Discussion: advantage to using sync over async for I/O? #15963
Comments
|
One more important note. You're effectively telling me to implement .NET's Open(), a sync API, by internally calling an async method and waiting on it. This is a scenario discussed (and warned against) by Stephen Toub: http://blogs.msdn.com/b/pfxteam/archive/2012/04/13/10293638.aspx |
|
One additional reaction to something you said before:
That certainly seems true in a single application that's totally within my control, but what happens in a large complex concurrent application using several 3rd-party libraries which themselves may or may not rely on the TP? It can easily become complicated to to manage this and understand the exact TP needs across everything... At the end of the day, async APIs introduce a dependency on a global shared resource (the TP) which sync APIs don't have... Any comments on all this? |
You raise a valid concern, Note, that in .NET the TP (e.g ThreadPool Class) actually abstracts two "Thread Pool" implementations: A Managed Work Queue as well as various unrelated methods to bind IOCP callbacks with the Win32 Native ThreadPool The Socket API will invoke the callbacks using the Native ThreadPool worker thread. If you can guarantee (which I doubt) that users of your library won't abuse your callback context with cpu bound work than an alternative approach would be to have the Socket library provide the ability to bind with a dedicated user-defined (or framework created) Native Win32 ThreadPool. This is by the way how it's tackled in Native Win32 application development but again, the assumption here is that the usage of the dedicated ThreadPool is not abused by its caller. I agree that having a Sync API has it's benefits in certain situations - we don't live in a perfect world. Furthermore, putting aside async theory, Windows scheduler is super optimized and I recall reading some time ago a benchamrk for ASP.NET that showed Sync request handling actually outperformed async/await requests handling, I didn't have a chance to investigate this therefore you should judge this yourself, try searching for it online. |
|
Actually, the benchmark showed sync outperforming async in a client side test which is more relevant to this issue. Here is the link: http://www.ducons.com/blog/tests-and-thoughts-on-asynchronous-io-vs-multithreading |
|
@clrjunkie thanks for the added info and the benchmark! @CIPop @stephentoub any comments here? |
|
Just wondering if there are any reactions to the above discussion... |
|
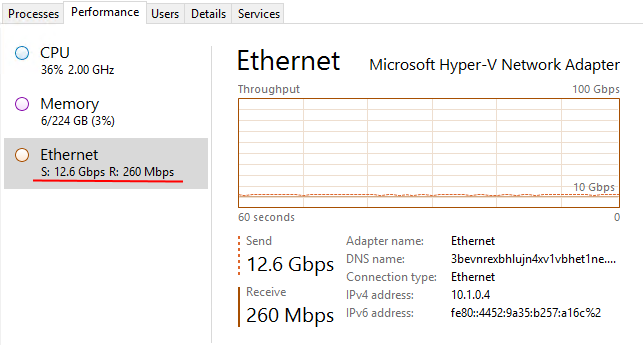
@clrjunkie that test is quite a bad implementation of both sync and async (async void with no coordination) and they aren't comparing the same or best approaches for both. Also 57 second to execute 1M requests is fairly slow; since the aspnet5 Kestrel Server using purely async/await methods will both happily execute over 1M requests in under a second for small requests: And crush a 10GbE network for large requests on (Azure G4 Windows VM -> Linux VM) All using coreclr x64 and pure managed async/await and asynchronous I/O |
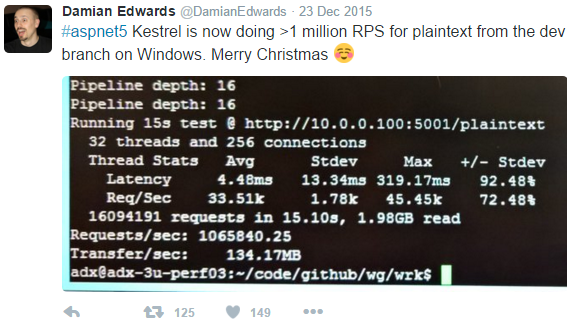
@roji the Task returning "async" method doesn't have to actually be async; it can just return a cached precompleted Task (like Task.CompletedTask) or ValueTask for returned values if it is mostly sync; or a cached result Task if it mostly returns the same value. Some good tips here https://channel9.msdn.com/Series/Three-Essential-Tips-for-Async/Async-libraries-APIs-should-be-chunky Sync methods are good for things that really are sync; but sync blocking apis aren't good. |
What do you mean by “quite bad”? Have you tried to apply the best approaches to the test code to see if they make any change to the final outcome?
I’m well aware of the TechEmpower Benchmark (e.g “Stress Test”) and Wrk (more than year) and suffice to say that aside from two points I’m not a big fan. I share the opinion of others that such benchmarks do not represent real world scenarios (see https://webtide.com/jetty-in-techempower-benchmarks/) Furthermore, there are many obvious points of concern for a production webserver that are not measured in this benchmark that have direct impact on performance but I currently don’t have the time to discuss them (although I think a serious discussion should take place). Saying that, there are two things I do find interesting about the stress tests 1) It tests if whether your code crashes during high load 2) it shows you what impact doing ‘new’ all over the place has and I consider the whole RPS thing as natural side effect, but looking at the bigger picture to me it’s not interesting. Quite frankly, I’m a bit disappointed that MS decided to participate in this race as I think it’s a marketing honey pot. It’s funny that when you look into the results that start remotely to resemble a real system test with a DB, then the difference between the top runner and the "old" ASP.NET is negligible.
Furthermore, I think @roji main concern is about a non-pipelining request/response exchange pattern so I don’t think the wrk pipelining test result that pass 50 - 100 bytes per request back and forth is applicable here, or to the majority of uses cases for that matter. Food for thought: Can you prove that for each request generated by wrk you actually get a full valid response containing all the bits the server sent? p.s To avoid any doubt I don't suggest that your optimization efforts are not important. I simply don’t agree with, well with the benchmark as well as the importance put on an RPS that changes instantly once you add a small requirement or slightly change the test environment. I simply don't think this is serious.. |

Its very much an apples and oranges comparison. The throttling in the async was achieved by limiting the connections with ServicePoint which is not simple (see FindConnection and SubmitRequest when over the limits) so queuing on threadpool vs queuing on ServicePoint is what's mostly being tested here; the threadpool being far more efficient and the threadpool is what async uses for its general use.
Also my point had nothing particularly to do with the TechEmpower Benchmarks. It was that non-blocking async I/O is not slow in .NET and you aren't loosing anything in perf by comparison to the time taken by the actual I/O (similar to your raw response vs response w/ db point). It is also hugely more scalable than (sync) blocking I/O; in fact that is one of the issue with the benchmark you linked to. It is 1M requests and the sync blocking is limited by how many requests it can process at one time as its throttled by the threadpool. One the other hand the async doesn't have that limit so it can send all the requests fairly concurrently (depending on RTT); which will probably additionally make the server unhappy; and then memory issues observed wil arise because so many responses arrive back at the same time.
The 12.6 GBps throughput screenshotted was from sending 300kB per request, non-pipelined, to 1000 connections which is half the page weight of for example the Angularjs or 60% of the npm homepage to pick two. So fits more with a "real world" scenario. Granted if you talk to a db that will be your bottleneck, but webserver generally does a lot more than that; whether its through memory caching, serving html+img+js; streaming videos, downloading files etc
Since I raised the criticism, I'll see if I can present a better approach - will get back to you. Caveat If there is no async, or blocking component (e.g. only cpu bound work) then sync is better than async Related async vs sync testing to ensure the server holds up some, for people that do use sync I/O aspnet/KestrelHttpServer#589 (comment) |
Maybe.. since I didn’t write the benchmark I’m reluctant to accept various explanations. However, since the author compared two approaches using out of box framework facilities one would reasonably expect a noticeable improvement in the client side test and not “because”; thus my initial remark “putting aside async theory”. The whole point of the link was to bring attention to the fact that an async api by itself says nothing about performance if the underlying implementation doesn’t deliver upon it.
Ye’h but it kinda slipped in… The 1M rps you mentioned was linked to Damian post and as far as I understand he uses or is inspired by the TechEmpower scenarios. Know any different for this particular test? https://github.com/aspnet/benchmarks
I didn’t say nor did I suggest that you are losing anything in perf by comparison to the time taken by the actual I/O. The players here are: .NET Async support, which depends on compiler generated code, threadpool implementation, o/s signaling implementation Vs. Sync support, which includes use of the Thread library and the O/S scheduler – a facility that is heavily optimized for fast context switching between many threads.
See first response above.
Nothing is “real world” with a burst test on pre setup connections, unless you consider DDOS the common scenario. The 12.6 GBps figure doesn’t say much as it aggregates protocol level headers etc.. All I can conclude from this figure by doing a ridiculously naïve calculation is that the server processed 44040/rps of such requests which is 44/rps per connection (1KB = 1024B). What does this have to do with a Sync? Did you see if a server backed by a 1000 thread threadpool shows substantially lower earth shattering results? Loading Angularjs front page generates 53 distinct requests on EDGE empty cache, even it reuses Keep-Alive connection I don’t see what’s the takeaway or how you correlate it to your test.
But it’s generally on the path… unless you’re after “geocities” style websites (gosh I miss those :) Anyway I think this whole performance discussion is completely deviating from the main concern of this issue which is single threadpool pressure. |
Can't currently manually increase the threadpool in coreclr https://github.com/dotnet/coreclr/issues/1606 & https://github.com/dotnet/cli/issues/889 and if you try 1000 connections the server out of the box it crawls. Obviously there aren't 1000 thread pool threads to start with; would have to jam the server for 16 min to create them. |
|
The thread pool would obviously lazy create them, when needed. The point was to guarantee a theoretical upper bound for processing. thread != connection, final outcome matters. |
|
Yeah, and it dies; because the I/O is inherently async and the sync-blocked threadpool threads use up all the threadpool threads in a blocked waiting state so the async I/O has nothing to run on to notify them to unblock. |
|
The full framework uses two threadpools to work round the issue one for i/O callbacks an one for user code. |
Implementation dependent. Look at other FW samples. |
Read my post addressing this.. above, above, above... |
Did we read the same article? Depending on where in the article you are, the sync method doesn't actually use an out of the box method. They async method might not either; It's hard to tell because the initial implementation apparently never returned any requests. There is text talking about changing the implementation in an attempt try and get more performance, and some alluding to using less 'out-of the box' methods to do so. However, it's never noted what exactly was changed, or what implementation was actually used in further tests. The only thing that can be said for sure is that the async code that is provided is very much not best practice. Last I saw Yes, the initial example code does use an 'out of the box' threading method. However, the author says that the initial example does such little work on each request that it hardly uses any threads. Providing this benchmark as supporting evidence of something, and then immediately saying the techempower benchmarks are meaningless because they aren't "real world" is extremely strange to me. |
|
clrjunkie wrote:
Here is the link: http://www.ducons.com/blog/tests-and-thoughts-on-asynchronous-io-vs-multithreading
|
|
Am back from a long project, sorry for not having participated more in the conversation above. First of all, it's somewhat disappointing to not hear anything from anyone at Microsoft on this (e.g. @CIPop). Beyond the question of "pure async vs. sync performance" discussed above, there are other factors as I tried to say. Thread pool pressure is one of them - I may want the added predictability/determinism that sync calls provide in that they don't add a dependency on the thread pool, which may be or may not be a problem in a given application. It's a choice that should be left to the programmer rather than saying "sync I/O is always bad". But more importantly, one of the key points of CoreCLR is portability. Saying "sync I/O is always bad" means you're sure that across Linux, MacOS etc. the kernel's sync system calls offer no advantage over whatever async mechanism the runtime does - that seems false, and should at least be shown. |
|
Network Programming for Microsoft Windows 2nd Ed., Table 6-3 has a comparison between all I/O models available in Windows at that time. Their conclusion was that IOCP was the best I/O model at that time while blocking calls was performing the worst. I don't know of any architecture (hardware or software) that implements synchronous I/O when the speeds between the processing unit and the transceiver are orders of magnitude apart. If that would be true, the processing unit's computing power is wasted by either spin-waiting or powering off while waiting for the transceiver to complete the transfer. For our discussion, the CPU is orders of magnitude faster than the network card and other processes exist in the system. There is no way to handle sync NIC/memory transfers unless the CPU waits. Transfers are managed by DMA which signals the CPU via interrupts whenever the transfer has been completed. The apparent blocking syscalls for *NIX are handled by suspending execution threads (processes) until the I/O is completed. Other platforms such as NodeJS use systems such like event loops/message pumps to dispatch completions on a single thread (this is similar in architecture with the WSAAsyncSelect). In Windows, a thread comes with high overheads for the CPU and memory resources. The performance guideline is to have the of threads equal to the number of CPUs and no threads in waiting/sleep states. |
|
