diff --git a/.github/workflows/doc_test_on_pr.yml b/.github/workflows/doc_test_on_pr.yml
index 8afc46b87aa2..27f7e76af4fe 100644
--- a/.github/workflows/doc_test_on_pr.yml
+++ b/.github/workflows/doc_test_on_pr.yml
@@ -56,7 +56,7 @@ jobs:
needs: detect-changed-doc
runs-on: [self-hosted, gpu]
container:
- image: hpcaitech/pytorch-cuda:2.0.0-11.7.0
+ image: hpcaitech/pytorch-cuda:2.1.0-12.1.0
options: --gpus all --rm
timeout-minutes: 20
defaults:
diff --git a/.github/workflows/release_docker_after_publish.yml b/.github/workflows/release_docker_after_publish.yml
index 6c8df9730b0d..0792544bf403 100644
--- a/.github/workflows/release_docker_after_publish.yml
+++ b/.github/workflows/release_docker_after_publish.yml
@@ -24,7 +24,7 @@ jobs:
version=$(cat version.txt)
tag=hpcaitech/colossalai:$version
latest=hpcaitech/colossalai:latest
- docker build --build-arg http_proxy=http://172.17.0.1:7890 --build-arg https_proxy=http://172.17.0.1:7890 --build-arg VERSION=v${version} -t $tag ./docker
+ docker build --build-arg VERSION=v${version} -t $tag ./docker
docker tag $tag $latest
echo "tag=${tag}" >> $GITHUB_OUTPUT
echo "latest=${latest}" >> $GITHUB_OUTPUT
diff --git a/LICENSE b/LICENSE
index 47197afe6644..f0b2ffa97953 100644
--- a/LICENSE
+++ b/LICENSE
@@ -552,3 +552,18 @@ Copyright 2021- HPC-AI Technology Inc. All rights reserved.
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
+ ---------------- LICENSE FOR Hugging Face accelerate ----------------
+
+ Copyright 2021 The HuggingFace Team
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
index c1e2da0d406f..9e215df63196 100644
--- a/README.md
+++ b/README.md
@@ -25,6 +25,8 @@
## Latest News
+* [2024/04] [Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
+* [2024/04] [Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series](https://hpc-ai.com/blog/most-cost-effective-solutions-for-inference-fine-tuning-and-pretraining-tailored-to-llama3-series)
* [2024/03] [314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here](https://hpc-ai.com/blog/314-billion-parameter-grok-1-inference-accelerated-by-3.8x-efficient-and-easy-to-use-pytorchhuggingface-version-is-here)
* [2024/03] [Open-Sora: Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models](https://hpc-ai.com/blog/open-sora-v1.0)
* [2024/03] [Open-Sora:Sora Replication Solution with 46% Cost Reduction, Sequence Expansion to Nearly a Million](https://hpc-ai.com/blog/open-sora)
@@ -131,7 +133,7 @@ distributed training and inference in a few lines.
[Open-Sora](https://github.com/hpcaitech/Open-Sora):Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models
[[code]](https://github.com/hpcaitech/Open-Sora)
-[[blog]](https://hpc-ai.com/blog/open-sora-v1.0)
+[[blog]](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
[[HuggingFace model weights]](https://huggingface.co/hpcai-tech/Open-Sora)
[[Demo]](https://github.com/hpcaitech/Open-Sora?tab=readme-ov-file#-latest-demo)
diff --git a/applications/Colossal-LLaMA/colossal_llama/dataset/loader.py b/applications/Colossal-LLaMA/colossal_llama/dataset/loader.py
index 327651f4e645..abe0fd51a4af 100644
--- a/applications/Colossal-LLaMA/colossal_llama/dataset/loader.py
+++ b/applications/Colossal-LLaMA/colossal_llama/dataset/loader.py
@@ -80,15 +80,19 @@ def __call__(self, instances: Sequence[Dict[str, List[int]]]) -> Dict[str, torch
# `List[torch.Tensor]`
batch_input_ids = [
- torch.LongTensor(instance["input_ids"][: self.max_length])
- if len(instance["input_ids"]) > self.max_length
- else torch.LongTensor(instance["input_ids"])
+ (
+ torch.LongTensor(instance["input_ids"][: self.max_length])
+ if len(instance["input_ids"]) > self.max_length
+ else torch.LongTensor(instance["input_ids"])
+ )
for instance in instances
]
batch_labels = [
- torch.LongTensor(instance["labels"][: self.max_length])
- if len(instance["labels"]) > self.max_length
- else torch.LongTensor(instance["labels"])
+ (
+ torch.LongTensor(instance["labels"][: self.max_length])
+ if len(instance["labels"]) > self.max_length
+ else torch.LongTensor(instance["labels"])
+ )
for instance in instances
]
diff --git a/applications/Colossal-LLaMA/train.py b/applications/Colossal-LLaMA/train.py
index dcd7be9f4e4c..43a360a9a49c 100644
--- a/applications/Colossal-LLaMA/train.py
+++ b/applications/Colossal-LLaMA/train.py
@@ -136,7 +136,7 @@ def main() -> None:
# ==============================
# Initialize Distributed Training
# ==============================
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
accelerator = get_accelerator()
coordinator = DistCoordinator()
@@ -253,9 +253,11 @@ def main() -> None:
coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
optimizer = HybridAdam(
- model_params=filter(lambda p: p.requires_grad, model.parameters())
- if args.freeze_non_embeds_params
- else model.parameters(),
+ model_params=(
+ filter(lambda p: p.requires_grad, model.parameters())
+ if args.freeze_non_embeds_params
+ else model.parameters()
+ ),
lr=args.lr,
betas=(0.9, 0.95),
weight_decay=args.weight_decay,
diff --git a/applications/ColossalChat/benchmarks/benchmark_ppo.py b/applications/ColossalChat/benchmarks/benchmark_ppo.py
index e1b7a313f981..00edf053410f 100644
--- a/applications/ColossalChat/benchmarks/benchmark_ppo.py
+++ b/applications/ColossalChat/benchmarks/benchmark_ppo.py
@@ -66,7 +66,7 @@ def benchmark_train(args):
# ==============================
# Initialize Distributed Training
# ==============================
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# ======================================================
diff --git a/applications/ColossalChat/examples/training_scripts/train_dpo.py b/applications/ColossalChat/examples/training_scripts/train_dpo.py
index b9287eb1a407..f06c23a9f704 100755
--- a/applications/ColossalChat/examples/training_scripts/train_dpo.py
+++ b/applications/ColossalChat/examples/training_scripts/train_dpo.py
@@ -37,7 +37,7 @@ def train(args):
# ==============================
# Initialize Distributed Training
# ==============================
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# ==============================
diff --git a/applications/ColossalChat/examples/training_scripts/train_ppo.py b/applications/ColossalChat/examples/training_scripts/train_ppo.py
index 7c91fa347847..727cff7ca564 100755
--- a/applications/ColossalChat/examples/training_scripts/train_ppo.py
+++ b/applications/ColossalChat/examples/training_scripts/train_ppo.py
@@ -39,7 +39,7 @@ def train(args):
# ==============================
# Initialize Distributed Training
# ==============================
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# ======================================================
diff --git a/applications/ColossalChat/examples/training_scripts/train_rm.py b/applications/ColossalChat/examples/training_scripts/train_rm.py
index a0c710f2bb7f..364198c1d78b 100755
--- a/applications/ColossalChat/examples/training_scripts/train_rm.py
+++ b/applications/ColossalChat/examples/training_scripts/train_rm.py
@@ -34,7 +34,7 @@ def train(args):
# ==============================
# Initialize Distributed Training
# ==============================
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# ======================================================
diff --git a/applications/ColossalChat/examples/training_scripts/train_sft.py b/applications/ColossalChat/examples/training_scripts/train_sft.py
index fcd1a429cc5f..ae20f2abcb5f 100755
--- a/applications/ColossalChat/examples/training_scripts/train_sft.py
+++ b/applications/ColossalChat/examples/training_scripts/train_sft.py
@@ -29,7 +29,7 @@ def train(args):
# ==============================
# Initialize Distributed Training
# ==============================
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# ==============================
diff --git a/applications/ColossalEval/examples/dataset_evaluation/inference.py b/applications/ColossalEval/examples/dataset_evaluation/inference.py
index 13bbb12b6990..a7307635d333 100644
--- a/applications/ColossalEval/examples/dataset_evaluation/inference.py
+++ b/applications/ColossalEval/examples/dataset_evaluation/inference.py
@@ -81,7 +81,7 @@ def rm_and_merge(
def main(args):
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
accelerator = get_accelerator()
world_size = dist.get_world_size()
diff --git a/applications/ColossalEval/examples/gpt_evaluation/inference.py b/applications/ColossalEval/examples/gpt_evaluation/inference.py
index 5b09f9de8da6..408ba3e7b084 100644
--- a/applications/ColossalEval/examples/gpt_evaluation/inference.py
+++ b/applications/ColossalEval/examples/gpt_evaluation/inference.py
@@ -81,7 +81,7 @@ def rm_and_merge(
def main(args):
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
world_size = dist.get_world_size()
rank = dist.get_rank()
diff --git a/applications/ColossalMoE/infer.py b/applications/ColossalMoE/infer.py
index c175fe9e3f3f..543c434d2a99 100644
--- a/applications/ColossalMoE/infer.py
+++ b/applications/ColossalMoE/infer.py
@@ -57,7 +57,7 @@ def main():
args = parse_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
config = MixtralConfig.from_pretrained(args.model_name)
@@ -96,7 +96,11 @@ def main():
if coordinator.rank == 0:
text = ["Hello my name is"]
else:
- text = ["What's the largest country in the world?", "How many people live in China?", "帮我续写这首诗:离离原上草"]
+ text = [
+ "What's the largest country in the world?",
+ "How many people live in China?",
+ "帮我续写这首诗:离离原上草",
+ ]
tokenizer.pad_token = tokenizer.unk_token
inputs = tokenizer(text, return_tensors="pt", padding=True).to(torch.cuda.current_device())
diff --git a/applications/ColossalMoE/tests/test_mixtral_layer.py b/applications/ColossalMoE/tests/test_mixtral_layer.py
index 57589ab20d22..cbb70f195258 100644
--- a/applications/ColossalMoE/tests/test_mixtral_layer.py
+++ b/applications/ColossalMoE/tests/test_mixtral_layer.py
@@ -50,7 +50,7 @@ def check_mixtral_moe_layer():
def run_dist(rank: int, world_size: int, port: int):
- colossalai.launch({}, rank, world_size, "localhost", port)
+ colossalai.launch(rank, world_size, "localhost", port)
check_mixtral_moe_layer()
diff --git a/applications/ColossalMoE/tests/test_moe_checkpoint.py b/applications/ColossalMoE/tests/test_moe_checkpoint.py
index 822e7410f016..074dbf835fa6 100644
--- a/applications/ColossalMoE/tests/test_moe_checkpoint.py
+++ b/applications/ColossalMoE/tests/test_moe_checkpoint.py
@@ -133,7 +133,7 @@ def check_mixtral_moe_layer():
def run_dist(rank: int, world_size: int, port: int):
- colossalai.launch({}, rank, world_size, "localhost", port)
+ colossalai.launch(rank, world_size, "localhost", port)
check_mixtral_moe_layer()
diff --git a/applications/ColossalMoE/train.py b/applications/ColossalMoE/train.py
index 850236726a27..d2789d644ca5 100644
--- a/applications/ColossalMoE/train.py
+++ b/applications/ColossalMoE/train.py
@@ -145,7 +145,7 @@ def main():
args = parse_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
# Set plugin
@@ -195,9 +195,9 @@ def main():
lr_scheduler = CosineAnnealingWarmupLR(
optimizer=optimizer,
total_steps=args.num_epochs * len(dataloader),
- warmup_steps=args.warmup_steps
- if args.warmup_steps is not None
- else int(args.num_epochs * len(dataloader) * 0.025),
+ warmup_steps=(
+ args.warmup_steps if args.warmup_steps is not None else int(args.num_epochs * len(dataloader) * 0.025)
+ ),
eta_min=0.1 * args.lr,
)
diff --git a/colossalai/auto_parallel/offload/amp_optimizer.py b/colossalai/auto_parallel/offload/amp_optimizer.py
index fe8439269f48..ab02de7ce109 100644
--- a/colossalai/auto_parallel/offload/amp_optimizer.py
+++ b/colossalai/auto_parallel/offload/amp_optimizer.py
@@ -126,7 +126,7 @@ def loss_scale(self):
return self.grad_scaler.scale.item()
def zero_grad(self, *args, **kwargs):
- self.module.overflow_counter = torch.cuda.IntTensor([0])
+ self.module.overflow_counter = torch.tensor([0], dtype=torch.int, device=get_accelerator().get_current_device())
return self.optim.zero_grad(set_to_none=True)
def step(self, *args, **kwargs):
diff --git a/colossalai/auto_parallel/offload/base_offload_module.py b/colossalai/auto_parallel/offload/base_offload_module.py
index 60de7743a52e..8afd29e436d7 100644
--- a/colossalai/auto_parallel/offload/base_offload_module.py
+++ b/colossalai/auto_parallel/offload/base_offload_module.py
@@ -4,7 +4,7 @@
import torch
import torch.nn as nn
-from colossalai.utils import _cast_float
+from colossalai.utils import _cast_float, get_current_device
from colossalai.utils.common import free_storage
from .region_manager import RegionManager
@@ -25,7 +25,7 @@ def __init__(self, model: nn.Module, region_manager: RegionManager, is_sync=True
self.model = model
self.region_manager = region_manager
self.grad_hook_list = []
- self.overflow_counter = torch.cuda.IntTensor([0])
+ self.overflow_counter = torch.tensor([0], dtype=torch.int, device=get_current_device())
self.grad_offload_stream = torch.cuda.current_stream() if is_sync else GlobalRuntimeInfo.d2h_stream
diff --git a/colossalai/booster/booster.py b/colossalai/booster/booster.py
index d73bc5babd80..56d8a0935f10 100644
--- a/colossalai/booster/booster.py
+++ b/colossalai/booster/booster.py
@@ -8,9 +8,18 @@
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
from torch.utils.data import DataLoader
+SUPPORT_PEFT = False
+try:
+ import peft
+
+ SUPPORT_PEFT = True
+except ImportError:
+ pass
+
import colossalai.interface.pretrained as pretrained_utils
from colossalai.checkpoint_io import GeneralCheckpointIO
from colossalai.interface import ModelWrapper, OptimizerWrapper
+from colossalai.quantization import BnbQuantizationConfig
from .accelerator import Accelerator
from .mixed_precision import MixedPrecision, mixed_precision_factory
@@ -221,6 +230,56 @@ def no_sync(self, model: nn.Module = None, optimizer: OptimizerWrapper = None) -
assert self.plugin.support_no_sync(), f"The plugin {self.plugin.__class__.__name__} does not support no_sync."
return self.plugin.no_sync(model, optimizer)
+ def enable_lora(
+ self,
+ model: nn.Module,
+ pretrained_dir: Optional[str] = None,
+ lora_config: "peft.LoraConfig" = None,
+ bnb_quantization_config: Optional[BnbQuantizationConfig] = None,
+ quantize=False,
+ ) -> nn.Module:
+ """
+ Wrap the passed in model with LoRA modules for training. If pretrained directory is provided, lora configs and weights are loaded from that directory.
+ Lora in ColossalAI is implemented using Huggingface peft library, so the arguments for Lora configuration are same as those of peft.
+
+ Args:
+ model (nn.Module): The model to be appended with LoRA modules.
+ pretrained_dir(str, optional): The path to the pretrained directory, can be a local directory
+ or model_id of a PEFT configuration hosted inside a model repo on the Hugging Face Hub.
+ When set to None, create new lora configs and weights for the model using the passed in lora_config. Defaults to None.
+ lora_config: (peft.LoraConfig, optional): Passed in LoraConfig for peft. Defaults to None.
+ """
+ if not SUPPORT_PEFT:
+ raise ImportError("Please install Huggingface Peft library to enable lora features in ColossalAI!")
+
+ assert self.plugin is not None, f"Lora can only be enabled when a plugin is provided."
+ assert self.plugin.support_lora(), f"The plugin {self.plugin.__class__.__name__} does not support lora."
+ if pretrained_dir is None:
+ assert (
+ lora_config is not None
+ ), "Please provide configuration for Lora when pretrained directory path isn't passed in."
+ assert isinstance(
+ lora_config, peft.LoraConfig
+ ), "The passed in configuration should be an instance of peft.LoraConfig."
+ if lora_config is None:
+ assert (
+ pretrained_dir is not None
+ ), "Please provide pretrained directory path if not passing in lora configuration."
+ if quantize is True:
+ if bnb_quantization_config is not None:
+ warnings.warn(
+ "User defined BnbQuantizationConfig is not fully tested in ColossalAI. Use it at your own risk."
+ )
+ else:
+ bnb_quantization_config = BnbQuantizationConfig(
+ load_in_4bit=True,
+ bnb_4bit_compute_dtype=torch.bfloat16,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type="nf4",
+ )
+
+ return self.plugin.enable_lora(model, pretrained_dir, lora_config, bnb_quantization_config)
+
def load_model(self, model: Union[nn.Module, ModelWrapper], checkpoint: str, strict: bool = True) -> None:
"""Load model from checkpoint.
@@ -323,3 +382,20 @@ def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str) -> None:
checkpoint (str): Path to the checkpoint. It must be a local file path.
"""
self.checkpoint_io.load_lr_scheduler(lr_scheduler, checkpoint)
+
+ def save_lora_as_pretrained(
+ self, model: Union[nn.Module, ModelWrapper], checkpoint: str, use_safetensors: bool = False
+ ) -> None:
+ """
+ Save the lora adapters and adapter configuration file to a pretrained checkpoint directory.
+
+ Args:
+ model (Union[nn.Module, ModelWrapper]): A model boosted by Booster.
+ checkpoint (str): Path to the checkpoint directory. It must be a local path.
+ use_safetensors (bool, optional): Whether to use safe tensors when saving. Defaults to False.
+ """
+ if not SUPPORT_PEFT:
+ raise ImportError("Please install Huggingface Peft library to enable lora features in ColossalAI!")
+ assert self.plugin is not None, f"Lora can only be enabled when a plugin is provided."
+ assert self.plugin.support_lora(), f"The plugin {self.plugin.__class__.__name__} does not support lora."
+ self.checkpoint_io.save_lora_as_pretrained(model, checkpoint, use_safetensors)
diff --git a/colossalai/booster/plugin/gemini_plugin.py b/colossalai/booster/plugin/gemini_plugin.py
index a4861c1b6f35..d67fa3a24070 100644
--- a/colossalai/booster/plugin/gemini_plugin.py
+++ b/colossalai/booster/plugin/gemini_plugin.py
@@ -4,7 +4,7 @@
import random
from pathlib import Path
from types import MethodType
-from typing import Callable, Iterator, List, Optional, Tuple
+from typing import Callable, Dict, Iterator, List, Optional, Tuple
import numpy as np
import torch
@@ -446,6 +446,9 @@ def __del__(self):
def support_no_sync(self) -> bool:
return False
+ def support_lora(self) -> bool:
+ return False
+
def control_precision(self) -> bool:
return True
@@ -576,3 +579,8 @@ def get_checkpoint_io(self) -> CheckpointIO:
def no_sync(self, model: nn.Module, optimizer: OptimizerWrapper) -> Iterator[None]:
raise NotImplementedError
+
+ def enable_lora(
+ self, model: nn.Module, pretrained_dir: Optional[str] = None, lora_config: Optional[Dict] = None
+ ) -> nn.Module:
+ raise NotImplementedError
diff --git a/colossalai/booster/plugin/hybrid_parallel_plugin.py b/colossalai/booster/plugin/hybrid_parallel_plugin.py
index 5237734f0212..97057481e380 100644
--- a/colossalai/booster/plugin/hybrid_parallel_plugin.py
+++ b/colossalai/booster/plugin/hybrid_parallel_plugin.py
@@ -4,7 +4,7 @@
from contextlib import contextmanager
from functools import partial
from types import MethodType
-from typing import Any, Callable, Iterator, List, Optional, OrderedDict, Tuple, Union
+from typing import Any, Callable, Dict, Iterator, List, Optional, OrderedDict, Tuple, Union
import numpy as np
import torch
@@ -1156,6 +1156,9 @@ def control_precision(self) -> bool:
def support_no_sync(self) -> bool:
return True
+ def support_lora(self) -> bool:
+ return False
+
def control_checkpoint_io(self) -> bool:
return True
@@ -1356,3 +1359,8 @@ def no_sync(self, model: Module, optimizer: OptimizerWrapper) -> Iterator[None]:
self.zero_stage != 2
), "ZERO2 is not compatible with no_sync function, please run gradient accumulation with gradient synchronization allowed."
return optimizer.no_sync() if isinstance(optimizer, HybridParallelZeroOptimizer) else model.no_sync()
+
+ def enable_lora(
+ self, model: Module, pretrained_dir: Optional[str] = None, lora_config: Optional[Dict] = None
+ ) -> Module:
+ raise NotImplementedError
diff --git a/colossalai/booster/plugin/low_level_zero_plugin.py b/colossalai/booster/plugin/low_level_zero_plugin.py
index 650cedf65a52..68127db5b121 100644
--- a/colossalai/booster/plugin/low_level_zero_plugin.py
+++ b/colossalai/booster/plugin/low_level_zero_plugin.py
@@ -1,12 +1,15 @@
+import enum
import logging
import os
+import warnings
from functools import partial
from pathlib import Path
from types import MethodType
-from typing import Callable, Iterator, List, Optional, Tuple
+from typing import Callable, Dict, Iterator, List, Optional, Tuple
import torch
import torch.nn as nn
+from torch.nn import Parameter
from torch.optim import Optimizer
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
from torch.utils._pytree import tree_map
@@ -25,6 +28,7 @@
sharded_optimizer_loading_epilogue,
)
from colossalai.interface import AMPModelMixin, ModelWrapper, OptimizerWrapper
+from colossalai.quantization import BnbQuantizationConfig, quantize_model
from colossalai.zero import LowLevelZeroOptimizer
from .dp_plugin_base import DPPluginBase
@@ -42,6 +46,12 @@ def _convert_floating_point(x, dtype: torch.dtype = torch.float16):
SUPPORTED_PRECISION = ["fp16", "bf16", "fp32"]
+class OptimizerParamCheckState(enum.Enum):
+ ORIGIN_PARAM_FINDED = 0
+ ORIGIN_PARAM_NOT_FIND = -1
+ LORA_PARM_EXISTED = -2
+
+
class LowLevelZeroModel(ModelWrapper, AMPModelMixin):
def __init__(self, module: nn.Module, precision: str) -> None:
super().__init__(module)
@@ -209,6 +219,19 @@ def load_sharded_model(
super().load_sharded_model(model, checkpoint_index_file, strict, use_safetensors, load_sub_module)
model.update_master_params()
+ def save_lora_as_pretrained(self, model, checkpoint, use_safetensors):
+ if os.path.isfile(checkpoint):
+ logging.error(f"Provided path ({checkpoint}) should be a directory, not a file")
+ return
+ from peft import PeftModel
+
+ assert isinstance(model, ModelWrapper), "Please boost the model before saving!"
+ peft_model = model.unwrap()
+ assert isinstance(
+ peft_model, PeftModel
+ ), "The model doesn't have lora adapters, please enable lora before saving."
+ return peft_model.save_pretrained(checkpoint, safe_serialization=use_safetensors)
+
class LowLevelZeroPlugin(DPPluginBase):
"""
@@ -288,6 +311,7 @@ def __init__(
cpu_offload=cpu_offload,
master_weights=master_weights,
)
+ self.lora_enabled = False
self.verbose = verbose
# set class name with stage, for better error message
@@ -299,6 +323,9 @@ def __del__(self):
def support_no_sync(self) -> bool:
return self.stage == 1
+ def support_lora(self) -> bool:
+ return False
+
def control_precision(self) -> bool:
return True
@@ -311,6 +338,79 @@ def control_device(self) -> bool:
def supported_devices(self) -> List[str]:
return ["cuda", "npu"]
+ def support_lora(self) -> bool:
+ return True
+
+ def enable_lora(
+ self,
+ model: nn.Module,
+ pretrained_dir: Optional[str] = None,
+ lora_config: Optional[Dict] = None,
+ bnb_quantization_config: Optional[BnbQuantizationConfig] = None,
+ ) -> nn.Module:
+ from peft import PeftModel, get_peft_model
+
+ assert not isinstance(model, LowLevelZeroModel), "Lora should be enabled before boosting the model."
+ self.lora_enabled = True
+ warnings.warn("You have enabled LoRa training. Please check the hyperparameters such as lr")
+
+ if bnb_quantization_config is not None:
+ model = quantize_model(model, bnb_quantization_config)
+
+ if pretrained_dir is None:
+ peft_model = get_peft_model(model, lora_config)
+ else:
+ peft_model = PeftModel.from_pretrained(model, pretrained_dir, is_trainable=True)
+ return peft_model
+
+ def get_param_group_id(self, optimizer: Optimizer, origin_param: Parameter):
+ origin_param_id = id(origin_param)
+ for group_id, param_group in enumerate(optimizer.param_groups):
+ for p in param_group["params"]:
+ if id(p) == origin_param_id:
+ return group_id
+ return -1
+
+ def get_param_group_id(self, optimizer: Optimizer, origin_param: Parameter, lora_param: Parameter):
+ origin_param_id = id(origin_param)
+ lora_param_id = id(lora_param)
+ target_group_id = None
+ for group_id, param_group in enumerate(optimizer.param_groups):
+ for p in param_group["params"]:
+ if id(p) == lora_param_id:
+ # check if the lora parameter exists.
+ return target_group_id, OptimizerParamCheckState.LORA_PARM_EXISTED
+ if id(p) == origin_param_id:
+ target_group_id = group_id
+ if target_group_id is not None:
+ return target_group_id, OptimizerParamCheckState.ORIGIN_PARAM_FINDED
+ else:
+ return target_group_id, OptimizerParamCheckState.ORIGIN_PARAM_NOT_FIND
+
+ def add_lora_params_to_optimizer(self, model, optimizer):
+ """add lora parameters to optimizer"""
+ name2param = {}
+ for name, param in model.named_parameters():
+ name2param[name] = param
+
+ for name, param in name2param.items():
+ if "lora_A" in name or "lora_B" in name:
+ origin_key = name.replace("lora_A.", "")
+ origin_key = origin_key.replace("lora_B.", "")
+ origin_key = origin_key.replace(f"{model.active_adapter}", "base_layer")
+ origin_param = name2param[origin_key]
+ group_id, check_state = self.get_param_group_id(optimizer, origin_param, param)
+ if check_state == OptimizerParamCheckState.ORIGIN_PARAM_NOT_FIND:
+ warnings.warn(
+ "Origin parameter {origin_key} related to {name} doesn't exist in optimizer param_groups."
+ )
+ elif (
+ check_state == OptimizerParamCheckState.ORIGIN_PARAM_FINDED
+ and group_id is not None
+ and group_id >= 0
+ ):
+ optimizer.param_groups[group_id]["params"].append(param)
+
def configure(
self,
model: nn.Module,
@@ -319,6 +419,15 @@ def configure(
dataloader: Optional[DataLoader] = None,
lr_scheduler: Optional[LRScheduler] = None,
) -> Tuple[nn.Module, OptimizerWrapper, Callable, DataLoader, LRScheduler]:
+ if self.lora_enabled:
+ from peft import PeftModel
+
+ assert isinstance(
+ model, PeftModel
+ ), "The model should have been wrapped as a PeftModel when self.lora_enabled is True"
+ if optimizer is not None:
+ self.add_lora_params_to_optimizer(model, optimizer)
+
if not isinstance(model, ModelWrapper):
model = LowLevelZeroModel(model, self.precision)
diff --git a/colossalai/booster/plugin/plugin_base.py b/colossalai/booster/plugin/plugin_base.py
index 4e570cbe8abc..6dc0c560d06d 100644
--- a/colossalai/booster/plugin/plugin_base.py
+++ b/colossalai/booster/plugin/plugin_base.py
@@ -1,5 +1,5 @@
from abc import ABC, abstractmethod
-from typing import Callable, Iterator, List, Optional, Tuple
+from typing import Callable, Dict, Iterator, List, Optional, Tuple
import torch.nn as nn
from torch.optim import Optimizer
@@ -33,6 +33,10 @@ def control_device(self) -> bool:
def support_no_sync(self) -> bool:
pass
+ @abstractmethod
+ def support_lora(self) -> bool:
+ pass
+
@abstractmethod
def configure(
self,
@@ -63,6 +67,12 @@ def no_sync(self, model: nn.Module, optimizer: OptimizerWrapper) -> Iterator[Non
Context manager to disable gradient synchronization.
"""
+ @abstractmethod
+ def enable_lora(self, model: nn.Module, pretrained_dir: str, lora_config: Dict) -> nn.Module:
+ """
+ Add LoRA modules to the model passed in. Should only be called in booster.enable_lora().
+ """
+
@abstractmethod
def prepare_dataloader(
self,
diff --git a/colossalai/booster/plugin/torch_ddp_plugin.py b/colossalai/booster/plugin/torch_ddp_plugin.py
index 738634473dbc..5116446a4295 100644
--- a/colossalai/booster/plugin/torch_ddp_plugin.py
+++ b/colossalai/booster/plugin/torch_ddp_plugin.py
@@ -1,4 +1,4 @@
-from typing import Callable, Iterator, List, Optional, Tuple
+from typing import Callable, Dict, Iterator, List, Optional, Tuple, Union
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as DDP
@@ -9,6 +9,8 @@
from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
from colossalai.cluster import DistCoordinator
from colossalai.interface import ModelWrapper, OptimizerWrapper
+from colossalai.quantization import BnbQuantizationConfig, quantize_model
+from colossalai.utils import get_current_device
from .dp_plugin_base import DPPluginBase
@@ -116,6 +118,22 @@ def load_sharded_optimizer(
assert isinstance(optimizer, OptimizerWrapper), "Please boost the optimizer before loading!"
super().load_sharded_optimizer(optimizer.unwrap(), index_file_path, prefix)
+ def save_lora_as_pretrained(
+ self, model: Union[nn.Module, ModelWrapper], checkpoint: str, use_safetensors: bool = False
+ ) -> None:
+ """
+ Save the lora adapters and adapter configuration file to checkpoint directory.
+ """
+ from peft import PeftModel
+
+ assert isinstance(model, ModelWrapper), "Please boost the model before saving!"
+ if self.coordinator.is_master():
+ peft_model = model.unwrap()
+ assert isinstance(
+ peft_model, PeftModel
+ ), "The model doesn't have lora adapters, please enable lora before saving."
+ peft_model.save_pretrained(save_directory=checkpoint, safe_serialization=use_safetensors)
+
class TorchDDPModel(ModelWrapper):
def __init__(self, module: nn.Module, *args, **kwargs) -> None:
@@ -173,6 +191,9 @@ def __init__(
def support_no_sync(self) -> bool:
return True
+ def support_lora(self) -> bool:
+ return True
+
def control_precision(self) -> bool:
return False
@@ -183,7 +204,7 @@ def control_device(self) -> bool:
return True
def supported_devices(self) -> List[str]:
- return ["cuda"]
+ return ["cuda", "npu"]
def configure(
self,
@@ -194,7 +215,7 @@ def configure(
lr_scheduler: Optional[LRScheduler] = None,
) -> Tuple[nn.Module, OptimizerWrapper, Callable, DataLoader, LRScheduler]:
# cast model to cuda
- model = model.cuda()
+ model = model.to(get_current_device())
# convert model to sync bn
model = nn.SyncBatchNorm.convert_sync_batchnorm(model, None)
@@ -216,3 +237,21 @@ def get_checkpoint_io(self) -> CheckpointIO:
def no_sync(self, model: nn.Module, optimizer: OptimizerWrapper) -> Iterator[None]:
assert isinstance(model, TorchDDPModel), "Model is not boosted by TorchDDPPlugin."
return model.module.no_sync()
+
+ def enable_lora(
+ self,
+ model: nn.Module,
+ pretrained_dir: Optional[str] = None,
+ lora_config: Optional[Dict] = None,
+ bnb_quantization_config: Optional[BnbQuantizationConfig] = None,
+ ) -> nn.Module:
+ from peft import PeftModel, get_peft_model
+
+ if bnb_quantization_config is not None:
+ model = quantize_model(model, bnb_quantization_config)
+
+ assert not isinstance(model, TorchDDPModel), "Lora should be enabled before boosting the model."
+ if pretrained_dir is None:
+ return get_peft_model(model, lora_config)
+ else:
+ return PeftModel.from_pretrained(model, pretrained_dir, is_trainable=True)
diff --git a/colossalai/booster/plugin/torch_fsdp_plugin.py b/colossalai/booster/plugin/torch_fsdp_plugin.py
index 0aa0caa9aafe..cd2f9e84018a 100644
--- a/colossalai/booster/plugin/torch_fsdp_plugin.py
+++ b/colossalai/booster/plugin/torch_fsdp_plugin.py
@@ -2,7 +2,7 @@
import os
import warnings
from pathlib import Path
-from typing import Callable, Iterable, Iterator, List, Optional, Tuple
+from typing import Callable, Dict, Iterable, Iterator, List, Optional, Tuple
import torch
import torch.nn as nn
@@ -318,6 +318,9 @@ def __init__(
def support_no_sync(self) -> bool:
return False
+ def support_lora(self) -> bool:
+ return False
+
def no_sync(self, model: nn.Module, optimizer: OptimizerWrapper) -> Iterator[None]:
raise NotImplementedError("Torch fsdp no_sync func not supported yet.")
@@ -361,3 +364,8 @@ def control_checkpoint_io(self) -> bool:
def get_checkpoint_io(self) -> CheckpointIO:
return TorchFSDPCheckpointIO()
+
+ def enable_lora(
+ self, model: nn.Module, pretrained_dir: Optional[str] = None, lora_config: Optional[Dict] = None
+ ) -> nn.Module:
+ raise NotImplementedError
diff --git a/colossalai/checkpoint_io/checkpoint_io_base.py b/colossalai/checkpoint_io/checkpoint_io_base.py
index 71232421586d..949ba4d44e24 100644
--- a/colossalai/checkpoint_io/checkpoint_io_base.py
+++ b/colossalai/checkpoint_io/checkpoint_io_base.py
@@ -335,3 +335,20 @@ def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
"""
state_dict = torch.load(checkpoint)
lr_scheduler.load_state_dict(state_dict)
+
+ # ================================================================================
+ # Abstract method for lora saving implementation.
+ # ================================================================================
+
+ @abstractmethod
+ def save_lora_as_pretrained(
+ self, model: Union[nn.Module, ModelWrapper], checkpoint: str, use_safetensors: bool = False
+ ) -> None:
+ """
+ Save the lora adapters and adapter configuration file to a pretrained checkpoint directory.
+
+ Args:
+ model (Union[nn.Module, ModelWrapper]): A model boosted by Booster.
+ checkpoint (str): Path to the checkpoint directory. It must be a local path.
+ use_safetensors (bool, optional): Whether to use safe tensors when saving. Defaults to False.
+ """
diff --git a/colossalai/checkpoint_io/general_checkpoint_io.py b/colossalai/checkpoint_io/general_checkpoint_io.py
index a652d9b4538e..b9253a56dcbb 100644
--- a/colossalai/checkpoint_io/general_checkpoint_io.py
+++ b/colossalai/checkpoint_io/general_checkpoint_io.py
@@ -228,3 +228,6 @@ def load_sharded_model(
self.__class__.__name__, "\n\t".join(error_msgs)
)
)
+
+ def save_lora_as_pretrained(self, model: nn.Module, checkpoint: str, use_safetensors: bool = False) -> None:
+ raise NotImplementedError
diff --git a/colossalai/inference/README.md b/colossalai/inference/README.md
index 287853a86383..0bdaf347d295 100644
--- a/colossalai/inference/README.md
+++ b/colossalai/inference/README.md
@@ -114,7 +114,7 @@ import colossalai
from transformers import LlamaForCausalLM, LlamaTokenizer
#launch distributed environment
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
# load original model and tokenizer
model = LlamaForCausalLM.from_pretrained("/path/to/model")
@@ -165,7 +165,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
##### Llama
| batch_size | 8 | 16 | 32 |
-| :---------------------: | :----: | :----: | :----: |
+|:-----------------------:|:------:|:------:|:------:|
| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
| colossal-inference | 326.4 | 582.72 | 816.64 |
@@ -174,7 +174,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
#### Bloom
| batch_size | 8 | 16 | 32 |
-| :---------------------: | :----: | :----: | :----: |
+|:-----------------------:|:------:|:------:|:------:|
| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
| colossal-inference | 323.28 | 538.52 | 611.64 |
@@ -187,40 +187,40 @@ We conducted multiple benchmark tests to evaluate the performance. We compared t
#### A10 7b, fp16
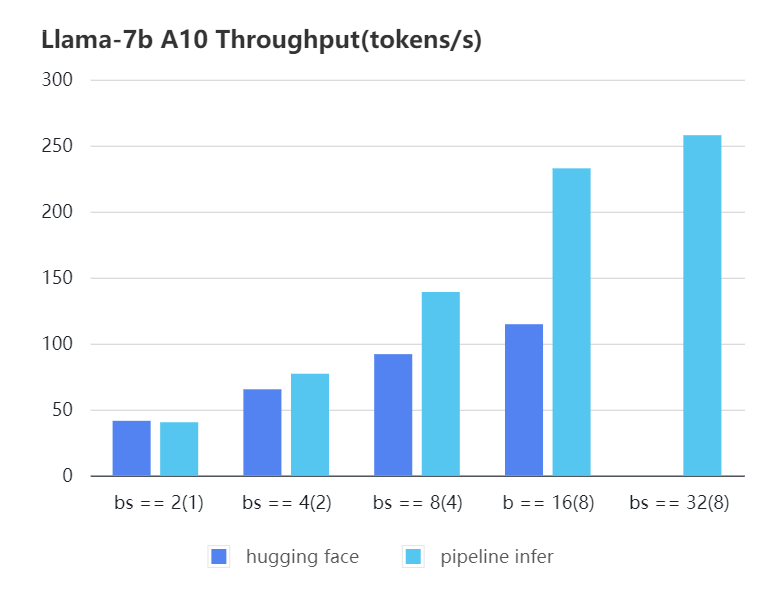
-| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
-| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
-| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
-| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16) |
+|:----------------------------:|:-----:|:-----:|:------:|:------:|:------:|:------:|
+| Pipeline Inference | 40.35 | 77.10 | 139.03 | 232.70 | 257.81 | OOM |
+| Hugging Face | 41.43 | 65.30 | 91.93 | 114.62 | OOM | OOM |
#### A10 13b, fp16
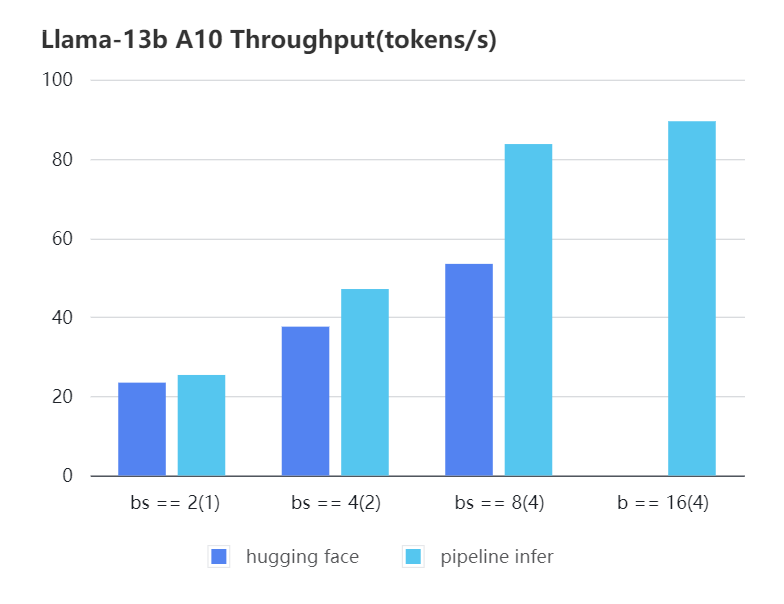
-| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
-| :---: | :---: | :---: | :---: | :---: |
-| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
-| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(4) |
+|:----------------------------:|:-----:|:-----:|:-----:|:-----:|
+| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
+| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
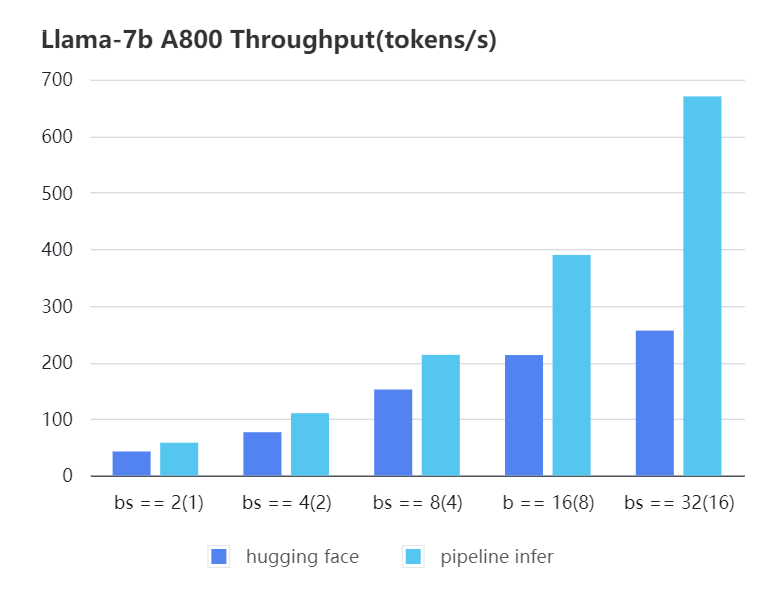
#### A800 7b, fp16
-| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
-| :---: | :---: | :---: | :---: | :---: | :---: |
-| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
-| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+|:----------------------------:|:-----:|:------:|:------:|:------:|:------:|
+| Pipeline Inference | 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
+| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
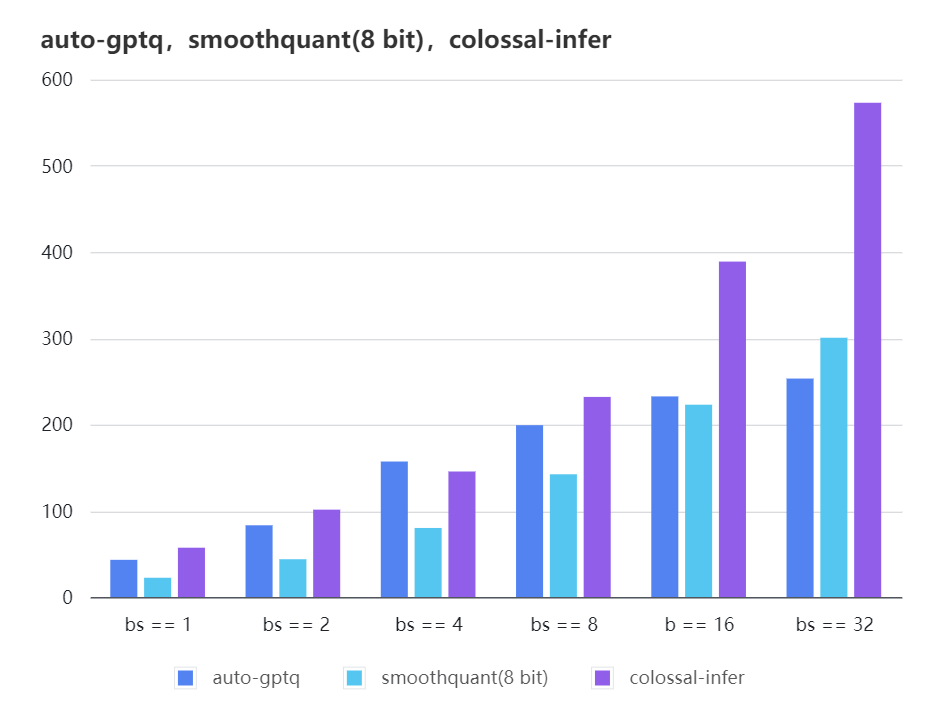
### Quantization LLama
-| batch_size | 8 | 16 | 32 |
-| :---------------------: | :----: | :----: | :----: |
-| auto-gptq | 199.20 | 232.56 | 253.26 |
-| smooth-quant | 142.28 | 222.96 | 300.59 |
-| colossal-gptq | 231.98 | 388.87 | 573.03 |
+| batch_size | 8 | 16 | 32 |
+|:-------------:|:------:|:------:|:------:|
+| auto-gptq | 199.20 | 232.56 | 253.26 |
+| smooth-quant | 142.28 | 222.96 | 300.59 |
+| colossal-gptq | 231.98 | 388.87 | 573.03 |
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
index aaeaad3828f5..934555e193fc 100644
--- a/colossalai/initialize.py
+++ b/colossalai/initialize.py
@@ -2,20 +2,15 @@
# -*- encoding: utf-8 -*-
import os
-import warnings
-from pathlib import Path
-from typing import Dict, Union
import torch.distributed as dist
from colossalai.accelerator import get_accelerator
-from colossalai.context import Config
from colossalai.logging import get_dist_logger
from colossalai.utils import set_seed
def launch(
- config: Union[str, Path, Config, Dict],
rank: int,
world_size: int,
host: str,
@@ -44,8 +39,6 @@ def launch(
Raises:
Exception: Raise exception when config type is wrong
"""
- if rank == 0:
- warnings.warn("`config` is deprecated and will be removed soon.")
cur_accelerator = get_accelerator()
@@ -68,7 +61,6 @@ def launch(
def launch_from_slurm(
- config: Union[str, Path, Config, Dict],
host: str,
port: int,
backend: str = "nccl",
@@ -95,7 +87,6 @@ def launch_from_slurm(
)
launch(
- config=config,
rank=rank,
world_size=world_size,
host=host,
@@ -107,7 +98,6 @@ def launch_from_slurm(
def launch_from_openmpi(
- config: Union[str, Path, Config, Dict],
host: str,
port: int,
backend: str = "nccl",
@@ -135,7 +125,6 @@ def launch_from_openmpi(
)
launch(
- config=config,
local_rank=local_rank,
rank=rank,
world_size=world_size,
@@ -147,9 +136,7 @@ def launch_from_openmpi(
)
-def launch_from_torch(
- config: Union[str, Path, Config, Dict], backend: str = "nccl", seed: int = 1024, verbose: bool = True
-):
+def launch_from_torch(backend: str = "nccl", seed: int = 1024, verbose: bool = True):
"""A wrapper for colossalai.launch for torchrun or torch.distributed.launch by reading rank and world size
from the environment variables set by PyTorch
@@ -171,7 +158,6 @@ def launch_from_torch(
)
launch(
- config=config,
local_rank=local_rank,
rank=rank,
world_size=world_size,
diff --git a/colossalai/legacy/inference/dynamic_batching/ray_dist_init.py b/colossalai/legacy/inference/dynamic_batching/ray_dist_init.py
index 3e40bb0eeb9d..7a74fb949e8f 100644
--- a/colossalai/legacy/inference/dynamic_batching/ray_dist_init.py
+++ b/colossalai/legacy/inference/dynamic_batching/ray_dist_init.py
@@ -56,7 +56,7 @@ def setup(self, world_size, rank, port):
# initialize a ray collective group, otherwise colossalai distributed env won't be built successfully
collective.init_collective_group(world_size, rank, "nccl", "default")
# initialize and set distributed environment
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
ray_serve_logger.info(f"Worker with rank {rank} (world size {world_size}) setting up..")
log_cuda_info("Worker.setup")
diff --git a/colossalai/legacy/inference/hybridengine/engine.py b/colossalai/legacy/inference/hybridengine/engine.py
index bc4e4fd199c0..019a678ceb02 100644
--- a/colossalai/legacy/inference/hybridengine/engine.py
+++ b/colossalai/legacy/inference/hybridengine/engine.py
@@ -42,7 +42,7 @@ class CaiInferEngine:
import colossalai
from transformers import LlamaForCausalLM, LlamaTokenizer
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
model = LlamaForCausalLM.from_pretrained("your_path_to_model")
tokenizer = LlamaTokenizer.from_pretrained("/home/lczyh/share/models/llama-7b-hf")
diff --git a/colossalai/legacy/inference/pipeline/README.md b/colossalai/legacy/inference/pipeline/README.md
index f9bb35cc4d4c..cbe96fff0404 100644
--- a/colossalai/legacy/inference/pipeline/README.md
+++ b/colossalai/legacy/inference/pipeline/README.md
@@ -36,7 +36,7 @@ from colossalai.inference.pipeline.policies import LlamaModelInferPolicy
import colossalai
from transformers import LlamaForCausalLM, LlamaTokenizer
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
model = LlamaForCausalLM.from_pretrained("/path/to/model")
tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
@@ -57,27 +57,27 @@ We conducted multiple benchmark tests to evaluate the performance. We compared t
### Llama Throughput (tokens/s) | input length=1024, output length=128
#### A10 7b, fp16
-| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
-| :---: | :---: | :---: | :---: | :---: | :---: | :---:|
-| Pipeline Inference | 40.35 | 77.1 | 139.03 | 232.7 | 257.81 | OOM |
-| Hugging Face | 41.43 | 65.30 | 91.93 | 114.62 | OOM| OOM |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16) |
+|:----------------------------:|:-----:|:-----:|:------:|:------:|:------:|:------:|
+| Pipeline Inference | 40.35 | 77.1 | 139.03 | 232.7 | 257.81 | OOM |
+| Hugging Face | 41.43 | 65.30 | 91.93 | 114.62 | OOM | OOM |
#### A10 13b, fp16
-| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
-| :---: | :---: | :---: | :---: | :---: |
-| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
-| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(4) |
+|:----------------------------:|:-----:|:-----:|:-----:|:-----:|
+| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
+| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
#### A800 7b, fp16
-| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
-| :---: | :---: | :---: | :---: | :---: | :---: |
-| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
-| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+|:----------------------------:|:-----:|:------:|:------:|:------:|:------:|
+| Pipeline Inference | 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
+| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
#### A800 13b, fp16
-| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
-| :---: | :---: | :---: | :---: | :---: | :---: |
-| Pipeline Inference | 41.78 | 94.18 | 172.67| 310.75| 470.15 |
-| Hugging Face | 36.57 | 68.4 | 105.81 | 139.51 | 166.34 |
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+|:----------------------------:|:-----:|:-----:|:------:|:------:|:------:|
+| Pipeline Inference | 41.78 | 94.18 | 172.67 | 310.75 | 470.15 |
+| Hugging Face | 36.57 | 68.4 | 105.81 | 139.51 | 166.34 |
diff --git a/colossalai/legacy/inference/pipeline/benchmark/benchmark.py b/colossalai/legacy/inference/pipeline/benchmark/benchmark.py
index 8392d0a1e579..7bb89f4f44f8 100644
--- a/colossalai/legacy/inference/pipeline/benchmark/benchmark.py
+++ b/colossalai/legacy/inference/pipeline/benchmark/benchmark.py
@@ -12,7 +12,7 @@
GIGABYTE = 1024**3
MEGABYTE = 1024 * 1024
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
def data_gen(batch_size: int = 4, seq_len: int = 512):
diff --git a/colossalai/legacy/inference/serving/ray_serve/Colossal_Inference_rayserve.py b/colossalai/legacy/inference/serving/ray_serve/Colossal_Inference_rayserve.py
index d758b467c730..37e7bae419e8 100644
--- a/colossalai/legacy/inference/serving/ray_serve/Colossal_Inference_rayserve.py
+++ b/colossalai/legacy/inference/serving/ray_serve/Colossal_Inference_rayserve.py
@@ -56,7 +56,7 @@ def setup(self, world_size, rank, port):
# initialize a ray collective group, otherwise colossalai distributed env won't be built successfully
collective.init_collective_group(world_size, rank, "nccl", "default")
# initialize and set distributed environment
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
ray_serve_logger.info(f"Worker with rank {rank} (world size {world_size}) setting up..")
log_cuda_info("Worker.setup")
diff --git a/colossalai/legacy/inference/serving/torch_serve/Colossal_Inference_Handler.py b/colossalai/legacy/inference/serving/torch_serve/Colossal_Inference_Handler.py
index e07494b8a1a9..bcbdee951021 100644
--- a/colossalai/legacy/inference/serving/torch_serve/Colossal_Inference_Handler.py
+++ b/colossalai/legacy/inference/serving/torch_serve/Colossal_Inference_Handler.py
@@ -98,7 +98,7 @@ def initialize(self, ctx):
self.model.cuda()
self.model.eval()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host=host, port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host=host, port=port, backend="nccl")
logger.info("Initializing TPInferEngine ...")
shard_config = ShardConfig(
enable_tensor_parallelism=True if self.tp_size > 1 else False, extra_kwargs={"inference_only": True}
diff --git a/colossalai/legacy/pipeline/rpc/utils.py b/colossalai/legacy/pipeline/rpc/utils.py
index 808de301a2a0..87060ab8a8ba 100644
--- a/colossalai/legacy/pipeline/rpc/utils.py
+++ b/colossalai/legacy/pipeline/rpc/utils.py
@@ -114,7 +114,7 @@ def run_worker(rank, args, master_func):
port = args.master_port
backend = "nccl" if device == "cuda" else "gloo"
- launch(dict(), rank, world_size, host, int(port), backend, verbose=False)
+ launch(rank, world_size, host, int(port), backend, verbose=False)
ppg.set_global_info(
rank=rank,
world_size=world_size,
diff --git a/colossalai/nn/optimizer/fused_adam.py b/colossalai/nn/optimizer/fused_adam.py
index aeb5cc91bb9e..c12551657318 100644
--- a/colossalai/nn/optimizer/fused_adam.py
+++ b/colossalai/nn/optimizer/fused_adam.py
@@ -8,7 +8,7 @@
"""
import torch
-from colossalai.utils import multi_tensor_applier
+from colossalai.utils import get_current_device, multi_tensor_applier
class FusedAdam(torch.optim.Optimizer):
@@ -75,7 +75,7 @@ def __init__(
fused_optim = FusedOptimizerLoader().load()
# Skip buffer
- self._dummy_overflow_buf = torch.cuda.IntTensor([0])
+ self._dummy_overflow_buf = torch.tensor([0], dtype=torch.int, device=get_current_device())
self.multi_tensor_adam = fused_optim.multi_tensor_adam
else:
raise RuntimeError("FusedAdam requires cuda extensions")
diff --git a/colossalai/nn/optimizer/hybrid_adam.py b/colossalai/nn/optimizer/hybrid_adam.py
index c9c1f81bfc9a..417881a0b93f 100644
--- a/colossalai/nn/optimizer/hybrid_adam.py
+++ b/colossalai/nn/optimizer/hybrid_adam.py
@@ -3,7 +3,7 @@
import torch
from colossalai.kernel.kernel_loader import FusedOptimizerLoader
-from colossalai.utils import multi_tensor_applier
+from colossalai.utils import get_current_device, multi_tensor_applier
from .cpu_adam import CPUAdam
@@ -87,7 +87,7 @@ def __init__(
if torch.cuda.is_available():
fused_optim = FusedOptimizerLoader().load()
self.gpu_adam_op = fused_optim.multi_tensor_adam
- self._dummy_overflow_buf = torch.cuda.IntTensor([0])
+ self._dummy_overflow_buf = torch.tensor([0], dtype=torch.int, device=get_current_device())
@torch.no_grad()
def step(self, closure=None, div_scale: float = -1):
diff --git a/colossalai/pipeline/p2p.py b/colossalai/pipeline/p2p.py
index 5588aa5789a9..1b55b140c0ba 100644
--- a/colossalai/pipeline/p2p.py
+++ b/colossalai/pipeline/p2p.py
@@ -45,6 +45,18 @@ def _cuda_safe_tensor_to_object(tensor: torch.Tensor, tensor_size: torch.Size) -
return unpickle
+def check_for_nccl_backend(group):
+ pg = group or c10d._get_default_group()
+ # Gate PG wrapper check on Gloo availability.
+ if c10d._GLOO_AVAILABLE:
+ # It is not expected for PG to be wrapped many times, but support it just
+ # in case
+ while isinstance(pg, c10d._ProcessGroupWrapper):
+ pg = pg.wrapped_pg
+
+ return c10d.is_nccl_available() and pg.name() == c10d.Backend.NCCL
+
+
# NOTE: FIXME: NPU DOES NOT support isend nor irecv, so broadcast is kept for future use
def _broadcast_object_list(
object_list: List[Any], src: int, group: ProcessGroup, device: Optional[Union[torch.device, str, int]] = None
diff --git a/colossalai/quantization/__init__.py b/colossalai/quantization/__init__.py
new file mode 100644
index 000000000000..e9707b479691
--- /dev/null
+++ b/colossalai/quantization/__init__.py
@@ -0,0 +1,7 @@
+from .bnb import quantize_model
+from .bnb_config import BnbQuantizationConfig
+
+__all__ = [
+ "BnbQuantizationConfig",
+ "quantize_model",
+]
diff --git a/colossalai/quantization/bnb.py b/colossalai/quantization/bnb.py
new file mode 100644
index 000000000000..fa214116afd1
--- /dev/null
+++ b/colossalai/quantization/bnb.py
@@ -0,0 +1,321 @@
+# adapted from Hugging Face accelerate/utils/bnb.py accelerate/utils/modeling.py
+
+import logging
+
+import torch
+import torch.nn as nn
+
+from .bnb_config import BnbQuantizationConfig
+
+try:
+ import bitsandbytes as bnb
+
+ IS_4BIT_BNB_AVAILABLE = bnb.__version__ >= "0.39.0"
+ IS_8BIT_BNB_AVAILABLE = bnb.__version__ >= "0.37.2"
+except ImportError:
+ pass
+
+
+logger = logging.getLogger(__name__)
+
+
+def quantize_model(
+ model: torch.nn.Module,
+ bnb_quantization_config: BnbQuantizationConfig,
+):
+ """
+ This function will quantize the input loaded model with the associated config passed in `bnb_quantization_config`.
+ We will quantize the model and put the model on the GPU.
+
+ Args:
+ model (`torch.nn.Module`):
+ Input model. The model already loaded
+ bnb_quantization_config (`BnbQuantizationConfig`):
+ The bitsandbytes quantization parameters
+
+ Returns:
+ `torch.nn.Module`: The quantized model
+ """
+
+ load_in_4bit = bnb_quantization_config.load_in_4bit
+ load_in_8bit = bnb_quantization_config.load_in_8bit
+
+ if load_in_8bit and not IS_8BIT_BNB_AVAILABLE:
+ raise ImportError(
+ "You have a version of `bitsandbytes` that is not compatible with 8bit quantization,"
+ " make sure you have the latest version of `bitsandbytes` installed."
+ )
+ if load_in_4bit and not IS_4BIT_BNB_AVAILABLE:
+ raise ValueError(
+ "You have a version of `bitsandbytes` that is not compatible with 4bit quantization,"
+ "make sure you have the latest version of `bitsandbytes` installed."
+ )
+
+ # We keep some modules such as the lm_head in their original dtype for numerical stability reasons
+ if bnb_quantization_config.skip_modules is None:
+ bnb_quantization_config.skip_modules = get_keys_to_not_convert(model)
+
+ modules_to_not_convert = bnb_quantization_config.skip_modules
+
+ # We add the modules we want to keep in full precision
+ if bnb_quantization_config.keep_in_fp32_modules is None:
+ bnb_quantization_config.keep_in_fp32_modules = []
+ keep_in_fp32_modules = bnb_quantization_config.keep_in_fp32_modules
+
+ # compatibility with peft
+ model.is_loaded_in_4bit = load_in_4bit
+ model.is_loaded_in_8bit = load_in_8bit
+
+ # assert model_device is cuda
+ model_device = next(model.parameters()).device
+
+ model = replace_with_bnb_layers(model, bnb_quantization_config, modules_to_not_convert=modules_to_not_convert)
+
+ # convert param to the right dtype
+ dtype = bnb_quantization_config.torch_dtype
+ for name, param in model.state_dict().items():
+ if any(module_to_keep_in_fp32 in name for module_to_keep_in_fp32 in keep_in_fp32_modules):
+ param.to(torch.float32)
+ if param.dtype != torch.float32:
+ name = name.replace(".weight", "").replace(".bias", "")
+ param = getattr(model, name, None)
+ if param is not None:
+ param.to(torch.float32)
+ elif torch.is_floating_point(param):
+ param.to(dtype)
+ if model_device.type == "cuda":
+ # move everything to cpu in the first place because we can't do quantization if the weights are already on cuda
+ model.cuda(torch.cuda.current_device())
+ torch.cuda.empty_cache()
+ elif torch.cuda.is_available():
+ model.to(torch.cuda.current_device())
+ logger.info(
+ f"The model device type is {model_device.type}. However, cuda is needed for quantization."
+ "We move the model to cuda."
+ )
+ else:
+ raise RuntimeError("No GPU found. A GPU is needed for quantization.")
+ return model
+
+
+def replace_with_bnb_layers(model, bnb_quantization_config, modules_to_not_convert=None, current_key_name=None):
+ """
+ A helper function to replace all `torch.nn.Linear` modules by `bnb.nn.Linear8bit` modules or by `bnb.nn.Linear4bit`
+ modules from the `bitsandbytes`library. The function will be run recursively and replace `torch.nn.Linear` modules.
+
+ Parameters:
+ model (`torch.nn.Module`):
+ Input model or `torch.nn.Module` as the function is run recursively.
+ modules_to_not_convert (`List[str]`):
+ Names of the modules to not quantize convert. In practice we keep the `lm_head` in full precision for
+ numerical stability reasons.
+ current_key_name (`List[str]`, *optional*):
+ An array to track the current key of the recursion. This is used to check whether the current key (part of
+ it) is not in the list of modules to not convert.
+ """
+
+ if modules_to_not_convert is None:
+ modules_to_not_convert = []
+
+ model, has_been_replaced = _replace_with_bnb_layers(
+ model, bnb_quantization_config, modules_to_not_convert, current_key_name
+ )
+ if not has_been_replaced:
+ logger.warning(
+ "You are loading your model in 8bit or 4bit but no linear modules were found in your model."
+ " this can happen for some architectures such as gpt2 that uses Conv1D instead of Linear layers."
+ " Please double check your model architecture, or submit an issue on github if you think this is"
+ " a bug."
+ )
+ return model
+
+
+def _replace_with_bnb_layers(
+ model,
+ bnb_quantization_config,
+ modules_to_not_convert=None,
+ current_key_name=None,
+):
+ """
+ Private method that wraps the recursion for module replacement.
+
+ Returns the converted model and a boolean that indicates if the conversion has been successfull or not.
+ """
+ # bitsandbytes will initialize CUDA on import, so it needs to be imported lazily
+
+ has_been_replaced = False
+ for name, module in model.named_children():
+ if current_key_name is None:
+ current_key_name = []
+ current_key_name.append(name)
+ if isinstance(module, nn.Linear) and name not in modules_to_not_convert:
+ # Check if the current key is not in the `modules_to_not_convert`
+ current_key_name_str = ".".join(current_key_name)
+ proceed = True
+ for key in modules_to_not_convert:
+ if (
+ (key in current_key_name_str) and (key + "." in current_key_name_str)
+ ) or key == current_key_name_str:
+ proceed = False
+ break
+ if proceed:
+ # Load bnb module with empty weight and replace ``nn.Linear` module
+ if bnb_quantization_config.load_in_8bit:
+ bnb_module = bnb.nn.Linear8bitLt(
+ module.in_features,
+ module.out_features,
+ module.bias is not None,
+ has_fp16_weights=False,
+ threshold=bnb_quantization_config.llm_int8_threshold,
+ )
+ elif bnb_quantization_config.load_in_4bit:
+ bnb_module = bnb.nn.Linear4bit(
+ module.in_features,
+ module.out_features,
+ module.bias is not None,
+ bnb_quantization_config.bnb_4bit_compute_dtype,
+ compress_statistics=bnb_quantization_config.bnb_4bit_use_double_quant,
+ quant_type=bnb_quantization_config.bnb_4bit_quant_type,
+ )
+ else:
+ raise ValueError("load_in_8bit and load_in_4bit can't be both False")
+ bnb_module.weight.data = module.weight.data
+ bnb_module.weight.skip_zero_check = True
+ if module.bias is not None:
+ bnb_module.bias.data = module.bias.data
+ bnb_module.bias.skip_zero_check = True
+ bnb_module.requires_grad_(False)
+ setattr(model, name, bnb_module)
+ has_been_replaced = True
+ if len(list(module.children())) > 0:
+ _, _has_been_replaced = _replace_with_bnb_layers(
+ module, bnb_quantization_config, modules_to_not_convert, current_key_name
+ )
+ has_been_replaced = has_been_replaced | _has_been_replaced
+ # Remove the last key for recursion
+ current_key_name.pop(-1)
+ return model, has_been_replaced
+
+
+def get_keys_to_not_convert(model):
+ r"""
+ An utility function to get the key of the module to keep in full precision if any For example for CausalLM modules
+ we may want to keep the lm_head in full precision for numerical stability reasons. For other architectures, we want
+ to keep the tied weights of the model. The function will return a list of the keys of the modules to not convert in
+ int8.
+
+ Parameters:
+ model (`torch.nn.Module`):
+ Input model
+ """
+ # Create a copy of the model
+ # with init_empty_weights():
+ # tied_model = deepcopy(model) # this has 0 cost since it is done inside `init_empty_weights` context manager`
+ tied_model = model
+
+ tied_params = find_tied_parameters(tied_model)
+ # For compatibility with Accelerate < 0.18
+ if isinstance(tied_params, dict):
+ tied_keys = sum(list(tied_params.values()), []) + list(tied_params.keys())
+ else:
+ tied_keys = sum(tied_params, [])
+ has_tied_params = len(tied_keys) > 0
+
+ # Check if it is a base model
+ is_base_model = False
+ if hasattr(model, "base_model_prefix"):
+ is_base_model = not hasattr(model, model.base_model_prefix)
+
+ # Ignore this for base models (BertModel, GPT2Model, etc.)
+ if (not has_tied_params) and is_base_model:
+ return []
+
+ # otherwise they have an attached head
+ list_modules = list(model.named_children())
+ list_last_module = [list_modules[-1][0]]
+
+ # add last module together with tied weights
+ intersection = set(list_last_module) - set(tied_keys)
+ list_untouched = list(set(tied_keys)) + list(intersection)
+
+ # remove ".weight" from the keys
+ names_to_remove = [".weight", ".bias"]
+ filtered_module_names = []
+ for name in list_untouched:
+ for name_to_remove in names_to_remove:
+ if name_to_remove in name:
+ name = name.replace(name_to_remove, "")
+ filtered_module_names.append(name)
+
+ return filtered_module_names
+
+
+def find_tied_parameters(model: nn.Module, **kwargs):
+ """
+ Find the tied parameters in a given model.
+
+
+
+ The signature accepts keyword arguments, but they are for the recursive part of this function and you should ignore
+ them.
+
+
+
+ Args:
+ model (`torch.nn.Module`): The model to inspect.
+
+ Returns:
+ List[List[str]]: A list of lists of parameter names being all tied together.
+
+ Example:
+
+ ```py
+ >>> from collections import OrderedDict
+ >>> import torch.nn as nn
+
+ >>> model = nn.Sequential(OrderedDict([("linear1", nn.Linear(4, 4)), ("linear2", nn.Linear(4, 4))]))
+ >>> model.linear2.weight = model.linear1.weight
+ >>> find_tied_parameters(model)
+ [['linear1.weight', 'linear2.weight']]
+ ```
+ """
+ # Initialize result and named_parameters before recursing.
+ named_parameters = kwargs.get("named_parameters", None)
+ prefix = kwargs.get("prefix", "")
+ result = kwargs.get("result", {})
+
+ if named_parameters is None:
+ named_parameters = {n: p for n, p in model.named_parameters()}
+ else:
+ # A tied parameter will not be in the full `named_parameters` seen above but will be in the `named_parameters`
+ # of the submodule it belongs to. So while recursing we track the names that are not in the initial
+ # `named_parameters`.
+ for name, parameter in model.named_parameters():
+ full_name = name if prefix == "" else f"{prefix}.{name}"
+ if full_name not in named_parameters:
+ # When we find one, it has to be one of the existing parameters.
+ for new_name, new_param in named_parameters.items():
+ if new_param is parameter:
+ if new_name not in result:
+ result[new_name] = []
+ result[new_name].append(full_name)
+
+ # Once we have treated direct parameters, we move to the child modules.
+ for name, child in model.named_children():
+ child_name = name if prefix == "" else f"{prefix}.{name}"
+ find_tied_parameters(child, named_parameters=named_parameters, prefix=child_name, result=result)
+
+ return FindTiedParametersResult([sorted([weight] + list(set(tied))) for weight, tied in result.items()])
+
+
+class FindTiedParametersResult(list):
+ """
+ This is a subclass of a list to handle backward compatibility for Transformers. Do not rely on the fact this is not
+ a list or on the `values` method as in the future this will be removed.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def values(self):
+ return sum([x[1:] for x in self], [])
diff --git a/colossalai/quantization/bnb_config.py b/colossalai/quantization/bnb_config.py
new file mode 100644
index 000000000000..98a30211b13d
--- /dev/null
+++ b/colossalai/quantization/bnb_config.py
@@ -0,0 +1,113 @@
+# adapted from Hugging Face accelerate/utils/dataclasses.py
+
+import warnings
+from dataclasses import dataclass, field
+from typing import List
+
+import torch
+
+
+@dataclass
+class BnbQuantizationConfig:
+ """
+ A plugin to enable BitsAndBytes 4bit and 8bit quantization
+ """
+
+ load_in_8bit: bool = field(default=False, metadata={"help": "enable 8bit quantization."})
+
+ llm_int8_threshold: float = field(
+ default=6.0, metadata={"help": "value of the outliner threshold. only relevant when load_in_8bit=True"}
+ )
+
+ load_in_4bit: bool = field(default=False, metadata={"help": "enable 4bit quantization."})
+
+ bnb_4bit_quant_type: str = field(
+ default="fp4",
+ metadata={
+ "help": "set the quantization data type in the `bnb.nn.Linear4Bit` layers. Options are {'fp4','np4'}."
+ },
+ )
+
+ bnb_4bit_use_double_quant: bool = field(
+ default=False,
+ metadata={
+ "help": "enable nested quantization where the quantization constants from the first quantization are quantized again."
+ },
+ )
+
+ bnb_4bit_compute_dtype: bool = field(
+ default="fp16",
+ metadata={
+ "help": "This sets the computational type which might be different than the input time. For example, inputs might be "
+ "fp32, but computation can be set to bf16 for speedups. Options are {'fp32','fp16','bf16'}."
+ },
+ )
+
+ torch_dtype: torch.dtype = field(
+ default=None,
+ metadata={
+ "help": "this sets the dtype of the remaining non quantized layers. `bitsandbytes` library suggests to set the value"
+ "to `torch.float16` for 8 bit model and use the same dtype as the compute dtype for 4 bit model "
+ },
+ )
+
+ skip_modules: List[str] = field(
+ default=None,
+ metadata={
+ "help": "an explicit list of the modules that we don't quantize. The dtype of these modules will be `torch_dtype`."
+ },
+ )
+
+ keep_in_fp32_modules: List[str] = field(
+ default=None,
+ metadata={"help": "an explicit list of the modules that we don't quantize. We keep them in `torch.float32`."},
+ )
+
+ def __post_init__(self):
+ if isinstance(self.bnb_4bit_compute_dtype, str):
+ if self.bnb_4bit_compute_dtype == "fp32":
+ self.bnb_4bit_compute_dtype = torch.float32
+ elif self.bnb_4bit_compute_dtype == "fp16":
+ self.bnb_4bit_compute_dtype = torch.float16
+ elif self.bnb_4bit_compute_dtype == "bf16":
+ self.bnb_4bit_compute_dtype = torch.bfloat16
+ else:
+ raise ValueError(
+ f"bnb_4bit_compute_dtype must be in ['fp32','fp16','bf16'] but found {self.bnb_4bit_compute_dtype}"
+ )
+ elif not isinstance(self.bnb_4bit_compute_dtype, torch.dtype):
+ raise ValueError("bnb_4bit_compute_dtype must be a string or a torch.dtype")
+
+ if self.skip_modules is not None and not isinstance(self.skip_modules, list):
+ raise ValueError("skip_modules must be a list of strings")
+
+ if self.keep_in_fp32_modules is not None and not isinstance(self.keep_in_fp32_modules, list):
+ raise ValueError("keep_in_fp_32_modules must be a list of strings")
+
+ if self.load_in_4bit:
+ self.target_dtype = "int4"
+
+ if self.load_in_8bit:
+ self.target_dtype = torch.int8
+
+ if self.load_in_4bit and self.llm_int8_threshold != 6.0:
+ warnings.warn("llm_int8_threshold can only be used for model loaded in 8bit")
+
+ if isinstance(self.torch_dtype, str):
+ if self.torch_dtype == "fp32":
+ self.torch_dtype = torch.float32
+ elif self.torch_dtype == "fp16":
+ self.torch_dtype = torch.float16
+ elif self.torch_dtype == "bf16":
+ self.torch_dtype = torch.bfloat16
+ else:
+ raise ValueError(f"torch_dtype must be in ['fp32','fp16','bf16'] but found {self.torch_dtype}")
+
+ if self.load_in_8bit and self.torch_dtype is None:
+ self.torch_dtype = torch.float16
+
+ if self.load_in_4bit and self.torch_dtype is None:
+ self.torch_dtype = self.bnb_4bit_compute_dtype
+
+ if not isinstance(self.torch_dtype, torch.dtype):
+ raise ValueError("torch_dtype must be a torch.dtype")
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index d45421868321..47ef98ccf7e8 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -38,7 +38,7 @@ from transformers import BertForMaskedLM
import colossalai
# launch colossalai
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
# create model
config = BertConfig.from_pretrained('bert-base-uncased')
diff --git a/colossalai/shardformer/examples/convergence_benchmark.py b/colossalai/shardformer/examples/convergence_benchmark.py
index b03e6201dce8..4caf61eb4ec4 100644
--- a/colossalai/shardformer/examples/convergence_benchmark.py
+++ b/colossalai/shardformer/examples/convergence_benchmark.py
@@ -28,7 +28,7 @@ def _to(t: Any):
def train(args):
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
coordinator = DistCoordinator()
# prepare for data and dataset
diff --git a/colossalai/shardformer/examples/performance_benchmark.py b/colossalai/shardformer/examples/performance_benchmark.py
index 81215dcdf5d4..cce8b6f3a40f 100644
--- a/colossalai/shardformer/examples/performance_benchmark.py
+++ b/colossalai/shardformer/examples/performance_benchmark.py
@@ -1,6 +1,7 @@
"""
Shardformer Benchmark
"""
+
import torch
import torch.distributed as dist
import transformers
@@ -84,5 +85,5 @@ def bench_shardformer(BATCH, N_CTX, provider, model_func, dtype=torch.float32, d
# start benchmark, command:
# torchrun --standalone --nproc_per_node=2 performance_benchmark.py
if __name__ == "__main__":
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
bench_shardformer.run(save_path=".", print_data=dist.get_rank() == 0)
diff --git a/colossalai/shardformer/modeling/bert.py b/colossalai/shardformer/modeling/bert.py
index 0838fcee682e..e7679f0ec846 100644
--- a/colossalai/shardformer/modeling/bert.py
+++ b/colossalai/shardformer/modeling/bert.py
@@ -1287,3 +1287,16 @@ def forward(
)
return forward
+
+
+def get_jit_fused_bert_intermediate_forward():
+ from transformers.models.bert.modeling_bert import BertIntermediate
+
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self: BertIntermediate, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states, bias = self.dense(hidden_states)
+ hidden_states = JitGeLUFunction.apply(hidden_states, bias)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/blip2.py b/colossalai/shardformer/modeling/blip2.py
index bd84c87c667d..96e8a9d0c127 100644
--- a/colossalai/shardformer/modeling/blip2.py
+++ b/colossalai/shardformer/modeling/blip2.py
@@ -129,3 +129,17 @@ def forward(
return hidden_states
return forward
+
+
+def get_jit_fused_blip2_mlp_forward():
+ from transformers.models.blip_2.modeling_blip_2 import Blip2MLP
+
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self: Blip2MLP, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states, bias = self.fc1(hidden_states)
+ hidden_states = JitGeLUFunction.apply(hidden_states, bias)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/gpt2.py b/colossalai/shardformer/modeling/gpt2.py
index 17acdf7fcbba..bfa995645ef1 100644
--- a/colossalai/shardformer/modeling/gpt2.py
+++ b/colossalai/shardformer/modeling/gpt2.py
@@ -1310,3 +1310,18 @@ def forward(
)
return forward
+
+
+def get_jit_fused_gpt2_mlp_forward():
+ from transformers.models.gpt2.modeling_gpt2 import GPT2MLP
+
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self: GPT2MLP, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor:
+ hidden_states, bias = self.c_fc(hidden_states)
+ hidden_states = JitGeLUFunction.apply(hidden_states, bias)
+ hidden_states = self.c_proj(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/vit.py b/colossalai/shardformer/modeling/vit.py
index 67b10988d100..b1a5c4143646 100644
--- a/colossalai/shardformer/modeling/vit.py
+++ b/colossalai/shardformer/modeling/vit.py
@@ -372,3 +372,15 @@ def forward(self: ViTOutput, hidden_states: torch.Tensor, input_tensor: torch.Te
return hidden_states
return forward
+
+
+def get_jit_fused_vit_intermediate_forward():
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states, bias = self.dense(hidden_states)
+ hidden_states = JitGeLUFunction.apply(hidden_states, bias)
+
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/policies/bert.py b/colossalai/shardformer/policies/bert.py
index d43fc893aedc..0c04f7d38ca0 100644
--- a/colossalai/shardformer/policies/bert.py
+++ b/colossalai/shardformer/policies/bert.py
@@ -12,6 +12,7 @@
BertPipelineForwards,
bert_sequence_parallel_forward_fn,
get_bert_flash_attention_forward,
+ get_jit_fused_bert_intermediate_forward,
get_jit_fused_bert_output_forward,
get_jit_fused_bert_self_output_forward,
)
@@ -38,11 +39,13 @@ def config_sanity_check(self):
def preprocess(self):
self.tie_weight = self.tie_weight_check()
+ self.enable_bias_gelu_fused = self.shard_config.enable_jit_fused and self.model.config.hidden_act == "gelu"
return self.model
def module_policy(self):
from transformers.models.bert.modeling_bert import (
BertEmbeddings,
+ BertIntermediate,
BertLayer,
BertModel,
BertOutput,
@@ -76,6 +79,9 @@ def module_policy(self):
sp_partial_derived = sp_mode == "split_gather"
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[BertLayer] = ModulePolicyDescription(
attribute_replacement={
"attention.self.all_head_size": self.model.config.hidden_size
@@ -131,6 +137,7 @@ def module_policy(self):
kwargs={
"seq_parallel_mode": sp_mode,
"overlap": overlap,
+ "skip_bias_add": self.enable_bias_gelu_fused,
},
),
SubModuleReplacementDescription(
@@ -153,6 +160,14 @@ def module_policy(self):
),
]
)
+ if self.enable_bias_gelu_fused:
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_jit_fused_bert_intermediate_forward(),
+ },
+ policy=policy,
+ target_key=BertIntermediate,
+ )
if sp_mode == "split_gather":
self.append_or_create_method_replacement(
diff --git a/colossalai/shardformer/policies/blip2.py b/colossalai/shardformer/policies/blip2.py
index b845e9336cac..32d4edadb3e4 100644
--- a/colossalai/shardformer/policies/blip2.py
+++ b/colossalai/shardformer/policies/blip2.py
@@ -3,6 +3,7 @@
from ..modeling.blip2 import (
forward_fn,
get_blip2_flash_attention_forward,
+ get_jit_fused_blip2_mlp_forward,
get_jit_fused_blip2_QFormer_output_forward,
get_jit_fused_blip2_QFormer_self_output_forward,
)
@@ -18,12 +19,16 @@ def config_sanity_check(self):
def preprocess(self):
self.tie_weight = self.tie_weight_check()
+ self.enable_bias_gelu_fused = (
+ self.shard_config.enable_jit_fused and self.model.config.vision_config.hidden_act == "gelu"
+ )
return self.model
def module_policy(self):
from transformers.models.blip_2.modeling_blip_2 import (
Blip2Attention,
Blip2EncoderLayer,
+ Blip2MLP,
Blip2QFormerLayer,
Blip2QFormerModel,
Blip2QFormerOutput,
@@ -47,6 +52,9 @@ def module_policy(self):
norm_cls = col_nn.LayerNorm
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.vision_config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[Blip2EncoderLayer] = ModulePolicyDescription(
attribute_replacement={
"self_attn.num_heads": self.model.config.vision_config.num_attention_heads
@@ -73,6 +81,7 @@ def module_policy(self):
SubModuleReplacementDescription(
suffix="mlp.fc1",
target_module=col_nn.Linear1D_Col,
+ kwargs={"skip_bias_add": self.enable_bias_gelu_fused},
),
SubModuleReplacementDescription(
suffix="mlp.fc2",
@@ -201,6 +210,14 @@ def module_policy(self):
)
policy[Blip2Attention] = ModulePolicyDescription(method_replacement={"forward": forward_fn()})
+ if self.enable_bias_gelu_fused:
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_jit_fused_blip2_mlp_forward(),
+ },
+ policy=policy,
+ target_key=Blip2MLP,
+ )
if embedding_cls is not None:
self.append_or_create_submodule_replacement(
diff --git a/colossalai/shardformer/policies/bloom.py b/colossalai/shardformer/policies/bloom.py
index 4894bda35bfc..4f076d23368b 100644
--- a/colossalai/shardformer/policies/bloom.py
+++ b/colossalai/shardformer/policies/bloom.py
@@ -61,6 +61,9 @@ def module_policy(self):
sp_partial_derived = sp_mode == "split_gather"
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.n_head % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[BloomBlock] = ModulePolicyDescription(
attribute_replacement={
"self_attention.hidden_size": self.model.config.hidden_size
diff --git a/colossalai/shardformer/policies/falcon.py b/colossalai/shardformer/policies/falcon.py
index e72a97e4bfc0..23d6efbeb27a 100644
--- a/colossalai/shardformer/policies/falcon.py
+++ b/colossalai/shardformer/policies/falcon.py
@@ -47,6 +47,12 @@ def module_policy(self):
embedding_cls = col_nn.PaddingEmbedding
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_kv_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
attn_attribute_replacement = {
"self_attention.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
"self_attention.split_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
diff --git a/colossalai/shardformer/policies/gpt2.py b/colossalai/shardformer/policies/gpt2.py
index 6f4f835a8dbe..281ea88c2162 100644
--- a/colossalai/shardformer/policies/gpt2.py
+++ b/colossalai/shardformer/policies/gpt2.py
@@ -10,6 +10,7 @@
GPT2PipelineForwards,
get_gpt2_flash_attention_forward,
get_gpt_model_forward_for_flash_attn,
+ get_jit_fused_gpt2_mlp_forward,
get_lm_forward_with_dist_cross_entropy,
gpt2_sequence_parallel_forward_fn,
)
@@ -36,10 +37,13 @@ def preprocess(self):
"""
self.tie_weight = self.tie_weight_check()
self.origin_attn_implement = self.model.config._attn_implementation
+ self.enable_bias_gelu_fused = (
+ self.shard_config.enable_jit_fused and self.model.config.activation_function == "gelu"
+ )
return self.model
def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2Attention, GPT2Block, GPT2Model
+ from transformers.models.gpt2.modeling_gpt2 import GPT2MLP, GPT2Attention, GPT2Block, GPT2Model
ATTN_IMPLEMENTATION = {
"eager": GPT2Attention,
@@ -80,6 +84,9 @@ def module_policy(self):
self.shard_config.enable_flash_attention = False
use_flash_attention = False
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[GPT2Model] = ModulePolicyDescription(
sub_module_replacement=[
SubModuleReplacementDescription(
@@ -119,6 +126,7 @@ def module_policy(self):
"n_fused": 1,
"seq_parallel_mode": sp_mode,
"overlap": overlap,
+ "skip_bias_add": self.enable_bias_gelu_fused,
},
),
SubModuleReplacementDescription(
@@ -142,6 +150,14 @@ def module_policy(self):
),
],
)
+ if self.enable_bias_gelu_fused:
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_jit_fused_gpt2_mlp_forward(),
+ },
+ policy=policy,
+ target_key=GPT2MLP,
+ )
if embedding_cls is not None:
# padding vocabulary size when using pp to make it divisible by shard_config.make_vocab_size_divisible_by
self.append_or_create_submodule_replacement(
diff --git a/colossalai/shardformer/policies/gptj.py b/colossalai/shardformer/policies/gptj.py
index 1280efaec921..3315eb1e9256 100644
--- a/colossalai/shardformer/policies/gptj.py
+++ b/colossalai/shardformer/policies/gptj.py
@@ -54,10 +54,12 @@ def module_policy(self):
if self.shard_config.enable_sequence_parallelism:
self.shard_config.enable_sequence_parallelism = False
warnings.warn("GPTJ doesn't support sequence parallelism now, will ignore the sequence parallelism flag.")
