Replies: 7 comments 7 replies
-
|
@yingsu00 thanks for the write-up! Just a minor correction. In Velox, we have both Hive and TPC-H connector support. |
Beta Was this translation helpful? Give feedback.
-
|
@majetideepak Yes there is TPCH connector too. Thanks for bringing it up. The TPCH connector is mostly used in testing. I meant the connectors as opposed to MySQL connector, Hudi connector, etc., which may not support filter pushdown. As for when to remove DuckDB reader, I think we shall stabilize the native reader and test it more. ByteDance has Velox clusters in production and they offered to test it when the function is complete. @frankobe , is this still true? |
Beta Was this translation helpful? Give feedback.
-
|
Yes, we can help test the native parquet reader performance against HDFS cc @markjin1990 @liushengxuan |
Beta Was this translation helpful? Give feedback.
-
|
Hi, in schema part, we found that: In your picture, the "key" is |
Beta Was this translation helpful? Give feedback.
-
|
The design looks great. Just curious why not investing in the native parquet implementation from apache arrow? @majetideepak |
Beta Was this translation helpful? Give feedback.
-
|
@wgtmac Velox implements a visitor pattern suitable for most columnar file formats. This visitor pattern implements file-format agnostic features like predicate pruning, filter evaluation, etc... There are also some IO optimizations like prefetching and I/O coalescing. Velox does use the parquet writer from apache arrow. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for the explanation. Looking forward to the final performance improvement. |
Beta Was this translation helpful? Give feedback.
-
|
@majetideepak Thanks for the explanation. Does the prefetch happen at the stripe/row group level or at the column level? I'm a little bit confused about the prefetching mechanism in Velox. It seems the ScanTracker tracks the column access frequency and the prefetching is conducted at the column level based on the frequency. If that's the case, why do we prefetch based on column access frequency given that all required columns need to be read anyway? Thanks for your time in advance. |
Beta Was this translation helpful? Give feedback.
-
|
Remote storage support for multiple types eg: s3, Azure ADLS, GCS etc.... What I have seen is most of the projects rely on corresponding SDKs. This cause a serious HTTP bottleneck. Every request is going to establish TCP connection, DNS lookup and TLS hand shakes. An ideal thing is to re-use connection pool and use HTTP/2 multiplexing. |
Beta Was this translation helpful? Give feedback.
-
|
The caching/spilling algorithms should avoid reading from remote storage to some extent. |
Beta Was this translation helpful? Give feedback.
-
|
Is there any thought on supporting table formats like delta or iceberg while reading the parquet files? |
Beta Was this translation helpful? Give feedback.
-
|
Velox should not need any extra operators for reading from these file formats. For updates/deletes, there is some related discussion here: #2452 |
Beta Was this translation helpful? Give feedback.
-
|
What's purpose of |
Beta Was this translation helpful? Give feedback.
-
|
@yingsu00 what benchmark was done comparing the parquet/orc reader? Can we run it again? |
Beta Was this translation helpful? Give feedback.
-
Background
As of the beginning of 2022, Velox has been using DuckDB’s Parquet reader. Our benchmark shows it was 2x slower than the Velox DWRF reader, and on par with the Presto Java Parquet Reader. We hope the Velox Parquet reader can achieve significantly better performance over the Velox DWRF reader and Presto Java Parquet reader, therefore we’re starting the native Parquet reader project.
This document briefly talks about the design for the new Parquet reader. Our initial prototype showed >2x times improvement over the original implementation, and can be further optimized in the future.
Externals & Integration with Presto
Velox requires Filter Pushdown to be enabled. To enable filter pushdown for the native Velox Parquet reader from Presto, users will need to turn on these Presto config/session properties:
The filter push down option is passed to Velox from the TableScan plan node in the plan fragment. Currently Velox only supports the Hive connector. For Hive, the filter push down needs to be turned on.
Compatibility With The DuckDB Parquet Reader
We will keep the existing DuckDB Parquet Reader together with the new Parquet reader for a period of time, until the new reader is complete and stable. We will allow the users to choose to register the new native Parquet reader, or the existing DuckDB Parquet reader. The DuckDB Parquet reader was moved to velox/dwio/parquet/duckdb_reader. The new native reader was added velox/dwio/parquet/reader.
In order to parse the Parquet file metadata and PageHeader, we need the Thrift definition of such structures. Since Velox has dependency on Arrow already, and Arrow Thrift is not compatible with FB Thrift, we would build the Parquet Reader on the Arrow Thrift. The generated Thrift header and cpp files were put in a separate folder at velox/dwio/parquet/thrift. There was also a side issue we needed to solve. The DuckDB/Velox integration copied the whole thrift library headers in velox/external/duckdb/parquet-amalgamation.hpp/cpp, but they were put under namespace “duckdb_apache::thrift” while the include guards were still the original:
and they would shadow the Arrow Thrift headers. We updated the include guards name to include “DUCKDB” in the DuckDB repo.
After porting the updated DuckDB code we are now able to compile with both readers present.
Design
The DuckDB Parquet reader supports Parquet V1 currently. This includes the following 3 encodings:
While we are going to support V2 in the near future, which supports more SIMD friendly encodings, we will now focus on V1 implementations and optimizations. Many of these optimizations apply to V2 implementations as well.
We will try to achieve balance between the performance and complexity of the improvements. There are some special cases where better performance can be achieved by addressing and optimizing them separately, e.g. aggregations that produce a small number of groups, special handling of filters, etc. Right now we want to focus on universally important major changes and leave many such optimizations as possible options for the future. The new Parquet reader will try to reuse the common components of the current DWRF reader and decoders, with necessary interface generalizations and simplifications.
In this section we will describe the design of the new Parquet reader.
Introduction To Parquet
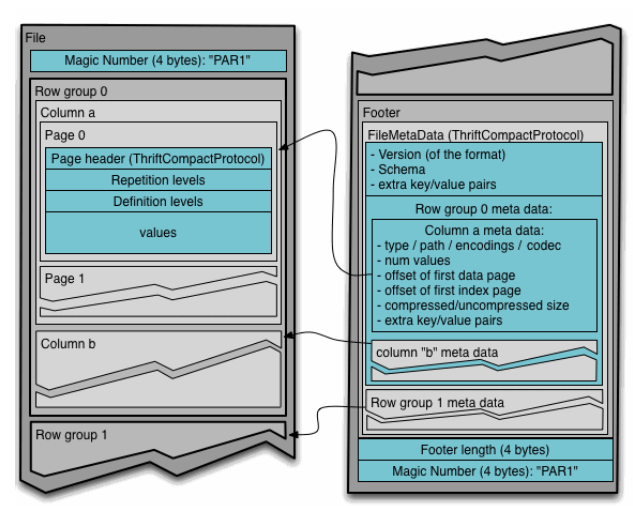
The Parquet file is organized as the following picture. A Parquet file may contain 1 or more row groups, which is analogous to “stripe” in ORC and DWRF. Each row group contains 1 or more column chunks, one for each column. Within each column chunk, the data could be stored in 1 or more dictionary and data pages. If the column chunk is dictionary encoded, the dictionary would be stored in a dictionary page per column chunk. The values are stored as integers using the RLE/Bit-Packing Hybrid encoding.
When writing a Parquet file, most implementations will use dictionary encoding to compress a column until the dictionary itself reaches a certain size threshold, usually around 1 megabyte. At this point, the column writer will “fall back” to PLAIN encoding where values are written end-to-end in “data pages” and then usually compressed with Snappy or Gzip. See the following rough diagram:

The Parquet file footer contains the FileMetadata, which would be to the following components:
We can explain the components a little bit here:
This is a serialized representation of the depth first traversal of table schema. Parquet uses extra levels for nested structures like Array and Map. An Array is represented as a LIST of repeating elements, and a map as a repeating group of Key-Value pairs. For example, a table of
ROW(BIGINT c0, MAP(VARCHR, ARRAY(INTEGER) c1) cis represented by the following tree structure.We can see that the “hive_schema”, “ key_value” and “bag” are the extra nodes Parquet adds.
Unlike ORC or DWRF, a Parquet file only contains data for the leaf columns. In the above example, there are only 3 columns in the file and they are:
The nested structure is identified through “repetition levels”, and null information is identified through “definition levels” in each data page header. To understand them you can read https://akshays-blog.medium.com/wrapping-head-around-repetition-and-definition-levels-in-dremel-powering-bigquery-c1a33c9695da
Reader Structures
The new native Parquet reader will follow the DWRF Reader structure. The high level classes include
As described in Generalize the reader and input interfaces #1533 we moved the common SelectiveColumnReaders to
dwio::common, and make the Parquet ColumnReaders inheriting from themThe PageReader is responsible for reading the Page headers, decoding the repetition levels, definition levels, and calling the visitors to read the data.
FIlter Pushdown
The pre-existing DWRF Readers and SelectiveColumnReaders support filter push down. The data that did not pass the filters in previous columns can be skipped for the current column, therefore saving the decoding costs. The native Parquet reader will get the benefits of data skipping by default, since it inherits from these SelectiveColumnReader classes.
For each split, the process can be described as the following pseudocode:
The ColumnReader’s
read()function currently calls common pre-existingColumnVisitor::readWithVisitor()code originally from DWRF. ThereadWithVisitor()would call into the underlying decoder’sreadWithVisitor()to process the data.Plain Data
For Parquet’s plain encoding, the reader just uses the existing DirectDecoder.
Dictionary Encoded Data
In Parquet, dictionary Id’s are encoded as Rle/BitPack runs. The decoding process will be done in RleBpDecoder, which will be using the fast bit unpacking lib: [Design] Fast C++ Bit Unpacking #2353
Velox supports 2 modes of read operations:
For example, in the
DirectDecoder::readWithVisitor(), we can see the fastpath would be run if certain conditions are met. This mode would read and decode the values in batch. In the skipping mode, a single value is read and decoded each time. The batch mode would be faster if the rows being read are dense.The Parquet reader, while using the
readWithVisitor()function now, also supports these two modes. However we will do more experiments to optimize them in the near future.Reading & Caching
Because reading from remote storage is expensive, we will try to minimize the time of this round trip. Similar to DWRF, the file size will be taken into account when issuing a read request. If the file size is smaller than a threshold (currently set as 8MB), the file will be read once and the content will be kept in memory for later processing.
Parsing Parquet file metadata and PageHeader is done by the generated Thrift code. There are multiple choices for how the data is provided through the ThriftTransport interface. The DuckDB Parquet reader uses ThriftFileTransport, which issues every read through a file read system call which is quite expensive. In the new implementation we would create a ThriftBufferedTransport, which takes a buffer that was preloaded before.
Velox already implemented a set of
BufferedInputandSeekableInputStreams. TheSeekableInputStreaminheritsgoogle::protobuf::io::ZeroCopyInputStreamand can be used to avoid memory copy when possible. TheCachedBufferedInputsupports asynchronous caching and read-ahead. The Parquet reader uses it when reading the real data. When we are opening a Parquet RowGroup, the next RowGroup will be scheduled to be loaded beforehand.Further Optimizations
Optimizing loops
The current decoder implementation has very long and complex code. To make it easier to read, maintain, and run even faster, I will try:
Filter Push Down On Encoded Data
We will push down the filter to the encoded data in future optimizations.
Rle/Bp Encoding
These are all unsigned integers of various output widths, and are used in dictionary ids, rep/def levels. We will make the RleBpDecoder and the BitUnpacking lib support the following functionalities in the near future:
The algorithms will use AVX2 and BMI2 intrinsics. To apply the filter, we will convert the Velox TupleDomainFilter to a packed filter to use SIMD comparisons.
Dictionary Encoding
When the dictionary is small, running the filters on the dictionary itself might be faster than running them on the values mapped by the decoded ids. We will automatically choose to do that based on the dictionary size and/or other heuristics.
Delta Encodings
We can also push down the filter to the delta encoded data. We can implement limited skipping and filtering capabilities. The algorithms will be explained later.
Use Dictionaries In Aggregation Pushdown
Parquet promotes dictionary encoding whenever possible. If these columns are grouping columns, we can avoid building the hash table or at least avoid the expensive hash value calculations in hash aggregation. Note that the dictionaries in different RowGroups might be different. But it’s possible to merge the dictionaries and remapping the dictionary ids. The Parquet spec says the dictionary shall be in dictionary order and use plain encoding. If that’s the case we can find the new dictionary values for the next RowGroup in linear time to the size of the dictionary.
Other Ideas
Try using bitmask and/or array of integers for the row numbers
Before the filters are run, or the query doesn’t have filters, it might be more memory efficient and faster to use bitmasks to identify the row numbers. The bitmasks can be converted to an array of integers when the rows become very sparse. This may accelerate the batch mode in some cases. Array of integers may be easier when the rows are sparse, and we can use them directly in the gather intrinsics. The code shall do automatic conversion when it sees the opportunity to optimize.
Optimize getValues()
Avoid copying and packing the values twice.
Optimize IO
Avoid memory copy for the file footer when it’s possible.
There may be new emerging ideas during the work. We will add more when the time comes.
Beta Was this translation helpful? Give feedback.
All reactions