CPU collector blocks every ~17 minutes on call to wmi.Query #89
Comments
|
Is the 2012r2 servers fully patched, especially I think there are some WMI related patches that is not security related so maybe have not been applied? Unfortunatley I cannot provide you with a complete list, google turns up some stuff, like https://support.microsoft.com/en-us/help/3103616/wmi-query-doesn-t-work-in-windows-server-2012-r2-or-windows-server-201 If you have the ability, is the issue reproducible in Windows Server 2016, or Windows 10? |
|
The tests I ran on the 2 CPU VM were all Windows 10 Pro. The issue is far less pronounced there; this might be because it has way fewer CPUs to poll. And yes, definitely fully patched. That specific hotfix was present on the 2012r2 server I was using to repro. Looking at a few 2016 systems, the issue was also present there. |
|
Thanks for your quick response! The os collector has been around for a while now and this is the first report of this kind. There was some additions to the os collector released in 0.2.3. Perhaps testing the 0.2.2 release could at least rule out those changes. (I am doubtful) So, what you're seeing is around every 17 minutes, the prometheus scrape makes the "WMI Provider Host" process spin up, ? When you were reproducing it on Win10, were the machines otherwise idle, or do they only experience this under load? |
|
Re: the VM: it's idle and is running on my desktop. The debug log output for a run over a longer period of time is attached. And yes, that is correct. Every 17 or so minutes, the poll of the CPU collector takes longer than expected, wmiprvse.exe spikes up in utilisation. I'll try to catch it in procmon next time it happens. To be clear, this seems to be due to the CPU collector rather than the OS collector. I'm testing with I just tested with 2.2 on the Windows 10 Pro VM and anecdotally, the poll which was expected to take 2-3 seconds at 13:33 did indeed take 2-3 seconds. (sample size of one etc. etc.) |
|
Procmon suggests that wmiprvse.exe is doing something completely different for those runs which take longer, but that wmi_exporter is not doing anything different in constructing the query. A normal run finishes in about 40 operations whereas the stalled ones spend 3 seconds reading a whole bunch of registry keys (starting in If I just leave it running without wmi_exporter polling it, this doesn't seem to happen. So, almost certainly a problem on the OS side. I'm just curious if there's something about my environment which is making it worse and if there's something we can do to prevent this behaviour from triggering. |
|
Okay, that's reassuring for us, but I do understand it's not helping you. |
|
Hm, quite disturbing... @higels What services/Windows features do you have enabled on the servers? Were those also present on the Windows 10 VM, or was that a mostly blank OS? I found this troubleshooting tip, which would also be interesting to know the output from:
One potential environmental thing this would point out is if you have some special WMI provider installed (as part as drivers, most commonly) which is misbehaving. |
