A simple toy of how to use caffe to train CNN on Windows
The dataset can be download from School Idol Tomodachi - Cards Album.
Or you can also use a download tool LoveLiveCardsAlbum - GitHub which is able to download all of images in the album automatically.
Crop the images you download into 128*128 and put them into .\complete_data
We provied a uncropped dataset, download: Mu's Dataset - BaiduYunPan
New Now we provide a detected and manual cleaned dataset, download: Mu's Detected Dataset - BaiduYunPan
You can use the anime face detection program in lbpcascade_animeface.Net - GitHub to crop ypur dataset.
New A pure C++ detection and dataset/label building script has been provide in .\cpp\main.cpp.
The label marking is very simple, take .\label\train.txt as example:
data\train\image_name.png label_num
Just format every line as the expression above, do NOT add your project root.
The label_num indexed 0 instead of 1. And the processing of val.txt is all the same as train.txt.
Excute .\setup\BatBuilder.exe to build 3 .bat files:
- convertimage2ldb_train.bat
- convertimage2ldb_val.bat
- Train.bat
If the excution end without any problem, then excute convertimage2ldb_train.bat and convertimage2ldb_val.bat to get the LEVELDB structure train/val dataset in .\trainLevelDB and .\valLevelDB.
After data converting then excute computeMean_train.bat and computeMean_val.bat to the compute the mean of the dataset, the results will be saved in .\model as train_mean.binaryproto and val_mean.binaryproto
We used a modified Light-CNN for training. In order to reducing overfitting and accelerating convergence, this model will be very small. As the results, this toy model CANNOT be taken a serious use.
Open .\model\train_val.prototxt to change the path and the same to .\model\solver.prototext.
Check all the roots is filled correcttly, you can excute .\setup\Train.bat to train this net.
After training, you will get caffemodel in the .\snapshot saved like "lovelive_lightcnn_train_iter_1000.caffemodel".
Open Prediction.py in the root, change the path you need. And just have fun...
We use 1530 images as training dataset and rest 178 images as validation dataset, the train-val partition is in random. Considered that there are only 9 girls in the dataset, the results will occourd a considerable degree of overfitting.
The plotting script is locating .\matlab\lovelive.m.
Result1:
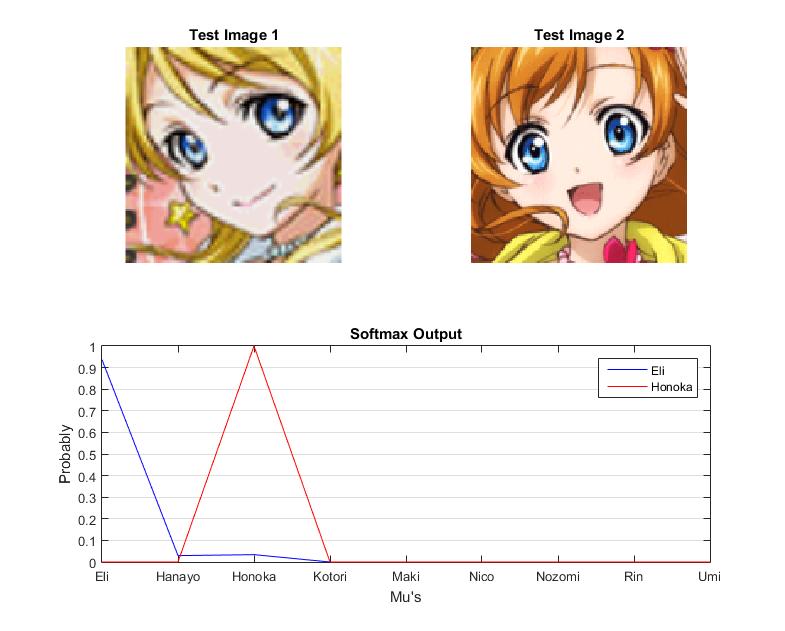
The fig above is a regular result. Both of the test image is classified into correct label with a high confidence.
