You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Link 组件就是绑定一个 onClick 事件,然后调用 context 传下来的 hisotry 对象中的 push/replace 方法。
react router 如何做性能优化的,每个页面存的 state 过多,占用内存。
还真没遇到过 state 过多导致浏览器卡的情况。
react-router 把路由的 state 信息存到了 sessionStorage,state 就是给每个路由保存的数据,开发者也可以往里面附带各种信息。 storage 快满的时候,getItem 会变慢,导致 Router 也变卡。那我们尽可能的少往 state 里塞数据,尽量通过 store 交互,另外也可以手动清理。
做过哪些性能优化
还是页面优化的几板斧。
1.减少体积。通过 webpack+babel 打包的优化,减小体积。
2.延迟加载(资源的异步加载)
3.网络加速(cdn、dns 预解析、http 并发数)
4.首屏渲染 (ssr、骨架图)
5.利用缓存(http 缓存)
预渲染
Prerender 介于服务端渲染和客户端渲染之间,即请求 html 的时候,html 中就包含首屏的结构。原理是先根据需要预渲染的路由,然后通过 webpack 插件增加预渲染的配置,插件内部通过无头浏览器(比如 phantomjs) 访问并把对应的 html 结构输出,并建立路由对应的目录。
缓存是如何用的
一般是用 http 强缓存,然后可以提一下 http 协商缓存和离线缓存。
cdn 是如何实现加速的
通过 DNS 系统和负载提醒,根据用户访问的 ip 找到最近的缓存服务器,并把网站提供服务器上的资源加载到缓存服务器。主要是减少了跨地域损耗
dns 预解析的方案
react ssr
算法
给一个数组,分成三份,使两两数组间的和差值最小,求差值的和。
二面
做过哪些技术建设,提升人效的工作
mobx 的坑,如何跳坑。
mobx-react 的原理
你面试通常会关注候选人的哪些点
三面
工作中遇到过的最大的挑战是什么
前端如何提效。
如何减少线上代码出问题的几率,也就是提高稳定性。以及快速的定位,修复问题。
你有什么问题
kuaishou
敬请期待
tiktok
敬请期待
The text was updated successfully, but these errors were encountered:
sunyongjian
changed the title
201903 面试总结(alicloud, tikTok, ke,ks)
2019-03 面试总结(alicloud, tikTok, ke, ks)
Jun 5, 2019
18 年太忙碌,发现已经过去一年多没有面试了,趁着转过年来事情不是很多,抓紧出去面面试看看。目的:
答案均为自己总结,可能会有疏漏
alicloud
一面
阿里第一面一般都是电话摸底
最近在做的事情
让你介绍一下最近在做什么,看看有什么可以深入聊的。
学委是干嘛的
因为我简历上写了“学委”,其实就是做一些技术建设相关的事,比如固定组织分享,发现一些有意思的 topic。
移动端开发,布局方案
说实话我对移动端的布局反正是能用就行。
mock 是如何做的
视情况:本地 mock 文件(我是用中间件做的)或者 mock 平台,可基于 yapi 搭建
Proxy 怎么做
本地做转发,一般都是在 dev-server 里,根据变量去区分走 mock 还是代理,代理的话就用 express-http-proxy 代理走,即 use 不同的中间件
eslint 是怎么做的
lint 规范是根据 Airbnb 做的修改,流程约束的话可以通过 loader 以及 pre-commit 去做
eslint 的原理是什么
只说了把代码转化成 ast,就可以分析了。细节推荐一篇文章
react 方面,介绍一下 mobx,是怎样的一个框架。