- use_sequence_parallel = self.shard_config.enable_sequence_parallelism
overlap = self.shard_config.enable_sequence_overlap
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[GPTJModel] = ModulePolicyDescription(
sub_module_replacement=[
SubModuleReplacementDescription(
@@ -78,7 +80,6 @@ def module_policy(self):
suffix="attn.k_proj",
target_module=col_nn.Linear1D_Col,
kwargs={
- "seq_parallel": use_sequence_parallel,
"overlap": overlap,
},
),
@@ -86,7 +87,6 @@ def module_policy(self):
suffix="attn.q_proj",
target_module=col_nn.Linear1D_Col,
kwargs={
- "seq_parallel": use_sequence_parallel,
"overlap": overlap,
},
),
@@ -94,24 +94,20 @@ def module_policy(self):
suffix="attn.v_proj",
target_module=col_nn.Linear1D_Col,
kwargs={
- "seq_parallel": use_sequence_parallel,
"overlap": overlap,
},
),
SubModuleReplacementDescription(
suffix="attn.out_proj",
target_module=col_nn.Linear1D_Row,
- kwargs={"seq_parallel": use_sequence_parallel},
),
SubModuleReplacementDescription(
suffix="mlp.fc_in",
target_module=col_nn.Linear1D_Col,
- kwargs={"seq_parallel": use_sequence_parallel},
),
SubModuleReplacementDescription(
suffix="mlp.fc_out",
target_module=col_nn.Linear1D_Row,
- kwargs={"seq_parallel": use_sequence_parallel},
),
SubModuleReplacementDescription(
suffix="attn.attn_dropout",
diff --git a/colossalai/shardformer/policies/llama.py b/colossalai/shardformer/policies/llama.py
index 0a95284bcfdf..6e541f792248 100644
--- a/colossalai/shardformer/policies/llama.py
+++ b/colossalai/shardformer/policies/llama.py
@@ -138,6 +138,12 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
)
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
decoder_attribute_replacement = {
"self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
"self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
diff --git a/colossalai/shardformer/policies/mistral.py b/colossalai/shardformer/policies/mistral.py
index b5018e47d65d..984b71646318 100644
--- a/colossalai/shardformer/policies/mistral.py
+++ b/colossalai/shardformer/policies/mistral.py
@@ -66,6 +66,12 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
)
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
decoder_attribute_replacement = {
"self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
"self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
diff --git a/colossalai/shardformer/policies/opt.py b/colossalai/shardformer/policies/opt.py
index 2f6eabd5fef9..9619b3d41b8a 100644
--- a/colossalai/shardformer/policies/opt.py
+++ b/colossalai/shardformer/policies/opt.py
@@ -76,6 +76,9 @@ def module_policy(self):
warnings.warn("OPT doesn't support sequence parallelism now, will ignore the sequence parallelism flag.")
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[OPTDecoderLayer] = ModulePolicyDescription(
sub_module_replacement=[
SubModuleReplacementDescription(
diff --git a/colossalai/shardformer/policies/sam.py b/colossalai/shardformer/policies/sam.py
index ce33925ff82e..c224d776957a 100644
--- a/colossalai/shardformer/policies/sam.py
+++ b/colossalai/shardformer/policies/sam.py
@@ -31,6 +31,9 @@ def module_policy(self):
norm_cls = col_nn.LayerNorm
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.vision_config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[SamVisionLayer] = ModulePolicyDescription(
attribute_replacement={
"attn.num_attention_heads": self.model.config.vision_config.num_attention_heads
diff --git a/colossalai/shardformer/policies/t5.py b/colossalai/shardformer/policies/t5.py
index 3c7e92b47db0..1298f0af3e61 100644
--- a/colossalai/shardformer/policies/t5.py
+++ b/colossalai/shardformer/policies/t5.py
@@ -72,6 +72,9 @@ def module_policy(self):
warnings.warn("T5 doesn't support sequence parallelism now, will ignore the sequence parallelism flag.")
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[T5Stack] = ModulePolicyDescription(
sub_module_replacement=[
SubModuleReplacementDescription(
diff --git a/colossalai/shardformer/policies/vit.py b/colossalai/shardformer/policies/vit.py
index 905398c4d51e..069ad0c2690c 100644
--- a/colossalai/shardformer/policies/vit.py
+++ b/colossalai/shardformer/policies/vit.py
@@ -11,6 +11,7 @@
ViTForImageClassification_pipeline_forward,
ViTForMaskedImageModeling_pipeline_forward,
ViTModel_pipeline_forward,
+ get_jit_fused_vit_intermediate_forward,
get_jit_fused_vit_output_forward,
get_vit_flash_self_attention_forward,
)
@@ -24,10 +25,17 @@ def config_sanity_check(self):
pass
def preprocess(self):
+ self.enable_bias_gelu_fused = self.shard_config.enable_jit_fused and self.model.config.hidden_act == "gelu"
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer, ViTOutput, ViTSelfAttention
+ from transformers.models.vit.modeling_vit import (
+ ViTEmbeddings,
+ ViTIntermediate,
+ ViTLayer,
+ ViTOutput,
+ ViTSelfAttention,
+ )
policy = {}
@@ -36,6 +44,9 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
warnings.warn("Vit doesn't support sequence parallelism now, will ignore the sequence parallelism flag.")
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[ViTEmbeddings] = ModulePolicyDescription(
attribute_replacement={},
param_replacement=[],
@@ -83,6 +94,9 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
SubModuleReplacementDescription(
suffix="intermediate.dense",
target_module=col_nn.Linear1D_Col,
+ kwargs={
+ "skip_bias_add": self.enable_bias_gelu_fused,
+ },
),
SubModuleReplacementDescription(
suffix="output.dense",
@@ -94,6 +108,14 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
),
],
)
+ if self.enable_bias_gelu_fused:
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_jit_fused_vit_intermediate_forward(),
+ },
+ policy=policy,
+ target_key=ViTIntermediate,
+ )
# use flash attention
if self.shard_config.enable_flash_attention:
@@ -115,6 +137,7 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
policy=policy,
target_key=ViTOutput,
)
+
return policy
def new_model_class(self):
diff --git a/colossalai/shardformer/policies/whisper.py b/colossalai/shardformer/policies/whisper.py
index aeb6687971e5..441e512bbb28 100644
--- a/colossalai/shardformer/policies/whisper.py
+++ b/colossalai/shardformer/policies/whisper.py
@@ -78,6 +78,9 @@ def module_policy(self):
warnings.warn("Whisper doesn't support jit fused operator now, will ignore the jit fused operator flag.")
if self.shard_config.enable_tensor_parallelism:
+ assert (
+ self.model.config.encoder_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
policy[WhisperEncoderLayer] = ModulePolicyDescription(
attribute_replacement={
"self_attn.embed_dim": self.model.config.d_model // self.shard_config.tensor_parallel_size,
diff --git a/colossalai/shardformer/shard/shardformer.py b/colossalai/shardformer/shard/shardformer.py
index b132f47fd810..b3991c4f0d9b 100644
--- a/colossalai/shardformer/shard/shardformer.py
+++ b/colossalai/shardformer/shard/shardformer.py
@@ -26,7 +26,7 @@ class ShardFormer:
import colossalai
import torch
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
org_model = BertForMaskedLM.from_pretrained('bert-base-uncased')
shard_config = ShardConfig()
diff --git a/colossalai/tensor/d_tensor/README.md b/colossalai/tensor/d_tensor/README.md
index 3d862dddbf20..367db5ccd2fc 100644
--- a/colossalai/tensor/d_tensor/README.md
+++ b/colossalai/tensor/d_tensor/README.md
@@ -69,7 +69,7 @@ import colossalai
from colossalai.device.device_mesh import DeviceMesh
from colossalai.tensor.d_tensor import DTensor, ShardingSpec
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
# define your device mesh
# assume you have 4 GPUs
diff --git a/colossalai/zero/low_level/bookkeeping/gradient_store.py b/colossalai/zero/low_level/bookkeeping/gradient_store.py
index 73a1db5a0c0d..6d4fcbb86ec6 100644
--- a/colossalai/zero/low_level/bookkeeping/gradient_store.py
+++ b/colossalai/zero/low_level/bookkeeping/gradient_store.py
@@ -82,6 +82,9 @@ def get_working_grads_by_group_id(self, group_id: int) -> List:
"""
grad_list = []
+ # When using LoRa and the user sets multiple param_groups, it is possible that some param_groups have no parameters with gradients.
+ if group_id not in self._grads_of_params.keys():
+ return grad_list
for param_grads in self._grads_of_params[group_id].values():
grad_list.append(param_grads[self._working_index])
diff --git a/colossalai/zero/low_level/low_level_optim.py b/colossalai/zero/low_level/low_level_optim.py
index d22913d60924..bdcda8264dd5 100644
--- a/colossalai/zero/low_level/low_level_optim.py
+++ b/colossalai/zero/low_level/low_level_optim.py
@@ -235,9 +235,10 @@ def _sanity_checks(self):
for param_group in self.optim.param_groups:
group_params = param_group["params"]
for param in group_params:
- assert (
- param.dtype == self._dtype
- ), f"Parameters are expected to have the same dtype `{self._dtype}`, but got `{param.dtype}`"
+ if not hasattr(param, "skip_zero_check") or param.skip_zero_check is False:
+ assert (
+ param.dtype == self._dtype
+ ), f"Parameters are expected to have the same dtype `{self._dtype}`, but got `{param.dtype}`"
def _create_master_param_current_rank(self, param_list):
# split each param evenly by world size
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 7e0ed07fec16..2e54377525f1 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,6 +24,8 @@
## 新闻
+* [2024/04] [Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
+* [2024/04] [Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series](https://hpc-ai.com/blog/most-cost-effective-solutions-for-inference-fine-tuning-and-pretraining-tailored-to-llama3-series)
* [2024/03] [314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here](https://hpc-ai.com/blog/314-billion-parameter-grok-1-inference-accelerated-by-3.8x-efficient-and-easy-to-use-pytorchhuggingface-version-is-here)
* [2024/03] [Open-Sora: Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models](https://hpc-ai.com/blog/open-sora-v1.0)
* [2024/03] [Open-Sora:Sora Replication Solution with 46% Cost Reduction, Sequence Expansion to Nearly a Million](https://hpc-ai.com/blog/open-sora)
@@ -126,7 +128,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
[Open-Sora](https://github.com/hpcaitech/Open-Sora):全面开源类Sora模型参数和所有训练细节
[[代码]](https://github.com/hpcaitech/Open-Sora)
-[[博客]](https://hpc-ai.com/blog/open-sora-v1.0)
+[[博客]](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
[[模型权重]](https://huggingface.co/hpcai-tech/Open-Sora)
[[演示样例]](https://github.com/hpcaitech/Open-Sora?tab=readme-ov-file#-latest-demo)
diff --git a/docs/source/en/advanced_tutorials/train_gpt_using_hybrid_parallelism.md b/docs/source/en/advanced_tutorials/train_gpt_using_hybrid_parallelism.md
index 0133dfd86ddf..b27f9c811090 100644
--- a/docs/source/en/advanced_tutorials/train_gpt_using_hybrid_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_gpt_using_hybrid_parallelism.md
@@ -75,7 +75,7 @@ WARMUP_FRACTION = 0.1
we create a distributed environment.
```python
# Launch ColossalAI
-colossalai.launch_from_torch(config={}, seed=42)
+colossalai.launch_from_torch( seed=42)
coordinator = DistCoordinator()
```
prepare the dataset. You can use `plugin.prepare_dataloader` to generate a dataloader or customize your own dataloader.
diff --git a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index dfc2cd596d79..ac4169344af5 100644
--- a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -71,7 +71,7 @@ PP_SIZE = 2
Create a distributed environment.
```python
# Launch ColossalAI
-colossalai.launch_from_torch(config={}, seed=SEEDå)
+colossalai.launch_from_torch( seed=SEEDå)
coordinator = DistCoordinator()
world_size = coordinator.world_size
```
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
index 2c75dd9acfea..a33be3b494db 100644
--- a/docs/source/en/basics/booster_api.md
+++ b/docs/source/en/basics/booster_api.md
@@ -55,7 +55,7 @@ from colossalai.booster.plugin import TorchDDPPlugin
def train():
# launch colossalai
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host='localhost')
# create plugin and objects for training
plugin = TorchDDPPlugin()
diff --git a/docs/source/en/basics/launch_colossalai.md b/docs/source/en/basics/launch_colossalai.md
index 334757ea75af..8a6028d6c49a 100644
--- a/docs/source/en/basics/launch_colossalai.md
+++ b/docs/source/en/basics/launch_colossalai.md
@@ -87,8 +87,7 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=args.config,
- rank=args.rank,
+colossalai.launch(rank=args.rank,
world_size=args.world_size,
host=args.host,
port=args.port,
@@ -106,20 +105,11 @@ First, we need to set the launch method in our code. As this is a wrapper of the
use `colossalai.launch_from_torch`. The arguments required for distributed environment such as rank, world size, host and port are all set by the PyTorch
launcher and can be read from the environment variable directly.
-config.py
-```python
-BATCH_SIZE = 512
-LEARNING_RATE = 3e-3
-WEIGHT_DECAY = 0.3
-NUM_EPOCHS = 2
-```
train.py
```python
import colossalai
-colossalai.launch_from_torch(
- config="./config.py",
-)
+colossalai.launch_from_torch()
...
```
@@ -203,7 +193,6 @@ Do this in your training script:
import colossalai
colossalai.launch_from_slurm(
- config=,
host=args.host,
port=args.port
)
@@ -224,7 +213,6 @@ use them to start the distributed backend.
Do this in your train.py:
```python
colossalai.launch_from_openmpi(
- config=,
host=args.host,
port=args.port
)
@@ -238,3 +226,5 @@ mpirun --hostfile -np python train.py --host
diff --git a/docs/source/en/features/gradient_accumulation_with_booster.md b/docs/source/en/features/gradient_accumulation_with_booster.md
index ea97dd92e885..f1e47e9bb1df 100644
--- a/docs/source/en/features/gradient_accumulation_with_booster.md
+++ b/docs/source/en/features/gradient_accumulation_with_booster.md
@@ -45,7 +45,7 @@ We then need to initialize distributed environment. For demo purpose, we uses `l
parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
-colossalai.launch_from_torch(config=dict())
+colossalai.launch_from_torch()
```
### Step 3. Create training components
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index 14eee67bc019..9f9074e1d942 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -61,7 +61,7 @@ We then need to initialize distributed environment. For demo purpose, we uses `l
for other initialization methods.
```python
-colossalai.launch_from_torch(config=dict())
+colossalai.launch_from_torch()
logger = get_dist_logger()
```
diff --git a/docs/source/en/features/lazy_init.md b/docs/source/en/features/lazy_init.md
index 160f68767156..30b33b52f122 100644
--- a/docs/source/en/features/lazy_init.md
+++ b/docs/source/en/features/lazy_init.md
@@ -29,7 +29,7 @@ from colossalai.booster.plugin import GeminiPlugin
from transformers import LlamaForCausalLM, LlamaConfig, BertForPreTraining
-colossalai.launch({})
+colossalai.launch()
plugin = GeminiPlugin()
booster = Booster(plugin)
diff --git a/docs/source/en/features/mixed_precision_training_with_booster.md b/docs/source/en/features/mixed_precision_training_with_booster.md
index 8e702a578ea4..baaaacdddf9e 100644
--- a/docs/source/en/features/mixed_precision_training_with_booster.md
+++ b/docs/source/en/features/mixed_precision_training_with_booster.md
@@ -20,10 +20,10 @@ In Colossal-AI, we have incorporated different implementations of mixed precisio
3. naive amp
| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
-| -------------- | ----------------------- | ------------------------- | ---------------------------------------------------------------------------------------------------- |
-| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
-| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
-| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
+|----------------|-------------------------|---------------------------|------------------------------------------------------------------------------------------------------|
+| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
+| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex.
The last method is similar to Apex O2 level.
@@ -164,7 +164,7 @@ parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
-colossalai.launch_from_torch(config=dict())
+colossalai.launch_from_torch()
```
diff --git a/docs/source/en/features/nvme_offload.md b/docs/source/en/features/nvme_offload.md
index 6ed6f2dee5d6..343a1f67e8a5 100644
--- a/docs/source/en/features/nvme_offload.md
+++ b/docs/source/en/features/nvme_offload.md
@@ -185,7 +185,7 @@ Then we can train GPT model with Gemini. The placement policy of Gemini should b
```python
def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
config = GPT2Config()
with ColoInitContext(device=torch.cuda.current_device()):
model = GPT2LMHeadModel(config)
diff --git a/docs/source/en/features/zero_with_chunk.md b/docs/source/en/features/zero_with_chunk.md
index 62be864884b7..f0c13830a37c 100644
--- a/docs/source/en/features/zero_with_chunk.md
+++ b/docs/source/en/features/zero_with_chunk.md
@@ -174,7 +174,7 @@ def main():
SEQ_LEN = 1024
VOCAB_SIZE = 50257
NUM_STEPS = 10
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
# build criterion
criterion = GPTLMLoss()
diff --git a/docs/source/zh-Hans/advanced_tutorials/train_gpt_using_hybrid_parallelism.md b/docs/source/zh-Hans/advanced_tutorials/train_gpt_using_hybrid_parallelism.md
index cf7d191723e1..4d4ea8163775 100644
--- a/docs/source/zh-Hans/advanced_tutorials/train_gpt_using_hybrid_parallelism.md
+++ b/docs/source/zh-Hans/advanced_tutorials/train_gpt_using_hybrid_parallelism.md
@@ -62,7 +62,7 @@ plugin = HybridParallelPlugin(
## 创建分布式环境.
```python
# Launch ColossalAI
-colossalai.launch_from_torch(config={}, seed=42)
+colossalai.launch_from_torch(seed=42)
coordinator = DistCoordinator()
```
## 定义GPT-2模型的训练组件
diff --git a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index f32f6c367fe3..c234a3c6e5e2 100644
--- a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -70,7 +70,7 @@ PP_SIZE = 2
首先我们创建一个分布式环境
```python
# Launch ColossalAI
-colossalai.launch_from_torch(config={}, seed=SEEDå)
+colossalai.launch_from_torch(seed=SEEDå)
coordinator = DistCoordinator()
world_size = coordinator.world_size
```
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
index bb100964da4c..a9357617dd7b 100644
--- a/docs/source/zh-Hans/basics/booster_api.md
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -60,7 +60,7 @@ from colossalai.booster.plugin import TorchDDPPlugin
def train():
# launch colossalai
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host='localhost')
# create plugin and objects for training
plugin = TorchDDPPlugin()
diff --git a/docs/source/zh-Hans/basics/launch_colossalai.md b/docs/source/zh-Hans/basics/launch_colossalai.md
index 39b09deae085..a80d16717e40 100644
--- a/docs/source/zh-Hans/basics/launch_colossalai.md
+++ b/docs/source/zh-Hans/basics/launch_colossalai.md
@@ -74,8 +74,7 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=args.config,
- rank=args.rank,
+colossalai.launch(rank=args.rank,
world_size=args.world_size,
host=args.host,
port=args.port,
@@ -93,20 +92,11 @@ PyTorch自带的启动器需要在每个节点上都启动命令才能启动多
首先,我们需要在代码里指定我们的启动方式。由于这个启动器是PyTorch启动器的封装,那么我们自然而然应该使用`colossalai.launch_from_torch`。
分布式环境所需的参数,如 rank, world size, host 和 port 都是由 PyTorch 启动器设置的,可以直接从环境变量中读取。
-config.py
-```python
-BATCH_SIZE = 512
-LEARNING_RATE = 3e-3
-WEIGHT_DECAY = 0.3
-NUM_EPOCHS = 2
-```
train.py
```python
import colossalai
-colossalai.launch_from_torch(
- config="./config.py",
-)
+colossalai.launch_from_torch()
...
```
@@ -186,7 +176,6 @@ colossalai run --nproc_per_node 4 --hostfile ./hostfile --master_addr host1 --e
import colossalai
colossalai.launch_from_slurm(
- config=,
host=args.host,
port=args.port
)
@@ -206,7 +195,6 @@ srun python train.py --host --port 29500
您可以在您的训练脚本中尝试以下操作。
```python
colossalai.launch_from_openmpi(
- config=,
host=args.host,
port=args.port
)
@@ -219,3 +207,5 @@ mpirun --hostfile -np python train.py --host
diff --git a/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
index 824308f94654..7ad8fb1455e9 100644
--- a/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
@@ -46,7 +46,7 @@ parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
-colossalai.launch_from_torch(config=dict())
+colossalai.launch_from_torch()
```
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index fdec09bf128a..b000d4585cd2 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -61,7 +61,7 @@ from colossalai.nn.lr_scheduler import CosineAnnealingLR
我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
```python
-colossalai.launch_from_torch(config=dict())
+colossalai.launch_from_torch()
logger = get_dist_logger()
```
diff --git a/docs/source/zh-Hans/features/lazy_init.md b/docs/source/zh-Hans/features/lazy_init.md
index 137719c69de2..c9cc0e4ba76f 100644
--- a/docs/source/zh-Hans/features/lazy_init.md
+++ b/docs/source/zh-Hans/features/lazy_init.md
@@ -29,7 +29,7 @@ from colossalai.booster.plugin import GeminiPlugin
from transformers import LlamaForCausalLM, LlamaConfig, BertForPreTraining
-colossalai.launch({})
+colossalai.launch()
plugin = GeminiPlugin()
booster = Booster(plugin)
diff --git a/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
index 8e9f614a25af..53d9013db296 100644
--- a/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
+++ b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
@@ -19,11 +19,11 @@ AMP 代表自动混合精度训练。
2. apex.amp
3. naive amp
-| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16 范围 |
-| -------------- | ------------ | ------------ | --------------------------------------------------------- |
-| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至 fp16 |
-| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
-| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至 fp16 |
+| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16 范围 |
+|----------------|--------------|--------------|-------------------------------------------------------|
+| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至 fp16 |
+| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至 fp16 |
前两个依赖于 PyTorch (1.6 及以上) 和 NVIDIA Apex 的原始实现。最后一种方法类似 Apex O2。在这些方法中,Apex-AMP 与张量并行不兼容。这是因为张量是以张量并行的方式在设备之间拆分的,因此,需要在不同的进程之间进行通信,以检查整个模型权重中是否出现 inf 或 nan。我们修改了 torch amp 实现,使其现在与张量并行兼容。
@@ -153,7 +153,7 @@ parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
-colossalai.launch_from_torch(config=dict())
+colossalai.launch_from_torch()
```
diff --git a/docs/source/zh-Hans/features/nvme_offload.md b/docs/source/zh-Hans/features/nvme_offload.md
index 1feb9dde5725..f013e755d262 100644
--- a/docs/source/zh-Hans/features/nvme_offload.md
+++ b/docs/source/zh-Hans/features/nvme_offload.md
@@ -175,7 +175,7 @@ Mem usage: 4968.016 MB
```python
def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
config = GPT2Config()
with ColoInitContext(device=torch.cuda.current_device()):
model = GPT2LMHeadModel(config)
diff --git a/docs/source/zh-Hans/features/zero_with_chunk.md b/docs/source/zh-Hans/features/zero_with_chunk.md
index c4f21c73c586..4a4655d607a8 100644
--- a/docs/source/zh-Hans/features/zero_with_chunk.md
+++ b/docs/source/zh-Hans/features/zero_with_chunk.md
@@ -174,7 +174,7 @@ def main():
SEQ_LEN = 1024
VOCAB_SIZE = 50257
NUM_STEPS = 10
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
# build criterion
criterion = GPTLMLoss()
diff --git a/examples/community/roberta/pretraining/run_pretraining.py b/examples/community/roberta/pretraining/run_pretraining.py
index 40b11d649ae0..48cde8239775 100644
--- a/examples/community/roberta/pretraining/run_pretraining.py
+++ b/examples/community/roberta/pretraining/run_pretraining.py
@@ -35,12 +35,12 @@ def main():
if args.vscode_debug:
colossalai.launch(
- config={}, rank=args.rank, world_size=args.world_size, host=args.host, port=args.port, backend=args.backend
+ rank=args.rank, world_size=args.world_size, host=args.host, port=args.port, backend=args.backend
)
args.local_rank = -1
args.log_interval = 1
else:
- colossalai.launch_from_torch(config={}) # args.colossal_config
+ colossalai.launch_from_torch() # args.colossal_config
args.local_rank = int(os.environ["LOCAL_RANK"])
logger.info(
f"launch_from_torch, world size: {torch.distributed.get_world_size()} | "
diff --git a/examples/images/dreambooth/debug.py b/examples/images/dreambooth/debug.py
index 8ce4dc3bbd80..64588e904b3c 100644
--- a/examples/images/dreambooth/debug.py
+++ b/examples/images/dreambooth/debug.py
@@ -9,7 +9,7 @@
path = "/data/scratch/diffuser/stable-diffusion-v1-4"
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
with ColoInitContext(device="cpu"):
vae = AutoencoderKL.from_pretrained(
path,
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai.py b/examples/images/dreambooth/train_dreambooth_colossalai.py
index cc2b2ebc7b88..2bacb3a0470e 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai.py
@@ -372,9 +372,9 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
def main(args):
if args.seed is None:
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
else:
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
local_rank = dist.get_rank()
world_size = dist.get_world_size()
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
index 227488abe204..c4ef2a34e65d 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
@@ -371,9 +371,9 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
def main(args):
if args.seed is None:
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
else:
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
local_rank = gpc.get_local_rank(ParallelMode.DATA)
world_size = gpc.get_world_size(ParallelMode.DATA)
diff --git a/examples/images/resnet/train.py b/examples/images/resnet/train.py
index 5871bbf8748b..a53a851806ef 100644
--- a/examples/images/resnet/train.py
+++ b/examples/images/resnet/train.py
@@ -128,7 +128,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# update the learning rate with linear scaling
diff --git a/examples/images/vit/vit_benchmark.py b/examples/images/vit/vit_benchmark.py
index fdae9ee01537..790bb2b74480 100644
--- a/examples/images/vit/vit_benchmark.py
+++ b/examples/images/vit/vit_benchmark.py
@@ -46,7 +46,7 @@ def main():
args = parse_benchmark_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
world_size = coordinator.world_size
diff --git a/examples/images/vit/vit_train_demo.py b/examples/images/vit/vit_train_demo.py
index 81009b3707b6..a65f89171a03 100644
--- a/examples/images/vit/vit_train_demo.py
+++ b/examples/images/vit/vit_train_demo.py
@@ -137,7 +137,7 @@ def main():
args = parse_demo_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
world_size = coordinator.world_size
diff --git a/examples/inference/benchmark_llama.py b/examples/inference/benchmark_llama.py
index 26cac977a931..a23ab500a6c2 100644
--- a/examples/inference/benchmark_llama.py
+++ b/examples/inference/benchmark_llama.py
@@ -136,7 +136,7 @@ def benchmark_inference(args):
def hybrid_inference(rank, world_size, port, args):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
benchmark_inference(args)
diff --git a/examples/inference/run_llama_inference.py b/examples/inference/run_llama_inference.py
index b5228c64efa5..a4e6fd0a143d 100644
--- a/examples/inference/run_llama_inference.py
+++ b/examples/inference/run_llama_inference.py
@@ -68,7 +68,7 @@ def run_inference(args):
def run_tp_pipeline_inference(rank, world_size, port, args):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_inference(args)
diff --git a/examples/language/bert/benchmark.py b/examples/language/bert/benchmark.py
index 10bd367fda5b..9270c1b0cd3d 100644
--- a/examples/language/bert/benchmark.py
+++ b/examples/language/bert/benchmark.py
@@ -81,7 +81,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
coordinator = DistCoordinator()
# local_batch_size = BATCH_SIZE // coordinator.world_size
diff --git a/examples/language/bert/finetune.py b/examples/language/bert/finetune.py
index bd6c393a7ddc..7e8c07fdce47 100644
--- a/examples/language/bert/finetune.py
+++ b/examples/language/bert/finetune.py
@@ -202,7 +202,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
coordinator = DistCoordinator()
lr = LEARNING_RATE * coordinator.world_size
diff --git a/examples/language/gpt/experiments/auto_offload/train_gpt_offload.py b/examples/language/gpt/experiments/auto_offload/train_gpt_offload.py
index b35112498978..fbb3a151a2b6 100644
--- a/examples/language/gpt/experiments/auto_offload/train_gpt_offload.py
+++ b/examples/language/gpt/experiments/auto_offload/train_gpt_offload.py
@@ -94,8 +94,7 @@ def train_gpt(args):
def run(rank, world_size, port, args):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
train_gpt(args)
diff --git a/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py b/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py
index f3d35dd9042b..9a33c6598701 100644
--- a/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py
+++ b/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py
@@ -47,7 +47,7 @@ def get_data(batch_size, seq_len, vocab_size):
def main():
disable_existing_loggers()
- launch_from_torch(config={})
+ launch_from_torch()
logger = get_dist_logger()
config = transformers.GPT2Config(n_position=SEQ_LENGTH, n_layer=NUM_LAYERS, n_head=NUM_HEADS, n_embd=HIDDEN_DIM)
if FP16:
diff --git a/examples/language/gpt/gemini/train_gpt_demo.py b/examples/language/gpt/gemini/train_gpt_demo.py
index 78d090ba29da..4911ff124328 100644
--- a/examples/language/gpt/gemini/train_gpt_demo.py
+++ b/examples/language/gpt/gemini/train_gpt_demo.py
@@ -132,7 +132,7 @@ def main():
PROF_FLAG = False # The flag of profiling, False by default
disable_existing_loggers()
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
logger = get_dist_logger()
logger.info(f"{args.model_type}, {args.distplan}, batch size {BATCH_SIZE}", ranks=[0])
diff --git a/examples/language/gpt/hybridparallelism/benchmark.py b/examples/language/gpt/hybridparallelism/benchmark.py
index 1315deae6eb0..8c236b524c26 100644
--- a/examples/language/gpt/hybridparallelism/benchmark.py
+++ b/examples/language/gpt/hybridparallelism/benchmark.py
@@ -67,7 +67,7 @@ def main():
parser.add_argument("--cpu_offload", action="store_true", help="Use gradient checkpointing")
args = parser.parse_args()
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
def empty_init():
diff --git a/examples/language/gpt/hybridparallelism/finetune.py b/examples/language/gpt/hybridparallelism/finetune.py
index 888f47aaaab0..32b2dfcc08b5 100644
--- a/examples/language/gpt/hybridparallelism/finetune.py
+++ b/examples/language/gpt/hybridparallelism/finetune.py
@@ -196,7 +196,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
coordinator = DistCoordinator()
# local_batch_size = BATCH_SIZE // coordinator.world_size
diff --git a/examples/language/gpt/titans/train_gpt.py b/examples/language/gpt/titans/train_gpt.py
index 565cf1e016cc..6b45bd33ec05 100644
--- a/examples/language/gpt/titans/train_gpt.py
+++ b/examples/language/gpt/titans/train_gpt.py
@@ -36,9 +36,9 @@ def main():
args = parser.parse_args()
disable_existing_loggers()
if args.from_torch:
- colossalai.launch_from_torch(config=args.config)
+ colossalai.launch_from_torch()
else:
- colossalai.launch_from_slurm(config=args.config, host=args.host, port=29500, seed=42)
+ colossalai.launch_from_slurm(host=args.host, port=29500, seed=42)
logger = get_dist_logger()
data_path = None if args.use_dummy_dataset else os.environ["DATA"]
diff --git a/examples/language/grok-1/inference_tp.py b/examples/language/grok-1/inference_tp.py
index e10c4929cdbf..f7d7cf864e9b 100644
--- a/examples/language/grok-1/inference_tp.py
+++ b/examples/language/grok-1/inference_tp.py
@@ -16,7 +16,7 @@
parser = get_default_parser()
args = parser.parse_args()
start = time.time()
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
plugin = HybridParallelPlugin(
tp_size=coordinator.world_size,
diff --git a/examples/language/llama/benchmark.py b/examples/language/llama/benchmark.py
index d26975fc5071..5cc602181e83 100644
--- a/examples/language/llama/benchmark.py
+++ b/examples/language/llama/benchmark.py
@@ -19,9 +19,6 @@
from colossalai.lazy import LazyInitContext
from colossalai.nn.optimizer import HybridAdam
from colossalai.shardformer import PipelineGradientCheckpointConfig
-from examples.language.data_utils import RandomDataset
-from examples.language.model_utils import format_numel_str, get_model_numel
-from examples.language.performance_evaluator import PerformanceEvaluator
# ==============================
# Constants
@@ -81,7 +78,7 @@ def main():
parser.add_argument("--custom-ckpt", action="store_true", help="Customize checkpoint", default=False)
args = parser.parse_args()
- colossalai.launch_from_torch({})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
def empty_init():
diff --git a/examples/language/llama/data_utils.py b/examples/language/llama/data_utils.py
new file mode 120000
index 000000000000..2da9822dfc57
--- /dev/null
+++ b/examples/language/llama/data_utils.py
@@ -0,0 +1 @@
+../data_utils.py
\ No newline at end of file
diff --git a/examples/language/llama/model_utils.py b/examples/language/llama/model_utils.py
new file mode 120000
index 000000000000..73c6818a8c8f
--- /dev/null
+++ b/examples/language/llama/model_utils.py
@@ -0,0 +1 @@
+../model_utils.py
\ No newline at end of file
diff --git a/examples/language/llama/performance_evaluator.py b/examples/language/llama/performance_evaluator.py
new file mode 120000
index 000000000000..f4736354b1f3
--- /dev/null
+++ b/examples/language/llama/performance_evaluator.py
@@ -0,0 +1 @@
+../performance_evaluator.py
\ No newline at end of file
diff --git a/examples/language/openmoe/benchmark/benchmark_cai.py b/examples/language/openmoe/benchmark/benchmark_cai.py
index a6d5f8bf2c0e..22e0c790b17f 100644
--- a/examples/language/openmoe/benchmark/benchmark_cai.py
+++ b/examples/language/openmoe/benchmark/benchmark_cai.py
@@ -146,7 +146,7 @@ def main():
args = parse_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
# Set plugin
diff --git a/examples/language/openmoe/train.py b/examples/language/openmoe/train.py
index 92f4e066a7a5..40f072f13c54 100644
--- a/examples/language/openmoe/train.py
+++ b/examples/language/openmoe/train.py
@@ -207,7 +207,7 @@ def main():
args = parse_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
test_mode = args.model_name == "test"
diff --git a/examples/language/opt/opt_benchmark.py b/examples/language/opt/opt_benchmark.py
index d16c9fdf99ad..c2883d96c16e 100755
--- a/examples/language/opt/opt_benchmark.py
+++ b/examples/language/opt/opt_benchmark.py
@@ -46,7 +46,7 @@ def main():
args = parse_benchmark_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
world_size = coordinator.world_size
diff --git a/examples/language/opt/opt_train_demo.py b/examples/language/opt/opt_train_demo.py
index 05336bec42c5..b5b50305cc34 100644
--- a/examples/language/opt/opt_train_demo.py
+++ b/examples/language/opt/opt_train_demo.py
@@ -64,7 +64,7 @@ def main():
args = parse_demo_args()
# Launch ColossalAI
- colossalai.launch_from_torch(config={}, seed=args.seed)
+ colossalai.launch_from_torch(seed=args.seed)
coordinator = DistCoordinator()
world_size = coordinator.world_size
diff --git a/examples/language/palm/train.py b/examples/language/palm/train.py
index 4fac7b5072ed..76a86600b344 100644
--- a/examples/language/palm/train.py
+++ b/examples/language/palm/train.py
@@ -102,7 +102,7 @@ def get_model_size(model: nn.Module):
if args.distplan not in ["colossalai", "pytorch"]:
raise TypeError(f"{args.distplan} is error")
disable_existing_loggers()
-colossalai.launch_from_torch(config={})
+colossalai.launch_from_torch()
logger = get_dist_logger()
diff --git a/examples/tutorial/auto_parallel/auto_ckpt_batchsize_test.py b/examples/tutorial/auto_parallel/auto_ckpt_batchsize_test.py
index 29101ce08434..b7a3f4320fa6 100644
--- a/examples/tutorial/auto_parallel/auto_ckpt_batchsize_test.py
+++ b/examples/tutorial/auto_parallel/auto_ckpt_batchsize_test.py
@@ -20,7 +20,7 @@ def _benchmark(rank, world_size, port):
only result in minor performance drop. So at last we might be able to find better training batch size for our
model (combine with large batch training optimizer such as LAMB).
"""
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = tm.resnet152()
gm = symbolic_trace(model)
raw_graph = deepcopy(gm.graph)
diff --git a/examples/tutorial/auto_parallel/auto_ckpt_solver_test.py b/examples/tutorial/auto_parallel/auto_ckpt_solver_test.py
index cd03a917912e..81ef7ca03154 100644
--- a/examples/tutorial/auto_parallel/auto_ckpt_solver_test.py
+++ b/examples/tutorial/auto_parallel/auto_ckpt_solver_test.py
@@ -17,7 +17,7 @@ def _benchmark(rank, world_size, port, args):
The benchmark will sample in a range of memory budget for each model and output the benchmark summary and
data visualization of peak memory vs. budget memory and relative step time vs. peak memory.
"""
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
if args.model == "resnet50":
model = tm.resnet50()
data_gen = partial(data_gen_resnet, batch_size=128, shape=(3, 224, 224))
diff --git a/examples/tutorial/new_api/cifar_resnet/train.py b/examples/tutorial/new_api/cifar_resnet/train.py
index a4733126f3ee..2b388fe36196 100644
--- a/examples/tutorial/new_api/cifar_resnet/train.py
+++ b/examples/tutorial/new_api/cifar_resnet/train.py
@@ -128,7 +128,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# update the learning rate with linear scaling
diff --git a/examples/tutorial/new_api/cifar_vit/train.py b/examples/tutorial/new_api/cifar_vit/train.py
index ec6c852b5965..84245d48748d 100644
--- a/examples/tutorial/new_api/cifar_vit/train.py
+++ b/examples/tutorial/new_api/cifar_vit/train.py
@@ -148,7 +148,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={})
+ colossalai.launch_from_torch()
coordinator = DistCoordinator()
# update the learning rate with linear scaling
diff --git a/examples/tutorial/new_api/glue_bert/finetune.py b/examples/tutorial/new_api/glue_bert/finetune.py
index e97c9017fe56..624783a792b7 100644
--- a/examples/tutorial/new_api/glue_bert/finetune.py
+++ b/examples/tutorial/new_api/glue_bert/finetune.py
@@ -125,7 +125,7 @@ def main():
# ==============================
# Launch Distributed Environment
# ==============================
- colossalai.launch_from_torch(config={}, seed=42)
+ colossalai.launch_from_torch(seed=42)
coordinator = DistCoordinator()
# local_batch_size = BATCH_SIZE // coordinator.world_size
diff --git a/examples/tutorial/opt/opt/run_clm.py b/examples/tutorial/opt/opt/run_clm.py
index ae8a0f4a044e..cb62f77e1add 100644
--- a/examples/tutorial/opt/opt/run_clm.py
+++ b/examples/tutorial/opt/opt/run_clm.py
@@ -289,7 +289,7 @@ def __len__(self):
def main():
args = parse_args()
disable_existing_loggers()
- colossalai.legacy.launch_from_torch(config=dict())
+ colossalai.legacy.launch_from_torch()
logger = get_dist_logger()
is_main_process = dist.get_rank() == 0
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 0b15b9311937..58c7f780fbb0 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -5,7 +5,7 @@ git+https://github.com/hpcaitech/pytest-testmon
torchvision
timm
titans
-torchaudio
+torchaudio>=0.13.1
torchx-nightly==2022.6.29 # torchrec 0.2.0 requires torchx-nightly. This package is updated every day. We fix the version to a specific date to avoid breaking changes.
torchrec==0.2.0
contexttimer
@@ -18,4 +18,5 @@ flash_attn
datasets
pydantic
ray
+peft>=0.7.1
#auto-gptq now not support torch1.12
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index d307312ded8e..8ab13c0ade44 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -17,3 +17,5 @@ sentencepiece
google
protobuf
transformers==4.36.2
+peft>=0.7.1
+bitsandbytes>=0.39.0
diff --git a/tests/test_auto_parallel/test_ckpt_solvers/test_C_solver_consistency.py b/tests/test_auto_parallel/test_ckpt_solvers/test_C_solver_consistency.py
index 03bba8e64772..14bc7aa57f0b 100644
--- a/tests/test_auto_parallel/test_ckpt_solvers/test_C_solver_consistency.py
+++ b/tests/test_auto_parallel/test_ckpt_solvers/test_C_solver_consistency.py
@@ -27,7 +27,7 @@
def _run_C_solver_consistency_test(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
for M, mem_budget in [(tm.resnet50, 4000), (tm.densenet121, 8080)]:
model = M()
diff --git a/tests/test_auto_parallel/test_ckpt_solvers/test_ckpt_torchvision.py b/tests/test_auto_parallel/test_ckpt_solvers/test_ckpt_torchvision.py
index c46f57f75303..19d5265249cb 100644
--- a/tests/test_auto_parallel/test_ckpt_solvers/test_ckpt_torchvision.py
+++ b/tests/test_auto_parallel/test_ckpt_solvers/test_ckpt_torchvision.py
@@ -75,7 +75,7 @@ def check_backward_consistency(
def _run_ckpt_solver(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
MODEL_LIST = [tm.densenet121]
torch.backends.cudnn.deterministic = True
@@ -111,7 +111,7 @@ def test_ckpt_solver():
def _run_ckpt_solver_torch11(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
MODEL_LIST = [tm.densenet121]
torch.backends.cudnn.deterministic = True
diff --git a/tests/test_auto_parallel/test_offload/test_perf.py b/tests/test_auto_parallel/test_offload/test_perf.py
index 373ba28b8545..3db7a1925c11 100644
--- a/tests/test_auto_parallel/test_offload/test_perf.py
+++ b/tests/test_auto_parallel/test_offload/test_perf.py
@@ -141,8 +141,7 @@ def exam_fwd_bwd(model_name: str, memory_budget: float, solver_name: str):
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_fwd_bwd()
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_bias_addition_forward.py b/tests/test_auto_parallel/test_tensor_shard/test_bias_addition_forward.py
index c41c66745012..f39f09d54a0b 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_bias_addition_forward.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_bias_addition_forward.py
@@ -42,7 +42,7 @@ def forward(self, x):
def check_linear_module(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = LinearModel(4, 8).cuda()
input = torch.rand(4, 4).cuda()
output_compare = model(input)
@@ -59,7 +59,7 @@ def check_linear_module(rank, world_size, port):
def check_conv_module(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = ConvModel(3, 6, 2).cuda()
input = torch.rand(4, 3, 64, 64).cuda()
output_compare = model(input)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py b/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py
index c800f54da66c..f2b966b10620 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py
@@ -39,7 +39,7 @@ def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.Fl
def check_act_ckpt(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = GPT2MLPWithCkpt(intermediate_size=4 * HIDDEN_SIZE, hidden_size=HIDDEN_SIZE)
torch.rand(1, 64, HIDDEN_SIZE)
input_sample = {
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_ddp.py b/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_ddp.py
index e8f175326bb1..202f3e3bf6f4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_ddp.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_ddp.py
@@ -32,7 +32,7 @@ def forward(self, x):
def check_compatibility_with_ddp(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = MLP(4).cuda()
if rank in [0, 1]:
input = torch.arange(0, 16, dtype=torch.float).reshape(4, 4).cuda()
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_gemini.py b/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_gemini.py
index d577173266da..18de92e2a9e8 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_gemini.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_compatibility_with_gemini.py
@@ -34,7 +34,7 @@ def forward(self, x):
def check_auto_parallel_with_gemini(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = MLP(4).half().cuda()
if rank in [0, 1]:
input = torch.arange(0, 16).reshape(4, 4).half().cuda()
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_gpt/test_runtime_with_gpt_modules.py b/tests/test_auto_parallel/test_tensor_shard/test_gpt/test_runtime_with_gpt_modules.py
index 24968e670e3f..25c5d4ef154e 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_gpt/test_runtime_with_gpt_modules.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_gpt/test_runtime_with_gpt_modules.py
@@ -73,7 +73,7 @@ def _check_module_grad(
def check_attention_layer(rank, model_cls, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
config = transformers.GPT2Config(n_position=64, n_layer=2, n_head=16, n_embd=HIDDEN_DIM)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_binary_elementwise_metainfo.py b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_binary_elementwise_metainfo.py
index ba9e282144b7..d2f3e3724e31 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_binary_elementwise_metainfo.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_binary_elementwise_metainfo.py
@@ -31,7 +31,7 @@ def _binary_elementwise_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = BinaryElementwiseOpModule(token=torch.add, shape=1024).cuda()
input = torch.rand(32, 1024).cuda()
input.requires_grad = True
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_conv_metainfo.py b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_conv_metainfo.py
index 45558154547f..5495282bcf22 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_conv_metainfo.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_conv_metainfo.py
@@ -31,7 +31,7 @@ def _conv_module_mem_test(rank, world_size, port, bias):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.Conv2d(4, 64, 3, padding=1, bias=bias)).cuda()
input = torch.rand(4, 4, 64, 64).cuda()
input.requires_grad = True
@@ -72,7 +72,7 @@ def _conv_function_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = ConvFunctionModule().cuda()
input = torch.rand(4, 4, 64, 64).cuda()
input.requires_grad = True
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_linear_metainfo.py b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_linear_metainfo.py
index 639870c89a82..4958bad6b1e3 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_linear_metainfo.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_linear_metainfo.py
@@ -30,7 +30,7 @@ def _linear_module_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.Linear(64, 128, bias=False)).cuda()
input = torch.rand(8, 8, 16, 64).cuda()
input.requires_grad = True
@@ -68,7 +68,7 @@ def _linear_function_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = MyModule().cuda()
input = torch.rand(8, 8, 16, 64).cuda()
input.requires_grad = True
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_norm_metainfo.py b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_norm_metainfo.py
index ed809a758dfd..a0b81edab65c 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_norm_metainfo.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_norm_metainfo.py
@@ -25,7 +25,7 @@ def _batchnorm_module_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.BatchNorm2d(128)).cuda()
input = torch.rand(4, 128, 64, 64).cuda()
input.requires_grad = True
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_pooling_metainfo.py b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_pooling_metainfo.py
index bd1deb40ca7b..92d91383e414 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_pooling_metainfo.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_metainfo/test_pooling_metainfo.py
@@ -21,7 +21,7 @@ def _adaptiveavgpool_module_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.AdaptiveAvgPool2d((16, 16))).cuda()
input = torch.rand(4, 128, 64, 64).cuda()
input.requires_grad = True
@@ -62,7 +62,7 @@ def _maxpool_module_mem_test(rank, world_size, port):
port: port for initializing process group
"""
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.MaxPool2d((16, 16))).cuda()
input = torch.rand(4, 128, 64, 64).cuda()
input.requires_grad = True
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addbmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addbmm_handler.py
index 73a15f3ba4de..a8d2fbdfb124 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addbmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addbmm_handler.py
@@ -40,7 +40,7 @@ def forward(self, bias, x1, x2):
def check_2d_device_mesh(rank, world_size, port, module, bias_shape, using_kwargs):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = module(using_kwargs).cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -150,7 +150,7 @@ def check_2d_device_mesh(rank, world_size, port, module, bias_shape, using_kwarg
def check_1d_device_mesh(rank, module, bias_shape, using_kwargs, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (1, 4)
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
index 26f9c4ab1e3c..60eadeff9809 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
@@ -40,7 +40,7 @@ def forward(self, m1):
def check_addmm_function_handler(rank, world_size, port, input_shape, model_cls):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
if model_cls == AddmmModel:
model = AddmmModel().cuda()
else:
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
index 86df7237a219..e52cf28ab1f2 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
@@ -16,7 +16,7 @@
def check_bn_module_handler(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.BatchNorm2d(16)).cuda()
physical_mesh_id = torch.arange(0, 4)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
index e06625e1c42c..5982227b6301 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
@@ -34,7 +34,7 @@ def forward(self, x):
def check_linear_module_handler(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = LinearModule(weight_shape=WEIGHT_SHAPE).cuda()
physical_mesh_id = torch.arange(0, 4)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
index 690f0c12387c..c45e3e014b7b 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
@@ -30,7 +30,7 @@ def forward(self, x):
def check_linear_module_handler(rank, world_size, port, bias):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = LinearModule(16, 32, bias=bias).cuda()
physical_mesh_id = torch.arange(0, 4)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
index 5b2e2ab49f6d..ad0d6d18cf46 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
@@ -16,7 +16,7 @@
def check_binary_elementwise_handler_with_tensor(rank, world_size, port, op, other_dim):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
class BinaryElementwiseOpModel(nn.Module):
def __init__(self, op):
@@ -145,7 +145,7 @@ def forward(self, x1):
def check_binary_elementwise_handler_with_int(rank, world_size, port, op, other_dim, model_cls):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
index 29df12832241..ac54f12302cf 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
@@ -26,7 +26,7 @@ def forward(self, x1, x2):
def check_2d_device_mesh(rank, module, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = module().cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -121,7 +121,7 @@ def check_2d_device_mesh(rank, module, world_size, port):
def check_1d_device_mesh(rank, module, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = module().cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (1, 4)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
index 8a37dd9256dd..407216f46b92 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
@@ -16,7 +16,7 @@
def check_conv_module_handler(rank, world_size, port, bias):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.Conv2d(4, 16, 3, padding=1, bias=bias)).cuda()
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -153,7 +153,7 @@ def forward(self, input, others, bias=None):
def check_conv_function_handler(rank, world_size, port, bias):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = ConvModel().cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
index 9ac6ba95da48..f9a5b40a031e 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
@@ -33,7 +33,7 @@ def forward(self, input):
def check_embedding_module_handler(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = EmbeddingModule(num_embeddings=NUM_EMBEDDINGS, embedding_dims=EMBEDDING_DIMS).cuda()
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -150,7 +150,7 @@ def forward(self, input, others):
def check_embedding_function_handler(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = EmbeddingFunction().cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
index cf802a228034..eb8e8ed3e5de 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
@@ -31,7 +31,7 @@ def forward(self, input, other):
def check_getitem_from_tensor_handler(rank, getitem_index, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = GetItemFromTensorModel(getitem_index=getitem_index)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
index 59a66bc6a5d6..45aae2ea9d42 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
@@ -17,7 +17,7 @@
def check_ln_module_handler(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.LayerNorm(16)).cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
index da88b735f7c1..ddabdb700974 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
@@ -23,7 +23,7 @@
def check_linear_module_handler(rank, world_size, port, bias, input_shape):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = nn.Sequential(nn.Linear(16, 32, bias=bias)).cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -171,7 +171,7 @@ def forward(self, input, others, bias=None):
def check_linear_function_handler(rank, world_size, port, bias, input_shape):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = LinearModel().cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
index 958dc288fa16..09ad2ae320f7 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
@@ -51,7 +51,7 @@ def forward(self, input, other):
def check_view_handler(rank, world_size, port, call_function, reshape_dims, model_cls):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
if call_function == torch.permute:
reshape_dims = reshape_dims[0]
elif call_function == torch.transpose:
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
index 1a99c32ebcb9..88f34ff100a0 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
@@ -29,7 +29,7 @@ def forward(self, input, other):
def check_split_handler(rank, world_size, port, softmax_dim, model_cls):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = model_cls(softmax_dim=softmax_dim).cuda()
input = torch.rand(8, 16, 64, 32).to("cuda")
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
index 0318023c858d..225a729efa31 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
@@ -42,7 +42,7 @@ def forward(self, input, other):
def check_split_handler(rank, world_size, port, split_size, split_dim, model_cls):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = model_cls(split_size=split_size, split_dim=split_dim).cuda()
if model_cls.__name__ == "ConvSplitModel":
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
index cbd3e47044b3..a79cfdf6ff1b 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
@@ -32,7 +32,7 @@ def forward(self, input, other):
def check_sum_handler(rank, world_size, port, sum_dims, keepdim):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = LinearSumModel(sum_dims=sum_dims, keepdim=keepdim).cuda()
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
index 466168c79a0b..de483c997bf5 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
@@ -41,7 +41,7 @@ def forward(self, input, other):
def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
model = model_cls(tgt_shape).cuda()
if model_cls.__name__ == "ConvViewModel":
diff --git a/tests/test_booster/test_mixed_precision/test_fp16_torch.py b/tests/test_booster/test_mixed_precision/test_fp16_torch.py
index 3aefb37974f0..f6d6e8303904 100644
--- a/tests/test_booster/test_mixed_precision/test_fp16_torch.py
+++ b/tests/test_booster/test_mixed_precision/test_fp16_torch.py
@@ -9,7 +9,7 @@
def run_torch_amp(rank, world_size, port):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
sub_model_zoo = model_zoo.get_sub_registry("timm")
for name, (model_fn, data_gen_fn, output_transform_fn, _, _) in sub_model_zoo.items():
# dlrm_interactionarch has not parameters, so skip
diff --git a/tests/test_booster/test_plugin/test_3d_plugin.py b/tests/test_booster/test_plugin/test_3d_plugin.py
index 52cb8c46ed41..e57cadfd8673 100644
--- a/tests/test_booster/test_plugin/test_3d_plugin.py
+++ b/tests/test_booster/test_plugin/test_3d_plugin.py
@@ -265,7 +265,7 @@ def run_grad_acc_test(test_args):
def run_dist(rank, world_size, port, early_stop: bool = True):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_3d_plugin(early_stop=early_stop)
run_grad_acc_test()
diff --git a/tests/test_booster/test_plugin/test_dp_plugin_base.py b/tests/test_booster/test_plugin/test_dp_plugin_base.py
index 0ac9d0f6d409..a2a4a0c070ae 100644
--- a/tests/test_booster/test_plugin/test_dp_plugin_base.py
+++ b/tests/test_booster/test_plugin/test_dp_plugin_base.py
@@ -1,4 +1,4 @@
-from typing import Callable, Iterator, List, Tuple, Union
+from typing import Callable, Dict, Iterator, List, Tuple, Union
import torch
import torch.distributed as dist
@@ -51,6 +51,12 @@ def supported_precisions(self) -> List[str]:
def no_sync(self, model: nn.Module) -> Iterator[None]:
pass
+ def enable_lora(self, model: nn.Module, pretrained_dir: str, lora_config: Dict) -> nn.Module:
+ pass
+
+ def support_lora(self) -> bool:
+ pass
+
def check_dataloader_sharding():
plugin = DPPluginWrapper()
@@ -79,7 +85,7 @@ def check_dataloader_sharding():
def run_dist(rank, world_size, port):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_dataloader_sharding()
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
index 89214477239b..b2790c0e7504 100644
--- a/tests/test_booster/test_plugin/test_gemini_plugin.py
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -161,7 +161,7 @@ def check_gemini_plugin(
def run_dist(rank, world_size, port, early_stop: bool = True):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_gemini_plugin(early_stop=early_stop)
diff --git a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
index 861fa0131397..4908b2d4fcf7 100644
--- a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
+++ b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
@@ -2,6 +2,7 @@
import torch
import torch.distributed as dist
+from peft import LoraConfig
from torch.optim import Adam
import colossalai
@@ -22,13 +23,17 @@
@clear_cache_before_run()
-def run_fn(stage, model_fn, data_gen_fn, output_transform_fn) -> Optional[str]:
+def run_fn(stage, model_fn, data_gen_fn, output_transform_fn, lora_config=None) -> Optional[str]:
device = get_accelerator().get_current_device()
try:
plugin = LowLevelZeroPlugin(stage=stage, max_norm=1.0, initial_scale=2**5)
booster = Booster(plugin=plugin)
model = model_fn()
optimizer = Adam(model.parameters(), lr=1e-3)
+
+ if lora_config is not None:
+ model = booster.enable_lora(model, lora_config=lora_config)
+
criterion = lambda x: x.mean()
data = data_gen_fn()
@@ -48,6 +53,7 @@ def run_fn(stage, model_fn, data_gen_fn, output_transform_fn) -> Optional[str]:
except Exception as e:
return repr(e)
+ # raise e
@parameterize("stage", [2])
@@ -91,10 +97,42 @@ def check_low_level_zero_plugin(stage: int, early_stop: bool = True):
assert len(failed_info) == 0, "\n".join([f"{k}: {v}" for k, v in failed_info.items()])
+@parameterize("stage", [2])
+@parameterize("model_name", ["transformers_llama"])
+def check_low_level_zero_lora(stage, model_name, early_stop: bool = True):
+ passed_models = []
+ failed_info = {} # (model_name, error) pair
+
+ sub_model_zoo = model_zoo.get_sub_registry(model_name)
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ task_type = None
+ if name == "transformers_llama_for_casual_lm":
+ task_type = "CAUSAL_LM"
+ if name == "transformers_llama_for_sequence_classification":
+ task_type = "SEQ_CLS"
+ lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
+ err = run_fn(stage, model_fn, data_gen_fn, output_transform_fn, lora_config)
+
+ torch.cuda.empty_cache()
+
+ if err is None:
+ passed_models.append(name)
+ else:
+ failed_info[name] = err
+ if early_stop:
+ break
+
+ if dist.get_rank() == 0:
+ print(f"Passed models({len(passed_models)}): {passed_models}\n\n")
+ print(f"Failed models({len(failed_info)}): {list(failed_info.keys())}\n\n")
+ assert len(failed_info) == 0, "\n".join([f"{k}: {v}" for k, v in failed_info.items()])
+
+
def run_dist(rank, world_size, port, early_stop: bool = True):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_low_level_zero_plugin(early_stop=early_stop)
+ check_low_level_zero_lora(early_stop=early_stop)
@rerun_if_address_is_in_use()
diff --git a/tests/test_booster/test_plugin/test_torch_ddp_plugin.py b/tests/test_booster/test_plugin/test_torch_ddp_plugin.py
index e785843fb053..052782047eee 100644
--- a/tests/test_booster/test_plugin/test_torch_ddp_plugin.py
+++ b/tests/test_booster/test_plugin/test_torch_ddp_plugin.py
@@ -109,7 +109,7 @@ def get_grad_set_over_all_ranks():
def run_dist(rank, world_size, port):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_torch_ddp_plugin()
check_torch_ddp_no_sync()
diff --git a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
index f698070465d6..90e98f325021 100644
--- a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
+++ b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
@@ -73,7 +73,7 @@ def check_torch_fsdp_plugin():
def run_dist(rank, world_size, port):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_torch_fsdp_plugin()
diff --git a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
index ac6f8caef816..ade927e6edfc 100644
--- a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
@@ -173,8 +173,7 @@ def exam_lazy_from_pretrained():
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_state_dict()
exam_state_dict_with_origin()
exam_lazy_from_pretrained()
diff --git a/tests/test_checkpoint_io/test_gemini_torch_compability.py b/tests/test_checkpoint_io/test_gemini_torch_compability.py
index 44a000113629..cd313c2404eb 100644
--- a/tests/test_checkpoint_io/test_gemini_torch_compability.py
+++ b/tests/test_checkpoint_io/test_gemini_torch_compability.py
@@ -163,8 +163,7 @@ def exam_gemini_load_from_torch(shard: bool, model_name: str):
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_torch_load_from_gemini()
exam_gemini_load_from_torch()
diff --git a/tests/test_checkpoint_io/test_hybrid_parallel_plugin_checkpoint_io.py b/tests/test_checkpoint_io/test_hybrid_parallel_plugin_checkpoint_io.py
index 4753ab637f01..1cf94433da24 100644
--- a/tests/test_checkpoint_io/test_hybrid_parallel_plugin_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_hybrid_parallel_plugin_checkpoint_io.py
@@ -132,8 +132,7 @@ def _preprocess_data(data):
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_state_dict()
diff --git a/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py b/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
index e7f44f97e3cf..119e42e3178f 100644
--- a/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
@@ -1,5 +1,9 @@
+from copy import deepcopy
+from typing import Optional
+
import torch
import torch.distributed as dist
+from peft import LoraConfig
from torchvision.models import resnet18
from utils import shared_tempdir
@@ -15,6 +19,7 @@
spawn,
)
from colossalai.zero import LowLevelZeroOptimizer
+from tests.kit.model_zoo import model_zoo
# stage 1 and 2 process the optimizer/mode the same way
@@ -69,9 +74,107 @@ def check_low_level_zero_checkpointIO(stage: int, shard: bool, offload: bool):
torch.cuda.empty_cache()
+def run_fn(stage, shard, offload, model_fn, data_gen_fn, output_transform_fn, lora_config=None) -> Optional[str]:
+ try:
+ plugin = LowLevelZeroPlugin(stage=stage, max_norm=1.0, initial_scale=2**5, cpu_offload=offload)
+ new_plugin = LowLevelZeroPlugin(stage=stage, max_norm=1.0, initial_scale=2**5, cpu_offload=offload)
+ booster = Booster(plugin=plugin)
+ new_booster = Booster(plugin=new_plugin)
+ model = model_fn()
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
+ new_model = deepcopy(model)
+ new_optimizer = HybridAdam(new_model.parameters(), lr=1e-3)
+ model = booster.enable_lora(model, lora_config=lora_config)
+ criterion = lambda x: x.mean()
+ data = data_gen_fn()
+
+ data = {
+ k: v.to("cuda") if torch.is_tensor(v) or "Tensor" in v.__class__.__name__ else v for k, v in data.items()
+ }
+
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ output = model(**data)
+ output = output_transform_fn(output)
+ output_key = list(output.keys())[0]
+ loss = criterion(output[output_key])
+
+ booster.backward(loss, optimizer)
+ optimizer.step()
+
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+
+ booster.save_lora_as_pretrained(model, model_ckpt_path)
+ booster.save_optimizer(optimizer, optimizer_ckpt_path, shard=False)
+ new_model = new_booster.enable_lora(new_model, pretrained_dir=model_ckpt_path, lora_config=lora_config)
+ new_model, new_optimizer, criterion, _, _ = new_booster.boost(new_model, new_optimizer, criterion)
+ check_state_dict_equal(model.state_dict(), new_model.state_dict(), False)
+
+ # check master weight
+ assert isinstance(new_optimizer, LowLevelZeroOptimizer)
+ working_param_id_set = set(id(p) for p in new_model.parameters())
+ for p_id, master_param in new_optimizer._param_store.working_to_master_param.items():
+ assert p_id in working_param_id_set
+ working_param = new_optimizer._param_store.master_to_working_param[id(master_param)]
+ padding = new_optimizer._param_store.get_param_padding_size(working_param)
+ padded_param = torch.nn.functional.pad(working_param.data.view(-1), (0, padding))
+ working_shard = padded_param.chunk(dist.get_world_size())[dist.get_rank()]
+ assert torch.equal(
+ working_shard, master_param.data.view(-1).to(dtype=padded_param.dtype, device=padded_param.device)
+ )
+
+ new_booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.optim.state_dict(), new_optimizer.optim.state_dict(), False)
+
+ except Exception as e:
+ # return repr(e)
+ raise e
+
+
+@clear_cache_before_run()
+@parameterize("stage", [2])
+@parameterize("shard", [True, False])
+@parameterize("offload", [False, True])
+@parameterize("model_name", ["transformers_llama"])
+def check_low_level_zero_lora_checkpointIO(
+ stage: int, shard: bool, offload: bool, model_name: str, early_stop: bool = True
+):
+ passed_models = []
+ failed_info = {} # (model_name, error) pair
+
+ sub_model_zoo = model_zoo.get_sub_registry(model_name)
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ if name != "transformers_llama":
+ continue
+ task_type = None
+ if name == "transformers_llama_for_casual_lm":
+ task_type = "CAUSAL_LM"
+ if name == "transformers_llama_for_sequence_classification":
+ task_type = "SEQ_CLS"
+ lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
+ err = run_fn(stage, shard, offload, model_fn, data_gen_fn, output_transform_fn, lora_config)
+
+ torch.cuda.empty_cache()
+
+ if err is None:
+ passed_models.append(name)
+ else:
+ failed_info[name] = err
+ if early_stop:
+ break
+
+ if dist.get_rank() == 0:
+ print(f"Passed models({len(passed_models)}): {passed_models}\n\n")
+ print(f"Failed models({len(failed_info)}): {list(failed_info.keys())}\n\n")
+ assert len(failed_info) == 0, "\n".join([f"{k}: {v}" for k, v in failed_info.items()])
+
+
def run_dist(rank, world_size, port):
- colossalai.launch(config=(dict()), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_low_level_zero_checkpointIO()
+ check_low_level_zero_lora_checkpointIO()
torch.cuda.empty_cache()
diff --git a/tests/test_checkpoint_io/test_plugins_huggingface_compatibility.py b/tests/test_checkpoint_io/test_plugins_huggingface_compatibility.py
index 0353ff115840..da0d52d061a8 100644
--- a/tests/test_checkpoint_io/test_plugins_huggingface_compatibility.py
+++ b/tests/test_checkpoint_io/test_plugins_huggingface_compatibility.py
@@ -68,8 +68,7 @@ def exam_from_pretrained(plugin_type: str, model_name: str, shard=True, size_per
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_from_pretrained()
diff --git a/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
index eeb04df0f42d..0b9a1605c385 100644
--- a/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
@@ -61,7 +61,7 @@ def check_torch_ddp_checkpointIO(shard: bool, size_per_shard: int):
def run_dist(rank, world_size, port):
- colossalai.launch(config=(dict()), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_torch_ddp_checkpointIO()
diff --git a/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
index 1ea70368eabf..12b70cc04d3c 100644
--- a/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
@@ -141,7 +141,7 @@ def run_model():
def run_dist(rank, world_size, port):
# init dist env
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_torch_fsdp_ckpt()
diff --git a/tests/test_cluster/test_device_mesh_manager.py b/tests/test_cluster/test_device_mesh_manager.py
index ab61cdae5bb0..5d140064ba94 100644
--- a/tests/test_cluster/test_device_mesh_manager.py
+++ b/tests/test_cluster/test_device_mesh_manager.py
@@ -6,7 +6,7 @@
def check_device_mesh_manager(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
device_mesh_manager = DeviceMeshManager()
# TODO(ver217): this test is strictly relies on hardware, temporary skip it
# device_mesh_info_auto = DeviceMeshInfo(physical_ids=[0, 1, 2, 3],)
diff --git a/tests/test_cluster/test_process_group_mesh.py b/tests/test_cluster/test_process_group_mesh.py
index 3d206622d644..3071c0f59044 100644
--- a/tests/test_cluster/test_process_group_mesh.py
+++ b/tests/test_cluster/test_process_group_mesh.py
@@ -6,57 +6,6 @@
from colossalai.testing import spawn
-def check_process_group_mesh_with_gpc():
- from colossalai.legacy.context import ParallelMode
- from colossalai.legacy.core import global_context as gpc
-
- DP_DIM, PP_DIM, TP_DIM = 0, 1, 2
- pg_mesh = ProcessGroupMesh(1, 2, 2)
-
- # check world size
- assert gpc.get_world_size(ParallelMode.TENSOR) == pg_mesh.size(
- TP_DIM
- ), f"{gpc.get_world_size(ParallelMode.TENSOR)} != {pg_mesh.size(TP_DIM)}"
- assert gpc.get_world_size(ParallelMode.PIPELINE) == pg_mesh.size(PP_DIM)
- assert gpc.get_world_size(ParallelMode.DATA) == pg_mesh.size(DP_DIM)
-
- # check locak rank (coordinate)
- assert gpc.get_local_rank(ParallelMode.TENSOR) == pg_mesh.coordinate(
- TP_DIM
- ), f"{gpc.get_local_rank(ParallelMode.TENSOR)} != {pg_mesh.coordinate(TP_DIM)}"
- assert gpc.get_local_rank(ParallelMode.PIPELINE) == pg_mesh.coordinate(PP_DIM)
- assert gpc.get_local_rank(ParallelMode.DATA) == pg_mesh.coordinate(DP_DIM)
-
- # check ranks in group
- tp_group = pg_mesh.get_group_along_axis(TP_DIM)
- assert gpc.get_ranks_in_group(ParallelMode.TENSOR) == pg_mesh.get_ranks_in_group(tp_group)
- pp_group = pg_mesh.get_group_along_axis(PP_DIM)
- assert gpc.get_ranks_in_group(ParallelMode.PIPELINE) == pg_mesh.get_ranks_in_group(pp_group)
- dp_group = pg_mesh.get_group_along_axis(DP_DIM)
- assert gpc.get_ranks_in_group(ParallelMode.DATA) == pg_mesh.get_ranks_in_group(dp_group)
-
- # check prev rank
- coord = pg_mesh.coordinate()
- if not gpc.is_first_rank(ParallelMode.TENSOR):
- assert coord[TP_DIM] != 0
- prev_coord = coord[:TP_DIM] + (coord[TP_DIM] - 1,) + coord[TP_DIM + 1 :]
- assert gpc.get_prev_global_rank(ParallelMode.TENSOR) == pg_mesh.ravel(prev_coord, pg_mesh.shape)
- if not gpc.is_first_rank(ParallelMode.PIPELINE):
- assert coord[PP_DIM] != 0
- prev_coord = coord[:PP_DIM] + (coord[PP_DIM] - 1,) + coord[PP_DIM + 1 :]
- assert gpc.get_prev_global_rank(ParallelMode.PIPELINE) == pg_mesh.ravel(prev_coord, pg_mesh.shape)
-
- # check next rank
- if not gpc.is_last_rank(ParallelMode.TENSOR):
- assert coord[TP_DIM] != pg_mesh.size(TP_DIM) - 1
- next_coord = coord[:TP_DIM] + (coord[TP_DIM] + 1,) + coord[TP_DIM + 1 :]
- assert gpc.get_next_global_rank(ParallelMode.TENSOR) == pg_mesh.ravel(next_coord, pg_mesh.shape)
- if not gpc.is_last_rank(ParallelMode.PIPELINE):
- assert coord[PP_DIM] != pg_mesh.size(PP_DIM) - 1
- next_coord = coord[:PP_DIM] + (coord[PP_DIM] + 1,) + coord[PP_DIM + 1 :]
- assert gpc.get_next_global_rank(ParallelMode.PIPELINE) == pg_mesh.ravel(next_coord, pg_mesh.shape)
-
-
def check_process_group_mesh_with_cases():
DP_DIM, PP_DIM, TP_DIM = 0, 1, 2
DP_SIZE, PP_SIZE, TP_SIZE = 1, 2, 2
@@ -177,14 +126,11 @@ def check_process_group_mesh_with_cases():
def run_dist(rank, world_size, port):
colossalai.launch(
- config=dict(parallel=dict(data=1, pipeline=2, tensor=dict(mode="1d", size=2))),
rank=rank,
world_size=world_size,
port=port,
host="localhost",
)
- # TODO(ver217): this function should be removed when gpc is removed
- # check_process_group_mesh_with_gpc()
check_process_group_mesh_with_cases()
diff --git a/tests/test_device/test_alpha_beta.py b/tests/test_device/test_alpha_beta.py
index f4a88f79c37b..3d9c6d7ce5d1 100644
--- a/tests/test_device/test_alpha_beta.py
+++ b/tests/test_device/test_alpha_beta.py
@@ -8,7 +8,7 @@
def check_alpha_beta(rank, world_size, port, physical_devices):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
profiler = AlphaBetaProfiler(physical_devices)
ab_dict = profiler.profile_ab()
for _, (alpha, beta) in ab_dict.items():
diff --git a/tests/test_device/test_device_mesh.py b/tests/test_device/test_device_mesh.py
index af44af5d9097..b2d057273e1c 100644
--- a/tests/test_device/test_device_mesh.py
+++ b/tests/test_device/test_device_mesh.py
@@ -75,7 +75,7 @@ def check_2d_device_mesh():
def check_init_from_process_group(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
@pytest.mark.dist
diff --git a/tests/test_device/test_extract_alpha_beta.py b/tests/test_device/test_extract_alpha_beta.py
index 34f2aacc18b2..7633f59b91d2 100644
--- a/tests/test_device/test_extract_alpha_beta.py
+++ b/tests/test_device/test_extract_alpha_beta.py
@@ -8,7 +8,7 @@
def check_extract_alpha_beta(rank, world_size, port, physical_devices):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
profiler = AlphaBetaProfiler(physical_devices)
mesh_alpha, mesh_beta = profiler.extract_alpha_beta_for_device_mesh()
diff --git a/tests/test_device/test_init_logical_pg.py b/tests/test_device/test_init_logical_pg.py
index 3b398a917182..d93f656983d4 100644
--- a/tests/test_device/test_init_logical_pg.py
+++ b/tests/test_device/test_init_logical_pg.py
@@ -9,7 +9,7 @@
def check_layer(rank, world_size, port):
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 4)
assert rank == dist.get_rank()
diff --git a/tests/test_device/test_search_logical_device_mesh.py b/tests/test_device/test_search_logical_device_mesh.py
index d9d4e79c1f57..a44b8e3d6253 100644
--- a/tests/test_device/test_search_logical_device_mesh.py
+++ b/tests/test_device/test_search_logical_device_mesh.py
@@ -8,7 +8,7 @@
def check_alpha_beta(rank, world_size, port, physical_devices):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
profiler = AlphaBetaProfiler(physical_devices)
best_logical_mesh = profiler.search_best_logical_mesh()
diff --git a/tests/test_fx/test_codegen/test_activation_checkpoint_codegen.py b/tests/test_fx/test_codegen/test_activation_checkpoint_codegen.py
index 10fe9815541c..8a3e2d6ec7b5 100644
--- a/tests/test_fx/test_codegen/test_activation_checkpoint_codegen.py
+++ b/tests/test_fx/test_codegen/test_activation_checkpoint_codegen.py
@@ -64,7 +64,7 @@ def forward(self, x, y):
def _run_act_ckpt_codegen(rank, world_size, port):
# launch colossalai to make sure we could execute colossalai.utils.checkpoint currently
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model and run forward
model = MyModule()
@@ -127,7 +127,7 @@ def test_act_ckpt_codegen():
def _run_act_ckpt_python_code_torch11(rank, world_size, port):
# launch colossalai to make sure we could execute colossalai.utils.checkpoint currently
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model and run forward
model = MyModule()
diff --git a/tests/test_fx/test_codegen/test_nested_activation_checkpoint_codegen.py b/tests/test_fx/test_codegen/test_nested_activation_checkpoint_codegen.py
index f1e87e5ed140..69767db2d16e 100644
--- a/tests/test_fx/test_codegen/test_nested_activation_checkpoint_codegen.py
+++ b/tests/test_fx/test_codegen/test_nested_activation_checkpoint_codegen.py
@@ -32,7 +32,7 @@ def forward(self, x):
def _run_act_ckpt_codegen(rank, world_size, port):
# launch colossalai to make sure we could execute colossalai.utils.checkpoint currently
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model and run forward
model = MyModule()
@@ -96,7 +96,7 @@ def test_act_ckpt_codegen():
def _run_act_ckpt_python_code_torch11(rank, world_size, port):
# launch colossalai to make sure we could execute colossalai.utils.checkpoint currently
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model and run forward
model = MyModule()
diff --git a/tests/test_fx/test_codegen/test_offload_codegen.py b/tests/test_fx/test_codegen/test_offload_codegen.py
index da1e73ec3dfe..9df4a6899d21 100644
--- a/tests/test_fx/test_codegen/test_offload_codegen.py
+++ b/tests/test_fx/test_codegen/test_offload_codegen.py
@@ -66,7 +66,7 @@ def _test_fwd_and_bwd(model: torch.nn.Module, gm: ColoGraphModule, data: torch.T
def _run_offload_codegen(rank, world_size, port):
# launch colossalai to make sure we could execute colossalai.utils.checkpoint currently
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model and input
model = MyNet().cuda()
@@ -124,7 +124,7 @@ def test_act_ckpt_codegen():
def _run_offload_codegen_torch11(rank, world_size, port):
# launch colossalai to make sure we could execute colossalai.utils.checkpoint currently
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model and input
model = MyNet().cuda()
diff --git a/tests/test_fx/test_parallel_1d.py b/tests/test_fx/test_parallel_1d.py
index 6d890f59d5c5..6b0e12609f23 100644
--- a/tests/test_fx/test_parallel_1d.py
+++ b/tests/test_fx/test_parallel_1d.py
@@ -33,7 +33,7 @@ def forward(self, x):
def check_layer(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
input_tensor = torch.rand(2, 16).cuda()
model = MLP(16).cuda()
symbolic_traced = symbolic_trace(model)
diff --git a/tests/test_infer/test_hybrid_bloom.py b/tests/test_infer/test_hybrid_bloom.py
index 8cad06dca6d9..ef2aac1d1aa7 100644
--- a/tests/test_infer/test_hybrid_bloom.py
+++ b/tests/test_infer/test_hybrid_bloom.py
@@ -89,18 +89,18 @@ def run_single_inference_test(tp_size, pp_size, max_output_len, micro_batch_size
def check_tp_pp_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_tp_pipeline_inference_test()
def check_tp_or_pp_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_tp_inference_test()
run_pipeline_inference_test()
def check_single_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_single_inference_test
diff --git a/tests/test_infer/test_hybrid_chatglm2.py b/tests/test_infer/test_hybrid_chatglm2.py
index b53bb25f442f..e80b3477f736 100644
--- a/tests/test_infer/test_hybrid_chatglm2.py
+++ b/tests/test_infer/test_hybrid_chatglm2.py
@@ -97,18 +97,18 @@ def run_single_inference_test(tp_size, pp_size, max_output_len, micro_batch_size
def check_tp_pp_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_tp_pipeline_inference_test()
def check_tp_or_pp_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_tp_inference_test()
run_pipeline_inference_test()
def check_single_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_single_inference_test
diff --git a/tests/test_infer/test_hybrid_llama.py b/tests/test_infer/test_hybrid_llama.py
index 30b8b0a991d0..a997948178e0 100644
--- a/tests/test_infer/test_hybrid_llama.py
+++ b/tests/test_infer/test_hybrid_llama.py
@@ -94,18 +94,18 @@ def run_single_inference_test(tp_size, pp_size, max_output_len, micro_batch_size
def check_tp_pp_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_tp_pipeline_inference_test()
def check_tp_or_pp_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_tp_inference_test()
run_pipeline_inference_test()
def check_single_inference(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_single_inference_test
diff --git a/tests/test_lazy/test_models.py b/tests/test_lazy/test_models.py
index d0c4cd0a7c48..c85860a8d253 100644
--- a/tests/test_lazy/test_models.py
+++ b/tests/test_lazy/test_models.py
@@ -7,21 +7,23 @@
@pytest.mark.skipif(not SUPPORT_LAZY, reason="requires torch >= 1.12.0")
@pytest.mark.parametrize(
"subset",
- [COMMON_MODELS]
- if IS_FAST_TEST
- else ["torchvision", "diffusers", "timm", "transformers", "torchaudio", "deepfm", "dlrm"],
+ (
+ [COMMON_MODELS]
+ if IS_FAST_TEST
+ else ["torchvision", "diffusers", "timm", "transformers", "torchaudio", "deepfm", "dlrm"]
+ ),
)
@pytest.mark.parametrize("default_device", ["cpu", "cuda"])
-def test_torchvision_models_lazy_init(subset, default_device):
+def test_models_lazy_init(subset, default_device):
sub_model_zoo = model_zoo.get_sub_registry(subset, allow_empty=True)
for name, entry in sub_model_zoo.items():
# TODO(ver217): lazy init does not support weight norm, skip these models
if name in ("torchaudio_wav2vec2_base", "torchaudio_hubert_base") or name.startswith(
- ("transformers_vit", "transformers_blip2")
+ ("transformers_vit", "transformers_blip2", "transformers_whisper")
):
continue
check_lazy_init(entry, verbose=True, default_device=default_device)
if __name__ == "__main__":
- test_torchvision_models_lazy_init("transformers", "cpu")
+ test_models_lazy_init("transformers", "cpu")
diff --git a/tests/test_legacy/test_amp/test_naive_fp16.py b/tests/test_legacy/test_amp/test_naive_fp16.py
index fe16bc4d480a..0df6335f5df1 100644
--- a/tests/test_legacy/test_amp/test_naive_fp16.py
+++ b/tests/test_legacy/test_amp/test_naive_fp16.py
@@ -77,7 +77,7 @@ def run_naive_amp():
def run_dist(rank, world_size, port):
- colossalai.legacy.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.legacy.launch(rank=rank, world_size=world_size, port=port, host="localhost")
run_naive_amp()
diff --git a/tests/test_legacy/test_amp/test_torch_fp16.py b/tests/test_legacy/test_amp/test_torch_fp16.py
index 5e2e1ede5725..dc47dfc7299e 100644
--- a/tests/test_legacy/test_amp/test_torch_fp16.py
+++ b/tests/test_legacy/test_amp/test_torch_fp16.py
@@ -76,7 +76,7 @@ def run_torch_amp():
def run_dist(rank, world_size, port):
- colossalai.legacy.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.legacy.launch(rank=rank, world_size=world_size, port=port, host="localhost")
run_torch_amp()
diff --git a/tests/test_legacy/test_comm/test_boardcast_send_recv_v2.py b/tests/test_legacy/test_comm/test_boardcast_send_recv_v2.py
index bc243631a6c5..bd15e10f3ccf 100644
--- a/tests/test_legacy/test_comm/test_boardcast_send_recv_v2.py
+++ b/tests/test_legacy/test_comm/test_boardcast_send_recv_v2.py
@@ -16,7 +16,7 @@
def check_layer(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl", verbose=False)
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl", verbose=False)
rank = gpc.get_local_rank(ParallelMode.PIPELINE)
if rank == 0:
diff --git a/tests/test_legacy/test_comm/test_comm.py b/tests/test_legacy/test_comm/test_comm.py
index 079022e930cf..75955df69578 100644
--- a/tests/test_legacy/test_comm/test_comm.py
+++ b/tests/test_legacy/test_comm/test_comm.py
@@ -48,7 +48,7 @@ def check_all_reduce():
def check_layer(rank, world_size, port):
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
assert dist.get_rank() == gpc.get_global_rank()
print("Rank {} / {}".format(dist.get_rank(), dist.get_world_size()))
diff --git a/tests/test_legacy/test_comm/test_object_list_p2p.py b/tests/test_legacy/test_comm/test_object_list_p2p.py
index 69c68c7159e4..1d618a65f491 100644
--- a/tests/test_legacy/test_comm/test_object_list_p2p.py
+++ b/tests/test_legacy/test_comm/test_object_list_p2p.py
@@ -88,7 +88,7 @@ def check_send_recv_forward_backward():
def check_layer(rank, world_size, port):
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_send_recv_forward()
check_send_recv_backward()
check_send_recv_forward_backward()
diff --git a/tests/test_legacy/test_comm/test_object_list_p2p_v2.py b/tests/test_legacy/test_comm/test_object_list_p2p_v2.py
index eb05ea4839c6..c272f51f46f1 100644
--- a/tests/test_legacy/test_comm/test_object_list_p2p_v2.py
+++ b/tests/test_legacy/test_comm/test_object_list_p2p_v2.py
@@ -104,7 +104,7 @@ def check_small_pipeline():
def check_layer(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
disable_existing_loggers()
# check_send_recv_forward()
diff --git a/tests/test_legacy/test_layers/test_1d/test_1d.py b/tests/test_legacy/test_layers/test_1d/test_1d.py
index cebbedd303ee..9057c2c68e8f 100644
--- a/tests/test_legacy/test_layers/test_1d/test_1d.py
+++ b/tests/test_legacy/test_layers/test_1d/test_1d.py
@@ -17,7 +17,7 @@
def check_layer(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_linear_col()
check_linear_row()
diff --git a/tests/test_legacy/test_layers/test_2d/test_2d.py b/tests/test_legacy/test_layers/test_2d/test_2d.py
index 77a4b281a746..5be498f90754 100644
--- a/tests/test_legacy/test_layers/test_2d/test_2d.py
+++ b/tests/test_legacy/test_layers/test_2d/test_2d.py
@@ -50,7 +50,7 @@ def check_layer():
def check_layer_and_operation(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
diff --git a/tests/test_legacy/test_layers/test_2p5d/test_2p5d.py b/tests/test_legacy/test_layers/test_2p5d/test_2p5d.py
index 437a8f8a7265..029274570670 100644
--- a/tests/test_legacy/test_layers/test_2p5d/test_2p5d.py
+++ b/tests/test_legacy/test_layers/test_2p5d/test_2p5d.py
@@ -38,7 +38,7 @@ def check_layer():
def check_layer_and_operation(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
diff --git a/tests/test_legacy/test_layers/test_3d/test_3d.py b/tests/test_legacy/test_layers/test_3d/test_3d.py
index 7057e2308b39..876aa7ba8aa5 100644
--- a/tests/test_legacy/test_layers/test_3d/test_3d.py
+++ b/tests/test_legacy/test_layers/test_3d/test_3d.py
@@ -44,7 +44,7 @@ def check_layer():
def check_layer_and_operation(rank, world_size, port):
disable_existing_loggers()
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
torch.backends.cudnn.deterministic = True
diff --git a/tests/test_legacy/test_layers/test_cache_embedding.py b/tests/test_legacy/test_layers/test_cache_embedding.py
index d64ff56b8a65..c45097232f95 100644
--- a/tests/test_legacy/test_layers/test_cache_embedding.py
+++ b/tests/test_legacy/test_layers/test_cache_embedding.py
@@ -378,7 +378,7 @@ def run_parallel_freq_aware_embed_columnwise(rank, world_size):
def run_dist(rank, world_size, port):
- colossalai.legacy.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.legacy.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# run_parallel_freq_aware_embed_columnwise(rank, world_size)
run_parallel_freq_aware_embed_tablewise(rank, world_size)
diff --git a/tests/test_legacy/test_tensor/core/test_dist_spec_mgr.py b/tests/test_legacy/test_tensor/core/test_dist_spec_mgr.py
index 506244447054..bfedb779ca1e 100644
--- a/tests/test_legacy/test_tensor/core/test_dist_spec_mgr.py
+++ b/tests/test_legacy/test_tensor/core/test_dist_spec_mgr.py
@@ -48,7 +48,7 @@ def check_mem():
def run_dist(rank, world_size, port):
- colossalai.legacy.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.legacy.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_mem()
run()
diff --git a/tests/test_legacy/test_tensor/test_parameter.py b/tests/test_legacy/test_tensor/test_parameter.py
index 5217e22cc422..eae3e0eb38d2 100644
--- a/tests/test_legacy/test_tensor/test_parameter.py
+++ b/tests/test_legacy/test_tensor/test_parameter.py
@@ -9,7 +9,7 @@
@pytest.mark.skip
def test_multiinheritance():
- colossalai.legacy.launch(config={}, rank=0, world_size=1, host="localhost", port=free_port(), backend="nccl")
+ colossalai.legacy.launch(rank=0, world_size=1, host="localhost", port=free_port(), backend="nccl")
colo_param = ColoParameter(None, requires_grad=True)
assert colo_param.dist_spec.placement.value == "r"
assert isinstance(colo_param, ColoTensor)
diff --git a/tests/test_legacy/test_trainer/test_pipeline/test_p2p.py b/tests/test_legacy/test_trainer/test_pipeline/test_p2p.py
index cab111358c9c..ba8504d06140 100644
--- a/tests/test_legacy/test_trainer/test_pipeline/test_p2p.py
+++ b/tests/test_legacy/test_trainer/test_pipeline/test_p2p.py
@@ -86,7 +86,7 @@ def check_comm(size, rank, prev_rank, next_rank, logger):
def run_check(rank, world_size, port):
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
logger = get_dist_logger()
rank = gpc.get_global_rank()
prev_rank = gpc.get_prev_global_rank(ParallelMode.PIPELINE)
diff --git a/tests/test_legacy/test_trainer/test_pipeline/test_pipeline_schedule.py b/tests/test_legacy/test_trainer/test_pipeline/test_pipeline_schedule.py
index cd7fcfe5635d..ae7b961ae62f 100644
--- a/tests/test_legacy/test_trainer/test_pipeline/test_pipeline_schedule.py
+++ b/tests/test_legacy/test_trainer/test_pipeline/test_pipeline_schedule.py
@@ -23,7 +23,7 @@
def run_schedule(rank, world_size, port):
- launch(config=CONFIG, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# build model
model = resnet18(num_classes=10)
diff --git a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_1d.py b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_1d.py
index c07ff132b79e..e1b2128aab67 100644
--- a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_1d.py
+++ b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_1d.py
@@ -43,7 +43,7 @@ def check_checkpoint_1d(rank, world_size, port):
)
disable_existing_loggers()
- launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
m1 = nn.Sequential(nn.Linear(4, 8), nn.Linear(8, 4))
sd1 = m1.state_dict()
diff --git a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2d.py b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2d.py
index 2ec1facf21b1..12747951bd6a 100644
--- a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2d.py
+++ b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2d.py
@@ -43,7 +43,7 @@ def check_checkpoint_2d(rank, world_size, port):
)
disable_existing_loggers()
- launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
m1 = nn.Sequential(nn.Linear(4, 8), nn.Linear(8, 4))
sd1 = m1.state_dict()
diff --git a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2p5d.py b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2p5d.py
index a6bf702a8482..f7e7b6fad769 100644
--- a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2p5d.py
+++ b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_2p5d.py
@@ -43,7 +43,7 @@ def check_checkpoint_2p5d(rank, world_size, port):
)
disable_existing_loggers()
- launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
m1 = nn.Sequential(nn.Linear(4, 8), nn.Linear(8, 4))
sd1 = m1.state_dict()
diff --git a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_3d.py b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_3d.py
index 12d928312969..05666cc937b1 100644
--- a/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_3d.py
+++ b/tests/test_legacy/test_utils/test_checkpoint/test_checkpoint_3d.py
@@ -43,7 +43,7 @@ def check_checkpoint_3d(rank, world_size, port):
)
disable_existing_loggers()
- launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
m1 = nn.Sequential(nn.Linear(4, 8), nn.Linear(8, 4))
sd1 = m1.state_dict()
diff --git a/tests/test_legacy/test_utils/test_memory.py b/tests/test_legacy/test_utils/test_memory.py
index 4993df4f3713..30fc17b8e7af 100644
--- a/tests/test_legacy/test_utils/test_memory.py
+++ b/tests/test_legacy/test_utils/test_memory.py
@@ -14,7 +14,7 @@ def _run_colo_set_process_memory_fraction_and_colo_device_memory_capacity():
def run_dist(rank, world_size, port):
- colossalai.legacy.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.legacy.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
_run_colo_set_process_memory_fraction_and_colo_device_memory_capacity()
diff --git a/tests/test_legacy/test_utils/test_norm_gradient_clipping.py b/tests/test_legacy/test_utils/test_norm_gradient_clipping.py
index 9975cc04ff30..c5fab49f4fad 100644
--- a/tests/test_legacy/test_utils/test_norm_gradient_clipping.py
+++ b/tests/test_legacy/test_utils/test_norm_gradient_clipping.py
@@ -62,7 +62,7 @@ def run_grad_clip_norm(world_size: int, dtype: torch.dtype, device: str, norm_ty
def run_dist(rank, world_size, port):
disable_existing_loggers()
- colossalai.legacy.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.legacy.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_grad_clip_norm(world_size=world_size)
diff --git a/tests/test_legacy/test_zero/test_commons.py b/tests/test_legacy/test_zero/test_commons.py
index 741f519e1376..32b15706d651 100644
--- a/tests/test_legacy/test_zero/test_commons.py
+++ b/tests/test_legacy/test_zero/test_commons.py
@@ -7,7 +7,7 @@
def run_tensor_move(rank, world_size, port):
- colossalai.legacy.launch(config={}, rank=0, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.legacy.launch(rank=0, world_size=world_size, host="localhost", port=port, backend="nccl")
src_t = torch.ones(2, 3).cuda()
tgt_t = torch.zeros(2, 3)
diff --git a/tests/test_lora/test_lora.py b/tests/test_lora/test_lora.py
new file mode 100644
index 000000000000..b8daf775db0e
--- /dev/null
+++ b/tests/test_lora/test_lora.py
@@ -0,0 +1,105 @@
+import copy
+import os
+from itertools import product
+
+import torch
+from peft import LoraConfig
+from torch import distributed as dist
+from torch.optim import AdamW
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import LowLevelZeroPlugin, TorchDDPPlugin
+from colossalai.testing import check_state_dict_equal, clear_cache_before_run, rerun_if_address_is_in_use, spawn
+from tests.kit.model_zoo import model_zoo
+from tests.test_checkpoint_io.utils import shared_tempdir
+
+
+@clear_cache_before_run()
+def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type):
+ model = model_fn()
+ lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
+
+ test_plugins = [TorchDDPPlugin(), LowLevelZeroPlugin()]
+ test_configs = [
+ {
+ "lora_config": lora_config,
+ "quantize": False,
+ },
+ {
+ "lora_config": lora_config,
+ "quantize": True,
+ },
+ ]
+ for plugin, test_config in product(test_plugins, test_configs):
+ # checkpoint loaded model
+ model_save = model_fn()
+ model_load = copy.deepcopy(model_save)
+
+ optimizer = AdamW(model.parameters(), lr=0.001)
+ criterion = loss_fn
+
+ booster = Booster(plugin=plugin)
+ model_save = booster.enable_lora(model_save, **test_config)
+ model_save, optimizer, criterion, _, _ = booster.boost(model_save, optimizer, criterion)
+
+ with shared_tempdir() as tempdir:
+ lora_ckpt_path = os.path.join(tempdir, "ckpt")
+ booster.save_lora_as_pretrained(model_save, lora_ckpt_path)
+ dist.barrier()
+
+ # The Lora checkpoint should be small in size
+ checkpoint_size_mb = os.path.getsize(os.path.join(lora_ckpt_path, "adapter_model.bin")) / (1024 * 1024)
+ assert checkpoint_size_mb < 1
+
+ model_load = booster.enable_lora(model_load, pretrained_dir=lora_ckpt_path, **test_config)
+ model_load, _, _, _, _ = booster.boost(model_load)
+
+ check_state_dict_equal(model_save.state_dict(), model_load.state_dict())
+
+ # test fwd bwd correctness
+ test_model = model_load
+ model_copy = copy.deepcopy(model_load)
+
+ data = data_gen_fn()
+ data = {
+ k: v.to("cuda") if torch.is_tensor(v) or "Tensor" in v.__class__.__name__ else v for k, v in data.items()
+ }
+
+ output = test_model(**data)
+ output = output_transform_fn(output)
+ loss = criterion(output)
+
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+
+ for (n1, p1), (n2, p2) in zip(test_model.named_parameters(), model_copy.named_parameters()):
+ if "lora_" in n1:
+ # lora modules require gradients, thus updated
+ assert p1.requires_grad
+ assert not torch.testing.assert_close(p1.to(p2.device).to(p2.dtype), p2, atol=5e-3, rtol=5e-3)
+ else:
+ if not p1.requires_grad:
+ torch.testing.assert_close(p1.to(p2.device).to(p2.dtype), p2, atol=5e-3, rtol=5e-3)
+
+
+def run_lora_test():
+ sub_model_zoo = model_zoo.get_sub_registry("transformers_llama")
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ task_type = None
+ if name == "transformers_llama_for_casual_lm":
+ task_type = "CAUSAL_LM"
+ if name == "transformers_llama_for_sequence_classification":
+ task_type = "SEQ_CLS"
+ check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type)
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_lora_test()
+
+
+@rerun_if_address_is_in_use()
+def test_torch_ddp_lora():
+ spawn(run_dist, 2)
diff --git a/tests/test_moe/test_grad_handler.py b/tests/test_moe/test_grad_handler.py
index a349bc5a910a..a88f5f9cce51 100644
--- a/tests/test_moe/test_grad_handler.py
+++ b/tests/test_moe/test_grad_handler.py
@@ -16,7 +16,6 @@
def run_test(rank, world_size, port):
colossalai.launch(
- config=dict(),
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_moe/test_kernel.py b/tests/test_moe/test_kernel.py
index 62d61a3d4b2c..30122d31a32f 100644
--- a/tests/test_moe/test_kernel.py
+++ b/tests/test_moe/test_kernel.py
@@ -20,7 +20,7 @@ def run_routing(rank, world_size, port, rs=2, hidden_size=128, data_type=torch.f
# Here we do not need TF32, since it brings absolute error on results
torch.backends.cuda.matmul.allow_tf32 = False
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
local_rank = dist.get_rank()
MOE_MANAGER.setup(parallel="EP") # MOE environment initialization
diff --git a/tests/test_moe/test_moe_ep_tp.py b/tests/test_moe/test_moe_ep_tp.py
index 74feeeb59722..660fbd3585e3 100644
--- a/tests/test_moe/test_moe_ep_tp.py
+++ b/tests/test_moe/test_moe_ep_tp.py
@@ -128,7 +128,7 @@ def sync_local_from_ep(local_model: SparseMLP, ep_model: SparseMLP, assert_grad_
def run_test(rank: int, world_size: int, port: int, num_experts: int, batch_size: int, dim: int, config: Dict):
assert batch_size % world_size == 0
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
MOE_MANAGER.__init__()
MOE_MANAGER.setup(parallel=None)
diff --git a/tests/test_moe/test_moe_group.py b/tests/test_moe/test_moe_group.py
index 2f08a335de5a..b7be54d26fe3 100644
--- a/tests/test_moe/test_moe_group.py
+++ b/tests/test_moe/test_moe_group.py
@@ -60,7 +60,6 @@ def run_moe_init(expert_parallel):
def _run_test(rank, world_size, port, expert_parallel):
colossalai.launch(
- config=dict(),
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_moe/test_moe_hybrid_zero.py b/tests/test_moe/test_moe_hybrid_zero.py
index 7ada4090fb47..7932fa8a7c5b 100644
--- a/tests/test_moe/test_moe_hybrid_zero.py
+++ b/tests/test_moe/test_moe_hybrid_zero.py
@@ -81,7 +81,7 @@ def run_zero_optim_test(local_rank, world_size, stage=1):
def run_dist(rank, world_size, port):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_zero_optim_test(rank, world_size, stage=1)
run_zero_optim_test(rank, world_size, stage=2)
diff --git a/tests/test_moe/test_moe_load_balance.py b/tests/test_moe/test_moe_load_balance.py
index 717bb99fb830..fae189bac4fd 100644
--- a/tests/test_moe/test_moe_load_balance.py
+++ b/tests/test_moe/test_moe_load_balance.py
@@ -164,7 +164,6 @@ def run_hybrid_zero_optim_test(local_rank, world_size, stage=1):
def run_dist(rank, world_size, port):
colossalai.launch(
- config=dict(),
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_moe/test_moe_zero_fwd_bwd.py b/tests/test_moe/test_moe_zero_fwd_bwd.py
index 1bff2106675e..3bb08b49e8fe 100644
--- a/tests/test_moe/test_moe_zero_fwd_bwd.py
+++ b/tests/test_moe/test_moe_zero_fwd_bwd.py
@@ -61,7 +61,7 @@ def run_zero_test(local_rank, stage=1):
def run_dist(rank, world_size, port, stage):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
seed_all(42 + rank)
run_zero_test(rank, stage=stage)
diff --git a/tests/test_moe/test_moe_zero_optim.py b/tests/test_moe/test_moe_zero_optim.py
index 4f6067aaa10a..224c5c3b9247 100644
--- a/tests/test_moe/test_moe_zero_optim.py
+++ b/tests/test_moe/test_moe_zero_optim.py
@@ -66,7 +66,7 @@ def run_zero_test(local_rank, stage=1):
def run_dist(rank, world_size, port, stage):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
seed_all(42 + rank)
run_zero_test(rank, stage=stage)
diff --git a/tests/test_optimizer/test_adam_kernel.py b/tests/test_optimizer/test_adam_kernel.py
index 6d932156a270..0026499057fd 100644
--- a/tests/test_optimizer/test_adam_kernel.py
+++ b/tests/test_optimizer/test_adam_kernel.py
@@ -69,7 +69,7 @@ def __init__(self, lr: float, beta1: float, beta2: float, eps: float, weight_dec
fused_optim = FusedOptimizerLoader().load()
self.fused_adam = fused_optim.multi_tensor_adam
- self.dummy_overflow_buf = torch.cuda.IntTensor([0])
+ self.dummy_overflow_buf = torch.tensor([0], dtype=torch.int, device=get_accelerator().get_current_device())
def update(self, step: int, param: Tensor, grad: Tensor, exp_avg: Tensor, exp_avg_sq: Tensor):
multi_tensor_applier(
diff --git a/tests/test_pipeline/test_p2p_communication.py b/tests/test_pipeline/test_p2p_communication.py
index 6f5e734b7472..48a8d12e0ff7 100644
--- a/tests/test_pipeline/test_p2p_communication.py
+++ b/tests/test_pipeline/test_p2p_communication.py
@@ -71,7 +71,7 @@ def check_p2p_communication():
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_p2p_communication()
diff --git a/tests/test_pipeline/test_schedule/test_interleaved.py b/tests/test_pipeline/test_schedule/test_interleaved.py
index f8820688e610..a626b834a891 100644
--- a/tests/test_pipeline/test_schedule/test_interleaved.py
+++ b/tests/test_pipeline/test_schedule/test_interleaved.py
@@ -58,7 +58,7 @@ def run_pp(
This test is to examine the correctness of interleaved 1F1B, compared with torch.
