runtime: scheduler work stealing slow for high GOMAXPROCS #28808
Comments
|
I suspect this falls in the general category of "Go does not play well with other loads on the system", the "other loads" in this case the other 4 instances of the Go program. This might be a dup of either #17969 or #18237. Did you try running only one instance of the program on your host with 1.11? I'm curious whether the fixes since 1.9 mean you no longer have to run 5 separate processes. |
|
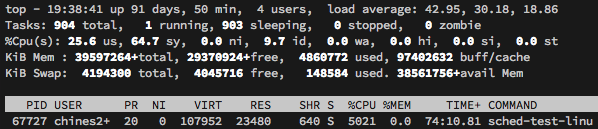
@randall77 Yes, we tried running only one instance with 1.11. It consumed all available CPU on the box and was not able to handle the equivalent load. I didn't mention that above because the data from that run was a little confusing and the initial report was already rather long. In that test the content cache server also started using a lot of CPU by the end of the test and we weren't sure if it was a valid test since the OS was limiting how many cores the Go process could actually use. However, I also tried running the small program above with a single instance and equivalent goroutine count and it produced these results: Go 1.11, GOMAXPROCS=56, 1 proc x 2500 goroutinesschedtrace sample pprof data I'm not sure why pprof reports the program was consuming 1000% CPU, but top reports it was using 5000% and a high amount of system CPU, as seen in this screen capture.
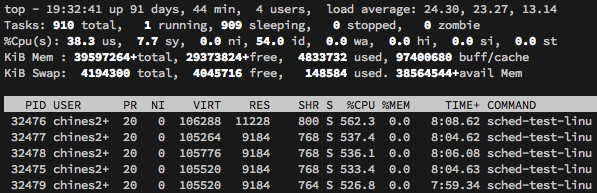
It seems clear to me that by the time the load has reached this level the scheduler has phase shifted from spinning on work stealing from empty queues to some other mode of operation where it is servicing deep local and global run queues and struggling to keep up even though we have the same total number of goroutines and tickers in the system. So I did some bisecting on the goroutine count for the single process case just now and found that this phase shift takes place somewhere between 1000 and 1200 goroutines. Go 1.11, GOMAXPROCS=56, 1 proc x 1200 goroutinesschedtrace sample Go 1.11, GOMAXPROCS=56, 1 proc x 1100 goroutinesschedtrace sample Go 1.11, GOMAXPROCS=56, 1 proc x 1000 goroutinesschedtrace sample pprof data Here is what top shows for this case. |

Before this CL, the work-stealing loop in findrunnable() has the following behavior: - In the first 3 iterations, attempt to steal Gs from p.runq from other Ps (i.e. Gs not at the head of other P's queues). - In the final (4th) iteration, also attempt to steal from p.runnext (i.e. Gs at the head of other P's queues), but only after sleeping for 3us before each stealing attempt. Note that the number of loop iterations is arbitrary: golang#16476 (comment) This approach causes findrunnable() to scale poorly with GOMAXPROCS for two reasons: - The amount of time per iteration is linear in GOMAXPROCS. - The amount of time spent sleeping in the last iteration is also linear in GOMAXPROCS. This CL changes the work-stealing loop to take at most 4us + 1 iteration through all Ps, without any sleeping, by allowing the loop to spin iff there is a p.runnext that will be, but is not yet, stealable. (The amount of time to wait before stealing runnext is empirically bumped up from 3us to 4us.) Updates golang#28808
Before this CL, the work-stealing loop in findrunnable() has the following behavior: - In the first 3 iterations, attempt to steal Gs from p.runq from other Ps (i.e. Gs not at the head of other P's queues). - In the final (4th) iteration, also attempt to steal from p.runnext (i.e. Gs at the head of other P's queues), but only after sleeping for 3us before each stealing attempt. Note that the number of loop iterations is arbitrary: golang#16476 (comment) This approach causes findrunnable() to scale poorly with GOMAXPROCS for two reasons: - The amount of time per iteration is linear in GOMAXPROCS. - The amount of time spent sleeping in the last iteration is also linear in GOMAXPROCS. This CL changes the work-stealing loop to take at most 4us + 1 iteration through all Ps, without any sleeping, by allowing the loop to spin iff there is a p.runnext that will be, but is not yet, stealable. (The amount of time to wait before stealing runnext is empirically bumped up from 3us to 4us.) Updates golang#28808
|
Change https://golang.org/cl/228577 mentions this issue: |
|
Change https://golang.org/cl/259578 mentions this issue: |
|
Change https://golang.org/cl/264477 mentions this issue: |
Work stealing is a scalability bottleneck in the scheduler. Since each P has a work queue, work stealing must look at every P to determine if there is any work. The number of Ps scales linearly with GOMAXPROCS (i.e., the number of Ps _is_ GOMAXPROCS), thus this work scales linearly with GOMAXPROCS. Work stealing is a later attempt by a P to find work before it goes idle. Since the P has no work of its own, extra costs here tend not to directly affect application-level benchmarks. Where they show up is extra CPU usage by the process as a whole. These costs get particularly expensive for applications that transition between blocked and running frequently. Long term, we need a more scalable approach in general, but for now we can make a simple observation: idle Ps ([1]) cannot possibly have anything in their runq, so we need not bother checking at all. We track idle Ps via a new global bitmap, updated in pidleput/pidleget. This is already a slow path (requires sched.lock), so we don't expect high contention there. Using a single bitmap avoids the need to touch every P to read p.status. Currently, the bitmap approach is not significantly better than reading p.status. However, in a future CL I'd like to apply a similiar optimization to timers. Once done, findrunnable would not touch most Ps at all (in mostly idle programs), which will avoid memory latency to pull those Ps into cache. When reading this bitmap, we are racing with Ps going in and out of idle, so there are a few cases to consider: 1. _Prunning -> _Pidle: Running P goes idle after we check the bitmap. In this case, we will try to steal (and find nothing) so there is no harm. 2. _Pidle -> _Prunning while spinning: A P that starts running may queue new work that we miss. This is OK: (a) that P cannot go back to sleep without completing its work, and (b) more fundamentally, we will recheck after we drop our P. 3. _Pidle -> _Prunning after spinning: After spinning, we really can miss work from a newly woken P. (a) above still applies here as well, but this is also the same delicate dance case described in findrunnable: if nothing is spinning anymore, the other P will unpark a thread to run the work it submits. Benchmark results from WakeupParallel/syscall/pair/race/1ms (see golang.org/cl/228577): name old msec new msec delta Perf-task-clock-8 250 ± 1% 247 ± 4% ~ (p=0.690 n=5+5) Perf-task-clock-16 258 ± 2% 259 ± 2% ~ (p=0.841 n=5+5) Perf-task-clock-32 284 ± 2% 270 ± 4% -4.94% (p=0.032 n=5+5) Perf-task-clock-64 326 ± 3% 303 ± 2% -6.92% (p=0.008 n=5+5) Perf-task-clock-128 407 ± 2% 363 ± 5% -10.69% (p=0.008 n=5+5) Perf-task-clock-256 561 ± 1% 481 ± 1% -14.20% (p=0.016 n=4+5) Perf-task-clock-512 840 ± 5% 683 ± 2% -18.70% (p=0.008 n=5+5) Perf-task-clock-1024 1.38k ±14% 1.07k ± 2% -21.85% (p=0.008 n=5+5) [1] "Idle Ps" here refers to _Pidle Ps in the sched.pidle list. In other contexts, Ps may temporarily transition through _Pidle (e.g., in handoffp); those Ps may have work. Updates #28808 Updates #18237 Change-Id: Ieeb958bd72e7d8fb375b0b1f414e8d7378b14e29 Reviewed-on: https://go-review.googlesource.com/c/go/+/259578 Run-TryBot: Michael Pratt <[email protected]> TryBot-Result: Go Bot <[email protected]> Reviewed-by: Michael Knyszek <[email protected]> Reviewed-by: Austin Clements <[email protected]> Trust: Michael Pratt <[email protected]>
|
Change https://golang.org/cl/264697 mentions this issue: |
Following golang.org/cl/259578, findrunnable still must touch every other P in checkTimers in order to look for timers to steal. This scales poorly with GOMAXPROCS and potentially performs poorly by pulling remote Ps into cache. Add timerpMask, a bitmask that tracks whether each P may have any timers on its timer heap. Ideally we would update this field on any timer add / remove to always keep it up to date. Unfortunately, updating a shared global structure is antithetical to sharding timers by P, and doing so approximately doubles the cost of addtimer / deltimer in microbenchmarks. Instead we only (potentially) clear the mask when the P goes idle. This covers the best case of avoiding looking at a P _at all_ when it is idle and has no timers. See the comment on updateTimerPMask for more details on the trade-off. Future CLs may be able to expand cases we can avoid looking at the timers. Note that the addition of idlepMask to p.init is a no-op. The zero value of the mask is the correct init value so it is not necessary, but it is included for clarity. Benchmark results from WakeupParallel/syscall/pair/race/1ms (see golang.org/cl/228577). Note that these are on top of golang.org/cl/259578: name old msec new msec delta Perf-task-clock-8 244 ± 4% 246 ± 4% ~ (p=0.841 n=5+5) Perf-task-clock-16 247 ±11% 252 ± 4% ~ (p=1.000 n=5+5) Perf-task-clock-32 270 ± 1% 268 ± 2% ~ (p=0.548 n=5+5) Perf-task-clock-64 302 ± 3% 296 ± 1% ~ (p=0.222 n=5+5) Perf-task-clock-128 358 ± 3% 352 ± 2% ~ (p=0.310 n=5+5) Perf-task-clock-256 483 ± 3% 458 ± 1% -5.16% (p=0.008 n=5+5) Perf-task-clock-512 663 ± 1% 612 ± 4% -7.61% (p=0.008 n=5+5) Perf-task-clock-1024 1.06k ± 1% 0.95k ± 2% -10.24% (p=0.008 n=5+5) Updates #28808 Updates #18237 Change-Id: I4239cd89f21ad16dfbbef58d81981da48acd0605 Reviewed-on: https://go-review.googlesource.com/c/go/+/264477 Run-TryBot: Michael Pratt <[email protected]> TryBot-Result: Go Bot <[email protected]> Reviewed-by: Michael Knyszek <[email protected]> Trust: Michael Pratt <[email protected]>
|
Change https://golang.org/cl/266367 mentions this issue: |
In golang.org/cl/264477, I missed this new block after rebasing past golang.org/cl/232298. These fields must be zero if there are no timers. Updates #28808 Updates #18237 Change-Id: I2d9e1cbf326497c833daa26b11aed9a1e12c2270 Reviewed-on: https://go-review.googlesource.com/c/go/+/266367 Run-TryBot: Michael Pratt <[email protected]> Reviewed-by: Austin Clements <[email protected]> Reviewed-by: Ian Lance Taylor <[email protected]> Reviewed-by: Michael Knyszek <[email protected]> TryBot-Result: Go Bot <[email protected]> Trust: Michael Pratt <[email protected]>
|
Any plan for numa or split scheduler pool? Work stealing need support numa affinity. |
https://docs.google.com/document/d/1d3iI2QWURgDIsSR6G2275vMeQ_X7w-qxM2Vp7iGwwuM/pub |
|
To my knowledge, there's no work currently planned in this area. The document linked by @kscooo is from 2014 and the runtime has changed a bit since then, though it may still serve as a good starting point. However, as that document implies, it'll likely require a substantial restructuring of the runtime. |
What version of Go are you using (
go version)?We don't have Go installed in the production environment. The program reports this info as part of reporting its version.
Does this issue reproduce with the latest release?
Yes
What operating system and processor architecture are you using (
go env)?We don't have Go installed in the production environment. I think the following info is relevant to this issue.
What did you do?
We have an application that primarily retrieves data in large chunks from a node-local cache server via HTTP, packetizes it, and sends the packets out at a target bitrate via UDP. It does this for many concurrent streaming sessions per node. A node with the CPU shown above will serve several hundred streaming sessions at once.
The application currently starts separate goroutines for each streaming session. Each session has a goroutine responsible for outputting the UDP packets as close to the target bitrate as possible. That goroutine uses a
time.Tickerto wake up periodically and transmit data. The Go execution tracer shows that each of these transmitting goroutines typically runs for about 15µs once every 2.4ms.Until recently the application was built with Go 1.9. We found empirically that running five instances of the program on a node—each instance handling one fifth of the work—handled our work load the best. At the time we didn't understand why we had to shard the workload across multiple processes, but the empirical data was conclusive.
We built our latest release with Go 1.11 and began load testing it with the same configuration of five instances per node.
What did you expect to see?
We expected to see that the new release built with Go 1.11 performed at least as well as the previous release built with Go 1.9.
What did you see instead?
The new release built with Go 1.11 consumed significantly more CPU for the same workload compared with the previous release built with Go 1.9. We eliminated the possibility that the changes in our new release were the cause by rebuilding the previous release with Go 1.11 and observed that it also consumed significantly more CPU for the same load as the same code built with Go 1.9.
We collected CPU profile data from these three builds of the program under load and began looking for culprits. The data showed that the Go 1.11 builds were spending about 3x CPU time in
runtime.findrunnableand its helpers than the Go 1.9 builds.Looking at the commit history since Go 1.9 for that part of the runtime we identified commit "runtime: improve timers scalability on multi-CPU systems" as the only change that seemed relevant. But we were puzzled that despite the performance improvements to timer handling we saw increased CPU load rather than performance improvements for our program.
After further analysis, however, we realized that the inefficient timer implementation was the likely reason we were forced to shard the load across five processes when using Go 1.9. Since the profile data for the Go 1.11 build showed that the cumulative time spent in
runtime.runqstealwas the largest contributor to the cumulative time ofruntime.findrunnablewe hypothesized that with the timer handling bottleneck reduced each P in the scheduler could advance to the work stealing loop instead of contending for the timer lock. Furthermore, since we were running on hardware with 56 hardware threads and had not set an explicitGOMAXPROCSthe work stealing loop was rather expensive, especially if it typically found all the other run queues empty, which we confirmed by running withGODEBUG=schedtrace=1000.With that hypothesis seeming sound we next hypothesized that running each of the five Go 1.11 processes with
GOMAXPROCS=12would be a better configuration to reduce the work stealing iterations and without under utilizing the available hardware threads. This idea also matched the conclusion of this similar issue (now closed) #16476. Load tests with five instances of a Go 1.11 build each withGOMAXPROCS=12found a similar amount of CPU consumption as with Go 1.9 builds. This is a reasonable workaround and we are using it now.Although there is a simple workaround, it is unsettling that the runtime scheduler does not scale well for this type of workload on high core counts. Notably, the work stealing algorithm degenerates to O(N²) due to N cores all inspecting each other's mostly empty run queues. The CPU time spent fruitlessly attempting to steal work from empty run queues contributes to overall system load and competes with the demands of other processes on the node, such as the local content cache server mentioned earlier.
The problem I've described here is almost the same as #18237, in which @aclements explained:
I am creating a new issue because our goroutines are made runnable largely by runtime timers instead of network events. I believe that is a significant difference because although the scheduler cannot easily predict the arrival of network events, runtime timers have known expiration times.
Reproducing
Below is a small program that models the critical path of the application. The code will not run on the playground, but here is a link in case that is more convenient that the inline code below. https://play.golang.org/p/gcGT2v2mZjU
Profile data we've collected from this program shows a strong resemblance to the profile data from the bigger program we originally witnessed this issue with, at least with regard to the Go runtime functions involved.
Profile Data
We ran the above program in several configurations and captured profile and schedtrace data.
Go 1.9, GOMAXPROCS=56, 5 procs x 500 goroutines
schedtrace sample
pprof data
Go 1.11, GOMAXPROCS=56, 5 procs x 500 goroutines
schedtrace sample
pprof data
Go 1.11, GOMAXPROCS=12, 5 procs x 500 goroutines
schedtrace sample
pprof data
I can test other configurations if it will help.
The text was updated successfully, but these errors were encountered: