proposal: runtime/pprof: add “heaptime” bytes*GCs memory profile #55900
Comments
|
While Another alternative is an opaque "GC impact" profile that has no meaningful unit; it's just a relative impact. The unit stays stable within a Go version, but not necessarily across Go versions. That way we can actually capture all the different costs and track them as they shift over time. One additional complication is objects that live forever. To get this right, I think we might need to count them separately. Otherwise, I'm not sure how the pprof package would know how long they were alive (or how to count them, exactly). I imagine that will look something like stopping the world and collecting every object that's sampled but still alive? On the topic of stacks and globals, I think we can model both as just large allocations (at least stacks come from the page heap anyway). They may have an outsized impact in the profile (especially globals, since they're always there), so we may want a way to filter them out. |
|
+1 on the usefulness of understanding the lifetime of heap allocations. Another approach to estimate this is to apply Little's Law ( Below is an screenshot from one of our biggest production services at Datadog (frames anonymized) that shows the estimated average age as a virtual leaf node in the frame graph:
As far as I can tell, the results seem to match my intuition for what the code is doing. But the limitation of this approach is that the estimate will be poor if the number of allocations observed in the delta period is small. Additionally it's impossible to compute an estimate (other than lifetime > period) for objects that had no allocation in the period. Anyway, I figured it's worth sharing this approach in case you hadn't seen or considered it. The feature could be built directly into the pprof UI using the data available today. I like the idea of a GC Impact view that scales the frame graph, but objects that had no allocation in the period will problematic as explained above. Perhaps the only issue we face as a profiling vendor is that the delta heap profiles are only available via |
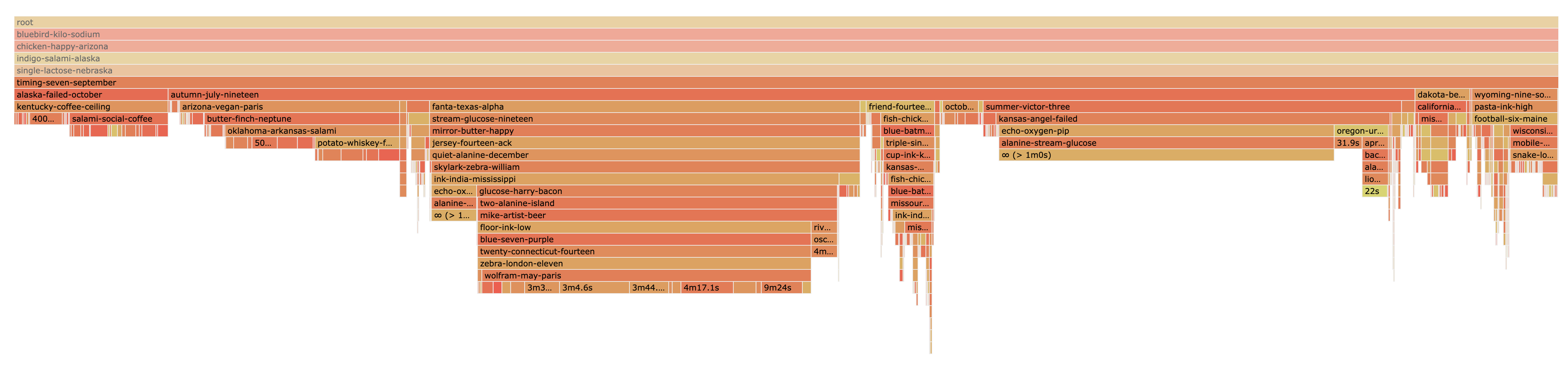
|
The intuition in this profile is that e.g., a 64 byte object that lives for 10 GC cycles should have the same weight as 10 64 byte objects that live for 1 GC cycle. I was initially confused how this new profile is fundamentally different from the existing Since the |
|
Another idea: building on my previous comment about filtering, we could tag allocations as either having pointers or not with a label. We don't currently support user-provided labels for memory profiles, but the main issue seems to be that we can't ever throw away labels for monotonic profiles (#23458). In this case, however, the runtime could add just a few labels of its own that are always relevant, like "has pointers" or "goroutine stack" or something. i.e. a small number of categories that are always meaningful. |
|
On a facial read of the proposal, I would be a big fan of it due to past concerns with heap fragmentation, which motivated me to report this feature request: Heap age as proposed may provide the tenure information I was requesting in bullet no. six in the aforementioned link. |
While that may be more general, I think it tells you less about actual costs.
That's interesting. This could still be "bytes * GCs", but it would be bytes scanned, not just total bytes. I would want to call that something more specific than "heaptime" (maybe "GC impact" as you suggested), but I think the unit could be concrete. Then we could count just the scan size of objects, including 0 for pointer-free objects.
That's a good point that I totally overlooked. They don't necessarily have to "live forever", but just objects that are still live when the profile snapshot is taken. I think those should just count for all of the GC cycles that have happened since they were allocated. That does mess up my proposed implementation of this profile, though... We could do the accounting during sweep. Sweep walks the specials anyway, so when it sees an mprof special for a marked object, it could bump the appropriate profile counter.
If we have a more general "GC impact" profile, I think you're right that we could just account these like any other allocation. Globals do have an outsize impact on marking time since they are by definition marked on every cycle, so I don't feel bad about indicating that. :) |
|
@felixge , that's clever. :) As you say, it has some limitations, and I would love to just build this in. |
You gave a good summary of the differences, and in particular any advice we give should probably distinguish long-running steady-state systems from bounded executions, the way you did. If we went with a profile definition that more closely modeled the costs to marking, then the inuse profile and the heaptime (or whatever we would call it) profiles would be more different. |
|
@prattmic I agree with your analysis that the existing
@aclements should I create a proposal with google/pprof or what did you have in mind? I'd probably suggest to add it as a hover tooltip in the flamegraph or something like that. |
|
For when to do the calculation: If a user collects a "heap" profile from a running system, they don't need to also collect an "allocs" profile (and vice versa); they can instead pass an explicit sample type when they run |
That works fine for long-running services that are generally in a steady-state, which is what Google Cloud Profiler and Datadog target, but it's not a good fit for single-shot, phased applications. For example, profiling the compiler was the original motivation for this.
Sorry, by "I would love to just build this in" I meant add built-in support to runtime/pprof for generating this data, rather than a statistical approximation. We could certainly explore both approaches simultaneously, though, so you're welcome to file a proposal with pprof.
That's an interesting question. I'd originally thought of this as a new profile type, but it could be added as two new sample types to the existing heap profile. You have an interesting point about the added costs if you are already collecting heap profiles. |
I propose we add a new “heaptime” profile type to runtime/pprof. This is equivalent to the existing allocs profile, except that allocations are scaled by the number of GC cycles they survive. Hence, the profile would measure “space” in bytes*GCs and “objects” in objects*GCs. This can also be viewed as the “inuse” profile integrated over time.
This type of profile would help with understanding applications where a CPU profile shows significant time spent in GC scanning/marking by attributing the cause of the time. GC marking time scales with the number of GC cycles an object survives and its size, so an object that survives no cycles costs essentially nothing to GC, while an object that survives many cycles costs a lot in total. A heaptime profile would show users which allocations to reduce in order to reduce marking time.
For example, this came up in the context of improving compiler performance. The compiler spends a significant amount of CPU time in marking, but looking at the existing allocs profile is a poor proxy for attributing mark time.
One downside is that this profile would not be totally representative of marking costs, and hence may be misleading. For one, marking is more closely proportional to the “scan size” of an object, which is the size up to an object’s last pointer. Pointer-free objects are very cheap to mark, even if they are very large. It also wouldn’t capture time spent scanning non-heap objects like stacks and globals. Capturing these would require complicating the definition (and implementation) of the profile, but may be doable.
Taking this downside to the extreme, if we were to substantially change the GC algorithm, this type of profile may no longer reflect marking time at all. For example, in a generational garbage collector, it’s not entirely clear what this profile would mean (perhaps you would count the number of minor cycles an object survived while young plus the number of major cycles it survived while old, but that’s certainly harder to explain).
I believe this would be straightforward to implement. We would add the current GC cycle count to
runtime.specialprofileand new counters toruntime.memRecordCycle.runtime.mProf_Freewould subtract the allocating GC cycle counter stored in the special from the current cycle counter, use this to scale the allocation count and size, and accumulate these into the new fields ofmemRecordCycle. One complication is that I don’t think we want to add these toruntime.MemProfileRecord, so we would need some other way to get them into theruntime/pprofpackage. We already use private APIs betweenruntimeandruntime/pproffor the CPU profile, and I think we would do something similar for this./cc @golang/runtime @mknyszek @dr2chase
The text was updated successfully, but these errors were encountered: