Kerchunk enhancements for Fast NODD Grib Aggregations #42
Comments
|
Some extra detail on some of the technologies referenced in this proposal.
|
|
Pangeo Presentation introducing this work |
|
|
|
Your order is not quite right.
The last three points can be achieved in a single line: |
|
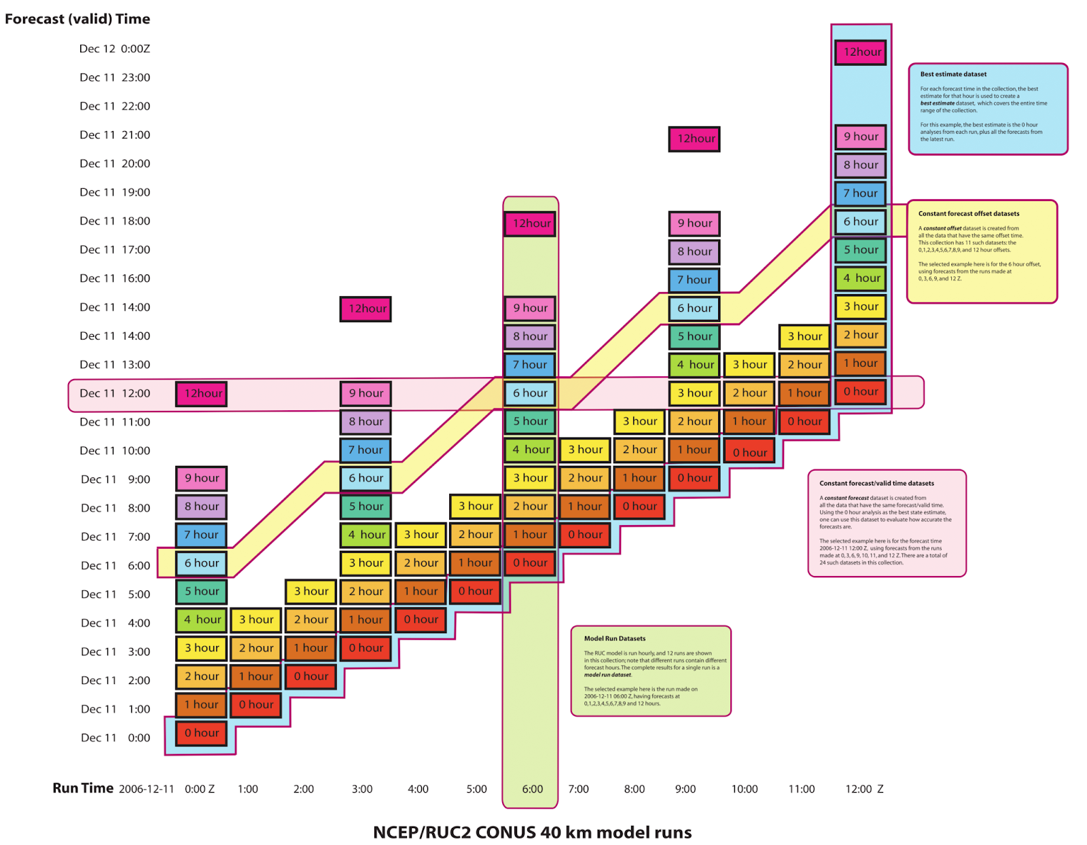
Here is a high level view of how we use these tools operationally.
Links from the image: The proposed project is to refine the api/methods in the V2 aggregation code and move it into Kerchunk |

{kind=link}
|
So it is So this project only involves, kerchunk to create indexes for the references of the grib files during scanning or only the indexes for the grib files during the scanning ? P.S:- I'm new to this whole field and I'd love to learn about it. I used kerchunk to produce the references locally using some sample grib files. Also it would be very helpful if you could provide some resources to get started with moving the V2 aggregation into kerchunk. |
We are not producing zarr files, only ephemeral zarr datasets - that is, an object you can use as any other zarr dataset, but without any real zarr store. Not copying/translating the original grib data is a big feature of kerchunk. I'm afraid I didn't understand what you asked in the second paragraph. |
|
I meant to ask for this project, we're to add the indexing process for grib files in V2 NODD Aggregations to kerchunk. It'd to very helpful if you could provide me some resources to understand this whole field to know it better and contribute to kerchunk, as I'm totally new to this domain. |
|
As far as the kerchunk stack is concerned, you can go through tutorials:
What else would you like to know? We don't expect you to know the byte-wise details within the grib format. |
|
@emfdavid The role of zarr references made by scan_grib in one-to-one mapping of the index files to the grib files is to help in making the index table from the grib tree which is made using the references, right? chunks are referred to the groups made from the grib messages? Is there any template for writing out the GSOC proposal. What should be the proposal about? |
The scan grib message reads the actual grib file message and parses it to get the metadata. This is expensive and slow (both the IO and the processing time!). By making a mapping with the index file, we can get the same information from the small text files.
Yes, each zarr chunk is a reference to a range of bytes in a grib file that can be decoded to get the array of values. Some of the chunks contain only a single value, like the timestamp, so these are stored by value rather than by reference. Have you been able to try out any of the Kerchunk tutorials? You can also try running the notebook liked from this issue. The setup instructions are a bit terse, but if you let me know where you have trouble I can help.
I am still new to this process too, but I think this github issue is the proposal. We will follow up with more questions as the selection process gets going. This is an open discussion of the project where applicants can ask clarifying questions and start to learn about the project. |
So in fast aggregations we're not writing out the json files instead just create the mapping? @emfdavid I've been able to read some sample grib files with kerchunk which I've collected over the Internet and produced the json references for the same on a Jupyter notebook locally. I also went through the Pangeo Presentation for the enhancements and along with that kerchunk's guide. I want to apply for this project during this year's Google Summer of Code. In what format and file should I write the proposal? |
|
@martindurant This is a medium size project, right? Can you give a brief idea of what should the proposal consist of? I'm writing a proposal for this project using the IOOS's template. |
|
Essentially the template, together with our description and discussion here should be plenty. If you are setting up specific milestones, we can help with that. But don't be hung up on them - what you would produce by the end of the project doesn't need to match closely with what you propose, so long as the work is useful in some way. We, the mentors, don't care what format you write, so stick to Google's guidelines. @emfdavid did you have any tangible milestones beyond the "expected outcomes" you think worth mentioning? |
|
@martindurant I'm getting this error NoCredentialsError: Unable to locate credentials while I'm trying to run this notebook https://nbviewer.org/gist/peterm790/92eb1df3d58ba41d3411f8a840be2452. I don't think any credentials were involved in this notebook. Can I get your email so that I can send you the proposal for review? |
|
Cell [2] says: If you don't have AWS credentials or otherwise an s3 bucket to write to, you need to use the second variant, not the first. |
|
I figure it out, the error was here |
|
@martindurant On opening the references as a dataset, I'm getting this error I also tried doing this, |
|
|
For the first, I wrote the references as json files. I'm trying to open the local reference jsons as a single dataset to view it in a jupyter notebook. I tried doing this, |
Please name your files ".json"
This is wrong. You want filesystems of type "reference", or use |
|
@martindurant I was able to produce and view the datasets in the jupyter notebook, with your help. Thank you for that. Right now I'm going through the code of grib_tree function and V2 NODD aggregation. Along with this, the project primarily involves working with grib2.py module. What kind of milestones should I mention in the proposal? |
|
@emfdavid , I'l leave that one to you: what does minimal useful outcome look like, do you think? |
|
@emfdavid @martindurant I've sent the proposal. Kindly review it and suggest any changes. |
|
Thank you for your application @Anu-Ra-g |
|
I'm wondering in case the index file is not present, how should we create the mapping for the aggregation? |
|
To build the mapping definitely requires both the idx file and the grib file to be present and correct. |
|
If it isn't clear: all of the information in the idx is also in the main grib file, but it takes more time and bytes to get it from grib. That's the whole point of idx files, to give a shortcut to getting this meta information. |
|
All, I believe an Org administrator needs to assign mentors to applications individually in the GSoC portal. I just did this for @Anu-Ra-g 's application, I believe. Not sure if you get a notification or not @emfdavid and @martindurant - but please log in to confirm you can see it now. |
|
Yes - thank you @mwengren I can see the Contributor Proposal from Anurag now - thank you. |
Project Description
This project improves on previous GSOC work to provide faster, easier access to public weather forecast data via widely used open source python libraries.
Motivation
Weather data and weather forecasts in particular are essential information for individuals, businesses and government. Extreme weather events are becoming more common with climate change. The electric utility industry in particular needs weather forecasts to make choices that help reduce emissions.
Details
A prototype has demonstrated the ability to build large aggregations from NODD grib forecasts in a fraction of the time using the idx files. The intern would work with the mentors to generalize the Camus Energy implementation and move it into the open source Kerchunk library. Some Camus code has already moved into Kerchunk but we believe there is more value to share with the community that will help realize the potential of the Google-NOAA NODD program.
(AWS and Azure participate in NODD as well and the techniques are equally useful)
Technical background
Expected Outcomes
In addition to IOOS & NOAA, these tools are already widely used in the ESIP and PanGeo community. We will also be working with the ESIG community to share this work and expand the impact.
Skills required
Python, Cloud Storage (S3, GCS), Git, multi dimensional arrays. Prior experience with Xarray, Zarr, Kerchunk, Fsspec or Rust would be very helpful.
Mentor(s)
David Stuebe (@emfdavid), Martin Durant (@martindurant)
Expected Project Size
175
What is the difficulty of the project?
Expert
The text was updated successfully, but these errors were encountered: