Masked Autoencoders Are Scalable Vision Learners
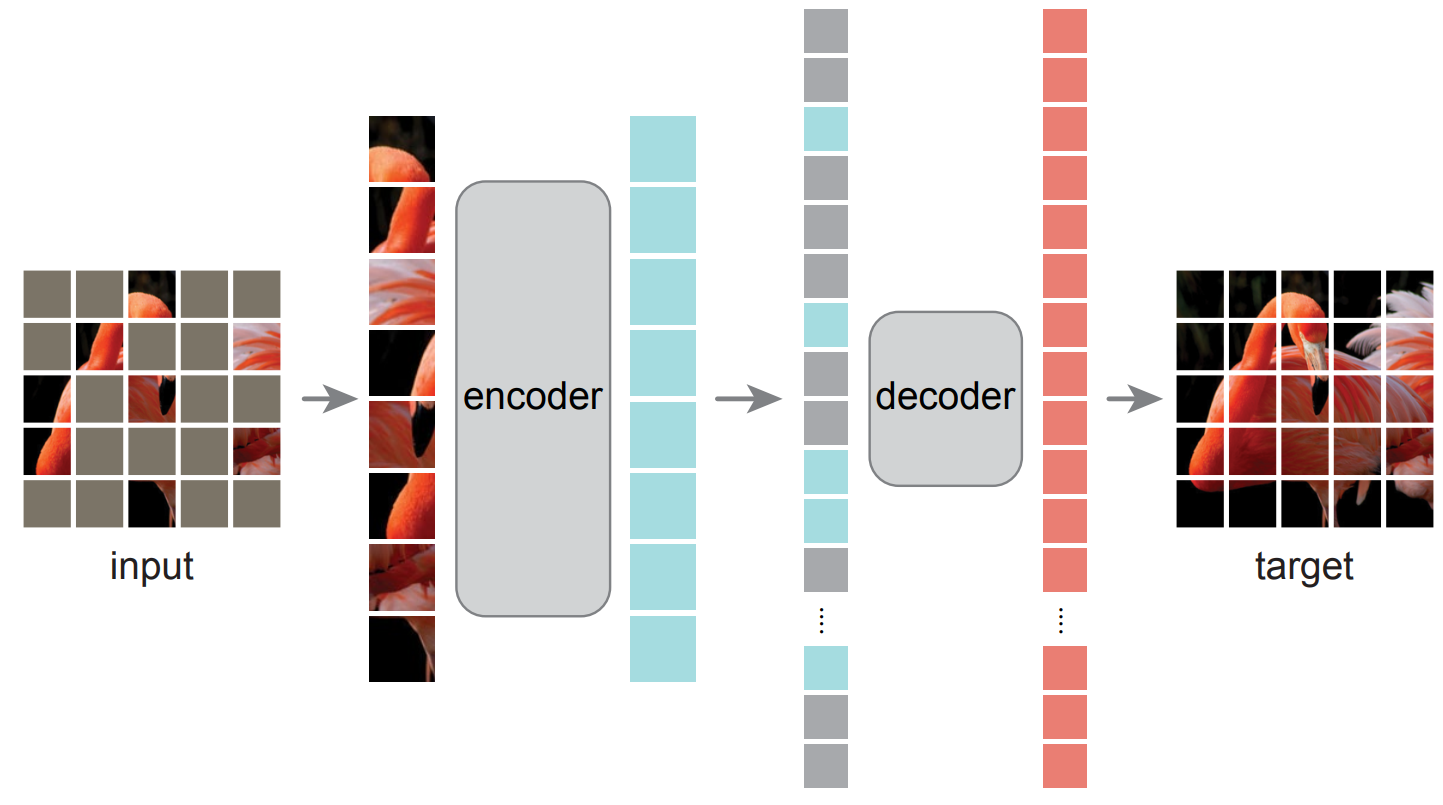
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.
@article{he2021masked,
title={Masked autoencoders are scalable vision learners},
author={He, Kaiming and Chen, Xinlei and Xie, Saining and Li, Yanghao and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv preprint arXiv:2111.06377},
year={2021}
}To use other repositories' pre-trained models, it is necessary to convert keys.
We provide a script beit2mmseg.py in the tools directory to convert the key of MAE model from the official repo to MMSegmentation style.
python tools/model_converters/beit2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}E.g.
python tools/model_converters/beit2mmseg.py https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth pretrain/mae_pretrain_vit_base_mmcls.pthThis script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
In our default setting, pretrained models could be defined below:
| pretrained models | original models |
|---|---|
| mae_pretrain_vit_base_mmcls.pth | 'mae_pretrain_vit_base' |
Verify the single-scale results of the model:
sh tools/dist_test.sh \
configs/mae/upernet_mae-base_fp16_8x2_512x512_160k_ade20k.py \
upernet_mae-base_fp16_8x2_512x512_160k_ade20k_20220426_174752-f92a2975.pth $GPUS --eval mIoUSince relative position embedding requires the input length and width to be equal, the sliding window is adopted for multi-scale inference. So we set min_size=512, that is, the shortest edge is 512. So the multi-scale inference of config is performed separately, instead of '--aug-test'. For multi-scale inference:
sh tools/dist_test.sh \
configs/mae/upernet_mae-base_fp16_512x512_160k_ade20k_ms.py \
upernet_mae-base_fp16_8x2_512x512_160k_ade20k_20220426_174752-f92a2975.pth $GPUS --eval mIoU| Method | Backbone | Crop Size | pretrain | pretrain img size | Batch Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UPerNet | ViT-B | 512x512 | ImageNet-1K | 224x224 | 16 | 160000 | 9.96 | 7.14 | 48.13 | 48.70 | config | model | log |