Add jupyter notebook with common neighbours metric on football dataset #342
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
FYI, Github will actually render a |
devoxel
reviewed
Feb 12, 2019
devoxel
approved these changes
Feb 13, 2019
Closed
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Connects to #304.
This PR implements the common neighbours metric, and runs it on one of the Pajek datasets used in the paper in #313. Included is loading the dataset, computing the similarity matrix, and computing the AUC (area under receiver operating characteristic curve), which is a measure of true positives vs. false positives. The formula to calculate the AUC (based on n1, n2, n3) comes from the same paper mentioned above.
Added in a new
research/directory, which we can use for a lot of non-prod code in future I guess - experiments, explorations, etc.What will be required in the actual implementation of this metric in Rabble is a microservice including the computation of a similarity matrix, with some extra bits for eg. updating the matrix regularly (as our follow graph changes), an API for actually getting recommendations from the similarity matrix (ie. return some number of
js whereS[i][j]is maximal for some giveni), and maybe a slightly different accuracy measurement, depending on how easy it is to apply AUC to our own database. Some of the code here might be replicated there later, IDK for sure.Our results in this notebook:
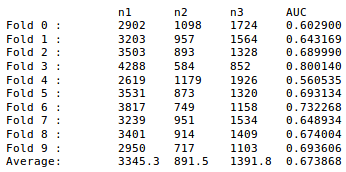
vs. the paper's results with this metric on the same dataset:

Compare the
Averagerow of our output with the[n1 n2 n3 AUC]in theAveragecolumn from the paper.