Placeholder issue for discussion of issues in ABP/AdGuard issue tracker -- and possible solutions #1930
Comments
|
Regarding issue https://issues.adblockplus.org/ticket/2278: Being able to have a token for regex-based filters would definitely help performance. However trying to programmatically extract a token from a regex-based filter sounds scary to me, too much risk of extracting erroneous tokens. Suggestion: create a new filter option, For example, this filter in EasyList: Could simply have been written by a filter creator: |
|
Hey guys! I was thinking about solving this issue a while ago. Even tried to implement a simple token-extracting algorithm. I will post my ideas a bit later though. Meanwhile, here is a list of known regexp rules:
|
|
Please note the number of rules which are mistakenly made regexp-type. |
|
@gorhill I've not been involved in that issue so far, so just done a quick bit of reading. I might get some things wrong. While I agree that grabbing a keyword from the regexp seems scary, I'm not sure how the suggested Now if you think of a more advanced example which matches one of two possible domains, what would you put for the |
|
(I wonder if we could copy the content blocking approach of compiling all these regular expressions into a finite state machine? That could be a way to make matching regular expression filters faster without worrying about keywords.) |
|
Yes, bad example. Here is another one found in EasyList: Not sure if a token was available for this one -- whoever created the filter knows, but mainly my point is that |
|
Let's first think about what issue we are trying to solve. First of all, domain-restricted filters are not a problem as there is no influence on the overall performance. I suppose, that what we really need is to reduce the negative impact of the mistakes made by filters authors. For instance, the filters like Here is just a dirty example of a token extracting function: I've tried this function with the rules above and here is the result: What for the
|
They are using ABP's filtering engine since AdBlock v3.0. See https://github.com/kzar/watchadblock/releases/tag/3.0. |
|
The other points still stand though:) |
|
I wasn't aware of the many erroneous regex filters, looks like this can be easily addressed with a trivial code for these cases. Mainly it was just to throw an idea out there, since these untokenizable filters have always bothered me[1], and I knew there was an issue like this opened on ABP issue tracker -- so I just threw the idea out there to have an easy fix, worth only if actually used by filter list maintainers. Anyway, I will just use this issue here to throw ideas once in a while which I think might be good for all blockers[2], especially when it comes to make the life of filter list maintainers easier. [1] I was looking to even skip testing for domain hit -- but this is an implementation-dependent detail I suppose |
By the way, I'd like to raise a question about the non-standard syntax. You have recently added a couple of pseudo-classes extending element hiding rules syntax. I am talking about The idea is really great and we will support some of these extended selectors as well ( However, there is one issue that bothers me. The syntax you use (pseudo-classes syntax) is not backward-compatible and it will break good old stylesheet-based ad blockers like Adguard and ABP. I suggest introducing a backward-compatible syntax along with the modern pseudo-classes-based one. Backward compatible synonym for [1] As I understand, there is a backward compatible |
FWIW We are working towards adding the :has selectors too https://issues.adblockplus.org/ticket/3143
👍 Please do, I think collaboration benefits us all. |
|
@kzar so, what do you think about the backward compatible syntax proposition? |
|
@kzar regarding Lain's comment:
Using proposed syntax it could look like this: |
|
@ameshkov Well I think the idea is that when browsers eventually support As for the general point of using backward compatible syntax like you've suggested, I think it's a good idea. (We already do something like that for CSS property filters using the |
True. However, here is one more argument for that type of syntax. We all support a lot of different browsers (including mobile and such) and trying to use
Yeah, I know, that's why I was surprised by the implementation proposed in the issue 3143. |
I will support the backward-compatible syntax where possible, but personally, internally I prefer using the It does feel to me like a backward-compatible syntax would complicate writing such filters (especially the use of quotes): Aren't you validating element hiding filters at load time (or else using invalid CSS selector would break element hiding) so isn't true that old versions will discard filters with this new syntax? ( [1] Ok, the example is contrived, but it's just to illustrate easily combining such filters. |
Yeah, frankly, when I check something, I prefer to use the newer syntax as well. However, it's not that bad, there's no need to support it inside of a composite filter. Here, look at this example: |
Nope, in fact it was all of a sudden for us:) Also there's no way we could do it in desktop and mobile versions. |
|
@gorhill one more thing regarding the Could you please read this issue description and tell me what you think about it? |
I already support
I agree with (optional) pattern matching. Pattern-matching is not something I implemented, but I don't see a problem supporting this. For the implementation side of such filter however, I would just want to be sure its semantic does not force a very specific implementation.[1]
Note that ABP's For example, a filter such as [1] I see using |
It may look pretty good, but it bothers me that
Yep, I've run into a number of issues while implementing it. For now I've used a cross-browser function for extracting the cssText string: Also I agree with you on the enumerated properties approach. There's no need in building the
Yeah, you're right. Also now when I know how this type of rules work, I find it a bit misleading. At least I think Lain_13 does not understand how it works. @kzar what do you think about implementing something more "straightforward"? |
|
I guess if we use the properties approach and agree on *-before/after postfix, there is no need for me to use another name for that pseudo class. |
I agreed with this. This new selector, combinable with |
|
I've updated the syntax description: |
|
Looking into this specific case this morning: uBlockOrigin/uAssets#110. This would be solvable without exception filters if it was possible to outright remove the targeted nodes from the DOM: The current implicit action to take on targeted nodes is to hide them. However, being to re-style has make the job of working against anti-blocker mechanisms much easier (AdGuard support this). Additionally, being able to remove nodes from the DOM is something I have found would take care of many other cases as well (I do believe AdGuard support this in some ways, not sure). From my point of view, being forced to whitelist network requests from 3rd-party advertisers/trackers is always the worst option, and we should extend the capabilities of cosmetic filtering (element hiding) to avoid such whitelisting. |
|
Oh, you have finally faced these german wunderwaffe-anti-adblock-solutions:) Currently the easiest way to circumvent it is to inject a script like this: |
|
Why does the chrome store say it is corrupted now ? :( |
|
@hemantgoyal That is a Chrome hash function bug. See |
|
Hey guys, I've recently stumbled upon an interesting adblocking circumvention technique used by Yandex. The thing is that they use shadow DOM to circumvent element hiding rules: The open root is used in the screenshot so we can get inside with a Possible solution (rather ugly though):
Have you already faced anything like that? Thoughts? |
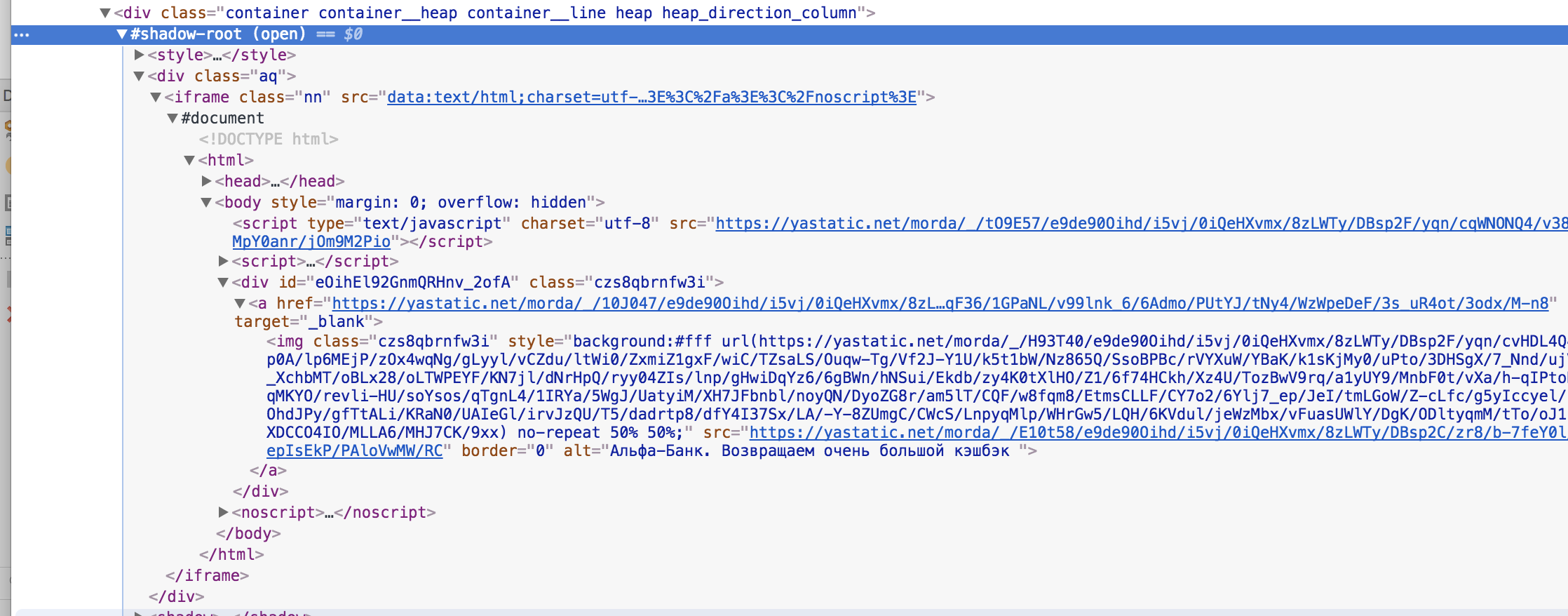{kind=link}
|
@ameshkov perhaps it's about the same yandex stuff |
|
@mapx- thank you! Yeah, it's been a while since they began their crusade and both issues are relevant. What bothers me is that the "closed shadow root" approach seems to be a universal way to avoid elements hiding and even user stylesheets won't help us defeat it once Chrome stops supporting |
|
The So currently, not an issue with Firefox I presume (does not support shadow stuff yet). An issue with Chrome, but can be worked around by manually hiding through |
That's basically what I meant -- support either Good news is that |
I just realized we can probably already just use Would this work now? |
We don't yet support it (but we definitely will), but this is a partial solution anyway. For instance, in Yandex case they shadow contains legit elements as well so we need something like |
I'm experimenting with this and this works fine so far on both Chromium and Firefox. I see 10-20ms gain in how earlier the scriptlets are injected (using Anyway, I want to ask why did you chose to go through messaging to inject the scriptlets rather than injecting directly using |
As I recall, we compared both and didn't see any serious difference. Actually, in future updates, we'll migrate to |
|
@ameshkov regarding Shadow DOM, we have user style sheets in Chromium now (works on Canary) along with the |
|
Hi @mjethani! I'm actually keeping an eye on all the pull requests you're pushing to Chromium, and you're doing a great job, thank you! |
|
Hey guys, coming at you with a new modifier idea: I suppose it can benefit all the privacy-oriented subscriptions so we're planning to implement it in one of the future updates. |
|
@ameshkov I don't see that much privacy value in dealing with cookies alone given that data can be stored in other local storage such as localStorage, indexedDB, etc.Blocking 3rd-party cookies in browser settings should be the first step for any privacy conscious person -- this also takes care of all local storages. |
|
Extending this modifier to handle However, I've never seen |
[Intentionally empty]
The text was updated successfully, but these errors were encountered: