Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
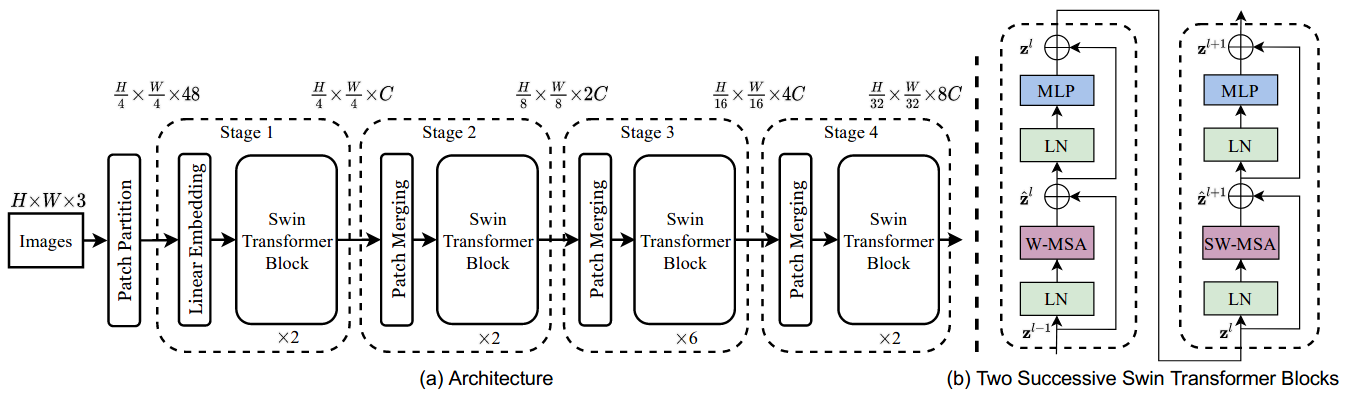
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at this https URL.
@article{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
journal={arXiv preprint arXiv:2103.14030},
year={2021}
}We have provided pretrained models converted from official repo.
If you want to convert keys on your own to use official repositories' pre-trained models, we also provide a script swin2mmseg.py in the tools directory to convert the key of models from the official repo to MMSegmentation style.
python tools/model_converters/swin2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}E.g.
python tools/model_converters/swin2mmseg.py https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth pretrain/swin_base_patch4_window7_224.pthThis script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
In our default setting, pretrained models and their corresponding original models models could be defined below:
| pretrained models | original models |
|---|---|
| pretrain/swin_tiny_patch4_window7_224.pth | swin_tiny_patch4_window7_224.pth |
| pretrain/swin_small_patch4_window7_224.pth | swin_small_patch4_window7_224.pth |
| pretrain/swin_base_patch4_window7_224.pth | swin_base_patch4_window7_224.pth |
| pretrain/swin_base_patch4_window7_224_22k.pth | swin_base_patch4_window7_224_22k.pth |
| pretrain/swin_base_patch4_window12_384.pth | swin_base_patch4_window12_384.pth |
| pretrain/swin_base_patch4_window12_384_22k.pth | swin_base_patch4_window12_384_22k.pth |
| pretrain/swin_large_patch4_window7_224_22k.pth | swin_large_patch4_window7_224_22k.pth |
| pretrain/swin_large_patch4_window12_384_22k.pth | swin_large_patch4_window12_384_22k.pth |
| Method | Backbone | Crop Size | pretrain | pretrain img size | Batch Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UPerNet | Swin-T | 512x512 | ImageNet-1K | 224x224 | 16 | 160000 | 5.02 | 21.06 | 44.41 | 45.79 | config | model | log |
| UPerNet | Swin-S | 512x512 | ImageNet-1K | 224x224 | 16 | 160000 | 6.17 | 14.72 | 47.72 | 49.24 | config | model | log |
| UPerNet | Swin-B | 512x512 | ImageNet-1K | 224x224 | 16 | 160000 | 7.61 | 12.65 | 47.99 | 49.57 | config | model | log |
| UPerNet | Swin-B | 512x512 | ImageNet-22K | 224x224 | 16 | 160000 | - | - | 50.13 | 51.9 | config | model | log |
| UPerNet | Swin-B | 512x512 | ImageNet-1K | 384x384 | 16 | 160000 | 8.52 | 12.10 | 48.35 | 49.65 | config | model | log |
| UPerNet | Swin-B | 512x512 | ImageNet-22K | 384x384 | 16 | 160000 | - | - | 50.76 | 52.4 | config | model | log |
| UPerNet | Swin-L | 512x512 | ImageNet-22K | 224x224 | 16 | 160000 | 10.98 | 8.23 | 51.17 | 52.99 | config | model | log |
| UPerNet | Swin-L | 512x512 | ImageNet-22K | 384x384 | 16 | 160000 | 12.42 | 7.57 | 52.25 | 54.12 | config | model | log |