The following code has as main objective to obtain video-action features using pretrained models from the PySlowFast and TSN,TSM framework. The code provided here focuses on obtaining features offline using the Decord library.
The logic used for the extraction of features is generating an output prior to the head of each model arranged in the framework. We obtain for each architecture a temporal component referring to each time segment.
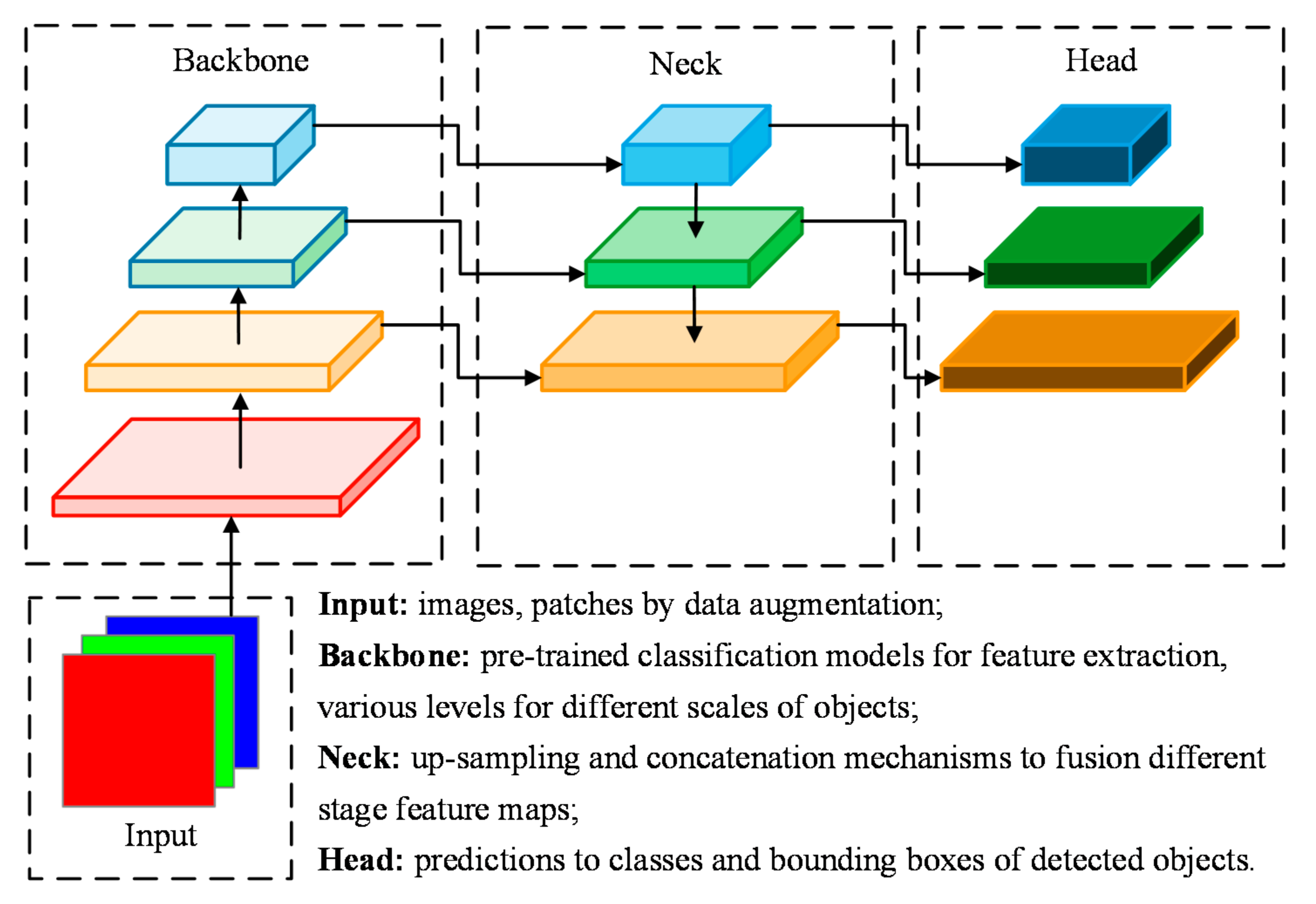
If you want to use the code read the "installation" and "How to use" section. For the execution of the script it is necessary to set/define in the configuration file some relevant inputs for each model.
Pretrained models with varying sampling rates are employed to extract features. This approach ensures that frames are iteratively processed while adhering to the frame rate of each respective model. In cases where videos possess a frame count that doesn't align with the frame rate of the models, the final bucket is populated by sampling the last frames to preserve the temporal information.

As illustrated in figure below, encoding a video introduces a change in temporal representation due to the processing in buckets of size

To install and run the current code, you must install the pySlowFast framework. In other hand, you must install:
pip install scipy
pip install moviepy
pip install decord
Note: Sometimes moviepy may give some problems to execute the code, in that case please try this:
pip uninstall moviepy
pip install moviepyTo execute the code see the following instructions, in HOWTOUSE.md you will find the execution script for each supported model (see supported models here) and in checkpoints you will find the different models pretrained by Meta.
To load weights for Resnet, SlowFast and MViT models, use the following weights.
Due to the size of the features, they will be uploaded as soon as possible.
If you use our code please consider citing our work:
@INPROCEEDINGS{10350366,
author={De La Jara, Ignacio M. and Rodriguez-Opazo, Cristian and Marrese-Taylor, Edison and Bravo-Marquez, Felipe},
booktitle={2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)},
title={An empirical study of the effect of video encoders on Temporal Video Grounding},
year={2023},
volume={},
number={},
pages={2842-2847},
keywords={Location awareness;Computer vision;Grounding;Conferences;Natural languages;Computer architecture;Complex networks;Temporal video grounding;computer vision;benchmark;features;action classification;video encoder},
doi={10.1109/ICCVW60793.2023.00306}}