@CIPop thanks for the reply. I understand (and am aware of) what you're saying. Obviously sync I/O doesn't imply having the CPU spin-wait or power off - the thread/process is simply put into a non-runnable state until the operation completes. So the question here is not how I/O is actually handled at the lowest levels, but rather how the interaction between the application and the kernel takes place with regards to I/O. In that context, it may make sense in certain scenarios to have independence from the thread-pool which sync I/O calls provide - you know which thread will execute "the callback", you're 100% sure it will be there waiting when the operation completes. You don't depend on all kinds of external conditions like what other libraries are operating inside the application, putting pressure on the thread pool and making things less predictable for you. In addition, you need to take into account non-Windows platforms. AFAIK thread overheads in Linux aren't as high as in Windows, and async I/O (both underlying kernel mechanisms and implementation in .NET runtimes) isn't necessarily as widely-used or efficient as Windows. The "everything async" vs. "let's leave room for sync" debate has taken place before, and despite some current trends (and the hype around NodeJS) in some scenarios sync I/O may make sense. Don't get me wrong, I agree that in the vast majority of cases I/O should be async. I'm just arguing that you should be leaving a choice to programmers rather than completely remove the possibility of sync I/O. |
|
@CIPop and others, I'll just give a quick concrete example. I'm the maintainer of Npgsql, the PostgreSQL driver for .NET. We've frequently received complaints that under load, and frequently at program startup, DNS queries performed by Npgsql time out. Now, the current stable Npgsql does DNS resolution with I'm mentioning this specific scenario because in CoreCLR, the sync API |
|
@roji I think that's a bug, see https://github.com/dotnet/corefx/issues/8371 |
|
@benaadams see my comment https://github.com/dotnet/corefx/issues/8371#issuecomment-217705749: the risk of threadpool starvation seems like a general problem with async, not a specific problem with how DNS resolution works - that's the point I'm trying to make here (unless I'm missing something). |
|
The starvation issue should always be worse with sync IO running on pool threads as it is with async completion callbacks posted to the TP. It is true that "pathologically" bad cases can happen due to scheduling etc. but the way to avoid all of those systematically is to not overload the TP. In a pure async IO workload the only way the pool can be overloaded is when the CPU becomes saturated. That case is to be avoided as well, and it's just as troublesome with many threads performing sync IO.
Yes, this is a significant problem with the .NET thread pool. I really wish this was addressed. In the Dns case that you mention the root cause is the bad async implementation, not async IO (there is no async IO ATM).
I did not know that CoreClr has a strategy of dropping synchronous IO methods?! That would be a really bad policy. Async IO has a significant productivity cost and it is a bad default choice. Async IO should be used when a tangible benefit can be obtained by doing that. Such benefits are saving threads and GUI programming simplification. If enough threads are available saving threads has zero customer value and negative value for productivity. A common misconception is about performance, so note that DNS queries do not become one bit faster by using async IO. |
|
@GSPP we more or less agree... About dropping synchronous IO methods, see dotnet/corefx#4868 where I complain about the removal of However I don't agree 100% with the starvation issue always being worse with sync I/O. If you know your precise application needs and have no serious scability goals (as you say) a sync I/O program can be more predictable and less sensitive to issues like dotnet/corefx#1754. You own the threads, you have no dependency on the TP whatsoever, everything is simple. But that's not very important - my only goal here is to make a case for leaving sync I/O methods in .NET... |
|
Maybe you should open a ticket dedicated to that request. This one is a discussion about many things. Make a formal request to continue to provide synchronous methods except in special cases. Fyi, starting with .NET 4.6 (I think) the ADO.NET query methods are internally async and the sync methods are sync-over-async. Not sure if that was a good choice. Might be an OK engineering trade-off. On the other hand database calls are a classic case where async is almost always not helping throughput. |
|
@aL3891 if you are removing stuff, you have better had a good something to replace it. Now, it made sort of sense when it was Silverlight and the browser, but when talking about "port you existing systems", that is a big bad thing to do. |
|
Well different people hold different opinions regarding what's good and what has really been lost :) i'm just describing what I think their reasoning was. if enough people want it and make a good case for it, they'll add it, as it seems they are in the process of doing right now |
|
@ayende I can totally understand why they decided to go with async/await, only for the sake of simplifying the port for them. Implementing one code path instead of two is simpler and simplicity is an engineering criteria. Now the problem with this issue is the title because all what I’m reading here is people complaining about async/await short-comings thinking somehow that Sync is the solution, but that’s not necessarily true (heck I complained about it to a dead end #15864). Sync is a different Programming Model and I didn't read here even one scenario to justify it. "allocation", "ThreadPool pressure" are not Sync Api scenarios!! I’m not arguing Sync doesn’t have value but if it was up to me I wouldn't invest a dime in Sync unless I see a concrete use-case that shows a noticeable difference over async! So till then, if your immediate problem is due to async/await – shout FIX ASYNC AWAIT! |
Maybe the implementation is a rewrite, but with regards to APIs and contracts it really isn't - backwards compatibility with .NET Framework is a major (if not absolute) goal of .NET Core.
@clrjunkie the cost of maintaining both a sync and an async path in any library is indeed high - you're right. I faced this exact same problem in Npgsql and ended up writing a code generator called AsyncRewriter for creating async methods from sync counterparts. There's nothing pretty about this but it does get the job done - Npgsql fully supports both sync and async I/O without me maintaining 2 full code paths. But at the end of the day sync I/O simply isn't some small self-contained piece of functionality that can be dropped for simplifying the port for the MS team. Note that nobody at MS ever raised this argument - "we're dropping sync because it's too much work for us"). Nobody at MS even said "we're dropping sync", almost all sync I/O APIs are still there. It's just a sync method here and there that's missing, with a vague and uncommitted "sync is bad" argument.
You're looking at it the other way around. Sync isn't a "solution" to async's problems! There are simply some scenarios where async provides no advantage over sync (e.g. no scalability requirements) and only makes things worse. Also, some of async's "problems" are inherent in the programming model - they're not something that can be fixed (your suggestions notwithstanding). And even those things that can be improved or fixed aren't there yet now. If after this thread you still refuse to admit the async has its costs and that sync can sometimes make sense - heap allocation and GC pressure, programming model complexity, TP pressure - then you're just stuck in an ideological "async all the things" loophole that doesn't care about actual facts and programmer concerns. |
Who said so? Where did you read this??
No problem, since you argue so strongly about what you consider facts and programmer concerns I challenge you to paste here 2 short console applications (async/sync) which do something useful for you and clearly show how sync outperforms async. That way we can discuss an actual programming use case instead of buzz words.and ideology. Ready? |
Read this blog post by Immo Landwerth, and especially the section "Relationship of .NET Core and .NET Framework". .NET Core isn't a new "let's break-everything" effort. Note also how "technologies discontinued for .NET Core" are explicitly discussed and analyzed (app domains, remoting...). Note how "sync I/O" is not listed in that list.
I'm sorry, I'm done wasting my time with you on this - me (and others) have already given examples in this thread many times over. Avoiding the increased heap allocation associated with async is an actual concern for at least some programmers, it's directly linked to your application's performance. Until you answer here why programmers shouldn't be concerned about heap allocations and GC pressure (and the other issues listed above) there's no point in continuing this conversation with you. |
|
@clrjunkie, regarding compatibility between .NET Framework and .NET Core take a look at the corefx breaking changes guide, you'll understand to what extent Microsoft is trying to make .NET Core compatible. |
|
For further discussion, see this PR: *Hibernating Rhinos Ltd * Oren Eini* l CEO l *Mobile: + 972-52-548-6969 Office: +972-4-622-7811 *l *Fax: +972-153-4-622-7811 On Tue, May 17, 2016 at 3:25 PM, Shay Rojansky [email protected]
|
|
@ayende Saying that, I would argue that synchronous File I/O can be more efficient when the access pattern involves many small read/writes. I actually thought about posting here a sample program to demonstrate this, but I haven’t found a real world use-case that’s important or general enough and I didn't want to use some artificial write "counter" example. I would bet that a work queue of fixed dedicated threads issuing many small writes per work item synchronously would process items faster than submitting those writes asynchronously. (assuming of course the number of work queue threads correspond to the number of CPU’s, again one work item yields many small writes). You are welcome to find and test a business use-case that fits this model and submit it to justify the need. |
Coming to think about it, even so, if you find these truly nice then submit them, maybe they will get in someday, at least they will be documented, so do that. (No cross-reference required :) |
Nah; as you can double buffer with async and you can't with sync. So you can be preparing the next batch of data while the current one is being written out breaking the read+write dependency; and giving the task time to complete before you await it, so its usually a completed task. e.g. the throughput on private async Task CopyToAsync(Stream source, Stream destination, int bufferSize, CancellationToken cancellationToken)
{
var buffer0 = new byte[bufferSize];
var buffer1 = new byte[bufferSize];
var readTask = source.ReadAsync(buffer0, 0, buffer0.Length, cancellationToken);
var writeTask = Task.CompletedTask;
var isOdd = false;
int bytesRead;
while ((bytesRead = await readTask.ConfigureAwait(false)) != 0)
{
readTask = source.ReadAsync(isOdd ? buffer0 : buffer1, 0, bufferSize, cancellationToken);
isOdd = !isOdd;
await writeTask.ConfigureAwait(false);
writeTask = destination.WriteAsync(isOdd ? buffer0 : buffer1, 0, bytesRead, cancellationToken);
}
await writeTask.ConfigureAwait(false);
}will be much higher than public void CopyTo(Stream source, Stream destination, int bufferSize)
{
var buffer = new byte[bufferSize];
int read;
while ((read = source.Read(buffer, 0, buffer.Length)) != 0)
{
destination.Write(buffer, 0, read);
}
}Alas the framework doesn't do |
|
@benaadams I tried that with buffered IO. Throughput was not better because the kernel does read-aheand and write-behind in the kernel. Also, if this was beneficial you could get the same benefit with sync IO and threads at a slight expense of CPU time. |
|
Features implemented years from now have very little use at this point. *Hibernating Rhinos Ltd * Oren Eini* l CEO l *Mobile: + 972-52-548-6969 Office: +972-4-622-7811 *l *Fax: +972-153-4-622-7811 On Wed, May 18, 2016 at 4:26 PM, clrjunkie [email protected] wrote:
|
|
@benaadams Each Thread: var count= fileBatch.Count; for(var i = 0; i < count; ++i) |
First, you don't know what priority these feature will get. Second better late then never :) |
|
@benaadams |
|
Buffering log records in memory into buckets - delimited, not concatenated - and submitting them to be flushed concurrently to a set of new files after X ? Ex: A high performance logging solution that trades-off 100% durability for speed? |
|
@clrjunkie, regarding the question of API compatibility between .NET Core and .NET Framework, please see this blog post from yesterday. I think that pretty much closes the discussion about whether sync I/O APIs will be added. Of course you can still claim they're useless and bad. EDIT: Fixed link |
|
@roji Thanks for the heads up. (though the link you posted self references this issue..!@? ) I assume you meant this: https://blogs.msdn.microsoft.com/dotnet/2016/05/27/making-it-easier-to-port-to-net-core/ Well, my only "claim" is that it appears the same "rules" apply - See ya' in .NET Core V3. Until then...Count me out on this. -Unsubscribed- |
|
@clrjunkie thanks, fixed the link. @CIPop and others at Microsoft, I'll leave this open to track bringing back SSLStream's missing sync methods, feel free to close. |
|
Thanks @roji. The scope for API surface changes that are being considered is broader than SslStream. Assigning this discussion to @terrajobst to track the necessary API changes. |
|
@karelz - the request is simply for BCL APIs to include synchronous APIs alongside asynchronous APIs, in order to support the sync programming model. A special emphasis should be made on bringing back sync APIs which exist in .NET Framework but were dropped in .NET Core 1.0 (e.g. With the shift towards making .NET Core more API-compatible with .NET Framework to help porting, I'm not sure another issue is necessary here for that - although if you think so I'll open one. |
|
Agreed that a new issue is likely not needed at this point. Thanks! |
Continuation of discussion from dotnet/corefx#4868
Thanks for this detail. I was aware that at least in some cases sync methods actually perform async operations under the hood.
However, coming from the Unix universe, it doesn't seem to hold that there's "no such thing as synchronous I/O" at least at the kernel level: I would expect .NET I/O operations to map to simple sync I/O system calls such as write and read. Also, the implementation details underlying async operations across platforms may make sync I/O more attractive at least in some cases (i.e. is async I/O implemented efficiently on Linux with mono, or with coreclr for that matter?). I admit I'm just asking questions, I don't have enough solid knowledge here.
Regardless of these questions, and I said back in dotnet/corefx#4868, there's something odd about removing such a specific sync API (SslStream.AuthenticateAsClient) for such a general "sync I/O is bad" argument, without touching any other sync API. In other words, I'd expect either all sync APIs to stay for backwards compatibility or for a more sweeping removal of sync I/O APIs.
The text was updated successfully, but these errors were encountered: