作为Java世界最好的HTML 解析库,Jsoup的parser实现非常具有代表性。这部分也是Jsoup最复杂的部分,需要一些数据结构、状态机乃至编译器的知识。好在HTML语法不复杂,解析只是到DOM树为止,所以作为编译器入门倒是挺合适的。这一块不要指望囫囵吞枣,我们还是泡一杯咖啡,细细品味其中的奥妙吧。
将计算机语言转化为另一种计算机语言(通常是更底层的语言,例如机器码、汇编、或者JVM字节码)的过程就叫做编译(compile)。编译器(Compiler)是计算机科学的一个重要领域,已经有很多年历史了,而最近各种通用语言层出不穷,加上跨语言编译的兴起、DSL概念的流行,都让编译器变成了一个很时髦的东西。
编译器领域相关有三本公认的经典书籍,龙书《Compilers: Principles, Techniques, and Tools 》,虎书《Modern Compiler Implementation in X (X表示各种语言)》,鲸书《Advanced Compiler Design and Implementation》。其中龙书是编译理论方面公认的不二之选,而后面两本则对实践更有指导意义。另外@装配脑袋有个很好的编译器入门系列博客:http://www.cnblogs.com/Ninputer/archive/2011/06/07/2074632.html
编译器的基本流程如下:
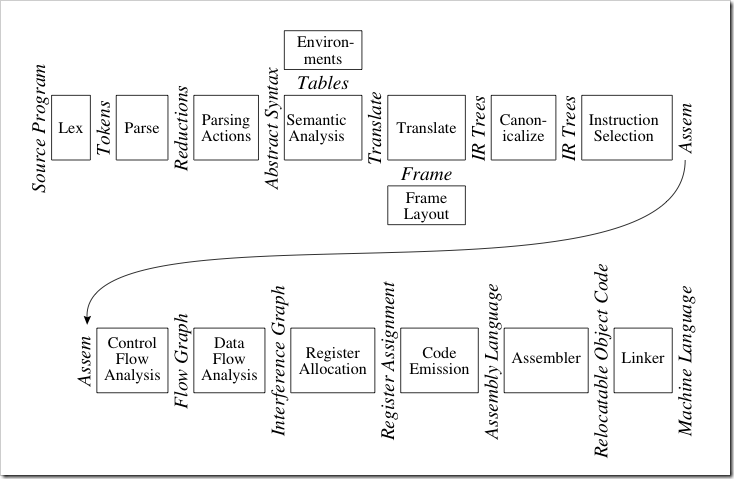
其中词法分析、语法分析、语义分析这部分又叫编译器的前端(front-end),而此后的中间代码生成直到目标生成、优化等属于编译器的后端(back-end)。编译器的前端技术已经很成熟了,也有yacc这样的工具来自动进行词法、语法分析(Java里也有一个类似的工具ANTLR),而后端技术更加复杂,也是目前编译器研究的重点。
说了这么多,回到咱们的HTML上来。HTML是一种声明式的语言,可以理解它的最终的输出是浏览器里图形化的页面,而并非可执行的目标语言,因此我将这里的Translate改为了Render。
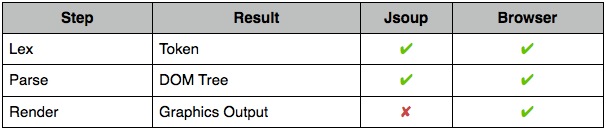
在Jsoup(包括类似的HTML parser)里,只做了Lex(词法分析)、Parse(语法分析)两步,而HTML parse最终产出结果,就是DOM树。至于HTML的语义解析以及渲染,不妨看看携程UED团队的这篇文章:《浏览器是怎样工作的:渲染引擎,HTML解析》。
Jsoup的词法分析和语法分析都用到了状态机。状态机可以理解为一个特殊的程序模型,例如经常跟我们打交道的正则表达式就是用状态机实现的。
它由状态(state)和转移(transition)两部分构成。根据状态转移的可能性,状态机又分为DFA(确定有限状态机)和NFA(非确定有限状态自动机)。这里拿一个最简单的正则表达式"a[b]*"作为例子,我们先把它映射到一个状态机DFA,大概是这样子:

状态机本身是一个编程模型,这里我们尝试用程序去实现它,那么最直接的方式大概是这样:
public void process(StringReader reader) throws StringReader.EOFException {
char ch;
switch (state) {
case Init:
ch = reader.read();
if (ch == 'a') {
state = State.AfterA;
accum.append(ch);
}
break;
case AfterA:
...
break;
case AfterB:
...
break;
case Accept:
...
break;
}
}这样写简单的状态机倒没有问题,但是复杂情况下就有点难受了。还有一种标准的状态机解法,先建立状态转移表,然后使用这个表建立状态机。这个方法的问题就是,只能做纯状态转移,无法在代码级别操作输入输出。
Jsoup里则使用了状态模式来实现状态机,初次看到时,确实让人眼前一亮。状态模式是设计模式的一种,它将状态和对应的行为绑定在一起。而在状态机的实现过程中,使用它来实现状态转移时的处理再合适不过了。
"a[b]*"的例子的状态模式实现如下,这里采用了与Jsoup相同的方式,用到了枚举来实现状态模式:
public class StateModelABStateMachine implements ABStateMachine {
State state;
StringBuilder accum;
enum State {
Init {
@Override
public void process(StateModelABStateMachine stateModelABStateMachine, StringReader reader) throws StringReader.EOFException {
char ch = reader.read();
if (ch == 'a') {
stateModelABStateMachine.state = AfterA;
stateModelABStateMachine.accum.append(ch);
}
}
},
Accept {
...
},
AfterA {
...
},
AfterB {
...
};
public void process(StateModelABStateMachine stateModelABStateMachine, StringReader reader) throws StringReader.EOFException {
}
}
public void process(StringReader reader) throws StringReader.EOFException {
state.process(this, reader);
}
}本文中提到的几种状态机的完整实现在这个仓库的https://github.com/code4craft/jsoup-learning/tree/master/src/main/java/us/codecraft/learning/automata路径下。
下一篇文章将从Jsoup的词法分析器开始来讲状态机的使用。