The main aim of the pander R package is to provide a minimal and easy tool for rendering R objects into Pandoc's markdown. The package is also capable of exporting/converting complex Pandoc documents (reports) in various ways. Regarding the difference between pander and other packages for exporting R objects to different file formats, please refer to this section.
Current build and test coverage status: 

Some CRAN statistics:
The stable version can be installed easily in the
R console like any other package:
install.packages('pander')On the other hand, I welcome everyone to use the most recent version of the package with quick-fixes, new features and probably new bugs. It's currently hosted on GitHub. To get the latest development version from GitHub of the devtools package from CRAN:
devtools::install_github('Rapporter/pander')Few cool packages from CRAN are needed for installing and/or using pander:
And there are also a few optional suggested or supported R packages, such as:
- sylly to use hyphenation when splitting large table cells,
- lattice and ggplot2 for unified plot theme,
- logger for logging capabilities inside
evals, - survival, microbenchmark, zoo, nlme, descr, MASS, tables, reshape, memisc, Epi, randomForest, tseries, rms packages include some supported R classes,
- and pander can be also very useful inside of knitr. More information about how to use pander and knitr can be found specialized vignette, which can be accessed by
vignette('knitr', package = 'pander')or available online here.
pander heavily builds on Pandoc, which should be pre-installed before trying to convert your reports to different formats. Although main functions work without Pandoc, e.g. you can transform R objects into markdown or generate a markdown formatted report via Pandoc.brew or the custom reference class, but installing that great piece of software is suggested if you want to convert markdown to PDF/docx/HTML or other formats.
Starting v0.98.932 RStudio comes with a bundled Pandoc binary, so one can save the tedious steps of installing Pandoc.
If you do not have RStudio installed, please refer to the installation process of Pandoc, which is quite straightforward on most-popular operating systems: download and run the binary (a few megabytes), and get a full-blown document converter in a few seconds/minutes. On some Linux distributions, it might be a bit more complicated (as repositories tend to provide out-dated versions of Pandoc, so you would need cabal-install to install from sources). Please do not forget to restart your R session to update your PATH after installation!
The package contains numerous helper functions, which render user specified inputs in Pandoc's markdown format or apply some extra formatting on it. All Pandoc-related functions' names are starting with pandoc. For example pandoc.table is used for rendering tables in markdown. For a technical documentation, see the HTML help files of the package at Rdocumentation.
All pandoc functions generally prints to console and do not return anything by default. If you want the opposite, to get markdown in a string, call each function ending in .return, for example pandoc.table.return. For more details, please see the official documentation in e.g. ?pandoc.strong.
The full list of currently available primitive Pandoc-related functions are:
- pandoc.indent
- pandoc.p
- pandoc.strong
- pandoc.emphasis
- pandoc.strikeout
- pandoc.verbatim
- pandoc.link
- pandoc.image
- pandoc.date
- pandoc.formula
- pandoc.footnote
- pandoc.horizontal.rule
- pandoc.header
- pandoc.title
For example there is a helper function rendering R lists into markdown:
> l <- list(
+ "First list element",
+ paste0(1:5, '. subelement'),
+ "Second element",
+ list('F', 'B', 'I', c('phone', 'pad', 'talics')))
> pandoc.list(l, 'roman')Which command produces the following output:
I. First list element
I. 1. subelement
II. 2. subelement
III. 3. subelement
IV. 4. subelement
V. 5. subelement
II. Second element
I. F
II. B
III. I
I. phone
II. pad
III. talics
<!-- end of list -->
One of the most popular feature in pander is pandoc.table, rendering most tabular R objects into markdown tables with various options and settings (e.g. style, caption, cell highlighting, cell alignment, width). This section aims to provide quick introduction to most common options, but for more usage/implementation details and examples, please refer to specialized vignette, which can be accessed by vignette('pandoc_table') or available online here.
Let's start with a small example:
> pandoc.table(mtcars[1:3, 1:4])Which command produces the following output by default:
-------------------------------------------
mpg cyl disp hp
------------------- ----- ----- ------ ----
**Mazda RX4** 21 6 160 110
**Mazda RX4 Wag** 21 6 160 110
**Datsun 710** 22.8 4 108 93
-------------------------------------------
Please note that all below features are also supported by the more concise pander generic S3 method!
All four Pandoc formats are supported by pander. From those (multiline, simple, grid, pipe/rmarkdown), I'd suggest sticking to the default multiline format with the most features, except when using rmarkdown v1.0 or jupyter notebook, where multiline is not supported (for this end the default table format is rmarkdown when pander is called inside of a jupyter notebook). Please see a few examples below:
The default style is the multiline format (except for calling pander inside of a of a jupyter notebook) as most features (e.g. multi-line cells and alignment) are supported:
> m <- mtcars[1:2, 1:3]
> pandoc.table(m)
--------------------------------------
mpg cyl disp
------------------- ----- ----- ------
**Mazda RX4** 21 6 160
**Mazda RX4 Wag** 21 6 160
--------------------------------------
While simple tables are much more compact, but do not support line breaks in cells:
> pandoc.table(m, style = "simple")
mpg cyl disp
------------------- ----- ----- ------
**Mazda RX4** 21 6 160
**Mazda RX4 Wag** 21 6 160
My personal favorite, the grid format is really handy for emacs users and it does support line breaks inside of cells, but cell alignment is not possible in most parsers:
> pandoc.table(m, style = "grid")
+---------------------+-------+-------+--------+
| | mpg | cyl | disp |
+=====================+=======+=======+========+
| **Mazda RX4** | 21 | 6 | 160 |
+---------------------+-------+-------+--------+
| **Mazda RX4 Wag** | 21 | 6 | 160 |
+---------------------+-------+-------+--------+
And the so called rmarkdown or pipe table format is often used directly with knitr, since it was supporters by the first versions of the markdown package:
> pandoc.table(m, style = "rmarkdown")
| | mpg | cyl | disp |
|:-------------------:|:-----:|:-----:|:------:|
| **Mazda RX4** | 21 | 6 | 160 |
| **Mazda RX4 Wag** | 21 | 6 | 160 |
But once again, you should simply stick to the default multiline table format in most cases. Otherwise, it's wise to update the default table format via panderOptions.
It's really easy to add a caption to a table:
> pandoc.table(m, style = "grid", caption = "Hello caption!")
+---------------------+-------+-------+--------+
| | mpg | cyl | disp |
+=====================+=======+=======+========+
| **Mazda RX4** | 21 | 6 | 160 |
+---------------------+-------+-------+--------+
| **Mazda RX4 Wag** | 21 | 6 | 160 |
+---------------------+-------+-------+--------+
Table: Hello caption!
For more convenient and flexible usage, you might be interested in the special set.caption helper function. Call the function at any time, and the next table or plot will catch up the provided caption:
> set.caption("Hello caption!")
> pandoc.table(m)
--------------------------------------
mpg cyl disp
------------------- ----- ----- ------
**Mazda RX4** 21 6 160
**Mazda RX4 Wag** 21 6 160
--------------------------------------
Table: Hello caption!
Unless permanent option is set for TRUE (by default), caption will be set only for next table. To disable permanently set caption, just call set.caption(NULL) or call set.caption with permanent parameter being set to FALSE.
One of the fanciest features in pander is the ease of highlighting rows, columns or any cells in a table. This is a real markdown feature without custom HTML or LaTeX-only tweaks, so all HTML/PDF/MS Word/OpenOffice etc. formats are supported.
This can be achieved by calling pandoc.table directly and passing any (or more) of the following arguments or calling the R function with the same names before rendering a table with either the pander generic S3 method or via pandoc.table:
- emphasize.italics.rows
- emphasize.italics.cols
- emphasize.italics.cells
- emphasize.strong.rows
- emphasize.strong.cols
- emphasize.strong.cells
- emphasize.verbatim.rows
- emphasize.verbatim.cols
- emphasize.verbatim.cells
The emphasize.italics helpers would turn the affected cells to italic, emphasize.strong would apply a bold style to the cell and emphasize.verbatim would apply a verbatim style to the cell. A cell can be also italic, bold and verbatim at the same time.
Those functions and arguments ending in rows or cols take a vector (like which columns or rows to emphasize in a table), while the cells argument take either a vector (for one dimensional "tables") or an array-like data structure with two columns holding row and column indexes of cells to be emphasized -- just like what which(..., arr.ind = TRUE) returns. A quick-example:
> t <- mtcars[1:3, 1:5]
> emphasize.italics.cols(1)
> emphasize.italics.rows(1)
> emphasize.strong.cells(which(t > 20, arr.ind = TRUE))
> pandoc.table(t)
---------------------------------------------------------------
mpg cyl disp hp drat
------------------- ---------- ----- --------- --------- ------
**Mazda RX4** ***21*** *6* ***160*** ***110*** *3.9*
**Mazda RX4 Wag** ***21*** 6 **160** **110** 3.9
**Datsun 710** ***22.8*** 4 **108** **93** 3.85
---------------------------------------------------------------
For more examples, please see our "Highlight cells in markdown tables" blog post.
You can specify the alignment of the cells (left, right or center/centre) in a table directly by setting the justify parameter:
> pandoc.table(head(iris[,1:3], 2), justify = c('right', 'center', 'left'))
-------------------------------------------
Sepal.Length Sepal.Width Petal.Length
-------------- ------------- --------------
5.1 3.5 1.4
4.9 3 1.4
-------------------------------------------
Or pre-define the alignment for (all future) pandoc.table or the pander S3 generic method by a helper function:
> set.alignment('left', row.names = 'right')
> pandoc.table(mtcars[1:2, 1:5])
--------------------------------------------------
mpg cyl disp hp drat
------------------- ----- ----- ------ ---- ------
**Mazda RX4** 21 6 160 110 3.9
**Mazda RX4 Wag** 21 6 160 110 3.9
--------------------------------------------------
Just like with captions, you can also specify the permanent option to be TRUE to update the default cell alignment for all future tables. And beside using set.alignment helper function or passing parameters directly to pandoc.table, you may also set the default alignment styles with panderOptions.
What's even more fun, you can specify a function that takes the R object as its argument to compute some unique alignment for your table based on e.g. column values or variable types:
> panderOptions('table.alignment.default',
+ function(df)
+ ifelse(sapply(df, mean) > 2, 'left', 'right'))
> pandoc.table(head(iris[,1:3], 2))
-------------------------------------------
Sepal.Length Sepal.Width Petal.Length
-------------- ------------- --------------
5.1 3.5 1.4
4.9 3 1.4
-------------------------------------------
pandoc.table can also deal with the problem of really wide tables. Ever had an issue in LaTeX or MS Word when tried to print a correlation matrix of 40 variables? Not a problem any more as you can split up the table with auto-added captions. The split.table option defaults to 80 characters:
> pandoc.table(mtcars[1:2, ], style = "grid", caption = "Hello caption!")
+---------------------+-------+-------+--------+------+--------+-------+
| | mpg | cyl | disp | hp | drat | wt |
+=====================+=======+=======+========+======+========+=======+
| **Mazda RX4** | 21 | 6 | 160 | 110 | 3.9 | 2.62 |
+---------------------+-------+-------+--------+------+--------+-------+
| **Mazda RX4 Wag** | 21 | 6 | 160 | 110 | 3.9 | 2.875 |
+---------------------+-------+-------+--------+------+--------+-------+
Table: Hello caption! (continued below)
+---------------------+--------+------+------+--------+--------+
| | qsec | vs | am | gear | carb |
+=====================+========+======+======+========+========+
| **Mazda RX4** | 16.46 | 0 | 1 | 4 | 4 |
+---------------------+--------+------+------+--------+--------+
| **Mazda RX4 Wag** | 17.02 | 0 | 1 | 4 | 4 |
+---------------------+--------+------+------+--------+--------+
And too wide cells can also be split by line breaks. The maximum number of characters in a cell is specified by split.cells parameter (default to 30), can be a single value, vector (values for each column separately) and relative vector (percentages of split.tables parameter):
> df <- data.frame(a = 'Lorem ipsum', b = 'dolor sit', c = 'amet')
> pandoc.table(df, split.cells = 5)
----------------
a b c
----- ----- ----
Lorem dolor amet
ipsum sit
----------------
> pandoc.table(df, split.cells = c(5, 20, 5))
--------------------
a b c
----- --------- ----
Lorem dolor sit amet
ipsum
--------------------
> pandoc.table(df, split.cells = c("80%", "10%", "10%"))
----------------------
a b c
----------- ----- ----
Lorem ipsum dolor amet
sit
----------------------
If the sylly package is installed, pandoc.table can even split the cells with hyphening support:
> pandoc.table(data.frame(baz = 'foobar'), use.hyphening = TRUE, split.cells = 3)
-----
baz
-----
foo-
bar
-----
Funtionality described in other sections is most notable, but pander/pandoc.table also has smaller nifty features that are worth mentioning:
plain.ascii- allows to have the output withoutmarkdownmarkup:
> pandoc.table(mtcars[1:3, 1:4])
-------------------------------------------
mpg cyl disp hp
------------------- ----- ----- ------ ----
**Mazda RX4** 21 6 160 110
**Mazda RX4 Wag** 21 6 160 110
**Datsun 710** 22.8 4 108 93
-------------------------------------------
> pandoc.table(mtcars[1:3, 1:4], plain.ascii = TRUE)
-------------------------------------------
mpg cyl disp hp
------------------- ----- ----- ------ ----
Mazda RX4 21 6 160 110
Mazda RX4 Wag 21 6 160 110
Datsun 710 22.8 4 108 93
-------------------------------------------
missing- set a string to replace missing values:
> m <- mtcars[1:3, 1:5]
> m$mpg <- NA
> pandoc.table(m, missing = '?')
--------------------------------------------------
mpg cyl disp hp drat
------------------- ----- ----- ------ ---- ------
**Mazda RX4** ? 6 160 110 3.9
**Mazda RX4 Wag** ? 6 160 110 3.9
**Datsun 710** ? 4 108 93 3.85
--------------------------------------------------
keep.line.breaks- allows to preserve line breaks inside cells. Not that by defaultpandoc.tableautomatically omits all line breaks found in each table cell to be able to apply thetable.splitfunctionality.
> m <- data.frame(a="foo\nbar", b="pander")
> pandoc.table(m)
--------------
a b
------- ------
foo bar pander
--------------
> pandoc.table(m, keep.line.breaks = TRUE)
----------
a b
--- ------
foo pander
bar
----------
To see all possible options, please check ?pandoc.table
And please note, that all above mentioned features are also supported by the pander generic S3 method and defaults can be updated via panderOptions for permanent settings.
pander or pandoc (call as you wish) can deal with a bunch of R object types as being a pandocized S3 generic method with a variety of already supported classes:
> methods(pander)
[1] pander.anova* pander.aov* pander.aovlist* pander.Arima* pander.call*
[6] pander.cast_df* pander.character* pander.clogit* pander.coxph* pander.cph*
[11] pander.CrossTable* pander.data.frame* pander.Date* pander.default* pander.density*
[16] pander.describe* pander.evals* pander.factor* pander.formula* pander.ftable*
[21] pander.function* pander.glm* pander.Glm* pander.gtable* pander.htest*
[26] pander.image* pander.irts* pander.list* pander.lm* pander.lme*
[31] pander.logical* pander.lrm* pander.manova* pander.matrix* pander.microbenchmark*
[36] pander.mtable* pander.name* pander.nls* pander.NULL* pander.numeric*
[41] pander.ols* pander.orm* pander.polr* pander.POSIXct* pander.POSIXlt*
[46] pander.prcomp* pander.randomForest* pander.rapport* pander.rlm* pander.sessionInfo*
[51] pander.smooth.spline* pander.stat.table* pander.summary.aov* pander.summary.aovlist* pander.summary.glm*
[56] pander.summary.lm* pander.summary.lme* pander.summary.manova* pander.summary.nls* pander.summary.polr*
[61] pander.summary.prcomp* pander.summary.rms* pander.summary.survreg* pander.summary.table* pander.survdiff*
[66] pander.survfit* pander.survreg* pander.table* pander.tabular* pander.ts*
[71] pander.zoo*
If you think that pander lacks support for any other R class(es), please feel free to open a ticket suggesting a new feature or submit pull request and we will be happy to extend the package.
Besides the most basic R object types (vectors, matrices, tables or data frames), list-support might be interesting for you:
> pander(list(a = 1, b = 2, c = table(mtcars$am), x = list(myname = 1, 2), 56))
A nested list can be seen above with a table and all (optional) list names. As a matter of fact, pander.list is the default method of pander too, when you call it on an unsupported R object class:
> x <- chisq.test(table(mtcars$am, mtcars$gear))
> class(x) <- "I've never heard of!"
> pander(x)
**WARNING**^[Chi-squared approximation may be incorrect]
* **statistic**:
-----------
X-squared
-----------
20.94
-----------
* **parameter**:
----
df
----
2
----
* **p.value**: _2.831e-05_
* **method**: Pearson's Chi-squared test
* **data.name**: table(mtcars$am, mtcars$gear)
* **observed**:
-------------------
3 4 5
------- --- --- ---
**0** 15 4 0
**1** 0 8 5
-------------------
* **expected**:
-------------------------
3 4 5
------- ----- ----- -----
**0** 8.906 7.125 2.969
**1** 6.094 4.875 2.031
-------------------------
* **residuals**:
----------------------------
3 4 5
------- ------ ------ ------
**0** 2.042 -1.171 -1.723
**1** -2.469 1.415 2.083
----------------------------
* **stdres**:
----------------------------
3 4 5
------- ------ ------ ------
**0** 4.395 -2.323 -2.943
**1** -4.395 2.323 2.943
----------------------------
<!-- end of list -->
So pander showed a not known class in an (almost) user-friendly way. And we got some warnings too styled with Pandoc footnote! If that document is exported to e.g. HTML or pdf, then the error/warning message could be found on the bottom of the page with a link. Note: there were two warnings in the above call - both captured and returned! Well, this is the feature of Pandoc.brew, see below.
But the output of different statistical methods are tried to be prettyfied. Some the above call normally returns like:
> pander(chisq.test(table(mtcars$am, mtcars$gear)))
-------------------------------------
Test statistic df P value
---------------- ---- ---------------
20.94 2 2.831e-05 * * *
-------------------------------------
Table: Pearson's Chi-squared test: `table(mtcars$am, mtcars$gear)`
**WARNING**^[Chi-squared approximation may be incorrect]
A few other examples on the supported R classes:
> pander(t.test(extra ~ group, data = sleep))
---------------------------------------------------------
Test statistic df P value Alternative hypothesis
---------------- ----- --------- ------------------------
-1.861 17.78 0.07939 two.sided
---------------------------------------------------------
Table: Welch Two Sample t-test: `extra` by `group`
> ## Dobson (1990) Page 93: Randomized Controlled Trial (examples from: ?glm)
> counts <- c(18, 17, 15, 20, 10, 20, 25, 13, 12)
> outcome <- gl(3, 1, 9)
> treatment <- gl(3, 3)
> m <- glm(counts ~ outcome + treatment, family = poisson())
> pander(m)
--------------------------------------------------------------
Estimate Std. Error z value Pr(>|z|)
----------------- ---------- ------------ --------- ----------
**(Intercept)** 3.045 0.1709 17.81 5.427e-71
**outcome2** -0.4543 0.2022 -2.247 0.02465
**outcome3** -0.293 0.1927 -1.52 0.1285
**treatment2** 1.338e-15 0.2 6.69e-15 1
**treatment3** 1.421e-15 0.2 7.105e-15 1
--------------------------------------------------------------
Table: Fitting generalized (poisson/log) linear model: counts ~ outcome + treatment
> pander(anova(m))
--------------------------------------------------------
Df Deviance Resid. Df Resid. Dev
--------------- ---- ---------- ----------- ------------
**NULL** NA NA 8 10.58
**outcome** 2 5.452 6 5.129
**treatment** 2 2.665e-15 4 5.129
--------------------------------------------------------
Table: Analysis of Deviance Table
> pander(aov(m))
-----------------------------------------------------------
Df Sum Sq Mean Sq F value Pr(>F)
--------------- ---- --------- --------- --------- --------
**outcome** 2 92.67 46.33 2.224 0.2242
**treatment** 2 8.382e-31 4.191e-31 2.012e-32 1
**Residuals** 4 83.33 20.83 NA NA
-----------------------------------------------------------
Table: Analysis of Variance Model
> pander(prcomp(USArrests))
-------------------------------------------------
PC1 PC2 PC3 PC4
-------------- ------- -------- -------- --------
**Murder** 0.0417 -0.04482 0.07989 -0.9949
**Assault** 0.9952 -0.05876 -0.06757 0.03894
**UrbanPop** 0.04634 0.9769 -0.2005 -0.05817
**Rape** 0.07516 0.2007 0.9741 0.07233
-------------------------------------------------
Table: Principal Components Analysis
> pander(density(mtcars$hp))
--------------------------------------------
Coordinates Density values
------------- ------------- ----------------
**Min.** -32.12 5e-06
**1st Qu.** 80.69 0.0004068
**Median** 193.5 0.001665
**Mean** 193.5 0.002214
**3rd Qu.** 306.3 0.00409
**Max.** 419.1 0.006051
--------------------------------------------
Table: Kernel density of *mtcars$hp* (bandwidth: 28.04104)
> ## Don't like scientific notation?
> panderOptions('round', 2)
> pander(density(mtcars$hp))
--------------------------------------------
Coordinates Density values
------------- ------------- ----------------
**Min.** -32.12 0
**1st Qu.** 80.69 0
**Median** 193.5 0
**Mean** 193.5 0
**3rd Qu.** 306.3 0
**Max.** 419.1 0.01
--------------------------------------------
Table: Kernel density of *mtcars$hp* (bandwidth: 28.04104)
And of course tables are formatted (e.g. auto add of line breaks, splitting up tables, hyphenation support or markdown format) based on the user specified panderOptions.
The package is also capable of creating complex Pandoc documents (reports) from R objects in multiple ways:
-
create somehow a markdown text file (e.g. with
brew,knitror any scripts of yours, maybe withPandoc.brew- see just below) and transform that to other formats (like HTML, odt, PDF, docx etc.) withPandoc.convert- similarly topandocfunction in knitr. Basically this is a wrapper around a Pandoc call, which has not much to do with R actually. -
users might write some reports with literate programming (similar to
knitr) in a forked version of brew syntax resulting. This means that the user can include R code chunks in a document, and brewing that results in a pretty Pandoc's markdown document and also in a bunch of other formats (like HTML, odt, PDF, docx etc.). The great advantage of this function is that you do not have to transform your R objects to markdown manually, it's all handled automagically.Example: this
README.mdis cooked withPandoc.brewbased oninst/README.brewand also exported to HTML. Details can be found below or head directly to examples.
- and users might create a report in a live R session by adding some R objects and paragraphs to a
Pandocreference class object. Details can be found below.
The brew package, which is a templating framework for report generation, has not been updated on CRAN since 2011, but it's still used in bunch of R projects based on its simple design and useful features in literate programming. For a quick overview, please see the following documents if you are not familiar with brew:
In short: a brew document is a simple text file with some special tags. Pandoc.brew uses only two of them (as building on a personalized version of Jeff's really great brew function):
<% ... %>stand for running inline R commands as usual,<%= ... %>does pretty much the same but appliespanderto the returning R object (instead ofcatlike the originalbrewfunction does). So putting there any R object, it would return in a nice Pandoc's markdown format with all possible error/warning messages etc.
This latter tries to be smart in some ways:
- A code chunk block (R commands between the tags) can return any number of values at any part of the block.
- Plots and images are grabbed in the document, rendered to a
pngfile andpandermethod would result in a Pandoc markdown formatted image link. This means that the image would be rendered/shown/included in the exported document. - All warnings/messages and errors are recorded in the blocks and returned in the document as footnotes or inline messages.
- All heavy R commands (e.g. those taking more then 0.1 sec to evaluate) are cached so re
brewing a report would not result in a coffee break.
Besides this, the custom brew function can do more and also less compared to the original brew package. First of all, the internal caching mechanism of brew has been removed and rewritten for some extra profits besides improved caching.
For example now multiple R expressions can be passed between the <%= ... %> tags, and not only the text results, but the evaluated R objects are also (invisibly) returned in a structured list. This can be really useful while post-processing the results of brew. Quick example:
> str(Pandoc.brew(text ='
+ Pi equals to `<%= pi %>`.
+ And here are some random data:
+ `<%= runif(10) %>`
+ '))
Pi equals to _3.142_.
And here are some random data:
_0.6631_, _0.849_, _0.06986_, _0.3343_, _0.5209_, _0.3471_, _0.866_, _0.05548_, _0.8933_ and _0.2121_
List of 2
$ :List of 4
..$ type : chr "text"
..$ text :List of 2
.. ..$ raw : chr "Pi equals to _3.142_.\nAnd here are some random data:\n"
.. ..$ eval: chr "Pi equals to _3.142_.\nAnd here are some random data:\n"
..$ chunks:List of 2
.. ..$ raw : chr "_3.142_"
.. ..$ eval: chr "_3.142_"
..$ msg :List of 3
.. ..$ messages: NULL
.. ..$ warnings: NULL
.. ..$ errors : NULL
$ :List of 2
..$ type : chr "block"
..$ robject:List of 6
.. ..$ src : chr "runif(10)"
.. ..$ result: num [1:10] 0.6631 0.849 0.0699 0.3343 0.5209 ...
.. ..$ output: chr "_0.6631_, _0.849_, _0.06986_, _0.3343_, _0.5209_, _0.3471_, _0.866_, _0.05548_, _0.8933_ and _0.2121_"
.. ..$ type : chr "numeric"
.. ..$ msg :List of 3
.. .. ..$ messages: NULL
.. .. ..$ warnings: NULL
.. .. ..$ errors : NULL
.. ..$ stdout: NULL
.. ..- attr(*, "class")= chr "evals"
This document was generated by Pandoc.brew based on inst/README.brew so the above examples were generated automatically by running:
Pandoc.brew(system.file('README.brew', package = 'pander'))The output is set to stdout by default, which means that the resulting text is written to the R console. But setting the output to a text file and running Pandoc on that to create a HTML, odt, docx or other document in one go is also possible. To export a brewed file to other then Pandoc's markdown, please use the convert parameter. For example:
text <- paste('# Header',
'',
'What a lovely list:\n<%= as.list(runif(10)) %>',
'A wide table:\n<%= mtcars[1:3, ] %>',
'And a nice chart:\n\n<%= plot(1:10) %>',
sep = '\n')
Pandoc.brew(text = text, output = tempfile(), convert = 'html')
Pandoc.brew(text = text, output = tempfile(), convert = 'pdf')So to brew this README with all R chunks automatically converted to html, please run:
Pandoc.brew(system.file('README.brew', package='pander'), output = tempfile(), convert = 'html')The package bundles some examples for Pandoc.brew to let you check its features pretty fast. These are:
To brew these examples on your machine, try to run the followings commands:
Pandoc.brew(system.file('examples/minimal.brew', package='pander'))
Pandoc.brew(system.file('examples/minimal.brew', package='pander'), output = tempfile(), convert = 'html')
Pandoc.brew(system.file('examples/short-code-long-report.brew', package='pander'))
Pandoc.brew(system.file('examples/short-code-long-report.brew', package='pander'), output = tempfile(), convert = 'html')
Pandoc.brew(system.file('examples/graphs.brew', package='pander'))
Pandoc.brew(system.file('examples/graphs.brew', package='pander'), output = tempfile(), convert = 'html')For easier access, I have uploaded some exported documents of the above examples as well:
- minimal.brew: markdown html pdf odt docx
- short-code-long-report.brew: markdown html pdf odt docx
- graphs.brew: markdown html pdf odt docx
Please check out pdf, docx, odt and other formats by changing the above convert option on your machine, and do not forget to give some feedback!
pander package has a special reference class called Pandoc which could collect some blocks in a live R session and export the whole document to Pandoc/PDF/HTML etc. Without any serious further explanations, please check out the below (self-commenting) example:
## Initialize a new Pandoc object
myReport <- Pandoc$new()
## Add author, title and date of document
myReport$author <- 'Gergely Daróczi'
myReport$title <- 'Demo'
## Or it could be done while initializing
myReport <- Pandoc$new('Gergely Daróczi', 'Demo')
## Add some free text
myReport$add.paragraph('Hello there, this is a really short tutorial!')
## Add maybe a header for later stuff
myReport$add.paragraph('# Showing some raw R objects below')
## Adding a short matrix
myReport$add(matrix(5,5,5))
## Or a table with even
myReport$add.paragraph('Hello table:')
myReport$add(table(mtcars$am, mtcars$gear))
## Or a "large" data frame which barely fits on a page
myReport$add(mtcars)
## And a simple linear model with Anova tables
ml <- with(lm(mpg ~ hp + wt), data = mtcars)
myReport$add(ml)
myReport$add(anova(ml))
myReport$add(aov(ml))
## And do some principal component analysis at last
myReport$add(prcomp(USArrests))
## Sorry, I did not show how Pandoc deals with plots:
myReport$add(plot(1:10))
## Want to see the report? Just print it:
myReport
## Exporting to PDF (default)
myReport$export()
## Or to docx in tempdir():
myReport$format <- 'docx'
myReport$export(tempfile())
## You do not want to see the generated report after generation?
myReport$export(open = FALSE)When working on the rapport package, I really needed some nifty R function that can evaluate R expression along with capturing errors and warnings. Unfortunately the evaluate package had only limited features at that time, as it could not return the raw R object, but only the standard output with messages. So I wrote my own function, and soon some further feature requests arose, like identifying if an R expression results in a plot etc. This section aims to give a quick introduction to the functionality of evals, but for more usage/implementation details, please refer to specialized vignette, which can be accessed by vignette('evals', package='pander') or available online here.
But probably it's easier to explain what evals can do with a simple example:
> evals('1:10')
[[1]]
$src
[1] "1:10"
$result
[1] 1 2 3 4 5 6 7 8 9 10
$output
[1] " [1] 1 2 3 4 5 6 7 8 9 10"
$type
[1] "integer"
$msg
$msg$messages
NULL
$msg$warnings
NULL
$msg$errors
NULL
$stdout
NULL
attr(,"class")
[1] "evals"
So evals can evaluate a character vector of R expressions, and it returns a list of captured stuff while running those:
srcholds the R expression,resultcontains the raw R object as is,outputrepresents how the R object is printed to the standard output,typeis theclassof the returned R object,msgis a list of possible messages captured while running the R expression andstdoutcontains if anything was written to the standard output.
Besides capturing this nifty list of important circumstances, evals can automatically identify if an R expression is returning anything to a graphical device, and can save the resulting image in a variety of file formats along with some extra options, like applying a custom theme on base, lattice or ggplot2 plots:
> evals('hist(mtcars$hp)')[[1]]$result

So instead of a captured R object (which would be NULL in this situation by the way), we get the path of the image where the plot was saved:
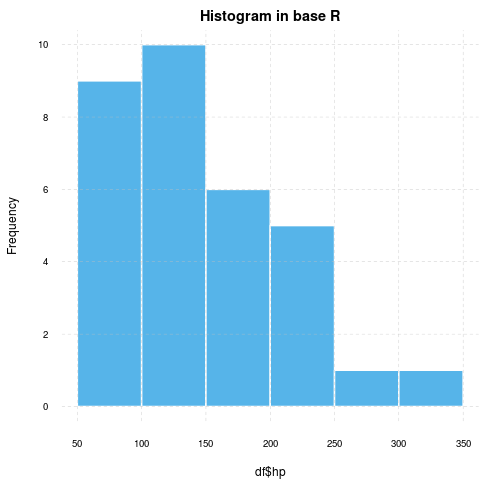
Well, this is not a standard histogram usually returned by the hist function, right? As mentioned before, evals have some extra features like applying the user defined theme on various plots automatically. Please see the graphs.brew example above for further details, or check the related global options. If you do not like this feature, simply add evalsOptions('graph.unify', FALSE) to your .Rprofile.
Further features are described in the technical docs, and now I'll only give a brief introduction to another important feature of evals.
As pander::evals is using a custom caching algorithm in the means of evaluating R expressions, it might be worthwhile to give a short summary of what is going on in the background when you are running e.g. Pandoc.brew, the "live report generation" engine or evals directly:
- Each passed R chunk is
parsed to single R expressions. - Each parsed expression's part (let it be a function, variable, constant etc.) is evaluated (as
name) separately to alist. This list describes the unique structure and the content of the passed R expressions. This has some really great benefits (see below). - A hash is computed of each list element and cached too in
pander's local environments. This is useful if you are using large data frames, just imagine: the caching algorithm would have to compute the hash for the same data frame each time it's touched! This way the hash is recomputed only if the R object with the given name is changed. - The list of such R objects is serialized, then an
SHA-1hash is computed, which is unique and there is no real risk of collision. - If
evalscan find the cached results in an environment ofpander's namespace (ifcache.modeset toenviroment- see below) or in a file named to the computed hash (ifcache.modeset todisk), then it is returned on the spot. The objects modified/created by the cached code are also updated. - Otherwise the call is evaluated and the results and the modified R objects of the environment are optionally saved to cache (e.g. if
cacheis active and if theproc.time()of the evaluation is higher then it is defined incache.time- see details in evals' options).
As pander does not cache based on raw sources of chunks and there is no easy way of enabling/disabling caching on a chunk basis, the users have to live with some great advantages and some minor tricky situations - which latter cannot be solved theoretically in my opinion, but I'd love to hear your feedback.
The caching hash is computed based on the structure and content of the R commands instead of the used variable names or R expressions, so let us make some POC example to show the greatest asset:
x <- mtcars$hp
y <- 1e3
evals('sapply(rep(x, y), mean)')It took a while, huh? :)
Let us create some custom functions and variables, which are not identical to the above call:
f <- sapply
g <- rep
h <- mean
X <- mtcars$hp * 1
Y <- 1000And now try to run something like:
evals('f(g(X, Y), h)')Yes, it was returned from cache!
About the kickback:
As pander (or rather: evals) does not really deal with what is written in the provided sources but rather checks what is inside that, there might be some tricky situations where you would expect the cache to work, but it would not. Short example: we are computing and saving to a variable something heavy in a chunk (please run these in a clean R session to avoid conflicts):
evals('x <- sapply(rep(mtcars$hp, 1e3), mean)')It is cached, just run again, you will see.
But if you would create x in your global environment with any value (which has nothing to do with the special environment of the report!) and x was not defined in the report before this call (and you had no x value in your global environment before), then the content of x would result in a new hash for the cache - so caching would not work. E.g.:
x <- 'foobar'
evals('x <- sapply(rep(mtcars$hp, 1e3), mean)')I really think this is a minor issue (with very special coincidences) which cannot be addressed cleverly - but could be avoided with some cautions (e.g. run Pandoc.brew in a clean R session like with Rscript or littler - if you are really afraid of this issue). And after all: you loose nothing, just the cache would not work for that only line and only once in most of the cases.
Other cases when the hash of a call will not match cached hashes:
- a number is replaced by a variable holding the number, e.g.:
evals('1:5')vs.x <- 1:5;evals('x') - a part of an R object is replaced by a variable holding that, e.g.:
evals('mean(mtcars$hp)')vs.x <- mtcars$hp;evals('mean(x)')
But the e.g. following do work from cache fine:
x <- mtcars$hp
xx <- mtcars$hp*1
evals('mean(x)')
evals('mean(xx)')
The package comes with a variety of globally adjustable options, which have an effect on the result of your reports. You can query and update these options with the panderOptions function:
-
digits: numeric (default:2) passed toformat. Can be a vector specifying values for each column (has to be the same length as number of columns). Values for non-numeric columns will be disregarded. -
decimal.mark: string (default:.) passed toformat -
formula.caption.prefix: string (default:Formula:) passed topandoc.formulato be used as caption prefix. Be sure about what you are doing if changing to other thanFormula:or:. -
big.mark: string (default:'') passed toformat -
round: numeric (default:Inf) passed toround. Can be a vector specifying values for each column (has to be the same length as number of columns). Values for non-numeric columns will be disregarded. -
keep.trailing.zeros: boolean (default:FALSE) show or remove trailing zeros in numbers (e.g. in numeric vectors or in columns of tables with numeric values) -
keep.line.breaks: boolean (default:FALSE) to keep or remove line breaks from cells in a table -
missing: string (default:NA) to replace missing values in vectors, tables etc. -
date: string (default:'%Y/%m/%d %X') passed toformatwhen printing dates (POSIXctorPOSIXt) -
header.style:'atx'or'setext'passed topandoc.header -
list.style:'bullet'(default),'ordered'or'roman'passed topandoc.list. Please not that this has no effect onpandermethods. -
table.style:'multiline','grid'or'simple'passed topandoc.table -
table.emphasize.rownames: boolean (default:TRUE) if row names should be highlighted -
table.split.table: numeric passed topandoc.tableand also affectspandermethods. This option tellspanderwhere to split too wide tables. The default value (80) suggests the conventional number of characters used in a line, feel free to change (e.g. toInfto disable this feature) if you are not using a VT100 terminal any more :) -
table.split.cells: numeric (default: 30) passed topandoc.tableand also affects pander methods. This option tells pander where to split too wide cells with line breaks. Set `Inf`` to disable. -
table.caption.prefix: string (default:Table:) passed topandoc.tableto be used as caption prefix. Be sure about what you are doing if changing to other thanTable:or:. -
table.continues: string (default:Table continues below) passed topandoc.tableto be used as caption for long (split) without a use defined caption -
table.continues.affix: string (default:(continued below)) passed topandoc.tableto be used as an affix concatenated to the user defined caption for long (split) tables -
table.alignment.default: string (default:centre) that defines the default alignment of cells. Can beleft,rightorcentrethat latter can be also spelled ascenter -
table.alignment.rownames: string (default:centre) that defines the alignment of rownames in tables. Can beleft,rightorcentrethat latter can be also spelled ascenter -
use.hyphening: boolean (default:FALSE) if try to use hyphening when splitting large cells according to table.split.cells. Requiressyllypackage. -
evals.messages: boolean (default:TRUE) passed toevals'pandermethod specifying if messages should be rendered -
p.wrap: a string (default:'_') to wrap vector elements passed topfunction -
p.sep: a string (default:', ') with the main separator passed topfunction -
p.copula: a string (default:'and') a string with ending separator passed topfunction -
plain.ascii: boolean (default: FALSE) to define if output should be in plain ascii or not -
graph.nomargin: boolean (default:TRUE) if trying to keep plots' margins at minimal -
graph.fontfamily: string (default:'sans') specifying the font family to be used in images. Please note, that using a custom font on Windows requiresgrDevices:::windowsFontsfirst. -
graph.fontcolor: string (default:'black') specifying the default font color -
graph.fontsize: numeric (default:12) specifying the base font size in pixels. Main title is rendered with1.2and labels with0.8multiplier. -
graph.grid: boolean (default:TRUE) if a grid should be added to the plot -
graph.grid.minor: boolean (default:TRUE) if a miner grid should be also rendered -
graph.grid.color: string (default:'grey') specifying the color of the rendered grid -
graph.grid.lty: string (default:'dashed') specifying the line type of grid -
graph.boxes: boolean (default:FALSE) if to render a border around of plot (and e.g. around strip) -
graph.legend.position: string (default:'right') specifying the position of the legend: 'top', 'right', 'bottom' or 'left' -
graph.background: string (default:'white') specifying the plots main background's color -
graph.panel.background: string (default:'transparent') specifying the plot's main panel background. Please note, that this option is not supported withbasegraphics. -
graph.colors: character vector of default color palette (defaults to a colorblind theme). Please note that this update work withbaseplots by appending thecolargument to the call if not set. -
graph.color.rnd: boolean (default:FALSE) specifying if the palette should be reordered randomly before rendering each plot to get colorful images -
graph.axis.angle: numeric (default:1) specifying the angle of axes' labels. The available options are based onpar(les)and sets if the labels should be:1: parallel to the axis,2: horizontal,3: perpendicular to the axis or4: vertical.
-
graph.symbol: numeric (default:1) specifying a symbol (see thepchparameter ofpar) -
knitr.auto.asis: boolean (default:TRUE) if the results ofpandershould be considered asasisinknitr. Equals to specifyingresults='asis'in the R chunk, so thus there is no need to do so if set toTRUE.
Besides localization of numeric formats or the styles of tables, lists and plots, there are some technical options as well, which would effect e.g. caching or the format of rendered image files. You can query/update those with the evalsOptions function as the main backend of pander calls is a custom evaluation function called evals.
The list of possible options are:
parse: ifTRUEthe providedtxtelements would be merged into one string and parsed to logical chunks. This is useful if you would want to get separate results of your code parts - not just the last returned value, but you are passing the whole script in one string. To manually lock lines to each other (e.g. calling aplotand on next line adding anablineortextto it), use a plus char (+) at the beginning of each line which should be evaluated with the previous one(s). If set toFALSE,evalswould not try to parse R code, it would get evaluated in separate runs - as provided. Please see the documentation ofevals.cache: caching the result of R calls if set toTRUEcache.mode: cached results could be stored in anenvironmentin current R session or let it be permanent ondisk.cache.dir: path to a directory holding cache files ifcache.modeset todisk. Default set to.cachein current working directory.cache.time: number of seconds to limit caching based onproc.time. If set to0, all R commands, if set toInf, none is cached (despite thecacheparameter).cache.copy.images: copy images to new file names if an image is returned from the disk cache? If set toFALSE(default), the cached path would be returned.classes: a vector or list of classes which should be returned. If set toNULL(by default) all R objects will be returned.hooks: list of hooks to be run for given classes in the form oflist(class = fn). If you would also specify some parameters of the function, a list should be provided in the form oflist(fn, param1, param2=NULL)etc. So the hooks would becomelist(class1=list(fn, param1, param2=NULL), ...). See example ofevalsfor more details. A default hook can be specified too by setting the class to'default'. This can be handy if you do not want to define separate methods/functions to each possible class, but automatically apply the default hook to all classes not mentioned in the list. You may also specify only one element in the list like:hooks=list('default' = pander_return). Please note, that nor error/warning messages, nor stdout is captured (so: updated) while running hooks!length: any R object exceeding the specified length will not be returned. The default value (Inf) does not filter out any R objects.output: a character vector of required returned values. This might be useful if you are only interested in theresult, and do not want to save/see e.g.messagesorprintedoutput. See examples ofevals.graph.unify: shouldevalstry to unify the style of (base,latticeandggplot2) plots? If set toTRUE, somepanderOptions()would apply. By default this is disabled not to freak out useRs :)graph.name: set the file name of saved plots which is%sby default. A simple character string might be provided where%dwould be replaced by the index of the generatingtxtsource,%nwith an incremented integer ingraph.dirwith similar file names and%tby some unique random characters. When used in abrewfile,%iis also available which would be replaced by the chunk number.graph.dir: path to a directory where to place generated images. If the directory does not exist,evalstry to create that. Default set toplotsin current working directory.graph.output: set the required file format of saved plots. Currently it could be any ofgrDevices:png,bmp,jpeg,jpg,tiff,svgorpdf. Set toNAnot to save plots at all and tweak that setting withcapture.plot()on demand.width: width of generated plot in pixels for even vector formatsheight: height of generated plot in pixels for even vector formatsres: nominal resolution inppi. The height and width of vector images will be calculated based in this.hi.res: generate high resolution plots also? If set toTRUE, each R code parts resulting an image would be run twice.hi.res.width: width of generated high resolution plot in pixels for even vector formats. Theheightandresof high resolution image is automatically computed based on the above options to preserve original plot aspect ratio.graph.env: save the environments in which plots were generated to distinct files (based ongraph.name) withenvextension?graph.recordplot: save the plot viarecordPlotto distinct files (based ongraph.name) withrecodplotextension?graph.RDSsave the raw R object returned (usually withlatticeorggplot2) while generating the plots to distinct files (based ongraph.name) withRDSextension?log:NULLor an optionally passed namespace forloggerto record all info, trace, debug and error messages.
How does pander differ from Sweave, brew, knitr, R2HTML and the other tools of literate programming? First of all pander can be used as a helper with any other literate programming solution, so you can call pander inside of knitr chunks.
But if you stick with pander's literate programming engine, then there's not much need for calling ascii, xtable, Hmisc, tables etc. or even pander in the R command chunks to transform R objects into markdown, HTML, tex etc. as Pandoc.brew automatically results in Pandoc's markdown, which can be converted to almost any text document format. Conversion can be done automatically after calling pander reporting functions (Pander.brew or Pandoc).
Based on the fact that pander transforms R objects into markdown, no "traditional" R console output is shown in the resulting document (nor in markdown, nor in exported docs), but all R objects are transformed to tables, list etc. Well, there is an option (show.src) to show the original R commands before the formatted output, and pander calls can be also easily tweaked to return the printed version of the R objects - if you would need that in some strange situation - like writing an R tutorial. But really think that nor R code, nor raw R results have anything to do with an exported report.
Of course all warnings, messages and errors are captured while evaluating R expressions just like stdout besides the raw R objects. So the resulting report also includes the raw R objects for further edits if needed - which is a very unique feature.
Graphs and plots are automatically identified in code chunks and saved to disk in a png file linked in the resulting document. This means that if you create a report (e.g. brew a text file) and export it to PDF/docx etc. all the plots/images would be there. There are some parameters to specify the resolution of the image and also the type (e.g. jpg, svg or pdf) besides a wide variety of theme options. About the latter, please check the graphs.brew example above.
And pander uses its built-in (IMHO quite decent) caching engine. This means that if the evaluation of some R commands takes too long time (which can be set by option/parameter), then the results are saved in a file and returned from there on next similar R code's evaluation. This caching algorithm tries to be smart, as it not only checks the passed R sources, but the content of all variables and functions, and saves the hash of those. This is a quite secure way of caching (see details above), but if you would encounter any issues, just switch off the cache. I've not seen any issues for years :)
I have created some simple LISP functions which would be handy if you are using the best damn IDE for R. These functions and default key-bindings are shipped with the package, feel free to personalize.
As time passed these small functions grew heavier (with my Emacs knowledge) so I ended up with a small library:
I am currently working on pander-mode which is a small minor-mode for Emacs. There are a few (but useful) functions with default keybindings:
pander-brew(C-c p b): RunPandoc.brewon current buffer or region (if mark is active), show results in ess-output and (optionally) copy results to clipboard while setting working directory totempdir()temporary.pander-brew-export(C-c p B): RunPandoc.brewon current buffer or region (if mark is active) and export results to specified (auto-complete in minibuffer) format. Also tries to open exported document.pander-eval(C-c p e): Runpanderon (automatically evaluated) region or current chunk (if marker is not set), show results (of last returned R object) in*ess-output*and (optionally) copy those to clipboard while setting working directory totempdir()temporary.
Few options of pander-mode: M-x customize-group pander
pander-clipboard: If non-nil then the result ofpander-*functions would be copied to clipboard.pander-show-source: If non-nil then the source of R commands would also show up in generated documents while running 'pander-eval'. This would not affectbrewfunctions ATM.
To use this small lib, just type: M-x pander-mode on any document. It might be useful to add a hook to markdown-mode if you find this useful.
![https://travis-ci.org/Rapporter/pander.png?branch=master"]').css('border](https://travis-ci.org/Rapporter/pander.png?branch=master"]').css('border){kind=link}
![https://coveralls.io/repos/Rapporter/pander/badge.svg?branch=master"]').css('border](https://coveralls.io/repos/Rapporter/pander/badge.svg?branch=master"]').css('border){kind=link}