Be aware it contains some hardcodes.
"""
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
# create model
seed_all(1453)
diff --git a/tests/test_pipeline/test_schedule/test_oneF_oneB.py b/tests/test_pipeline/test_schedule/test_oneF_oneB.py
index 590800780ab4..c4bfa7b697f8 100644
--- a/tests/test_pipeline/test_schedule/test_oneF_oneB.py
+++ b/tests/test_pipeline/test_schedule/test_oneF_oneB.py
@@ -148,7 +148,7 @@ def run_dist(
num_microbatch: int,
batch_size: int,
):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
examine_pp(num_microbatch, batch_size)
diff --git a/tests/test_pipeline/test_stage_manager.py b/tests/test_pipeline/test_stage_manager.py
index ed8284b3e64c..5146a86c8a0d 100644
--- a/tests/test_pipeline/test_stage_manager.py
+++ b/tests/test_pipeline/test_stage_manager.py
@@ -64,7 +64,7 @@ def check_stage_manager():
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
check_stage_manager()
diff --git a/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_amp_optimizer.py b/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_amp_optimizer.py
index f652d18e9494..b2c81f8ab095 100644
--- a/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_amp_optimizer.py
+++ b/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_amp_optimizer.py
@@ -193,13 +193,13 @@ def run_3d_test(test_config):
def check_grad_clip_norm(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_test()
def check_grad_clip_norm_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_3d_test()
diff --git a/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_naive_optimizer.py b/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_naive_optimizer.py
index a749a2966fde..ee1fd93335f5 100644
--- a/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_naive_optimizer.py
+++ b/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_naive_optimizer.py
@@ -151,13 +151,13 @@ def run_3d_test(test_config):
def check_grad_clip_norm(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_test()
def check_grad_clip_norm_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_3d_test()
diff --git a/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_zero_optimizer.py b/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_zero_optimizer.py
index 41f06a4c3888..be257e81860e 100644
--- a/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_zero_optimizer.py
+++ b/tests/test_shardformer/test_hybrid_parallel_grad_clip_norm/test_zero_optimizer.py
@@ -183,13 +183,13 @@ def run_3d_test(test_config):
def check_grad_clip_norm(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_test()
def check_grad_clip_norm_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_3d_test()
diff --git a/tests/test_shardformer/test_layer/test_dist_crossentropy.py b/tests/test_shardformer/test_layer/test_dist_crossentropy.py
index 414157c2233d..8ace0e0281b2 100644
--- a/tests/test_shardformer/test_layer/test_dist_crossentropy.py
+++ b/tests/test_shardformer/test_layer/test_dist_crossentropy.py
@@ -14,7 +14,7 @@
def check_dist_crossentropy(rank, world_size, port, ignore_index):
disable_existing_loggers()
- colossalai.launch(config=CONFIG, rank=rank, world_size=world_size, port=port, host="localhost", backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost", backend="nccl")
# prepare data
pred = torch.randn(2, 4, 8, requires_grad=True).cuda()
diff --git a/tests/test_shardformer/test_layer/test_dropout.py b/tests/test_shardformer/test_layer/test_dropout.py
index 576620e6c7f3..f1e646ed2487 100644
--- a/tests/test_shardformer/test_layer/test_dropout.py
+++ b/tests/test_shardformer/test_layer/test_dropout.py
@@ -56,7 +56,7 @@ def check_dropout_replicated_input():
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_dropout_parallel_input()
check_dropout_replicated_input()
diff --git a/tests/test_shardformer/test_layer/test_embedding.py b/tests/test_shardformer/test_layer/test_embedding.py
index 3dbbcd766bf4..3d7dc20889ae 100644
--- a/tests/test_shardformer/test_layer/test_embedding.py
+++ b/tests/test_shardformer/test_layer/test_embedding.py
@@ -43,7 +43,7 @@ def check_embedding_1d(lazy_init: bool):
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_embedding_1d()
diff --git a/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py b/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py
index e9aa0dbedbc8..5aa8584a0092 100644
--- a/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py
+++ b/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py
@@ -143,7 +143,7 @@ def check_gpt2_qkv_fused_linear_1d(lazy_init: bool, seq_parallel_mode: bool, ove
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# test for linear conv
check_gpt2_qkv_fused_linear_1d()
diff --git a/tests/test_shardformer/test_layer/test_layernorm.py b/tests/test_shardformer/test_layer/test_layernorm.py
index 3eb3bb2e5b8d..b0deff6b8fa4 100644
--- a/tests/test_shardformer/test_layer/test_layernorm.py
+++ b/tests/test_shardformer/test_layer/test_layernorm.py
@@ -41,7 +41,7 @@ def check_layernorm(lazy_init: bool):
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_layernorm()
diff --git a/tests/test_shardformer/test_layer/test_linear_1d.py b/tests/test_shardformer/test_layer/test_linear_1d.py
index 21d3190de7ae..541aa3251400 100644
--- a/tests/test_shardformer/test_layer/test_linear_1d.py
+++ b/tests/test_shardformer/test_layer/test_linear_1d.py
@@ -185,7 +185,7 @@ def run_dist_linear_test(lazy_init, seq_parallel_mode, overlap):
def check_dist_linear(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_dist_linear_test()
diff --git a/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py b/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py
index 5e996d2ba985..dc14fd59175a 100644
--- a/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py
+++ b/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py
@@ -126,7 +126,7 @@ def check_linear_conv_1d_row(lazy_init: bool):
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# test for linear conv
check_linear_conv_1d_col()
diff --git a/tests/test_shardformer/test_layer/test_sequence_parallel.py b/tests/test_shardformer/test_layer/test_sequence_parallel.py
index 13b1a13e7f94..a6cf61f8f0fd 100644
--- a/tests/test_shardformer/test_layer/test_sequence_parallel.py
+++ b/tests/test_shardformer/test_layer/test_sequence_parallel.py
@@ -165,7 +165,7 @@ def run_seq_parallel_attn(seq_len, hidden_dim, head_num, batch_size):
def check_all2all_attn(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_seq_parallel_attn()
diff --git a/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py b/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py
index 91cc1a987a29..fdd304256cae 100644
--- a/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py
+++ b/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py
@@ -45,7 +45,7 @@ def check_vocab_embedding_1d(lazy_init: bool):
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_vocab_embedding_1d()
diff --git a/tests/test_shardformer/test_model/test_shard_bert.py b/tests/test_shardformer/test_model/test_shard_bert.py
index 919557797fcd..3ec394768669 100644
--- a/tests/test_shardformer/test_model/test_shard_bert.py
+++ b/tests/test_shardformer/test_model/test_shard_bert.py
@@ -231,13 +231,13 @@ def run_bert_3d_test(test_config):
def check_bert(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_bert_test()
def check_bert_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_bert_3d_test()
diff --git a/tests/test_shardformer/test_model/test_shard_blip2.py b/tests/test_shardformer/test_model/test_shard_blip2.py
index 2c56b0435a6d..712c5c1e19fd 100644
--- a/tests/test_shardformer/test_model/test_shard_blip2.py
+++ b/tests/test_shardformer/test_model/test_shard_blip2.py
@@ -99,7 +99,6 @@ def run_blip2_test(
def check_blip2(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_shardformer/test_model/test_shard_bloom.py b/tests/test_shardformer/test_model/test_shard_bloom.py
index cc0786618853..6ab0369e0b91 100644
--- a/tests/test_shardformer/test_model/test_shard_bloom.py
+++ b/tests/test_shardformer/test_model/test_shard_bloom.py
@@ -209,13 +209,13 @@ def run_bloom_3d_test(test_config):
def check_bloom(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_bloom_test()
def check_bloom_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_bloom_3d_test()
diff --git a/tests/test_shardformer/test_model/test_shard_chatglm2.py b/tests/test_shardformer/test_model/test_shard_chatglm2.py
index 376d315c1c27..6ce020b68ab5 100644
--- a/tests/test_shardformer/test_model/test_shard_chatglm2.py
+++ b/tests/test_shardformer/test_model/test_shard_chatglm2.py
@@ -259,7 +259,6 @@ def run_chatglm_3d_test(test_config):
def check_chatglm(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
@@ -272,7 +271,6 @@ def check_chatglm(rank, world_size, port):
def check_chatglm_3d(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_shardformer/test_model/test_shard_falcon.py b/tests/test_shardformer/test_model/test_shard_falcon.py
index 5e2efcd80367..8074f9d61140 100644
--- a/tests/test_shardformer/test_model/test_shard_falcon.py
+++ b/tests/test_shardformer/test_model/test_shard_falcon.py
@@ -176,13 +176,13 @@ def run_falcon_3d_test(test_config):
def check_falcon(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_falcon_test()
def check_falcon_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_falcon_3d_test()
diff --git a/tests/test_shardformer/test_model/test_shard_gpt2.py b/tests/test_shardformer/test_model/test_shard_gpt2.py
index 4aac7f3d4ed7..72ea2b0895e9 100644
--- a/tests/test_shardformer/test_model/test_shard_gpt2.py
+++ b/tests/test_shardformer/test_model/test_shard_gpt2.py
@@ -275,7 +275,6 @@ def run_gpt2_3d_test(test_config):
def check_gpt2(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
@@ -288,7 +287,6 @@ def check_gpt2(rank, world_size, port):
def check_gpt2_3d(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_shardformer/test_model/test_shard_llama.py b/tests/test_shardformer/test_model/test_shard_llama.py
index 3945926889eb..104ede98159d 100644
--- a/tests/test_shardformer/test_model/test_shard_llama.py
+++ b/tests/test_shardformer/test_model/test_shard_llama.py
@@ -319,13 +319,13 @@ def run_llama_3d_test(test_config):
def check_llama(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_llama_test()
def check_llama_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_llama_3d_test()
diff --git a/tests/test_shardformer/test_model/test_shard_mistral.py b/tests/test_shardformer/test_model/test_shard_mistral.py
index 05c1998146b6..deced9d56507 100644
--- a/tests/test_shardformer/test_model/test_shard_mistral.py
+++ b/tests/test_shardformer/test_model/test_shard_mistral.py
@@ -170,7 +170,7 @@ def run_mistral_test(test_config):
def check_mistral(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_mistral_test()
diff --git a/tests/test_shardformer/test_model/test_shard_opt.py b/tests/test_shardformer/test_model/test_shard_opt.py
index 523ed879bcf7..b7c77d20b807 100644
--- a/tests/test_shardformer/test_model/test_shard_opt.py
+++ b/tests/test_shardformer/test_model/test_shard_opt.py
@@ -233,7 +233,6 @@ def run_opt_3d_test(test_config):
def check_OPTModel(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
@@ -246,7 +245,6 @@ def check_OPTModel(rank, world_size, port):
def check_opt_3d(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_shardformer/test_model/test_shard_sam.py b/tests/test_shardformer/test_model/test_shard_sam.py
index a8d4cb635221..e872d7f7bf8c 100644
--- a/tests/test_shardformer/test_model/test_shard_sam.py
+++ b/tests/test_shardformer/test_model/test_shard_sam.py
@@ -57,7 +57,7 @@ def run_sam_test(enable_fused_normalization, enable_tensor_parallelism, enable_f
def check_sam(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_sam_test()
diff --git a/tests/test_shardformer/test_model/test_shard_t5.py b/tests/test_shardformer/test_model/test_shard_t5.py
index a6fe2dd39383..521dc9130b7e 100644
--- a/tests/test_shardformer/test_model/test_shard_t5.py
+++ b/tests/test_shardformer/test_model/test_shard_t5.py
@@ -222,7 +222,6 @@ def run_t5_3d_test(test_config):
def check_t5(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
@@ -235,7 +234,6 @@ def check_t5(rank, world_size, port):
def check_t5_3d(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(
- config={},
rank=rank,
world_size=world_size,
host="localhost",
diff --git a/tests/test_shardformer/test_model/test_shard_vit.py b/tests/test_shardformer/test_model/test_shard_vit.py
index 3a8af2d6d481..d33b52b422dc 100644
--- a/tests/test_shardformer/test_model/test_shard_vit.py
+++ b/tests/test_shardformer/test_model/test_shard_vit.py
@@ -168,13 +168,13 @@ def run_vit_3d_test(test_config):
def check_vit(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_vit_test()
def check_vit_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_vit_3d_test()
diff --git a/tests/test_shardformer/test_model/test_shard_whisper.py b/tests/test_shardformer/test_model/test_shard_whisper.py
index af61e464014f..beb2a6761813 100644
--- a/tests/test_shardformer/test_model/test_shard_whisper.py
+++ b/tests/test_shardformer/test_model/test_shard_whisper.py
@@ -196,13 +196,13 @@ def run_whisper_3d_test(test_config):
def check_whisper(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_whisper_test()
def check_whisper_3d(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_whisper_3d_test()
diff --git a/tests/test_shardformer/test_with_torch_ddp.py b/tests/test_shardformer/test_with_torch_ddp.py
index 4b741c21b48c..4735df717882 100644
--- a/tests/test_shardformer/test_with_torch_ddp.py
+++ b/tests/test_shardformer/test_with_torch_ddp.py
@@ -71,7 +71,7 @@ def check_shardformer_with_ddp(lazy_init: bool):
def run_dist(rank, world_size, port):
disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
check_shardformer_with_ddp()
diff --git a/tests/test_tensor/test_comm_spec_apply.py b/tests/test_tensor/test_comm_spec_apply.py
index 5e969b1aaf98..a2414d949f01 100644
--- a/tests/test_tensor/test_comm_spec_apply.py
+++ b/tests/test_tensor/test_comm_spec_apply.py
@@ -178,7 +178,7 @@ def check_all_reduce_in_flatten_device_mesh(device_mesh, rank):
def check_comm(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 4)
assert rank == dist.get_rank()
diff --git a/tests/test_tensor/test_dtensor/test_comm_spec.py b/tests/test_tensor/test_dtensor/test_comm_spec.py
index 6d1640b4f3dc..fd99967107f6 100644
--- a/tests/test_tensor/test_dtensor/test_comm_spec.py
+++ b/tests/test_tensor/test_dtensor/test_comm_spec.py
@@ -124,7 +124,7 @@ def check_all_reduce_bwd(process_groups_dict, rank):
def check_comm(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 4)
assert rank == dist.get_rank()
diff --git a/tests/test_tensor/test_dtensor/test_dtensor.py b/tests/test_tensor/test_dtensor/test_dtensor.py
index 33ae59d01550..60efa315e7f9 100644
--- a/tests/test_tensor/test_dtensor/test_dtensor.py
+++ b/tests/test_tensor/test_dtensor/test_dtensor.py
@@ -21,7 +21,7 @@ def forward(self, x):
def check_dtensor(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
test_model = TestModel(8, 8).to("cuda")
original_tensor = torch.rand(4, 8).to("cuda")
compare_output = test_model(original_tensor)
diff --git a/tests/test_tensor/test_dtensor/test_layout_converter.py b/tests/test_tensor/test_dtensor/test_layout_converter.py
index 3bface1d286f..6e426d0e83cb 100644
--- a/tests/test_tensor/test_dtensor/test_layout_converter.py
+++ b/tests/test_tensor/test_dtensor/test_layout_converter.py
@@ -20,7 +20,7 @@
def check_one_step_transform(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
# [[0, 1],
# [2, 3]]
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
@@ -82,7 +82,7 @@ def check_one_step_transform(rank, world_size, port):
def check_layout_converting(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
dim_partition_source = {1: [0, 1]}
dim_partition_target = {0: [0, 1]}
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
@@ -141,7 +141,7 @@ def check_layout_converting(rank, world_size, port):
def check_layout_converting_apply(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
dim_partition_source = {1: [0, 1]}
dim_partition_target = {0: [0, 1]}
diff --git a/tests/test_tensor/test_mix_gather.py b/tests/test_tensor/test_mix_gather.py
index 7d6f8979dd0b..6dbbe5de6ff1 100644
--- a/tests/test_tensor/test_mix_gather.py
+++ b/tests/test_tensor/test_mix_gather.py
@@ -296,7 +296,7 @@ def check_two_all_gather_RS01(device_mesh, rank):
def check_comm(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 8)
assert rank == dist.get_rank()
diff --git a/tests/test_tensor/test_padded_tensor.py b/tests/test_tensor/test_padded_tensor.py
index 31a267c15286..6d19845dff2f 100644
--- a/tests/test_tensor/test_padded_tensor.py
+++ b/tests/test_tensor/test_padded_tensor.py
@@ -10,7 +10,7 @@
def check_padded_tensor(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
original_tensor = torch.rand(32, 64).to("cuda")
device_mesh = DeviceMesh(torch.Tensor([0, 1, 2, 3]), (2, 2), init_process_group=True)
diff --git a/tests/test_tensor/test_shape_consistency_apply.py b/tests/test_tensor/test_shape_consistency_apply.py
index b2bc84edd87f..8d8d8ef5148f 100644
--- a/tests/test_tensor/test_shape_consistency_apply.py
+++ b/tests/test_tensor/test_shape_consistency_apply.py
@@ -11,7 +11,7 @@
def check_apply(rank, world_size, port):
disable_existing_loggers()
- launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_zero/test_gemini/test_chunk_mgrv2.py b/tests/test_zero/test_gemini/test_chunk_mgrv2.py
index 879eeccde3b4..412a95f6aaea 100644
--- a/tests/test_zero/test_gemini/test_chunk_mgrv2.py
+++ b/tests/test_zero/test_gemini/test_chunk_mgrv2.py
@@ -49,7 +49,7 @@ def exam_chunk_memory(keep_gathered, pin_memory):
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_chunk_memory()
diff --git a/tests/test_zero/test_gemini/test_chunkv2.py b/tests/test_zero/test_gemini/test_chunkv2.py
index e4dc569b825b..25731132887b 100644
--- a/tests/test_zero/test_gemini/test_chunkv2.py
+++ b/tests/test_zero/test_gemini/test_chunkv2.py
@@ -108,7 +108,7 @@ def exam_chunk_basic(init_device, keep_gathered, pin_memory):
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_chunk_basic()
diff --git a/tests/test_zero/test_gemini/test_fwd_bwd.py b/tests/test_zero/test_gemini/test_fwd_bwd.py
index 3a9742e01566..d9084fd5ae47 100644
--- a/tests/test_zero/test_gemini/test_fwd_bwd.py
+++ b/tests/test_zero/test_gemini/test_fwd_bwd.py
@@ -100,8 +100,7 @@ def exam_gpt_fwd_bwd(
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_gpt_fwd_bwd()
diff --git a/tests/test_zero/test_gemini/test_gemini_use_rmt.py b/tests/test_zero/test_gemini/test_gemini_use_rmt.py
index 90ad62d1ac78..1e49f2851e2e 100644
--- a/tests/test_zero/test_gemini/test_gemini_use_rmt.py
+++ b/tests/test_zero/test_gemini/test_gemini_use_rmt.py
@@ -80,8 +80,7 @@ def run_gemini_use_rmt(placement_policy, keep_gather, model_name: str, use_grad_
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
run_gemini_use_rmt()
diff --git a/tests/test_zero/test_gemini/test_grad_accum.py b/tests/test_zero/test_gemini/test_grad_accum.py
index 36a803492b6d..fd0e9fd7c89b 100644
--- a/tests/test_zero/test_gemini/test_grad_accum.py
+++ b/tests/test_zero/test_gemini/test_grad_accum.py
@@ -138,8 +138,7 @@ def exam_gemini_grad_acc(
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_gemini_grad_acc()
diff --git a/tests/test_zero/test_gemini/test_grad_clip.py b/tests/test_zero/test_gemini/test_grad_clip.py
index 23b3504fdb7c..0a9bac0926d9 100644
--- a/tests/test_zero/test_gemini/test_grad_clip.py
+++ b/tests/test_zero/test_gemini/test_grad_clip.py
@@ -117,8 +117,7 @@ def exam_grad_clipping(placement_config, model_name: str, master_weights: bool):
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_grad_clipping()
diff --git a/tests/test_zero/test_gemini/test_inference.py b/tests/test_zero/test_gemini/test_inference.py
index 7f3c7176e99e..e54804fc53d7 100644
--- a/tests/test_zero/test_gemini/test_inference.py
+++ b/tests/test_zero/test_gemini/test_inference.py
@@ -107,8 +107,7 @@ def inference_iter():
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_inference()
diff --git a/tests/test_zero/test_gemini/test_optim.py b/tests/test_zero/test_gemini/test_optim.py
index 71bb27b4aca1..a9366e7bc5d8 100644
--- a/tests/test_zero/test_gemini/test_optim.py
+++ b/tests/test_zero/test_gemini/test_optim.py
@@ -183,8 +183,7 @@ def exam_tiny_example(placement_config, model_name: str, mixed_precision: torch.
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_model_step()
exam_tiny_example()
diff --git a/tests/test_zero/test_gemini/test_search.py b/tests/test_zero/test_gemini/test_search.py
index cf3658bf9920..9c8c497f322e 100644
--- a/tests/test_zero/test_gemini/test_search.py
+++ b/tests/test_zero/test_gemini/test_search.py
@@ -47,7 +47,7 @@ def exam_chunk_manager():
def run_dist(rank, world_size, port):
- colossalai.launch(config={}, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_search_chunk_size()
exam_chunk_manager()
diff --git a/tests/test_zero/test_gemini/test_zeroddp_state_dict.py b/tests/test_zero/test_gemini/test_zeroddp_state_dict.py
index cbf5169fc621..23e2d8083945 100644
--- a/tests/test_zero/test_gemini/test_zeroddp_state_dict.py
+++ b/tests/test_zero/test_gemini/test_zeroddp_state_dict.py
@@ -76,8 +76,7 @@ def exam_state_dict(placement_config, keep_gathered, model_name: str, master_wei
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_state_dict()
diff --git a/tests/test_zero/test_gemini/test_zerooptim_state_dict.py b/tests/test_zero/test_gemini/test_zerooptim_state_dict.py
index 87cb1cdfe43f..8d70ae3b1c10 100644
--- a/tests/test_zero/test_gemini/test_zerooptim_state_dict.py
+++ b/tests/test_zero/test_gemini/test_zerooptim_state_dict.py
@@ -68,8 +68,7 @@ def exam_zero_optim_state_dict(placement_config, keep_gathered):
def run_dist(rank, world_size, port):
- config = {}
- colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
exam_zero_optim_state_dict()
diff --git a/tests/test_zero/test_low_level/test_grad_acc.py b/tests/test_zero/test_low_level/test_grad_acc.py
index 11f738615d16..ed12bb72dc3e 100644
--- a/tests/test_zero/test_low_level/test_grad_acc.py
+++ b/tests/test_zero/test_low_level/test_grad_acc.py
@@ -130,7 +130,7 @@ def fwd_bwd_func(no_sync, cur_data, check_flag):
def run_dist(rank, world_size, port):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
exam_zero_1_grad_acc(sync=True)
exam_zero_1_grad_acc(sync=False)
diff --git a/tests/test_zero/test_low_level/test_zero1_2.py b/tests/test_zero/test_low_level/test_zero1_2.py
index e2196cfbf0f2..06a29bd1dde2 100644
--- a/tests/test_zero/test_low_level/test_zero1_2.py
+++ b/tests/test_zero/test_low_level/test_zero1_2.py
@@ -178,7 +178,7 @@ def exam_zero_1_torch_ddp(world_size, dtype: torch.dtype, master_weights: bool):
def run_dist(rank, world_size, port):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
exam_zero_1_torch_ddp(world_size=world_size)
exam_zero_1_2()
diff --git a/tests/test_zero/test_low_level/test_zero_ckpt.py b/tests/test_zero/test_low_level/test_zero_ckpt.py
index e9fc8598a62d..8543dfba0c15 100644
--- a/tests/test_zero/test_low_level/test_zero_ckpt.py
+++ b/tests/test_zero/test_low_level/test_zero_ckpt.py
@@ -103,7 +103,7 @@ def exam_zero_1_torch_ddp_ckpt():
def run_dist(rank, world_size, port):
- colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host="localhost")
+ colossalai.launch(rank=rank, world_size=world_size, port=port, host="localhost")
exam_zero_1_torch_ddp_ckpt()
diff --git a/version.txt b/version.txt
index 449d7e73a966..0f82685331ef 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.3.6
+0.3.7