A curated list for Efficient Large Language Models
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this main page, only papers released in the past 90 days are shown.
- May 29, 2024: We've had this awesome list for a year now 🥰!
- Sep 6, 2023: Add a new subdirectory project/ to organize efficient LLM projects.
- July 11, 2023: A new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs.
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.
For each topic, we have curated a list of recommended papers that have garnered a lot of GitHub stars or citations.
Paper from July 13, 2024 - Now (see Full List from May 22, 2023 here)
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey



















































































































































































| Title & Authors | Introduction | Links |
|---|---|---|
 ⭐ Fast Inference of Mixture-of-Experts Language Models with Offloading Artyom Eliseev, Denis Mazur |
 |
Github Paper |
| ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference Xin He, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, Ong Yew Soon |
 |
Paper |
| EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference Yulei Qian, Fengcun Li, Xiangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai |
Paper | |
 MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi |
 |
Github Paper |
| Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, Jianfeng Gao |
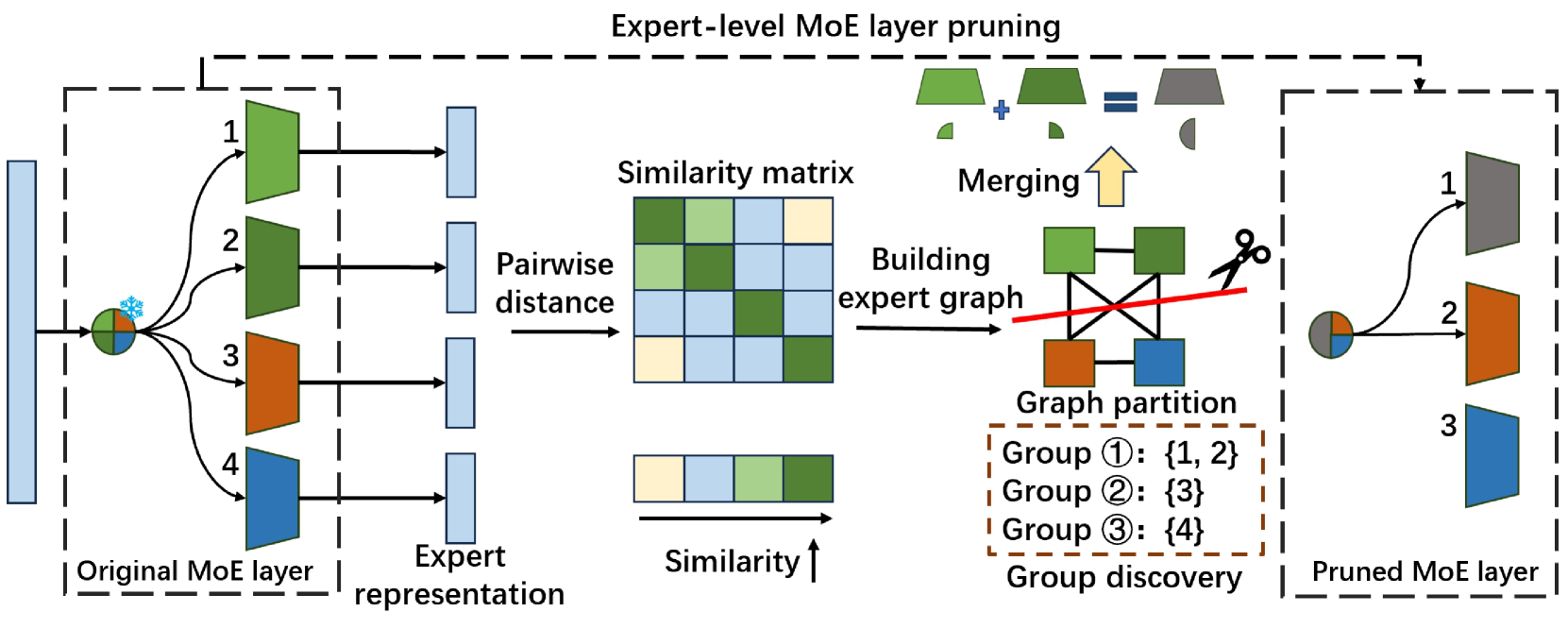 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 ⭐ MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github Paper Model |
 ⭐ Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
 |
Github Paper |
| Taipan: Efficient and Expressive State Space Language Models with Selective Attention Chien Van Nguyen, Huy Huu Nguyen, Thang M. Pham, Ruiyi Zhang, Hanieh Deilamsalehy, Puneet Mathur, Ryan A. Rossi, Trung Bui, Viet Dac Lai, Franck Dernoncourt, Thien Huu Nguyen |
 |
Paper |
 SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang |
 |
Github Paper |
 Basis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, Grace Li Zhang |
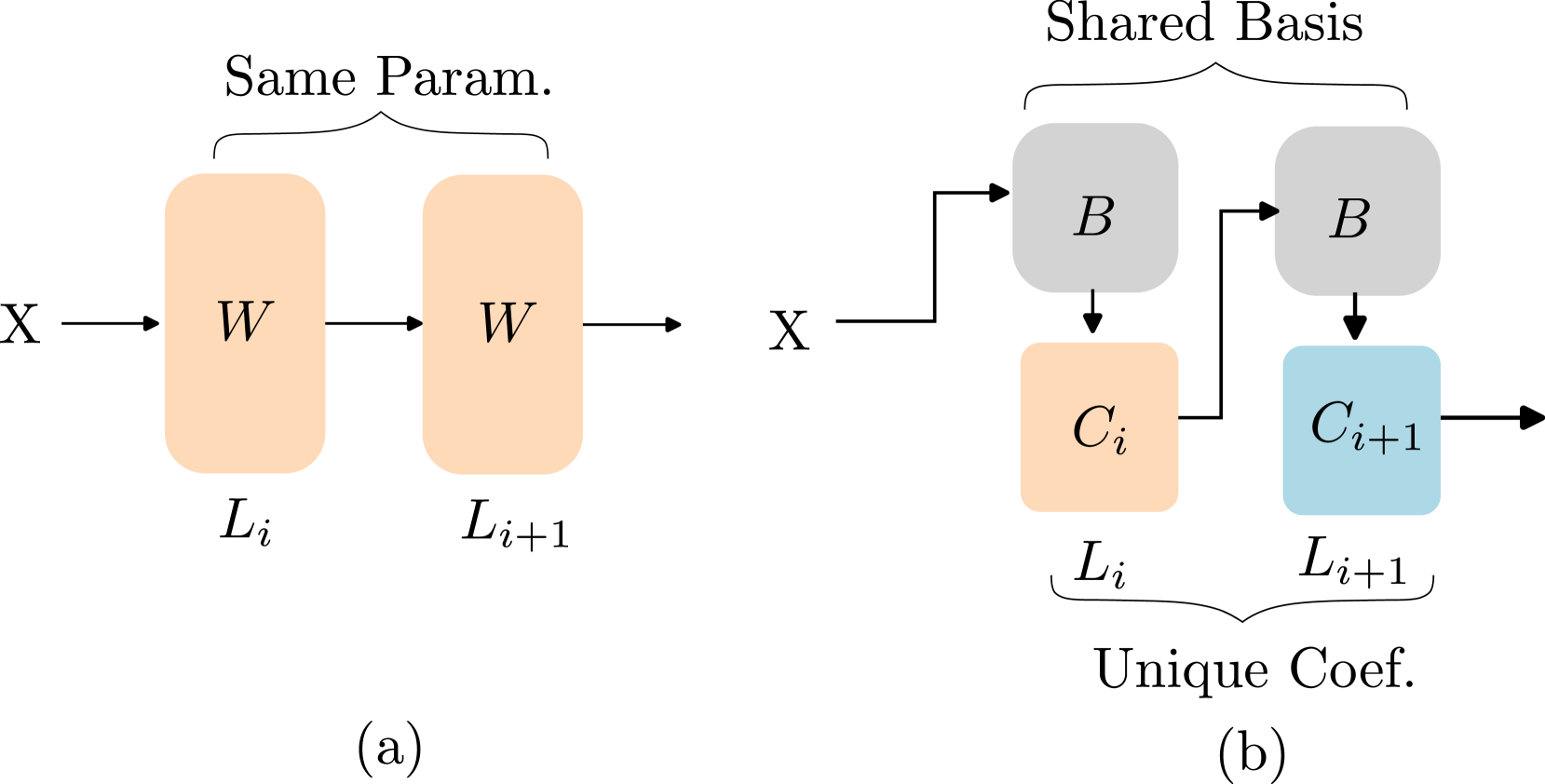 |
Github Paper |
| Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin |
 |
Paper |
| SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context Hongjun An, Yifan Chen, Zhe Sun, Xuelong Li |
 |
Paper |
 Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads Xihui Lin, Yunan Zhang, Suyu Ge, Barun Patra, Vishrav Chaudhary, Xia Song |
 |
Github Paper |
 Beyond KV Caching: Shared Attention for Efficient LLMs Bingli Liao, Danilo Vasconcellos Vargas |
 |
Github Paper |




























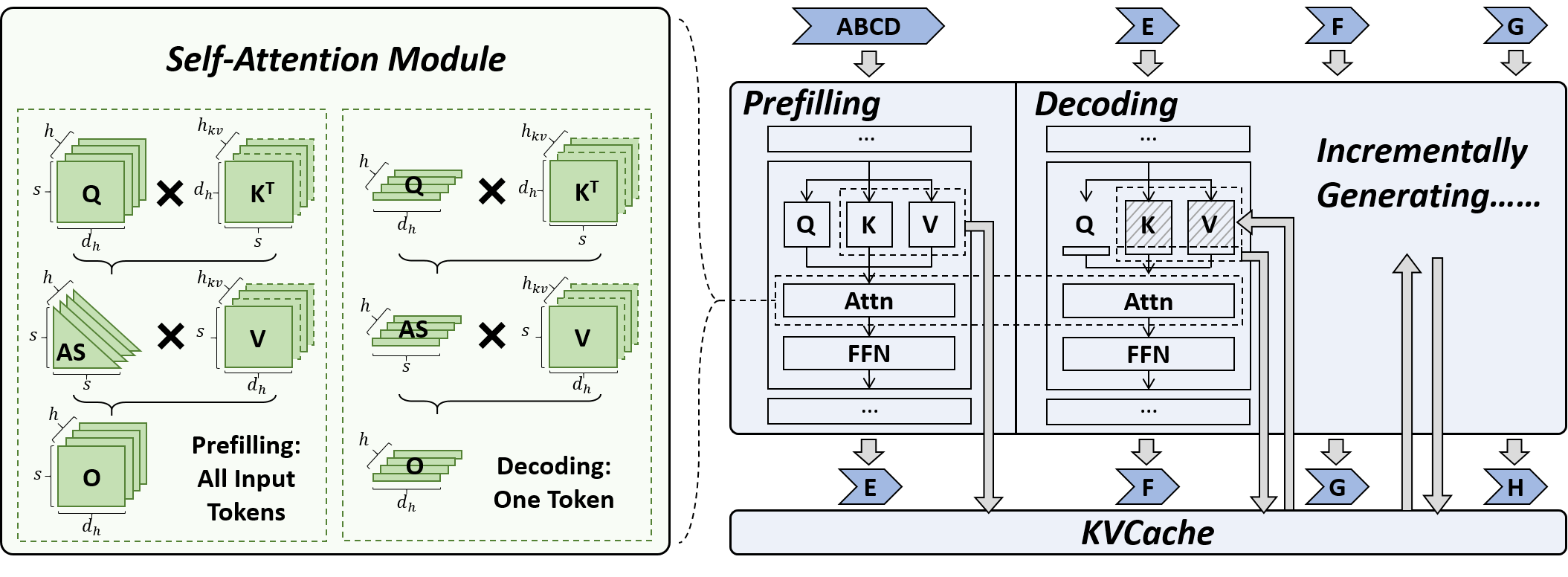






















| Title & Authors | Introduction | Links |
|---|---|---|
 Natural GaLore: Accelerating GaLore for memory-efficient LLM Training and Fine-tuning Arijit Das |
Github Paper |
|
| CompAct: Compressed Activations for Memory-Efficient LLM Training Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, Assaf Schuster |
 |
Paper |
ESPACE: Dimensionality Reduction of Activations for Model Compression Charbel Sakr, Brucek Khailany |
 |
Paper |
| MoDeGPT: Modular Decomposition for Large Language Model Compression Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models Junhao Hu, Wenrui Huang, Haoyi Wang, Weidong Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, Tao Xie |
 |
Paper |
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training Jinda Jia, Cong Xie, Hanlin Lu, Daoce Wang, Hao Feng, Chengming Zhang, Baixi Sun, Haibin Lin, Zhi Zhang, Xin Liu, Dingwen Tao |
 |
Paper |
| FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs Haoran Lin, Xianzhi Yu, Kang Zhao, Lu Hou, Zongyuan Zhan et al |
 |
Paper |
| POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, Ashish Panwar |
 |
Paper |
 TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices Zonghang Li, Wenjiao Feng, Mohsen Guizani, Hongfang Yu |
 |
Github Paper |
Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores Shaobo Ma, Chao Fang, Haikuo Shao, Zhongfeng Wang |
 |
Paper |
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models Jahyun Koo, Dahoon Park, Sangwoo Jung, Jaeha Kung |
 |
Paper |
| Accelerating Large Language Model Training with Hybrid GPU-based Compression Lang Xu, Quentin Anthony, Qinghua Zhou, Nawras Alnaasan, Radha R. Gulhane, Aamir Shafi, Hari Subramoni, Dhabaleswar K. Panda |
 |
Paper |
| LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration Zhiwen Mo, Lei Wang, Jianyu Wei, Zhichen Zeng, Shijie Cao, Lingxiao Ma, Naifeng Jing, Ting Cao, Jilong Xue, Fan Yang, Mao Yang |