|
@higels I've been tinkering a bit with my own systems now to see if I've simply been missing this, but I cannot seem to reproduce it. Tested Win 10, Server 2012 and Server 2016, so I think there must be something specific in your setup that is required to trigger it. Would be most interesting to know more! |
|
The VM is just a pretty normal Parallels Windows VM. It has some domain admin tools installed and the Parallels integration utilities. It is definitely based on time rather than request frequency; I can spam requests as fast as I like outside of that window. I noticed that every time this issue occurred, I'd see an event like this in the WMI event viewer bucket thing (I tidied it up a bit to make it more readable): This event rarely happens outside of that window. I turned on event tracing for WMI and I've noticed that along with this, the following occurs whenever the stall happens: And then I spotted that every time we have a stalled request, the following is being run on WMI, presumably by WBEM (if I've understood the architecture correctly...) So, some kind of re-index task which is triggered by the first request on a particular group after a given amount of time? Am I really the only person seeing this? |
|
Well, you are at least the only one observant enough to notice it :) |
|
Actually, I do see it on my local machine. Its just much less pronounced that what you see @higels. Running that powershell snippet, every 16 minutes, the cpu scrape took ~1 second, instead of a few tens of milliseconds. |
|
I've left this: running on my VM for a few hours and it's pretty clear that every 946 iterations, the job takes roughly 3 seconds, so I'm guessing whatever is triggering this leaves 950 seconds between runs. I'm running that on an unloaded production class 2012r2 system now. Let's see what happens. The daemon that pushes the traffic on the prod systems interacts with WMI every second (in a separate thread), so that likely explains why perf tanked. I suspect the answer to "why does it affect the CPU collector" is someone decided to put a trigger for re-initialisation into the Processor object and arbitrarily decided that 950 seconds was an appropriate interval. I'll do some more debugging today, maybe one of the registry keys it reads allows us to control this. |
|
I think we'll have to chalk this one up to weirdness in Perflib. I'll see if I can open a bug with Microsoft, it definitely seems like bad and undesirable behavior, amplified by a few orders of magnitude by how we're interacting with WMI. I've tried a few different things to see if it's possible to reduce the impact of this which might be useful to someone down the line: Thanks for your help, sorry I wasn't able to find a fix. |
|
@higels Thank you very much yourself, a very thorough investigation! If you do get any information back from Microsoft, that would also be very interesting. I guess we'll close this, as it appears there is not much we can do from what we know now. |
|
I'm encountering the same issue but only on 2 out of 3 servers (no VMs):
Version: 0.2.7 |

|
I'm also experiencing this issue on multiple bare-metal Windows Server 2012 R2 hosts. Same symptoms - WMI process CPU spikes in 16-17 minute intervals. While unlikely, I wouldn't fully discount the possibility that wmi_exporter is using WMI in a way that makes it hang. I've seen similar bugs in software before. |
|
After some profiling, it looks like the WMI Provider Server regularly refreshes some sort of class name cache, calling
It appears that EnumCounterObjects is not supposed to do this, and there's a fix in KB4038774 (and presumably the following non-security rollup, even though there's no further mention of it).
I see no mention of Windows Server 2008 being affected. However, after installing the KB in question, I'm still getting timeouts. |

|
I'm seeing the same things and initially logged issue #140, I did increase my scrape timeouts on the prometheus job and made things a bit better in terms of the missing gaps in the time series, however you can definitely still see in the exporter scrape duration I'm tracking. also noticed that it depends on what options you have enabled in the wmi-exporter, i.e. having the defaults and IIS will increase considerably very deterministic though wmi-exporter defaults only wmi-exporter with defaults + IIS enabled |
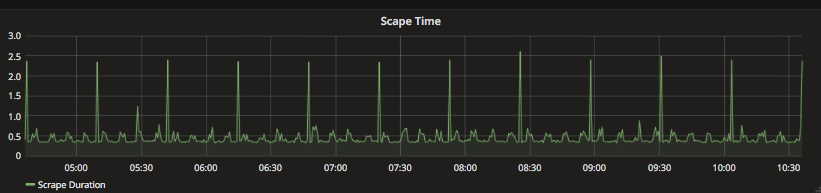

|
I think @leoluk's observations match closely what is going down. ("it looks like the WMI Provider Server regularly refreshes some sort of class name cache"). The issue seems to be with the wmi code we are using. From our code, we call This function internally uses a Client https://github.com/StackExchange/wmi/blob/master/wmi.go#L74 It seems we are not initializing the Client used by wmi properly, as this comment indicates at line https://github.com/StackExchange/wmi/blob/master/wmi.go#L106: I can make an experimental program changing this behavior if someone's up for testing it |
Sure, happy to test (separate branch is fine). |
|
Great! Am working on such change now. |
|
How is this different from https://github.com/martinlindhe/wmi_exporter/blob/94caf8ee61027bd02ae694353597741182b00829/exporter.go#L148 though? |
|
@leoluk good question, i didn't consider this code :... Got to look through it some more, but with your comment it seems we already are doing this. |
|
My current assumption is that the bug is in Windows, not wmi_exporter. I can reproduce it by querying WMI through PowerShell and the hang is system-wide. To me it appears like querying performance data via WMI, in low intervals, is fundamentally broken. About every 1000 seconds, there's a spike in query latency where WMI updates its list of perflib providers. The KB lessens the impact by making it less expensive, but does not fully resolve the issue (it didn't help in my case). The refresh would have to happen asynchronously in a way that does not affect queries. The reason this affects some users but not others is that the duration depends on the hardware configuration. On a tiny VM it took less than 6 seconds, much longer on beefy bare-metal hosts. Depending on scrape interval and timeout, it makes sense that it would only lead to issues in some configurations. Apparently, it takes a longer time the more RAM a host has. Stack profiling shows that the most expensive call is
Even if you do not get timeouts, you'll probably see the spikes in the
(red = VM, green = bare metal, for the bare-metal host one scrape fails so the actual value is even higher) To me, this implies that in the presence of this bug, WMI is unsuitable for high-resolution performance monitoring. Even it does not lead to timeouts, it will slightly decrease accuracy. This issue also explains a long-standing issue I've had with WMI blocking the Check_MK windows agent, which reported false CPU load spikes on hosts with more than 500GB of RAM, with three minute check intervals, mind you:
|
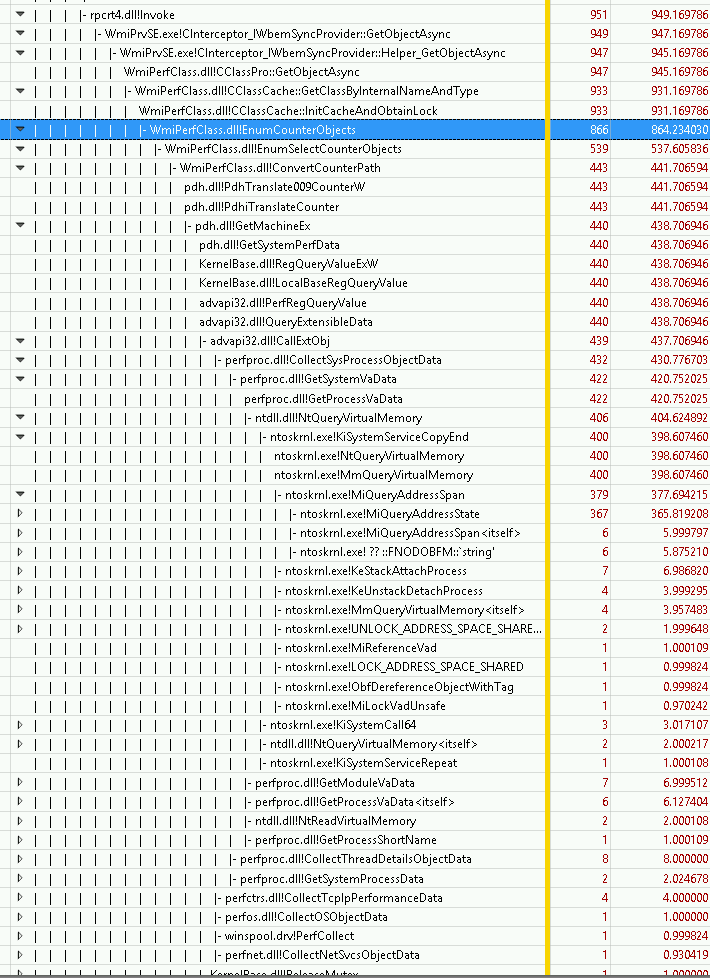
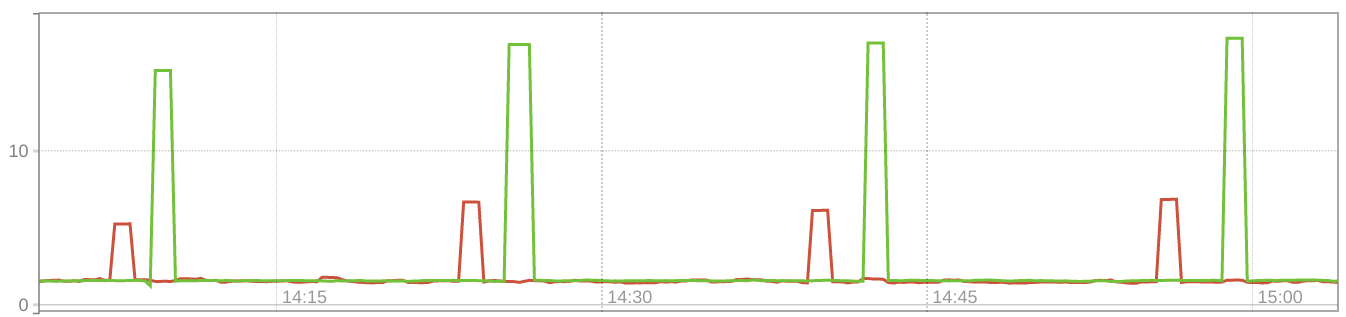

|
I've gone through the code more and realize the fix I was suggesting is already in code as @leoluk pointed out. That would be the only possible cause in our end for such stall as far as I can figure. Additionally, with more feedback from @leoluk it seems more plausible this is actually an issue in the WMI agent in Windows. (I don't like to simplifying stuff down to "not our bug", but it seems we cannot do much about it). Sorry for the noise! |
|
@leoluk Kudos on the very impressive troubleshooting here :) |
|
Perfmon uses the PDH library, not WMI. I did not test with Perfmon, but PDH is not affected. Here's a quick summary of the relationship: https://msdn.microsoft.com/en-us/library/windows/desktop/aa371643(v=vs.85).aspx I've started to work on a Go library for the HKEY_PERFORMANCE_DATA interface. You basically do one RegQueryValueEx call and get a 300k binary blob in return that you'll have to parse yourself, but it has all the metrics in it and only takes a few ms to complete. Preliminary testing looks great so far. |
|
Hey all, |
|
Tested with scrape timeout 60s:
Dash for 30 last min:
Dash for 3hour:
11-30 start tesing new version. |



|
Thanks @Teriand, |
Yes, the scrape timer is 15 seconds. |
|
What I would have expected would be that you'd still get "holes" for the metrics that we time out internally in the exporter, but that |
|
start test 9-30, with 10s
last 1h last 30min current wmi-exporter version - from 20.12.17 (dont update after i merge msmq support) |

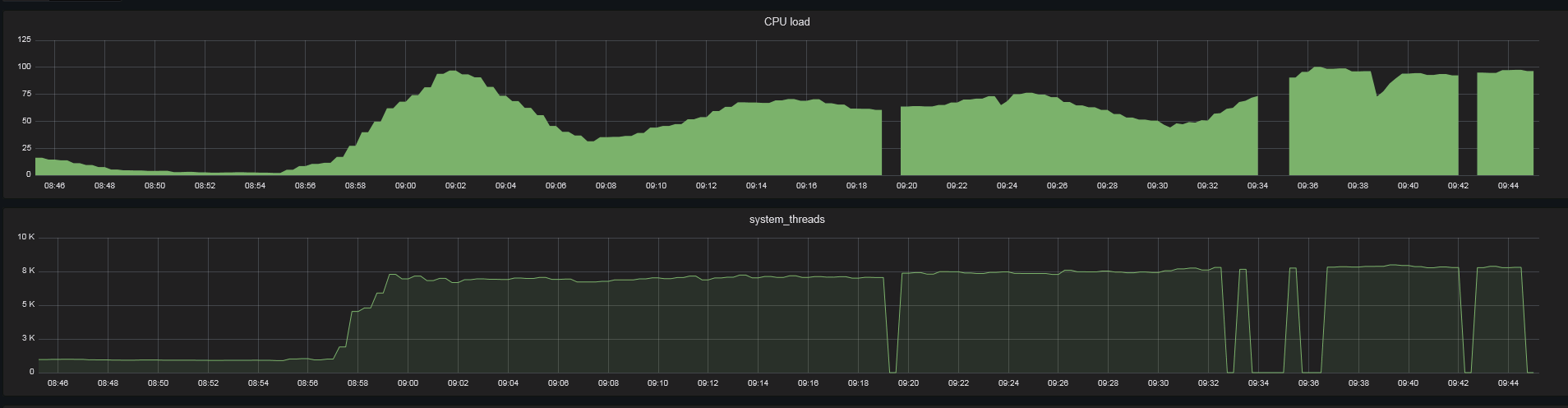
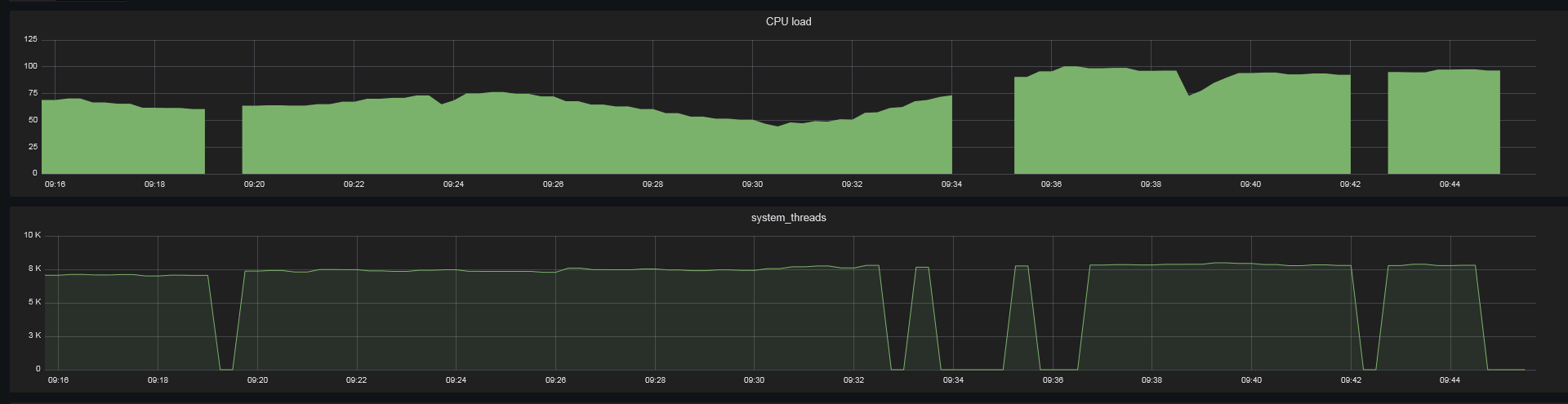
|
This issue has been solved for me 👍 |

|
Nice - maybe this issue can be closed then. |
|
I've got release v0.10.2 (the newest as of this date) installed on multiple AWS EC2 instances running Windows Server 2016 and I still see this problem in my collector metrics. It seems to specifically impact iis, process, and .NET framework based collectors.
|

|
I believe this will remain a problem as long as we use WMI. We've successfully migrated a lot of them to perflib, but there are still quite a few remaining. And some of them, such as the |
@carlpett Yes unfortunately. I was just hunting down an issue like this on version 0.14 and it seems to be caused by the But in addition there seem to be no more spikes happening without the logon collector until now. I configured two equal machines, one with and the other without logon to see if this theory hold up. |
|
OP here... I completely forgot to update this issue. We randomly found out what made the scrapes jam up so badly in our particular use-case. We had left a virtual media ISO mounted through the iDrac (Dell's BMC thing). As soon as we unmounted that, the impact of the 17 minute scrape went from a many 10s of seconds down to a more normal time. So, if you are:
Then, just make sure you unmount the ISO when you aren't using it. |
Thanks, I double checked that, but that was not the issue in my case - disabling the With logon enabled: When running without logon: Mind the scaling! As you can see @carlpett do you see any chance of improving the performance on collecting session data? |


|
From a quick look there doesn't appear to be an equivalent perflib counter for |
|
@breed808 thanks a lot for looking into this issue so quickly. If switching PerfLib is not possible, maybe there is potential for optimizing the query? Maybe there even is another metric just giving the number of logins without all those expensive details to be fetched? |
|
@frittentheke I haven't found any good sources for those metrics aside from the LogonSession class either, sadly. Re efficient querying, if you have a busy server to test on, could you share the results from running these two? Measure-Command -Expression {Get-WmiObject -query "SELECT * FROM Win32_LogonSession"}
Measure-Command -Expression {Get-WmiObject -query "SELECT LogonType FROM Win32_LogonSession"}I haven't seen major differences previously, but I suspect the people seeing issues with the logon collector might have much larger datasets, so worth testing! |
|
@carlpett I ran those commands ... but apparently there is not much of a difference: |
|
I'm NOT having any problems with this issue anymore. I always thought it was fixed by some Windows Update. That said, I did the same tests on both Windows Server 2016 and Server 2019. Windows Server 2016 (Version 10.0.14393 / 83 users currently logged in / AvgCpu*: 22%) Measure-Command -Expression {Get-WmiObject -query "SELECT LogonType FROM Win32_LogonSession"}
TotalMilliseconds : 791,1173
Measure-Command -Expression {Get-WmiObject -query "SELECT * FROM Win32_LogonSession"}
TotalMilliseconds : 1159,6284Windows Server 2019 (Version 10.0.17763.1518 / 101 users currently logged in / AvgCpu*: 19%) Measure-Command -Expression {Get-WmiObject -query "SELECT LogonType FROM Win32_LogonSession"}
TotalMilliseconds : 747,9188
Measure-Command -Expression {Get-WmiObject -query "SELECT * FROM Win32_LogonSession"}
TotalMilliseconds : 844,6833These numbers are considerably faster than the ones posted by @frittentheke. Maybe my servers have some update that aren't present in the ones having the problem? I'm available to investigate this matter further, if you wish. Edit: * Added average CPU usage in the last 3 hours |
|
@fdcastel thanks for posting the queries on your systems. I believe my > 2k logon sessions due to exchange running on this machine might be the issue for the difference in performance. I run Win 2016 with a quite recent patch level. Do you believe there is a particular patch I should check for then? |
There's always an explanation 😄
No. I'm sorry. I'm just trying to keep the servers up-to-date, mostly for security reasons. But I don't keep a close watch on every patch release. It was just a hunch, given the significant difference in the times I saw. But, surely, 20x more users could explain it 😅. |
|
This issue has been marked as stale because it has been open for 90 days with no activity. This thread will be automatically closed in 30 days if no further activity occurs. |
We've deployed the wmi-exporter on a number of our Windows systems running Server 2012r2 standard. This was a version built several months ago with Go 1.8.
These systems typically push 20-30 Gbps of traffic and have 24 hyperthreads. There is generally plenty of room on half of these threads.
Having deployed the exporter, we observed that every 17-18 minutes (independent of when the exporter was started), the traffic being served by them would drop significantly for roughly 120 seconds and CPU consumption on one or two cores would spike. The "WMI Provider Host" would also increase in CPU utilisation during this time.
Killing the exporter did not cause the load to drop off immediately.
We also noticed that calls to the exporter would block during this time.
We set GOMAXPROCS to 2, to see if there was any concurrency issues that might be overloading WMI, but that didn't improve matters.
We built a new version from master on Friday June 30th with Go 1.8.1. The issue persisted.
We started to disable collectors to isolate where the problem was occurring and found that it only happened when the CPU collector was enabled. We put some printfs around the calls inside the collect function and found that it was blocking on the call to wmi.Query.
Interestingly, we did not see any pauses or breaks in the data while monitoring that data in perfmon while the query was running.
We dialled testing back to a 2 CPU VM running Windows 10 not doing anything particularly difficult or interesting and polling using "curl $blah ; sleep 60" in a loop.
The results suggest that something is going wrong every 17-18 minutes (the lines with *** were added by me):
< snip a few more ~0.04 second runs >
I tested again using official version v0.2.5 and again observed an unexpected increase in gathering time ~17 minutes after the last spike.
I don't understand WMI enough to understand where to start digging, but it would be useful to understand if anyone else observes this.
If there's other data that is useful to gather. please let me know.
The text was updated successfully, but these errors were encountered: