diff --git a/README.md b/README.md
index 5e0f4237..b2c3f753 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,19 @@
+# Brainlife Warehouse
-Please see http://www.brainlife.io/warehouse/
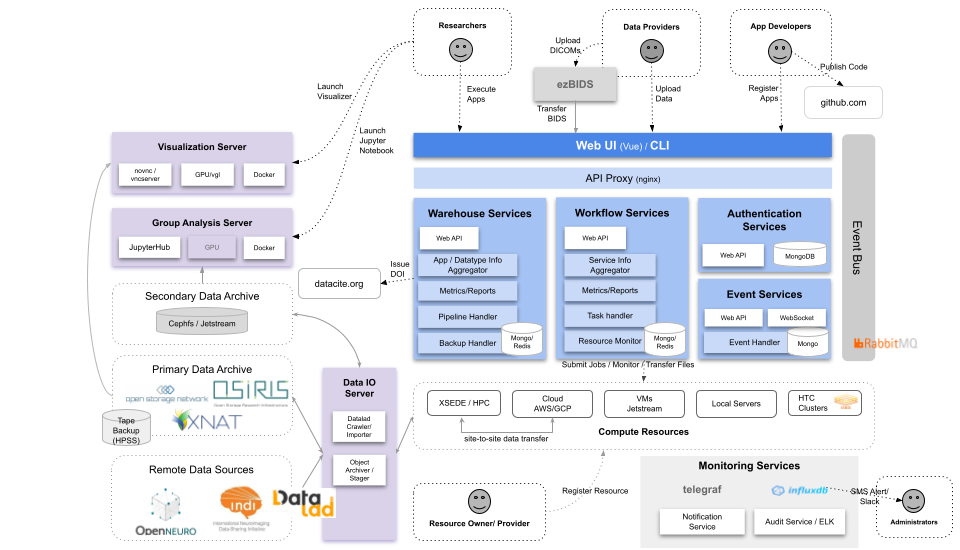
+Brainlife warehouse provides most of web UI hosted under https://brainlife.io and the API services that are unique to Brainlife.
-touched
+
+
+For more information, please read [Brainlife Doc](https://brain-life.github.io/docs/)
+
+For Warehouse API doc, please read [Warehouse API Doc](https://brain-life.github.io/warehouse/apidoc/)
+
+### Authors
+- Soichi Hayashi (hayashis@iu.edu)
+
+### Project directors
+- Franco Pestilli (franpest@indiana.edu)
+
+### Funding
+[](https://nsf.gov/awardsearch/showAward?AWD_ID=1734853)
+[](https://nsf.gov/awardsearch/showAward?AWD_ID=1636893)
diff --git a/api/common.js b/api/common.js
index 39d63819..293376ce 100644
--- a/api/common.js
+++ b/api/common.js
@@ -137,7 +137,7 @@ exports.archive_task = function(task, dataset, files_override, auth, cb) {
});
}
- //now start feeding the writestream
+ //now start feeding the writestream (/tmp/archive-XXX/thing)
request({
url: config.amaretti.api+"/task/download/"+task._id,
qs: {
@@ -157,10 +157,15 @@ exports.archive_task = function(task, dataset, files_override, auth, cb) {
if (err.file) dataset.desc = "Expected output " + (err.file.filename||err.file.dirname) + " not found";
else dataset.desc = "Failed to store all files under tmpdir";
dataset.status = "failed";
- return dataset.save(cb);
+ //return dataset.save(cb);
+ dataset.save(_err=>{
+ if(_err) logger.error(_err); //ignore..?
+ cb(dataset.desc);
+ });
+ return;
}
- logger.debug(filenames);
+ //logger.debug(filenames);
//all items stored under tmpdir! call cb, but then asynchrnously copy content to the storage
var storage = config.storage_default();
@@ -180,6 +185,9 @@ exports.archive_task = function(task, dataset, files_override, auth, cb) {
}
});
+ logger.debug("streaming to storage");
+ tar.stdout.pipe(writestream);
+
//TODO - I am not sure if all writestream returnes file object (pkgcloud does.. but this makes it a bit less generic)
//maybe I should run system.stat()?
//writestream.on('success', file=>{
@@ -198,9 +206,6 @@ exports.archive_task = function(task, dataset, files_override, auth, cb) {
cb(err); //return error from streaming which is more interesting
});
});
-
- logger.debug("streaming to storage");
- tar.stdout.pipe(writestream);
});
});
});
@@ -272,18 +277,14 @@ exports.compose_app_datacite_metadata = function(app) {
return;
}
//TODO - add 12312312131
- creators.push(`
- ${xmlescape(contact.fullname)}
- `);
+ creators.push(`${xmlescape(contact.fullname)}`);
});
let contributors = [];
- app.contributors.forEach(contact=>{
+ if(app.contributors) app.contributors.forEach(contact=>{
//contributorType can be ..
