Welcome to the GitHub repository for the Interactive Website Chatbot!🚀 This project showcases a robust chatbot application that interacts with websites to extract and present information dynamically. The solution combines the power of LangChain with a Streamlit-based user interface for seamless and interactive user experiences.
- Website Interaction: Utilizing the latest version of LangChain, this chatbot can seamlessly extract and leverage information from a variety of websites.
- Integration with Large Language Models: The chatbot is compatible with advanced models like GPT-4, Mistral, Llama2, and ollama. The default configuration uses GPT-3.5, however, you can easily switch to other models as needed.
- Streamlit GUI: Features a clean and intuitive user interface crafted with Streamlit, suitable for users of all technical backgrounds.
- Python-based Framework: Fully implemented in Python for ease of use and customization.
- Query Submission: The user submits a query or question to the RAG system.
- Information Retrieval: The IR component searches a database or knowledge source to retrieve relevant documents, passages, or information related to the query. [3]
- Context Integration: The retrieved information is then provided as additional context to the LLM, along with the original query. [1]
- Response Generation: The LLM generates a response by considering both the query and the retrieved context, allowing it to produce more accurate, up-to-date, and relevant answers. [4]
- User Presentation: The generated response is presented to the user, often with citations or references to the sources used from the retrieved information. [3]
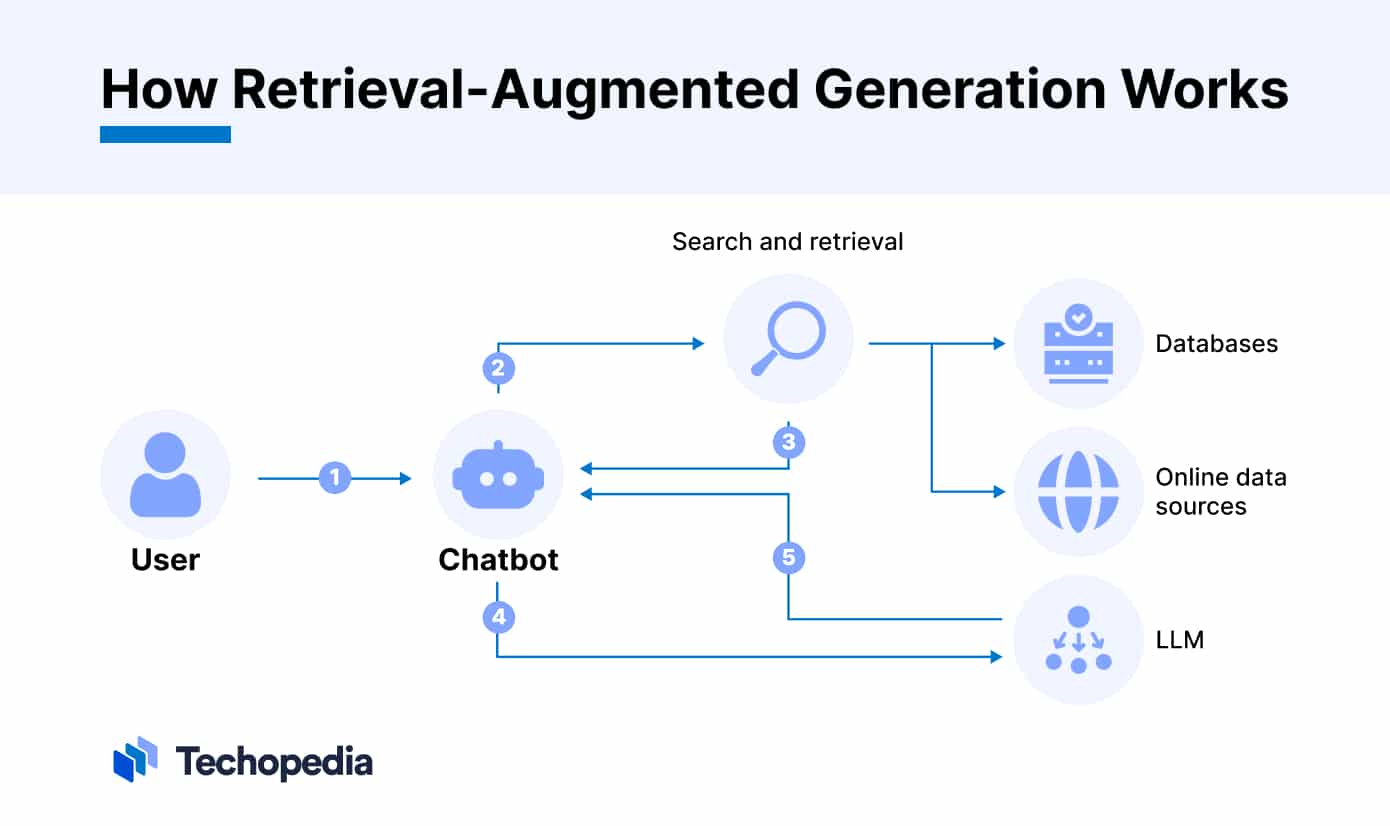
In essence, RAG combines the generative power of LLMs with the ability to dynamically access and incorporate external knowledge sources. [2] This approach addresses the limitations of LLMs, such as knowledge cutoff dates and lack of domain-specific or real-time information, by augmenting them with relevant data from external sources. [4][1]
The key steps involve parsing the query, retrieving relevant information (often using vector embeddings and semantic search), providing the retrieved context to the LLM, and generating a response that integrates the external knowledge with the LLM's capabilities. [3][5]
- [1] Telnyx: What is Retrieval Augmented Generation (RAG)?
- [2] Veritas AI Group: What is Retrieval-Augmented Generation or RAG?
- [3] Pinecone: Retrieval-Augmented Generation
- [4] SuperAnnotate: RAG Explained
- [5] Reddit MLQuestions: How does Retrieval-Augmented Generation (RAG) work?

The image above shows the user interface of this Interactive Website Chatbot with the URL 'https://en.wikipedia.org/wiki/2024_United_States_presidential_election' entered in the sidebar. Despite using GPT-3.5, which does not contain this latest information in its training data, the chatbot can display current information by retrieving data directly from the specified URL.
Ensure you have Python installed on your system. Then clone this repository:
git clone [repository-link]
cd [repository-directory]Install the required packages:
pip install -r requirements.txtCreate your own .env file with the following variables:
OPENAI_API_KEY=[your-openai-api-key]To run the Streamlit app:
streamlit run app.pyI would like to express my gratitude to the creators of the original Interactive Website Chatbot project. Their detailed explanations and demonstrations on YouTube provided the foundation for this project. Their insights into Retrieval-Augmented Generation and Streamlit integration have been invaluable.
This project is licensed under the MIT License - see the LICENSE file for details.
Thank you for visiting this project! If you find it useful, please consider starring it on GitHub.❤️🚀🚀