ORC-1041: Use memcpy during LZO decompression
#958
Conversation
|
Thank you for making a PR, @guiyanakuang . |
|
cc @wgtmac , @stiga-huang , and @williamhyun |
| @@ -312,13 +312,11 @@ namespace orc { | |||
| output += SIZE_OF_INT; | |||
| matchAddress += increment32; | |||
|
|
|||
| *reinterpret_cast<int32_t*>(output) = | |||
| *reinterpret_cast<int32_t*>(matchAddress); | |||
| memcpy(output, matchAddress, SIZE_OF_INT); | |||
There was a problem hiding this comment.
The combination of reinterpret_cast + assignment looks cheaper than memcpy function invocation. I'm wondering if we need to pay some performance penalty here.
There was a problem hiding this comment.
The combination of
reinterpret_cast+assignmentlooks cheaper thanmemcpyfunction invocation. I'm wondering if we need to pay some performance penalty here.
I'll do some performance tests later, repeat_cast + assignment makes direct use of registers, memcpy is usually used for larger copies of data, I'm not sure if it's lossy yet
There was a problem hiding this comment.
The compiler may optimize the memcpy call. BTW, should we wrap a bit_cast function which uses memcpy before C++20 and uses the native one if C++20 is available?
There was a problem hiding this comment.
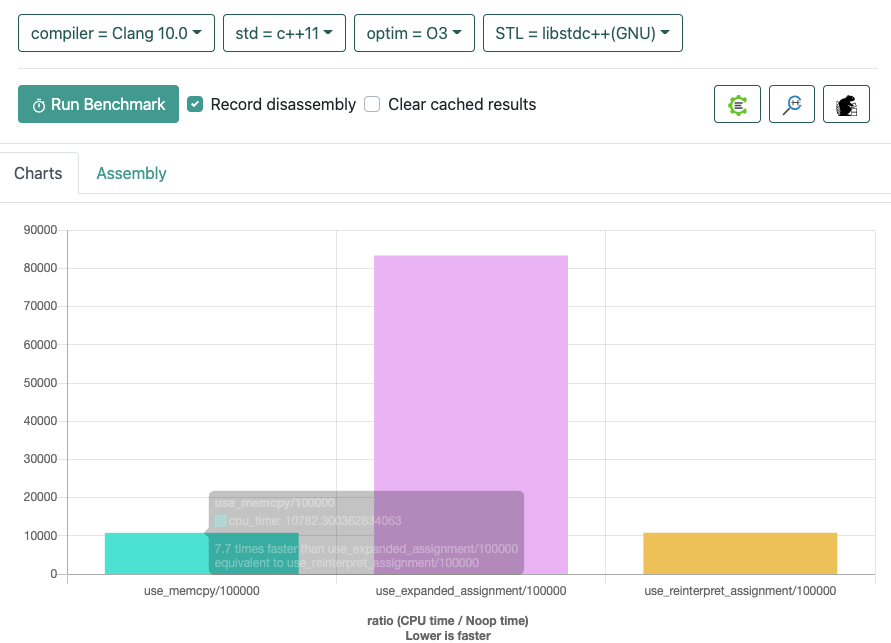
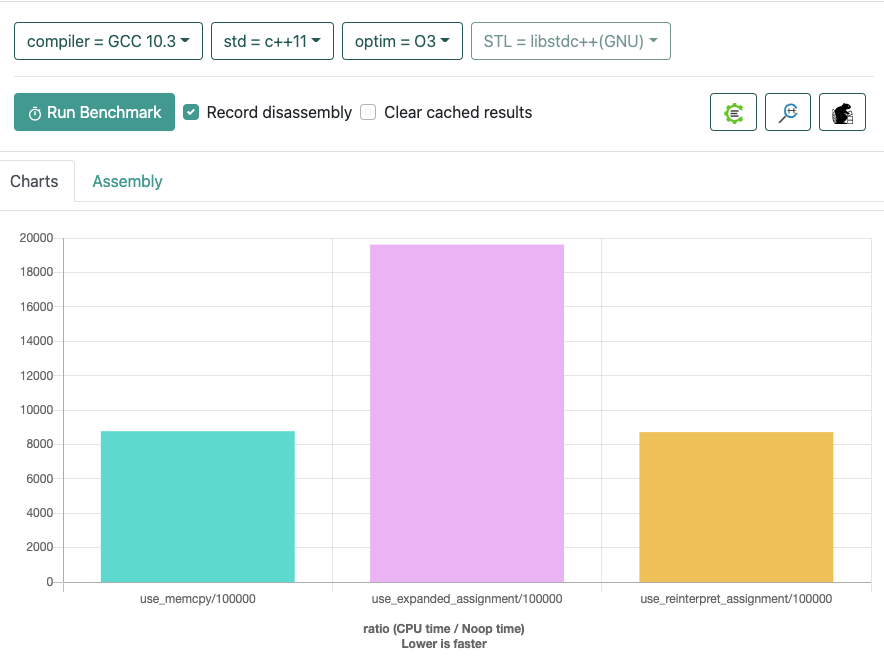
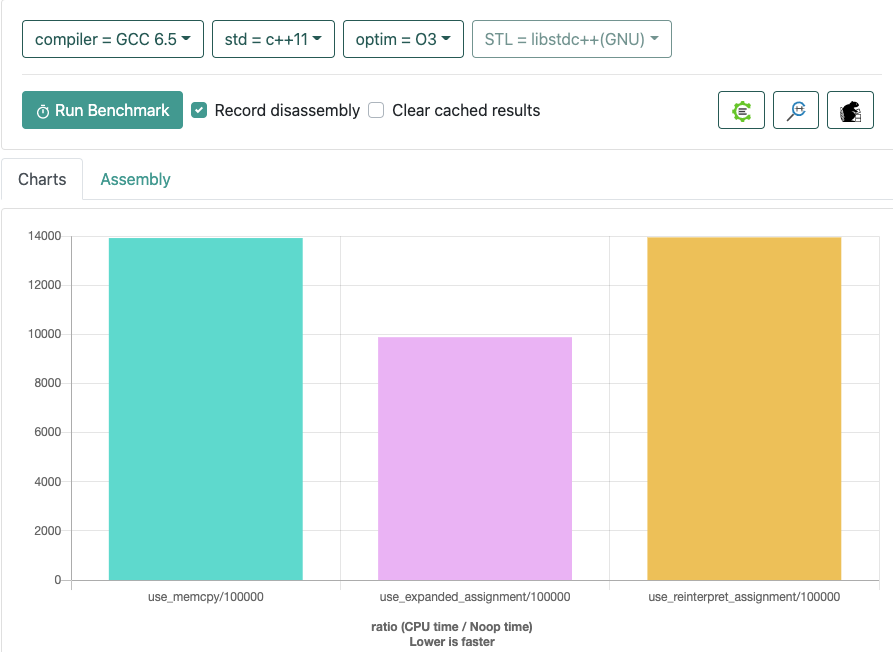
@wgtmac you are right, the compiler does optimize memcpy, the performance of both ways is similar in different compilers, in older versions of the compiler expand the assignment will be faster.
I agree to wrap a bit_cast function for binary copy between different types.
@dongjoon-hyun, So I don't think there's any performance loss here compared to the original.
#include <string.h>
static void use_memcpy(benchmark::State& state) {
auto size = state.range(0);
char buf[size];
for (int i = 0; i < 8; ++i) {
buf[i] = 'a';
}
for (auto _ : state) {
char *output = buf + 8;
char *matchAddress = buf;
char *matchOutputLimit = buf + size;
while (output < matchOutputLimit) {
memcpy(output, matchAddress, 8);
matchAddress += 8;
output += 8;
}
}
}
static void use_expanded_assignment(benchmark::State& state) {
auto size = state.range(0);
char buf[size];
for (int i = 0; i < 8; ++i) {
buf[i] = 'a';
}
for (auto _ : state) {
char *output = buf + 8;
char *matchAddress = buf;
char *matchOutputLimit = buf + size;
while (output < matchOutputLimit) {
output[0] = *matchOutputLimit;
output[1] = *(matchOutputLimit + 1);
output[2] = *(matchOutputLimit + 2);
output[3] = *(matchOutputLimit + 3);
output[4] = *(matchOutputLimit + 4);
output[5] = *(matchOutputLimit + 5);
output[6] = *(matchOutputLimit + 6);
output[7] = *(matchOutputLimit + 7);
matchAddress += 8;
output += 8;
}
}
}
static void use_reinterpret_assignment(benchmark::State& state) {
auto size = state.range(0);
char buf[size];
for (int i = 0; i < 8; ++i) {
buf[i] = 'a';
}
for (auto _ : state) {
char *output = buf + 8;
char *matchAddress = buf;
char *matchOutputLimit = buf + size;
while (output < matchOutputLimit) {
*reinterpret_cast<int64_t*>(output) =
*reinterpret_cast<int64_t*>(matchAddress);
matchAddress += 8;
output += 8;
}
}
}
BENCHMARK(use_memcpy)->Arg(100000);
BENCHMARK(use_expanded_assignment)->Arg(100000);
BENCHMARK(use_reinterpret_assignment)->Arg(100000);There was a problem hiding this comment.