Error1:
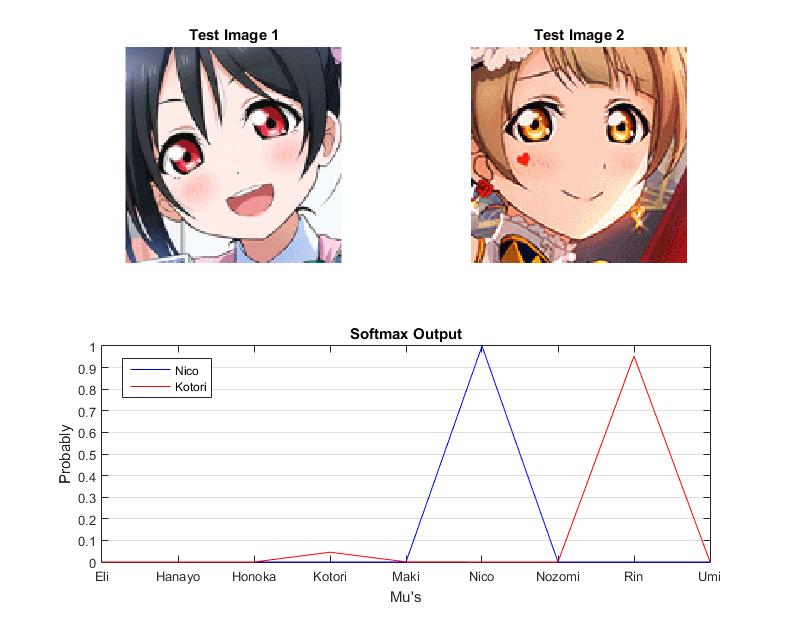
So we guess that it caused by the special lighting condition of Kotori in the testset in considerable probability own the similar hair color with Rin's. The following error may validate this problem: here these 2 test images which out of the training dataset show a very similar hair color as Maki and Umi, and the prediction result recogized will go incorrect directly.
Error2:
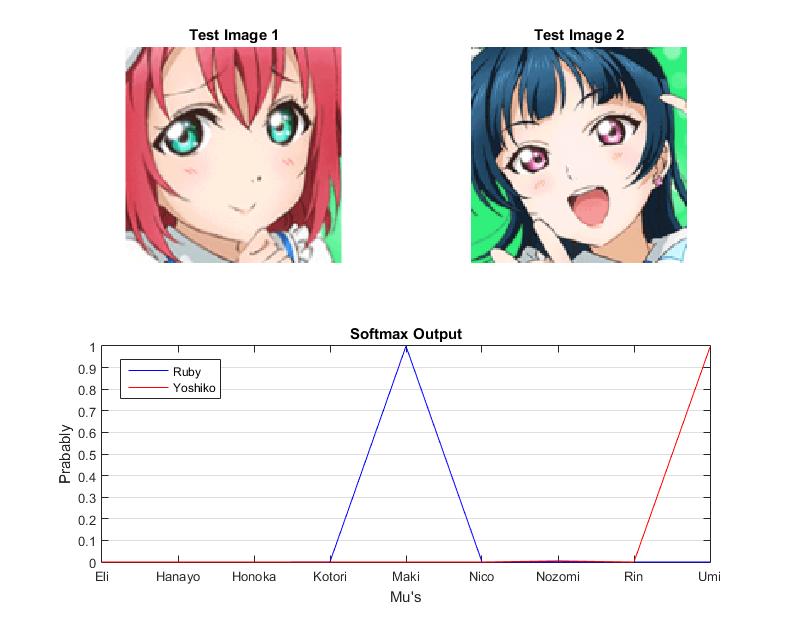
Error3:
In order to validate our conjecture, we erase the hair of all test images. The results show that none of the test images are correctly classifed.
The next 2 poster does not show up in the train-val dataset, so we choosed them as test images.
 Here Umi is recognized as Nozomi.
Here Umi is recognized as Nozomi.
 Kotori is recognized as Hanayo, the same error as Error1.
Kotori is recognized as Hanayo, the same error as Error1.
Validation Accrency and Training Loss fig has paste below:
Acc&Loss:
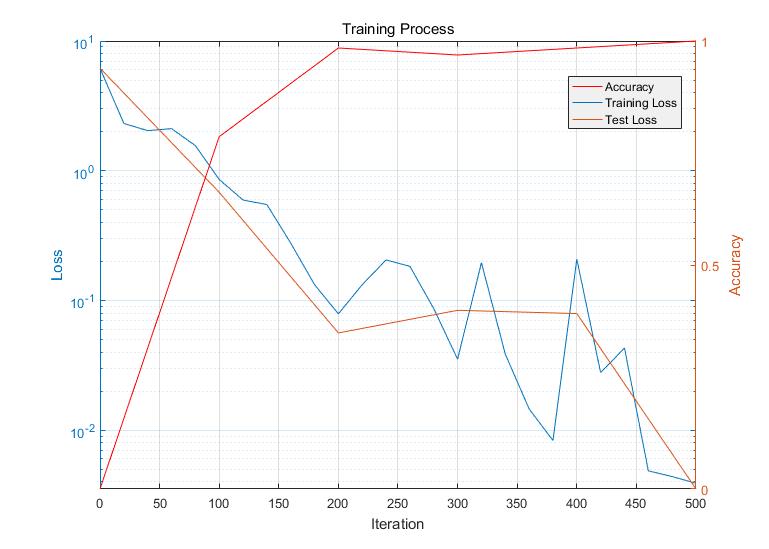
The plotting script can be found in .\matlab\loss_parser.m.
Fortunately, maybe due to the tiny model, it has been not overfitted.
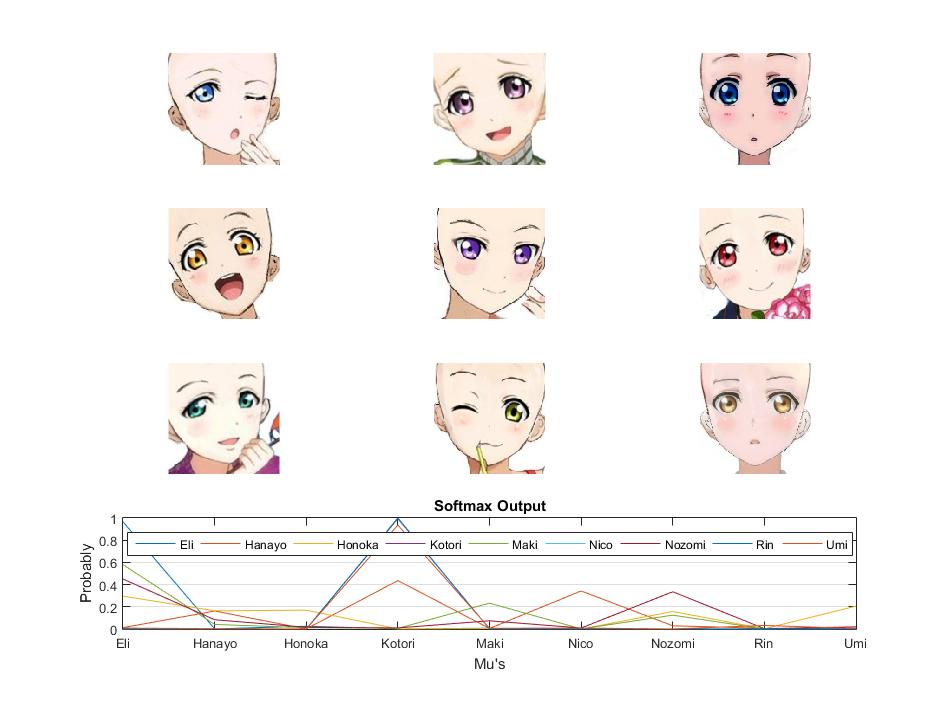
The intersting fact is that even human beings are difficult to distinguish these 9 girls by face(in the strict sense) in grayscale images. So we guess that the features that CNN learned will be eye colors, hair colors and facial exppressions. The following fig is visualized features of conv2 layer with idolizedRuby input, it may be confirmed our guess from another side:
Visualized Feature:
