RIP 29 Optimize RocketMQ NameServer
- Current State: Accept
- Authors: RongtongJin
- Shepherds: [email protected], [email protected]
- Mailing List discussion: [email protected]
- Pull Request:
- Released: <relased_version>
- Related Docs: Optimize RocketMQ NameServer
What do we need to do
- Will we add a new module?
No. - Will we add new APIs?
No. - Will we add a new feature?
Yes.
Why should we do that
- Are there any problems of our current project?
Nameserver is a very important component in RocketMQ cluster, which is used for route discovery. At present, the nameserver is stateless and lightweight, but it still bears a certain amount of pressure especially when the cluster reaches a certain scale. RIP-29 will optimize RocketMQ nameserver in rocketmq 5.0 from many aspects.
- What can we benefit from proposed changes?
- By separating the broker registration thread pool and the topic route info acquisition thread pool, we can ensure that different types of requests will not affect each other.
- Optimize topic routing cache to speed up topic routing acquisition, reduce nameserver CPU pressure.
- Unregister brokers in batches to speed up the broker offline.
- What problem is this proposal designed to solve?
Optimize nameserver through various aspects.
- What problem is this proposal NOT designed to solve?
- Add new features to nameserver.
- Affect compatibility
- Are there any limits of this proposal?
Only newer clients with changes in this proposal will benefit.
- Thread pool separation
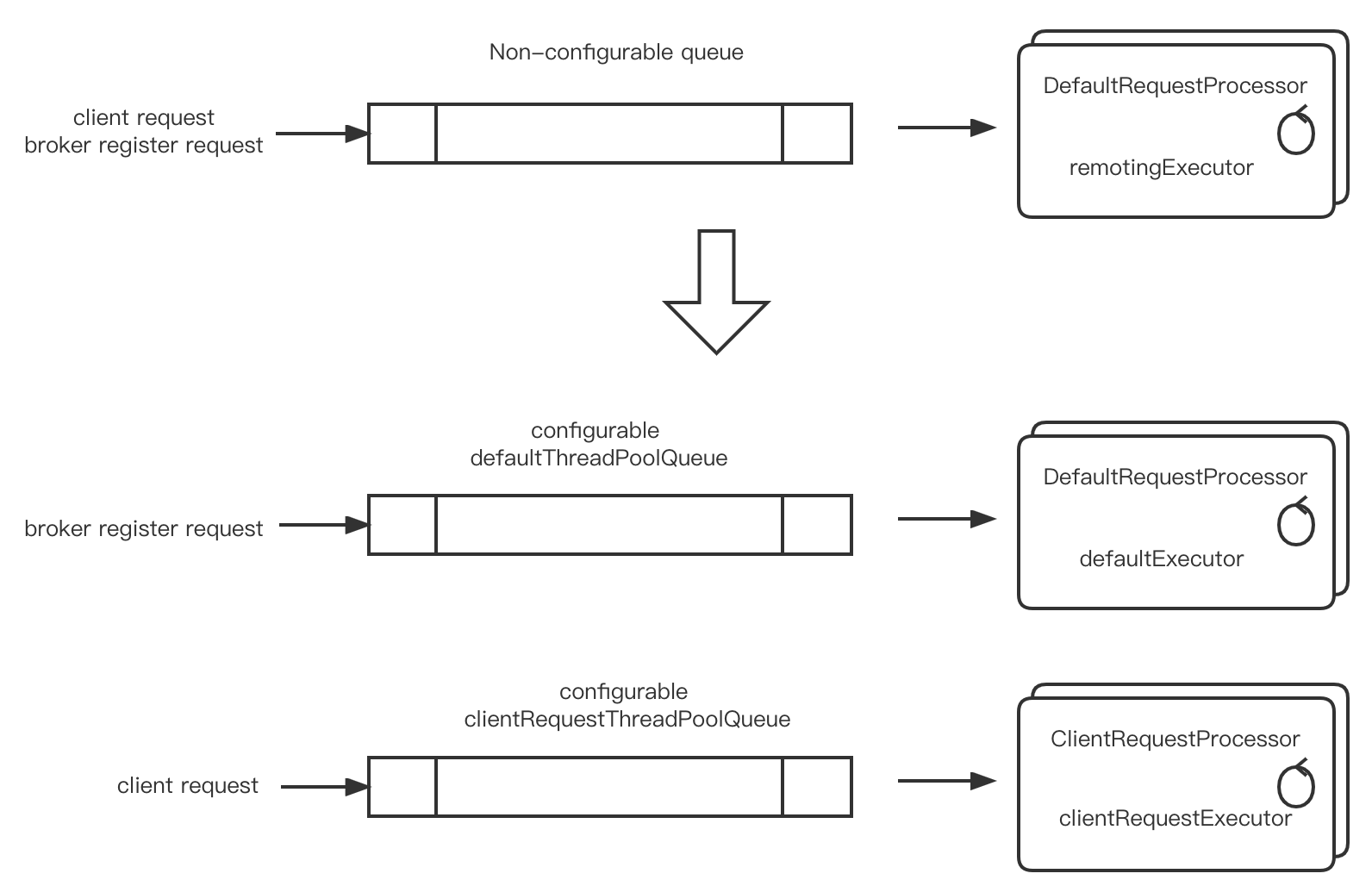
Currently, nameserver uses the same thread pool and queue to process all client routing requests, broker registration requests, and the queue size and a number of threads are not configurable. If one of the types of requests bursts the thread pool, it will affect all requests. RIP-29 isolates the most important client routing requests separately. The size of the queue and the number of threads are configurable. The request processing between the thread pools is isolated from each other and is not affected
- Topic route cache optimization
At present, when the client sends a routing request, the nameserver will use topicQueueTable and brokerAddrTable to construct the final TopicRouteData. This involves traversing the broker in the read lock, which has a certain CPU consumption. RIP-29 directly returns the topic route when requested by the client by constructing the cached of the topic route(topicRouteDataMap). The additional cost is to modify the topicRouteDataMap when the broker register, the broker offline deletes topics, etc. For the nameserver, the read operation is more frequent than the write operation, so the cost is worth it.
- Batch unregister broker in nameserver
Add BatchUnRegisterService to batch processing of broker offline and accelerate the broker offline.
-
Method signature changes
Nothing specific.
-
Method behavior changes
Nothing specific.
-
CLI command changes
Nothing specific.
-
Log format or content changes
Add new log to print nameserver's watermark
-
Are backward and forward compatibility taken into consideration?
Yes, there are no nameserver's functional changes and compatibility issues
-
Are there deprecated APIs?
Nothing specific.
-
How do we do migration?
Upgrade normally, no additional migration required
We will implement the proposed changes by 1 phases.
- Complete the thread pool separation
- Complete topic routing cache optimization
- Batch unregister broker in NameServer
There are no other alternatives.