Stock price is a small project generating random prices of Bovespa stocks and its goal is to guide my studies using Kafka ecosystem.
![]()
Simply put, Apache Kafka is a kind of merge between message queue and publish-subscribe message patterns, and both part of a larger message-oriented middleware system.
Kafka is a distributed stream-processing platform designed to provide high-throughput, low-latency platform for handling real-time data feeds. It is heavily influenced by transaction logs (history of actions executed by RDBMS to guarantee ACID transactions).
What does that mean? It is like a log file, an append-only system ordered by time. Every incoming record is appended to the end of the "file" (log) and consumers read from left to right.
 Records are published into topics and each topic can have one or more partitions. And each partition is an ordered and immutable sequence of events that is appended to.
Every record in the partition is assigned a sequential id number called offset which uniquely identifies that record inside a partition.
Records are published into topics and each topic can have one or more partitions. And each partition is an ordered and immutable sequence of events that is appended to.
Every record in the partition is assigned a sequential id number called offset which uniquely identifies that record inside a partition.
Kafka records are durable using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space.
Performance is effectively constant with respect to data size so storing data for a long time is not a problem. Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
Partitions of a topic are distributed over the servers in a Kafka cluster and they are replicated to handle fault tolerance (configurable number of replicas).
Producers publish data to topics. The producer is responsible for choosing the partition in a topic where it wants to publish. This can be done in a round-robin fashion to balance load or according to some specific semantic, like data-affinity where some keys go to a specific partition.
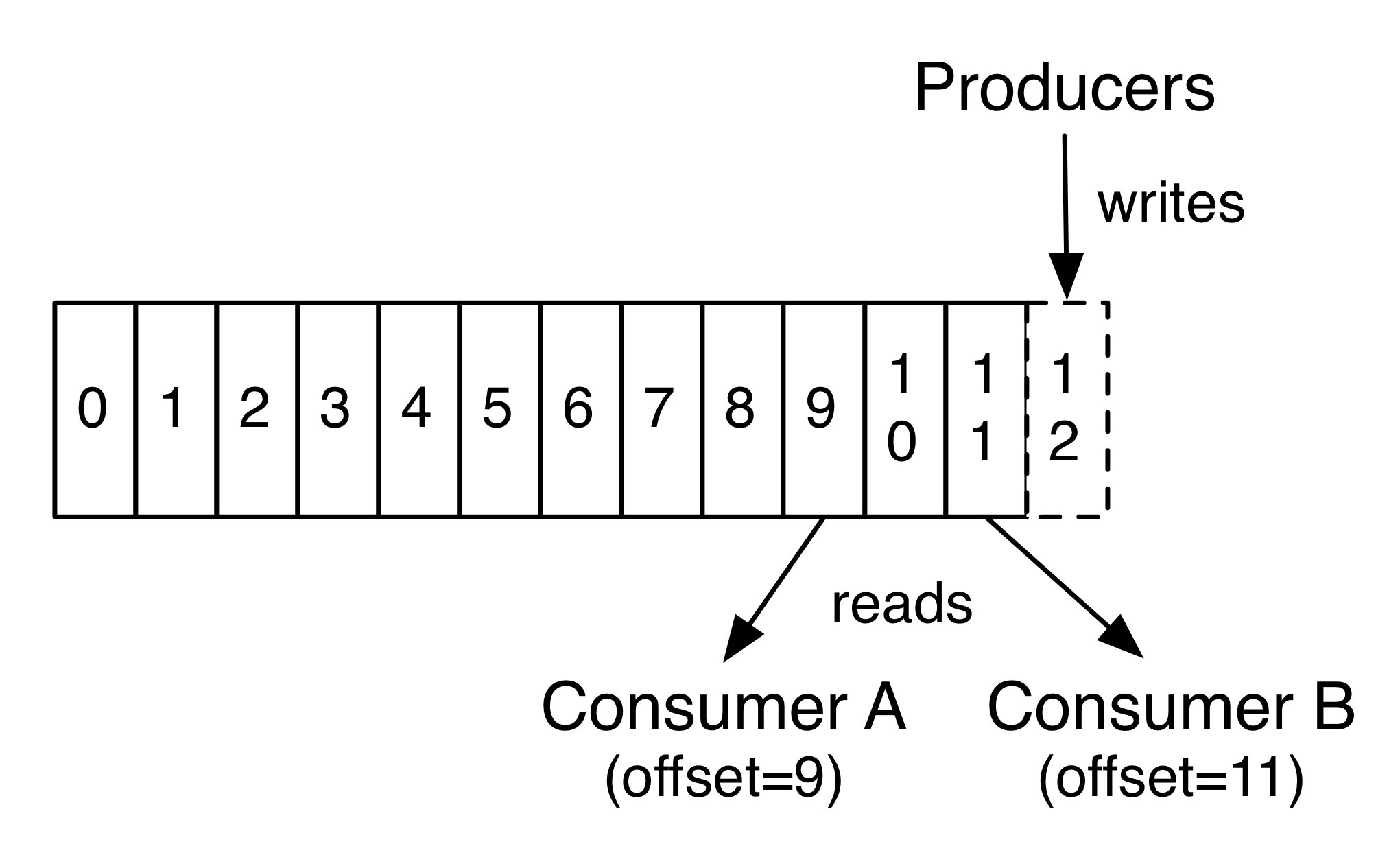
Consumers live in a consumer group and each record published on a topic is delivered to only one consumer within a consumer group.

After downloading Kafka and setting it up, use the following commands:
- Start ZooKeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties - Start Kafka:
bin/kafka-server-start.sh config/server.properties - Run
MainAppStockPriceProducer.java - Run
MainAppStockPriceConsumer.java
- Replace Jackson by Avro aiming to improve serialization speed
- Too many things to list here :P
- Java 10
- Scala 2.12
- Apache Kafka version 1.1.0