-
Notifications
You must be signed in to change notification settings - Fork 997
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #601 from Daydaylight/master
tensors and transforms
- Loading branch information
Showing
5 changed files
with
299 additions
and
0 deletions.
There are no files selected for viewing
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
202 changes: 202 additions & 0 deletions
202
docs/2.0/tutorials/Introduction_to_PyTorch/datasets_dataloaders.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,202 @@ | ||
| # 数据集和数据加载器 | ||
|
|
||
| > 译者:[Daydaylight](https://github.com/Daydaylight) | ||
| > | ||
| > 项目地址:<https://pytorch.apachecn.org/2.0/tutorials/datasets_dataloaders> | ||
| > | ||
| > 原始地址:<https://pytorch.org/tutorials/beginner/basics/data_tutorial.html> | ||
| 处理数据样本的代码可能会变得杂乱无章,难以维护;我们希望我们的数据集代码与我们的模型训练代码分段,以提高可读性和模块化。 | ||
| PyTorch提供了两个数据基元: ``torch.utils.data.DataLoader``和``torch.utils.data.Dataset``。允许你使用预先加载的数据集以及你自己的数据。 | ||
| ``Dataset``存储样本和它们相应的标签,``DataLoader``在``Dataset``基础上添加了一个迭代器,迭代器可以迭代数据集,以便能够轻松地访问``Dataset``中的样本。 | ||
|
|
||
| PyTorch领域库提供了一些预加载的数据集(如FashionMNIST),这些数据集是``torch.utils.data.Dataset``的子类,并实现特定数据的功能。它们可以被用来为你的模型制作原型和基准。你可以找到它们这里:[Image Datasets](https://pytorch.org/vision/stable/datasets.html)、[Text Datasets](https://pytorch.org/text/stable/datasets.html),和[Audio Datasets](https://pytorch.org/audio/stable/datasets.html) | ||
|
|
||
| ##加载一个数据集 | ||
|
|
||
| 下面是一个如何从TorchVision加载[Fashion-MNIST](https://research.zalando.com/project/fashion_mnist/fashion_mnist/)数据集的例子。 | ||
| Fashion-MNIST是一个由60,000个训练实例和10,000个测试实例组成的Zalando的文章图像数据集。 | ||
| 每个例子包括一个28×28的灰度图像和10个类别中的一个相关标签。 | ||
| 我们加载 [FashionMNIST Dataset](https://pytorch.org/vision/stable/datasets.html#fashion-mnist) ,参数如下: | ||
| - ``root`` 是存储训练/测试数据的路径, | ||
| - ``train`` 指定训练或测试数据集, | ||
| - ``download=True`` 如果``root``没有数据,就从网上下载数据。 | ||
| - ``transform`` 和 ``target_transform`` 指定特征和标签的转换。 | ||
|
|
||
| ```py | ||
| import torch | ||
| from torch.utils.data import Dataset | ||
| from torchvision import datasets | ||
| from torchvision.transforms import ToTensor | ||
| import matplotlib.pyplot as plt | ||
|
|
||
|
|
||
| training_data = datasets.FashionMNIST( | ||
| root="data", | ||
| train=True, | ||
| download=True, | ||
| transform=ToTensor() | ||
| ) | ||
|
|
||
| test_data = datasets.FashionMNIST( | ||
| root="data", | ||
| train=False, | ||
| download=True, | ||
| transform=ToTensor() | ||
| ) | ||
| ``` | ||
|
|
||
| ## 迭代和可视化数据集 | ||
|
|
||
| 我们可以像列表一样手动索引``Datasets``:``training_data[index]``。 | ||
| 我们使用``matplotlib``来可视化我们训练数据中的一些样本。 | ||
|
|
||
| ```py | ||
| labels_map = { | ||
| 0: "T-Shirt", | ||
| 1: "Trouser", | ||
| 2: "Pullover", | ||
| 3: "Dress", | ||
| 4: "Coat", | ||
| 5: "Sandal", | ||
| 6: "Shirt", | ||
| 7: "Sneaker", | ||
| 8: "Bag", | ||
| 9: "Ankle Boot", | ||
| } | ||
| figure = plt.figure(figsize=(8, 8)) | ||
| cols, rows = 3, 3 | ||
| for i in range(1, cols * rows + 1): | ||
| sample_idx = torch.randint(len(training_data), size=(1,)).item() | ||
| img, label = training_data[sample_idx] | ||
| figure.add_subplot(rows, cols, i) | ||
| plt.title(labels_map[label]) | ||
| plt.axis("off") | ||
| plt.imshow(img.squeeze(), cmap="gray") | ||
| plt.show() | ||
| ``` | ||
|
|
||
|  | ||
|
|
||
| ## 为你的文件创建一个自定义数据集 | ||
|
|
||
| 一个自定义的数据集类必须实现三个函数: `__init__`, `__len__`, 和 `__getitem__`。 | ||
| 看看这个实现;FashionMNIST的图片被存储在一个`img_dir'`的目录中,而它们的标签则分别存储在一个CSV文件``annotations_file`中。 | ||
|
|
||
| 在接下来的章节中,我们将分解这些函数中的每一个发生了什么。 | ||
|
|
||
| ```py | ||
| import os | ||
| import pandas as pd | ||
| from torchvision.io import read_image | ||
|
|
||
| class CustomImageDataset(Dataset): | ||
| def __init__(self, annotations_file, img_dir, transform=None, target_transform=None): | ||
| self.img_labels = pd.read_csv(annotations_file) | ||
| self.img_dir = img_dir | ||
| self.transform = transform | ||
| self.target_transform = target_transform | ||
|
|
||
| def __len__(self): | ||
| return len(self.img_labels) | ||
|
|
||
| def __getitem__(self, idx): | ||
| img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) | ||
| image = read_image(img_path) | ||
| label = self.img_labels.iloc[idx, 1] | ||
| if self.transform: | ||
| image = self.transform(image) | ||
| if self.target_transform: | ||
| label = self.target_transform(label) | ||
| return image, label | ||
| ``` | ||
|
|
||
| ### __init__ | ||
|
|
||
| 在实例化数据集对象时,__init__函数被运行一次。我们初始化包含图像的目录、注释文件和两种转换(下一节将详细介绍)。 | ||
|
|
||
| 标签.csv文件看起来像: | ||
|
|
||
| ```py | ||
| tshirt1.jpg, 0 | ||
| tshirt2.jpg, 0 | ||
| ...... | ||
| ankleboot999.jpg, 9 | ||
|
|
||
| ``` | ||
|
|
||
| ```py | ||
| def __init__(self, annotations_file, img_dir, transform=None, target_transform=None): | ||
| self.img_labels = pd.read_csv(annotations_file) | ||
| self.img_dir = img_dir | ||
| self.transform = transform | ||
| self.target_transform = target_transform | ||
| ``` | ||
|
|
||
| ### __len__ | ||
|
|
||
| 函数__len__返回我们数据集中的样本数。 | ||
|
|
||
| Example: | ||
|
|
||
| ```py | ||
| def __len__(self): | ||
| return len(self.img_labels) | ||
| ``` | ||
| ### __getitem__ | ||
|
|
||
| 函数 __getitem__ 从数据集中给定的索引``idx``处加载并返回一个样本。根据索引,它确定图像在磁盘上的位置,用``read_image``将其转换为张量,从``self.img_labels``的csv数据中获取相应的标签。从``self.img_labels``中的csv数据中获取相应的标签,对它们调用transform函数(如果适用),并返回张量图像和相应的标签的元组。 | ||
|
|
||
| ```py | ||
| def __getitem__(self, idx): | ||
| img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) | ||
| image = read_image(img_path) | ||
| label = self.img_labels.iloc[idx, 1] | ||
| if self.transform: | ||
| image = self.transform(image) | ||
| if self.target_transform: | ||
| label = self.target_transform(label) | ||
| return image, label | ||
| ``` | ||
|
|
||
| ## 用DataLoaders准备你的数据进行训练 | ||
|
|
||
| ``Dataset``每次检索一个我们数据集的特征和标签样本。在训练一个模型时,我们通常希望以 "小批量 "的方式传递样本,在每个周期重新洗牌数据以减少模型的过拟合,并使用Python的``multiprocessing``来加快数据的检索速度。 | ||
|
|
||
| `DataLoader'是一个可迭代的,它用一个简单的API为我们抽象出这种复杂性。 | ||
|
|
||
| ```py | ||
| from torch.utils.data import DataLoader | ||
|
|
||
| train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) | ||
| test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True) | ||
| ``` | ||
|
|
||
| ## 遍历DataLoader | ||
|
|
||
| 我们已经将该数据集加载到``DataLoader``中,并可以根据需要迭代该数据集。下面的每次迭代都会返回一批``train_features``和``train_labels``(分别包含``batch_size=64``的特征和标签)。因为我们指定了``shuffle=True``,在我们遍历所有批次后,数据会被洗牌(为了更精细地控制数据加载顺序的精细控制,请看[Samplers](https://pytorch.org/docs/stable/data.html#data-loading-order-and-sampler))。 | ||
|
|
||
| ```py | ||
| # 显示图像和标签。 | ||
| train_features, train_labels = next(iter(train_dataloader)) | ||
| print(f"Feature batch shape: {train_features.size()}") | ||
| print(f"Labels batch shape: {train_labels.size()}") | ||
| img = train_features[0].squeeze() | ||
| label = train_labels[0] | ||
| plt.imshow(img, cmap="gray") | ||
| plt.show() | ||
| print(f"Label: {label}") | ||
| ``` | ||
|
|
||
| 输出: | ||
|
|
||
| 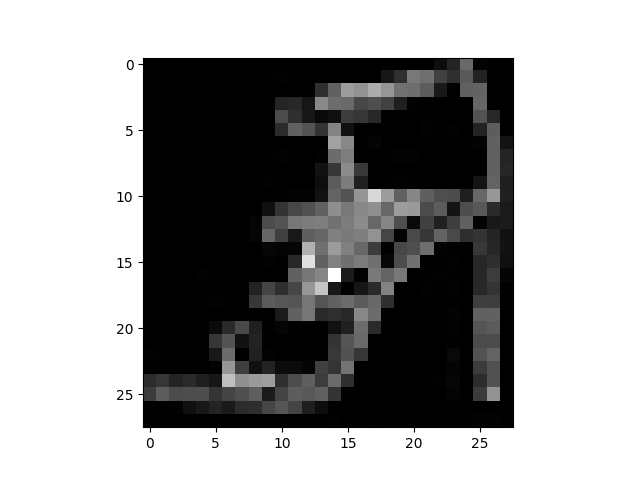 | ||
|
|
||
| ```py | ||
| Feature batch shape: torch.Size([64, 1, 28, 28]) | ||
| Labels batch shape: torch.Size([64]) | ||
| Label: 5 | ||
| ``` | ||
|
|
||
| ## 阅读更多 | ||
| - [torch.utils.data API](https://pytorch.org/docs/stable/data.html) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,95 @@ | ||
| # TRANSFORMS | ||
|
|
||
| > 译者:[Daydaylight](https://github.com/Daydaylight) | ||
| > | ||
| > 项目地址:<https://pytorch.apachecn.org/2.0/tutorials/transforms> | ||
| > | ||
| > 原始地址:<https://pytorch.org/tutorials/beginner/basics/transforms_tutorial.html> | ||
| 数据并不总是以训练机器学习算法所需的最终处理形式出现。我们使用变换来对数据进行一些处理,使其适合训练。 | ||
|
|
||
| 所有的TorchVision数据集都有两个参数-``transform``用于修改特征和``target_transform``用于修改标签,它们接受包含转换逻辑的callables。[torchvision.transforms](https://pytorch.org/vision/stable/transforms.html)模块提供了几个常用的转换,开箱即用。 | ||
| FashionMNIST的特征是PIL图像格式,而标签是整数。对于训练,我们需要将特征作为归一化的张量,将标签作为一热编码的张量。 | ||
| 为了进行这些转换,我们使用 "ToTensor "和 "Lambda"。 | ||
|
|
||
| ```py | ||
| import torch | ||
| from torchvision import datasets | ||
| from torchvision.transforms import ToTensor, Lambda | ||
|
|
||
| ds = datasets.FashionMNIST( | ||
| root="data", | ||
| train=True, | ||
| download=True, | ||
| transform=ToTensor(), | ||
| target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1)) | ||
| ) | ||
| ``` | ||
|
|
||
| 输出: | ||
|
|
||
| ```py | ||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz | ||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz | ||
|
|
||
| 0%| | 0/26421880 [00:00<?, ?it/s] | ||
| 0%| | 65536/26421880 [00:00<01:12, 361690.02it/s] | ||
| 1%| | 229376/26421880 [00:00<00:38, 679756.53it/s] | ||
| 2%|2 | 655360/26421880 [00:00<00:14, 1775435.30it/s] | ||
| 7%|6 | 1736704/26421880 [00:00<00:06, 3785228.35it/s] | ||
| 15%|#4 | 3833856/26421880 [00:00<00:02, 8223694.86it/s] | ||
| 21%|##1 | 5570560/26421880 [00:00<00:02, 9088903.43it/s] | ||
| 32%|###1 | 8454144/26421880 [00:01<00:01, 13772389.09it/s] | ||
| 39%|###9 | 10420224/26421880 [00:01<00:01, 13068367.31it/s] | ||
| 50%|##### | 13238272/26421880 [00:01<00:00, 16440554.97it/s] | ||
| 58%|#####7 | 15269888/26421880 [00:01<00:00, 14938744.03it/s] | ||
| 68%|######8 | 18055168/26421880 [00:01<00:00, 17703674.30it/s] | ||
| 76%|#######6 | 20119552/26421880 [00:01<00:00, 15854480.37it/s] | ||
| 87%|########6 | 22904832/26421880 [00:01<00:00, 18366169.37it/s] | ||
| 95%|#########4| 25034752/26421880 [00:01<00:00, 16404116.31it/s] | ||
| 100%|##########| 26421880/26421880 [00:02<00:00, 13106029.06it/s] | ||
| Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/raw | ||
|
|
||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz | ||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz | ||
|
|
||
| 0%| | 0/29515 [00:00<?, ?it/s] | ||
| 100%|##########| 29515/29515 [00:00<00:00, 326257.67it/s] | ||
| Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw | ||
|
|
||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz | ||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz | ||
|
|
||
| 0%| | 0/4422102 [00:00<?, ?it/s] | ||
| 1%|1 | 65536/4422102 [00:00<00:12, 362747.74it/s] | ||
| 5%|5 | 229376/4422102 [00:00<00:06, 681864.40it/s] | ||
| 15%|#4 | 655360/4422102 [00:00<00:02, 1798436.42it/s] | ||
| 40%|#### | 1769472/4422102 [00:00<00:00, 3872995.18it/s] | ||
| 79%|#######9 | 3506176/4422102 [00:00<00:00, 7404355.18it/s] | ||
| 100%|##########| 4422102/4422102 [00:00<00:00, 5422111.79it/s] | ||
| Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw | ||
|
|
||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz | ||
| Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz | ||
|
|
||
| 0%| | 0/5148 [00:00<?, ?it/s] | ||
| 100%|##########| 5148/5148 [00:00<00:00, 35867569.75it/s] | ||
| Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw | ||
| ``` | ||
|
|
||
| ## ToTensor() | ||
|
|
||
| [ToTensor](https://pytorch.org/vision/stable/transforms.html#torchvision.transforms.ToTensor)将PIL图像或NumPy的``ndarray``转换为``FloatTensor``。图像的像素强度值在[0., 1.]范围内缩放。 | ||
|
|
||
| ## Lambda Transforms | ||
|
|
||
| Lambda transforms 应用任何用户定义的lambda函数。在这里,我们定义了一个函数来把整数变成一个单热编码的张量。 | ||
| 它首先创建一个大小为10(我们数据集中的标签数量)的零张量,然后调用[scatter_](https://pytorch.org/docs/stable/generated/torch.Tensor.scatter_.html) ,指定了一个``value=1``在标签``y``所给的索引上。 | ||
|
|
||
| ```py | ||
| target_transform = Lambda(lambda y: torch.zeros( | ||
| 10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1)) | ||
| ``` | ||
|
|
||
| ### 阅读更多 | ||
| - [torchvision.transforms API](https://pytorch.org/vision/stable/transforms.html) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
2d1b09fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Successfully deployed to the following URLs:
pytorch-doc-zh – ./
pytorch-doc-zh.vercel.app
pytorch-doc-zh-apachecn.vercel.app
pytorch-doc-zh-git-master-apachecn.vercel.app