


Infomate is a small web service that shows multiple RSS sources on one page and performs tricky parsing and summarizing articles using TextRank algorithm.
It helps to keep track of news from different areas without subscribing to hundreds of media accounts and getting annoying notifications.
Thematic and people-based collections does a really good job for discovery of new sources of information. Since we all are biased, such compilations can really help us to get out of information bubbles.
Live URL: infomate.club
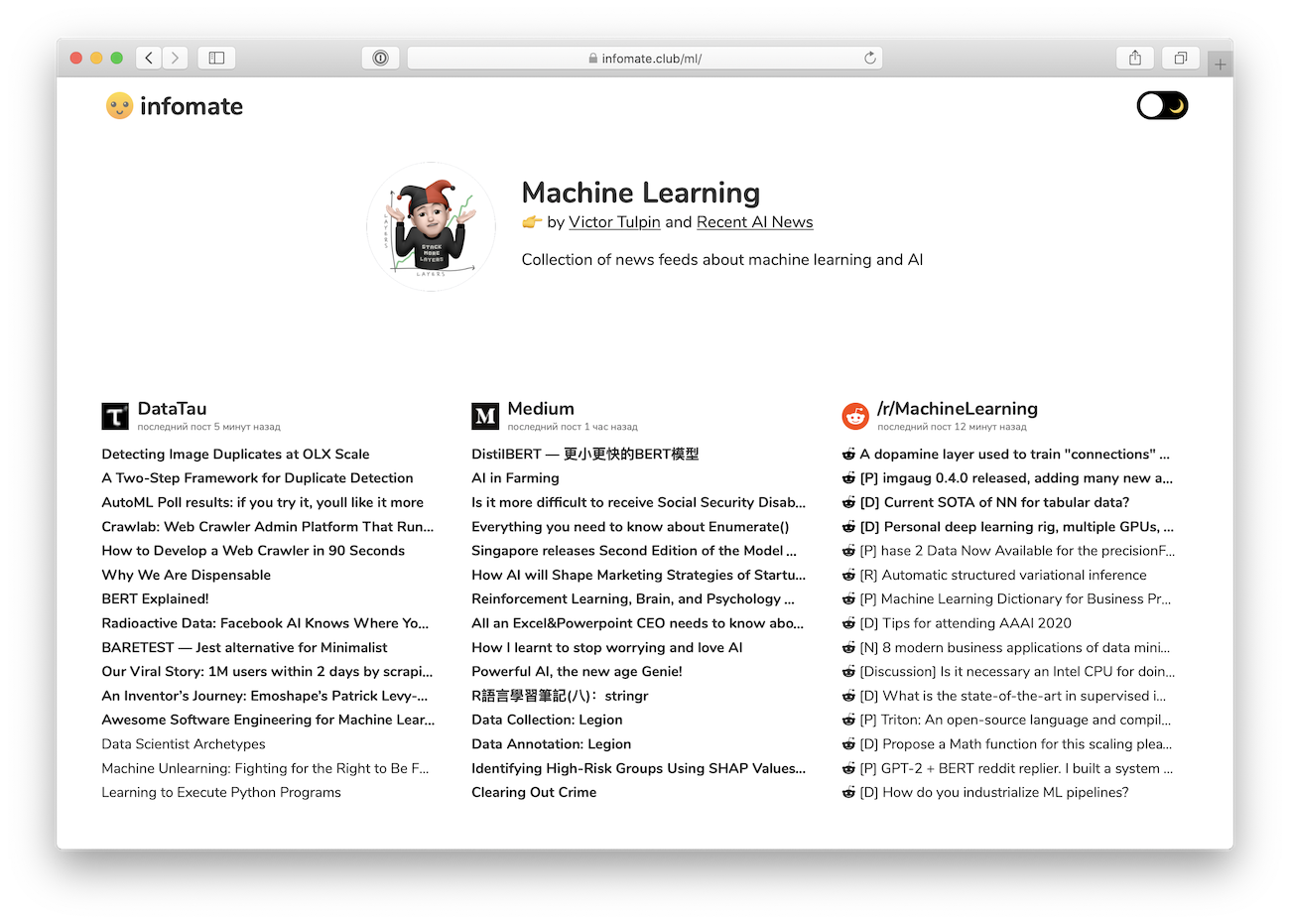
Which means you really shouldn't expect much from it. I wrote it over the weekend to solve my own pain. No state-of-art kubernetes bullshit, no architecture patterns, even no tests at all. It's here just to show people what a pet-project might look like.
This code has been written for fun, not for business. There is usually a big difference. Like between riding a bike on the streets and cycling in the wild for fun :)
It's basically a Django web app with a bunch of scripts for RSS parsing. It stores the parsed data in a PostgreSQL database.
The web app is only used to show the data (with heavy caching). Parsing and feed updates are performed by the three scripts running in cron. Like poor people do.
Feedparser and BeautifulSoup are used to find, download and parse RSS.
Text summarization is done via newspaper3k with some additional protection against bad types of content like podcasts and too big pages in general, which can eat all your memory. Anything can happen in the RSS world :)
The easy way. Install docker on your machine. Then:
git clone [email protected]:vas3k/infomate.club.git
cd infomate.club
docker-compose up --build
After that navigate to localhost:8000
To terminate it:
docker-compose down --remove-orphansMake sure you have python3 and postresql installed locally.
pip3 install -r requirements.txt --user
python3 manage.py migrate
Step 3: Take a look at boards.yml
This is the main source of truth for all RSS streams and collections in the service. All updates to the database are made through it. For the first time you can just use the existing one.
python3 scripts/initialize.py --config boards.yml
Every time you make a change to boards.yml, just run this script again. He is smart enough to create the missing ones and remove the old ones.
python3 scripts/update.py
Don't run it too often, otherwise sites may ban your IP. There is a hardcoded cooldown interval for each feed, but you can use
--forceflag to ignore it.
python3 manage.py runserver 8000
Then go to localhost:8000 again
boards:
- name: Tech # board title
slug: tech # board url
is_visible: true # visibility on the main page
is_private: false # private boards require logging in
curator: # board author profile
name: John Wick
title: Main news
avatar: https://i.vas3k.ru/fhr.png
bio: Major technology media in English and Russian
footer: >
this is a general selection of popular technology media.
The page is updated once per hour.
blocks: # list of logical feed blocks
- name: English # block title
slug: en # unique board id
feeds:
- name: Hacker News
url: https://news.ycombinator.com
rss: https://news.ycombinator.com/rss
- name: dev.to
url: https://dev.to
rss: https://dev.to/feed
- name: TechCrunch
rss: http://feeds.feedburner.com/TechCrunch/
url: https://techcrunch.com
is_parsable: false # do not try to parse pages, show RSS content only
conditions:
- type: not_in
field: title
word: Trump # exclude articles with a word "Trump" in title
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
You can help us with opened issues too. There's always something to work on.
We don't have any strict rules on formatting, just explain your motivation and the changes you've made to the PR description so that others understand what's going on.
Apache 2.0 © Vasily Zubarev
TL;DR: you can modify, distribute and use it commercially, but you MUST reference the original author or give a link to service