cmd/asm: refactor the framework of the arm64 assembler #44734
Comments
|
Keep in mind that the "Why?" section applies to pretty much all of the architectures. To the extent that we can design a system that works across architectures (sharing code, or even just sharing high-level design & testing), that would be great. See also CL 275454 for the testing piece. See also my comment in CL 283533. |
I agree, but designing a general framework requires knowledge of multiple architectures. If Google can do this design, it would be best. We are happy to follow and complete the arm64 part.
Yes, I know this patch, Junchen is my colleague. This patch takes the mutual test of assembler and disassembler one step forward, and we also hope to use the gnu toolchain to test the Go assembler.
This table is best to be as simple as possible, preferably decoupled from the I hope to create a new branch to complete the refactoring of the arm64 assembler if this is acceptable. |
|
Hi, are there any further comments or suggestions? If you think the above scheme is feasible, I am willing to extend it to all architectures. I can complete this architecture-independent framework and the arm64 part, and other architectures need to be completed by others. Of course, we will retain the old code before completing the porting of an architecture and set a switch for the new and old code paths. |
|
We have tried to add initial SVE support to the assembler under the existing framework, see CL 153358, but in order to get rid of the many existing cases, we had to add an |
|
Thanks for the proposal.
I think this is subjective. That said, I agree that the current optab approach is probably not the best fit for ARM64. I'm not the original author of the ARM64 assembler, but I'm pretty sure the design comes from the assembler of other RISC architectures, which comes from the Plan 9 assemblers. In my perspective the original design is actually quite simple, if the encoding of the machine instruction is simple. Think of MIPS or RISC-V, there are just a small number of encodings (that's where Given that the ARM64 instruction encoding is not like what the optab approach is best suited, I think it is reasonable to come up a different approach. I'm willing to give this a try.
This sounds reasonable to me. It might simplify a bunch of things. It may also make it possible to machine-generate the encoding table that converts individual machine instruction to bytes. But keep in mind that there are things handled in the Prog level, e.g. unsafe point and restartable sequence marking. Doing it at Prog level is simple because some Prog is restartable while its underlying individual instructions are not. I wonder how this is handled. ====== cc @laboger @pmur Currently, in my perspective there are essentially 4 kinds of assembler backends in Go: x86, ARM32/ARM64/MIPS/PPC64/S390X which are somewhat similar, RISC-V which is a bit different, and WebAssembly. As someone maintaining or co-maintaining those backends, I'd really appreciate if we can keep this number small. Thanks. |
|
I have not had much time to digest this yet. Speaking for my PPC64 work, I have no existing plans to rewrite our assembler. Adding ISA 3.1 support (particularly for 64b instructions) requires some extra work, but not so much to make it look much different than it does today. A couple thoughts below on the current PPC64 asm deficiencies: A framework to decompose go opcodes which don't map 1-1 with a machine instruction would likely simplify laying out code. Similarly, we need to fixup large jumps from conditional operations and respect alignment restrictions with 64b ISA 3.1 instructions. Likewise, something to more reliably synchronize the supported assembler opcodes against pp64.csv (residing with the disassembler) would be desirable to avoid the churn of adding new instruction support as needed. |
This is easy to fix, we just need to mark the first instruction of the sequence as restartable. For example: Another problem is the printing of assembly instructions. Currently we print Go syntax assembly listing, namely unfolded "Prog"s, after unfolding, we can no longer print the previous |
|
The situation of different architectures seems to be different, but arm64 has many new features and instructions that are moving from design to real device, so I can see how much work is needed to add and maintain new instructions. so can we just do arm64 first? In the future, other architectures can decide whether to adopt the arm64 solution according to their own situation. I believe that even if Google designs a general assembly framework later, our work will not be wasted. |
We were not the original authors of the PPC64 assembler either and there is a lot of opportunity for clean up. The refactoring work @pmur is doing now is a lot of simplification of existing code, in addition to making changes to prepare for instructions in the new ISA. IMO his current work won't necessarily be a wasted effort if we want to use a new design at some point because he is eliminating a lot of clutter. I'm not an ARM64 expert but my understanding is that we are similar enough that their design should be compatible for us. I'm not sure about all the other architectures you list above -- depends on whether the goal is to have a common one for all or just start with ARM64 and PPC64. It sounds like ARM64 wants to move ahead soon, probably this release, and I'm not sure that is feasible for all other architectures. But if others later adopt the same or similar design that should at least simplify the support effort Cherry mentions above. I am totally in favor of sharing code as much as possible. |
|
