equals()를 재정의한 클래스를 collection의 원소로 사용될 때를 생각해보자.
public class MemberInfo {
private String grade;
private String gender;
private int age;
public MemberInfo(String grade, String gender, int age) {
this.grade = grade;
this.gender = gender;
this.age = age;
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof MemberInfo)){
return false;
}
return this.grade==(((MemberInfo)obj).grade) &&
this.gender==(((MemberInfo)obj).gender) &&
this.age==(((MemberInfo)obj).age);
}
public static void main(String[] args) {
Map<MemberInfo,String> m = new HashMap<>();
m.put(new MemberInfo("VIP","MAN",20),"KIM");
System.out.println(m.get(new MemberInfo("VIP","MAN",20))); //null
Set<MemberInfo> set = new HashSet<>();
set.add(new MemberInfo("VIP","MAN",20));
set.add(new MemberInfo("VIP","MAN",20));
System.out.println(set.size()); // 2
}
}HashMap<>
- MemberInfo객체를 한개 만들어 HashMap의 키로 넣고 내용은 "KIM"을 넣어보았다.
- [ 문제발생 ] 그 후 KIM을 출력해보기 위해, m.get()을 해보았지만 Null이 출력된 것을 확인할 수 있다.
HashSet<>
- 동일한 내용을 가진 MemberInfo객체를 2개 만들어 HashSet에 넣었다.
- [ 문제발생 ] 그 후 집합안의 개수를 살펴보았는데 원소 중복으로 1이 출력될 것 같았지만 2가 출력되었다.
Hash값을 사용하는 Collection의 동작원리를 살펴보자.
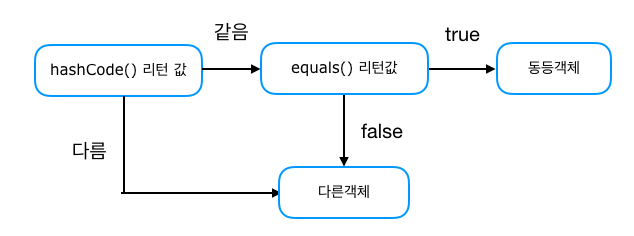
Collection 내에서 동치를 판단하는 기준은 다음과 같다.
- HashCode()의 값이 서로 같은지 살펴본다.
- HashCode()의 값이 다르다면 서로 다른 객체로 인식한다.
- HashCode()의 값이 같다면, equals()를 통해 한번 더 서로 같은지 살펴본다.
- equals()도 True이면, 그때 같은 객체로 인식한다.
위와 같이, 먼저 HashCode()값을 통해 동치인지를 확인한다.
Map<MemberInfo,String> m = new HashMap<>();
m.put(new MemberInfo("VIP","MAN",20),"KIM"); //new 연산자 발생 1
System.out.println(m.get(new MemberInfo("VIP","MAN",20))); // new 연산자 발생 2- HashMap<>의 경우, 위와 같이 2개의 MemberInfo 객체가 생성된다.
- 객체 내용은 같을지라도, new연산자로 생성되기 때문에 서로 다른 참조값을 가지게 된다.
- 즉, put()으로 Map에 들어가는 참조값의 HashCode과 get()으로 꺼내는 참조값의 HashCode는 달라지게 되어 Null을 출력한 것이다.
Set<MemberInfo> set = new HashSet<>();
set.add(new MemberInfo("VIP","MAN",20)); //new 연산자 발생 1
set.add(new MemberInfo("VIP","MAN",20)); //new 연산자 발생 2
System.out.println(set.size()); // 2- HashSet<>의 경우도 동일한 이유로 집합에 서로 다른 2개의 참조값이 들어가 중복으로 인식되지 않았다.
이처럼 Hash를 사용한 Collection은 해시코드가 다른 엔트리끼리는 동치성 비교를 시도조차 하지 않도록 최적화되어 있다.
- equals 비교에 사용되는 정보가 변경되지 않았다면, 애플리케이션이 실행되는 동안 그 객체의 hashCode 메서드는 몇 번을 호출해도 일관되게 항상 같은 값을 반환해야 한다.
- equals(Object)가 두 객체를 같다고 판단했다면,
두 객체의 hashCode는 똑같은 값을 반환해야 한다. - ... 단, 다른 객체에 대해서는 다른 값을 반환해야 해시테이블의 성능이 좋아진다.
@Override
public int hashCode() { return 42; }- 위 방식으로, MemberInfo의 예시에는 문제를 해결할 수 있다.
- 하지만 객체에게 똑같은 해시값을 주는 것은 해시테이블을 Linked List 처럼 동작하게해 성능을 떨어트린다.
- 3번째 일반 규약에 나와 있듯이 다른 인스턴스에는 다른 해시코드를 제공하는 것이 올바른 방식이다.
