![]()
Very fast link-checking.
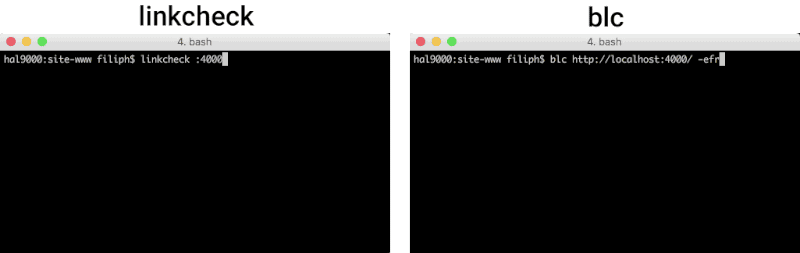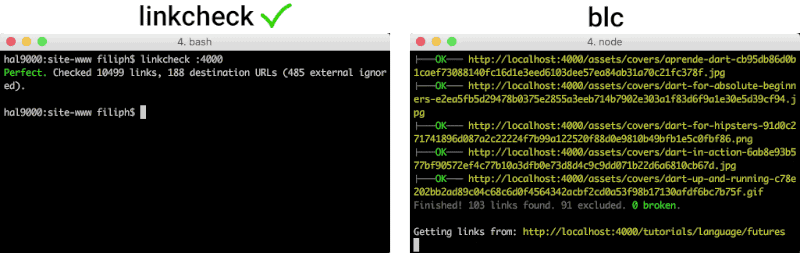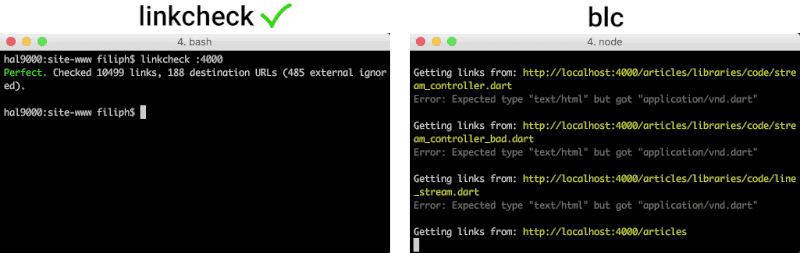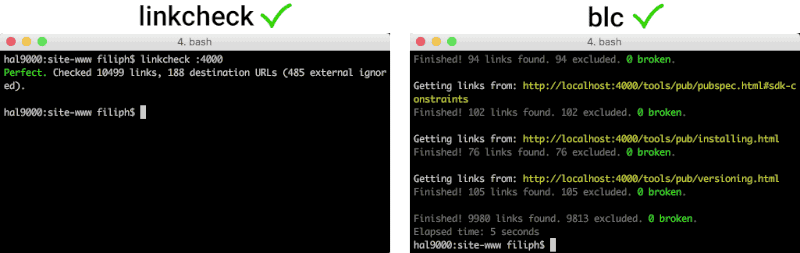
A good utility is custom-made for a job. There are many link checkers out there, but none of them seems to be striving for the following set of goals.
-
You want to run the link-checker at least before every deploy (on CI or manually). When it takes ages, you're less likely to do so.
-
linkcheckis currently several times faster than blc and all other link checkers that go to at least comparable depth. It is 40 times faster than the only tool that goes to the same depth (linkchecker).
-
No link-checker can guarantee correct results: the web is too flaky for that. But at least the tool should correctly parse the HTML (not just try to guess what's a URL and what isn't) and the CSS (for
url(...)links).- PENDING: srcset support
-
linkcheckfinds more than linklint and blc. It finds the same amount or more problems than the best alternative, linkchecker.
-
linkcheckdoesn't attempt to render JavaScript. It would make it at least an order of magnitude slower and way more complex. (For example, what links and buttons should the tool attempt to click, and how many times? Should we only click visible links? How exactly do we detect broken links?) Validating SPAs is a very different problem than checking static links, and should be approached by dedicated tools. -
linkcheckonly supportshttp:andhttps:. It won't try to check FTP or telnet or nntp links.- Note:
linkcheckwill currently completely ignore unsupported schemes likeftp:ormailto:ordata:. This may change in the future to at least show info-level warning.
- Note:
-
linkcheckdoesn't validate file system directories. Servers often behave very differently than file systems, so validating links on the file system often leads to both false positives and false negatives. Links should be checked in their natural habitat, and as close to the production environment as possible. You can (and should) runlinkcheckon your localhost server, of course.
-
Yes, a command line utility can have good or bad UX. It has mostly to do with giving sane defaults, not forcing users to learn new constructs, not making them type more than needed, and showing concise output.
-
The most frequent use cases should be only a few arguments.
- For example, unleashing
linkcheckon http://localhost:4001/ can be done vialinkcheck :4001.
- For example, unleashing
-
linkcheckdoesn't throttle itself on localhost. -
linkcheckfollows POSIX CLI standards (no@inputand similar constructs like in linklint).
-
When everything works, you don't want to see a huge list of links.
- In this scenario,
linkcheckjust outputs 'Perfect' and some stats on a single line.
- In this scenario,
-
When things are broken, you want to see where exactly is the problem and you want to have it sorted in a sane way.
linkchecklists broken links by their source URL first so that you can fix many links at once. It also sorts the URLs alphabetically, and shows both the exact location of the link (line:column) and the anchor text (or the tag if it wasn't an anchor).
-
For CI builds, you want non-zero exit code whenever there is a problem.
linkcheckreturns status code1if there are warnings, and status code2if there are errors.
It goes without saying that linkcheck fully respects definitions
in robots.txt and throttles itself when accessing websites.
- Download the latest executable from the
Releases page on GitHub.
Pick the executable for your system (for example,
linkcheck-win-x64.exefor a 64-bit machine running Microsoft Windows).
You should be able to immediately run this executable -- it has no external
dependencies. For example, assuming you are on macOS and downloaded the file
to the default downloads directory, you can go to your Terminal
(or iTerm, or SSH) and run ./Downloads/linkcheck-mac-x64.
You can rename the file and move it to any directory. For example,
on a Linux box, you might want to rename the executable to simply
linkcheck, and move it to /usr/local/bin, $HOME/bin or another
directory in your $PATH.
Latest executable in a docker image:
docker run --rm tennox/linkcheck --help
(built from a repo mirror by @tennox)
Follow the installation instructions for your platform from the Get the Dart SDK documentation.
For example, on a Mac, assuming you have homebrew, you just run:
$ brew tap dart-lang/dart
$ brew install dart
Once Dart is installed, run:
$ dart pub global activate linkcheck
Pub installs executables into ~/.pub-cache/bin, which may not be on your path.
You can fix that by adding the following to your shell's config file (.bashrc,
.bash_profile, etc.):
export PATH="$PATH":"~/.pub-cache/bin"
Then either restart the terminal or run source ~/.bash_profile (assuming
~/.bash_profile is where you put the PATH export above).
If you have Docker installed, you can build the image and use the container avoiding local Dart installation.
In the project directory, for x86 and x64 architectures, run
docker build -t filiph/linkcheck .
On ARM architectures (Raspberry, M1 Mac), run
docker build --platform linux/arm64 -t filiph/linkcheck .
docker run filiph/linkcheck <URL>
All below usage guidelines are valid running on container too.
uses: filiph/[email protected]
with:
arguments: <URL>
All below usage guidelines are valid running as a GitHub action too.
If in doubt, run linkcheck -h. Here are some examples to get you started.
Running linkcheck without arguments will try to crawl
http://localhost:8080/ (which is the most common local server URL).
linkcheckto crawl the site and ignore external linkslinkcheck -eto try external links
If you run your local server on http://localhost:4000/, for example, you can do:
linkcheck :4000to crawl the site and ignore external linkslinkcheck :4000 -eto try external links
linkcheck will not throttle itself when accessing localhost. It will go as
fast as possible.
linkcheck www.example.comto crawl www.example.com and ignore external linkslinkcheck https://www.example.comto start directly on httpslinkcheck www.example.com www.other.comto crawl both sites and check links between the two (but ignore external links outside those two sites)
Assuming you have a text file mysites.txt like this:
http://egamebook.com/
http://filiph.net/
https://alojz.cz/
You can run linkcheck -i mysites.txt and it will crawl all of them and also
check links between them. This is useful for:
- Link-checking projects spanning many domains (or subdomains).
- Checking all your public websites / blogs / etc.
There's another use for this, and that is when you have a list of inbound links, like this:
https://www.dart.dev/
https://www.dart.dev/tools/
https://www.dart.dev/guides/
You probably want to make sure you never break your inbound links. For example, if a page changes URL, the previous URL should still work (redirecting to the new page when appropriate).
Where do you get a list of inbound links? Try your site's sitemap.xml as a starting point, and — additionally — try something like the Google Webmaster Tools’ crawl error page.
Sometimes, it is legitimate to ignore some failing URLs. This is done via
the --skip-file option.
Let's say you're working on a site and a significant portion of it is currently
under construction. You can create a file called my_skip_file.txt, for
example, and fill it with regular expressions like so:
# Lines starting with a hash are comments.
admin/
\.s?css$
\#info
The file above includes a comment on line 1 which will be ignored. Line 2 is
blank and will be ignored as well. Line 3 contains a broad regular expression
that will make linkcheck ignore any link to a URL containing admin/
anywhere in it. Line 4 shows that there is full support for
regular expressions – it will ignore URLs ending with .css and
.scss. Line 5 shows the only special escape sequence.
If you need to start your regular expression with a #
(which linkcheck would normally parse as a comment) you can
precede the # with a backslash (\). This will force linkcheck
not to ignore the line. In this case, the regular expression on line 4
will match #info anywhere in the URL.
To use this file, you run linkcheck like this:
linkcheck example.com --skip-file my_skip_file.txt
Regular expressions are hard. If unsure, use the -d option to see what URLs
your skip file is ignoring, exactly.
To use a skipfile while running linkchecker through docker create a directory to use as a volume in docker and put your skip file in it. Then use a command similar to the following (assuming the folder was named skipfiles):
docker run -v "$(pwd)/skipfiles/:/skipfiles/" filiph/linkcheck http://example.com/ --skip-file /skipfiles/skipfile.txt
The tool identifies itself to servers with the following user agent string:
linkcheck tool (https://github.com/filiph/linkcheck)
- Commit all your changes, including updates to
CHANGELOG, and including updating the version number inpubspec.yamlandlib/linkcheck.dart. Let's say your new version number is3.4.56. That number should be reflected in all three files. - Tag the last commit with the same version number.
In our case, it would be
3.4.56. - Push to
master.
This will run the GitHub Actions script in .github/workflows/release.yml,
building binaries and placing a new release into
github.com/filiph/linkcheck/releases.
In order to populate it to the GitHub Actions Marketplace as well, it's currently required to manually Edit and hit Update release on the release page once. No changes needed. (Source: GitHub Community)