Optimize memory:Support shrinking in ConcurrentLongLongPairHashMap #3061
Conversation
|
@merlimat @hangc0276 @eolivelli PTAL,thanks! |
|
in addition,I added the following logic to reduce unnecessary rehash in method of cleanBucket: @merlimat @hangc0276 @eolivelli |
|
When clear, also shrink? or fallback to initialize size ?@merlimat |
|
rerun failure checks |
1 similar comment
|
rerun failure checks |
...rver/src/main/java/org/apache/bookkeeper/util/collections/ConcurrentLongLongPairHashMap.java
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
What about making this new behaviour configurable?
Like adding a new boolean parameter 'autoShrink'?
The default is false, to keep previous behaviour.
My concern is that this implementation may help in your case but this is a utility class possibly used by many other applications
...rver/src/main/java/org/apache/bookkeeper/util/collections/ConcurrentLongLongPairHashMap.java
Outdated
Show resolved
Hide resolved
.../src/test/java/org/apache/bookkeeper/util/collections/ConcurrentLongLongPairHashMapTest.java
Show resolved
Hide resolved
.../src/test/java/org/apache/bookkeeper/util/collections/ConcurrentLongLongPairHashMapTest.java
Show resolved
Hide resolved
@eolivelli @merlimat I agree to add autoShrink, but when we configure autoShrink=false, the following situation cannot be solved: step1: step2: step3: .... step6601: usedBuckets=6601>resizeThreshold=6600 so expand. |
...rver/src/main/java/org/apache/bookkeeper/util/collections/ConcurrentLongLongPairHashMap.java
Outdated
Show resolved
Hide resolved
OK, I will create another PR to fix the scaling condition problem. |
In the constructor method of this class of ConcurrentLongLongPairHashMap, pass in the parameter MapIdleFactor, the default MapIdleFactor=0, if you want to enable automatic shrink, then set MapIdleFactor>0,like: What do you think? @eolivelli |
There was a problem hiding this comment.
Change looks mostly good to me. Thanks for initiating this.
I agree with Enrico that we should make it configurable wether to shrink the capacity or not, and probably we should keep the current default and change it based on the intended use.
For example, the main use case in BK code for the DbLedgerStorage WriteCache involves filling the map and clear it, constantly repeating. In this scenario we should not shrink the map because it will get re-expanded immediately.
In other use cases like the subscriptions pending acks, it does indeed make sense to shrink after a peak.
Also we could make the thresholds and step up/down factor configurable. Given that is many parameters, we should consider adding a "Builder" interface.
| @@ -48,6 +48,7 @@ | |||
| private static final long ValueNotFound = -1L; | |||
|
|
|||
| private static final float MapFillFactor = 0.66f; | |||
| private static final float MapIdleFactor = 0.25f; | |||
There was a problem hiding this comment.
I think we should be cautious in avoiding constantly flickering between shrink & expand. We should try to use a smaller threshold here to limit that. Maybe 0.15?
...rver/src/main/java/org/apache/bookkeeper/util/collections/ConcurrentLongLongPairHashMap.java
Outdated
Show resolved
Hide resolved
| @@ -388,6 +401,18 @@ private void cleanBucket(int bucket) { | |||
| table[bucket + 2] = ValueNotFound; | |||
| table[bucket + 3] = ValueNotFound; | |||
| --usedBuckets; | |||
|
|
|||
| // Reduce unnecessary rehash | |||
There was a problem hiding this comment.
| // Reduce unnecessary rehash | |
| // Cleanup all the buckets that were in `DeletedKey` state, so that we can reduce unnecessary expansions |
| try { | ||
| rehash(); | ||
| // Expand the hashmap | ||
| rehash(capacity * 2); |
There was a problem hiding this comment.
The existing "double the size" strategy was probably not the best one for all use cases either, as it can end up wasting a considerable amount of memory in empty buckets.
We could leave it configurable (both the step up and and down), to accommodate different needs.
There was a problem hiding this comment.
@merlimat like this?:
float upFactor = 0.5;
float downFactor = 0.5;
// Expand the hashmap
rehash(capacity * (1 + upFactor));
// shrink the hashmap
rehash(capacity * (1-downFactor));
There was a problem hiding this comment.
Also we could make the thresholds and step up/down factor configurable.
What does the thresholds mean here?
Are you referring to the MapFillFactor and MapIdleFactor variables here?
I agree to support the configuration of these two variables. @merlimat
2.add config: ①MapFillFactor;②MapIdleFactor;③autoShrink;④expandFactor;⑤shrinkFactor
|
@eolivelli @merlimat PTAL,thanks! |
| try { | ||
| rehash(); | ||
| // Expand the hashmap | ||
| rehash((int) (capacity * (1 + expandFactor))); |
There was a problem hiding this comment.
If expandFactor == 2, I would expect the size to double each time.
I think this should be:
| rehash((int) (capacity * (1 + expandFactor))); | |
| rehash((int) (capacity * expandFactor)); |
| if (autoShrink && size < resizeThresholdBelow) { | ||
| try { | ||
| // shrink the hashmap | ||
| rehash((int) (capacity * (1 - shrinkFactor))); |
There was a problem hiding this comment.
Shouldn't this be like:
| rehash((int) (capacity * (1 - shrinkFactor))); | |
| rehash((int) (capacity / shrinkFactor)); |
There was a problem hiding this comment.
I agree.
In addition, should the parameter range check be added? like: @merlimat
shrinkFactor>1
expandFactor>1
There was a problem hiding this comment.
fixed.
PTAL,thanks! @merlimat
2.add check : shrinkFactor>1 expandFactor>1
|
Since here we use bucket = (bucket + 4) & (table.length - 1) instead of (bucket + 4) % (table.length - 1) , expandFactor and shrinkFactor must be multiples of 2,like: 2,4, 5,8,10,... |
|
rerun failure checks |
|
rerun failure checks |
2 similar comments
|
rerun failure checks |
|
rerun failure checks |
… ②reduce unnecessary shrinkage;
added shrink in clear(). PTAL,thanks @merlimat |
2. fix initCapacity value
|
rerun failure checks |
…hMap of this version supports to shrink when removing, which can solve the problem of continuous memory increase and frequent FGC in pulsar broker. See the PR corresponding to bookkeeper: apache/bookkeeper#3061
|
The following classes have the same problem, so these changes are also required. what you think? @merlimat |
|
@lordcheng10 |
Ok, I will reopen a PR |
@eolivelli I've recreated a PR to support shrinking of other map structures:#3074 |
### Motivation Optimize concurrent collection's shrink and clear logic ### Changes 1. Reduce the repeated `Arrays.fill` in the clear process 2. When `capacity` is already equal to `initCapacity`,`rehash` should not be executed 3. Reduce the `rehash` logic in the `clear` process 4. Shrinking must at least ensure `initCapacity`, so as to avoid frequent shrinking and expansion near `initCapacity`, frequent shrinking and expansion, additionally opened `arrays` will consume more memory and affect GC. If this PR is accepted, I will optimize the same `concurrent collection's shrink and clear logic ` defined in pulsar. Related to #3061 and #3074
### Motivation Optimize concurrent collection's shrink and clear logic ### Changes 1. Reduce the repeated `Arrays.fill` in the clear process 2. When `capacity` is already equal to `initCapacity`,`rehash` should not be executed 3. Reduce the `rehash` logic in the `clear` process 4. Shrinking must at least ensure `initCapacity`, so as to avoid frequent shrinking and expansion near `initCapacity`, frequent shrinking and expansion, additionally opened `arrays` will consume more memory and affect GC. If this PR is accepted, I will optimize the same `concurrent collection's shrink and clear logic ` defined in pulsar. Related to #3061 and #3074 (cherry picked from commit a580547)
…pache#3061) * support shrink * Reduce unnecessary rehash * check style * fix: unnecessary rehash * add unit test: testExpandAndShrink * fix unit test: testExpandAndShrink * fix test: 1.verify that the map is able to expand after shrink; 2.does not keep shrinking at every remove() operation; * 1.add builder; 2.add config: ①MapFillFactor;②MapIdleFactor;③autoShrink;④expandFactor;⑤shrinkFactor * check style * 1.check style; 2.add check : shrinkFactor>1 expandFactor>1 * check style * keep and Deprecate all the public constructors. * add final for autoShrink * fix unit test testExpandAndShrink, set autoShrink true * add method for update parameters value: ①setMapFillFactor ②setMapIdleFactor ③setExpandFactor ④setShrinkFactor ⑤setAutoShrink * use lombok.Setter replace lombok.Data * use pulic for getUsedBucketCount * 1.check parameters; 2.fix the shrinkage condition: ①newCapacity > size: in order to prevent the infinite loop of rehash, newCapacity should be larger than the currently used size; ②newCapacity > resizeThresholdUp: in order to prevent continuous expansion and contraction, newCapacity should be greater than the expansion threshold; * 1.update parameters check; 2.fix newCapacity calculation when shrinking : rehash((int) Math.max(size / mapFillFactor, capacity / shrinkFactor)); * remove set methods: ①setMapFillFactor ②setMapIdleFactor ③setExpandFactor ④setShrinkFactor ⑤setAutoShrink * Repair shrinkage conditions: ①newCapacity must be the nth power of 2; ②reduce unnecessary shrinkage; * Repair shrinkage conditions * add shrinkage when clear * 1.add test for clear shrink 2. fix initCapacity value
### Motivation Optimize concurrent collection's shrink and clear logic ### Changes 1. Reduce the repeated `Arrays.fill` in the clear process 2. When `capacity` is already equal to `initCapacity`,`rehash` should not be executed 3. Reduce the `rehash` logic in the `clear` process 4. Shrinking must at least ensure `initCapacity`, so as to avoid frequent shrinking and expansion near `initCapacity`, frequent shrinking and expansion, additionally opened `arrays` will consume more memory and affect GC. If this PR is accepted, I will optimize the same `concurrent collection's shrink and clear logic ` defined in pulsar. Related to apache#3061 and apache#3074
Motivation
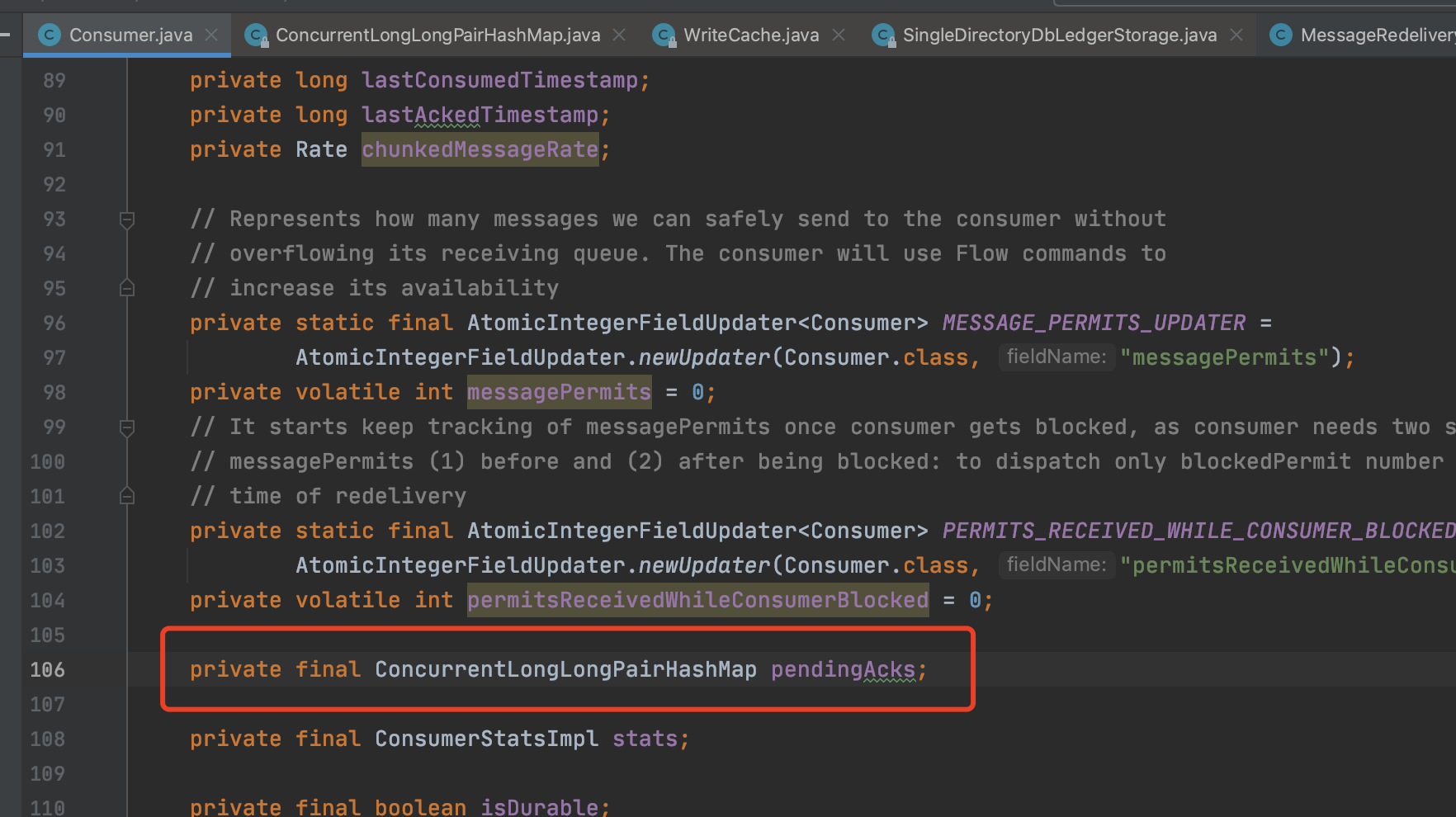
We found that the pulsar broker frequently appeared Full Gc, and found by dumping the heap memory: org.apache.pulsar.broker.service.Consumer#pendingAcks occupies 9.9G of memory. The pendingAcks variable is defined as follows:
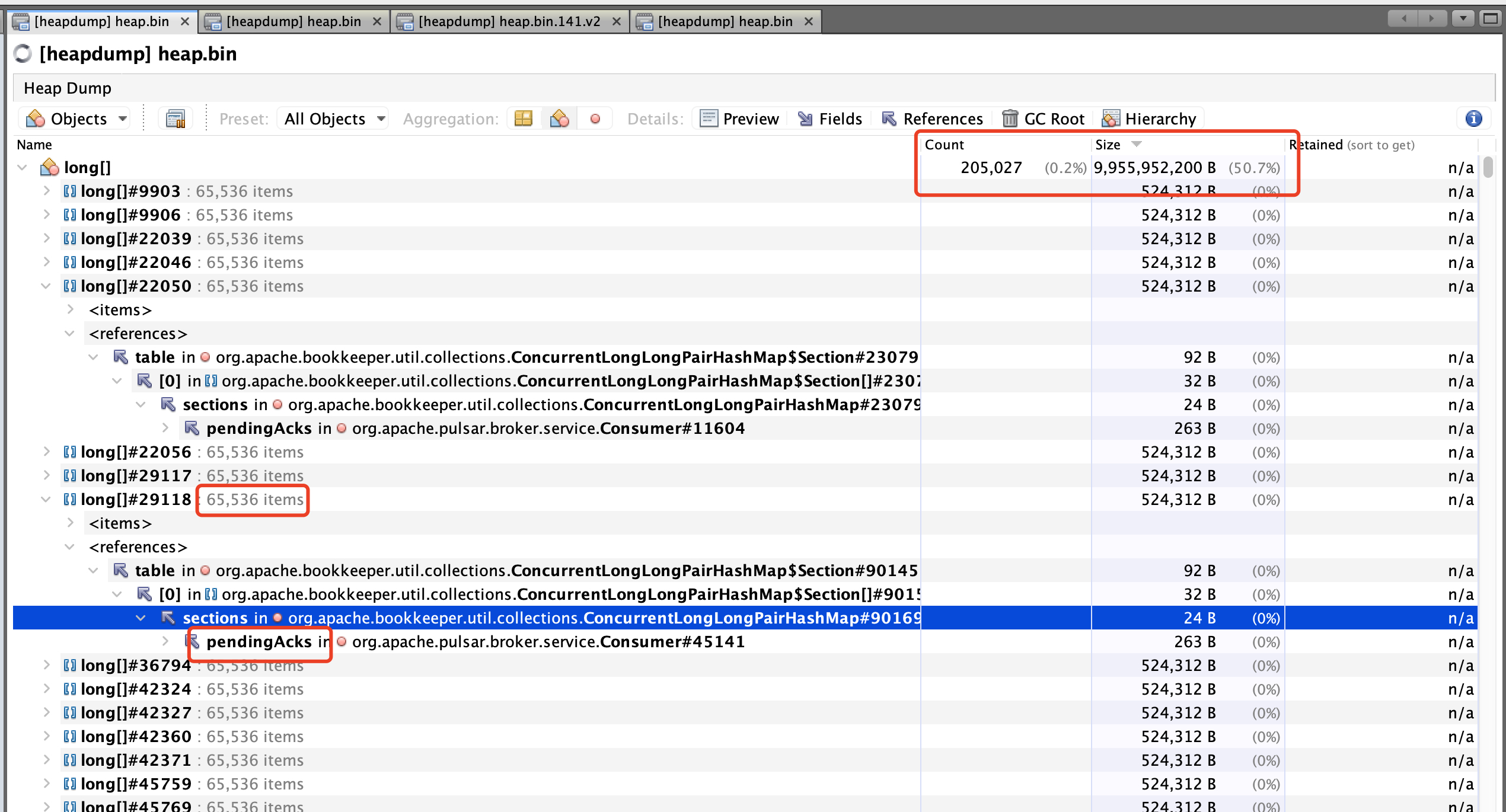
The heap memory usage is as follows:
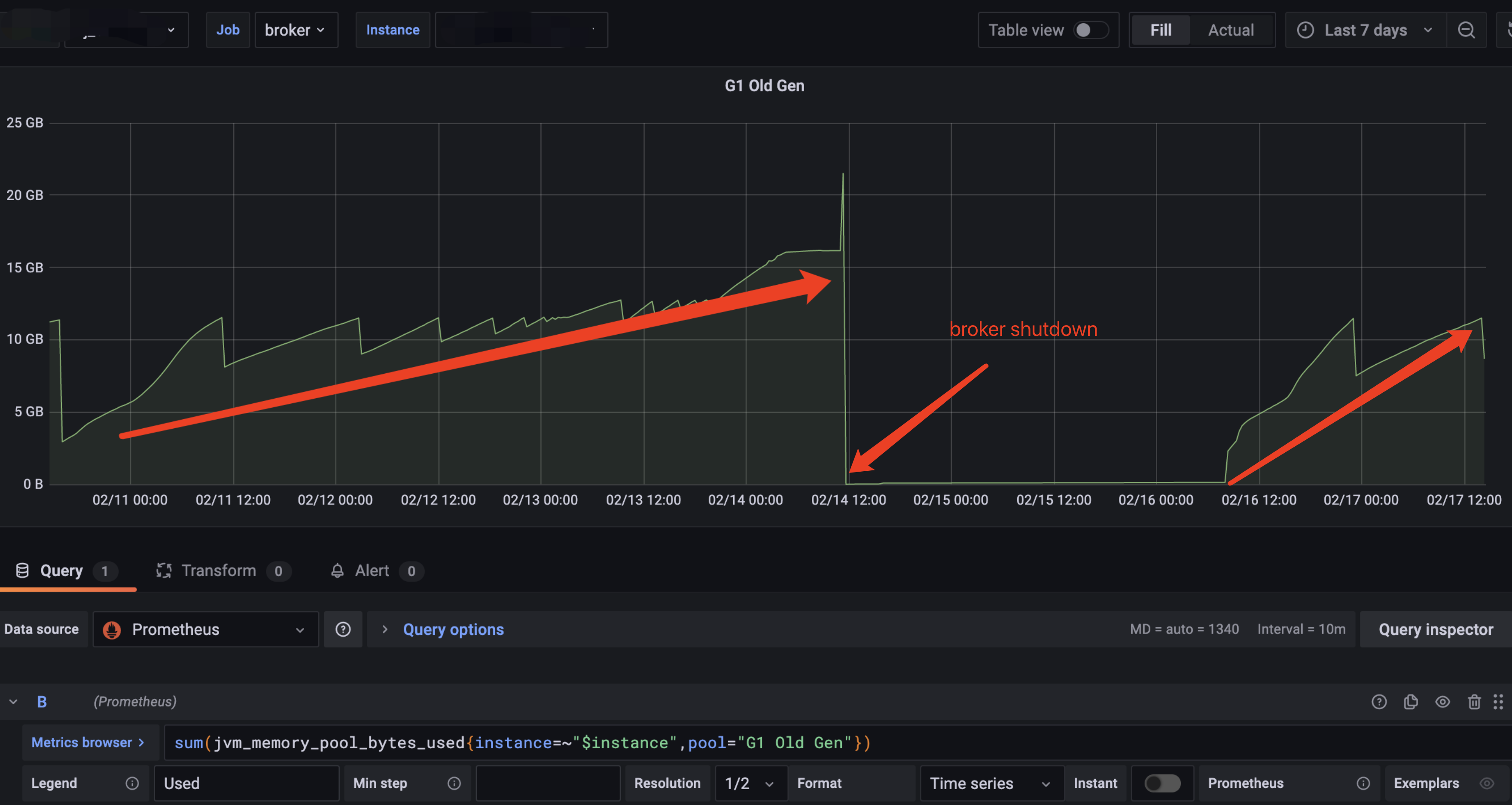
The old age continues to rise until the FULL GC is triggered, which causes the connection between the broker and the zookeeper to time out, and finally causes the pulsar broker process to exit:
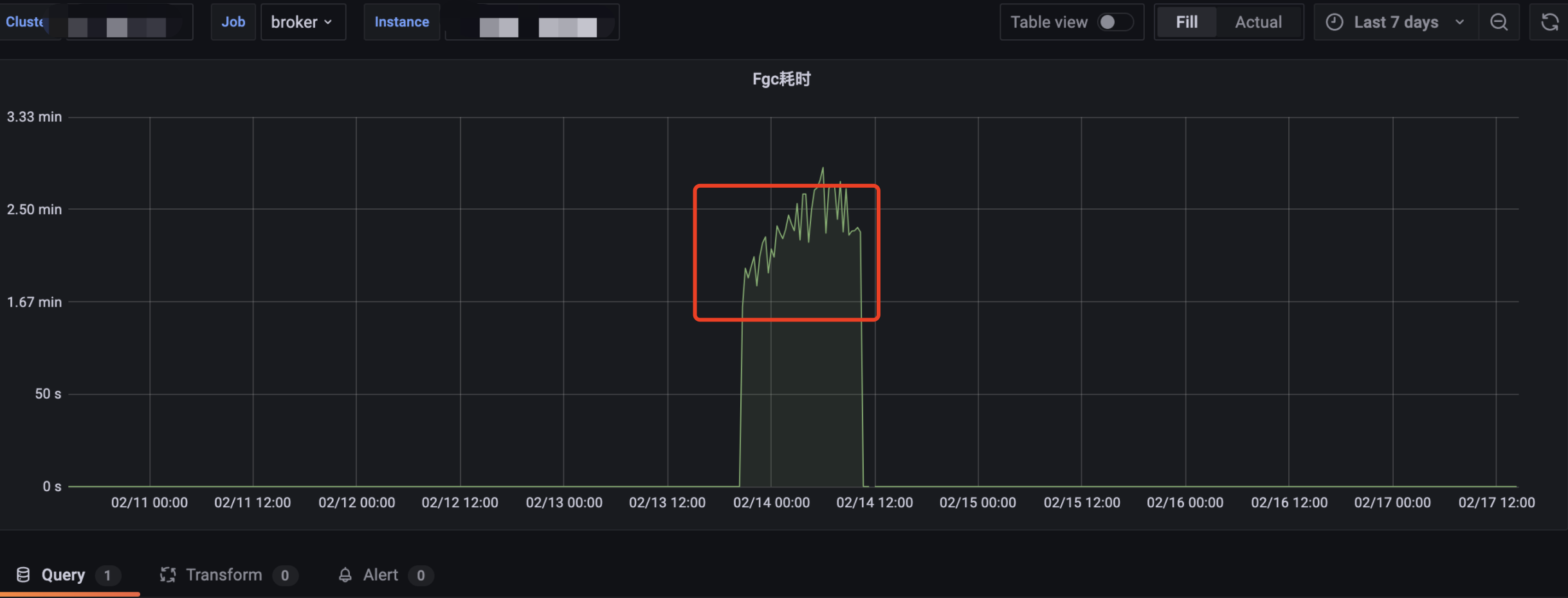
Full GC:
zookkepeer session timeout:
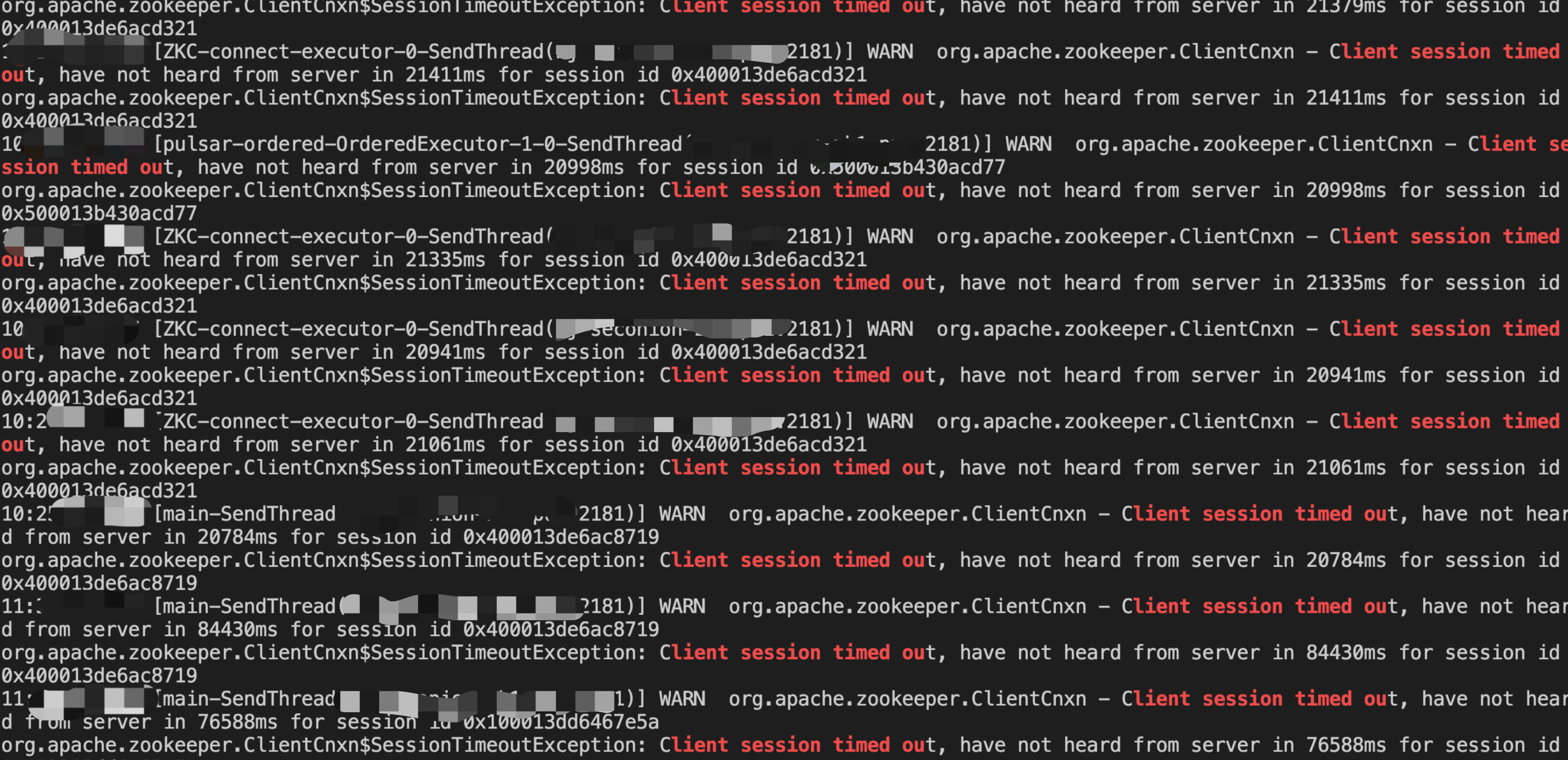
I found that ConcurrentLongLongPairHashMap only supports expansion, not shrinkage, and most of the memory is not used and wasted.
Of course, this structure is used not only in pulsar, but also in the read and write cache of bookkeeper, which will also lead to a lot of memory waste:
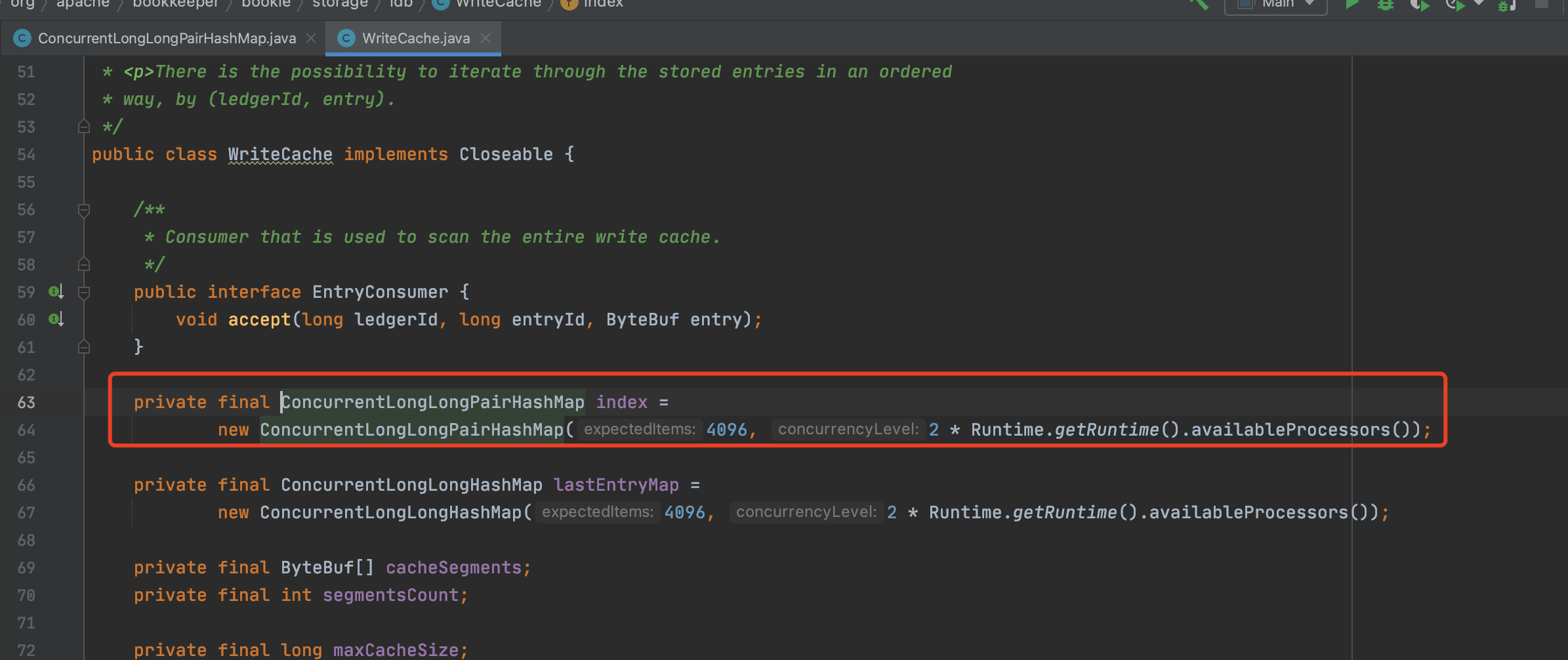
Changes
When removing, judge whether to shrink. If the current use size is less than resizeThresholdBelow, then shrinking is required.
if (size < resizeThresholdBelow) {
try {
// shrink the hashmap
rehash(capacity / 2);
} finally {
unlockWrite(stamp);
}
} else {
unlockWrite(stamp);
}