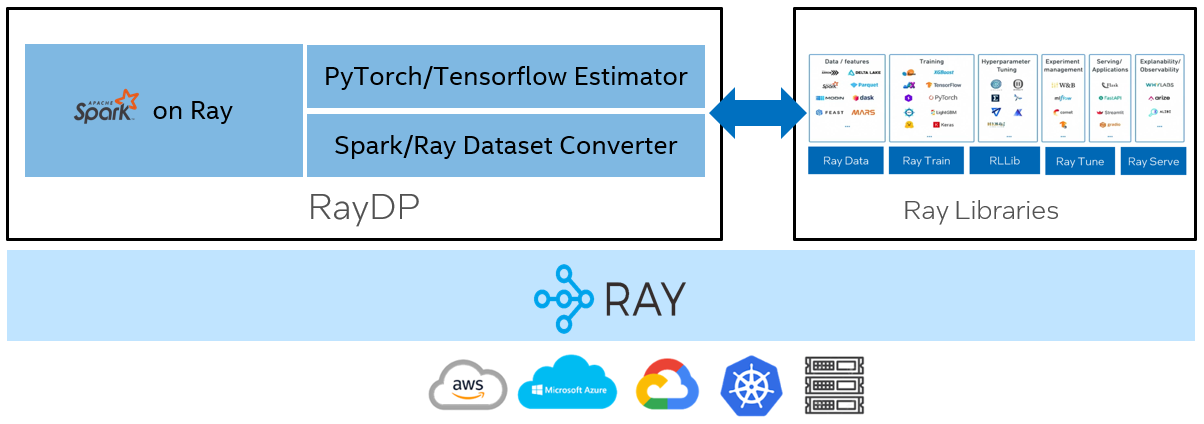
RayDP provides simple APIs for running Spark on Ray and integrating Spark with AI libraries, making it simple to build distributed data and AI pipeline in a single python program.
A large-scale AI workflow usually involves multiple systems, for example Spark for data processing and PyTorch or Tensorflow for distributed training. A common setup is to use two separate clusters and stitch together multiple programs using glue code or a workflow orchestrator such as AirFlow or KubeFlow. However, in many cases this adds costs in terms of system efficiency and operations. The setup overhead of the workflow tasks adds latency. Data exchange among frameworks has to rely on external storage system which also adds latency. On operation side, managing two separate clusters introduces additional cost. Writing the pipeline using workflow orchestrator usually is also more complex than writing a single python program.
To solve the above challenges, more and more companies have adopted Ray as a single substrate for data processing, model training, serving and more. Ray makes it simple to build the data and AI pipeline in a single python program and scale from laptop to a cluster seamlessly. Ray has built a rich ecosystem by providing high quality libraries and integrating with other popular ones.
Spark as a popular big data framework plays an important role in data and AI pipelines. RayDP brings Spark to the Ray ecosystem by supporting running Spark on top of Ray. By using RayDP, you can easily write PySpark code together with other Ray libraries in the same python program which improves productivity and expressivity. RayDP makes it simple to build distributed end-to-end data analytics and AI pipeline. RayDP supports exchanging data between Spark and other frameworks using Ray's in-memory object to provide best performance.
- ML infrastructure team can build a modern ML platform on top of Ray, utilize RayDP to run Spark on Ray and unify with other AI components.
- Data scientists can use RayDP to write PySpark code together with other AI libraries, scale from laptop to cloud seamlessly.
- Data engineers can use RayDP to run on-demand Spark job in cloud without a need to setup a Spark cluster manually. The Ray cluster launcher helps to start a Ray cluster in cloud and RayDP allows you to run Spark in that cluster with auto scaling.
- Data + AI Summit 2021: Build Large-Scale Data Analytics and AI Pipeline Using RayDP
- Ray Summit 2021: RayDP: Build Large-scale End-to-end Data Analytics and AI Pipelines Using Spark and Ray
RayDP provides simple APIs for running Spark on Ray and APIs for converting a Spark DataFrame to a Ray Dataset which can be consumed by XGBoost, Ray Train, Horovod on Ray, etc. RayDP also provides high level scikit-learn style Estimator APIs for distributed training with PyTorch or Tensorflow.
RayDP supports Ray as a Spark resource manager and runs Spark executors in Ray actors. The communication between Spark executors still uses Spark's internal protocol.
You can install latest RayDP using pip. RayDP requires Ray and PySpark. Please also make sure java is installed and JAVA_HOME is set properly.
pip install raydpOr you can install RayDP nightly build:
pip install --pre raydpNOTICE: formerly used raydp-nightly will no longer be updated.
If you'd like to build and install the latest master, use the following command:
./build.sh
pip install dist/raydp*.whlRayDP provides an API for starting a Spark job on Ray. To create a Spark session, call the raydp.init_spark API. After that, you can use any Spark API as you want. For example:
import ray
import raydp
# connect to ray cluster
ray.init(address='auto')
# create a Spark cluster with specified resource requirements
spark = raydp.init_spark(app_name='RayDP Example',
num_executors=2,
executor_cores=2,
executor_memory='4GB')
# normal data processesing with Spark
df = spark.createDataFrame([('look',), ('spark',), ('tutorial',), ('spark',), ('look', ), ('python', )], ['word'])
df.show()
word_count = df.groupBy('word').count()
word_count.show()
# stop the spark cluster
raydp.stop_spark()Spark features such as dynamic resource allocation, spark-submit script, etc are also supported. Please refer to Spark on Ray for more details.
RayDP provides APIs for converting a Spark DataFrame to a Ray Dataset which can be consumed by XGBoost, Ray Train, Horovod on Ray, etc. RayDP also provides high level scikit-learn style Estimator APIs for distributed training with PyTorch or Tensorflow. To get started with end-to-end Spark + AI pipeline, the easiest way is to run the following tutorials on Google Collab. More examples are also available in the examples folder.
Spark DataFrame & Ray Dataset conversion
You can use ray.data.from_spark and ds.to_spark to convert between Spark DataFrame and Ray Dataset.
import ray
import raydp
ray.init()
spark = raydp.init_spark(app_name="RayDP Example",
num_executors=2,
executor_cores=2,
executor_memory="4GB")
# Spark Dataframe to Ray Dataset
df1 = spark.range(0, 1000)
ds1 = ray.data.from_spark(df1)
# Ray Dataset to Spark Dataframe
ds2 = ray.data.from_items([{"id": i} for i in range(1000)])
df2 = ds2.to_spark(spark)Ray dataset converted from Spark dataframe this way will be no longer accessible after raydp.stop_spark(). If you want to access the data after spark is shutdown, please use raydp.stop_spark(cleanup_data=False).
Please refer to Spark+XGBoost on Ray for a full example.
Estimator API
The Estimator APIs allow you to train a deep neural network directly on a Spark DataFrame, leveraging Ray’s ability to scale out across the cluster. The Estimator APIs are wrappers of Ray Train and hide the complexity of converting a Spark DataFrame to a PyTorch/Tensorflow dataset and distributing the training. RayDP provides raydp.torch.TorchEstimator for PyTorch and raydp.tf.TFEstimator for Tensorflow. The following is an example of using TorchEstimator.
import ray
import raydp
from raydp.torch import TorchEstimator
ray.init(address="auto")
spark = raydp.init_spark(app_name="RayDP Example",
num_executors=2,
executor_cores=2,
executor_memory="4GB")
# Spark DataFrame Code
df = spark.read.parquet(…)
train_df = df.withColumn(…)
# PyTorch Code
model = torch.nn.Sequential(torch.nn.Linear(2, 1))
optimizer = torch.optim.Adam(model.parameters())
estimator = TorchEstimator(model=model, optimizer=optimizer, ...)
estimator.fit_on_spark(train_df)
raydp.stop_spark()Please refer to NYC Taxi PyTorch Estimator and NYC Taxi Tensorflow Estimator for full examples.
Fault Tolerance
The ray dataset converted from spark dataframe like above is not fault-tolerant. This is because we implement it using Ray.put combined with spark mapPartitions. Objects created by Ray.put is not recoverable in Ray.
RayDP now supports converting data in a way such that the resulting ray dataset is fault-tolerant. This feature is currently experimental. Here is how to use it:
import ray
import raydp
ray.init(address="auto")
# set fault_tolerance_mode to True to enable the feature
# this will connect pyspark driver to ray cluster
spark = raydp.init_spark(app_name="RayDP Example",
num_executors=2,
executor_cores=2,
executor_memory="4GB",
fault_tolerance_mode=True)
# df should be large enough so that result will be put into plasma
df = spark.range(100000)
# use this API instead of ray.data.from_spark
ds = raydp.spark.from_spark_recoverable(df)
# ds is now fault-tolerant.Notice that from_spark_recoverable will persist the converted dataframe. You can provide the storage level through keyword parameter storage_level. In addition, this feature is not available in ray client mode. If you need to use ray client, please wrap your application in a ray actor, as described in the ray client chapter.
To report bugs or request new features, please open a github issue.