The implementation of Medical Visual Question Answering via Conditional Reasoning [ACM MM 2020]
We evaluate our proposal on VQA-RAD dataset.
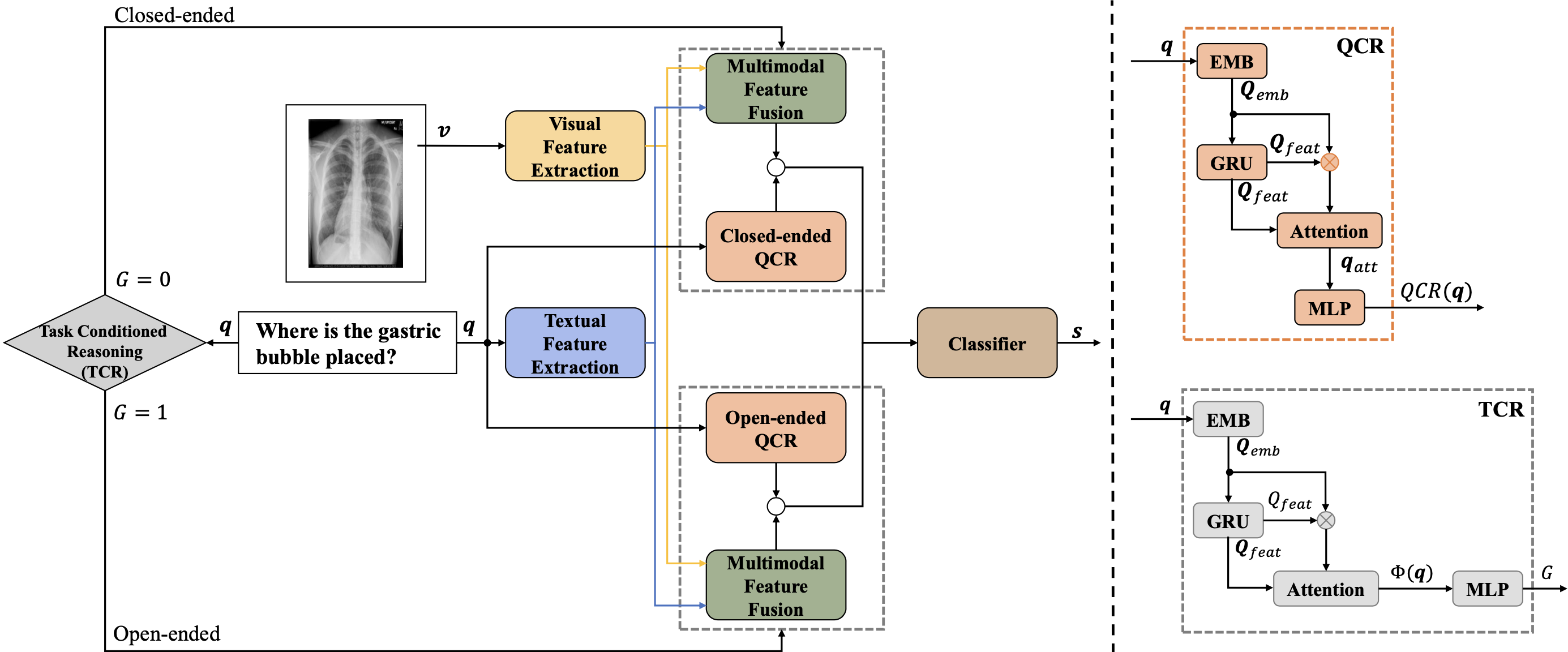
We propose QCR [Question-Conditioned Reasoning Module] and TCR [Type-Conditioned Reasoning] modules, which guide the importance selection over multimodal fusion features and learn different reasoning skills for different types of tasks separately. The detailed architecture is shown in the figure below.
| Overall | Open-ended | Closed-ended | |
|---|---|---|---|
| Base | 66.1 | 49.2 | 77.2 |
| Our proposal | 71.6 | 60.0 | 79.3 |
Our proposal achieves significantly increased accuracy in predicting answers to both closed-ended and open-ended questions, especially for open-ended questions.
pip install -r requirements.txt
All pre-prepared data can be found in data package
git clone https://github.com/Awenbocc/Med-VQA.git
cd ./Med-VQA
python main.py --gpu 0 --seed 88
MIT License
Please cite following in your publications if they help you.
@inproceedings{zhan2020medical,
title={Medical visual question answering via conditional reasoning},
author={Zhan, Li-Ming and Liu, Bo and Fan, Lu and Chen, Jiaxin and Wu, Xiao-Ming},
booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
pages={2345--2354},
year={2020}
}