


Run Large-Language Models (LLMs) 🚀 directly in your browser!
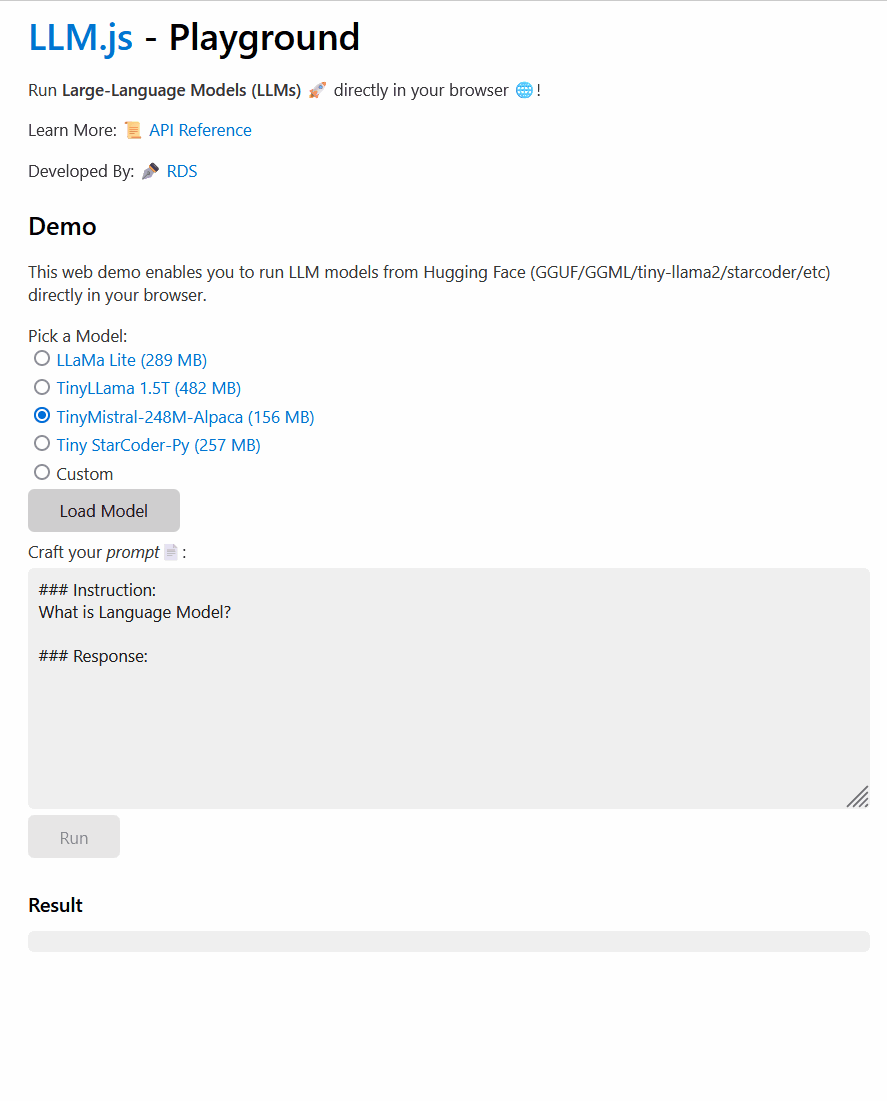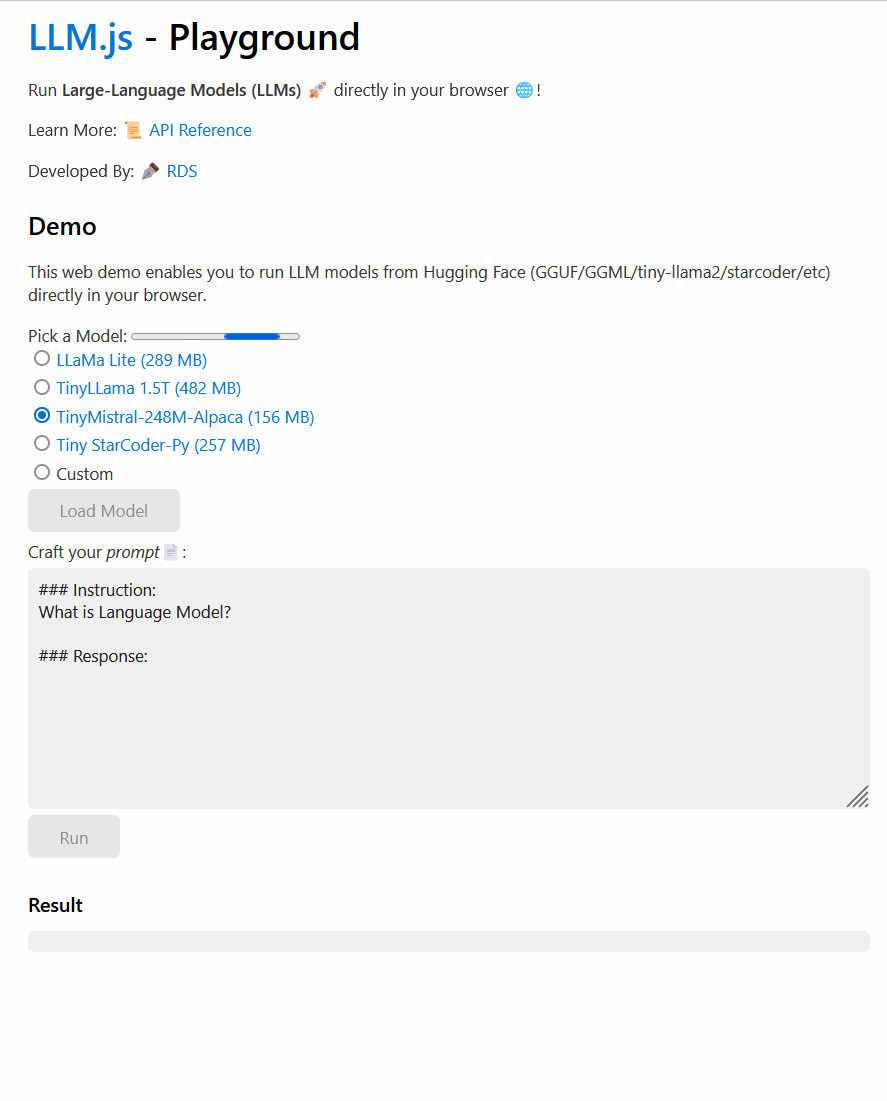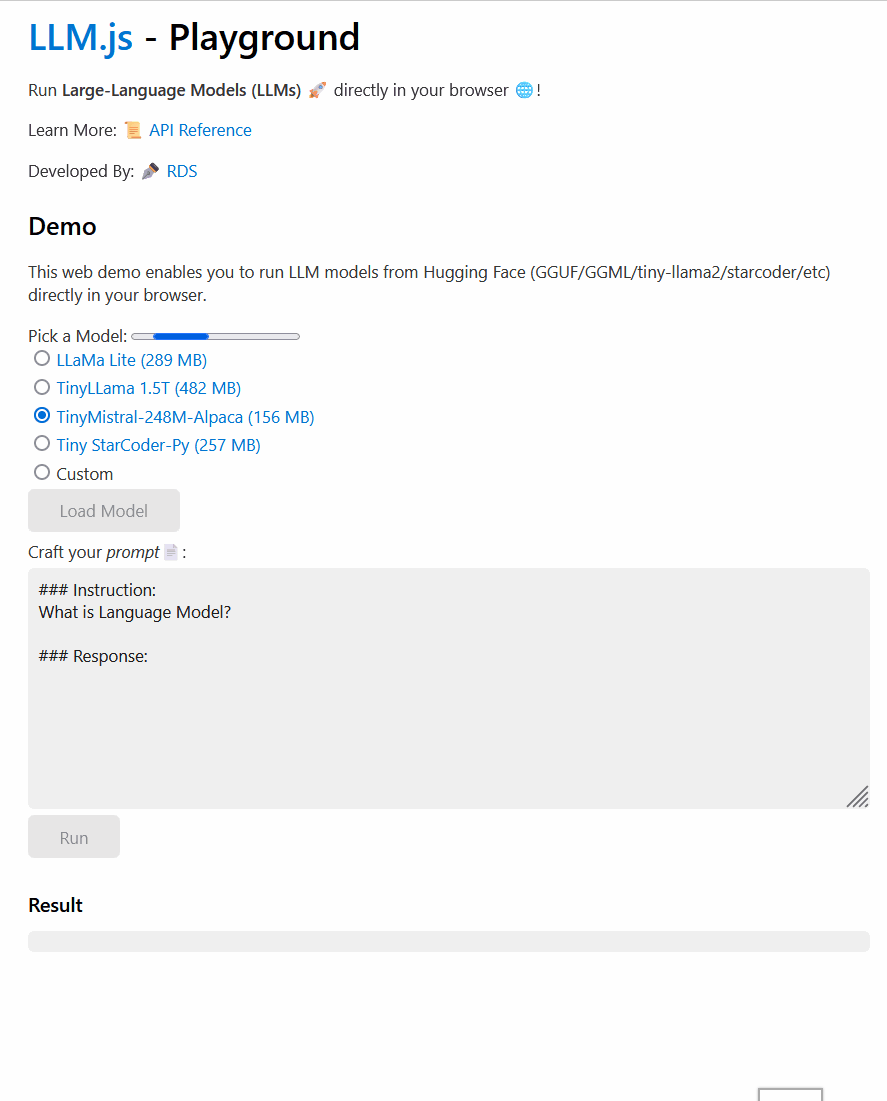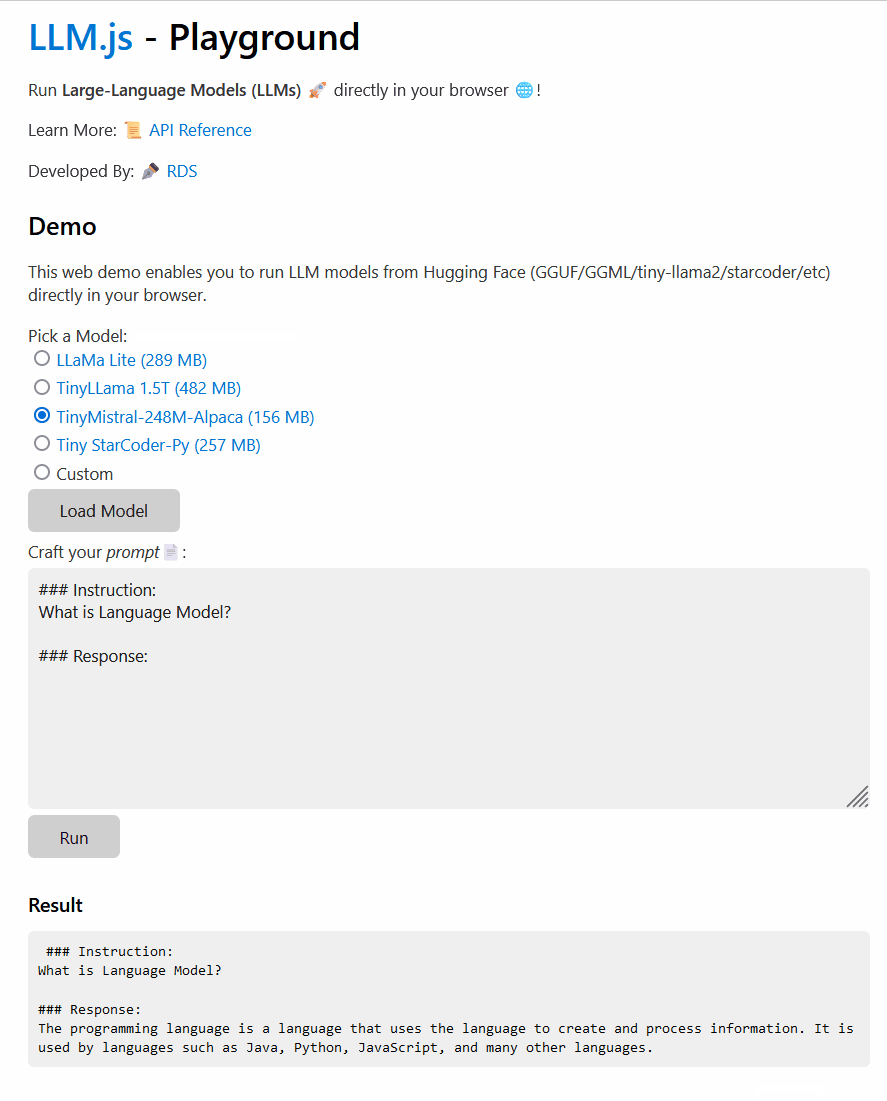
Example projects🌐✨: Live Demo
Learn More: Documentation
Models Supported:
- TinyLLaMA Series - 1,2,3🦙
- GPT-2
- Tiny Mistral Series
- Tiny StarCoder Py
- Qwen Models
- TinySolar
- Pythia
- Mamba and much more✨
- Run inference directly on browser (even on smartphones) with power of WebAssembly
- Guidance: Structure responses with CFG Grammar and JSON schema
- Developed in pure JavaScript
- Web Worker to perform background tasks (model downloading/inference)
- Model Caching support
- Pre-built packages to directly plug-and-play into your web apps.
Download and extract the latest release of the llm.js package to your web application📦💻.
// Import LLM app
import {LLM} from "llm.js/llm.js";
// State variable to track model load status
var model_loaded = false;
// Initial Prompt
var initial_prompt = "def fibonacci(n):"
// Callback functions
const on_loaded = () => {
model_loaded = true;
}
const write_result = (text) => { document.getElementById('result').innerText += text + "\n" }
const run_complete = () => {}
// Configure LLM app
const app = new LLM(
// Type of Model
'GGUF_CPU',
// Model URL
'https://huggingface.co/RichardErkhov/bigcode_-_tiny_starcoder_py-gguf/resolve/main/tiny_starcoder_py.Q8_0.gguf',
// Model Load callback function
on_loaded,
// Model Result callback function
write_result,
// On Model completion callback function
run_complete
);
// Download & Load Model GGML bin file
app.load_worker();
// Trigger model once its loaded
const checkInterval = setInterval(timer, 5000);
function timer() {
if(model_loaded){
app.run({
prompt: initial_prompt,
top_k: 1
});
clearInterval(checkInterval);
} else{
console.log('Waiting...')
}
}