LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li at UC Berkeley/UCSF.
Paper | Project Page | HuggingFace Demo (coming soon) | Related Project: LMD | Citation

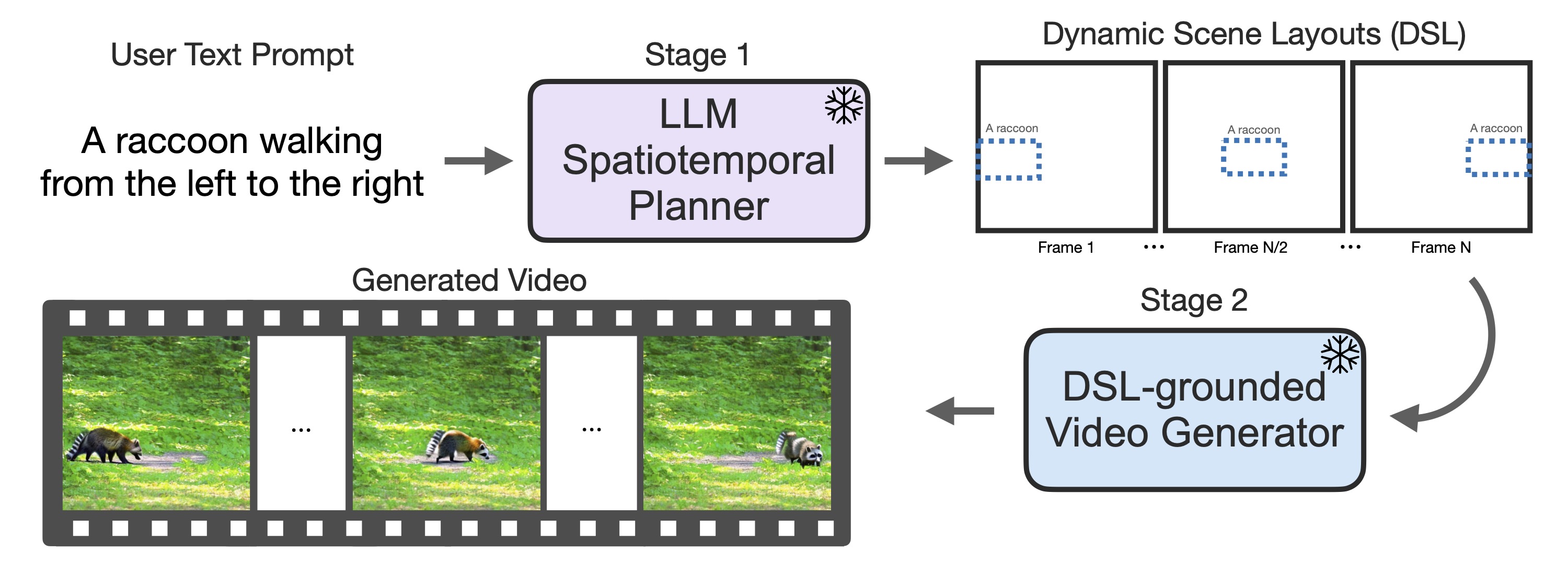
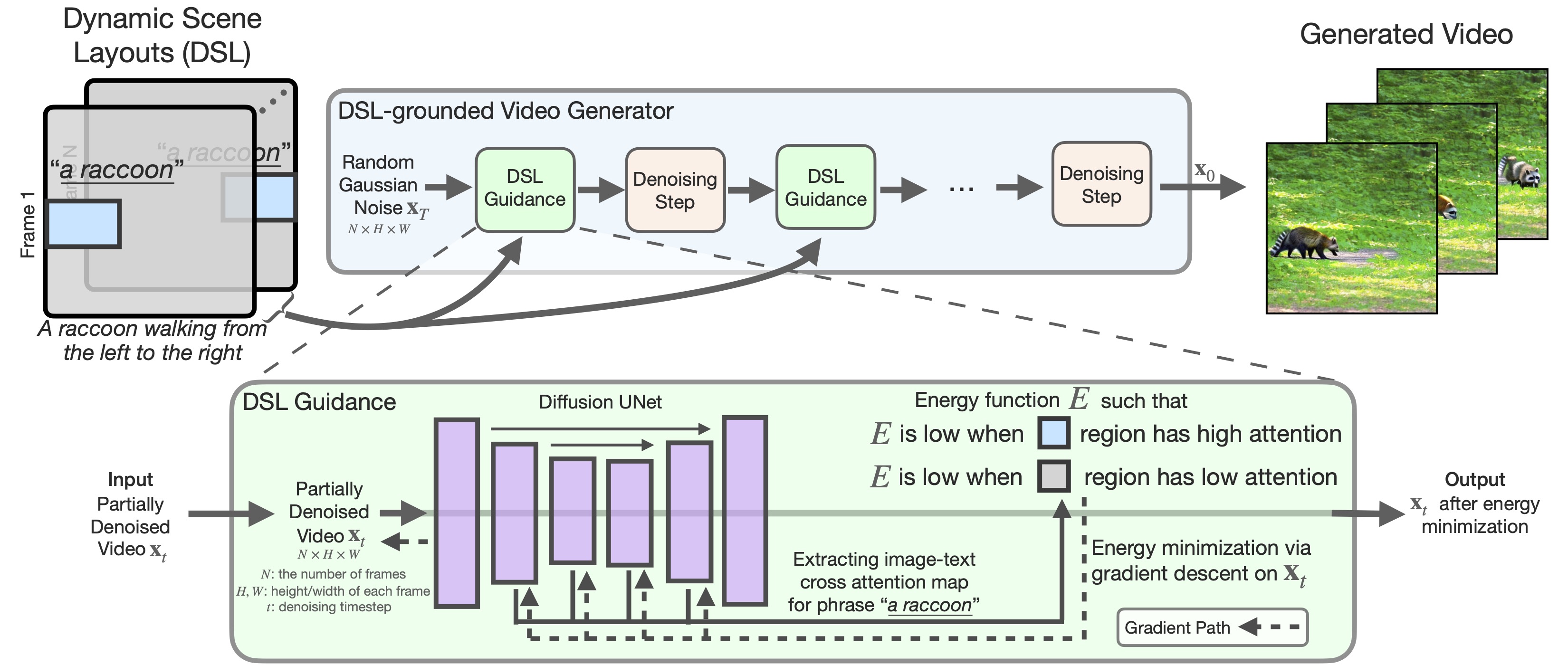
Our DSL-grounded Video Generator:
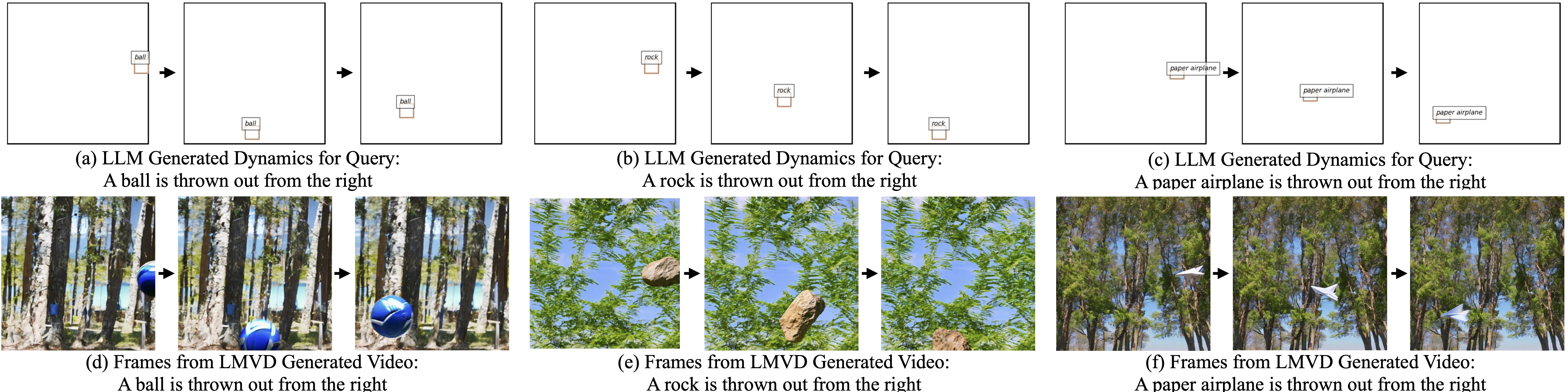
LLM generates dynamic scene layouts, taking the world properties (e.g., gravity, elasticity, air friction) into account:
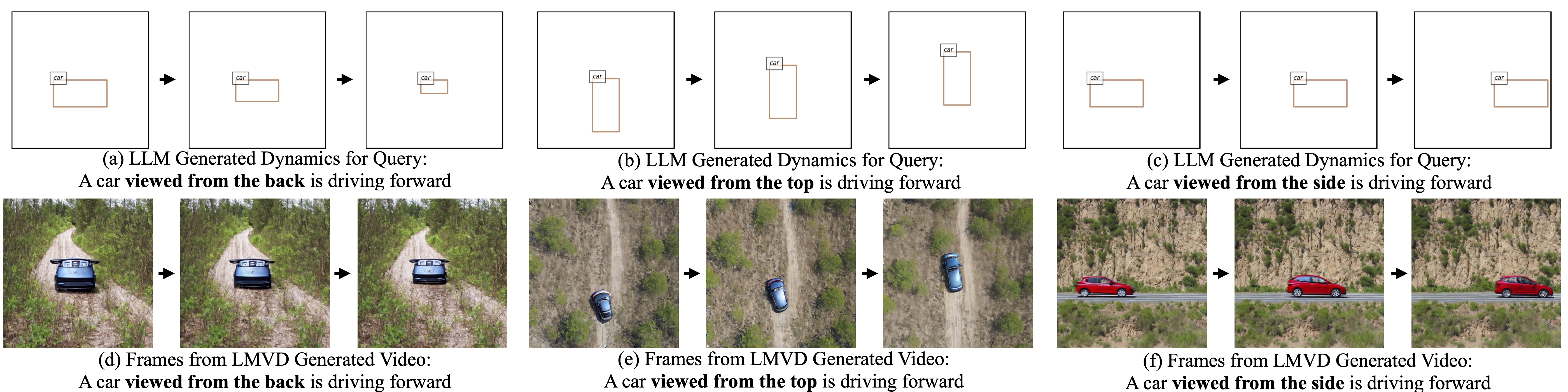
LLM generates dynamic scene layouts, taking the camera properties (e.g., perspective projection) into account:
We propose a benchmark of five tasks. Our method improves on all five tasks without specifically aiming for each one:

The code is coming soon! Meanwhile, give this repo a star to support us!
Please contact Long (Tony) Lian if you have any questions: [email protected].
If you use our work or our implementation in this repo, or find them helpful, please consider giving a citation.
@article{lian2023llmgroundedvideo,
title={LLM-grounded Video Diffusion Models},
author={Lian, Long and Shi, Baifeng and Yala, Adam and Darrell, Trevor and Li, Boyi},
journal={arXiv preprint arXiv:2309.17444},
year={2023},
}
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}