We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
在进行垃圾回收的时候,对于栈内存和堆内存,使用了不同的方式进行垃圾回收。栈内存的回收方式很简单,我们先看一下。
function foo(){ var a = 1 var b = {name:"极客邦"} function showName(){ var c = 2 var d = {name:"极客时间"} } showName() } foo()
当执行 showName 的时候,会有一个记录当前执行状态的指针(ESP)指向 showName 的执行上下文,然后当 showName 执行完成以后,ESP 向下滑动到 foo 上,原来的 showName 执行上下文就没有用了。如果 foo 里再有个函数要被执行,那个那个新的执行上下文就会出现在原本 showName 的执行上下文的地方。如下图:
showName
foo
当 foo 也执行完成以后,就只剩下全局执行上下文了。但是,在堆内存中的数据,依然还在:
所以,**栈内存中的垃圾回收,就是 JavaScript 引擎通过移动 ESP 指针来释放函数保存在栈中执行上下文。**效率很快。
函数中的执行上下文用完被释放掉了,但是堆内存中的值怎么才能被回收呢?这就比较复杂了,有不同的垃圾回收机制来针对不同的情况来进行堆内存中的垃圾回收。
有一个「代际假说」,垃圾回收是建立在在这假说上的。
代际假说认为:
V8 的垃圾回收机制就跟这个假说很像了。
在 V8 中,堆内存被分为了两个部分,一个是新生代内存空间,一个是老生代内存空间。其中新生代存放存活时间短的对象,老生代存放存活时间长或者常驻的对象。
新生代和老生代虽然回收的算法不一样,但是工作流程都是一样的:
新生代和老生代的标记活动对象都是一样的。
依然使用文章开头的代码,当执行完成 showName 以后,ESP 指向了 foo ,此时 1003 的地址没有被其他地方所引用了,在图中被标记为了红色。1050 的地址还在被 foo 引用着,会被标记成为活动对象。
堆内存在 V8 的源码中可以看见,默认的最大值在 64 位的系统上是 1464 MB(约 1.4 GB),在 32 位的系统上是 732 MB(约 0.7GB)。
新生代内存在堆内存占的比较小,从上图可以看出来。这是因为新生代内存经常使用,如果太大,每次清理时间就会变久。
新生代内存默认在 64 位的系统上是 32 MB,在 32 位的系统上是 16 MB。
新生代内存采用 Scavenge 算法。Scavenge 又是采用 Cheney 算法实现的。这个听一耳朵就行。
Cheney 将新生代内存等分,一分为二。每次只使用一个,使用的叫做 From 空间,也可以叫对象区域。空闲的叫做 To 空间,也可以叫做空闲区域。
把内存一分为二,会比较浪费空间,但是新生代内存空间比较小,用空间换时间,还是很不错的选择,所以在新生代的常见下,使用 Scavenge 算法是很合适的。
当一个新对象进入堆内存时(对比上面的通用工作流程):
但是这时一定会有疑问了,新生代内存空间很小,如果当前存活的对象很多,那岂不是新生代的内存要溢出了?所以还会有另一个机制,来保证新生代内存不会被占满。
对象的晋升机制有两种:
为什么有 25% 的限制呢?因为当 Scavenge 回收完成以后,To 就要变成 From 了。变成 From 以后,内存已经被使用了超过了 25%,可能会影响到新进来的对象的内存分配。
老生代内存默认在 64 位的系统上是 1400 MB,在 32 位的系统上是 700 MB。
老生代内存存放的都是生命周期较长的对象,并且老生代内存比较大,这个时候再用 Scavenge 算法会有两个问题:
如此一来,就是用了 Mark-Sweep 和 Mark-Compact 算法结合的方式来处理了。
Mark-Sweep 算法的做法是对一组元素从根开始递归便利能达到的元素就是活动对象,没有达到的就是失活的垃圾数据。会对活动的对象进行标记,然后清除掉没有标记的对象。
但是这么做会有个问题,就是会产生不连续的内存空间。当大内存的对象进来可能会放不下,就会提前触发垃圾回收,这次的回收是没有必要的。所以又出现了一种Mark-Compact 算法,使内存不会有不连续的空间。
Mark-Compact 基于 Mark-Sweep 演变过来。同样都是要标记活的对象,区别在于在整理时,会把活的对象网一端移动,移动完成后,直接清理表边界外的内存。
下图:白色是存活对象,黑色是死亡的对象,浅色是碎片内存空间。
对比新生代内存的回收,与新生代一样的是都标记活着的对象。与新生代不同的是,新生代移动的是活着的对象,而老生代移动的是死亡的对象。
在 V8 中,这两种回收策略是结合使用的。
看一下不同策略的对比:
看到有人说:现代的浏览器用闭包不会造成内存泄漏,因为垃圾回收是用的标记清除。但是如果没有用的闭包还保存在全局变量中,依然会造成内存泄漏。
不管使用 3 种哪种垃圾回收机制,在回收的时候都会暂停一下逻辑的执行,JavaScript 是运行在主线程上的。在 V8 分代式的回收机制中,一次小的垃圾回收只收集新生代的,这个还好,毕竟新生代的内存小,影响不会太大。但是老生代的就不行了,内存大,活动对象多,标记费时间。
所以 V8 采取了增量标记的方法。从标记阶段入手,拆成一小段,一小段的来标记,与 JavaScript 的执行交替执行,直到标记阶段完成。经过增量标记以后,垃圾回收的最大停顿时间可以减小到原来的 1/6。
同时,清理和整理阶段也都变成增量式的,进一步降低时间。
《深入浅出 Node.js》
极客时间《浏览器工作原理与实践》13 | 垃圾回收:垃圾数据是如何自动回收的?
The text was updated successfully, but these errors were encountered:
No branches or pull requests
浏览器的垃圾回收机制
在进行垃圾回收的时候,对于栈内存和堆内存,使用了不同的方式进行垃圾回收。栈内存的回收方式很简单,我们先看一下。
栈内存的垃圾回收
当执行
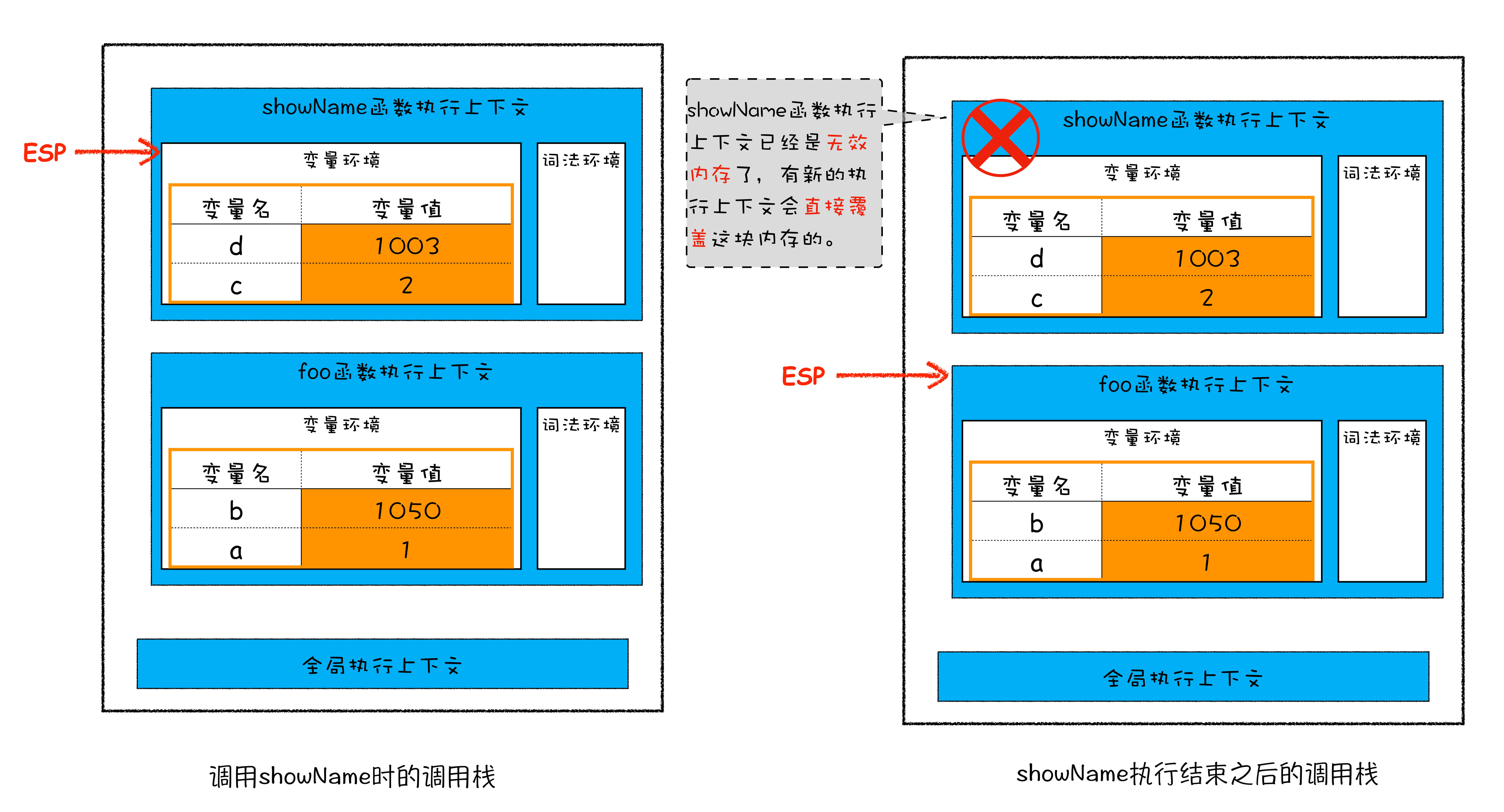
showName的时候,会有一个记录当前执行状态的指针(ESP)指向showName的执行上下文,然后当showName执行完成以后,ESP 向下滑动到foo上,原来的showName执行上下文就没有用了。如果foo里再有个函数要被执行,那个那个新的执行上下文就会出现在原本 showName 的执行上下文的地方。如下图:当

foo也执行完成以后,就只剩下全局执行上下文了。但是,在堆内存中的数据,依然还在:所以,**栈内存中的垃圾回收,就是 JavaScript 引擎通过移动 ESP 指针来释放函数保存在栈中执行上下文。**效率很快。
堆内存的垃圾回收
函数中的执行上下文用完被释放掉了,但是堆内存中的值怎么才能被回收呢?这就比较复杂了,有不同的垃圾回收机制来针对不同的情况来进行堆内存中的垃圾回收。
有一个「代际假说」,垃圾回收是建立在在这假说上的。
代际假说认为:
V8 的垃圾回收机制就跟这个假说很像了。
在 V8 中,堆内存被分为了两个部分,一个是新生代内存空间,一个是老生代内存空间。其中新生代存放存活时间短的对象,老生代存放存活时间长或者常驻的对象。
新生代和老生代虽然回收的算法不一样,但是工作流程都是一样的:
标记活动对象
新生代和老生代的标记活动对象都是一样的。
依然使用文章开头的代码,当执行完成
showName以后,ESP 指向了foo,此时 1003 的地址没有被其他地方所引用了,在图中被标记为了红色。1050 的地址还在被foo引用着,会被标记成为活动对象。堆内存在 V8 的源码中可以看见,默认的最大值在 64 位的系统上是 1464 MB(约 1.4 GB),在 32 位的系统上是 732 MB(约 0.7GB)。
新生代内存
新生代内存在堆内存占的比较小,从上图可以看出来。这是因为新生代内存经常使用,如果太大,每次清理时间就会变久。
新生代内存默认在 64 位的系统上是 32 MB,在 32 位的系统上是 16 MB。
Scavenge 算法
新生代内存采用 Scavenge 算法。Scavenge 又是采用 Cheney 算法实现的。这个听一耳朵就行。
Cheney 将新生代内存等分,一分为二。每次只使用一个,使用的叫做 From 空间,也可以叫对象区域。空闲的叫做 To 空间,也可以叫做空闲区域。
把内存一分为二,会比较浪费空间,但是新生代内存空间比较小,用空间换时间,还是很不错的选择,所以在新生代的常见下,使用 Scavenge 算法是很合适的。
当一个新对象进入堆内存时(对比上面的通用工作流程):
但是这时一定会有疑问了,新生代内存空间很小,如果当前存活的对象很多,那岂不是新生代的内存要溢出了?所以还会有另一个机制,来保证新生代内存不会被占满。
新生代内存向老生代内存的晋升
对象的晋升机制有两种:
为什么有 25% 的限制呢?因为当 Scavenge 回收完成以后,To 就要变成 From 了。变成 From 以后,内存已经被使用了超过了 25%,可能会影响到新进来的对象的内存分配。
老生代内存
老生代内存默认在 64 位的系统上是 1400 MB,在 32 位的系统上是 700 MB。
老生代内存存放的都是生命周期较长的对象,并且老生代内存比较大,这个时候再用 Scavenge 算法会有两个问题:
如此一来,就是用了 Mark-Sweep 和 Mark-Compact 算法结合的方式来处理了。
Mark-Sweep 标记-清除
Mark-Sweep 算法的做法是对一组元素从根开始递归便利能达到的元素就是活动对象,没有达到的就是失活的垃圾数据。会对活动的对象进行标记,然后清除掉没有标记的对象。
但是这么做会有个问题,就是会产生不连续的内存空间。当大内存的对象进来可能会放不下,就会提前触发垃圾回收,这次的回收是没有必要的。所以又出现了一种Mark-Compact 算法,使内存不会有不连续的空间。
Mark-Compact 标记-整理
Mark-Compact 基于 Mark-Sweep 演变过来。同样都是要标记活的对象,区别在于在整理时,会把活的对象网一端移动,移动完成后,直接清理表边界外的内存。
下图:白色是存活对象,黑色是死亡的对象,浅色是碎片内存空间。
对比新生代内存的回收,与新生代一样的是都标记活着的对象。与新生代不同的是,新生代移动的是活着的对象,而老生代移动的是死亡的对象。
在 V8 中,这两种回收策略是结合使用的。
看一下不同策略的对比:
看到有人说:现代的浏览器用闭包不会造成内存泄漏,因为垃圾回收是用的标记清除。但是如果没有用的闭包还保存在全局变量中,依然会造成内存泄漏。
全暂停
不管使用 3 种哪种垃圾回收机制,在回收的时候都会暂停一下逻辑的执行,JavaScript 是运行在主线程上的。在 V8 分代式的回收机制中,一次小的垃圾回收只收集新生代的,这个还好,毕竟新生代的内存小,影响不会太大。但是老生代的就不行了,内存大,活动对象多,标记费时间。
所以 V8 采取了增量标记的方法。从标记阶段入手,拆成一小段,一小段的来标记,与 JavaScript 的执行交替执行,直到标记阶段完成。经过增量标记以后,垃圾回收的最大停顿时间可以减小到原来的 1/6。
同时,清理和整理阶段也都变成增量式的,进一步降低时间。
参考:
《深入浅出 Node.js》
极客时间《浏览器工作原理与实践》13 | 垃圾回收:垃圾数据是如何自动回收的?
The text was updated successfully, but these errors were encountered: