Sun Yu, Ye Yun, Liu Wu, Gao Wenpeng, Fu YiLi, Mei Tao
Update: Please refer to ROMP for detection-free single-shot multi-person 3D mesh recovery.
This repository is no longer maintained.
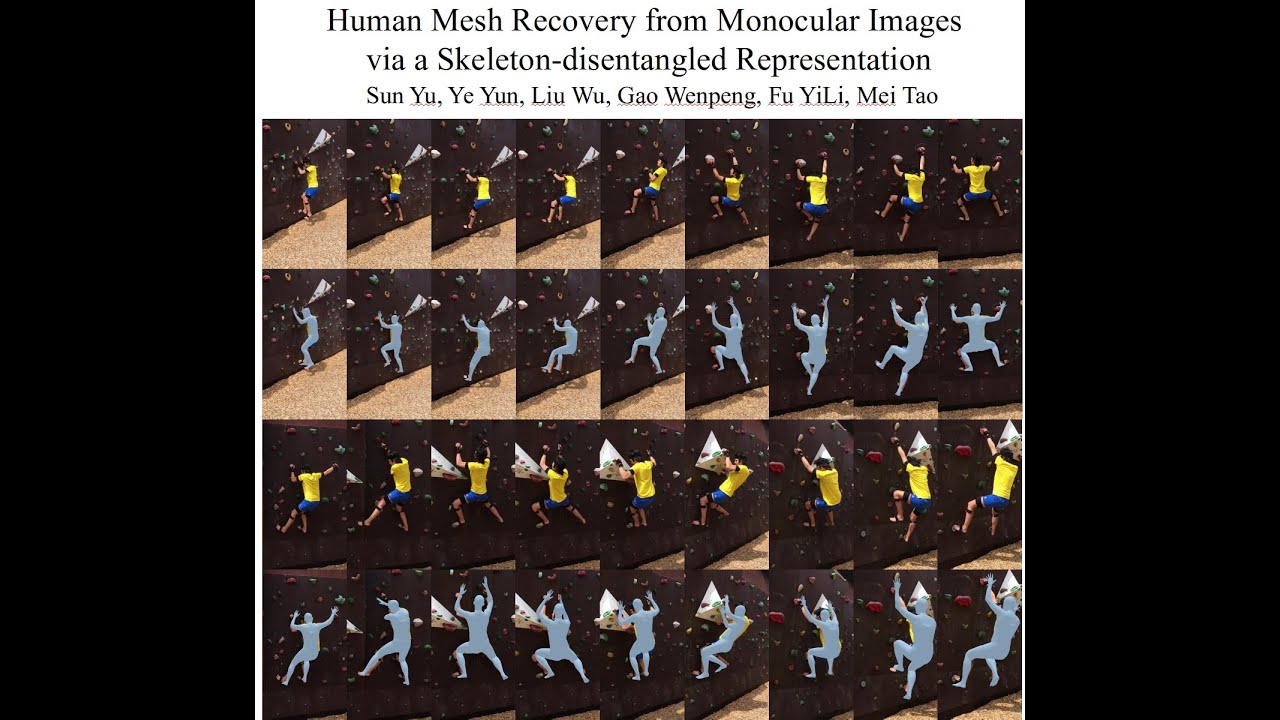
Accepted to ICCV 2019 https://arxiv.org/abs/1908.07172 Paper Link


- Python 3.6+
- Pytorch tested on 0.4.1/1.0/1.2 versions
- PyTorch implementation of the Neural 3D Mesh Renderer for visualization
pip install -r requirements.txt
Simply go into DSD-SATN/src/, and run
sh run.sh
The results are saved in DSD-SATN/resources/results.




- Prepare model and data.
Step 1) Download the pre-trained models and statistical model from google drive. Unzip them under the project dir (e.g. DSD-SATN/trained_model, DSD-SATN/model)
Step 2) To download the processed annotations, please refer to the docs/dataset.md of ROMP. Unzip them and set their location in data_set_path of src/config.py like
data_set_path = {
'h36m':'PATH/TO/H36M',
...
'pw3d':'/PATH/TO/3DPW',}
About extracting frames from Human3.6M dataset that consist with the 3D annotation, please refer to src/dataset/extract_imgs_h36m.py.
Step 3) Apply for the datasets from official Human3.6M and 3DPW. Especially, pre-processing the input images of Human3.6M dataset. Extracting 1 frame from every 5 frame of video in Human3.6M dataset. Set the path of extracted images as {H36m_dir}/images and name each image as the format (Sn_action name_camera id_frame number.jpg) shown in h36m/h36m_test.txt (e.g. S11_Discussion 2_2_149.jpg).
- Re-implement the evaluation results on Human3.6M and 3DPW datasets.
# Evaluating single-frame DSD network on Human3.6M dataset
CUDA_VISIBLE_DEVICES=0 python3 test.py --gpu=0 --dataset=h36m --tab=single_h36m --eval
# Evaluating entire network (DSD-SATN) on Human3.6M dataset
CUDA_VISIBLE_DEVICES=0 python3 test.py --gpu=0 --dataset=h36m --tab=video_h36m --eval --video --eval-with-single-frame-network
# Evaluating single-frame DSD network on 3DPW dataset
CUDA_VISIBLE_DEVICES=0 python3 test.py --gpu=0 --tab=single_3dpw --eval --eval-pw3d
# Evaluating entire network (DSD-SATN) on 3DPW dataset
CUDA_VISIBLE_DEVICES=0 python3 test.py --gpu=0 --tab=video_3dpw --eval --eval-pw3d --video --eval-with-single-frame-network
Additionally, if you want to save the results, please add some options:
--save-obj # saving obj file of 3D human body mesh.
--save-smpl-params # saving smpl parameters.
--visual-all # saving all visual rendering results.
For example, saving all results of single-frame DSD network on Human3.6M dataset, just type
CUDA_VISIBLE_DEVICES=0 python3 test.py --gpu=0 --dataset=h36m --tab=single_h36m --eval --save-obj --save-smpl-params --visual-all
- Releasing code for
- testing
- demo of single image
- webcam demo
If you use this code for your research, please consider citing:
@InProceedings{sun2019dsd-satn,
title = {Human Mesh Recovery from Monocular Images via a Skeleton-disentangled Representation},
author = {Sun, Yu and Ye, Yun and Liu, Wu and Gao, Wenpeng and Fu, YiLi and Mei, Tao},
booktitle = {IEEE International Conference on Computer Vision, ICCV},
year = {2019}
}
Please contect me if you have any question, e-mail: [email protected]
we refer to pytorch_hmr for training code. The fast rendering module is brought from face3d. The transformer module is brought from transformer-pytorch.