diff --git a/docs/zh/api/arch.md b/docs/zh/api/arch.md
index bacbc56ad..39e173bce 100644
--- a/docs/zh/api/arch.md
+++ b/docs/zh/api/arch.md
@@ -8,6 +8,7 @@
- AMGNet
- MLP
- ModifiedMLP
+ - PirateNet
- DeepONet
- DeepPhyLSTM
- LorenzEmbedding
diff --git a/docs/zh/examples/allen_cahn.md b/docs/zh/examples/allen_cahn.md
index 59ebd8414..f7b19fa5b 100644
--- a/docs/zh/examples/allen_cahn.md
+++ b/docs/zh/examples/allen_cahn.md
@@ -1,34 +1,46 @@
# Allen-Cahn
-
+AI Studio快速体验
=== "模型训练命令"
``` sh
- python allen_cahn_default.py
+ # linux
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/AllenCahn/allen_cahn.mat -P ./dataset/
+ # windows
+ # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/AllenCahn/allen_cahn.mat --output ./dataset/antiderivative_unaligned_train.npz
+ python allen_cahn_piratenet.py
```
=== "模型评估命令"
``` sh
- python allen_cahn_default.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/allen_cahn/allen_cahn_default_pretrained.pdparams
+ # linux
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/AllenCahn/allen_cahn.mat -P ./dataset/
+ # windows
+ # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/AllenCahn/allen_cahn.mat --output ./dataset/antiderivative_unaligned_train.npz
+ python allen_cahn_piratenet.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/AllenCahn/allen_cahn_piratenet_pretrained.pdparams
```
=== "模型导出命令"
``` sh
- python allen_cahn_default.py mode=export
+ python allen_cahn_piratenet.py mode=export
```
=== "模型推理命令"
``` sh
- python allen_cahn_default.py mode=infer
+ # linux
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/AllenCahn/allen_cahn.mat -P ./dataset/
+ # windows
+ # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/AllenCahn/allen_cahn.mat --output ./dataset/antiderivative_unaligned_train.npz
+ python allen_cahn_piratenet.py mode=infer
```
| 预训练模型 | 指标 |
|:--| :--|
-| [allen_cahn_default_pretrained.pdparams](TODO) | TODO |
+| [allen_cahn_piratenet_pretrained.pdparams](https://paddle-org.bj.bcebos.com/paddlescience/models/AllenCahn/allen_cahn_piratenet_pretrained.pdparams) | L2Rel.u: 8.32403e-06 |
## 1. 背景简介
@@ -72,27 +84,27 @@ $$
### 3.1 模型构建
在 Allen-Cahn 问题中,每一个已知的坐标点 $(t, x)$ 都有对应的待求解的未知量 $(u)$,
-,在这里使用比较简单的 MLP(Multilayer Perceptron, 多层感知机) 来表示 $(t, x)$ 到 $(u)$ 的映射函数 $f: \mathbb{R}^2 \to \mathbb{R}^1$ ,即:
+,在这里使用 PirateNet 来表示 $(t, x)$ 到 $(u)$ 的映射函数 $f: \mathbb{R}^2 \to \mathbb{R}^1$ ,即:
$$
u = f(t, x)
$$
-上式中 $f$ 即为 MLP 模型本身,用 PaddleScience 代码表示如下
+上式中 $f$ 即为 PirateNet 模型本身,用 PaddleScience 代码表示如下
``` py linenums="63"
--8<--
-examples/allen_cahn/allen_cahn_default.py:63:64
+examples/allen_cahn/allen_cahn_piratenet.py:63:64
--8<--
```
为了在计算时,准确快速地访问具体变量的值,在这里指定网络模型的输入变量名是 `("t", "x")`,输出变量名是 `("u")`,这些命名与后续代码保持一致。
-接着通过指定 MLP 的层数、神经元个数,就实例化出了一个拥有 4 层隐藏神经元,每层神经元数为 256 的神经网络模型 `model`,使用 `tanh` 作为激活函数。
+接着通过指定 PirateNet 的层数、神经元个数,就实例化出了一个拥有 3 个 PiraBlock,每个 PiraBlock 的隐层神经元个数为 256 的神经网络模型 `model`, 并且使用 `tanh` 作为激活函数。
-``` yaml linenums="35"
+``` yaml linenums="34"
--8<--
-examples/allen_cahn/conf/allen_cahn_default.yaml:35:41
+examples/allen_cahn/conf/allen_cahn_piratenet.yaml:34:40
--8<--
```
@@ -102,7 +114,7 @@ Allen-Cahn 微分方程可以用如下代码表示:
``` py linenums="66"
--8<--
-examples/allen_cahn/allen_cahn_default.py:66:67
+examples/allen_cahn/allen_cahn_piratenet.py:66:67
--8<--
```
@@ -112,7 +124,7 @@ examples/allen_cahn/allen_cahn_default.py:66:67
``` py linenums="69"
--8<--
-examples/allen_cahn/allen_cahn_default.py:69:81
+examples/allen_cahn/allen_cahn_piratenet.py:69:81
--8<--
```
@@ -124,7 +136,7 @@ examples/allen_cahn/allen_cahn_default.py:69:81
``` py linenums="94"
--8<--
-examples/allen_cahn/allen_cahn_default.py:94:110
+examples/allen_cahn/allen_cahn_piratenet.py:94:110
--8<--
```
@@ -139,11 +151,11 @@ examples/allen_cahn/allen_cahn_default.py:94:110
#### 3.4.2 周期边界约束
此处我们采用 hard-constraint 的方式,在神经网络模型中,对输入数据使用cos、sin等周期函数进行周期化,从而让$u_{\theta}$在数学上直接满足方程的周期性质。
-根据方程可得函数$u(t, x)$在$x$轴上的周期为2,因此将该周期设置到模型配置里即可。
+根据方程可得函数$u(t, x)$在$x$轴上的周期为 2,因此将该周期设置到模型配置里即可。
-``` yaml linenums="35"
+``` yaml linenums="41"
--8<--
-examples/allen_cahn/conf/allen_cahn_default.yaml:35:43
+examples/allen_cahn/conf/allen_cahn_piratenet.yaml:41:42
--8<--
```
@@ -153,7 +165,7 @@ examples/allen_cahn/conf/allen_cahn_default.yaml:35:43
``` py linenums="112"
--8<--
-examples/allen_cahn/allen_cahn_default.py:112:125
+examples/allen_cahn/allen_cahn_piratenet.py:112:125
--8<--
```
@@ -161,17 +173,17 @@ examples/allen_cahn/allen_cahn_default.py:112:125
``` py linenums="126"
--8<--
-examples/allen_cahn/allen_cahn_default.py:126:130
+examples/allen_cahn/allen_cahn_piratenet.py:126:130
--8<--
```
### 3.5 超参数设定
-接下来需要指定训练轮数和学习率,此处按实验经验,使用 200 轮训练轮数,0.001 的初始学习率。
+接下来需要指定训练轮数和学习率,此处按实验经验,使用 300 轮训练轮数,0.001 的初始学习率。
-``` yaml linenums="51"
+``` yaml linenums="50"
--8<--
-examples/allen_cahn/conf/allen_cahn_default.yaml:51:73
+examples/allen_cahn/conf/allen_cahn_piratenet.yaml:50:63
--8<--
```
@@ -181,7 +193,7 @@ examples/allen_cahn/conf/allen_cahn_default.yaml:51:73
``` py linenums="132"
--8<--
-examples/allen_cahn/allen_cahn_default.py:132:136
+examples/allen_cahn/allen_cahn_piratenet.py:132:136
--8<--
```
@@ -191,7 +203,7 @@ examples/allen_cahn/allen_cahn_default.py:132:136
``` py linenums="138"
--8<--
-examples/allen_cahn/allen_cahn_default.py:138:156
+examples/allen_cahn/allen_cahn_piratenet.py:138:156
--8<--
```
@@ -201,15 +213,15 @@ examples/allen_cahn/allen_cahn_default.py:138:156
``` py linenums="158"
--8<--
-examples/allen_cahn/allen_cahn_default.py:158:194
+examples/allen_cahn/allen_cahn_piratenet.py:158:184
--8<--
```
## 4. 完整代码
-``` py linenums="1" title="allen_cahn_default.py"
+``` py linenums="1" title="allen_cahn_piratenet.py"
--8<--
-examples/allen_cahn/allen_cahn_default.py
+examples/allen_cahn/allen_cahn_piratenet.py
--8<--
```
@@ -218,7 +230,7 @@ examples/allen_cahn/allen_cahn_default.py
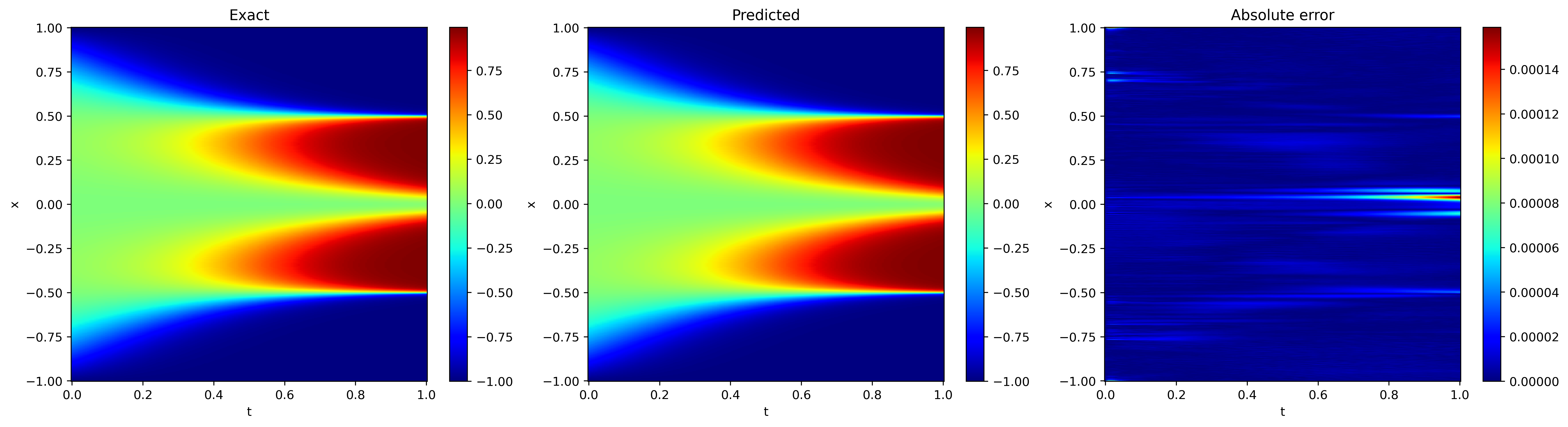
在计算域上均匀采样出 $201\times501$ 个点,其预测结果和解析解如下图所示。
- { loading=lazy }
+ { loading=lazy }
左侧为 PaddleScience 预测结果,中间为解析解结果,右侧为两者的差值
@@ -226,4 +238,5 @@ examples/allen_cahn/allen_cahn_default.py
## 6. 参考资料
+- [PIRATENETS: PHYSICS-INFORMED DEEP LEARNING WITHRESIDUAL ADAPTIVE NETWORKS](https://arxiv.org/pdf/2402.00326.pdf)
- [Allen-Cahn equation](https://github.com/PredictiveIntelligenceLab/jaxpi/blob/main/examples/allen_cahn/README.md)
diff --git a/examples/allen_cahn/allen_cahn_causal.py b/examples/allen_cahn/allen_cahn_causal.py
index 89840177a..64dd9c37c 100644
--- a/examples/allen_cahn/allen_cahn_causal.py
+++ b/examples/allen_cahn/allen_cahn_causal.py
@@ -271,12 +271,12 @@ def inference(cfg: DictConfig):
input_dict = {"t": tx_star[:, 0:1], "x": tx_star[:, 1:2]}
output_dict = predictor.predict(input_dict, cfg.INFER.batch_size)
+ # mapping data to cfg.INFER.output_keys
output_dict = {
store_key: output_dict[infer_key]
for store_key, infer_key in zip(cfg.MODEL.output_keys, output_dict.keys())
}
u_pred = output_dict["u"].reshape([len(t_star), len(x_star)])
- # mapping data to cfg.INFER.output_keys
plot(t_star, x_star, u_ref, u_pred, cfg.output_dir)
diff --git a/examples/allen_cahn/allen_cahn_default.py b/examples/allen_cahn/allen_cahn_default.py
index 47d0ba400..baa0cb0dd 100644
--- a/examples/allen_cahn/allen_cahn_default.py
+++ b/examples/allen_cahn/allen_cahn_default.py
@@ -159,19 +159,9 @@ def gen_label_batch(input_batch):
solver = ppsci.solver.Solver(
model,
constraint,
- cfg.output_dir,
- optimizer,
- epochs=cfg.TRAIN.epochs,
- iters_per_epoch=cfg.TRAIN.iters_per_epoch,
- save_freq=cfg.TRAIN.save_freq,
- log_freq=cfg.log_freq,
- eval_during_train=True,
- eval_freq=cfg.TRAIN.eval_freq,
+ optimizer=optimizer,
equation=equation,
validator=validator,
- pretrained_model_path=cfg.TRAIN.pretrained_model_path,
- checkpoint_path=cfg.TRAIN.checkpoint_path,
- eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
loss_aggregator=mtl.GradNorm(
model,
len(constraint),
@@ -226,11 +216,9 @@ def evaluate(cfg: DictConfig):
# initialize solver
solver = ppsci.solver.Solver(
model,
- output_dir=cfg.output_dir,
log_freq=cfg.log_freq,
validator=validator,
- pretrained_model_path=cfg.EVAL.pretrained_model_path,
- eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
+ cfg=cfg,
)
# evaluate after finished training
@@ -250,10 +238,7 @@ def export(cfg: DictConfig):
model = ppsci.arch.MLP(**cfg.MODEL)
# initialize solver
- solver = ppsci.solver.Solver(
- model,
- pretrained_model_path=cfg.INFER.pretrained_model_path,
- )
+ solver = ppsci.solver.Solver(model, cfg=cfg)
# export model
from paddle.static import InputSpec
@@ -275,12 +260,12 @@ def inference(cfg: DictConfig):
input_dict = {"t": tx_star[:, 0:1], "x": tx_star[:, 1:2]}
output_dict = predictor.predict(input_dict, cfg.INFER.batch_size)
+ # mapping data to cfg.INFER.output_keys
output_dict = {
store_key: output_dict[infer_key]
for store_key, infer_key in zip(cfg.MODEL.output_keys, output_dict.keys())
}
u_pred = output_dict["u"].reshape([len(t_star), len(x_star)])
- # mapping data to cfg.INFER.output_keys
plot(t_star, x_star, u_ref, u_pred, cfg.output_dir)
diff --git a/examples/allen_cahn/allen_cahn_piratenet.py b/examples/allen_cahn/allen_cahn_piratenet.py
new file mode 100644
index 000000000..5806b8485
--- /dev/null
+++ b/examples/allen_cahn/allen_cahn_piratenet.py
@@ -0,0 +1,291 @@
+"""
+Reference: https://github.com/PredictiveIntelligenceLab/jaxpi/tree/main/examples/allen_cahn
+"""
+
+from os import path as osp
+
+import hydra
+import numpy as np
+import paddle
+import scipy.io as sio
+from matplotlib import pyplot as plt
+from omegaconf import DictConfig
+
+import ppsci
+from ppsci.loss import mtl
+from ppsci.utils import misc
+
+dtype = paddle.get_default_dtype()
+
+
+def plot(
+ t_star: np.ndarray,
+ x_star: np.ndarray,
+ u_ref: np.ndarray,
+ u_pred: np.ndarray,
+ output_dir: str,
+):
+ fig = plt.figure(figsize=(18, 5))
+ TT, XX = np.meshgrid(t_star, x_star, indexing="ij")
+ u_ref = u_ref.reshape([len(t_star), len(x_star)])
+
+ plt.subplot(1, 3, 1)
+ plt.pcolor(TT, XX, u_ref, cmap="jet")
+ plt.colorbar()
+ plt.xlabel("t")
+ plt.ylabel("x")
+ plt.title("Exact")
+ plt.tight_layout()
+
+ plt.subplot(1, 3, 2)
+ plt.pcolor(TT, XX, u_pred, cmap="jet")
+ plt.colorbar()
+ plt.xlabel("t")
+ plt.ylabel("x")
+ plt.title("Predicted")
+ plt.tight_layout()
+
+ plt.subplot(1, 3, 3)
+ plt.pcolor(TT, XX, np.abs(u_ref - u_pred), cmap="jet")
+ plt.colorbar()
+ plt.xlabel("t")
+ plt.ylabel("x")
+ plt.title("Absolute error")
+ plt.tight_layout()
+
+ fig_path = osp.join(output_dir, "ac.png")
+ print(f"Saving figure to {fig_path}")
+ fig.savefig(fig_path, bbox_inches="tight", dpi=400)
+ plt.close()
+
+
+def train(cfg: DictConfig):
+ # set model
+ model = ppsci.arch.PirateNet(**cfg.MODEL)
+
+ # set equation
+ equation = {"AllenCahn": ppsci.equation.AllenCahn(0.01**2)}
+
+ # set constraint
+ data = sio.loadmat(cfg.DATA_PATH)
+ u_ref = data["usol"].astype(dtype) # (nt, nx)
+ t_star = data["t"].flatten().astype(dtype) # [nt, ]
+ x_star = data["x"].flatten().astype(dtype) # [nx, ]
+
+ u0 = u_ref[0, :] # [nx, ]
+
+ t0 = t_star[0] # float
+ t1 = t_star[-1] # float
+
+ x0 = x_star[0] # float
+ x1 = x_star[-1] # float
+
+ def gen_input_batch():
+ tx = np.random.uniform(
+ [t0, x0],
+ [t1, x1],
+ (cfg.TRAIN.batch_size, 2),
+ ).astype(dtype)
+ return {
+ "t": np.sort(tx[:, 0:1], axis=0),
+ "x": tx[:, 1:2],
+ }
+
+ def gen_label_batch(input_batch):
+ return {"allen_cahn": np.zeros([cfg.TRAIN.batch_size, 1], dtype)}
+
+ pde_constraint = ppsci.constraint.SupervisedConstraint(
+ {
+ "dataset": {
+ "name": "ContinuousNamedArrayDataset",
+ "input": gen_input_batch,
+ "label": gen_label_batch,
+ },
+ },
+ output_expr=equation["AllenCahn"].equations,
+ loss=ppsci.loss.CausalMSELoss(
+ cfg.TRAIN.causal.n_chunks, "mean", tol=cfg.TRAIN.causal.tol
+ ),
+ name="PDE",
+ )
+
+ ic_input = {"t": np.full([len(x_star), 1], t0), "x": x_star.reshape([-1, 1])}
+ ic_label = {"u": u0.reshape([-1, 1])}
+ ic = ppsci.constraint.SupervisedConstraint(
+ {
+ "dataset": {
+ "name": "IterableNamedArrayDataset",
+ "input": ic_input,
+ "label": ic_label,
+ },
+ },
+ output_expr={"u": lambda out: out["u"]},
+ loss=ppsci.loss.MSELoss("mean"),
+ name="IC",
+ )
+ # wrap constraints together
+ constraint = {
+ pde_constraint.name: pde_constraint,
+ ic.name: ic,
+ }
+
+ # set optimizer
+ lr_scheduler = ppsci.optimizer.lr_scheduler.ExponentialDecay(
+ **cfg.TRAIN.lr_scheduler
+ )()
+ optimizer = ppsci.optimizer.Adam(lr_scheduler)(model)
+
+ # set validator
+ tx_star = misc.cartesian_product(t_star, x_star).astype(dtype)
+ eval_data = {"t": tx_star[:, 0:1], "x": tx_star[:, 1:2]}
+ eval_label = {"u": u_ref.reshape([-1, 1])}
+ u_validator = ppsci.validate.SupervisedValidator(
+ {
+ "dataset": {
+ "name": "NamedArrayDataset",
+ "input": eval_data,
+ "label": eval_label,
+ },
+ "batch_size": cfg.EVAL.batch_size,
+ },
+ ppsci.loss.MSELoss("mean"),
+ {"u": lambda out: out["u"]},
+ metric={"L2Rel": ppsci.metric.L2Rel()},
+ name="u_validator",
+ )
+ validator = {u_validator.name: u_validator}
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ constraint,
+ optimizer=optimizer,
+ equation=equation,
+ validator=validator,
+ loss_aggregator=mtl.GradNorm(
+ model,
+ len(constraint),
+ cfg.TRAIN.grad_norm.update_freq,
+ cfg.TRAIN.grad_norm.momentum,
+ ),
+ cfg=cfg,
+ )
+ # train model
+ solver.train()
+ # evaluate after finished training
+ solver.eval()
+ # visualize prediction after finished training
+ u_pred = solver.predict(
+ eval_data, batch_size=cfg.EVAL.batch_size, return_numpy=True
+ )["u"]
+ u_pred = u_pred.reshape([len(t_star), len(x_star)])
+
+ # plot
+ plot(t_star, x_star, u_ref, u_pred, cfg.output_dir)
+
+
+def evaluate(cfg: DictConfig):
+ # set model
+ model = ppsci.arch.PirateNet(**cfg.MODEL)
+
+ data = sio.loadmat(cfg.DATA_PATH)
+ u_ref = data["usol"].astype(dtype) # (nt, nx)
+ t_star = data["t"].flatten().astype(dtype) # [nt, ]
+ x_star = data["x"].flatten().astype(dtype) # [nx, ]
+
+ # set validator
+ tx_star = misc.cartesian_product(t_star, x_star).astype(dtype)
+ eval_data = {"t": tx_star[:, 0:1], "x": tx_star[:, 1:2]}
+ eval_label = {"u": u_ref.reshape([-1, 1])}
+ u_validator = ppsci.validate.SupervisedValidator(
+ {
+ "dataset": {
+ "name": "NamedArrayDataset",
+ "input": eval_data,
+ "label": eval_label,
+ },
+ "batch_size": cfg.EVAL.batch_size,
+ },
+ ppsci.loss.MSELoss("mean"),
+ {"u": lambda out: out["u"]},
+ metric={"L2Rel": ppsci.metric.L2Rel()},
+ name="u_validator",
+ )
+ validator = {u_validator.name: u_validator}
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ validator=validator,
+ cfg=cfg,
+ )
+
+ # evaluate after finished training
+ solver.eval()
+ # visualize prediction after finished training
+ u_pred = solver.predict(
+ eval_data, batch_size=cfg.EVAL.batch_size, return_numpy=True
+ )["u"]
+ u_pred = u_pred.reshape([len(t_star), len(x_star)])
+
+ # plot
+ plot(t_star, x_star, u_ref, u_pred, cfg.output_dir)
+
+
+def export(cfg: DictConfig):
+ # set model
+ model = ppsci.arch.PirateNet(**cfg.MODEL)
+
+ # initialize solver
+ solver = ppsci.solver.Solver(model, cfg=cfg)
+ # export model
+ from paddle.static import InputSpec
+
+ input_spec = [
+ {key: InputSpec([None, 1], "float32", name=key) for key in model.input_keys},
+ ]
+ solver.export(input_spec, cfg.INFER.export_path, with_onnx=False)
+
+
+def inference(cfg: DictConfig):
+ from deploy.python_infer import pinn_predictor
+
+ predictor = pinn_predictor.PINNPredictor(cfg)
+ data = sio.loadmat(cfg.DATA_PATH)
+ u_ref = data["usol"].astype(dtype) # (nt, nx)
+ t_star = data["t"].flatten().astype(dtype) # [nt, ]
+ x_star = data["x"].flatten().astype(dtype) # [nx, ]
+ tx_star = misc.cartesian_product(t_star, x_star).astype(dtype)
+
+ input_dict = {"t": tx_star[:, 0:1], "x": tx_star[:, 1:2]}
+ output_dict = predictor.predict(input_dict, cfg.INFER.batch_size)
+ # mapping data to cfg.INFER.output_keys
+ output_dict = {
+ store_key: output_dict[infer_key]
+ for store_key, infer_key in zip(cfg.MODEL.output_keys, output_dict.keys())
+ }
+ u_pred = output_dict["u"].reshape([len(t_star), len(x_star)])
+
+ plot(t_star, x_star, u_ref, u_pred, cfg.output_dir)
+
+
+@hydra.main(
+ version_base=None, config_path="./conf", config_name="allen_cahn_piratenet.yaml"
+)
+def main(cfg: DictConfig):
+ if cfg.mode == "train":
+ train(cfg)
+ elif cfg.mode == "eval":
+ evaluate(cfg)
+ elif cfg.mode == "export":
+ export(cfg)
+ elif cfg.mode == "infer":
+ inference(cfg)
+ else:
+ raise ValueError(
+ f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'"
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/allen_cahn/allen_cahn_plain.py b/examples/allen_cahn/allen_cahn_plain.py
index e1cbcc10d..0f3796fb7 100644
--- a/examples/allen_cahn/allen_cahn_plain.py
+++ b/examples/allen_cahn/allen_cahn_plain.py
@@ -269,12 +269,12 @@ def inference(cfg: DictConfig):
input_dict = {"t": tx_star[:, 0:1], "x": tx_star[:, 1:2]}
output_dict = predictor.predict(input_dict, cfg.INFER.batch_size)
+ # mapping data to cfg.INFER.output_keys
output_dict = {
store_key: output_dict[infer_key]
for store_key, infer_key in zip(cfg.MODEL.output_keys, output_dict.keys())
}
u_pred = output_dict["u"].reshape([len(t_star), len(x_star)])
- # mapping data to cfg.INFER.output_keys
plot(t_star, x_star, u_ref, u_pred, cfg.output_dir)
diff --git a/examples/allen_cahn/conf/allen_cahn_piratenet.yaml b/examples/allen_cahn/conf/allen_cahn_piratenet.yaml
new file mode 100644
index 000000000..48ed0250e
--- /dev/null
+++ b/examples/allen_cahn/conf/allen_cahn_piratenet.yaml
@@ -0,0 +1,96 @@
+defaults:
+ - ppsci_default
+ - TRAIN: train_default
+ - TRAIN/ema: ema_default
+ - TRAIN/swa: swa_default
+ - EVAL: eval_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: outputs_allen_cahn_piratenet/${now:%Y-%m-%d}/${now:%H-%M-%S}/${hydra.job.override_dirname}
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: train # running mode: train/eval
+seed: 42
+output_dir: ${hydra:run.dir}
+log_freq: 100
+
+DATA_PATH: ./dataset/allen_cahn.mat
+
+# model settings
+MODEL:
+ input_keys: [t, x]
+ output_keys: [u]
+ num_blocks: 3
+ hidden_size: 256
+ activation: tanh
+ periods:
+ x: [2.0, False]
+ fourier:
+ dim: 256
+ scale: 2.0
+ random_weight:
+ mean: 1.0
+ std: 0.1
+
+# training settings
+TRAIN:
+ epochs: 300
+ iters_per_epoch: 1000
+ save_freq: 10
+ eval_during_train: true
+ eval_freq: 10
+ lr_scheduler:
+ epochs: ${TRAIN.epochs}
+ iters_per_epoch: ${TRAIN.iters_per_epoch}
+ learning_rate: 1.0e-3
+ gamma: 0.9
+ decay_steps: 5000
+ by_epoch: false
+ batch_size: 8192
+ pretrained_model_path: null
+ checkpoint_path: null
+ causal:
+ n_chunks: 32
+ tol: 1.0
+ grad_norm:
+ update_freq: 1000
+ momentum: 0.9
+
+# evaluation settings
+EVAL:
+ pretrained_model_path: null
+ eval_with_no_grad: true
+ batch_size: 4096
+
+# inference settings
+INFER:
+ pretrained_model_path: https://paddle-org.bj.bcebos.com/paddlescience/models/AllenCahn/allen_cahn_piratenet_pretrained.pdparams
+ export_path: ./inference/allen_cahn
+ pdmodel_path: ${INFER.export_path}.pdmodel
+ pdiparams_path: ${INFER.export_path}.pdiparams
+ onnx_path: ${INFER.export_path}.onnx
+ device: gpu
+ engine: native
+ precision: fp32
+ ir_optim: true
+ min_subgraph_size: 5
+ gpu_mem: 2000
+ gpu_id: 0
+ max_batch_size: 1024
+ num_cpu_threads: 10
+ batch_size: 1024
diff --git a/mkdocs.yml b/mkdocs.yml
index 8d69421d3..6e5dea09c 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -38,6 +38,7 @@ nav:
- 经典案例:
- " ":
- 数学(AI for Math):
+ - AllenCahn: zh/examples/allen_cahn.md
- DeepHPMs: zh/examples/deephpms.md
- DeepONet: zh/examples/deeponet.md
- Euler_Beam: zh/examples/euler_beam.md
@@ -47,7 +48,6 @@ nav:
- Rossler_transform_physx: zh/examples/rossler.md
- Volterra_IDE: zh/examples/volterra_ide.md
- NLSMB: zh/examples/nlsmb.md
- - AllenCahn: zh/examples/allen_cahn.md
- 技术科学(AI for Technology):
- 流体:
- AMGNet: zh/examples/amgnet.md
diff --git a/ppsci/arch/__init__.py b/ppsci/arch/__init__.py
index 807ad07db..545df5a1c 100644
--- a/ppsci/arch/__init__.py
+++ b/ppsci/arch/__init__.py
@@ -22,6 +22,7 @@
from ppsci.arch.amgnet import AMGNet # isort:skip
from ppsci.arch.mlp import MLP # isort:skip
from ppsci.arch.mlp import ModifiedMLP # isort:skip
+from ppsci.arch.mlp import PirateNet # isort:skip
from ppsci.arch.deeponet import DeepONet # isort:skip
from ppsci.arch.embedding_koopman import LorenzEmbedding # isort:skip
from ppsci.arch.embedding_koopman import RosslerEmbedding # isort:skip
@@ -51,6 +52,7 @@
"AMGNet",
"MLP",
"ModifiedMLP",
+ "PirateNet",
"DeepONet",
"DeepPhyLSTM",
"LorenzEmbedding",
diff --git a/ppsci/arch/mlp.py b/ppsci/arch/mlp.py
index 42b93cc36..294d8f2a0 100644
--- a/ppsci/arch/mlp.py
+++ b/ppsci/arch/mlp.py
@@ -154,7 +154,7 @@ class MLP(base.Arch):
input in given channel will be period embeded if specified, each tuple of
periods list is [period, trainable]. Defaults to None.
fourier (Optional[Dict[str, Union[float, int]]]): Random fourier feature embedding,
- e.g. {'dim': 256, 'sclae': 1.0}. Defaults to None.
+ e.g. {'dim': 256, 'scale': 1.0}. Defaults to None.
random_weight (Optional[Dict[str, float]]): Mean and std of random weight
factorization layer, e.g. {"mean": 0.5, "std: 0.1"}. Defaults to None.
@@ -167,13 +167,13 @@ class MLP(base.Arch):
... num_layers=5,
... hidden_size=128
... )
- >>> input_dict = {"x": paddle.rand([64, 64, 1]),
- ... "y": paddle.rand([64, 64, 1])}
+ >>> input_dict = {"x": paddle.rand([64, 1]),
+ ... "y": paddle.rand([64, 1])}
>>> output_dict = model(input_dict)
>>> print(output_dict["u"].shape)
- [64, 64, 1]
+ [64, 1]
>>> print(output_dict["v"].shape)
- [64, 64, 1]
+ [64, 1]
"""
def __init__(
@@ -341,13 +341,13 @@ class ModifiedMLP(base.Arch):
... num_layers=5,
... hidden_size=128
... )
- >>> input_dict = {"x": paddle.rand([64, 64, 1]),
- ... "y": paddle.rand([64, 64, 1])}
+ >>> input_dict = {"x": paddle.rand([64, 1]),
+ ... "y": paddle.rand([64, 1])}
>>> output_dict = model(input_dict)
>>> print(output_dict["u"].shape)
- [64, 64, 1]
+ [64, 1]
>>> print(output_dict["v"].shape)
- [64, 64, 1]
+ [64, 1]
"""
def __init__(
@@ -464,3 +464,266 @@ def forward(self, x):
if self._output_transform is not None:
y = self._output_transform(x, y)
return y
+
+
+class PirateNetBlock(nn.Layer):
+ r"""Basic block of PirateNet.
+
+ $$
+ \begin{align*}
+ \Phi(\mathbf{x})=\left[\begin{array}{l}
+ \cos (\mathbf{B} \mathbf{x}) \\
+ \sin (\mathbf{B} \mathbf{x})
+ \end{array}\right] \\
+ \mathbf{f}^{(l)} & =\sigma\left(\mathbf{W}_1^{(l)} \mathbf{x}^{(l)}+\mathbf{b}_1^{(l)}\right) \\
+ \mathbf{z}_1^{(l)} & =\mathbf{f}^{(l)} \odot \mathbf{U}+\left(1-\mathbf{f}^{(l)}\right) \odot \mathbf{V} \\
+ \mathbf{g}^{(l)} & =\sigma\left(\mathbf{W}_2^{(l)} \mathbf{z}_1^{(l)}+\mathbf{b}_2^{(l)}\right) \\
+ \mathbf{z}_2^{(l)} & =\mathbf{g}^{(l)} \odot \mathbf{U}+\left(1-\mathbf{g}^{(l)}\right) \odot \mathbf{V} \\
+ \mathbf{h}^{(l)} & =\sigma\left(\mathbf{W}_3^{(l)} \mathbf{z}_2^{(l)}+\mathbf{b}_3^{(l)}\right) \\
+ \mathbf{x}^{(l+1)} & =\alpha^{(l)} \cdot \mathbf{h}^{(l)}+\left(1-\alpha^{(l)}\right) \cdot \mathbf{x}^{(l)}
+ \end{align*}
+ $$
+
+ Args:
+ embed_dim (int): Embedding dimension.
+ activation (str, optional): Name of activation function. Defaults to "tanh".
+ random_weight (Optional[Dict[str, float]]): Mean and std of random weight
+ factorization layer, e.g. {"mean": 0.5, "std: 0.1"}. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ embed_dim: int,
+ activation: str = "tanh",
+ random_weight: Optional[Dict[str, float]] = None,
+ ):
+ super().__init__()
+ self.linear1 = (
+ nn.Linear(embed_dim, embed_dim)
+ if random_weight is None
+ else RandomWeightFactorization(
+ embed_dim,
+ embed_dim,
+ mean=random_weight["mean"],
+ std=random_weight["std"],
+ )
+ )
+ self.linear2 = (
+ nn.Linear(embed_dim, embed_dim)
+ if random_weight is None
+ else RandomWeightFactorization(
+ embed_dim,
+ embed_dim,
+ mean=random_weight["mean"],
+ std=random_weight["std"],
+ )
+ )
+ self.linear3 = (
+ nn.Linear(embed_dim, embed_dim)
+ if random_weight is None
+ else RandomWeightFactorization(
+ embed_dim,
+ embed_dim,
+ mean=random_weight["mean"],
+ std=random_weight["std"],
+ )
+ )
+ self.alpha = self.create_parameter(
+ [
+ 1,
+ ],
+ default_initializer=nn.initializer.Constant(0),
+ )
+ self.act1 = act_mod.get_activation(activation)
+ self.act2 = act_mod.get_activation(activation)
+ self.act3 = act_mod.get_activation(activation)
+
+ def forward(self, x, u, v):
+ f = self.act1(self.linear1(x))
+ z1 = f * u + (1 - f) * v
+ g = self.act2(self.linear2(z1))
+ z2 = g * u + (1 - g) * v
+ h = self.act3(self.linear3(z2))
+ out = self.alpha * h + (1 - self.alpha) * x
+ return out
+
+
+class PirateNet(base.Arch):
+ r"""PirateNet.
+
+ [PIRATENETS: PHYSICS-INFORMED DEEP LEARNING WITHRESIDUAL ADAPTIVE NETWORKS](https://arxiv.org/pdf/2402.00326.pdf)
+
+ $$
+ \begin{align*}
+ \Phi(\mathbf{x}) &= \left[\begin{array}{l}
+ \cos (\mathbf{B} \mathbf{x}) \\
+ \sin (\mathbf{B} \mathbf{x})
+ \end{array}\right] \\
+ \mathbf{f}^{(l)} &= \sigma\left(\mathbf{W}_1^{(l)} \mathbf{x}^{(l)}+\mathbf{b}_1^{(l)}\right) \\
+ \mathbf{z}_1^{(l)} &= \mathbf{f}^{(l)} \odot \mathbf{U}+\left(1-\mathbf{f}^{(l)}\right) \odot \mathbf{V} \\
+ \mathbf{g}^{(l)} &= \sigma\left(\mathbf{W}_2^{(l)} \mathbf{z}_1^{(l)}+\mathbf{b}_2^{(l)}\right) \\
+ \mathbf{z}_2^{(l)} &= \mathbf{g}^{(l)} \odot \mathbf{U}+\left(1-\mathbf{g}^{(l)}\right) \odot \mathbf{V} \\
+ \mathbf{h}^{(l)} &= \sigma\left(\mathbf{W}_3^{(l)} \mathbf{z}_2^{(l)}+\mathbf{b}_3^{(l)}\right) \\
+ \mathbf{x}^{(l+1)} &= \text{PirateBlock}^{(l)}\left(\mathbf{x}^{(l)}\right), l=1...L-1\\
+ \mathbf{u}_\theta &= \mathbf{W}^{(L+1)} \mathbf{x}^{(L)}
+ \end{align*}
+ $$
+
+ Args:
+ input_keys (Tuple[str, ...]): Name of input keys, such as ("x", "y", "z").
+ output_keys (Tuple[str, ...]): Name of output keys, such as ("u", "v", "w").
+ num_blocks (int): Number of PirateBlocks.
+ hidden_size (Union[int, Tuple[int, ...]]): Number of hidden size.
+ An integer for all layers, or list of integer specify each layer's size.
+ activation (str, optional): Name of activation function. Defaults to "tanh".
+ weight_norm (bool, optional): Whether to apply weight norm on parameter(s). Defaults to False.
+ input_dim (Optional[int]): Number of input's dimension. Defaults to None.
+ output_dim (Optional[int]): Number of output's dimension. Defaults to None.
+ periods (Optional[Dict[int, Tuple[float, bool]]]): Period of each input key,
+ input in given channel will be period embeded if specified, each tuple of
+ periods list is [period, trainable]. Defaults to None.
+ fourier (Optional[Dict[str, Union[float, int]]]): Random fourier feature embedding,
+ e.g. {'dim': 256, 'scale': 1.0}. Defaults to None.
+ random_weight (Optional[Dict[str, float]]): Mean and std of random weight
+ factorization layer, e.g. {"mean": 0.5, "std: 0.1"}. Defaults to None.
+
+ Examples:
+ >>> import paddle
+ >>> import ppsci
+ >>> model = ppsci.arch.PirateNet(
+ ... input_keys=("x", "y"),
+ ... output_keys=("u", "v"),
+ ... num_blocks=3,
+ ... hidden_size=256,
+ ... fourier={'dim': 256, 'scale': 1.0},
+ ... )
+ >>> input_dict = {"x": paddle.rand([64, 1]),
+ ... "y": paddle.rand([64, 1])}
+ >>> output_dict = model(input_dict)
+ >>> print(output_dict["u"].shape)
+ [64, 1]
+ >>> print(output_dict["v"].shape)
+ [64, 1]
+ """
+
+ def __init__(
+ self,
+ input_keys: Tuple[str, ...],
+ output_keys: Tuple[str, ...],
+ num_blocks: int,
+ hidden_size: int,
+ activation: str = "tanh",
+ weight_norm: bool = False,
+ input_dim: Optional[int] = None,
+ output_dim: Optional[int] = None,
+ periods: Optional[Dict[int, Tuple[float, bool]]] = None,
+ fourier: Optional[Dict[str, Union[float, int]]] = None,
+ random_weight: Optional[Dict[str, float]] = None,
+ ):
+ super().__init__()
+ self.input_keys = input_keys
+ self.output_keys = output_keys
+ self.blocks = []
+ self.periods = periods
+ self.fourier = fourier
+ if periods:
+ self.period_emb = PeriodEmbedding(periods)
+
+ if isinstance(hidden_size, int):
+ if not isinstance(num_blocks, int):
+ raise ValueError("num_blocks should be an int")
+ hidden_size = [hidden_size] * num_blocks
+ else:
+ raise ValueError(f"hidden_size should be int, but got {type(hidden_size)}")
+
+ # initialize FC layer(s)
+ cur_size = len(self.input_keys) if input_dim is None else input_dim
+ if input_dim is None and periods:
+ # period embeded channel(s) will be doubled automatically
+ # if input_dim is not specified
+ cur_size += len(periods)
+
+ if fourier:
+ self.fourier_emb = FourierEmbedding(
+ cur_size, fourier["dim"], fourier["scale"]
+ )
+ cur_size = fourier["dim"]
+
+ self.embed_u = nn.Sequential(
+ (
+ WeightNormLinear(cur_size, hidden_size[0])
+ if weight_norm
+ else nn.Linear(cur_size, hidden_size[0])
+ ),
+ (
+ act_mod.get_activation(activation)
+ if activation != "stan"
+ else act_mod.get_activation(activation)(hidden_size[0])
+ ),
+ )
+ self.embed_v = nn.Sequential(
+ (
+ WeightNormLinear(cur_size, hidden_size[0])
+ if weight_norm
+ else nn.Linear(cur_size, hidden_size[0])
+ ),
+ (
+ act_mod.get_activation(activation)
+ if activation != "stan"
+ else act_mod.get_activation(activation)(hidden_size[0])
+ ),
+ )
+
+ for i, _size in enumerate(hidden_size):
+ self.blocks.append(
+ PirateNetBlock(
+ cur_size,
+ activation=activation,
+ random_weight=random_weight,
+ )
+ )
+ cur_size = _size
+
+ self.blocks = nn.LayerList(self.blocks)
+ if random_weight:
+ self.last_fc = RandomWeightFactorization(
+ cur_size,
+ len(self.output_keys) if output_dim is None else output_dim,
+ mean=random_weight["mean"],
+ std=random_weight["std"],
+ )
+ else:
+ self.last_fc = nn.Linear(
+ cur_size,
+ len(self.output_keys) if output_dim is None else output_dim,
+ )
+
+ def forward_tensor(self, x):
+ u = self.embed_u(x)
+ v = self.embed_v(x)
+
+ y = x
+ for i, block in enumerate(self.blocks):
+ y = block(y, u, v)
+
+ y = self.last_fc(y)
+ return y
+
+ def forward(self, x):
+ if self._input_transform is not None:
+ x = self._input_transform(x)
+
+ if self.periods:
+ x = self.period_emb(x)
+
+ y = self.concat_to_tensor(x, self.input_keys, axis=-1)
+
+ if self.fourier:
+ y = self.fourier_emb(y)
+
+ y = self.forward_tensor(y)
+ y = self.split_to_dict(y, self.output_keys, axis=-1)
+
+ if self._output_transform is not None:
+ y = self._output_transform(x, y)
+ return y