- int 변수인 result를 선언한 후 값을 c로 초기화한다.
- 해당 객체의 나머지 핵심 필드 f 각각에 대해 다음 작업을 수행한다.
- 해당 필드의 해시코드 c 를 계산한다.
- 기본 타입 필드라면, Type.hashCode(f)를 수행한다. 여기서 Type은 해당 기본타입의 박싱 클래스다.
- 참조 타입 필드면서 이 클래스의 equals 메소드가 이 필드의 equals를 재귀적으로 호출하여 비교한다면, 이 필드의 hashCode를 재귀적으로 호출한다. 복잡해질 것 같다면, 표준형의 hashCode를 호출한다.
- 필드가 배열이라면, 핵심 원소 각각을 별도 필드처럼 다룬다. 배열에 핵심 원소가 하나도 없다면 0을 사용하고, 모든 원소가 핵심 원소라면 Arrays.hashCode를 사용한다.
- 2.a 에서 계산한 해시코드 c로 result를 갱신한다.
result = 31 * result + c;
- 해당 필드의 해시코드 c 를 계산한다.
위의 hashCode 작성하는 방법을 참고해서 hashCode를 재정의 해보았다.
public class PhoneNumber {
private int first, middle, end;
public PhoneNumber(int first, int middle, int end) {
this.first = first;
this.middle = middle;
this.end = end;
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof PhoneNumber)) {
return false;
}
return this.first == (((PhoneNumber) obj).first) &&
this.middle == (((PhoneNumber) obj).middle) &&
this.end == (((PhoneNumber) obj).end);
}
@Override
public int hashCode() { //hashCode 재정의
int result = Integer.hashCode(first);
result = 31 * result + Integer.hashCode(middle);
result = 31 * result + Integer.hashCode(end);
return result;
}
public static void main(String[] args) {
Map<PhoneNumber,String> m = new HashMap<>();
PhoneNumber a = new PhoneNumber(010, 1234, 5678);
m.put(new PhoneNumber(010, 1234, 5678),"KIM");
System.out.println(m.get(new PhoneNumber(010, 1234, 5678))); //KIM
Set<PhoneNumber> set = new HashSet<>();
set.add(new PhoneNumber(010, 1234, 5678));
set.add(new PhoneNumber(010, 1234, 5678));
System.out.println(set.size()); // 1
}
}- hashCode를 재정의한 후 동일하게 new HashMap<>, new HashSet<>을 테스트 해보았다.
- 이전과 다르게 m.get()으로 KIM이 출력되었고, set.size()는 1이 출력되었다.
- 객체 값을 가지고 동일한 메서드로 hash값을 생성하기 때문에 같은 객체로 인식할 수 있게 되었다.
@Override
public int hashCode() {
return Objects.hash(first, middle, end);
}- 위와 같이 Objects.hash로 간단히 구현 가능하며, 동일한 결과를 얻을 수 있다.
- 하지만 느리다는 단점이 있어, 성능에 민감하지 않는 상황에만 사용하자.
private int hashCode; // 자바 원시타입의 기본값 0
@Override
public int hashCode() {
int result = hashCode;
//만약 hashCode를 생성한 적이 없다면? -> 생성
// 생성한 적이 있다면 그대로 return (캐싱)
if(result == 0) {
result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
hashCode = result;
}
return result;
}- 클래스가 불변이고 해시코드를 계산하는 비용이 크다면, 캐싱하는 방식을 생각해보자.
- 위 코드는
지연 초기화 ( lazy initialization )전략으로 캐싱을 구현한 방식이다.
지연 초기화 ( lazy initialization ) 란?
필드의 초기화 시점을 그 값이 처음 필요할 때까지 늦추는 기법으로 값이 전혀 쓰이지 않으면 초기화도 결코 일어나지 않는다.
주로 최적화를 위해 사용된다.
- 성능을 높인답시고 해시코들르 계산할 때, 핵심 필드를 생략해서는 안된다.
- hashCode가 반환하는 값의 생성 규칙을 API 사용자에게 너무 자세히 알려주지 말자.
어렵진 않지만, hashCode를 주의사항에 참고하여 재정의하고 상황에서 따라서는 캐싱을 구현하는 것이 귀찮을 수도 있다.
그렇다면 @AutoValue를 사용하자.
- item 12에 나올
@AutoValue를 사용하면 자동으로equals()와hashCode()를 만들어준다.
- equals()를 재정의 했다면, hashCode()도 주의사항을 참고해서 필수적으로 재정의하자.
- 혹시 귀찮다면,
@AutoValue를 사용하자.
Guide to hashCode
equals와 hashCode는 왜 같이 재정의해야 할까?
equals, hashCode와 HashMap의 관계
지연초기화