- Threaded Pipeline
- Introduction
- More ways to use pipelines
- How to write steps
- Coroutine Pipeline
Here we will look at a fully featured example which you can run right away. This should give you an idea of what the library can provide for you.
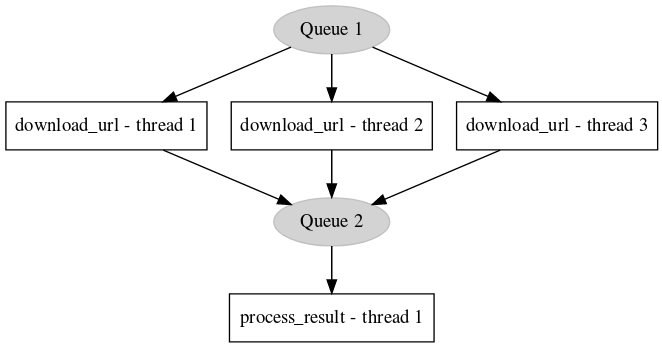
Items can be ingested into the pipeline in various ways which can be handy depending on use-cases and data-sizes. For the examples we have a fictional scenario where we want to download and print some URLs and their contents. We'll use 3 threads for downloading and 1 thread for printing the result to stdout.
How it works in a nutshell
The output of the previous step is the input of the next step.
import paipa
import requests
def download_url(url):
resp = requests.get(url)
return resp
def process_response(resp):
print(("== Fetched %s =" % resp.url) + "=" * 50)
print(resp.content)
# We have no subsequent step, so we don't really need to return
# anything, but returning the response for further processing could
# be interesting.
return resp
pipeline = paipa.Pipeline(
[
(paipa.funcstep(download_url), 3),
# Only one thread because that way the console printout is
# nicely readable. Try to tune this and see what it does.
(paipa.funcstep(process_response), 1),
]
)
pipeline.put("http://example.com/2")
pipeline.put("http://example.com/4")
pipeline.put("http://example.com/6")
pipeline.finish()
pipeline.run()
# Observe that the order in which the URLs are printed may vary due to
# runtime differences in the requests.To recap, this example spawns 3 download threads (most of which will actually do nothing at all in this example) and 1 printing thread. The URLs fed into this system will first be downloaded and the response forwarded to the one printing thread.
This diagram shows the structure of the pipeline being generated by the above code.