mobx 本身是 MVVM 架构的状态管理库,他是跟 view 框架解耦的,通过中间层 connect 起两者。他使对象的属性可观察,并对属性变化做出响应。跟 react 本身建议的 smart 组件(state 管理的) + dumb 组件相悖,它崇尚尽可能多的使用 observer,都是 smart 组件已达到最细微颗粒度的更新组件。并且可以让 react 轻易的做到双向数据绑定。
本质是 mvvm,那跟 mvc 的区别
mvc 是流程是单向的,比如 view 层接收用户操作,发到 controller 层,controller 处理业务逻辑并修改 model,model 再将新的数据给 view,反馈给用户。
MVVM 的话,是 viewmodel 取代 controller,连接起 view 和 model,view 和 model 不直接通信,都通过 VM 传递,所以 VM 跟 view 和 model 是双向通信的。比如 mobx-react 就是一个 view-model。
如果让你实现一个 mobx,如何做
最基础的我觉得主要实现 observable 跟 autorun 两个 Api 就够了。observable 可以通过 es6 Proxy 给对象的属性增加 get,set,通过 get 来收集依赖,比如 autorun 里的函数访问到了某个属性,那便可以把回调函数存到一个数组,当然外层是一个 map,通过唯一的 id 访问到这个数组。然后属性修改,发生 set 的时候,把对应的监听函数列表遍历执行即可。
推荐阅读1、2
装饰器有哪些好处,跟继承相比
两者都可以拓展某个类或者对象上的属性和方法,但是装饰器相对来说比较灵活,简介。比如类继承的时候,首先你需要基于需要拓展的方法封装一个类,然后也必须是在定义类的时候继承,而装饰器就不需要创建更多的类,而且可以动态的给对象拓展,并且多个装饰器还可以很容易的组合。
amd 和 cmd 的区别,commonjs,esmodule
首先 amd 和 cmd 是两种 js 模块化开发的规范,分别是 RequireJS 和 SeaJS 提出的,最根本的区别是:amd 是依赖前置,即先写好依赖并且先加载依赖,再运行下面的代码。而 cmd 是就近依赖,在你代码里用到某个依赖的时候,在 require 即可。
cmd规范、amd规范
commonjs 是 node 推出的模块化方案,commonjs 最大的特点就是同步加载,因为在服务器端都是磁盘存储和读取,所以不适用于浏览器端。
esmodule 很显然是 es6 推出的新一代模块化,跟之前的模块化相比,esmodule 不需要在执行的时候遍能知道引用关系,因为 import 命令会被 JavaScript 引擎分析,则在代码编译的过程中即可引入依赖的代码。而 commonjs 等是代码运行的时候才知道引用关系,就是通过 function 注入依赖:
所以 esmodule 可以做静态分析,比如 tree-shaking,相应的它也无法做条件加载。
另外跟 commonjs 的区别,cjs 的模块输出的是值的拷贝,而 esm 是值的引用。所以在 commonjs 里某个依赖里发生改变之后,模块内部是感知不到的。
柯理化是什么
柯理化,是把接收多个参数的函数,变换成接收一个单一参数的函数,并返回一个接收余下参数的函数。本质的柯理化是 lambda 演算中,用来处理函数传入多个参数的情况。
那在 js 中,柯理化的好处就是可以预置参数,举个栗子
问这个是因为我简历上写了研究函数式
es6 如何让某个对象的属性只可读。defineProperty 属性描述
React 中函数组件和普通组件有什么区别
函数组件也可以称为无状态组件,顾名思义就是没有 state 的,并且没有生命周期函数,写法更简洁并且也不需要关注 this,它只接收 props 并作出响应。当然因为 react 16.8 hooks 的出现,函数组件也可以拥有自己的 state 和生命周期,比如 didMount 和 didUpdate。
普通组件也就是 class 组件,拥有 react 所有的生命周期函数,并且本身是 class,所以有 class 的一切特点,比如 this。
虽然由于 hooks 的出现,函数组件可以取代 class 组件,但是 react 官方也没有强推函数组件,大家仍然可以用之前的 class 写法,并尽可能的通过 hooks 去优化代码。
react 16 的新特性,生命周期
新的 fiber 架构,portal(modal 窗),render 支持 return 数组(不用再套 div 了),componentDidCatch 处理错误等等。
新的生命周期,干掉了各种 will 开头的生命周期,增加了
static getDerivedStateFromProps和getSnapshotBeforeUpdate,新的生命周期从三个阶段内来看的话Mounting 阶段:
constroctor -> getDerivedStateFromProps -> render -> DidMountUpdating 阶段:
getDerivedStateFromProps -> shouldComponentUpdate -> render -> getSnapshotBeforeUpdate -> DidUpdateUnmounting 阶段:
WillUnMount老的生命周期图
新的生命周期图
为什么要有这些改动
首先,重构的 fiber 架构是为了解决 react 的性能问题,其次再顺手解决一些其他痛点。
对生命周期的影响:
之前的 virtual dom tree 做 Diff 的时候,是递归调用比对的,一旦开始则无法暂停,受限于递归的上下文。而因为浏览器是单线程,并且 tasks 和渲染是互斥的,导致比对的时候浏览器无法处理其他的事情,尤其是动画这种对帧数要求较高,会带来明显的卡顿,所以让浏览器休息好才可以。fiber 的策略是分时间段调度任务,在浏览器空闲的时间段内进行比对,一旦有其他高优任务立马暂停。有两个关键点,一个是递归栈调用改为了单链表结构,每个 virtual dom 升级为 fiber node,也就是每个 fiber node 都有自己的 return(父),child(子),sibling(兄),并进行深度优先遍历,因为链表的缘故,比对任务才可以暂停。第二个是利用了浏览器的 requestIdleCallback api,回调函数可以得到非常精确的浏览器空闲时间,react 抓紧在此时进行 updateFiberAndView,一旦这个时间小于 1,则会暂停,并把此时的 fiber node 放进 queue。queue.length 存在,则继续利用 requetIdleCallback 去检查是否存在空闲时间,存在则从 queue 取出第一个 fiber node 继续遍历。
因为新的 reconciler 阶段(即 diff 阶段)fiber 链是可以断开的,停在某个 fiber node,下次再进入,这个阶段是会调用组件的一些生命周期的,比如 WillXXX,而因为 reconciler 阶段会调用多次,所以对应组件的 WillXXX 也会调用多次,而之前的 WillXXX 是可以 setState 以及操作 Dom 的,这显然容易出现问题,比如操作 dom 的 reflow,或者代码出错(都加 try catch 影响性能),所以干掉也是为了语义化。
之所以用
static getDerivedStateFromProps就是为了不让用户操作 refs,只需要返回新的 state,纯函数明显没有副作用,多调用几次也没关系。getSnapshotBeforeUpdate的话,就是为了在最终的那一次 commit 之前(即根据比对结果,更新实际的 dom),给用户最后的机会做一些 dom 操作的机会,并且在一次 update 只会调用一次。react native 什么水平
实验,写 demo 水平...
redux 用过哪些中间件
thunk, redux-promise, redux-sagasaga 是用来解决什么问题的
保持 action 的简介,集中在 saga 处理副作用,因为 generator 的缘故,可以处理一些复杂的异步问题,并提供了一些常用的 Effects。
你们平常开发 react 用什么脚手架
团队自己的一个脚手架,由我主导开发。
介绍一下你的脚手架
功能类似于 vue-cli,只做项目的初始化,通用的逻辑集成到项目模板里,然后提了一下 react 模板的一些功能。public-cli
