From fdb85be40fa255c015819e711c15117c2aaa5101 Mon Sep 17 00:00:00 2001
From: Younes Belkada <49240599+younesbelkada@users.noreply.github.com>
Date: Tue, 5 Dec 2023 12:14:45 +0100
Subject: [PATCH] Faster generation using AWQ + Fused modules (#27411)
* v1 fusing modules
* add fused mlp support
* up
* fix CI
* block save_pretrained
* fixup
* small fix
* add new condition
* add v1 docs
* add some comments
* style
* fix nit
* adapt from suggestion
* add check
* change arg names
* change variables name
* Update src/transformers/integrations/awq.py
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
* style
* split up into 3 different private methods
* more conditions
* more checks
* add fused tests for custom models
* fix
* fix tests
* final update docs
* final fixes
* fix importlib metadata
* Update src/transformers/utils/quantization_config.py
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
* change it to `do_fuse`
* nit
* Update src/transformers/utils/quantization_config.py
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* Update src/transformers/utils/quantization_config.py
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* Update src/transformers/utils/quantization_config.py
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* few fixes
* revert
* fix test
* fix copies
* raise error if model is not quantized
* add test
* use quantization_config.config when fusing
* Update src/transformers/modeling_utils.py
---------
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
---
docker/transformers-all-latest-gpu/Dockerfile | 2 +-
docs/source/en/quantization.md | 141 +++++++++++
src/transformers/integrations/__init__.py | 4 +-
src/transformers/integrations/awq.py | 237 +++++++++++++++++-
src/transformers/modeling_utils.py | 44 +++-
src/transformers/utils/quantization_config.py | 58 ++++-
tests/quantization/autoawq/test_awq.py | 170 +++++++++++--
7 files changed, 623 insertions(+), 33 deletions(-)
diff --git a/docker/transformers-all-latest-gpu/Dockerfile b/docker/transformers-all-latest-gpu/Dockerfile
index d108ba5ace5805..7ab236a55d5902 100644
--- a/docker/transformers-all-latest-gpu/Dockerfile
+++ b/docker/transformers-all-latest-gpu/Dockerfile
@@ -56,7 +56,7 @@ RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://hu
RUN python3 -m pip install --no-cache-dir einops
# Add autoawq for quantization testing
-RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp38-cp38-linux_x86_64.whl
+RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.7/autoawq-0.1.7+cu118-cp38-cp38-linux_x86_64.whl
# For bettertransformer + gptq
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
diff --git a/docs/source/en/quantization.md b/docs/source/en/quantization.md
index 60903e36ad5968..00fe899e73bcbc 100644
--- a/docs/source/en/quantization.md
+++ b/docs/source/en/quantization.md
@@ -85,6 +85,147 @@ from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", use_flash_attention_2=True, device_map="cuda:0")
```
+
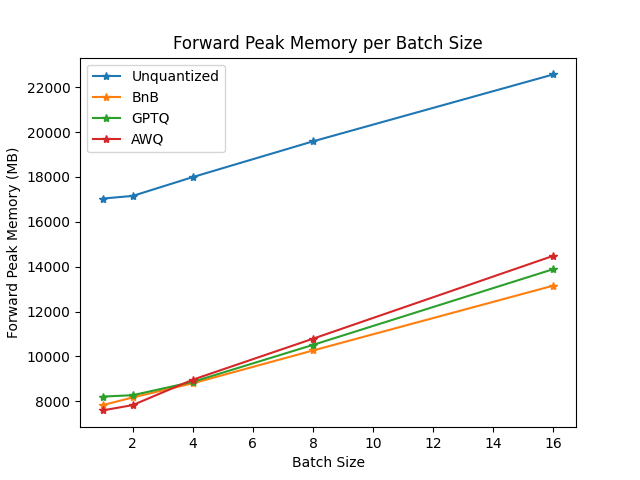
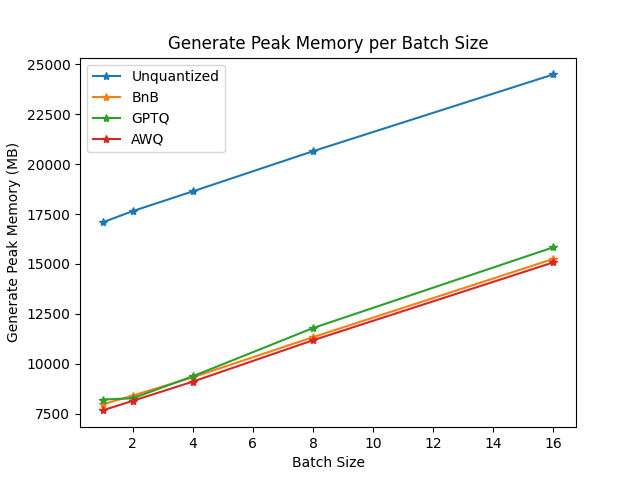
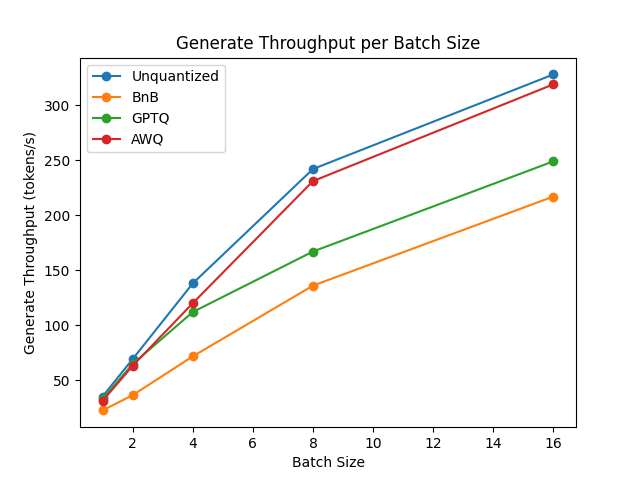
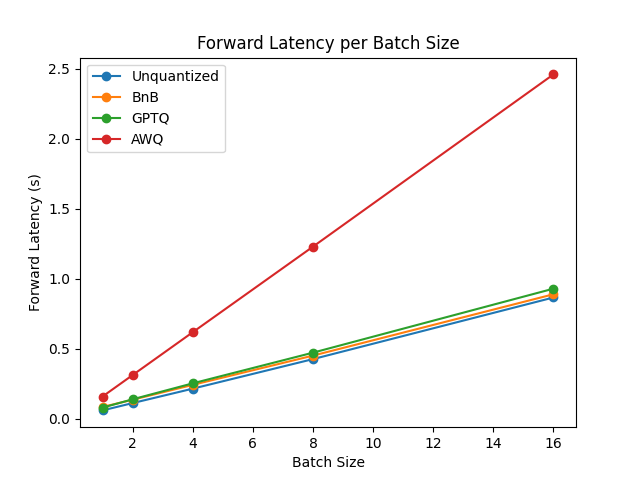
+### Benchmarks
+
+We performed some speed, throughput and latency benchmarks using [`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark) library.
+
+Note at that time of writing this documentation section, the available quantization methods were: `awq`, `gptq` and `bitsandbytes`.
+
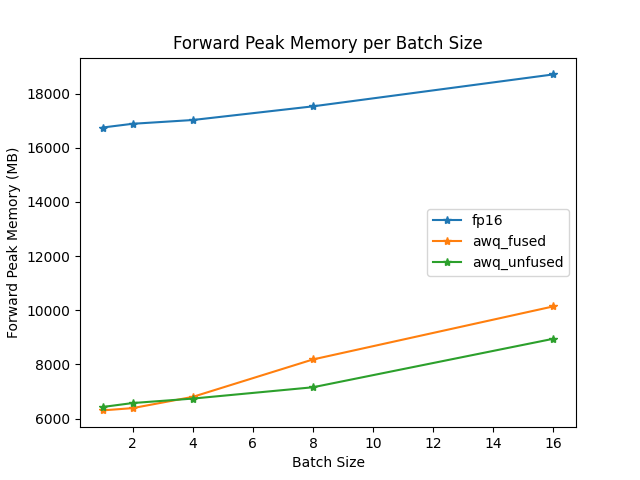
+The benchmark was run on a NVIDIA-A100 instance and the model used was [`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ) for the AWQ model, [`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ) for the GPTQ model. We also benchmarked it against `bitsandbytes` quantization methods and native `float16` model. Some results are shown below:
+
+
+
+
+
+
+
+
+
+
+
+
+

+