PyTorch implementation for GAL.
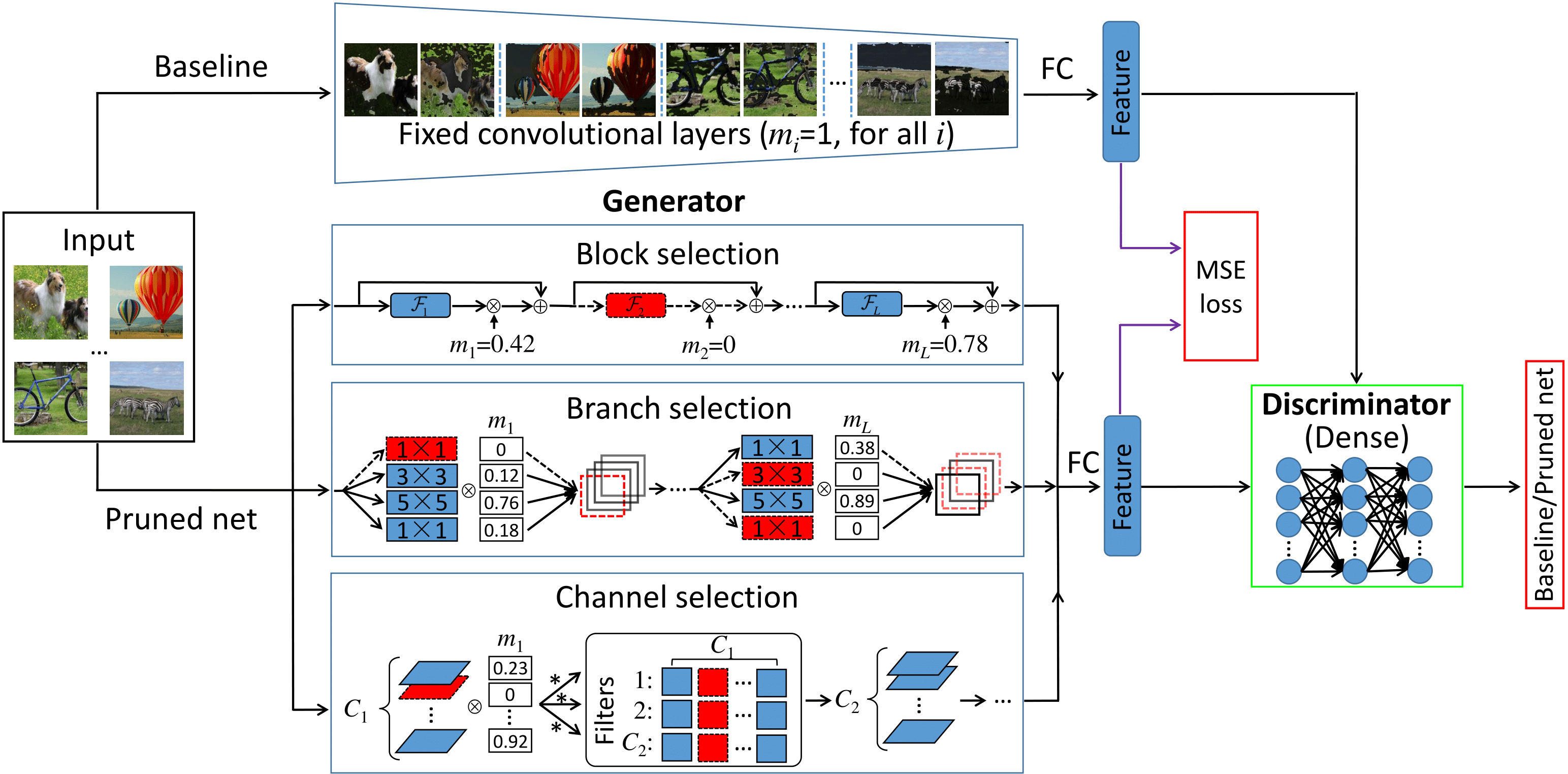
An illustration of GAL. Blue solid block, branch and channel elements are active, while red dotted elements are inactive and can be pruned since their corresponding scaling factors in the soft mask are 0.
Structured pruning of filters or neurons has received increased focus for compressing convolutional neural networks. Most existing methods rely on multi-stage optimizations in a layer-wise manner for iteratively pruning and retraining which may not be optimal and may be computation intensive. Besides, these methods are designed for pruning a specific structure, such as filter or block structures without jointly pruning heterogeneous structures. In this paper, we propose an effective structured pruning approach that jointly prunes filters as well as other structures in an end-to-end manner. To accomplish this, we first introduce a soft mask to scale the output of these structures by defining a new objective function with sparsity regularization to align the output of baseline and network with this mask. We then effectively solve the optimization problem by generative adversarial learning (GAL), which learns a sparse soft mask in a label-free and an end-to-end manner. By forcing more scaling factors in the soft mask to zero, the fast iterative shrinkage-thresholding algorithm (FISTA) can be leveraged to fast and reliably remove the corresponding structures. Extensive experiments demonstrate the effectiveness of GAL on different datasets, including MNIST, CIFAR-10 and ImageNet ILSVRC 2012. For example, on ImageNet ILSVRC 2012, the pruned ResNet-50 achieves 10.88% Top-5 error and results in a factor of 3.7x speedup. This significantly outperforms state-of-the-art methods.
If you find GAL useful in your research, please consider citing:
@inproceedings{lin2019towards,
title = {Towards Optimal Structured CNN Pruning via Generative Adversarial Learning},
author = {Lin, Shaohui and Ji, Rongrong and Yan, Chenqian and Zhang, Baochang and Cao, Liujuan and Ye, Qixiang and Huang, Feiyue and Doermann, David},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
In this code, you can run our models on CIFAR10 dataset. The code has been tested by Python 3.6, Pytorch 0.4.1 and CUDA 9.0 on Ubuntu 16.04.
The scripts of training and fine-tuning are provided in the run.sh, please kindly uncomment the appropriate line in run.sh to execute the training and fine-tuning.
bash run.shFor training, change the teacher_dir to the place where the pretrained model is located.
# ResNet-56
MIU=1
LAMBDA=0.8
python main.py \
--teacher_dir [pre-trained model dir] \
--arch resnet --teacher_model resnet_56 --student_model resnet_56_sparse \
--lambda $LAMBDA --miu $MIU \
--job_dir 'experiment/resnet/lambda_'$LAMBDA'_miu_'$MIUAfter training, checkpoints and loggers can be found in the job_dir, The pruned model of best performance will be named [arch]_pruned_[pruned_num].pt. For example: resnet_pruned_11.pt
For fine-tuning, change the refine to the place where the pruned model is allowed to be fine-tuned.
# ResNet-56
python finetune.py \
--arch resnet --lr 1e-4 \
--refine experiment/resnet/lambda_0.8_miu_1/resnet_pruned_11.pt \
--job_dir experiment/resnet/ft_lambda_0.8_miu_1/ \
--pruned You can set --pruned to reuse the pruned model.
Evaluate our ImageNet model
python test.py \
--target_model gal_05 \
--student_model resnet_50_sparse \
--dataset imagenet --data_dir $DATA_DIR \
--eval_batch_size 256 --job_dir ./checkpoints/gal_05.pth.tar
--test_only We also provide our baseline models below. Enjoy your training and testing!
Cifar10: | ResNet56 | Vgg-16 | DenseNet-40 | GoogleNet |
ImageNet: Baidu Wangpan (password:77zk) | Google Drive
If you find any problems, please feel free to contact to the authors ([email protected] or [email protected]).