Yeah, I think we can start with ARM64. If there is anything that PPC64 or other architecture needs, it is probably a good time to bring it up now. Then we can incorporate that and come up a design that is common/similar across architectures. I think ARM64 and PPC64 are the more relatively complex ones. If a new design works for them, it probably will work well for MIPS and perhaps ARM32 as well. |
|
Okay, then I will start to complete the above prototype patch. Let me repeat our refactoring ideas: ... -> Unfold -> Fixup -> Encoding ->...What we do in the
What we do in the
What we do in the I'm going do it according to this idea, and I also welcome any suggestions on this design and code at any time. |
|
I'm looking at the design and code and I have a question related to the unfoldTab and using it to include the function to be called for processing. I believe that means as each prog is processed, the function being called to process it will be called through a function pointer found in the table, and I don't think a function called this way can be inlined. Won't this cause a lot more overhead at compile/assembly time, since currently the handling of each opcode is done through a huge switch statement? |
Yes. originally I guess table lookup maybe better than switch-case, I didn't consider inlining. I'll check which one is better, thanks. |
|
Hi, update my progress and the problems encountered, and hope to get your help. I only changed the arm64/linux assembler at present, and the plan is to do the arm64 first and then consider the cross-architecture part. The code is basically completed, all tests of Repeat the implementation ideas before talking about the problems encountered:
The two problems encountered are:
These problems are all caused by the original Prog being split or modified. The test failures can be fixed by some methods, what I want to ask is whether the change in the assembly printing format is acceptable? |
|
I think it is okay to change the printing or adjusting tests, if the instructions have the same semantics. Rewriting a Prog to other Prog (or Progs) is more of a concern for me. Things like rewriting |
I will prepare two versions, one with Prog split, and the other without Prog split.
Yes, this is also the most troublesome part. According to what I have observed so far, splitting a Prog into multiple Progs only affects whether an instructions is isRestartable. Because if a Prog does not use REGTMP, the split has no effect on it. If a Prog uses REGTMP, the small Prog after splitting becomes an unsafe point due to the use of REGTMP and becomes non-preemptible. It was restartable before, but it is not anymore. But this does not affect the correctness, and the performance impact should be relatively small. |
|
Change https://golang.org/cl/347490 mentions this issue: |
|
Change https://golang.org/cl/297776 mentions this issue: |
|
Change https://golang.org/cl/347531 mentions this issue: |
|
Hi, I uploaded three implementation versions, of which the second and third versions are based on the first, because I'm not sure which one is better. Their implementation ideas are basically the same, the difference is whether to modify the original Prog when unfolding, and whether to use a new data structure.
Generally speaking, the instructions generated by the three versions are the same, so there is no difference in speed. However, there will be a little difference in memory usage. The second version causes the smallest memory allocation regression, the first version is the second, and the third version is the worst. https://go-review.googlesource.com/c/go/+/347532 is an example of adding instructions, based on the first version. This example is relatively simple, I will add a more representative example later. Finally we'll only select one of them, so could you help review these patches help me figure out which one is what we want, or better idea? I know these patches are quite large and hard to review, but I don't find a good way to split them into smaller ones, because then bootstrapping will fail. |
|
Based on some early feedback from @cherrymui , we now only keep one version, which is basically version 3 mentioned above, but with a little difference. Due to the large amount of change, it is not easy to review, so the code has been reviewed for several release cycles. I wonder if it's possible to merge this into the master branch in the early stage when the 1.20 tree is open? That way, if there are issues, we'll have plenty of time to deal with them before the 1.20 release. In fact, since this implementation only affects arm64, and the logic is relatively simple, I am very confident in maintaining the code. |
|
I've rebased the code many times since the first push, and the implementation compiles successfully and passes all tests, which also proves that my implementation has no correctness issues. So what are our concerns? The design or code quality or just no time to review? |
|
@mmcloughlin I have finished the parsing work and got an instruction table. But I'm still dealing with some issues about opcode naming and operand classification. Encoding and decoding of operand rules has not been done. The instruction table I generated is the same as inst.go, I'm not sure if this will work for you. If it is useful, I can generate such a table and send it to you. If you want to make some custom changes on the parser, then you may have to wait a while, I will submit the code to the community recently, and discuss some problems with @cherrymui. Thanks. |
|
@erifan Thanks for the quick reply! The I did spend some time working on parsing the specs myself, but I stalled on it. I could revive that work, but I thought there might be some benefits to reusing your approach that will presumably be landed in |
I'm sorry that the arm instruction document does not mark whether an operand is a read or write operation. If you only need to distinguish whether an operand is a read or write operation, and you don't care about how to read and write, then I think it's doable. Because usually the source operand is read and the destination operand is write. Take the most common three-operand arm instruction as an example, the first operand is the destination operand, and the last two are source operands. And there are some special cases, such as STR, CAS, we need to do some special handling. If you also need to know how the operand is read and written, then this needs to be combined with encoding and decoding of operand rules. |
|
@mmcloughlin I have uploaded the xml parser |
|
Change https://go.dev/cl/506118 mentions this issue: |
|
Change https://go.dev/cl/518117 mentions this issue: |
|
Change https://go.dev/cl/424138 mentions this issue: |
|
Change https://go.dev/cl/518118 mentions this issue: |
|
Change https://go.dev/cl/527256 mentions this issue: |
|
Change https://go.dev/cl/527257 mentions this issue: |
|
Change https://go.dev/cl/538136 mentions this issue: |
|
Change https://go.dev/cl/538456 mentions this issue: |
|
The last Go compiler and runtime meeting notes #43930 (comment) said:
I hope you're not affected @erifan? |
Thank you for your greetings. Unfortunately, I was also affected. I don't know how to deal with this work now. If you care about the new assembler, maybe you can ask Arm. They may build a new Go team, may not, I don't know. Personally, I really want to finish this, but I'm not sure if I still have time and opportunity to do it. Sorry for this bad situation. |
|
@erifan That's awful news, I'm so sorry. Thank you for all your work on this so far. @cherrymui What's the plan for this work going forward? Sorry I haven't been keeping up with the details of the CLs, but it seemed like it might be close? Is it possible to get this over the finish line from here? Or is there another contact at ARM we can ask for support? |
|
Thanks very much for your contribution, @erifan and others on ARM who have contributed! @mmcloughlin I think @erifan 's CLs are in a good shape, and we can proceed along that direction. Unfortunately I'm a bit occupied and I won't be able to work on the CLs myself in the near future. If someone is interested, feel free to take a look at the CLs and go from there. Thanks. |
Got it, thanks for the update. I'd be interested in doing the work but I suspect I won't have the time to devote to it any time soon. I've emailed some contacts at ARM as recommended by @erifan and CC'd you. It would be great if they are able to sponsor the completion of the work. However I'm just a random Go developer, I think the request would have more weight if it came directly from the Go team. Would it be worth asking Russ Cox to reach out to them about this? |
|
@honeycombio as a reference arm customer is also very interested in this work as it blocks us using the latest vector processing instructions in our hot path. We'll be reaching out to our marketing/partnership contacts. |
|
@lizthegrey What specific instructions do you need in the short term? Are they SVE instructions, or the "old" "advanced SIMD" instructions? For the latter, we support a number of such instructions. So if you name the missing instructions we might be able to add them in short term without finishing the refactoring. (Another possibility is to write Thanks. |
We need two things to happen: (1) we need to have SVE1/2 support added (for Graviton 3/4 respectively), and then (2) we need Avo to support arm64. So it's a two step process with a longer time horizon, and Graviton4 isn't even GA yet. Don't worry about doing a short-term hack. |
|
Change https://go.dev/cl/587315 mentions this issue: |
…er builds Some of the tests for the arm64 assembler are not running for cross-compiled arm64 builds with GOARCH=arm64. This patch allows the tests to run for all architectures and moves the test that can only run on arm64 into its own conditionally compiled file. Updates #44734 Change-Id: I045870d47cdc1280bfacc1ef275f34504278ed89 Reviewed-on: https://go-review.googlesource.com/c/go/+/587315 Reviewed-by: Cherry Mui <[email protected]> LUCI-TryBot-Result: Go LUCI <[email protected]> Reviewed-by: David Chase <[email protected]> Reviewed-by: Sebastian Nickolls <[email protected]>
|
Change https://go.dev/cl/595755 mentions this issue: |
…er builds Some of the tests for the arm64 assembler are not running for cross-compiled arm64 builds with GOARCH=arm64. This patch allows the tests to run for all architectures and moves the test that can only run on arm64 into its own conditionally compiled file. Updates golang#44734 Change-Id: I045870d47cdc1280bfacc1ef275f34504278ed89 Reviewed-on: https://go-review.googlesource.com/c/go/+/587315 Reviewed-by: Cherry Mui <[email protected]> LUCI-TryBot-Result: Go LUCI <[email protected]> Reviewed-by: David Chase <[email protected]> Reviewed-by: Sebastian Nickolls <[email protected]>
|
Change https://go.dev/cl/602355 mentions this issue: |
|
Change https://go.dev/cl/606195 mentions this issue: |
Adds helper functions for the literal pooling, large branch handling and code emission stages of the span7 assembler pass. This hides the implementation of the current assembler from the general workflow in span7 to make the implementation easier to change in future. Updates #44734 Change-Id: I8859956b23ad4faebeeff6df28051b098ef90fed Reviewed-on: https://go-review.googlesource.com/c/go/+/595755 Reviewed-by: Cherry Mui <[email protected]> Reviewed-by: Dmitri Shuralyov <[email protected]> LUCI-TryBot-Result: Go LUCI <[email protected]>
I propose to refactor the framework of the arm64 assembler.
Why ?
1, The current framework is a bit complicated, not easy to understand, maintain and extend. Especially the handling of constants and the design of
optab.2, Adding a new arm64 instruction is taking more and more effort. For some complex instructions with many formats, a lot of modifications are needed. For example, https://go-review.googlesource.com/c/go/+/273668, https://go-review.googlesource.com/c/go/+/233277, etc.
3, At the moment, we are still missing ~1000 assembly instructions, including NEON and SVE. The potential cost for adding those instructions are high.
People is paying more and more attention to arm64 platform, and there are more and more requests to add new instructions, see #40725, #42326, #41092 etc. Arm64 also has many new features, such as SVE. We hope to construct a better framework to solve the above problems and make future work easier.
Goals for the changes
1, More readable and easy to maintain.
2, Easy to add new instructions.
3, Friendly to testing, Can be cross checked with GNU tools.
4, Share instruction definition with disassembly to avoid mismatch between assembler and disassembler.
How to refactor ?
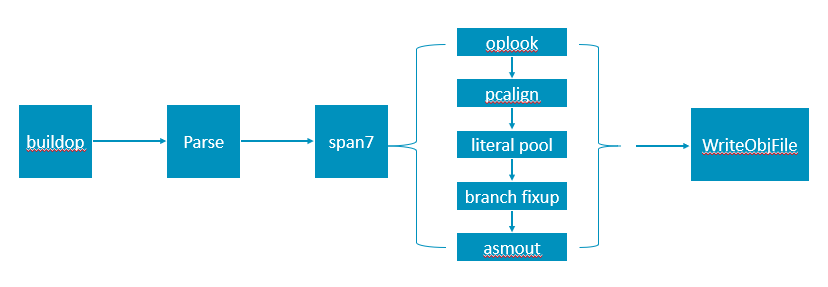
First let's take a look of the current framework.
We mainly focus on the
span7function which encodes a function's Prog list. The main idea of this function is that for a specificProg, first find its corresponding item inoptab(byoplookfunction), and then encode it according tooptab._type(inasmoutfunction).In oplook, we need to handle the matching relationship between a
Progand anoptabitem, which is quite complex especially those constant types and constant offset types. Inoptab, each format of an instruction has an entry. In theory, we need to write an encoding function for each entry, fortunately we can reuse some similar cases. However sometimes we don't know whether there is a similar implementation, and as instructions increase, the code becomes more and more complex and difficult to maintain.We propose to change this logic to: separate the preprocessing and encoding of a
Prog. The specific method is to first unfold the Prog into aProgcorresponding to only one machine instruction (by hardcode), and then encode it according to the known bits and argument types. Namely: encoding_of_P = Known_bits | arg1 | arg2 | ... | argnThe control flow of span7 becomes:
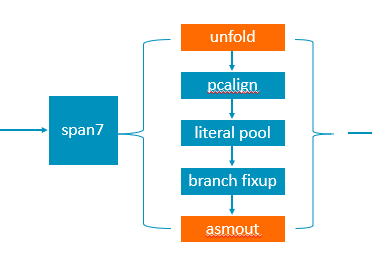
We basically have a complete argument type description list and arm64 instruction table, see argument types and instruction table When we know the known bits and parameter types of an instruction, it is easy to encode it.
With this change, we don't need to handle the matching relationship between the
Progand the item ofoptabany more, and we won't encode a specific instruction but the instruction argument type. The number of the instruction argument type is much less than the instruction number, so theoretically the reusability will increase and complexity will decrease. In the future to add new instructions we only need to do this:1, Set an index to the goal instruction in the arm64 instruction table.
2, Unfold a
Progto one or multiple arm64 instructions.3, Encode the parameters of the arm64 instruction if they have not been implemented.
I have a prototype patch for this proposal, including the complete framework and support for a few instructions such as ADD, SUB, MOV, LDR and STR. See https://go-review.googlesource.com/c/go/+/297776. The patch is incomplete, more work is required to make it work. If the proposal is accepted, we are committed to taking charge of the work.
TODO list:
1, Enable more instructions.
2, Add more tests.
3, Fix the assembly printing issue.
4, Cross check with GNU tools.
CC @cherrymui @randall77 @ianlancetaylor
The text was updated successfully, but these errors were encountered: