Better grouped convolution for CPU targets #6137
Conversation
|
cc @anijain2305 @FrozenGene @mbaret @giuseros it would be great if you can help to review the PR |
|
@Wheest please help to fix the CI lint error |
| # pack kernel | ||
| shape = (G, KPG//oc_bn, CPG//ic_bn, | ||
| KH, KW, ic_bn, oc_bn) | ||
| kernel_vec = te.compute(shape, |
There was a problem hiding this comment.
I think we could do this in alter_op_layout for kernel, then we won't need do schedule kernel_vec as it will become tensor when we do inference. Could refer spatial pack of arm conv2d.
There was a problem hiding this comment.
Regarding the issue I was having, I think I misunderstood, and was trying to alter the shape of both the data and the kernel ahead of time. Am making the fix now.
There was a problem hiding this comment.
Hi @FrozenGene, my final blocker to completing this PR is adding the GSPC kernel layout to the C++ runtime. I've got the Python side working, however the alter_op requires the layout to be available in the C++ runtime, and I'm unsure of how to do this.
See this post on the forums where I explain my issue. Would you be able to give any pointers please?
There was a problem hiding this comment.
@merrymercy @minminsun does this issue have the same reason as our auto scheduler layout rewrite issue? Do you have any idea about it?
There was a problem hiding this comment.
Hey @FrozenGene @merrymercy @minminsun, any thoughts on adding custom kernel layouts to the C++ runtime, so that alter_op can have kernels reshaped AoT?
There was a problem hiding this comment.
If this issue cannot be easily resolved, and the pull request be merged without alter_op_layout, and a new PR be made that tracks the issue, and includes my attempts thus far in solving it?
There was a problem hiding this comment.
Yes. Sorry to delay this too long. We could open one issue to tracker it.
There was a problem hiding this comment.
Thanks. I believe I have responded to the issues, and will see when the latest commit passes PR. For the nn.utils.infer_pad issue, it's not being used by any code in TVM, but I will I will be making a discussion on the forums about it, as it could be used in future.
| # schedule data | ||
| if DOPAD: | ||
| s[A0].compute_inline() | ||
| groups, batch, ic_chunk, ih, ic_block, iw = s[A1].op.axis |
There was a problem hiding this comment.
Maybe we should have one compute_at for A1 at CC? Not only just parallel.
|
|
||
| # schedule data | ||
| if DOPAD: | ||
| s[A0].compute_inline() |
There was a problem hiding this comment.
Consider using compute_at and vectorize data load. According to experiment of #6095 (comment), we should have better performance than compute inline directly.
|
Ping for update @FrozenGene @Wheest |
|
@ZihengJiang Have updated linting errors. Have added asymmetric padding support, however this isn't consistent across the rest of TOPI. Have added a new workload type in Have been looking at suggested scheduled improvements, however have not been able to get any improvements to date. Have not yet figured out how to do the kernel packing step in |
|
Sounds good! Just ping the reviewers when you feel it is ready to be reviewed again. Thanks for the works! |
|
Hello there, updating this pull request to be up-to-date with the latest In terms of things remaining to do:
In the interests of more transparent development, here's part of my test suite. |
Sorry, @Wheest I just noticed your mention. Could you give me some spare time to review your code? I could allocate some buffer next week. |
|
Sure thing, thanks for reviewing! You can see my ongoing PR for the asymmetric padding here |
|
We can also try the auto-scheduler. It should deliver very good performance for group convolution. |
|
Hi @merrymercy, I'm just reading about the auto-scheduler now, is the RFC the best learning resource? How does it compare to Ansor? I'm willing to give it a try, though perhaps it would be better to get this PR merged first (since it's providing an immediate and clear performance improvement over the existing solution), and add improvements as another one? |
|
The RFC you mentioned is very old and that project is deprecated. We started another project "Ansor" to bring auto-scheduler for TVM. Ansor is integrated as I totally agree with you we can merge this PR first. |
@Wheest Not very clearly understand you problem. inside this pass, we should only handle kernel layout, not related with data layout. Could you explain it a bit more clearly? |
python/tvm/relay/op/strategy/x86.py
Outdated
| if not is_auto_scheduler_enabled(): | ||
| logger.warning("group_conv2d is not optimized for x86 with autotvm.") | ||
| strategy.add_implementation( | ||
| wrap_compute_conv2d(topi.nn.group_conv2d_nchw, has_groups=True), | ||
| wrap_topi_schedule(topi.generic.schedule_group_conv2d_nchw), | ||
| name="group_conv2d_nchw.generic", | ||
| ) |
There was a problem hiding this comment.
We should compare your implementation performance with auto scheduler. We shouldn't delete auto scheduler support directly.
There was a problem hiding this comment.
What kind of strategy logic would include both? Having this code on an else branch of if not is_auto_scheduler_enabled():? Or something else?
There was a problem hiding this comment.
if not is_auto_scheduler_enabled(): ... We prefer auto scheduler be the default stragegy.
There was a problem hiding this comment.
Current code should now be able to run with auto scheduler by running with "relay.backend.use_auto_scheduler": True, and otherwise using my schedule.
python/tvm/topi/x86/group_conv2d.py
Outdated
|
|
||
| # no stride and padding info here | ||
| padding = infer_pad(data, data_pad) | ||
| hpad, wpad = padding |
There was a problem hiding this comment.
Should this be pad_t, pad_l, pad_b, pad_r?
There was a problem hiding this comment.
We only get hpad and wpad from nn.utils.infer_pad, since this information can't be recovered from data and data_pad alone. This has no effect on the schedule, since we only use it to get the DOPAD variable.
There was a problem hiding this comment.
I think we should fix the issue of nn.utils.infer_pad as we support asymmetric padding for now. Previous nn.utils.infer_pad only return 2 values is the history reason. However, as it doesn't affect performance and correctness, it is up to you to decide whether to support it or not in this pr.
There was a problem hiding this comment.
Thanks, I think I will figure out nn.utils.infer_pad as a separate PR this weekend, since there are a couple of design issues around it that need to be answered.
The conv2d codebase has changed a lot since I last looked at it. I did some digging, and found that the non-grouped version of spatial pack convolution has dropped using nn.utils.infer_pad, so I have updated the GSPC code to follow a similar convention.
python/tvm/relay/op/strategy/x86.py
Outdated
| if not is_auto_scheduler_enabled(): | ||
| logger.warning("group_conv2d is not optimized for x86 with autotvm.") | ||
| strategy.add_implementation( | ||
| wrap_compute_conv2d(topi.nn.group_conv2d_nchw, has_groups=True), | ||
| wrap_topi_schedule(topi.generic.schedule_group_conv2d_nchw), | ||
| name="group_conv2d_nchw.generic", | ||
| wrap_compute_conv2d(topi.x86.group_conv2d_nchw, has_groups=True), | ||
| wrap_topi_schedule(topi.x86.schedule_group_conv2d_nchw), | ||
| name="group_conv2d_nchw.x86", | ||
| ) | ||
| elif layout == "NHWC": | ||
| assert kernel_layout == "HWIO" | ||
| if not is_auto_scheduler_enabled(): | ||
| logger.warning("group_conv2d is not optimized for x86 with autotvm.") | ||
| strategy.add_implementation( | ||
| wrap_compute_conv2d(topi.nn.group_conv2d_nhwc, has_groups=True), | ||
| wrap_topi_schedule(topi.generic.schedule_group_conv2d_nhwc), | ||
| name="group_conv2d_nhwc.generic", | ||
| ) | ||
| strategy.add_implementation( | ||
| wrap_compute_conv2d(topi.nn.group_conv2d_nhwc, has_groups=True), | ||
| wrap_topi_schedule(topi.generic.schedule_group_conv2d_nhwc), | ||
| name="group_conv2d_nhwc.generic", | ||
| ) |
There was a problem hiding this comment.
The fix has bug when we enable auto scheduler. When auto scheduler is enabled, we can not have any compute declaration for auto scheduler, please fix it.
There was a problem hiding this comment.
Bug has been fixed by removing the indentation.
|
@Wheest Seems you have wrong rebase. please refer this documentation : https://tvm.apache.org/docs/contribute/git_howto.html |
Fixed linting
Fixed merge issue
Believe I have fixed the rebase/commit problems, will try to avoid these in future for a cleaner PR. |
|
Thanks @Wheest Merged now |
|
Thanks for helping me through my first PR for a major OSS project @FrozenGene. Have learned a lot, and I hope to be a more productive member of the community in future. |
|
Thank you @Wheest ! and @FrozenGene for sheperding |
* integrated with v0.8 * Rebase, and undoing accidental removal of auto scheduler NHWC support * Added ASF license header * Minor bug fixes * Added asymmetric padding support Fixed linting * Improve linting * Better linting, disable final linting checks * Fixed final linting errors (figured out how to run lint tests locally) * fixing linter formatting part 1 * fixing linter formatting part 2 * fixing linter formatting part 3 * Update conv2d.py Fixed merge issue * Rebase, and update responding to some comments * Fixed AutoScheduler bug for NHWC case * removed infer_pad from GSPC * Rebase, and undoing accidental removal of auto scheduler NHWC support * Added ASF license header * Minor bug fixes * Added asymmetric padding support Fixed linting * Improve linting * Better linting, disable final linting checks * Fixed final linting errors (figured out how to run lint tests locally) * Update conv2d.py Fixed merge issue * Rebase, and update responding to some comments * Fixed AutoScheduler bug for NHWC case * Minor fix * Fixed removal of infer_pad to no padding * Fixed unexpected linting error Co-authored-by: Perry Gibson <[email protected]>
* integrated with v0.8 * Rebase, and undoing accidental removal of auto scheduler NHWC support * Added ASF license header * Minor bug fixes * Added asymmetric padding support Fixed linting * Improve linting * Better linting, disable final linting checks * Fixed final linting errors (figured out how to run lint tests locally) * fixing linter formatting part 1 * fixing linter formatting part 2 * fixing linter formatting part 3 * Update conv2d.py Fixed merge issue * Rebase, and update responding to some comments * Fixed AutoScheduler bug for NHWC case * removed infer_pad from GSPC * Rebase, and undoing accidental removal of auto scheduler NHWC support * Added ASF license header * Minor bug fixes * Added asymmetric padding support Fixed linting * Improve linting * Better linting, disable final linting checks * Fixed final linting errors (figured out how to run lint tests locally) * Update conv2d.py Fixed merge issue * Rebase, and update responding to some comments * Fixed AutoScheduler bug for NHWC case * Minor fix * Fixed removal of infer_pad to no padding * Fixed unexpected linting error Co-authored-by: Perry Gibson <[email protected]>
This pull request is to replace the current grouped direct convolution algorithm on x86 and Arm targets, with the faster Grouped Spatial Pack Convolutions (GSPC) algorithm.
Here's a performance comparison graph for ResNet34 on a single big core of a Hikey 970 as we increase the number of groups:
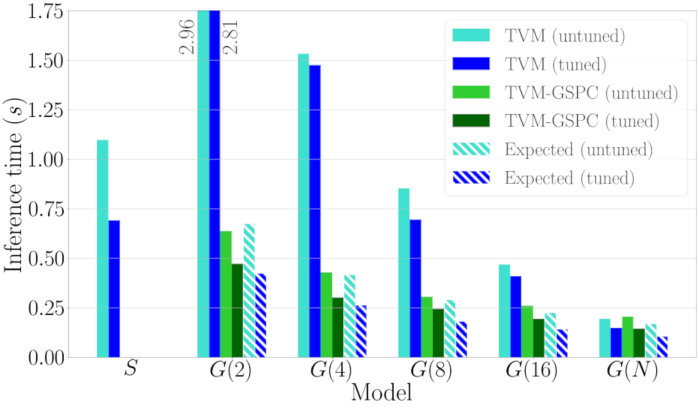
Note that in the untuned case the current depthwise convolution outperforms GSPC, thus I have omitted it from the pull request.
This is my first proper full request to TVM, so I may be have some issues I haven't spotted, or style problems.
In short, this commit adds identical GSPC compute definitions and schedules for x86 and arm_cpu targets for grouped convolutions, as well as updating the Relay operator strategy for each.