//Value \'Contributor\' is not facet-valid with respect to enumeration \'[ContactPerson, DataCollector, DataCurator, DataManager, Distributor, Editor, HostingInstitution, Other, Producer, ProjectLeader, ProjectManager, ProjectMember, RegistrationAgency, RegistrationAuthority, RelatedPerson, ResearchGroup, RightsHolder, Researcher, Sponsor, Supervisor, WorkPackageLeader]\'. It must be a value from the enumeration.'
- contributors.push(`
- ${xmlescape(contact.name)}
- `);
+ contributors.push(`${xmlescape(contact.name)}`);
});
let subjects = []; //aka "keyword"
@@ -295,13 +296,13 @@ exports.compose_app_datacite_metadata = function(app) {
${app.doi}
- ${creators.join("\n")}
+ ${creators.join('\n')}
- ${contributors.join("\n")}
+ ${contributors.join('\n')}
- ${subjects.join("\n")}
+ ${subjects.join('\n')}
${xmlescape(app.name)}
@@ -324,9 +325,6 @@ exports.compose_pub_datacite_metadata = function(pub) {
let year = pub.create_date.getFullYear();
let publication_year = ""+year+"";
- //creators
- //let creators = cached_contacts[pub.user_id];
-
//in case author is empty.. let's use submitter as author..
//TODO - we need to make author required field
if(pub.authors.length == 0) pub.authors.push(pub.user_id);
@@ -339,9 +337,7 @@ exports.compose_pub_datacite_metadata = function(pub) {
return;
}
//TODO - add 12312312131
- creators.push(`
- ${xmlescape(contact.fullname)}
- `);
+ creators.push(`${xmlescape(contact.fullname)}`);
});
@@ -356,9 +352,7 @@ exports.compose_pub_datacite_metadata = function(pub) {
//contributorType can be ..
//Value \'Contributor\' is not facet-valid with respect to enumeration \'[ContactPerson, DataCollector, DataCurator, DataManager, Distributor, Editor, HostingInstitution, Other, Producer, ProjectLeader, ProjectManager, ProjectMember, RegistrationAgency, RegistrationAuthority, RelatedPerson, ResearchGroup, RightsHolder, Researcher, Sponsor, Supervisor, WorkPackageLeader]\'. It must be a value from the enumeration.'
- contributors.push(`
- ${xmlescape(contact.fullname)}
- `);
+ contributors.push(`${xmlescape(contact.fullname)}`);
});
@@ -371,13 +365,13 @@ exports.compose_pub_datacite_metadata = function(pub) {
${pub.doi}
- ${creators.join("\n")}
+ ${creators.join('\n')}
- ${contributors.join("\n")}
+ ${contributors.join('\n')}
- ${subjects.join("\n")}
+ ${subjects.join('\n')}
${xmlescape(pub.name)}
@@ -434,8 +428,7 @@ exports.doi_put_url = function(doi, url, cb) {
}
let cached_contacts = {};
-function cache_contact() {
- logger.info("caching auth profiles");
+exports.cache_contact = function(cb) {
request({
url: config.auth.api+"/profile", json: true,
qs: {
@@ -449,11 +442,12 @@ function cache_contact() {
body.profiles.forEach(profile=>{
cached_contacts[profile.id.toString()] = profile;
});
+ if(cb) cb();
}
});
}
-cache_contact();
-setInterval(cache_contact, 1000*60*30); //cache every 30 minutes
+exports.cache_contact();
+setInterval(exports.cache_contact, 1000*60*30); //cache every 30 minutes
exports.deref_contact = function(id) {
return cached_contacts[id];
diff --git a/api/config/index.js.sample b/api/config/index.js.sample
index f456e5bb..58c422f9 100644
--- a/api/config/index.js.sample
+++ b/api/config/index.js.sample
@@ -28,7 +28,7 @@ exports.amaretti = {
//jwt used to query things from workflow service as admin
jwt: fs.readFileSync(__dirname+'/amaretti.jwt', 'ascii').trim(),
}
-exports.wf = exports.amaretti; //deprecated
+exports.wf = exports.amaretti; //deprecated (use amaretti)
exports.auth = {
api: "https://dev1.soichi.us/api/auth",
@@ -42,7 +42,6 @@ exports.warehouse = {
api: "https://dev1.soichi.us/api/warehouse",
//base url
- //url: "https://localhost:8080",
url: "https://localhost.brainlife.io", //to test datacite
//used to issue warehouse token to allow dataset download
diff --git a/api/controllers/dataset.js b/api/controllers/dataset.js
index 5ebede1a..92c28133 100644
--- a/api/controllers/dataset.js
+++ b/api/controllers/dataset.js
@@ -166,8 +166,11 @@ router.get('/inventory', jwt({secret: config.express.pubkey, credentialsRequired
//{removed: false, project: mongoose.Types.ObjectId("592dcc5b0188fd1eecf7b4ec")},
]
})
- .group({_id: {"subject": "$meta.subject", "datatype": "$datatype", "datatype_tags": "$datatype_tags"},
- count: {$sum: 1}, size: {$sum: "$size"} })
+ .group({_id: {
+ "subject": "$meta.subject",
+ "datatype": "$datatype",
+ "datatype_tags": "$datatype_tags"
+ }, count: {$sum: 1}, size: {$sum: "$size"} })
.sort({"_id.subject":1})
.exec((err, stats)=>{
if(err) return next(err);
@@ -241,14 +244,14 @@ router.get('/prov/:id', (req, res, next)=>{
if(task.service == "soichih/sca-product-raw" || task.service == "soichih/sca-service-noop") { //TODO might change in the future
if(defer) {
add_node(defer.node);
- edges.push(defer.edge);
+ if(defer.edge.to != defer.edge.from) edges.push(defer.edge);
}
if(dataset.prov.subdir) load_product_raw(to, dataset.prov.subdir, cb);
else load_product_raw(to, dataset._id, cb);
} else if(task.service && task.service.indexOf("brain-life/validator-") === 0) {
if(defer) {
add_node(defer.node);
- edges.push(defer.edge);
+ if(defer.edge.to != defer.edge.from) edges.push(defer.edge);
}
cb(); //ignore validator
} else {
@@ -275,7 +278,7 @@ router.get('/prov/:id', (req, res, next)=>{
var found = false;
var from = "dataset."+dataset_id;
var found = edges.find(e=>(e.from == from && e.to == to));
- if(!found) edges.push({ from, to, arrows: "to", });
+ if(to != from && !found) edges.push({ from, to, arrows: "to", });
return cb();
}
datasets_analyzed.push(dataset_id.toString());
@@ -474,7 +477,7 @@ router.post('/', jwt({secret: config.express.pubkey}), (req, res, cb)=>{
if(err) return next(err);
dataset = _dataset;
logger.debug("created dataset record......................", dataset.toObject());
- res.json(dataset); //not respond back to the caller - but processing has just began
+ //res.json(dataset);
next(err);
});
},
@@ -486,7 +489,8 @@ router.post('/', jwt({secret: config.express.pubkey}), (req, res, cb)=>{
], err=>{
if(err) return cb(err);
- else logger.debug("all done archiving");
+ logger.debug("all done archiving");
+ res.json(dataset);
});
});
diff --git a/api/controllers/pub.js b/api/controllers/pub.js
index 2dbe9efd..f5d604b3 100644
--- a/api/controllers/pub.js
+++ b/api/controllers/pub.js
@@ -55,7 +55,7 @@ router.get('/', (req, res, next)=>{
.lean()
.exec((err, pubs)=>{
if(err) return next(err);
- db.Datatypes.count(find).exec((err, count)=>{
+ db.Publications.count(find).exec((err, count)=>{
if(err) return next(err);
//dereference user ID to name/email
@@ -75,14 +75,14 @@ router.get('/', (req, res, next)=>{
/**
* @apiGroup Publications
- * @api {get} /pub/datasets-inventory/:pubid Get counts of unique subject/datatype/datatype_tags. You can then use /pub/datasets/:pubid to
+ * @api {get} /pub/datasets-inventory/:releaseid Get counts of unique subject/datatype/datatype_tags. You can then use /pub/datasets/:releaseid to
* get the actual list of datasets for each subject / datatypes / etc..
* @apiSuccess {Object} Object containing counts
*/
//WARNING: similar code in dataset.js
-router.get('/datasets-inventory/:pubid', (req, res, next)=>{
+router.get('/datasets-inventory/:releaseid', (req, res, next)=>{
db.Datasets.aggregate()
- .match({ publications: mongoose.Types.ObjectId(req.params.pubid) })
+ .match({ publications: mongoose.Types.ObjectId(req.params.releaseid) })
.group({_id: {"subject": "$meta.subject", "datatype": "$datatype", "datatype_tags": "$datatype_tags"},
count: {$sum: 1}, size: {$sum: "$size"} })
.sort({"_id.subject":1})
@@ -94,22 +94,16 @@ router.get('/datasets-inventory/:pubid', (req, res, next)=>{
/**
* @apiGroup Publications
- * @api {get} /pub/apps/:pubid
+ * @api {get} /pub/apps/:releaseid
* Enumerate applications used to generate datasets
*
* @apiSuccess {Object[]} Application objects
*
*/
-router.get('/apps/:pubid', (req, res, next)=>{
- /*
- db.Datasets.find({
- publications: mongoose.Types.ObjectId(req.params.pubid)
- })
- .distinct("prov.task.config._app")
- */
+router.get('/apps/:releaseid', (req, res, next)=>{
db.Datasets.aggregate([
{$match: {
- publications: mongoose.Types.ObjectId(req.params.pubid)
+ publications: mongoose.Types.ObjectId(req.params.releaseid)
}},
{$group: {
_id: {
@@ -172,7 +166,7 @@ router.get('/apps/:pubid', (req, res, next)=>{
/**
* @apiGroup Publications
- * @api {get} /pub/datasets/:pubid
+ * @api {get} /pub/datasets/:releaseid
* Query published datasets
*
* @apiParam {Object} [find] Optional Mongo find query - defaults to {}
@@ -184,12 +178,12 @@ router.get('/apps/:pubid', (req, res, next)=>{
*
* @apiSuccess {Object} List of dataasets (maybe limited / skipped) and total count
*/
-router.get('/datasets/:pubid', (req, res, next)=>{
+router.get('/datasets/:releaseid', (req, res, next)=>{
let find = {};
let skip = req.query.skip || 0;
let limit = req.query.limit || 100;
if(req.query.find) find = JSON.parse(req.query.find);
- let query = {$and: [ find, {publications: req.params.pubid}]};
+ let query = {$and: [ find, {publications: req.params.releaseid}]};
db.Datasets.find(query)
.populate(req.query.populate || '') //all by default
.select(req.query.select)
@@ -206,7 +200,6 @@ router.get('/datasets/:pubid', (req, res, next)=>{
});
});
-
/**
* @apiGroup Publications
* @api {post} /pub Register new publication
@@ -223,6 +216,7 @@ router.get('/datasets/:pubid', (req, res, next)=>{
* @apiParam {String} desc Publication desc (short summary)
* @apiParam {String} readme Publication detail (paper abstract)
* @apiParam {String[]} tags Publication tags
+ * @apiParam {Object[]} releases Release records
*
* @apiParam {Boolean} removed If this is a removed publication
*
@@ -246,7 +240,6 @@ router.post('/', jwt({secret: config.express.pubkey}), (req, res, next)=>{
let override = {
user_id: req.user.sub,
}
- //new db.Publications(Object.assign(def, req.body, override)).save((err, pub)=>{
let pub = new db.Publications(Object.assign(def, req.body, override));
//mint new doi - get next doi id - use number of publication record with doi (brittle?)
@@ -268,7 +261,19 @@ router.post('/', jwt({secret: config.express.pubkey}), (req, res, next)=>{
let url = config.warehouse.url+"/pub/"+pub._id; //TODO make it configurable?
common.doi_put_url(pub.doi, url, logger.error);
});
- });
+
+ //I have to use req.body.releases which has "sets", but not release._id
+ //so let's set release._id on req.body.releases and use that list to
+ //handle new publications
+ req.body.releases.forEach((release, idx)=>{
+ release._id = pub.releases[idx]._id;
+ });
+ async.eachSeries(req.body.releases, (release, next_release)=>{
+ handle_release(release, pub.project, next_release);
+ }, err=>{
+ if(err) logger.error(err);
+ });
+ });
});
});
});
@@ -284,14 +289,13 @@ router.post('/', jwt({secret: config.express.pubkey}), (req, res, next)=>{
*
* @apiParam {String[]} authors List of author IDs.
* @apiParam {String[]} contributors List of contributor IDs.
+ * @apiParam {Object[]} releases Release records
*
* @apiParam {String} name Publication title
* @apiParam {String} desc Publication desc (short summary)
* @apiParam {String} readme Publication detail (paper abstract)
* @apiParam {String[]} tags Publication tags
*
- * @apiParam {Boolean} removed If this is a removed publication
- *
* @apiHeader {String} authorization
* A valid JWT token "Bearer: xxxxx"
*
@@ -322,99 +326,52 @@ router.put('/:id', jwt({secret: config.express.pubkey}), (req, res, next)=>{
if(err) return next(err);
res.json(pub);
- if(pub.doi) { //old test pubs doesn't have doi
+ if(!pub.doi) {
+ logger.error("no doi set.. skippping metadata update");
+ } else {
+ //update doi meta
let metadata = common.compose_pub_datacite_metadata(pub);
common.doi_post_metadata(metadata, logger.error);
}
- });
- });
- });
-});
-
-/**
- * @apiGroup Publications
- * @api {put} /pub/:pubid/datasets
- *
- * @apiDescription Publish datasets
- *
- * @apiParam {Object} [find] Mongo query to subset datasets (all datasets in the project by default)
- *
- * @apiHeader {String} authorization A valid JWT token "Bearer: xxxxx"
- *
- * @apiSuccess {Object} Number of published datasets, etc..
- */
-router.put('/:id/datasets', jwt({secret: config.express.pubkey}), (req, res, next)=>{
- var id = req.params.id;
- db.Publications.findById(id, (err, pub)=>{
- if(err) return next(err);
- if(!pub) return res.status(404).end();
-
- can_publish(req, pub.project, (err, can)=>{
- if(err) return next(err);
- if(!can) return res.status(401).end("you can't publish this project");
-
- let find = {};
- if(req.body.find) find = JSON.parse(req.body.find);
-
- //override to make sure user only publishes datasets from specific project
- find.project = pub.project;
- find.removed = false; //no point of publishing removed dataset right?
- db.Datasets.update(
- find,
- {$addToSet: {publications: pub._id}},
- {multi: true},
- (err, _res)=>{
- if(err) return next(err);
- res.json(_res);
+ //I have to use req.body.releases which has "sets", but not release._id
+ //so let's set release._id on req.body.releases and use that list to
+ //handle new publications
+ req.body.releases.forEach((release, idx)=>{
+ release._id = pub.releases[idx]._id;
+ });
+ async.eachSeries(req.body.releases, (release, next_release)=>{
+ handle_release(release, pub.project, next_release);
+ }, err=>{
+ if(err) logger.error(err);
+ });
});
});
});
-});
-
-/**
- * @apiGroup Publications
- * @api {put} /pub/:pubid/doi
- *
- * @apiDescription Issue DOI for publication record (or update URL)
- *
- * @apiParam {String} url URL to associate the minted DOI
- *
- * @apiHeader {String} authorization A valid JWT token "Bearer: xxxxx"
- *
- * @apiSuccess {Object} Publication object with doi field
- */
-/*
-router.put('/:id/doi', jwt({secret: config.express.pubkey}), (req, res, next)=>{
- let id = req.params.id;
- let url = req.body.url;
- //logger.debug(id, url);
-
- //TODO - maybe we shouldn't let user control the url?
+});
- db.Publications.findById(id, (err, pub)=>{
- if(err) return next(err);
- if(!pub) return res.status(404).end();
- if(pub.doi) return res.status(404).end("doi already issued");
+function handle_release(release, project, cb) {
+ async.eachSeries(release.sets, (set, next_set)=>{
+ if(!set.add) return next_set();
+ logger.debug("------------------need to add!------------------------");
+ logger.debug(set);
- can_publish(req, pub.project, (err, can)=>{
- if(err) return next(err);
- if(!can) return res.status(401).end("you can't publish on this project");
-
- //register metadata and attach url to it
- common.doi_post_metadata(pub, (err, doi)=>{
- if(err) return next(err);
- //let url = "https://brainlife.io/pub/"+pub._id;
- logger.debug("making request", doi, url);
- common.doi_put_url(doi, url, err=>{
- if(err) return next(err);
- res.json(pub);
- });
- });
+ let find = {
+ project,
+ removed: false,
+ datatype: set.datatype._id,
+ datatype_tags: set.datatype_tags,
+ };
+
+ /*
+ db.Datasets.find(find, (err, datasets)=>{
+ if(err) throw err;
+ console.dir(datasets);
});
- });
-});
-*/
+ */
+ db.Datasets.update(find, {$addToSet: {publications: release._id}}, {multi: true}, next_set);
+ }, cb);
+}
//proxy doi.org doi resolver
router.get('/doi', (req, res, next)=>{
diff --git a/api/models.js b/api/models.js
index 96e75faa..cb2bb86d 100644
--- a/api/models.js
+++ b/api/models.js
@@ -112,14 +112,19 @@ exports.Projects = mongoose.model("Projects", projectSchema);
///////////////////////////////////////////////////////////////////////////////////////////////////
+var releaseSchema = mongoose.Schema({
+ name: String, //"1", "2", etc..
+ create_date: { type: Date, default: Date.now }, //release date
+ removed: { type: Boolean, default: false }, //release should not removed.. but just in case
+});
+mongoose.model("Releases", releaseSchema);
+
var publicationSchema = mongoose.Schema({
//user who created this publication
user_id: {type: String, index: true},
- //citation: String, //preferred citation
license: String, //cc0, ccby.40, etc.
-
doi: String, //doi for this dataset (we generate this)
paper_doi: String, //doi for the paper (journal should publish this)
@@ -129,35 +134,20 @@ var publicationSchema = mongoose.Schema({
project: {type: mongoose.Schema.Types.ObjectId, ref: "Projects"},
authors: [ String ], //list of users who are the author/creator of this publicaions
- //authors_ext: [new mongoose.Schema({name: 'string', email: 'string'})],
-
contributors: [ String ], //list of users who contributed (PI, etc..)
- //contributor_ext: [new mongoose.Schema({name: 'string', email: 'string'})],
- //DOI metadata
- publisher: String, //NatureScientificData
+ publisher: String, //NatureScientificData //TODO - is this used?
- //contacts: [ String ], //list of users who can be used as contact
-
name: String, //title of the publication
desc: String,
tags: [String], //software, eeg, mri, etc..
readme: String, //markdown (abstract in https://purl.stanford.edu/rt034xr8593)
- /*
- //list of app used to generated datasets
- apps: [ new mongoose.Schema({
- app: {type: mongoose.Schema.Types.ObjectId, ref: 'Apps'},
- service: String,
- service_branch: String,
- })
- ],
- */
+ releases: [ releaseSchema ],
create_date: { type: Date, default: Date.now },
- //publish_date: { type: Date, default: Date.now }, //used for publication date
- removed: { type: Boolean, default: false },
+ removed: { type: Boolean, default: false }, //only admin can remove publication for now (so that doi won't break)
});
exports.Publications = mongoose.model("Publications", publicationSchema);
@@ -222,9 +212,10 @@ var datasetSchema = mongoose.Schema({
removed: { type: Boolean, default: false},
- //list of publications that this datasets is published under
- publications: [{type: mongoose.Schema.Types.ObjectId, ref: 'Publications'}],
+ //list of publications that this datasets is published under (point to releases ID under publications)
+ publications: [{type: mongoose.Schema.Types.ObjectId, ref: 'Releases'}],
});
+
datasetSchema.post('validate', function() {
//normalize meta fields that needs to be in string
if(this.meta) {
@@ -233,6 +224,7 @@ datasetSchema.post('validate', function() {
if(typeof this.meta.run == 'number') this.meta.run = this.meta.run.toString();
}
});
+
datasetSchema.post('save', dataset_event);
datasetSchema.post('findOneAndUpdate', dataset_event);
datasetSchema.post('findOneAndRemove', dataset_event);
diff --git a/bin/appinfo.js b/bin/appinfo.js
index 65a15076..1b98acf5 100755
--- a/bin/appinfo.js
+++ b/bin/appinfo.js
@@ -59,7 +59,7 @@ function handle_app(app, cb) {
logger.debug("querying service stats");
request.get({
- url: config.wf.api+"/task/stats", json: true,
+ url: config.amaretti.api+"/task/stats", json: true,
headers: { authorization: "Bearer "+config.auth.jwt },
qs: {
service: app.github,
diff --git a/bin/meta.js b/bin/meta.js
new file mode 100755
index 00000000..82b0294f
--- /dev/null
+++ b/bin/meta.js
@@ -0,0 +1,198 @@
+#!/usr/bin/env node
+
+const winston = require('winston');
+const async = require('async');
+const request = require('request');
+const fs = require('fs');
+const jsonwebtoken = require('jsonwebtoken');
+const mkdirp = require('mkdirp');
+//const xml2js = require('xml2js');
+
+const config = require('../api/config');
+const logger = new winston.Logger(config.logger.winston);
+const db = require('../api/models');
+const common = require('../api/common');
+
+
+//suppress non error out
+config.logger.winston.transports[0].level = 'error';
+
+let info_apps = {};
+let info_pubs = {};
+let info_projs = {};
+
+db.init(err=>{
+ if(err) throw err;
+ async.series(
+ [
+ next=>{
+ logger.info("caching contact");
+ common.cache_contact(next);
+ },
+ next=>{
+ logger.info("processing apps");
+ db.Apps.find({
+ //removed: false, //let's just output all..