node。介绍一下 koa
使用了 generator(koa1)、async(koa2) 来处理异步操作,语法跟 express 类似,因为是原班人马打造。本身的 koa 包体积很小,把其他的一些中间件独立发包,比如 koa-router, koa-bodyparser,更轻便。中间件模型采用了洋葱模型,相较 express 能够处理更丰富的业务场景。
洋葱模型是什么
中间件是先入后出的,即第一个加载的中间件,最后一个出去,由 next 分割代码。
node 进程之间如何通信,几种方法
大多数是 master-worker 的管理方式,即一个主进程管理+多个自进程。
1.通过内置的 ipc 方式。首先通过
child_process创建子进程,比如child_process.fork,会返回一个实例,然后通过p.on监听2.通过stdin/stdout传递json
这种方式是利用 stream 的方式。
写法都差不多。
3.其他的查了一下还有通过 socket 等网络传输的方式,跨机器都可以了,就不做讨论了。
restful api 接口设计风格
主要是语义化以及路径的规范吧。
包括 http-method、状态码等都代表不同的语义。
举了个栗子
git 中的 mr 跟 pr 的区别
其实都差不多😆,
github 的 fork 工作流和 gitlab 的 merge 工作流,本质都是用来协同工作合并代码的。
区别就是 pr 需要 fork 一份代码仓库,然后去合并代码。mr 共用一个仓库,使用分支去提即可。
二
面谈,聊项目聊的比较多,问了很多技术和业务上的细节,忘得差不多了,总之自己做过的项目一定要准备一下,看如何组织语言介绍,以及一些技术细节回顾一下,说起来才能自如。再就是要多思考这些项目的价值,以及不足。
比如如何实现一个通用的 form 组件,如何解决管理页面的重复开发问题,这个我们的思路是通过 schema 的方式去生成 UI,可以参考之前开源的 amis,思路是差不多的,比我们的功能强大。以及一些 crm 系统的业务逻辑。
最后考了两个笔试题,手写 EventEmitter 和 list2tree
三
介绍一下自己前端职业的发展历程。
非计算机出身,但是一直对计算机方向感兴趣,毕业半年之后因为兴趣和工作前景不错转前端,去参加一些课和培训、自学,再找工作,目前是从业过两家公司,以及第一次换工作的原因。再就是谈谈自己的学习方法。
比如如何学前端。做过哪些项目
好好说就行了,比如参加一些网课啊,看书、听书,一定要体现自己会系统的去学习,而不是零零散散的看。比如自己会整理笔记,画一画脑图之类的。
现在在团队的角色是怎么样的
如实说就好了,不然容易暴露。
那在团队内是如何做基础建设的
其实就是规范、基础工具和服务设施
1.尽可能的统一技术栈,我们是 pc react,移动端小程序 vue
2.通过脚手架和工具解决的配置问题,规范大家的开发流程,并帮助大家只需要关心 code 即可,打包、mock、联调、上线都可以自助化。这块要注意公司内部有的设施(mock 服务、发布平台、基础组建)应当避免重复建设,尽可能的接入,并减少接入成本。
3.文档建设。比如新人文档,我们团队的规范是怎样的,用到了哪些技术,工具和服务,都要有说明。项目文档一定要完善,利人利己,也方便工作交接。
让我说一下最近做的项目,出彩的地方
嗯,吹就完了。
各种问我做到什么程度,中后台的事情
hybird 混合开发做过吗
node 都用来做什么
中间层开发、内部工具、前端工程化
node 应用如何部署的
在打包平台安装好依赖,然后打好包,通过上线平台搞到远程机器上。环境问题:因为大部分都是 docker 容器,搞好一次,下次复用镜像就可以了。进程托管是用的 pm2。
如何选择框架。如果没有 react,和 vue ,你会用什么
看业务场景和团队情况。比如对打开速度要求较高,可能会使用体积更小的 vue,比如大家更爱用 react 并感兴趣。
我回答的是用其他类 MVVM 框架,因为肯定无法回到 jQuery 时代了。另外就是要关注一些原生的方案,比如 web-components。这个是发散性问题,主要看你的视角有没有打开。
同源策略的原理,为什么要有这个东西
规定同一个协议、域名、端口为同域,非同域下你无法通过脚本获取 cookie,也无法发送 ajax。主要是为了信息安全,防止自己网站的信息数据被窃取。 请求获取其他域下的资源。
如何跨过同源策略的限制
像一些静态资源加载引用是没有同源策略的,比如 img,css,script。
ajax 跨域的主要方法是: jsonp 和 cors(服务端去允许跨域访问)
说一下 jsonp 的原理
就是利用了 script 标签不受同源策略的限制,传给后端的 query
/a?callback=foo,response 里为foo({ a: 'b'}),前端直接执行 foo 就可以拿到注入的数据了。如何做页面的性能优化
1.减少体积(打包优化、babel 优化)
2.延迟加载(资源的异步加载)
3.网络加速(cdn、dns 预解析、http 并发数)
4.首屏渲染 (ssr、骨架图)
5.利用缓存(http 缓存)
每一点都可以展开说。
说一下浏览器缓存
http 缓存分为强缓存和协商缓存。
强缓存:通过服务端设置 response header 生效,http1.0 是 Expires,设置过期时间,http1.1 是 Cache-Control,里面有一个 maxage 设置缓存的相对时间。只要是在时间内,浏览器就不会向服务器发起请求,而是从本地获取。状态码 200,size 是from memory cache 或 from disk cache
协商缓存:服务器设置 Last-Modified,即文件的最后修改时间,然后下次浏览器发请求的时候,如果没有强缓存,则发送请求,request header 里携带 If-Modified-Since:服务端上次设置的值,服务端比对最后修改时间是否一致,如果一致则返回状态码 304,内容空,告诉浏览器文件无变化可以从本地缓存读取。
由于过期时间不是那么可靠,时间不准确或者可能加了空行但是文件内容无改变。ETag header 是服务器根据文件内容生成的,交互流程跟 Last-Modified 类似,并且优先级比它高,即优先进行 Etag 的验证。
cdn 的原理和应用
一图胜千言。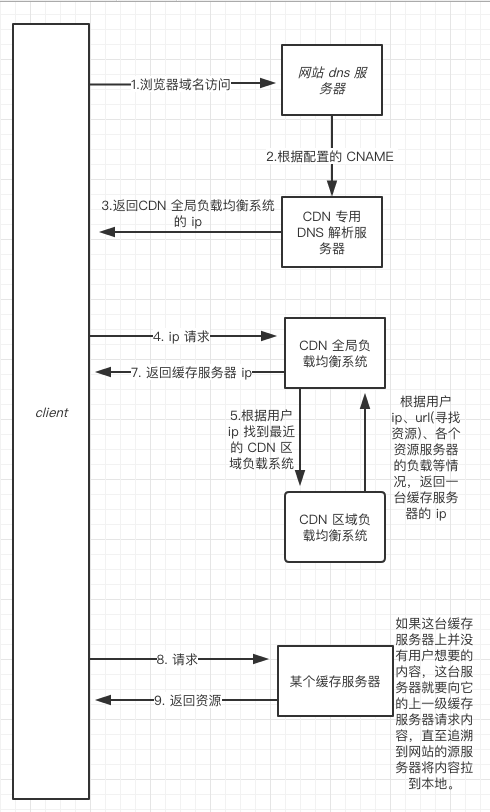
节流和防抖
节流是指在一段时间内,事件只触发第一次,防抖则是一段时间只触发最后一次。分别的应用是,节流是按钮连点、滚轮是否滚动到底部等,比如滚轮节流后第一次触发已经到底部了,就直接可以触发。防抖是用户输入、浏览器窗口的 resize等,只关心最新的一次输入。
内部系统的兼容性要求如何。利用高版本浏览器支持较多的新特性,做过哪些事情
内部系统的兼容性还好,甚至你直接可以推荐使用 Chrome,当然某些不兼容 Safari 或者火狐也会被吐槽。
1.webworker,新开线程去做一些计算密集的操作 或其他会阻塞 UI 渲染 的逻辑,比如 数学计算、图像处理,甚至是请求回来的 ajax 数据,需要经过前端的大量处理。
2.利用 webSocket 通信代替传统的轮询
3.使用 html5 的一些事件,比如 drag 和 drop 去做拖拽控件
4.利用 html5 的 file 对象对上传文件进行切片,FormData 做数据的暂存,实现大文件的切分上传以及断点续传等功能。
5.通过创建 cache manifest 文件,实现 web 应用的离线存储。
100 万条数据如何展示
没有处理过这么大的数据量,并且也没有收到这种需求。首先上万条的数据,不应该一次展示在页面上,因为用户也看不完啊,太多反而会影响阅读体验。如果一定要展示,举个栗子,假设后端能够一次性返回 100w 条数据,前端 js 去拼接字符串:
拼接 html 字符串这段因为是 js 去处理,不会太慢,我用 for 循环模拟,也是毫秒级能完成的。
性能瓶颈在于通过 Dom 插入页面,一次性插入 100w 个元素,少说也得一二十秒吧,页面会明显的卡顿。
所以我们要做分部处理,把大任务切分成多个小任务,尽可能的不堵塞 UI 渲染。首先接口做 sql 查询肯定也是要做优化的,要不然也不用都做分页查询,这个我们可以先不去关心,假设后端一次返回 100w 条数据。怎么拆分才能不堵塞 UI 渲染呢,最简单的,用 setTimeout。写 100 个 setTimeout,间隔 10ms,每个 setTimeout 做字符串拼接以及 html 的 append,因为 setTimeout 是异步事件,定时器到时间之后会放到任务队列里,一个任务取出到 JS 线程执行,然后 UI 渲染,因为 JS 跟 UI 渲染是互斥的,任务队列无法入 JS 主线程,渲染完之后才取下一个任务。问题是定时器的 10ms 间隔,不一定是准确的,所以无法保证加入任务队列的顺序,所以需要有判断条件。另外,这样看起来至少 1000ms 多能渲染完页面,因为定时器的缘故,所以也不一定是最快的。用
requestidlecallback估计会好一些,在浏览器空闲的时候做渲染,也不用做任务拆分,记住当时渲染到哪就行了。比如:当然上面的代码我也没实践过,感兴趣的同学可以试一下。不过我觉得
setTimeout和requetIdleCallback都可以提升渲染效率,因为浏览器就是你越让他休息好,他就会越快,反之就会堵塞。响应式布局有几种方案
我觉得很多情况下是要多种方案一起用的,很多情况下是互补的,媒体查询是必需的。
1.媒体查询 2.百分百 3.rem 4.vm/vh
Bootstrap 的几个响应式尺寸:
xs(小屏 <576px),sm(≥576px),md(≥768px),lg(≥992px),xl(≥1200px)css 中的 @ 符号
来自 winter 的重学前端中的知识。at-rule 是由一个 @ 关键字和后续的一个区块组成,常见的 at-rule 有,
@media: 媒体查询,设备判断,@import: 引入一个 css 文件,@keyframes:定义动画的关键帧,@fontface:定义一种字体,icon font 就是利用它实现的了解阿里前端的技术栈吗,知道阿里的哪些框架
这个应该都有所了解吧。
说一下微服务
微服务架构将一体化的架构进行拆分,也就是说一个大型的软件应用或者服务,由多个独立的微服务组成。这些服务相互之间不依赖,每个服务只聚焦一件事情,独立开发、部署、扩展伸缩,并且可以由不同的团队维护。比如说滴滴 app 发单使用的背后有很复杂的逻辑,首先是用户中心,分乘客和司机,登录之后才能发单,然后也会有地图服务提供选起止点,发单当然会有匹配算法和调度逻辑的服务来提供,到达目的地之后调用的交易中心,最终完成出行之后数据归到订单中心。独立的好处是,举个栗子,交易中心有独立的收银台服务,假如某一天我突然想做外卖业务了,那我的交易逻辑和匹配逻辑都是可以复用的,减少成本。当然微服务架构也会带来很多问题,因为服务之间相互独立,不可避免存在服务相互调用协作的问题,一旦某个上游服务挂了,怎么才能不影响自己,这都是微服务架构会去解决的,比如说通过服务治理。
ke.com
一面
自我介绍
介绍项目
你们这个脚手架跟 ant-design-pro 的 cli 有什么区别吗
首先 ant-design-pro 的脚手架只能初始化 pro 的项目,我们的脚手架模板可选,比如 react、vue、node、react-library等等的模板,那对于我们也做后台系统相关的项目并且技术栈也是 react+antd,pro 的项目模板有很多组件、文件是我们不需要的,而且 umi 的二次封装,只对开发者暴露配置,也让我们感到没有安全感,这里肯定会踩坑,而且当时有些需求也是不满足的,总之 ant-design-pro 的这个项目模板对我们来说不是很适合,但是我们采用了 ant-design 的 ui 设计以及 pro 里一些优秀的组件。
node 方面(用什么开发、做过哪些积累、做过哪些中间件、进程托管、日志如何管理。)
进程管理是 pm2,日志的话是用 log4js,直接把 log 挂到 koa 的 ctx 上, 对日志进行分级,然后通过 Appender 输出到某个目录下,并接入了公司内部的日志系统,能够在 web 上查看日志,并且接收报警。
dva 的优势
dva 解决了日常使用 redux 的约定、胶水代码多的问题,并且因为 saga 的缘故,可以更好的处理 Effect,dva model 的概念更贴近 mvc 的架构模式中的 m。并且还内置了 react-router,总之是为了简化 react 全家桶、提升开发体验的。
react router 的原理
router 的作用是使 url 和 view 发生绑定,当 url 上的路由改变的时候,view 自动做出改变。
要使 url 变化并且页面不刷新,只能通过 hash 或者 h5 的 history,然后在 url 发生变化的几种情况做监听,再触发事件回调让 react 做出 render 即可。
在一个应用内 url 变化的三种情况以及如何监听:
1.浏览器的回退和前进。hash 通过 onhashchange 事件做监听,history 通过 popstate 事件。
2.点击 a 标签。用 Link 替换 a 标签,然后在 Link 组件内部通过 onClick 实现 url change
3.触发 history.push / replace,即 HTML5 的原生 api。内部实现一个 history 对象,在使用 history.push 的时候去执行回调。
以上算是理论基础。具体的组件实现,以 history 的为例:
BrowserRouter 内部创建一个 history 对象,主要是阻止 a 标签的默认行为,以及监听 popstate(对应回调是 update 所有 Route,即遍历一个数组 instances,这个数组里存了所有 Route 的实例,更新调用 forceUpdate 方法即可)。创建好的 history 对象通过 context 传给 Route 组件,实现其对应的组件内部可以
this.props.historyRoute 就是处理 path 跟组件的映射,如果 match 的上呢就返回
React.createElement,否则就return null。上面提到的 instances 是从每个 Route 里添加的,在 Route 的 WillMount 里 register,添加进数组, UNmount 里删除。Link 组件就是绑定一个 onClick 事件,然后调用 context 传下来的 hisotry 对象中的 push/replace 方法。
react router 如何做性能优化的,每个页面存的 state 过多,占用内存。
还真没遇到过 state 过多导致浏览器卡的情况。
react-router 把路由的 state 信息存到了 sessionStorage,state 就是给每个路由保存的数据,开发者也可以往里面附带各种信息。 storage 快满的时候,getItem 会变慢,导致 Router 也变卡。那我们尽可能的少往 state 里塞数据,尽量通过 store 交互,另外也可以手动清理。
做过哪些性能优化
还是页面优化的几板斧。
1.减少体积。通过 webpack+babel 打包的优化,减小体积。
2.延迟加载(资源的异步加载)
3.网络加速(cdn、dns 预解析、http 并发数)
4.首屏渲染 (ssr、骨架图)
5.利用缓存(http 缓存)
预渲染
Prerender 介于服务端渲染和客户端渲染之间,即请求 html 的时候,html 中就包含首屏的结构。原理是先根据需要预渲染的路由,然后通过 webpack 插件增加预渲染的配置,插件内部通过无头浏览器(比如 phantomjs) 访问并把对应的 html 结构输出,并建立路由对应的目录。
缓存是如何用的
一般是用 http 强缓存,然后可以提一下 http 协商缓存和离线缓存。
cdn 是如何实现加速的
通过 DNS 系统和负载提醒,根据用户访问的 ip 找到最近的缓存服务器,并把网站提供服务器上的资源加载到缓存服务器。主要是减少了跨地域损耗
dns 预解析的方案
react ssr
算法
给一个数组,分成三份,使两两数组间的和差值最小,求差值的和。
二面
三面
kuaishou
敬请期待
tiktok
敬请期待
The text was updated successfully, but these errors were encountered: