[Hackathon 6th Code Camp No.15] support neuraloperator docs #917
Conversation
…/PaddleScience into add_neuraloperator
… into add_neuraloperator
…/PaddleScience into add_neuraloperator
…/PaddleScience into add_neuraloperator
…/PaddleScience into add_neuraloperator
…/PaddleScience into add_neuraloperator
…/PaddleScience into add_neuraloperator
|
Thanks for your contribution! |
docs/zh/examples/neuraloperator.md
Outdated
| | [sfno 模型]() | 1.01075 | 2.33481 | | ||
|
|
||
| ## 1. 背景简介 | ||
| 许多科学和工程问题涉及反复求解复杂的偏微分方程 (PDE) 系统,以获取某些参数的不同值。例如分子动力学、微力学和湍流流动。通常这样的系统需要精细的离散化才能捕捉所模拟的现象。因此,传统数值求解器速度慢,有时效率低下。机器学习方法可能通过提供快速的求解器来革新科学领域,这些求解器可以近似或增强传统求解器。然而,经典神经网络在有限维空间之间进行映射,因此只能学习与特定离散化相关的解决方案。这通常是实际应用中的一个限制,因此需要开发与网格无关的神经网络。最近,一项新的工作提出了用神经网络学习无网格、无限维算子。神经算子通过产生一组用于不同离散化、且与网格无关的参数,来弥补有限维算子方法中网格依赖性的问题。 neuraloperator 通过直接在傅里叶空间 (Fourier space) 中参数化 (parameterize) 积分核 (integral kernel) 来制定一个新的神经算子,从而实现了富有表现力和高效的架构。论文对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验。傅里叶神经算子是第一个基于机器学习的方法,成功地用零样本超分辨率模拟湍流。与传统 PDE 求解器相比,它快达三个数量级。 |
There was a problem hiding this comment.
多加了一个空格
| 许多科学和工程问题涉及反复求解复杂的偏微分方程 (PDE) 系统,以获取某些参数的不同值。例如分子动力学、微力学和湍流流动。通常这样的系统需要精细的离散化才能捕捉所模拟的现象。因此,传统数值求解器速度慢,有时效率低下。机器学习方法可能通过提供快速的求解器来革新科学领域,这些求解器可以近似或增强传统求解器。然而,经典神经网络在有限维空间之间进行映射,因此只能学习与特定离散化相关的解决方案。这通常是实际应用中的一个限制,因此需要开发与网格无关的神经网络。最近,一项新的工作提出了用神经网络学习无网格、无限维算子。神经算子通过产生一组用于不同离散化、且与网格无关的参数,来弥补有限维算子方法中网格依赖性的问题。 neuraloperator 通过直接在傅里叶空间 (Fourier space) 中参数化 (parameterize) 积分核 (integral kernel) 来制定一个新的神经算子,从而实现了富有表现力和高效的架构。论文对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验。傅里叶神经算子是第一个基于机器学习的方法,成功地用零样本超分辨率模拟湍流。与传统 PDE 求解器相比,它快达三个数量级。 | |
| 许多科学和工程问题涉及反复求解复杂的偏微分方程 (PDE) 系统,以获取某些参数的不同值。例如分子动力学、微力学和湍流流动。通常这样的系统需要精细的离散化才能捕捉所模拟的现象。因此,传统数值求解器速度慢,有时效率低下。机器学习方法可能通过提供快速的求解器来革新科学领域,这些求解器可以近似或增强传统求解器。然而,经典神经网络在有限维空间之间进行映射,因此只能学习与特定离散化相关的解决方案。这通常是实际应用中的一个限制,因此需要开发与网格无关的神经网络。最近,一项新的工作提出了用神经网络学习无网格、无限维算子。神经算子通过产生一组用于不同离散化、且与网格无关的参数,来弥补有限维算子方法中网格依赖性的问题。 neuraloperator 通过直接在傅里叶空间 (Fourier space) 中参数化 (parameterize) 积分核 (integral kernel) 来制定一个新的神经算子,从而实现了富有表现力和高效的架构。论文对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验。傅里叶神经算子是第一个基于机器学习的方法,成功地用零样本超分辨率模拟湍流。与传统 PDE 求解器相比,它快达三个数量级。 |
docs/zh/examples/neuraloperator.md
Outdated
| 许多科学和工程问题涉及反复求解复杂的偏微分方程 (PDE) 系统,以获取某些参数的不同值。例如分子动力学、微力学和湍流流动。通常这样的系统需要精细的离散化才能捕捉所模拟的现象。因此,传统数值求解器速度慢,有时效率低下。机器学习方法可能通过提供快速的求解器来革新科学领域,这些求解器可以近似或增强传统求解器。然而,经典神经网络在有限维空间之间进行映射,因此只能学习与特定离散化相关的解决方案。这通常是实际应用中的一个限制,因此需要开发与网格无关的神经网络。最近,一项新的工作提出了用神经网络学习无网格、无限维算子。神经算子通过产生一组用于不同离散化、且与网格无关的参数,来弥补有限维算子方法中网格依赖性的问题。 neuraloperator 通过直接在傅里叶空间 (Fourier space) 中参数化 (parameterize) 积分核 (integral kernel) 来制定一个新的神经算子,从而实现了富有表现力和高效的架构。论文对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验。傅里叶神经算子是第一个基于机器学习的方法,成功地用零样本超分辨率模拟湍流。与传统 PDE 求解器相比,它快达三个数量级。 | ||
| ## 2. 模型原理 | ||
| 本章节仅对 NeuralOperator 的模型原理进行简单地介绍,详细的理论推导请阅读 | ||
| [Fourier Neural Operator for Parametric Partial Differential Equations](https://arxiv.org/abs/2010.08895)。 |
docs/zh/examples/neuraloperator.md
Outdated
|
|
||
| | 模型 | 32x64_l2 | 64x128_l2 | | ||
| | :-- | :-- | :-- | | ||
| | [sfno 模型]() | 1.01075 | 2.33481 | |
There was a problem hiding this comment.
更新模型和数据集下载链接,更新完之后三个模型的训练、推理、导出等流程跑一遍,保证使用上述提供的命令能够完成该案例。
模型:
sfno模型:https://paddle-org.bj.bcebos.com/paddlescience/models/neuraloperator/neuraloperator_sfno.pdparams
tfno模型:https://paddle-org.bj.bcebos.com/paddlescience/models/neuraloperator/neuraloperator_tfno.pdparams
uno模型:https://paddle-org.bj.bcebos.com/paddlescience/models/neuraloperator/neuraloperator_uno.pdparams
数据集:
darcy_flow:
https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_test_16.npy
https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_test_32.npy
https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_train_16.npy
swe:
https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/test_SWE_32x64.npy
https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/test_SWE_64x128.npy
https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/train_SWE_32x64.npy
docs/zh/examples/neuraloperator.md
Outdated
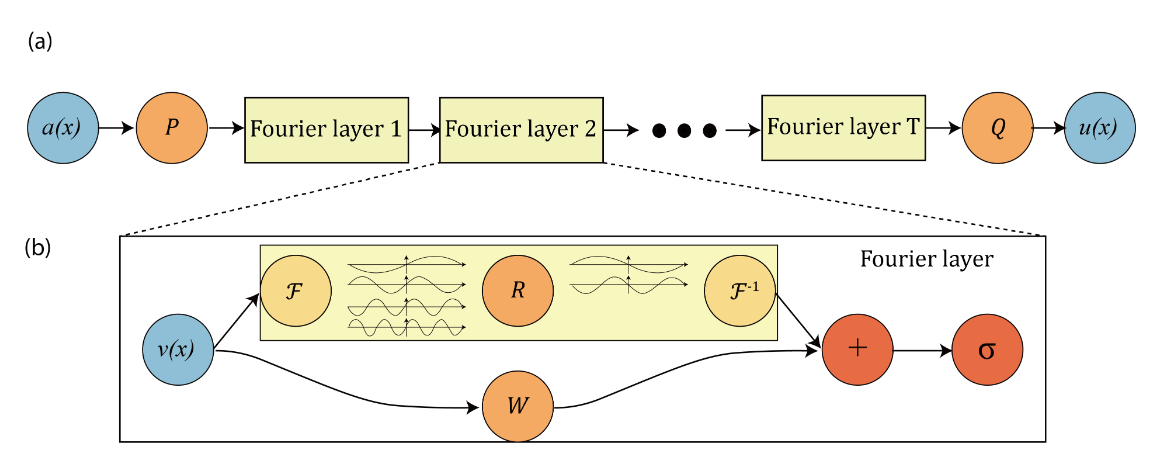
| 模型的总体结构如图所示: | ||
|
|
||
| <figure markdown> | ||
| { loading=lazy style="margin:0 auto"} |
There was a problem hiding this comment.
{kind=link}
docs/zh/examples/neuraloperator.md
Outdated
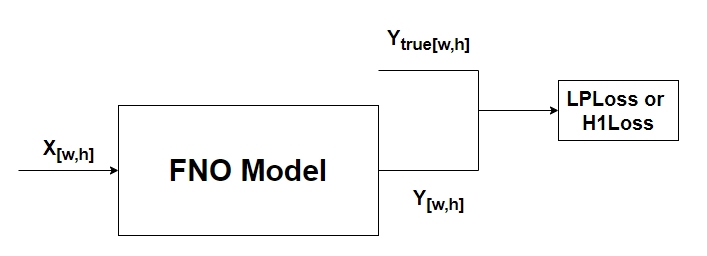
| 模型预训练阶段是基于随机初始化的网络权重对模型进行训练,如下图所示,其中 $X_[w,h]$ 表示大小为 $w*h$ 的二维偏微分数据,$Y_[w,h]$ 表示预测的大小为 $w*h$ 的二维偏微分方程数值解,$Y_{true[w,h]}$ 表示真实二维偏微分方程数值解。最后网络模型预测的输出和真值计算 LpLoss 或者 H1 损失函数。 | ||
|
|
||
| <figure markdown> | ||
| { loading=lazy style="margin:0 auto;height:70%;width:70%"} |
There was a problem hiding this comment.
{kind=link}
docs/zh/examples/neuraloperator.md
Outdated
| 在推理阶段,给定大小为 $w*h$ 的二维偏微分数据,预测得到大小为 $w*h$ 的二维偏微分方程数值解。 | ||
|
|
||
| <figure markdown> | ||
| { loading=lazy style="margin:0 auto;height:60%;width:60%"} |
There was a problem hiding this comment.
{kind=link}
docs/zh/examples/neuraloperator.md
Outdated
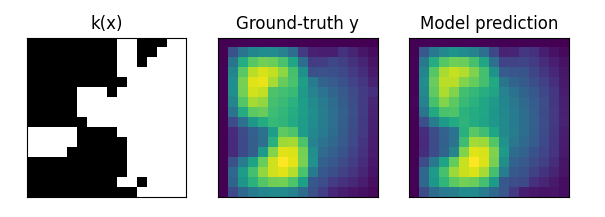
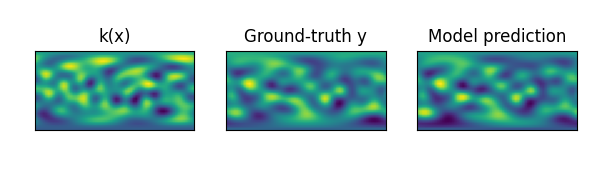
| k(x) 的黑色区域就是可以渗透的地方,白色为不可渗透的区域。右侧是目标结果,颜色越亮,压力越大。 | ||
|
|
||
| <figure markdown> | ||
| { loading=lazy style="margin:0 auto;height:100%;width:100%"} |
There was a problem hiding this comment.
{kind=link}
docs/zh/examples/neuraloperator.md
Outdated
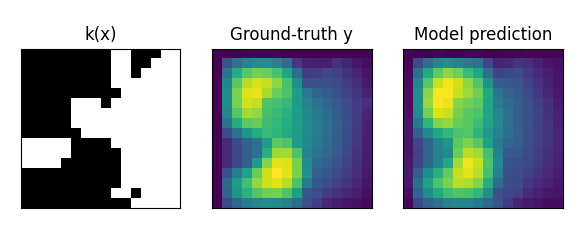
| 下图展示了 UNO 对 Darcy-flow 数据的预测结果和真值结果。 | ||
|
|
||
| <figure markdown> | ||
| { loading=lazy style="margin:0 auto;height:100%;width:100%"} |
There was a problem hiding this comment.
{kind=link}
docs/zh/examples/neuraloperator.md
Outdated
| 下图展示了 SFNO 对 SWE 数据的预测结果和真值结果。 | ||
|
|
||
| <figure markdown> | ||
| { loading=lazy style="margin:0 auto;height:100%;width:100%"} |
There was a problem hiding this comment.
{kind=link}
There was a problem hiding this comment.
图片也上传了,更新后预览看一下,保证图片大小合适
|
|
||
| === "模型训练命令" | ||
|
|
||
| ``` sh |
There was a problem hiding this comment.
训练数据集的下载辛苦按照这个格式命令下载。
# linux
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/DeepONet/antiderivative_unaligned_train.npz
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/DeepONet/antiderivative_unaligned_test.npz
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/deeponet/antiderivative_unaligned_train.npz -o antiderivative_unaligned_train.npz
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/deeponet/antiderivative_unaligned_test.npz -o antiderivative_unaligned_test.npz
python deeponet.py| python examples/neuraloperator/train_tfno.py mode=eval | ||
| # uno 模型评估 | ||
| python examples/neuraloperator/train_uno.py mode=eval | ||
| ``` |
There was a problem hiding this comment.
模型评估辛苦按照下面的格式下载数据集和模型权重,将模型权重放到EVAL.pretrained_model_path参数下
# linux
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/DeepONet/antiderivative_unaligned_train.npz
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/DeepONet/antiderivative_unaligned_test.npz
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/deeponet/antiderivative_unaligned_train.npz -o antiderivative_unaligned_train.npz
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/deeponet/antiderivative_unaligned_test.npz -o antiderivative_unaligned_test.npz
python deeponet.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/deeponet/deeponet_pretrained.pdparams
docs/zh/examples/neuraloperator.md
Outdated
| | [sfno 模型](https://paddle-org.bj.bcebos.com/paddlescience/models/neuraloperator/neuraloperator_sfno.pdparams) | 1.01075 | 2.33481 | | ||
|
|
||
| ## 1. 背景简介 | ||
| 许多科学和工程问题涉及反复求解复杂的偏微分方程 (PDE) 系统,以获取某些参数的不同值。例如分子动力学、微力学和湍流流动。通常这样的系统需要精细的离散化才能捕捉所模拟的现象。因此,传统数值求解器速度慢,有时效率低下。机器学习方法可能通过提供快速的求解器来革新科学领域,这些求解器可以近似或增强传统求解器。然而,经典神经网络在有限维空间之间进行映射,因此只能学习与特定离散化相关的解决方案。这通常是实际应用中的一个限制,因此需要开发与网格无关的神经网络。最近,一项新的工作提出了用神经网络学习无网格、无限维算子。神经算子通过产生一组用于不同离散化、且与网格无关的参数,来弥补有限维算子方法中网格依赖性的问题。 Neuraloperator 通过直接在傅里叶空间 (Fourier space) 中参数化 (parameterize) 积分核 (integral kernel) 来制定一个新的神经算子,从而实现了富有表现力和高效的架构。论文对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验。傅里叶神经算子是第一个基于机器学习的方法,成功地用零样本超分辨率模拟湍流。与传统 PDE 求解器相比,它快达三个数量级。 |
There was a problem hiding this comment.
| 许多科学和工程问题涉及反复求解复杂的偏微分方程 (PDE) 系统,以获取某些参数的不同值。例如分子动力学、微力学和湍流流动。通常这样的系统需要精细的离散化才能捕捉所模拟的现象。因此,传统数值求解器速度慢,有时效率低下。机器学习方法可能通过提供快速的求解器来革新科学领域,这些求解器可以近似或增强传统求解器。然而,经典神经网络在有限维空间之间进行映射,因此只能学习与特定离散化相关的解决方案。这通常是实际应用中的一个限制,因此需要开发与网格无关的神经网络。最近,一项新的工作提出了用神经网络学习无网格、无限维算子。神经算子通过产生一组用于不同离散化、且与网格无关的参数,来弥补有限维算子方法中网格依赖性的问题。 Neuraloperator 通过直接在傅里叶空间 (Fourier space) 中参数化 (parameterize) 积分核 (integral kernel) 来制定一个新的神经算子,从而实现了富有表现力和高效的架构。论文对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验。傅里叶神经算子是第一个基于机器学习的方法,成功地用零样本超分辨率模拟湍流。与传统 PDE 求解器相比,它快达三个数量级。 | |
| 许多科学和工程问题,如分子动力学、微力学和湍流流动,都需要反复求解复杂的偏微分方程(PDE)系统,以便获取某些参数的不同值。为了准确捕捉所模拟的现象,这些系统通常需要进行精细的离散化。然而,这也导致了传统数值求解器运行缓慢,有时甚至效率低下。在这种情况下,机器学习方法有望通过提供快速求解器来革新科学领域,这些求解器能够近似或增强传统方法。但值得注意的是,经典神经网络是在有限维空间之间进行映射,因此它们只能学习与特定离散化相关的解决方案,这在实际应用中是一个限制。为了克服这一限制,最近的一项新研究提出了使用神经网络来学习无网格、无限维的算子。这种神经算子通过生成一组用于不同离散化且与网格无关的参数,解决了有限维算子方法中的网格依赖性问题。该研究通过直接在傅里叶空间中参数化积分核,制定了一个新的神经算子,从而创建了一个富有表现力和高效的架构。论文中对 Burgers 方程、Darcy 流和 Navier-Stokes 方程进行了实验验证。值得一提的是,傅里叶神经算子作为首个基于机器学习的方法,成功地以零样本超分辨率模拟了湍流,其速度比传统PDE求解器快达三个数量级。 |
docs/zh/examples/neuraloperator.md
Outdated
|
|
||
| ### 2.1 模型训练、推理过程 | ||
|
|
||
| 模型预训练阶段是基于随机初始化的网络权重对模型进行训练,如下图所示,其中 $X_[w,h]$ 表示大小为 $w*h$ 的二维偏微分数据,$Y_[w,h]$ 表示预测的大小为 $w*h$ 的二维偏微分方程数值解,$Y_{true[w,h]}$ 表示真实二维偏微分方程数值解。最后网络模型预测的输出和真值计算 LpLoss 或者 H1 损失函数。 |
There was a problem hiding this comment.
| 模型预训练阶段是基于随机初始化的网络权重对模型进行训练,如下图所示,其中 $X_[w,h]$ 表示大小为 $w*h$ 的二维偏微分数据,$Y_[w,h]$ 表示预测的大小为 $w*h$ 的二维偏微分方程数值解,$Y_{true[w,h]}$ 表示真实二维偏微分方程数值解。最后网络模型预测的输出和真值计算 LpLoss 或者 H1 损失函数。 | |
| 模型预训练阶段是基于随机初始化的网络权重对模型进行训练,如下图所示,其中 $X_{[w,h]}$ 表示大小为 $w*h$ 的二维偏微分数据,$Y_{[w,h]}$ 表示预测的大小为 $w*h$ 的二维偏微分方程数值解,$Y_{true[w,h]}$ 表示真实二维偏微分方程数值解。最后网络模型预测的输出和真值计算 LpLoss 或者 H1 损失函数。 |
… into add_neuraloperator
docs/zh/examples/neuraloperator.md
Outdated
| ``` sh | ||
| # darcy-flow 数据集下载 | ||
| # linux | ||
| wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_train_16.npy |
There was a problem hiding this comment.
保证用户下载完成数据后能够直接运行代码,按照config配置添加数据保存路径
| wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_train_16.npy | |
| wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_train_16.npy -P ./datasets/darcyflow/ |
docs/zh/examples/neuraloperator.md
Outdated
| # uno 模型训练 | ||
| python examples/neuraloperator/train_uno.py | ||
|
|
||
| # SEVIR 数据集下载 |
docs/zh/examples/neuraloperator.md
Outdated
| # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_test_32.npy -o darcy_test_32.npy | ||
| # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_test_16.npy -o darcy_test_16.npy | ||
| # tfno 模型训练 | ||
| python examples/neuraloperator/train_tfno.py |
There was a problem hiding this comment.
默认用户在neuraloperator目录下,因此 python train_tfno.py 即可。其他运行命令也修改下
docs/zh/examples/neuraloperator.md
Outdated
|
|
||
| # SEVIR 数据集下载 | ||
| # linux | ||
| wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/train_SWE_32x64.npy |
There was a problem hiding this comment.
| wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/train_SWE_32x64.npy | |
| wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/train_SWE_32x64.npy -P ./datasets/SWE/ |
docs/zh/examples/neuraloperator.md
Outdated
| # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/SWE_data/test_SWE_32x64.npy -o test_SWE_32x64.npy | ||
|
|
||
| # sfno 模型训练 | ||
| python examples/neuraloperator/train_sfno.py |
There was a problem hiding this comment.
sfno模型训练报错,请检查一下。paddle develop版本
There was a problem hiding this comment.
请问报什么错呢,我这边可以正常训练,直接拉取的develop版本的paddlescience版本,paddle develop版本

docs/zh/examples/neuraloperator.md
Outdated
| # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_test_32.npy -o darcy_test_32.npy | ||
| # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/neuraloperator/darcy_flow/darcy_test_16.npy -o darcy_test_16.npy | ||
| # tfno 模型评估 | ||
| python examples/neuraloperator/train_tfno.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/neuraloperator/neuraloperator_tfno.pdparams |
There was a problem hiding this comment.
把 examples/neuraloperator/ 去掉吧,其他的命令也类似改下
… into add_neuraloperator
…/PaddleScience into add_neuraloperator
docs/zh/examples/neuraloperator.md
Outdated
| # uno 模型评估 | ||
| python train_uno.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/neuraloperator/neuraloperator_uno.pdparams | ||
|
|
||
| # SEVIR 数据集下载 |
…ddle#917) * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator * add-neuraloperator-doc * add-neuraloperator-doc * move-paddle-harmonics * add-neuraloperator-doc * add-neuraloperator-doc * add-neuraloperator-doc * add-neuraloperator-doc * add-neuraloperator-doc * add-neuraloperator-doc * add-neuraloperator-docs * add-neuraloperator-docs * add-neuraloperator-docs * add-neuraloperator-doc * add-neuraloperator-doc
PR types
Others
PR changes
Docs
Describe
add neuraloperator