| title | tags | date | slug | |
|---|---|---|---|---|
The scale cube in Nodejs |
|
2024/03/16 |
2024-03-16-the-scale-cube-in-nodejs |
To scale an application, we have 3 dimensions that need to be scaled as described below with the cubic model from AKF Scale Cube:

X-axis scaling consists of running N instances of a cloned application or replicated database. Proxied by a load balancer, each instance handles 1/Nth the load.
Load-balancing is the key of it. There are some ways that can be implemented:
- Cluster module: core library --> distribute work to the workers (child processes) --> but it's stateless.
- Reverse proxy/Gateway: act as a load balancer (Nginx).
Functional decomposition, monoliths are separated along functional or resource oriented boundaries to create macro and microservices. This allows you to scale each service independently and apply more resources only to the services that need them.
Microservice Architecture (MA) is the key of this:
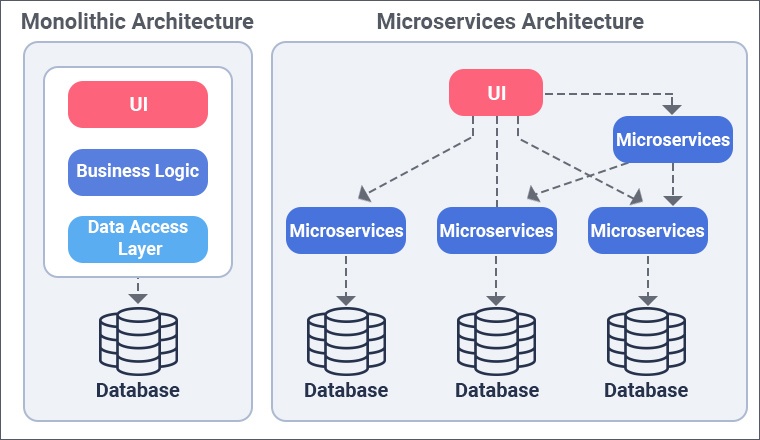
But there's also pros and cons:
-
Pros:
- Every service is expendable: having it's own context.
- Reusability across different platforms, languages.
-
Cons: hard to manage, deployment, code sharing,..
To make all the services to collab in MA, we need some patterns such as: API Proxy (API Gateway), API orchestration, Message broker.
It is quite similar to X- Scaling and hence confused a lot. Here, each replica runs the same copy of code. But each replica is not doing exactly the same thing. The workload is distributed amongst them. One replica only works on a subset of data. A part of the application routes each request to the appropriate server. It can be done on a geographical basis to increase the response speed. It is also done on the basis of customer. For example, a privilege customer of an application will be routed to a faster set of servers. Just like there are a lot of download servers which limit download speed for non-paying customers.
We're not gonna mention much about this for Nodejs applications.
Refs:
[Book] Node.js Design Patterns by Mario Casciaro