+ })
+ .lean()
+ .exec((err, apps)=>{
+ if(err) throw err;
+ async.eachSeries(apps, handle_app, next);
+ });
+ },
+ next=>{
+ logger.info("processing pubs");
+ db.Publications.find({
+ //removed: false, //let's just output all..
+ })
+ .populate('project')
+ .lean()
+ .exec((err, pubs)=>{
+ if(err) throw err;
+ async.eachSeries(pubs, handle_pub, next);
+ });
+ },
+ next=>{
+ logger.info("processing projects");
+ db.Projects.find({
+ //removed: false, //let's just output all..
+ $or: [
+ { access: "public" },
+ {
+ access: "private",
+ listed: true,
+ }
+ ]
+ })
+ .lean()
+ .exec((err, projs)=>{
+ if(err) throw err;
+ async.eachSeries(projs, handle_proj, next);
+ });
+ },
+
+ ],
+ err=>{
+ if(err) logger.error(err);
+ //console.log(JSON.stringify(info_apps, null, 4));
+ //console.log(JSON.stringify(info_pubs, null, 4));
+
+ console.log(JSON.stringify({apps: info_apps, pubs: info_pubs, projs: info_projs}, null, 4));
+
+ logger.info("all done");
+ db.disconnect();
+
+ //amqp disconnect() is broken
+ //https://github.com/postwait/node-amqp/issues/462
+ setTimeout(()=>{
+ console.error("done");
+ process.exit(0);
+ }, 1000);
+
+ });
+});
+
+function format_date(d) {
+ let month = '' + (d.getMonth() + 1);
+ let day = '' + d.getDate();
+ let year = d.getFullYear();
+
+ if (month.length < 2) month = '0' + month;
+ if (day.length < 2) day = '0' + day;
+ return [year, month, day].join('-');
+}
+
+function handle_app(app, cb) {
+ logger.debug(app.name, app._id.toString());
+ let info = {
+ title: app.name,
+ meta: {
+ ID: app._id.toString(),
+ description: app.desc,
+
+ //for slack
+ //https://medium.com/slack-developer-blog/everything-you-ever-wanted-to-know-about-unfurling-but-were-afraid-to-ask-or-how-to-make-your-e64b4bb9254
+ "og:title": app.name,
+ "og:image": app.avatar,
+ "og:description": app.desc,
+
+ doi: app.doi,
+ date: format_date(app.create_date),
+ }
+ };
+ if(app.contributors) info.meta.citation_author = app.contributors.map(contact=>{ return contact.name}).join(", "),
+ info_apps[app._id.toString()] = info;
+ /*
+ xml2js.parseString(common.compose_app_datacite_metadata(app), {trim: false}, (err, info)=>{
+ if(err) return cb(err);
+ info_pubs[app._id.toString()] = info.resource;
+ });
+ */
+ cb();
+}
+
+function handle_pub(pub, cb) {
+ logger.debug(pub.name, pub._id.toString());
+ let info = {
+ title: pub.name,
+ meta: {
+ ID: pub._id.toString(),
+ description: pub.desc,
+
+ //for slack
+ //https://medium.com/slack-developer-blog/everything-you-ever-wanted-to-know-about-unfurling-but-were-afraid-to-ask-or-how-to-make-your-e64b4bb9254
+ "og:title": pub.name,
+ "og:image": pub.project.avatar,
+ "og:description": pub.desc,
+
+ //for altmetrics
+ //https://help.altmetric.com/support/solutions/articles/6000141419-what-metadata-is-required-to-track-our-content-
+ citation_doi: pub.doi,
+ citation_title: pub.name,
+ citation_date: format_date(pub.create_date),
+ }
+ };
+ info.meta.citation_author = pub.authors.map(sub=>{
+ let contact = common.deref_contact(sub);
+ return contact.fullname;
+ }).join(", "),
+ info_pubs[pub._id.toString()] = info;
+ /*
+ xml2js.parseString(common.compose_pub_datacite_metadata(pub), {trim: false}, (err, info)=>{
+ if(err) return cb(err);
+ info_pubs[pub._id.toString()] = info.resource;
+ });
+ */
+ cb();
+}
+
+function handle_proj(proj, cb) {
+ logger.debug(proj.name, proj._id.toString());
+ let info = {
+ title: proj.name,
+ meta: {
+ ID: proj._id.toString(),
+ description: proj.desc,
+
+ //for slack
+ //https://medium.com/slack-developer-blog/everything-you-ever-wanted-to-know-about-unfurling-but-were-afraid-to-ask-or-how-to-make-your-e64b4bb9254
+ "og:title": proj.name,
+ "og:image": proj.avatar,
+ "og:description": proj.desc,
+
+ description: proj.desc,
+ citation_title: proj.name,
+ publish_date: format_date(proj.create_date),
+ }
+ };
+ //if(app.contributors) info.meta.citation_author = app.contributors.map(contact=>{ return contact.name}).join(", "),
+ info_projs[proj._id.toString()] = info;
+ /*
+ xml2js.parseString(common.compose_app_datacite_metadata(app), {trim: false}, (err, info)=>{
+ if(err) return cb(err);
+ info_pubs[app._id.toString()] = info.resource;
+ });
+ */
+ cb();
+}
+
diff --git a/bin/rule_handler.js b/bin/rule_handler.js
index 46fd47b7..842af047 100755
--- a/bin/rule_handler.js
+++ b/bin/rule_handler.js
@@ -175,7 +175,7 @@ function handle_rule(rule, cb) {
next=>{
var limit = 5000;
request.get({
- url: config.wf.api+"/task", json: true,
+ url: config.amaretti.api+"/task", json: true,
headers: { authorization: "Bearer "+jwt },
qs: {
find: JSON.stringify({
@@ -506,7 +506,7 @@ function handle_rule(rule, cb) {
//look for instance that we can use
next=>{
request.get({
- url: config.wf.api+"/instance", json: true,
+ url: config.amaretti.api+"/instance", json: true,
headers: { authorization: "Bearer "+jwt },
qs: {
find: JSON.stringify({
@@ -531,7 +531,7 @@ function handle_rule(rule, cb) {
if(instance) return next();
rlogger.debug("creating a new instance");
request.post({
- url: config.wf.api+'/instance', json: true,
+ url: config.amaretti.api+'/instance', json: true,
headers: { authorization: "Bearer "+jwt },
body: {
name: instance_name,
@@ -551,7 +551,7 @@ function handle_rule(rule, cb) {
//find next tid by counting number of tasks (including removed)
next=>{
request.get({
- url: config.wf.api+"/task", json: true,
+ url: config.amaretti.api+"/task", json: true,
headers: { authorization: "Bearer "+jwt },
qs: {
find: JSON.stringify({
@@ -691,7 +691,7 @@ function handle_rule(rule, cb) {
//need to submit download task first.
request.post({
- url: config.wf.api+'/task', json: true,
+ url: config.amaretti.api+'/task', json: true,
headers: { authorization: "Bearer "+jwt },
body: {
instance_id: instance._id,
@@ -784,7 +784,7 @@ function handle_rule(rule, cb) {
});
request.post({
- url: config.wf.api+'/task', json: true,
+ url: config.amaretti.api+'/task', json: true,
headers: { authorization: "Bearer "+jwt },
body: {
instance_id: instance._id,
diff --git a/docker/build.sh b/docker/build.sh
index 4d3e7345..17336e9d 100755
--- a/docker/build.sh
+++ b/docker/build.sh
@@ -1,4 +1,4 @@
-tag=1.1.30
+tag=1.1.32
#docker pull node:8
diff --git a/package.json b/package.json
index 85a47f80..1cbf446c 100644
--- a/package.json
+++ b/package.json
@@ -32,7 +32,7 @@
"express-winston": "^2.6.0",
"istanbul": "^0.4.5",
"mkdirp": "^0.5.1",
- "mongoose": "^5.2.9",
+ "mongoose": "^5.2.17",
"nocache": "^2.0.0",
"pkgcloud": "^1.5.0",
"redis": "^2.8.0",
@@ -41,12 +41,13 @@
"stream-meter": "^1.0.4",
"tar": "^4.4.6",
"tmp": "0.0.33",
- "winston": "^2.4.3",
- "xml-escape": "^1.1.0"
+ "winston": "^2.4.4",
+ "xml-escape": "^1.1.0",
+ "xml2js": "^0.4.19"
},
"devDependencies": {
"chai": "^4.1.2",
"mocha": "^5.2.0",
- "supertest": "^3.1.0"
+ "supertest": "^3.3.0"
}
}
diff --git a/ui/index.html b/ui/index.html
index 20ed2071..fdc5321c 100644
--- a/ui/index.html
+++ b/ui/index.html
@@ -7,6 +7,8 @@
+
+