This folder contains scripts to train SSD model with a ResNet-34 backbone on Intel® Gaudi® AI accelerator to achieve state-of-the-art accuracy. The scripts included in this release is Lazy mode training for BS128 with FP32 and BF16 mixed precision.To obtain model performance data, refer to the Intel Gaudi Model Performance Data page. Before you get started, make sure to review the Supported Configurations.
For more information on training deep learning models using Gaudi, refer to developer.habana.ai.
- Model-References
- Model Overview
- Setup
- Media Loading Acceleration
- Training and Examples
- Dataset/Environment
- Model
- Quality
- Supported Configurations
- Changelog
- Known Issues
Single Shot MultiBox Detector (SSD) is an object detection network. For an input image, the network outputs a set of bounding boxes around the detected objects, along with their classes.
SSD is a one-stage detector, both localization and classification are done in a single pass of the network. This allows for a faster inference than region proposal network (RPN) based networks, making it more suited for real time applications like automotive and low power devices like mobile phones. This is also sometimes referred to as being a "single shot" detector for inference.
The base training and modelling scripts for training are based on a clone of https://github.com/mlcommons/training/tree/master/single_stage_detector with certain changes for modeling and training script. Please refer to later sections on training script and model modifications for a summary of modifications to the original files.
Please follow the instructions provided in the Gaudi Installation Guide
to set up the environment including the $PYTHON environment variable. To achieve the best performance, please follow the methods outlined in the Optimizing Training Platform guide.
The guides will walk you through the process of setting up your system to run the model on Gaudi.
In the docker container, clone this repository and switch to the branch that
matches your Intel Gaudi software version. You can run the
hl-smi
utility to determine the Intel Gaudi software version.
git clone -b [Intel Gaudi software version] https://github.com/HabanaAI/Model-ReferencesGo to PyTorch SSD directory:
cd Model-References/PyTorch/computer_vision/detection/mlcommons/SSDNote: If the repository is not in the PYTHONPATH, make sure to update by running the below:
export PYTHONPATH=/path/to/Model-References:$PYTHONPATHInstall the required packages using pip:
pip install -r requirements.txtcd Model-References/PyTorch/computer_vision/detection/mlcommons/SSD
source download_dataset.sh
The ResNet-34 backbone is initialized with weights from PyTorch hub file
https://download.pytorch.org/models/resnet34-333f7ec4.pth by calling
torchvision.models.resnet34(pretrained=True)
as described in the Torch Model Zoo code.
By default, the code will automatically download the weights to
$TORCH_HOME/hub (default is ~/.cache/torch/hub) and save them for later use.
Alternatively, you can manually download the weights using the below command. Then use the downloaded file with --pretrained-backbone <PATH TO WEIGHTS>:
cd Model-References/PyTorch/computer_vision/detection/mlcommons/SSD
./download_resnet34_backbone.sh
To read the weights without installing PyTorch, use the provided pth_to_pickle.py script to
convert them to a pickled dictionary of numpy arrays. The pickled file can later be read with pickle.load("resnet34-333f7ec4.pickle"):
cd Model-References/PyTorch/computer_vision/detection/mlcommons/SSD
python pth_to_pickle.py resnet34-333f7ec4.pth resnet34-333f7ec4.pickle
Gaudi 2 offers a dedicated hardware engine for Media Loading operations. For more details, please refer to Intel Gaudi Media Loader
The commands in the following sub-sections assume that coco2017 dataset is available at /data/pytorch/coco2017/ directory.
Please refer to the following command for available training parameters:
$PYTHON train.py --helpGo to the ssd directory:
cd Model-References/PyTorch/computer_vision/detection/mlcommons/SSD/ssdRun training on 1 HPU:
- 1 HPU, Lazy mode, BF16 mixed precision, batch size 128, 12 data loader workers:
$PYTHON train.py --batch-size 128 --num-workers 12 --epochs 50 --log-interval 100 --val-interval 5 --data /data/pytorch/coco2017/ --use-hpu --hpu-lazy-mode --autocast
- 1 HPU, Lazy mode, FP32, batch size 128, 12 data loader workers:
$PYTHON train.py --batch-size 128 --num-workers 12 --epochs 50 --log-interval 100 --val-interval 5 --data /data/pytorch/coco2017/ --use-hpu --hpu-lazy-mode
- 1 HPU, Lazy mode, BF16 mixed precision, batch size 128, 12
habana_dataloaderworkers (with hardware decode support on Gaudi 2):$PYTHON train.py --batch-size 128 --num-workers 12 --epochs 50 --log-interval 100 --val-interval 5 --data /data/pytorch/coco2017/ --use-hpu --hpu-lazy-mode --autocast --dl-worker-type HABANA
Run training on 8 HPUs:
NOTE: mpirun map-by PE attribute value may vary on your setup. For the recommended calculation, refer to the instructions detailed in mpirun Configuration.
- 8 HPUs, Lazy mode, BF16 mixed precision, batch size 128, 12 data loader workers:
mpirun -n 8 --bind-to core --map-by socket:PE=6 --rank-by core --report-bindings --allow-run-as-root $PYTHON train.py -d /data/pytorch/coco2017/ --batch-size 128 --log-interval 100 --val-interval 10 --use-hpu --hpu-lazy-mode --autocast --warmup 2.619685 --num-workers 12 - 8 HPUs, Lazy mode, FP32, batch size 128, 12 data loader workers:
mpirun -n 8 --bind-to core --map-by socket:PE=6 --rank-by core --report-bindings --allow-run-as-root $PYTHON train.py -d /data/pytorch/coco2017/ --batch-size 128 --log-interval 100 --val-interval 5 --use-hpu --hpu-lazy-mode --warmup 2.619685 --num-workers 12 - 8 HPUs, Lazy mode, BF16 mixed precision, batch size 128, 12
habana_dataloaderworkers:mpirun -n 8 --bind-to core --map-by socket:PE=6 --rank-by core --report-bindings --allow-run-as-root $PYTHON train.py -d /data/pytorch/coco2017/ --batch-size 128 --log-interval 100 --val-interval 10 --use-hpu --hpu-lazy-mode --autocast --warmup 2.619685 --num-workers 12 --dl-worker-type HABANA
Microsoft COCO: Common Objects in Context. 2017.
Train on 2017 COCO train data set, compute mAP on 2017 COCO val data set.
This network takes an input 300x300 image from Coco 2017 and 80 categories, and computes a set of bounding boxes and categories. Other detector models use multiple stages, first proposing regions of interest that might contain objects, then iterating over the regions of interest to try to categorize each object. SSD does both of these in one stage, leading to lower-latency and higher-performance inference.
The backbone is based on adapting a ResNet-34. Using the same notation as Table 1 of the original ResNet paper the backbone looks like:
| layer name | output size | ssd-backbone |
|---|---|---|
| conv1 | 150x150 | 7x7, 64, stride 2 |
| 75x75 | 3x3 max pool, stride 2 | |
| conv2_x | 75x75 | pair-of[3x3, 64] x 3 |
| conv3_x | 38x38 | pair-of[3x3, 128] x 4 |
| conv4_x | 38x38 | pair-of[3x3, 256] x 6 |
The original ResNet-34 network is adapted by removing the conv5_x layers and the fully-connected layer at the end, and by only downsampling in conv3_1, not in conv4_1. Using the terminology of Section 3.1.3 of the Google Research paper, our network has an effective stride of 8, and no atrous convolution.
Input images are 300x300 RGB. They are fed to a 7x7 stride 2 convolution with 64 output channels, then through a 3x3 stride 2 max-pool layer, resulting in a 75x75x64 (HWC) tensor. The rest of the backbone is built from "building blocks": pairs of 3x3 convolutions with a "short-cut" residual connection around the pair. All convolutions in the backbone are followed by batch-norm and ReLU.
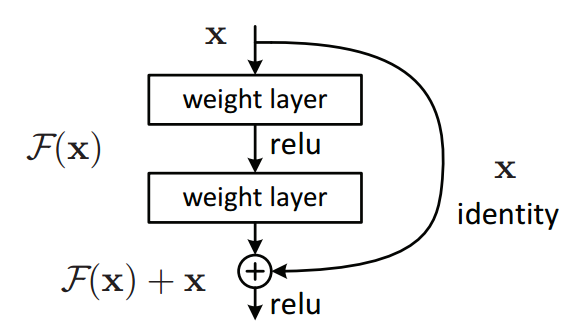
The conv3_1 layer is stride 2 in the first convolution, while also increasing the number of channels from 64 to 128, and has a 1x1 stride 2 convolution in its residual shortcut path to increase the number of channels to 128. The conv4_1 layer is not strided, but does increase the number of channels from 128 to 256, and so also has a 1x1 convolution in the residual shortcut path to increase the number of channels to 256.
The backbone is initialized with the pretrained weights from the corresponding layers of the ResNet-34 implementation from the Torchvision model zoo, described in detail here. It is a ResNet-34 network trained on 224x224 ImageNet to achieve a Top-1 error rate of 26.7 and a Top-5 error rate of 8.58.
The 38x38, 256 channel output of the conv4_6 layer gets fed into a downsizing network with a set of detector head layers.
| layer name | input size | input channels | filter size | padding | stride | output size | output channels | detector head layer | anchors per center point | default scale | | :------: | :---: | :-: | :-: | :-: | :-: | :---: | :-: | :-----: | :-: | --: | | conv4_6 | 38x38 | 256 | 3x3 | 1 | 1 | 38x38 | 256 | conv4_mbox | 4 | 21 | | conv7_1 | 38x38 | 256 | 1x1 | 0 | 1 | 38x38 | 256 | | | | | conv7_2 | 38x38 | 256 | 3x3 | 1 | 2 | 19x19 | 512 | conv7_mbox | 6 | 45 | | conv8_1 | 19x19 | 512 | 1x1 | 0 | 1 | 19x19 | 256 | | | | | conv8_2 | 19x19 | 256 | 3x3 | 1 | 2 | 10x10 | 512 | conv8_mbox | 6 | 99 | | conv9_1 | 10x10 | 512 | 1x1 | 0 | 1 | 10x10 | 128 | | | | | conv9_2 | 10x10 | 128 | 3x3 | 1 | 2 | 5x5 | 256 | conv9_mbox | 6 | 153 | | conv10_1 | 5x5 | 256 | 1x1 | 0 | 1 | 5x5 | 128 | | | | | conv10_2 | 5x5 | 128 | 3x3 | 0 | 1 | 3x3 | 256 | conv10_mbox | 4 | 207 | | conv11_1 | 3x3 | 256 | 1x1 | 0 | 1 | 3x3 | 128 | | | | | conv11_2 | 3x3 | 128 | 3x3 | 0 | 1 | 1x1 | 256 | conv11_mbox | 4 | 261 |
As in the original SSD paper, each convolution in the downsizing network is followed by bias/ReLU, but not batch-norm.
The last layers of the network are the detector heads. These consist of a total of 8732 anchors, each with an implicit default center and bounding box size (some papers call the implicit defaults a prior). Each anchor has 85 channels associated with it. The Coco dataset has 80 categories, so each anchor has 80 channels for categorization of what's "in" that anchor, plus an 81st channel indicating "nothing here", and then 4 channels to indicate adjustments to the bounding box. The adjustment channels are xywh where xy are centered at the default center, and in the scale of the default bounding box. The wh channels are given in natural log of a multiplicative factor to the implicit default bounding box width and height. Each of the 8732 default anchor center points in the pyramid has either 4 or 6 anchors associated with it. When there are 4 anchors, they have default aspect ratios 1:1, 1:1, 1:2, and 2:1. When there are 6 anchors, the additional two have aspect ratios 1:3, and 3:1. The first 1:1 box is at the default scale for the image pyramid layer, while the second 1:1 box is at a scale which is the geometric mean of the default scale this image pyramid layer and the next. For the final, 1x1, image pyramid layer, conv11_mbox, the default scale is 261 and the scale for the "next" layer is assumed to be 315.
In the deployed inference network non-maximum suppression is used to select only the most confident of any set of overlapping bounding boxes detecting an object of class x. Correctness is evaluated by comparing the Jaccard overlap of the selected bounding box with the ground truth. The training script, on the other hand, must associate ground truth with anchor boxes:
-
Encode the ground truth tensor from the list of ground truth bounding boxes:
a. Calculate the Jaccard overlap of each anchor's default box with each ground truth bounding box.
b. For each ground-truth bounding box: assign a "positive" to the single anchor box with the highest Jaccard overlap for that ground truth.
c. For each remaining unassigned anchor box: assign a "positive" for the ground truth bounding box with the highest Jaccard overlap > 0.5 (if any).
d. For each "positive" anchor identified in steps b and c, calculate the 4 offset channels as the difference between the ground truth bounding-box and the defaults for that anchor.
-
Hard negative mining in the loss function (implemented in
base_model.py). The ground-truth tells you which anchors are assigned as "positives", but most anchors will be negatives and so would overwhelm the loss calculation, so we need to choose a subset to train against.a. Count the number of positive anchors, P, identified in steps 1b and 1c.
b. Of the remaining unassigned anchors, choose the 3P of them that are most strongly predicting a category other than "background", and assign them to the "background" category.
-
For each assigned anchor: The loss over categories is the softmax loss over class confidences. The loss over offsets is the Smooth L1 loss between the predicted box and the ground truth box. (These losses are implemented just after hard negative mining in
base_model.py)
The input images are assumed to be sRGB with values in range 0.0 through 1.0. The input pipeline does the following.
-
Normalize the colors to a mean of (0.485, 0.456, 0.406) and standard deviation (0.229, 0.224, 0.225).
-
To both the image and its ground-truth bounding boxes:
a. Random crop with equal probability choose between (1) original input, (2-7) minimum overlap crop of 0, 0.1, 0.3, 0.5, 0.7, 0.9, with the additional constraints that the width and height are (uniformly) chosen between 30% and 100% of the original image, and the aspect ratio is less than 2:1 (or 1:2).
b. Random horizontal flip.
c. Scale to 300x300.
-
Color is jittered by adjusting brightness by a multiplicative factor chosen uniformly between (.875, 1.125), adjusting contrast by a multiplicative factor chosen uniformly between 0.5, 1.5, adjusting saturation by a multiplicative factor chose uniformly from 0.5 to 1.5, and adjusting hue by an additive factor chosen uniformly from -18 to +18 degrees. This is done with the call to
torchvision.transforms.ColorJitter(brightness=0.125, contrast=0.5, saturation=0.5, hue=0.05)inutils.py.
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg. SSD: Single Shot MultiBox Detector. In the Proceedings of the European Conference on Computer Vision, (ECCV-14):21-37, 2016.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. In the Proceedings of the Conference on Computer Vision and Pattern Recognition, (CVPR):770-778, 2016.
Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Kevin Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. In the Proceedings of the Conference on Computer Vision and Pattern Recognition, (CVPR):3296-3305, 2017.
Metric is COCO box mAP (averaged over IoU of 0.5:0.95), computed over 2017 COCO val data.
mAP of 0.23
Every 5th epoch, starting with epoch 5.
All the images in COCO 2017 val data set.
| Validated on | Intel Gaudi Software Version | PyTorch Version | Mode |
|---|---|---|---|
| Gaudi | 1.12.1 | 2.0.1 | Training |
| Gaudi 2 | 1.16.2 | 2.2.2 | Training |
- Enabled dynamic shapes for all modes.
- Removed HMP; switched to autocast.
- Eager mode support is deprecated.
- Dynamic shapes will be enabled by default in future releases. It is now enabled in training script as a temporary solution.
- Enabled dynamic shapes.
- Enable usage of PyTorch autocast.
- Disabled dynamic shapes.
- Added support for
habana_dataloaderwith hardware decode support for Gaudi 2 (training on 1 instance only).
- Removed .to WA in SSD.
- Removed permute pass from SSD.
- Used initialize_distributed_hpu in SSD.
- Library load from htcore - Part2.
- Added aeon to SSD training script.
- Moved decode_batch in SSD validation to HPU.
- Used non-blocking copy in SSD validation.
- SSD validation moved to all ranks.
- Placed barrier() before collective to prevent HCL timeout.
- Removed increased timeout value in SSD.
- Enabled pinned memory with dataloader.
The following are the changes added to the training script (train.py) and utilities (utils.py):
-
Added support for Gaudi devices:
a. Load Intel Gaudi specific library.
b. Certain environment variables are defined for Gaudi.
c. Added support to run SSD training in Lazy mode in addition to the Eager mode. mark_step() is performed to trigger execution of the graph.
d. Added mixed precision support.
-
Dataloader related changes:
a. Added --num-workers flag to specify number of dataloader workers.
b. Added CPU based
habana_dataloaderwith faster image preprocessing for 8 card training.c. Added
habana_dataloaderwith hardware decode support on Gaudi 2 for 1 card training. -
To improve performance:
a. Permute convolution weight tensors & and any other dependent tensors like 'momentum' for better performance.
b. Checkpoint saving involves getting trainable params and other state variables to CPU and permuting the weight tensors. Hence, checkpoint saving is done only at evaluation frequency. This can be disabled by using the --no-save argument.
c. Optimized FusedSGD operator is used in place of torch.optim.SGD for lazy mode.
d. Added support for accumulating the loss per iteration in the device and only calculating loss metrics at print frequency.
e. Changed use of boolean mask to a mul with complement of positive values in the mask to avoid index_put_ usage.
-
Other model changes:
a. All instances of transpose on host and copy to device are changed to copy to device and transpose on device. This will be fixed in subsequent releases.
b. The decode_batch() method in the evaluation phase is run on CPU. This will be fixed in subsequent releases.
c. HCCL backend is used to enable distributed training.
-
Updated requirements.txt file for mlperf-logging installation.
- Placing mark_step() arbitrarily may lead to undefined behavior. Recommend to keep mark_step() as shown in provided scripts.
- Only scripts & configurations mentioned in this README are supported and verified.
- Distributed training is verified with 8 cards only.
- Hardware decode support for Gaudi 2 in
habana_dataloaderis verified with 1 card only.