Using Leshan server in a cluster
This page aims to regroup all information about using Leshan servers (Device management and Bootstrap) in a cluster.
This is clearly not so easy, we face a lot of problems which are detailed below in this page. But doing more DTLS handshake and if you implements your kind of northbound interface this should be doable. Actually we do it in production.
You should easily be able to create a cluster of bootstrap servers. Just by implementing some shared stores (BootstrapStore and SecurityStore). There is no such implementation provided for now.
This is easier than Leshan Server because there is no northbound interface needed. And device session are pretty short with regular message exchange which avoid issues with dynamic IP like NAT environment and no need to share DTLS session.
Southbound interface: this is the interface between the device and server communication (Leshan).
Northbound interface: this is the interface between the Leshan cluster and the end user, like an IoT backend.
Here is the network infrastructure we aim. There are probably other solutions but in this page we will mainly focus on this.
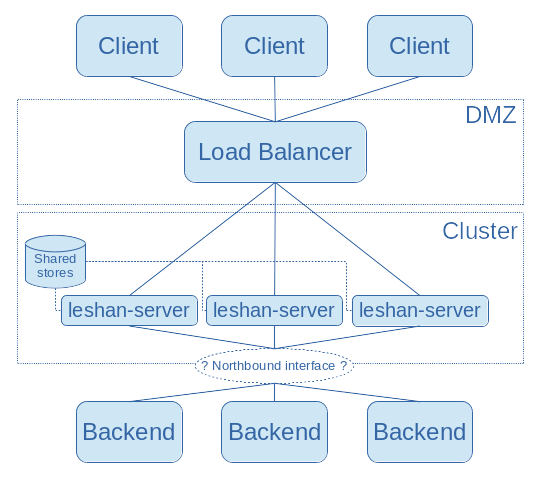
The idea is to use a load balancer for the southbound interface and so deploy Leshan as mutiple machine behind this load balancer for sending the incoming messages to one of the cluster Leshan instance.
Today Leshan accept CoAP+DTLS device communications. It's all based on UDP (maybe later TCP). One of the few load-balancer supporting UDP is LVS - Linux Virtual Server. We will focus on providing a solution compatible with it.
LVS will do the load balancing using IP/Port, we can't find better for now, if you have better idea, please share it.
This means that client UDP datagrams from the same IP/port will be redirect to the same Leshan server instance.
But this mapping expired after a configurable timeout(last time we check LVS default timeout was 300s). If client and server stop to talk each other during more than this timeout, mapping is deleted!
Here is short description of what could be shared or not shared thought instances :
- At DTLS/Scandium level : By default there is no shared state. DTLS session or connection is not shared. Scandium provides a way to share Session via SessionCache but we never experiment it.
- At CoAP/Californium level : The only state shared is about observation. MID/Token for short living request could not be shared.
- At LWM2M/Leshan level : we share registrations, observations, bootstrap configuration and security information.
leshan-server-rediscontains persistent shared implementation for registration, observation and security stores.
(You could also look at Failover wiki page)
MID and token are not shared, so all responses or acknowledgements for a request should be sent to the Leshan Server instance which send it. So,
- if this response/ACK is sent without undue delay this should works.
- if this response/ACK is sent after the LVS UDP timed-out, there is lot of chances that this will be lost...
Keep this in mind when you configure the LVS UDP timeout.
One exception, observe notification could be sent to any leshan-server-instance as registration and observation state was shared between instances.
DTLS connection are not shared. So if client send encrypted packet to a different Leshan server instance than the one which established the connection, this packet will be ignored as this server instance will not be able to decrypt it.
What are consequences of this ? That's mean if LVS UDP timed-out, client should re-do a full handshake.
If you're using Queue mode, this is not so impacting. When clients wake up and try to communicate to the server, the LVS mapping will probably be lost. So you should start all your new client communications with a fresh new handshake. If you want to support devices behind a NAT you probably already have this constraint so this is OK.
For "none queue" mode, without cluster you generally need to do 1 full handshake per day as a DTLS session should live 24h. With cluster you will need to redo a full handshake each time LVS UDP timeout will expired ...
Keep this in mind when you configure the LVS UDP timeout.
We will see below that this have also impact the northbound API !
Can I use DTLS Session resumption ? You could try to use session resumption but there is a lot of chance that you don't fall on the same server instance and as DTLS session are not shared, this will end up with a full handshake. (Using SessionCache to share session state could solve this issue but we never experiment it)
Here is a simple way to defined the northbound interface. We have one or several northbound client(s) which are probably kind of backend or UI component. This northbound client can be notified for event (registration, observe notification) and can ask for sending request.
Now let's see limitations because some states are shared and other not.
When northbound client ask for sending request, there is maximum one leshan server instance which have a valid DTLS connection established with the targeted device. That should be this instance which should send the request.
Until now we have been pretty vague about Northbound API. This is because we don't have a clear idea about what this could be.
leshan-server-cluster is an experimental module which aims to provide this kind of API based on redis pub/sub.
This page is some documentation of what we try to achieve.
This works (Northbound API) is currently abandoned but if you think this is valuable and/or you want to contribute to it, do not hesitate to manifest yourself through the mailing list or via github issues. Help is welcomed ;)
