main page #1
Comments
Catalog
Pre-trained Base ModelsSimple Version
Licences
|


Track of Open LLMs
|
Instruction and Conversational Datasets
Pre-training Datasets
Efficient Training Library
|
Evaluation Benchmark
Star History |

Evaluation Dilemma
Evaluation In a Afforable WayHuman Exams
Question Answering and Classification
Reasoning(Common Sense, Math)
Coding
Translation/Multi-lingual
Natural language generation
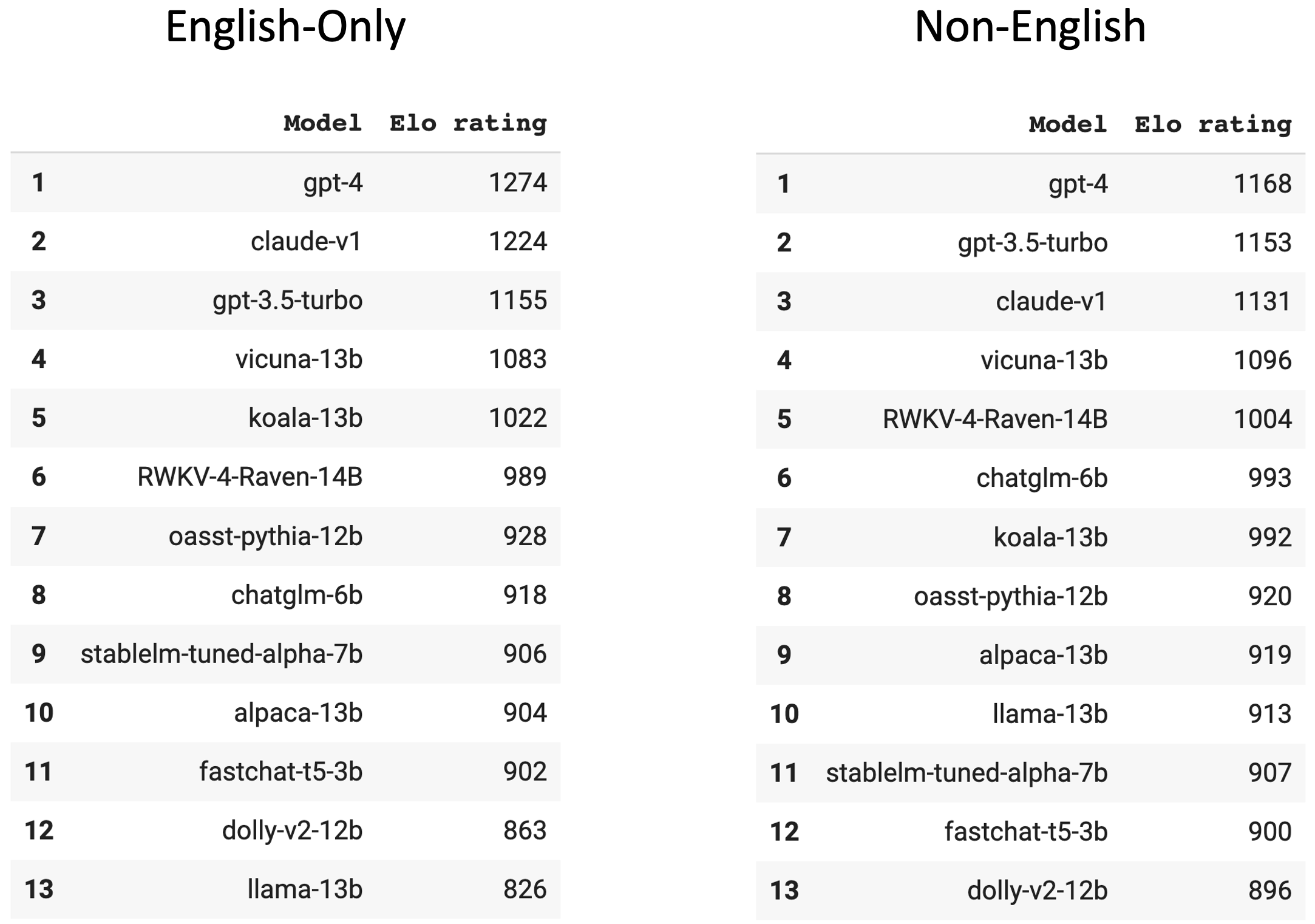
LLM Arena (side by side comparison)
|










<!DOCTYPE html>
<style>
body {
background-image: url('https://boson.ai/bg.jpg');
background-attachment: fixed;
background-size: cover;
}
.header {
padding-top: 50px;
margin: auto;
width: 60%;
font-family: Arial,Helvetica,sans-serif;
}
h1 {
font-size: 110px;
color: #fff;
}
h2 {
font-size: 80px;
color: #aaa;
}
</style>
<html>
<body>
<div class="header">
<h1>Large Models for All</h1>
<h2>We're building something big...</h2>
<h2>Stay tuned! </h2>
<a href="https://github.com/shm007g/LLaMA-Cult-and-More">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=shm007g/LLaMA-Cult-and-More&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=shm007g/LLaMA-Cult-and-More&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=shm007g/LLaMA-Cult-and-More&type=Date" />
</picture>
</a>
<input type="hidden" id="thanks" name="to" value="https://github.com/boson-ai">
<h2></h2>
<div>
</body>
</html> |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
track
The text was updated successfully, but these errors were encountered: