Differences in # of connections between MySql.Data and MySqlConnector #305
Comments
|
One caveat here is the lack of default command timeout difference that could be causing MySqlConnector to wait longer for some queries to finish while they might be timing out before and releasing the connection. Might be an explanation. |
|
Does your app make use of |
|
Can you elaborate more on that @caleblloyd ? Why would that be the case? I do use async, but I was already using the same number of threads before. So, with MySql.Data, a thread opens a connection, does it's thing and returns it to the pool. With MySqlConnector supporting async correctly, what would change? |
|
We published a Concurrency Benchmark that shows the difference in practice. If a flood of requests for |
Thanks for sharing this; it's a really interesting finding. Along with #302 this suggests that there may possibly be some kind of leak of open connections over time that could be worth digging deeper into. Is it easy for you to estimate how many open connections "should" be needed based on the number of requests per second to the service(s), the average response time, and the average number of MySQL connections made for each request? Should the number of connections be holding at a steady state instead of slowly increasing over time? |
|
Are you using any ORM layer, or directly using the MySqlConnector ADO.NET objects? If the latter, is your code disposing (either via |
@nvivo A command timeout throws a |
|
@caleblloyd Now that I think about, it makes sense. I was thinking about having the same number of threads starting the query, but not what happens after that. I use Akka, and with real async, once it starts awaiting, Akka schedules the continuation of async as a message to the actor. In that case, it considers the message as processed and as you said, that frees the thread in the pool, allowing it to start processing another message in another actor. Given a lot of actors, it may be the case that more actors start processing messages to the point of starting queries than they would with MySql.Data. It's a real possibility. @bgrainger It's a mix of dapper and EF Core with Pomelo's driver. It's always either I noticed this morning that although I have a max pool size of 45 for most services, some of them had a more than 70 connections open (counting through mariadb processlist table). I don't have an estimate of the ideal, but I have a history. Looking for the last 2 weeks:
There is definitely a difference. My guess now is it's a mix of being able to better use the thread pool and something allowing more connections to be open than the max pool (although I'm not sure all services have a max pool set, most of them have - that specific one with 70 connections was set to 45). But it doesn't look like a permanent leak so far, otherwise I would have seen it increasing constantly over the last 2 days, and it decreases from time to time. |

|
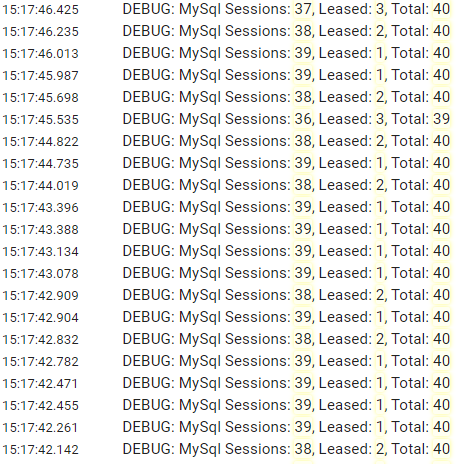
Okay, I may have some evidence that indeed something strange is happening and there may be a leak here. I added some reflection to log some internals, specifically the counts of m_sessions and m_leasedSessions in ConnectionPool. This is what I get (note these are all mixed hosts):
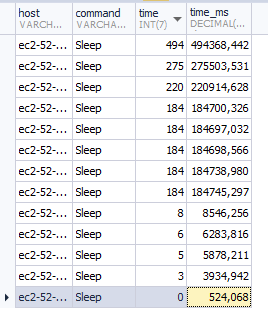
This is what the ProcessList table shows me:
The Max Pool Size is 45. It started as 45, after a few seconds it started to grow 1 every second or so per host. When I look at one specific host at some point, this is what I see:
But mysql shows me:
If the watchdog runs every 3 minutes or so, there shouldn't be sleeping connections open for more than that. Before adding the log, there were open connections with 20000 seconds. If the pattern from the log means what I think it means, it seems I'm using 40 connections when the service starts, but then it drops to only 1-3 per server after that. Still, I had dozens of open connections with 20000+ seconds open in sleeping state. Makes sense? |


|
Thanks; this is fantastic debugging info. I'm still not quite sure exactly what it means yet, but it definitely provides a direction for further investigation. |
|
Hi, some additional evidence to help with this. This is the processlist since yesterday: https://docs.google.com/spreadsheets/d/1zoCpy0JAneE3ecdZEo6FYJQpH7hMS80XaUjCuBpXkpE/edit?usp=sharing These processes come from a cluster of 25 servers with the same service, same connection string and same access pattern. Aside from basic settings, I override these settings:
Some interesting things here:
Edit: The incremenets seem to have a pattern, but it's actually different for each server. |
|
|
For 1 makes perfect sense, just didn't connect the dots. Just a note, this morning I had to restart all servers as no new connections were able to be open. From the logs this was gradual from 2am to 6am. I'm not discarding a bug in my code, since the migration to EF Core required some additional changes, but since the driver is not seeing the connections in the leased or the idle sessions, my bet is in a bug in the driver. For now I'm adding some periodic housekeeping to a background job to kill long standing connections. |
This makes me wonder if this and #302 share the same underlying issue.
Thanks for your help working through this, and sorry you have to employ a workaround; I want to figure this out. Are you running the client on Linux or Windows? |
|
OK, I can repro long-running idle connections if--in my test app--I periodically omit calling |
|
There's a serious bug in the code to recover leaked sessions that's triggered if the last |
|
I double checked every use of a connection or a context in the service. Did a check yesterday and one this morning, to avoid missing something, and absolutely all of them are enclosed by an What I do have is a lot of lock wait timeouts and occasional MySqlExceptions due to increase in load. Is it possible that an exception or a connection in a bad state might be causing some step to not execute? I find it curious that at some point the connection is being removed from the sessions list, but remains open. I'll try to debug this to see if I find something. |
|
Just for an update. I did some debugging today in production. I added MySqlConnector source to my project, added an "m_allSessions" into ConnectionPool to track everything, independently of being leased or not, and stored an I saw that most connections were cleaned up after 180 seconds as expected, and after that these "lost" connections didn't go back to m_sessions or m_leasedSessions. Also, they came from everywhere, not a single place, and from correct code, like this: I wasn't able to find out why this happens yet. For now, setting Note: I did notice however that some connections opened by each server had the following settings appended to the connection string: |
|
I'll put your minds at ease in exchange for some public embarrassment. There is a problem, but it is not as crazy as I made it appear. It turns out I have a single connection string in my config file, but I forgot I turn that into two during runtime in order to setup an EF context for another database. This creates 2 app pools. The way I was tracking the sessions before was looking at one pool only. When taking into account all the pools, all connections are accounted for and processlist matches what I see in the ConnectionPool over 2 hours at least. Now, the chart with increased connections is still real, the spreadsheet is still real, and I still see these idle connections piling up over time that should have been cleaned up. From my logs, I can see all pools are periodically cleaned up, but these connections with long sleeping time were never disposed. Any ideas? |
That does put my mind at rest because I could not figure out how there would be more connections open to the server than sessions in the pool. Thanks for the update. (I assume this explains the second connection string with Does the second pool still have I still can't rule out the session leaking bug I discovered and mentioned earlier. If I were to try to write a fix for that (or add some additional diagnostics), what would be your preferred way of accessing it? Beta version on Nuget? Private build of the DLL sent directly to you? Something else? |
|
I just discovered that my test code that leaks readers also causes a connection timeout with MySql.Data. So this does not appear to be a new bug in MySqlConnector. (I've filed that as #306.) |
Not really. It seems this comes from Pomelo's EF driver. The first 2 settings are set globally, the Pooling=false seem to be for the first connection only, looks like some infrastructure call for discovery. As for the issue, maybe you're on the right track with both issues you found. They explain part of the issues. As for the idle connections, I added some logs to this part here, so I see when any connection is disposed and also the connections that are kept. What I see is that these connections with long sleep times were never cleaned (never pass through the if block), but they stop being seen in m_sessions (stop passing through the else block). And the time they stop appearing there matches the sleep time in mysql. For example, it's 2:32pm here and I see this:
5822 / 60 = ~97 - that means 1:37 minutes ago (~12:55) I should see the that connection the last time in the logs.
That data being a dump of info on m_sessions inside that else block. Any ideas what could be going on here? Edit: BTW, I know it wasn't disposed because I would see it as I see for other connections:
And the dump from the last event before disposing, as it looks confusing on the screenshot: |



I'm thinking "unhandled exception". It sounds like you're building a local copy of the library? Can you add exception logging here and see if it catches anything? I'm suspecting that an exception in I can add some simple exception handling there, but I'd like to know what the underlying problem is to know if there's a better way to handle it. |
|
Okay, looks like I got to the bottom of this and I know what is happening, but I don't know why. =) DisposeAsync had an exception, but not during reap. It was during Return. This is the pattern for all these lost connections:
Everytime the command executes, it goes to Querying, then goes back to Connected, but not that last time. It returns to the pool as Querying, it checks if it's connected, the state is not There are some stacktraces in this log, in this case, this is the code that triggered this last query:
The query is something like this: The service logs then show me this for the moment of the query: Note: I've checked and I'm setting this via ConnectionStringBuilder, but it doesn't seem to be taken into account. Or I may be tired, will check again tomorrow. After looking at other connections in the same state, it seems there was always an exception being thrown at some point, and even though there is an using clause, it is not clearing the status after the exception. |


|
Unfortunately, user variables in SQL statements are not permitted by default; see #194 for the full rationale. Doubly unfortunately, that leads to unexpected failures for code like yours that assumes they should just work by default. Our assumption (see #194) was that this exception would bubble up and be presented to the programmer immediately, letting them know what was wrong. I'd love to know exactly where it's being swallowed--is it in MySqlConnector itself, or Dapper, or EF, somewhere else? (Or is it actually making its way to a log, as expected, but wasn't seen until now?) Ideally, this fatal exception would be presented to the user so it could be fixed. But even if it's not, it shouldn't put this library into a bad state. If you're able to give a self-contained repro, that'd be great; otherwise, I can try to work on figuring one out. |
|
I think I have a repro, which is: I can reproduce this problem in MySqlConnector, but not in MySql.Data, which makes it seem very likely to be the explanation for the original reported problem. |
|
I was able to reproduce this too: https://gist.github.com/nvivo/3fc457baa29870c3395d46ecae4da2d2
Sleeping connections go over the idle connection timeout. Also, the open connections go over the Max Pool Size, this explains a lot. |

|
0.24.2 should fix this problem and will be available on NuGet very soon; can you retest with it to confirm? Thanks again so much for your help in tracking this down. |
|
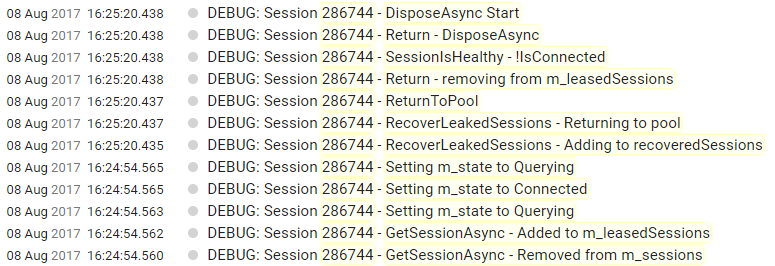
90% solved! But about an hour later I saw some connections sleeping there, fewer than before, only one or two per server. I tracked where they're coming from, and all of them are coming from RecoverLeakedSessions now:
Maybe you could ping these connections and reset them to Connected before returning them to the pool? |
|
Is there an exception being thrown from |
|
DisposeAsync gives the same: I looked at some of these connections, I couldn't see any exception thrown between querying and the recover. All servers are NTP syncd, but I put a few minutes before and after and nothing for about half a dozen of them. |
|
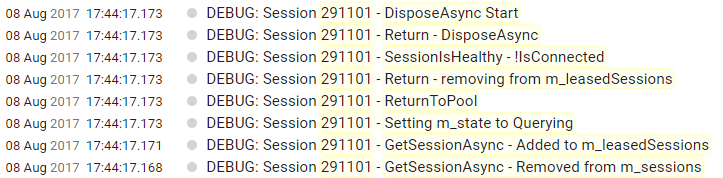
Just found something interesting here. There is one connection that was returned correctly to the pool by MySqlConnection.Dispose() and kept the Querying state, had the same issue. |
|
I can put a |
|
If it helps, the ReturnToPool was called from here: Querying state was set from here: Everything points to the flow working as expected and just ending in that state. Note: These are 2 different problems, but it seems that if there is a chance of ending up in a querying state in a normal flow, there might not be a bug in the recover code. |
|
Are you able to tell me what the particular command is? Also, is it possible that some object is keeping the Otherwise, because the MySqlSession isn't actually returned to the pool, it and the Socket it owns would be GCed, the Socket would be finalized, and the TCP socket would be rudely shut down by the OS, leading to an increase of "Aborted Clients" in MySQL Server. So I think what we have is a failure in |
|
Wow, in this last case this may be just the bug that may be causing it: an incorrectly placed async call in a void method. I'll need to check if there isn't more of these in the code. |
|
In the previous case of the RecoverLeakedSessions, it's an EF mix of code that I'm not sure if it's allowed. Didn't cause issues with EF6, but maybe EF core works differently. It's something like: The problem seems to frequently come from there. It's a legacy thing. I'll move everything to a single SQL statement inside of dapper and see if this goes away. You have been very patient @bgrainger with me. Thank you a lot for your support with this. I'll let you know if changing this code fixes the issue. |
I think this one should be OK. Calling
I don't really know EF, but I don't see anything obviously wrong in that code. CC @caleblloyd in case you can spot a problem there. I think there still is a problem that the library can get in a bad state if |
|
An update here. I fixed some stuff in the code, changed others and tried to avoid as many exceptions as possible. Things seem MUCH more stable since 0.24.2. Some connections are still leaking, but in lower numbers. The cluster has been running for more than 12 hours since my last update and there are between 1 to 6 of these lost connections per server, vs up to 30 before. The total open connections didn't pass 600 since yesterday (using wait_timeout = 1 hour), so it's manageable and I'm not getting any Connect timeout exceptions as far as I can tell. |
|
I'd be interested to know if someone else that is running an app for a long time is getting these lost connections or it's something affecting only me. |
I'm assuming that this is a bug in MySqlConnector, but I don't think I've been able to reproduce it yet. Any further information you can provide about any exceptions that are being thrown would probably be extremely helpful. |
|
I've been able to fix most errors and exceptions now are close to zero, but there are 2 exceptions that are constantly being thrown due to the high load:
I handle these exceptions and retry. But I guess if this was causing the leak, there would be much more connections open. These things happen hundreds of times per hour. I know AWS sometimes has issues even between VMs in local network. Sometimes I have connections dropping between nodes, and that has caused some strange behavior in Akka before. |
|
Just gonna post this here in the hope you may have some insight... I have been adding more and more logs trying to pinpoint the exact location the issue happens. It's still quite obscure so please excuse my verbosity. It seems to always happen in this code: Note, the issue happens on _contextFactory being a EF Context, registered on DI as: The only thing special there is that the SQL is dynamic with a fixed DELETE + INSERT and it may generate 1 or 2 additional INSERT statements. But doesn't make sense any error in SQL could cause this, also I can see the same transaction runs fins in most cases - about 1.5 million times a day in fact. I don't know the exact rate they happen per parameter, but I know they happen often enough to not match by far the lost connection rate of tens over many hours for the entire cluster. So, I found that in these cases, it reaches Then, looking inside, The continuation for this task just never fires for these cases, and I couldn't figure out why. There is no exceptions being thrown, the cancellationtoken is not cancelled, TryAsyncContinuation is never called. That same method appear to keep working for other connections, it looks quite random but there must be some logic there, maybe a race condition, don't know. I added a continuation as: It just never fires the continuation. I could see the handler is always the StandardPayloadHandler, behavior is Asynchronous. Payload length varies from 1 byte to 400 bytes. tmp.Status reports I also tried scheduling a continuation directly in the ValueTask but didn't seem to fire for these cases either. If you have any idea on what could be or what I could do to dig deeper, let me know. |
|
My guess is that the actual async I/O (e.g., started by If so, this may be something to be addressed as part of #67 by ensuring that all I/O operations have some timeout. It'd also be worthwhile for me to do some local testing that injects failures, to make sure exceptions are bubbled up correctly. Since you were successfully using this code with MySql.Data, which is not asynchronous, it might be useful to try adding Thanks again for persisting in debugging this issue! |
|
I've added code to (I still would like to know how they're ending up in an unexpected state, though.) |
|
Sorry, has been a busy week. I updated to 0.25.1, and after 3 hours running I didn't see any connections over the idle timeout limit. Didn't see any exceptions so far. I'm curious to see what will happen to these transactions. I'll keep a close eye on them and let you know if I find anything. Thanks for your support on this! |
This is not an actual issue, but more for information purposes. I migrated 30 VMs to MySqlConnector, and I noticed a slight increase in the number of open connections to the database, even though all connection strings and services are the same.
The stable part are the services running without intervention. The middle gap is the upgrade window where servers were up and down all the time, so additional connections are expected.
Interestingly, when doing the math, the # of open connections of all servers multiplied by the maxPoolSize should be around 1400, which matches the MySqlConnector behavior. So MySql.Data might be either smarter or more conservative with connections, even though it uses queues instead of stacks to manage the pool.
This is not being an issue, and it seems to be obbeying the limits. But since there is a difference in behavior, I thought it would be nice to share, in case this is something worth investigating.
The text was updated successfully, but these errors were encountered: