diff --git a/docs/source/en/perf_infer_gpu_many.md b/docs/source/en/perf_infer_gpu_many.md
index 756d2b3ef57b0b..2118b5ddb40431 100644
--- a/docs/source/en/perf_infer_gpu_many.md
+++ b/docs/source/en/perf_infer_gpu_many.md
@@ -22,6 +22,10 @@ Note: A multi GPU setup can use the majority of the strategies described in the
+## Flash Attention 2
+
+Flash Attention 2 integration also works in a multi-GPU setup, check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2)
+
## BetterTransformer
[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) converts 🤗 Transformers models to use the PyTorch-native fastpath execution, which calls optimized kernels like Flash Attention under the hood.
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 855c52ffd98c62..86e137cf14d7a1 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -17,6 +17,154 @@ rendered properly in your Markdown viewer.
In addition to this guide, relevant information can be found as well in [the guide for training on a single GPU](perf_train_gpu_one) and [the guide for inference on CPUs](perf_infer_cpu).
+## Flash Attention 2
+
+
+
+Note that this feature is experimental and might considerably change in future versions. For instance, the Flash Attention 2 API might migrate to `BetterTransformer` API in the near future.
+
+
+
+Flash Attention 2 can considerably speed up transformer-based models' training and inference speed. Flash Attention 2 has been introduced in the [official Flash Attention repository](https://github.com/Dao-AILab/flash-attention) by Tri Dao et al. The scientific paper on Flash Attention can be found [here](https://arxiv.org/abs/2205.14135).
+
+Make sure to follow the installation guide on the repository mentioned above to properly install Flash Attention 2. Once that package is installed, you can benefit from this feature.
+
+We natively support Flash Attention 2 for the following models:
+
+- Llama
+- Falcon
+
+You can request to add Flash Attention 2 support for more models by opening an issue on GitHub, and even open a Pull Request to integrate the changes. The supported models can be used for inference and training, including training with padding tokens - *which is currently not supported for `BetterTransformer` API below.*
+
+
+
+Flash Attention 2 can only be used when the models' dtype is `fp16` or `bf16` and runs only on NVIDIA-GPU devices. Make sure to cast your model to the appropriate dtype and load them on a supported device before using that feature.
+
+
+
+### Quick usage
+
+To enable Flash Attention 2 in your model, add `use_flash_attention_2` in the `from_pretrained` arguments:
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
+
+model_id = "tiiuae/falcon-7b"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+model = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ torch_dtype=torch.bfloat16,
+ use_flash_attention_2=True,
+)
+```
+
+And use it for generation or fine-tuning.
+
+### Expected speedups
+
+You can benefit from considerable speedups for fine-tuning and inference, especially for long sequences. However, since Flash Attention does not support computing attention scores with padding tokens under the hood, we must manually pad / unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
+
+To overcome this, one should use Flash Attention without padding tokens in the sequence for training (e.g., by packing a dataset, i.e., concatenating sequences until reaching the maximum sequence length. An example is provided [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516).
+
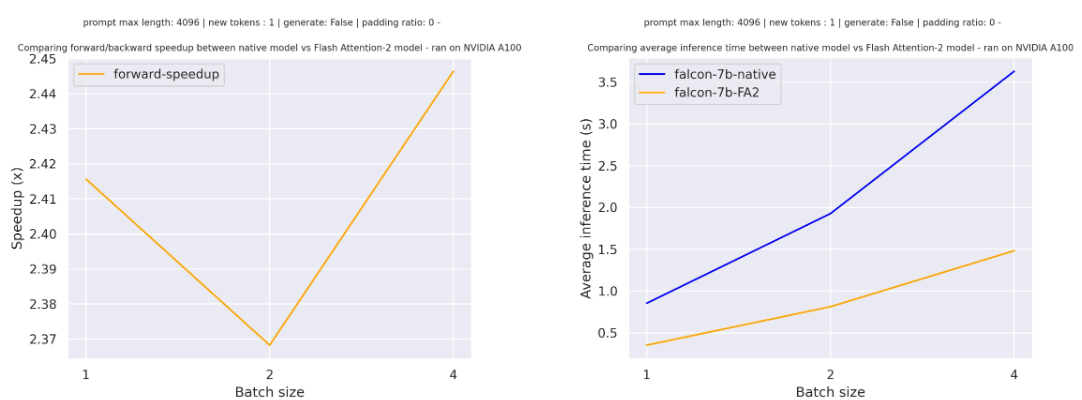
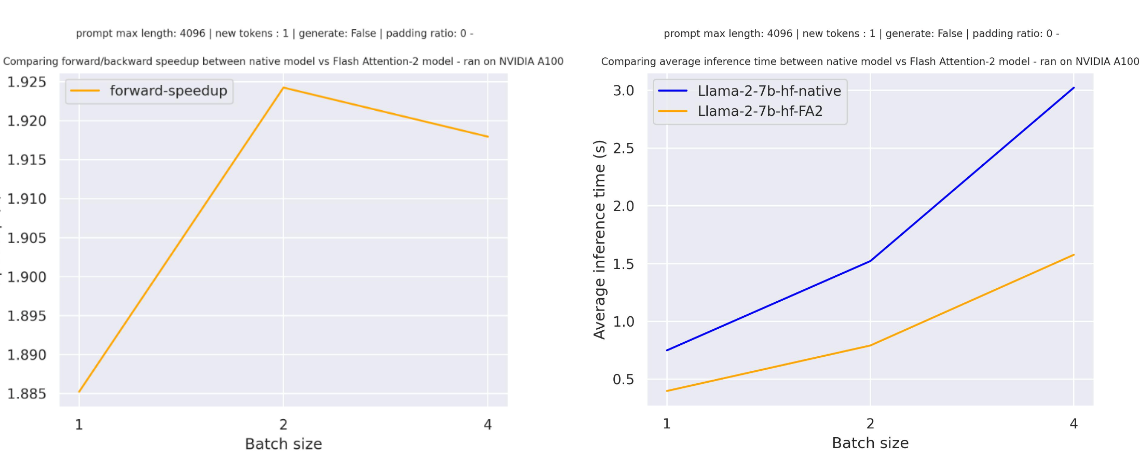
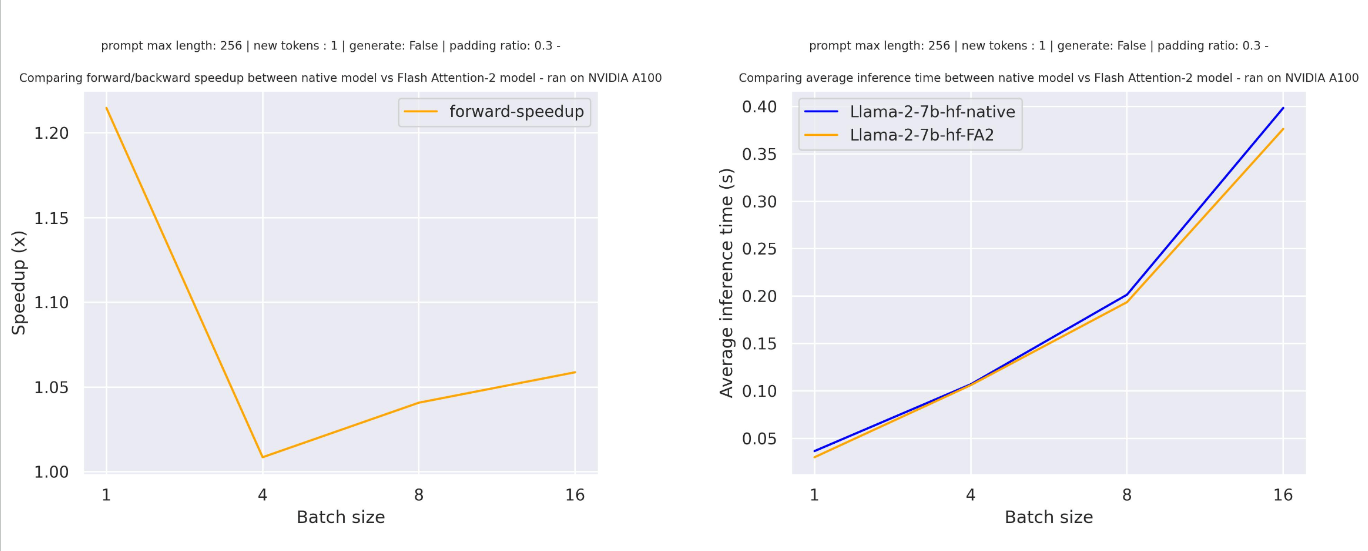
+Below is the expected speedup you can get for a simple forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes without padding tokens:
+
+Below is the expected speedup you can get for a simple forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes, without padding tokens:
+
+
+
+
+
+
+
+
+

+