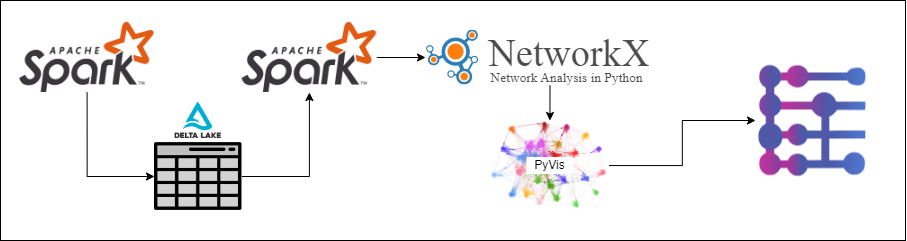
A lightweight lineage tool based on Spark and Delta Lake
pip install lineage-keeper
from lineage_keeper import load_listener, LineageViewer
load_listener(spark)
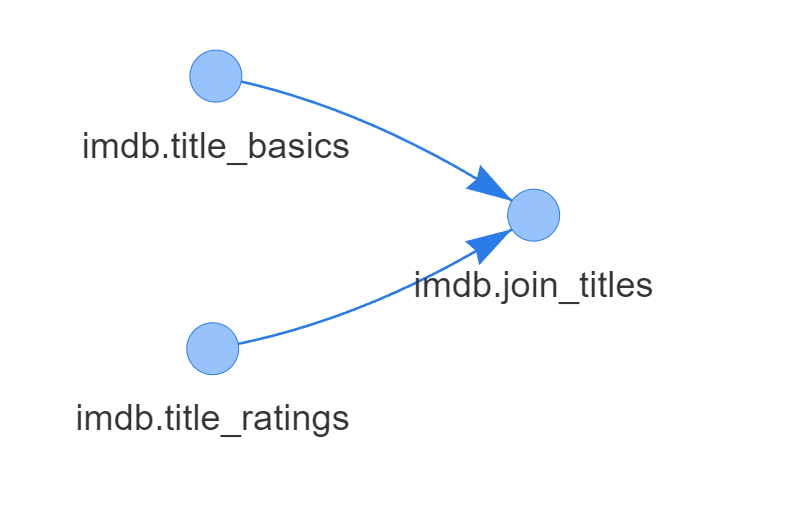
df1 = spark.read.table("db.table_1")
df2 = spark.read.table("db.table_2")
df_join = df1.join(df2, "key")
df_join.write.saveAsTable("db.join_tables")
LineageViewer(spark).viewer()
By default Lineage Keeper use "default._service_table_lineage_keeper" as a service table.
If wanted its possible to use a different service table.
Manually input lineage information on the service table
LineageListener : spark sesison
listener : source DataFrame, target table
ll = LineageListener(spark)
ll.listener(df, "target_db.target_table")
Change df.write.saveAsTable to automatically input lineage information on the service table
load_listener(spark)
Generate a static HTML with the lineage graph
LineageViewer(spark).viewer()
Save a static HTML with the lineage graph on disk
LineageViewer(spark).save_graph(path)
- Its necessary to use tables sintax to read data
spark.read.table("db.table")spark.sql("SELECT * FROM db.table")
- To use
load_listenerto is necessary to usedf.write.saveAsTable("db.table")otherwise need to callLineageListener(spark).listener(df, "db.table")