Thanks. Could you put this investigation result into the PR description?
There was a problem hiding this comment.
No problem, I've updated the pr description
|
Do we have one remaining comment to address? |
@wgtmac Do you want to use the wrapped bit_cast in this pr instead of memcpy? |
I am OK not to address the wrapper of bit_cast in this patch. |
@wgtmac Thanks for the review and approval |
There was a problem hiding this comment.
+1, LGTM. Thank you so much, @guiyanakuang and @wgtmac .
BTW, this will be tested more in the branch and released as 1.8.0/1.7.2/1.6.13 to be safe.
Please participate on the current on-going votes without considering this.
memcpy during LZO decompression
|
Also, cc @williamhyun . |
### What changes were proposed in this pull request? This pr is aimed to fix the implementation of copy data blocks during LZO decompression. `*reinterpret_cast< int64_t*>(output) = *reinterpret_cast< int64_t*>(matchAddress);` can lead to unexpected behavior, and in failed test cases it does not appear to be an atomic operation. This pr uses memcpy instead of the above statement. Here are the performance benchmarks, where `memcpy` is basically the same as `reinterpret_cast` + `assignment`. The newer compilers outperform unfolded assignment, so here is a screenshot of the results with only some of the parameters, which you can reproduce with the following test code at https://quick-bench.com/    ```c++ #include <string.h> static void use_memcpy(benchmark::State& state) { auto size = state.range(0); char buf[size]; for (int i = 0; i < 8; ++i) { buf[i] = 'a'; } for (auto _ : state) { char *output = buf + 8; char *matchAddress = buf; char *matchOutputLimit = buf + size; while (output < matchOutputLimit) { memcpy(output, matchAddress, 8); matchAddress += 8; output += 8; } } } static void use_expanded_assignment(benchmark::State& state) { auto size = state.range(0); char buf[size]; for (int i = 0; i < 8; ++i) { buf[i] = 'a'; } for (auto _ : state) { char *output = buf + 8; char *matchAddress = buf; char *matchOutputLimit = buf + size; while (output < matchOutputLimit) { output[0] = *matchOutputLimit; output[1] = *(matchOutputLimit + 1); output[2] = *(matchOutputLimit + 2); output[3] = *(matchOutputLimit + 3); output[4] = *(matchOutputLimit + 4); output[5] = *(matchOutputLimit + 5); output[6] = *(matchOutputLimit + 6); output[7] = *(matchOutputLimit + 7); matchAddress += 8; output += 8; } } } static void use_reinterpret_assignment(benchmark::State& state) { auto size = state.range(0); char buf[size]; for (int i = 0; i < 8; ++i) { buf[i] = 'a'; } for (auto _ : state) { char *output = buf + 8; char *matchAddress = buf; char *matchOutputLimit = buf + size; while (output < matchOutputLimit) { *reinterpret_cast<int64_t*>(output) = *reinterpret_cast<int64_t*>(matchAddress); matchAddress += 8; output += 8; } } } BENCHMARK(use_memcpy)->Arg(100000); BENCHMARK(use_expanded_assignment)->Arg(100000); BENCHMARK(use_reinterpret_assignment)->Arg(100000); ``` ### Why are the changes needed? Fix the bug of LZO decompression. ### How was this patch tested? Pass the CIs. (cherry picked from commit 502661a) Signed-off-by: Dongjoon Hyun <[email protected]>
|
This is backported to branch-1.7 for 1.7.2. |
What changes were proposed in this pull request?
This pr is aimed to fix the implementation of copy data blocks during LZO decompression.
*reinterpret_cast< int64_t*>(output) = *reinterpret_cast< int64_t*>(matchAddress);can lead to unexpected behavior, and in failed test cases it does not appear to be an atomic operation.This pr uses memcpy instead of the above statement.
Here are the performance benchmarks, where
memcpyis basically the same asreinterpret_cast+assignment. The newer compilers outperform unfolded assignment, so here is a screenshot of the results with only some of the parameters, which you can reproduce with the following test code at https://quick-bench.com/Why are the changes needed?
Fix the bug of LZO decompression.
How was this patch tested?
Pass the CIs.