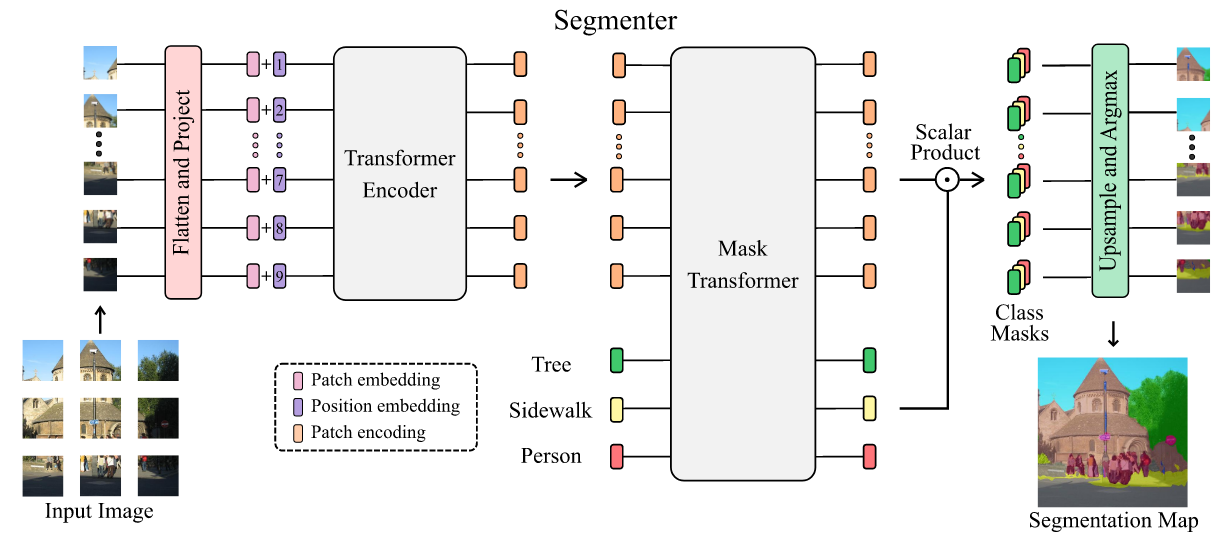
Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus. In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution-based methods, our approach allows to model global context already at the first layer and throughout the network. We build on the recent Vision Transformer (ViT) and extend it to semantic segmentation. To do so, we rely on the output embeddings corresponding to image patches and obtain class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. We leverage models pre-trained for image classification and show that we can fine-tune them on moderate sized datasets available for semantic segmentation. The linear decoder allows to obtain excellent results already, but the performance can be further improved by a mask transformer generating class masks. We conduct an extensive ablation study to show the impact of the different parameters, in particular the performance is better for large models and small patch sizes. Segmenter attains excellent results for semantic segmentation. It outperforms the state of the art on both ADE20K and Pascal Context datasets and is competitive on Cityscapes.
We have provided pretrained models converted from ViT-AugReg.
If you want to convert keys on your own to use the pre-trained ViT model from Segmenter, we also provide a script vitjax2mmseg.py in the tools directory to convert the key of models from ViT-AugReg to MMSegmentation style.
python tools/model_converters/vitjax2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}E.g.
python tools/model_converters/vitjax2mmseg.py \
Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz \
pretrain/vit_tiny_p16_384.pthThis script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
In our default setting, pretrained models and their corresponding ViT-AugReg models could be defined below:
| pretrained models | original models |
|---|---|
| vit_tiny_p16_384.pth | vit_tiny_patch16_384 |
| vit_small_p16_384.pth | vit_small_patch16_384 |
| vit_base_p16_384.pth | vit_base_patch16_384 |
| vit_large_p16_384.pth | vit_large_patch16_384 |
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| Segmenter Mask | ViT-T_16 | 512x512 | 160000 | 1.21 | 27.98 | V100 | 39.99 | 40.83 | config | model | log |
| Segmenter Linear | ViT-S_16 | 512x512 | 160000 | 1.78 | 28.07 | V100 | 45.75 | 46.82 | config | model | log |
| Segmenter Mask | ViT-S_16 | 512x512 | 160000 | 2.03 | 24.80 | V100 | 46.19 | 47.85 | config | model | log |
| Segmenter Mask | ViT-B_16 | 512x512 | 160000 | 4.20 | 13.20 | V100 | 49.60 | 51.07 | config | model | log |
| Segmenter Mask | ViT-L_16 | 640x640 | 160000 | 16.56 | 2.62 | V100 | 52.16 | 53.65 | config | model | log |
@inproceedings{strudel2021segmenter,
title={Segmenter: Transformer for semantic segmentation},
author={Strudel, Robin and Garcia, Ricardo and Laptev, Ivan and Schmid, Cordelia},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={7262--7272},
year={2021}
}