 |
Paper |
| Kraken: Inherently Parallel Transformers For Efficient Multi-Device Inference Rohan Baskar Prabhakar, Hengrui Zhang, David Wentzlaff |
 |
Paper |
| SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavaroutsos, Sotirios Xydis, Dimitrios Soudris |
 |
Paper |
| Designing Efficient LLM Accelerators for Edge Devices Jude Haris, Rappy Saha, Wenhao Hu, José Cano |
 |
Paper |
| PipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation Branden Butler, Sixing Yu, Arya Mazaheri, Ali Jannesari |
 |
Paper |

















| Title & Authors | Introduction | Links |
|---|---|---|
 Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier |
 |
Github Paper |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai |
 |
Paper |
| A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Haotong Qin, Jinyang Guo, Michele Magno, Xianglong Liu |
 |
Paper |
 Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey Sourav Verma |
 |
Github Paper |
| Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview Yanshu Wang, Tong Yang, Xiyan Liang, Guoan Wang, Hanning Lu, Xu Zhe, Yaoming Li, Li Weitao |
Paper | |
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris |
Paper | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song |
 |
Paper |
Inference Optimization of Foundation Models on AI Accelerators Youngsuk Park, Kailash Budhathoki, Liangfu Chen, Jonas Kübler, Jiaji Huang, Matthäus Kleindessner, Jun Huan, Volkan Cevher, Yida Wang, George Karypis |
Paper |