problématique, compte tenu de l'importance de la sécurité et de la sécurité des données des utilisateurs.
-
Il y a beaucoup plus de sujets que nous pouvons étudier pour en savoir plus sur les meilleures pratiques du référencement. Cela est essentiel en raison de la nature évolutive de l'industrie de la recherche et de la vitesse à laquelle les changements se produisent. Les moteurs de recherche apportent des milliers d'améliorations à leurs algorithmes chaque année, et nous devons suivre si nous voulons que nos sites web atteignent plus de visiteurs dans la recherche organique.
-{% endblock %}
diff --git a/src/templates/fr/2019/chapters/third-parties.html b/src/templates/fr/2019/chapters/third-parties.html
deleted file mode 100644
index 2eec4a8ca0a..00000000000
--- a/src/templates/fr/2019/chapters/third-parties.html
+++ /dev/null
@@ -1,366 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":5,"title":"Tierces Parties","description":"Le chapitre sur les ressources tierces du Web Almanac 2019, qui aborde les tierces parties utilisées, pourquoi elles le sont et les répercussions de leur usage sur le rendu et la confidentialité.","authors":["patrickhulce"],"reviewers":["zcorpan","obto","jasti"],"translators":["borisschapira"],"discuss":"1760","results":"https://docs.google.com/spreadsheets/d/1iC4WkdadDdkqkrTY32g7hHKhXs9iHrr3Bva8CuPjVrQ/","queries":"05_Third_Parties","published":"2019-12-23T00:00:00.000Z","last_updated":"2020-05-05T00:00:00.000Z","chapter":"third-parties"} %} {% block index %}
-
Le web ouvert a été conçu pour être vaste, interconnectable et interopérable. La possibilité d’accéder à de puissantes librairies tierces et de les utiliser sur votre site avec des éléments <link> ou <script> a décuplé la productivité des développeurs et permis de nouvelles et incroyables expériences web. Par contre, l’immense popularité de quelques fournisseurs tiers pose d’importants problèmes en termes de performances et de confidentialité. Ce chapitre examine la prévalence et l’impact du code tiers sur le web en 2019, les modèles d’utilisation du web qui mènent à la popularité des solutions tierces et les répercussions potentielles sur l’avenir des expériences sur le web.
Une tierce partie est une entité extérieure à la relation principale entre le site et l’utilisateur. Autrement dit, tous les aspects du site qui ne sont pas directement sous le contrôle du propriétaire du site mais qui sont présents avec son approbation. Par exemple, le script Google Analytics est un exemple de ressource tierce courante.
-
Les ressources tierces sont :
-
-
Hébergées sur une origine partagée et publique.
-
Largement utilisées par une variété de sites
-
Aucunement influencées par un propriétaire de site individuel
-
-
Pour se rapprocher le plus possible de ces objectifs, la définition formelle utilisée tout au long de ce chapitre d’une ressource tierce est une ressource qui provient d’un domaine dont les ressources se trouvent sur au moins 50 pages uniques dans le jeu de données HTTP Archive.
-
Notez qu’en utilisant ces définitions, le contenu de tiers servi à partir d’un domaine "en propre" est considéré comme du contenu de première partie. Par exemple, les polices Google ou bootstrap.css auto-hébergées sont considérées comme du contenu de première partie. De même, le contenu de première partie servi à partir d’un domaine tiers est considéré comme du contenu tiers. Par exemple, les images de première partie diffusées via un CDN sur un domaine tiers sont considérées comme du contenu tiers.
Le présent chapitre classe les fournisseurs tiers dans l’une de ces grandes catégories. Une brève description est incluse ci-dessous et la correspondance entre chaque domaine et sa catégorie peut être trouvée dans le dépôt third-party-web.
-
-
Publicité (Ad) - affichage et mesures relatives aux annonces
-
Télémétrie (Analytics) - suivi du comportement des visiteurs du site
-
CDN - fournisseurs de services communément utilisés, publics comme privés
-
Contenu (Content) - fournisseurs qui facilitent la tâche des éditeurs et hébergent du contenu syndiqué
-
Relation Client (Customer Success) - fonctionnalités de support et de gestion de la relation client
-
Hébergement (Hosting) - fournisseurs qui hébergent n’importe quel contenu de leurs utilisateurs
-
Marketing - fonctionnalités de vente, de génération de prospects et d’email marketing
-
Social - réseaux sociaux et leurs intégrations affiliées
-
Gestionnaires de tags (Tag Manager) - fournisseur dont le seul rôle est de gérer l’inclusion d’autres tiers
-
Services (Utility) - code qui contribue à la réalisation des objectifs du propriétaire du site en termes de services
-
Video - fournisseurs qui hébergent un contenu vidéo quelconque de leurs utilisateurs
-
Autre (Other) - activité non classée ou considérée comme non conforme
-
-
Note sur les CDN : d’après les critères que nous utilisons, seuls sont comptabilisés dans la catégorie CDN les fournisseurs qui fournissent des ressources sur des domaines de CDN publics (par exemple bootstrapcdn.com, cdnjs.cloudflare.com, etc.). Cela n’inclut pas les ressources qui sont simplement servies sur un CDN. Exemple : même si vous mettez Cloudflare devant une page, nous la considérerons comme une première partie.
Toutes les données présentées ici sont basées sur une sollicitation à froid, sans interaction. Ces valeurs seraient rapidement très différentes après l’interaction d’un utilisateur ou d’une utilisatrice.
-
Environ 84 % de tous les domaines tiers (en volume) ont été identifiés et catégorisés. Les 16 % restants appartiennent à la catégorie "Autres".
- Figure 1. Pourcentage des pages destinées aux ordinateurs de bureau qui comprennent au moins une ressource tierce.
-
-
Le code tiers est partout. 93 % des pages comprennent au moins une ressource tierce, 76 % des pages émettent une requête vers un domaine de télémétrie, une page requête, en médiane, du contenu en provenance d’au moins 9 domaines tiers uniques, ce qui représente 35 % de l’activité réseau totale. 10 % des pages, les plus "actives", émettent plus de 175 requêtes vers des ressources tierces. Il n’est pas exagéré de dire que les tierces parties font partie intégrante du web.
-
-
55,63 %
- Figure 2. Pourcentage de pages destinées aux ordinateurs de bureau qui comprennent au moins une ressource publicitaire.
-
-
Si l’omniprésence du contenu tiers n’est pas surprenante, la répartition du contenu de tiers par type de fournisseur est peut-être plus intéressante.
-
Alors que la publicité pourrait être l’exemple le plus visible de contenus tiers sur le web, les fournisseurs de services de télémétrie sont la catégorie de tiers la plus courante avec 76 % des sites incluant au moins une requête de ce type. Les CDN à 63 %, les annonces à 57 %, et les services comme Sentry, Stripe et Google Maps SDK à 56 % suivent de près en deuxième, troisième et quatrième position pour apparaître sur la plupart des plate-formes web. La popularité de ces catégories constitue le fondement de nos usage sur le web, décrits plus loin dans ce chapitre.
Un nombre relativement restreint de fournisseurs dominent le paysage des services tiers : les 100 premiers domaines représentent 30 % des requêtes réseau sur le web. Des moteurs comme Google, Facebook et YouTube sont en tête avec des pourcentages entiers de parts de marché chacun, mais des entités plus petites comme Wix et Shopify représentent aussi une partie substantielle de la popularité des tiers.
-
Bien que l’on puisse dire beaucoup de choses sur la popularité et l’impact de chaque fournisseur sur la performance, nous laissons au lecteur et à d’autres outils conçus à cet effet, tels que third-party-web, le soin de faire faire une analyse plus objective de ces questions.
-
-
-
-
-
-
-
Rang
-
Domaines tiers
-
Pourcentage des requêtes
-
-
-
-
-
1
-
fonts.gstatic.com
-
2,53 %
-
-
-
2
-
www.facebook.com
-
2,38 %
-
-
-
3
-
www.google-analytics.com
-
1,71 %
-
-
-
4
-
www.google.com
-
1,17 %
-
-
-
5
-
fonts.googleapis.com
-
1,05 %
-
-
-
6
-
www.youtube.com
-
0,99 %
-
-
-
7
-
connect.facebook.net
-
0,97 %
-
-
-
8
-
googleads.g.doubleclick.net
-
0,93 %
-
-
-
9
-
cdn.shopify.com
-
0,76 %
-
-
-
10
-
maps.googleapis.com
-
0,75 %
-
-
-
-
-
- Figure 3. Top 10 des domaines tiers les plus populaires.
-
La répartition du volume de contenu par type de ressource donne également un aperçu de la façon dont le code tiers est utilisé sur le web. Alors que les requêtes sur le domaine principal sont composées à 56 % d’images, à 23 % de scripts, à 14 % de CSS, et seulement à 4 % de HTML, les requêtes vers des domaines tiers contienne davantage de scripts et de code HTML (32 % de scripts, 34 % d’images, 12 % HTML, et seulement 6 % de CSS). On pourrait penser que le code d’une tierce partie est moins souvent utilisé pour faciliter la conception et plus fréquemment pour faciliter ou observer les interactions que le code du domaine principal, mais une ventilation des types de ressources par type de tierce partie apporte de la nuance à cette idée. Alors que les CSS et les images sont majoritairement issus du domaine principal (respectivement 70 % et 64 %), les polices sont largement servies par des fournisseurs tiers, avec seulement 28 % provenant du domaie principal. Nous explorerons plus en détails ces usages plus loin dans ce chapitre.
Graphique montrant la répartition des types de contenu pour chaque catégorie de tiers. Les images et les scripts constituent la majorité des requêtes pour chaque catégorie. Les requêtes CDN présentent une proportion particulièrement importante de polices d’écriture.
- Figure 5. Pourcentage de requêtes de ressources tierces par catégorie et par type de contenu.
-
-
Ces données regorgent d’autres faits amusants. Les pixels de suivi (requêtes d’images situées sur des domaines de télémétrie) représentent 1,6 % de toutes les requêtes réseau. Les réseaux sociaux comme Facebook et Twitter délivrent six fois plus de vidéos que les fournisseurs dédiés comme YouTube et Vimeo (probablement parce que l’intégration par défaut de YouTube est composée d’un peu de HTML et d’une prévisualisation mais pas une vidéo en lecture automatique). Enfin, il existe plus de requêtes pour des images du domaine principal que tous les scripts combinés.
49 % de toutes les requêtes pointent vers des tiers. Avec 51 %, le domaine principal conserve garde donc la tête, puisqu’il héberge la moitié des ressources web. Mais les sites qui utilisent des ressources tierces doivent le faire de manière importante car même si un peu moins de la moitié de toutes les requêtes proviennent de tiers, un petit nombre de pages n’en référencent pas du tout. En détails : aux 75e, 90e et 99e percentiles, la quasi-totalité de la page est constituée de contenu de tiers. En fait, pour certains sites s’appuyant fortement sur des plates-formes WYSIWYG distribuées comme Wix et SquareSpace, le document racine est parfois la seule requête sur le domaine principal !
-
< !-- insert graphic of metric 05_11 -->
-
Le nombre de demandes émises par chaque fournisseur tiers varie aussi considérablement selon la catégorie. Bien que les services de télémétrie soient la catégorie de tiers la plus répandue sur les sites web, ils ne représentent que 7 % de toutes les requêtes réseau vers des tiers. Les publicités, en revanche, se trouvent sur environ 20 % de sites en moins, mais elles représentent 25 % de toutes les requêtes réseau vers des tiers. L’impact disproportionné de leurs ressources par rapport à leur popularité sera un thème que nous ne manquerons pas d’approfondir dans les données restantes.
Bien que 49 % des requêtes proviennent de tiers, leur part sur le web en termes d’octets est un peu plus faible, atteignant seulement 28 %. Il en va de même pour la répartition par types de ressources. Les polices d’écriture tierces représentent 72 % de toutes les polices d’écritures, mais seulement 53 % des octets correspondant aux polices d’écriture ; 74 % des requêtes concernent des documents HTML tiers, mais ils ne représentent que 39 % des octets HTML ; 68 % des requêtes vidéo viennent de tiers, mais ne représentent que 31 % des octets vidéo. Tout cela semble indiquer que les fournisseurs tiers sont des intendants responsables qui maintiennent la taille de leurs réponses à un niveau bas. Dans la plupart des cas, c’est effectivement. Enfin, jusqu’à ce que vous examiniez les scripts.
-
Bien qu’ils servent 57 % des scripts, les tiers représentent 64 % des octets de script, ce qui signifie que leurs scripts sont en moyenne plus volumineux que les scripts des domaines principaux. C’est un signe avant-coureur de l’impact de leurs performances qui sera présenté dans les prochaines sections.
Graphique montrant la répartition des octets pour chaque type de contenu par catégorie de tiers. Les images et les scripts sont répartis de manière relativement égale entre les catégories. 80 % des polices proviennent de CDN. La vidéo provient de tiers spécialisés en "Contenus".
- Figure 7. Répartition des octets de ressource par catégorie de tiers.
-
-
< !--
-
<insert graphic of metric 05_12> -->
-
En ce qui concerne les fournisseurs tiers spécifiques, on trouve les mêmes poids-lourds en tête du classement du nombre de requêtes, qu’en tête du classement des poids en octets. Les seuls à ne pas respecter cette tendance sont les fournisseurs très médiatiques que sont YouTube, Shopify et Twitter, qui se hissent en tête des tableaux d’impact en poids.
57 % du temps d’exécution des scripts provient de scripts tiers, et les 100 premiers domaines représentent déjà 48 % de la durée totale d’exécution des scripts sur le web. Cela souligne l’impact considérable que quelques entités bien définies ont réellement sur les performances du web. Ce sujet est étudié plus en profondeur dans la section Répercussions > Performance.
-
< !--<insert graphic of metric 05_05>-->
-
< !--<insert graphic of metric 05_13>-->
-
La répartition par catégorie de l’exécution des scripts suit largement celle du nombre de requêtes. Ici aussi, la publicité est la plus imposante. Les scripts publicitaires représentent 25 % du temps d’exécution de scripts tiers, les fournisseurs de services d’hébergement et les fournisseurs liés aux réseaux sociaux arrivant en deuxième position, à 12 %.
-
< !--<insert table of metric 05_08>-->
-
< !--<insert table of metric 05_10>-->
-
Bien que l’on puisse dire beaucoup de choses sur la popularité et l’impact sur le rendement de chaque fournisseur, cette analyse plus subjective est laissée à la discrétion du lecteur et d’autres outils conçus à cette fin, comme le third-party-web.
Pourquoi les propriétaires de sites utilisent-ils un code tiers ? Comment ces contenus tiers peuvent-ils désormais représenter plus de la moitié des requêtes réseau ? Que font toutes ces requêtes ? Les réponses à ces questions se trouvent dans les trois principaux modèles d’utilisation des ressources tierces. En général, les propriétaires de sites font appel à des tiers pour générer et consommer les données de leurs utilisateurs, monétiser leurs expériences sur le site et simplifier le développement web.
La télémétrie est la catégorie de tiers la plus populaire sur le web et pourtant, elle est peu visible pour l’utilisateur. Considérez le volume d’information en jeu pendant la durée de vie d’une visite sur le Web : le contexte de l’utilisateur·ice, le dispositif, le navigateur, la qualité de la connexion, la localisation, les interactions avec la page, la durée de la session, l’information selon laquelle il ou elle a déjà visité le site ou cette page, etc. sont générés en permanence. Il est difficile, encombrant et coûteux de maintenir des outils qui permettent d’entreposer, de normaliser et d’analyser des séries chronologiques de données de cette ampleur. Bien que rien n’exige catégoriquement que la télémétrie relève du domaine des fournisseurs tiers, l’attrait grandissant pour la compréhension de vos utilisateur·ice·s, la grande complexité de l’espace des problèmes et l’importance croissante accordée à la gestion respectueuse et responsable des données font naturellement apparaître la télémétrie comme un modèle d’utilisation tiers très répandu.
-
Mais il y a aussi un revers à la médaille pour les données des utilisateurs : la consommation. Alors que les outiles de télémétrie consistent à générer des données sur les visiteurs et visiteuses de votre site, d’autres ressources tierces se concentrent sur la consommation de données sur ces personnes, en provenance d’autres sources. Les fournisseurs sociaux s’inscrivent parfaitement dans ce schéma d’utilisation. Un propriétaire de site doit utiliser les ressources Facebook s’il souhaite intégrer à son site des informations provenant du profil Facebook d’une personne. Tant que les propriétaires de sites sont intéressés à personnaliser leur expérience avec les widgets des réseaux sociaux et à tirer parti des réseaux sociaux de leurs visiteurs et visiteuses pour accroître leur audience, les intégrations sociales resteront probablement la chasse gardée de fournisseurs ters dans le futur.
- Le modèle ouvert du web ne sert pas toujours les intérêts financiers des personnes créatrices de contenu aussi bien qu’elles le souhaiteraient et de nombreux propriétaires de sites ont recours à la publicité pour monétiser leurs sites. Comme l’établissement de relations directes avec les annonceurs et la négociation de contrats de prix est un processus relativement difficile et long, cette responsabilité est en grande partie assumée par des fournisseurs tiers qui se chargent de la publicité ciblée et des appels d’offres en temps réel. L’opinion publique globalement négative, la popularité de la technologie de blocage des publicités et les mesures réglementaires prises sur les principaux marchés mondiaux tels que l’Europe constituent la plus grande menace à la poursuite du recours à des fournisseurs tiers pour la monétisation. Bien qu’il soit peu probable que les propriétaires de sites concluent soudainement leurs propres contrats publicitaires ou construisent des réseaux publicitaires sur mesure, d’autres modèles de monétisation comme les paywalls et des expériences comme le Basic Attention Token du navigateur Brave ont une réelle chance de secouer, à l’avenir, le paysage de la publicité de tiers.
-
Plus que tout autre usage, les ressources tierces sont surtout utilisées pour simplifier l’expérience de développement web. Il est possible que même des modes d’utilisation antérieurs s’inscrivent dans ce schéma. Qu’il s’agisse d’analyser le comportement des utilisateurs, de communiquer avec les annonceurs ou de personnaliser l’expérience utilisateur, les ressources tierces sont utilisées pour faciliter le développement initial du site.
-
Les fournisseurs d’hébergement sont l’exemple le plus extrême de ce schéma. Certains de ces fournisseurs permettent même à n’importe qui sur Terre de devenir propriétaire d’un site sans avoir besoin de compétences techniques. Ils fournissent l’hébergement des ressources, des outils pour construire des sites sans aucune compétence en matière de programmation et des services d’enregistrement de domaines.
-
Le reste des fournisseurs tiers ont également tendance à s’inscrire dans ce schéma d’utilisation. Qu’il s’agisse de l’hébergement d’une bibliothèque d’utilitaires telle que jQuery pour l’utilisation par les développeurs frontaux mis en cache sur les serveurs de périphérie de Cloudflare ou d’une vaste bibliothèque de polices d’écriture usuelles, servies à partir du très populaire CDN de Google, le contenu de tiers est une autre façon de soulager le propriétaire du site et, peut-être, simplement, de lui faciliter un peu la tâche pour offrir une expérience agréable.
L’impact des contenus de tiers sur la performance n’est ni catégoriquement bon ni mauvais. Il y a de bons et de mauvais acteurs dans toutes les catégories et les différents types de tiers ont des niveaux d’influence variables.
-
Le point positif : les polices de caractères et les styles partagés par des domaines tiers sont, en moyenne, plus efficaces que celles de leurs homologues du domaine principal.
-
Les catégories Utilitaires, CDN et Contenu sont les meilleures en termes de performances, au sein du paysage des performances tierces. Elles offrent des versions optimisées du même type de contenu qui serait autrement servi par des ressources du domaine principal. Google Fonts et Typekit proposent des polices optimisées qui sont en moyenne plus petites que les polices de première partie, Cloudflare CDN propose une version minifiée des bibliothèques open source qui pourraient être accidentellement servies en mode développement par certains propriétaires de sites, le SDK Google Maps fournit efficacement des cartes complexes qui pourraient, sinon, être naïvement livrées sous forme de grandes images.
-
Le mauvais : un très petit nombre d’entités génère une très grande partie du temps d’exécution de JavaScript, alors qu’elles ne fournissent qu’un petit ensemble de fonctionnalités, très limité, sur les pages.
-
Les publicités, les fournisseurs de services de réseautage social, d’hébergement et certains fournisseurs de services de télémétrie exercent une influence des plus négatives sur la performance du web. Alors que les fournisseurs d’hébergement fournissent la majorité du contenu d’un site et ont naturellement un impact plus important sur les performances que les autres catégories de tiers, ils servent également des sites presque entièrement statiques qui exigent, dans la plupart des cas, très peu de JavaScript, ce qui ne devrait pas justifier le volume de temps d’exécution des scripts. Les autres catégories qui nuisent aux performances ont cependant encore moins d’excuses. Elles jouent un rôle très limité sur chaque page sur laquelle elles apparaissent et pourtant elles prennent rapidement le dessus sur une majorité de ressources. Par exemple, le bouton " J’aime " de Facebook et les widgets des réseaux sociaux associés occupent un espace extraordinairement réduit sur l’écran et ne représentent qu’une fraction de la plupart des expériences web, et pourtant l’impact médian sur les pages avec des tiers sociaux est de près de 20 % de leur temps d’exécution JavaScript total. La situation est similaire pour l’analyse - les bibliothèques de suivi ne contribuent pas directement à l’expérience utilisateur perçue, et pourtant l’impact du 90e percentile sur les pages avec des tiers d’analyse est de 44 % de leur temps d’exécution JavaScript total.
-
Le bon côté de ce petit nombre d’entités jouissant d’une si grande part de marché est qu’un effort très limité et concentré peut avoir un impact énorme sur le web dans son ensemble. L’amélioration des performances chez les quelques premiers hébergeurs peut améliorer de 2 à 3 % de toutes les requêtes web.
L’abondance des fournisseurs de services de télémétrie et la forte concentration de l’exécution des scripts posent deux problèmes majeurs de confidentialité pour les visiteurs des sites : les propriétaires de sites sont très nombreux à pister leurs utilisateurs avec des scripts tiers, permettant à une poignée d’entreprises de recevoir des informations sur une grande partie du trafic web.
-
L’intérêt des propriétaires de sites pour la compréhension et l’analyse du comportement des utilisateurs n’est pas malveillant en soi, mais le caractère généralisé et plutôt dissimulé du pistage sur le web soulève des préoccupations légitimes. Les utilisateurs et utilisatrices, les entreprises et les autorités législatives en ont pris conscience ces dernières années, aboutissant aux réglementations sur la protection de la vie privée telles que le RGPD en Europe et le CCPA en Californie. Il est essentiel de s’assurer que les équipes de développement traitent les données des utilisateurs et utilisatrices de manière responsable, qu’elles les traitent avec respect et qu’elles soient transparentes quant aux données recueillies pour que la télémétrie demeure la catégorie de tiers la plus populaire et pour s’assurer que l’analyse du comportement des utilisateurs reste en symbiose avec l’amélioration de la valeur d’usage pour les utilisateurs et utilisatrices.
-
La forte concentration de l’exécution des scripts est excellente au regard de l’impact potentiel des futures améliorations de performance, mais moins excitante pour ses implications en termes de confidentialité. 29 % de tous les temps d’exécution de scripts sur le web proviennent uniquement de scripts sur des domaines appartenant à Google ou à Facebook. C’est un pourcentage très important du temps CPU qui est contrôlé par ces deux seules entités. Il est essentiel de s’assurer que les mêmes protections de la vie privée que celles dont bénéficient les fournisseurs de services de télémétrie sont également appliquées dans les autres catégories : services, publicités, réseaux sociaux et développement.
Bien que le sujet de la sécurité soit traité plus en profondeur dans le chapitre Sécurité, les conséquences de l’introduction de dépendances externes sur votre site en matière de sécurité sont indissociables de la protection de la vie privée. Permettre à des tiers d’exécuter des JavaScript arbitraires leur donne un contrôle total sur votre page. Quand un script peut contrôler le DOM et window, il peut tout faire. Même si le code n’a pas de problèmes de sécurité, il peut introduire un point unique de défaillance, ce qui a été reconnu comme un problème potentiel depuis un certain temps maintenant.
-
Auto-héberger du contenu de tierces parties répond à certaines des préoccupations mentionnées ici – et à d’autres. De plus, comme les navigateurs partitionnement de plus en plus les caches HTTP, les avantages du chargement direct à partir de la tierce partie semblent plus que jamais incertains. Cette méthode est peut-être meilleure pour de nombreux cas d’utilisation, même si elle rend la mesure de son impact plus difficile.
Le contenu tiers est partout. Cela n’est guère surprenant ; le principe de base du web est de permettre l’interconnexion et la mise en relation. Dans ce chapitre, nous avons examiné les contenus de tiers en termes de ressources hébergées en dehors du domaine principal. Si nous avions inclus les contenus tiers auto-hébergés (par exemple, les bibliothèques open source communes hébergées sur le domaine principal), l’utilisation de contenus tiers aurait été encore plus importante !
-
Bien que la réutilisation dans les technologies informatiques soit généralement une pratique exemplaire, les tiers sur le web introduisent des dépendances qui ont un impact considérable sur la performance, la confidentialité et la sécurité d’une page. L’auto-hébergement et la sélection minutieuse des fournisseurs peuvent grandement contribuer à atténuer ces effets.
-
Indépendamment de la question importante de savoir comment les contenus de tiers sont ajoutés à une page, la conclusion est la même : les tiers font partie intégrante du web !
-{% endblock %}
diff --git a/src/templates/ja/2019/chapters/accessibility.html b/src/templates/ja/2019/chapters/accessibility.html
deleted file mode 100644
index e3bd02e0004..00000000000
--- a/src/templates/ja/2019/chapters/accessibility.html
+++ /dev/null
@@ -1,397 +0,0 @@
-{% extends "%s/2019/base_chapter.html" % lang %}
-
-
-
-{% set metadata = {"part_number":"II","chapter_number":9,"title":"アクセシビリティ","description":"読みやすさ、メディア、操作性の容易さ、および支援技術とその互換性をカバーする2019 Web Almanacアクセシビリティの章。","authors":["nektarios-paisios","obto","kleinab"],"reviewers":["ljme"],"translators":["MSakamaki"],"discuss":"1764","results":"https://docs.google.com/spreadsheets/d/16JGy-ehf4taU0w4ABiKjsHGEXNDXxOlb__idY8ifUtQ/","queries":"09_Accessibility","published":"2019-11-11T00:00:00.000Z","last_updated":"2020-05-27T00:00:00.000Z","chapter":"accessibility"} %} {% block index %}
-
Web上でもっとも一般的かつ広く活用されているアクセシビリティの使用の1つにAccessible Rich Internet Applications (ARIA)という標準があります。この標準は視覚的要素の背景にある目的(つまり、セマンティクスな意味)と、それにより可能になるアクションの種類を教えるのに役立つ追加のHTML属性をもった大きな配列を提供します。
このリストに表示される別の興味深いディレクティブセットは、pre-checkとpost-checkです。これらは、Cache-Controlレスポンスヘッダーの2.2%(約780万件のレスポンス)で使用されます。このヘッダーのペアは、バックグラウンドで検証を提供するためにInternet Explorer 5で導入されたものですが、Webサイトによって正しく実装されることはほとんどありませんでした。これらのヘッダーを使用したレスポンスの99.2%は、pre-check=0とpost-check=0の組み合わせを使用していました。これらのディレクティブの両方が0に設定されている場合、両方のディレクティブは無視されます。したがって、これらのディレクティブは正しく使用されなかったようです!
s-maxageディレクティブは、応答をキャッシュできる期間をプロキシに通知します。 Web Almanacデータセット全体で、jsDelivrは複数のリソースで高いレベルの使用が見られた唯一のCDNです。これは、jsDelivrのライブラリのパブリックCDNとしての役割を考えると驚くことではありません。他のCDNでの使用は、個々の顧客、たとえばその特定のCDNを使用するサードパーティのスクリプトまたはSaaSプロバイダーによって推進されているようです。
言語は色によっても興味深いことに推測されます。イギリス式の「grey」よりもアメリカ式の「gray」の例が多くあります。グレー色(グレー、ライトグレー、ダークグレー、スレートグレーなど)のほぼすべてのインスタンスは、「e」ではなく「a」で綴ると、使用率がほぼ2倍になりました。 gr [a/e] ysが組み合わされた場合、それらは青よりも上位にランクされ、#4スポットで固まります。これが、チャートで銀がグレーよりも高いランクになっている理由です。
当然のことながら、上の図5では、pxが最もよく使用されるユニットタイプであり、Webページの約95%が何らかの形式のピクセルを使用しています(これは要素のサイズ、フォントサイズなどです)。ただし、emユニットの使用率はほぼ同じで約90%です。これは、Webページで40%の頻度しかないremユニットよりも2倍以上人気があります。違いを知りたい場合は、emは親フォントサイズに基づいており、remはページに設定されている基本フォントサイズに基づいています。 em のようにコンポーネントごとに変更されることはないため、すべての間隔を均等に調整できます。
最も人気のあるフォントの棒グラフ。デスクトップページの中で、Open Sans(24%)、Roboto(15%)、Montserrat(5%)、Source Sans Pro(4%)、Noto Sans JP(3%)、Lato(3%)です。モバイルで最も顕著な違いは、Open Sansが時間の22%で使用され(24%から減少)、Robotoが時間の19%で使用される(15%から増加)ことです。
多くのウェブサイト、特にオンラインストアでは、分析、A/Bテスト、顧客行動追跡、広告、ソーシャルメディアのサポートなどのためにサードパーティのコードやコンテンツを大量にロードしています。サードパーティのコンテンツは、パフォーマンスに大きな影響を与えることがあります。 Patrick Hulceのサードパーティウェブツールは、本レポートのサードパーティのリクエストを判断するために使用されており、これについてはサードパーティの章で詳しく説明しています。
ホストされたWebフォントを使用すると、実装やメンテナンスが容易になりますが、セルフホスティングは最高のパフォーマンスを提供します。Webフォントはデフォルトで、Webフォントの読み込み中にテキストを非表示にする(Flash of Invisible Text、またはFOITとしても知られています)ことを考えると、Webフォントのパフォーマンスは画像のような非ブロッキング資産よりも重要になる可能性があります。
Google Fontsのドキュメントでは、Google Fonts CSSの<link>はページの<head>の最初の子として配置することを推奨しています。これは大きなお願いです! 実際、これは一般的でありません。全ページの半分のパーセント(約20,000ページ)しかこのアドバイスを受けていないので、これは一般的でありません。
- うわー! 2%未満のページがpreconnectを使用している! Google Fontsが75%であることを考えると、これはもっと高いはずです! 開発者の皆さん: Google Fontsを使うなら、preconnectを使いましょう! Google Fonts:preconnectをもっと宣伝しよう!
-
Google FontsはそのCSSのほとんど(すべてではないにしても)でunicode-rangeを使用しているので、これもGoogle Fontsの使用状況によって偏っていると予想される指標です。ユーザーの世界でこれはあまり一般的でないと思いますが、Web Almanacの次の版ではGoogle Fontsのリクエストをフィルタリングして除外することが可能かもしれません。
Patrick Meenanは、優先度の高いオンスクリーンイメージを要求する前に、優先度の低いオフスクリーンイメージのロードを意図的にダウンロードしようとするサンプルテストページを作成しました。優れたHTTP/2サーバーはこれを認識し、優先度の低い画像を犠牲にして、要求後すぐに優先度の高い画像を送信できるはずです。貧弱なHTTP/2サーバーはリクエストの順番で応答し、優先順位のシグナルを無視します。 Andy Daviesには、Patrickのテスト用にさまざまなCDNのステータスを追跡するページがあります。 HTTP Archiveは、クロールの一部としてCDNが使用されるタイミングを識別しこれら2つのデータセットをマージすると、合格または失敗したCDNを使用しているページの割合を知ることができます。
14年すぎて、新しい見方をする時が来ました。 以降、カスタム要素(Custom Elements)とExtensible Web Manifestoの導入により、開発者は要素そのものの空間を探し、標準化団体が辞書編集者のようになることで、牛の通り道を舗装する(pave the cowpaths)よりよい方法を見つけることを推奨しています。 様々なものに使われる可能性があるCSSクラス名とは異なり、非標準の要素は作成者が要素であることを意識しているため、さらに確実なものとなります。
ウェブページのクロールで使用したモバイル端末では、512 x 360の表示で、0.18MPのCSSコンテンツが表示されています(物理的な画面である3xや3^2以上の画素である1.7MPと混同しないように)。このビューアーのピクセル量を画像に割り当てられたCSSピクセルの数で割ると、相対的なピクセル量が得られます。
Service Workerの転送サイズの分布を示す棒グラフ。デスクトップService Worker転送サイズの10、25、50、75、および90パーセンタイルは、176、350、895、2,010、および4,138バイトです。デスクトップService Workerは、90パーセンタイルの1,000バイトから、パーセンタイルごとに大きくなります。
HTTPヘッダー内のリソースヒントの使用量が非常に少ないため、本章の残りの部分では、<link>タグと組み合わせたリソースヒントの使用量の分析のみに焦点を当てています。しかし、今後、HTTP/2 Pushが採用されるようになると、HTTPヘッダーでのリソースヒントの使用量が増える可能性のあることは注目に値します。これは、HTTP/2 Pushがリソースをプッシュするためのシグナルとして、HTTPのプリロード Link ヘッダーを再利用していることに起因しています。
CSPの一般的なアプローチは、JavaScriptなどのコンテンツをページにロードすることを許可されているサードパーティドメインのホワイトリストを作成することです。これらのホワイトリストの作成と管理は困難な場合があるため、ハッシュとノンスが代替的なアプローチとして導入されました。ハッシュはスクリプトの内容に基づいて計算されるので、ウェブサイト運営者が公開しているスクリプトが変更されたり、別のスクリプトが追加されたりするとハッシュと一致せずブロックされてしまいます。ノンスは、CSPによって許可され、スクリプトにタグが付けられているワンタイムコード(ページが読み込まれるたびに変更され推測されるのを防ぐ必要があります)です。このページのノンスの例は、ソースを見てGoogle Tag Managerがどのように読み込まれているかを見ることで見ることができます。
Reporting API は、サイト運営者がブラウザからの遠隔測定の様々な情報を収集できるようにするため導入されました。サイト上の多くのエラーや問題は、ユーザーの体験を低下させる可能性がありますが、サイト運営者はユーザーが連絡しなければ知ることができません。Reporting APIは、ユーザーの操作や中断なしに、ブラウザがこれらの問題を自動的に報告するメカニズムを提供します。Reporting APIはReport-Toヘッダーを提供することで設定されます。
クッキー、キャッシュ、ローカルストレージなどを介してユーザーのデバイスにデータをローカルに保存する機能が増えているため、サイト運営者はこのデータを管理する信頼性の高い方法を必要としていました。Clear Site Dataヘッダーは、特定のタイプのすべてのデータがデバイスから削除されることを確実にする手段を提供しますが、すべてのブラウザではまだサポートされていません。
-
このヘッダの性質を考えると、使用量がほとんど報告されていないのは驚くに値しません。デスクトップリクエストが9件、モバイルリクエストが7件だけです。私たちのデータはサイトのホームページしか見ていないので、ログアウトのエンドポイントでヘッダーが最もよく使われているのを見ることはないでしょう。サイトからログアウトすると、サイト運営者はClear Site Dataヘッダを返し、ブラウザは指定されたタイプのすべてのデータを削除します。これはサイトのホームページでは行われないでしょう。
同時に、TLS設定のギャップは依然としてかなり一般的です。15%以上のページが混合コンテンツの問題に悩まされており、ブラウザに警告が表示され、4%のサイトではセキュリティ上の理由から最新のブラウザにブロックされています。同様に、HTTP Strict Transport Securityの利点は、主要なサイトのごく一部にしか及ばず、大多数のWebサイトでは最も安全なHSTS構成を有効にしておらず、HSTS プリロードの対象外となっています。HTTPSの採用が進んでいるにもかかわらず、未だに多くのクッキーがSecureフラグなしで設定されており、クッキーを設定しているホームページのうち、暗号化されていないHTTPでの送信を防止しているのはわずか4%に過ぎません。
Web AlmanacのSEOの章の目的は、検索エンジンによるコンテンツのクロールとインデックス付け、そして最終的にWebサイトのパフォーマンスに影響を与えるWebのオンサイト要素を分析することです。 この章では、上位のWebサイトがユーザーおよび検索エンジンに優れた体験を提供するためにどれだけ十分な整備がされているか、そしてどのような作業を行うべきかについて見ていきます。
HTML lang属性が英語に設定されているデスクトップ用サイトの38.40%(モバイルでは33.79%)で、別の言語バージョンへの hreflangリンクが含まれるサイトはたった7.43%(モバイルで6.79%)しかありませんでした。 これから、分析したWebサイトの殆どが言語ターゲティングを必要とするホームページの別バージョンを提供していないことを示しています。しかしそれは、個別のバージョンは存在するが構成が正しく無い場合を除きます。
言語は色によっても興味深いことに推測されます。イギリス式の「grey」よりもアメリカ式の「gray」の例が多くあります。グレー色(グレー、ライトグレー、ダークグレー、スレートグレーなど)のほぼすべてのインスタンスは、「e」ではなく「a」で綴ると、使用率がほぼ2倍になりました。 gr [a/e] ysが組み合わされた場合、それらは青よりも上位にランクされ、#4スポットで固まります。これが、チャートで銀がグレーよりも高いランクになっている理由です。
当然のことながら、上の図5では、pxが最もよく使用されるユニットタイプであり、Webページの約95%が何らかの形式のピクセルを使用しています(これは要素のサイズ、フォントサイズなどです)。ただし、emユニットの使用率はほぼ同じで約90%です。これは、Webページで40%の頻度しかないremユニットよりも2倍以上人気があります。違いを知りたい場合は、emは親フォントサイズに基づいており、remはページに設定されている基本フォントサイズに基づいています。 em のようにコンポーネントごとに変更されることはないため、すべての間隔を均等に調整できます。
最も人気のあるフォントの棒グラフ。デスクトップページの中で、Open Sans(24%)、Roboto(15%)、Montserrat(5%)、Source Sans Pro(4%)、Noto Sans JP(3%)、Lato(3%)です。モバイルで最も顕著な違いは、Open Sansが時間の22%で使用され(24%から減少)、Robotoが時間の19%で使用される(15%から増加)ことです。
14年すぎて、新しい見方をする時が来ました。 以降、カスタム要素(Custom Elements)とExtensible Web Manifestoの導入により、開発者は要素そのものの空間を探し、標準化団体が辞書編集者のようになることで、牛の通り道を舗装する(pave the cowpaths)よりよい方法を見つけることを推奨しています。 様々なものに使われる可能性があるCSSクラス名とは異なり、非標準の要素は作成者が要素であることを意識しているため、さらに確実なものとなります。
ウェブページのクロールで使用したモバイル端末では、512 x 360の表示で、0.18MPのCSSコンテンツが表示されています(物理的な画面である3xや3^2以上の画素である1.7MPと混同しないように)。このビューアーのピクセル量を画像に割り当てられたCSSピクセルの数で割ると、相対的なピクセル量が得られます。
ホストされたWebフォントを使用すると、実装やメンテナンスが容易になりますが、セルフホスティングは最高のパフォーマンスを提供します。Webフォントはデフォルトで、Webフォントの読み込み中にテキストを非表示にする(Flash of Invisible Text、またはFOITとしても知られています)ことを考えると、Webフォントのパフォーマンスは画像のような非ブロッキング資産よりも重要になる可能性があります。
Google Fontsのドキュメントでは、Google Fonts CSSの<link>はページの<head>の最初の子として配置することを推奨しています。これは大きなお願いです! 実際、これは一般的でありません。全ページの半分のパーセント(約20,000ページ)しかこのアドバイスを受けていないので、これは一般的でありません。
- うわー! 2%未満のページがpreconnectを使用している! Google Fontsが75%であることを考えると、これはもっと高いはずです! 開発者の皆さん: Google Fontsを使うなら、preconnectを使いましょう! Google Fonts:preconnectをもっと宣伝しよう!
-
Google FontsはそのCSSのほとんど(すべてではないにしても)でunicode-rangeを使用しているので、これもGoogle Fontsの使用状況によって偏っていると予想される指標です。ユーザーの世界でこれはあまり一般的でないと思いますが、Web Almanacの次の版ではGoogle Fontsのリクエストをフィルタリングして除外することが可能かもしれません。
CSPの一般的なアプローチは、JavaScriptなどのコンテンツをページにロードすることを許可されているサードパーティドメインのホワイトリストを作成することです。これらのホワイトリストの作成と管理は困難な場合があるため、ハッシュとノンスが代替的なアプローチとして導入されました。ハッシュはスクリプトの内容に基づいて計算されるので、ウェブサイト運営者が公開しているスクリプトが変更されたり、別のスクリプトが追加されたりするとハッシュと一致せずブロックされてしまいます。ノンスは、CSPによって許可され、スクリプトにタグが付けられているワンタイムコード(ページが読み込まれるたびに変更され推測されるのを防ぐ必要があります)です。このページのノンスの例は、ソースを見てGoogle Tag Managerがどのように読み込まれているかを見ることで見ることができます。
Reporting API は、サイト運営者がブラウザからの遠隔測定の様々な情報を収集できるようにするため導入されました。サイト上の多くのエラーや問題は、ユーザーの体験を低下させる可能性がありますが、サイト運営者はユーザーが連絡しなければ知ることができません。Reporting APIは、ユーザーの操作や中断なしに、ブラウザがこれらの問題を自動的に報告するメカニズムを提供します。Reporting APIはReport-Toヘッダーを提供することで設定されます。
クッキー、キャッシュ、ローカルストレージなどを介してユーザーのデバイスにデータをローカルに保存する機能が増えているため、サイト運営者はこのデータを管理する信頼性の高い方法を必要としていました。Clear Site Dataヘッダーは、特定のタイプのすべてのデータがデバイスから削除されることを確実にする手段を提供しますが、すべてのブラウザではまだサポートされていません。
-
このヘッダの性質を考えると、使用量がほとんど報告されていないのは驚くに値しません。デスクトップリクエストが9件、モバイルリクエストが7件だけです。私たちのデータはサイトのホームページしか見ていないので、ログアウトのエンドポイントでヘッダーが最もよく使われているのを見ることはないでしょう。サイトからログアウトすると、サイト運営者はClear Site Dataヘッダを返し、ブラウザは指定されたタイプのすべてのデータを削除します。これはサイトのホームページでは行われないでしょう。
同時に、TLS設定のギャップは依然としてかなり一般的です。15%以上のページが混合コンテンツの問題に悩まされており、ブラウザに警告が表示され、4%のサイトではセキュリティ上の理由から最新のブラウザにブロックされています。同様に、HTTP Strict Transport Securityの利点は、主要なサイトのごく一部にしか及ばず、大多数のWebサイトでは最も安全なHSTS構成を有効にしておらず、HSTS プリロードの対象外となっています。HTTPSの採用が進んでいるにもかかわらず、未だに多くのクッキーがSecureフラグなしで設定されており、クッキーを設定しているホームページのうち、暗号化されていないHTTPでの送信を防止しているのはわずか4%に過ぎません。
Web上でもっとも一般的かつ広く活用されているアクセシビリティの使用の1つにAccessible Rich Internet Applications (ARIA)という標準があります。この標準は視覚的要素の背景にある目的(つまり、セマンティクスな意味)と、それにより可能になるアクションの種類を教えるのに役立つ追加のHTML属性をもった大きな配列を提供します。
Web AlmanacのSEOの章の目的は、検索エンジンによるコンテンツのクロールとインデックス付け、そして最終的にWebサイトのパフォーマンスに影響を与えるWebのオンサイト要素を分析することです。 この章では、上位のWebサイトがユーザーおよび検索エンジンに優れた体験を提供するためにどれだけ十分な整備がされているか、そしてどのような作業を行うべきかについて見ていきます。
HTML lang属性が英語に設定されているデスクトップ用サイトの38.40%(モバイルでは33.79%)で、別の言語バージョンへの hreflangリンクが含まれるサイトはたった7.43%(モバイルで6.79%)しかありませんでした。 これから、分析したWebサイトの殆どが言語ターゲティングを必要とするホームページの別バージョンを提供していないことを示しています。しかしそれは、個別のバージョンは存在するが構成が正しく無い場合を除きます。
Service Workerの転送サイズの分布を示す棒グラフ。デスクトップService Worker転送サイズの10、25、50、75、および90パーセンタイルは、176、350、895、2,010、および4,138バイトです。デスクトップService Workerは、90パーセンタイルの1,000バイトから、パーセンタイルごとに大きくなります。
多くのウェブサイト、特にオンラインストアでは、分析、A/Bテスト、顧客行動追跡、広告、ソーシャルメディアのサポートなどのためにサードパーティのコードやコンテンツを大量にロードしています。サードパーティのコンテンツは、パフォーマンスに大きな影響を与えることがあります。 Patrick Hulceのサードパーティウェブツールは、本レポートのサードパーティのリクエストを判断するために使用されており、これについてはサードパーティの章で詳しく説明しています。
このリストに表示される別の興味深いディレクティブセットは、pre-checkとpost-checkです。これらは、Cache-Controlレスポンスヘッダーの2.2%(約780万件のレスポンス)で使用されます。このヘッダーのペアは、バックグラウンドで検証を提供するためにInternet Explorer 5で導入されたものですが、Webサイトによって正しく実装されることはほとんどありませんでした。これらのヘッダーを使用したレスポンスの99.2%は、pre-check=0とpost-check=0の組み合わせを使用していました。これらのディレクティブの両方が0に設定されている場合、両方のディレクティブは無視されます。したがって、これらのディレクティブは正しく使用されなかったようです!
s-maxageディレクティブは、応答をキャッシュできる期間をプロキシに通知します。 Web Almanacデータセット全体で、jsDelivrは複数のリソースで高いレベルの使用が見られた唯一のCDNです。これは、jsDelivrのライブラリのパブリックCDNとしての役割を考えると驚くことではありません。他のCDNでの使用は、個々の顧客、たとえばその特定のCDNを使用するサードパーティのスクリプトまたはSaaSプロバイダーによって推進されているようです。
HTTPヘッダー内のリソースヒントの使用量が非常に少ないため、本章の残りの部分では、<link>タグと組み合わせたリソースヒントの使用量の分析のみに焦点を当てています。しかし、今後、HTTP/2 Pushが採用されるようになると、HTTPヘッダーでのリソースヒントの使用量が増える可能性のあることは注目に値します。これは、HTTP/2 Pushがリソースをプッシュするためのシグナルとして、HTTPのプリロード Link ヘッダーを再利用していることに起因しています。
Patrick Meenanは、優先度の高いオンスクリーンイメージを要求する前に、優先度の低いオフスクリーンイメージのロードを意図的にダウンロードしようとするサンプルテストページを作成しました。優れたHTTP/2サーバーはこれを認識し、優先度の低い画像を犠牲にして、要求後すぐに優先度の高い画像を送信できるはずです。貧弱なHTTP/2サーバーはリクエストの順番で応答し、優先順位のシグナルを無視します。 Andy Daviesには、Patrickのテスト用にさまざまなCDNのステータスを追跡するページがあります。 HTTP Archiveは、クロールの一部としてCDNが使用されるタイミングを識別しこれら2つのデータセットをマージすると、合格または失敗したCDNを使用しているページの割合を知ることができます。
-{% endblock %}
diff --git a/src/tools/scripts/deploy.sh b/src/tools/scripts/deploy.sh
new file mode 100755
index 00000000000..024f406c16e
--- /dev/null
+++ b/src/tools/scripts/deploy.sh
@@ -0,0 +1,108 @@
+#!/bin/bash
+
+# This script is used to deploy the Web Alamanc to Google Cloud Platform (GCP).
+# Users must have push permissions on the production branch and also release
+# permissions for the Web Almanac on GCP
+
+# exit when any command fails instead of trying to continue on
+set -e
+
+# These color codes allow us to colour text output when used with "echo -e"
+RED="\033[0;31m"
+GREEN="\033[0;32m"
+AMBER="\033[0;33m"
+RESET_COLOR="\033[0m" # No Color
+
+# A helper function to ask if it is OK to continue with [y/N] answer
+function check_continue {
+ read -r -n 1 -p "${1} [y/N]: " REPLY
+ if [ "${REPLY}" != "Y" ] && [ "${REPLY}" != "y" ]; then
+ echo
+ echo -e "${RED}Cancelling deploy${RESET_COLOR}"
+ exit 1
+ else
+ echo
+ fi
+}
+
+echo "Beginning the Web Almanac deployment process"
+
+# Check branch is clean first
+if [ -n "$(git status --porcelain)" ]; then
+ check_continue "Your branch is not clean. Do you still want to continue deploying?"
+fi
+
+check_continue "Please confirm you've updated the eBooks via GitHub Actions."
+
+echo "Update local production branch"
+git checkout production
+git status
+git pull
+git pull origin main
+
+if [ "$(pgrep -f 'python main.py')" ]; then
+ echo "Killing existing server to run a fresh version"
+ pkill -9 python main.py
+fi
+
+echo "Run and test website"
+./tools/scripts/run_and_test_website.sh
+
+echo "Please test the site locally"
+
+check_continue "Are you ready to deploy?"
+
+LAST_TAGGED_VERSION=$(git tag -l "v*" | tail)
+echo "Last tagged version: ${LAST_TAGGED_VERSION}"
+if [[ "${LAST_TAGGED_VERSION}" =~ ^v[0-9]+\.[0-9]+\.[0-9]+$ ]]; then
+ SEMVER=( "${LAST_TAGGED_VERSION//./ }" )
+ MAJOR="${SEMVER[0]}"
+ MINOR="${SEMVER[1]}"
+ PATCH="${SEMVER[2]}"
+ NEXT_PATCH=$((PATCH + 1))
+ NEXT_VERSION="$MAJOR.$MINOR.$NEXT_PATCH"
+else
+ echo -e "${AMBER}Warning - last tagged version is not of the format vX.X.X!${RESET_COLOR}"
+fi
+
+TAG_VERSION=""
+while [[ ! "${TAG_VERSION}" =~ ^v[0-9]+\.[0-9]+\.[0-9]+$ ]]
+do
+ echo "Please update major tag version when changing default year"
+ echo "Please update minor tag version when adding new languages or other large changes"
+ read -r -p "Please select tag version of the format vX.X.X. [$NEXT_VERSION]: " TAG_VERSION
+done
+echo "Tagging as ${TAG_VERSION}"
+LONG_DATE=$(date -u +%Y-%m-%d\ %H:%M:%S)
+git tag -a "${TAG_VERSION}" -m "Version ${TAG_VERSION} ${LONG_DATE}"
+echo "Tagged ${TAG_VERSION} with message 'Version ${TAG_VERSION} ${LONG_DATE}'"
+
+if [[ -f deployed.zip ]]; then
+ echo "Removing old deploy.zip"
+ rm -f deployed.zip
+fi
+
+echo "Zipping artifacts into deploy.zip"
+# Exclude chapter images as quite large and tracked in git anyway
+zip -q -r deployed . --exclude @.gcloudignore static/images/*/*/* static/pdfs/*
+
+echo "Deploying to GCP"
+echo "Y" | gcloud app deploy --project webalmanac --stop-previous-version
+
+echo "Push production branch"
+git push
+git status
+
+echo "Checking out main branch"
+git checkout main
+
+echo
+echo -e "${GREEN}Successfully deployed!${RESET_COLOR}"
+echo
+echo -e "${AMBER}Please update release on GitHub: https://github.com/HTTPArchive/almanac.httparchive.org/releases${RESET_COLOR}"
+echo -e "${AMBER}Using tag ${TAG_VERSION}@production${RESET_COLOR}"
+echo -e "${AMBER}Please upload deploy.zip as the release artifact${RESET_COLOR}"
+echo
+echo "Have a good one!"
+echo
+exit 0
diff --git a/src/tools/scripts/run_and_test_website.sh b/src/tools/scripts/run_and_test_website.sh
index 8dfc3ba38cb..6d5c5e0bee8 100755
--- a/src/tools/scripts/run_and_test_website.sh
+++ b/src/tools/scripts/run_and_test_website.sh
@@ -33,6 +33,8 @@ npm run generate
echo "Starting website"
python main.py background &
+# Sleep for a couple of seconds to make sure server is up
+sleep 2
# Check website is running as won't have got feedback as backgrounded
pgrep -f "python main.py"
 -
-
-
-
-
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-
-
-  -
-  -
-
-
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
- 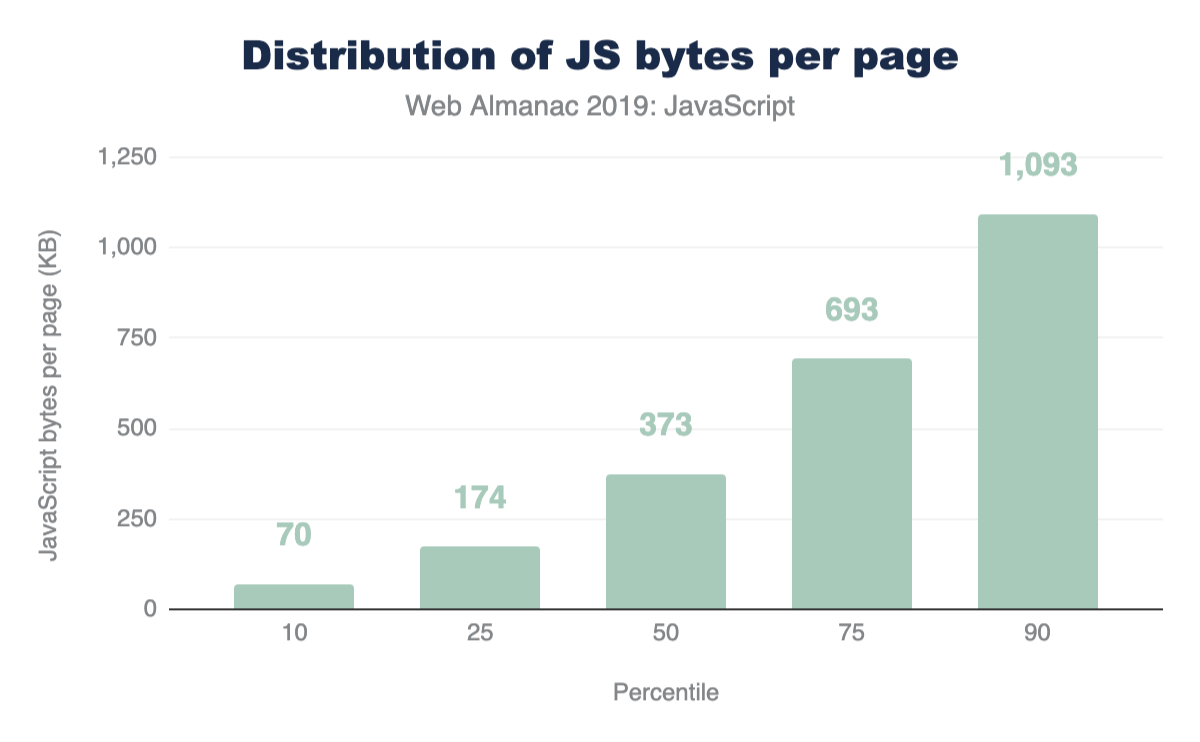 -
- 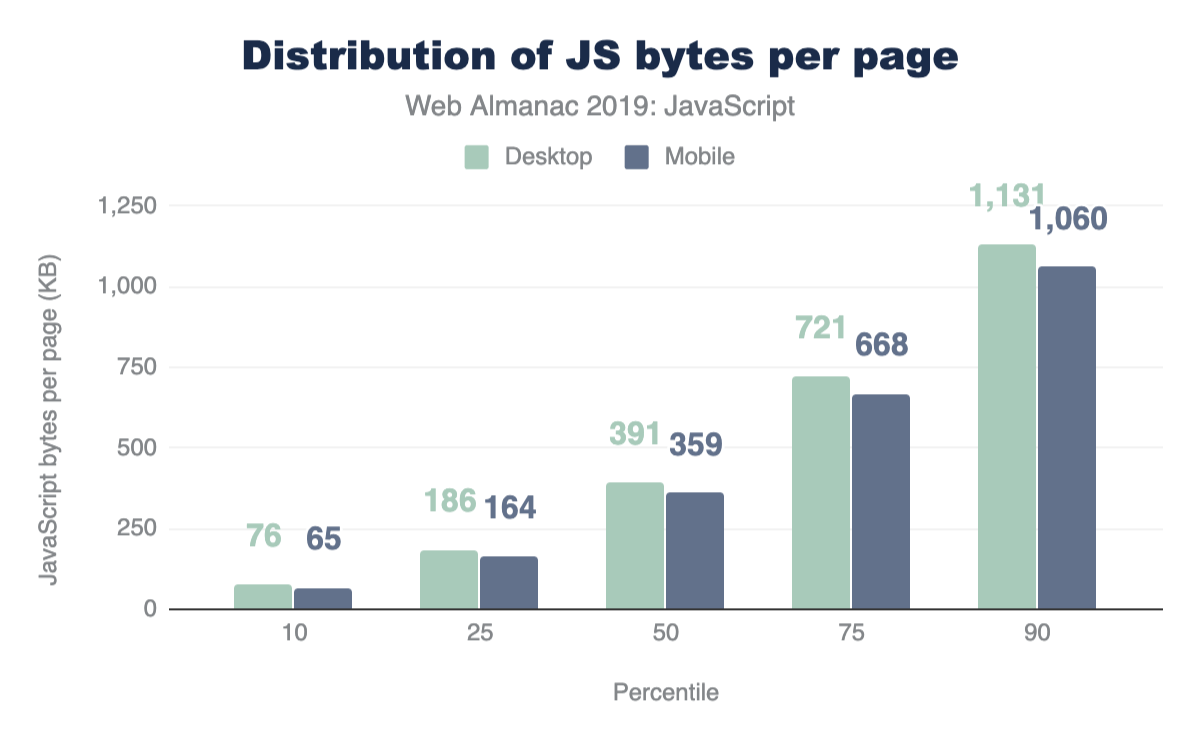 -
- 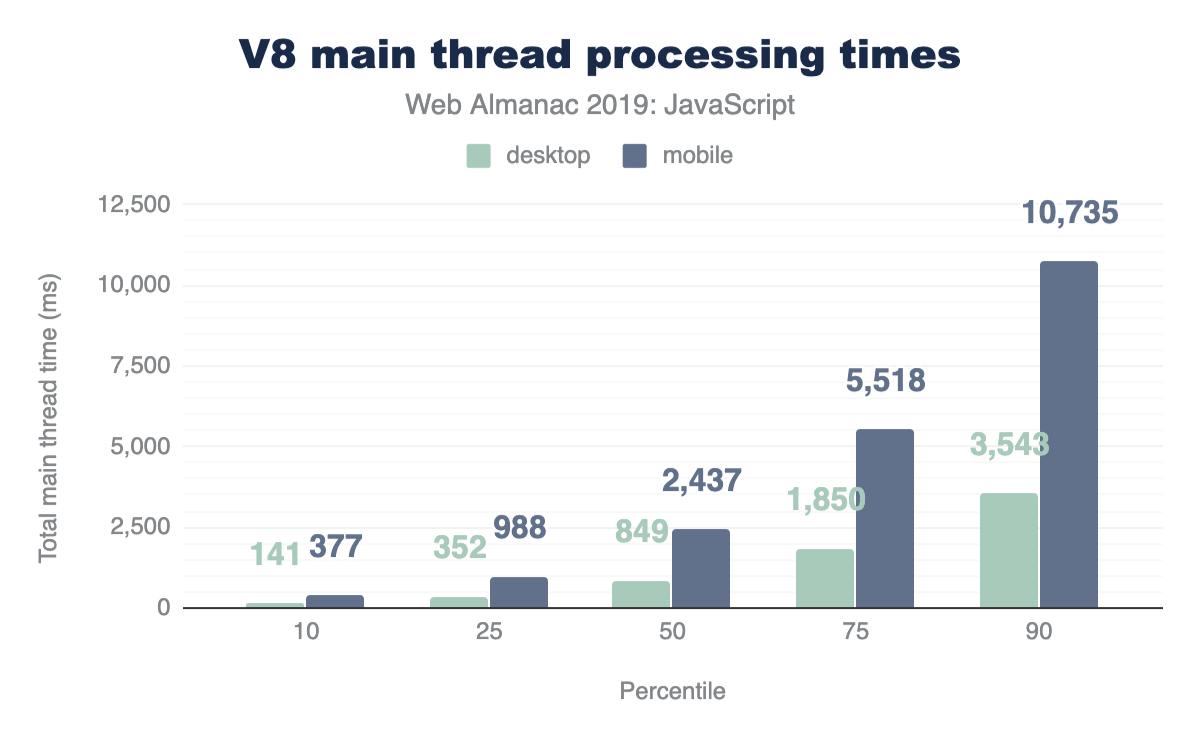 -
- 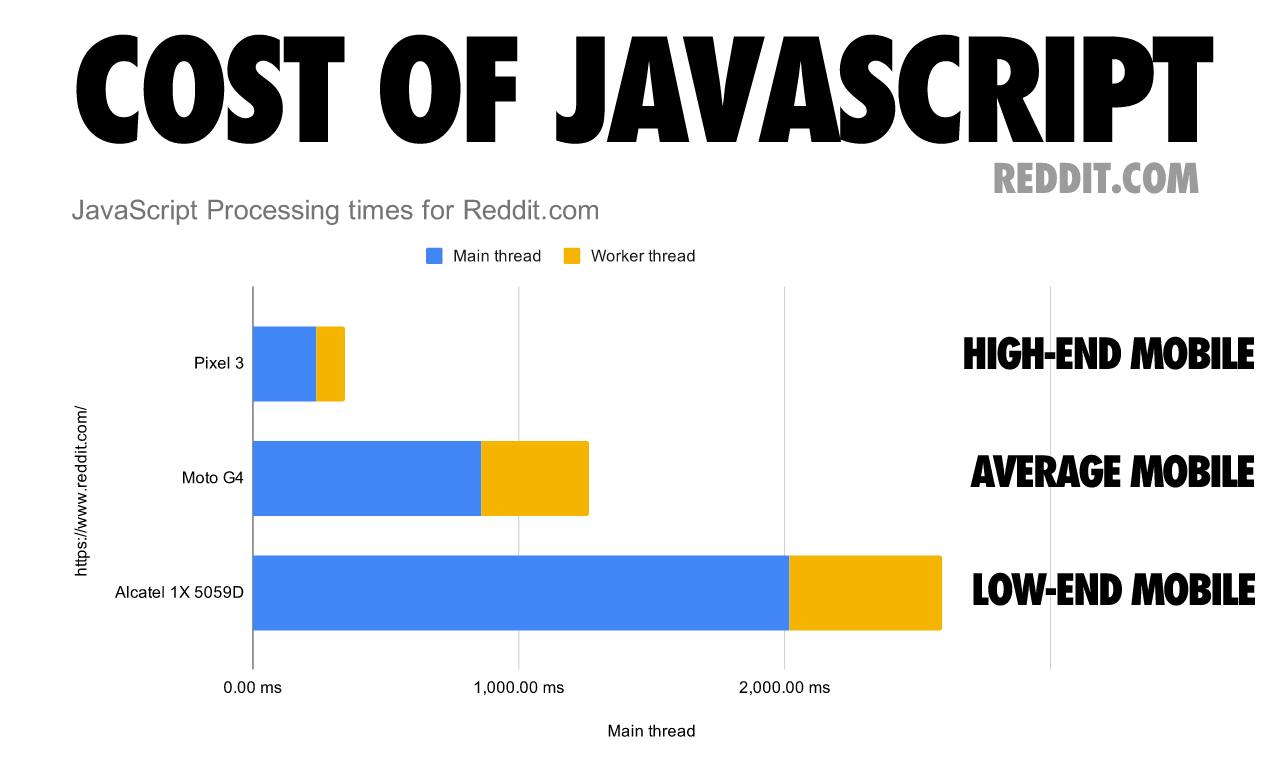 -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
- 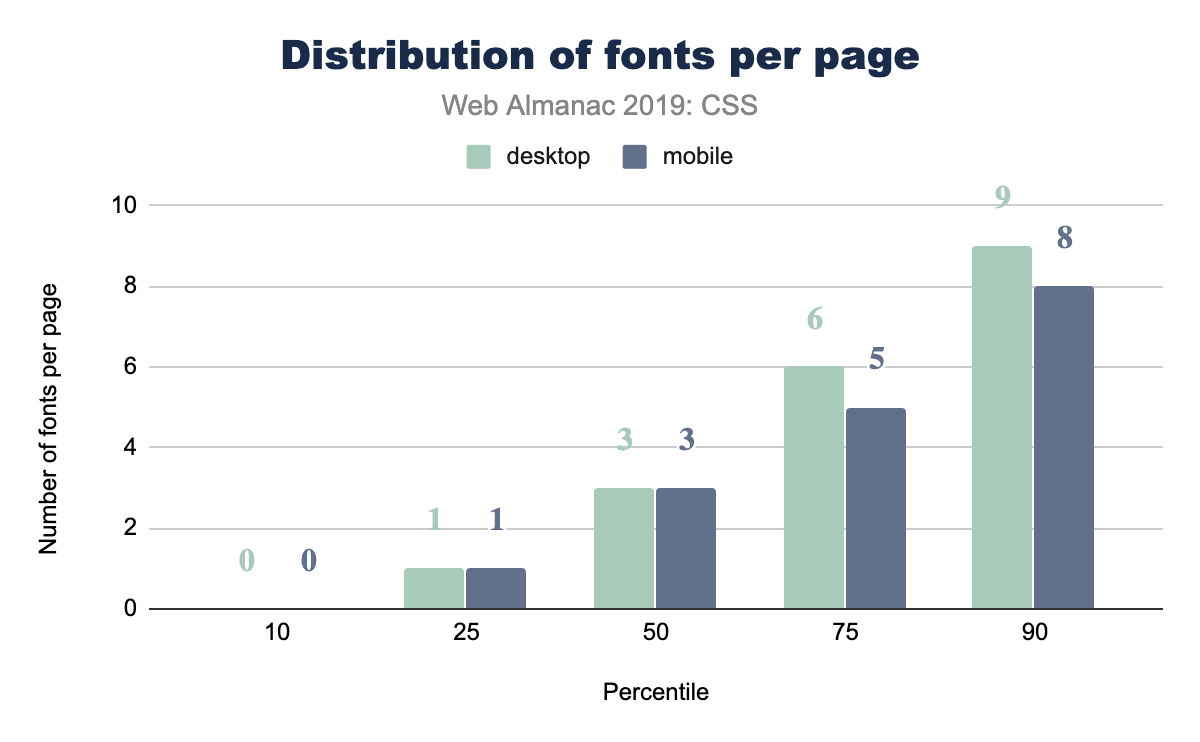 -
- 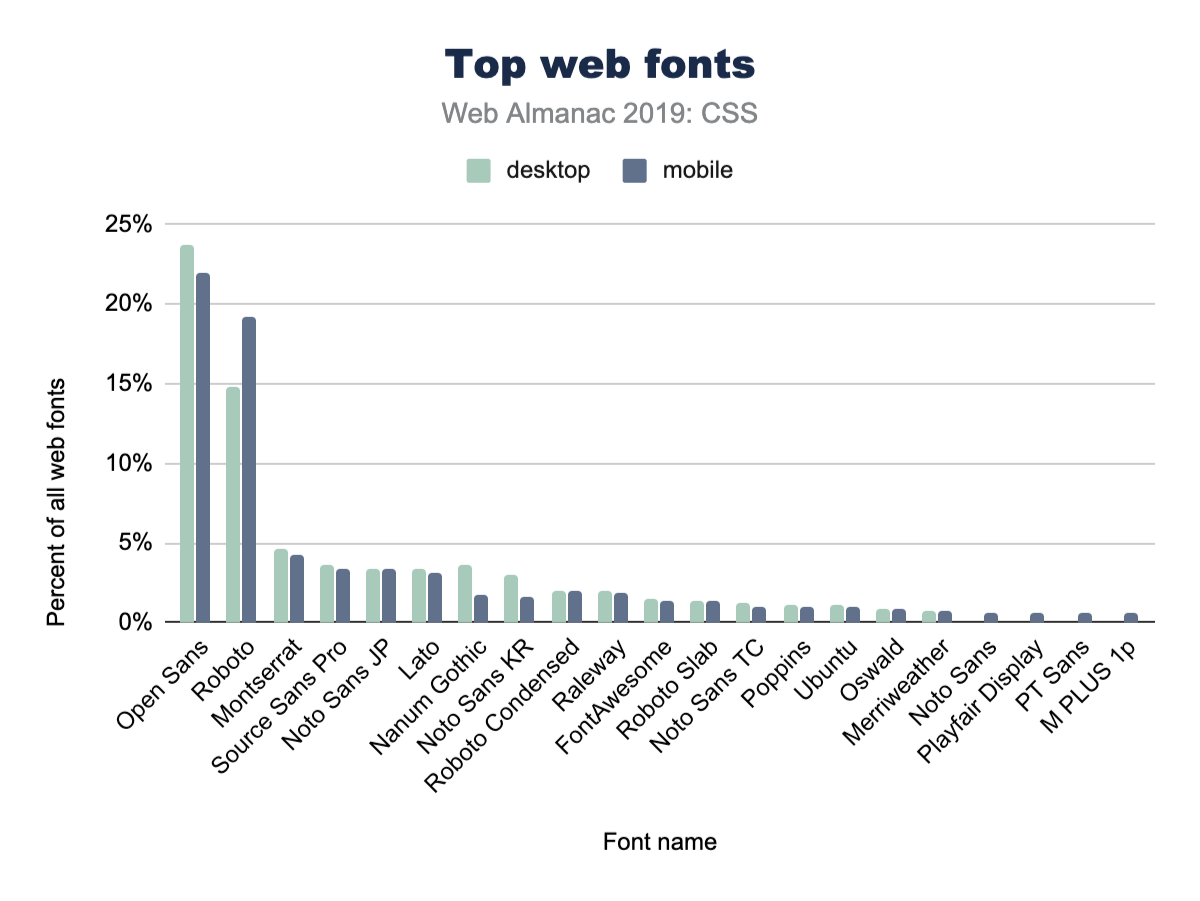 -
- 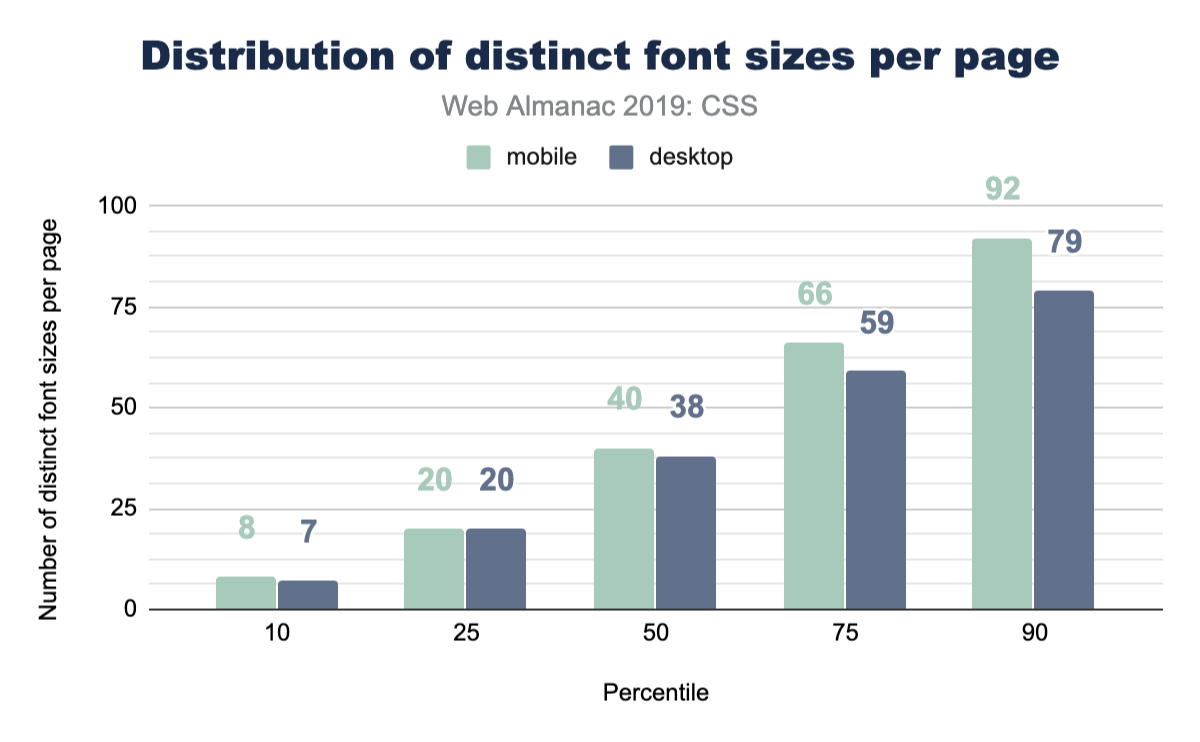 -
-  -
-  -
- 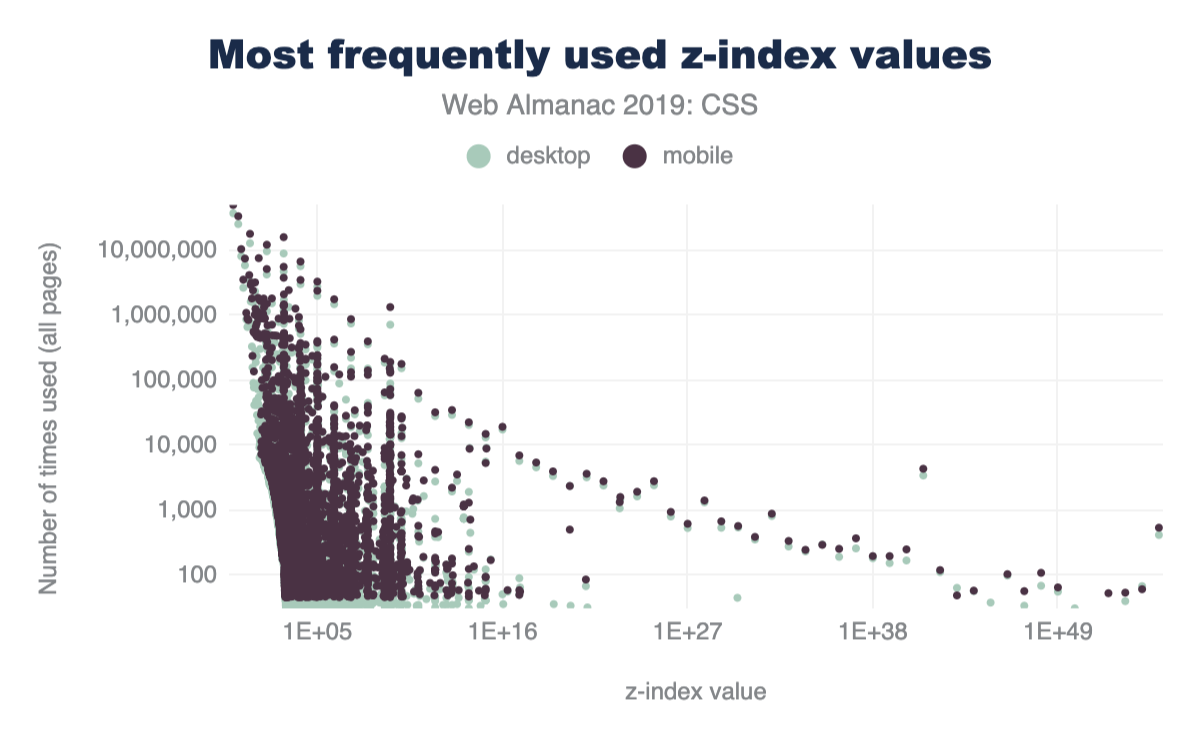 -
- 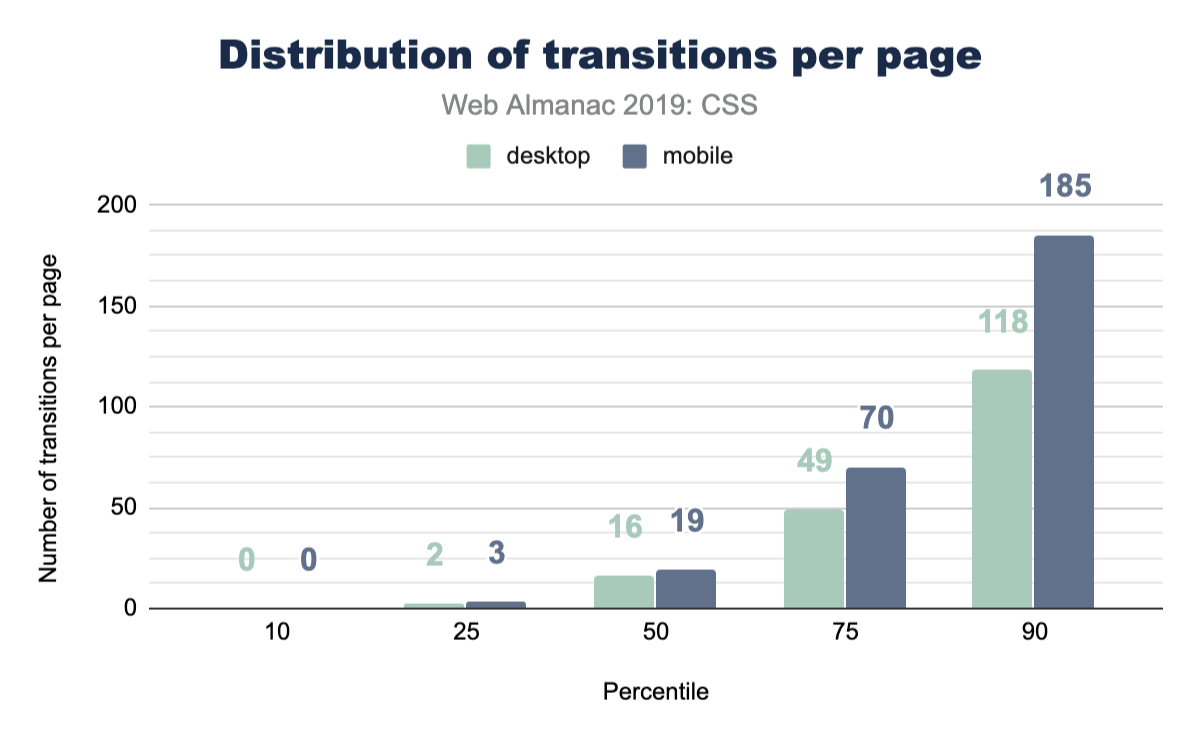 -
- 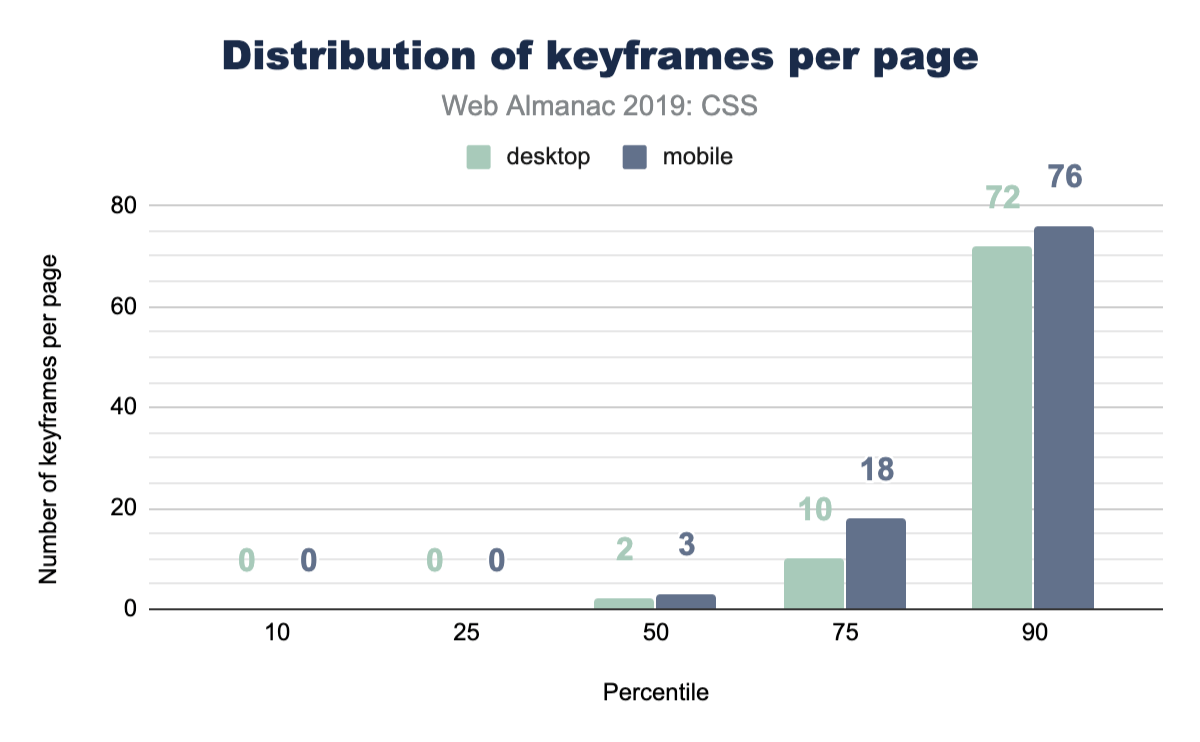 -
- 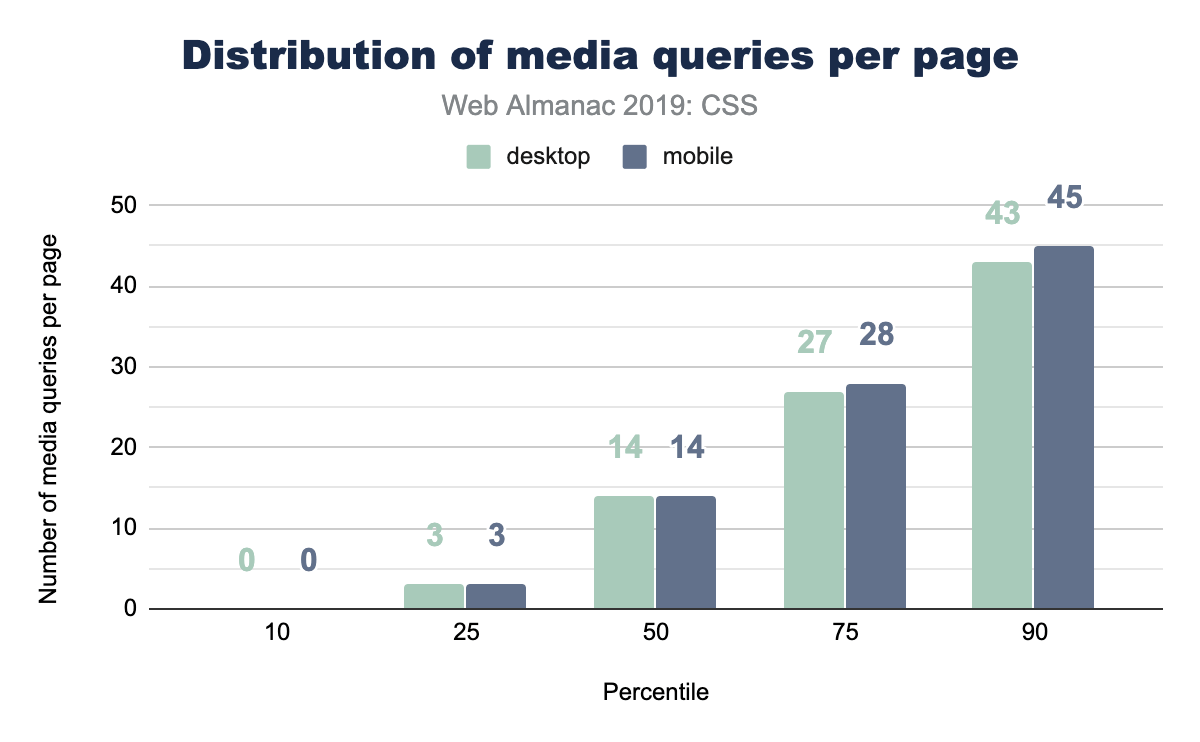 -
-  -
- 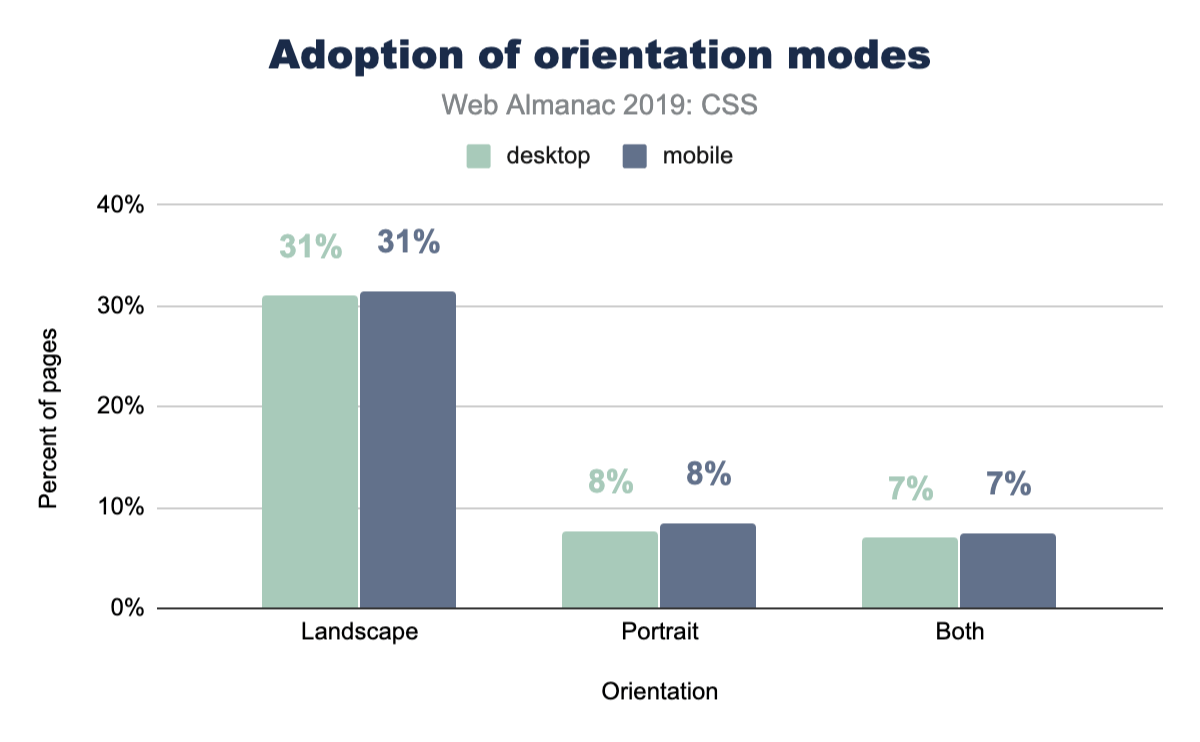 -
- 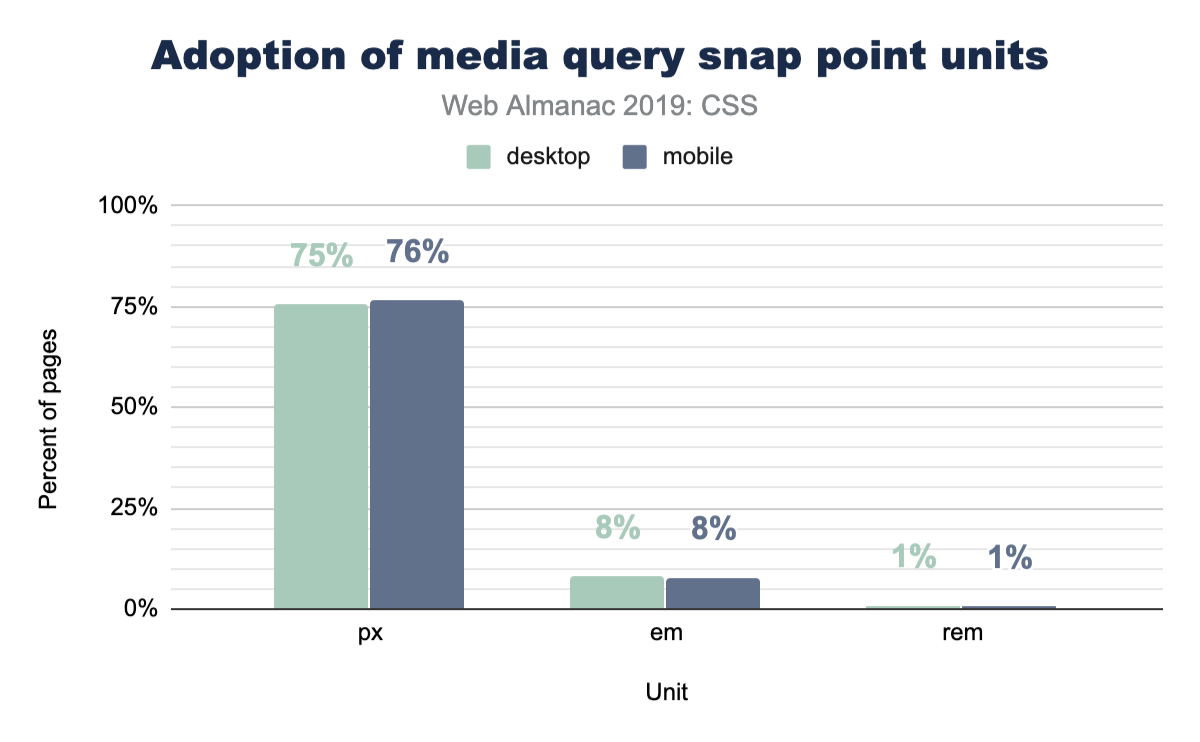 -
- 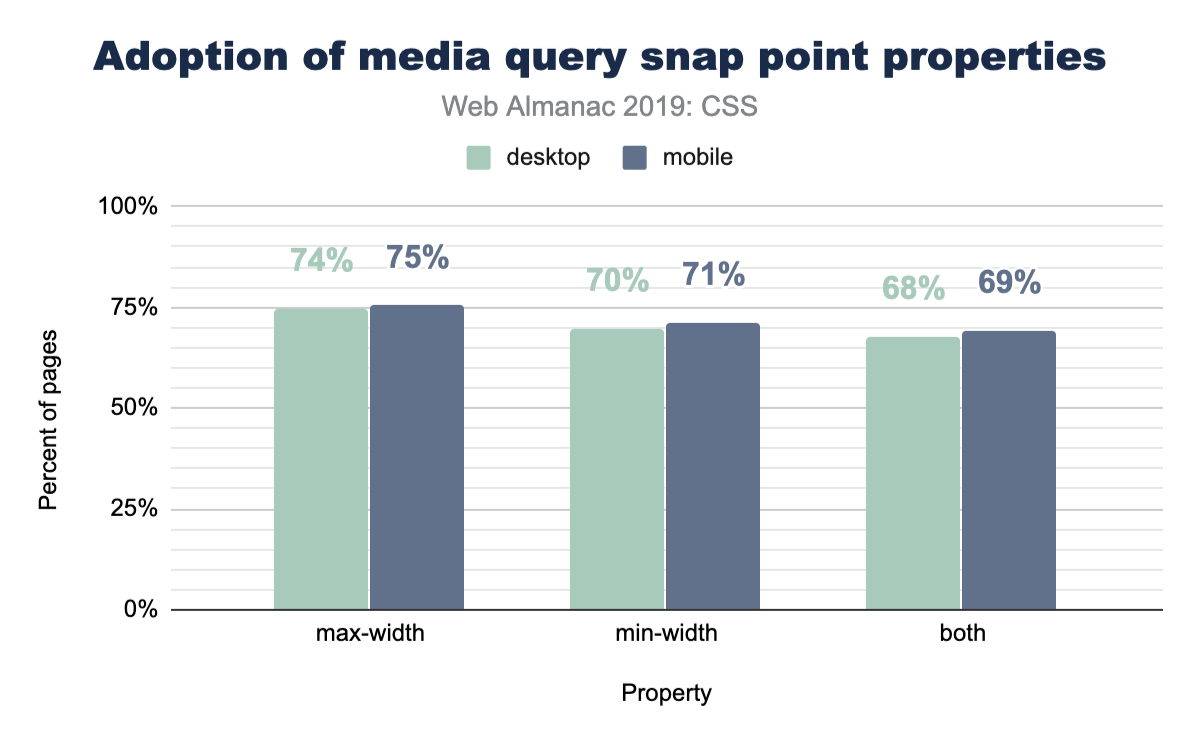 -
- 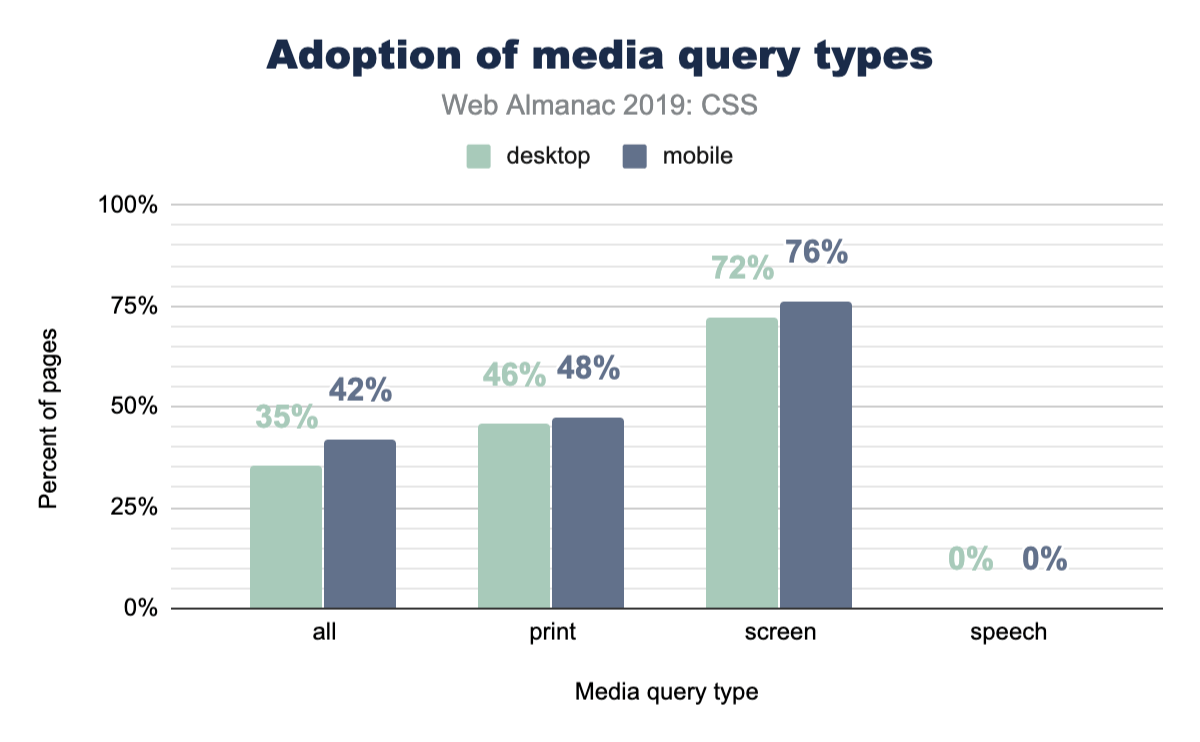 -
- 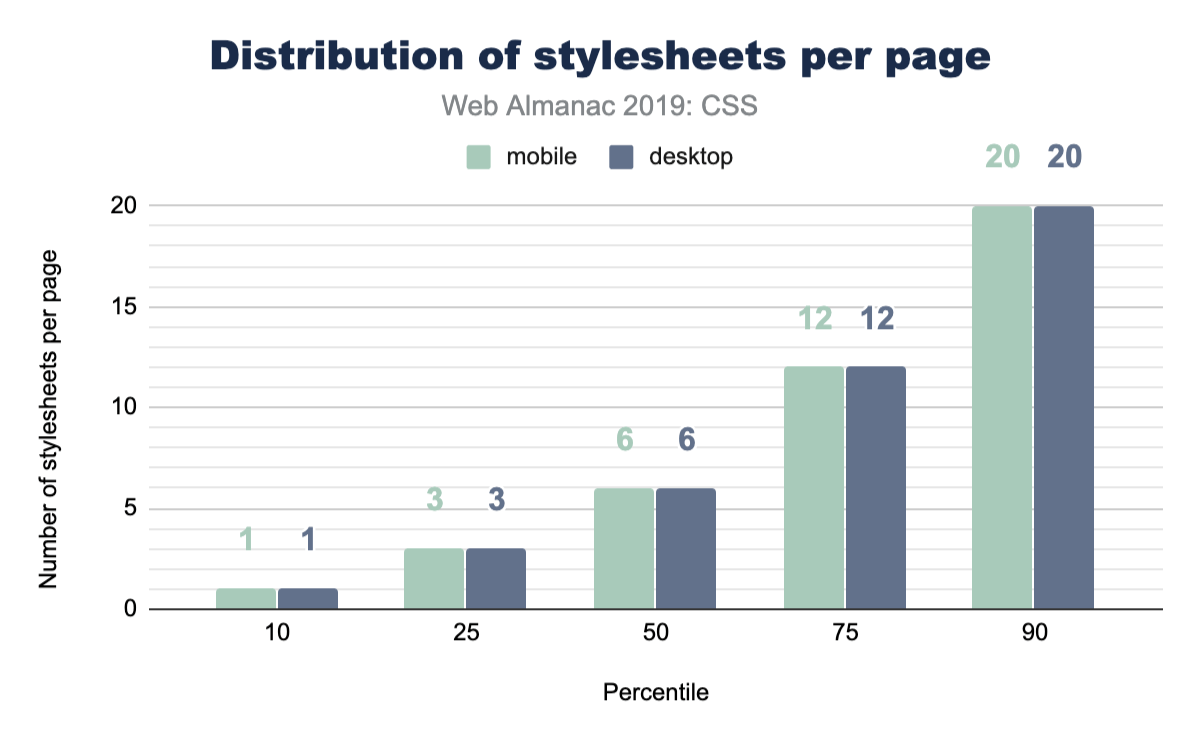 -
- 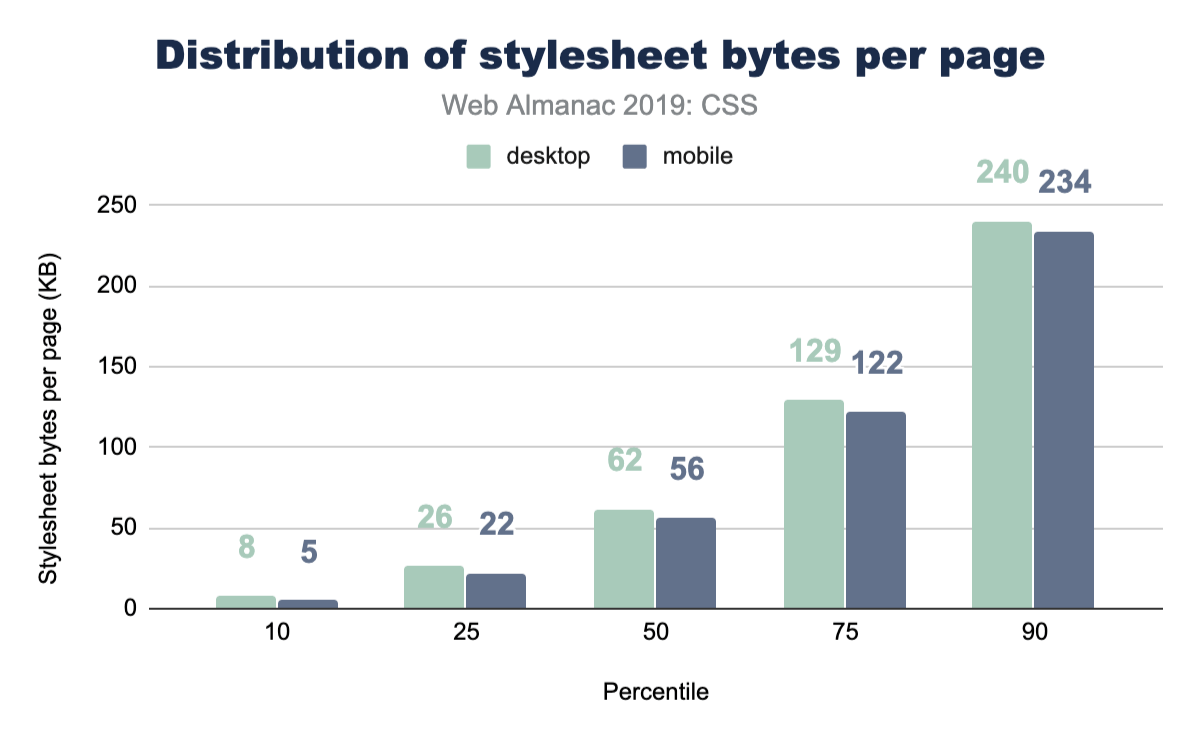 -
- 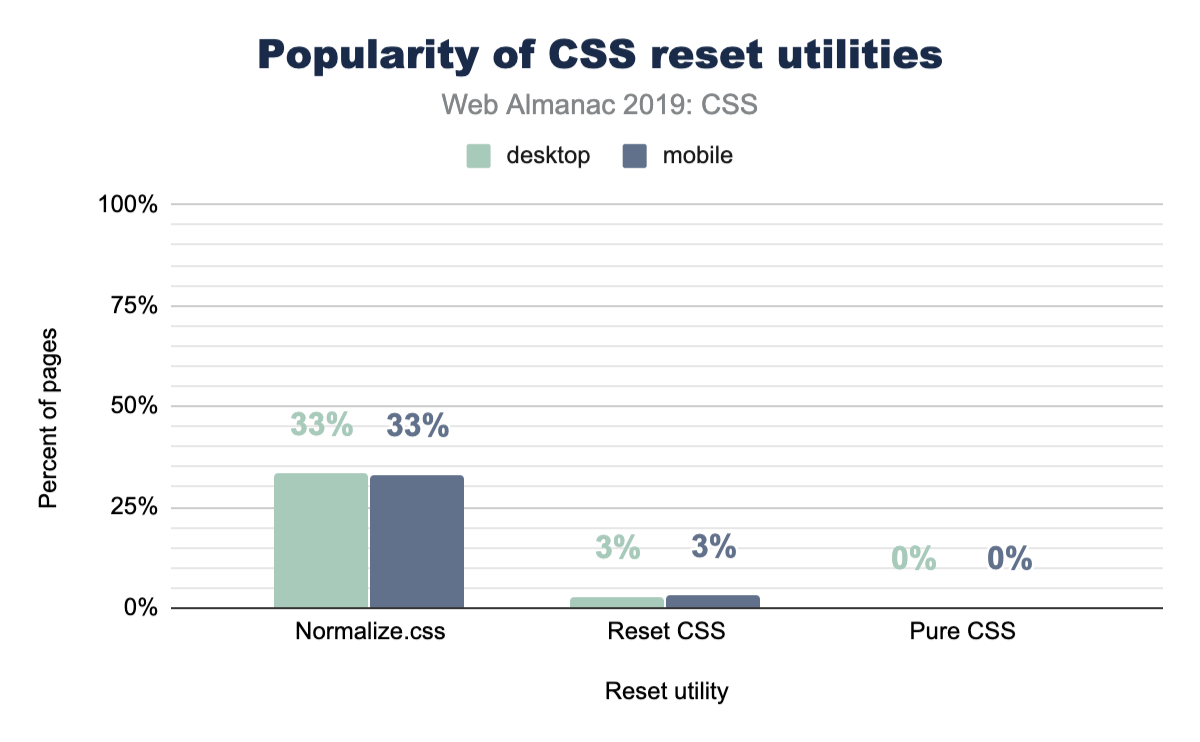 -
- 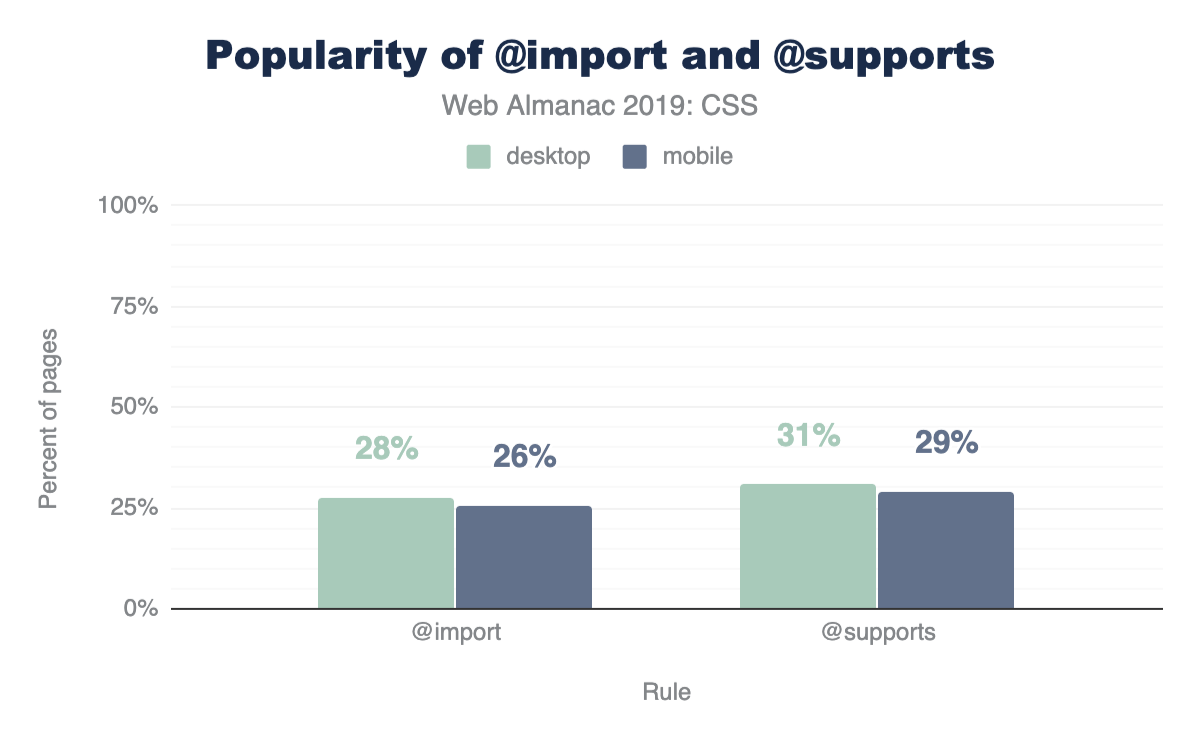 -
- 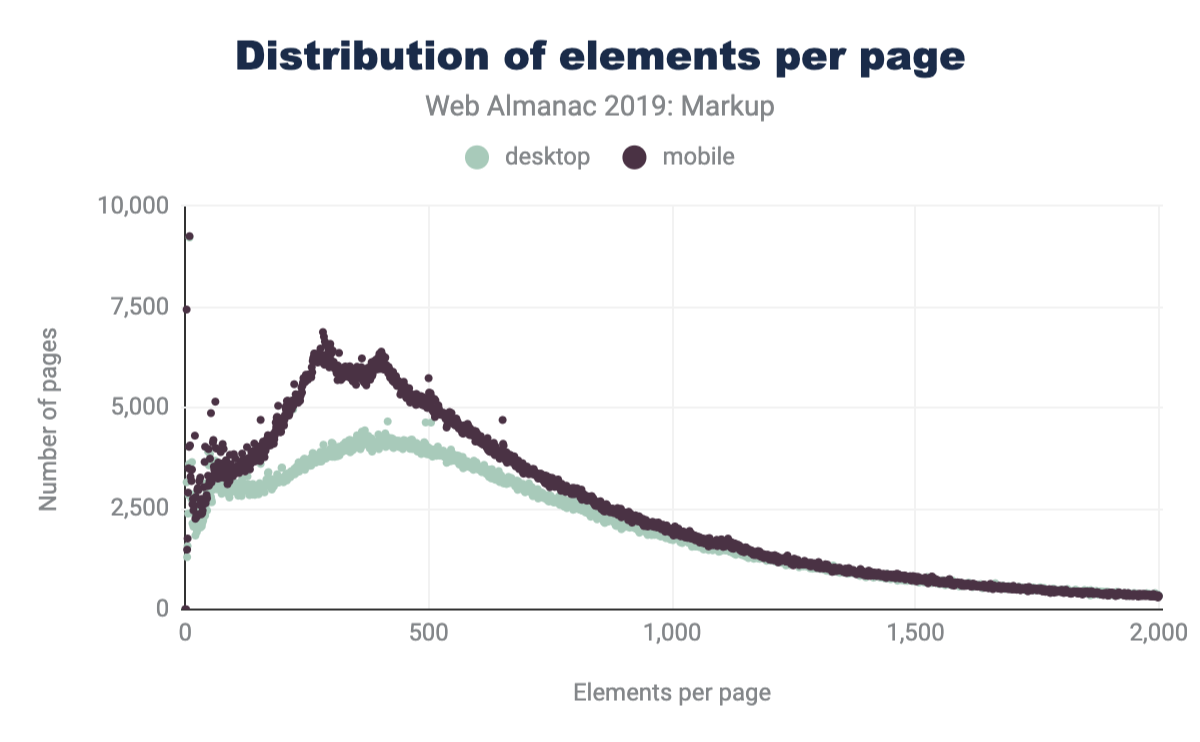 -
- 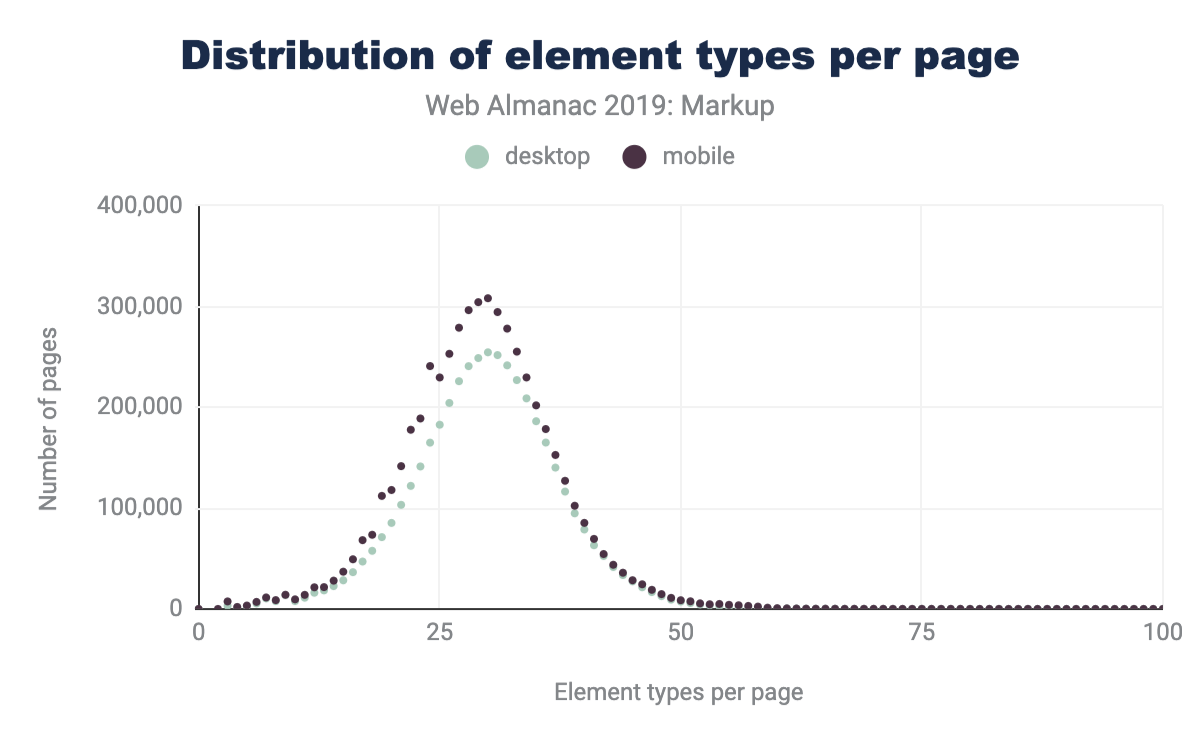 -
- 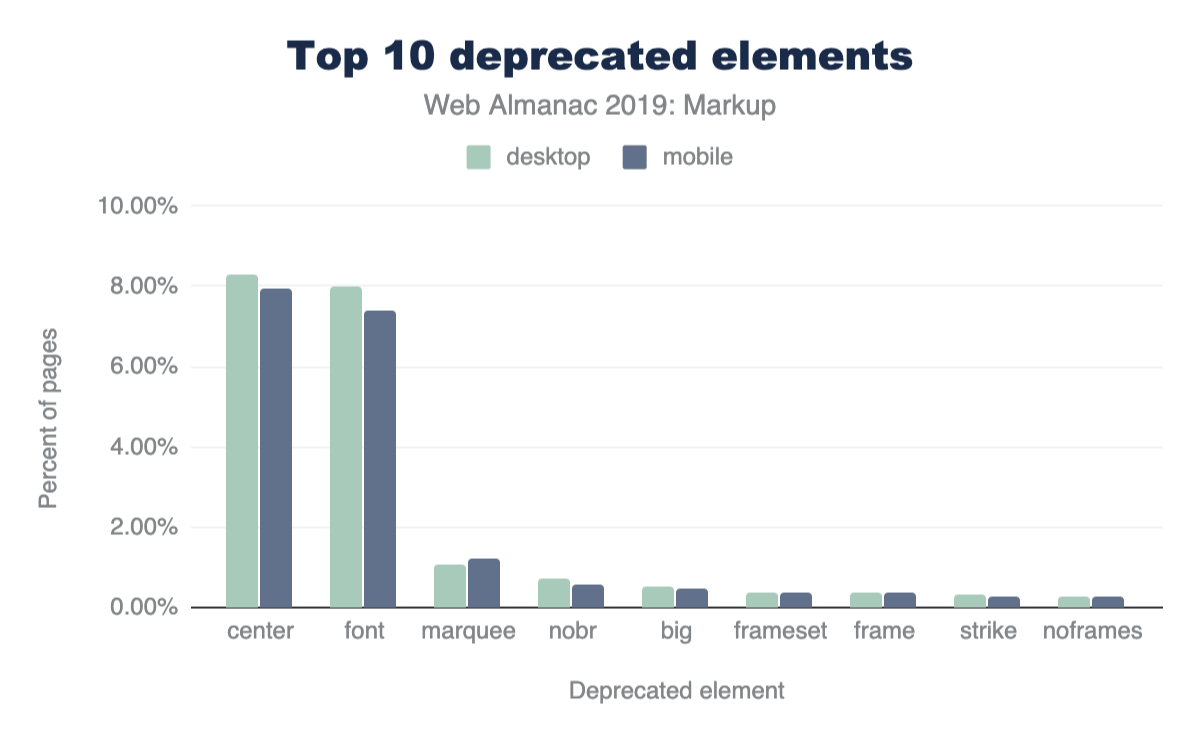 -
- 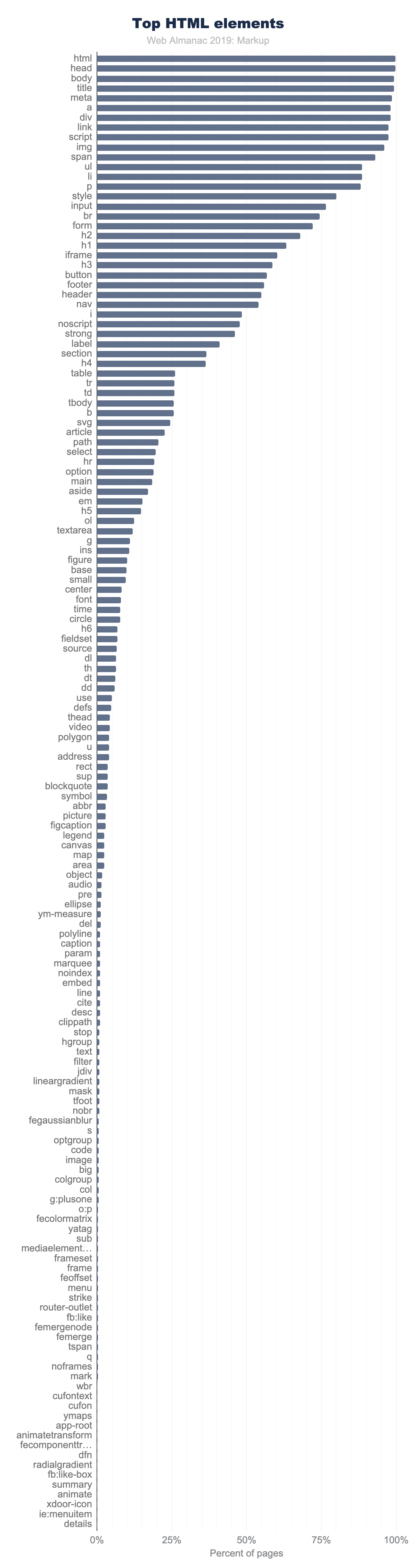 -
-  -
- 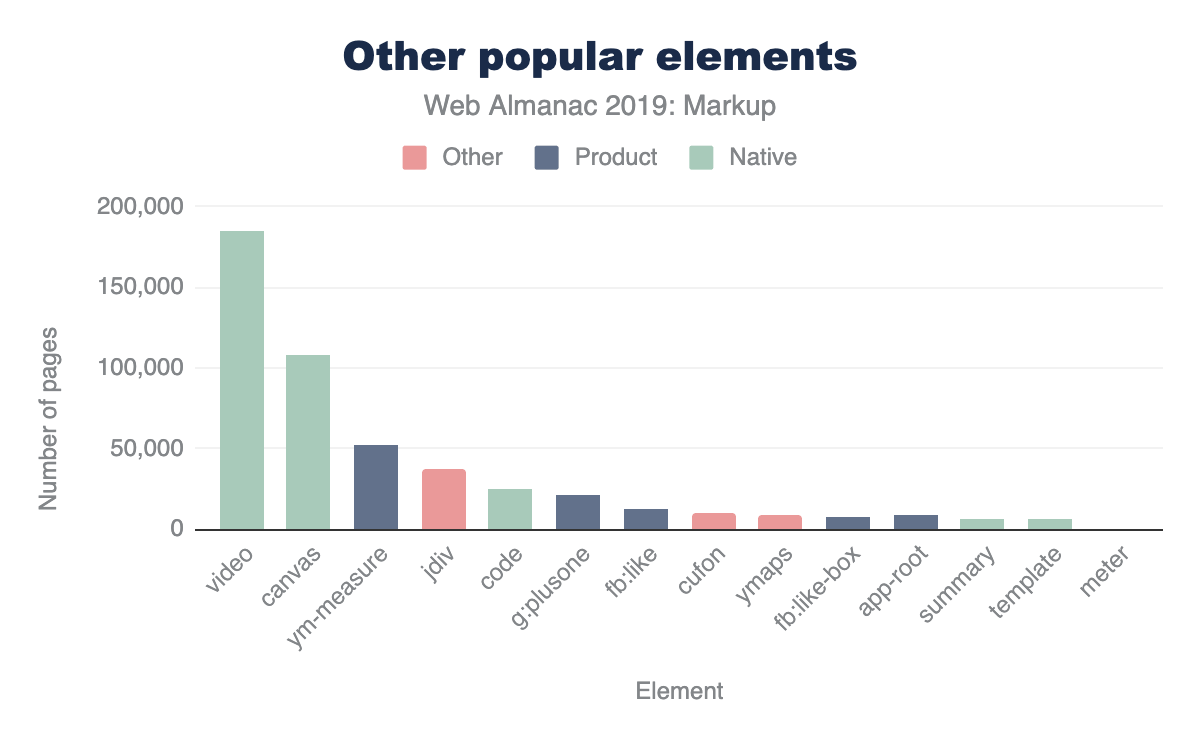 -
-  -
- 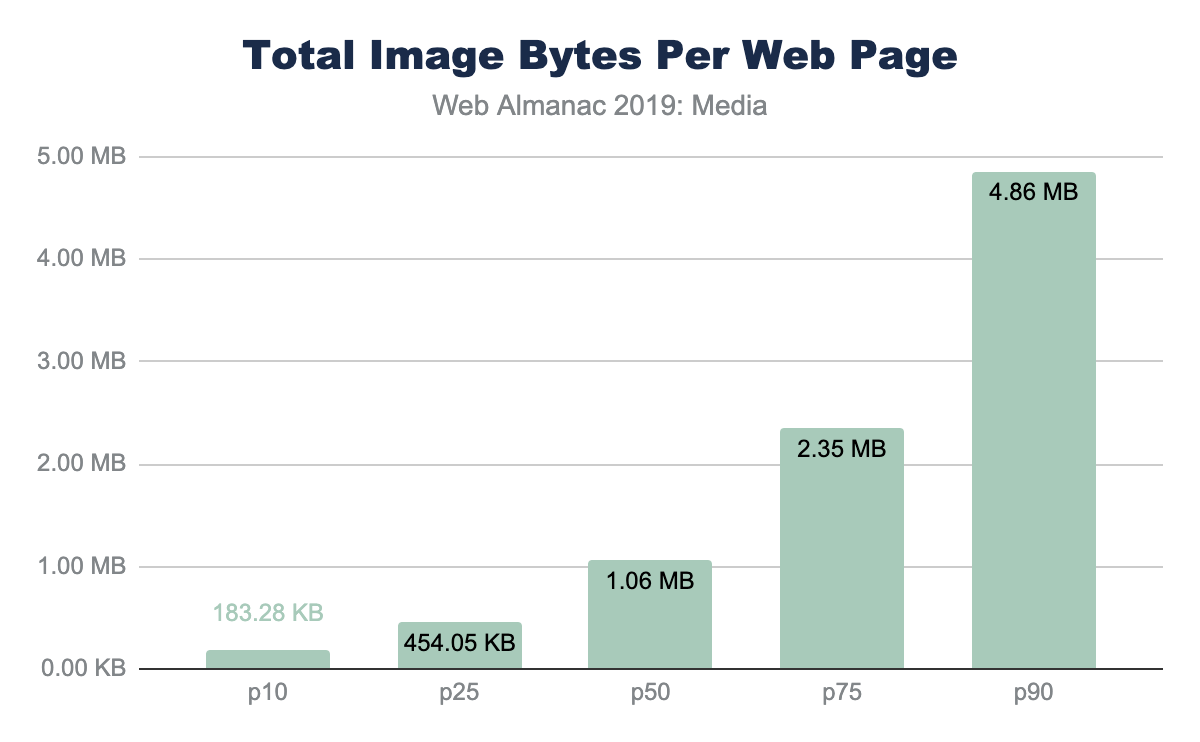 -
- 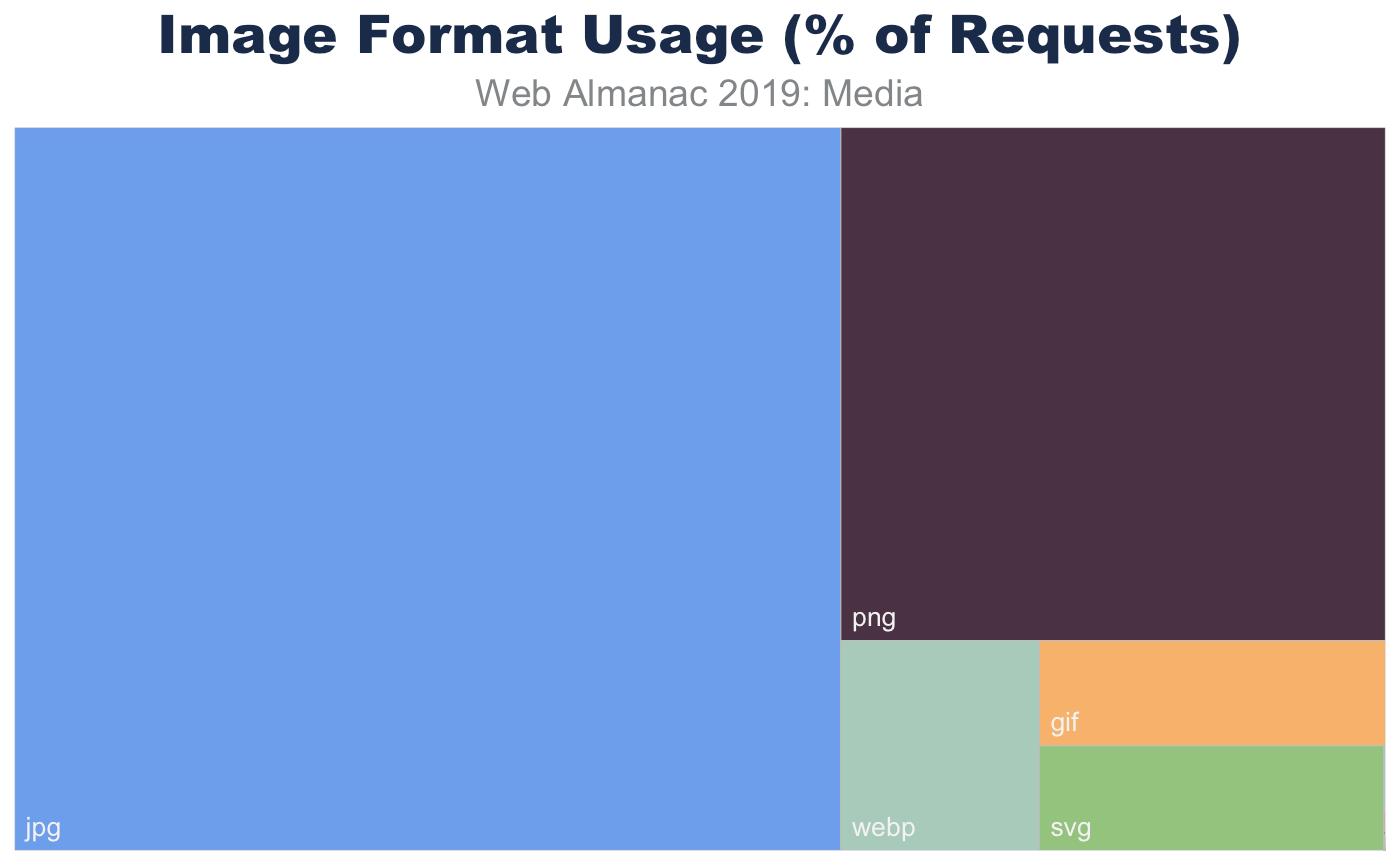 -
- 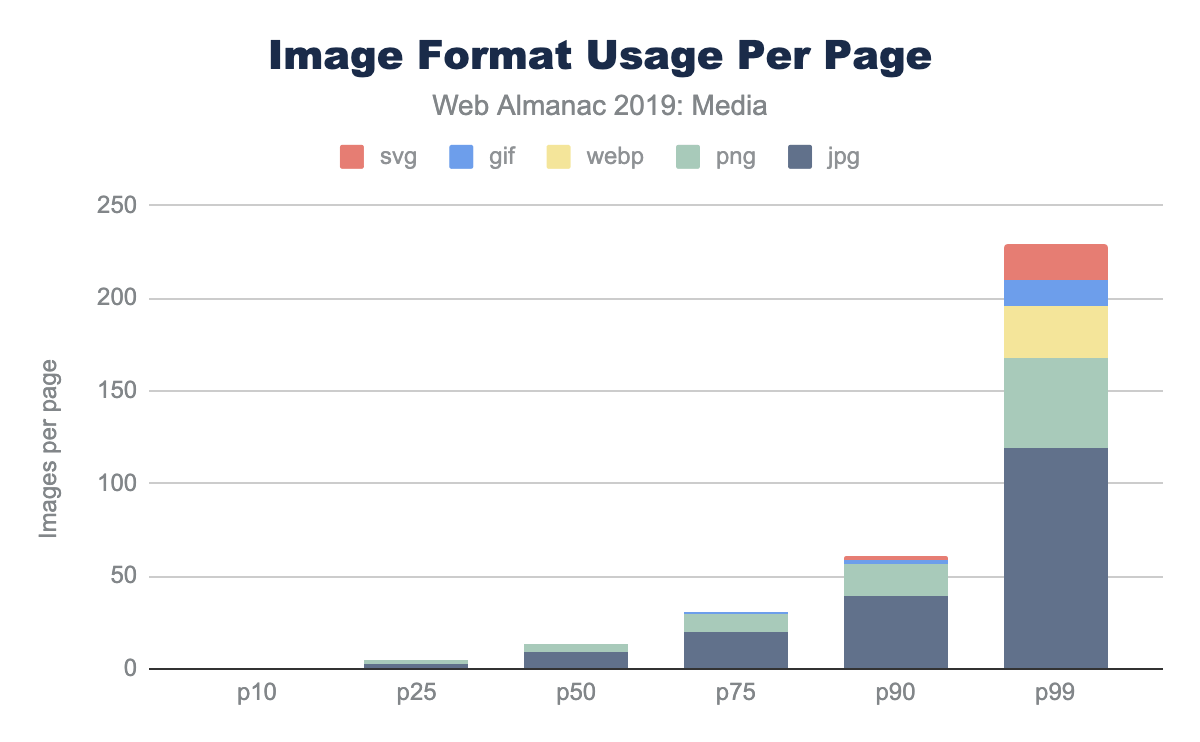 -
- 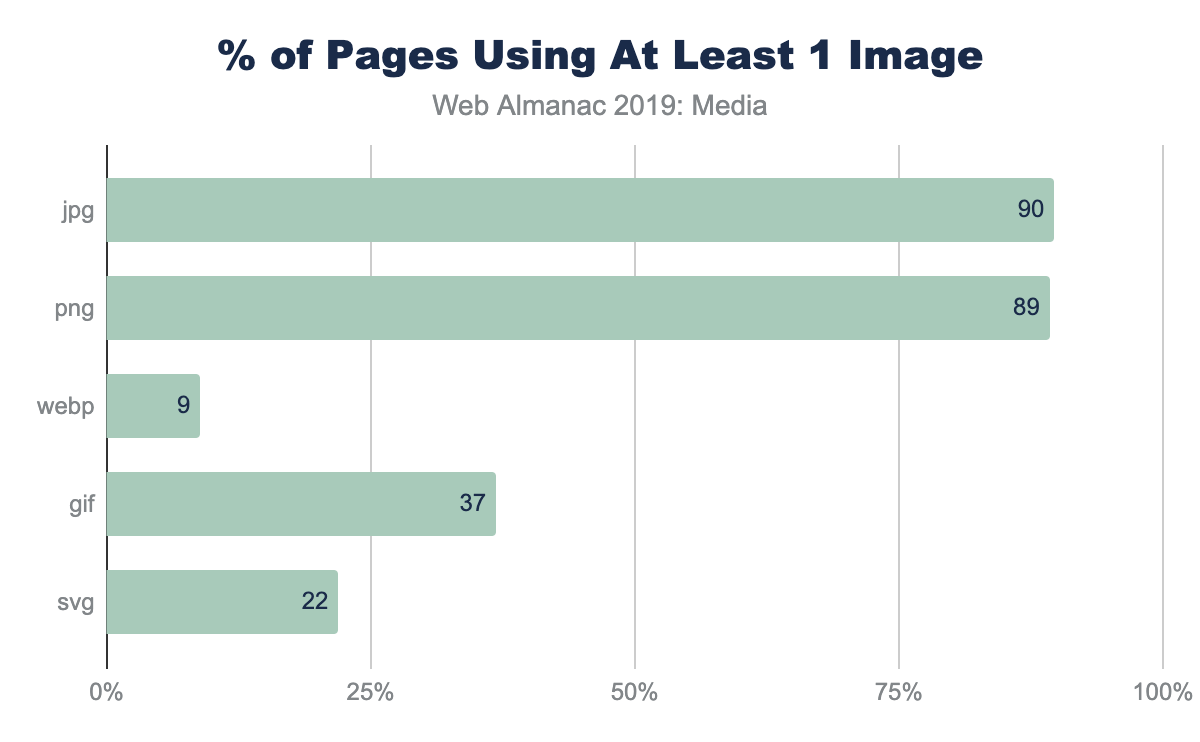 -
-  -
-  -
-  -
-  -
- 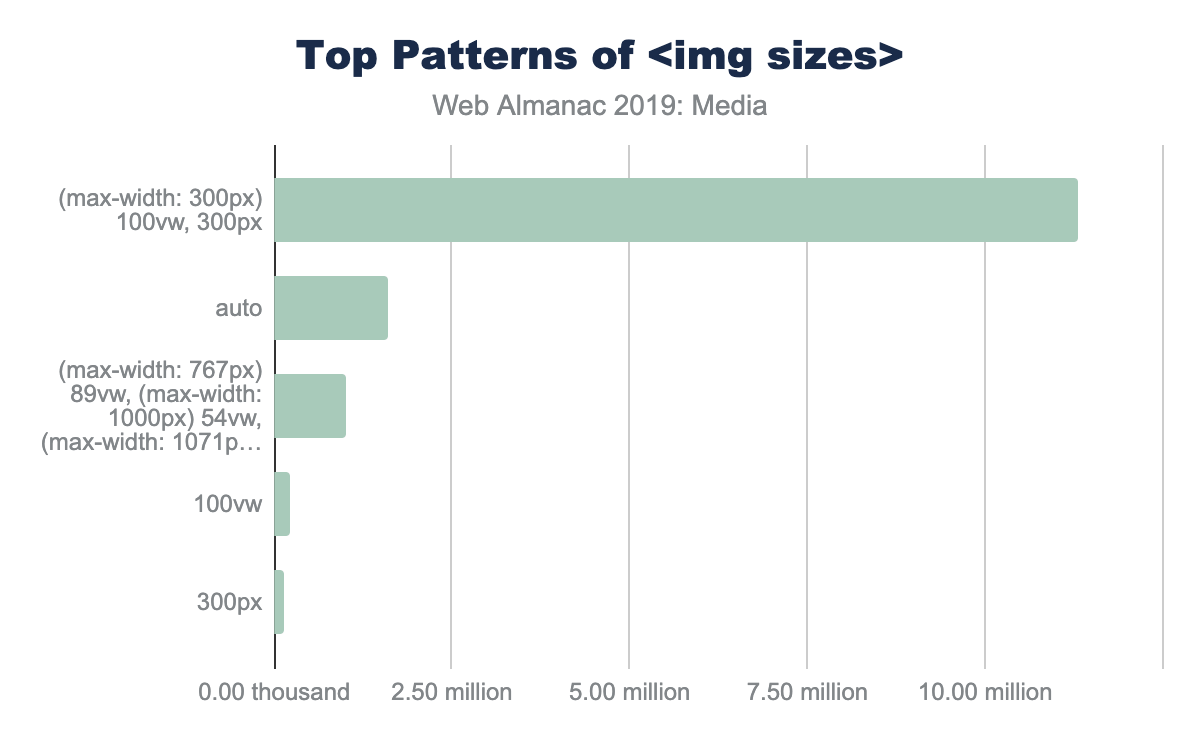 -
- 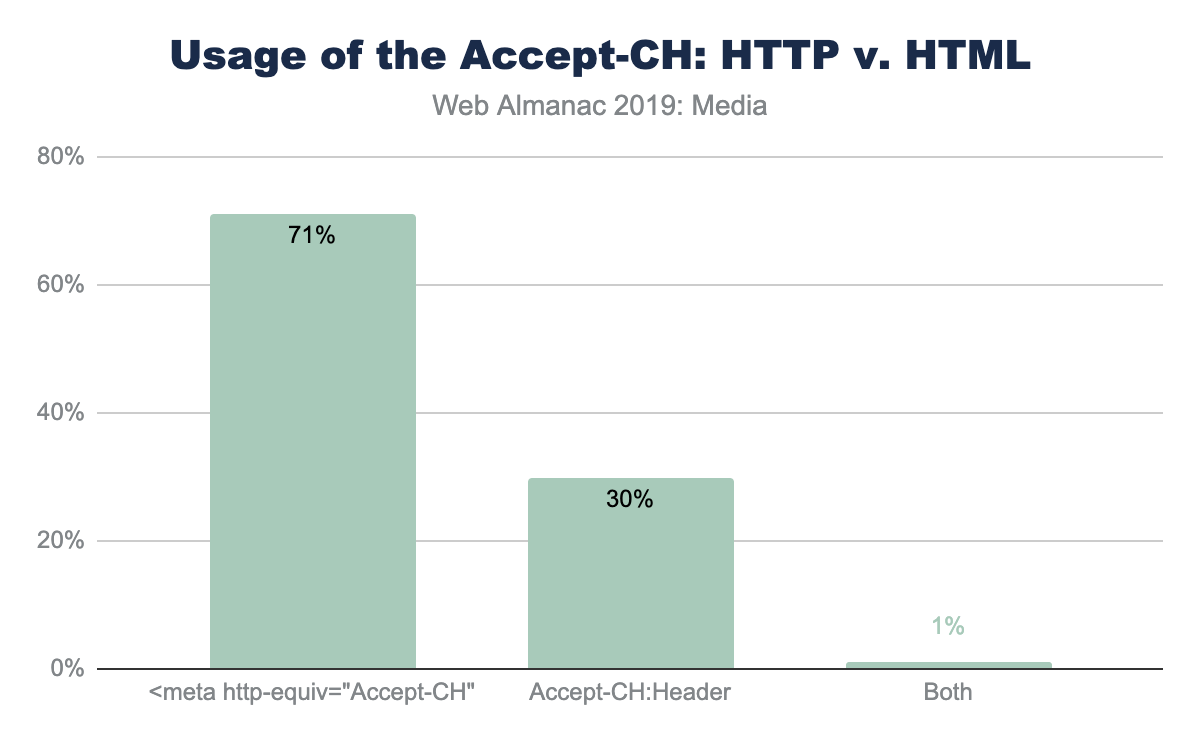 -
- 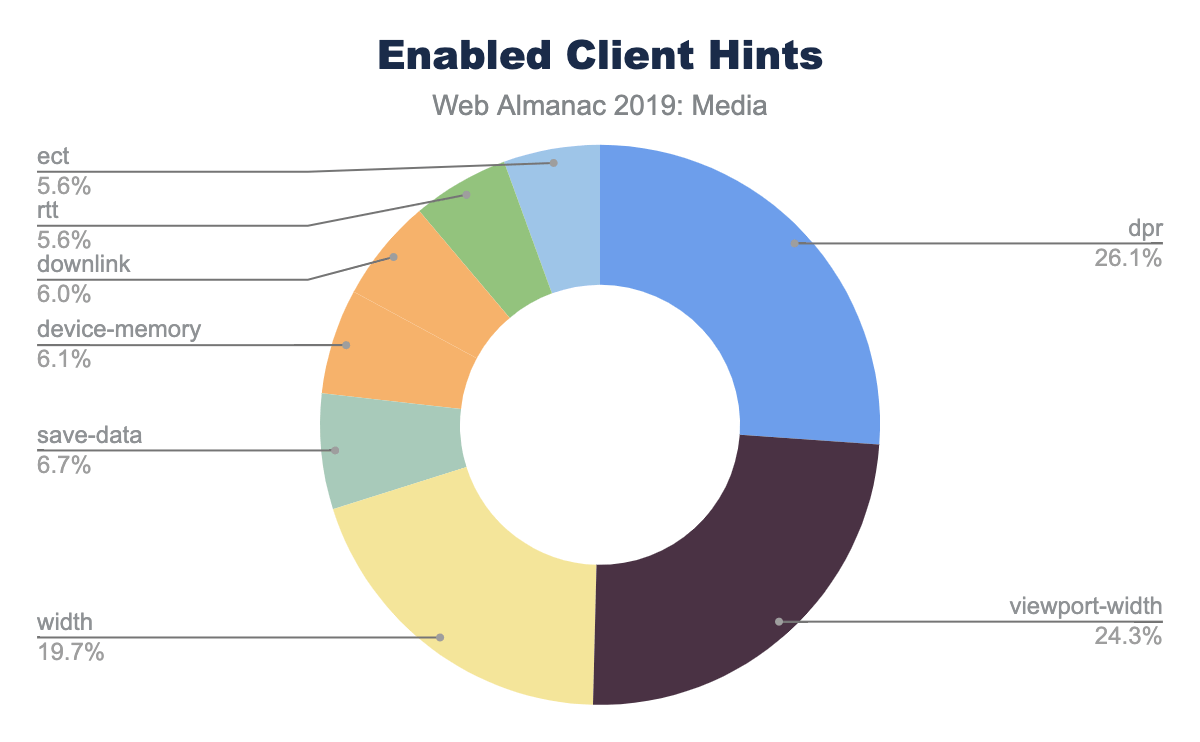 -
- 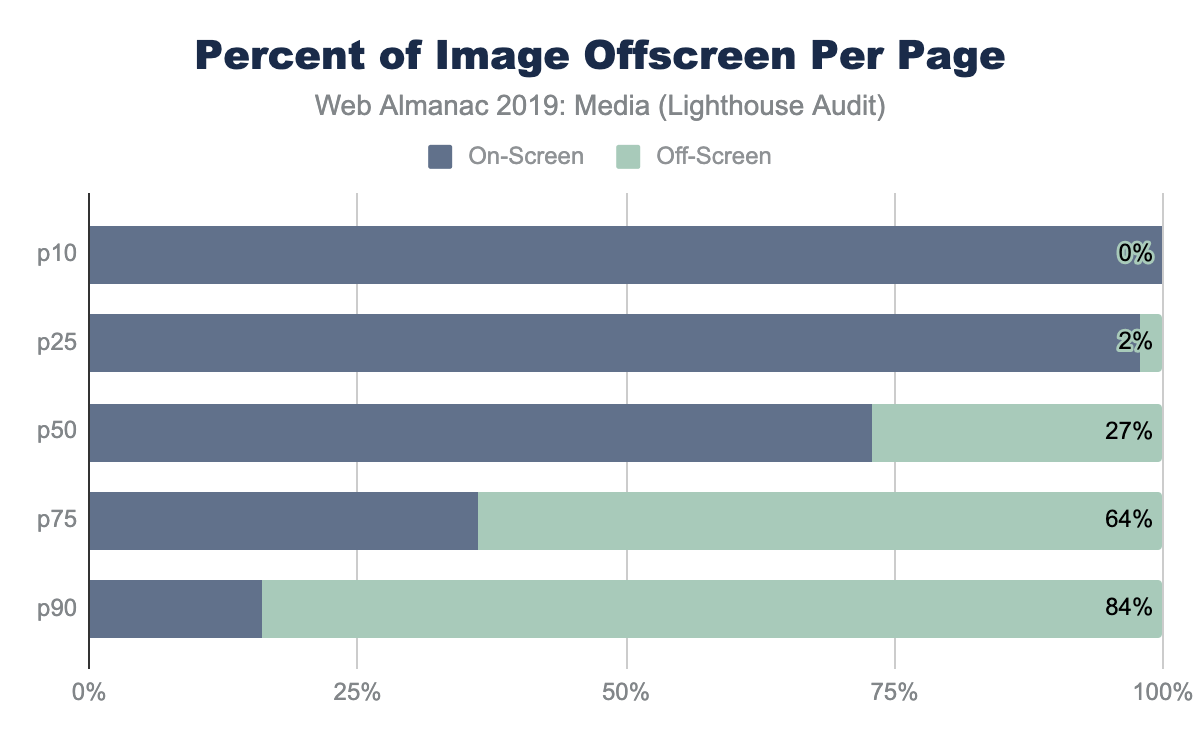 -
-  -
-  -
-  -
-  -
- 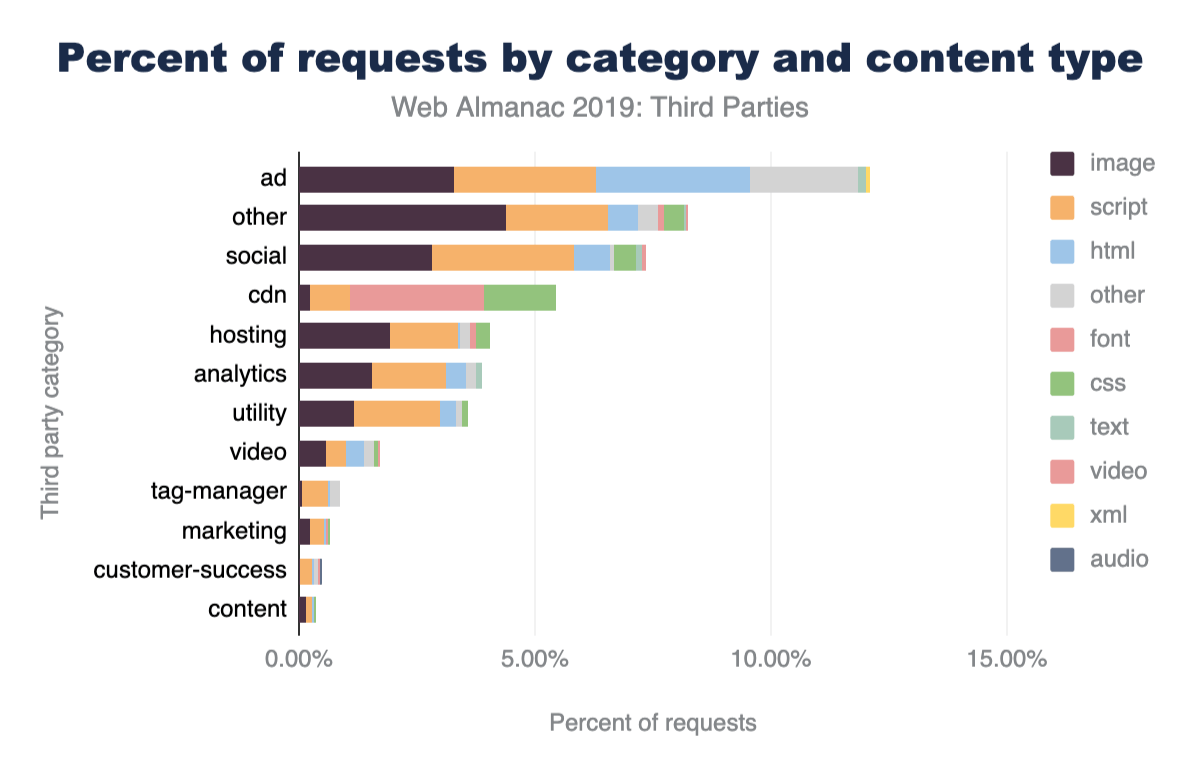 -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
- 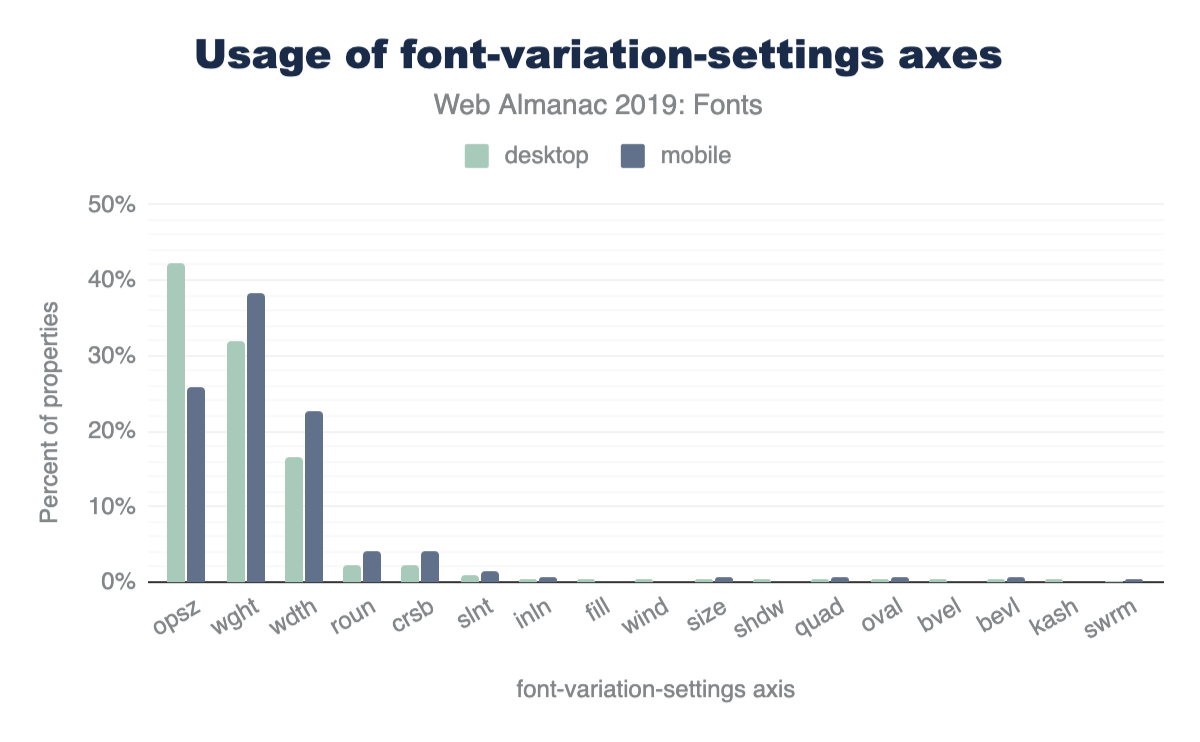 -
- 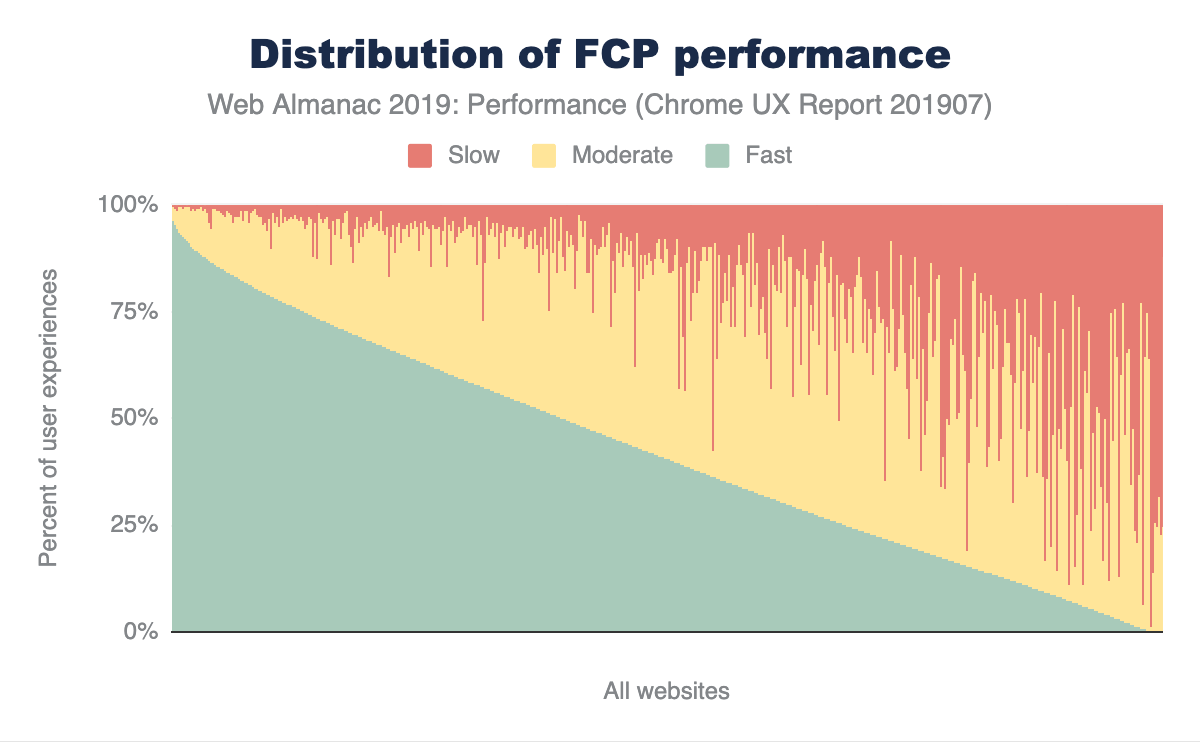 -
- 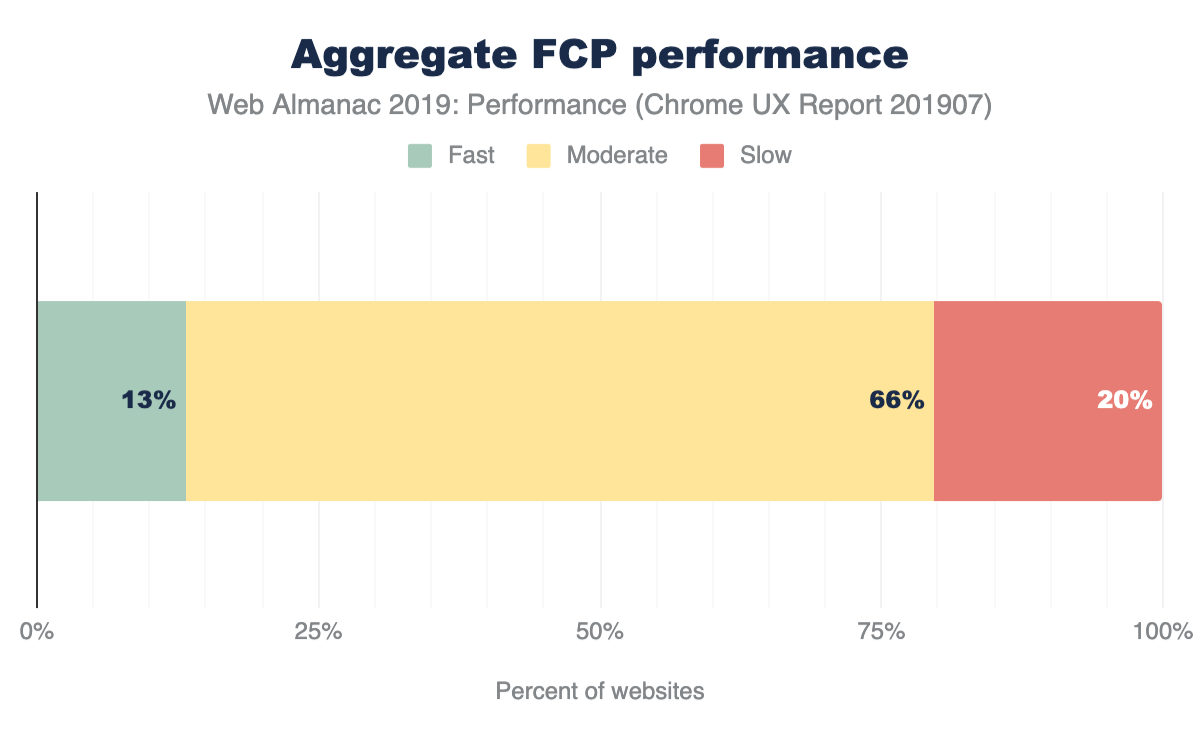 -
- 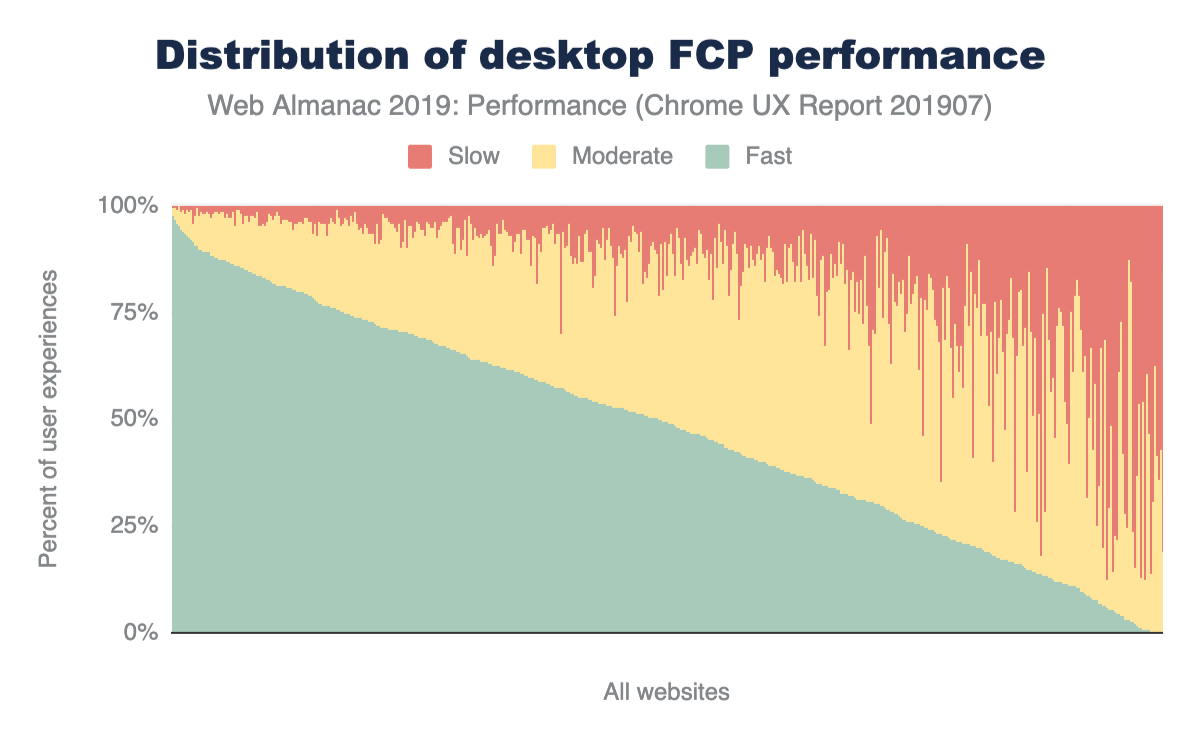 -
- 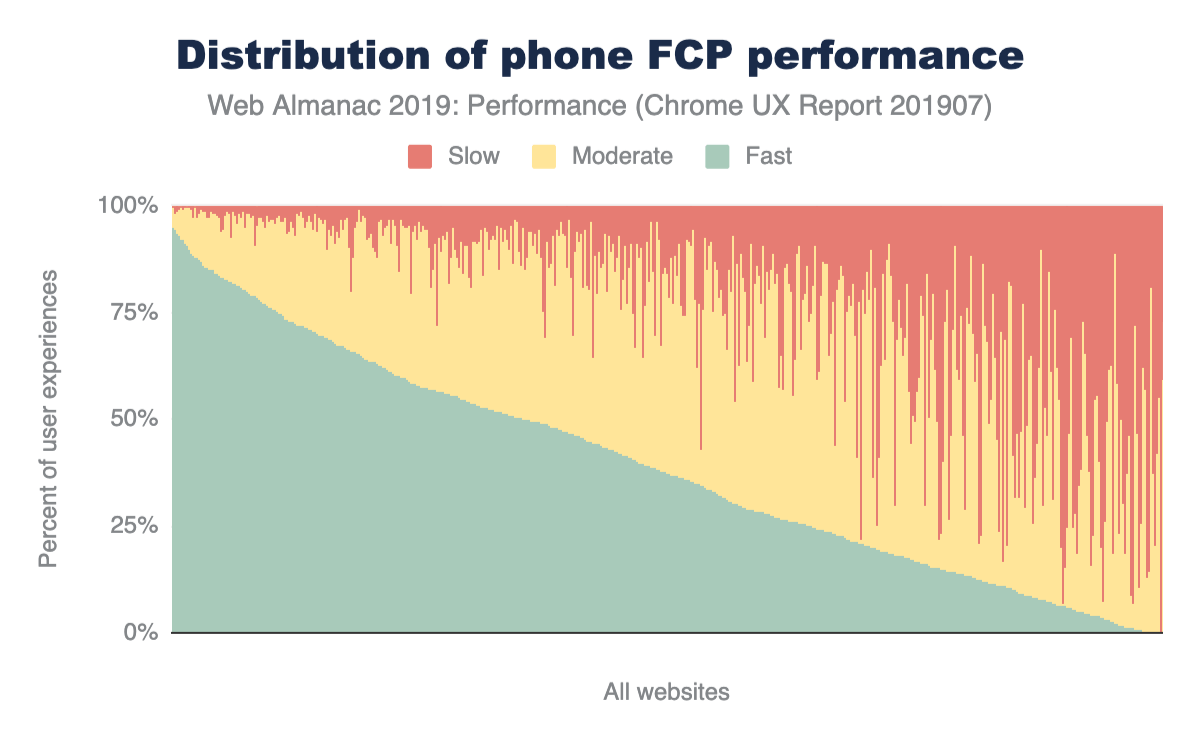 -
- 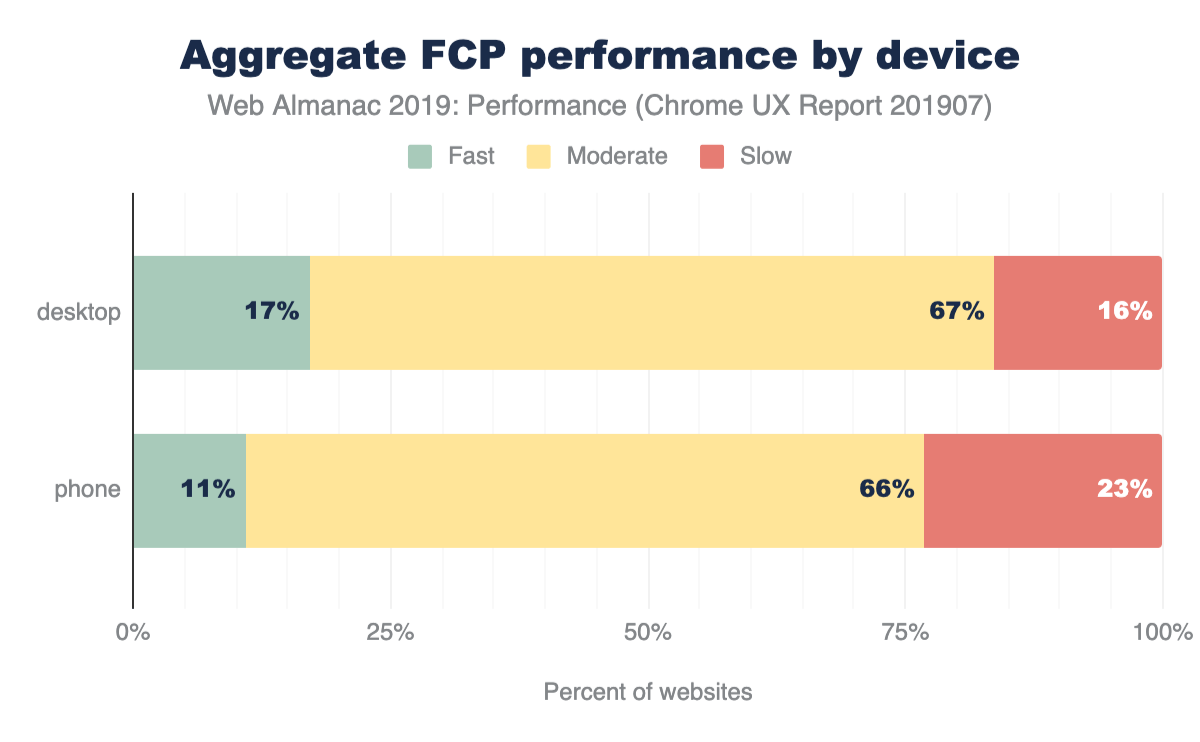 -
- 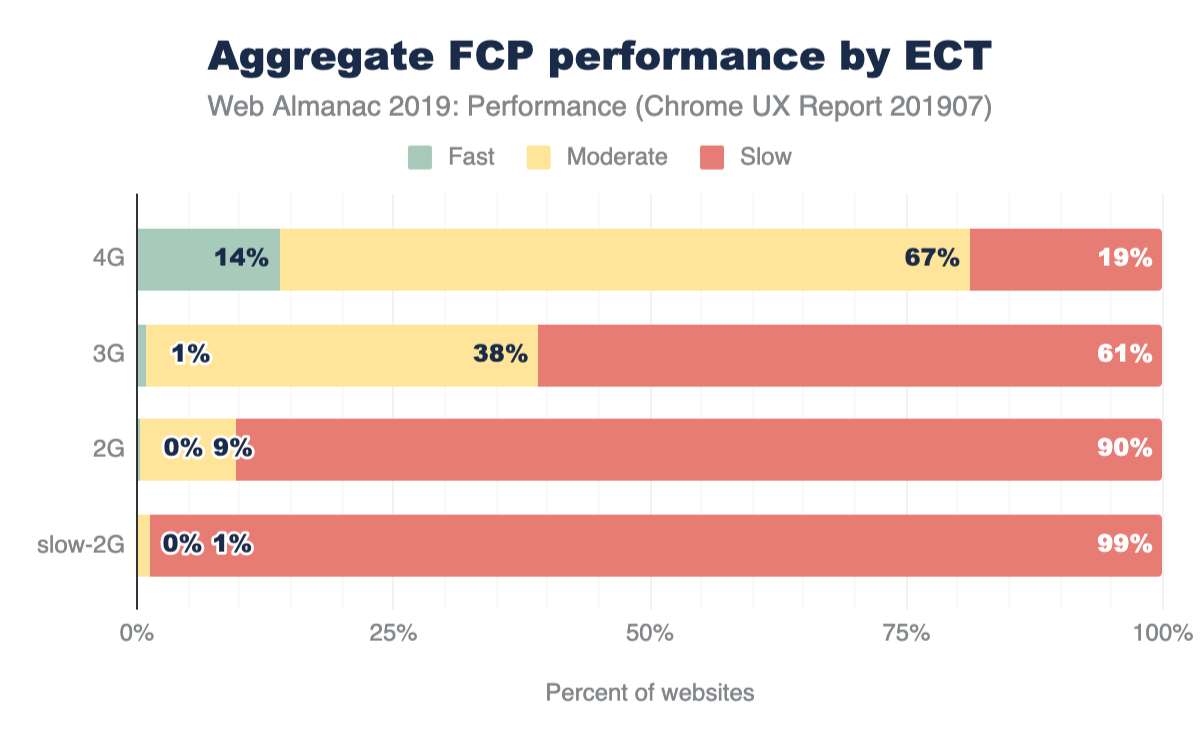 -
- 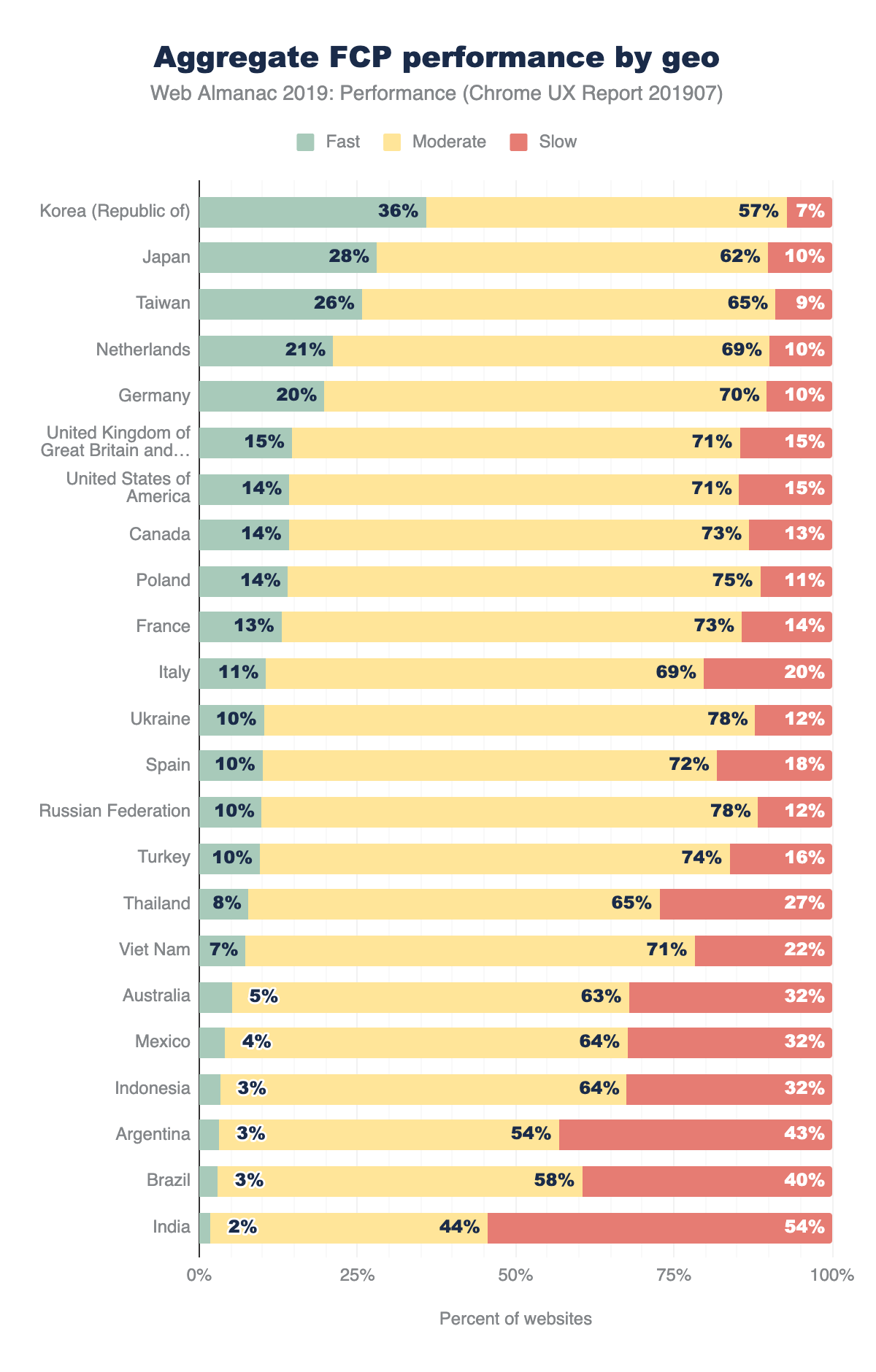 -
- 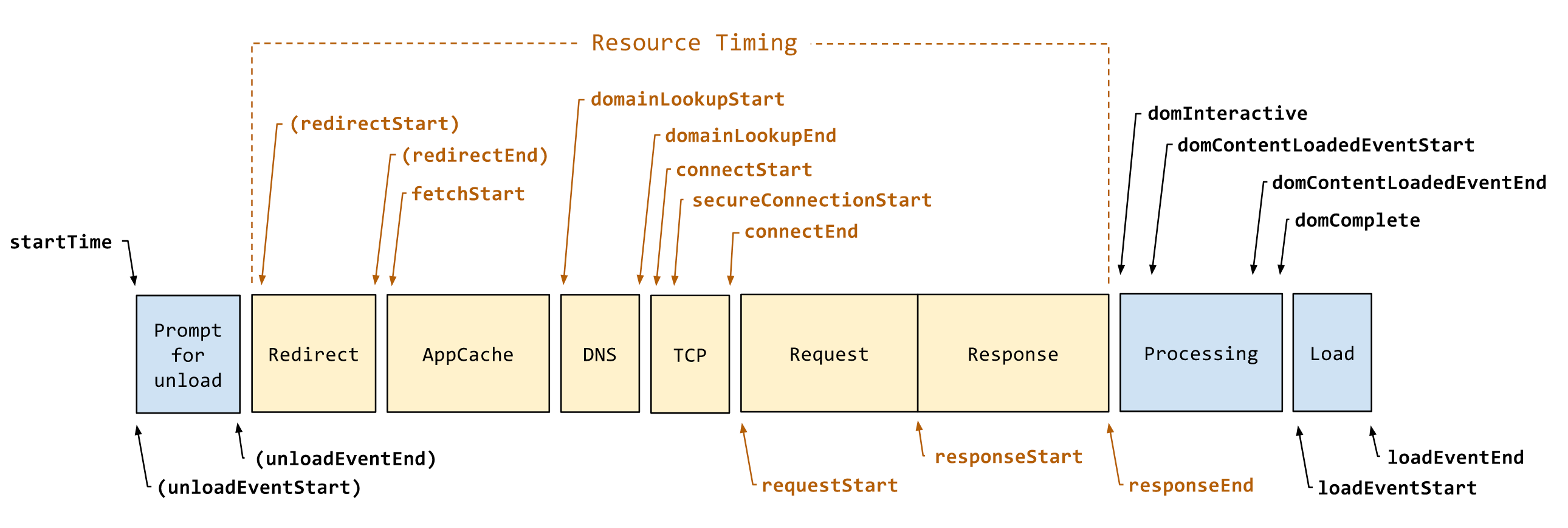 -
- 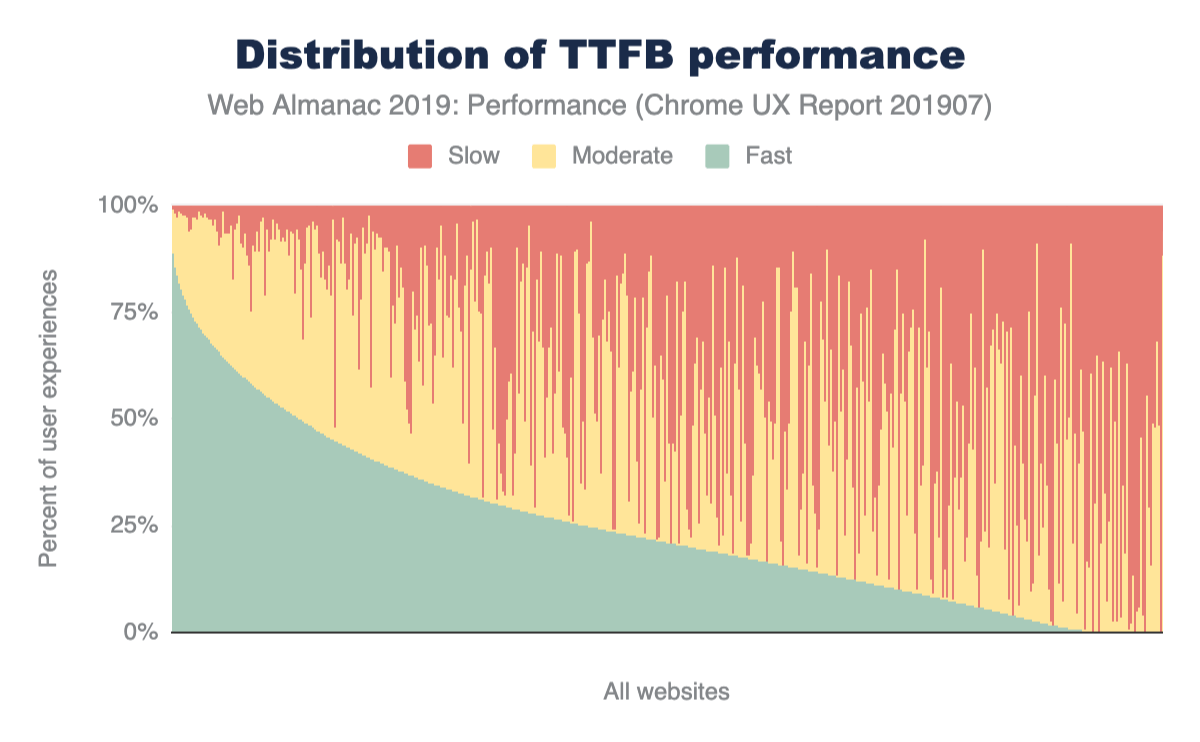 -
- 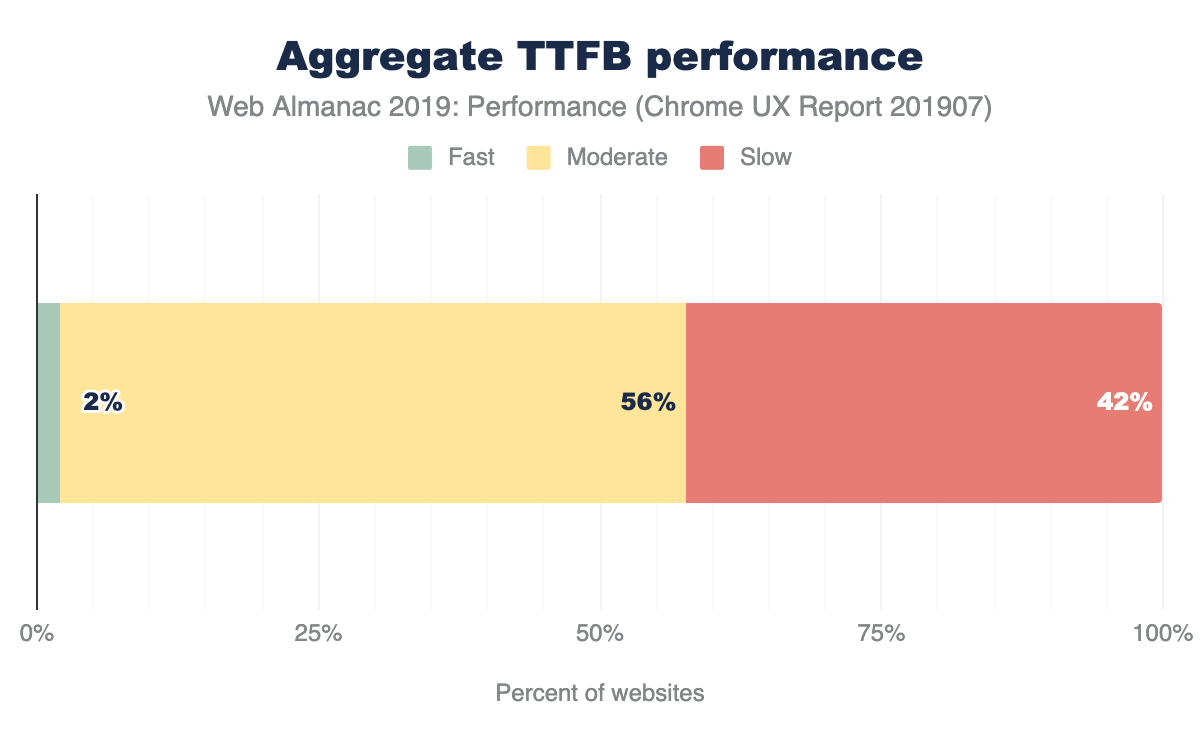 -
- 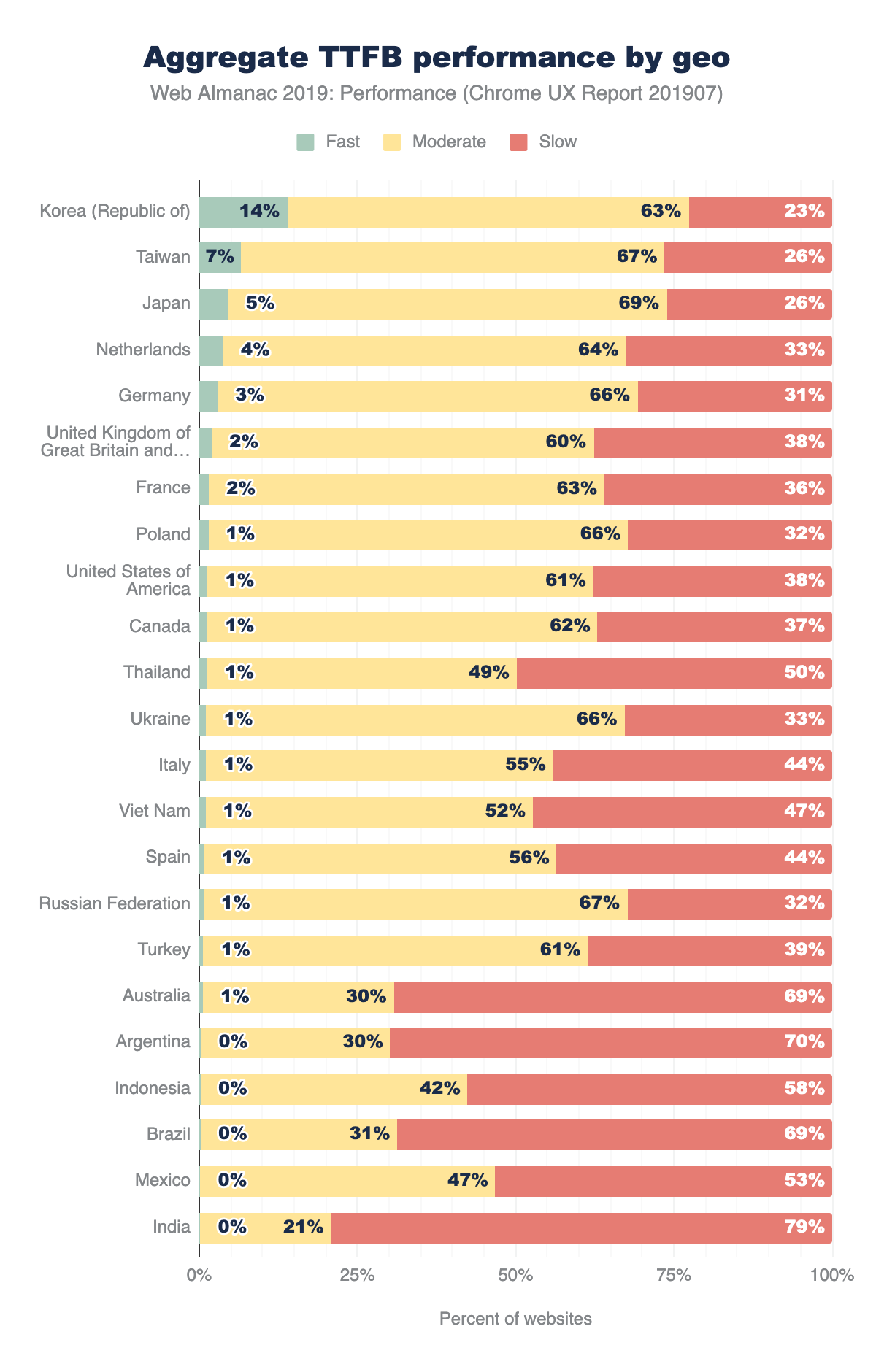 -
-  -
-  -
-  -
-  -
- 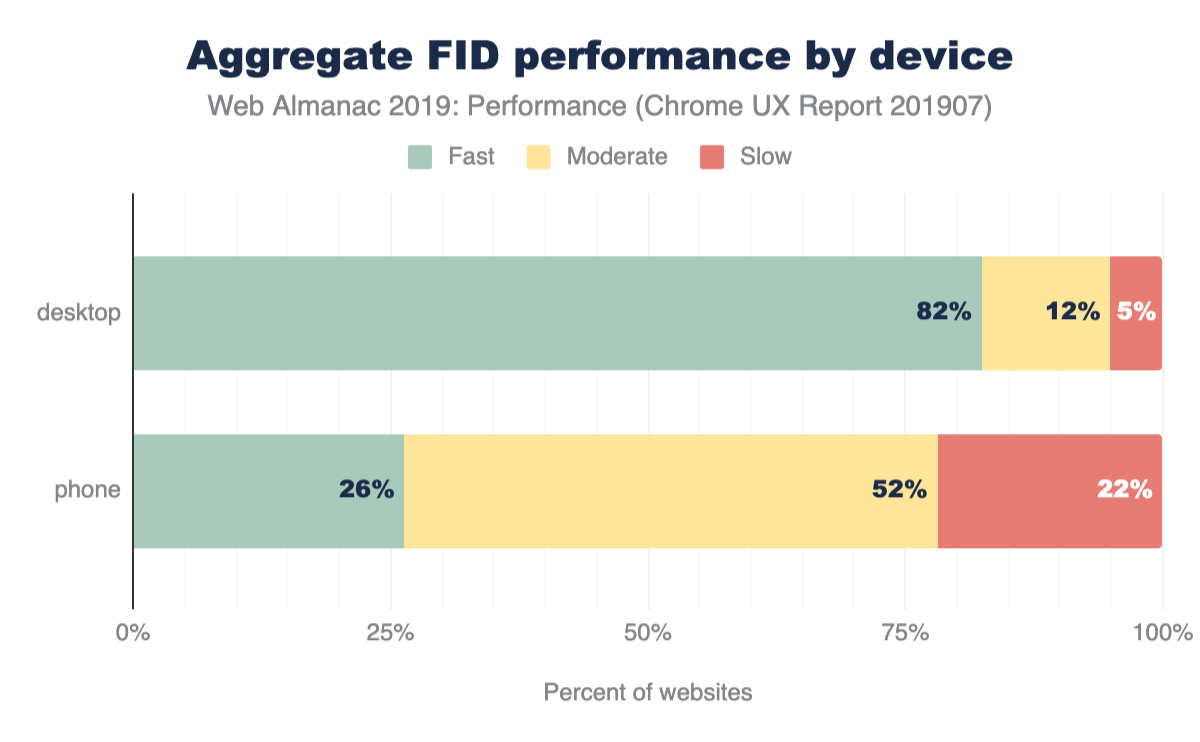 -
- 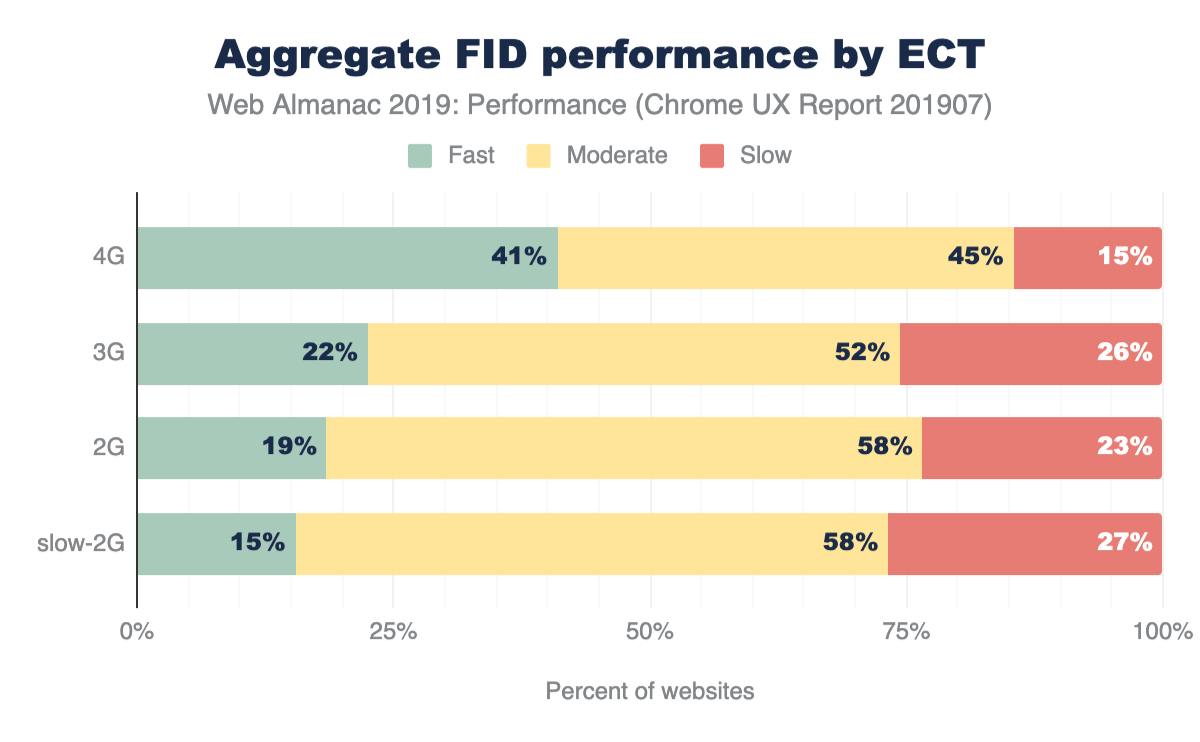 -
- 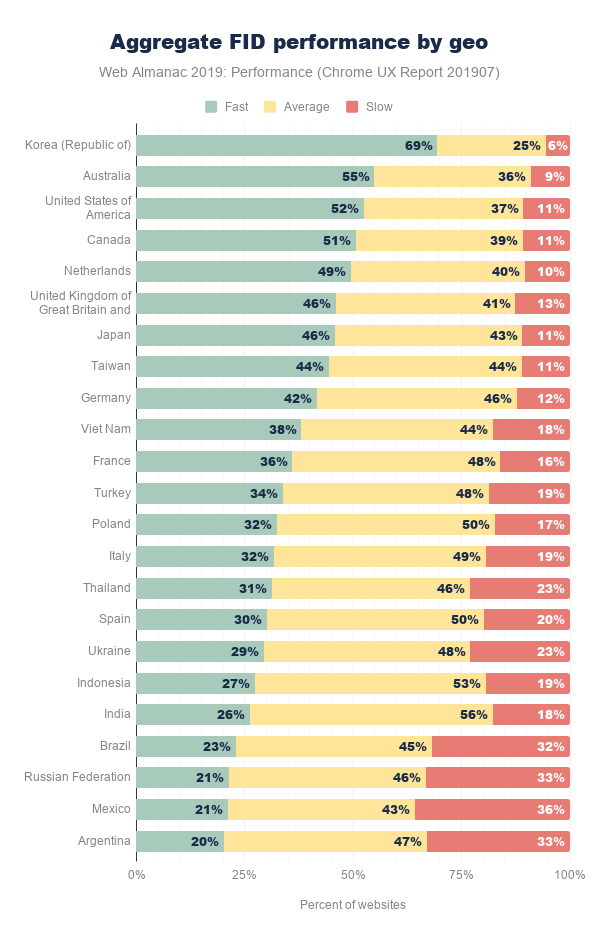 -
- 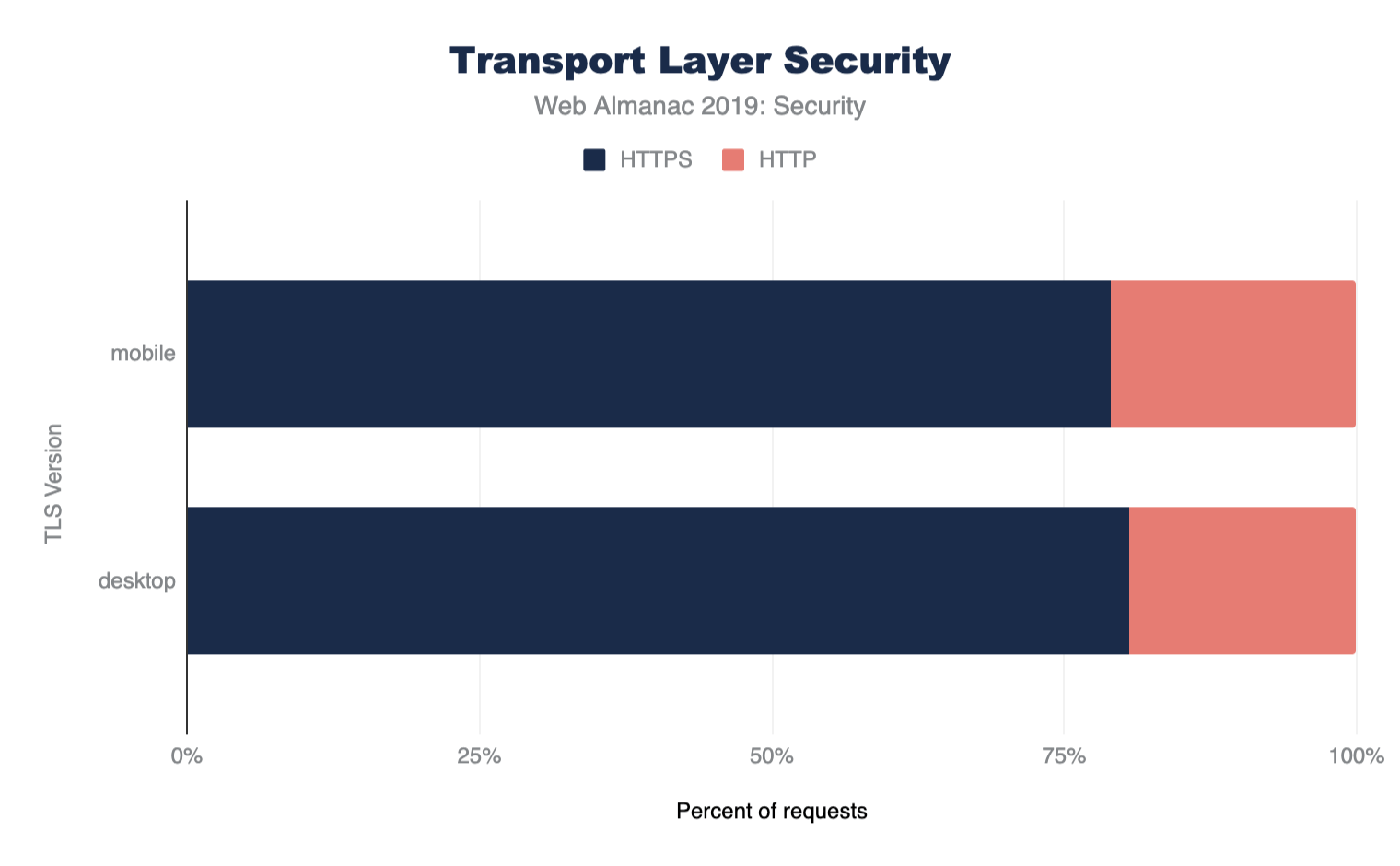 -
- 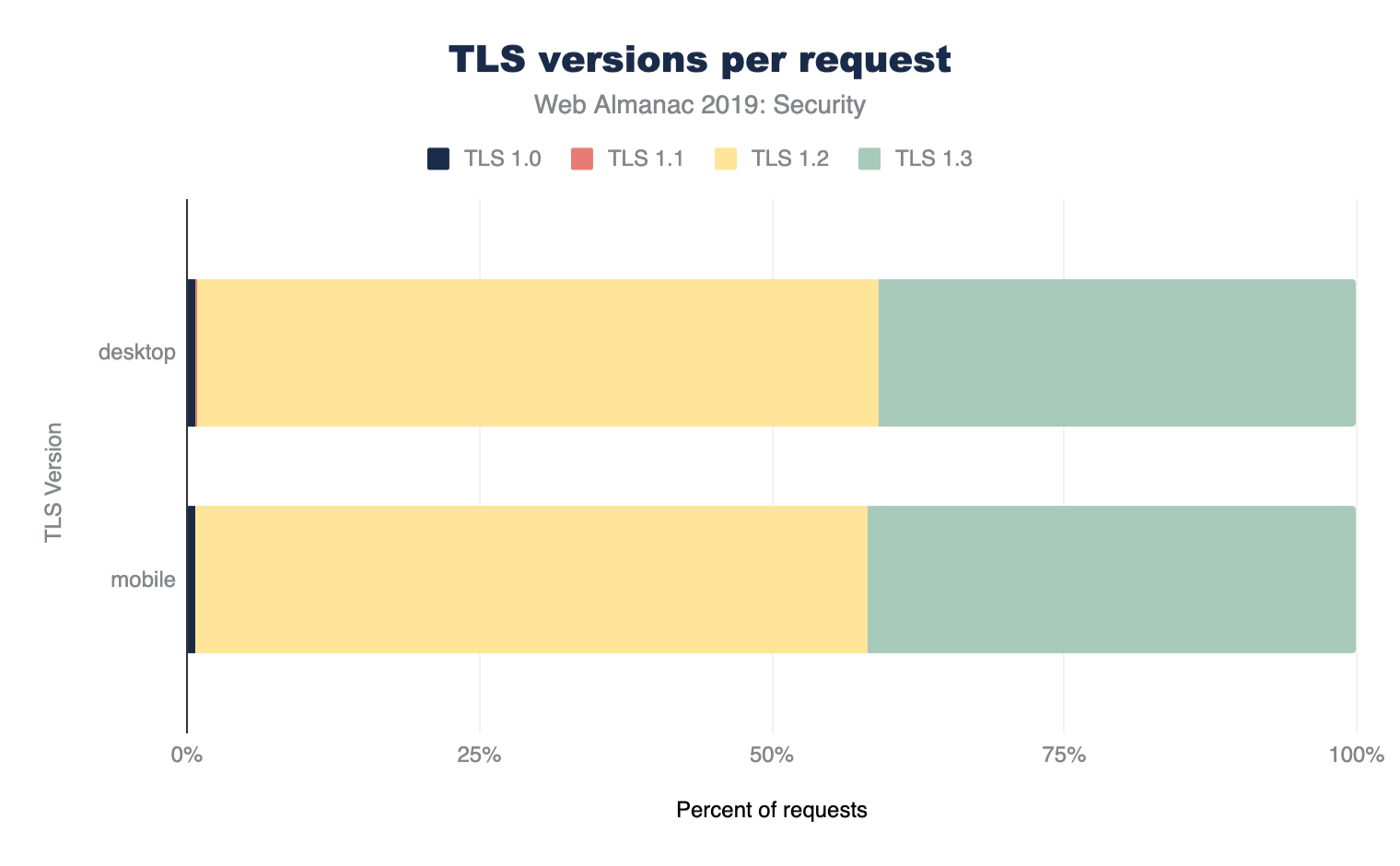 -
- 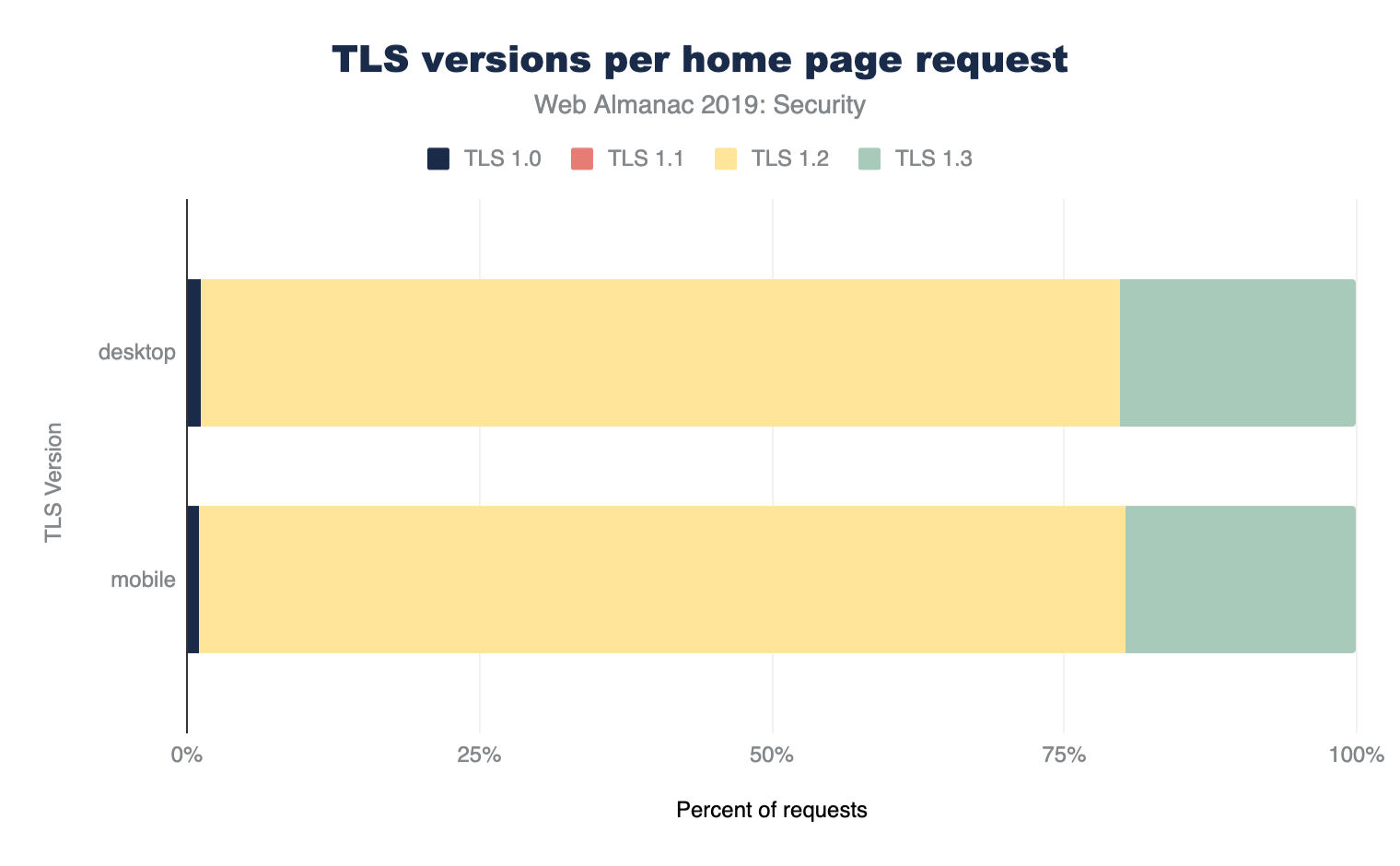 -
- 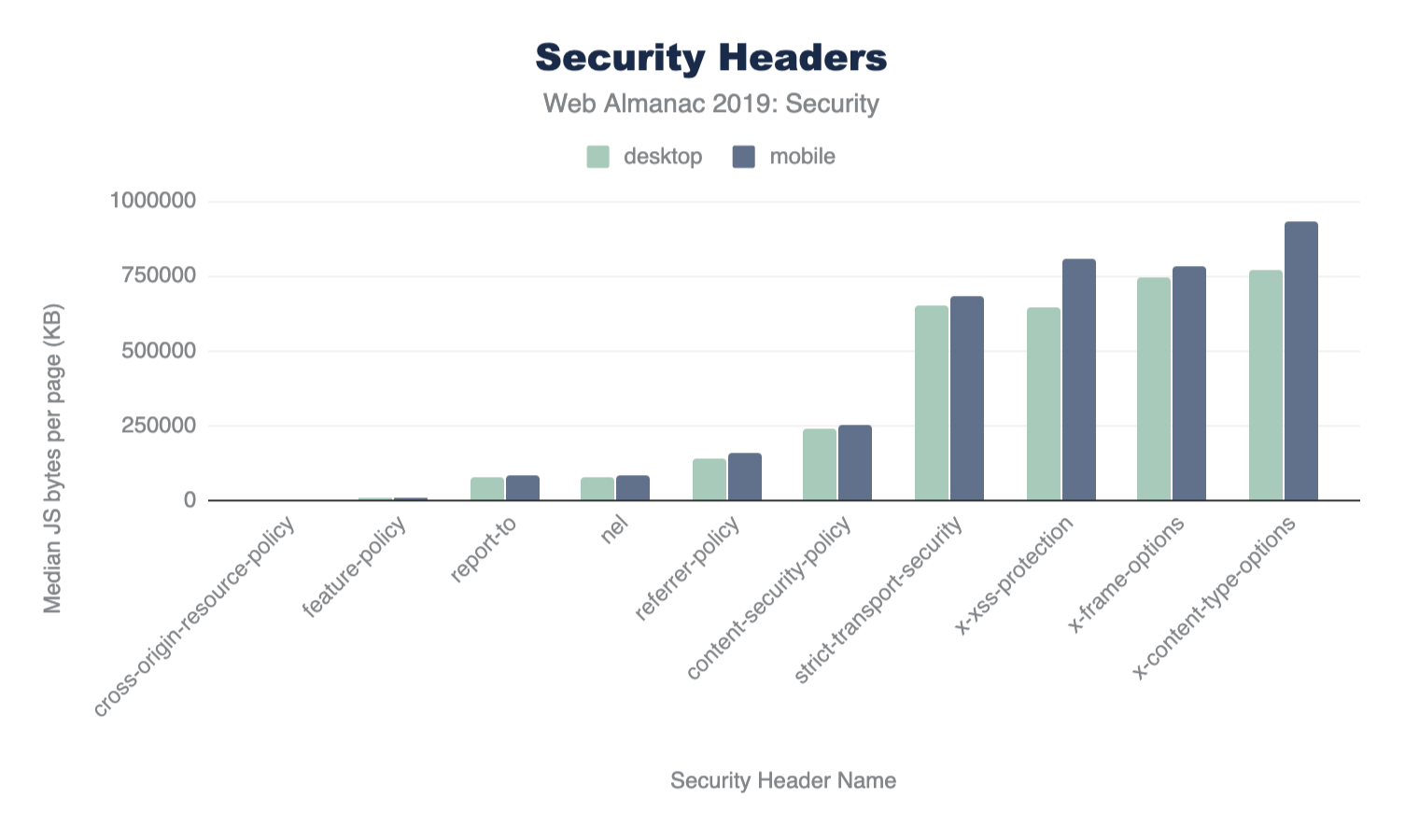 -
-  -
- 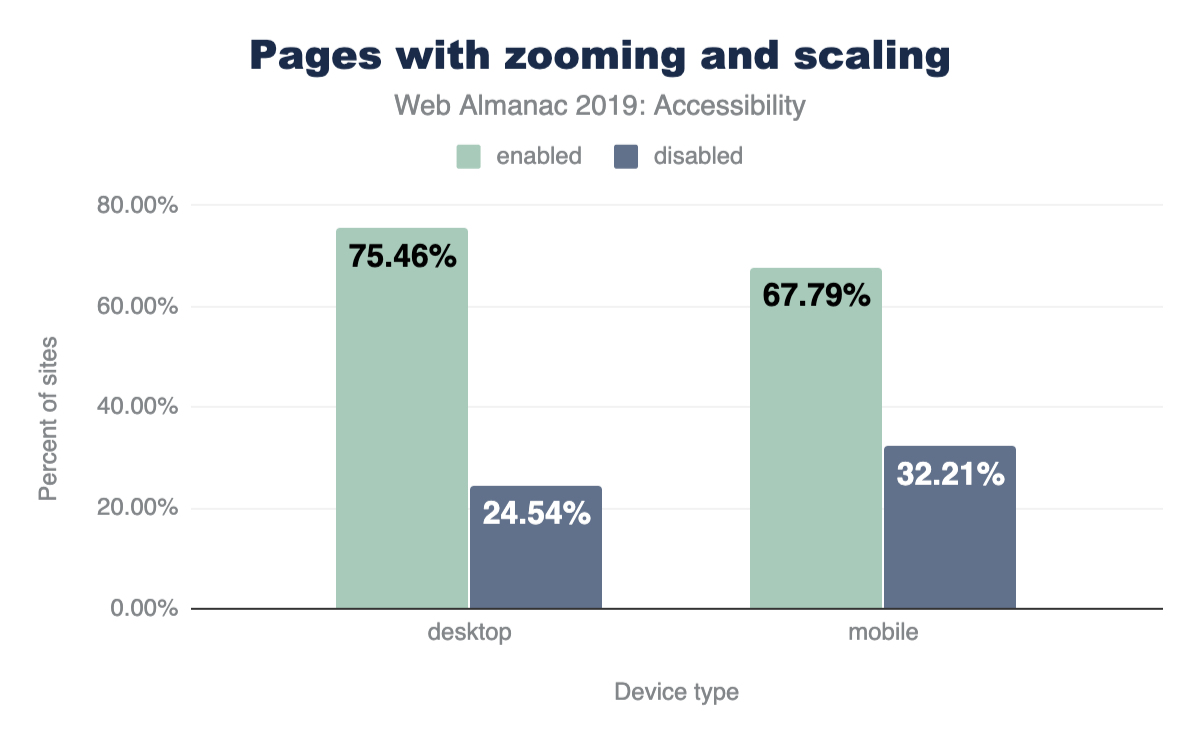 -
- 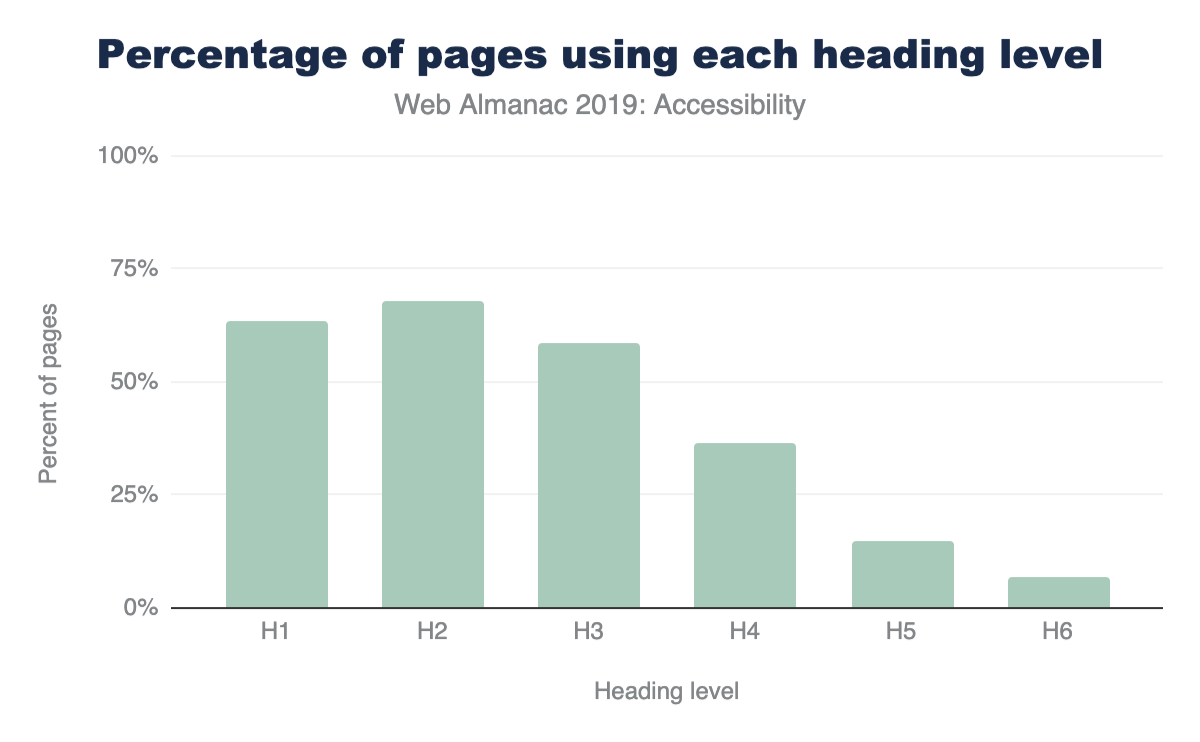 -
- 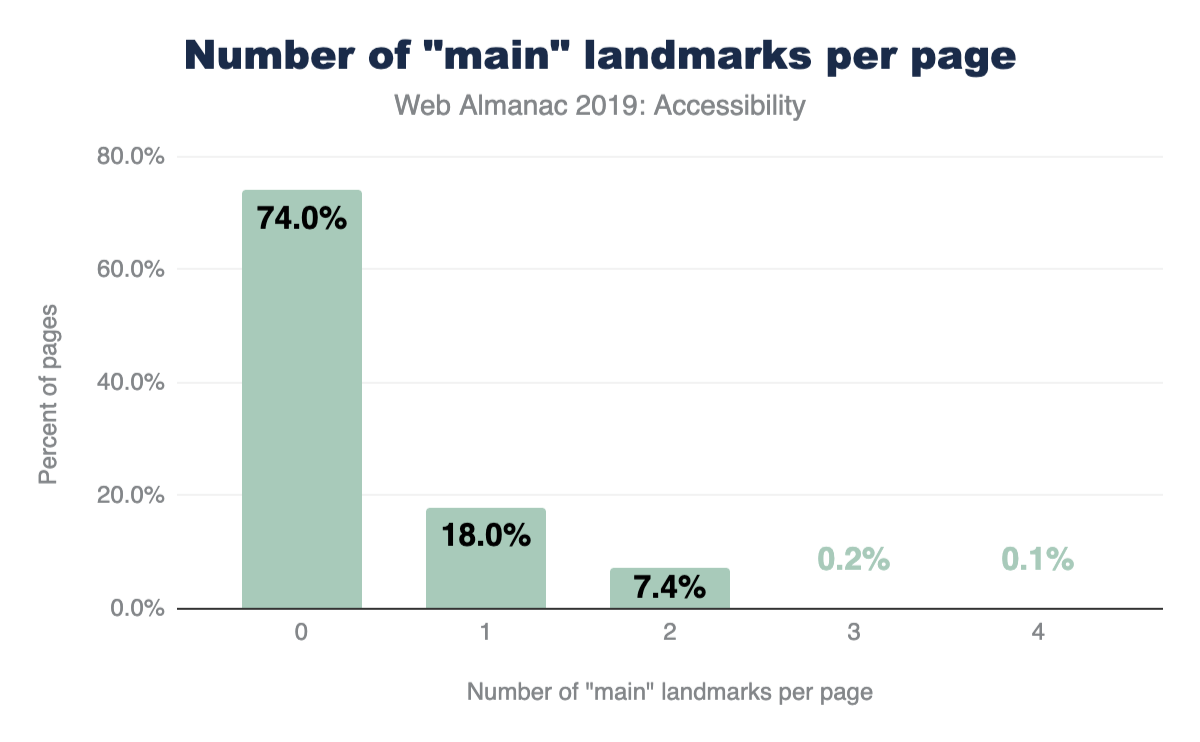 -
- 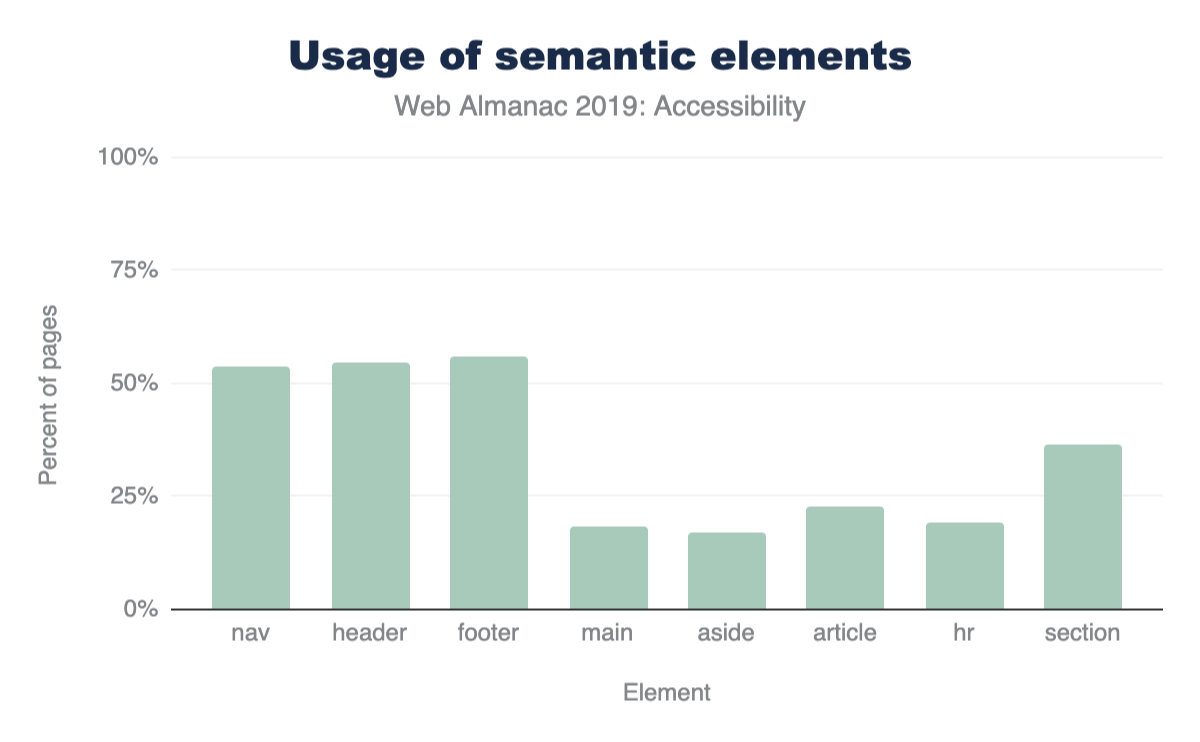 -
- 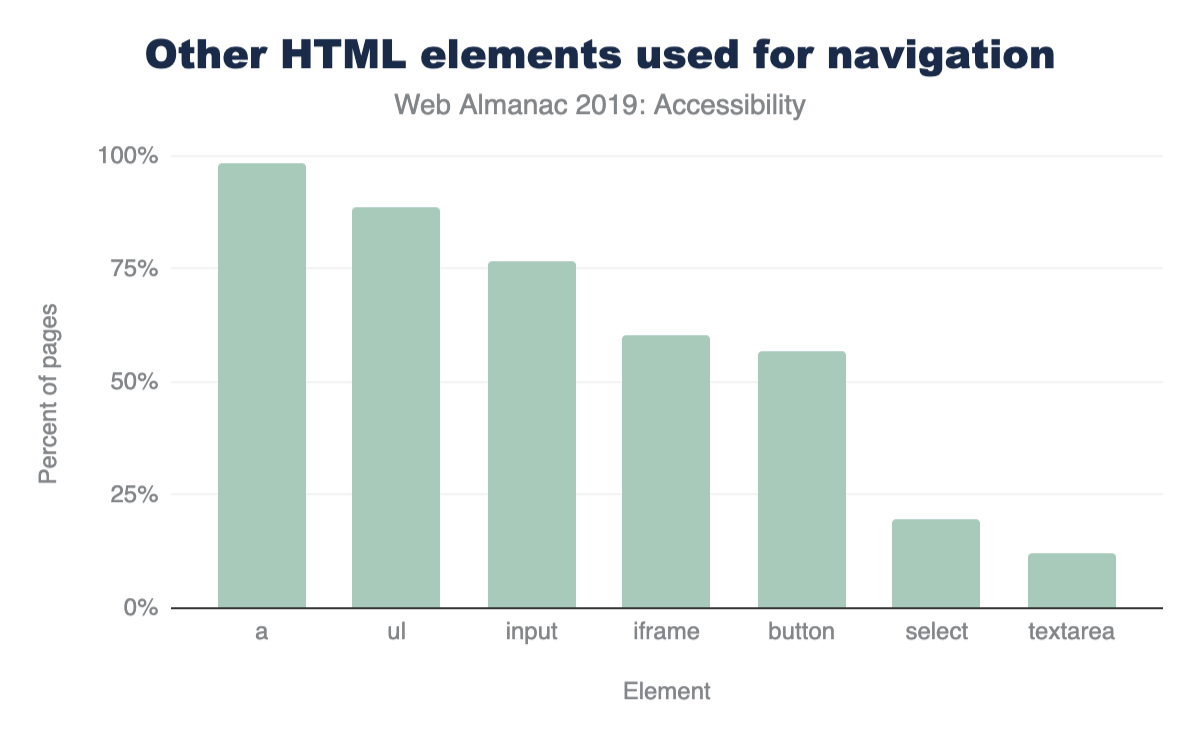 -
- 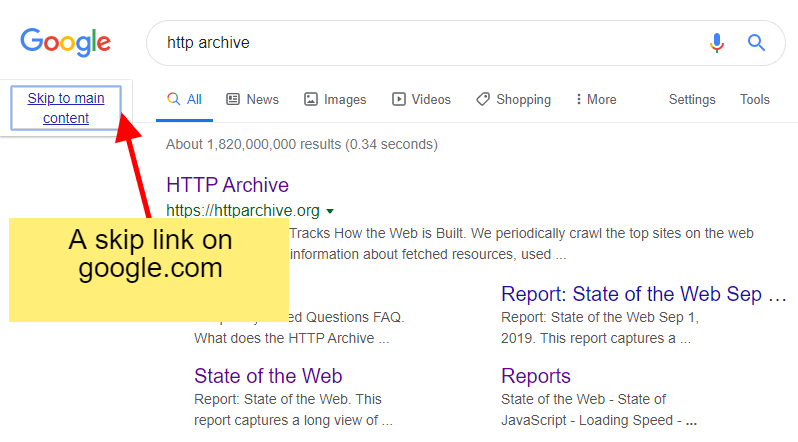 -
- 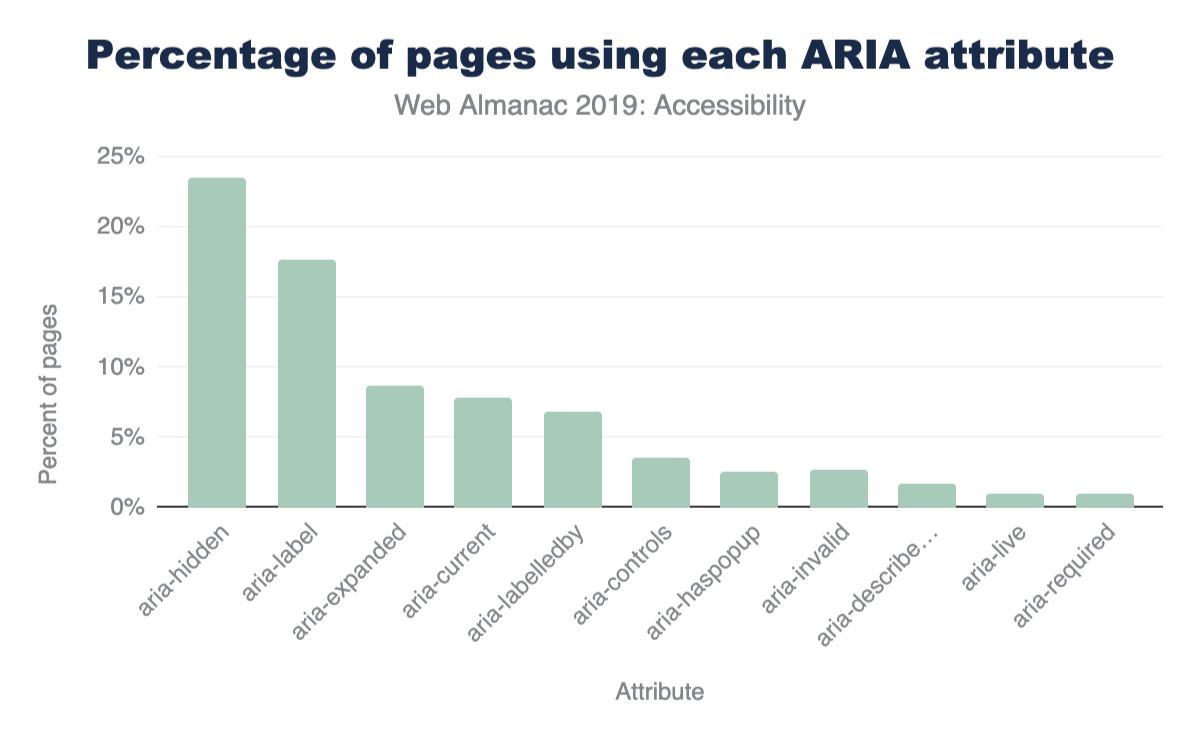 -
- 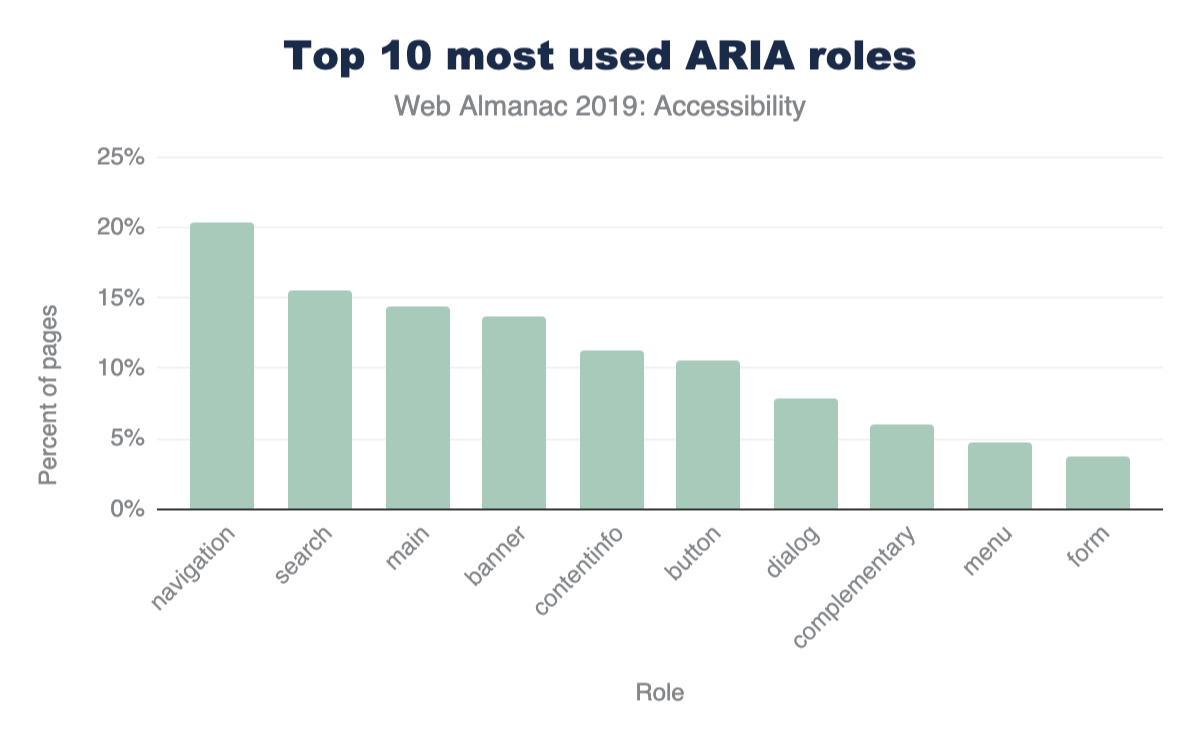 -
-  -
- 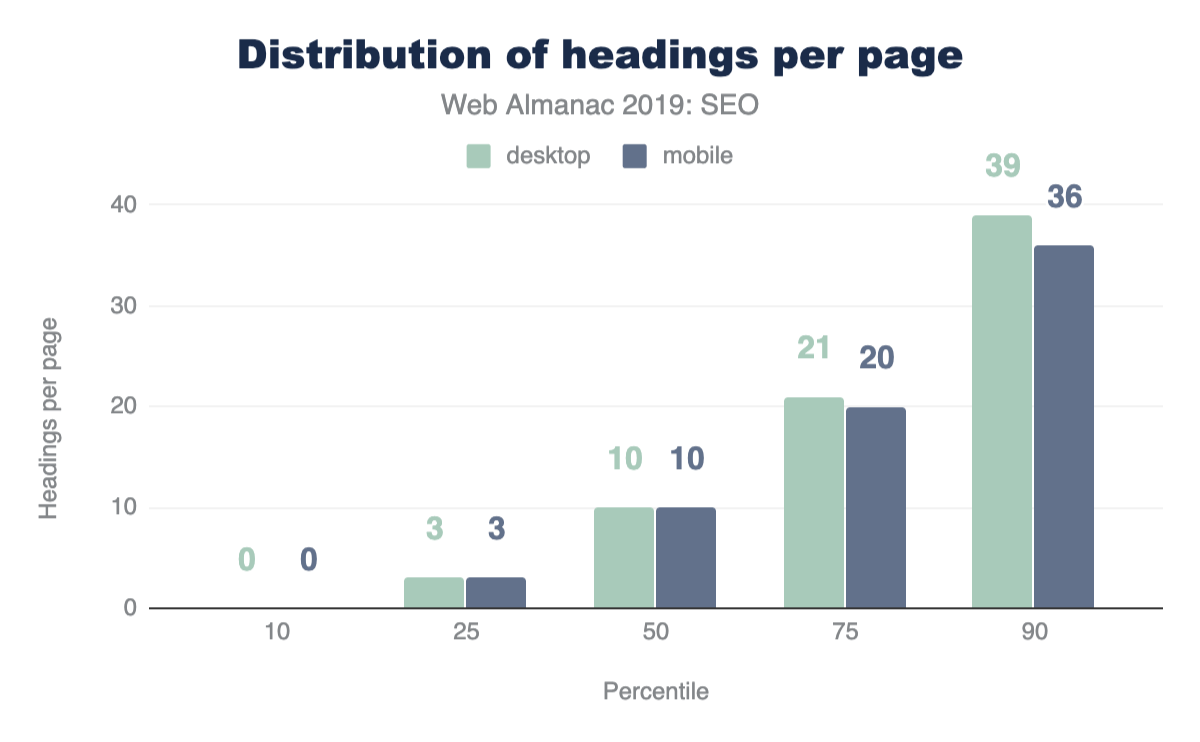 -
-  -
-  -
-  -
- 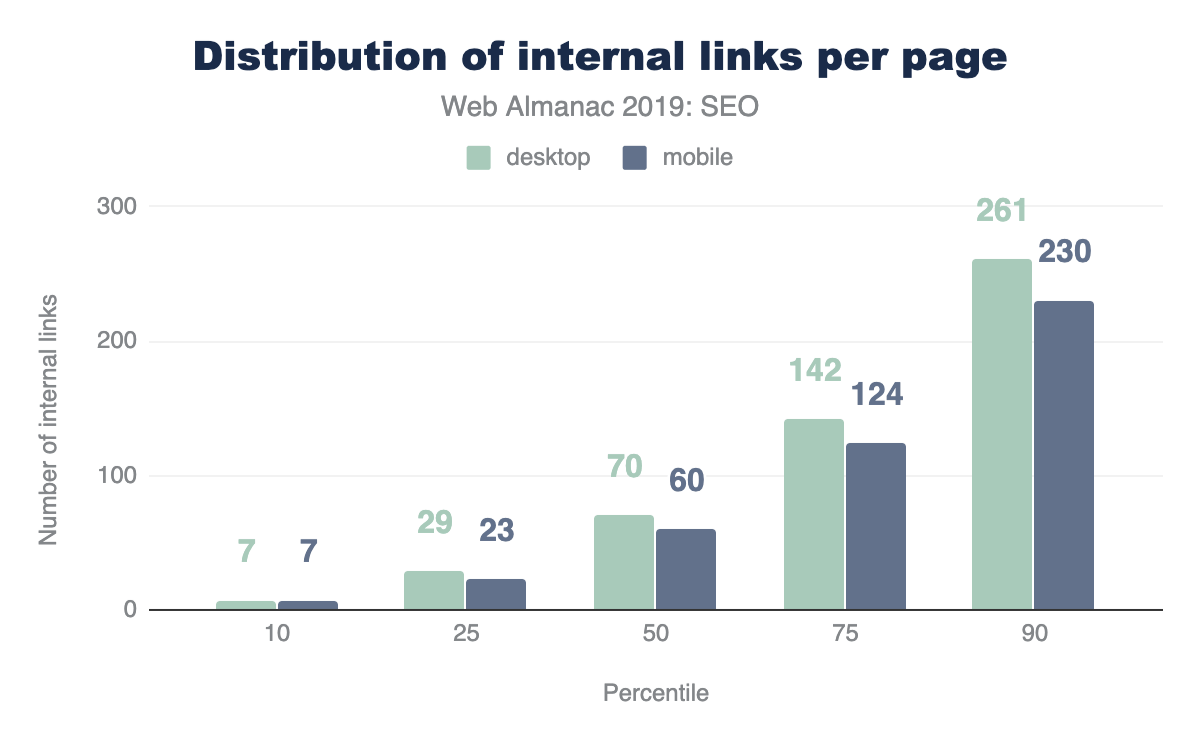 -
- 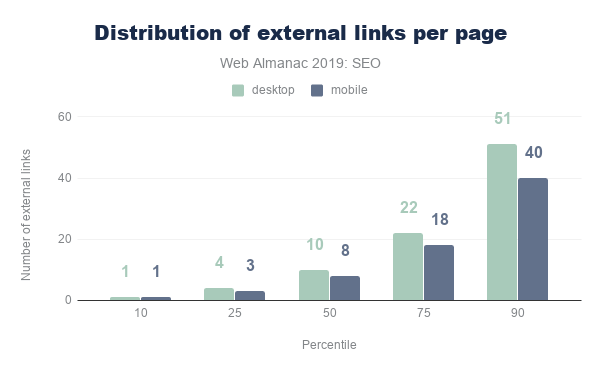 -
- 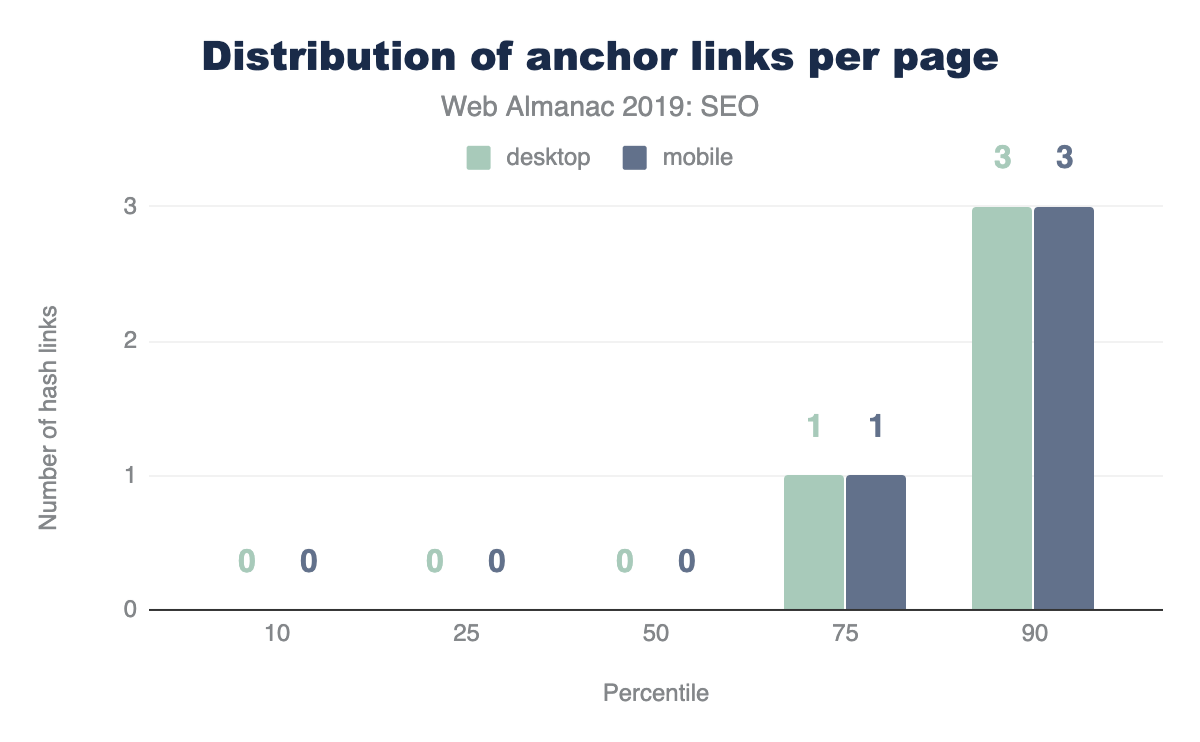 -
- 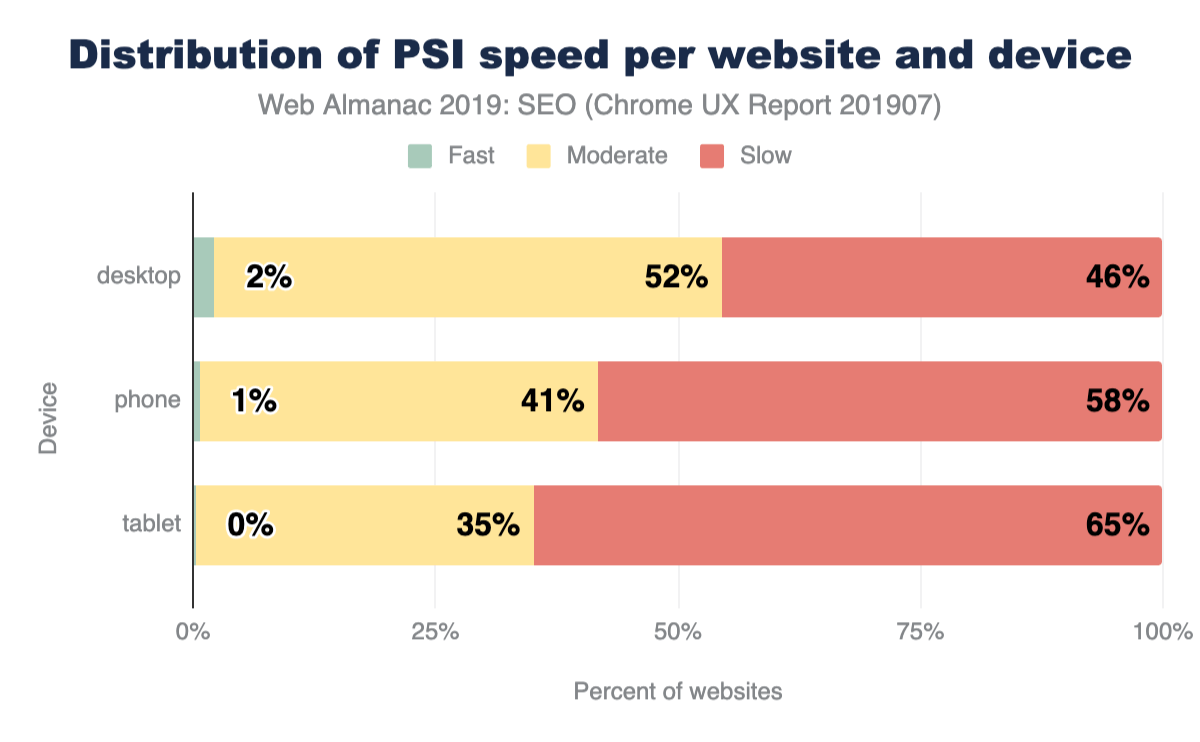 -
- 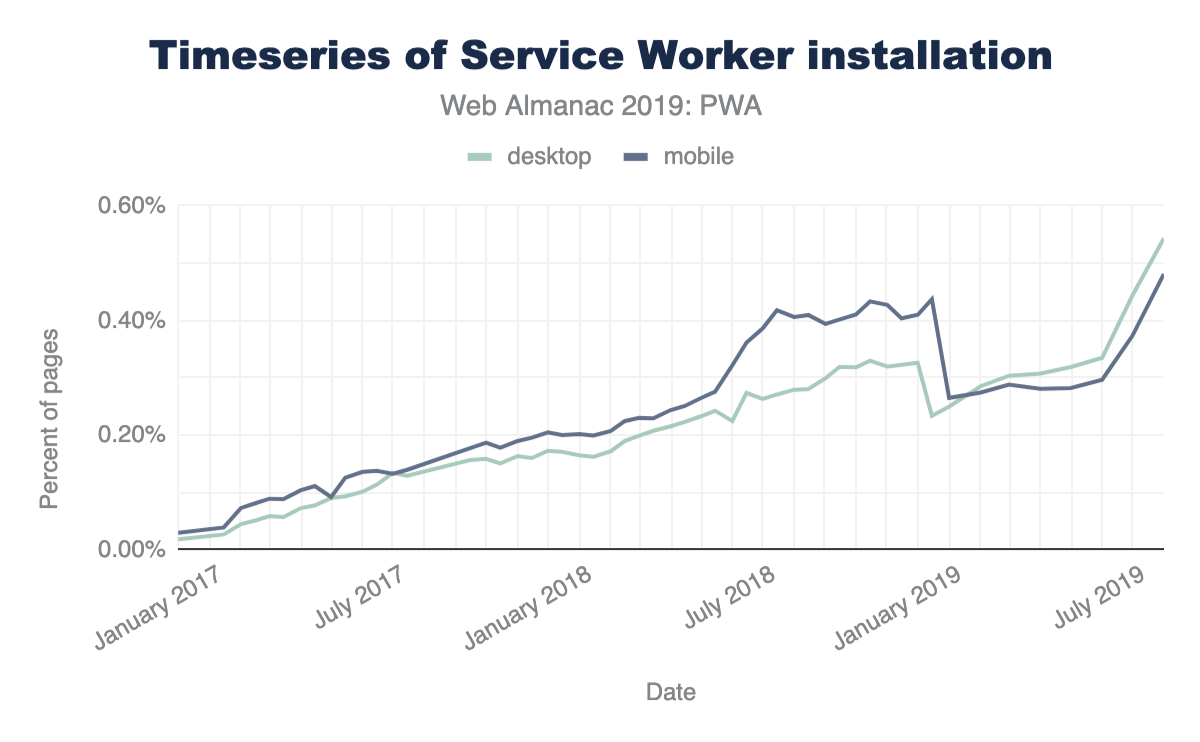 -
-  -
-  -
-  -
- 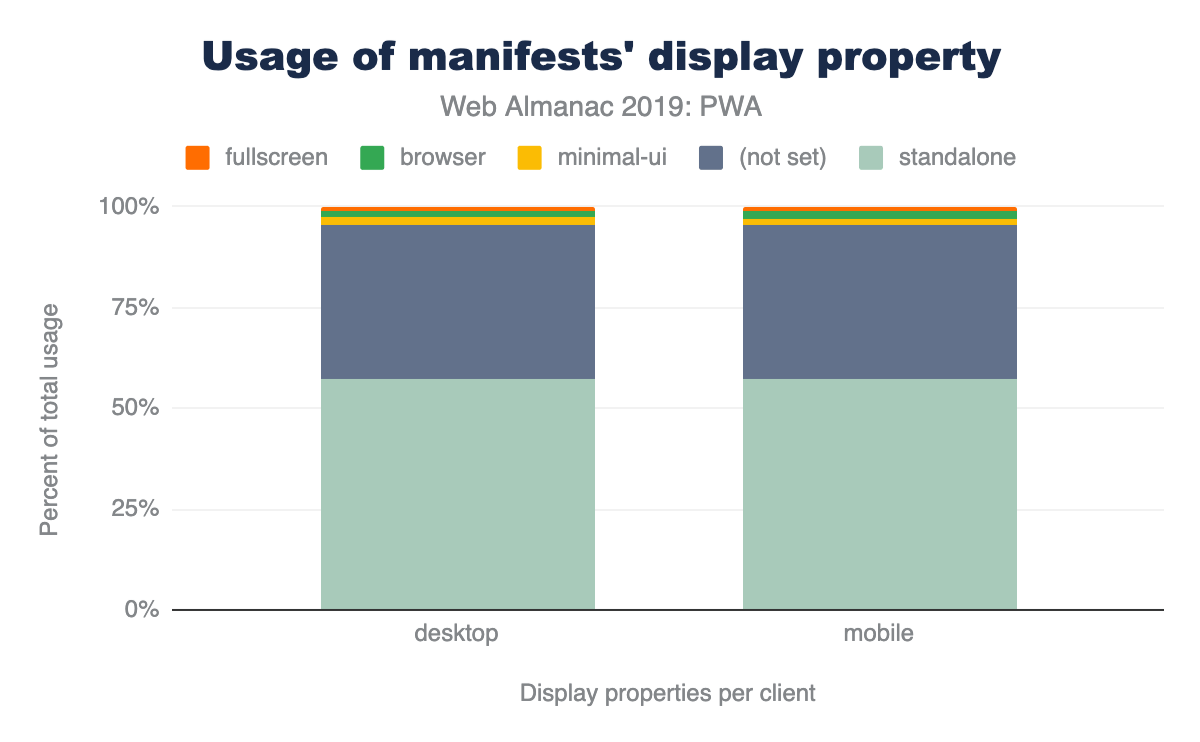 -
- 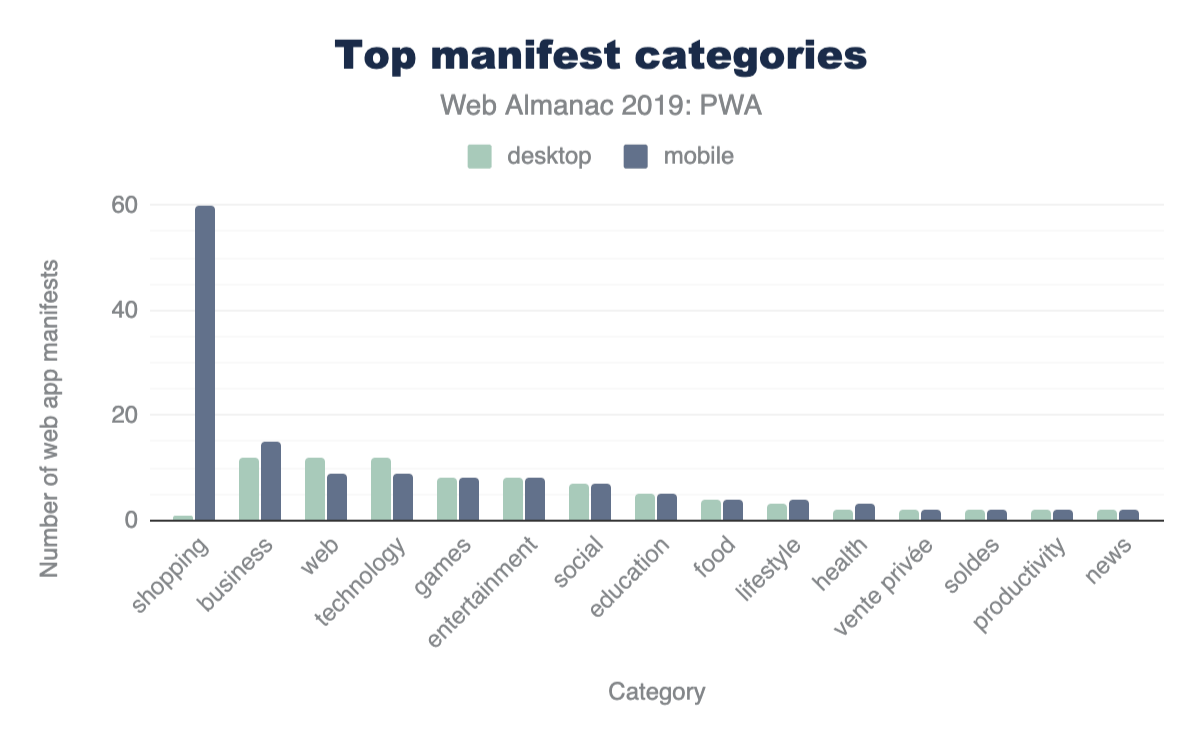 -
- 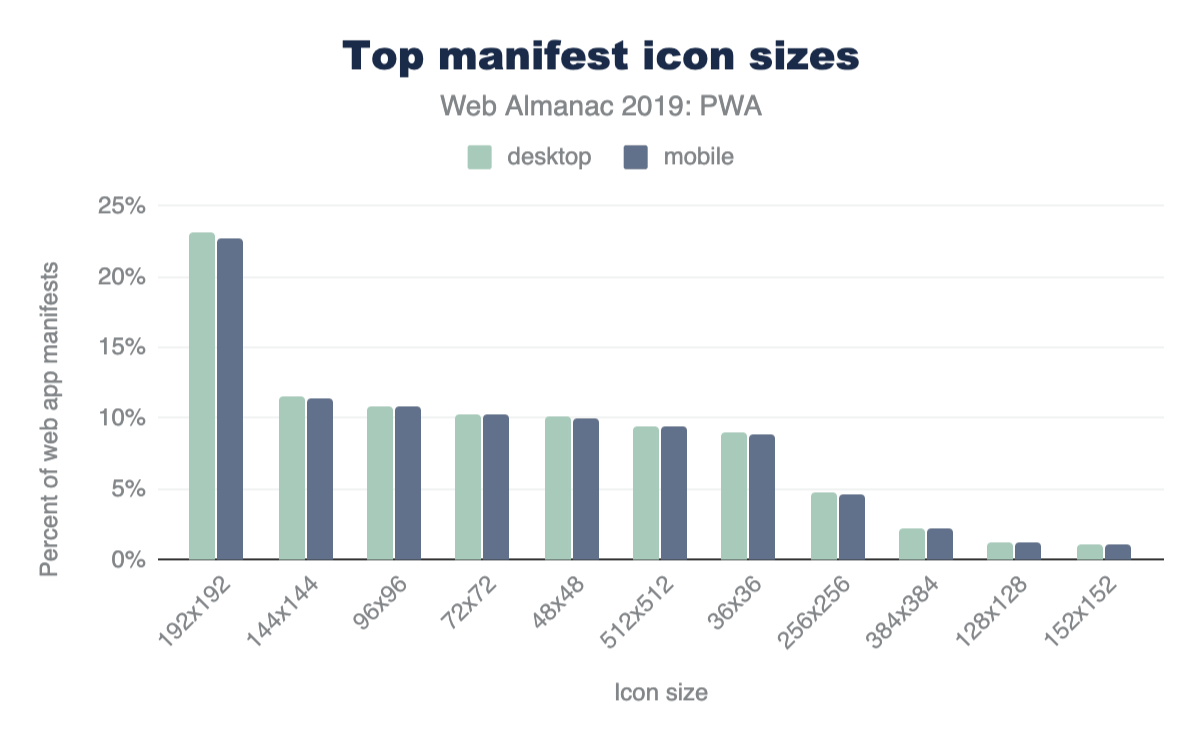 -
- 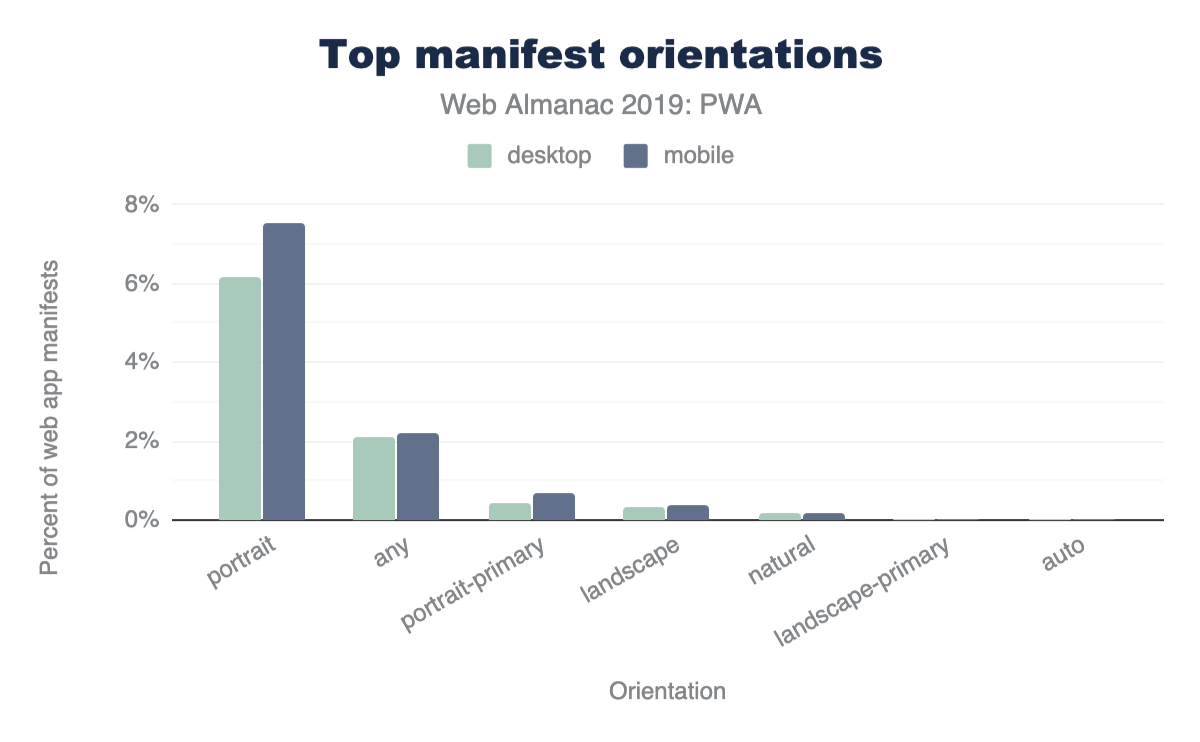 -
-  -
-  -
- 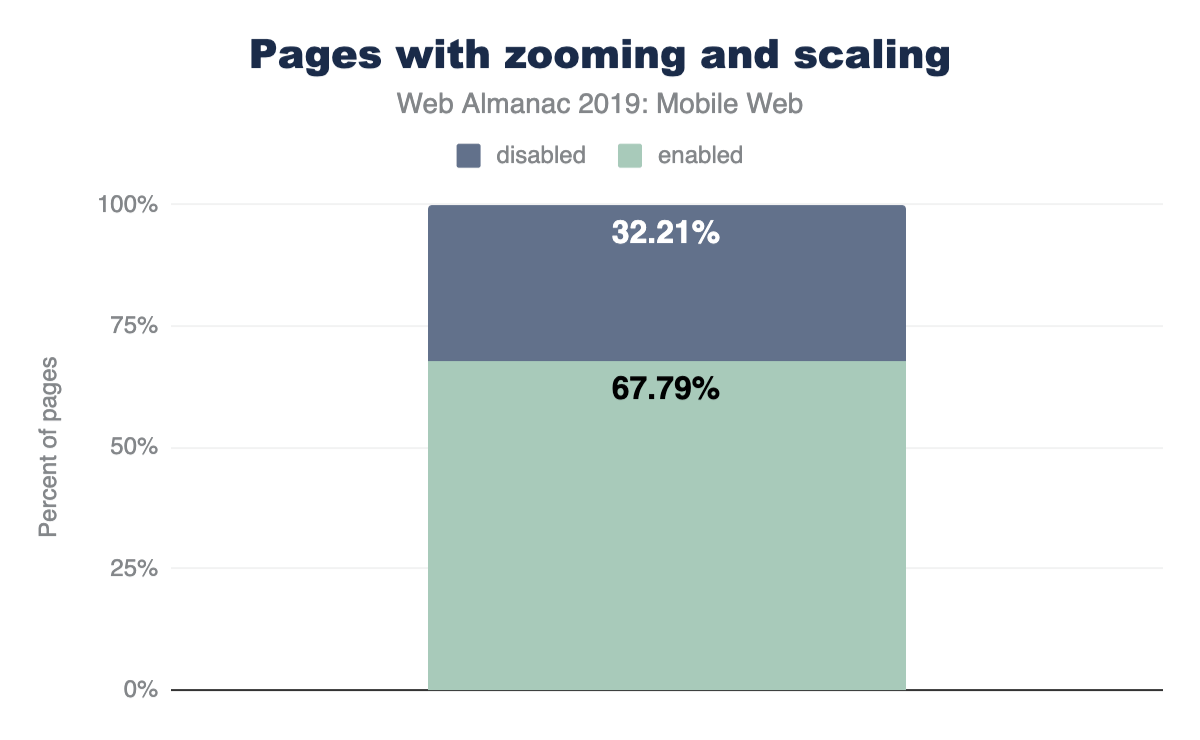 -
-  -
-  -
-  -
-  -
- 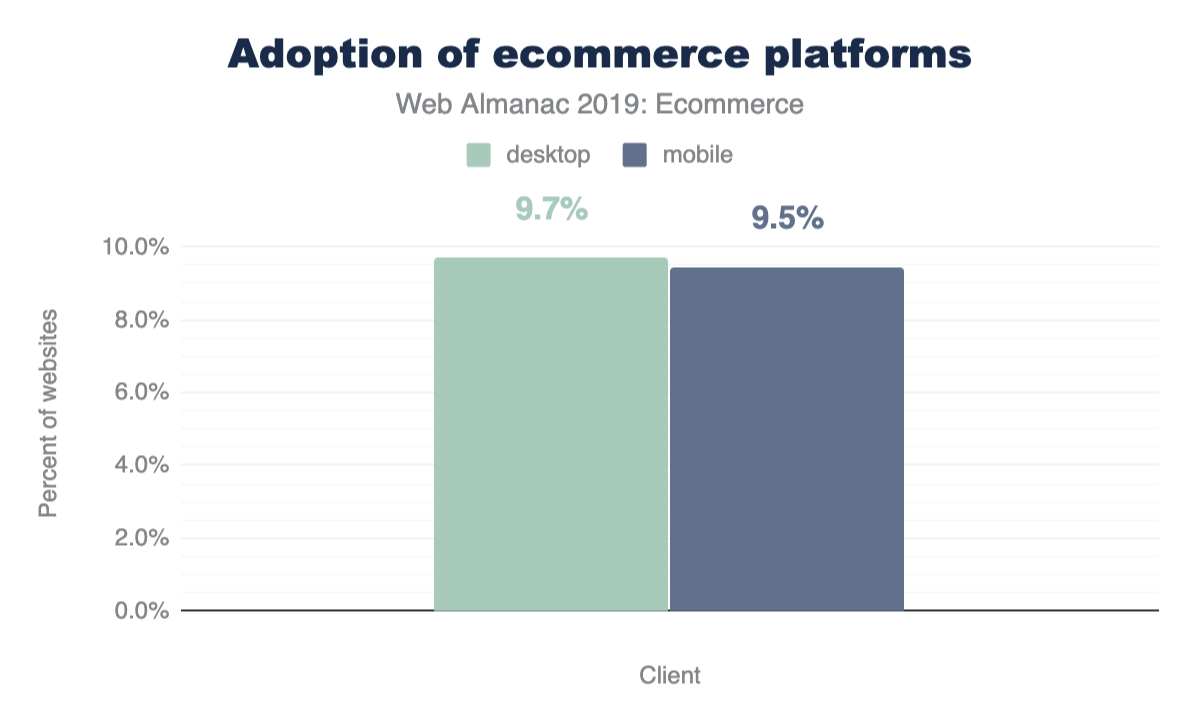 -
- 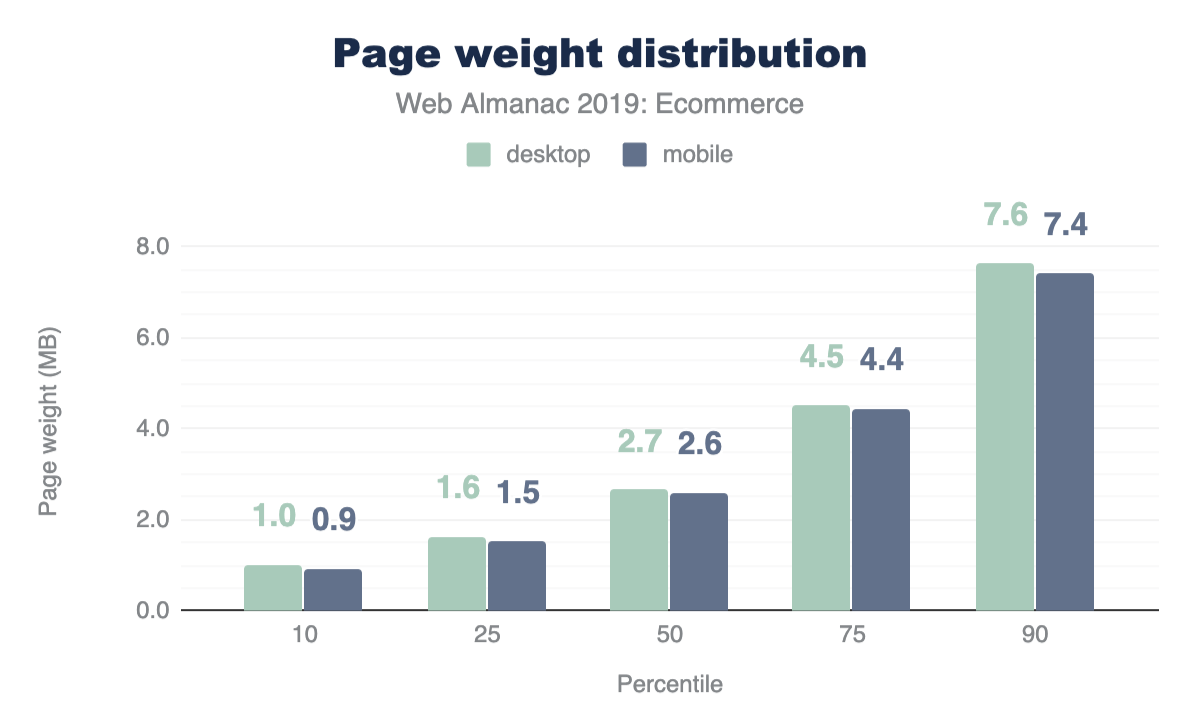 -
- 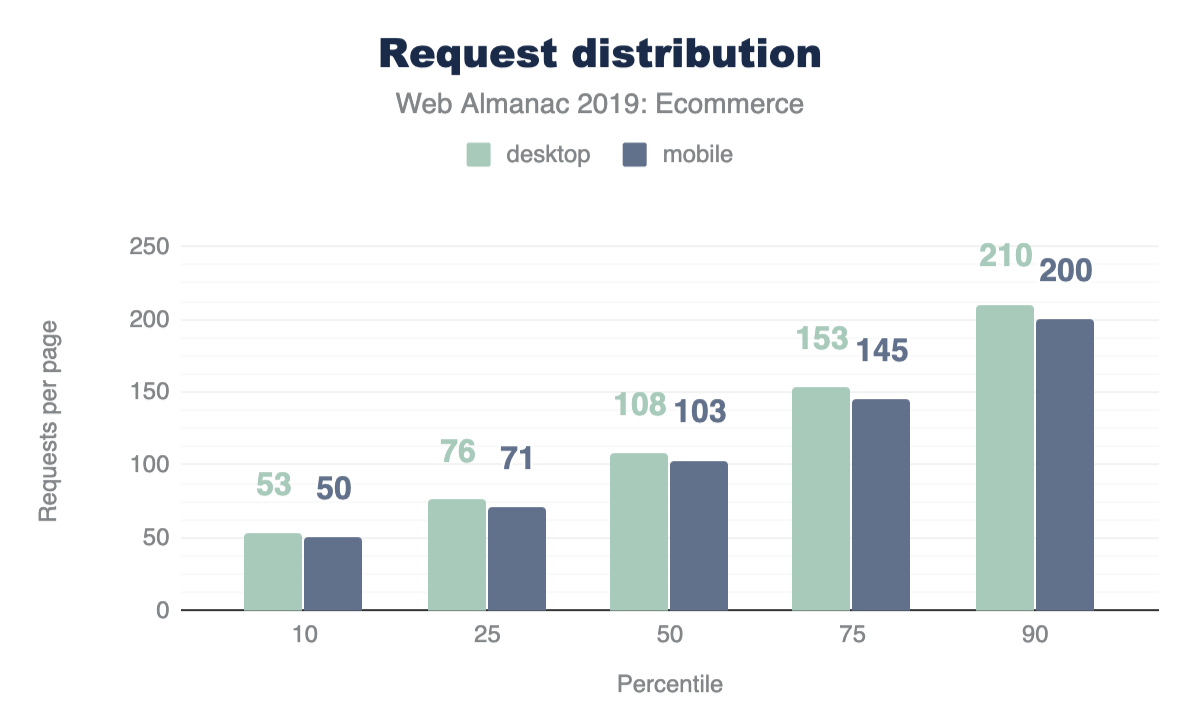 -
- 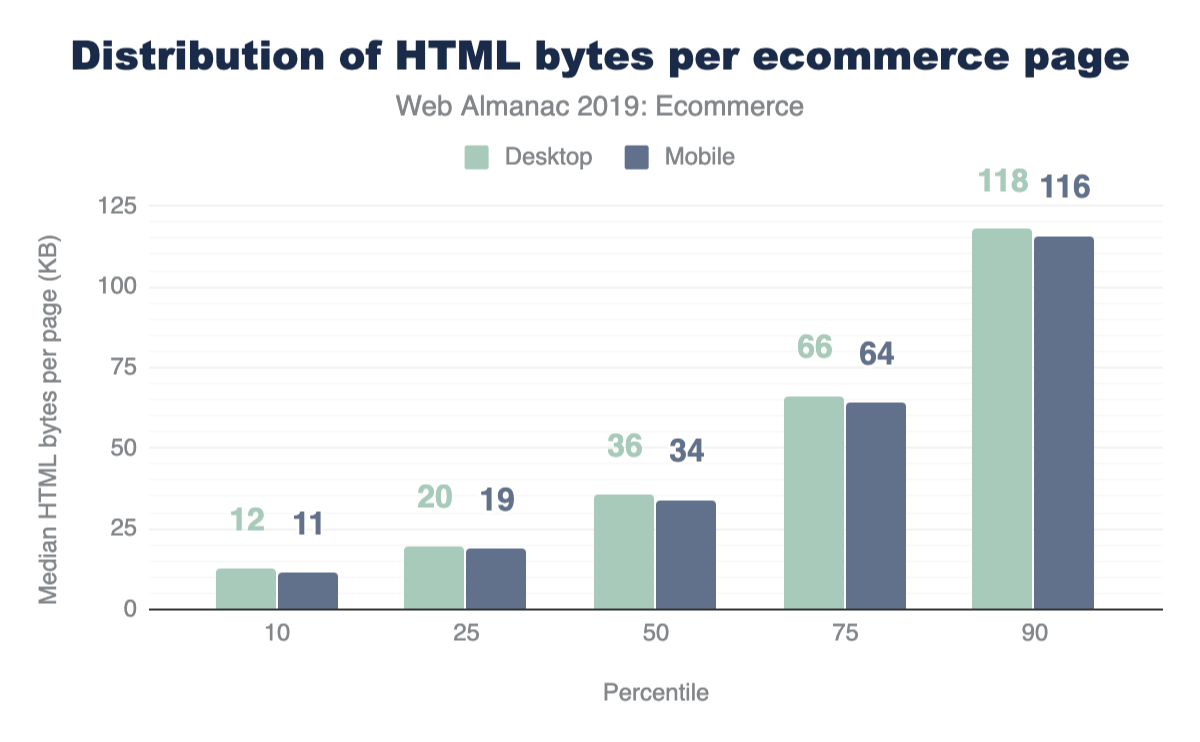 -
- 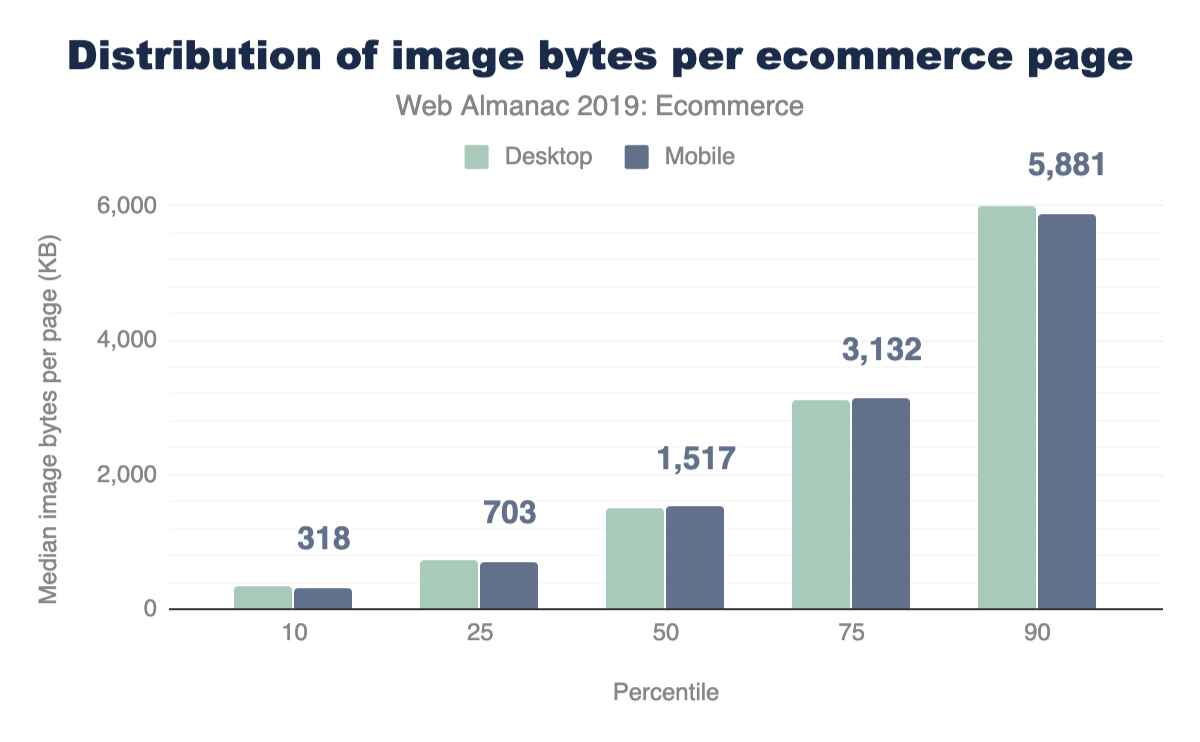 -
- 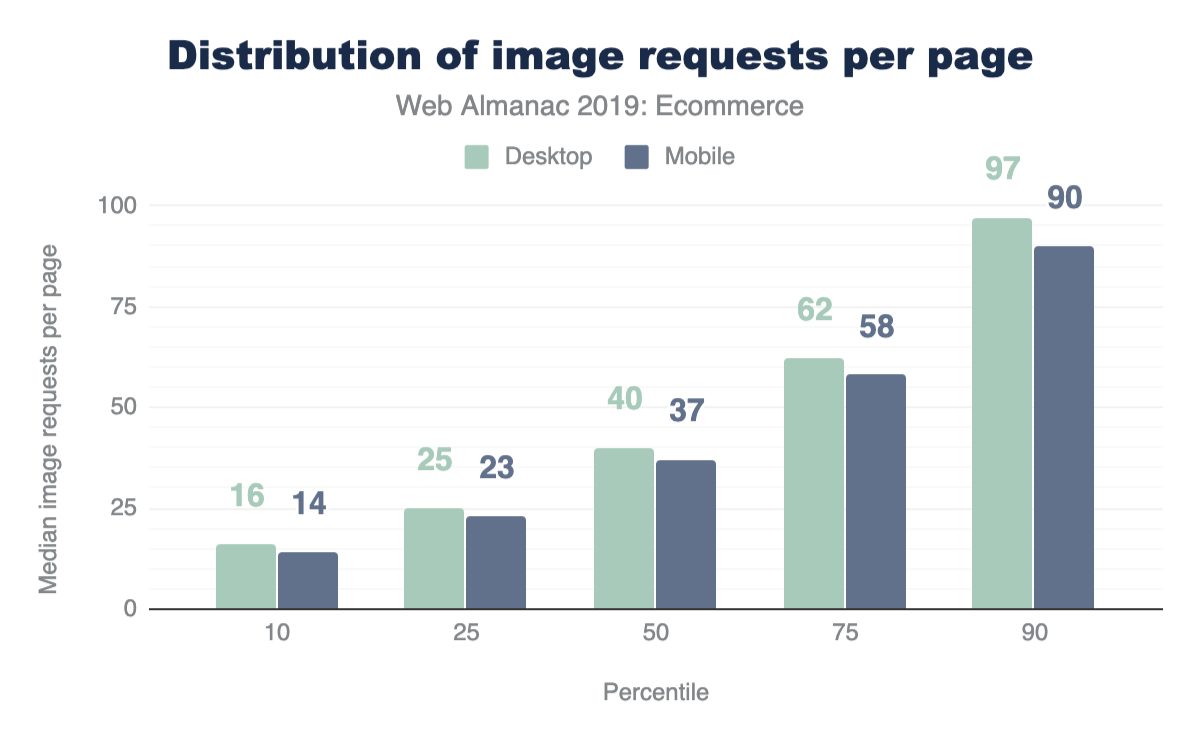 -
- 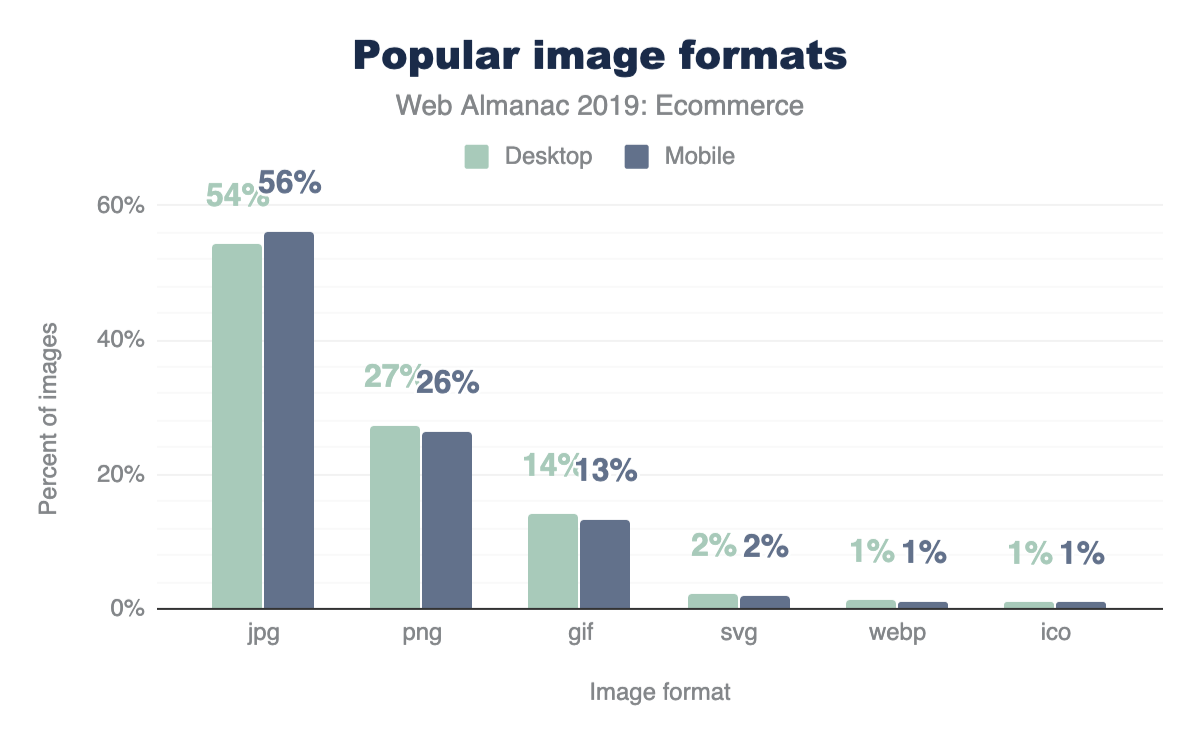 -
- 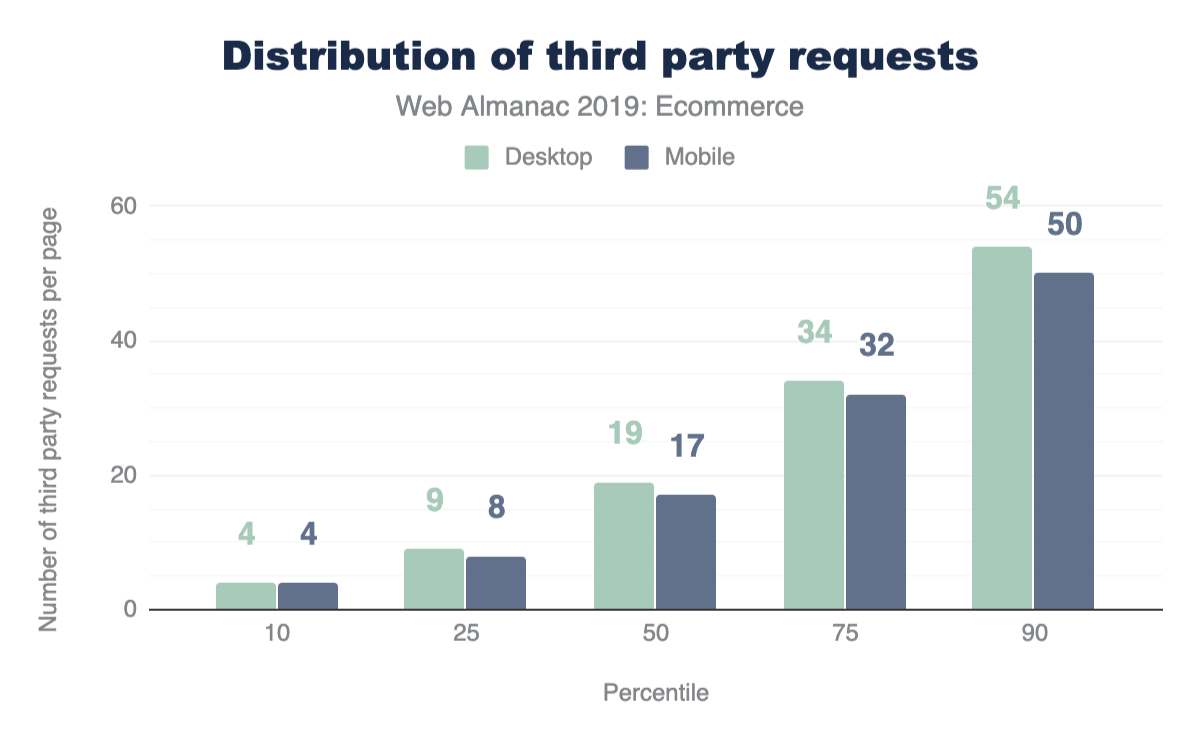 -
-  -
-  -
-  -
-  -
- 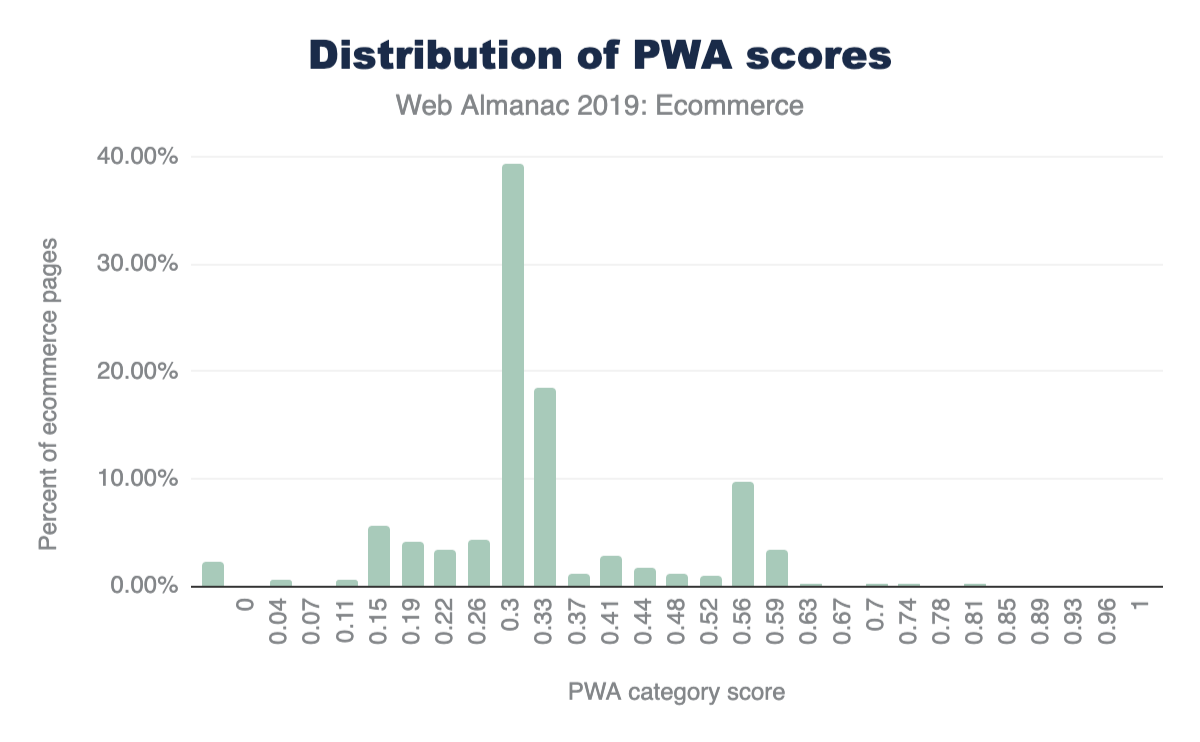 -
-  -
-  -
- 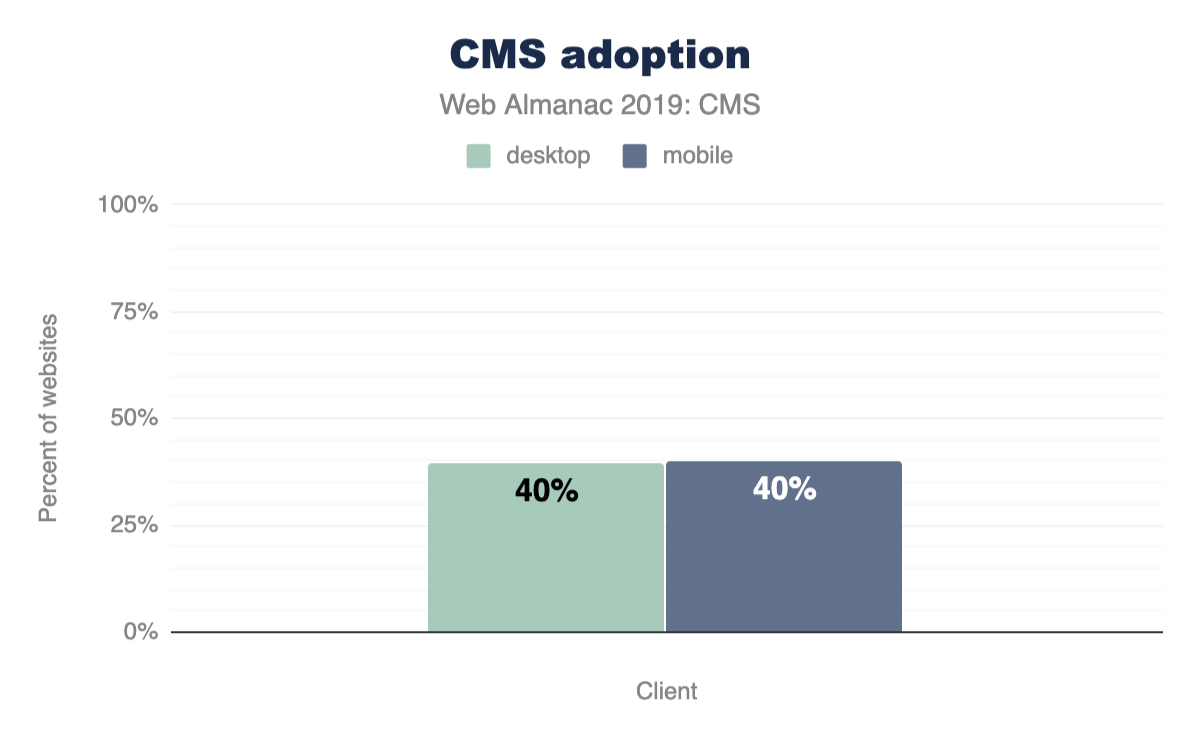 -
- 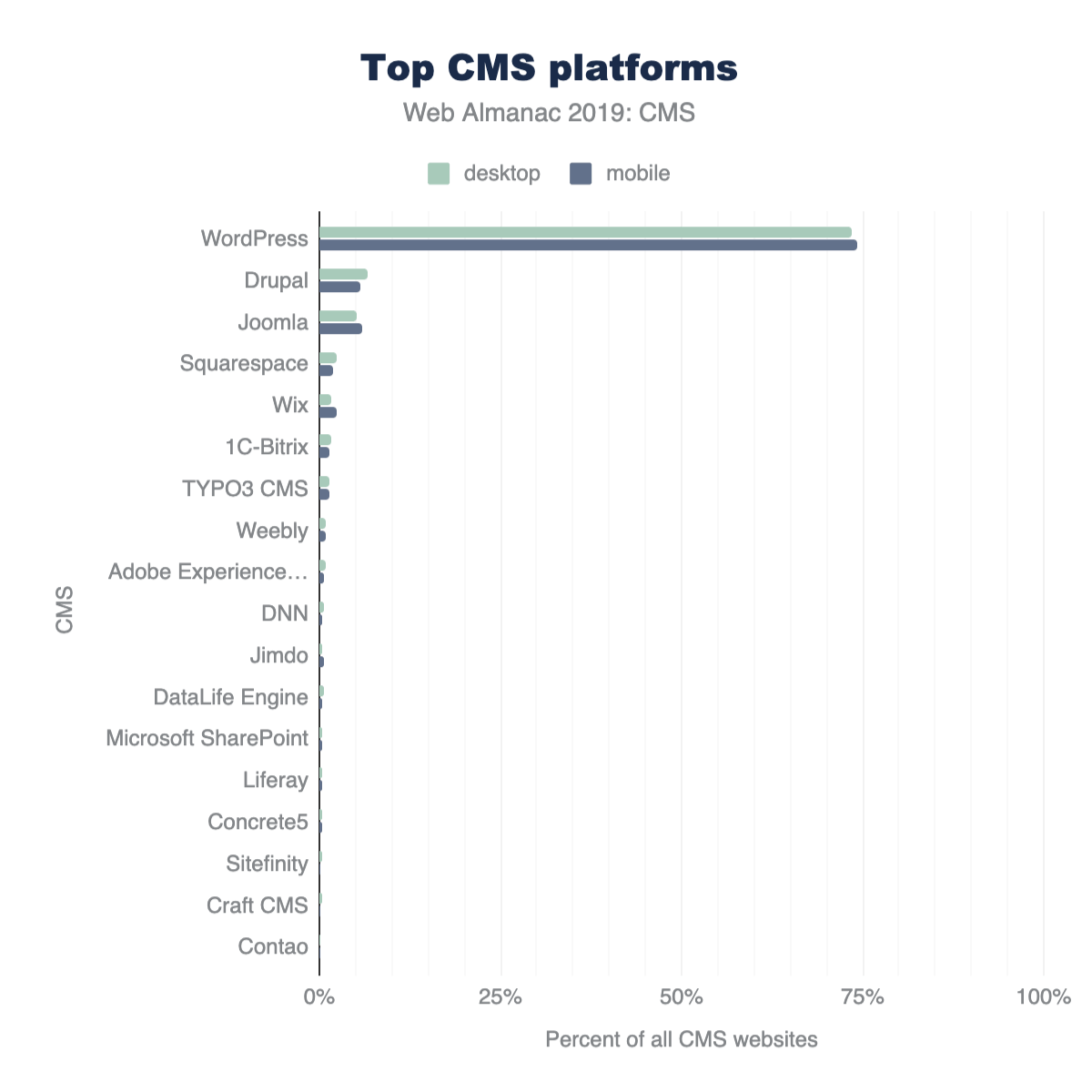 -
-  -
-  -
-  -
-  -
- 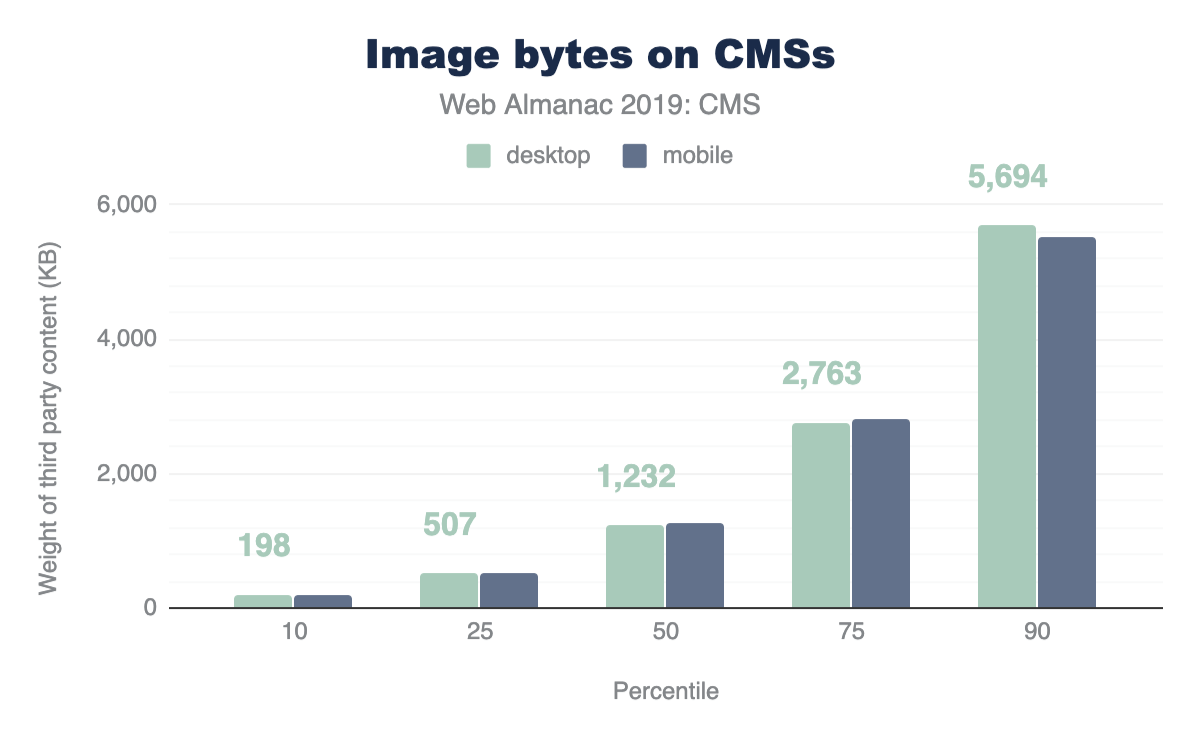 -
- 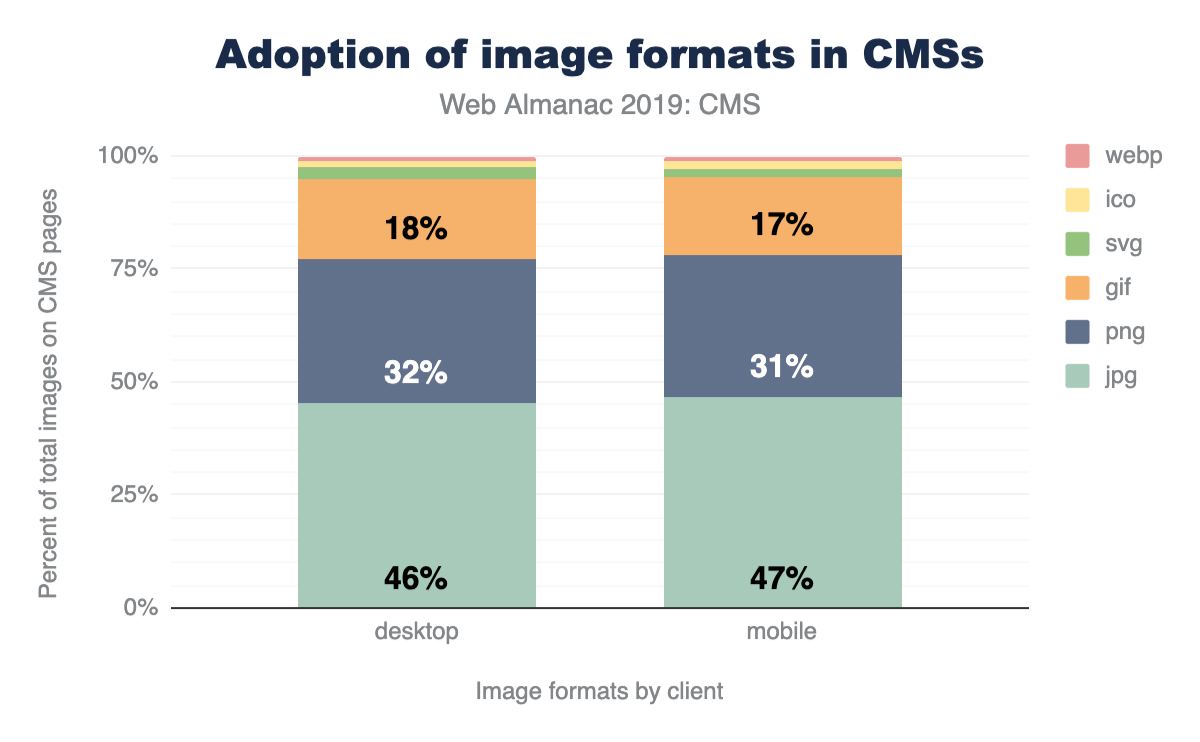 -
- 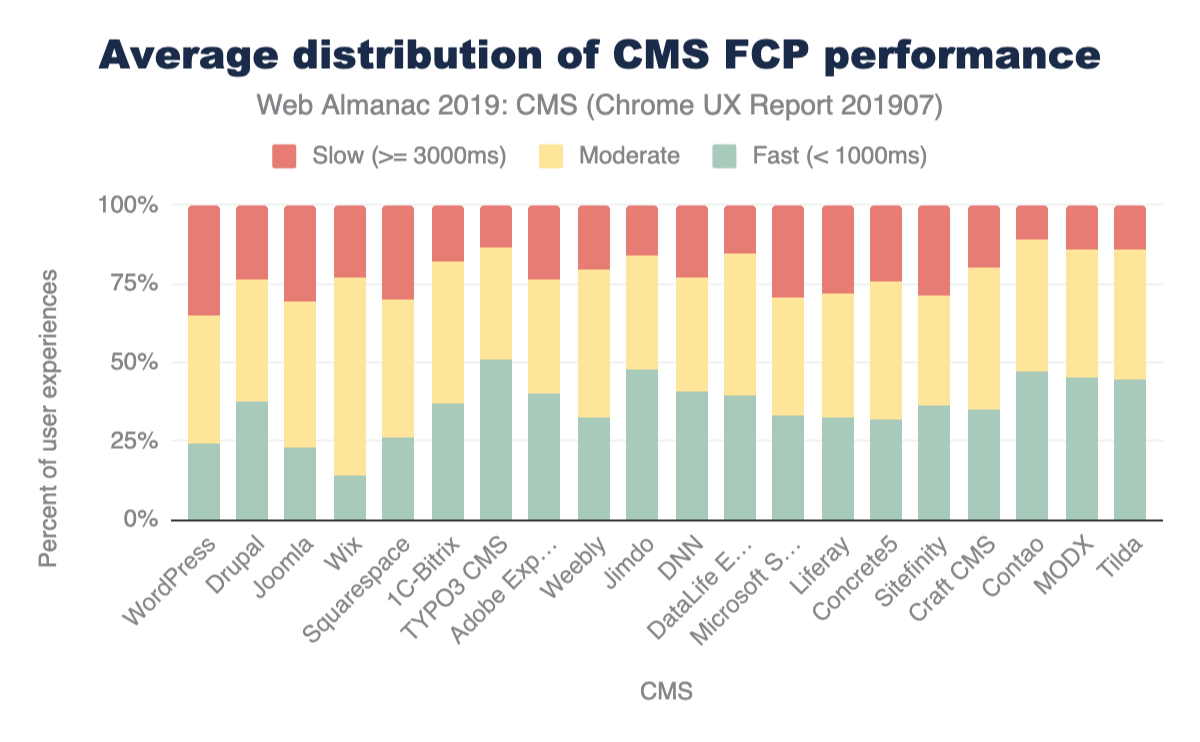 -
- 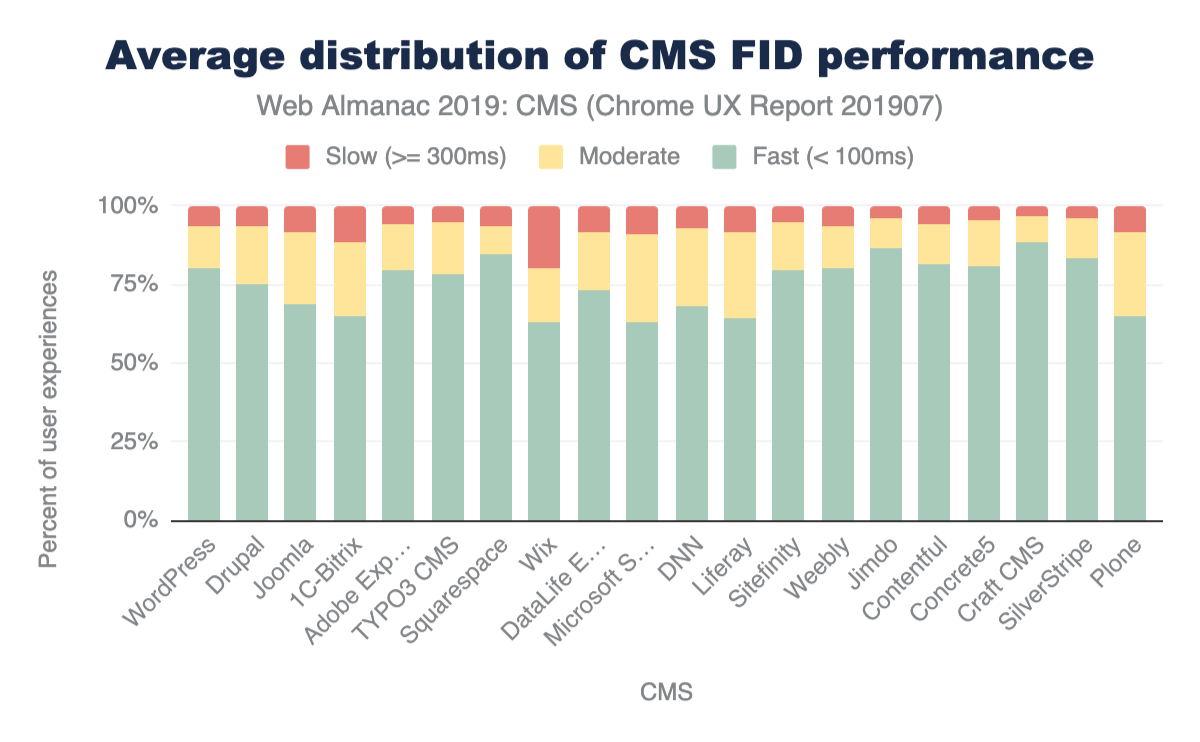 -
- 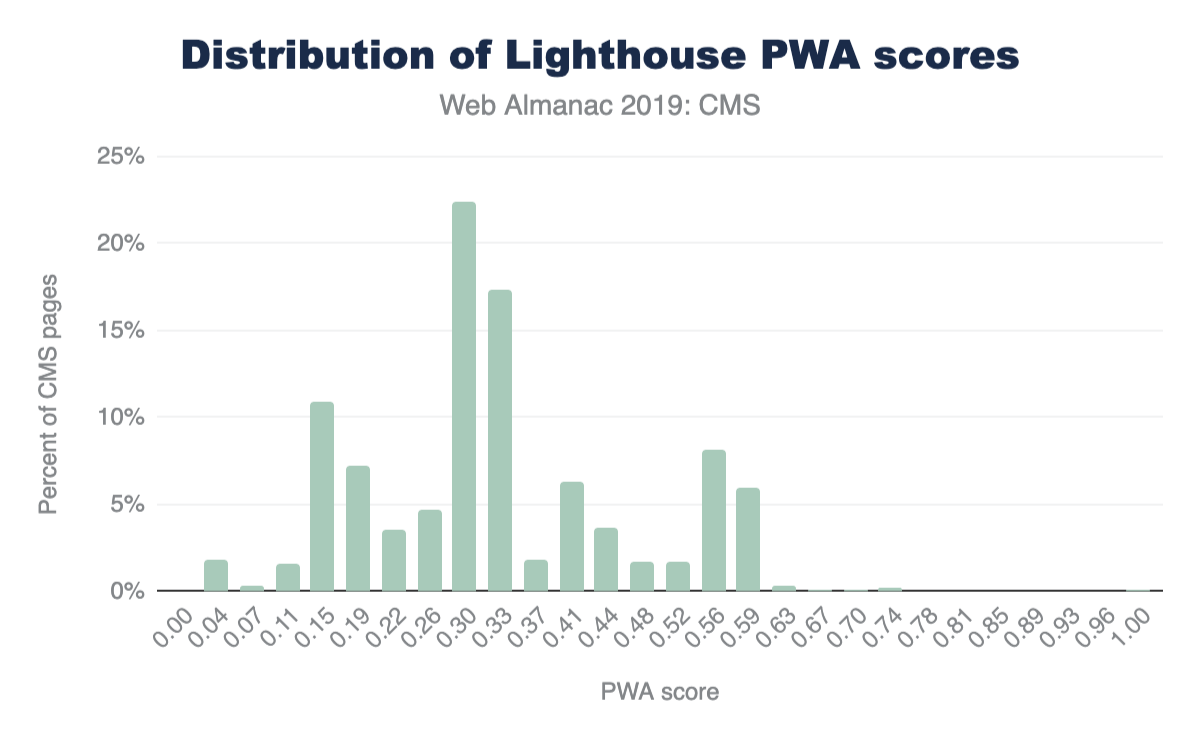 -
- 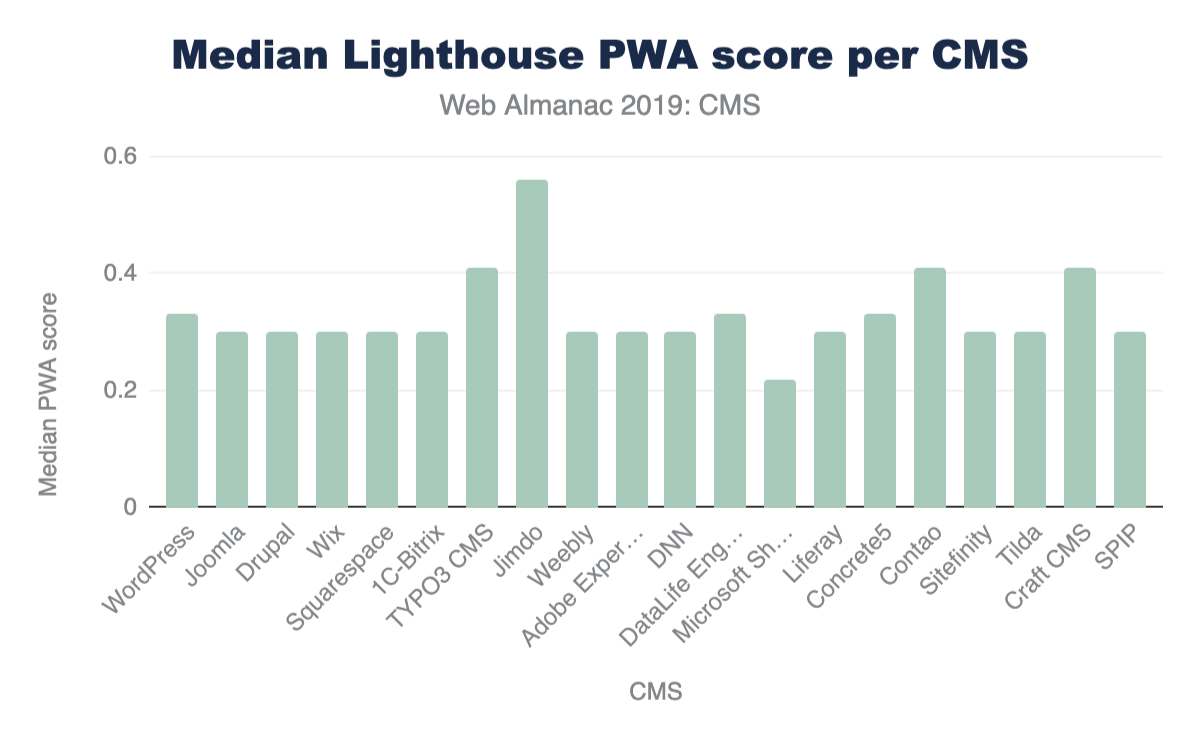 -
- 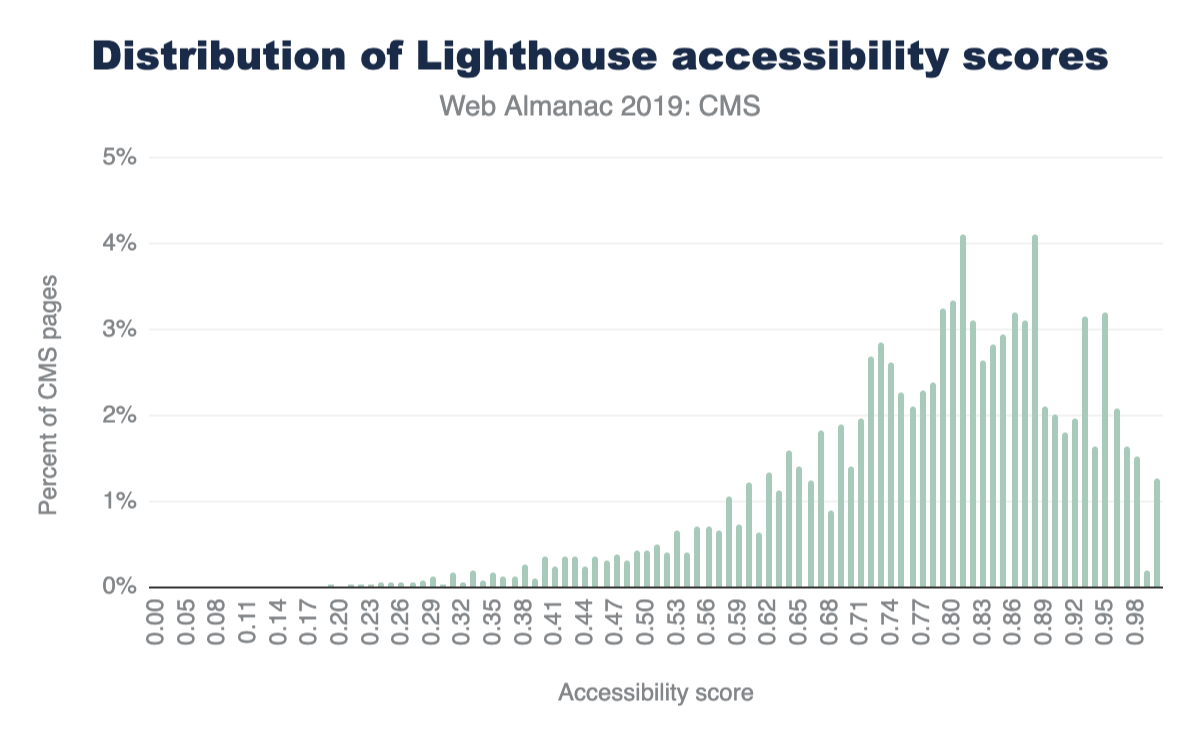 -
- 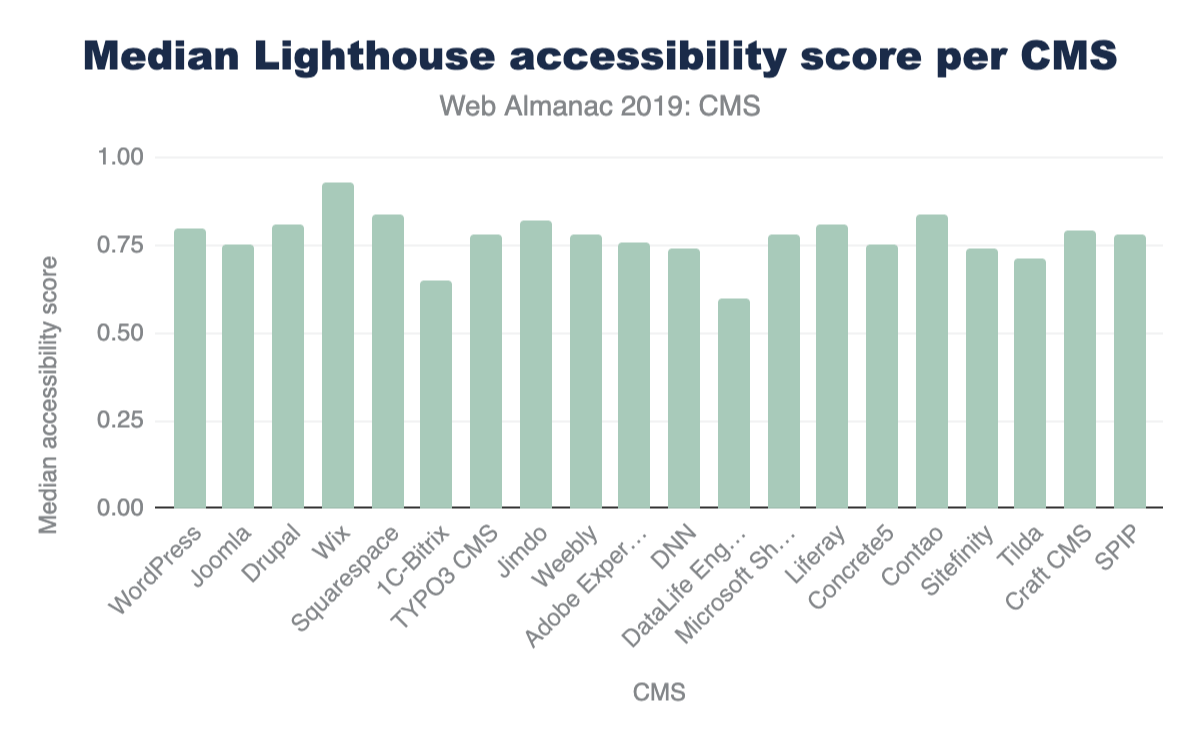 -
- 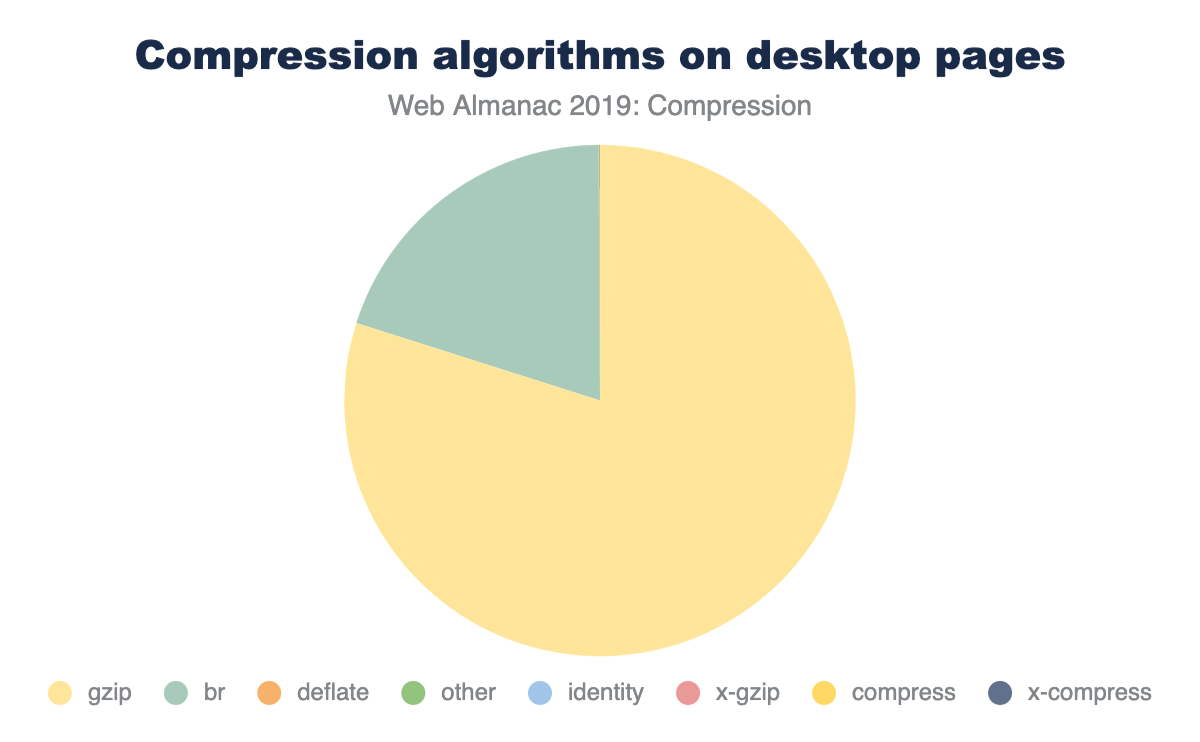 -
- 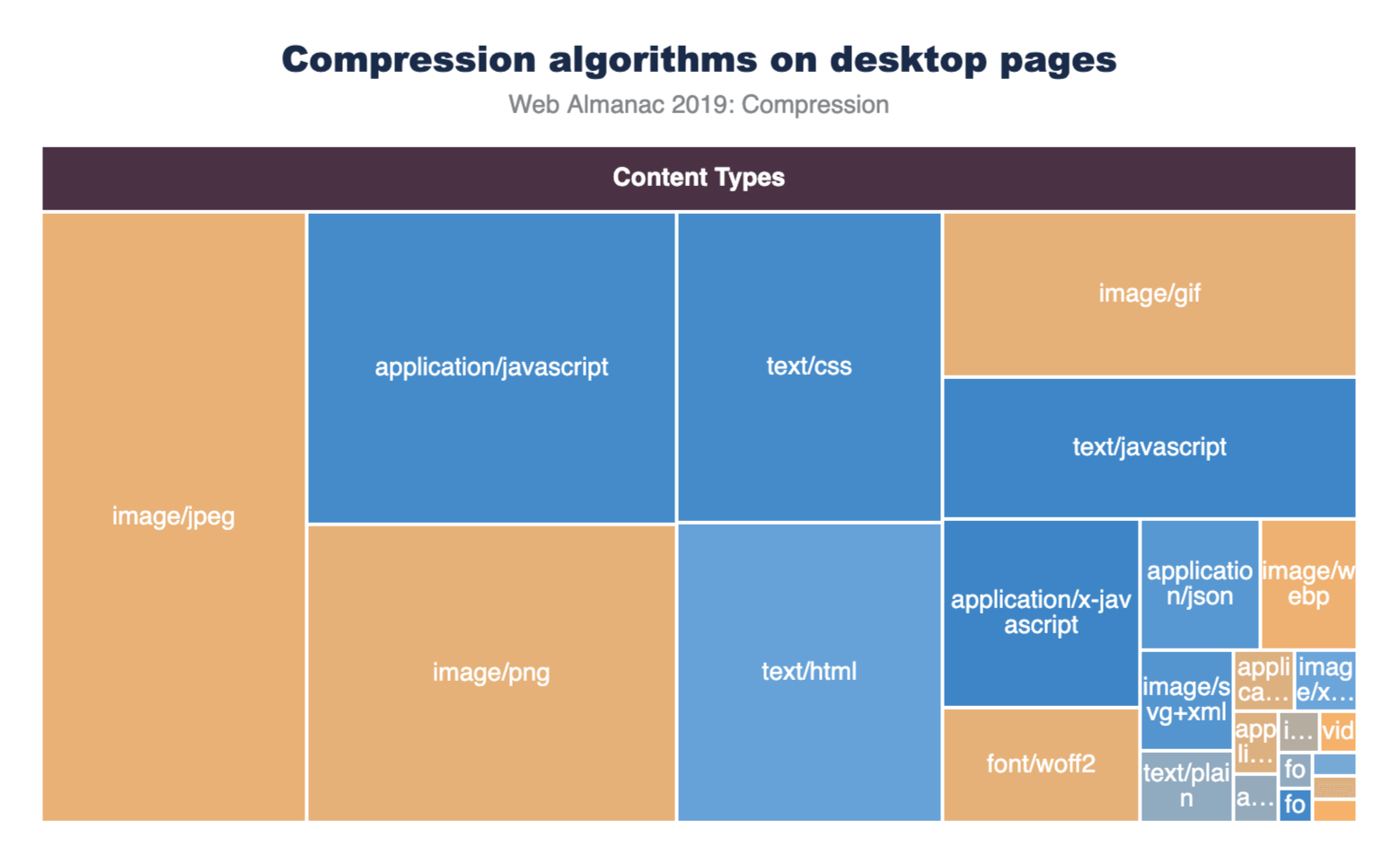 -
- 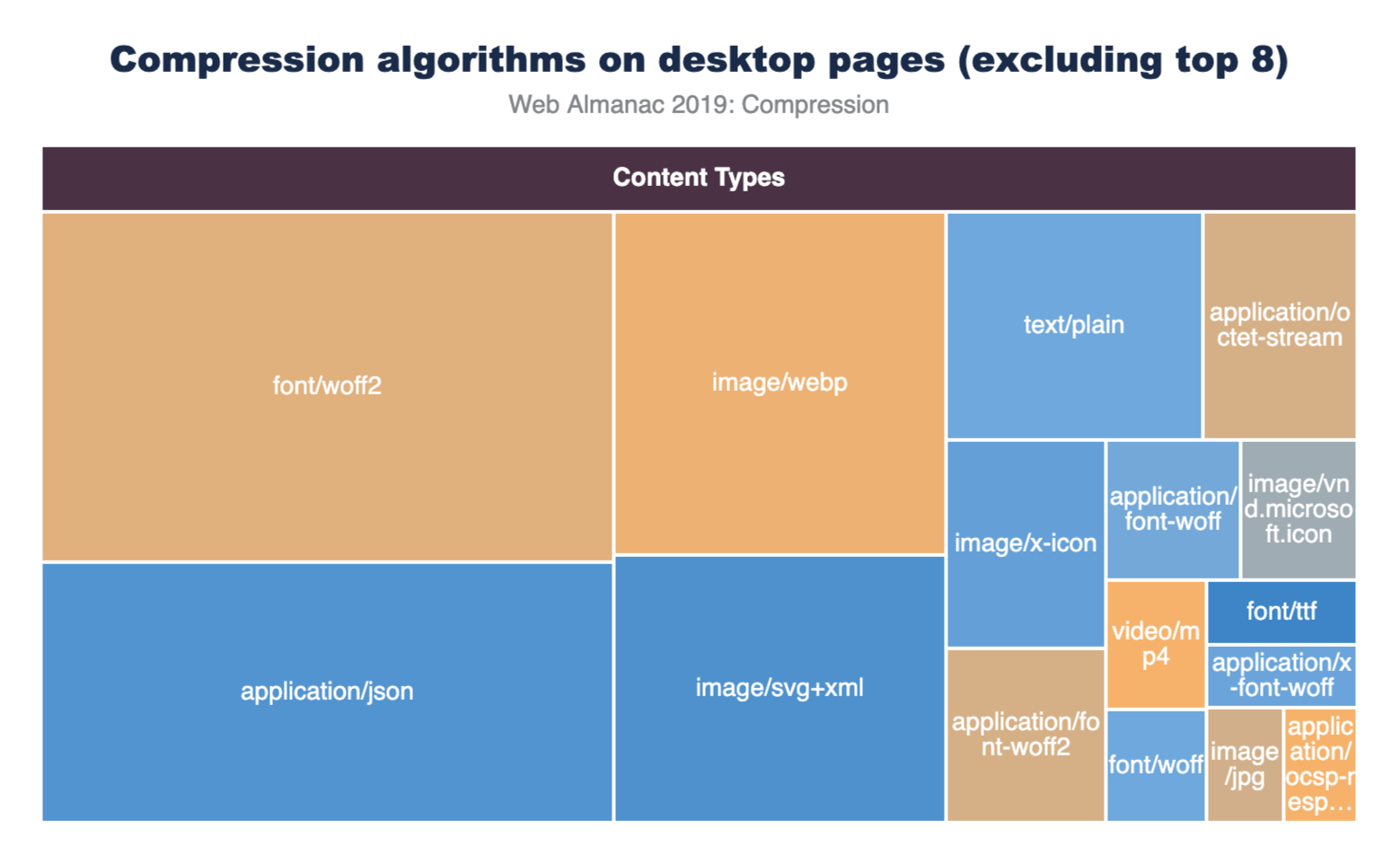 -
- 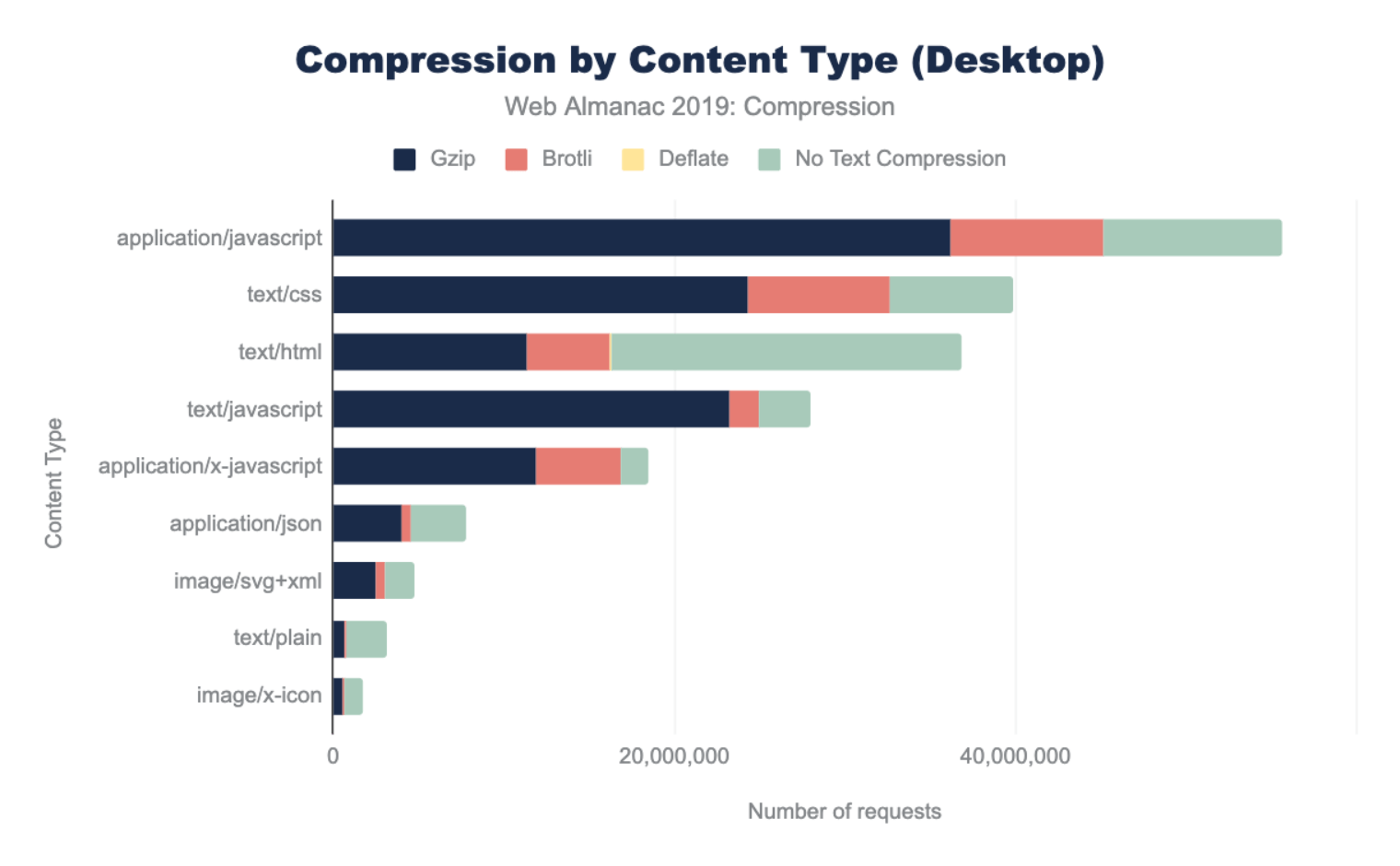 -
- 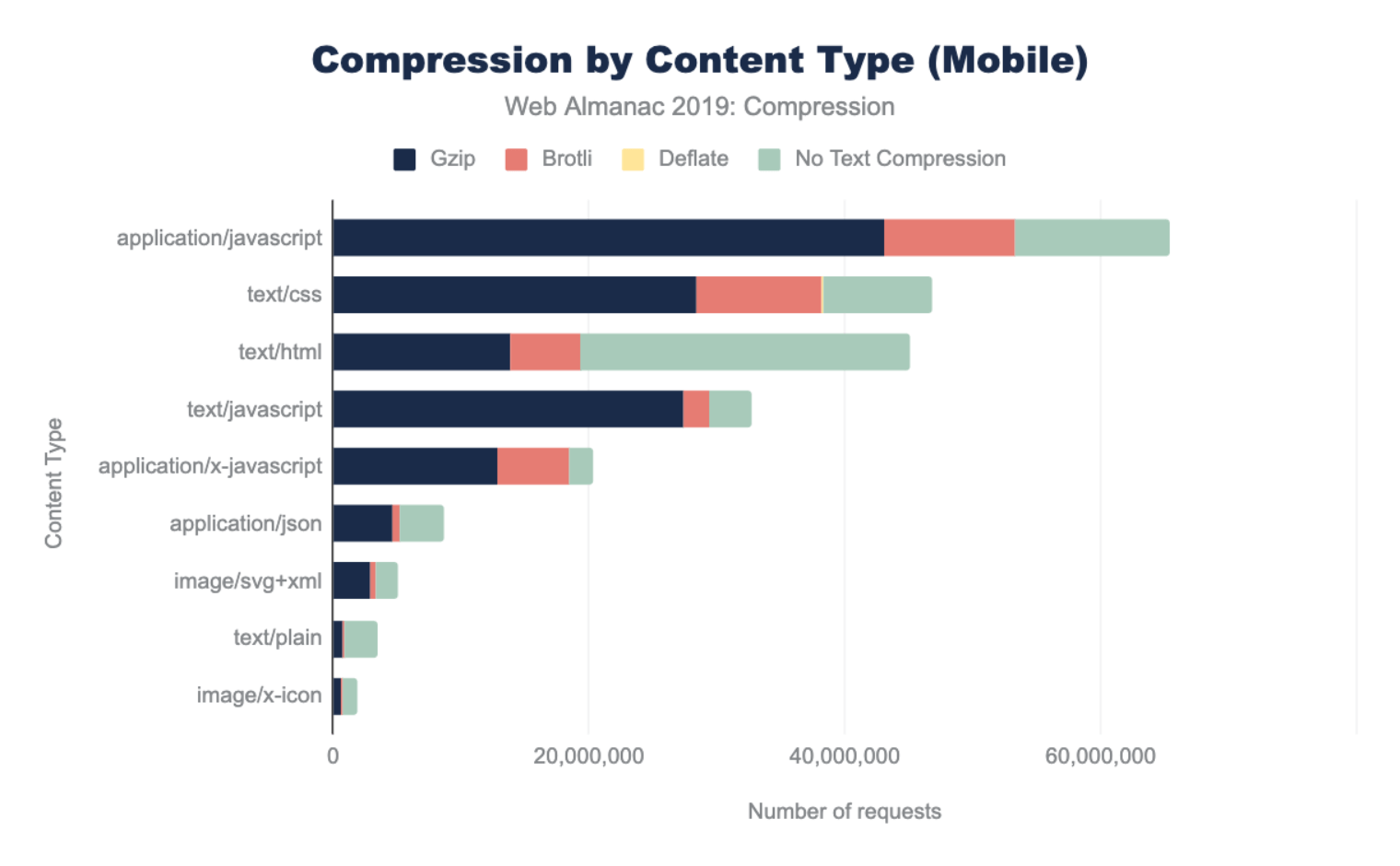 -
- 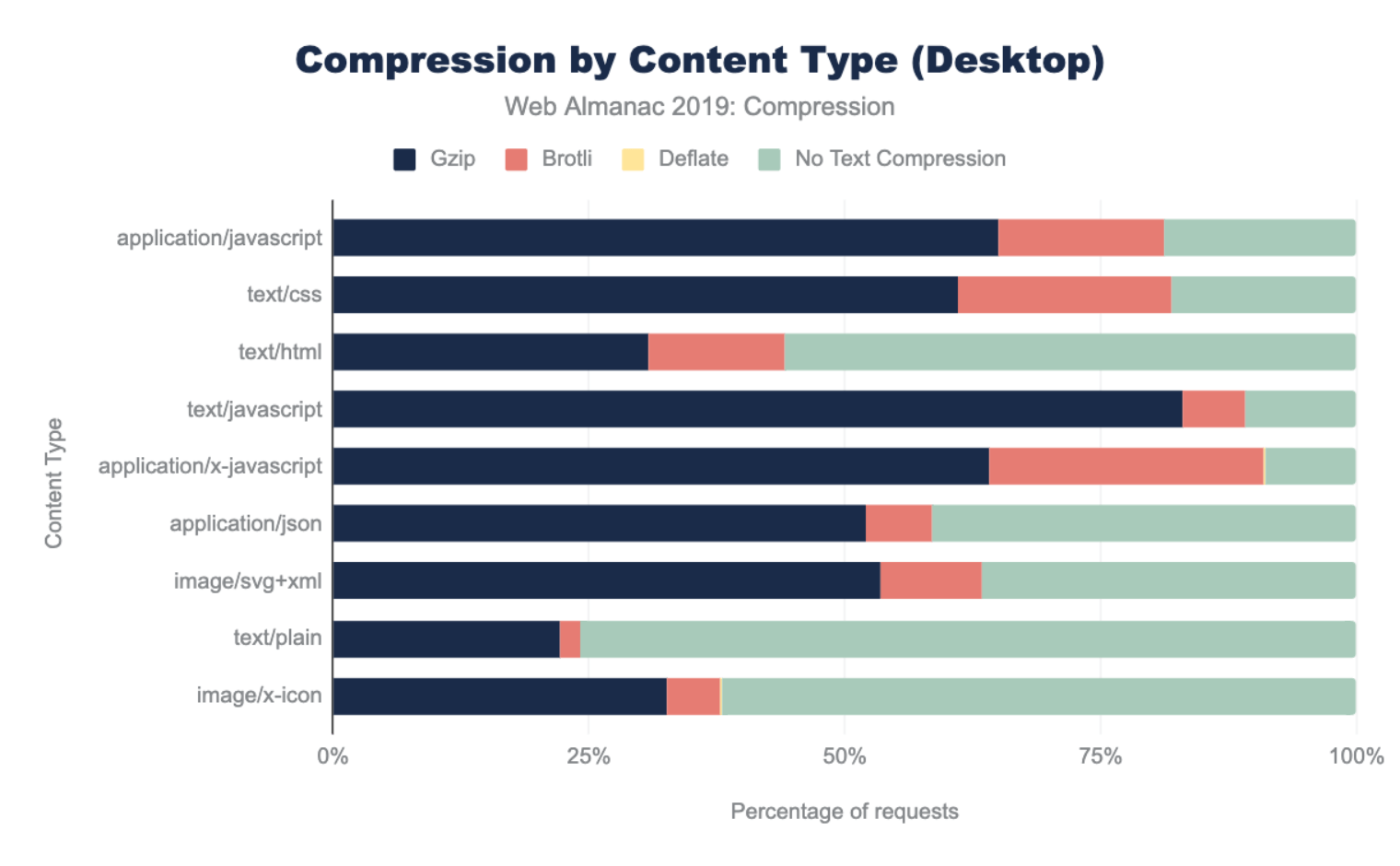 -
- 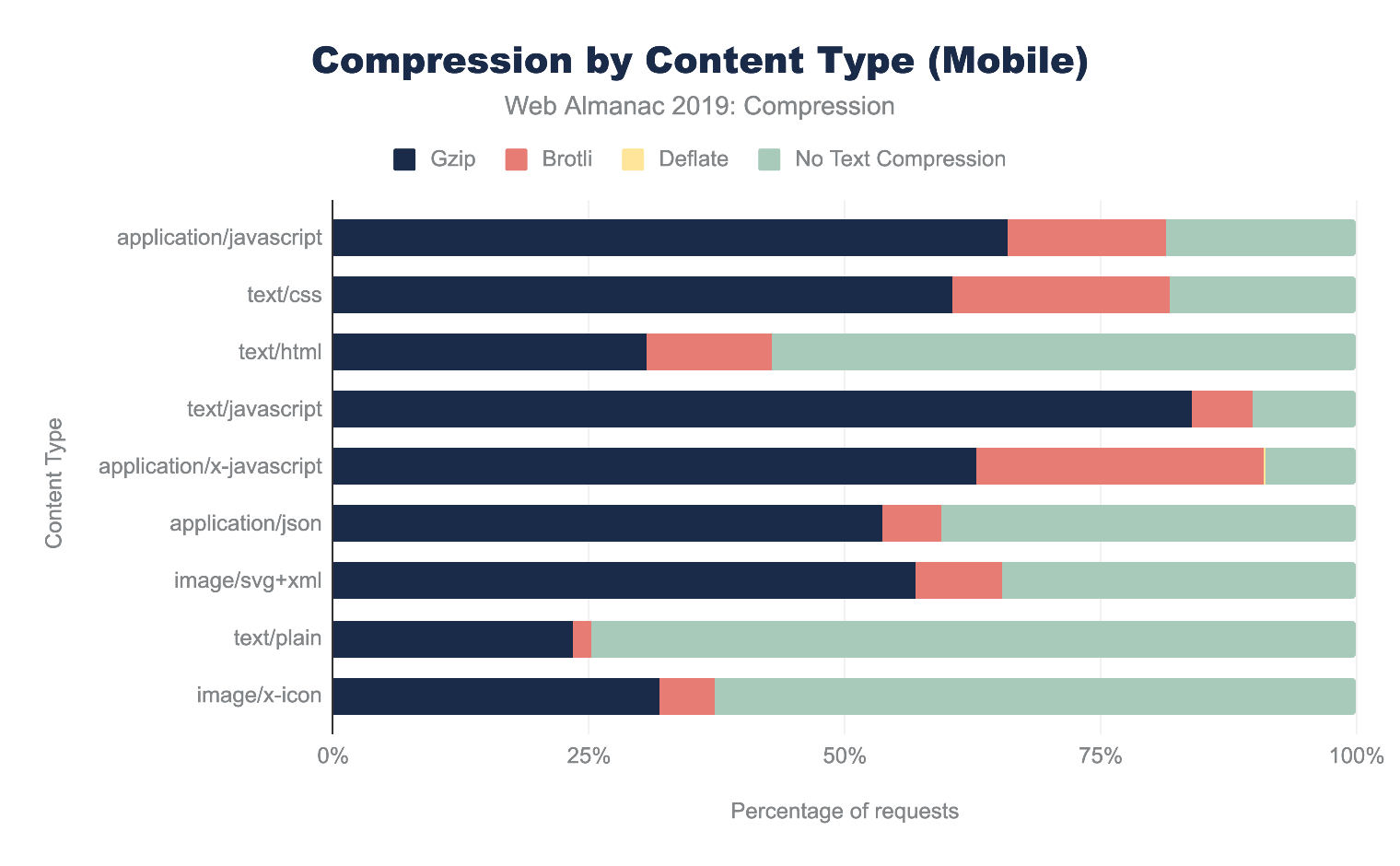 -
- 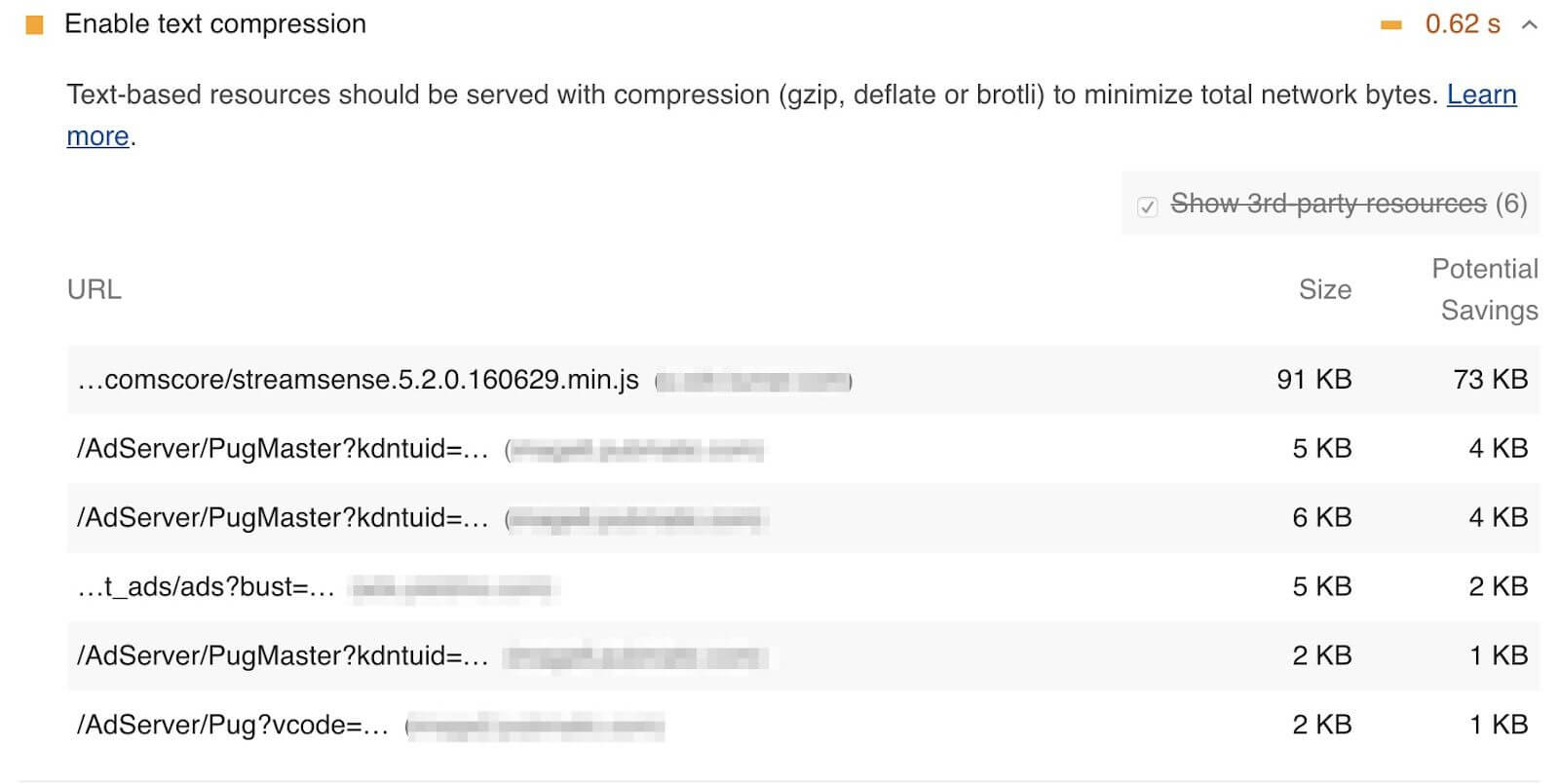 -
- 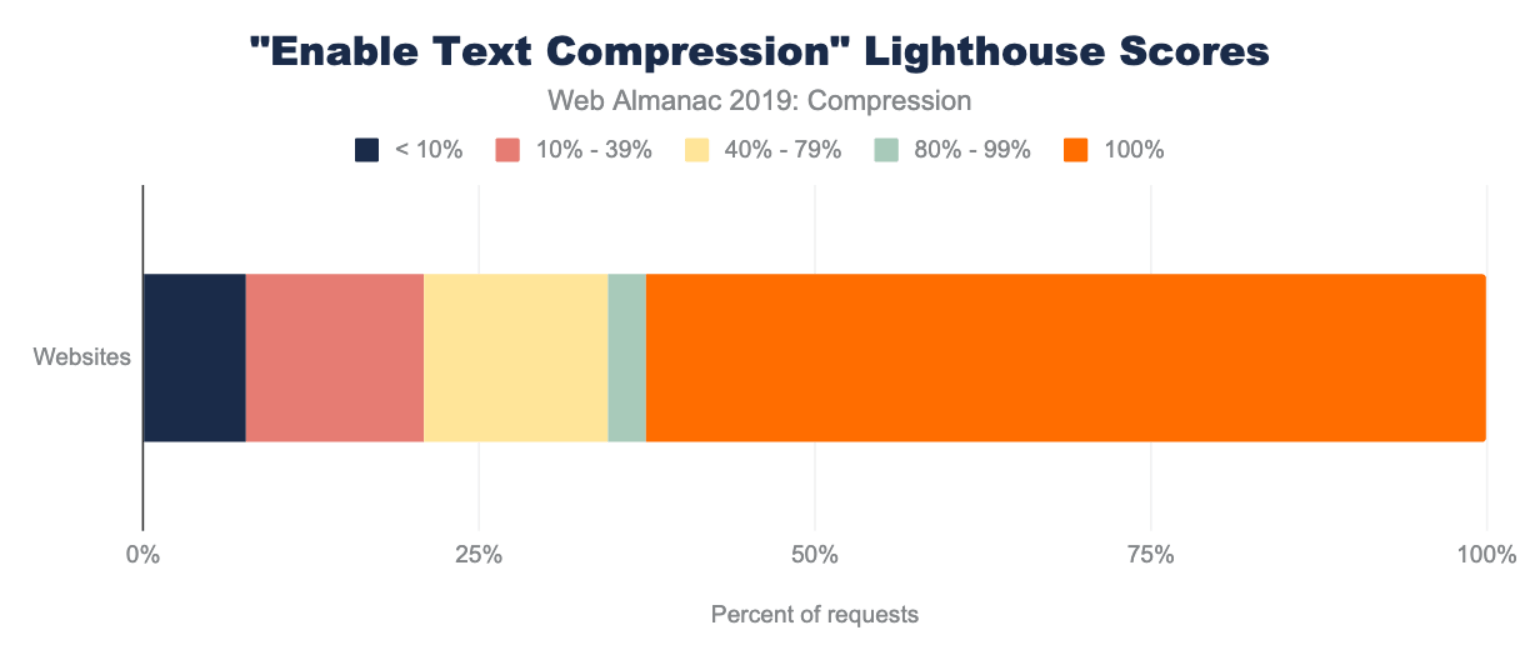 -
- 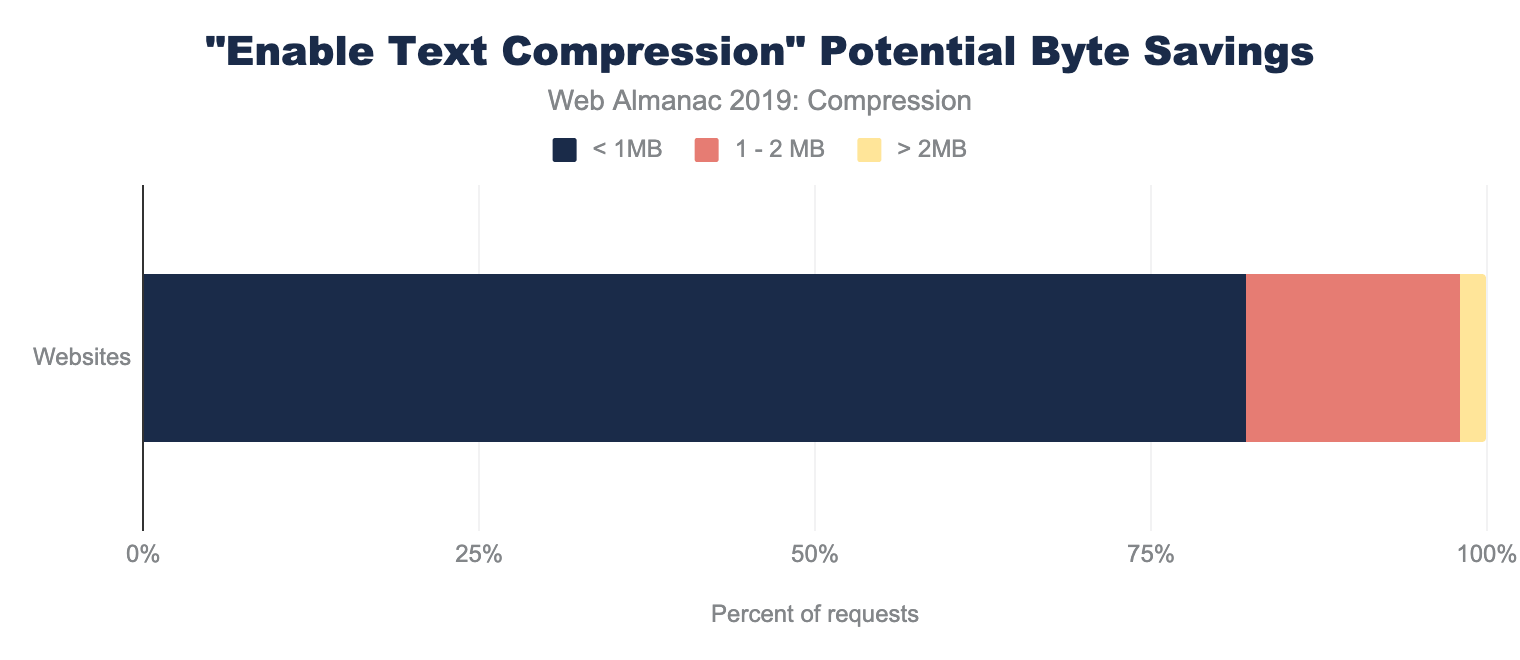 -
- 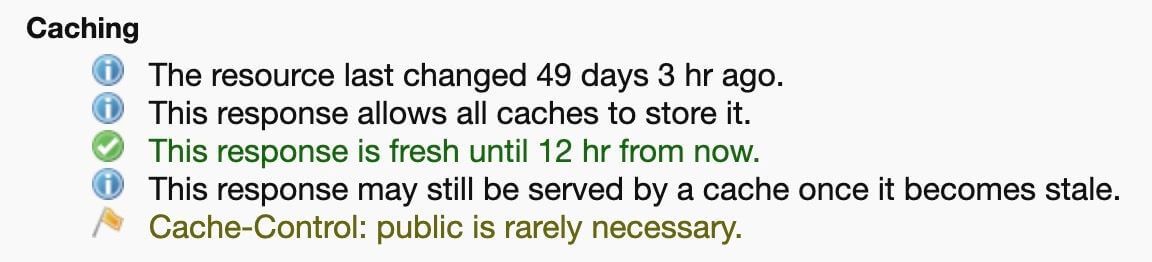 -
- 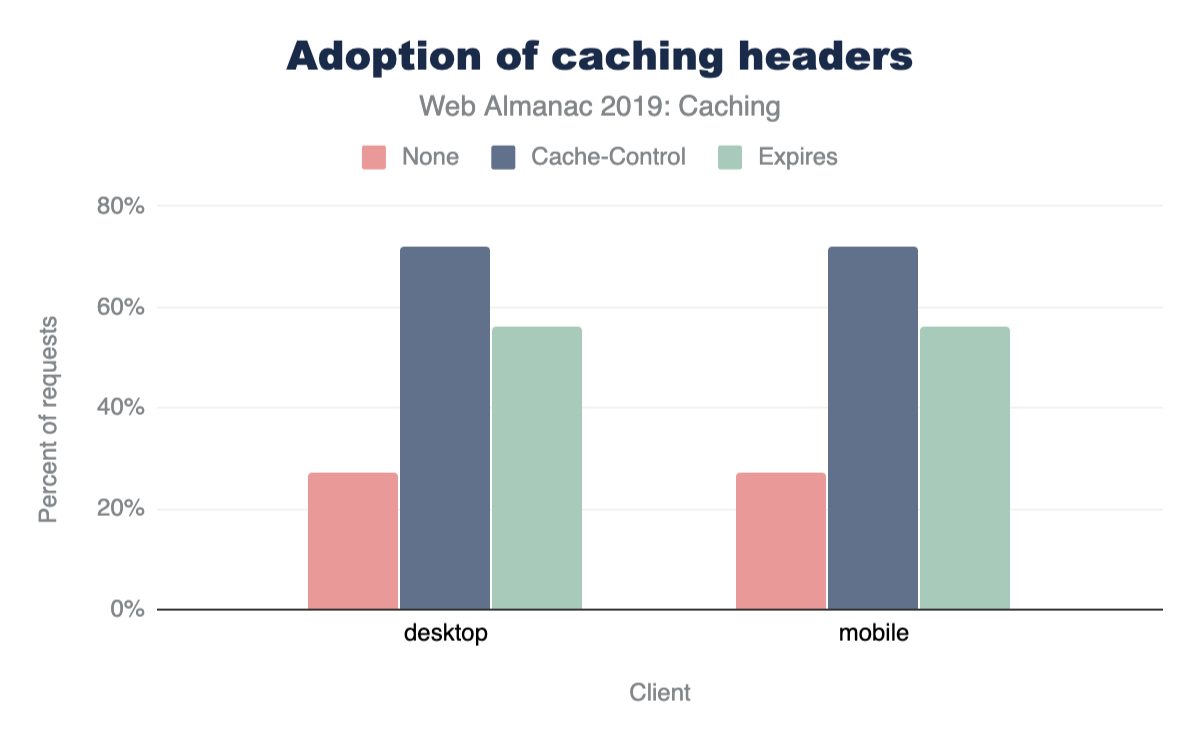 -
- 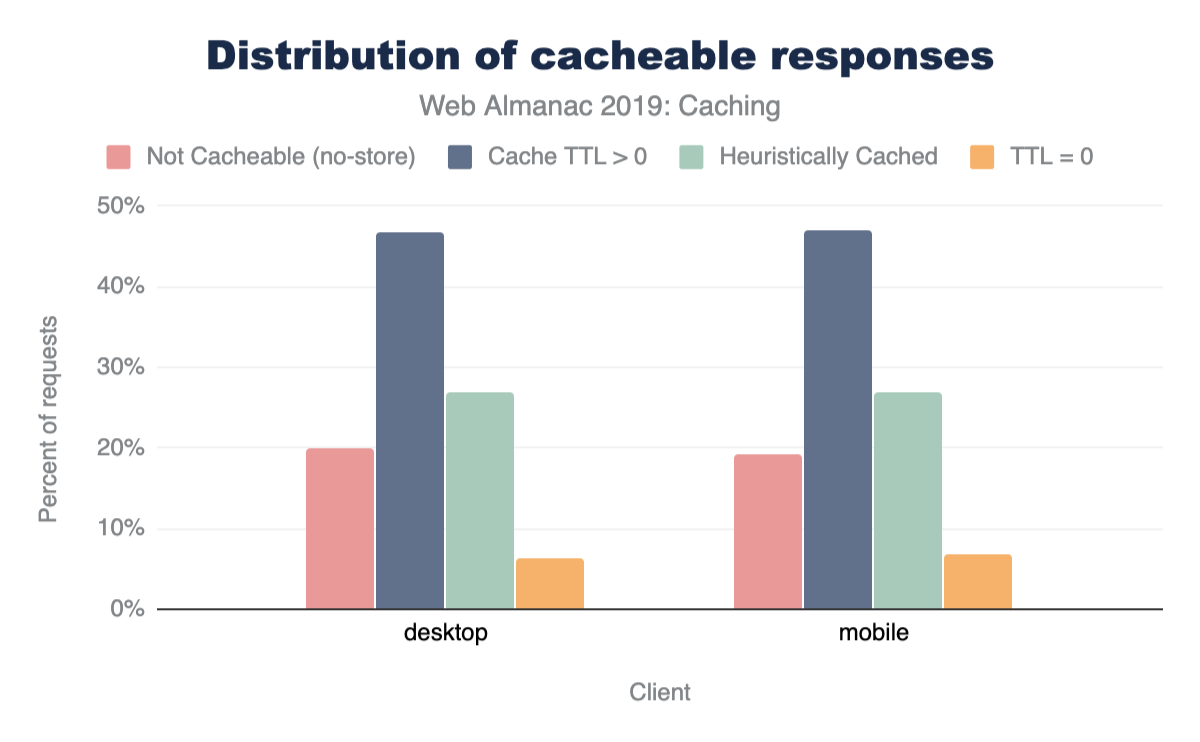 -
- 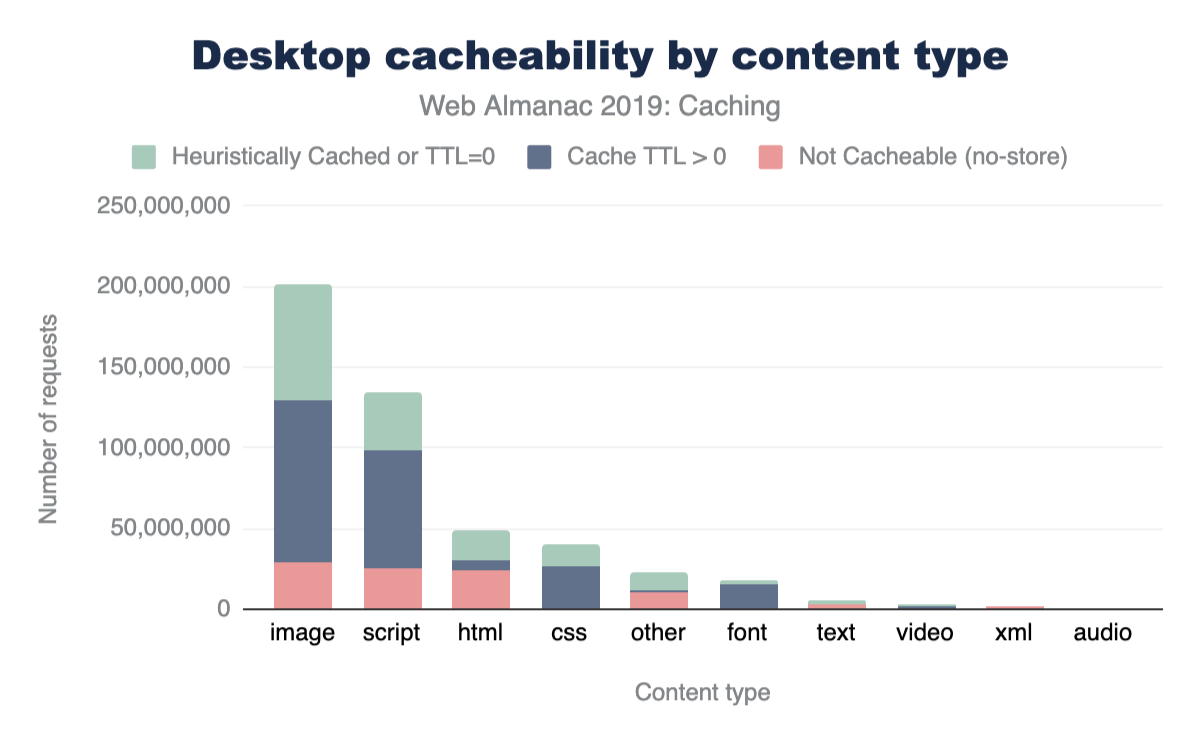 -
- 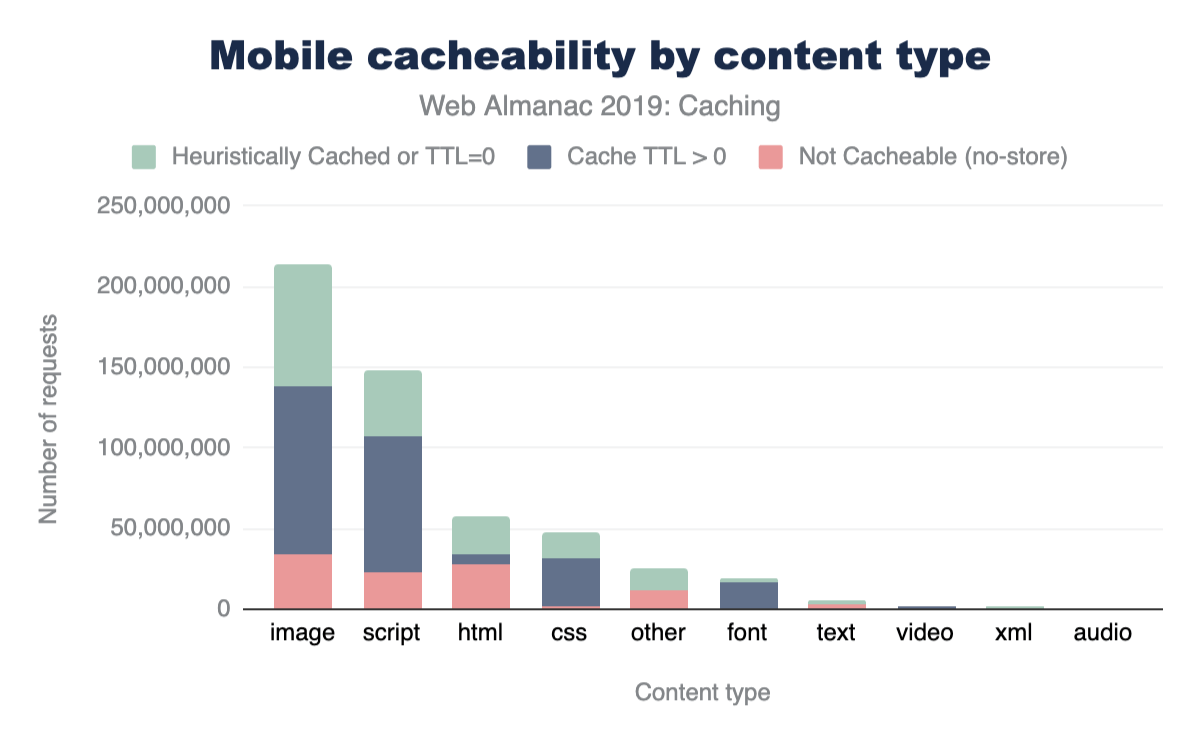 -
- 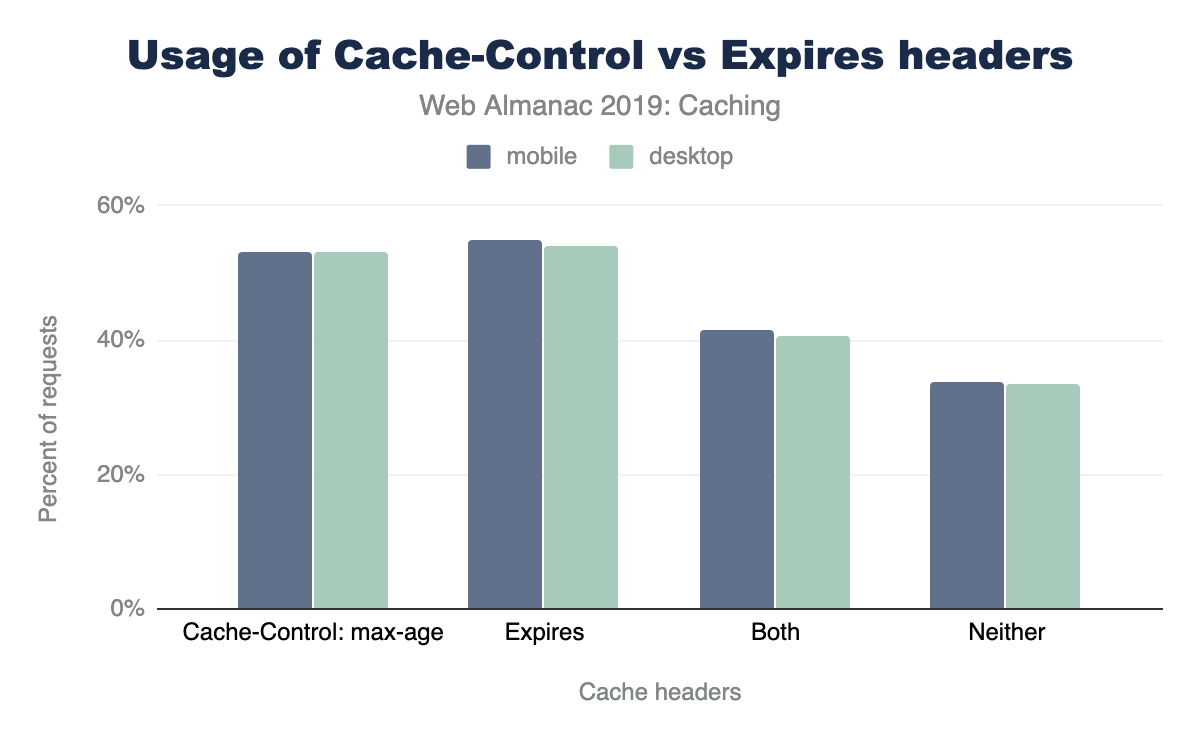 -
- 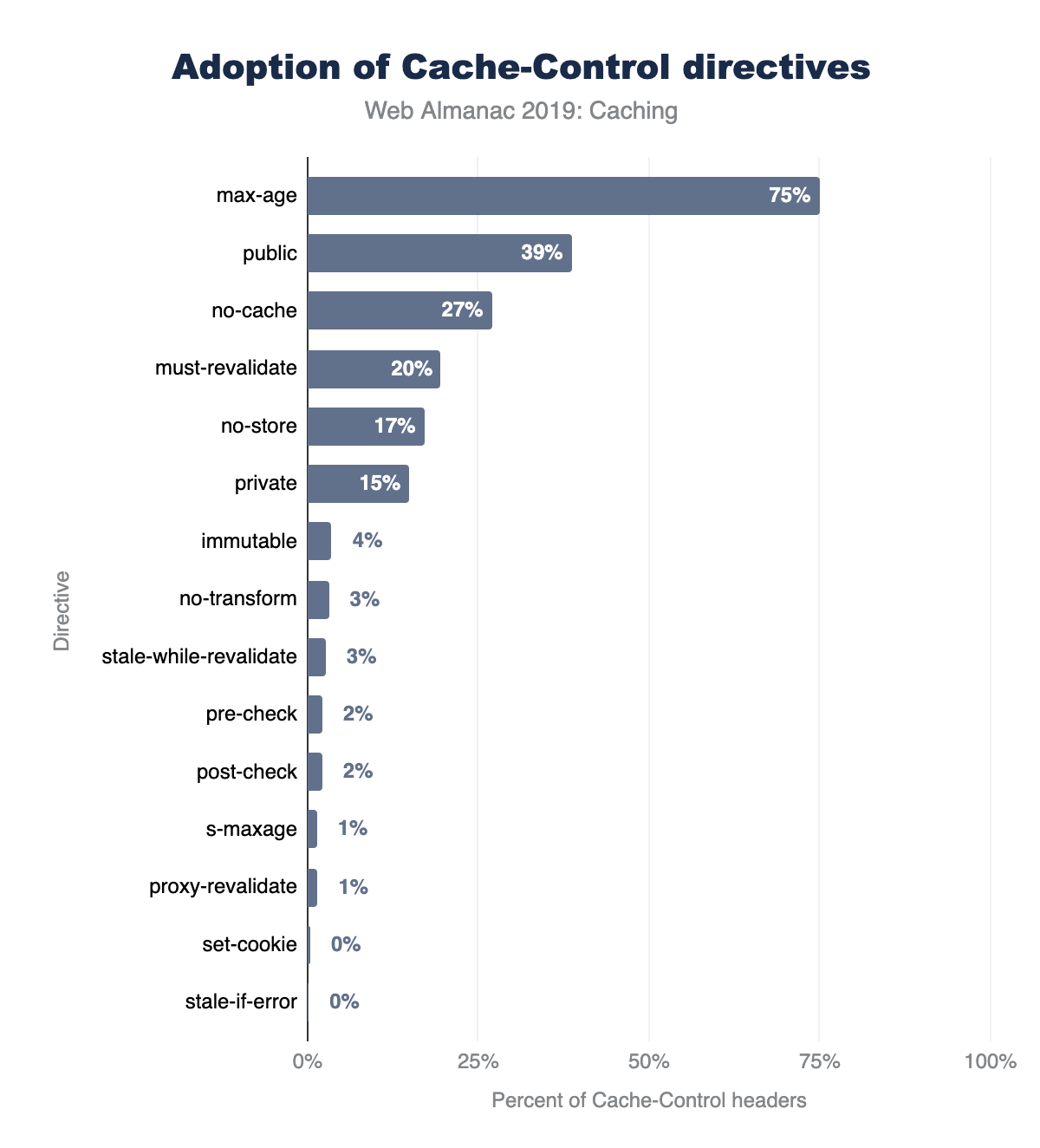 -
- 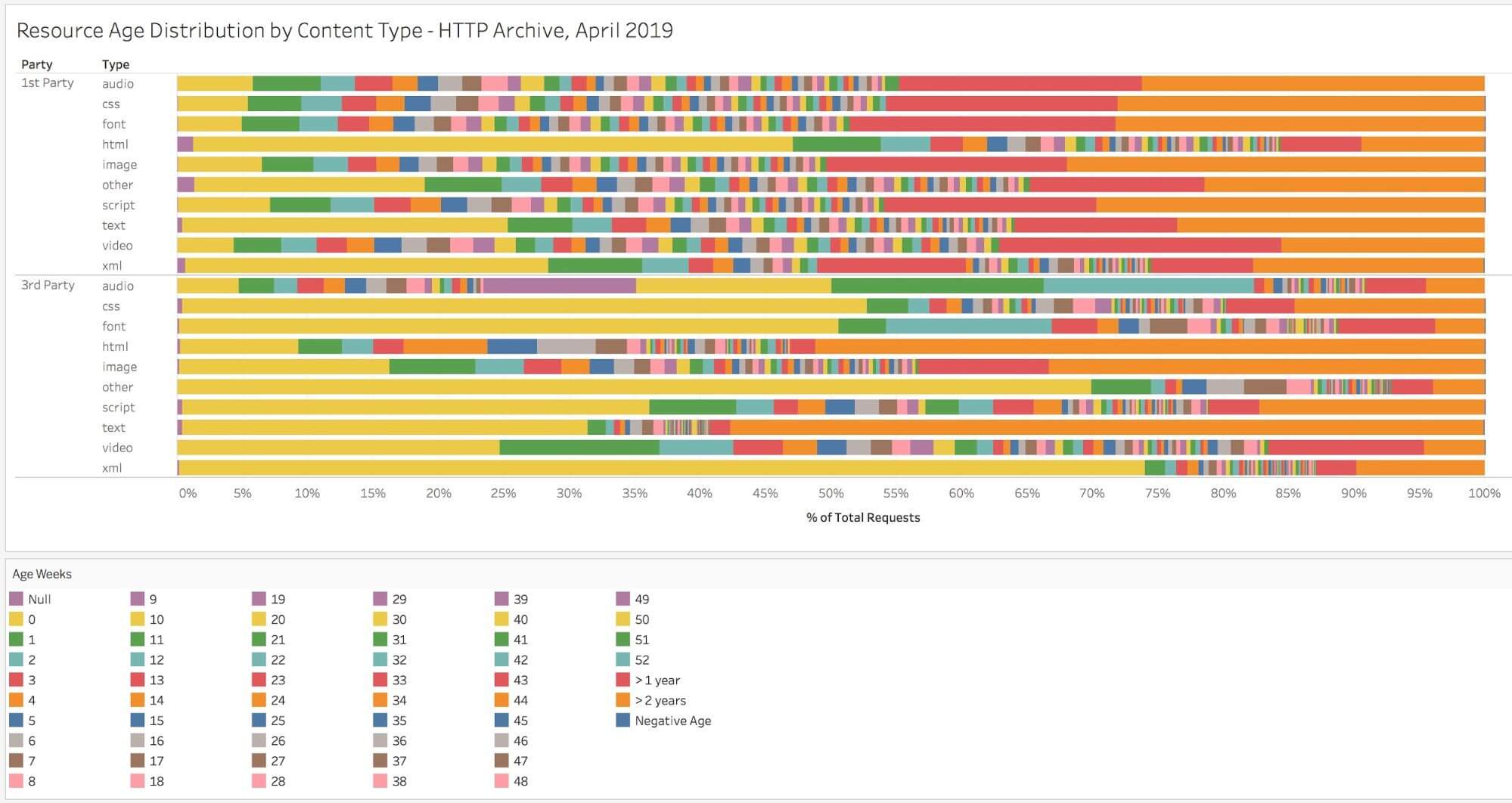 -
- 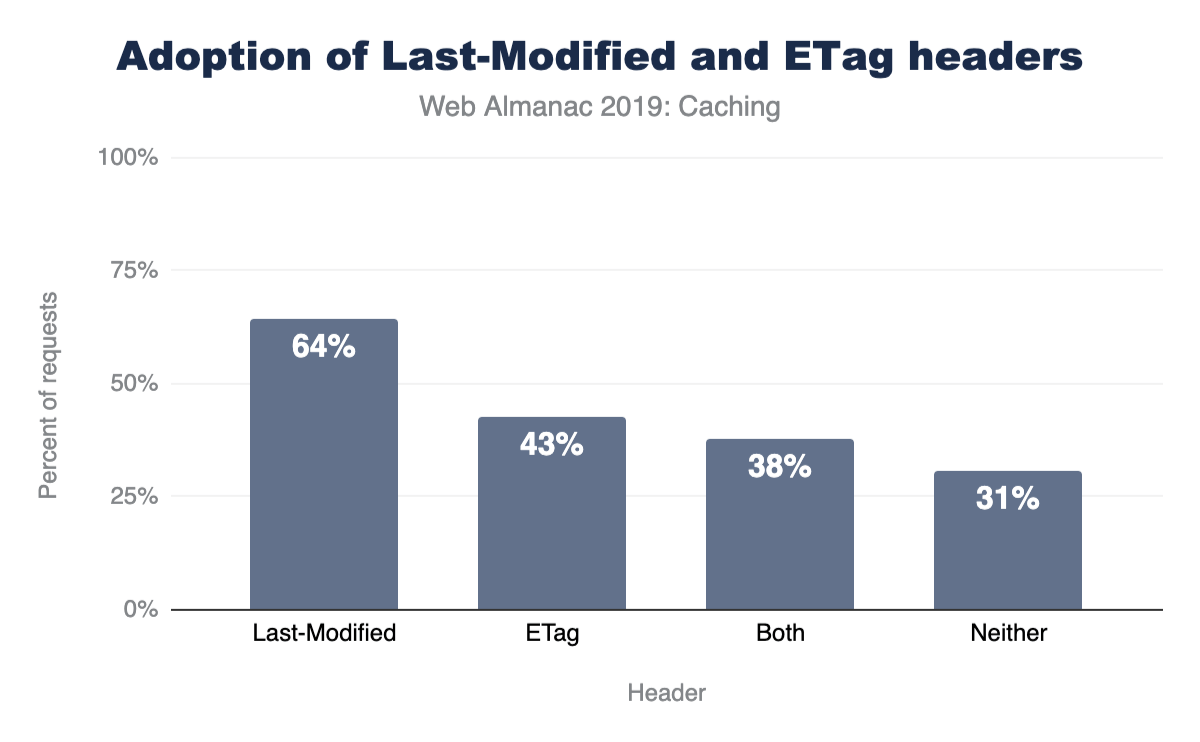 -
- 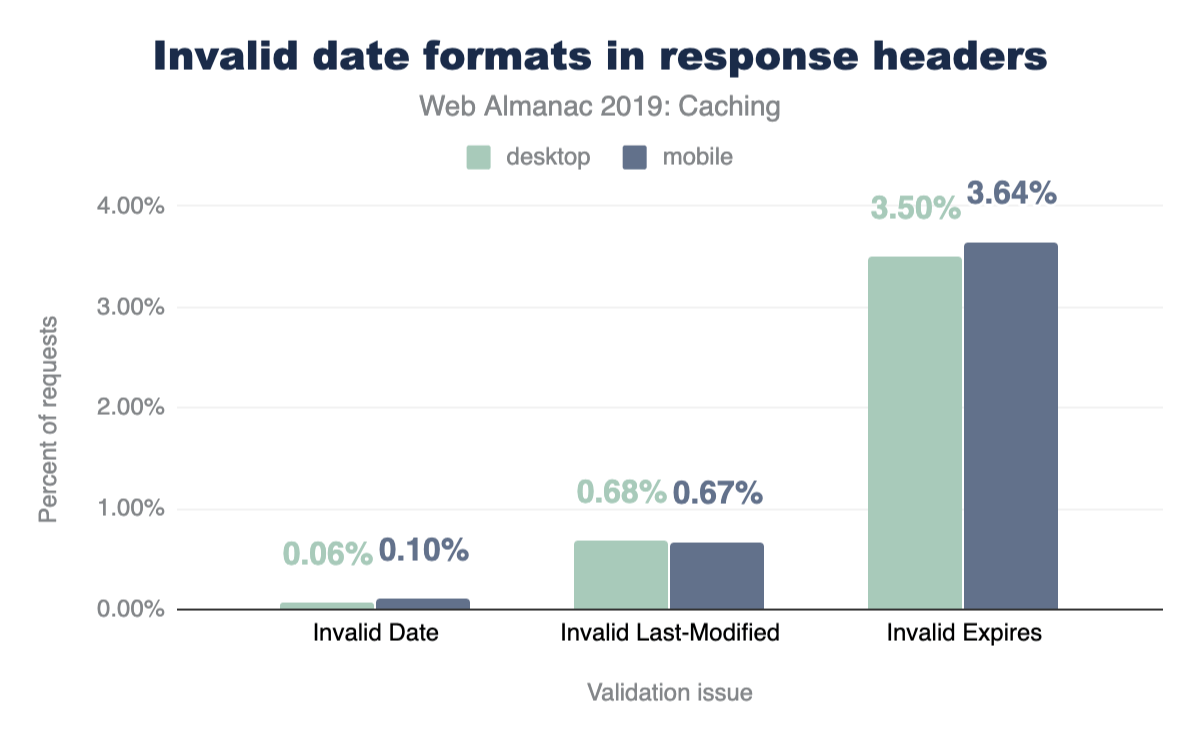 -
- 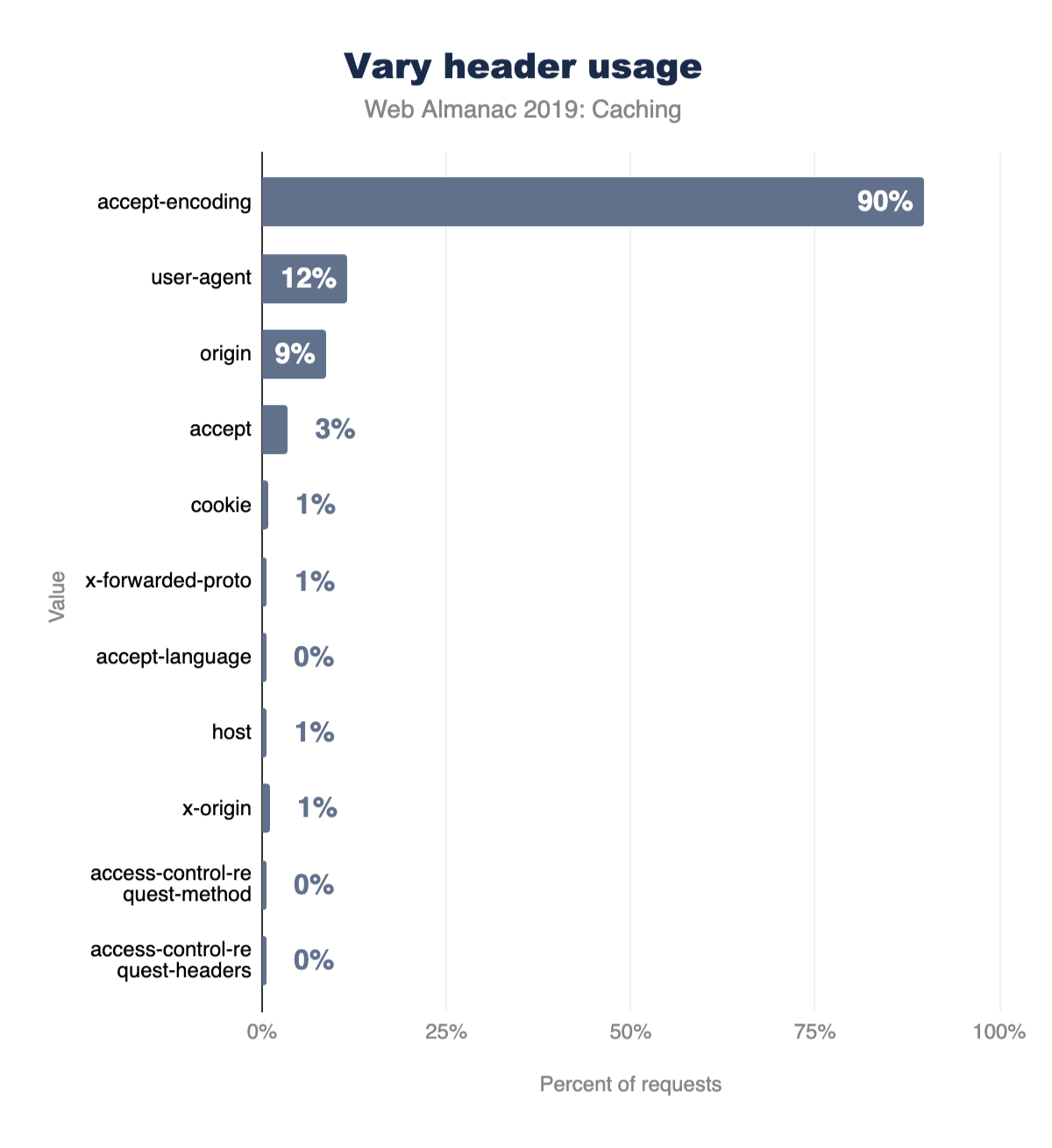 -
- 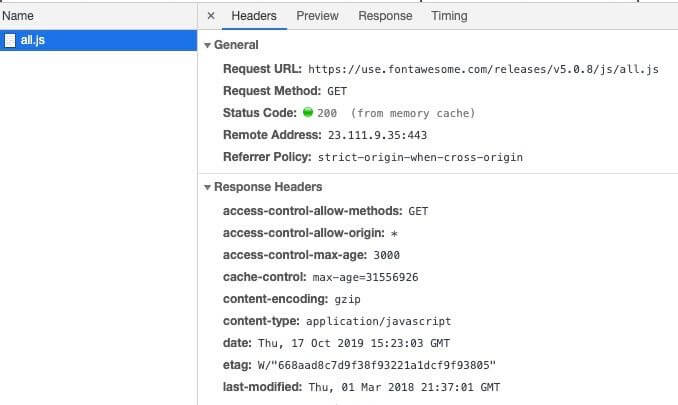 -
- 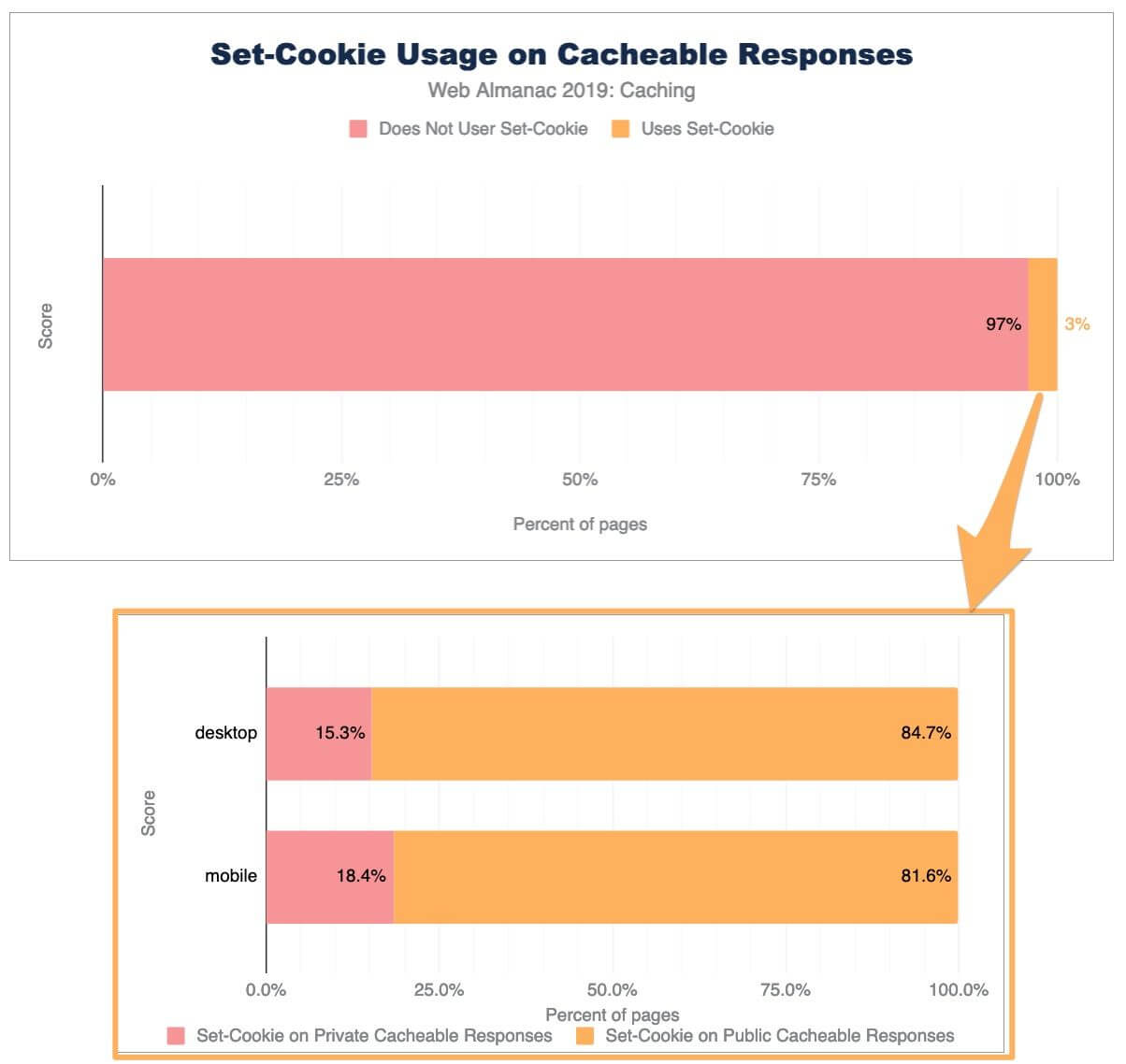 -
- 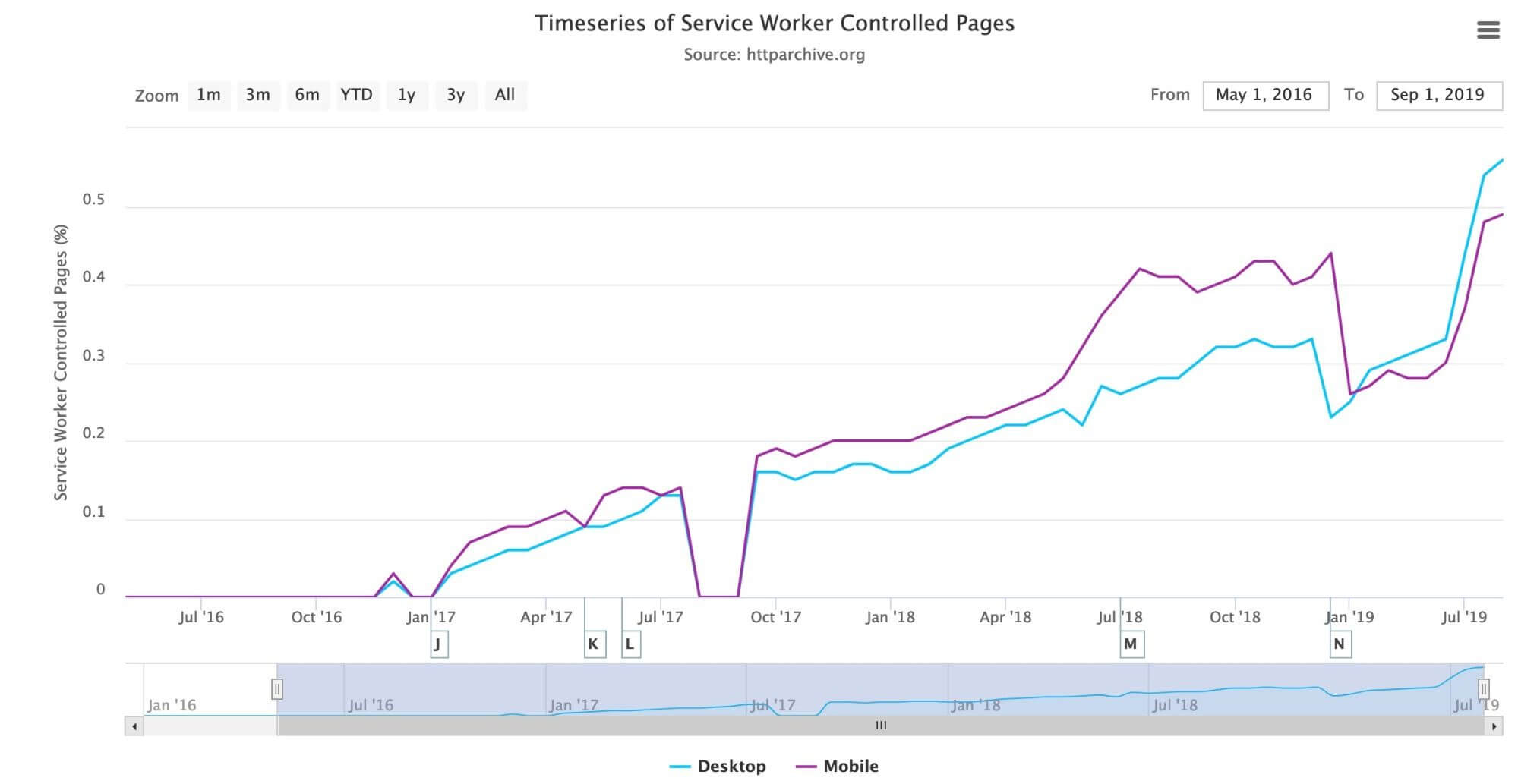 -
- 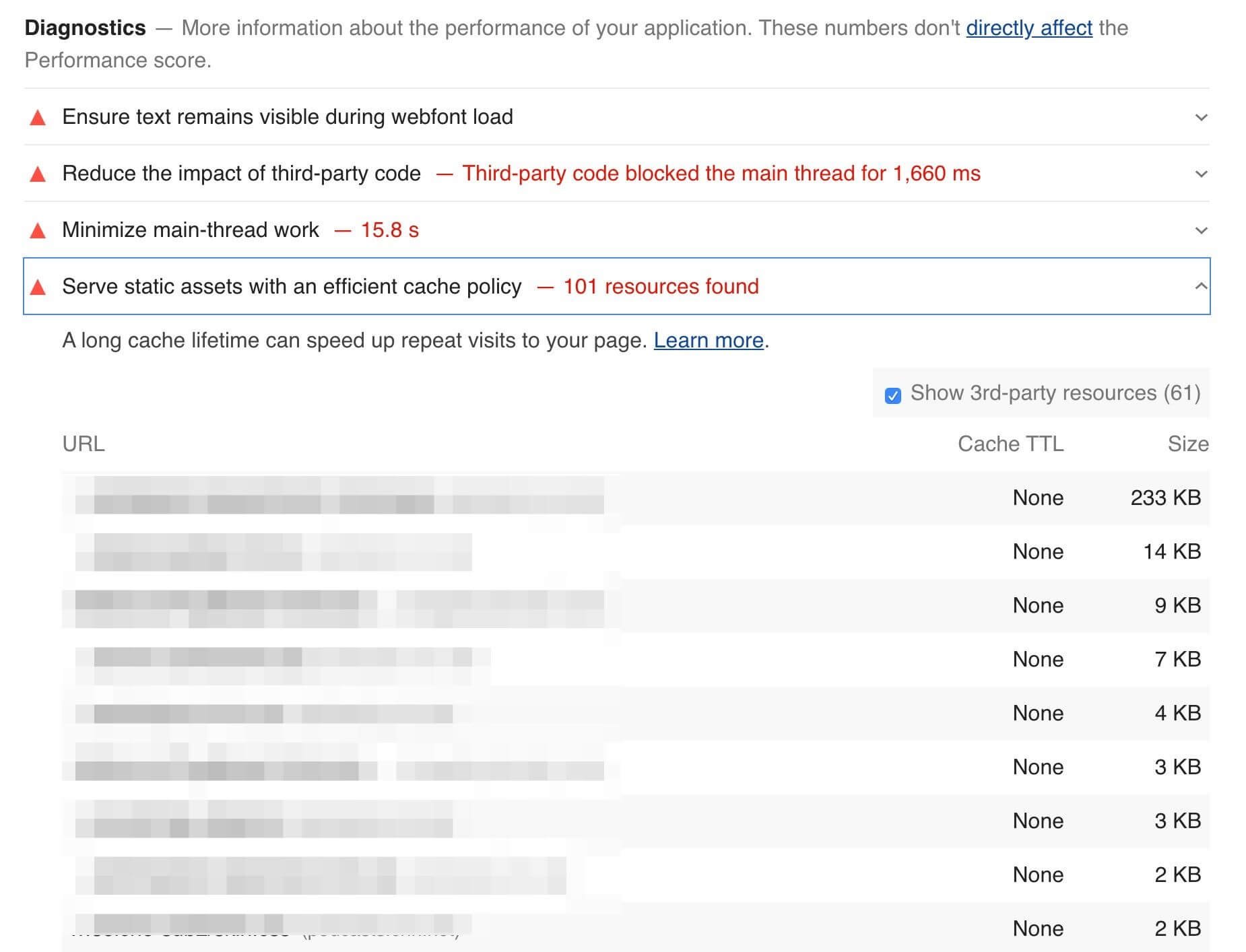 -
- 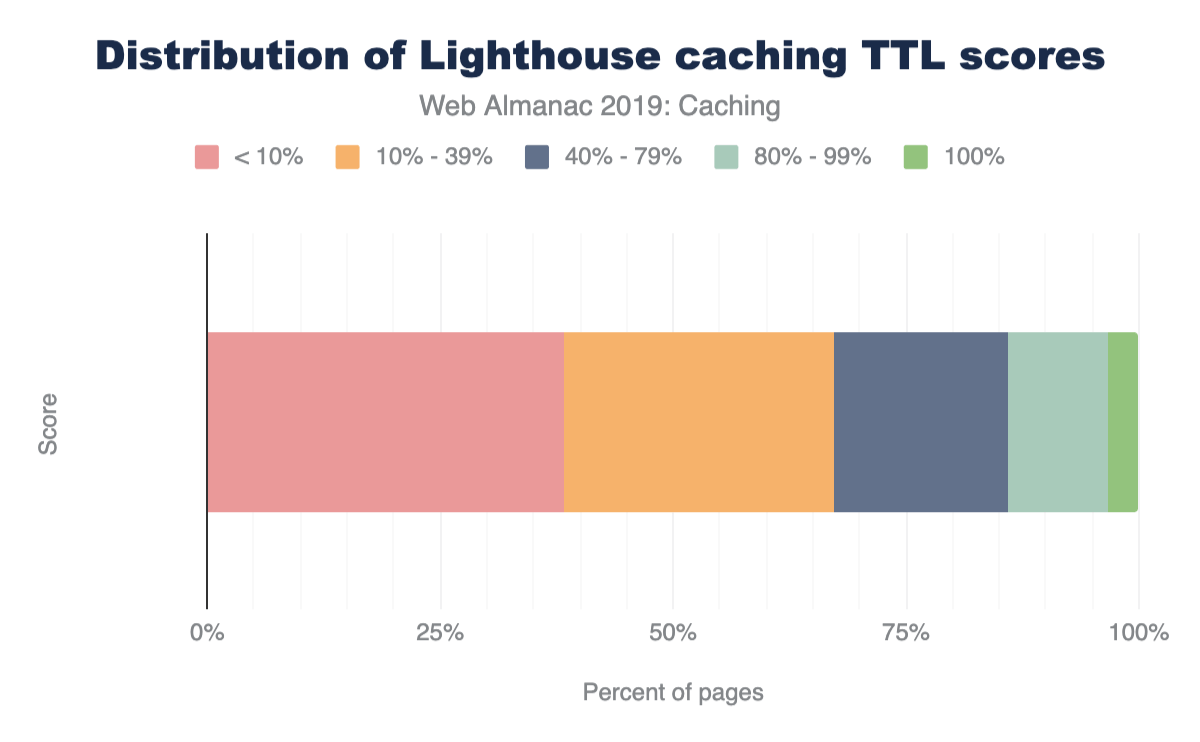 -
- 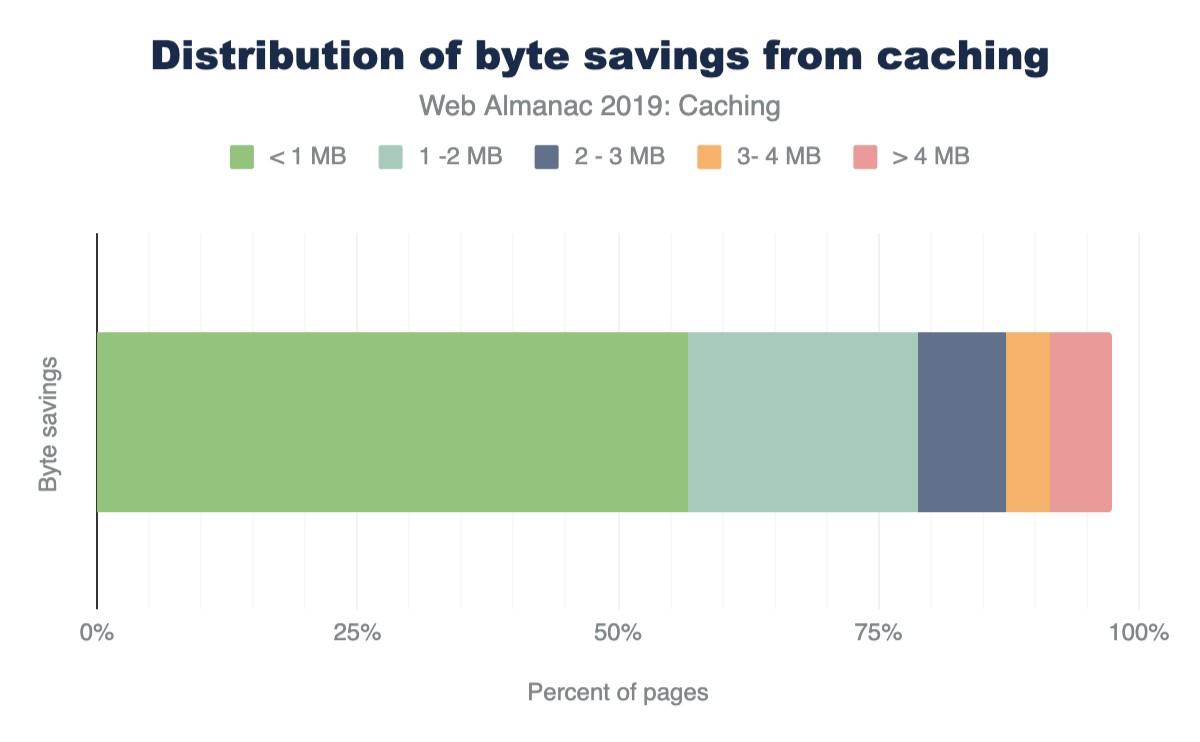 -
- 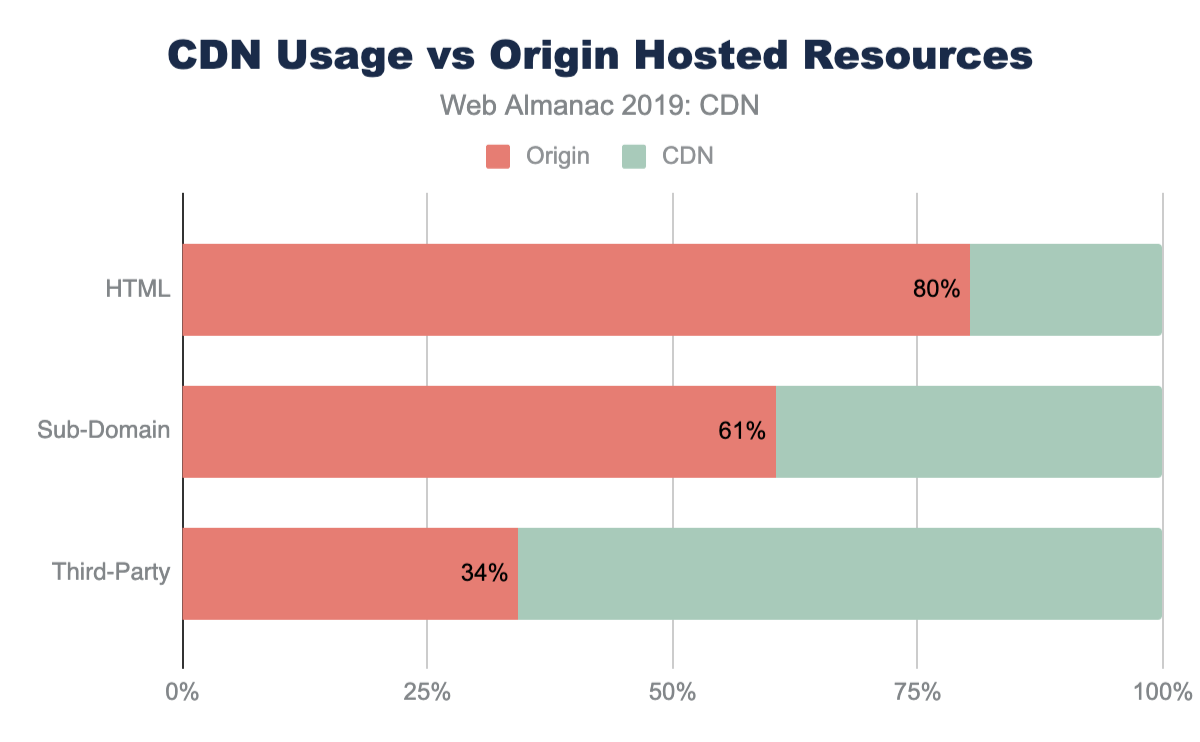 -
- 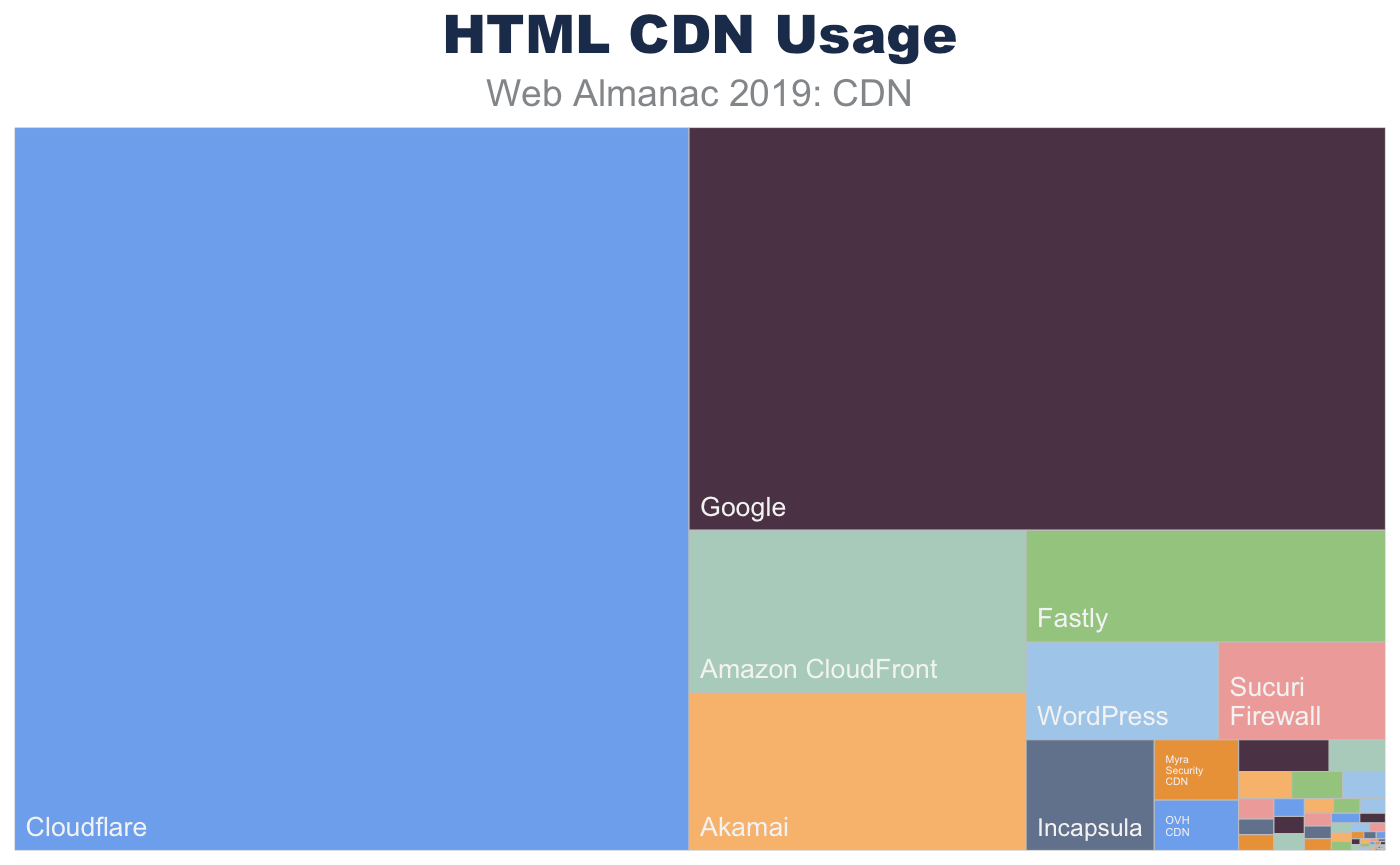 -
- 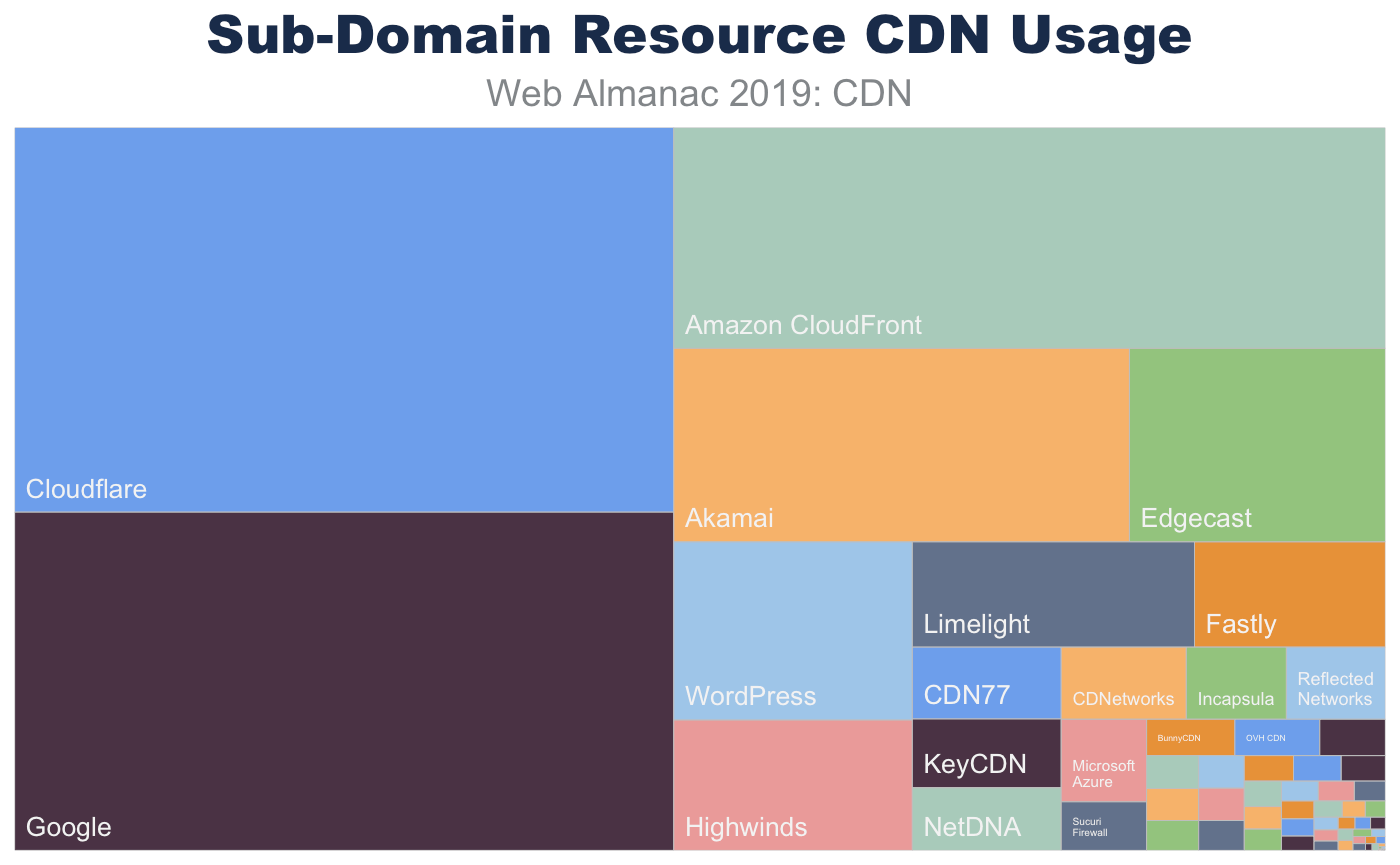 -
- 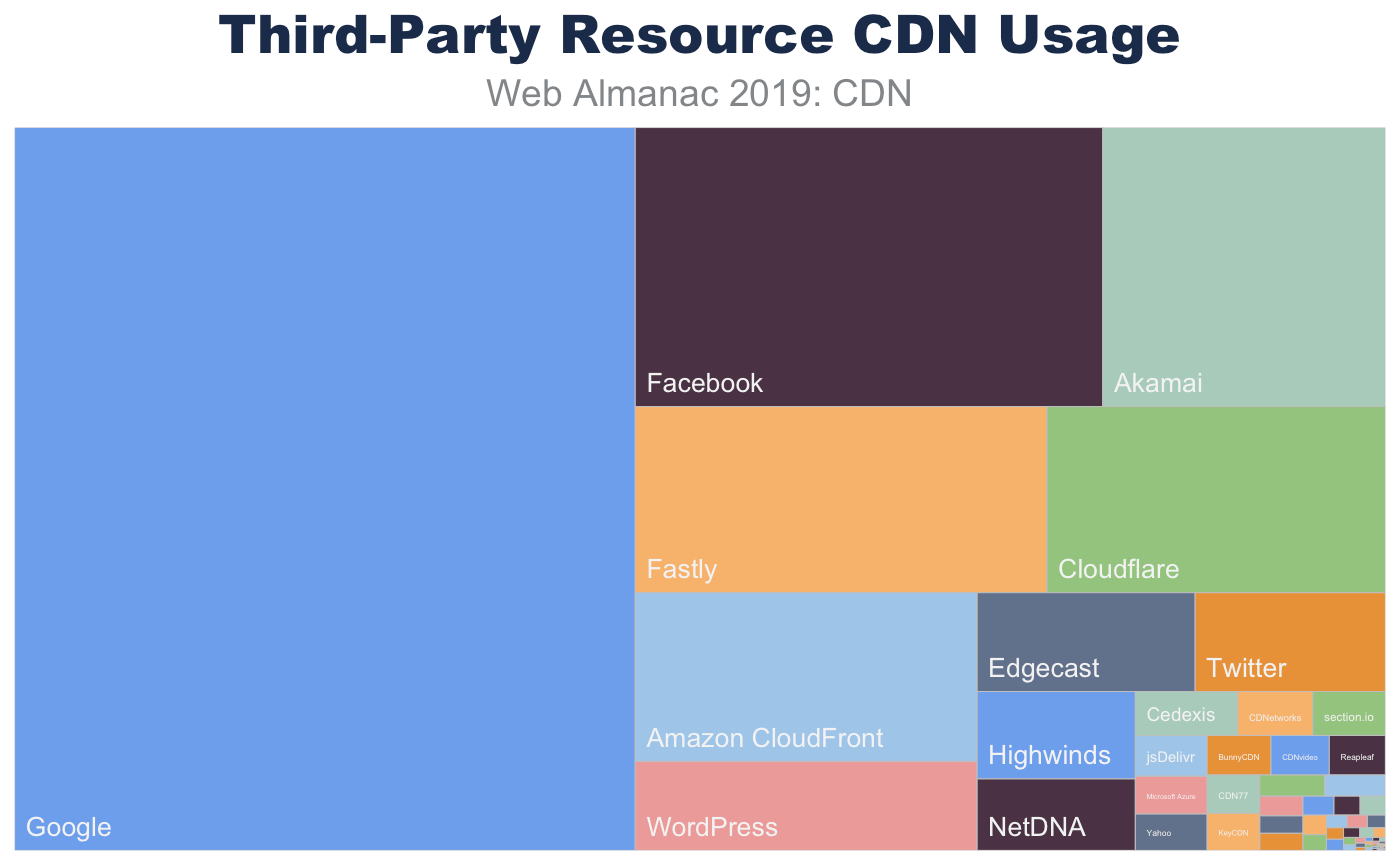 -
- 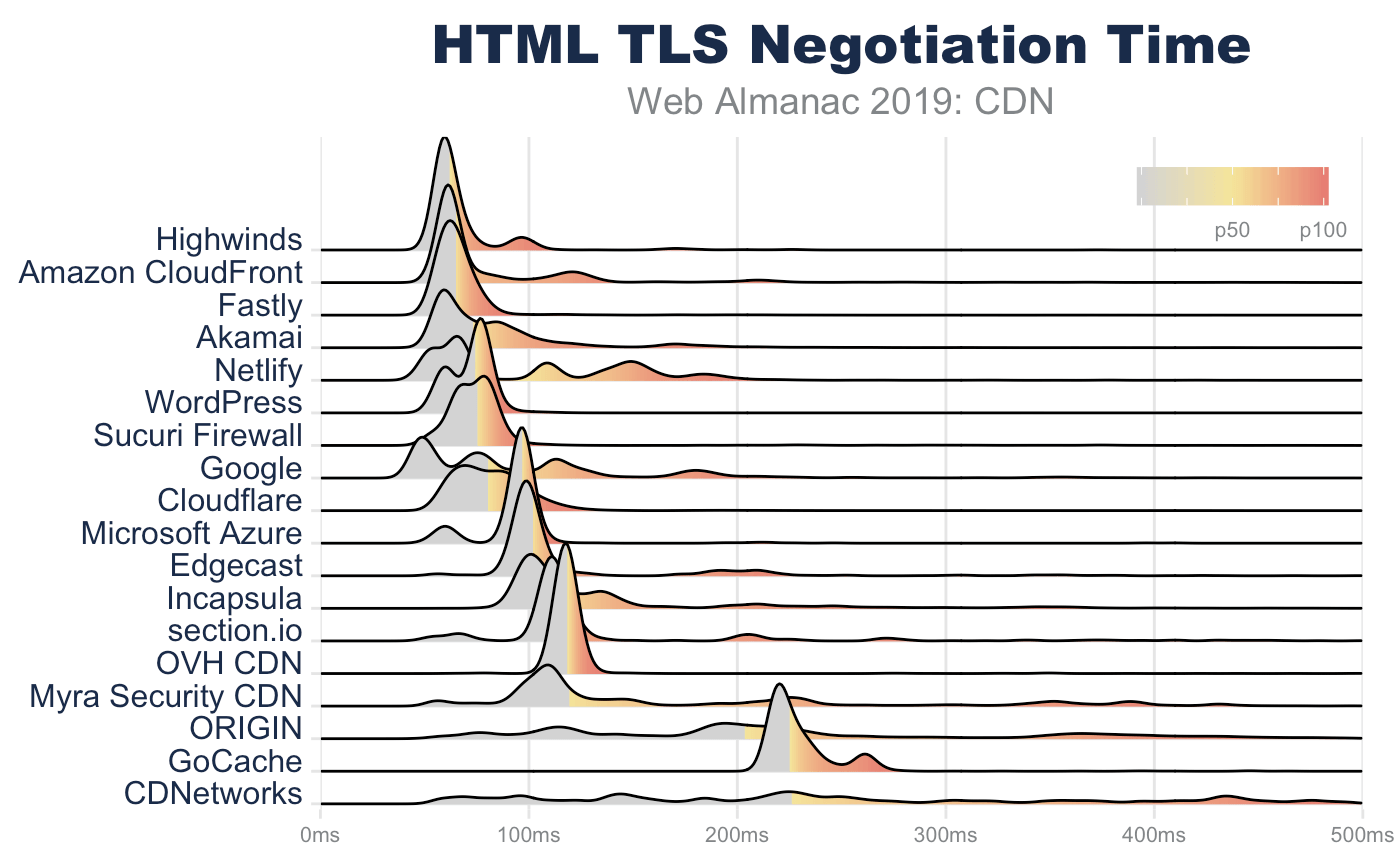 -
- 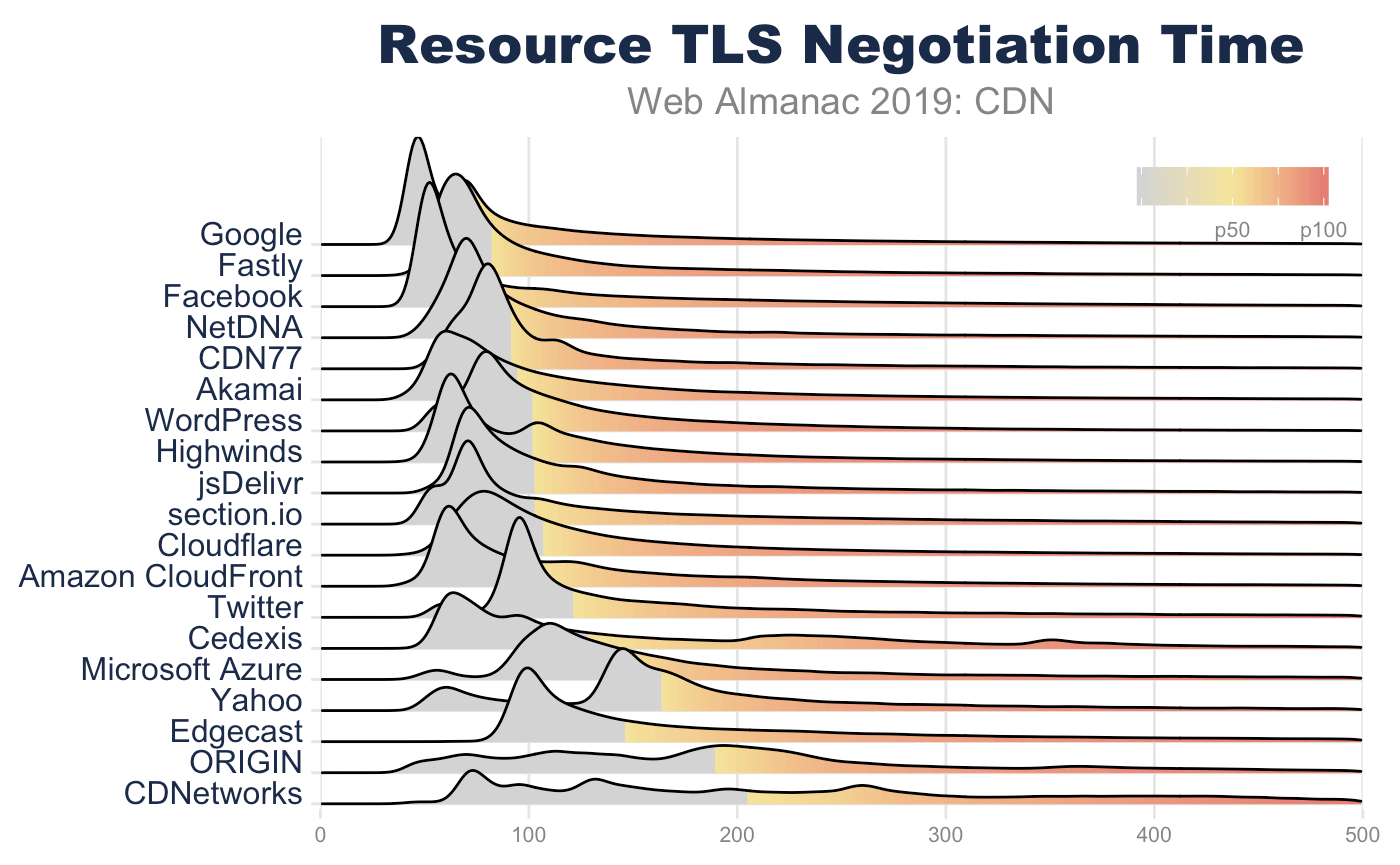 -
- 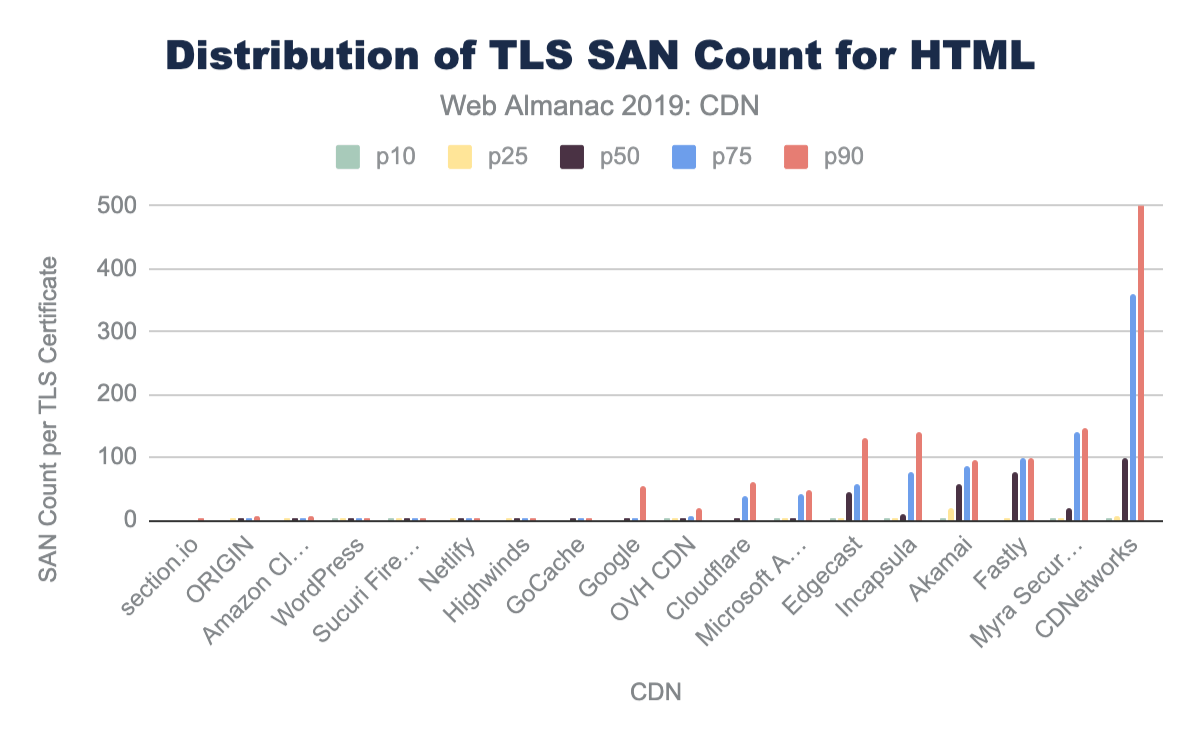 -
- 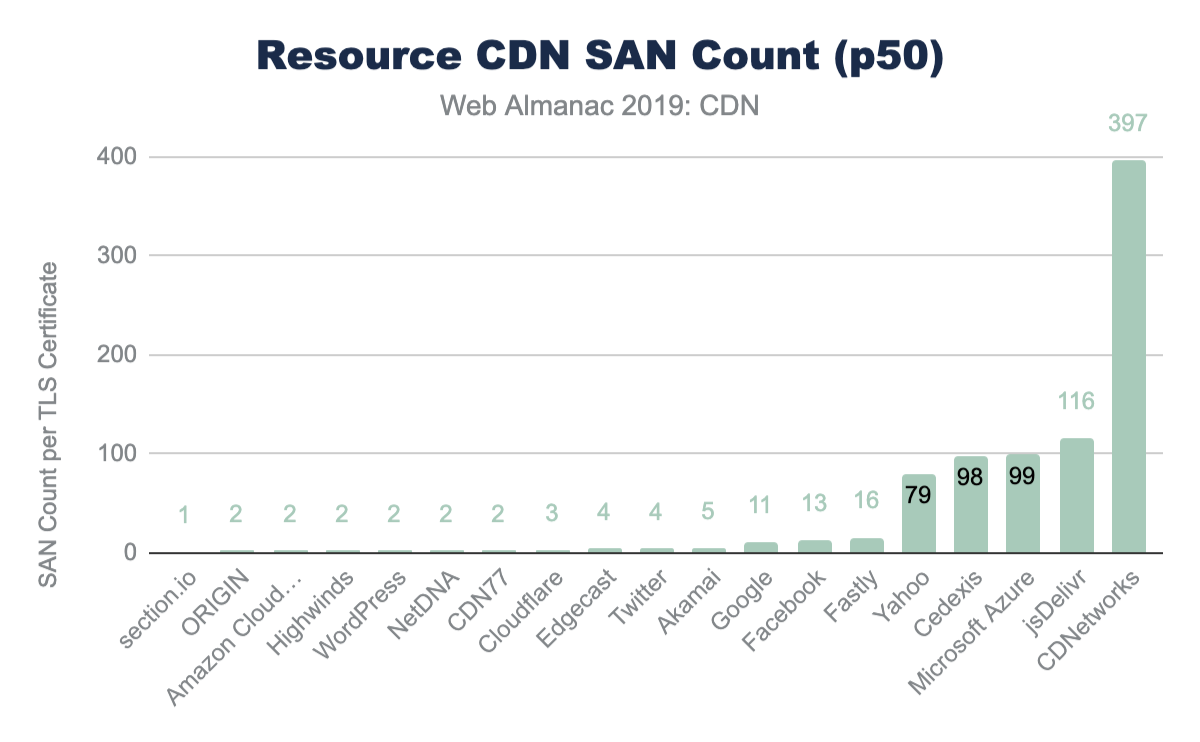 -
- 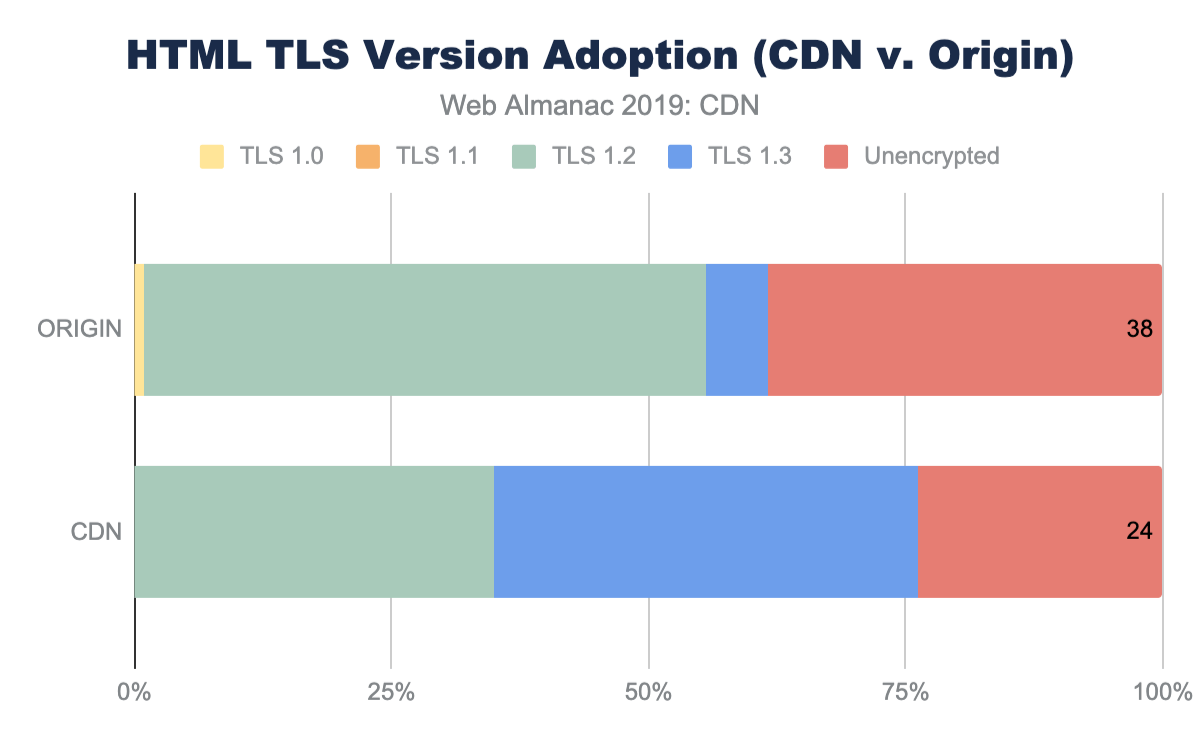 -
- 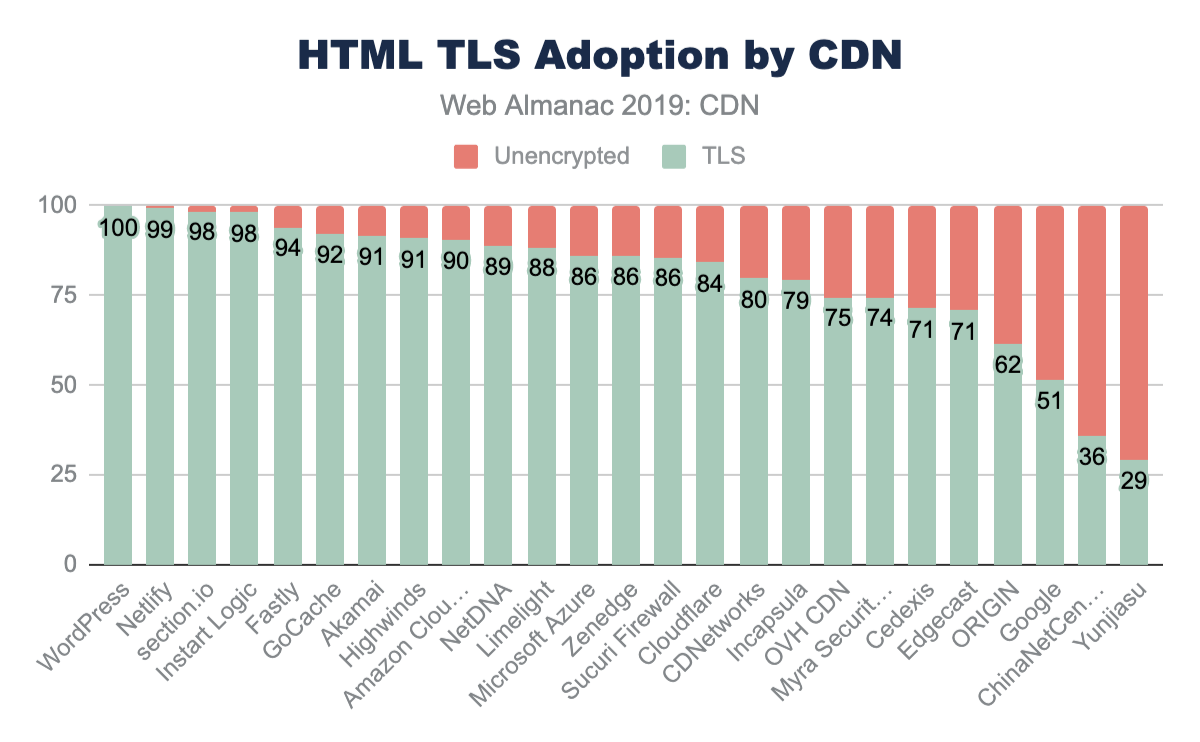 -
- 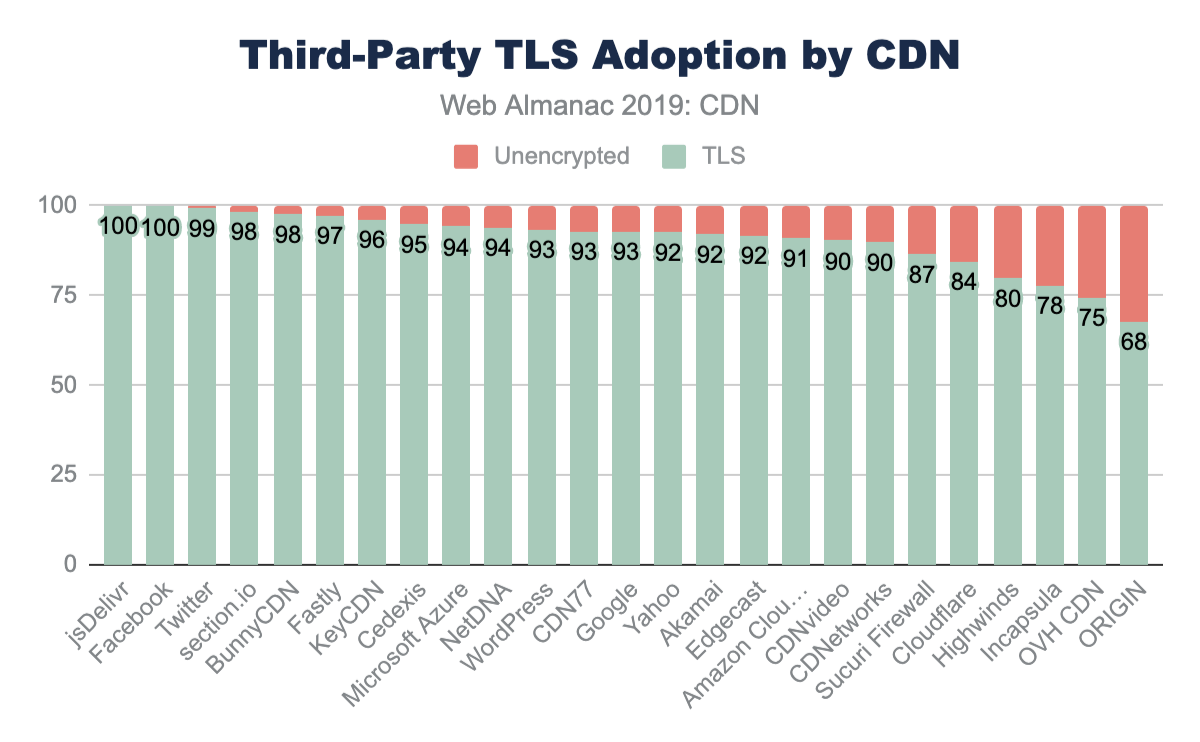 -
- 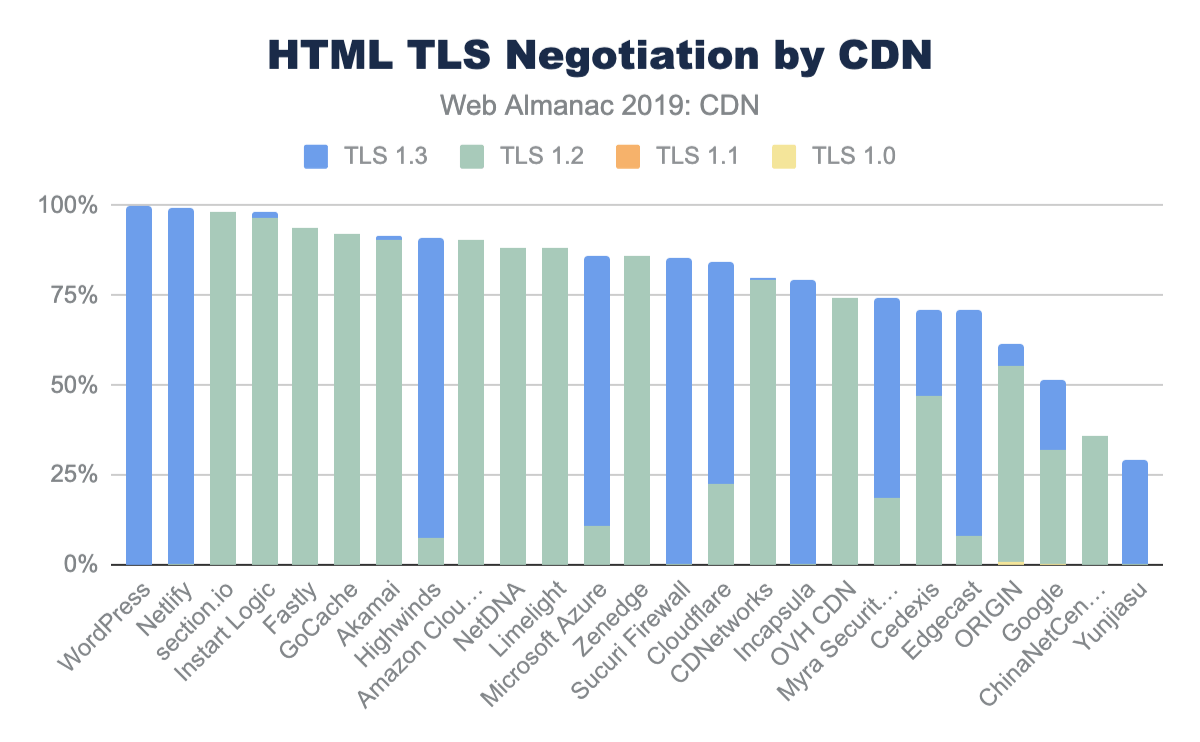 -
- 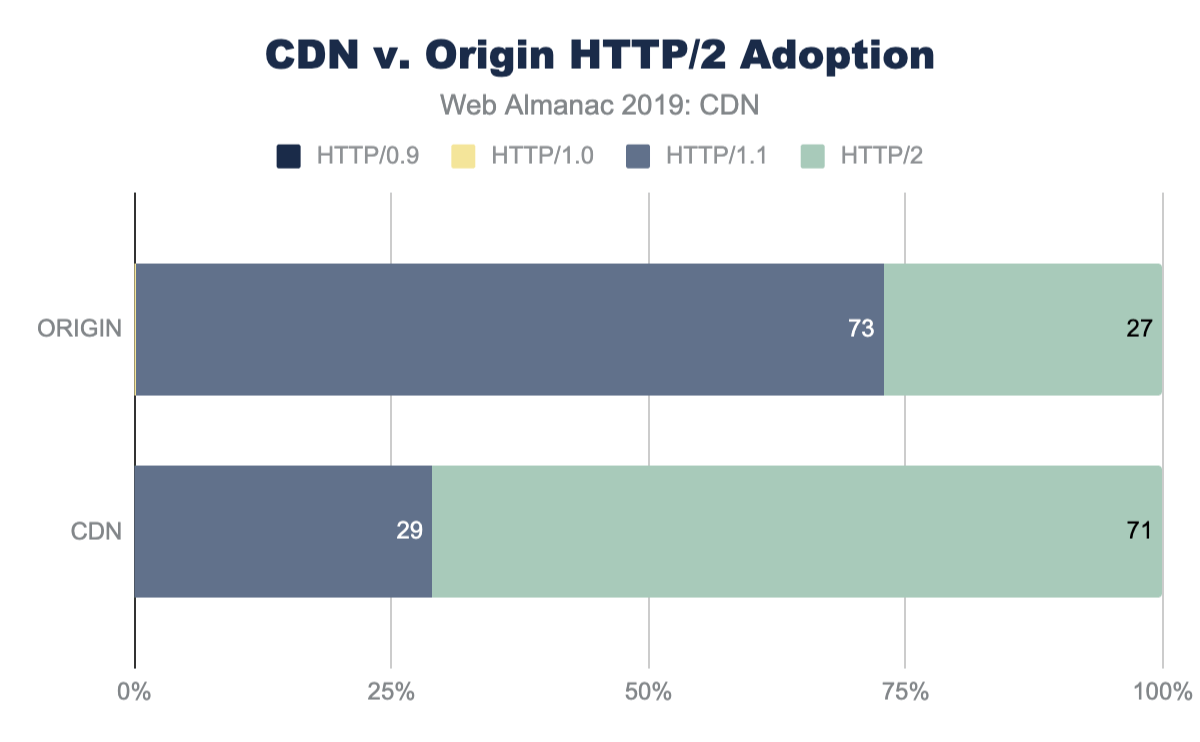 -
- 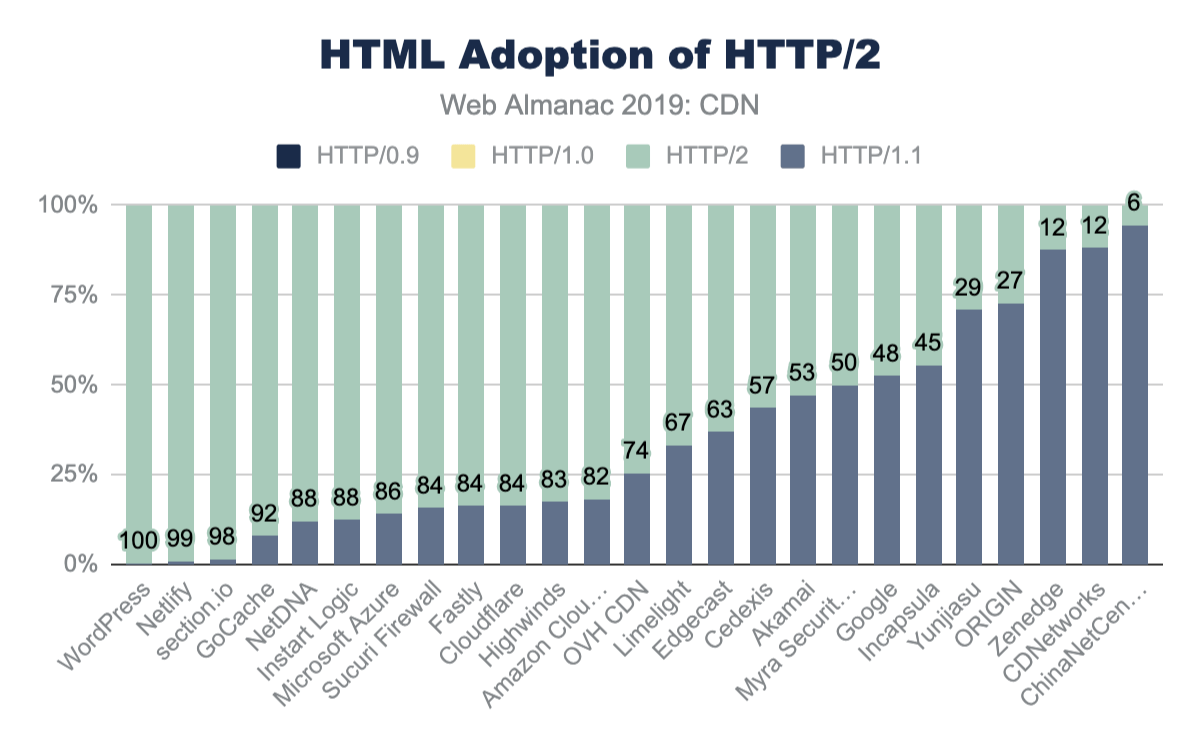 -
- 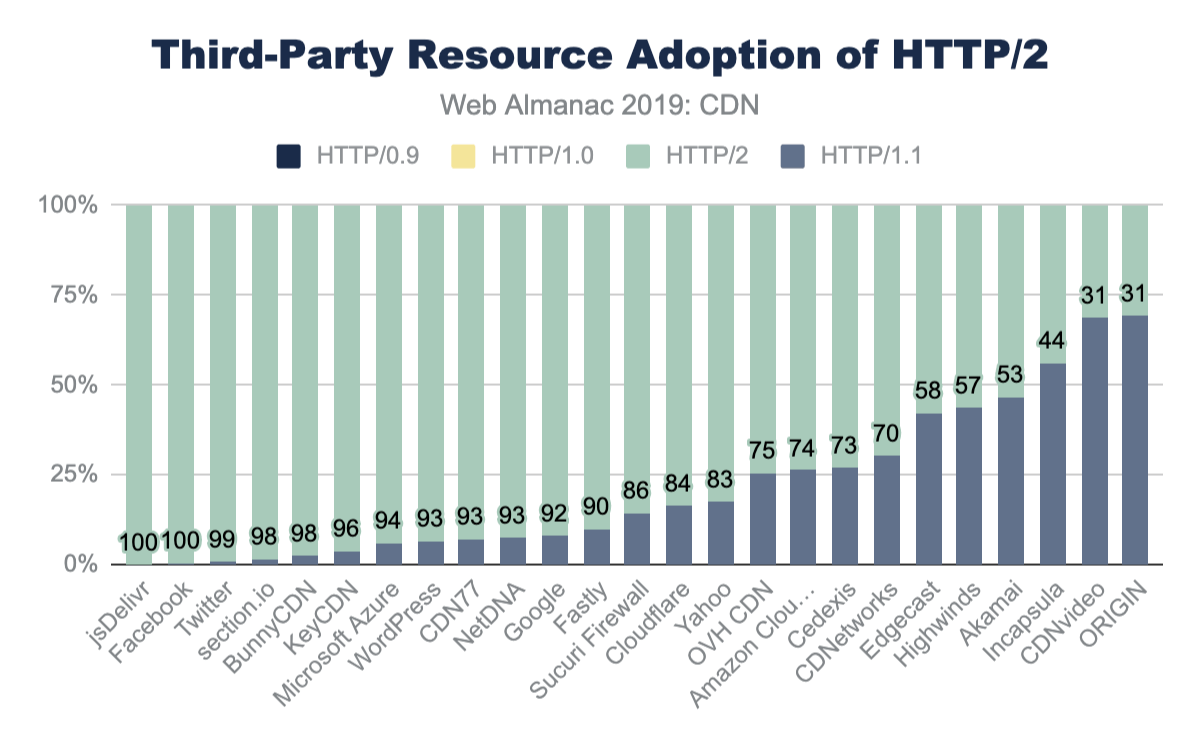 -
- 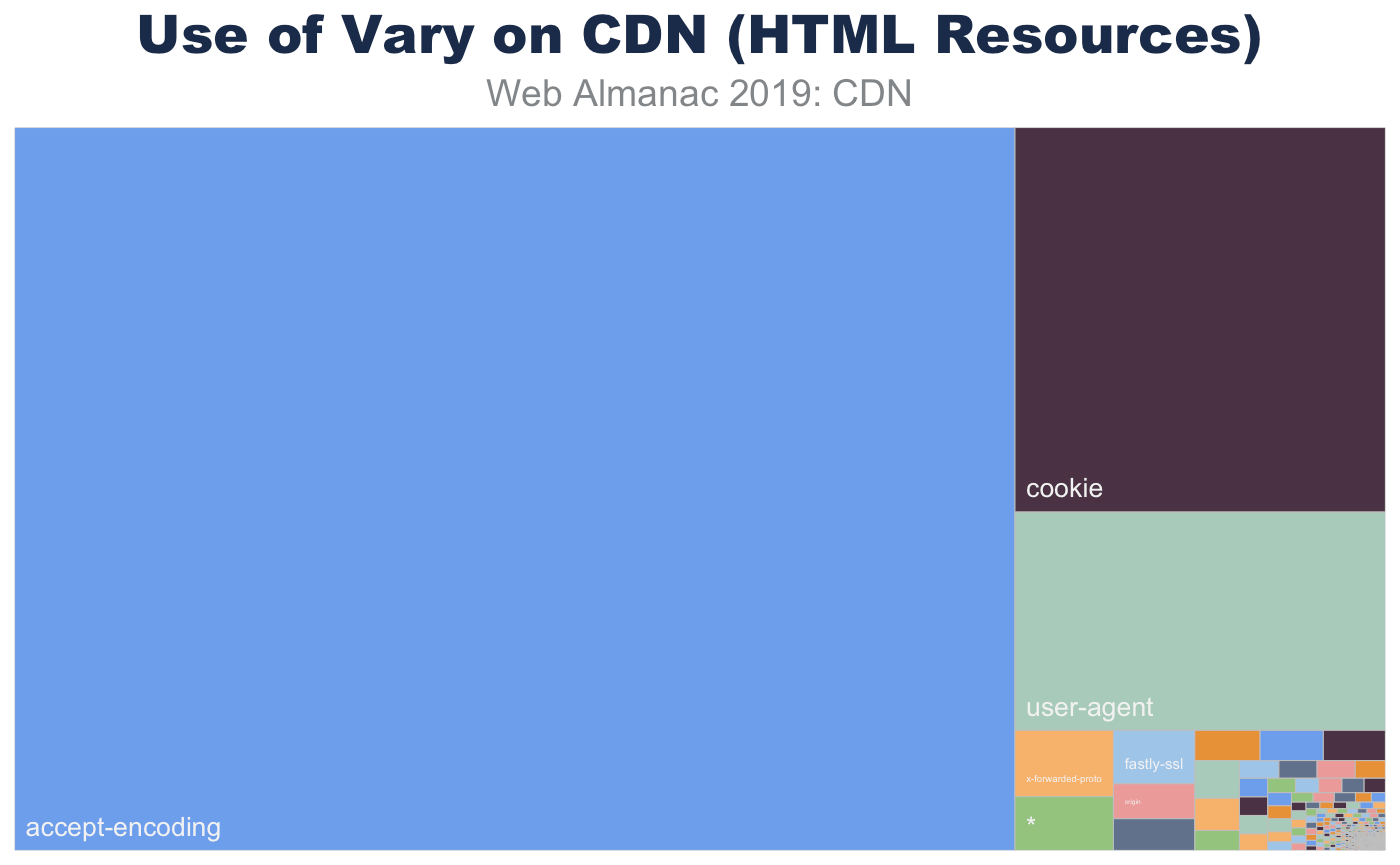 -
- 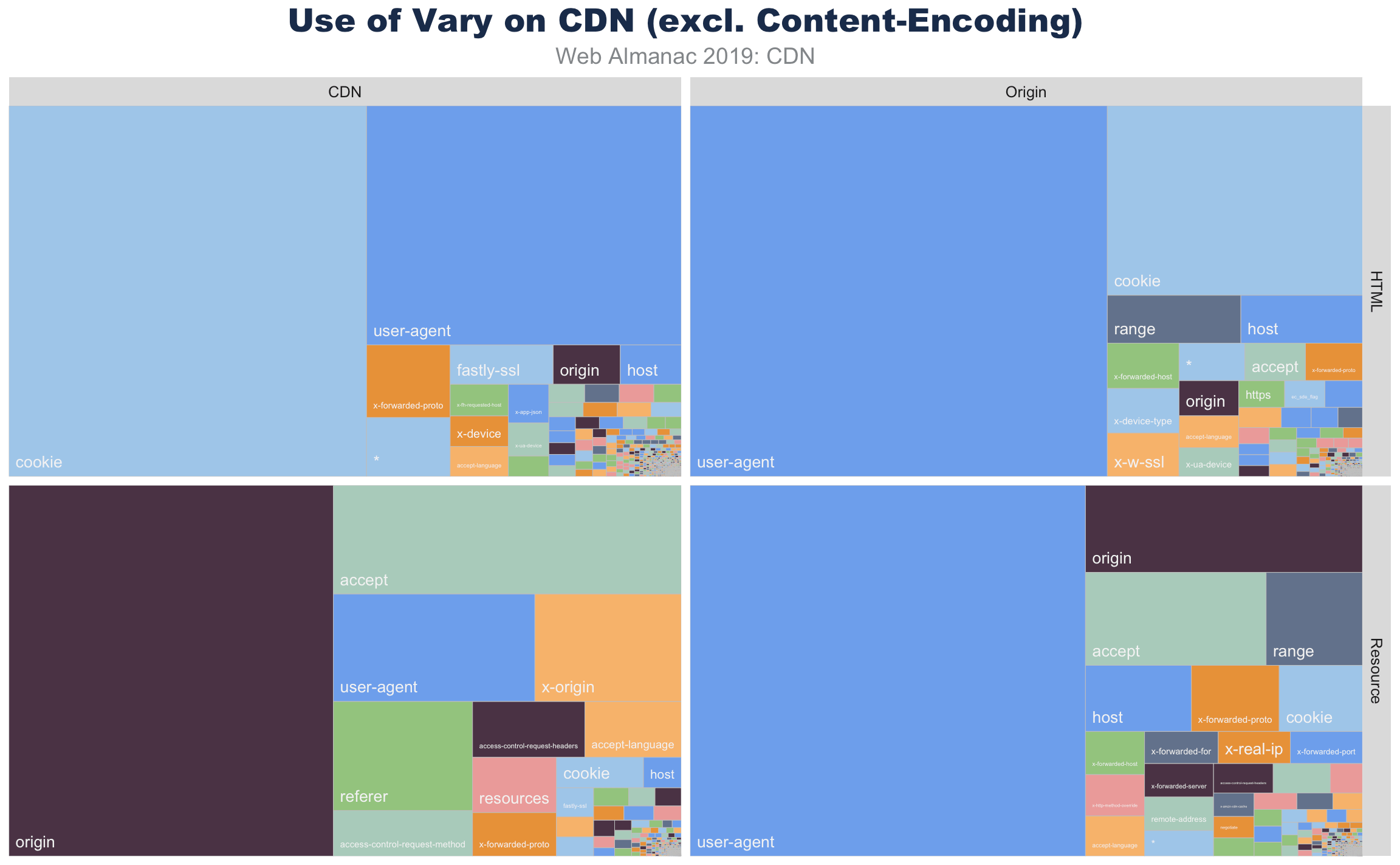 -
- 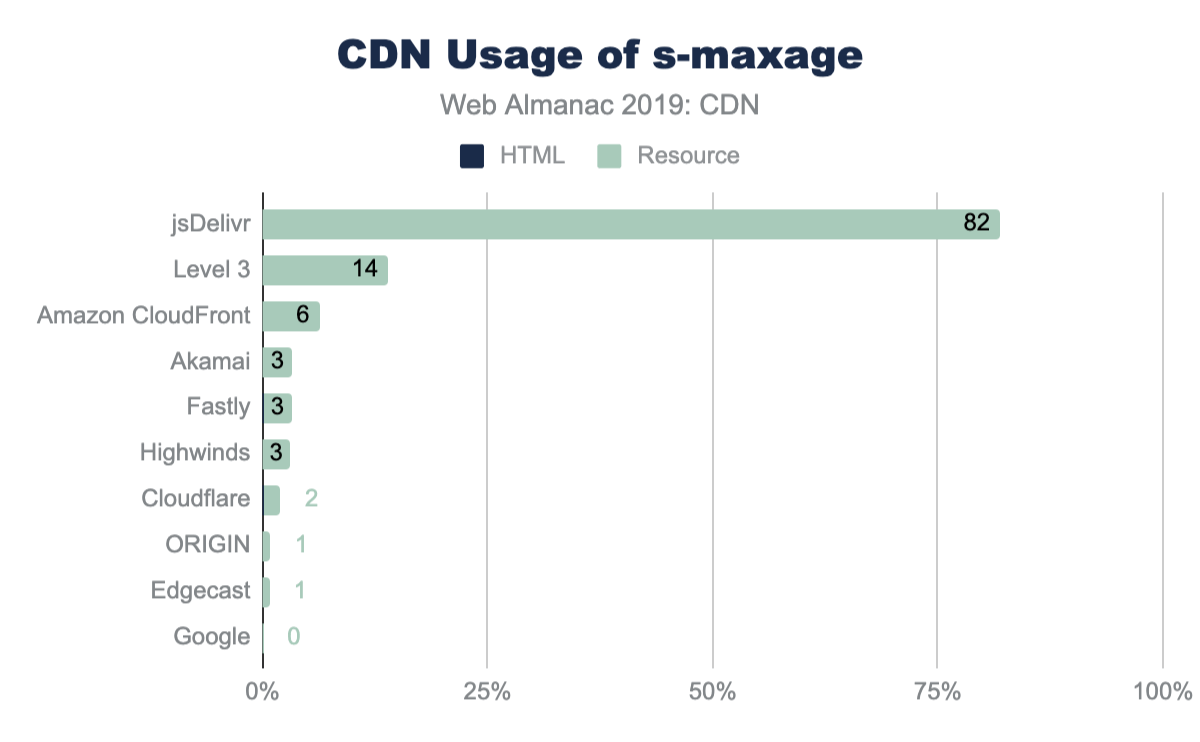 -
- 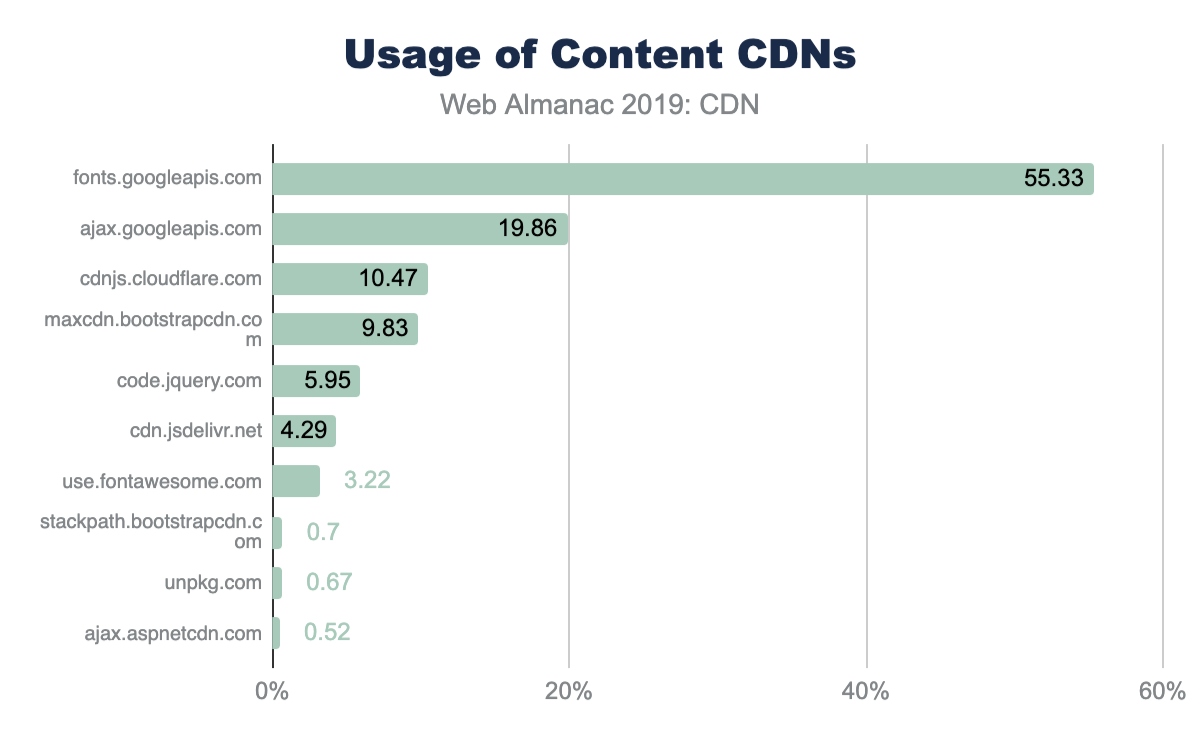 -
-  -
- 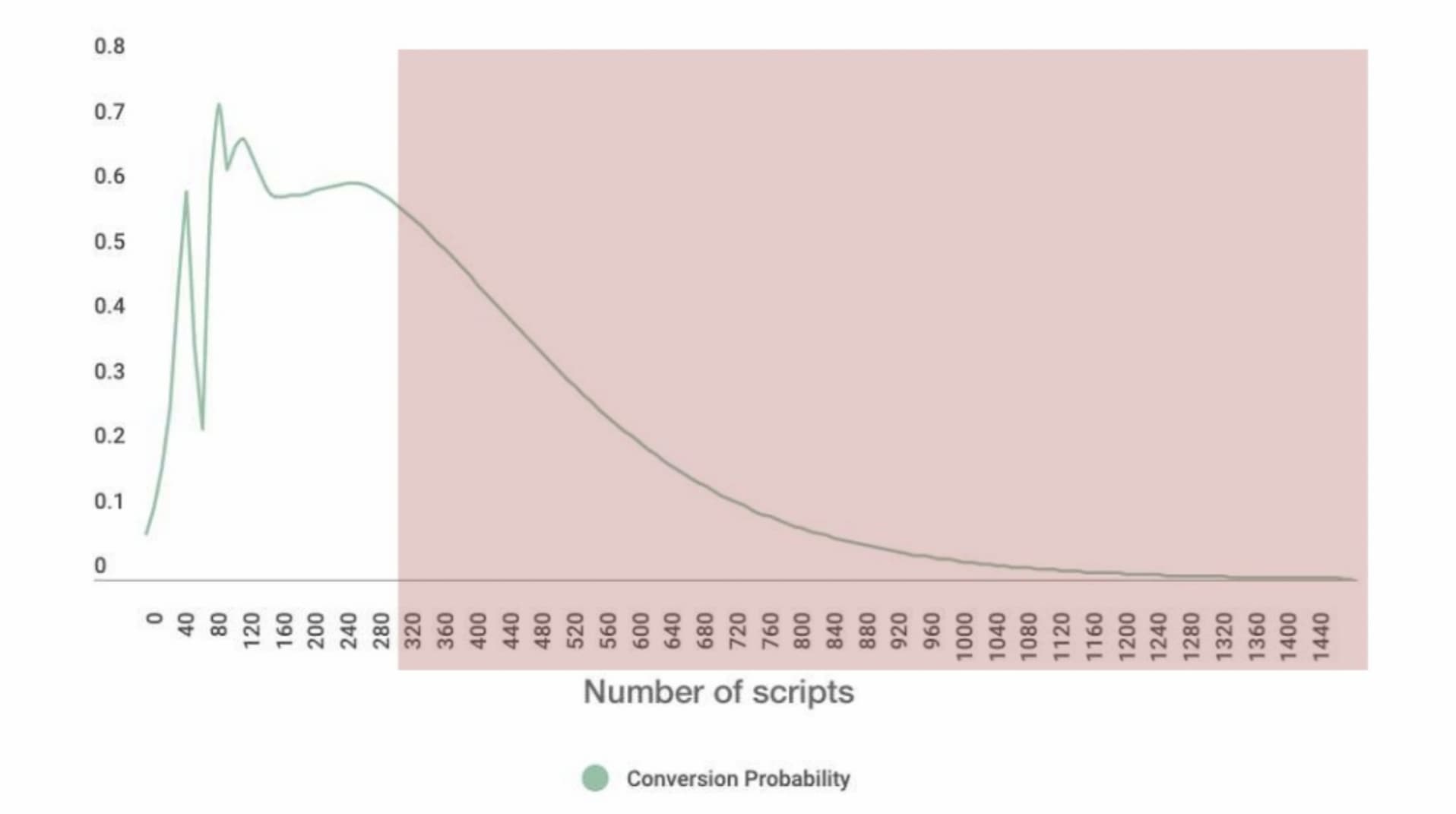 -
- 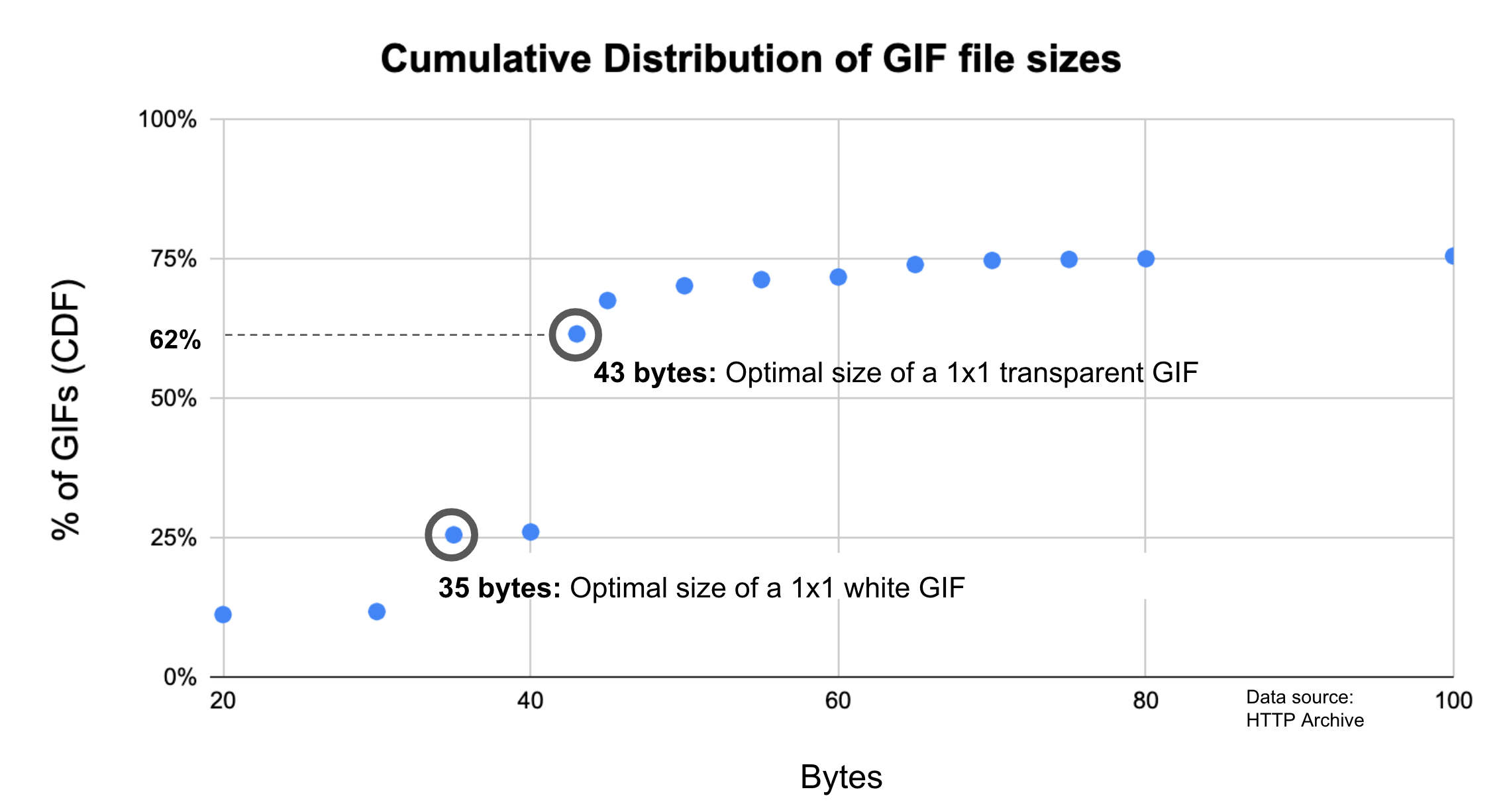 -
- 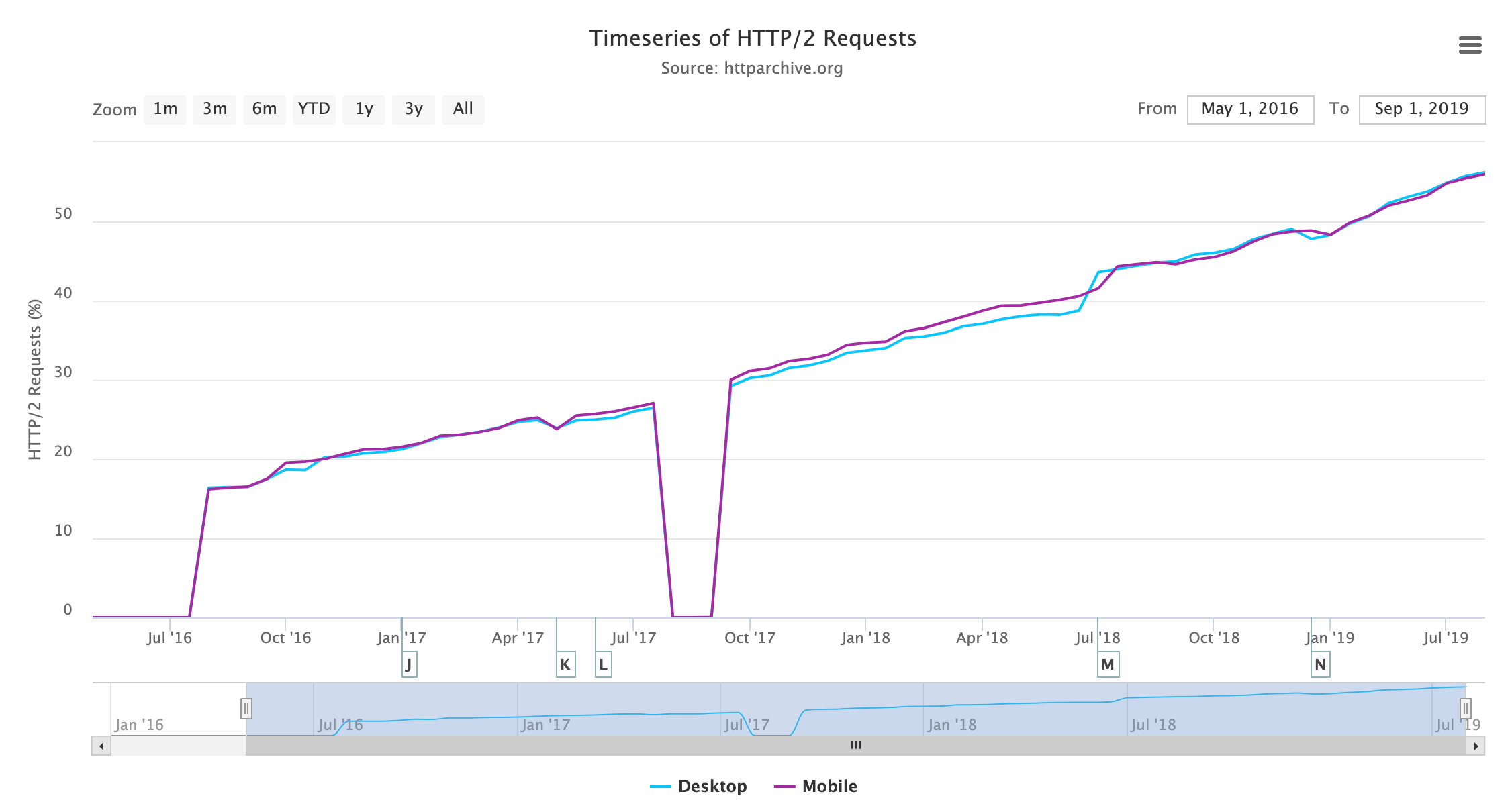 -
-  -
-  -
-  -
- {kind=link}